視覺化編排的資料整合和分發開源框架Nifi輕鬆入門-上
@
概述
定義
Nifi 官網地址 https://nifi.apache.org/
Nifi 官網檔案 https://nifi.apache.org/docs.html
Nifi GitHub原始碼地址 https://github.com/apache/nifi
Apache NiFi是一個易於使用、功能強大且可靠的系統,用於處理和分發資料,可以自動化管理系統間的資料流。最新版本為1.19.1
簡單來說,NiFi是用來處理資料整合場景的資料分發。NiFi是基於Java的,使用Maven支援包的構建管理。 NiFi基於Web方式工作,後臺在伺服器上進行排程。使用者可以為資料處理定義為一個流程,然後進行處理,後臺具有資料處理引擎、任務排程等元件。
dataflow面臨挑戰
- 系統失敗:網路故障,磁碟故障,軟體崩潰,人為犯錯。
- 資料存取超過了消費能力:有時,給定資料來源的速度可能超過處理或交付鏈的某些部分,而只需要某一個環節出現問題,整個流程都會受到影響。
- 超出邊界問題:總是會得到太大、太小、太快、太慢、損壞、錯誤或格式錯誤的資料。
- 現實業務或需求變化快:設計新的資料處理流程或者修改已有的資料處理流程必須要夠敏捷。
- 難以在測試環境模擬生產環境資料。
特性
Apache NiFi支援資料路由、轉換和系統中介邏輯的強大且可伸縮的有向圖。
- 基於瀏覽器的使用者介面:設計、控制、反饋和監控的無縫體驗。
- 資料來源跟蹤:完整從開始到結束跟蹤資訊。
- 豐富的設定
- 容錯和保證交付
- 低延遲,高吞吐量
- 動態優先順序
- 流設定的執行時修改
- 背壓控制
- 可延伸的設計
- 客製化處理器和服務的元件體系結構
- 快速開發和迭代測試
- 安全通訊
- HTTPS,具有可設定的身份驗證策略
- 多租戶授權和策略管理
- 用於加密通訊的標準協定,包括TLS和SSH
核心概念
- FlowFile:表示在系統中移動的每個物件,對於每個物件,NiFi跟蹤鍵/值對屬性字串的對映及其零或多位元組的相關內容。
- 每一塊「使用者資料」(即使用者帶入NiFi進行處理和分發的資料)都被稱為一個FlowFile。
- 一個FlowFile由兩部分組成:屬性和內容。內容就是使用者資料本身。屬性是與使用者資料相關聯的鍵值對
- FlowFile Processor:處理器實際執行工作,處理器是在系統之間進行資料路由、轉換或中介的某種組合。處理器可以存取給定的FlowFile及其內容流的屬性。處理器可以在給定的工作單元中操作零個或多個flowfile,並提交該工作或回滾。
- 處理器是NiFi元件,負責建立、傳送、接收、轉換、路由、拆分、合併和處理流檔案。它是NiFi使用者用於構建資料流的最重要的構建塊。
- Connection:連線提供處理器之間的實際連結。充當佇列,允許各種程序以不同的速率進行互動。這些佇列可以動態地劃分優先順序,並且可以設定負載上限,從而啟用背壓。
- Flow Controller:流控制器維護程序如何連線,並管理所有程序使用的執行緒及其分配。流控制器充當了促進處理器之間流檔案交換的代理。
- Process Group:行程群組是一組特定的程序及其連線,這些程序可以通過輸入埠接收資料,通過輸出埠傳送資料。通過這種方式,流程組允許通過簡單地組合其他元件來建立全新的元件。
這種設計模型幫助NiFi成為構建強大且可伸縮的資料流的非常有效的平臺,其好處如下:
- 很好地用於處理器有向圖的視覺化建立和管理。
- 本質上是非同步的,允許非常高的吞吐量和自然緩衝,即使處理和流速率波動。
- 提供了一個高度並行的模型,開發人員不必擔心並行性的典型複雜性。
- 促進內聚和鬆散耦合元件的開發,這些元件可以在其他上下文中重用,並促進可測試單元的開發。
- 資源受限的連線使得諸如回壓和壓力釋放等關鍵功能非常自然和直觀。
- 錯誤處理變得像快樂之路一樣自然,而不是粗粒度的一刀切。
- 資料進入和退出系統的點以及它如何流經系統都很容易理解和跟蹤。
架構
NiFi的設計目的是充分利用它所執行的底層主機系統的功能,對IO、CPU、RAM高效使用,這種資源最大化在CPU和磁碟方面表現得尤為突出,詳細資訊在管理指南中的最佳實踐和設定技巧中。
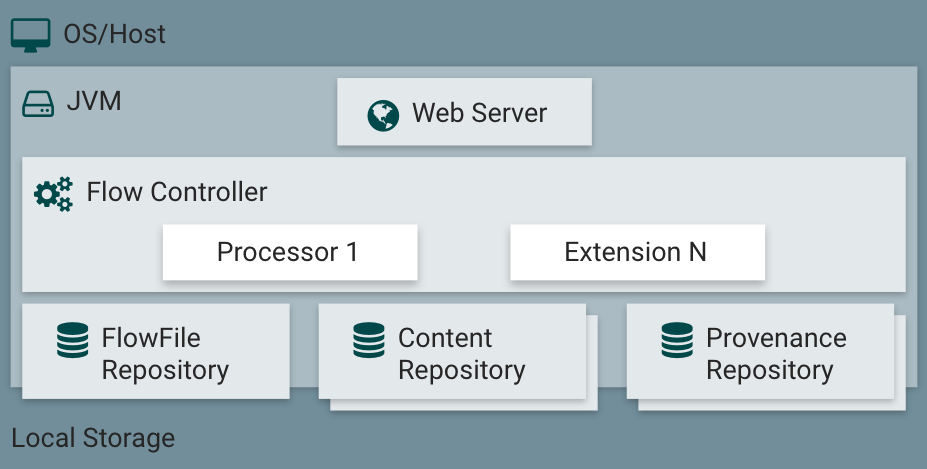
NiFi在主機作業系統上的JVM中執行,JVM上NiFi的主要元件如下:
- Web Server:web伺服器的目的是承載NiFi基於http的命令和控制API。
- Flow Controller:流量控制器是操作的大腦,它為要執行的擴充套件提供執行緒,並管理擴充套件何時接收要執行的資源的排程。
- Extensions:各種型別的NiFi擴充套件,這裡的關鍵點是擴充套件在JVM中操作和執行。
- FlowFile Repository:流檔案儲存庫是NiFi跟蹤當前流中活動的給定流檔案狀態的地方。儲存庫的實現是可插入的。預設方法是位於指定磁碟分割區上的持久預寫紀錄檔。
- Content Repository:內容儲存庫是一個給定的FlowFile的實際內容位元組所在的地方。儲存庫的實現是可插入的。預設的方法是一種相當簡單的機制,即在檔案系統中儲存資料塊。可以指定多個檔案系統儲存位置,以便使用不同的物理分割區,以減少任何單個捲上的爭用。
- Provenance Repository:源頭儲存庫是儲存所有源頭事件資料的地方。儲存庫結構是可插入的,預設實現是使用一個或多個物理磁碟卷。在每個位置中,事件資料都被索引並可搜尋。
NiFi也能夠在叢集中執行,NiFi 採用了零領導者叢集,NiFi叢集中的每個節點在資料上執行相同的任務,但每個節點操作不同的資料集。Apache ZooKeeper選擇一個節點作為Cluster Coordinator,故障轉移由ZooKeeper自動處理。所有叢集節點都向叢集協調器報告心跳和狀態資訊。叢集協調器負責斷開和連線節點。此外,每個叢集都有一個主節點,也由ZooKeeper選舉產生。作為DataFlow管理器,可通過任何節點的使用者介面(UI)與NiFi叢集互動,操作更改複製到叢集中的所有節點,允許多個入口點。
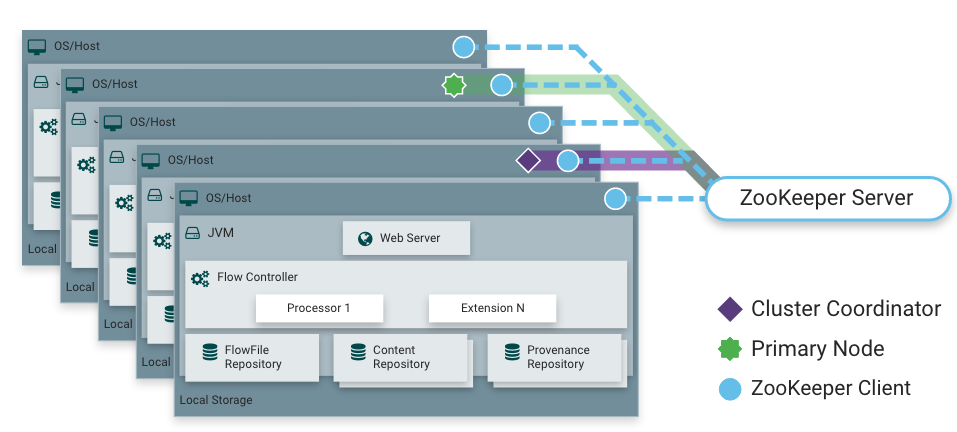
高階概述
Nifi高階概述包括流管理、易用性、安全性、可延伸的體系結構和靈活的伸縮模型。
- 流量管理
- 保證交付:NiFi的核心理念是,即使規模非常大,也必須保證交付。這是通過有效使用專門構建的持久預寫紀錄檔和內容儲存庫來實現的。它們一起被設計成這樣一種方式,允許非常高的事務率、有效的負載分散、寫時複製,並行揮傳統磁碟讀/寫的優勢。
- 帶背壓和壓力釋放的資料緩衝:NiFi支援對所有排隊的資料進行緩衝,並在這些佇列達到指定的限制時提供回壓,或者在資料達到指定的年齡(其值已經消亡)時使其老化。
- 優先佇列:NiFi允許為如何從佇列中檢索資料設定一個或多個優先順序方案。預設情況下是最早的先提取,但有時應該先提取最新的資料,先提取最大的資料,或者其他一些自定義方案。
- 特定於流的QoS(延遲v吞吐量,損失容忍度等):在資料流中,有些點的資料是絕對關鍵的,並且是不能容忍損失的,需要實時處理和交付,才能具有任何價值,NiFi支援這些關注點的細粒度流特定設定。
- 易用性
- 視覺化管理:資料流可能變得相當複雜。能夠視覺化這些流程並以視覺化的方式表達它們可以極大地幫助降低複雜性,並確定需要簡化的區域。NiFi不僅可以視覺化地建立資料流,而且可以實時地實現。對資料流進行更改立即生效。
- 流模板:資料流往往是高度面向模式的,模板允許主題專家構建和釋出他們的流設計,並讓其他人從中受益和共同作業。
- 資料來源:當物件流經系統時,NiFi自動記錄、索引並提供來源資料,即使是在扇入、扇出、轉換等過程中也是如此。這些資訊對於支援遵從性、故障排除、優化和其他場景非常重要。
- 恢復/記錄細粒度歷史的捲動緩衝區:NiFi的內容儲存庫被設計成歷史的捲動緩衝區。資料只有在內容儲存庫老化或需要空間時才會被刪除。這與資料來源功能相結合,形成了一個非常有用的基礎,可以在物件生命週期(甚至可以跨越幾代)的特定點上實現點選內容、下載內容和重播。
- 安全
- 系統到系統:資料流需要安全保障,資料流中的每個點上的NiFi通過使用帶有加密協定(如2-way SSL)提供安全交換。此外,NiFi使流能夠加密和解密內容,並在傳送方/接收方等式的任何一方使用共用金鑰或其他機制。
- 系統使用者:NiFi支援雙向SSL身份驗證,並提供可插拔授權,以便在特定級別(唯讀、資料流管理器、管理)正確控制使用者的存取。如果使用者將敏感屬性(如密碼)輸入到流中,它將立即在伺服器端加密,並且即使以加密形式也不會再次在使用者端公開。
- 多租戶授權:給定資料流的許可權級別應用於每個元件,允許admin使用者擁有細粒度級別的存取控制。這意味著每個NiFi叢集都能夠處理一個或多個組織的需求。與孤立的拓撲相比,多租戶授權支援資料流管理的自助服務模型,允許每個團隊或組織管理流,同時充分了解他們無法存取的其餘流。
- 可延伸體系結構
- 擴充套件:NiFi的核心是為擴充套件而構建的,因此它是一個平臺,資料流程序可以在其上以可預測和可重複的方式執行和互動。擴充套件點包括:處理器、控制器服務、報告任務、優先順序和客戶使用者介面。
- 類載入器隔離:對於任何基於元件的系統,依賴關係問題都可能很快發生。NiFi通過提供自定義類載入器模型來解決這個問題,確保每個擴充套件包只暴露給非常有限的一組依賴項。
- 點到點通訊協定:NiFi範例之間的首選通訊協定是NiFi Site-to-Site (S2S)協定。S2S可以輕鬆地將資料從一個NiFi範例傳輸到另一個NiFi範例,輕鬆、高效、安全。NiFi使用者端庫可以很容易地構建並捆綁到其他應用程式或裝置中,通過S2S與NiFi通訊。在S2S中,基於通訊端的協定和HTTP(S)協定都被支援作為底層傳輸協定,這使得在S2S通訊中嵌入代理伺服器成為可能。
- 靈活縮放模型
- 水平擴充套件(聚類):NiFi被設計為通過使用如上所述的群集多個節點來向外擴充套件。如果將單個節點設定為每秒處理數百MB,則可以將普通叢集設定為每秒處理GB。
- 擴縮容:NiFi還被設計成以非常靈活的方式擴大和縮小,從NiFi框架的角度來看,在設定時,可以在Scheduling索引標籤下增加處理器上並行任務的數量。
安裝
部署
# 下載最新版本1.19.1的nifi
wget --no-check-certificate https://dlcdn.apache.org/nifi/1.19.1/nifi-1.19.1-bin.zip
# 由於下載很慢我就直接下載原始碼安裝了,最低建議JDK 11.0.16、Apache Maven 3.8.6,最新需求是JDK 8 Update 251Apache Maven 3.6.0
wget
# 解壓原始碼包
tar -xvf nifi-1.19.1.tar.gz
# 進入原始碼根目錄
cd nifi-rel-nifi-1.19.1
# 執行編譯命令
mvn clean install -DskipTests
等待編譯完成
編譯好的目錄和包目錄如下
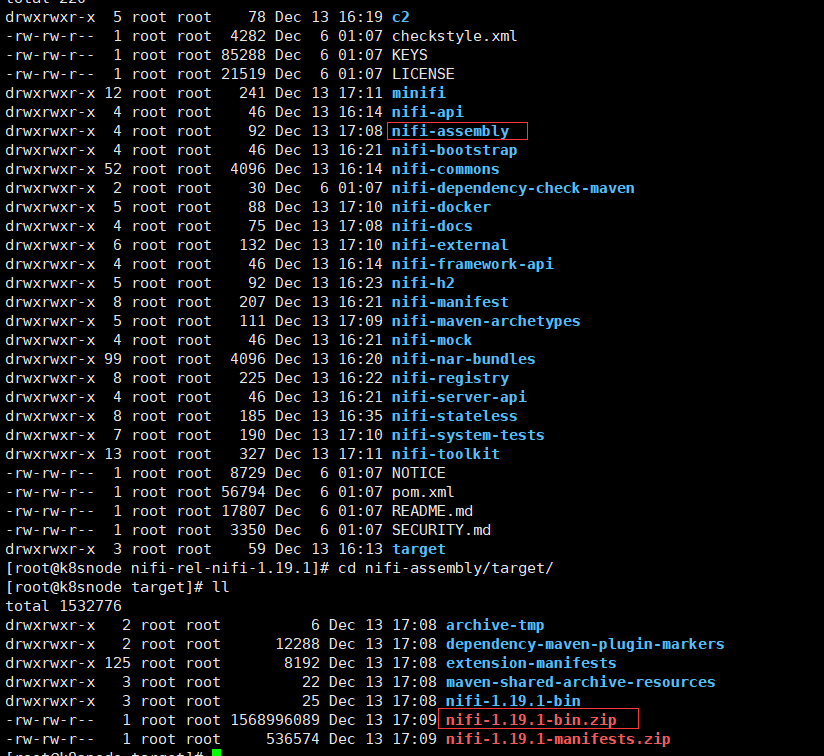
# 複製編譯好的安裝包nifi-1.19.1-bin.zip
cp -rf nifi-1.19.1-bin.zip /home/commons/
cd /home/commons/
# 解壓編譯好的安裝包
unzip nifi-1.19.1-bin.zip
# 進入安裝目錄
cd nifi-1.19.1
nifi主要組態檔在conf/nifi.properties,預設的https的埠為8443,修改host為本機IP地址
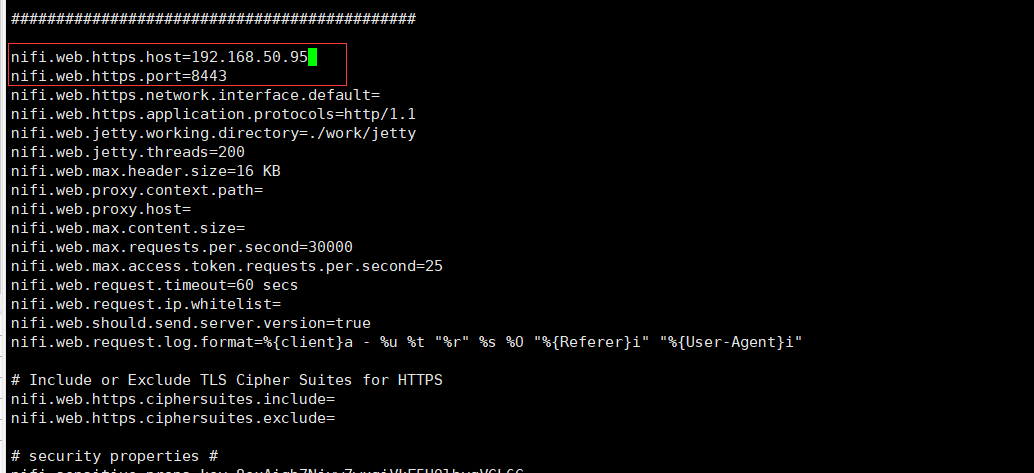
# 啟動nifi
./bin/nifi.sh start
# 得等一小會時間後檢視nifi程序狀態
./bin/nifi.sh status
# 檢視授權的密碼資訊
grep Generated logs/nifi-app*log
# 可以使用自定義憑證替換隨機使用者名稱和密碼,使用如下命令
./bin/nifi.sh set-single-user-credentials <username> <password>
# 其他命令如下,停止nifi ./bin/nifi.sh stop,重啟nifi./bin/nifi.sh restart

在web瀏覽器中開啟以下連結以存取NiFi:https://192.168.50.95:8443/nifi ,看到登入頁面後輸入上面的使用者名稱和密碼就可以進入nifi的首頁。
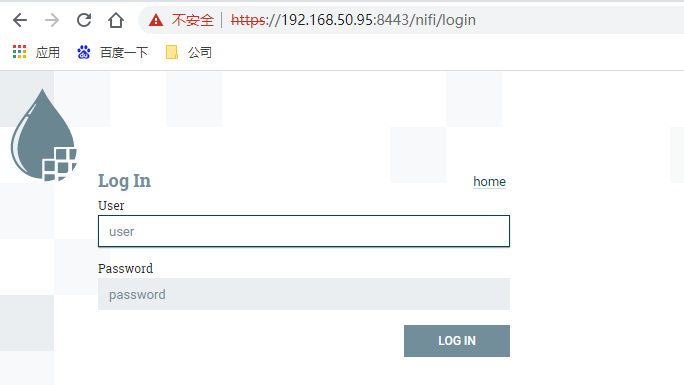
常見處理器
想到建立資料流必須瞭解可供使用的處理器型別,NiFi包含許多開箱即用的不同處理器,這些處理器提供了從許多不同系統攝取資料、路由、轉換、處理、分割和聚合資料以及將資料分發到許多系統的功能。幾乎在每一個NiFi發行版中,可用的處理器數量都會增加。因此將不嘗試為每個可用的處理器命名,下面重點介紹一些最常用的處理器,並根據它們的功能對它們進行分類。
- 資料轉換
- CompressContent:壓縮或解壓縮內容。
- ConvertCharacterSet:將用於對內容進行編碼的字元集轉換為另一個字元集。
- EncryptContent:加密或解密內容。
- ReplaceText:使用正規表示式修改文字內容。
- TransformXml:對XML內容應用XSLT轉換。
- JoltTransformJSON:應用JOLT規範轉換JSON內容
- 路由和中介
- ControlRate:限制資料通過流的一部分的速率。
- DetectDuplicate:基於一些使用者定義的標準,監控重複的flowfile。通常與HashContent一起使用。
- DistributeLoad:通過僅將一部分資料分發到每個使用者定義的關係來實現負載平衡或範例資料。
- MonitorActivity:當用戶定義的一段時間過去了,沒有任何資料通過流中的特定點時,傳送一個通知。可以選擇在資料流恢復時傳送通知。
- RouteOnAttribute:基於屬性th的路由流檔案。
- ScanAttribute:掃描FlowFile上的使用者定義屬性集,檢查是否有任何屬性與使用者定義字典中的術語匹配。
- RouteOnContent:搜尋FlowFile的內容,看它是否匹配任何使用者定義的正規表示式。如果是,則將FlowFile路由到設定的Relationship。
- ScanContent:根據使用者定義的字典和路由中存在或不存在的術語搜尋FlowFile的內容。字典可以由文字項或二進位制項組成。
- ValidateXml:根據XML模式驗證XML內容;根據使用者定義的XML模式,根據FlowFile的內容是否有效來路由FlowFile。
- 資料庫存取
- ConvertJSONToSQL:將JSON檔案轉換為SQL INSERT或UPDATE命令,然後傳遞給PutSQL處理器。
- ExecuteSQL:執行使用者定義的SQL SELECT命令,將結果以Avro格式寫入FlowFile。
- PutSQL:通過執行由FlowFile內容定義的SQL DDM語句來更新資料庫。
- SelectHiveQL:對Apache Hive資料庫執行使用者自定義的HiveQL SELECT命令,將結果以Avro或CSV格式寫入FlowFile。
- PutHiveQL:通過執行由FlowFile的內容定義的HiveQL DDM語句來更新Hive資料庫。
- 屬性提取
- EvaluateJsonPath:使用者提供JSONPath表示式(類似於XPath,用於XML解析/提取),然後根據JSON內容計算這些表示式,以替換FlowFile內容或將值提取到使用者命名的屬性中。
- EvaluateXPath:使用者提供XPath表示式,然後根據XML內容計算這些表示式,以替換FlowFile內容或將值提取到使用者命名的屬性中。
- EvaluateXQuery:使用者提供一個XQuery查詢,然後根據XML內容計算該查詢,以替換FlowFile內容或將值提取到使用者命名的屬性中。
- ExtractText:使用者提供一個或多個正規表示式,然後根據FlowFile的文字內容計算正規表示式,然後將提取的值作為使用者命名的屬性新增。
- 系統互動
- ExecuteProcess:執行使用者自定義的作業系統命令。流程的StdOut被重定向,這樣寫入StdOut的內容就變成了出站FlowFile的內容。這個處理器是一個源處理器——它的輸出預計會生成一個新的FlowFile,而系統呼叫預計不會接收任何輸入。為了向流程提供輸入,請使用ExecuteStreamCommand處理器。
- ExecuteStreamCommand:執行使用者自定義的作業系統命令。FlowFile的內容可選地流到程序的StdIn中。寫入StdOut的內容成為出站FlowFile的內容。
- 資料攝取
- GetFile:將本地磁碟(或網路連線磁碟)中的檔案內容流到NiFi中,然後刪除原始檔案。此處理器預計將檔案從一個位置移動到另一個位置,而不是用於複製資料。
- GetFTP:通過FTP將遠端檔案的內容下載到NiFi,然後刪除原始檔案。此處理器預計將資料從一個位置移動到另一個位置,而不是用於複製資料。
- GetHDFS:監控HDFS中使用者指定的目錄。每當有新檔案進入HDFS時,它就會被複制到NiFi中,然後從HDFS中刪除。此處理器預計將檔案從一個位置移動到另一個位置,而不是用於複製資料。如果在叢集中執行,這個處理器也只能在主節點上執行。為了從HDFS複製資料並保留資料,或者從叢集中的多個節點傳輸資料,請參閱ListHDFS處理器。
- GetKafka:從Apache Kafka中獲取訊息,特別是對於0.8。x版本。訊息可以作為每條訊息的FlowFile發出,也可以使用使用者指定的分隔符將訊息批次處理在一起。
- GetMongo:對MongoDB執行使用者指定的查詢,並將內容寫入新的FlowFile。
- 資料傳送
- PutFile:將FlowFile的內容寫入本地(或網路連線)檔案系統上的目錄。
- PutFTP:將FlowFile的內容複製到遠端FTP伺服器。
- PutKafka:將FlowFile的內容作為訊息傳送給Apache Kafka,特別是0.8。x版本。FlowFile可以作為單個訊息或分隔符傳送,例如可以指定一個新行,以便為單個FlowFile傳送多個訊息。
- PutMongo:將FlowFile的內容作為INSERT或UPDATE傳送到Mongo。
- 拆分和聚合
- SplitText:SplitText接收一個包含文字內容的FlowFile,並根據設定的行數將其拆分為1個或多個FlowFile。例如,處理器可以被設定為將一個FlowFile分割成許多個FlowFile,每個FlowFile只有1行。
- SplitJson:允許使用者將一個由陣列或許多子物件組成的JSON物件拆分為每個JSON元素的FlowFile。
- MergeContent:這個處理器負責將多個FlowFile合併為一個FlowFile。可以通過將它們的內容連同可選的頁首、頁尾和分界符連線在一起,或者通過指定歸檔格式(如ZIP或TAR)來合併flowfile。
入門範例
我們使用演示一個從本地原始檔夾拷貝到本地目的資料夾,主要使用到GetFile檔案資料攝取處理器和PutFile檔案傳送處理器。
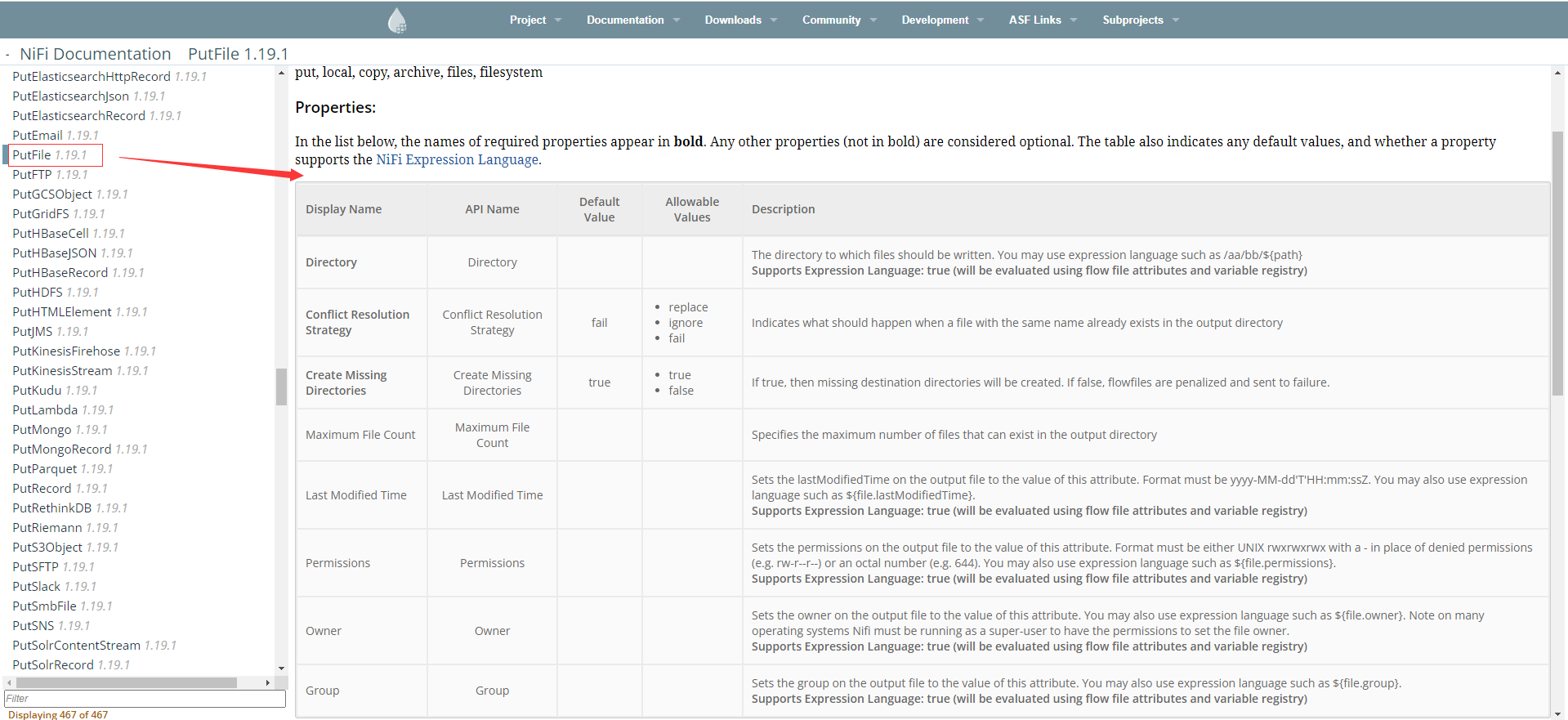
GetFile檔案資料攝取處理器,詳細屬性可以在官方檔案https://nifi.apache.org/docs.html的左邊處理器選單下找,例如GetFile處理器,從目錄中的檔案建立FlowFiles,NiFi將忽略它至少沒有讀許可權的檔案
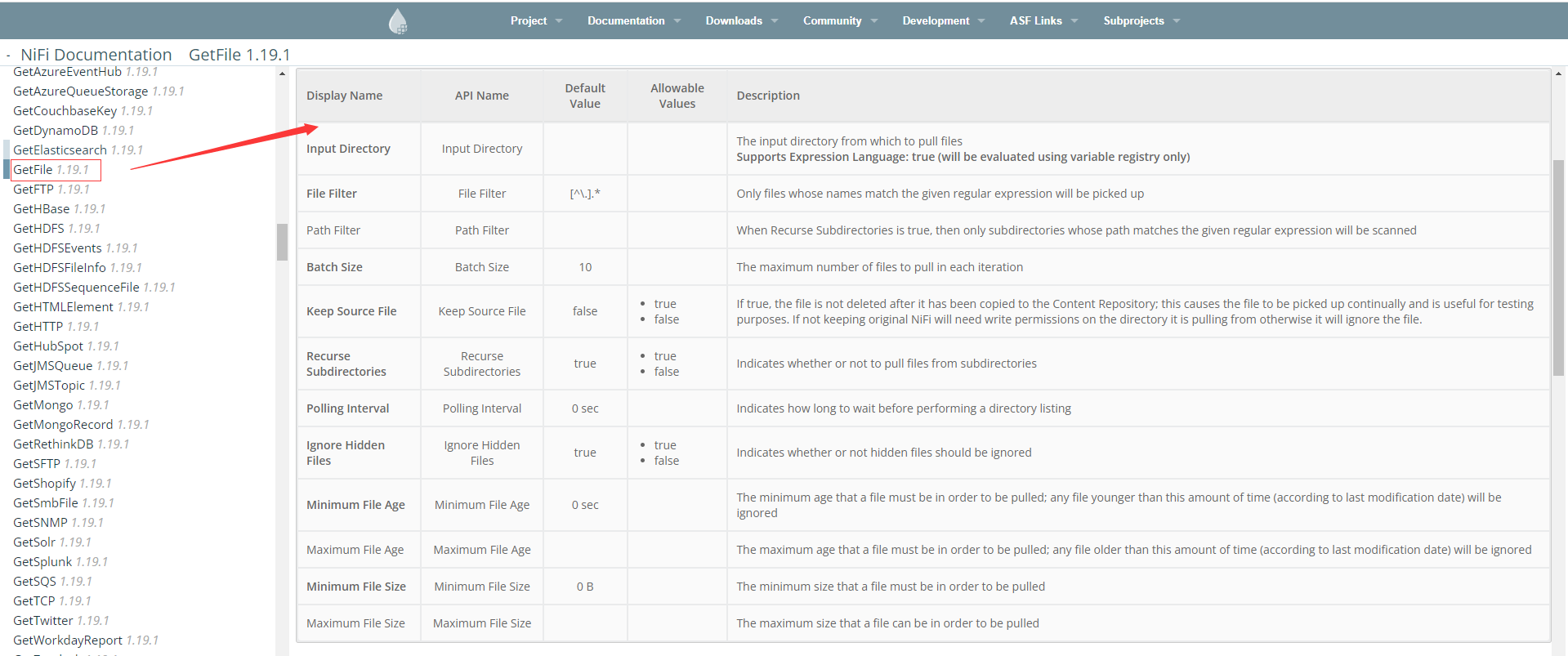
這裡我們使用預設引數,主要設定輸入目錄,新增一個GetFile處理器

"設定"中填寫名稱為my-first-get-file,屬性填寫輸入目錄。
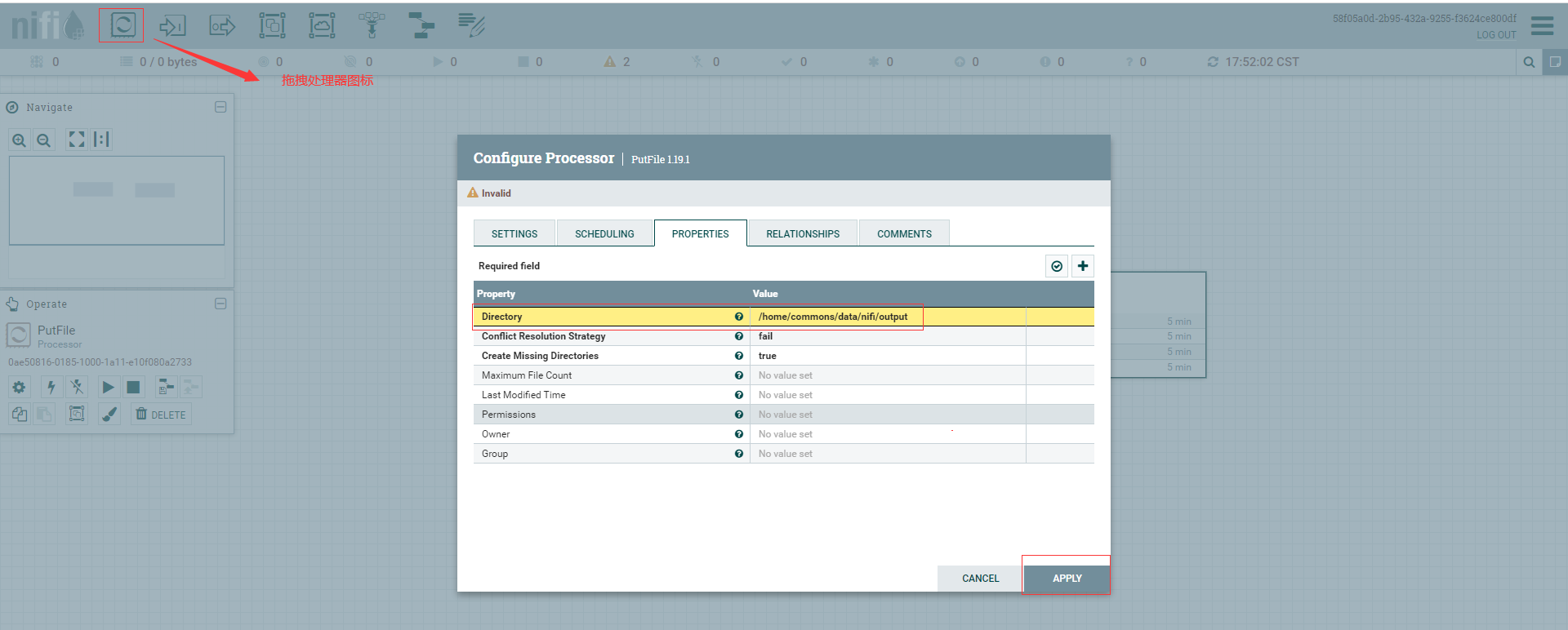
PutFile檔案資料攝取處理器,將FlowFile的內容寫入本地檔案系統,詳細屬性可直接查閱官方檔案
新增一個PutFile處理器,"設定"中填寫名稱為my-first-put-file,屬性填寫目錄

# 建立上傳檔案目錄,如果沒有建立在my-first-put-file的會有感嘆號提示資訊
mkdir /home/commons/data/nifi/input
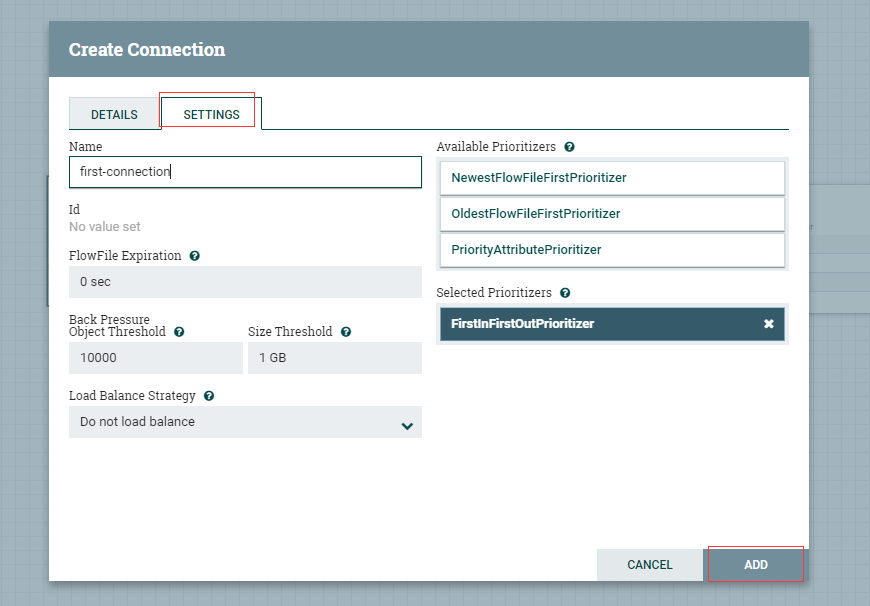
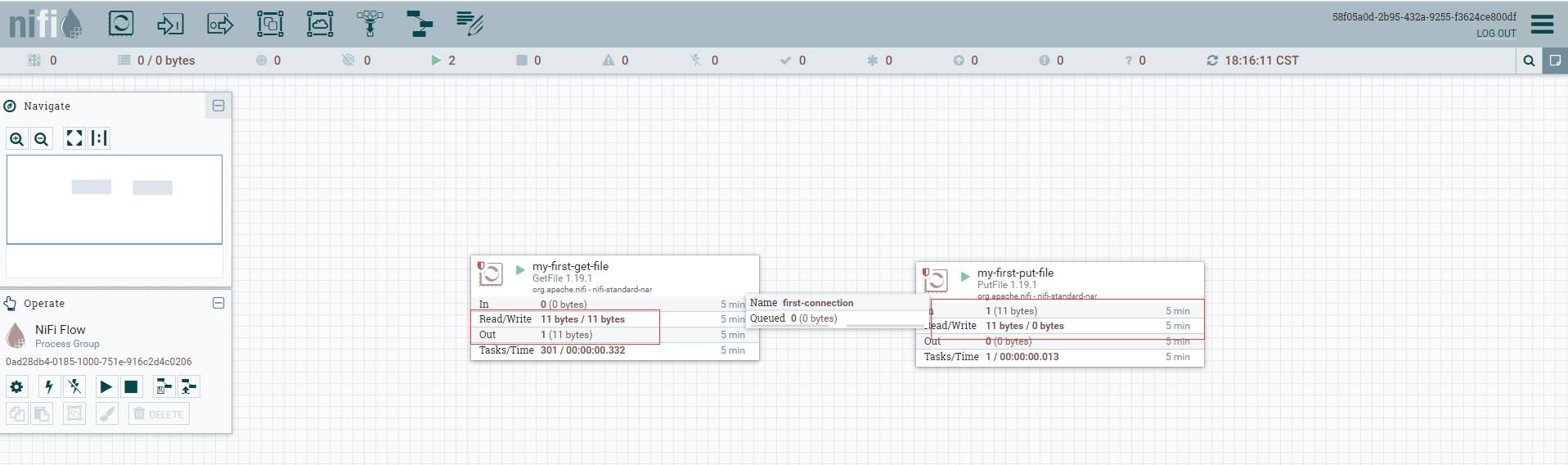
從my-first-get-file上點選拉動到my-first-put-file處理器形成連線,連線名稱為first-connection
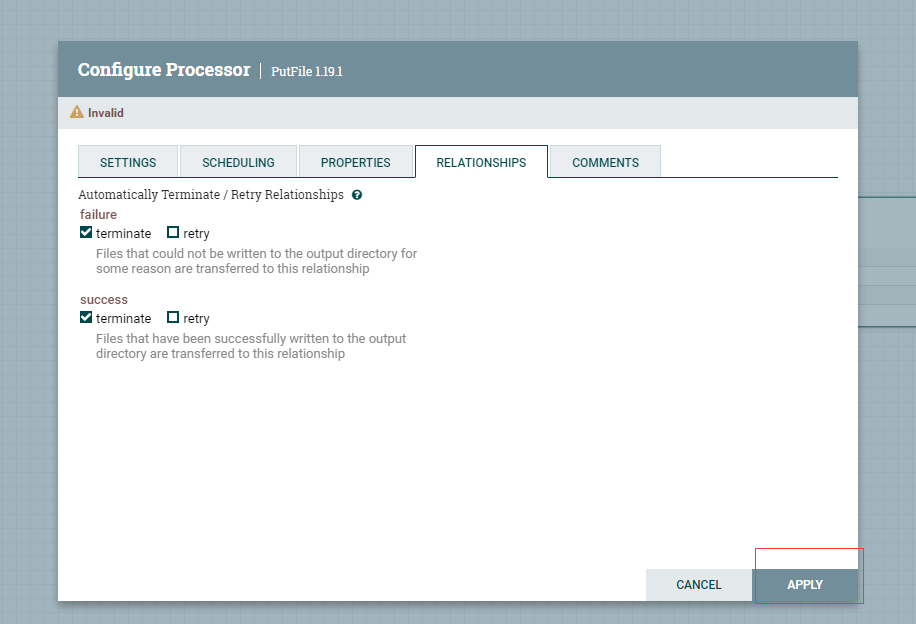
為my-first-put-file設定終止關聯關係
分別點選my-first-get-file和my-first-put-file啟動按鈕,啟動兩個的處理器

# 手工寫入資料檔案
echo "hello nifi" >> /home/commons/data/nifi/input/nifi.log
檢視nifi上可以看到資料檔案有複製資料
檢視原生的output資料夾下也有上面手工寫入後轉移的nifi.log檔案資料(由於PutFile建立缺失的目錄預設屬性設定是true,也即是會自動建立目錄)
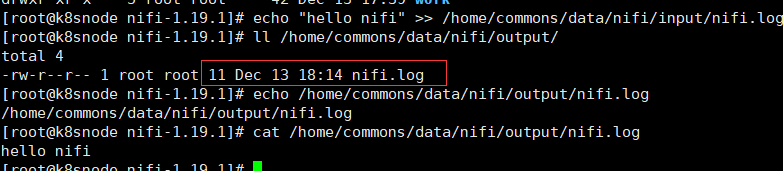
本地input檔案轉移就沒有檔案,重新執行上面寫入一個重名的檔案
echo "hello nifi" >> /home/commons/data/nifi/input/nifi.log
由於PutFile衝突解決的策略預設為false,所以同名檔案不會放到輸出目錄下,就直接在頁面出現警告資訊,可設定為true就不會有警告資訊了

本篇只是簡單入門,nifi的功能非常強大,針對資料採集和資料整合場景需求可以滿足大多數的場景
本人部落格網站IT小神 www.itxiaoshen.com