解讀JVM級別本地快取Caffeine青出於藍的要訣2 —— 弄清楚Caffeine的同步、非同步回源方式

大家好,又見面了。
本文是筆者作為掘金技術社群簽約作者的身份輸出的快取專欄系列內容,將會通過系列專題,講清楚快取的方方面面。如果感興趣,歡迎關注以獲取後續更新。
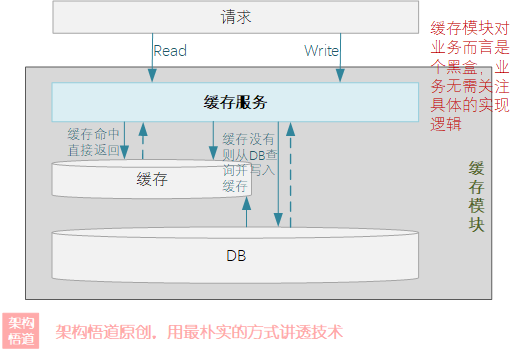
上一篇文章中,我們繼Guava Cache之後,又認識了青出於藍的Caffeine。作為一種對外提供黑盒快取能力的專門元件,Caffeine基於穿透型快取模式進行構建。也即對外提供資料查詢介面,會優先在快取中進行查詢,若命中快取則返回結果,未命中則嘗試去真正的源端(如:資料庫)去獲取資料並回填到快取中,返回給呼叫方。
與Guava Cache相似,Caffeine的回源填充主要有兩種手段:
-
Callable方式 -
CacheLoader方式
根據執行呼叫方式不同,又可以細分為同步阻塞方式與非同步非阻塞方式。
本文我們就一起探尋下Caffeine的多種不同的資料回源方式,以及對應的實際使用。

同步方式
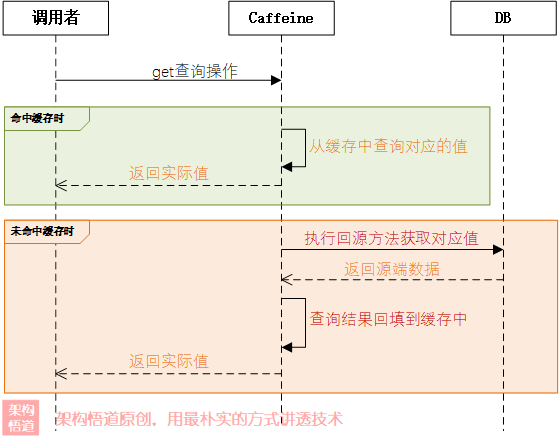
同步方式是最常被使用的一種形式。查詢快取、資料回源、資料回填快取、返回執行結果等一系列操作都是在一個呼叫執行緒中同步阻塞完成的。
Callable
在每次get請求的時候,傳入一個Callable函數式介面具體實現,當沒有命中快取的時候,Caffeine框架會執行給定的Callable實現邏輯,去獲取真實的資料並且回填到快取中,然後返回給呼叫方。
public static void main(String[] args) {
Cache<String, User> cache = Caffeine.newBuilder().build();
User user = cache.get("123", s -> userDao.getUser(s));
System.out.println(user);
}
Callable方式的回源填充,有個明顯的優勢就是呼叫方可以根據自己的場景,靈活的給定不同的回源執行邏輯。但是這樣也會帶來一個問題,就是如果需要獲取快取的地方太多,會導致每個呼叫的地方都得指定下對應Callable回源方法,呼叫起來比較麻煩,且對於需要保證回源邏輯統一的場景管控能力不夠強勢,無法約束所有的呼叫方使用相同的回源邏輯。
這種時候,便需要CacheLoader登場了。
CacheLoader
在建立快取物件的時候,可以通在build()方法中傳入指定的CacheLoader物件的方式來指定回源時預設使用的回源資料載入器,這樣當使用方呼叫get方法獲取不到資料的時候,框架就會自動使用給定的CacheLoader物件執行對應的資料載入邏輯。
比如下面的程式碼中,便在建立快取物件時指定了當快取未命中時通過userDao.getUser()方法去DB中執行資料查詢操作:
public LoadingCache<String, User> createUserCache() {
return Caffeine.newBuilder()
.maximumSize(10000L)
.build(key -> userDao.getUser(key));
}
相比於Callable方式,CacheLoader更適用於所有回源場景使用的回源策略都固定且統一的情況。對具體業務使用的時候更加的友好,呼叫get方法也更加簡單,只需要傳入帶查詢的key值即可。
上面的範例程式碼中還有個需要關注的點,即建立快取物件的時候指定了CacheLoader,最終建立出來的快取物件是LoadingCache型別,這個型別是Cache的一個子類,擴充套件提供了無需傳入Callable引數的get方法。進一步地,我們列印出對應的詳細類名,會發現得到的快取物件具體型別為:
com.github.benmanes.caffeine.cache.BoundedLocalCache.BoundedLocalLoadingCache
當然,如果建立快取物件的時候沒有指定最大容量限制,則建立出來的快取物件還可能會是下面這個:
com.github.benmanes.caffeine.cache.UnboundedLocalCache.UnboundedLocalManualCache
通過UML圖,可以清晰的看出其與Cache之間的繼承與實現鏈路情況:
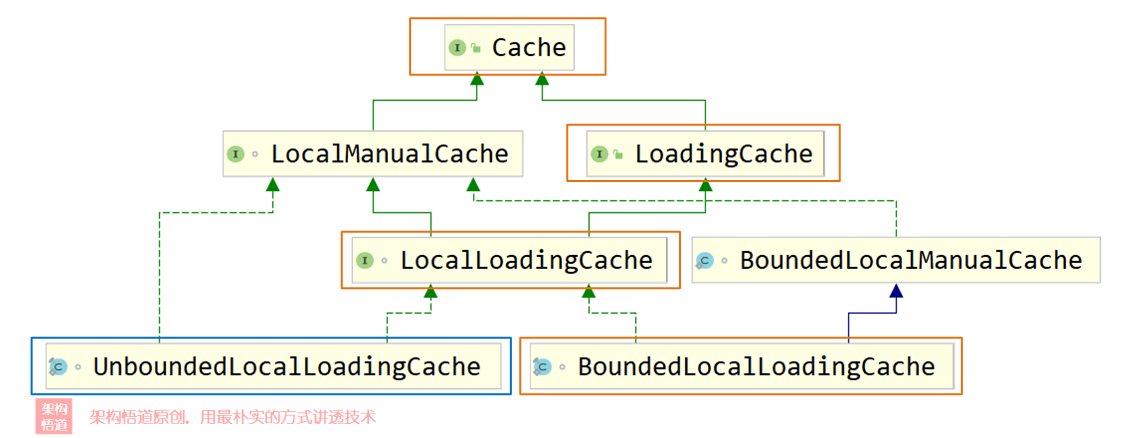
因為LoadingCache是Cache物件的子類,根據JAVA中類繼承的特性,LoadingCache也完全具備Cache所有的介面能力。所以,對於大部分場景都需要固定且統一的回源方式,但是某些特殊場景需要自定義回源邏輯的情況,也可以通過組合使用Callable的方式來實現。
比如下面這段程式碼:
public static void main(String[] args) {
LoadingCache<String, User> cache = Caffeine.newBuilder().build(userId -> userDao.getUser(userId));
// 使用CacheLoader回源
User user = cache.get("123");
System.out.println(user);
// 使用自定義Callable回源
User techUser = cache.get("J234", userId -> {
// 僅J開頭的使用者ID才會去回源
if (!StringUtils.isEmpty(userId) && userId.startsWith("J")) {
return userDao.getUser(userId);
} else {
return null;
}
});
System.out.println(techUser);
}
上述程式碼中,構造的是一個指定了CacheLoader的LoadingCache快取型別,這樣對於大眾場景可以直接使用get方法由CacheLoader提供統一的回源能力,而特殊場景中也可以在get方法中傳入需要的客製化化回源Callable邏輯。
不回源
在實際的快取應用場景中,並非是所有的場景都要求快取沒有命中的時候要去執行回源查詢。對於一些業務規劃上無需執行回源操作的請求,也可以要求Caffeine不要執行回源操作(比如黑名單列表,只要使用者在黑名單就禁止操作,不在黑名單則允許繼續往後操作,因為大部分請求都不會命中到黑名單中,所以不需要執行回源操作)。為了實現這一點,在查詢操作的時候,可以使用Caffeine提供的免回源查詢方法來實現。
具體梳理如下:
| 介面 | 功能說明 |
|---|---|
| getIfPresent | 從記憶體中查詢,如果存在則返回對應值,不存在則返回null |
| getAllPresent | 批次從記憶體中查詢,如果存在則返回存在的鍵值對,不存在的key則不出現在結果集裡 |
程式碼使用演示如下:
public static void main(String[] args) {
LoadingCache<String, User> cache = Caffeine.newBuilder().build(userId -> userDao.getUser(userId));
cache.put("124", new User("124", "張三"));
User userInfo = cache.getIfPresent("123");
System.out.println(userInfo);
Map<String, User> presentUsers =
cache.getAllPresent(Stream.of("123", "124", "125").collect(Collectors.toList()));
System.out.println(presentUsers);
}
執行結果如下,可以發現執行的過程中並沒有觸發自動回源與回填操作:
null
{124=User(userName=張三, userId=124)}
非同步方式
CompletableFuture並行流水線能力,是JAVA8在非同步程式設計領域的一個重大改進。可以將一系列耗時且無依賴的操作改為並行同步處理,並等待各自處理結果完成後繼續進行後續環節的處理,由此來降低阻塞等待時間,進而達到降低請求鏈路時長的效果。
很多小夥伴對JAVA8之後的CompletableFuture並行處理能力接觸的不是很多,有興趣的可以移步看下我之前專門介紹JAVA8流水線並行處理能力的介紹《JAVA基於CompletableFuture的流水線並行處理深度實踐,滿滿乾貨》,相信可以讓你對ComparableFututre並行程式設計有全面的認識與理解。
Caffeine完美的支援了在非同步場景下的流水線處理使用場景,回源操作也支援非同步的方式來完成。
非同步Callable
要想支援非同步場景下使用快取,則建立的時候必須要建立一個非同步快取型別,可以通過buildAsync()方法來構建一個AsyncCache型別快取物件,進而可以在非同步場景下進行使用。
看下面這段程式碼:
public static void main(String[] args) {
AsyncCache<String, User> asyncCache = Caffeine.newBuilder().buildAsyn();
CompletableFuture<User> userCompletableFuture = asyncCache.get("123", s -> userDao.getUser(s));
System.out.println(userCompletableFuture.join());
}
上述程式碼中,get方法傳入了Callable回源邏輯,然後會開始非同步的載入處理操作,並返回了個CompletableFuture型別結果,最後如果需要獲取其實際結果的時候,需要等待其非同步執行完成然後獲取到最終結果(通過上述程式碼中的join()方法等待並獲取結果)。
我們可以比對下同步和非同步兩種方式下Callable邏輯執行執行緒情況。看下面的程式碼:
public static void main(String[] args) {
System.out.println("main thread:" + Thread.currentThread().getId());
// 同步方式
Cache<String, User> cache = Caffeine.newBuilder().build();
cache.get("123", s -> {
System.out.println("同步callable thread:" + Thread.currentThread().getId());
return userDao.getUser(s);
});
// 非同步方式
AsyncCache<String, User> asyncCache = Caffeine.newBuilder().buildAsync();
asyncCache.get("123", s -> {
System.out.println("非同步callable thread:" + Thread.currentThread().getId());
return userDao.getUser(s);
});
}
執行結果如下:
main thread:1
同步callable thread:1
非同步callable thread:15
結果很明顯的可以看出,同步處理邏輯中,回源操作直接佔用的呼叫執行緒進行操作,而非同步處理時則是單獨執行緒負責回源處理、不會阻塞呼叫執行緒的執行 —— 這也是非同步處理的優勢所在。
看到這裡,也許會有小夥伴有疑問,雖然是非同步執行的回源操作,但是最後還是要在呼叫執行緒裡面阻塞等待非同步執行結果的完成,似乎沒有看出非同步有啥優勢?
非同步處理的魅力,在於當一個耗時操作執行的同時,主執行緒可以繼續去處理其它的事情,然後其餘事務處理完成後,直接去取非同步執行的結果然後繼續往後處理。如果主執行緒無需執行其餘處理邏輯,完全是阻塞等待非同步執行緒載入完成,這種情況確實沒有必要使用非同步處理。
想象一個生活中的場景:
週末休息的你出去逛街,去咖啡店點了一杯咖啡,然後服務員會給你一個訂單小票。
當服務員在後臺製作咖啡的時候,你並沒有在店裡等待,而是出門到隔壁甜品店又買了個麵包。
當面包買好之後,你回到咖啡店,拿著訂單小票去取咖啡。
取到咖啡後,你邊喝咖啡邊把麵包吃了……嗝~
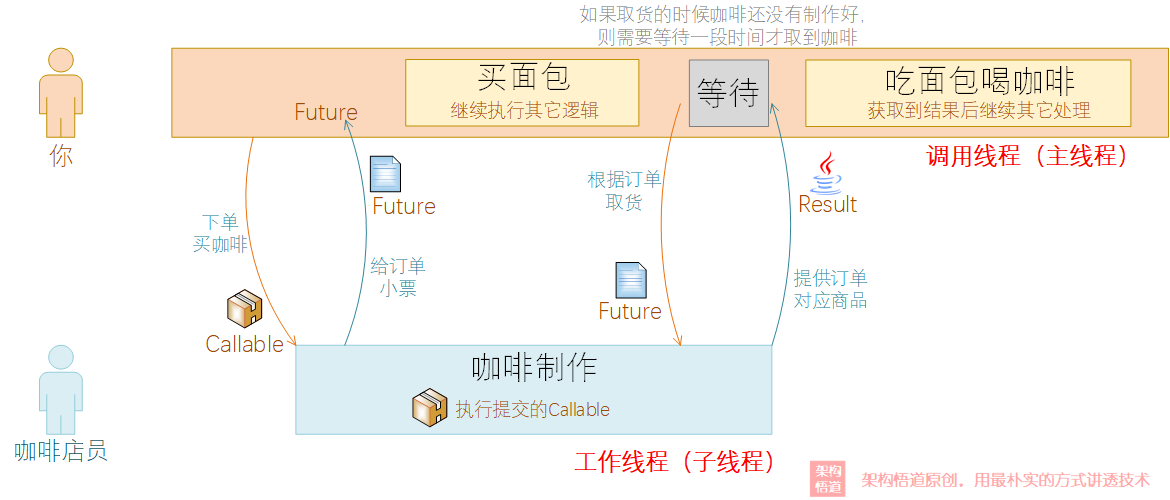
這種情況應該比較好理解了吧?如果是同步處理,你買咖啡的時候,需要在咖啡店一直等到咖啡做好然後才能再去甜品店買麵包,這樣耗時就比較長了。而採用非同步處理的策略,你在等待咖啡製作的時候,繼續去甜品店將麵包買了,然後回來等待咖啡完成,這樣整體的時間就縮短了。當然,如果你只想買個咖啡,也不需要買甜品麵包,即你等待咖啡製作期間沒有別的事情需要處理,那這時候你在不在咖啡店一直等到咖啡完成,都沒有區別。
回到程式碼層面,下面程式碼演示了非同步場景下AsyncCache的使用。
public boolean isDevUser(String userId) {
// 獲取使用者資訊
CompletableFuture<User> userFuture = asyncCache.get(userId, s -> userDao.getUser(s));
// 獲取公司研發體系部門列表
CompletableFuture<List<String>> devDeptFuture =
CompletableFuture.supplyAsync(() -> departmentDao.getDevDepartments());
// 等使用者資訊、研發部門列表都拉取完成後,判斷使用者是否屬於研發體系
CompletableFuture<Boolean> combineResult =
userFuture.thenCombine(devDeptFuture,
(user, devDepts) -> devDepts.contains(user.getDepartmentId()));
// 等待執行完成,呼叫執行緒獲取最終結果
return combineResult.join();
}
在上述程式碼中,需要獲取到使用者詳情與研發部門列表資訊,然後判斷使用者對應的部門是否屬於研發部門,從而判斷員工是否為研發人員。整體採用非同步程式設計的思路,並使用了Caffeine非同步快取的操作方式,實現了使用者獲取與研發部門列表獲取這兩個耗時操作並行的處理,提升整體處理效率。
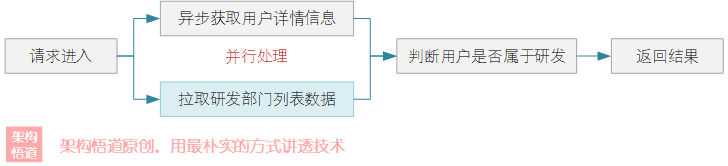
非同步CacheLoader
非同步處理的時候,Caffeine也支援直接在建立的時候指定CacheLoader物件,然後生成支援非同步回源操作的AsyncLoadingCache快取物件,然後在使用get方法獲取結果的時候,也是返回的CompletableFuture非同步封裝型別,滿足在非同步程式設計場景下的使用。
public static void main(String[] args) {
try {
AsyncLoadingCache<String, User> asyncLoadingCache =
Caffeine.newBuilder().maximumSize(1000L).buildAsync(key -> userDao.getUser(key));
CompletableFuture<User> userCompletableFuture = asyncLoadingCache.get("123");
System.out.println(userCompletableFuture.join());
} catch (Exception e) {
e.printStackTrace();
}
}
非同步AsyncCacheLoader
除了上述這種方式,在建立的時候給定一個用於回源處理的CacheLoader之外,Caffeine還有一個buildAsync的過載版本,允許傳入一個同樣是支援非同步並行處理的AsyncCacheLoader物件。使用方式如下:
public static void main(String[] args) {
try {
AsyncLoadingCache<String, User> asyncLoadingCache =
Caffeine.newBuilder().maximumSize(1000L).buildAsync(
(key, executor) -> CompletableFuture.supplyAsync(() -> userDao.getUser(key), executor)
);
CompletableFuture<User> userCompletableFuture = asyncLoadingCache.get("123");
System.out.println(userCompletableFuture.join());
} catch (Exception e) {
e.printStackTrace();
}
}
與上一章節中的程式碼比對可以發現,不管是使用CacheLoader還是AsyncCacheLoader物件,最終生成的快取型別都是AsyncLoadingCache型別,使用的時候也並沒有實質性的差異,兩種方式的差異點僅在於傳入buildAsync方法中的物件型別不同而已,使用的時候可以根據喜好自行選擇。
進一步地,如果我們嘗試將上面程式碼中的asyncLoadingCache快取物件的具體型別列印出來,我們會發現其具體型別可能是:
com.github.benmanes.caffeine.cache.BoundedLocalCache.BoundedLocalAsyncLoadingCache
而如果我們在構造快取物件的時候沒有限制其最大容量資訊,其構建出來的快取物件型別還可能會是下面這個:
com.github.benmanes.caffeine.cache.UnboundedLocalCache.UnboundedLocalAsyncLoadingCache
與前面同步方式一樣,我們也可以看下這兩個具體的快取型別對應的UML類圖關係:
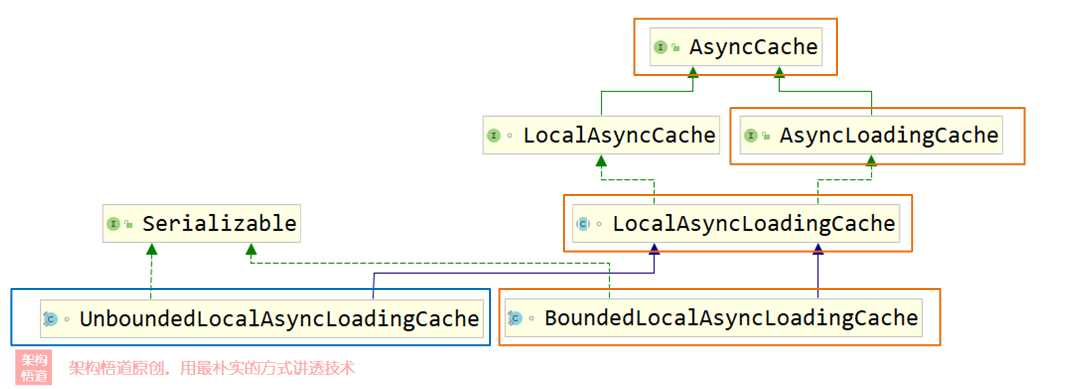
可以看出,非同步快取不同型別最終都實現了同一個AsyncCache頂層介面類,而AsyncLoadingCache作為繼承自AsyncCache的子類,除具備了AsyncCache的所有介面外,還額外擴充套件了部分的介面,以支援未命中目標時自動使用指定的CacheLoader或者AysncCacheLoader物件去執行回源邏輯。
小結回顧
好啦,關於Caffeine Cache的同步、非同步資料回源操作原理與使用方式的闡述,就介紹到這裡了。不知道小夥伴們是否對Caffeine Cache的回源機制有了全新的認識了呢?而關於Caffeine Cache,你是否有自己的一些想法與見解呢?歡迎評論區一起交流下,期待和各位小夥伴們一起切磋、共同成長。
下一篇文章中,我們將深入講解下Caffeine改良過的非同步資料驅逐處理實現,以及Caffeine支援的多種不同的資料淘汰驅逐機制和對應的實際使用。如有興趣,歡迎關注後續更新。