【Java難點攻克】「NIO和記憶體對映效能提升系列」徹底透析NIO底層的記憶體對映機制原理與Direct Memory的關係
NIO與記憶體對映檔案
Java類庫中的NIO包相對於IO包來說有一個新功能就是 【記憶體對映檔案】,在業務層面的日常開發過程中並不是經常會使用,但是一旦在處理大檔案時是比較理想的提高效率的手段,之前已經在基於API和開發實戰角度介紹了相關的大檔案讀取以及NIO操作的實現,而本文主要想結合作業系統(OS)底層中相關方面的內容進行分析原理,夯實大家對IO模型及作業系統相關的底層知識體系。
下圖就是Java應用程式以及作業系統OS核心的呼叫關係圖:
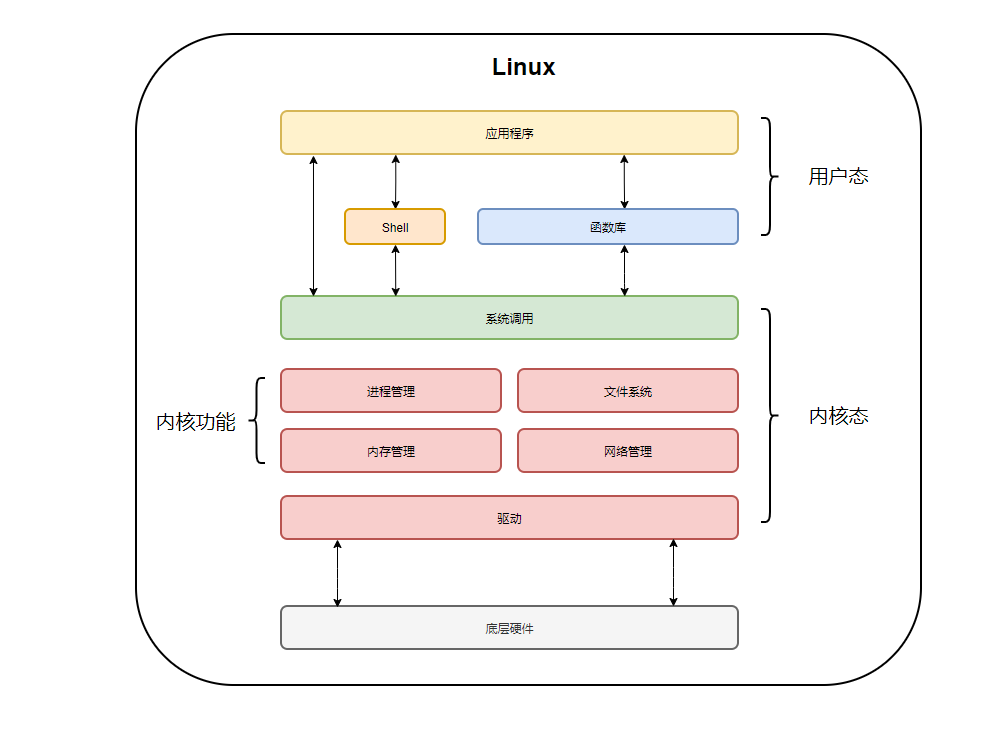
我們會針對於作業系統與應用程式之間建立的關係去分析IO處理底層機制。
傳統的IO技術
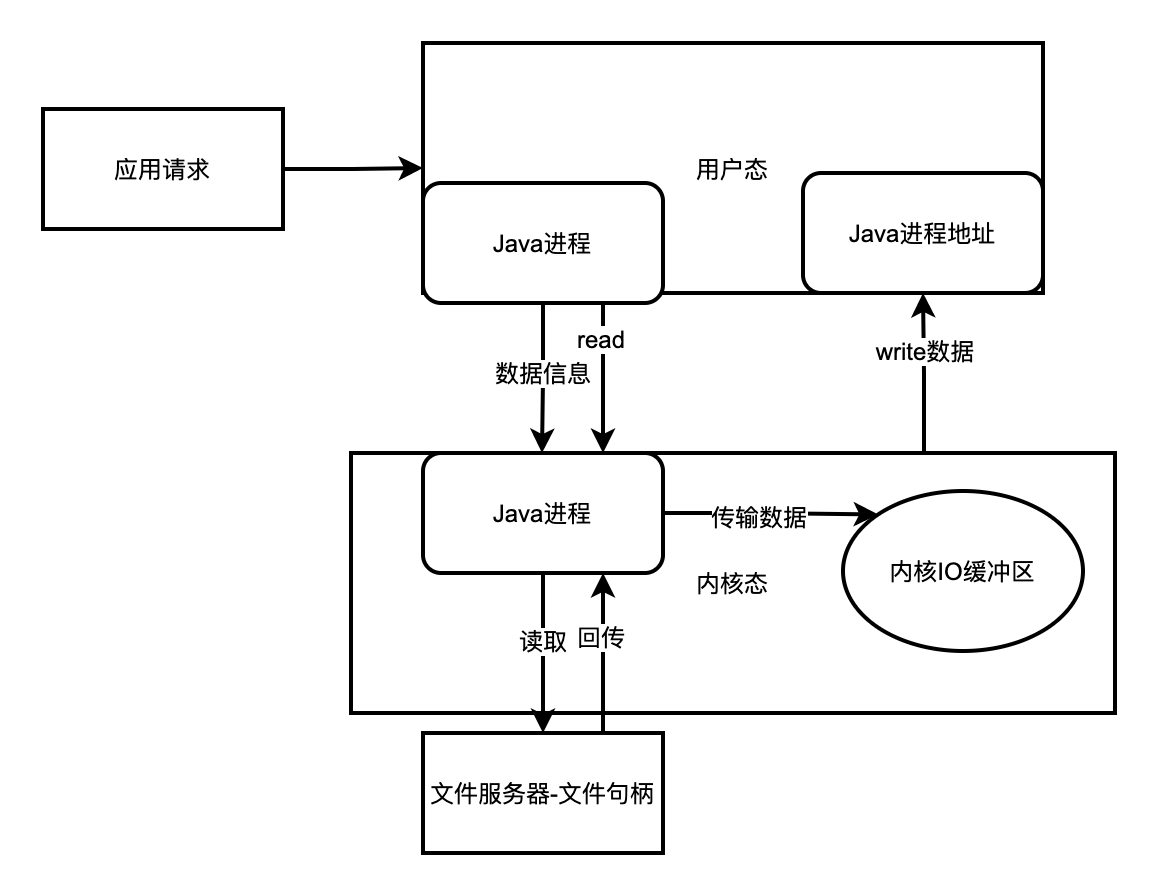
在傳統的檔案IO操作中, 我們都是呼叫作業系統提供的底層標準IO系統呼叫函數read()、write() , 此時呼叫此函數的程序(Java程序) 由當前的使用者態切換到核心態, 然後OS的核心程式碼負責將相應的檔案資料讀取到核心的IO緩衝區,然後再把資料從核心IO緩衝區拷貝到程序的私有地址空間中去,這樣便完成了一次IO操作,如下圖所示。
程式的區域性性原理
為什麼需要核心IO緩衝區
至於為什麼要多此一舉搞一個核心IO緩衝區把原本只需一次拷貝資料的事情搞成需要2次資料拷貝呢?
IO拷貝的預先區域性拷貝
為了減少磁碟的IO操作,為了提高效能而考慮的,因為我們的程式存取一般都帶有區域性性,也就是所謂的區域性性原理,在這裡主要是指的空間區域性性,即我們存取了檔案的某一段資料,那麼接下去很可能還會存取接下去的一段資料,由於磁碟IO操作的速度比直接存取記憶體慢了好幾個數量級,所以OS根據區域性性原理會在一次read(系統呼叫過程中預讀更多的檔案資料快取在核心IO緩衝區中, 當繼續存取的檔案資料在緩衝區中時便直接拷貝資料到程序私有空間, 避免了再次的低效率磁碟IO操作。
應用程式IO操作範例
在Java中當我們採用IO包下的檔案操作流,如:
FileInputStream in=new FileInputStream("/usr/text") ;
in.read();
JAVA虛擬機器器內部便會呼叫OS底層的read()系統呼叫完成操作, 在第二次呼叫read()的時候很可能就是從核心緩衝區直接返回資料了,此外還有可能需要經過native堆做一次中轉,因為這些函數都被宣告為native, 即本地方法, 所以可能在C語言中有做一次中轉, 如win32/win64中就是通過C語言從OS讀取資料, 然後再傳給JVM記憶體 。
系統呼叫與應用程式
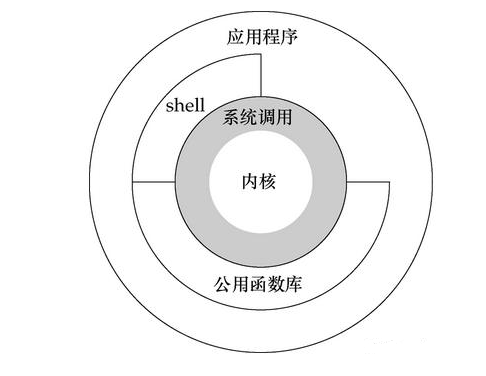
既然如此, Java-IO包中為啥還要提供一個BufferedInputStream類來作為緩衝區呢,關鍵在於四個字, "系統呼叫",當讀取OS核心緩衝區資料的時候, 便發起了一次系統呼叫操作(通過native的C函數呼叫),而系統呼叫的代價相對來說是比較高的,涉及到程序使用者態和核心態的上下文切換等一系列操作,所以我們經常採用如下的包裝:
File ln put Stream in=new FileInputStream("/user/txt") ;
BufferedInputStream buf in=new BufferedInputStream(in) ;
buf in.read();
通過Buffer減少系統呼叫次數(經常被理解錯誤)
- 有了Buffer快取,我們每一次in.read() 時候, BufferedInputStream會根據情況自動為我們預讀更多的位元組資料到它自己維護的一個內部位元組陣列緩衝區中,這樣我們便可以減少系統呼叫次數, 從而達到其緩衝區的目的。

- 所以要明確的一點是BufferedInputStream的作用不是減少磁碟IO操作次數,因為作業系統OS已經幫我們完成了,而是通過減少系統呼叫次數來提高效能的。
- 同理BufferedOuputStream, BufferedReader/Writer也是一樣的。在C語言的函數庫中也有類似的實現, 如,fread()是C語言中的緩衝IO, 與BufferedInputStream()相同.
BufferedInputStream分析
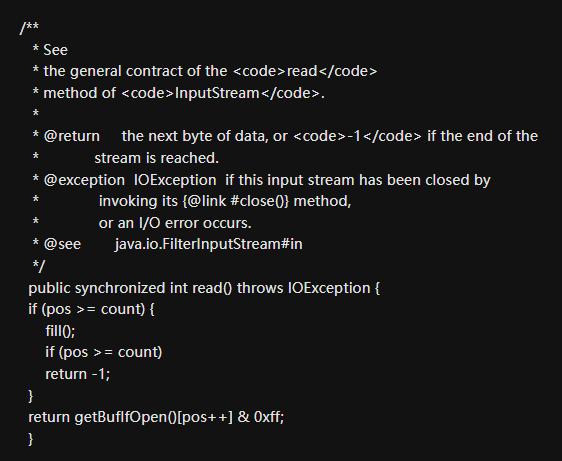
從上面的原始碼我們可以看到,BufferedInputStream內部維護著一個位元組陣列byte[] buf來實現緩衝區的功能,呼叫的buf的in.read()方法在返回資料之前有做一個if判斷, 如果buf陣列的當前索引不在有效的索引範圍之內, 即if條件成立, buf欄位維護的緩衝區已經不夠了, 這時候會呼叫內部的fill()方法進行填充, 而fill()會預讀更多的資料到buf陣列緩衝區中去, 然後再返回當前位元組資料, 如果if條件不成立便直接從buf緩衝區陣列返回資料了。
BufferedInputStream的buff的可見性
對於read方法中的getBufIfOpen()返回的就是buf欄位的參照,原始碼中的buf欄位宣告為
protected volatile byte buf;主要是為了通過volatile關鍵字保證buf陣列在多執行緒並行環
境中的記憶體可見性.
記憶體對映檔案的實現
記憶體對映檔案和之前說的標準IO操作最大的不同之處就在於它雖然最終也是要從磁碟讀取資料,但是它並不需要將資料讀取到OS核心緩衝區,而是直接將程序的使用者私有地址空間中的一部分割區域與檔案物件建立起對映關係,就好像直接從記憶體中讀、寫檔案一樣,速度當然快了,如下圖所示。
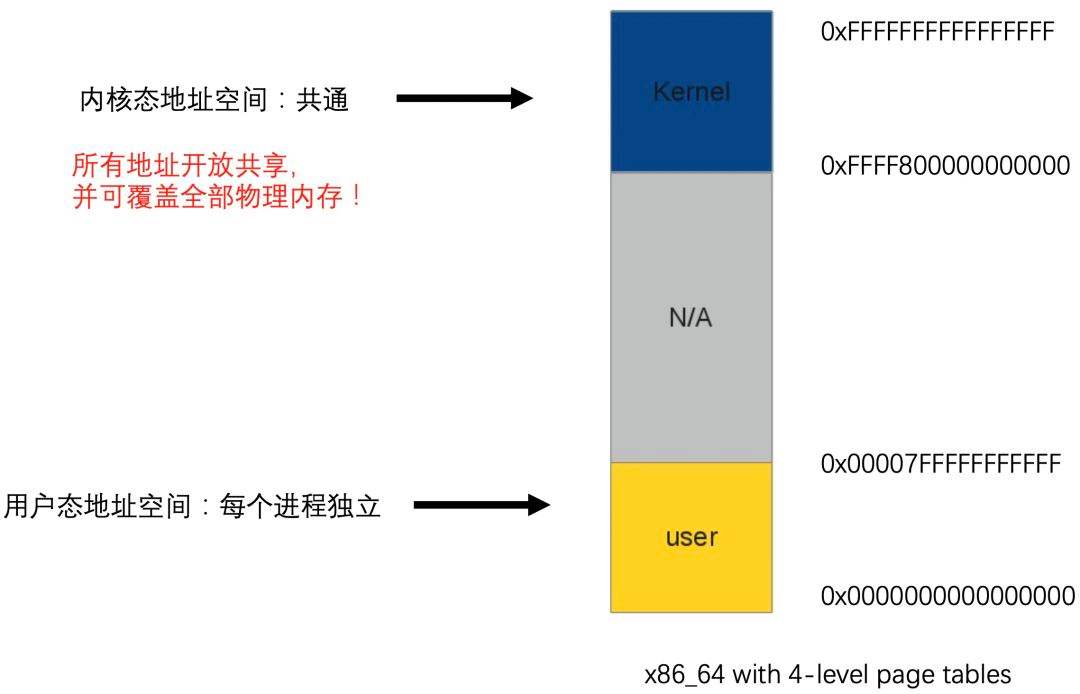
Linux中的程序虛擬記憶體, 即程序的虛擬地址空間, 如果你的機子是32位元,那麼就有2^32=4G的虛擬地址空間,我們可以看到圖中有一塊區域:
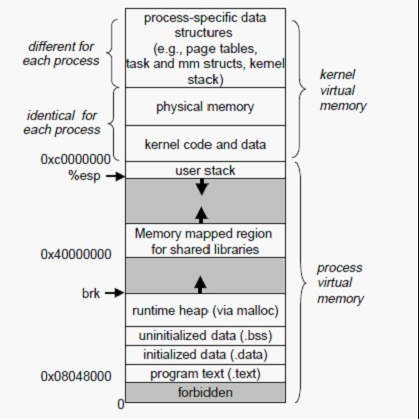
「Memory mapped region for shared libraries」
這段區域就是在記憶體對映檔案的時候將某一段的虛擬地址和檔案物件的某一部分建立起對映關係,此時並沒有拷貝資料到記憶體中去,而是當程序程式碼第一次參照這段程式碼內的虛擬地址時,觸發了缺頁異常,這時候OS根據對映關係直接將檔案的相關部分資料拷貝到程序的使用者私有空間中去,當有操作第N頁資料的時候重複這樣的OS頁面排程程式操作。
記憶體對映檔案的優點
記憶體對映檔案的效率比標準IO高的重要原因就是因為少了把資料拷貝到OS核心緩衝區這一步(可能還少了native堆中轉這一步) 。
Java中提供了3種記憶體對映模式:唯讀(readonly) 、讀寫(read_write) 、專用(private) 。
唯讀(readonly) 模式
對於唯讀模式來說,如果程式試圖進行寫操作,則會丟擲Readonly Buffer Exception異常。
read_write模式
NIO的read_write模式
read_write讀寫模式表明了通過記憶體對映檔案的方式寫或修改檔案內容的話是會立刻反映到磁碟檔案中去的,別的程序如果共用了同一個對映檔案,那麼也會立即看到變化!
標準IO的read_write模式
標準IO那樣每個程序有各自的核心緩衝區, 比如Java程式碼中, 沒有執行IO輸出流的flush()或者close()操作, 那麼對檔案的修改不會更新到磁碟去, 除非程序執行結束。
專用模式
專用模式採用的是OS的「寫時拷貝」原則,即在沒有發生寫操作的情況下,多個程序之間都是共用檔案的同一塊實體記憶體(程序各自的虛擬地址指向同一片實體地址),一旦某個程序進行寫操作,那麼將會把受影響的檔案資料單獨拷貝一份到程序的私有緩衝區中,不會反映到物理檔案中去。
File file=new File("/usr/txt") ;
FileInputStream in=new FileInputStream(file) ;
File Channel channel=in.getChannel();
MappedByteBuffer buff=channel.map(File Channel.Map Mode.READ_ONLY, 0, channel.size 0) ;
這裡建立了一個唯讀模式的記憶體對映檔案區域, 接下來我就來測試下與普通NIO中的通道操作相比效能上的優勢,先看如下程式碼:
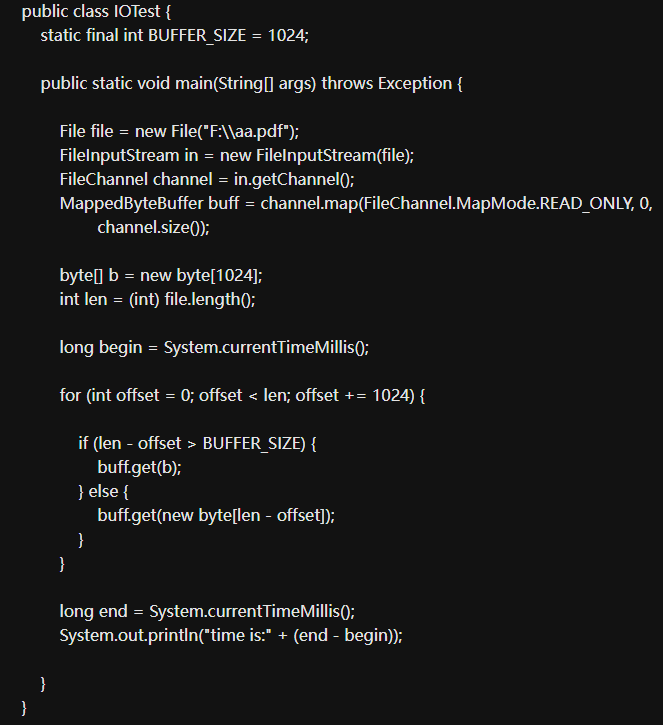
輸出為63,即通過記憶體對映檔案的方式讀取86M多的檔案只需要78毫秒,我現在改為普通
NIO的通道操作看下:
File file=new File("/usr/txt") ;
FileInputStream in=new FileInputStream(file) ;
File Channel channel=in.getChannel();
ByteBuffer buff=ByteBuffer.allocate(1024) ;
long begin=System.currentTimeMillis();
while(channel.read(buff) !=-1) {
buff.flip 0;
buff.clear 0;
long end=System.currentTimeMillis();
System.out.print In("time is:"+(end-begin) ) ;
輸出為468毫秒,幾乎是6倍的差距,檔案越大,差距便越大。
記憶體對映的使用場景
記憶體對映特別適合於對大檔案的操作, JAVA中的限制是最大不得超過Integer.MAXVALUE, 即2G左右, 不過我們可以通過分次對映檔案(channel.map) 的不同部分來達到操作整個檔案的目的。
記憶體對映的優勢特點
記憶體對映屬於JVM中的直接緩衝區, 還可以通過ByteBuffer.allocateDirect, 即Direct Memory的方式來建立直接緩衝區。
相比基礎的IO操作來說就是少了中間緩衝區的資料拷貝開銷,同時他們屬於JVM堆外記憶體, 不受JVM堆記憶體大小的限制。
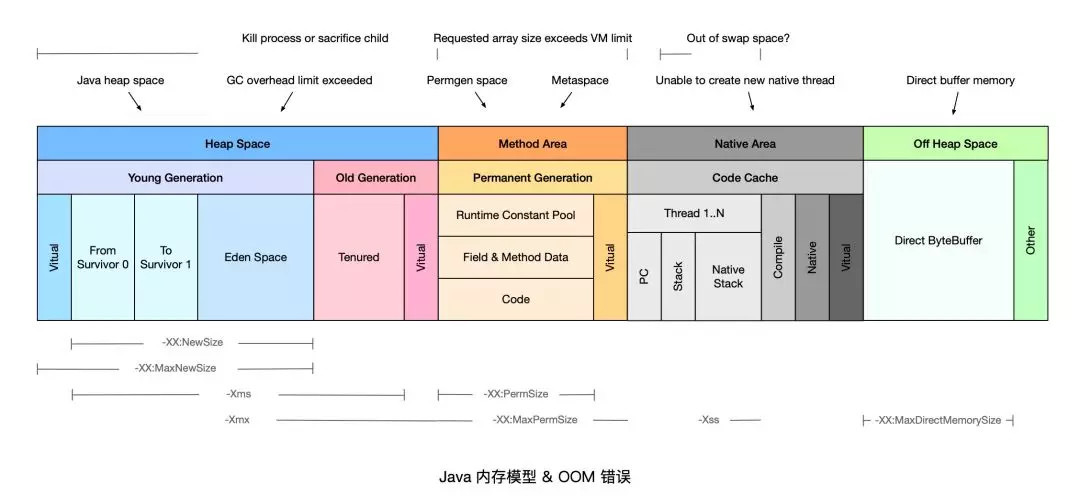
其中Direct Memory預設的大小是等同於JVM最大堆, 理論上說受限於程序的虛擬地址空間大小, 比如32位元的windows上, 每個程序有4G的虛擬空間除去2G為OS核心保留外, 再減去JVM堆的最大值, 剩餘的才是Direct Memory大小。
通過設定JVM引數-Xmx64M, 即JVM最大堆為64M, 然後執行以下程式可以證明Direct Memory不受JVM堆大小控制:
public static void main(String args) {
ByteBuffer.allocateDirect(1024*1024*100) ; //100MB
}
輸出結果如下:
[GC1371K->1328K(61312K) , 0.0070033secs][Full GC1328K->1297K(61312K),0.0329592secs]
[GC3029K->2481K(61312K) , 0.0037401secs][Full GC2481K->2435K(61312K) , 0.0102255secs]
看到這裡執行GC的次數較少, 但是觸發了兩次Full GC, 原因在於直接記憶體不受GC(新生代的Minor GC) 影響, 只有當執行老年代的Full GC時候才會順便回收直接記憶體!而直接記憶體是通過儲存在JVM堆中的Direct ByteBuffer物件來參照的, 所以當眾多的Direct ByteBuffer物件從新生代被送入老年代後才觸發了full gc。再看直接在JVM堆上分配記憶體區域的情況:
public static void main(String~args) {
for(inti=0; i<10000; i++) {
ByteBuffer.allocate(1024*100) ; //100K
}
}
ByteBuffer.allocate意味著直接在JVM堆上分配記憶體, 所以受新生代的Minor GC影響, 輸出如下:
[GC16023K->224K(61312K) , 0.0012432secs][GC16211K->192K(77376K) , 0.0006917secs][GC32242K->176K(77376K) , 0.0010613secs][GC32225K->224K(109504K) , 0.0005539secs][GC64423K->192K(109504K) , 0.0006151secs][GC64376K->192K(171392K, 0.0004968secs][GC128646K->204K(171392K) , 0.0007423secs][GC128646K->204K(299968K) , 0.0002067secs][GC257190K->204K(299968K) , 0.0003862secs][GC257193K->204K(287680K) , 0.0001718secs][GC245103K->204K(276480K) , 0.0001994secs][GC233662K->204K(265344K) , 0.0001828secs][GC222782K->172K(255232K) , 0.0001998secs][GC212374K->172K(245120K) , 0.0002217secs]
可以看到, 由於直接在JVM堆上分配記憶體, 所以觸發了多次GC, 且不會觸及Full GC, 因為物件根本沒機會進入老年代。
Direct Memory和記憶體對映
NIO中的Direct Memory和記憶體檔案對映同屬於直接緩衝區, 但是前者和-Xmx和-XX:MaxDirectMemorySize有關, 而後者完全沒有JVM引數可以影響和控制,這讓我不禁懷疑兩者的直接緩衝區是否相同。
Direct Memory
Direct Memory指的是JAVA程序中的native堆, 即涉及底層平臺如win 32的dII部分, 因為C語言中的malloc) 分配的記憶體就屬於native堆, 不屬於JVM堆,這也是Direct Memory能在一些場景中顯著提高效能的原因, 因為它避免了在native堆和jvm堆之間資料的來回複製;
記憶體對映
記憶體對映則是沒有經過native堆, 是由JAVA程序直接建立起某一段虛擬地址空間和檔案物件的關聯對映關係, 參見Linux虛擬記憶體圖中的「Memory mapped region for shared libraries」區域, 所以記憶體對映檔案的區域並不在JVM GC的回收範圍內, 因為它本身就不屬於堆區, 解除安裝這部分割區域只能通過系統呼叫unmap()來實現(Linux)中, 而JAVA API只提供了FileChannel.map的形式建立記憶體對映區域, 卻沒有提供對應的unmap(), 讓人十分費解, 導致要解除安裝這部分割區域比較麻煩。
Direct Memory和記憶體對映結合所實現的案例
通過Direct Memory來操作前面記憶體對映和基本通道操作的例子, 來看看直接記憶體操作的話,程式的效能如何:
File file=new File("/usr/txt") ;
FileInputStream in=new FilelnputStream(file) ;
FileChannel channel=in.getChannel 0;
ByteBuffer buff=ByteBuffer.allocateDirect(1024) ;
long begin=System.currentTimeMillis(;
while(channel.read(buff) !=-1) {
buff.flip();
buff.clear();
long end=System.currentTimeMillis();
System.out.printIn("time is:"+(end-begin) );
}
程式輸出為312毫秒, 看來比普通的NIO通道操作(468毫秒) 來的快, 但是比mmap記憶體對映的63秒差距太多了, 通過修改; ByteBuffer buff=ByteBuffer.allocateDirect(1024) ;
ByteBuffer buff=ByteBuffer.allocateDirect((in) file.length 0) , 即一次性分配整個檔案長度大小的堆外記憶體,最終輸出為78毫秒,由此可以得出堆外記憶體的分配耗時比較大,還是比mmap記憶體對映來得慢。
Direct Memory的記憶體回收(非常重要總結)
最後一點為Direct Memory的記憶體只有在JVM執行full gc的時候才會被回收, 那麼如果在其上分配過大的記憶體空間, 那麼也將出現OOM, 即便JVM堆中的很多記憶體處於空閒狀態。
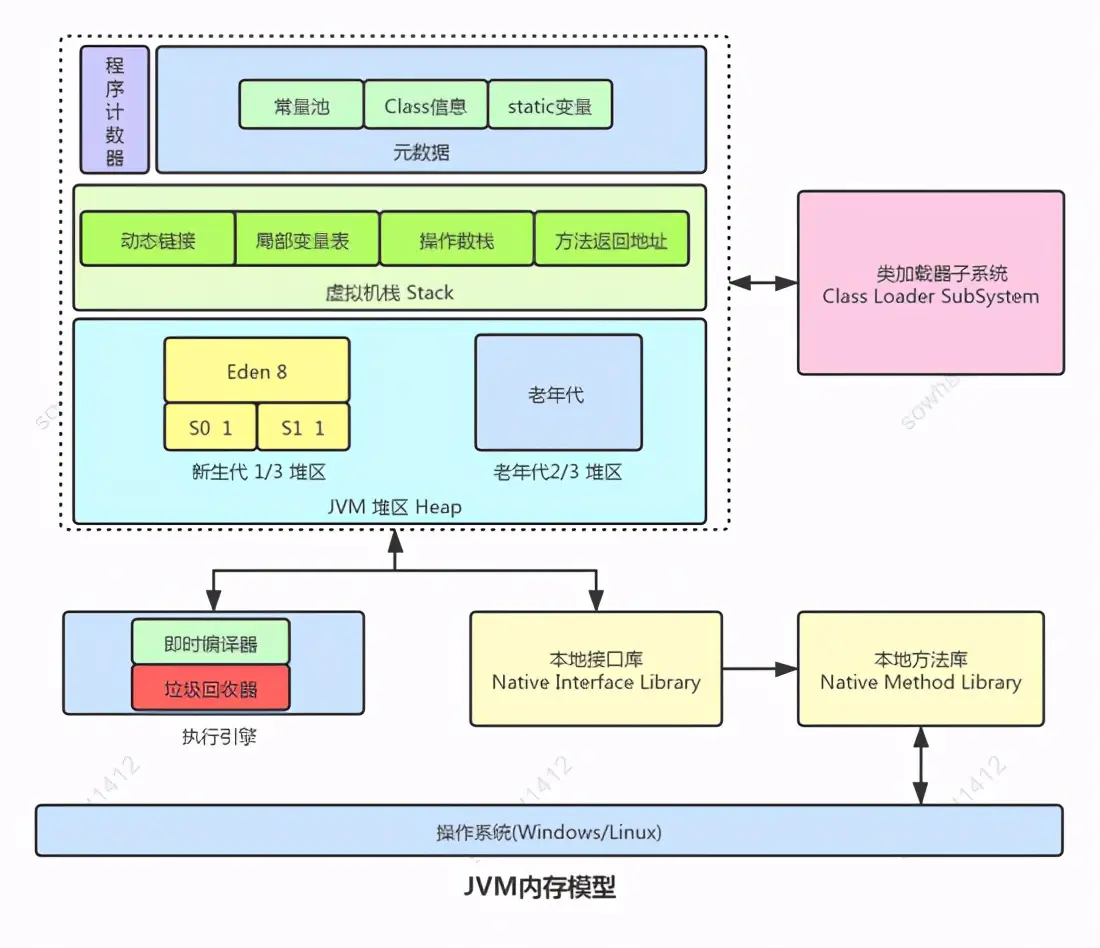
JVM堆記憶體的限制範圍
關於JVM堆大小的設定是不受限於實體記憶體, 而是受限於虛擬記憶體空間大小,理論上來說是程序的虛擬地址空間大小,但是實際上我們的虛擬記憶體空間是有限制的, 一般windows上預設在C槽, 大小為實體記憶體的2倍左右。
本文來自部落格園,作者:洛神灬殤,轉載請註明原文連結:https://www.cnblogs.com/liboware/p/16972966.html,任何足夠先進的科技,都與魔法無異。