雲原生時代資料庫運維體系演進
作者:vivo 網際網路伺服器團隊- Deng Song
本文根據鄧鬆老師在「2022 vivo開發者大會"現場演講內容整理而成。
資料庫運維面臨著大規模資料庫範例難以有效運維、資料庫難以做好資源彈性伸縮以及個人隱私資料安全難以保障這三個方面的挑戰。對此,vivo給出了自身的應對方案。
首先,vivo自研了資料庫運維平臺DaaS來支撐資料庫運維工作。在規模覆蓋、效率提升、故障告警處理等層面均衡發力,保障了資料的穩定性,以工單自助,故障自愈為核心,實現了資料庫的高效運維。
其次,在資料庫資源彈性管理層面,vivo重視資源成本優化。圍繞資源分配、資源彈性伸縮、資源隔離分別給出了智慧化解決方案,並通過套餐自動優化,進一步降低了管理成本。
最後,基於個人隱私資料,平臺也提供了對業務幾乎無影響的MySQL的透明加密方案,來減輕因為隱私資料加密帶來的研發和運維工作量。
一、雲原生時代資料庫運維挑戰
1.1 資料庫運維體系演進
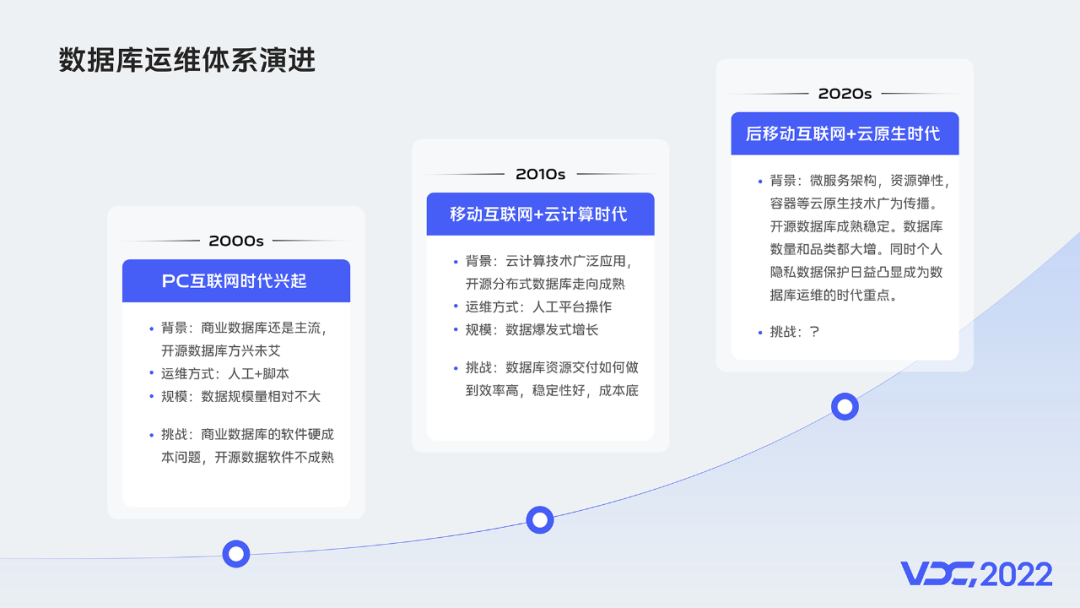
從資料庫運維繫的演進歷程來看,
1、2000年左右,PC網際網路時代興起,商業資料庫是市場主流,而開源資料庫方興未艾。普遍的資料庫運維方式,還是人工加指令碼,當時大部分公司資料庫規模量相對不大,這樣做完全夠用。人們面臨的主要運維挑戰是商業資料庫軟硬體成本高,而開源資料庫軟體和配套工具不成熟,通常要自研來滿足開源資料庫自身的穩定性和擴充套件性要求,門檻高。
2、到了2010年左右,行動網際網路時代興起,社會數位化程序陡然加速,資料量規模大增。此時,一個針對IT基礎設施的革命性的概念提出來了,那就是雲端計算,簡單來說,就是通過網路的方式提供伺服器,資料庫,或者某種軟體服務資源。在資料庫運維領域,則自然衍生出了雲端計算的一個分支概念,DaaS,data as a service,資料庫的運維方式因此由人工指令碼方式轉變為了資料庫平臺的方式。同時,隨著開源資料庫技術以及各種周邊生態軟體走向成熟,開源資料庫得到了廣泛應用。這時,資料庫運維的挑戰變成了如何高效率交付資源,保障資料庫穩定性,做好資料庫成本優化。
3、到了2020年左右,後行動網際網路時代,社會數位化程度進一步加深。雲原生的概念被提了出來。微服務架構,資源彈性,容器等雲原生技術廣為傳播。資料庫的穩定性方面,因為開源資料庫的高可用體系普遍成熟而大大緩解。資料庫規模方面,範例數量和品類都進一步大增。資料庫安全方面,2021年8月我國正式出臺了個人資訊保護法,個人隱私資料保護成為了資料庫運維的時代重點。
1.2 雲原生時代挑戰
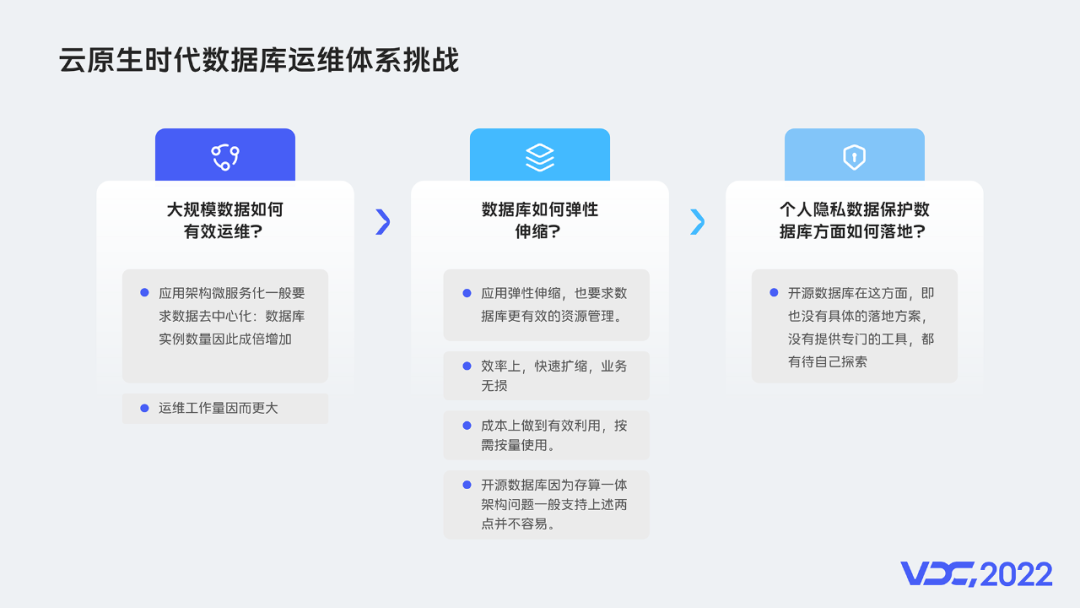
這樣的時代背景下,我以為資料庫運維主要有三個方面的挑戰:
-
雲原生時代應用架構普遍微服務化,一個系統拆成多個微服務,這個系統的資料庫也分拆成多個。這導致資料庫範例成倍增加,資料庫的運維工作量也成倍增加。因此大規模資料庫範例如何有效運維?這就是第一個挑戰。
-
雲原生理念應用架構層面的彈性伸縮,自然也要求資料庫層面做到彈性伸縮。具體來說,是效率上做到快速擴縮,業務無失真,成本上也要做到,按需按量使用。但是主流開源資料庫本身是存算一體架構,這兩點支援不容易。資料庫如何做好資源彈性伸縮?這是第二個挑戰。
-
資料庫安全方面,個人隱私資料需要保護,這個必要性無需多說,但是怎麼技術落地?怎麼識別個人隱私資料,識別之後又如何進行資料加密。而開源資料庫在這方面,即也沒有具體的落地方案,沒有提供專門的工具,這些都有待自己探索。這是第三個挑戰。
挑戰講完了,接下來我們看下vivo在這三個挑戰方向的應對。
二、vivo 大規模資料庫範例高效運維
2.1 高效運維實踐現狀

vivo是自研了資料庫運維平臺DaaS來支撐資料庫運維工作。
-
規模上,支撐了數萬資料庫範例的運維服務,包含了6種資料庫:MySQL,Redis,MongoDB,Elasticsearch,TiDB5個開源資料庫,1個公司內部自研的磁碟KV。
-
效率上,節省了92%的資料庫運維工作量。月均數千的總工單量,其中92%都是無需運維參與,由平臺使用者自助執行。
-
故障告警處理上,70%的資料庫告警實現自動分析或者處理,進一步解放了資料庫運維人力,保障了資料穩定性。
綜上所述,資料庫高效運維的核心就是,工單自助,故障自愈。接下來將詳細介紹這兩點。
2.2 工單自助
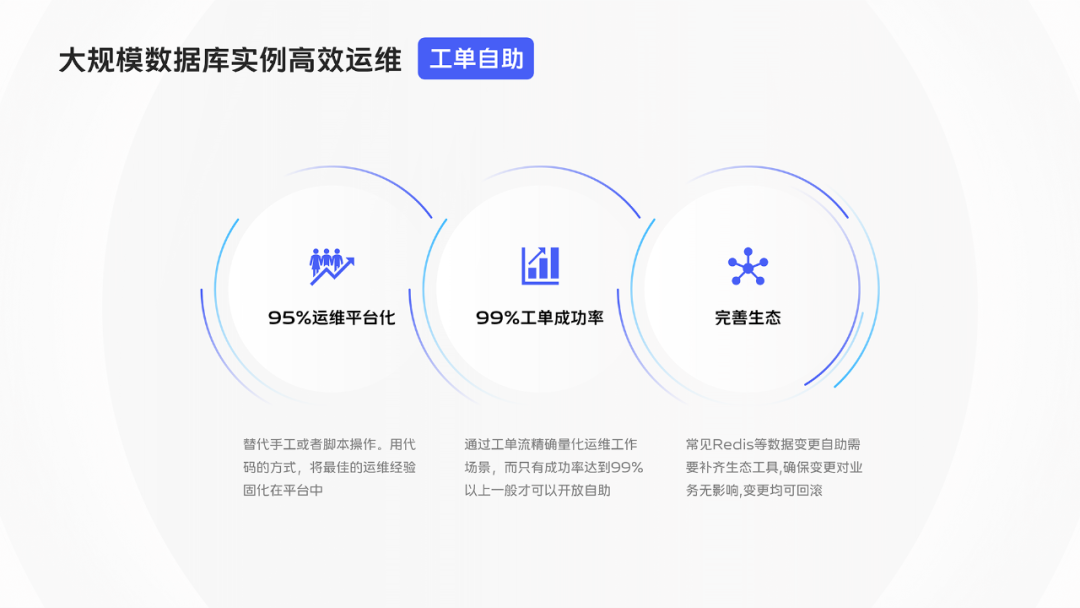
首先看工單自助,要實現工單自助,主要有三點:
-
95%運維操作平臺化,用平臺操作替代手工或者指令碼操作。所謂平臺化的本質,就是用程式碼的方式,將最佳的運維經驗固化在平臺中。這才是一切運維效率的基礎。
-
99%工單成功率,一方面是要做到,所有運維操作都有工單流記錄,這是運維工作量化和進步的基礎;另一方面,因為異常的工單還是要資料庫專業運維介入處理的,所以只有工單一鍵執行成功率達到99%以上才可以開放自助,才談得上提升了效率。
-
部分開源資料庫生態工具是空白的,例如常見資料庫Redis 要資料變更自助,一方面需要做到變更過程業務無影響,這要求做好變革速度&負載控制,變更前排除大key等風險因素。另一方面還需要做到變更過程資料安全,這要求變更前做好備份,變更後可隨時回滾。這些都沒有現成開源工具整合,vivo是通過自研逐個填補了這些工具空白。
2.3 故障自愈
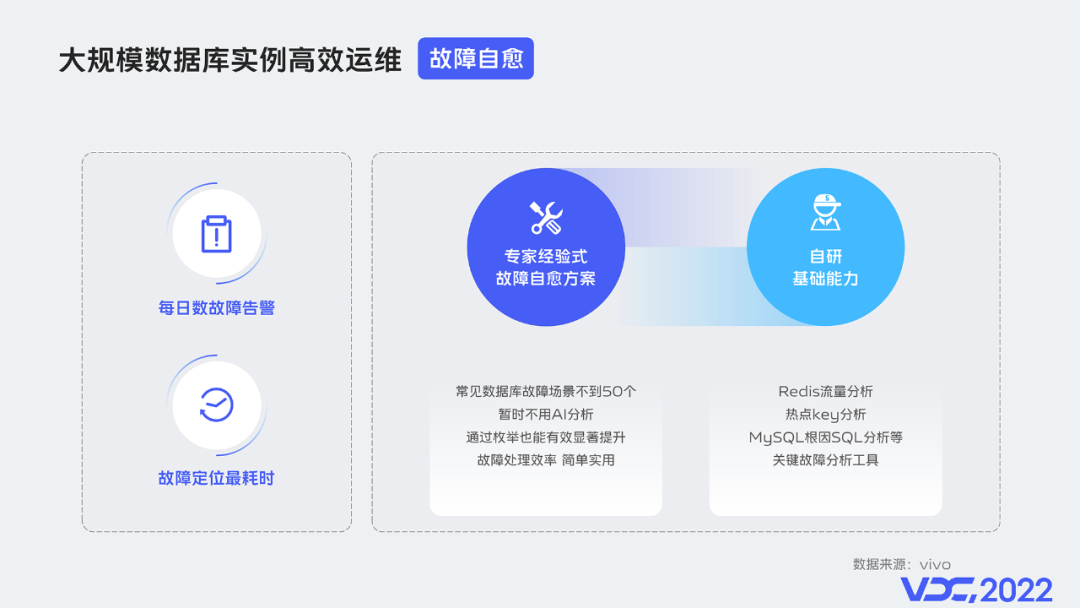
隨著資料庫規模的成倍增加,故障告警的數目也急劇增多,vivo日均數百資料庫故障告警,存粹靠手工進行告警問題排查處理越來越不能滿足資料庫穩定性的要求。
資料庫故障自愈的需求就被自然提了出來。故障處理簡單分為:發現,定位,恢復 三個步驟,針對已經發生的故障我們反覆分析確認,其中定位環節是最耗時,所以當前故障自愈系統主要做的就是故障分析定位的工作。整體上故障自愈主要是兩個難點,一個故障自愈方案的確認,另一個是相關基礎工具的開發。
通常認為故障自愈方案最好是全面資訊採集+機器學習自動確認的,這樣的方案具備普適性,也更有效率且準確。但是立足於團隊和問題現狀,我們認為當前的故障自愈方案可以是全基於運維專家經驗確認的。這是因為在資料庫運維方向,目前常見資料庫相關故障場景不到50個,且變數因素單一,所以即便憑藉優秀專家經驗列舉處理辦法,也能自動解決大部分故障,簡單實用。另外在故障自愈的基礎工具上,我們主要自研了:Redis流量分析,熱key分析,MySQL 根因SQL分析等工具。
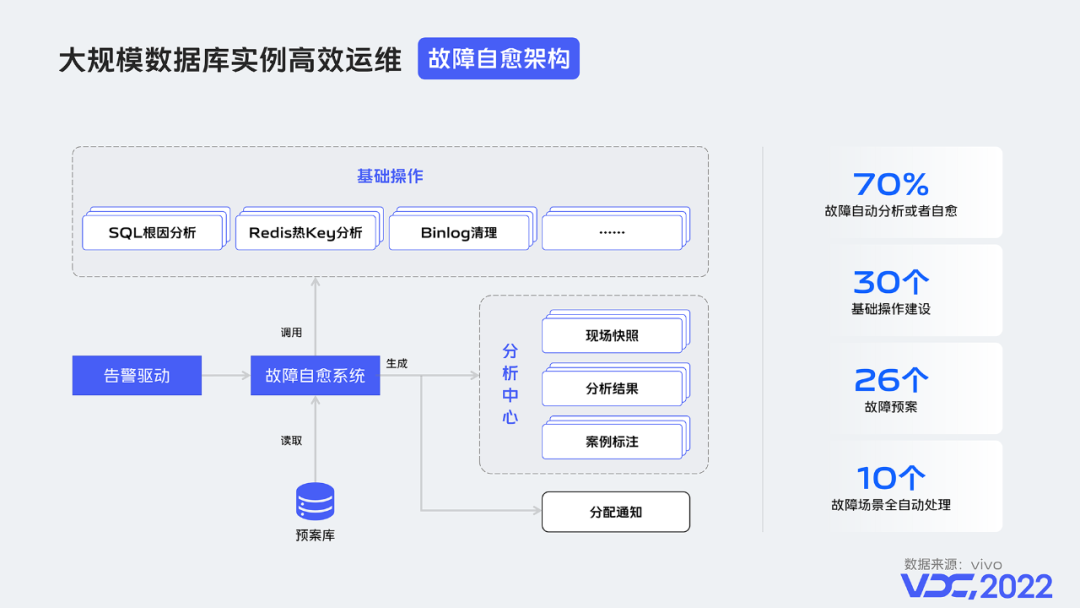
接下來介紹故障自愈的邏輯架構:
整個系統是由故障告警驅動,系統獲取到告警訊息後去查詢相匹配的預案,然後執行預案中設定的基礎操作,包括分析操作和恢復操作,例如Redis流量分析或者MySQL binlog清理等,最終生成執行報告,其中包括中間狀態的現場監控快照,智慧的分析結果等,同時也提供案例標註的能力。最後執行結果會自動分配並通知到對應負責的資料庫運維人員或者訊息群組當中。
通過這套架構,最後實現了超70%的故障自動分析或者處理,包括至少30個基礎能力建設,26個故障預案,10個故障場景全自動處理。
三、vivo 資料庫彈性資源管理
3.1 資源彈性管理問題&現狀
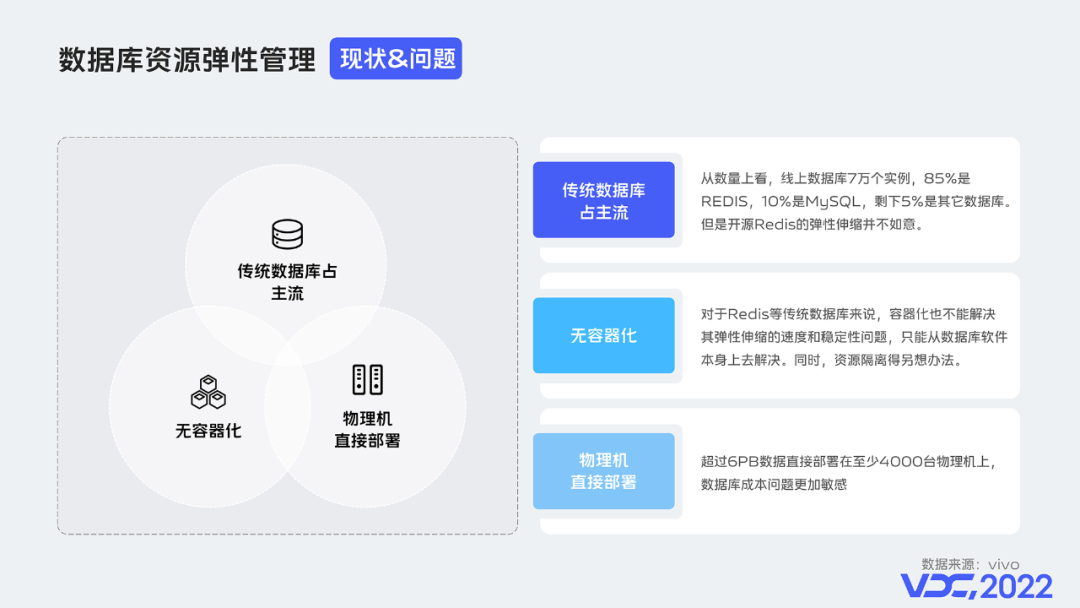
我們先來看vivo資料庫資源管理上要面臨的現狀和問題:
-
傳統資料庫佔主流,從數量上看,線上資料庫數萬個範例,85%是REDIS,10%是MySQL,剩下5%是其它資料庫。都是存算一體的傳統資料庫,彈性伸縮能力並不完美,例如開源Redis Cluster的彈性伸縮是單執行緒的,上了一定資料規模後其擴縮速度和穩定性都有待進一步提升。
-
當前資料庫資源管理還沒有容器化,資料庫資源隔離得另想辦法。同時對於Redis等傳統資料庫來說,容器化也不能解決其彈性伸縮的速度和穩定性問題,這些都只能從資料庫軟體本身上去解決。
-
目前資料庫資源都是直接部署在物理機上,PB級資料直接部署在數千臺物理機上,資料庫成本問題比較敏感。
3.2 資源彈性管理主要實現點

針對上述問題,vivo資料庫平臺主要做了如下工作:
-
資源分配上,實行單機器多範例多版本多套餐混合部署,同類資料庫資源池統一,提升資源利用率。
-
資源彈性伸縮上,自研多執行緒Redis Cluster擴縮工具,顯著加速Redis Cluster擴縮容過程,同時增加限速,大key巡檢,歷史負載檢測,腦裂檢測等功能儘量增擴縮容穩定性。
-
資源隔離上,則採用兩個措施。
(1)程式設定實現隔離,如Redis,執行緒模型決定了幾乎只消耗一個CPU核心,而記憶體佔用也主要由設定決定,其它網路磁碟很少存在爭用,所以混部就沒隔離問題了。
(2)通過巡檢和容量預測的方式實現軟隔離,儘量解決非突增的資源爭用問題。
3.3 套餐自動優化
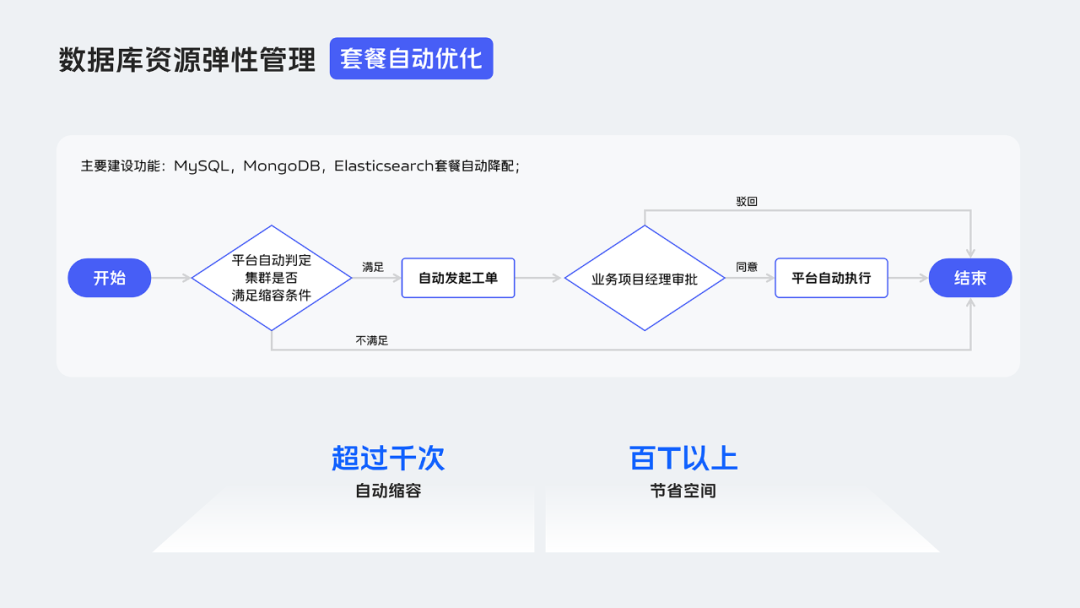
在資源成本優化上,除了剛才提過的混合部署,還可以做套餐自動優化,進一步降低成本。
下面介紹下具體的套餐自動優化流程:
-
第一步 平臺自動掃描全網資料庫範例,挑出其中被認定是滿足縮容條件的。
-
第二步 平臺自動傳送縮容工單交由範例對應的業務專案經理審批。
-
第三步 根據審批結果執行縮容,或者放棄本次縮容。
大概在這個功能上線後的4個月內,平臺自動發起超千次縮容,節省了超百T空間。
四、vivo個人隱私資料全鏈路保護
4.1 隱私保護資料庫層面現狀
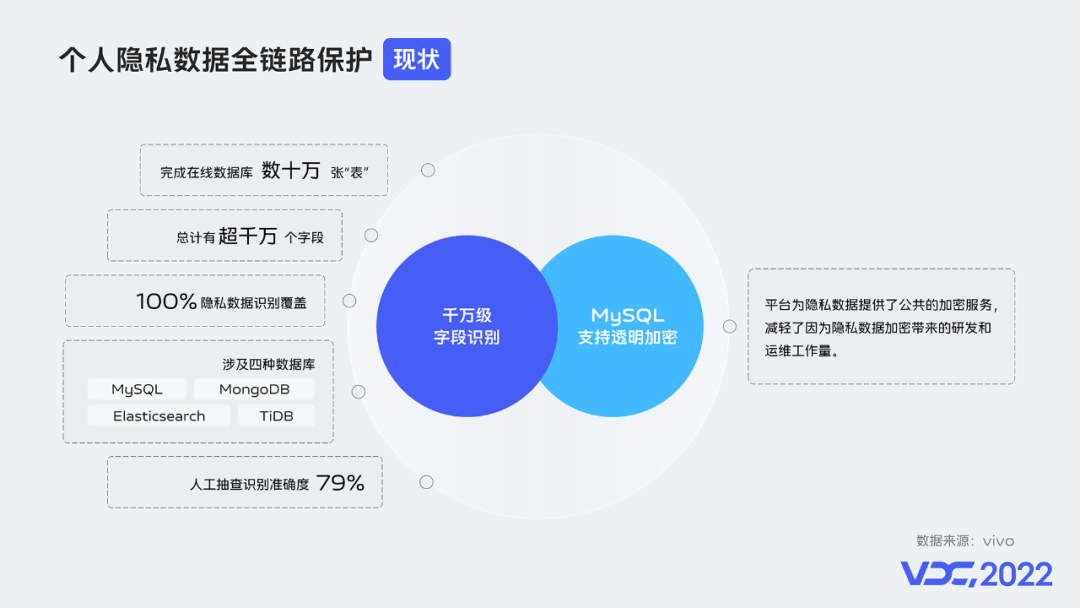
線上資料庫有數十萬張「表」,總計超千萬個欄位,其中隱私資料識別覆蓋100% ,涉及MySQL,MongoDB,Elasticsearch,TiDB四種資料庫,人工抽查識別準確度79%。而當個人隱私資料識別出來了,處理的主要手段就是加密,所以平臺也提供了對業務幾乎無影響的,MySQL的透明加密方案,來減輕因為隱私資料加密帶來的研發和運維工作量。
4.2 全鏈路功能
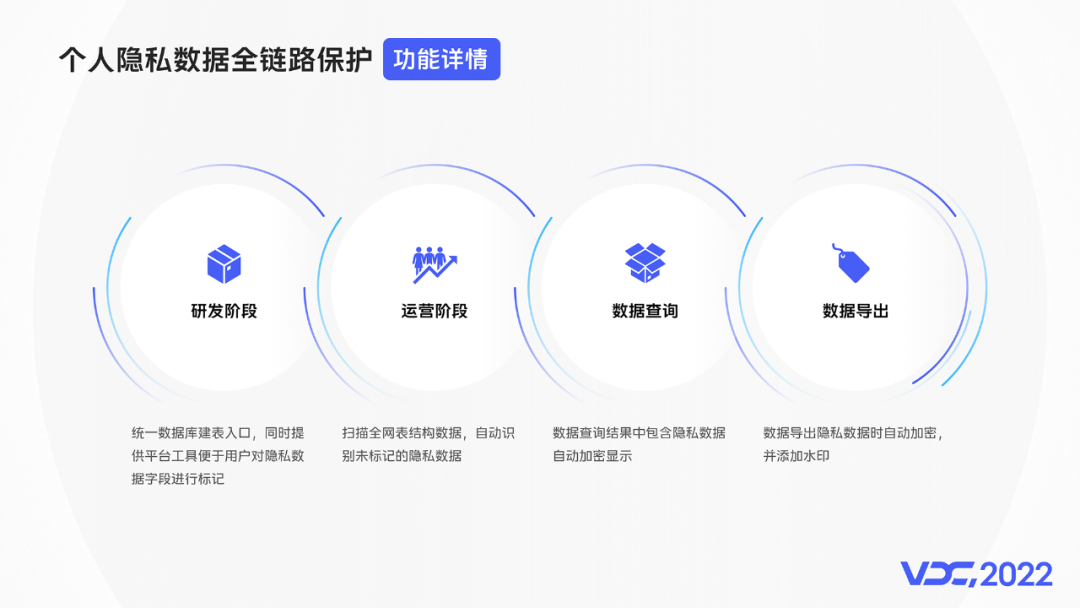
隱私資料庫保護應該是貫穿業務研發階段,運營階段的全鏈路保護。
-
研發階段:統一資料庫建表入口,同時提供平臺工具便於使用者對新建表中的隱私資料欄位進行標記,這主要解決日常新增資料結構的識別問題。
-
運營階段:定期掃描全網表結構資料,自動識別未標記的隱私資料,並人工抽查校準,這主要解決存量資料結構的識別問題,同時也是研發階段識別的補充。
-
運營階段操作:資料查詢結果中包含隱私資料自動加密顯示.資料匯出隱私資料時自動加密,並新增水印。
4.3 最後的防線:資料庫加密
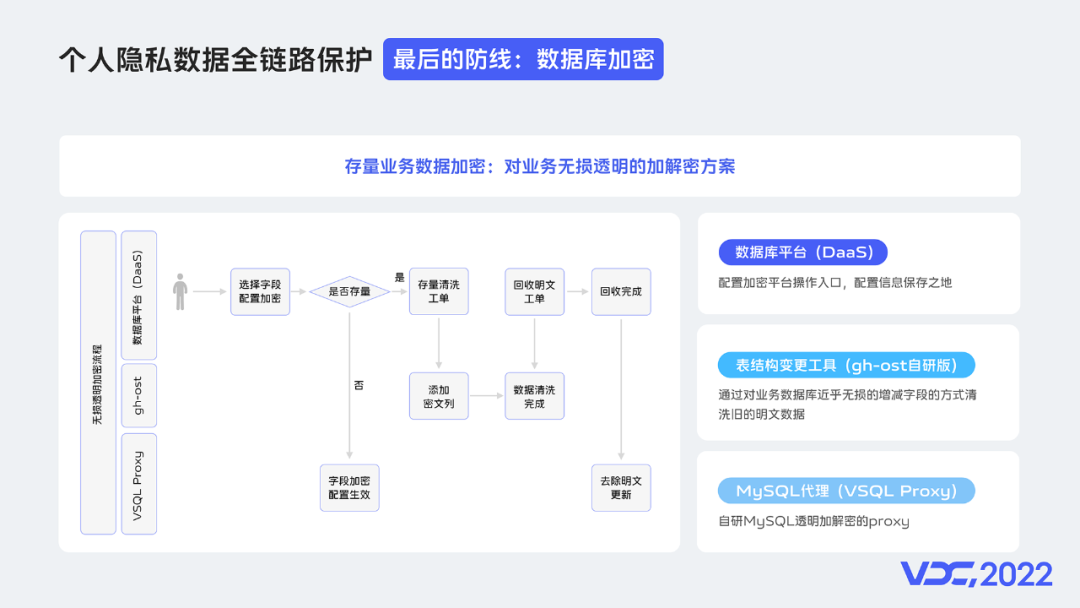
對於資料安全來說,資料庫加密是最後一道防線。前面提到隱私資料識別出來了,那麼加密的目標有了。基礎加密演演算法業界也比較成熟,加密方式也不缺。唯一的問題是,加密的過程。
對於新增業務來所,加密過程比較簡單,沒有業務存取怎麼做都行。但是對於存量的成熟業務來說,幾十張表,資料規模千萬記錄都是常事,怎麼加密還能不影響使用者存取,就是個麻煩的問題。為了解決這個痛點,目前資料庫平臺提供了一個存量業務資料無失真加密方案,因為主要隱私資料都在MySQL中,所以這是基於MySQL的。
首先介紹加密涉及的三個元件:資料庫平臺是使用者操作入口,表結構變更工具gh-ost負責歷史資料加密轉化,MySQL代理負責讓加解密過程對業務程式透明。
接下來介紹無失真加密的主要流程:
-
第一步、使用者要在資料庫平臺上設定需要加密的欄位。如果不需要對歷史資料加密那麼整個加密設定流程就結束了。
-
第二步、如果要加密歷史資料,就會產生一個資料淨化工單,交給表結構變更工具gh-ost執行,具體過程就是新增一個密文列複製明文列資料並加密。然後MySQL代理會自動將明文列請求轉向密文列,至此資料淨化完成。
-
第三步、步驟2執行後,業務如果發現有問題,可以隨時回滾。業務方認定資料加密後服務穩定時,就可以選擇回收明文列,最後更新MySQL代理設定,去掉明文資料同步更新,整個加密過程就算完結,全程幾乎無需業務改動程式碼,且對業務無失真。
五、未來展望
5.1 故障處理
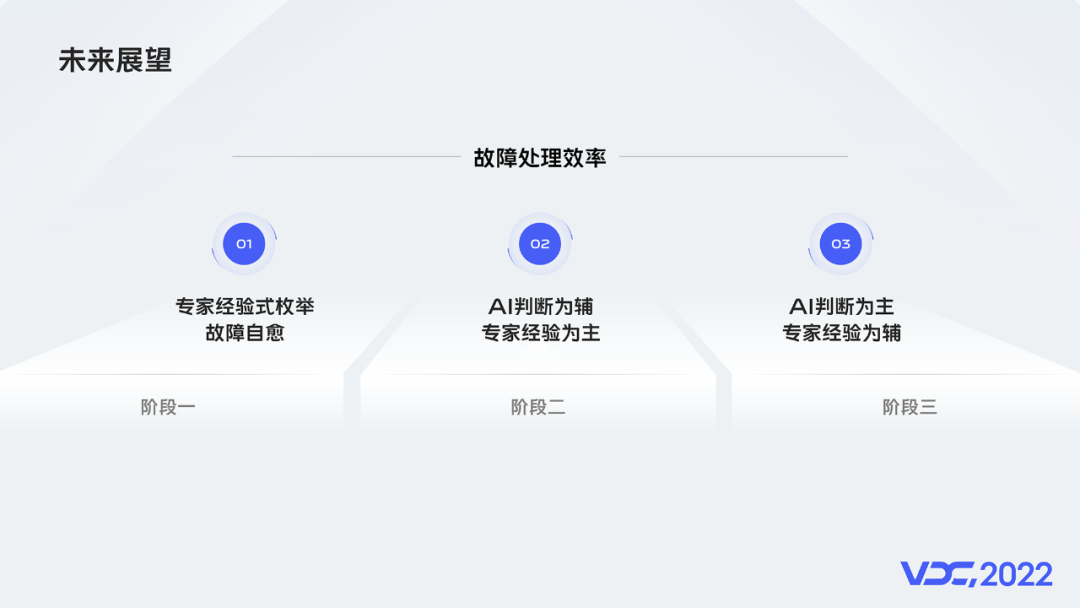
個人認為故障自愈的演進可以分為三個階段:
-
階段一:專家經驗式列舉故障自愈(這是當前所在的階段)。
-
階段二:在階段一基礎上引入AI判斷,形成AI判斷為輔,專家經驗為主的故障處理體系。
-
階段三:構建AI判斷為主,專家經驗為輔的自愈系統,進一步提升自動化程度。
5.2 資源管理

接下來在彈性資源管理這個方向,個人認為其發展可以分為三個階段:
-
階段一:資料庫混合資源管理(這是當前所在的階段,套餐,版本可以混合)。
-
階段二:資料庫容器混合資源管理,這一階段主要是利用容器消除機型隔離,品類隔離,有助於更高密度資源部署以及套餐統一標準化的實現。
-
階段三:存算分離架構資料庫的資源管理。在底層資源排程層面發揮到極致後,只能通過資料庫架構本身的升級提升資源彈性。
5.3 隱私資料治理
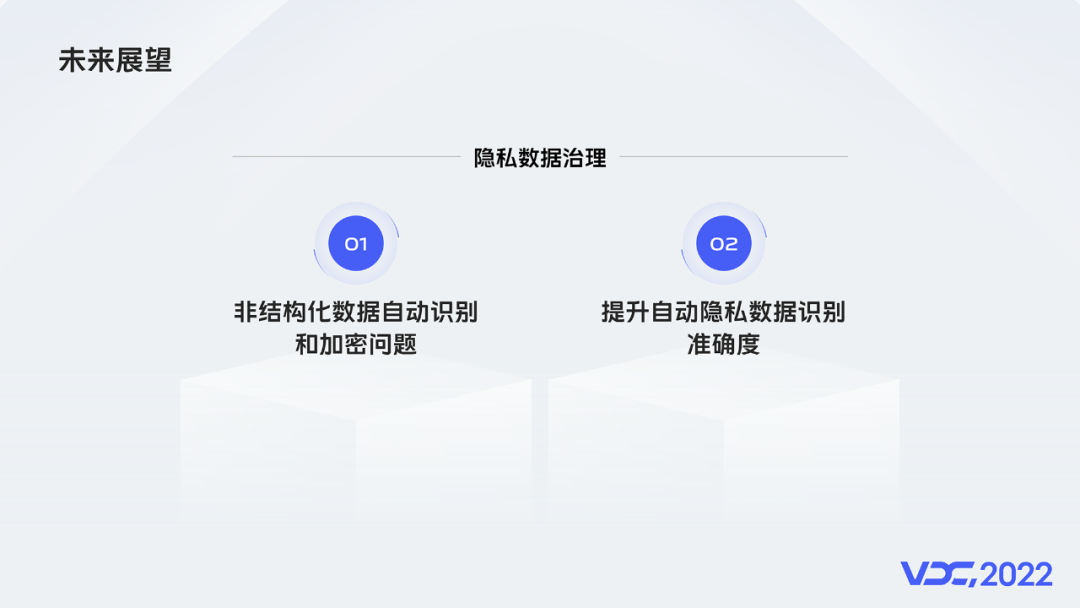
在個人隱私資料這個方向,還有兩個待解決的問題:
-
第一個是,非結構化資料隱私自動識別和加密問題。結構化和半結構化資料,就是MySQL,MongoDB這種,通過欄位的可以批次識別和處理一個表或者集合的隱私資料。但是對於Redis這種結構,當前一次只能識別和處理一個key-value鍵值對。解決思路是,非結構化轉為半結構化資料,例如特定字首key或者正則key,繫結固定的value結構。
-
第二個問題是,隱私資料的識別準確率問題,當前只有79%,這個目前思路是人工標註+AI識別。
5.4 資料庫平臺的未來展望

最後談下資料庫平臺建設,概括來說8個字,統一標準,開源共建。
展開來說,如今的資料庫技術市場百花齊放,DBengines網站榜上有名的資料庫就有395種,單個系統構建依賴多個品類資料庫的情況逐漸普及,通過統一的資料庫平臺來支撐資料庫運維工作,幾乎成了企業的剛性需求。但我們缺乏一個公認的跨品類的資料庫運維標準,也缺乏一個主流的跨越多品類的開源資料庫平臺。
個人期望用這樣的開源平臺來承載資料庫廠商,資料庫生態工具開發者以及企業使用者對資料庫服務共建的訴求,加速資料庫服務建設速度,讓雲原生時代沒有難運維的資料庫。