你不知道的Map家族中的那些冷門容器
概述
本篇文章主要講解下Map家族中3個相對冷門的容器,分別是WeakHashMap、EnumMap、IdentityHashMap, 想必大家在平時的工作中也很少用到,或者壓根不知道他們的特性以及適用場景,本篇文章就帶你一探究竟。
WeakHashMap
介紹
WeakHashMap稱為弱三列對映,實現了Map介面,具有如下特性:
- WeakHashMap中的entry是一個弱參照,當除了自身有對key的參照外,此key沒有其他參照,那麼GC之後此map會自動丟棄此值。
- 不是執行緒安全的
- 可以儲存null
演示案例
public static void main(String[] args) {
String a = new String("a");
String b = new String("b");
Map weakmap = new WeakHashMap();
weakmap.put(a, "aaa");
weakmap.put(b, "bbb");
a = null;
b = null;
// 進行gc
System.gc();
Iterator j = weakmap.entrySet().iterator();
while (j.hasNext()) {
Map.Entry en = (Map.Entry) j.next();
System.out.println("weakmap:" + en.getKey() + ":" + en.getValue());
}
}
執行結果:

已經被gc回收了。
原理實現
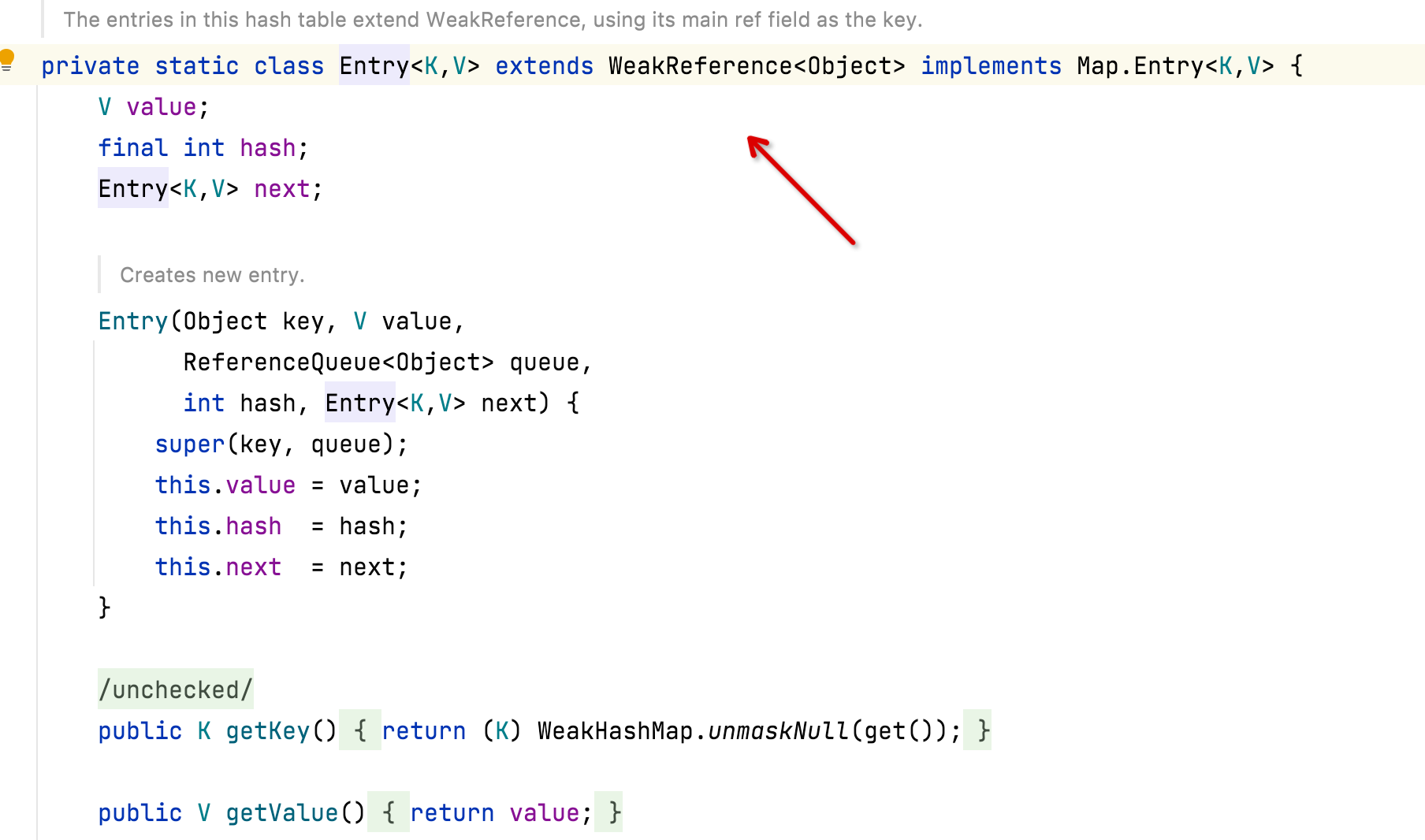
從這裡我們可以看到其內部的Entry繼承了WeakReference,也就是弱參照,所以就具有了弱參照的特點。
弱參照的特點是在垃圾回收器執行緒掃描它所管轄的記憶體區域的過程中,一旦發現了只具有弱參照的物件,不管當前記憶體空間足夠與否,都會回收它的記憶體。不過,由於垃圾回收器是一個優先順序很低的執行緒,因此不一定會很快發現那些只具有弱參照的物件。
WeakReference中有個成員變數ReferenceQueue,他的作用是GC會清理掉物件之後,參照物件會被放到ReferenceQueue中,然後遍歷這個queue進行刪除即可Entry。WeakHashMap內部有一個expungeStaleEntries函數,在這個函數內部實現移除其內部不用的entry從而達到的自動釋放記憶體的目的。因此我們每次存取WeakHashMap的時候,都會呼叫這個expungeStaleEntries函數清理一遍。

使用場景
在如今的並行氾濫的大環境下,大家應該都用過快取,快取都是放在記憶體中的,而記憶體幾乎是計算機中最寶貴也是最稀缺的資源,所以需要謹慎的使用,不然很容易就出現 OOM。快取的主要作用是為了更快的處理業務、降低伺服器的壓力,那麼就要保證快取命中率,這裡假設整個快取是一個 key-value 結構的(以鍵值對快取為例),HashMap 作為強參照物件在沒有主動將 key 刪除時是不會被 JVM 回收的,這樣 HashMap 中的物件就會越積越多直到 OOM 錯誤;那麼如何做到既讓快取的命中率高又不佔用那麼多的記憶體,這裡就可以採用 WeakHashMap,當然不會有 HashMap 100% 的命中率(假設記憶體足夠),但是在保證程式正常的前提下更好的實現了快取這套解決方案。
EnumMap
介紹
用於列舉型別鍵的專用Map實現。列舉對映中的所有鍵必須來自建立對映時顯式或隱式指定的單個列舉型別。
相對於HashMap中列舉作為key, EnumMap內部以一個非常緊湊的陣列儲存value,並且根據enum型別的key直接定位到內部陣列的索引,並不需要計算hashCode(),不但效率最高,而且沒有額外的空間浪費。
- 不是執行緒安全的
- 可以存放null值
演示案例
public static void main(String[] args) {
// 建構函式傳入型別
Map<DayOfWeek, String> map = new EnumMap<>(DayOfWeek.class);
map.put(DayOfWeek.MONDAY, "星期一");
map.put(DayOfWeek.TUESDAY, "星期二");
map.put(DayOfWeek.WEDNESDAY, "星期三");
map.put(DayOfWeek.THURSDAY, "星期四");
map.put(DayOfWeek.FRIDAY, "星期五");
map.put(DayOfWeek.SATURDAY, "星期六");
map.put(DayOfWeek.SUNDAY, "星期日");
System.out.println(map);
System.out.println(map.get(DayOfWeek.MONDAY));
}
enum DayOfWeek {
MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY
}
原理實現
put方法原始碼如下:
public V put(K key, V value) {
// 對列舉型別進行檢查,看key和建構函式傳入的class型別是否一致
typeCheck(key);
// 列舉的順序
int index = key.ordinal();
// 原來位置的值
Object oldValue = vals[index];
// 設定值
vals[index] = maskNull(value);
if (oldValue == null)
size++;
return unmaskNull(oldValue);
}
通過put原始碼發現是通過陣列的方式實現儲存,而且也不需要進行擴容。
使用場景
如果專案中遇到針對列舉作為key的對映容器,可以優先選擇EnumMap。
IdentityHashMap
介紹
該類使用雜湊表實現Map介面,在比較鍵(和值)時使用參照相等代替物件相等。換句話說,在一個IdentityHashMap中,當且僅當(k1k2)兩個鍵k1和k2被認為是相等的。(在正常的Map實現(如HashMap)兩個鍵k1和k2被認為是相等的,當且僅當(k1null ?k2 = = null: k1.equals (k2)))。
- 不是執行緒安全的
- 無序
- key不可以是null
演示案例
public static void main(String[] args) {
// hashMap
Map<Integer, String> hashMap = new HashMap<>();
// identityHashMap
Map<Integer, String> identityHashMap = new IdentityHashMap<>();
hashMap.put(new Integer(200), "a");
hashMap.put(new Integer(200), "b");
identityHashMap.put(new Integer(200), "a");
identityHashMap.put(new Integer(200), "b");
//遍歷hashmap
System.out.println("hashmap 結果:");
hashMap.forEach((key, value) -> {
System.out.println("key = " + key + ", value = " + value);
});
//遍歷hashmap
System.out.println("identityHashMap 結果:");
identityHashMap.forEach((key, value) -> {
System.out.println("key = " + key + ", value = " + value);
});
}
執行結果:

原理實現
IdentityHashMap底層的資料結構就是陣列,我們關注下put方法:

呼叫hash方法,獲取key在table的位置index,然後進行賦值操作,也是分成了3種情況:
1.item == k,找到了對應的key,value存在key右相鄰的位置,對tab[i + 1]進行更新,並返回原來的值;
2.item == null,表示table中沒有對應的key值,跳出for迴圈,執行tab[i] = k和tab[i + 1] = value進行新key的插入操作。個人覺得這裡的擴容時機選擇的不太好,好不容易找到的更新位置,因為擴容給整沒了,還得再次重新計算,可以和HashMap一樣,在更新後再擴容。
3.item != null && item != key,表示hash衝突發生,呼叫nextKeyIndex獲取處理衝突後的index位置,然後重複上面的過程。
我們再來看下hash方法:

IdentityHashMap中獲取hash值採用的System.identityHashCode方法,在不重寫Object.hashCode方法時,System.identityHashCode和Object.hashCode返回的值相同,相當於物件的唯一的HashCode。System.identityHashCode(null)始終返回0, 無論是否重寫Object.hashCode,都不影響System.identityHashCode的執行結果。
使用場景
當我們必須使用地址相等來判斷值相等的場合,以及我們確定只要其地址不相等,則其equals方法的結果也必定不相等的場合。
總結
本文主要講解了集中不常用的Map, 當然我們也需要了解他們的特性,在有些時候還是會用到的。
如果本文對你有幫助的話,請留下一個贊吧
歡迎關注個人公眾號——JAVA旭陽
更多學習資料請移步:程式設計師成神之路
本文來自部落格園,作者:JAVA旭陽,轉載請註明原文連結:https://www.cnblogs.com/alvinscript/p/16974891.html