深度學習煉丹-超引數設定和網路訓練
前言
所謂超引數,即不是通過學習演演算法本身學習出來的,需要作者手動調整(可優化引數)的引數(理論上我們也可以設計一個巢狀的學習過程,一個學習演演算法為另一個學習演演算法學出最優超引數),折積神經網路中常見的超引數有: 優化器學習率、訓練 Epochs 數、批次大小 batch_size 、輸入影象尺寸大小。
一般而言,我們將訓練資料分成兩個不相交的子集,其中一個用於學習引數,另一個作為驗證集,用於估計訓練中或訓練後的泛化誤差,用來更新超引數。
- 用於學習引數的資料子集通常仍被稱為訓練集(不要和整個訓練過程用到的更大的資料集搞混)。
- 用於挑選超引數的資料子集被稱為驗證集(
validation set)。
通常,80% 的訓練資料用於訓練,20% 用於驗證。因為驗證集是用來 「訓練」 超引數的,所以驗證集的誤差通常會比訓練集誤差小,驗證集會低估泛化誤差。完成所有超引數優化後,需要使用測試集估計泛化誤差。
網路層引數
在設計網路架構的時候,我們通常需要事先指定一些網路架構引數,比如:
- 折積層(
convlution)引數: 折積層通道數、折積核大小、折積步長。 - 池化層(
pooling)引數: 池化核大小、步長等。 - 權重引數初始化,常用的初始化方法有
Xavier,kaiming系列;或者使用模型fintune初始化模型權重引數。 - 網路深度(這裡特指折積神經網路 cnn),即
layer的層數;網路的深度一般決定了網路的表達(抽象)能力,網路越深學習能力越強。 - 網路寬度,即折積層通道(
channel)的數量,也是濾波器(3 維)的數量;網路寬度越寬,代表這一層網路能學習到更加豐富的特徵。
這些引數一般在設計網路架構時就已經確定下來了,引數的取值一般可以參考經典 paper 和一些模型訓練的經驗總結,比如有以下經驗:
使用 3x3 折積
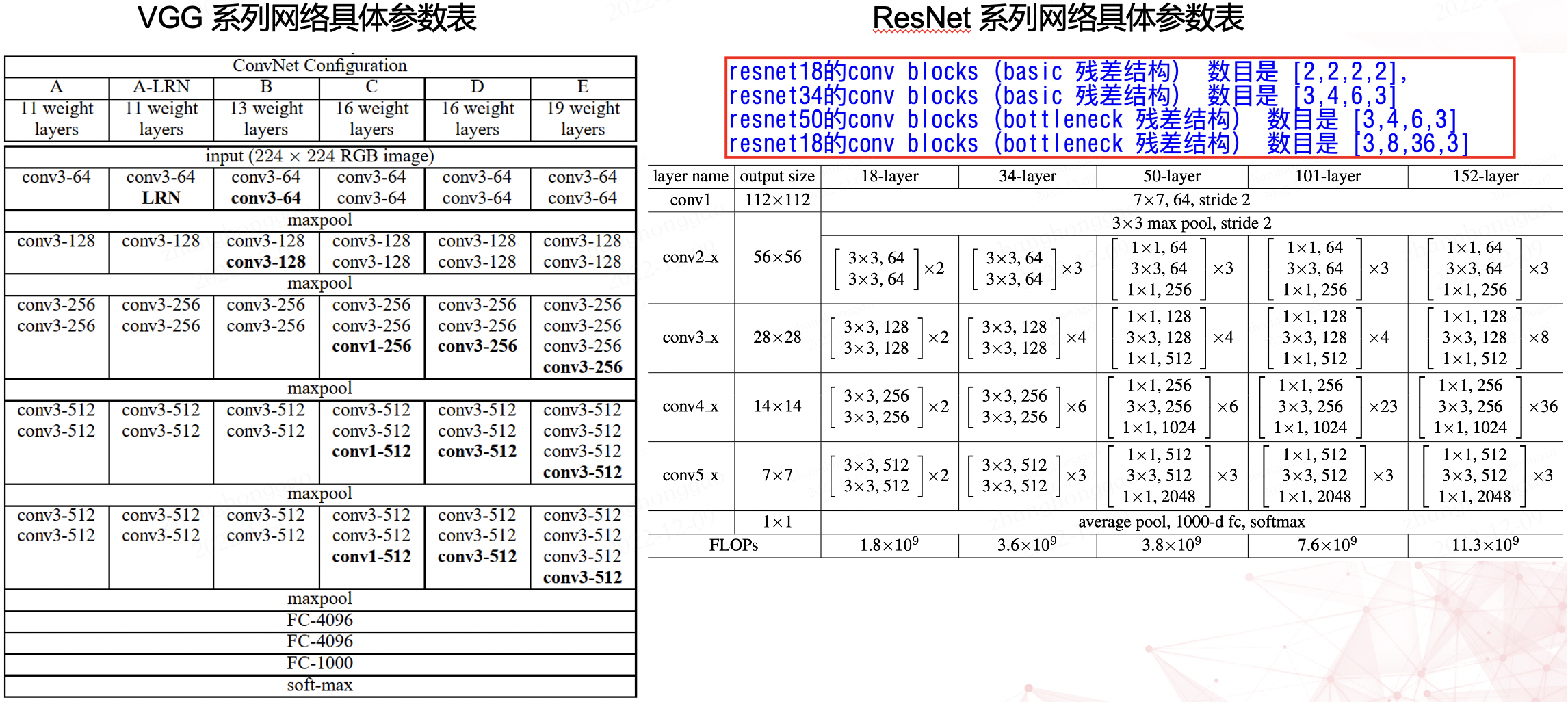
\(3\times 3\) 折積層是 cnn 的主流元件,比如提取影象特徵的 backbone 網路中,其折積層的折積核大小大部分都是 \(3\times 3\)。比如 vgg 和 resnet 系列網路具體參數列如下所示。
使用 cbr 組合
在 cnn 模型中,折積層(conv)一般後接 bn、relu 層,組成 cbr 套件。模型訓練好後,模型推理時的折積層和其後的 BN 層可以等價轉換為一個帶 bias 的折積層(也就是通常所謂的「吸BN」),其原理參考深度學習推理時融合BN,輕鬆獲得約5%的提速。
對於 cv 領域的任務,建議無腦用
ReLU啟用函數。
# cbr 元件範例程式碼
def convbn_relu(in_planes, out_planes, kernel_size, stride, pad, dilation):
return nn.Sequential(nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride,
padding=dilation if dilation > 1 else pad, dilation=dilation, bias=False),
nn.BatchNorm2d(out_planes),
nn.ReLU(inplace=True))
嘗試不同的權重初始化方法
嘗試不同的折積核權重初始化方式。目前常用的權重初始化方法有 Xavier 和 kaiming 系列,pytorch 在 torch.nn.init 中提供了常用的初始化方法函數,預設是使用 kaiming 均勻分佈函數: nn.init.kaiming_uniform_()。
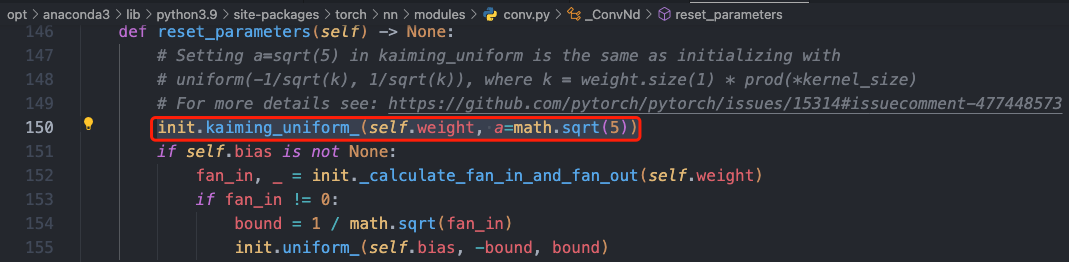
下面是一個使用 kaiming_normal_(kaiming正態分佈)設定折積層權重初始化的範例程式碼。
import torch
import torch.nn as nn
# 定義一個折積層
conv = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
# 使用He初始化方式設定折積層的權重
nn.init.kaiming_normal_(conv.weight, mode="fan_out", nonlinearity="relu")
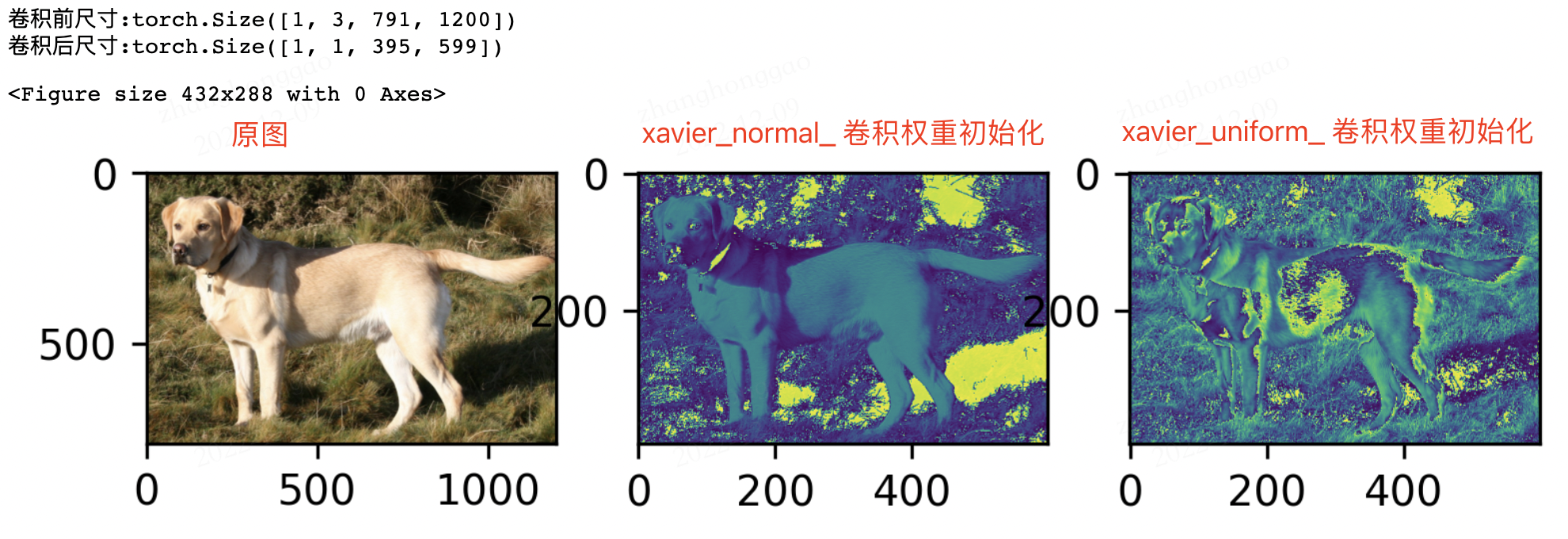
使用不同的折積層權重初始化方式,會有不同的輸出效果。分別使用 xavier_normal_ 和 xavier_normal_ 初始化權重,並使一個輸入圖片經過一層折積層,其輸出效果是不同的,對比圖如下所示:
圖片尺寸與資料增強
1,在視訊記憶體滿足的情況下,一般輸入圖片尺寸越大,模型精度越高!
2,資料增強(影象增強)的策略必須結合具體任務來設計!同時送入到模型訓練的資料一定要打亂(shuffle)!
資料增強的手段有多種,常見的如下(除了前三種以外,其他的要慎重考慮):
- 水平 / 豎直翻轉
- 90°,180°,270° 旋轉
- 翻轉 + 旋轉(旋轉和翻轉其實是保證了資料特徵的旋轉不變效能被模型學習到,折積層面的方法可以參考論文
ACNet) - 亮度,飽和度,對比度的隨機變化
- 隨機裁剪(Random Crop)
- 隨機縮放(Random Resize)
- 加模糊(Blurring)
- 加高斯噪聲(Gaussian Noise)
批次大小 batch size
背景知識
深度學習中經常看到 epoch、 iteration 和 batchsize 這三個名字的區別:
batchsize:批大小。在深度學習中,一般採用 SGD 訓練,即每次訓練在訓練集中取 batch_size 個樣本訓練;iteration:1 個 iteration 等於使用 batch_size 個樣本訓練一次;epoch:1 個 epoch 等於使用訓練集中的全部樣本訓練一次;
batch size 定義
batch 一般被翻譯為批次,設定 batch_size 的目的讓模型在訓練過程中每次選擇批次的資料來進行處理。Batch Size 的直觀理解就是一次訓練所選取的樣本數。
batch Size 的大小會影響模型的收斂速度和優化程度。同時其也直接影響到 GPU 記憶體的使用情況,如果你的 GPU 記憶體(視訊記憶體)不大,該數值最好設定小一點,否則會出現視訊記憶體溢位的錯誤。
選擇合適大小的 batch size
batch size 是所有超引數中最好調的一個,也是應該最早確定下來的超引數,其設定的原則就是,batch size 別太小,也別太大,取中間合適值為宜,通常最好是 2 的 n 次方,如 16, 32, 64, 128。在常見的 setting(~100 epochs),batch size 一般不會低於 16。
batch size 太小和太大的問題:
batch size太小:每次計算的梯度不穩定,引起訓練的震盪比較大,很難收斂。batch size太大: 深度學習的優化(training loss降不下去)和泛化(generalization gap很大)都會出問題。
設定為 2 的 n 次方的原因:計算機的 gpu 和 cpu 的 memory 都是 2 進位制方式儲存的,設定 2 的 n 次方可以加快計算速度。
合適的 batch size 範圍和訓練資料規模、神經網路層數、單元數都沒有顯著的關係。
合適的 batch size 範圍主要和收斂速度、隨機梯度噪音有關。
參考知乎問答-怎麼選取訓練神經網路時的Batch size?
學習率引數設定
什麼是學習率
模型架構和資料集構建好後,就可以訓練模型了,模型訓練的一個最關鍵超引數是是模型學習率(learning rate),一個理想的學習率會促進模型收斂,而不理想的學習率甚至會直接導致模型直接目標函數損失值 「爆炸」 無法完成訓練。
學習率(learning rate)決定目標函數能否收斂到區域性最小值,以及何時收斂到最小值。學習率越低,損失函數的變化速度就越慢。雖然使用低學習率可以確保我們不會錯過任何區域性極小值,但也意味著我們將花費更長的時間來進行收斂,特別是在被困在高原區域的情況下。下述公式表示了上面所說的這種關係。
new_weight = existing_weight — learning_rate * gradient
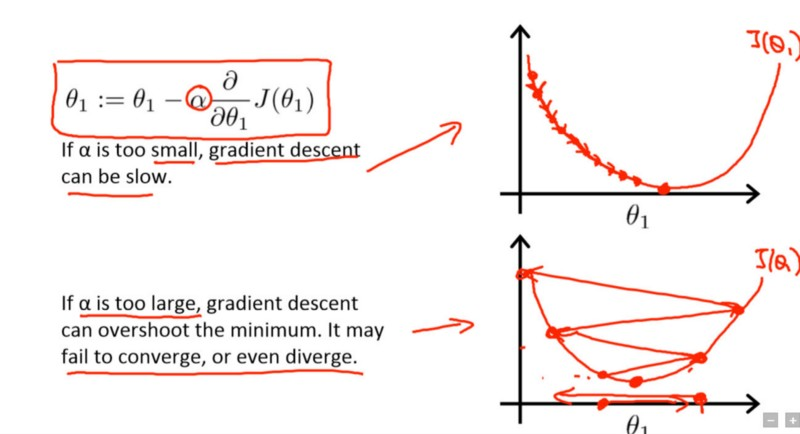
圖中公式是隨機梯度下降法(SGD)的公式,\(\alpha\) 是學習率引數,\(\theta\) 是待更新的權重引數。
採用小學習速率(頂部)和大學習速率(底部)的梯度下降。來源:Coursera 上吳恩達(Andrew Ng)的機器學習課程。
如何設定學習率
訓練 CNN 模型,如何設定學習率有兩個原則可以遵守:
- 模型訓練開始時的初始學習率不宜過大,
cv類模型以0.01和0.001為宜; - 模型訓練過程中,學習率應隨輪數(
epochs)增加而衰減。
除以上固定規則的方式之外,還有些經驗可以參考:
- 對於影象分類任務,使用
finetune方式訓練模型,訓練過程中,凍結層的不需要過多改變引數,因此需要設定較小的學習率,更改過的分類層則需要以較大的步子去收斂,學習率往往要設定大一點。(來源-pytorch 動態調整學習率) - 尋找理想學習率或診斷模型訓練學習率是否合適時也可藉助模型訓練曲線(learning curve)的幫助。學習率的好壞和損失函數大小的關係如下圖所示。
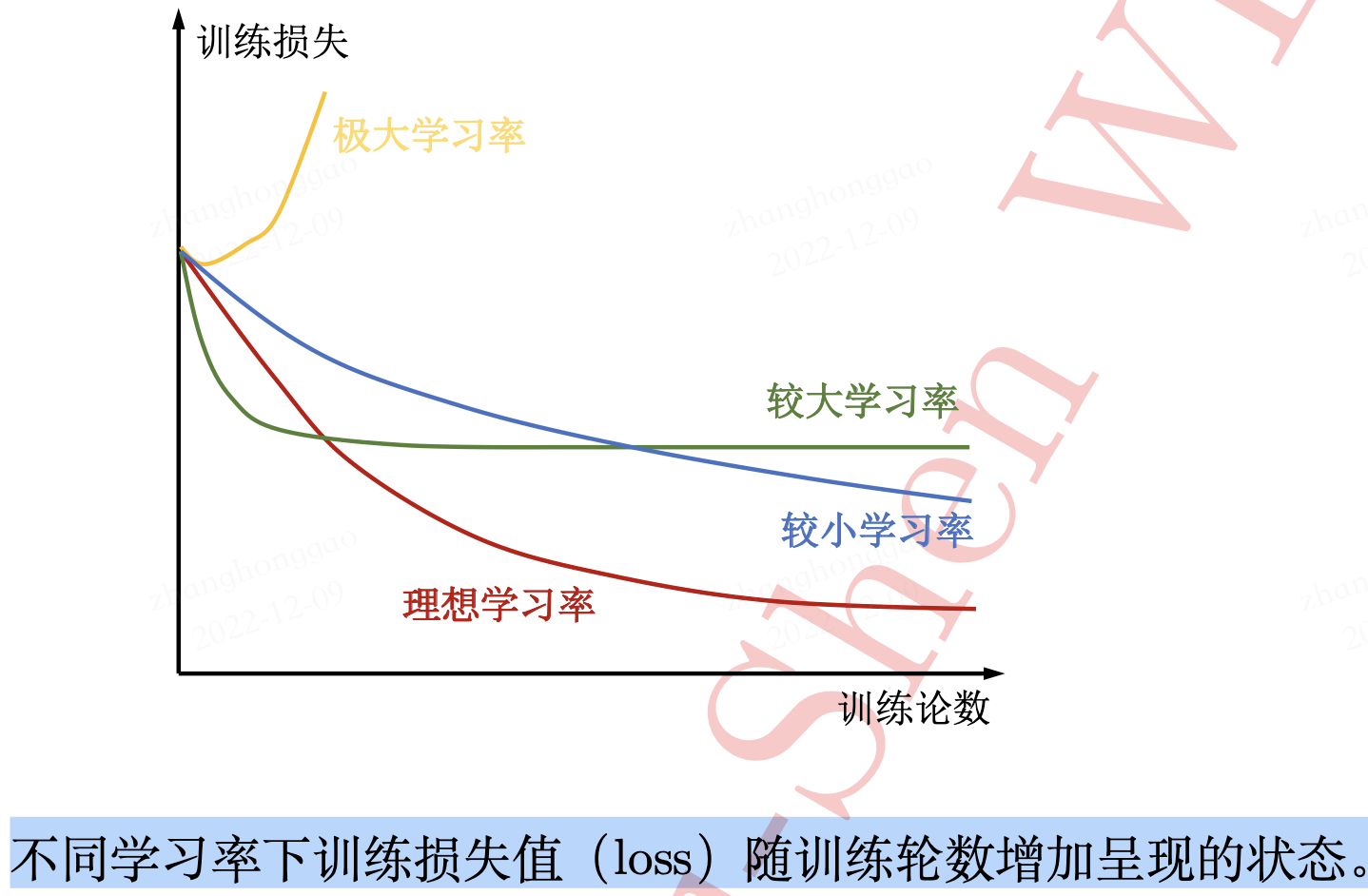
以上是理論分析,但在實際應用中,以 pytorch 框架為例,pyTorch 提供了六種學習率調整方法,可分為三大類,分別是:
- 有序調整: 按照一定規律有序進行調整,這一類是最常用的,分別是等間隔下降(
Step),
按需設定下降間隔(MultiStep),指數下降(Exponential)和CosineAnnealing。這四種方法的調整時機都是人為可控的,也是訓練時常用到的。 - 自適應調整: 如依據訓練狀況伺機調整
ReduceLROnPlateau方法。該法通過監測某一指標的變化情況,當該指標不再怎麼變化的時候,就是調整學習率的時機,因而屬於自適應的調整。 - 自定義調整: 自定義調整
Lambda。Lambda 方法提供的調整策略十分靈活,我們可以為不同的層設定不同的學習率調整方法,這在 fine-tune 中十分有用,我們不僅可為不同的層設定不同的學習率,還可以為其設定不同的學習率調整策略,簡直不能更棒了!
常見的學習率調整方法有:
lr_scheduler.StepLR: 等間隔調整學習率。調整倍數為gamma倍,調整間隔為step_size。lr_scheduler.MultiStepLR: 按設定的間隔調整學習率。適合後期使用,通過觀察 loss 曲線,手動客製化學習率調整時機。lr_scheduler.ExponentialLR: 按指數衰減調整學習率,調整公式: \(lr = lr * gamma^{epoch}\)lr_scheduler.CosineAnnealingLR: 以餘弦函數為週期,並在每個週期最大值時重新設定學習率。lr_scheduler.ReduceLROnPlateau: 當某指標不再變化(下降或升高),調整學習率(非常實用的策略)。lr_scheduler.LambdaLR: 為不同引陣列設定不同學習率調整策略。
學習率調整方法類的詳細引數及類方法定義,請參考 pytorch 官方庫檔案-torch.optim。
注意,PyTorch 1.1.0 之後版本,學習率調整策略的設定必須放在優化器設定的後面! 構建一個優化器,首先需要為它指定一個待優化的引數的可迭代物件,然後設定特定於優化器的選項,比如學習率、權重衰減策略等。
在 PyTorch 1.1.0 之前,學習率排程器應該在優化器更新之前被呼叫;1.1.0 以打破 BC 的方式改變了這種行為。 如果在優化器更新(呼叫 optimizer.step())之前使用學習率排程器(呼叫 scheduler.step()),這將跳過學習率排程的第一個值。
使用指數級衰減的學習率調整策略的模板程式碼如下。
import torchvision.models as models
import torch.optim as optim
model = models.resnet50(pretrained=False)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9) # 構建優化器,lr 是初始學習率
scheduler = optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9) # 設定學習率調整策略
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler.step()
print_lr(is_verbose=true) # pytorch 新版本可用,1.4及以下版本不可用
優化器選擇
優化器定義
優化器(優化演演算法)優化的是神經元引數的取值 \((w、b)\)。優化過程如下:假設 \(\theta\) 表示神經網路中的引數,\(J(\theta)\) 表示在給定的引數取值下,訓練資料集上損失函數的大小(包括正則化項),則優化過程即為尋找某一引數 \(\theta\),使得損失函數 \(J(\theta)\) 最小。
在完成資料預處理、資料增強,模型構建和損失函數確定之後,深度學習任務的數學模型也就確定下來了,接下來自然就是選擇一個合適的優化器(Optimizer)對該深度學習模型進行優化(優化器選擇好後,選擇合適的學習率調整策略也很重要)。
如何選擇適合不同ml專案的優化器
選擇優化器的問題在於沒有一個可以解決所有問題的單一優化器。實際上,優化器的效能高度依賴於設定。所以,優化器選擇的本質其實是: 哪種優化器最適合自身專案的特點?
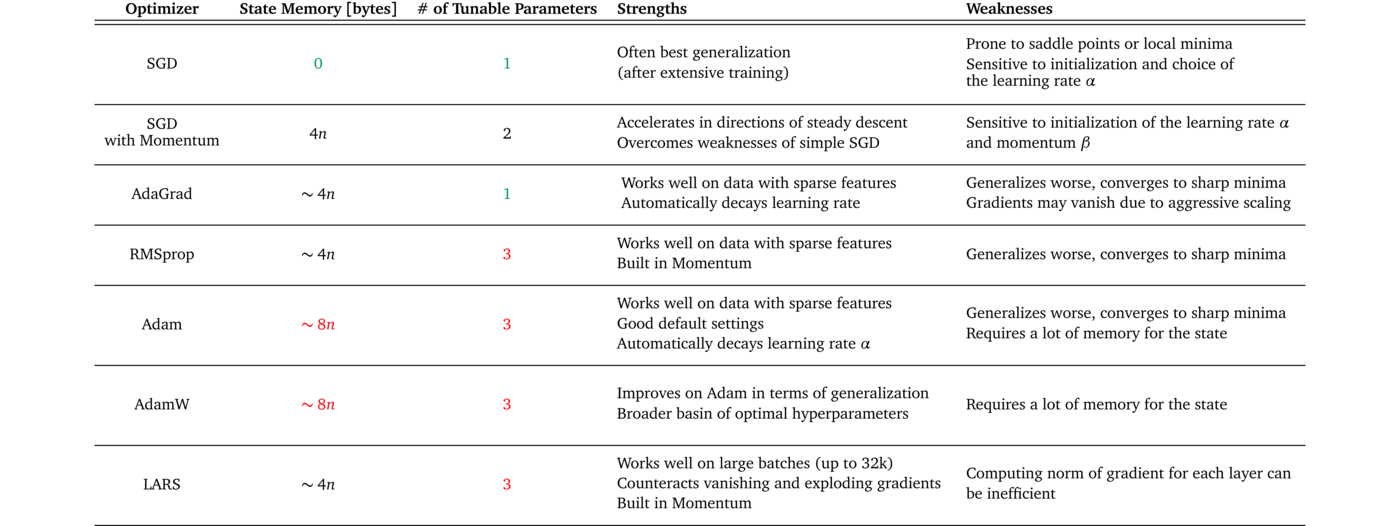
深度折積神經網路通常採用隨機梯度下降型別的優化演演算法進行模型訓練和引數求解。最為常用且經典的優化器演演算法是 (基於動量的)隨機梯度下降法 SGD(stochastic gradient descent) 和 Adam 法,其他常見的優化器演演算法有 Nesterov 型動量隨機下降法、Adagrad 法、Adadelta 法、RMSProp 法。
優化器的選擇雖然沒有通用的準則,但是也還是有些經驗可以總結的:
SGD是最常見的神經網路優化方法,收斂效果較穩定,但是收斂速度過慢。Adam等自適應學習率演演算法對於稀疏資料具有優勢,且且收斂速度很快,但是收斂效果不穩定(容易跳過全域性最優解)。
下表 1 概述了幾種優化器的優缺點,通過下表可以嘗試找到與資料集特徵、訓練設定和專案目標相匹配的優化器。
某些優化器在具有稀疏特徵的資料上表現出色,而其他優化器在將模型應用於以前未見過的資料時可能表現更好。一些優化器在大批次(batch_size 設定較大)下工作得很好,而而另一些優化器會在泛化不佳的情況下收斂到極小的最小值。
網路上有種 tricks 是將 SGD 和 Adam 組合使用,先用 Adam 快速下降,再用 SGD 調優。但是這種策略也面臨兩個問題: 什麼時候切換優化器和切換後的 SGD 優化器使用什麼樣的學習率?論文 SWATS Improving Generalization Performance by Switching from Adam to SGD給出了答案,感興趣的讀者可以深入閱讀下 paper。
PyTorch 中的優化器
以 Pytorch 框架為例,PyTorch 中所有的優化器(如: optim.Adadelta、optim.SGD、optim.RMSprop 等)均是 Optimizer 的子類,Optimizer 中也定義了一些常用的方法:
zero_grad(): 將梯度清零。step(closure): 執行一步權值更新, 其中可傳入引數 closure(一個閉包)。state_dict(): 獲取模型當前的引數,以一個有序字典形式返回,key 是各層引數名,value 就是引數。load_state_dict(state_dict): 將 state_dict 中的引數載入到當前網路,常用於模型finetune。add_param_group(param_group): 給 optimizer 管理的引陣列中增加一組引數,可為該組引數客製化 lr, momentum, weight_decay 等,在 finetune 中常用。
優化器設定和使用的模板程式碼如下:
# optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# 指定每一層的學習率
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9
)
for input, target in dataset:
optimizer.zero_grad()
output = model(input)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
優化器的演演算法原理可以參考花書第八章內容,Pytorch 框架優化器類的詳細引數及類方法定義,請參考 pytorch 官方庫檔案-torch.optim。
模型 finetune
一般情況下,我們在做深度學習任務時,backbone 一般會用 imagenet 的預訓練模型的權值引數作為我們自定義模型的初始化引數,這個過程稱為 finetune,更廣泛的稱之為遷移學習。fintune 的本質其實就是,讓我們有一個較好的權重初始化值。模型 finetune 一般步驟如下:
- 獲取預訓練模型的權重(如
imagenet); - 使用預訓練模型權重初始化我們的模型,即載入預訓練模型權重引數。
模型 finetune 一般有兩種情況:
- 直接使用
imagenet的resnet50預訓練模型權重當作特徵提取器,只改變模型最後的全連線層。程式碼範例如下:
import torch
import torchvision.models as models
model = models.resnet50(pretrained=True)
#遍歷每一個引數,將其設定為不更新引數,即凍結模型所有引數
for param in model.parameters():
param.requires_grad = False
# 只替換最後的全連線層, 改為訓練10類,全連線層requires_grad為True
model.fc = nn.Linear(2048, 10)
print(model.fc) # 這裡列印下全連線層的資訊
# 輸出結果: Linear(in_features=2048, out_features=10, bias=True)
- 使用自定義模型結構,儲存某次訓練好後比較好的權重用於後續訓練
finetune,可節省模型訓練時間,範例程式碼如下:
import torch
import torchvision.models as models
# 1,儲存模型權重引數值
# 假設已經建立了一個 net = Net(),並且經過訓練,通過以下方式儲存模型權重值
torch.save(net.state_dict(), 'net_params.pth')
# 2,載入模型權重檔案
# load(): Loads an object saved with :func:`torch.save` from a file
pretrained_dict = torch.load('net_params.pth')
# 3,初始化模型
net = Net() # 建立 net
net_state_dict = net.state_dict() # 獲取已建立 net 的 state_dict
# (可選)將 pretrained_dict 裡不屬於 net_state_dict 的鍵剔除掉:
pretrained_dict_new = {k: v for k, v in pretrained_dict.items() if k in net_state_dict}
# 用預訓練模型的引數字典 對 新模型的引數字典 net_state_dict 進行更新
net_state_dict.update(pretrained_dict_new)
# 載入需要的預訓練模型引數字典
net.load_state_dict(net_state_dict)
更進一步的模型 finetune,可以為不同網路層設定不同的學習率,請參考《PyTorch_tutorial_0.0.5_餘霆嵩》第二章。
模型
finetune是屬於遷移學習技術的一種。
模型視覺化
視覺化權重
視覺化啟用
參考資料
- 《PyTorch_tutorial_0.0.5_餘霆嵩》
- 知乎問答-怎麼選取訓練神經網路時的Batch size?
- batch size設定技巧
- 如何選擇適合不同ML專案的優化器
- 理解深度學習中的學習率及多種選擇策略
- 《深度學習》第五章-機器學習基礎
- 知乎問答-深度學習調參有哪些技巧?
- 深度學習500問-第十四章超 引數調整
- pytorch 學習筆記-3.2 折積層