RocketMQ 在網易雲音樂的實踐
本文作者:蔣星韜,網易雲音樂伺服器端開發工程師。

雲音樂線上場景眾多,比如直播、評論、廣告,各個業務線都會有訊息場景比如發獎券,也會有延遲訊息和事務訊息場景,以及巨量資料做埋點資料、資料淨化、離線處理等。
雲音樂線上 RocketMQ topic 為 1 萬+/天,QPS 流量峰值為150萬/s,日訊息量千億級別。為了支撐龐大的資料規模和場景,除了搭建開源RocketMQ叢集,我們也做了監控的完善和工具體驗。監控完善主要包括對整個叢集的容量、狀態、水位進行健康狀態的監控,針對訊息的傳送和消費提供流量、延遲、失敗、耗時等監控指標。基於以上監控指標,還需搭建一套業務巡檢體系,以實現線上告警。
另外,我們也提供改了一些工具幫助業務方提升使用 RocketMQ 的體驗,比如資料遷移和同步訊息路由的元件,提供穩定性保障的限流能力、降級能力以及動態引數干預的預案能力。當線上業務方發現消費不符合預期時,需要提供查詢幫助其快速定位,以及提供死信處理工具等。
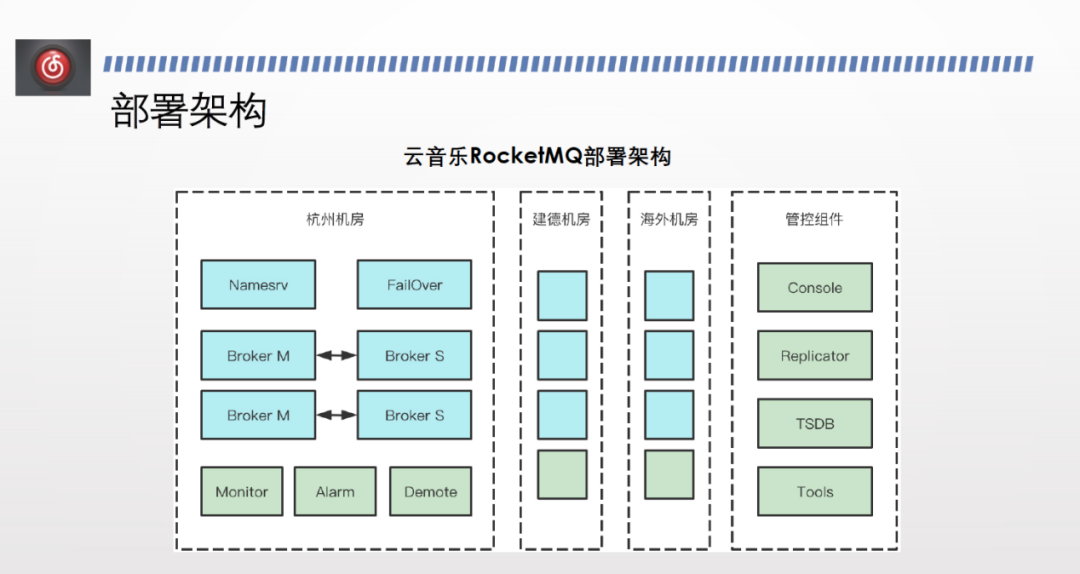
雲音樂目前有三個機房,每個機房部署了一套 RocketMQ 叢集,除了 Manesrv、 HA 等基礎元件,還有自研或開源改造的元件,比如 monitor 元件、告警巡檢元件、降級維穩元件等。
每個機房裡有一套平臺化的管控元件,管控端包含提工單、上下線、查資料、訂閱問題,還包括一套訊息路平臺和資料庫。
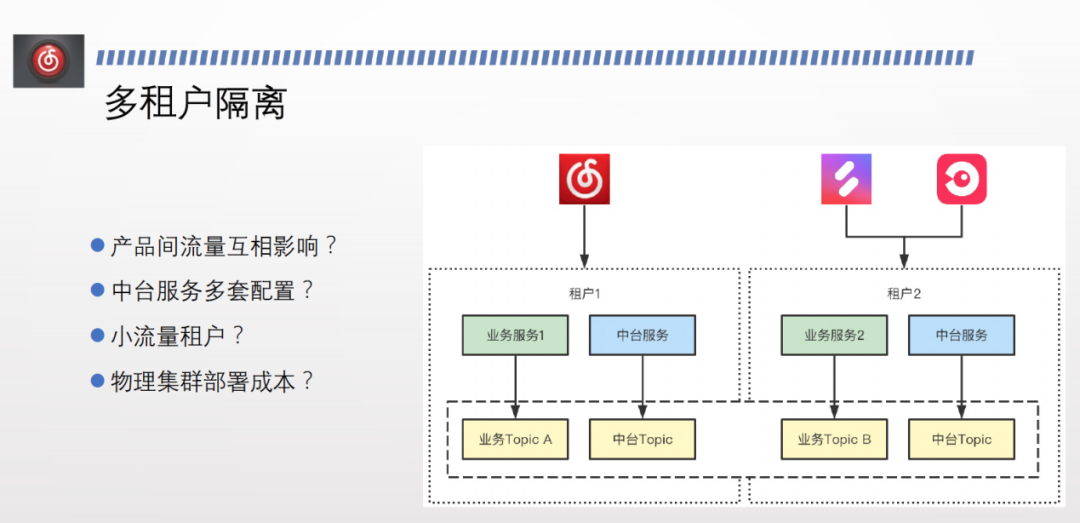
網易雲音樂擁有多個流量入口,不同業務的資料和流量需要做隔離,每個租戶下都是一套獨立的業務線。而物理隔離成本過高,因此我們實現了邏輯隔離。各個業務之間流量不互通,邏輯上無法相互呼叫,且租戶下所有 topic 名字一致,中臺只需要切換租戶名,無需改動任何其設定、程式碼,即可直接上線。
所有 topic 都在一個物理叢集內,每個租戶有自己的一套邏輯叢集,邏輯叢集內有自己的 topic,不同邏輯叢集之間的 topic 同名,實現了多租戶隔離。

隨著雲音樂的業務愈發龐大,業務方提出了更多需求。比如異地多活,訊息需要在多個機房消費,比如通用埋點資料,需要將多個產品的資料彙總到機場的資料處理叢集做離線處理,比如架構升級,不同單元間的流量能夠動態排程。
基於以上需求,訊息路由需要實現以下幾個功能:
①跨機房訊息複製。
②流量去重:訊息路由在複製時不可避免會有失敗,因此必然有內部的重試,可能會導致有訊息重複;此外,雙向路由必然需要提供雙向複製,而兩邊 topic 名字一樣,複製時會導致錯亂,因此需要有標籤來實現流量重。
③資料遷移任務。
④監控完善,進度可控。
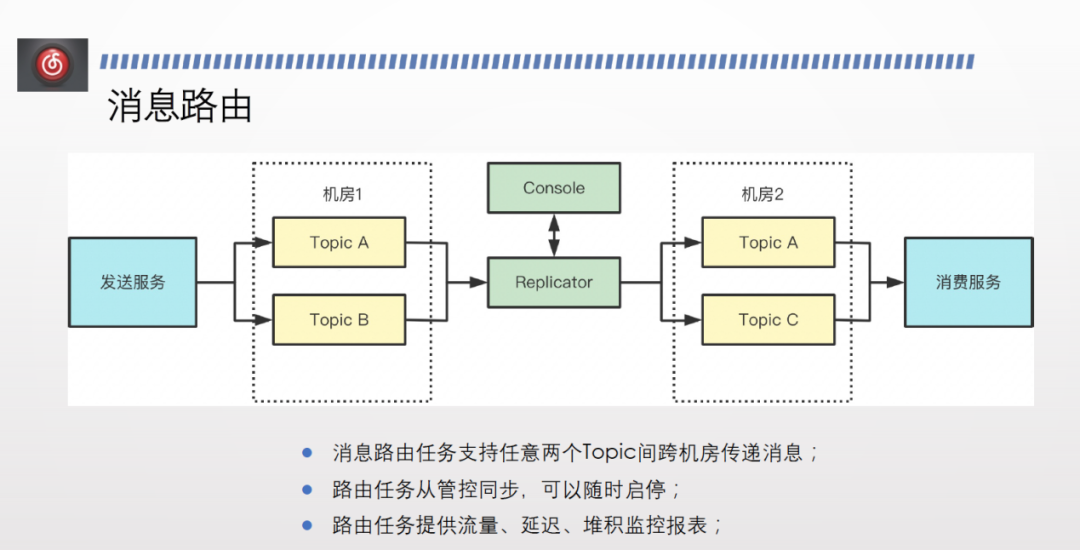
雲音樂的訊息路由實現方案如上圖所示。
首先,在管控平臺會維護一套路由任務後設資料表,業務方可以提工單或者通過其他方式申請路由任務,支援任意機房的任意兩個 topic 之間做訊息路由。任務提交之後,訊息路由叢集會定時同步管控端上的訊息路由任務的狀態,同時將訊息傳送到目標 topic 。路由任務能夠自行上報監控資料、消費延遲、堆積監控報表等,可在管控端進行檢視。
雲音樂的資料處理任務包括埋點、trace,大多使用Flink。但由於開源方向沒有與我們的需求非常匹配的 connector ,因此我們封裝實現了自己的 RocketMQ Flink connector。
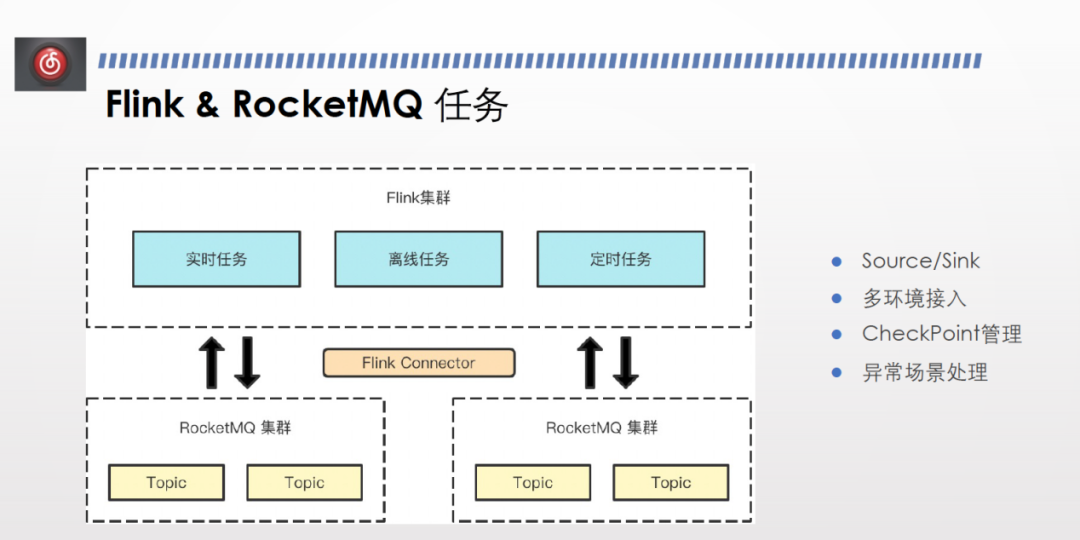
因為內部封裝了介面和叢集設定,RocketMQ 作為 Flink 的 source 和 sink 需要有資料來源的設定。我們對資料來源做了封裝,比如 connector 如何解析後設資料,從而正確地連線資料來源、讀寫訊息。
巨量資料任務的特點為測試環境與線上資料會混在一起,多環境都有接入需求,因此我們設計了一套後設資料,使得 connect 能夠連線多環境且能夠處理多環境裡面流量標、環境標等標籤的過濾。
Flink有自己的 checkpoint 機制,只有在做 checkpoint 時才會將 consumer offset 提交給 broker ,同時需要對 consumer offset 進行管理,否則消費位點消失會導致資料重新消費,因此我們實現了 state 管理機制。
Flink的 spot task 比較敏感,丟擲錯誤則會導致 task 重新執行,連續重複幾次後會導致TaskManager failover 。此外,RocketMQ 在網路場景下時常出現broker busy 或網路問題導致傳送失敗異常。我們針對Flink 客製化了一套異常場景處理,使其變得不敏感。
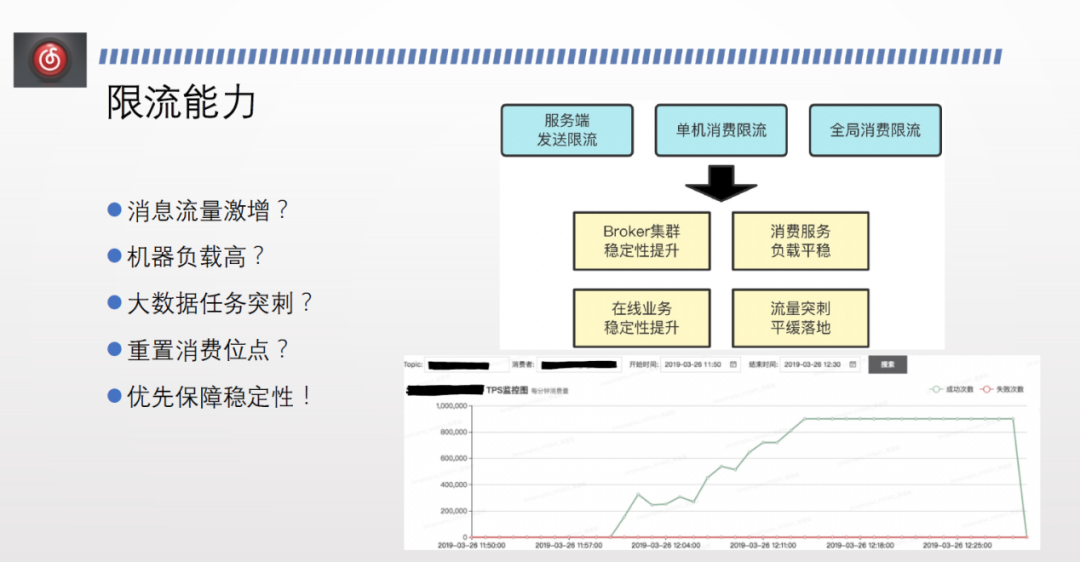
此外,我們目前面臨的線上問題主要包括訊息流量激增、機器負載高、巨量資料任務突刺、重置消費位點等。叢集突然出現大流量行動時,其穩定性會受到極大衝擊,頻繁傳送失敗,線上其業務也會受到 topic 的影響。
面對以上問題,除了提供隔離能力外,也需要限流降級的能力。
第一,伺服器端的傳送限流。支援 topic 級別,也支援 group 級別。後續將支援使用者端級別,支援多個維度的傳送端限流。
第二,全域性消費限流。分為 topic 和 group,可以對整個 group 消費關係下所有機器的總量進行限流,適用於巨量資料場景。
第三,單機消費限流。適用於線業務場景,因為線上業務場景每臺機器的負載有限,不希望某個業務無上限地佔用資源,因此需要對單機限流。線上業務叢集容量不夠時,可以做動態擴容來增加容量。增加叢集容量時無需修改全域性容量。
上圖折線圖反應了開啟單機限流之後,消費資料隨著釋出緩慢平穩上漲,解決了流量突刺,提升線上叢集穩定性和消費服務的負載平穩。
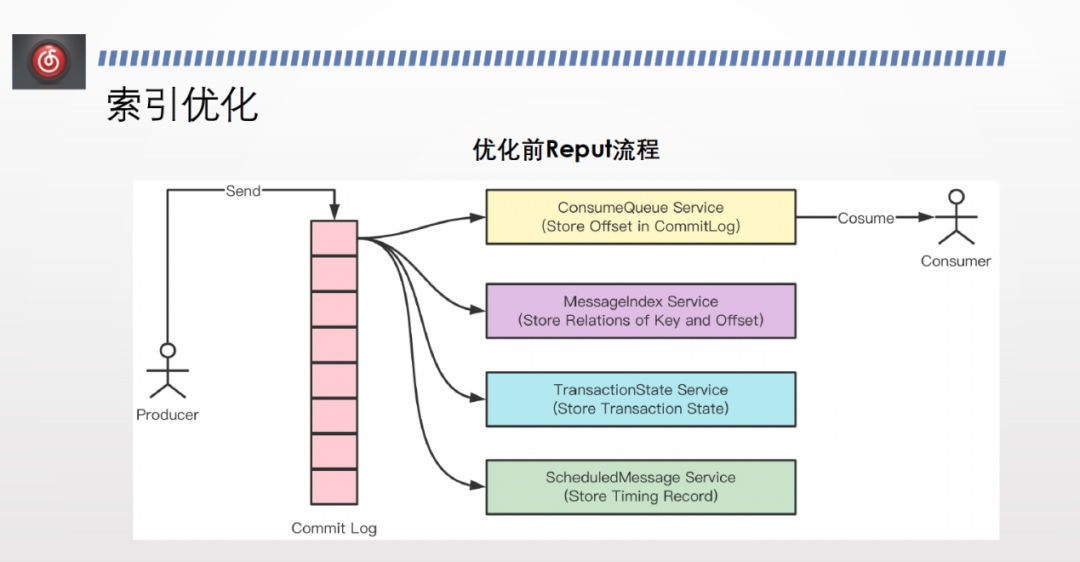
隨著叢集規模增大,逐漸出現了訊息延遲的情況。經排查發現,producer 能夠正常傳送訊息到 broker ,但是由於資料量非常大,後臺建立 consumer queue 的速度跟不上傳送速度,導致消費延遲。其次,消費也面臨瓶頸,跟不上傳送速度,因為同一個傳送可能存在多個消費方。
針對以上問題,我們進行了索引優化。
開源版本下, commit log 寫入之後,會有 Reput service 方法建 consumer queue 、index 索引等一套流程,從頭掃到尾,塊狀地建立 consumer queue。
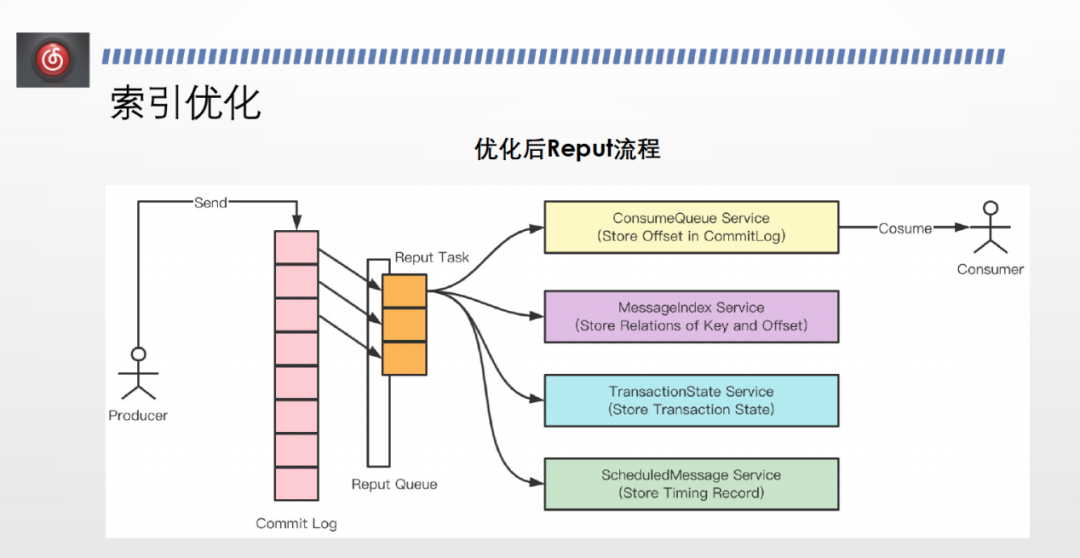
而我們發現,保證順序性和位點的有序性的前提下,可以並行地建索引,只需處理好位點的提交即可。因此,我們設定了 reput queue 非同步執行緒池,裡面有不同的 reput task ,每個 task 建立自己的 comment log 索引。建好之後,索引並不是立刻可見。建好之後會有全域性的索引往後推,如果前面的 commit log 索引已經建好,則後面的索引也立馬可見,提升了索引的建立效率。
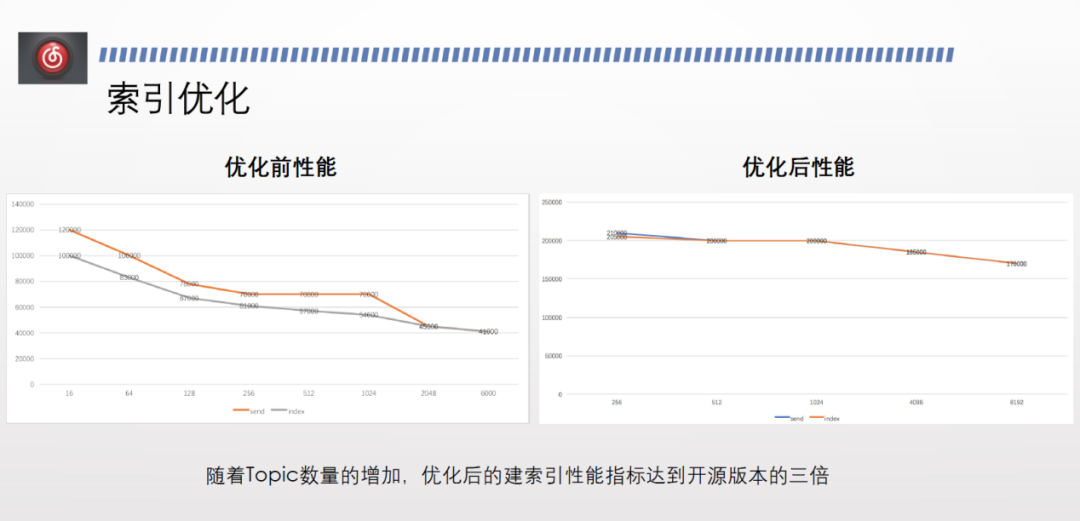
上圖為索引優化前後的效能對比。橫軸代表 topic 數量,縱軸代表建索引的速度。灰色線代表建索引的速度,橙色線代表傳送速度。
優化前,topic 較少時,建索引的速度慢於傳送速度。隨著 topic 數量增多,兩者速度逐漸一致,但效能均明顯下降。
優化後,建索引的速度基本與傳送速度持平,且效能不會隨著 topic 數量增加而大幅下降。優化後建索引的效能達到優化前的3倍,保證了消費效能。
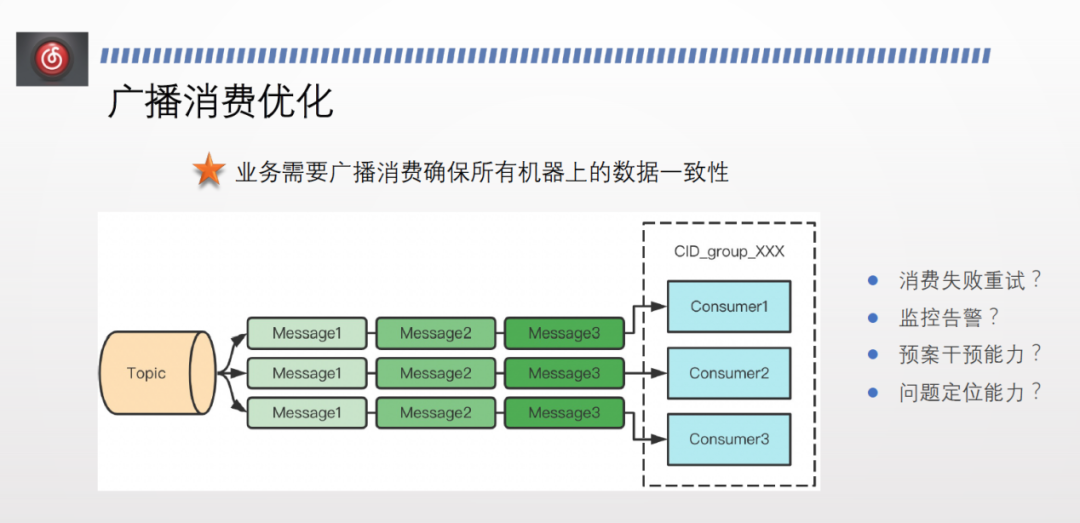
廣播消費場景下,通常需要確保所有機器上的資料最終一致。而開源的廣播消費失敗後不會重試也不會告警。且消費位點為 local,不會上報到遠端,如果本地服務重啟則offset 丟失,並且無法做預案干預。同時因為不上報,缺少問題定位的能力。
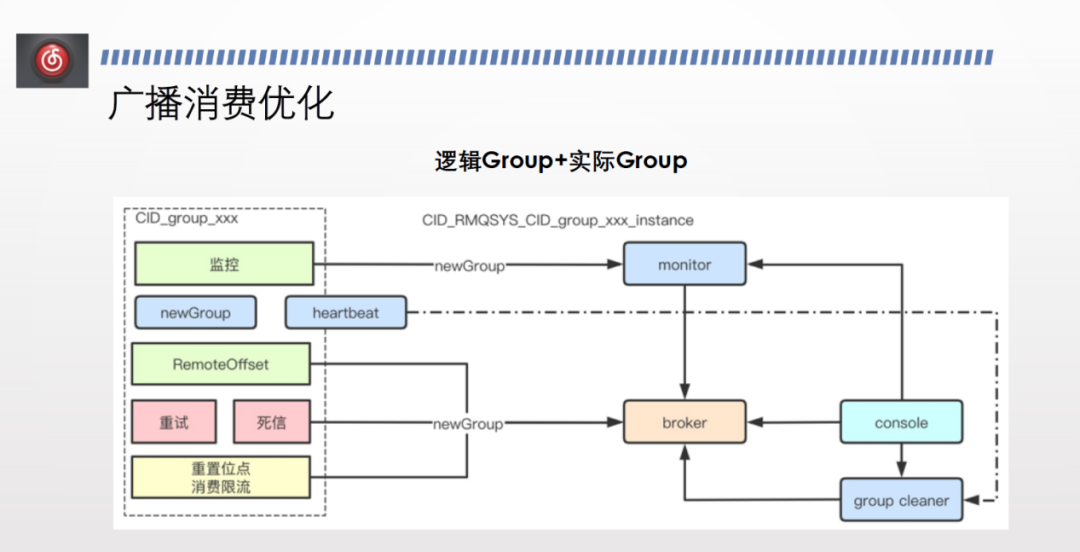
我們的解決方案為邏輯 group +實際 group 。
邏輯 group 指業務方在程式碼和在管控平臺申請的 consumer group 。申請 group 之後,在使用者端進行設定,將其標識為新版廣播消費的 group,每個範例啟動時在邏輯group 後加上擴充套件名來生成實際 group 。
實際 group 可以進行正常的叢集消費,也可以用複用叢集消費的所有能力,包括租戶隔離、訊息路由、監控、限流能力等,最終就解決了廣播消費的問題,能夠使用死信、重試、重置消費位點、位點查詢、監控告警等能力。
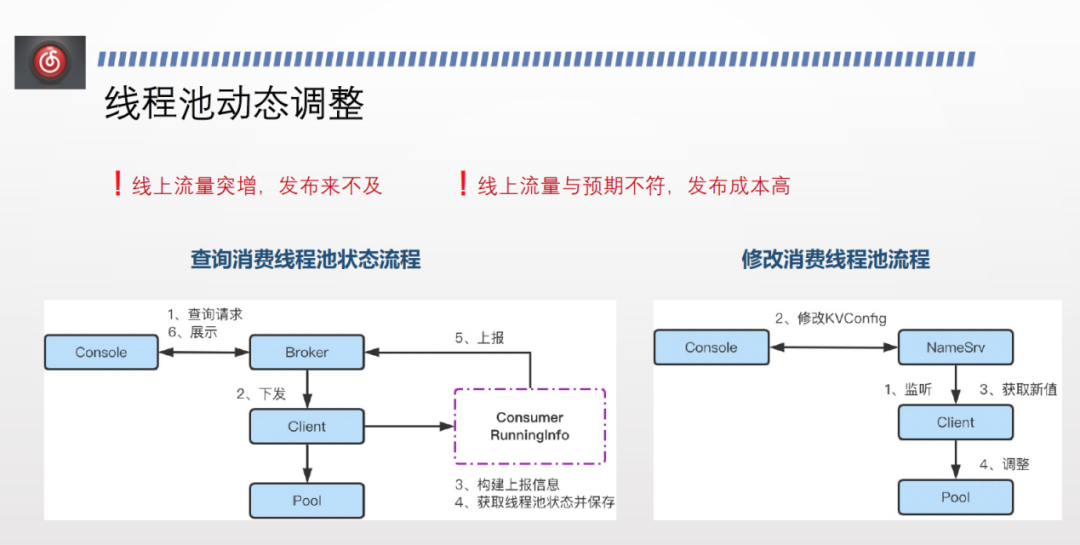
此外,雲音樂日常還會出現線上流量突增來不及釋出,或線上流量與預期不符而釋出成本過高等問題。
為此,我們為業務方提供了實時執行緒式調整的能力。開源版本中,每個使用者端都會向broker 做 Consumer RunningInfo 的上報,包括是否消費暫停、subscribe 的狀態、訂閱了哪些 topic、消費位點等。我們在在上報資訊里加上了每個 topic 自己消費的執行緒池的 coresize、maxsize ,並在管控端展示,使使用者能夠實時感知當前執行緒池的狀態。
此外,我們提供了非常簡單的修改方式。在管控端修改 kv config 並上報到 NameSvr ,NameSvr 監聽並下發。使用者端監聽到 kv config 變化後將最新設定下拉。然後再本地找到 topic 對應的執行緒池,修改 coresize、maxsize 值。
此前,業務線上上發現問題後釋出往往需要 10-20 分鐘起步。而現在只需修改一個引數、下發、輪詢即可完成,整個過程不超過 30 秒。

雲音樂在 RocketMQ 的未來規劃如下:
第一,雲原生。雲原生有彈性擴縮容的能力,可以更好地節約成本以及應對線上突發風險。
第二,提效率。比如 Topic 籤遷移、從一個叢集遷移到另一個叢集、從順序訊息改為非順序訊息等操作目前還未實現完全白屏化,後續會針對此方面提高效率,提高使用者體驗。
第三,開源社群交流貢獻。