剖析虛幻渲染體系(19)- 計算機硬體體系
- 19.1 計算機概述
- 19.2 計算機硬體基礎
- 19.3 計算機架構和組織
- 19.4 ISA
- 19.5 處理器
- 19.6 記憶體系統
- 19.7 多處理器系統
- 19.8 I/O和儲存裝置
- 19.9 GPU
- 19.10 電源
- 19.11 UE硬體
- 19.12 本篇總結
- 特別說明
- 參考文獻
19.1 計算機概述
之前的很多篇文章已經大量涉及了各種各樣的硬體和技術,本篇將更加全面、系統、深入地闡述計算機的硬體組成和體系架構,從而形成自上而下的計算機體知識體系。本篇主要闡述以下內容:
- 計算機基礎。
- 電子電路基礎。
- 計算機硬體。
- 計算機架構和組織。
- 計算機硬體執行機制。
- 計算機硬體的UE封裝和實現。
19.1.1 計算機是什麼
計算機(Computer)是什麼?計算機是一種通用裝置,可以程式設計處理資訊,併產生有意義的結果。它是一種被廣泛使用且使我們的工作變得輕鬆的裝置,是被動型機器,需要我們輸入指令或任務來執行,從而獲得我們需要的結果。
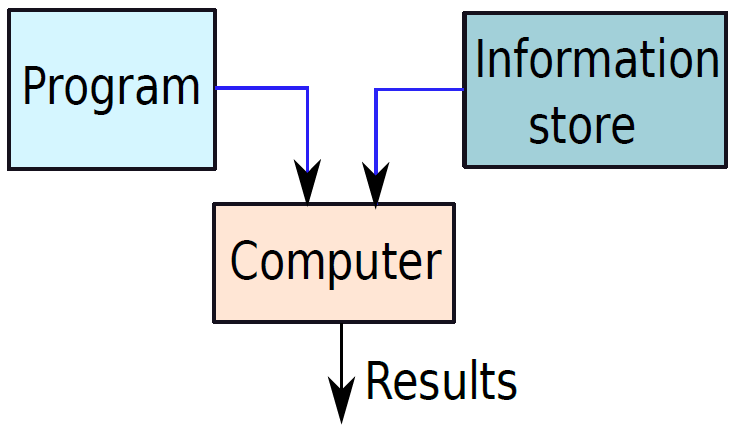
一個基礎的計算機。
簡單的單處理器計算機如下,提供了傳統單處理器計算機內部結構的分層檢視。有四個主要結構部件:CPU、主記憶體、I/O、系統連結。
如下圖所示,向用戶提供應用程式時使用的硬體和軟體可以以分層或分層的方式檢視。這些應用程式的使用者,即終端使用者,通常不關心計算機的架構,因此終端使用者根據應用來檢視計算機系統。該應用程式可以用程式語言表示,並由應用程式程式設計師開發,將應用程式開發為一組完全負責控制計算機硬體的處理器指令將是一項極其複雜的任務。為了簡化此任務,提供了一組系統程式。
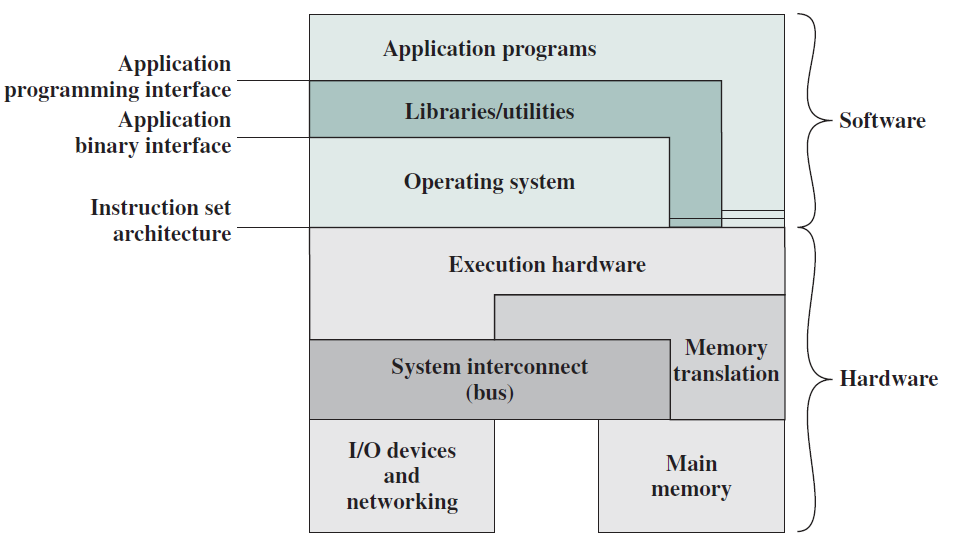
其中一些程式被稱為實用程式。這些實現了常用的功能,有助於程式建立、檔案管理和I/O裝置控制。程式設計師在開發應用程式時使用這些工具,應用程式在執行時呼叫實用程式來執行某些功能。最重要的系統程式是作業系統,作業系統向程式設計師隱藏了硬體的細節,併為程式設計師提供了使用系統的方便介面。它充當中介,使程式設計師和應用程式更容易存取和使用這些設施和服務。
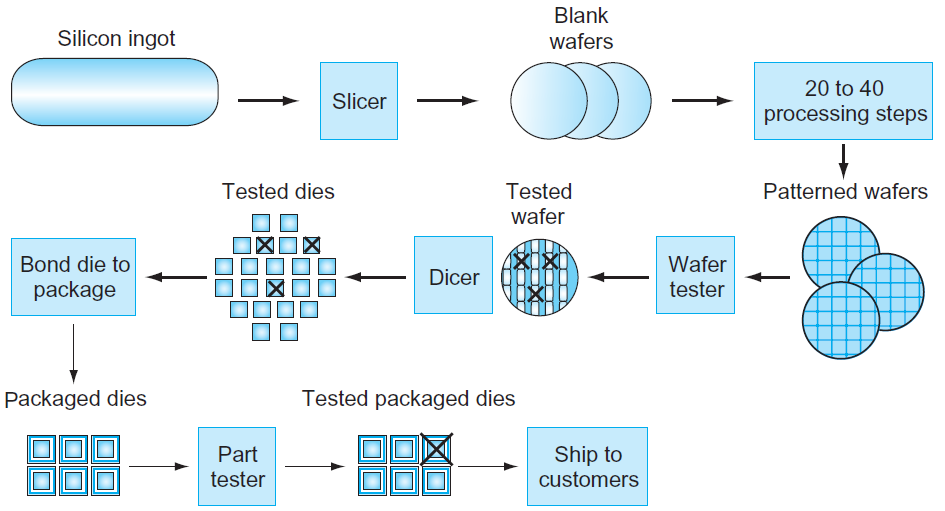
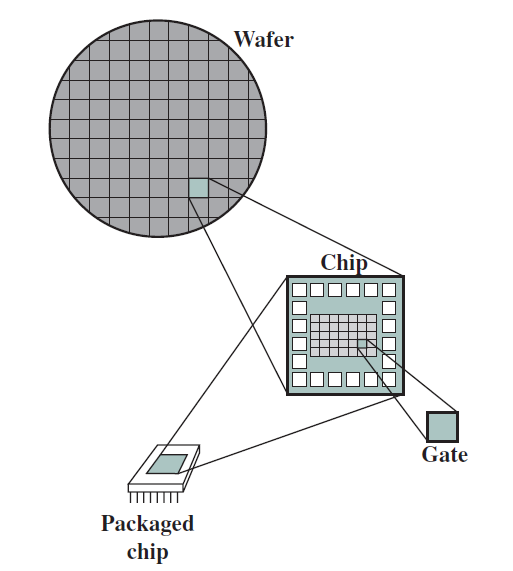
硬體之中,最重要的部件是晶片,其製造工藝如下圖。從矽錠切片後,將空白晶片經過20至40個步驟,以形成圖案化晶片。然後用晶片測試儀對這些圖案化的晶片進行測試,並繪製出良好零件的地圖。然後將晶片切成小片,在該圖中,一個晶片生產了20個管芯,其中17個管芯通過了測試(X表示模具不良)。在這種情況下,好模具的產量為17/20,即85%。然後將這些好的模具粘結到包裝中,並在將包裝好的零件運送給客戶之前再次進行測試。最終測試中發現一個包裝不良的零件。
19.1.2 計算機結構
典型的臺式計算機有三個主要物理部件——CPU(中央處理器)、主記憶體儲器和硬碟。CPU通常也被稱為處理器或簡單的機器,是計算機的大腦,是計算機的主要部分,將程式作為輸入並執行。主記憶體儲器用於儲存程式在執行過程中可能需要的資料(資訊儲存),處理器本身的儲存空間有限。當電源關閉時,處理器和主記憶體儲器會丟失所有資料,但硬碟代表永久儲存,程式、資料、照片、視訊和檔案等資料都儲存在硬碟中。

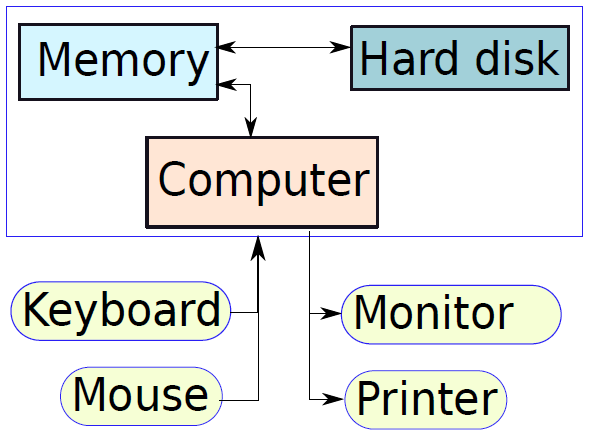
下圖顯示了三個元件的簡化框圖。除了這些主要元件之外,還有一系列與計算機相連的外圍元件,例如鍵盤和滑鼠連線到計算機。它們從使用者處獲取輸入,並將其傳遞給處理器上執行的程式。
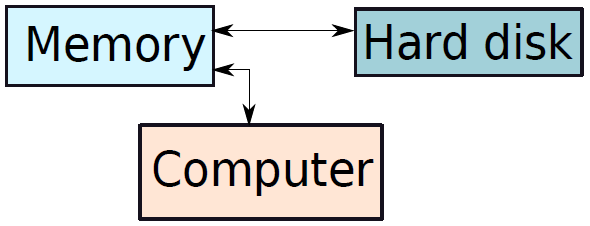
類似地,為了顯示程式的輸出,處理器通常將輸出資料傳送到監視器,監視器可以以圖形方式顯示結果,也可以使用印表機列印結果。最後,計算機可以通過網路連線到其他計算機。所有外圍裝置的方框圖如下所示。
19.1.3 計算機執行機制
不管底層技術如何,我們需要理解的一個基本概念是,計算機從根本上來說是一臺愚蠢的機器。與我們的大腦不同,它沒有被賦予抽象的思想、理性和良知。至少在目前,計算機不能自己做出非常複雜的決定,能做的就是執行一個程式。儘管如此,計算機之所以如此強大,是因為它們非常擅長執行程式,每秒可以執行數十億條基本指令。計算機與人腦的比較如下表所示。
| 特性 | 計算機 | 人腦 |
|---|---|---|
| 智力 | 愚蠢 | 智慧 |
| 算力 | 超快 | 慢 |
| 是否疲倦 | 絕不 | 一段時間後 |
| 是否厭倦 | 絕不 | 幾乎總是 |
計算機無法理解人類語言,只能理解二進位制資料,也就是0和1、True和False、On和Off,這些狀態是通過電晶體(transistor)實現的。電晶體是用於儲存2個值(1和0或開和關)的微型裝置,如果電晶體開啟,它的值為 1,如果它關閉,則值為 0。
例如,一個儲存晶片包含數億甚至數十億個電晶體,每個電晶體都可以單獨開啟或關閉。當極少量的電流通過電晶體時,它保持狀態1,當沒有電流時,電晶體的狀態為0。具體範例:
1 : 1
2 : 10
3 : 11
a : 01100001
A : 01000001
U : 01010101
Hello : 01001000 01100101 01101100 01101100 01101111
Hello World! : 01001000 01100101 01101100 01101100 01101111 00100000 01010111 01101111 01110010 01101100 01100100 00100001
問題在於,以上二進位制程式碼對於人類而言,太難以理解了,此時需要各類計算機軟體做翻譯的橋樑作用。軟體是一組指令,告訴計算機要做什麼、什麼時候做以及如何做。下圖顯示了操作流程。第一步是用高階語言(C或C++)編寫程式,第二步涉及編譯它,編譯器將高階程式作為輸入,並生成包含機器指令的程式,該程式通常稱為可執行檔案或二進位制檔案。注意,編譯器本身是一個由基本機器指令組成的程式。
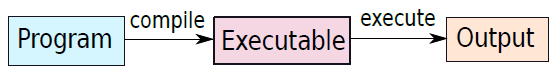
假設要執行2+2的指令,那麼我們必須給計算機指令:
- 第1步:取2個值。
- 第2步:儲存該2值。
- 第3步:使用 + 運運算元對它們進行相加。
- 第4步:儲存結果。
為 + 運運算元提供了單獨的說明,以便計算機在遇到 + 符號時知道如何進行加法。那麼誰來轉換這段程式碼呢?答案是直譯器(interpreter),它把我們的語言程式碼轉換成計算機可以理解的機器語言。同理,輸入和輸出資料也需要依賴特定的軟體和直譯器。
就像任何語言都有有限的單詞一樣,處理器可以支援的基本指令/基本命令的數量也必須是有限的,這組指令通常稱為指令集(instruction set),基本指令的一些範例是加法、減法、乘法、邏輯或和邏輯非。請注意,每條指令需要處理一組變數和常數,最後將結果儲存在變數中。這些變數不是程式設計師定義的變數,是計算機內的內部位置。
19.1.4 計算機設計準則
計算機設計是元件相互關聯的結構。設計者一次處理特定級別的系統,並且在不同級別存在不同型別的問題。在每一層,設計者都關心結構和功能,結構是相互關聯的用於通訊的各個元件的骨架,功能是系統中涉及的活動。 以下是計算機設計中的問題:
- 無限速度的假設: 不能假設計算機的無限速度,因為假設無限速度是不切實際的,也給設計者的思維帶來了問題。
- 記憶體無限的假設: 就像計算機的速度一樣,記憶體也不能假設為無限的,總是有限的。
- 記憶體和處理器之間的速度不匹配: 有時記憶體和處理器的速度可能不匹配,可能是記憶體速度更快或處理器速度更快。記憶體和處理器之間的不匹配會導致設計中出現問題。
- 處理錯誤和錯誤: 處理缺陷和錯誤是任何計算機設計者的巨大責任,缺陷和錯誤會導致計算機系統出現故障,有時這些錯誤可能更危險。
- 多處理器: 設計具有多個處理器的計算機系統會導致管理和程式設計的巨大任務,是計算機設計中的一大問題。
- 多執行緒: 具有多執行緒的計算機系統總是對設計者構成威脅,具有多個執行緒的計算機應該能夠進行多工和多處理。
- 共用記憶體: 如果一次要執行多個程序,則所有程序共用相同的記憶體空間。應該以特定的方式對其進行管理,以免發生衝突。
- 磁碟存取: 磁碟管理是計算機設計的關鍵,磁碟存取存在幾個問題,系統可能不支援多磁碟存取。
- 更好的效能: 始終是一個問題,設計者總是試圖簡化系統以獲得更好的效能來降低功耗和降低成本。
19.1.5 實用機器架構
下面闡述一下不同型別的實用機器的設計及架構。
- 哈佛架構
哈佛體系架構下圖所示,有單獨的結構來維護指令表和記憶體。指令表也被稱為指令記憶體,因為可以把它看作是專門為只儲存指令而設計的專用記憶體。記憶體儲存程式所需的資料值,因此被稱為資料記憶體。處理指令的引擎分為兩部分:控制和ALU,控制單元的工作是獲取指令、處理指令並協調指令的執行。ALU代表算術邏輯單元,有專門的電路,可以計算算術表示式或邏輯表示式(and/or/NOT等)。
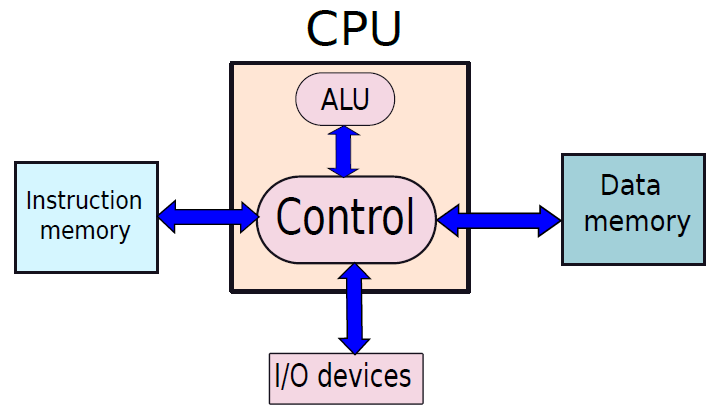
請注意,每臺計算機都需要從使用者/程式設計器處獲取輸入,並最終將結果傳回程式設計器,可通過多種方法實現,例如我們如今使用的鍵盤和顯示器。早期的計算機使用一組開關,最終結果列印在一張紙上。
- 馮諾依曼架構
約翰·馮·諾依曼提出了通用圖靈完備計算機的馮·諾伊曼體系結構,實際上,Eckert和Mauchly於1946年基於該架構設計了第一臺通用圖靈完備計算機(有個小限制),稱為ENIAC(電子數位積分器和計算器),該計算機用於計算美國陸軍彈道研究實驗室的火炮環表,後來在1949年被EDVAC計算機取代,該計算機也被美國陸軍的彈道研究實驗室使用。
作為ENIAC和EDVAC基礎的基本馮·諾依曼架構如下圖所示。指令表儲存在記憶體中,圖靈機的處理引擎被稱為CPU(中央處理單元),包含程式計數器,其工作是獲取新指令並執行它們。它有專用的功能單元來計算算術函數的結果,在記憶體位置載入和儲存值,以及計算分支指令的結果。最後,與哈佛體系結構一樣,CPU連線到I/O子系統。
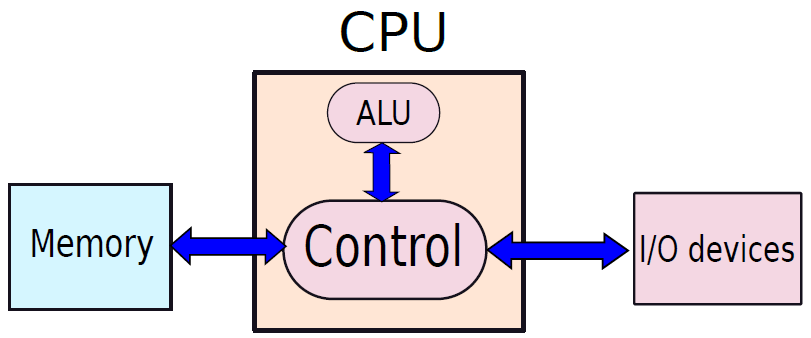
這臺機器的創新之處在於指令表儲存在記憶體中,使用通常儲存在記憶體中的同一組符號對每條指令進行編碼。例如,如果記憶體儲存十進位制值,則每條指令都需要編碼為十進位制數位串。馮·諾依曼CPU需要解碼每條指令,這個想法的核心是,指令被視為常規資料(記憶體值)。這個簡單的想法實際上是設計優雅計算系統的一個非常強大的工具,被稱為儲存程式概念。
儲存程式概念(stored program concept):程式儲存在記憶體中,指令被視為常規記憶體值。
儲存程式概念極大地簡化了計算機的設計。由於記憶體資料和指令在概念上是以相同的方式處理的,所以我們可以有一個統一的處理系統和一個以相同方式處理指令和資料的記憶體系統。從CPU的角度來看,程式計數器指向一個通用記憶體位置,其內容將被解釋為編碼指令的內容,很容易儲存、修改和傳輸程式,程式還可以在執行時通過修改自身甚至其他程式來動態更改其行為。這構成了當今複雜編譯器的基礎,這些編譯器將高階C程式轉換為機器指令。此外,許多現代系統(如Java虛擬機器器)動態地修改它們的指令以實現效率。
馮·諾伊曼機器或哈佛機器不像圖靈機器那樣擁有無限的記憶體,嚴格地說,它們並不完全等同於圖靈機,對於所有實用的機器都是如此,它們需要足夠的資源。然而,科學界已經學會接受這種近似。
19.2 計算機硬體基礎
19.2.1 組合語言
組合語言可以廣泛地定義為機器指令的文字表示。在構建處理器之前,我們需要了解不同機器指令的語意,在這方面,對組合語言的嚴格研究將是有益的。組合語言專用於ISA和編譯器框架,因此,組合語言有許多優點。本節將描述不同組合語言變體的基本原理,一些通用概念和術語。隨後,將描述針對基於ARM的處理器的ARM組合語言,描述針對Intel/AMD處理器的x86組合語言。
19.2.1.1 為什麼用組合語言?
先從軟體開發者的視角闡述之。
人類懂得自然語言,如中文、英語和西班牙語。通過一些額外的訓練,人類還可以理解計算機程式語言,如C或Java。然而,如前面所述,計算機是一臺愚蠢的機器,不夠聰明,無法理解人類語言(如英語)或程式語言(如C)中的命令,它只能理解零和一。因此,要給計算機程式設計,必須給它一個0和1的序列。事實上,一些早期的程式設計師曾經通過開啟或關閉一組開關來程式設計計算機,開啟一個開關對應於1,開啟它意味著0。對於今天的大規模數百萬行程式來說,不是一個可行的解決方案,需要另尋更好的方法。
因此,我們需要一個自動轉換器,它可以將用C或Java等高階語言編寫的程式轉換為一系列0和1,稱為機器程式碼(machine code)。機器程式碼包含一組稱為機器指令的指令,每個機器指令都是由零和一組成的序列,並指示處理器執行特定的操作。可以將用高階語言編寫的程式轉換為機器程式碼的程式稱為編譯器(見下圖)。
編譯過程。
請注意,編譯器是一個可執行程式,通常在應該為其生成機器程式碼的機器上執行。可能出現的一個自然問題是——誰編寫了第一個編譯器?
第一,鑑於編譯器的普遍存在,幾乎所有的程式都是用高階語言編寫的,編譯器用來將它們轉換為機器程式碼,但這一規則也有重要的例外。請注意,編譯器的作用有兩方面:首先,它需要正確地將高階語言的程式翻譯成機器指令;其次,它需要生成不佔用大量空間且速度快的高效機器程式碼。因此,多年來編譯器中的演演算法變得越來越複雜,但並不總是能夠滿足這些要求,例如在某些情況下,編譯器可能無法生成足夠快的程式碼,或者無法提供程式設計師期望的某種功能:
- 首先,編譯器中的演演算法受到它們對程式執行的分析量的限制。例如,我們不希望編譯過程極其緩慢,編譯器領域的許多問題在計算上很難解決,因此很耗時。
- 其次,編譯器不知道程式碼中的廣泛模式。例如,某個變數可能只取一組有限的值,在此基礎上,可能進一步優化機器程式碼,編譯器很難理解這一點。聰明的程式設計師有時可以生成比編譯器更優化的機器程式碼,因為他們知道一些廣泛的執行模式,可以勝過編譯器。
- 處理器供應商也可能在ISA中新增新指令。在這種情況下,用於舊版本處理器的編譯器可能無法利用新指令,需要在程式中手動新增它們。流行的編譯器(如gcc,GNU編譯器集合)是相當通用的,它們不使用處理器在生成機器程式碼時提供的所有可能的機器指令。通常,作業系統和裝置驅動程式(與印表機和掃描器等裝置介面的程式)需要大量遺漏的指令,因為它們需要對硬體的低階別存取,因此係統程式設計師有強烈的動機偶爾繞過編譯器。
在所有這些情況下,程式設計師都有必要在程式中手動嵌入一系列機器指令。如上所述,這樣做的兩個主要原因是效率和額外的功能。因此,從系統軟體開發人員的角度來看,有必要了解機器指令,以便他們在工作中更有效率。
現在,我們的目標是讓現代程式設計師遠離0和1的複雜細節。理想情況下,我們不希望程式設計師像50年前那樣通過手動開啟和關閉開關來程式設計,由此開發了一種稱為組合語言的低階語言。組合語言是機器程式碼的一種人類可讀形式,每個組合語言語句通常對應於一條機器指令。此外,它通過不強迫程式設計師記住編碼指令所需的0/1的確切序列,大大減輕了程式設計師的負擔。
- 低階程式語言(low level programming language)使用通常只對應於一條機器指令的簡單語句,這些語言是ISA特有的。
- 組合語言(assembly language)是指一系列特定於每個ISA的低階程式語言,具有由一系列組合語句組成的泛型結構。通常,每個組合語句有兩部分:
- 一個指令程式碼,是基本機器指令的助記符。
- 一個運算元列表。
從實際角度來看,可以編寫獨立的組合程式,並使用稱為組合器的程式將其轉換為可執行程式,也可以在高階語言(如C或C++)中嵌入組合程式碼片段,後者更為常見。
組合器(assembler)是將組合程式轉換為機器程式碼的可執行程式。
編譯器確保能夠將組合程式編譯為機器程式碼。組合語言的好處是多方面的:
- 可讀性。因為組合程式碼中的每一行對應於一條機器指令,所以它和機器程式碼一樣具有表達力。
- 高效性。由於這種一對一的對映,我們不必通過在組合中編寫程式來提高效率。
- 簡化性。它是一種可讀的、優雅的文字表示機器程式碼的形式,大大簡化了使用它編寫程式的過程,也可以在用C等高階語言編寫的軟體中清晰地嵌入組合程式碼片段,它定義了一個高於實際機器程式碼的抽象級別。兩個處理器可能與同一種組合語言相容,但實際上對同一條指令有不同的機器編碼。在這種情況下,組合程式將在這兩個處理器上相容。
再從硬體設計者的視角闡述之。
硬體設計師的職責是設計能夠實現ISA中所有指令的處理器。他們的主要目標是設計一個在面積、功率效率和設計複雜性方面最佳的高效處理器,從他們的角度來看,ISA是軟體和硬體之間的關鍵紐帶。這回答了他們的基本問題——構建什麼?因此,對他們來說,理解不同指令集的精確語意是非常重要的,這樣他們就可以為它們設計處理器。將指令僅僅看作一個0和1的序列是很麻煩的,通過檢視機器指令的文字表示,他們可以獲得很多好處,很清晰地知道是一條怎樣的組合指令。
組合語言專用於指令集和組合器。本節使用流行的GNU組合器的組合語言格式來解釋典型組合語言檔案的語法,請注意,其他系統具有類似的格式,並且概念大致相同。
19.2.1.2 組合語言基礎
機器模型
組合語言不將指令記憶體和資料記憶體視為不同的實體,假設一個抽象的馮·諾依曼機器增加了暫存器。
有關機器模型的圖示,請參見下圖。程式儲存在主記憶體的一部分中,中央處理單元(CPU)逐條指令讀出程式指令,並適當地執行指令,程式計數器(PC)跟蹤CPU正在執行的指令的記憶體地址,大多數指令都希望從暫存器中獲取其輸入運算元。回想一下,每個CPU都有固定數量的暫存器(通常<64),然而大量指令也可以直接從記憶體中獲取運算元。CPU的工作是協調主記憶體和暫存器之間的傳輸,CPU還需要執行所有算術/邏輯計算,並與外部輸入/輸出裝置保持聯絡。
大多數型別的組合語言在大多數語句中都採用這種抽象機器模型。但由於使用組合語言的另一個目的是對硬體進行更細粒度和侵入性的控制,因此有相當多的組合指令可以識別處理器的內部。
這些指令通常通過改變一些關鍵內部演演算法的行為來修改處理器的行為,它們修改內建引數,如電源管理設定,或讀/寫一些內部資料。最後請注意,組合語言不區分機器無關指令和機器相關指令。
每臺機器都有一組暫存器,這些暫存器對組合程式設計師是可見的。ARM有16個暫存器,x86(32位元)有8個暫存器,而x86_64(64位元)有16個。暫存器有名稱,ARM將它們命名為r0、r1、...、r14、r15,x86將它們命名成eax、ebx、ecx、edx、esi、edi、ebp和esp,可以使用這些名稱存取暫存器。
在大多數ISA中,返回地址暫存器用於函數呼叫。讓我們假設一個程式開始執行一個函數,它需要記住執行函數後需要返回的記憶體地址,此地址稱為返回地址。在跳轉到函數的起始地址之前,我們可以將返回地址的值儲存在這個暫存器中。通過將儲存在返回地址暫存器中的值複製到PC上,可以簡單地實現返回語句。在ARM和MIPS等組合語言中,程式設計師可以看到返回地址暫存器,然而x86不使用返回地址暫存器,使用堆疊。
在ARM處理器中,程式設計師可以看到PC,它是最後一個暫存器(r15)。可以讀取PC的值,也可以設定其值,設定PC的值意味著我們希望分支到程式中的新位置。然而x86的PC是隱式的,程式設計師不可見。
記憶體檢視
記憶體可以看作是一個大的位元組陣列,每個位元組都有一個唯一的地址,基本上就是它在陣列中的位置。第一位元組的地址是0,第二位元組的地址為1,以此類推。我們沒有一種方法來唯一地定址給定的位,地址在32位元機器中是32位元無符號整數,在64位元機器中則是64位元無符號。
在馮·諾依曼機器中,我們假設程式作為位元組序列儲存在記憶體中,程式計數器指向將要執行的下一條指令。
假設記憶體是一個大的位元組陣列,如果我們所有的資料項都只有一個位元組長,那麼就可以了,像C和Java這樣的語言有不同大小的資料型別:char(1位元組)、short(2位元組)、integer(4位元組)和long integer(8位元組)。對於多位元組資料型別,必須在記憶體中為其建立一個表示,在記憶體中表示多位元組資料型別有兩種可能的方式——小端和大端。其次,我們還需要找到表示記憶體中資料陣列或列表的方法。
- 小端和大端表示
讓我們考慮在位置0-3儲存整數的問題。讓整數為0x87654321,它可以分為四個位元組:87、65、43和21。一個選項是將最重要的位元組87儲存在最低的記憶體地址0中,下一個位置可以儲存65、43、21,這被稱為大端(big endian)表示,因為我們從最大位元組的位置開始。相比之下,我們可以先將最小的位元組儲存在位置0,然後繼續將最大的位元組儲存在位置3,這種表示方式稱為小端(big endian)。下圖顯示了差異。
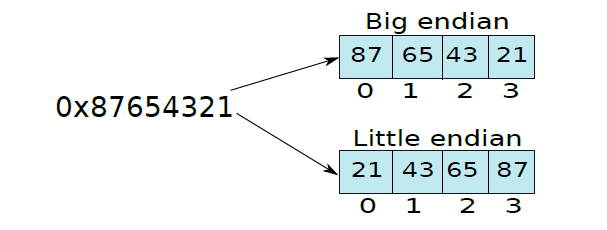
大端和小端表示。
因此,沒有理由選擇一種代表而不是另一種代表,例如,x86處理器使用little-endian格式。早期版本的ARM處理器曾經是小端的,然而,現在它們是雙端的,意味著ARM處理器可以根據使用者設定同時作為小端和大端機器工作。傳統上,IBM POWER處理器和Sun SPARC處理器都是大端的。
- 表示陣列
陣列是一組線性有序的物件,其中物件可以是簡單的資料型別(如整數或字元),也可以是複雜的資料型別。
int a[100];
char c[100];
讓我們考慮一個簡單的整數陣列a。如果陣列有100個條目,那麼記憶體中陣列的總大小等於100 4=400位元組。如果陣列的起始記憶體位置為loc,然後將[0]儲存在位置(loc + 0)、(loc + 1)、(loc + 2)、(loc + 3)中。請注意,有大端和小端兩種方法儲存資料。下一個陣列條目a[1]儲存在位置(loc + 4) ... (loc + 7)中,依此類推,我們注意到條目a[i]儲存在(loc + 4 x i) ... (loc + 4 x i + 3)中。
大多數程式語言都定義以下形式的多維陣列:
int a[100][100];
char c[100][100];
它們通常在記憶體中表示為規則的一維陣列,多維陣列中的位置與等效的一維陣列之間存在對映函數,我們可以擴充套件該方案以考慮維度大於2的多維陣列。
我們觀察到,通過以行優先(row major)方式儲存二維陣列,可以將其儲存為一維陣列,意味著資料按行儲存。我們儲存第一行,然後儲存第二行,以此類推。同樣,也可以以列優先(column major)的方式儲存多維陣列,其中儲存第一列,然後再儲存第二列,依此類推。
行優先(row major):陣列按行儲存在記憶體中。
列優先(column major):陣列按列儲存在記憶體中。
19.2.1.3 組合語言語法
組合檔案的確切語法取決於組合程式,不同的組合程式可以使用不同的語法,儘管它們可能在基本指令及其運算元格式上達成一致。本節將解釋GNU系列組合語言的語法,它們是為GNU組合程式設計的,是GNU編譯器集合(gcc)的一部分。與所有GNU軟體一樣,該組合程式和相關編譯器可免費用於大多數平臺,組合程式可在gnu.org上找到。請注意,其他組合程式(如NASM、MASM)都有自己的格式,但總體結構在概念上與本節描述的沒有太大區別。
組合檔案結構
程式集檔案是一個常規文字檔案,字尾是.s。如果安裝了GNU編譯器gcc,則可以通過發出以下命令快速生成C程式的組合檔案,當然也可以使用線上GCC。
gcc -S test.c
生成的程式集檔案將命名為test.s。GNU程式集的結構非常簡單,如下圖所示。不同部分的範例包括文字(實際程式)、資料(具有初始化值的資料)和bss(初始化為0的通用資料)。每個段(section)以節標題開頭,這是以「.」開頭的節的名稱符號,例如,文字部分以「.text」行開頭。接著是組合語言語句列表,每條語句通常以換行符結尾,同樣,資料部分包含資料值列表。
組合檔案以包含格式為「.file <檔名>」的行的檔案段開頭。當我們使用gcc編譯器從C程式生成程式集檔案時,.file部分中的檔名通常與我們的原始C程式(test.C)相同。文欄位是必填的,其餘段是可選的,可能有一個或多個資料段,也可以使用.section指令定義新的節。本節我們主要關注文字部分,因為對學習指令集的本質感興趣。
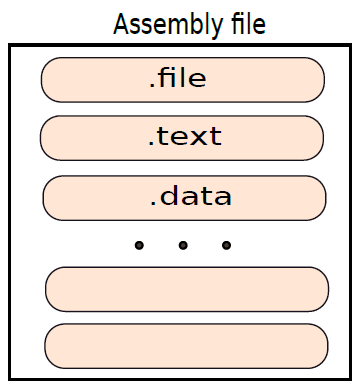
組合語言檔案結構。
組合基本語句
一條基本的組合語言語句指定了一條組合指令,有兩部分:指令及其運算元列表,如下圖所示。該指令是實際機器指令的文字識別符號,運算元列表包含每個運算元的值或位置。運算元的值是一個數值常數,也被稱為立即值(immediate value),運算元位置可以是暫存器位置或記憶體位置。

組合語言語句。
在計算機架構中,指令中指定的常數值也稱為立即數(immediate)。
假設有以下語句:
add r3, r1, r2
在這個ARM組合語句中,add指令指定了我們希望將兩個數位相加並將結果儲存在某個預先指定的位置的事實。在這種情況下,加法指令的格式如下:<指令><目標暫存器><運算元暫存器1><運算元暫存器2>。指令的名稱為add,目標暫存器為r3,運算元暫存器為r1和r2。指令的詳細步驟如下:
1.讀取暫存器r1的值。讓我們將該值稱為v1。
2.讀取暫存器r2的值。讓我們將該值稱為v2。
3.計算v3=v1+v2。
4.將v3儲存在暫存器r3中。
現在讓我們再舉一個以類似方式工作的兩條指令的範例:
sub r3, r1, r2
mul r3, r1, 3
sub指令減去儲存在暫存器中的兩個數,mul指令將儲存在暫存器r1中的一個數乘以數值常數3,這兩條指令都將結果儲存在暫存器r3中,它們的操作模式與加法指令類似。此外,算術指令(如add、sub和mul)也稱為資料處理指令。還有其他幾類指令,例如從記憶體載入或儲存值的資料傳輸指令,以及實現分支的控制指令。
通用語句結構
組合語句的一般結構如下圖所示,它由三個欄位組成:標籤(指令的識別符號)、鍵(組合指令或組合程式指令)和註釋。這三個欄位都是可選的,但是,任何組合語句都需要至少具有其中一個。
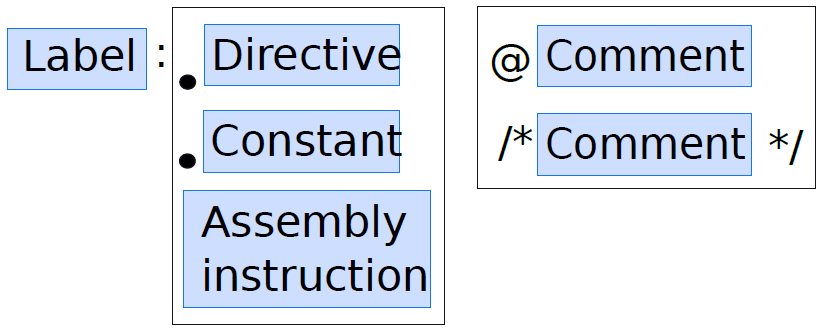
組合語句的通用結構。
語句可以選擇以標籤開頭,標籤是語句的文字識別符號,換句話說,標籤在組合中唯一地標識組合語句。請注意,我們不允許在同一組合檔案中重複標籤,標籤在執行分支指令時非常有用。
下面的範例程式碼中顯示了一個標籤的範例,這裡標籤的名稱是「label1」,後面是冒號。在標籤之後,我們編寫了一條組合指令,並給它一個運算元列表。標籤可以由有效的字母數位字元[a-z] [A-Z] [0-9] 以及符號「.」、「_」和「$」。通常,我們不能以數位作為標籤的開頭。在指定標籤之後,我們可以將該行保持為空,也可以指定鍵(組合語句的一部分)。如果鍵以「.」開頭,那麼它是一個組合程式指令,對所有計算機都有效,它指示組合程式執行某個操作,此操作可以包括啟動新節或宣告常數。該指令還可以採用參數列,如果鍵以字母開頭,則它是一條常規的組合指令。
label1: add r1, r2, r3
在標籤、組合指令和運算元列表之後,可以選擇插入註釋。GNU組合程式支援兩種型別的註釋,我們可以在插入類似C或Java風格的註釋。在ARM組合中,通過在註釋前面加上「@」字元,也可以有一個小的單行註釋。
label1: add r1, r2, r3 @ Add the values in r2 and r3
label2: add r3, r4, r5 @ Add the values in r4 and r5
add r5, r6, r7 /* Add the values in r6 and r7 */
組合語句可能只包含標籤,而不包含鍵。在這種情況下,標籤本質上指向一個空語句,不是很有用。因此,組合程式假定在這種情況下,標籤指向最近的包含鍵的後續組合語句。
19.2.1.4 指令型別
按功能分類
按功能,可分為四種主要型別,說明如下:
- 資料處理指令:資料處理指令通常是算術指令,如加法、減法和乘法,或按位元或、互斥或計算的邏輯指令,比較指令也屬於這個型別。
- 資料傳輸指令:這些指令在兩個位置之間傳輸值,位置可以是暫存器或記憶體地址。
- 分支指令:分支指令幫助處理器的控制單元根據運算元的值跳轉到程式的不同部分,在實現for迴圈和if-then-else語句時很有用。
- 異常生成指令:這些專用指令有助於將控制權從使用者級程式轉移到作業系統。
我們將介紹資料處理、資料傳輸和控制指令。
按運算元分類
GNU組合程式中的所有組合語言語句都具有相同的結構,它們以指令的名稱開頭,後面是運算元列表。我們可以根據指令所需的運算元對其進行分類,如果一條指令需要n個運算元,那麼通常稱它是n地址格式,例如,不需要任何運算元的指令是0地址格式指令,如果它需要3個運算元,則它是3地址格式指令。
如果一條指令需要n個運算元(包括源和目標),那麼我們稱其為n地址格式指令。
在ARM中,大多數資料處理指令採用3地址格式,資料傳輸指令採用2地址格式。然而,在x86中,大多數指令都是2地址格式。我們想到的第一個問題是,3地址格式指令與2地址格式指令的邏輯是什麼?這裡一定有一些權衡。
讓我們闡述一些一般的經驗法則。如果一條指令有更多的運算元,那麼它將需要更多的位來表示該指令,因此需要更多的資源來儲存和處理指令。然而,這一論點有另一面,擁有更多的運算元也會使指令更加通用和靈活,將使編譯器編寫者和組合程式設計師的生活變得更加輕鬆,因為使用更多運算元的指令可以做更多的事情。反向邏輯適用於佔用較少運算元的指令,佔用更少的儲存空間,也不那麼靈活。
讓我們考慮一個例子。假設我們試圖將兩個數位3和5相加,得到結果8。用於新增的ARM指令如下所示:
add r3, r1, r2
此指令將暫存器r1(3)和r2(5)的內容相加,並將其儲存在r3(8)中。然而,x86指令如下所示:
add edx, eax
此處假設edx包含3,eax包含5,執行加法,結果8儲存回edx。因此,在這種情況下,x86指令採用2地址格式,因為目標暫存器與第一源暫存器相同。
19.2.1.5 運算元型別
現在讓我們看看不同型別的運算元,在組合語句中指定和存取運算元的方法稱為定址模式。
在組合語句中指定和存取運算元的方法稱為定址模式(addressing mode)。
指定運算元的最簡單方法是將其值嵌入指令中,大多數組合語言允許使用者將整數常數的值指定為運算元,這種定址模式被稱為立即定址模式(immediate addressing mode),此方法對於初始化暫存器或記憶體位置或執行算術運算非常有用。
一旦必需的常數集被載入到暫存器和記憶體位置,程式就需要通過對暫存器和記憶體進行操作來繼續,這個空間有幾種定址模式。在介紹它們之前,讓我們以暫存器轉移符號(register transfer notation)的形式介紹一些額外的術語。
暫存器轉移符號
這個符號允許我們指定指令和運算元的語意,讓我們看看錶示指令基本動作的各種方法:
此表示式有兩個暫存器運算元r1和r2,r1是目標暫存器,r2是源暫存器,我們正在將暫存器r2的內容轉移到暫存器r1。我們可以用一個常數指定一個加法運算,如下所示:
我們還可以使用此符號指定暫存器上的操作,將r2和r3的內容相加,並將結果儲存在r1中:
也可以使用此符號表示記憶體存取:
上述語句中,記憶體地址等於暫存器r2的內容加4,然後從該記憶體地址的內容開始提取整數,並將其儲存在暫存器r1中。
運算元的通用定址模式
讓我們將運算元的值表示為V。在隨後的討論中,我們使用了\(V\leftarrow r1\)等表示式,並不意味著我們有一個新的稱為V的儲存位置,意味著運算元的數值由RHS指定(右側)。讓我們通過範例簡要地看一下一些最常用的定址模式:
- 立即:\(V\leftarrow imm\)。使用常數imm作為運算元的值。
- 暫存器:\(V\leftarrow r1\)。在此定址模式下,處理器使用暫存器中包含的值作為運算元。
- 暫存器間接:\(V\leftarrow [r1]\)。暫存器儲存包含該值的記憶體位置的地址。
- 基準偏移量:\(V\leftarrow [r1 + offset]\)。offset是一個常數,處理器從r1獲取基本記憶體地址,將常數offset新增到該地址,然後存取新的記憶體位置以獲取運算元的值。offset也稱為位移。
- 基址變址:\(V\leftarrow [r1 + r2]\)。r1是基址暫存器,r2是索引暫存器,記憶體地址等於(r1+r2)。
- 基址變址偏移:\(V\leftarrow [r1 + r2 + offset]\)。包含該值的記憶體地址為(r1+r2+offset),其中offset為常數。
- 記憶體直接:\(V\leftarrow addr\)。該值從地址addr開始包含在記憶體中,addr是一個常數。在這種情況下,記憶體地址直接嵌入指令中。
- 記憶體間接:\(V\leftarrow [[r1]]\)。該值存在於記憶體位置中,其地址包含在記憶體位置M中,M的地址包含在暫存器r1中。
- PC相關:\(V\leftarrow [PC + offset]\)。offset量是一個常數,記憶體地址計算為PC+offset,其中PC表示PC中包含的值。此定址模式對分支指令很有用,注意此處的PC是指程式計數器。
讓我們通過考慮基偏移定址模式來引入一個稱為有效記憶體地址(effective memory address)的新術語。記憶體地址等於基址暫存器的內容加上偏移量,計算出的記憶體地址稱為有效記憶體地址。在記憶體運算元的情況下,我們可以類似地為其他定址模式定義有效地址。
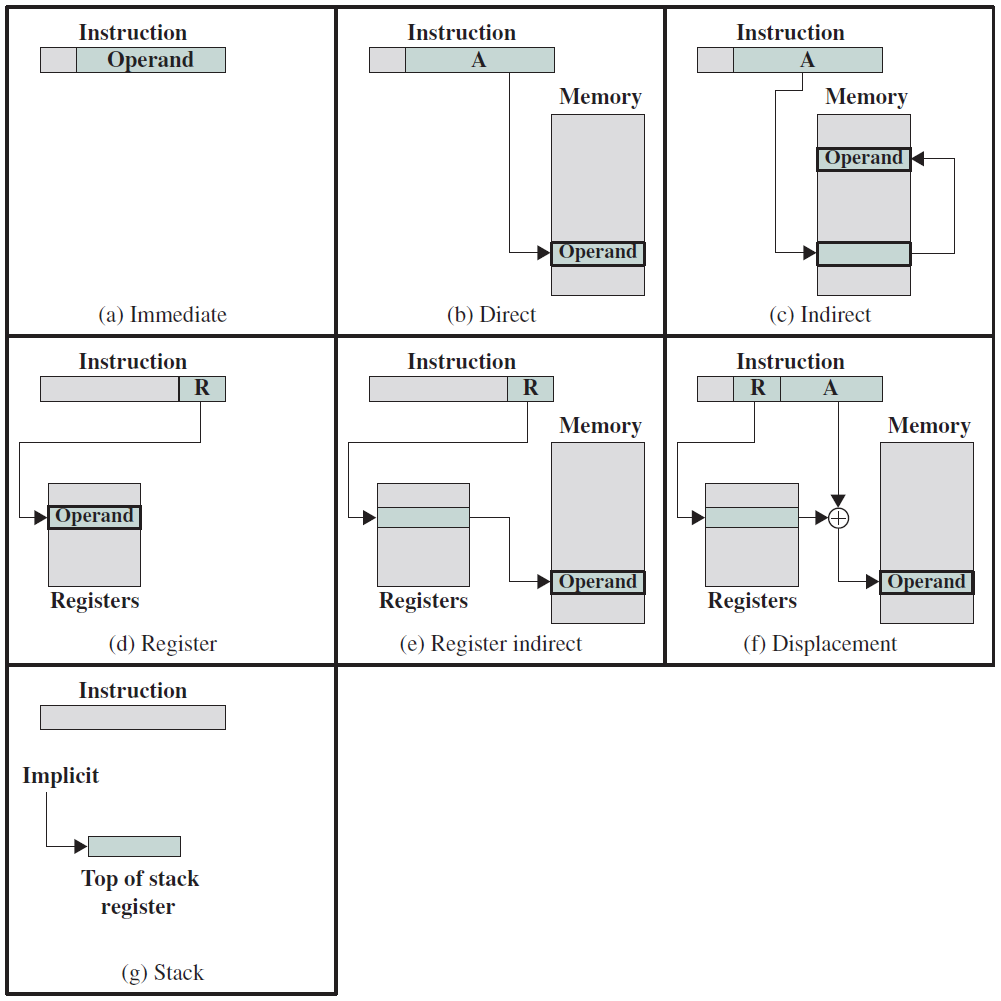
多種定址模式。
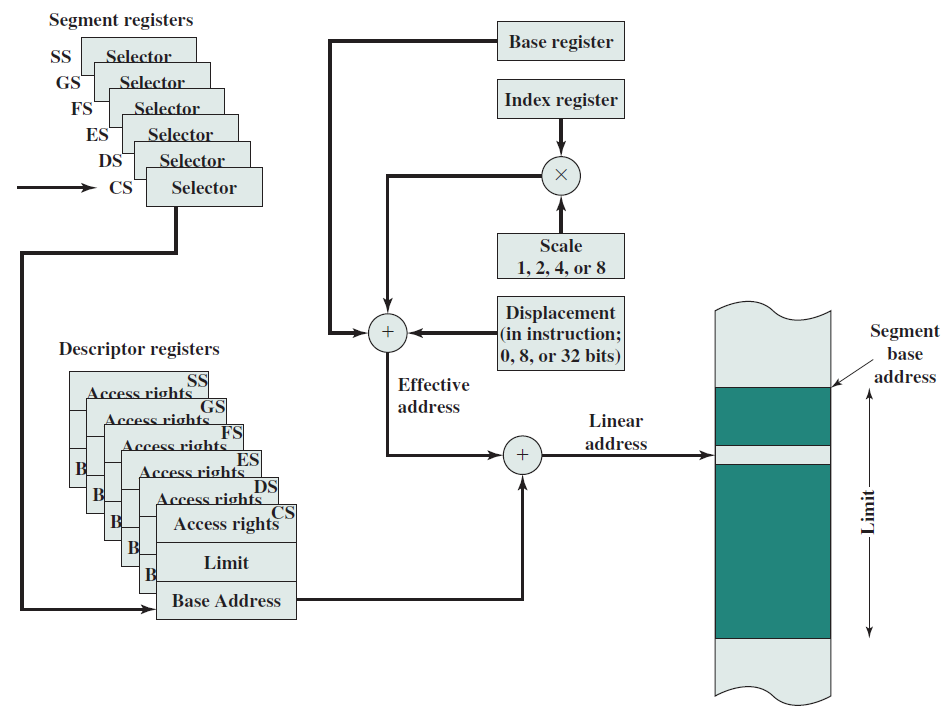
x86定址模式計算。
19.2.1.6 常見指令說明
本小節將以ARM為基準,闡述常見的RISC指令用法。
資料傳輸指令
資料傳輸指令包含以下幾類:
- LDR和STR
可載入暫存器和儲存暫存器,包含32位元字、8位元無符號位元組、半字、無符號位元組、雙字等。
LDR和STR都有四種可能的形式:零偏移量、預索引偏移、程式相關、後索引偏移。四種形式的語法順序相同,分別為:
op{cond}{B}{T} Rd, [Rn]
op{cond}{B} Rd, [Rn, FlexOffset]{!}
op{cond}{B} Rd, label
op{cond}{B}{T} Rd, [Rn], FlexOffset
以上是針對32位元字或8位元無符號位元組,如果需要雙字則B改成D:
op{cond}D Rd, [Rn]
op{cond}D Rd, [Rn, Offset]{!}
op{cond}D Rd, label
op{cond}D Rd, [Rn], Offset
半字、有符號位元組語法如下:
op{cond} type Rd, [Rn]
op{cond} type Rd, [Rn, Offset]{!}
op{cond} type Rd, label
op{cond} type Rd, [Rn], Offset
範例:
; 範例1
SUB R1, PC, #4 ; R1 = address of following STR instruction
STR PC, [R0] ; Store address of STR instruction + offset,
LDR R0, [R0] ; then reload it
SUB R0, R0, R1 ; Calculate the offset as the difference
; 範例2
LDRD r6,[r11]
LDRMID r4,[r7],r2
STRD r4,[r9,#24]
STRD r0,[r9,-r2]!
LDREQD r8,abc4
; 範例3
LDREQSH r11,[r6] ; (conditionally) loads r11 with a 16-bit halfword from the address in r6. Sign extends to 32 bits.
LDRH r1,[r0,#22] ; load r1 with a 16 bit halfword from 22 bytes above the address in r0. Zero extend to 32 bits.
STRH r4,[r0,r1]! ; store the least significant halfword from r4 to two bytes at an address equal to contents(r0) plus contents(r1). Write address back into r0.
LDRSB r6,constf ; load a byte located at label constf. Sign extend.
- LDM和STM
LDM、STM載入和儲存多個暫存器,暫存器r0到r15的任何組合都可以被傳送。語法如下:
op{cond}mode Rn{!}, reglist{^}
範例:
LDMIA r8,{r0,r2,r9}
STMDB r1!,{r3-r6,r11,r12}
STMFD r13!,{r0,r4-r7,LR} ; Push registers including the stack pointer
LDMFD r13!,{r0,r4-r7,PC} ; Pop the same registers and return from subroutine
- PLD
PLD快取預載入。語法:
PLD [Rn{, FlexOffset}]
範例:
PLD [r2]
PLD [r15,#280]
PLD [r9,#-2481]
PLD [r0,#av*4] ; av * 4 must evaluate, at assembly time, to an integer in the range -4095 to +4095
PLD [r0,r2]
PLD [r5,r8,LSL 2]
- SWP
在暫存器和記憶體之間交換資料,使用SWP實現號誌。語法:
SWP{cond}{B} Rd, Rm, [Rn]
通用資料處理指令
此類指令又包含以下幾種:
- 靈活第二運算元
大多數ARM通用資料處理指令都有一個靈活的第二運算元,在每條指令的語法描述中顯示為Operand2。語法有兩種形式:
#immed_8r
Rm{, shift}
範例:
ADD r3,r7,#1020 ; immed_8r. 1020 is 0xFF rotated right by 30 bits.
AND r0,r5,r2 ; r2 contains the data for Operand2.
SUB r11,r12,r3,ASR #5 ; Operand2 is the contents of r3 divided by 32.
MOVS r4,r4, LSR #32 ; Updates the C flag to r4 bit 31. Clears r4 to 0.
- ADD、SUB、RSB、ADC、SBC和RSC
此類指令的語法如下:
op{cond}{S} Rd, Rn, Operand2
範例:
ADD r2,r1,r3
SUBS r8,r6,#240 ; sets the flags on the result
RSB r4,r4,#1280 ; subtracts contents of r4 from 1280
ADCHI r11,r0,r3 ; only executed if C flag set and Z flag clear
RSCLES r0,r5,r0,LSL r4 ; conditional, flags set
- AND、ORR、EOR和BIC
邏輯操作,語法如下:
op{cond}{S} Rd, Rn, Operand2
範例:
AND r9,r2,#0xFF00
ORREQ r2,r0,r5
EORS r0,r0,r3,ROR r6
BICNES r8,r10,r0,RRX
- MOV、MVN、CMP、CMN、TST、TEQ、CLZ
移動、對比、測試、計數前導零指令,語法如下:
MOV{cond}{S} Rd, Operand2
MVN{cond}{S} Rd, Operand2
CMP{cond} Rn, Operand2
CMN{cond} Rn, Operand2
TST{cond} Rn, Operand2
TEQ{cond} Rn, Operand2
CLZ{cond} Rd, Rm
範例:
MOV r5,r2
MVNNE r11,#0xF000000B
MOVS r0,r0,ASR r3
CMP r2,r9
CMN r0,#6400
CMPGT r13,r7,LSL #2
TST r0,#0x3F8
TEQEQ r10,r9
TSTNE r1,r5,ASR r1
CLZ r4,r9
CLZNE r2,r3
算術指令
算術指令包含大量的乘法指令,乘法的指令較多較複雜。常見算術指令如下表所示:
| 指令 | 語法 | 說明 |
|---|---|---|
| MUL、MLA | MUL{cond}{S} Rd, Rm, Rs MLA{cond}{S} Rd, Rm, Rs, Rn |
乘法和乘法累加(32位元乘32位元,取底部32位元結果) |
| UMULL、UMLAL、SMULL、SMLAL | Op{cond}{S} RdLo, RdHi, Rm, Rs | 無符號和有符號長乘法和乘法累加(32位元乘32位元,64位元累加或結果)。 |
| SMULxy、SMLAxy、SMULWy、SMLAWy、SMLALxy | SMLA SMULW SMLAW |
有符號乘法(16、32位元乘16、32位元,結果是32位元或64位元,部分指令有累積)。 |
| MIA、MIAPH、MIAxy | MIA{cond} Acc, Rm, Rs MIA |
XScale協處理器0指令。 |
範例:
MUL r10,r2,r5
MLA r10,r2,r1,r5
MULS r0,r2,r2
MULLT r2,r3,r2
MLAVCS r8,r6,r3,r8
UMULL r0,r4,r5,r6
UMLALS r4,r5,r3,r8
SMLALLES r8,r9,r7,r6
SMULLNE r0,r1,r9,r0 ; Rs can be the same as other registers
SMLAWB r2,r4,r7,r1
SMLAWTVS r0,r0,r9,r2
MIA acc0,r5,r0
MIALE acc0,r1,r9
MIAPH acc0,r0,r7
MIAPHNE acc0,r11,r10
MIABB acc0,r8,r9
MIABT acc0,r8,r8
MIATB acc0,r5,r3
MIATT acc0,r0,r6
MIABTGT acc0,r2,r5
分支指令
分支語句的描述如下表:
| 指令 | 語法 | 說明 |
|---|---|---|
| B、BL | B/BL {cond} label | 分支和帶連結的分支 |
| BX | BX{cond} Rm | 分支和交換指令集 |
| BLX | BLX{cond} Rm BLX label |
使用Link分支,並可選地交換指令集。本說明有兩種可選形式: 1、連結到程式相對地址的無條件分支 2、與暫存器中儲存的絕對地址連結的條件分支。 |
範例:
B loopA
BLE ng+8
BL subC
BLLT rtX
BX r7
BXVS r0
BLX r2
BLXNE r0
BLX thumbsub
條件執行
幾乎所有ARM指令都可以包含可選條件程式碼。這在語法描述中顯示為{cond}。只有當CPSR中的條件程式碼標誌滿足指定條件時,才執行帶有條件程式碼的指令。可以使用的條件程式碼如下表所示(部分)。
| 字尾 | 標記 | 含義 |
|---|---|---|
| EQ | Z設定 | = |
| NE | Z清除 | != |
| CS、HS | C設定 | >=(無符號) |
| CC、LO | C清除 | =(無符號) |
| MI | N設定 | 負數 |
| PL | N清除 | 非負數 |
| VS | V設定 | 溢位 |
| VC | V清除 | 無溢位 |
| HI | C設定且Z清除 | >(無符號) |
| LS | C清除或Z設定 | <=(無符號) |
| GE | N和V一樣 | >=(有符號) |
| LT | N和V不一樣 | <(有符號) |
| GT | Z清除且N和V一樣 | >(有符號) |
| LE | Z設定或N和V不一樣 | <=(有符號) |
| AL | 任意 | 總是(通常省略) |
幾乎所有ARM資料處理指令都可以根據結果選擇性地更新條件程式碼標誌。要使指令更新標誌,請包含S字尾,如指令的語法描述所示。
有些指令(CMP、CMN、TST和TEQ)不需要S字尾,它們的唯一功能是更新標誌,總是更新標誌。
標誌將保留到更新,未執行的條件指令對標誌沒有影響,一些指令更新標誌的子集,其他標誌不受這些指令的影響。詳細資訊在說明說明中指定。可以根據另一條指令中設定的標誌,有條件地執行指令,或者:
- 緊接在更新標誌的指令之後。
- 在沒有更新標誌的任何數量的介入指令之後。
範例:
ADD r0, r1, r2 ; r0 = r1 + r2, don't update flags
ADDS r0, r1, r2 ; r0 = r1 + r2, and update flags
ADDCSS r0, r1, r2 ; If C flag set then r0 = r1 + r2, and update flags
CMP r0, r1 ; update flags based on r0-r1.
其它指令
ARM還有協調處理器、偽指令、雜項指令等其它指令,本文限於篇幅就不接受了。更多詳情參見:
19.2.2 二進位制位
計算機不像人類那樣理解單詞或句子,只理解0和1的序列,儲存、檢索和處理數十億個0和1非常容易。其次,使用矽電晶體(silicon transistor)實現計算機的現有技術與處理0和1的概念非常相容。基本矽電晶體是一種開關,可以根據輸入將輸出設定為邏輯0或1,矽電晶體是我們今天擁有的所有電子計算機的基礎,從手機的處理器到超級計算機的處理器。十九世紀末製造的一些早期計算機處理十進位制數位,本質上大多是機械的。首先讓我們明確定義一些簡單的術語:
位(bit):可以有兩個值的變數:0或1。
位元組(byte):8個位的序列。
19.2.2.1 邏輯操作
二進位制變數(0或1)最早由喬治·布林(George Boole)於1854年描述,他使用這些變數及其相關運算來描述數學意義上的邏輯,他設計了一個完整的代數,由簡單的二元變數、一組新的運運算元和基本運算組成。為了紀念喬治·布林,二進位制變數也稱為布林變數(Boolean variable),布林變數的代數系統稱為布林代數(Boolean algebra)。邏輯位元運算如下:
- NOT
邏輯二補數(logical complement)稱為NOT運運算元,任何布林運運算元都可以通過真值表來表示,真值表列出了所有可能的輸入組合的運運算元輸出,NOT運運算元的真值表如下表所示。
| 原始值 | NOT操作後 |
|---|---|
| 0 | 1 |
| 1 | 0 |
- OR
OR運運算元表示任一運算元等於1的事實。例如,如果A=1或B=1,則A或B等於1。OR運運算元的真值表如下所示。
| A | B | A OR B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
- AND
AND運運算元的操作是所有運算元為1,則結果才為1,其它則為0。例如,當A和B都為1時,A和B等於1。AND運運算元的真值表如下所示。
| A | B | A AND B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 0 |
| 1 | 0 | 0 |
| 1 | 1 | 1 |
- NAND、NOR
另外的兩個簡單的運運算元,即NAND和NOR非常有用。NAND是AND的邏輯二補數,NOR是OR的邏輯補。它們的真值表如下所示。
| A | B | A NAND B | A NOR B |
|---|---|---|---|
| 0 | 0 | 1 | 1 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 0 |
NAND和NOR是非常重要的運運算元,因為它們被稱為通用運運算元,我們可以只使用它們來構造任何其他運運算元。
- XOR
XOR是互斥或運運算元,當A和B相等時,值為0,否則為1。真值表如下所示。
| A | B | A XOR B |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
19.2.2.2 布林代數
讓我們來看看NOT運運算元的一些規則:
- 定義:\(\overline{0}=1, \text { 且 } \overline{1}=0\),即NOT運運算元的定義。
- 雙重否定:\(\overline{\overline{A}}=A\),非A的非等於A本身。
OR和AND運運算元:
- 恆等式:A+0=A,A.1=A,亦即如果計算布林變數A與0的OR或與1的AND,結果等於A。
- 相消性:A+1=1,A.0=0,亦即如果計算A OR 1,那麼結果總是等於1。類似地,A AND 0總是等於0,因為第二個運算元的值決定了最終結果。
- 冪等性:A+A=A,A.A=A,亦即計算A與自身的OR或AND的結果為A。
- 互補性:A+\(\overline{A}\)=1,A.\(\overline{A}\)=0,亦即A=1或\(\overline{A}\)=1。在任何一種情況下,A+\(\overline{A}\)都有一個項,它是1,因此結果是1。同樣,A.\(\overline{A}\)中的一個項是0,因此結果為0。
- 交換性:A.B=B.A,A+B=B+A,亦即布林變數的順序無關緊要。
- 關聯性:A+(B+C) = (A+B)+C,以及A.(B.C)=(A.B).C。
- 分配性:A.(B+C) = A.B+A.C,A+B.C=(A+B).(A+C),亦即可以使用這個定律來開啟括號並簡化表示式。
我們可以使用這些規則以各種方式操作包含布林變數的表示式,下面看看布林代數中的一組基本定理。
- 摩根定律(De Morgan's Laws)
有兩個摩根定律可以通過構造LHS和RHS的真值表來驗證。
- 邏輯閘(Logic Gate)
現在讓我們嘗試實現電路來實現複雜的布林公式,「邏輯閘」定義為實現布林函數的器件,可以由矽、真空管或任何其他材料製成。
邏輯閘是實現布林函數的裝置。
給定一組邏輯閘,我們可以設計一個電路來實現任何布林函數,不同邏輯閘的符號如下圖所示。
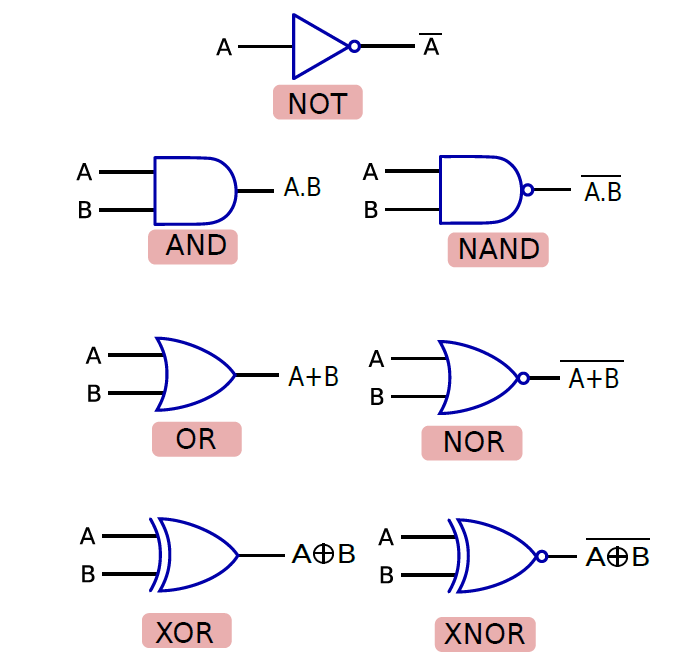
邏輯閘列表。
19.2.3 電晶體
矽是週期表中的第14種元素,有四個價電子,雖然與碳和鍺屬於同一組,但其化學反應性不如後兩者。
90%以上的地殼由矽基礦物組成,二氧化矽是沙子和石英的主要成分,它供應充足,而且製造起來相當便宜。矽具有一些有趣的特性,使其成為設計電路和處理器的理想襯底。讓我們考慮一下矽的分子結構,它有一個緻密的結構,每個矽原子都與其他四個矽原子相連,緊密相連的一組矽原子結合在一起形成一個強晶格,其他材料(尤其是金剛石)具有類似的晶體結構。因此,矽原子比大多數金屬更緊密。
由於缺乏自由電子,矽沒有很好的導電效能,介於良導體和絕緣體之間,因此被稱為半導體(semiconductor)。通過可控的方式新增一些雜質,可以稍微改變其性質,這個過程被稱為摻雜(doping)。
19.2.3.1 摻雜
通常,向矽中新增兩種雜質以改變其特性:n型和p型。n型雜質通常由週期表中的V族元素組成,磷是最常見的n型摻雜劑,偶爾也會使用砷。新增具有價電子的V族摻雜劑的效果是,額外的電子從晶格中分離出來,並可用於傳導電流。這種摻雜過程有效地提高了矽的導電性。
同樣,可以向矽中新增III族元素,如硼或鎵,以產生p型摻雜矽,會產生相反的效果,會在晶格中建立一個空隙,此空隙也稱為孔(hole),孔表示沒有電子。像電子一樣,孔可以自由移動,也有助於傳導電流。電子帶負電荷,孔在概念上與正電荷相關。
現在我們已經制作了兩種半導體材料:n型和p型,下面看看如果連線它們形成p-n結會發生什麼。
19.2.3.2 P-N結
讓我們考慮一個p-n結,如下圖所示。p型區有過量的孔,n型區有過剩的電子。在結處,一些孔交叉並移動到n區,因為它們被電子吸引。類似地,一些電子越過並聚集在p區一側。孔和電子的這種遷移稱為擴散,見證這種遷移的交界處周圍的區域被稱為耗盡區。然而,由於電子和孔的遷移,在耗盡區中產生了與遷移方向相反的電場,這個電場感應出一種稱為漂移電流的電流。在穩態下,漂移電流和擴散電流相互平衡,因此實際上沒有電流流過結。
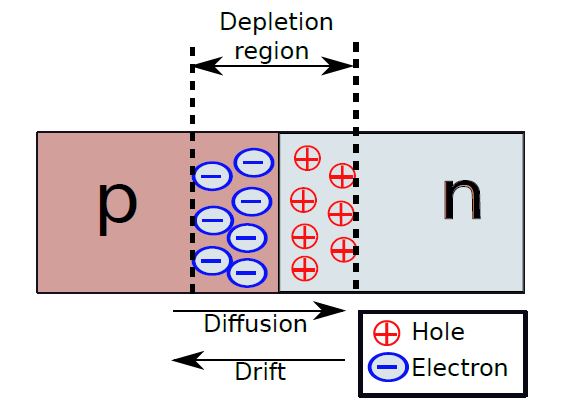
如果將p側連線到正端子,將n側連線到負端子,則這種設定稱為正向偏置。在這種情況下,孔從結的p側流向n側,電子則反向流動。因此,該結傳導電流。
如果我們將p側連線到負端子,將n側連線到正端子,則這種設定稱為反向偏置。在這種情況下,孔和電子被拉離結。因此,沒有電流流過結,並且在這種情況下p-n結不導電。所描述的簡單p-n結被稱為二極體(diode),它只在一個方向傳導電流,即當它處於正向偏置時。
二極體(diode)是一種典型地由單個p-n結制成的電子器件,其僅在一個方向上傳導電流。
19.2.3.3 NMOS電晶體
現在,讓我們將兩個p-n結相互連線,如下圖(a)所示,這種結構被稱為NMOS(負金氧半導體)電晶體。在這張圖中,有一個p型摻雜矽的中心襯底。兩側有兩個小區域含有n型摻雜矽,這些區域分別被稱為漏極和源極。注意,由於結構是完全對稱的,這兩個區域中的任何一個都可以被指定為源極或漏極,源極和漏極中間的區域稱為通道。在溝道的頂部有一個通常由二氧化矽(SiO2)製成的薄絕緣層,它由金屬或多晶矽基導電層覆蓋,就是所謂的門(gate)。
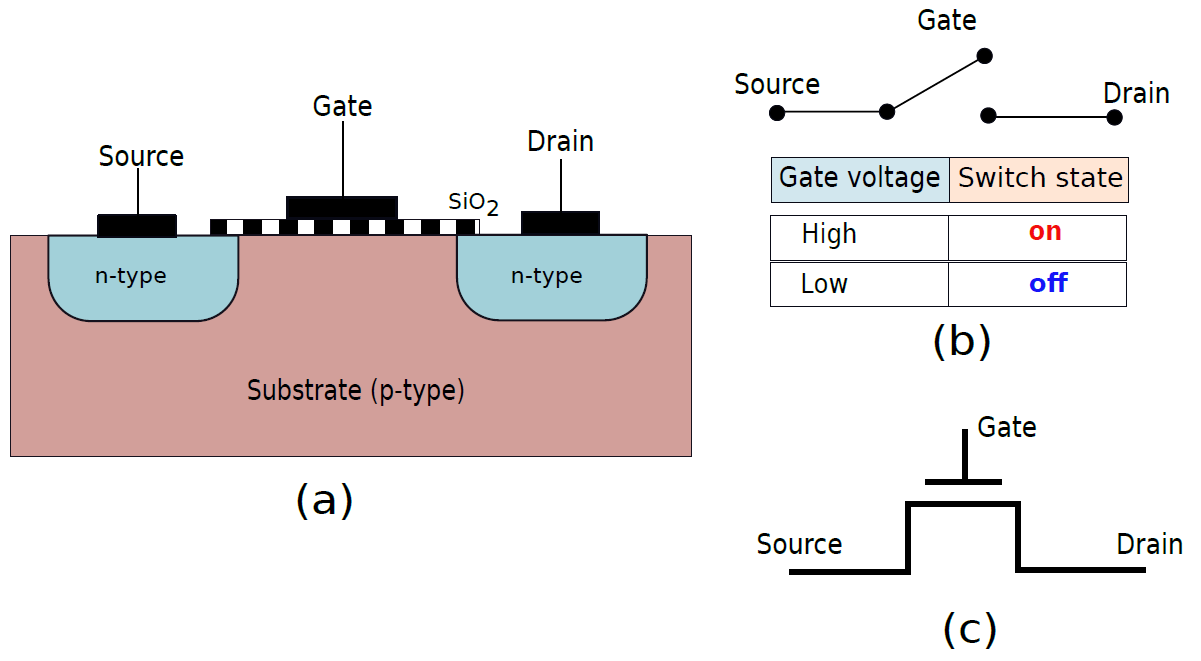
因此,典型的NMOS電晶體有三個端子:源極、漏極和柵極,它們中的每一個都可以連線到電壓源。我們現在有兩個柵極電壓選項——邏輯1(\(V_{dd}\)伏)或邏輯0(0伏)。如果柵極處的電壓為邏輯1(Vdd伏),則溝道中的電子被吸引到柵極。事實上,如果柵極處的電壓大於某個閾值電壓(在當前技術中通常為0.15V),則由於電子的積累,在漏極和源極之間形成低電阻導電路徑。因此,電流可以在漏極和源極之間流動。如果溝道的有效電阻是R溝道,那麼我們有\(V_{drain}=IR_{channel}+V_{source}\)。如果流經電晶體的電流量低,則由於低溝道電阻(R溝道),\(V_{drain}\)大致等於\(V_{source}\)。因此,我們可以將NMOS電晶體視為開關(見上圖b)。當柵極電壓為1時,它被開啟。
現在,如果我們將柵極電壓設定為0,那麼由電子組成的導電路徑就無法在溝道中形成。因此,電晶體將不能傳導電流,將處於o狀態。在這種情況下,開關關閉。
NMOS電晶體的電路符號如上圖(c)所示。
19.2.3.4 PMOS電晶體
像NMOS電晶體一樣,我們可以有一個PMOS電晶體,如下圖(a)所示,源極和漏極是由p型矽構成的區域,電晶體操作的邏輯與NMOS電晶體的邏輯完全相反。在這種情況下,如果柵極處於邏輯0,則空穴被吸引到溝道並形成導電路徑。然而,如果柵極處於邏輯1,則孔被溝道排斥,不形成導電路徑。
PMOS電晶體也可以被視為開關(圖b),當柵極電壓為0時,它開啟,當柵極處的電壓為邏輯1時,它關閉。PMOS電晶體的電路符號如圖(c)所示。
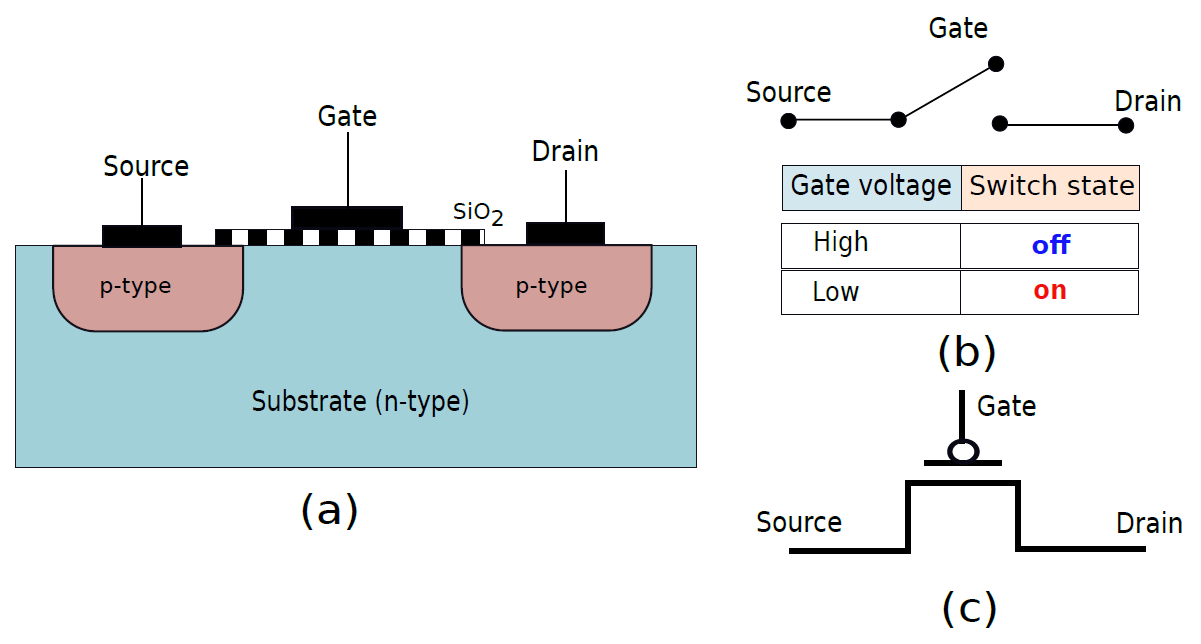
19.2.3.5 NAND和NOR門
下圖顯示瞭如何在CMOS技術中構建NAND門。兩個輸入端A和B連線到每個NMOS-PMOS對的柵極,如果A和B都等於1,則PMOS電晶體將關斷,NMOS電晶體將導通,將輸出設定為邏輯0。但是,如果其中一個輸入等於0,則其中一個NMOS電晶體將關閉,其中一個PMOS電晶體將開啟。因此,輸出將設定為邏輯1。
請注意,我們使用AND運算的運運算元「.」,這種符號在表示布林公式時被廣泛使用。同樣,對於OR運算,使用「+」符號。
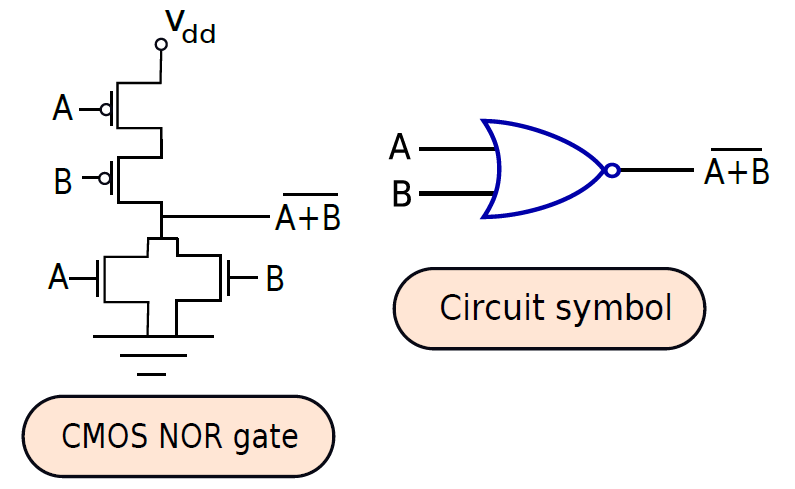
下圖顯示瞭如何構建NOR門。在這種情況下,兩個輸入端A和B也連線到每個NMOS-PMOS對的柵極。然而,與NAND門相比,拓撲結構有所不同。如果其中一個輸入為邏輯1,則其中一個NMOS電晶體將導通,其中一個PMOS電晶體將截止,輸出將設定為0。如果兩個輸入都等於0,則兩個NMOS晶體將截止,兩個PMOS晶體將導通,輸出將等於邏輯1。
NAND門的一些用途如下:
NOR門的一些用途如下:
19.2.4 組合邏輯電路
19.2.4.1 XOR門
讓我們實現互斥或(XOR)的邏輯函數,使用運運算元進行XOR運算,如果兩個輸入不相等,則互斥或操作返回1,否則返回0。已知\(A \oplus B=A \cdot \overline{B}+\overline{A} \cdot B\),則真值表和實現互斥或門的電路如下所示。
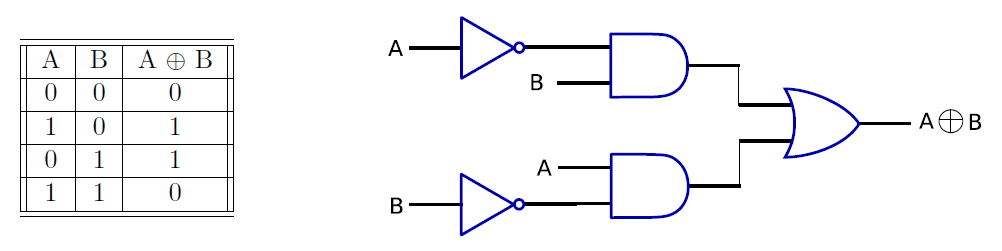
基本邏輯閘如下所示:
19.2.4.2 多路複用器和訊號分離器
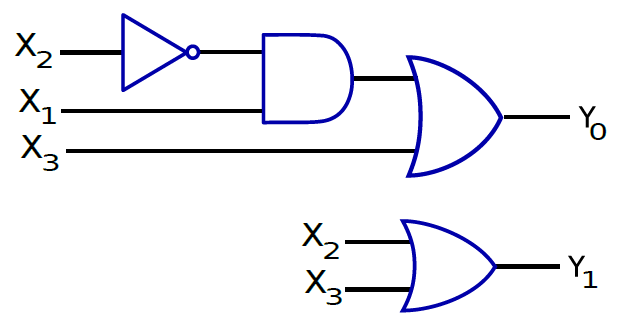
多路複用器(Multiplexer)的框圖如下圖左所示,採用n個輸入位和log(n)個選擇位,並根據選擇位的值,選擇一個輸入作為輸出(參見圖中帶箭頭的線)。多路複用器在處理器設計中大量使用,我們需要從一組輸入中選擇一個輸出。多路複用器也稱為多路複用器。
訊號分離器將log(n)位二進位制數作為輸入,1位輸入,並將輸入傳輸到n條輸出線中的一條,參見下圖右。多路分解器用於儲存單元的設計,其中輸入必須精確地反映在一條輸出線中。
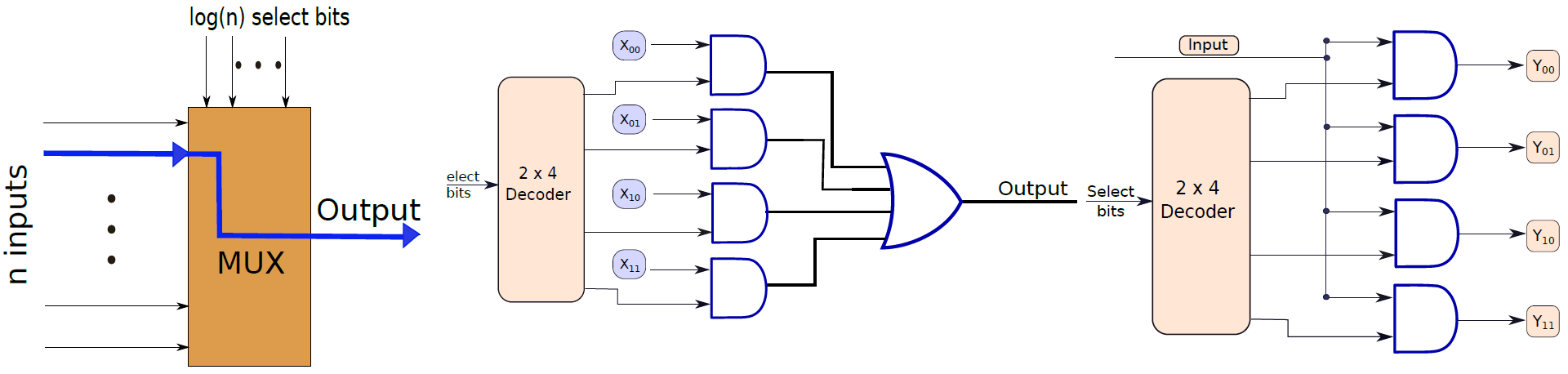
左:單個多路複用器結構圖。中:4輸入的多路複用器。右:訊號分離器。
多路複用器輸入至程式計數器。
19.2.4.3 編碼器和解碼器
解碼器將log(n)位二進位制數作為輸入,並具有n個輸出。根據輸入,它將其中一個輸出設定為1。
解碼器的設計如下圖左所示,具有兩個輸入和四個輸出的2x4解碼器的設計。假設輸入是A和B。我們生成所有可能的組合:\(\overline{A B}, \overline{A} B, A \overline{B}, AB\)。這些布林組合是通過計算A和B的邏輯「非」,然後將這些值路由到一組「與」門來生成的。
現在讓我們考慮一個與解碼器邏輯相反的電路,其框圖如下圖右所示。該電路有n個輸入和log(n)個輸出,n個輸入中的一個假定為1,其餘假定為0,輸出位提供等於1的輸入二進位制編碼。例如,在8輸入、3輸出編碼器中,如果第f行等於1,則輸出等於100(計數從0開始)。
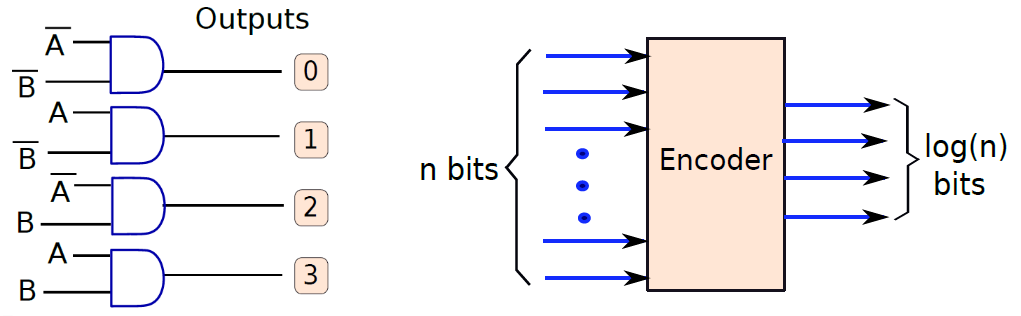
左:2x4解碼器的設計。右:n位編碼器框圖。
現在我們假設我們不存在只有一個輸入行可以等於1的限制,假設有多個輸入可以等於1。在這種情況下,我們需要報告具有最高索引(優先順序)的輸入行的二進位制編碼。例如,如果是第3行和第5行,那麼我們需要報告第5行的二進位制編碼,和上圖右一樣。此外,4-2位編碼器的電路圖如下圖所示。
用解碼器實現解複用器:
時鐘SR鎖存器(下圖左)和D鎖存器(下圖右):
J–K鎖存器:
基本鎖存器的比較:
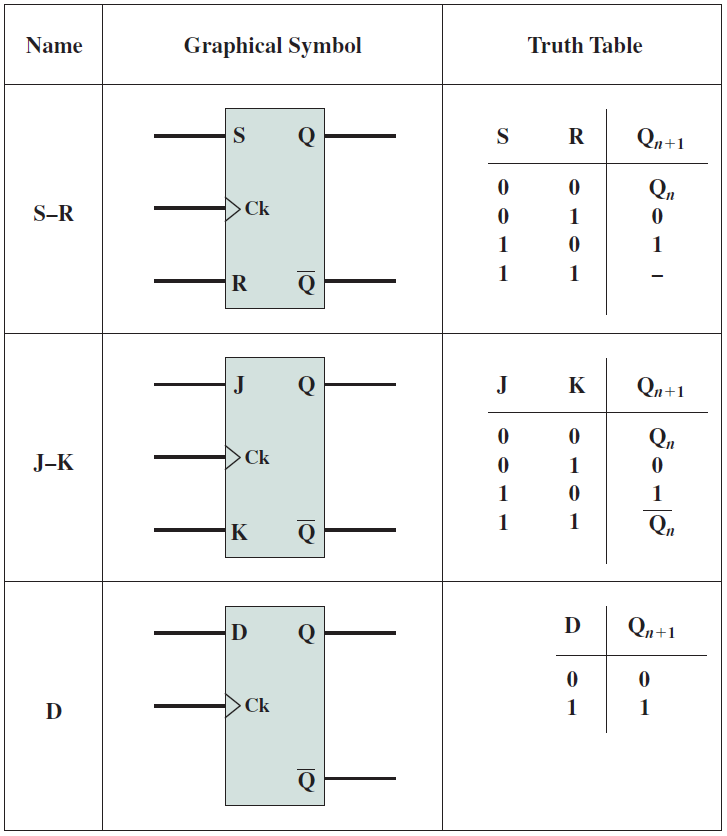
19.2.5 時序邏輯電路
前面已經研究了在位元上計算不同函數的組合邏輯電路,本小節將討論如何儲存位以供以後使用,這些結構被稱為順序邏輯元件(sequential logic element),因為輸出取決於過去的輸入,這些輸入在事件序列中較早出現。邏輯閘的基本思想是修改輸入值以獲得所需的輸出,在組合邏輯電路中,如果輸入被設定為0,那麼輸出也被重置。為了確保電路儲存一個值並在處理器通電時保持該值,需要設計一種具有某種「內建記憶體」的不同型別的電路。讓我們從制定一組要求開始:
1、電路應能自我維持,並在外部輸入復位後保持其值。不應依賴外部訊號來維持其儲存的元件。
2、應該有一種方法來讀取儲存的值而不破壞它。
3、應該有一種方法將儲存值設定為0或1。
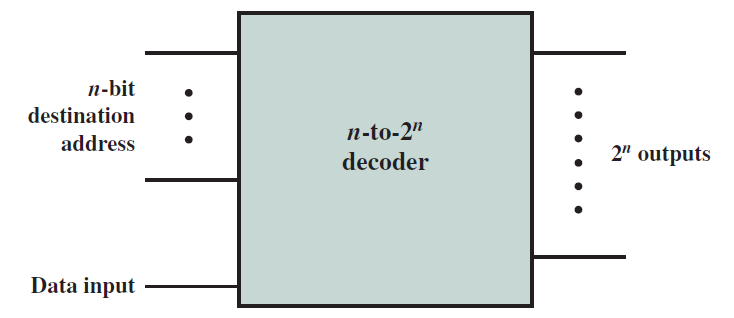
確保電路保持其值的最佳方法是建立反饋路徑,並將輸出連線回輸入,先看看最簡單的邏輯電路:SR鎖存器(SR latch)。
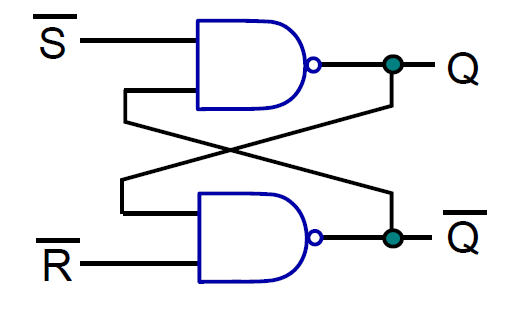
19.2.5.1 SR鎖存器
下圖顯示了SR鎖存器。有兩個輸入S(設定)和R(重置),有兩個輸出Q及其二補數Q,包含了兩個交叉耦合NAND門的電路。請注意,如果與非門的一個輸入為0,則輸出保證為1。然而,如果其中一個輸入是1,另一個輸入則為a,則輸出為a。
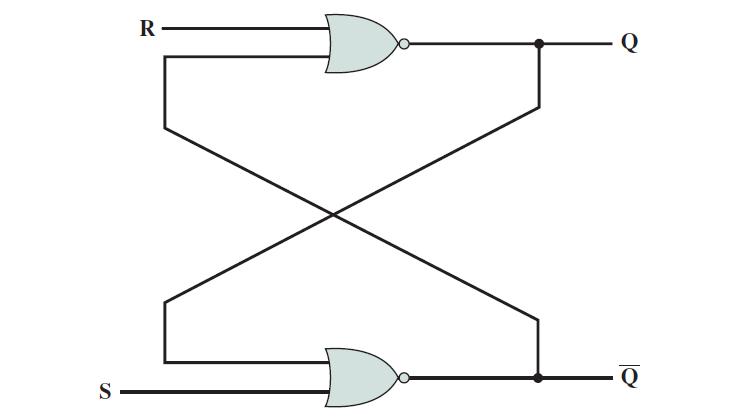
用NOR門實現的SR鎖存器:
19.2.5.2 時鐘和訊號
一個典型的處理器包含數百萬或可能數十億個邏輯閘和數千個鎖存器,不同的電路需要不同的時間,例如多路複用器可能需要1ns,解碼器可能需要0.5ns。電路完成計算後,就可以轉發輸出了。如果沒有全域性時間的概念,很難在不同的單元之間同步通訊,尤其是那些具有可變延遲的單元,導致難以設計、操作和驗證處理器。由此需要時間概念,例如可以說加法器需要兩個時間單位,在兩個單元結束時,預期資料將在鎖存器X中找到,其他單元可以在兩個時間單元后從鎖存器中獲取值並繼續計算。
考慮一個需要向印表機傳送一些資料的處理器的例子。為了傳輸資料,處理器通過一組銅線傳送一系列位元,印表機讀取這些位元,然後列印資料。問題是,處理器什麼時候傳送資料?計算完成後,需要傳送資料。我們可以問的下一個問題是,處理器如何知道計算何時結束?它需要知道不同單元的確切延遲,一旦計算的總持續時間過去,可以將輸出資料寫入鎖存器,並設定用於通訊的銅線的電壓。因此,處理器確實需要時間概念。其次,設計者需要告訴處理器不同子單元所需的時間。與處理2.34ns和1.92ns等數位相比,處理1、2和3等整數要簡單得多。這裡的1、2、3表示時間單位,時間單位可以是任何數位,例如0.9333ns。
時鐘訊號(clock signal):傳送到大型電路或處理器的每個部分的週期性方波。
時鐘週期(clock cycle):時鐘訊號的週期。
時脈頻率(clock frequency):時鐘週期的倒數。
因此,大多數數位電路與時鐘訊號同步,該時鐘訊號在完全相同的時間向處理器的每個部分傳送週期性脈衝。時鐘訊號為方波,如下圖所示,大多數時間,時鐘訊號是由主機板上的專用單元從外部生成的。讓我們考慮時鐘訊號從1轉變到0(向下/負邊緣)的點作為時鐘週期的開始,從時鐘的一個向下沿到下一個向下邊緣測量時鐘週期,時鐘週期的持續時間也稱為時鐘週期,時鐘週期的倒數被稱為時脈頻率。
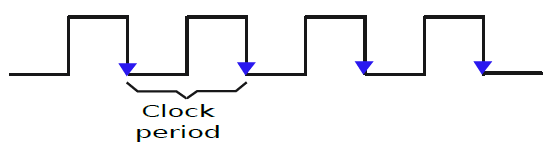
一個時鐘訊號。
電腦、筆記型電腦、平板電腦或行動電話通常會在其規格中列出頻率。例如,規範可能會說處理器執行在3GHz,這個數位是指時脈頻率。
典型的計算模型是:電路中執行所有基本動作所需的時間是按照時鐘週期來測量的,如果生產者單元佔用n個時鐘週期,那麼在n個時鐘迴圈結束時,它將其值寫入鎖存器。其他使用者單元知道此延遲,並且在第(n+1)個時鐘週期開始時,它們從鎖存器讀取值。由於所有單元都與時鐘明確同步,並且處理器知道每個單元的延遲,因此很容易對計算進行排序、與I/O裝置通訊、避免競爭條件、偵錯和驗證電路。我們想向印表機傳送資料的簡單範例可以通過使用時鐘輕鬆解決。
19.2.5.3 時鐘SR鎖存器
下圖顯示了SR鎖存器,其增加了兩個與非門,時鐘作為輸入之一,另外兩個輸入分別是S位和R位。如果時鐘為0,則交叉耦合NAND門的兩個輸入都為1,將保持先前的值。如果時鐘為1,則交叉耦合NAND門的輸入分別為S和R,這些輸入與基本SR鎖存器相同。請注意,時鐘鎖存器通常稱為觸發器(flip-flop)。
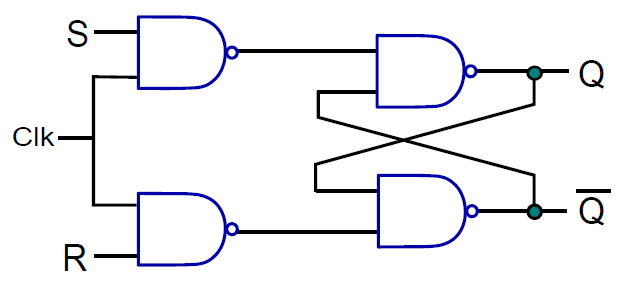
時鐘SR鎖存器圖例。
觸發器(flip-flop)是一個時鐘鎖存器,可以儲存一位(0或1)。
通過使用時鐘,我們部分解決了輸入和輸出同步的問題。在這種情況下,當時鍾為0時,輸出不受輸入的影響。當時鍾為1時,輸出受輸入影響。這種鎖存器也稱為電平敏感鎖存器(level sensitive latch)。
電平敏感鎖存器(level sensitive latch)取決於時鐘訊號的值:0或1。通常,它只能在時鐘為1時讀取新值。
在電平敏感鎖存器中,電路有半個時鐘週期來計算正確的輸出(當時鍾為0時)。當時鍾為1時,輸出可見。最好有一個完整的時鐘週期來計算輸出,這需要一個邊緣敏感鎖存器(edge sensitive latch),邊緣敏感鎖存器僅在時鐘的向下邊緣反映輸出端的輸入。
邊緣敏感鎖存器(edge sensitive latch)僅在固定的時鐘邊緣(例如向下邊緣,從1到0的轉換)反映輸出端的輸入。
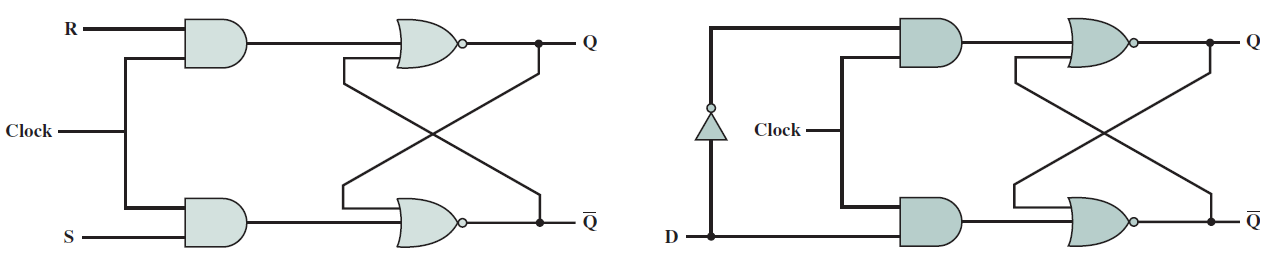
19.2.5.4 邊緣敏感SR觸發器
下圖顯示了邊緣敏感SR觸發器的結構圖,連線了兩個邊緣敏感SR觸發器,唯一的區別是第二個觸發器使用了時鐘訊號組合。第一個觸發器為主(master),而第二個為從(slave)。這種觸發器也被稱為主-從SR觸發器。這就是這個電路的工作原理。
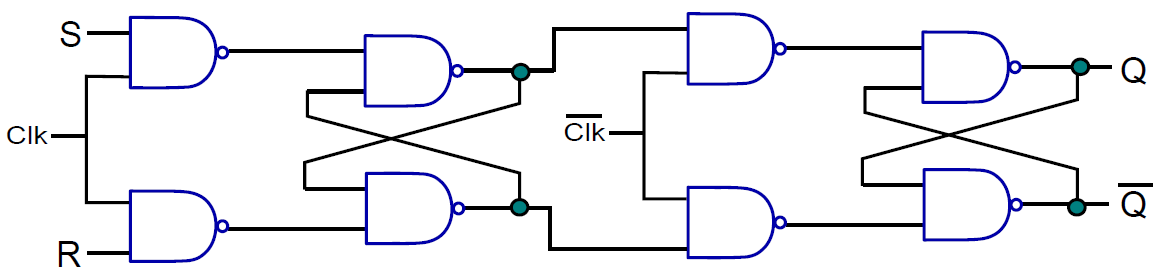
除了主從SR觸發器,還有其它各種型別的觸發器,如JK觸發器、D觸發器、主從D觸發器等。
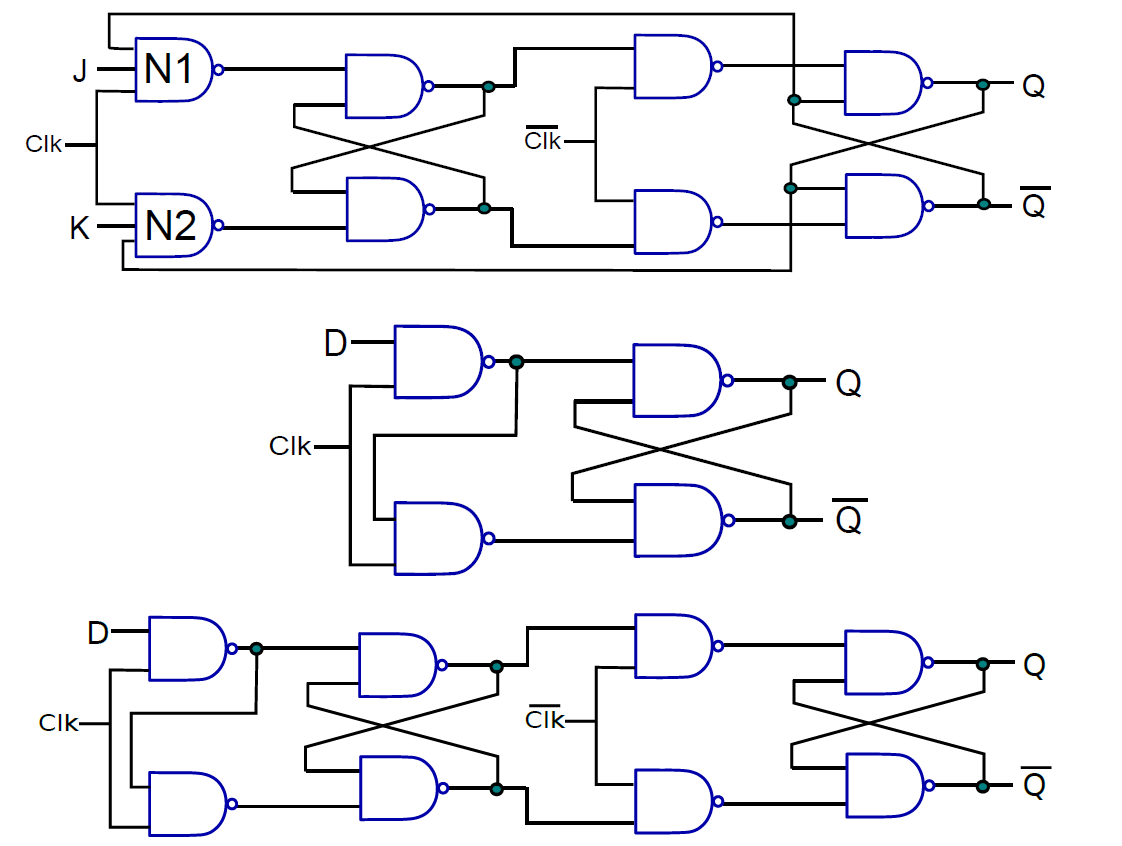
從上到下:JK觸發器、D觸發器、主從D觸發器。
19.2.5.5 暫存器
我們可以通過使用一組n個主從D觸發器來儲存n位資料,每個D觸發器連線到輸入線,其輸出端連線到輸出線,這種n位結構被稱為n位暫存器。我們可以並行載入n位,也可以在每個負時鐘邊沿並行讀取n位。因此,這種結構被稱為並行輸入——並行輸出暫存器。其結構如下圖所示。
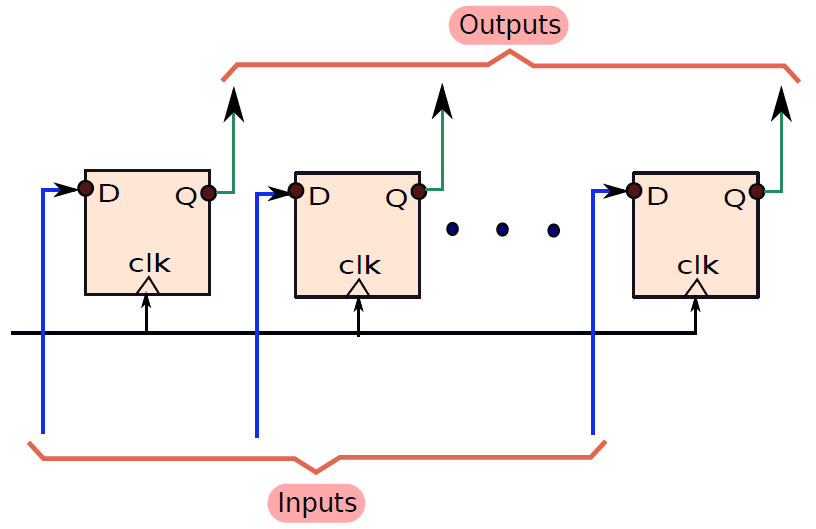
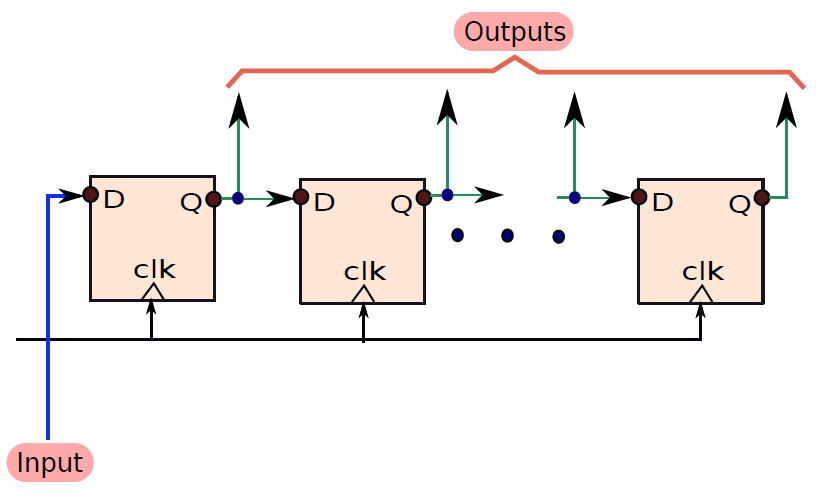
現在讓我們考慮一個序列輸入-並行輸出暫存器,如下圖所示,有一個輸入被饋送到最左邊的D觸發器, 每個週期,輸入都會移動到右側的相鄰觸發器。因此,要載入n位將需要n個週期。 第一位將在第一個週期被載入到最左邊的觸發器中,它需要n個週期才能到達最後一個觸發器。 到那時,其餘的n - 1觸發器將載入其餘的n - 1位,然後我們可以並行讀取所有 n 位(類似於並行並行輸出暫存器)。 該暫存器也稱為移位暫存器,用於實現高速I/O匯流排中使用的電路。
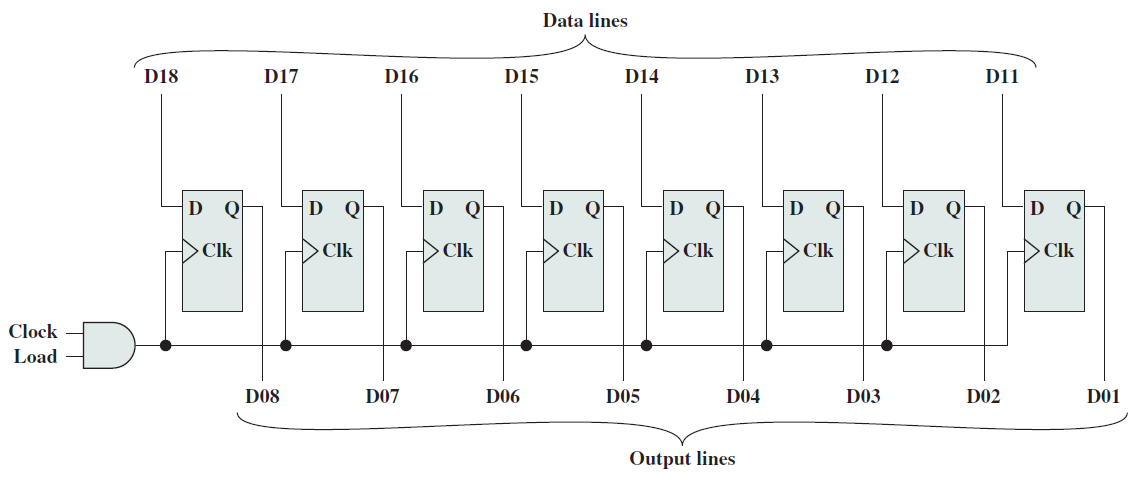
8位元並行暫存器的結構圖如下:
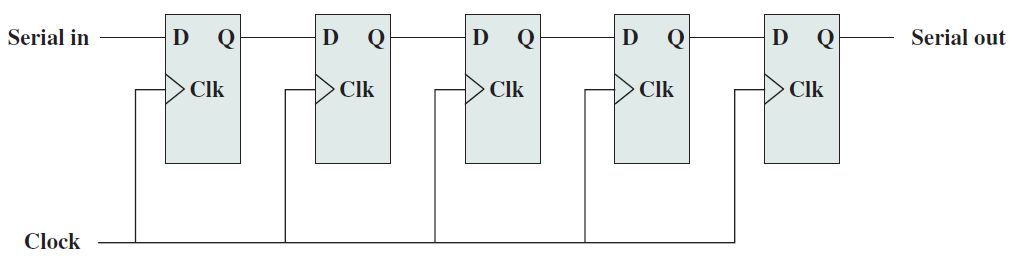
5位移位暫存器:
行波計數器:
19.2.6 記憶體
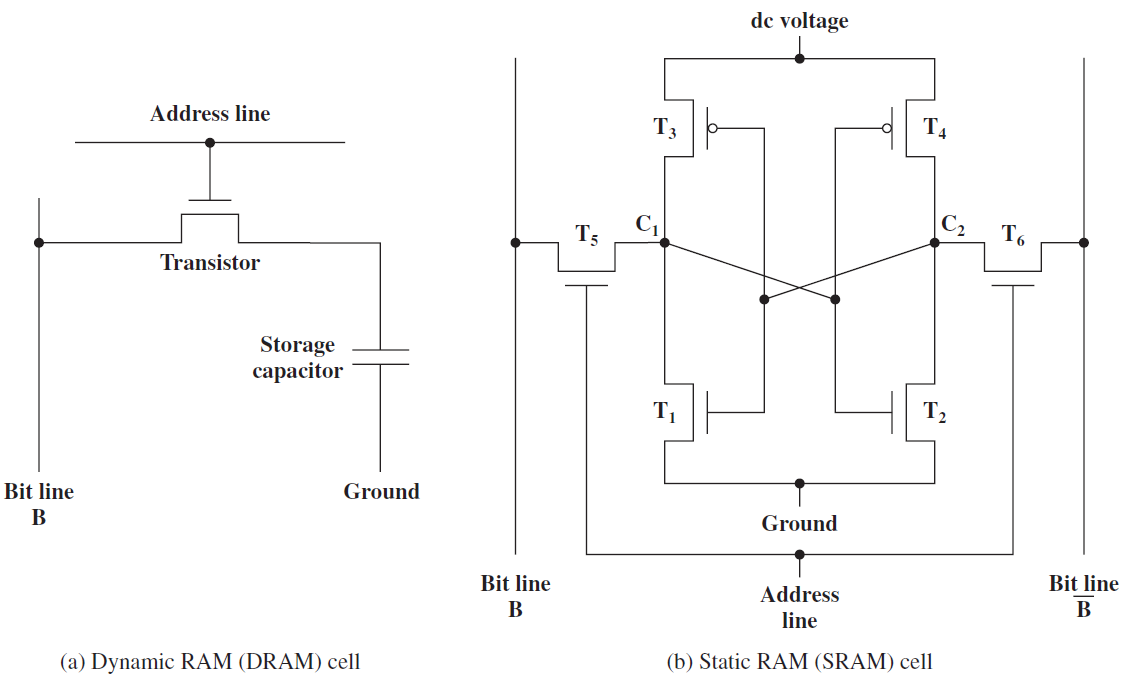
19.2.6.1 靜態記憶體(SRAM)
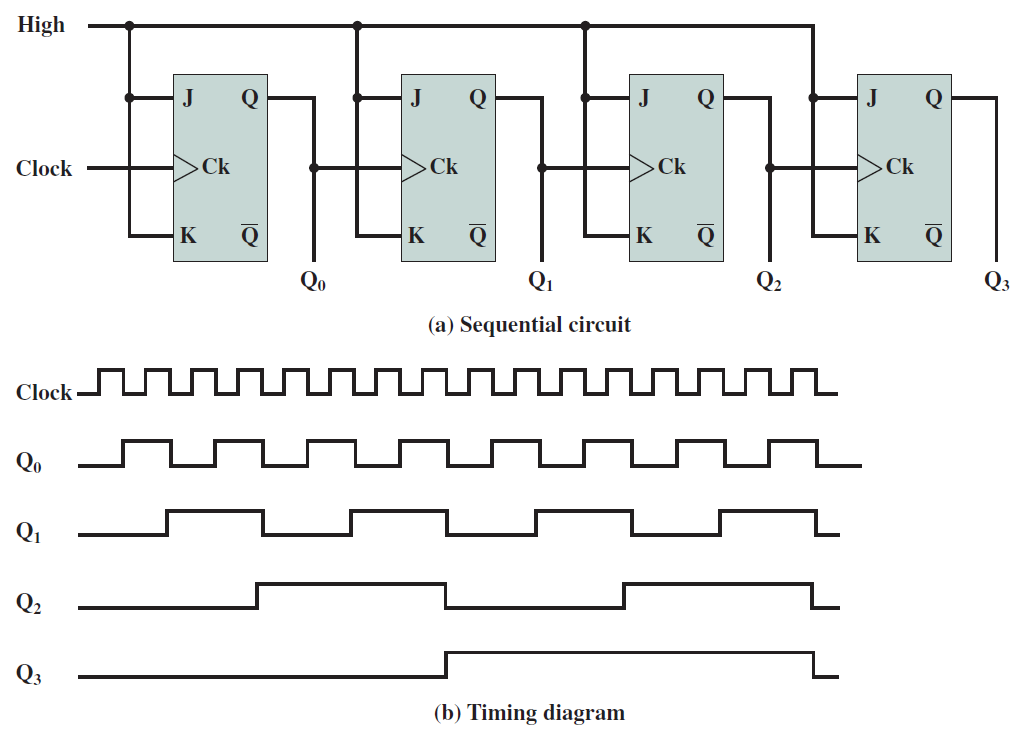
SRAM是指靜態隨機存取記憶體,基本SRAM單元包含兩個交叉耦合的反相器,如下圖所示。相比之下,基本SR觸發器或D觸發器包含交叉耦合的NAND門。設計如下所示。
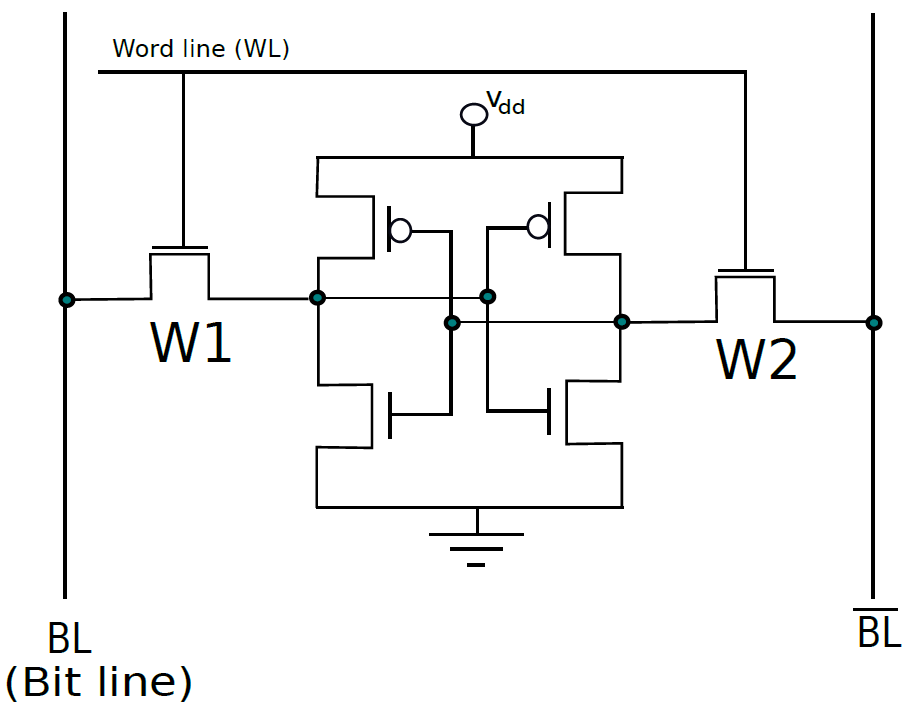
SRAM單元的核心包含4個電晶體(每個反相器中有2個),這種交叉耦合佈置足以節省單個位元(0或1)。然而,我們需要一些額外的電路來讀取和寫入值。此時,在鎖存器中使用交叉耦合反相器到底是不是一個壞主意,它們畢竟需要更少的電晶體。我們將看到,實現用於讀取和寫入SRAM單元的電路的開銷是非常重要的,開銷不足以證明以SRAM單元為核心製作鎖存器的合理性。
交叉耦合的反相器連線到每一側(W1、W2)上的電晶體,W1和W2的柵極連線到被稱為字線的相同訊號,兩個反相器W1和W2中的四個電晶體構成SRAM單元,它總共有六個電晶體。現在,如果字線上的電壓低,則W1和W2關斷,不可能讀取或寫入SRAM單元。然而,如果字線上的訊號為高,則W1和W2導通,可以存取SRAM單元。
下圖顯示了一個典型的SRAM陣列,SRAM單元被佈置為二維矩陣。一行中的所有SRAM單元共用字線,一列中的所有SRAM單元共用一對位線。要啟用某個SRAM單元,必須開啟其相關的字線,由解碼器完成,獲取地址位的子集,並開啟適當的字線。一行SRAM單元可能包含100多個SRAM單元,通常,我們會對32個SRAM單元(在32位元機器上)的值感興趣。在這種情況下,列複用器/解複用器選擇屬於感興趣的SRAM單元的位線,使用地址中的位的子集作為列選擇位。這種設計方法也稱為2.5D記憶體組織。
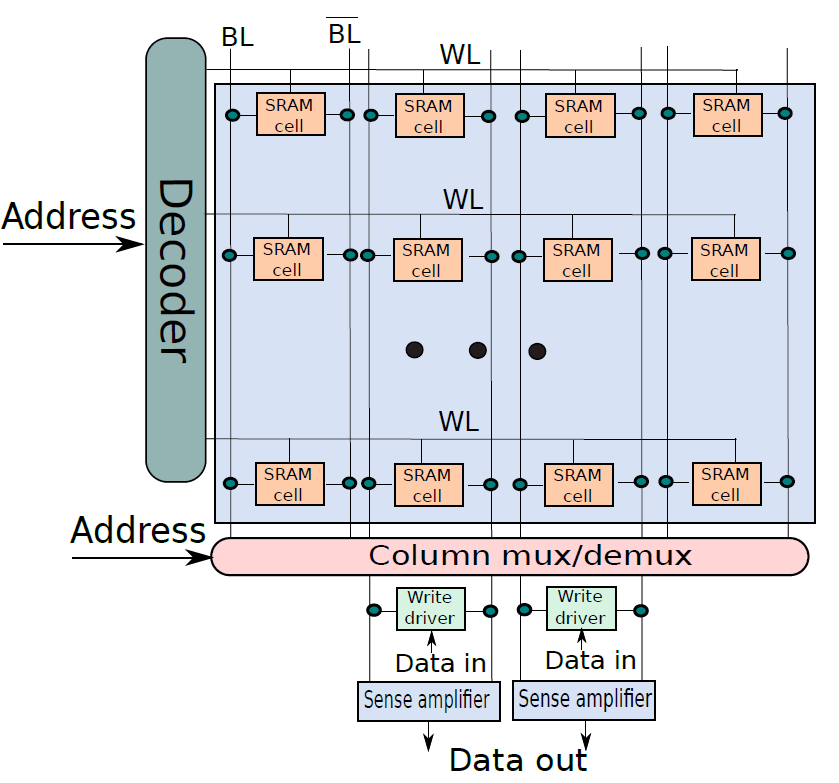
SRAM單元陣列。
19.2.6.2 內容定址記憶體(CAM)
下圖是10電晶體CAM單元,如果SRAM單元中儲存的值V不等於輸入位\(A_i\),那麼我們希望將匹配線的值設定為0。在CAM單元中,上半部分是具有6個電晶體的常規SRAM單元,下半部有4個額外的電晶體。現在讓我們考慮電晶體T1,它連線到全域性匹配線,電晶體T2。T1由儲存在SRAM單元中的值V控制,T2由\(\overline{A_i}\)控制。假設V=\(\overline{A_i}\),如果兩者都為1,則電晶體T1和T2處於導通狀態,並且匹配線和地之間存在直接導電路徑。因此,匹配線的值將設定為0。然而,如果V和\(\overline{A_i}\)都為0,則通過T1和T2的路徑不導通。但是,在這種情況下,通過T3和T4的路徑變得導通,因為這些電晶體的柵極分別連線到\(\overline{V}\)和\(A_i\)。兩個柵極的輸入都是邏輯1,因此匹配線將被下拉到0。讀取器可以反過來驗證,如果V=\(A_i\),則不形成導通路徑。因此,如果儲存的值與輸入位\(A_i\)不匹配,則CAM單元將匹配線驅動到邏輯0。
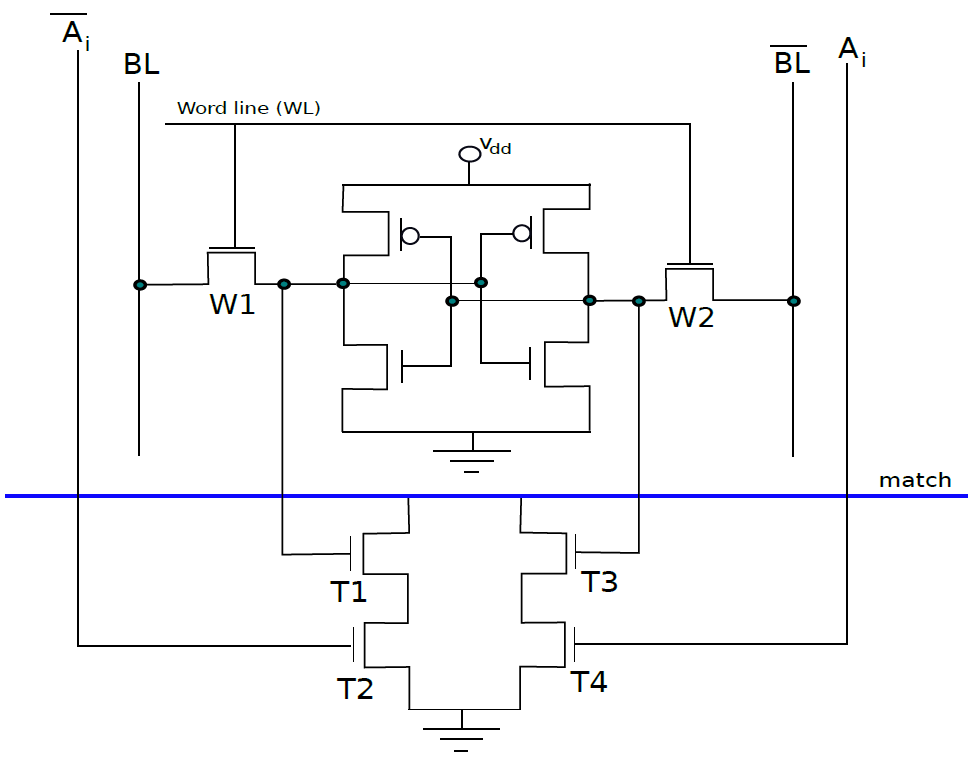
10電晶體CAM單元。
下圖顯示了CAM單元陣列。該結構主要類似於SRAM陣列。我們可以通過索引定址一行,並執行讀/寫存取,此外可以將CAM單元的每一行與輸入A進行比較。如果任何行與輸入匹配,則相應的匹配線的值將為1。可以計算所有匹配線的邏輯OR,並確定CAM陣列中是否匹配,此外可以將CAM陣列的所有匹配線連線到優先順序編碼器,以查詢與資料匹配的行的索引。
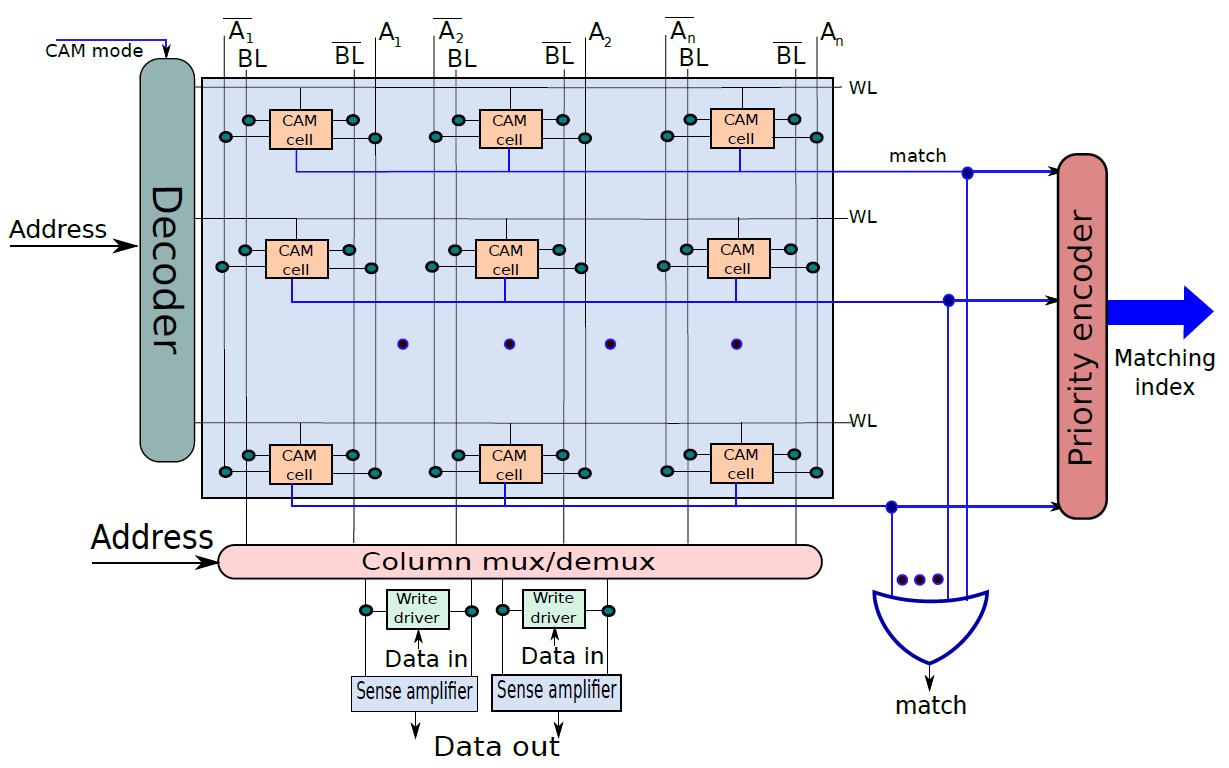
CAM單元陣列。
19.2.6.3 動態記憶體(DRAM)
現在來看看一種只使用一個電晶體來節省一點時間的記憶體技術,它非常密集、面積大,而且能效高,但比SRAM和鎖存器慢得多,適用於大型片外記憶體。
基本DRAM(動態記憶體)單元如下圖所示。單個電晶體的柵極連線到字線,從而啟用或禁用它,其中一個端子連線到儲存電荷的電容器。如果儲存的位是邏輯1,則電容器帶電,否則不帶電。
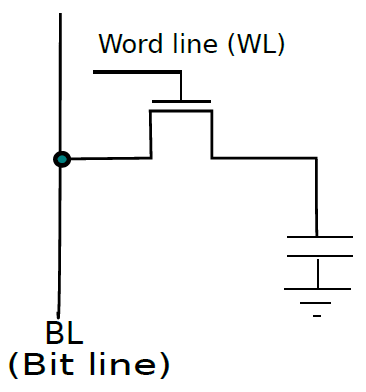
一個動態記憶體的單元。
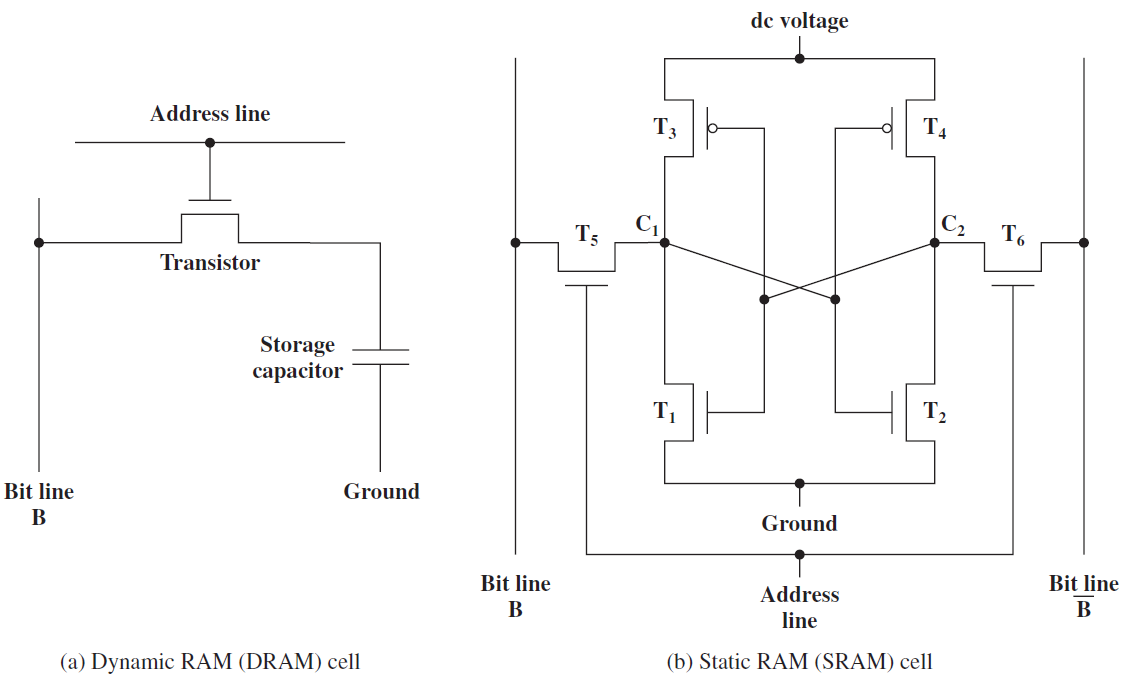
DRAM和SRAM單元的對比圖。
因此,讀取和寫入值非常容易。我們需要首先設定字線,以便可以存取電容器。為了讀取該值,需要感測位線上的電壓。如果它處於地電位,則單元儲存0,否則如果它接近電源電壓,則儲存1。類似地,要寫入值,我們需要將位線(BL)設定為適當的電壓,並設定字線,電容器將相應地充電或放電。
然而,就DRAM而言,並非一切都是免費的。讓我們假設電容器被充電到等於電源電壓的電壓,實際上,電容器將通過電媒介和電晶體逐漸洩漏一些電荷。該電流很小,但在長時間內電荷的總損失可能很大,最終會使電容器放電。為了防止這種情況,有必要定期重新整理DRAM單元的值,亦即需要讀取並寫回資料值。這也需要在讀取操作之後完成,因為電容器在對位線充電時會損失一些電荷。現在讓我們嘗試製作一個DRAM單元陣列。
我們可以用建立SRAM單元陣列的方法構建DRAM單元陣列(下圖),有三點不同:
- 存在一條位線而不是兩條位線。
- 有一個連線到位線的專用重新整理電路。這在讀取操作後使用,也會定期呼叫。
- 在這種情況下,感測放大器出現在列複用器/解複用器之前。讀出放大器還為整個DRAM行(也稱為DRAM頁)快取資料。它們確保對同一DRAM行的後續存取是快速的,因為它們可以直接從讀出放大器進行服務。
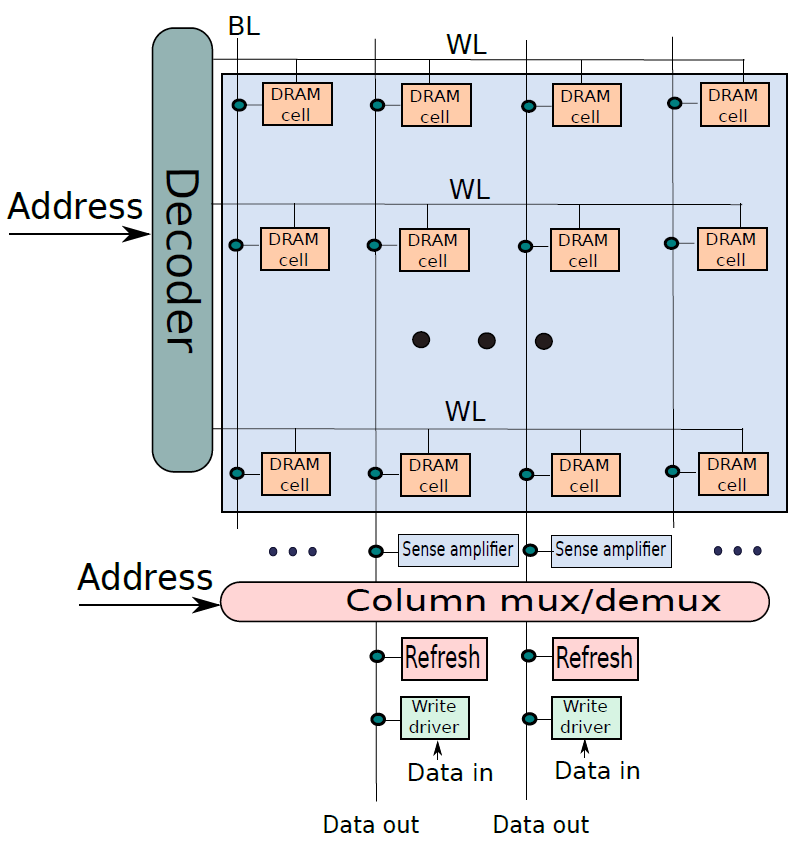
DRAM單元陣列。
接下來簡述現代DRAM的時序方面。在過去的好日子裡,DRAM記憶體是非同步存取的,意味著DRAM模組沒有做出任何時序保證。但現在每個DRAM操作都與系統時鐘同步,因此,如今的DRAM晶片是同步DRAM晶片(SDRAM晶片)。
截至目前,同步DRAM記憶體通常使用DDR4或DDR5標準,DDR代表雙倍資料速率,使用最早標準DDR1的裝置在時鐘的上升沿和下降沿向處理器傳送8位元組的封包,DDR也被稱為雙峰(double pump)操作。DDR1的峰值資料速率為1.6 GB/s,後續的DDR世代通過以更高的頻率傳輸資料來擴充套件DDR1,例如,DDR2的資料速率是DDR1裝置的兩倍(3.2 GB/s),DDR3通過使用更高的匯流排頻率將峰值傳輸速率進一步提高了一倍,自2007年開始使用(峰值速率為6.4GB/s)。
19.2.6.4 唯讀記憶體(ROM)
唯讀記憶體可分為普通ROM和PROM(可程式化ROM),下面分別是它們的單元圖例。
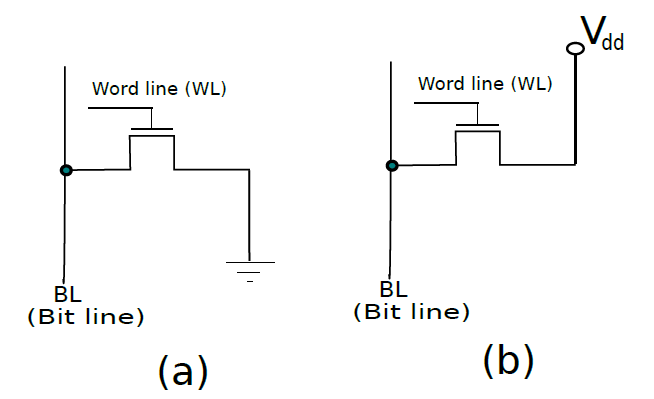
(a) 儲存邏輯0的ROM單元;(b) 儲存邏輯1的ROM單元。
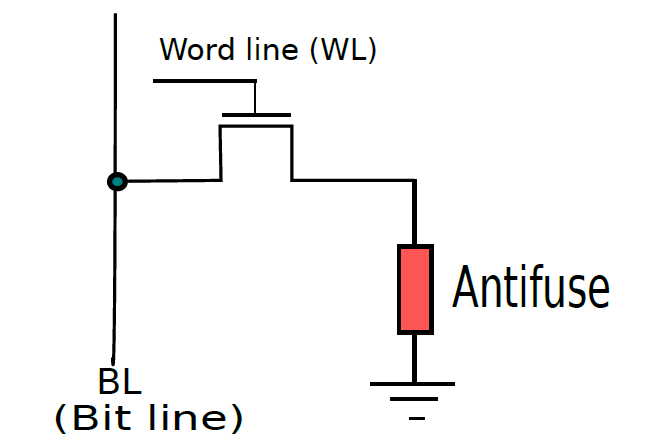
PROM單元。
19.2.6.5 可程式化邏輯陣列
事實證明,我們可以很容易地用類似於PROM單元的儲存單元製作組合邏輯電路,這種器件被稱為可程式化邏輯陣列或PLA。PLA在實踐中用於實現由數十或數百個小項(minterm)組成的複雜邏輯函數,相對於由邏輯閘組成的硬連線電路的優勢在於它是靈活的,我們可以在執行時更改PLA實現的布林運算,相比之下,由矽製成的電路永遠不會改變其邏輯。其次,PLA的設計和程式設計更簡單,而且有很多軟體工具可以設計和使用PLA。最後,PLA可以有多個輸出,因此可以很容易地實現多個布林函數。這種額外的靈活性是有代價的,代價是效能。
下圖(a)所示的PLA單元原則上類似於基本PROM單元。如果柵極處的值(E)等於1,則NMOS電晶體處於導通狀態。因此,NMOS電晶體的源極和漏極端子之間的電壓差非常小。換句話說,可以簡單地假設結果線的電壓等於訊號的電壓,X. If (E = 0),NMOS電晶體處於截止狀態。結果線是浮動的,並保持其預充電電壓。在這種情況下,我們建議推斷邏輯1。
現在讓我們構建一行PLA單元,其中每個PLA單元在其源極端子處連線到輸入線,如圖(b)所示。輸入編號為X1…Xn,所有NMOS電晶體的漏極連線到結果線,PLA單元的電晶體的柵極連線到一組使能訊號E1…En。如果任何一個使能訊號等於0,則該特定電晶體被禁用,我們可以將其視為從PLA陣列中邏輯移除。
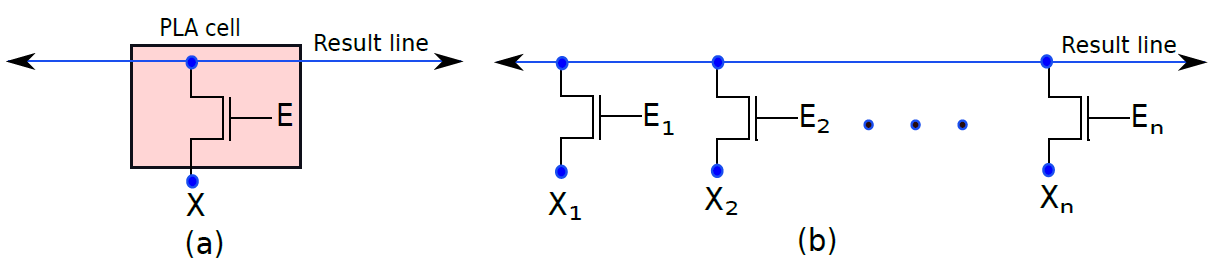
一個PLA單元。
現在讓我們建立一個PLA單元格陣列,如下圖所示,每行對應一個minterm。對於我們的3變數範例,每行由6列組成,每個變數有2列(原始和補充),例如,前兩列分別對應於A和\(\overline{A}\)。在任何一行中,這兩列中只有一列包含PLA單元,因為A和\(\overline{A}\)不能同時為真。在第一行,計算最小項\(\overline{ABC}\)的值,因此第一行包含對應於\(\overline{A}\)、\(\overline{B}\)和\(\overline{C}\)的列中的PLA單元。我們在其餘行中為剩餘的minterm進行類似的連線,PLA陣列的這一部分被稱為AND平面,因為我們正在計算變數值(原始值或二補數值)的邏輯AND。PLA陣列的AND平面獨立於我們希望計算的布林函數,給定輸入,它計算所有可能的最小項的值。
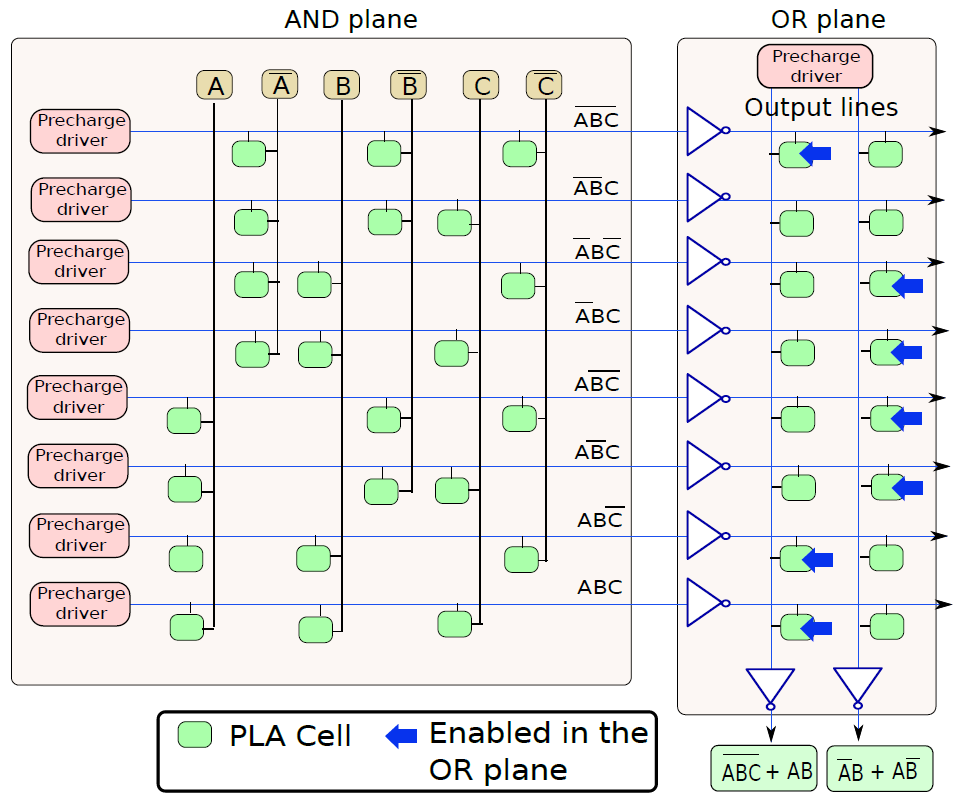
PLA單元陣列。

典型的記憶體封裝引腳和訊號。
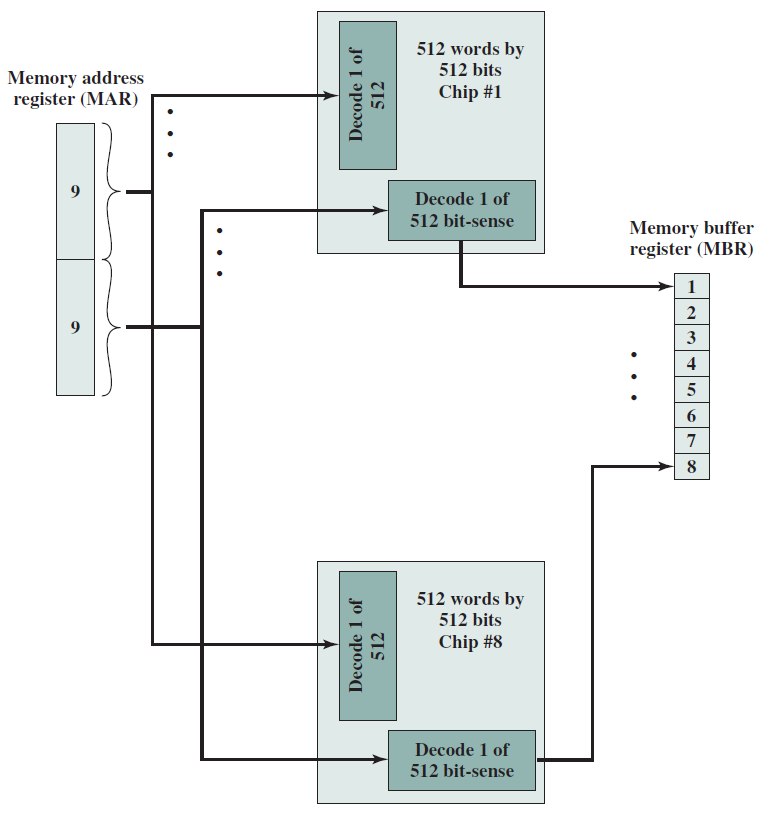
256 KB記憶體組織。
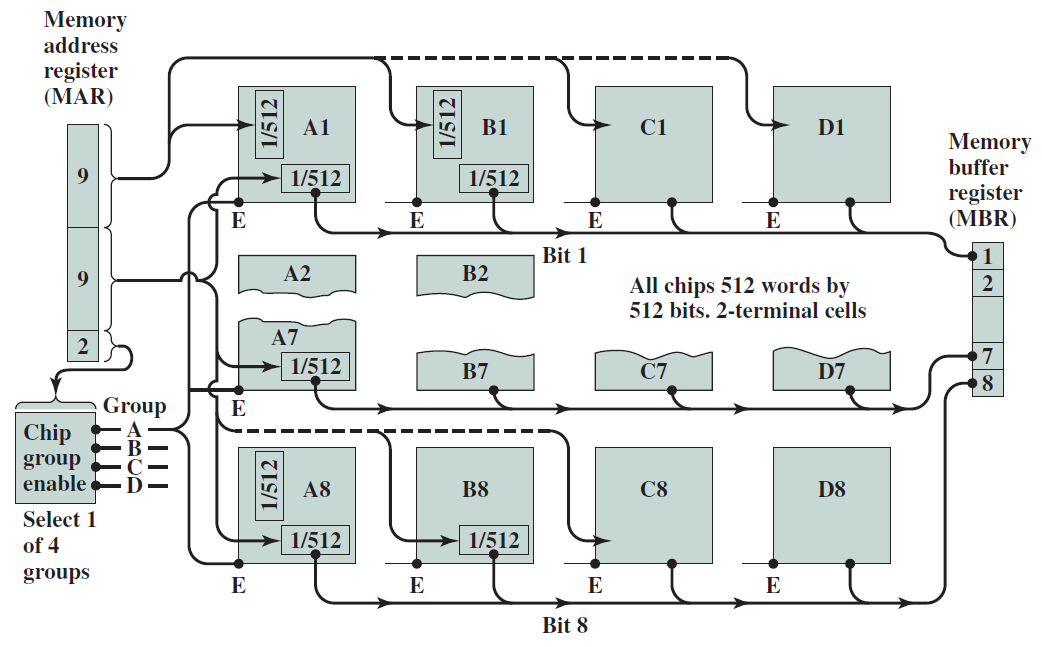
1MB記憶體組織。
DDR代次演進圖。
非易失性RAM技術。

上:簡化的DRAM讀取時序;下:Signetics 7489 SRAM的脈衝串。
19.2.7 計算機算術
本節將設計算術運算的硬體演演算法,先闡整數運算的演演算法,如兩個二進位制數相加的基本演演算法,有很多方法可以完成這些基本操作,每種方法都有自己的優缺點。注意,二進位制減法的問題在概念上與2的二補數系統中的二進位制加法相同。因此,我們不需要單獨對待它。隨後,我們將看到,n個數的相加問題與乘法問題密切相關,而且這是一個硬體上的快速操作。遺憾的是,整數除法並不存在非常有效的方法。然而,我們將考慮兩種用於劃分正二進位制數的流行演演算法。
整數算術之後,我們將研究浮點(帶小數點的數位)算術的方法,大多數整數演演算法稍作修改後都可以移植到浮點數領域。與整數除法相比,浮點除法可以非常有效地完成。
19.2.7.1 加法
讓我們看看將兩個1位數位a和b相加的問題,a和b都可以取兩個值:0或1,因此,a和b有四種可能的組合,它們的二進位制和可以是00、01或10。當a和b均為1時,它們的和將是10,兩個1位數位的總和可能有兩位長。讓我們將結果的LSB稱為和,將MSB稱為進位,例如,把8和9相加,和是7,進位是1。
可以將和和進位的概念擴充套件到加三個1位數位。如果我們將三個1位數位相加,那麼結果的範圍是二進位制的00到11之間。
和(sum):總和是兩個或三個1位數位相加結果的LSB。
進位(carry):進位是兩個或三個1位數位相加結果的MSB。
對於可以將兩個1位數位相加的加法器,將有兩個輸出位:和s和進位c,將兩個位相加的一個加法器稱為半加法器(half adder)。半加法的真值表如下表所示。
| a | b | s | c |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 1 | 0 |
| 1 | 0 | 1 | 0 |
| 1 | 1 | 0 | 1 |
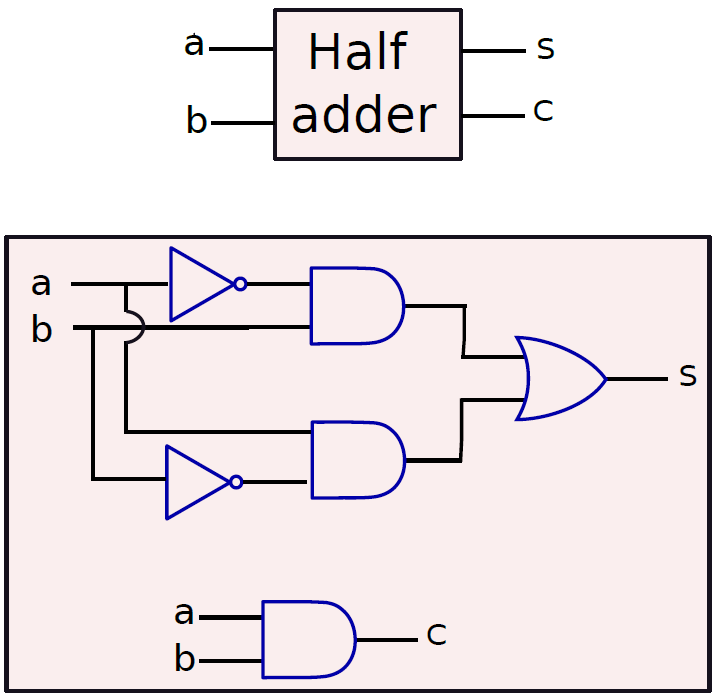
半加法器。
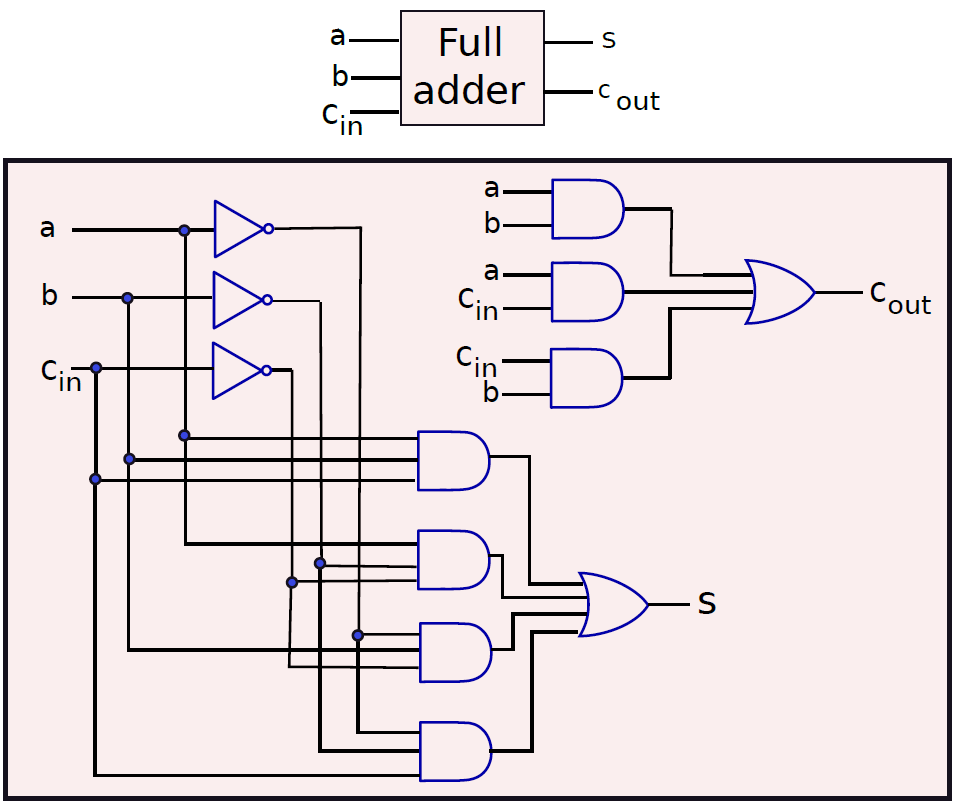
可以加3位的加法器稱為全加法器(full adder),它的電子構造如下:
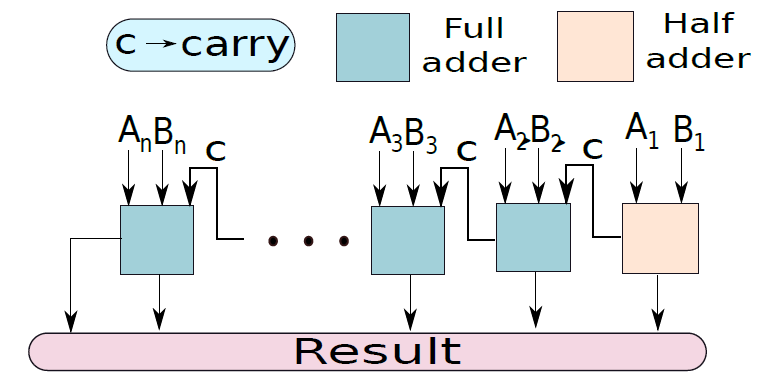
n位加法器被稱為紋波進位加法器(ripple carry adder),其設計如下所示:
考慮將兩個數位A和B相加的問題,首先將位元集劃分為4位元的塊,如下圖所示,每個塊包含一個a片段和一個B片段。通過考慮塊的輸入進位將這兩個片段相加,並生成一組和位和一個進位,此進位是後續塊的輸入進位。
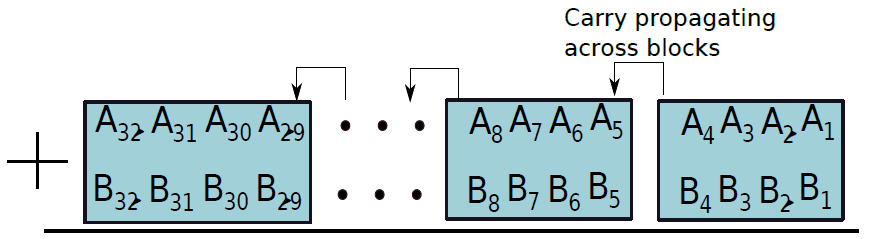
此外,還有超前進位加法器(Carry Lookahead Adder),其分為兩個階段,每個階段都擁有複雜的電子構造。
19.2.7.2 乘法
現與加法類似,先看看兩個十進位制數相乘的最簡單的方法,不妨嘗試將13乘以9。在這種情況下,13被稱為被乘數(multiplicand),9被稱為乘數(multiplier),117是乘積(product)。
下圖(a)顯示了十進位制的乘法,(b)顯示了二進位制的乘法。請注意,兩個二進位制數相乘的方法與十進位制數完全相同。我們需要考慮乘數從最小顯著位置到最大顯著位置的每一位。如果該位為1,那麼我們將被乘數的值寫在該行下方,否則我們將寫0。對於每個乘數位,我們將被乘數向左移動一位。其原因是每個乘數位代表2的更高冪。我們將每個這樣的值稱為部分和(見圖7.10(b))。如果乘法器有m位,那麼我們需要將m個部分和相加以獲得乘積。在這種情況下,乘積是十進位制117,二進位制1110101。讀者可以驗證它們實際上表示相同的數位。為了便於以後的表示,讓我們定義另一個稱為部分積的術語。它是部分和的連續序列的和。
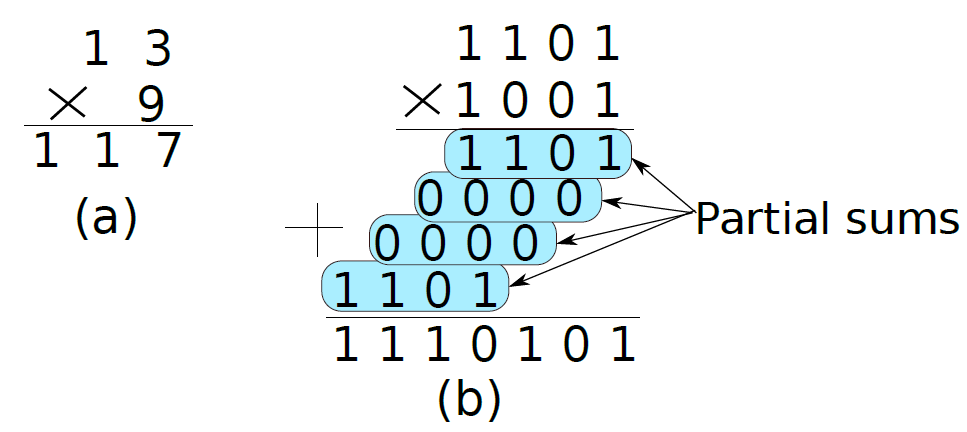
(a)十進位制乘法;(b)二進位制乘法。
常規的乘法器是\(O(n^2)\),而改進版的Booth乘法器或Wallace樹形乘法器(下圖)可以做到\(O(log(n))\)的演演算法複雜度。
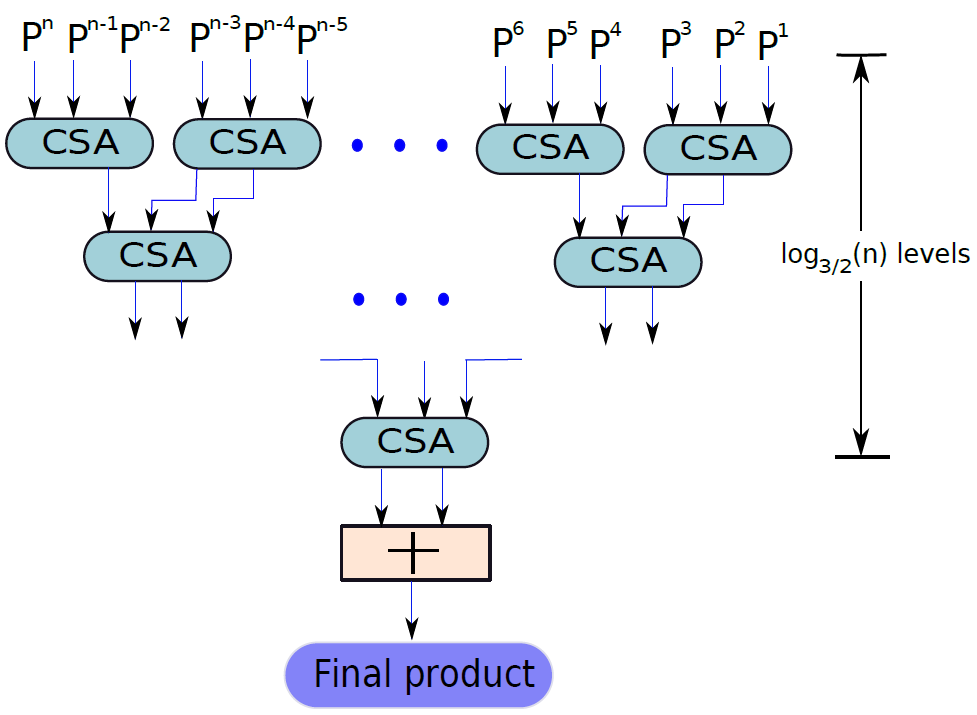
Wallace樹形乘數。
19.2.7.3 除法
現在讓我們看看整數除法。不幸的是,與加法、減法和乘法不同,除法是一個明顯較慢的過程。任何除法運算都可以表示如下:
N是被除數,D是除數,Q是商,R是餘數。假定除數和被除數為正,除法過程需要滿足以下屬性:
- \(R < D\)且\(R \ge 0\)。
- Q是滿足上述等式的最大正整數。
如果我們想除掉負數,那麼首先將它們轉換成正數,進行除法,然後調整商和餘數的符號,部分ISA試圖確保餘數始終為正。在這種情況下,需要將商減1,並將除數與餘數相加,使其為正。
實現除法的方式有迭代除法、佘數恢復除法(Restoring Division)、非餘數恢復除法(Non-Restoring Division)等。本文忽略這些演演算法的具體描述,有興趣的童鞋可以自行查閱資料。
19.2.7.4 浮點數運算
浮點加法和減法的問題實際上是同一問題的不同方面。A-B可以用兩種方式解釋,可以說正在從A中減去B,也可以說在將-B加到A中。因此,與其單獨看減法,不如將其視為加法的特例。浮點數的二進位制表示、屬性和特殊含義可以參見:17.2.2 浮點數。
下圖顯示了一個範例,說明了如何將有效位解壓縮,並將其放入普通浮點數的暫存器中。在32位元IEEE 754格式中,尾數有23位,小數點前有0或1。因此,有效位需要24位元,如果我們希望新增前導符號位(0),那麼我們需要25位儲存。讓我們把這個號碼儲存在一個暫存器中,並稱之為W。
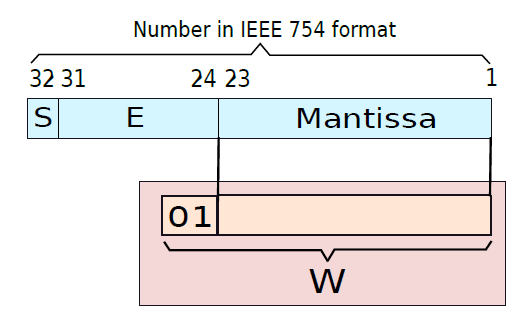
展開有效位並放入暫存器。
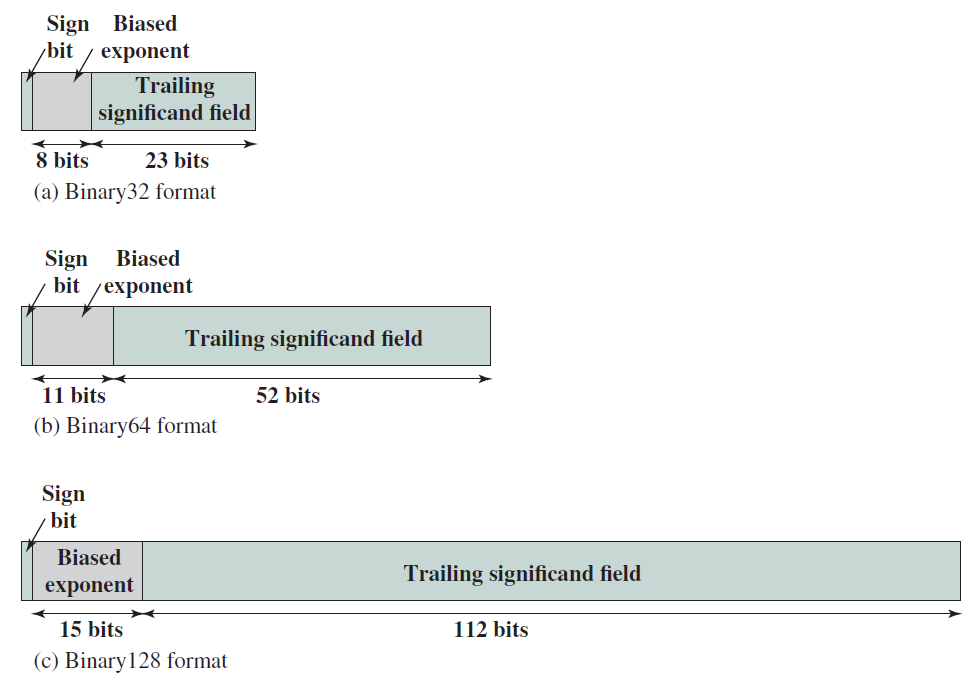
IEEE 754格式。
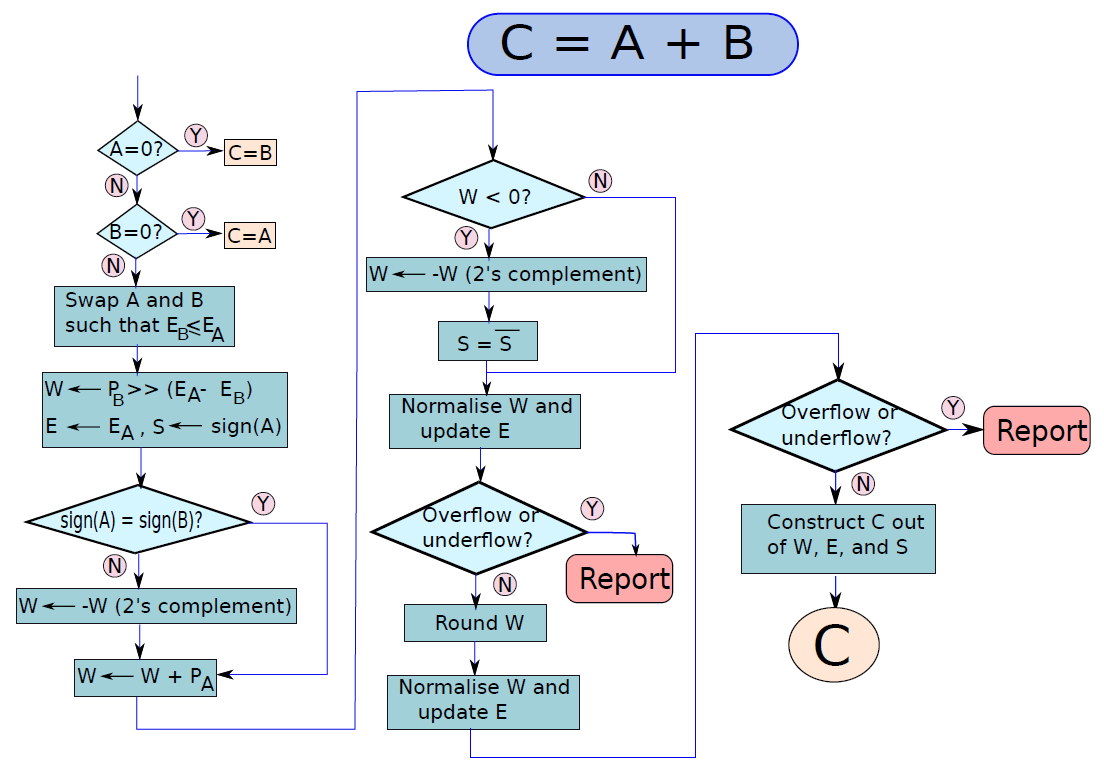
浮點數的運算涉及舍入等考量,下圖顯示了兩個浮點數相加的演演算法,考慮了0值。
累加兩個浮點值的流程圖。
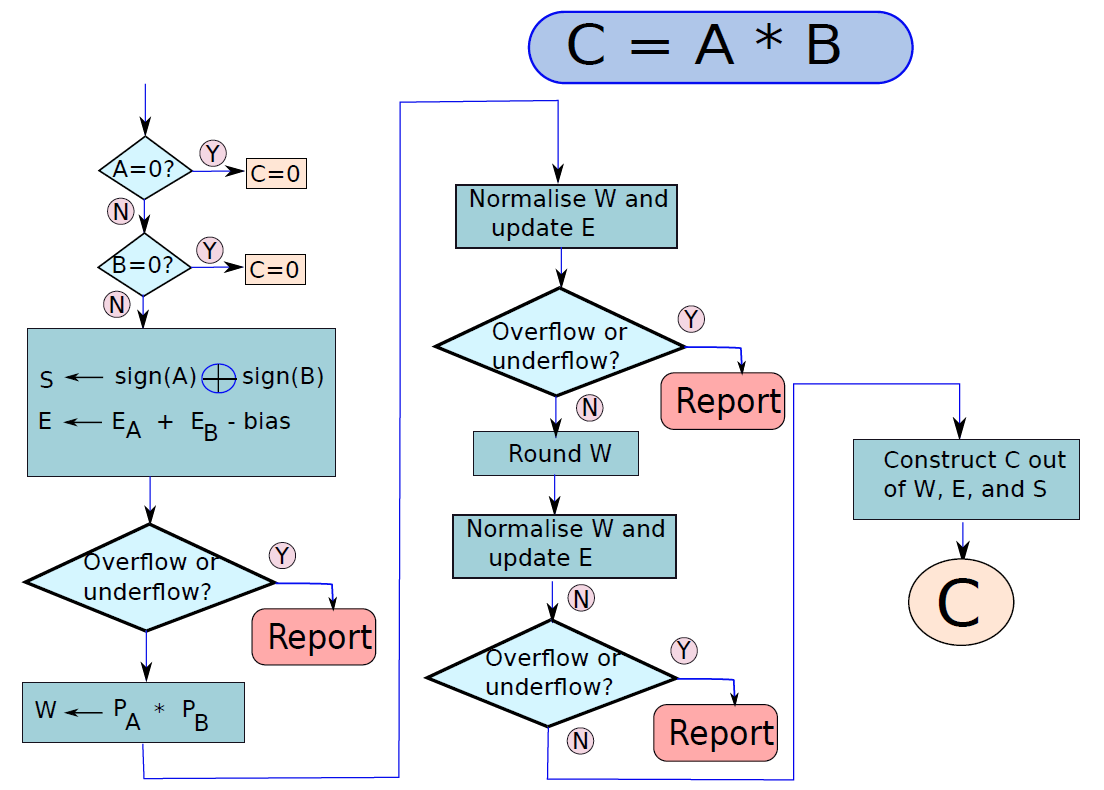
浮點數相乘演演算法與泛型加法演演算法的形式完全相同,只需幾步。讓我們嘗試乘以A x B以獲得乘積C,乘法的流程圖如下圖所示。在乘法的情況下,我們不必對齊指數,如下初始化演演算法,將B的符號和裝入暫存器W,W的寬度等於運算元大小的兩倍,就可以容納乘積。E暫存器初始化為\(E_A+E_B - bias\),因為在乘法的情況下,指數相加,減去bias以避免重複計數,計算結果的符號很簡單。
兩個浮點值相乘的流程圖。
此外,還有Goldschmidt除法以及Newton-Raphson除法。
Newton-Raphson方法。
19.3 計算機架構和組織
19.3.1 計算機層級
計算機系統級層次結構是將計算機與使用者連線起來並使用計算機的不同級別的組合,還描述瞭如何在計算機上執行計算活動,並顯示了在不同級別的系統中使用的所有元素。通用的計算機系統級層次結構由7個級別組成:
| 層級 | 功能 | 舉例 | 解析 |
|---|---|---|---|
| 層6 | 使用者 | 可執行程式 | 包含使用者和可執行程式。 |
| 層5 | 高階語言 | C++、Java | 高階語言套件括 C++、Java、FORTRAN和許多其他語言,是使用者發出命令的語言。 |
| 層4 | 組合語言 | 組合程式碼 | 組合語言是計算機系統的下一個層次。機器只理解組合語言,因此按照順序,所有高階語言都在組合語言中進行了更改,組合程式碼是為它編寫的。 |
| 層3 | 系統軟體 | 作業系統 | 系統軟體種類繁多,主要幫助操作程序,並建立硬體和使用者介面之間的連線,可能包括作業系統、庫程式碼等。 |
| 層2 | 機器 | 指令集架構(ISA) | 在計算機系統中使用不同型別的硬體來執行不同型別的活動,包含指令集架構。 |
| 層1 | 控制層 | 微碼(microcode) | 控制是系統中使用微碼的級別,控制單元包括在這一級別的計算機系統中。 |
| 層0 | 數位邏輯 | 電路、門 | 數位邏輯是數位計算的基礎,提供了對計算機內電路和硬體如何通訊的基本理解,由各種電路和門等組成。 |
當然,也存在另一種層級劃分,從上到下分別是:遊戲應用、遊戲引擎、圖形API、作業系統、裝置驅動、硬體裝置。
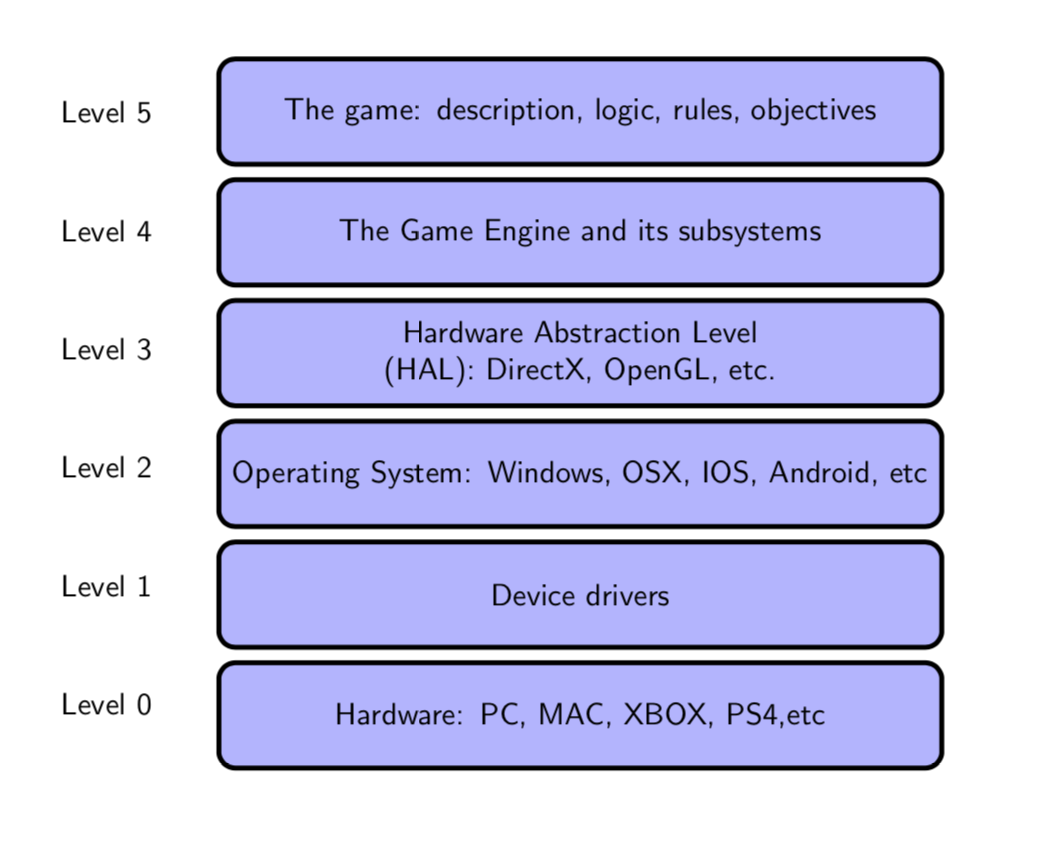
下圖是更加詳細的層級模組,其中作業系統(OS)處於圖形API等第三方SDK和驅動之間,充當著承上啟下的重要作用和通訊橋樑,是整個計算機層級架構極其重要的組成部分。
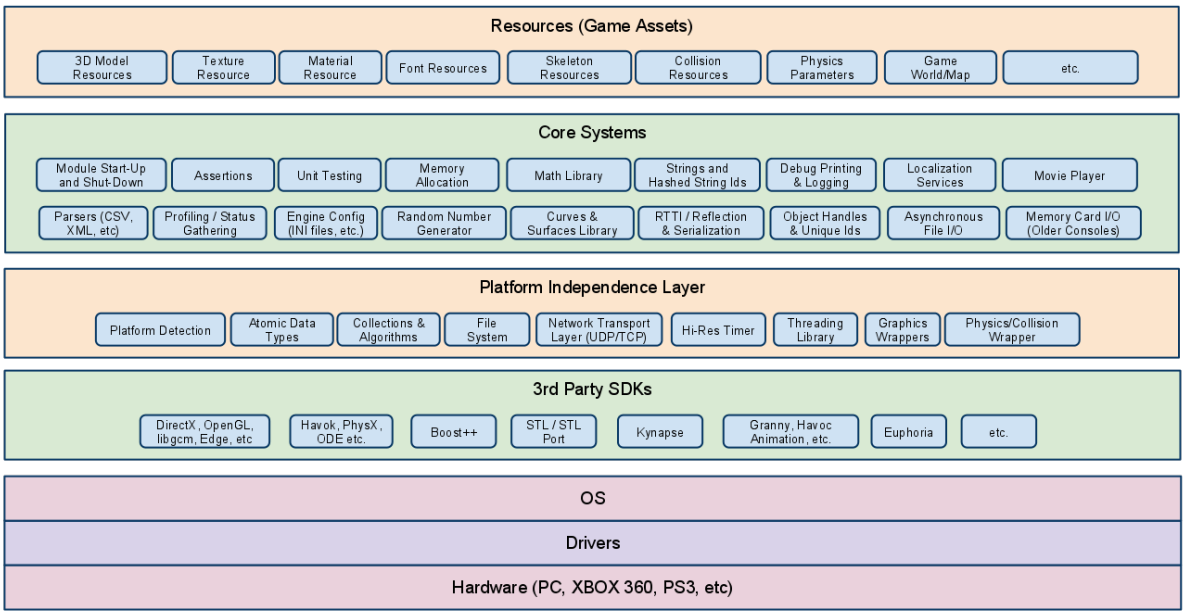
在底層,計算機硬體由處理器、記憶體和I/O元件組成,每種型別有一個或多個模組。這些元件以某種方式互連,以實現計算機的主要功能,即執行程式。有四個主要結構要素:
- 處理器:控制計算機的操作並執行其資料處理功能。當只有一個處理器時,它通常被稱為中央處理單元(CPU)。
- 主記憶體儲器:儲存資料和程式。易丟失,當計算機關閉時,記憶體中的內容會丟失。相反,即使計算機系統關閉,磁碟記憶體的內容也會保留。主記憶體儲器也稱為實記憶體或主記憶體儲器。
- I/O模組:在計算機及其外部環境之間行動資料外部環境由各種裝置組成,包括輔助記憶體裝置(如磁碟)、通訊裝置和終端。
- 系統匯流排:提供處理器、主記憶體儲器和I/O模組之間的通訊。
19.3.2 架構vs組織
計算機架構(Computer Architecture)是對計算機各個部分的需求和設計實現的功能描述,處理計算機系統的功能行為。在設計計算機時,它出現在計算機組織之前。
計算機組織(Computer Organization)出現在計算機體系架構之後,是操作屬性如何連結在一起並有助於實現架構規範的方式,處理的是結構關係。
簡單而言,架構是呈現給軟體設計師的計算機檢視,組織是計算機在硬體上的實際實現。
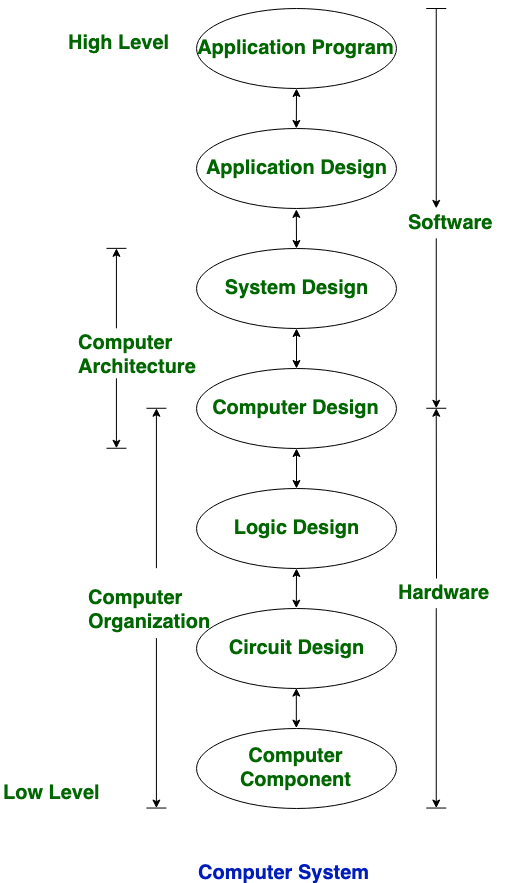
計算機的層級設計、硬體、軟體和架構、組織的關係圖。
數位計算機方框圖。
計算機體系架構和計算機組織之間的詳細區別如下表:
| 計算機架構 | 計算機組織 | |
|---|---|---|
| 1 | 描述計算機的功能。 | 描述計算機是如何做到的。 |
| 2 | 處理計算機的功能行為。 | 處理計算機的結構關係。 |
| 3 | 在上圖,很明顯它處理的是高層級的設計問題。 | 在上圖,也很明顯它處理的是低層級的設計問題。 |
| 4 | 表明硬體。 | 表明效能。 |
| 5 | 作為程式設計師,可以將架構視為一系列指令、定址模式和暫存器。 | 架構的實現稱為組織。 |
| 6 | 對於設計一臺計算機,它的架構是固定的。 | 為了設計一臺計算機,它的組織根據其架構而定。 |
| 7 | 也被稱為指令集架構 (ISA)。 | 通常被稱為微體系架構(microarchitecture)。 |
| 8 | 包括邏輯功能,例如指令集、暫存器、資料型別和定址模式。 | 由電路設計、外圍裝置和加法器等物理單元組成。 |
| 9 | 架構類別:馮諾依曼、Harvard、ISA、系統設計。 | CPU組織根據地址欄位的數量分為三類:單累加器組織、通用暫存器組織、堆疊組織。 |
| 10 | 使計算機的硬體可見。 | 提供了有關計算機效能的詳細資訊。 |
| 11 | 協調系統的硬體和軟體。 | 處理系統中的網路段。 |
| 12 | 軟體開發人員意識到它。 | 它逃脫了軟體程式設計師的檢測。 |
| 13 | 範例:Intel和AMD建立了x86處理器,Sun Microsystems和其他公司建立了SPARC處理器,Apple、IBM和摩托羅拉建立了PowerPC。 | 組織質量包括程式設計師看不到的硬體元素,例如計算機和外圍裝置的介面、記憶體技術和控制訊號。 |
19.3.3 馮·諾伊曼架構
歷史上有兩種型別的計算機:
- 固定程式計算機:它們的功能非常具體,不能重新程式設計,例如計算器。
- 儲存程式計算機:可以被程式設計以執行許多不同的任務,應用程式儲存在它們上面,因此得名。
現代計算機基於John Von Neumann(約翰·馮·諾依曼)引入的儲存程式概念。在這種儲存程式的概念中,程式和資料儲存在稱為記憶體的單獨儲存單元中,並被同等對待,意味著用這種架構構建的計算機將更容易重新程式設計。 其基本結構是這樣的:
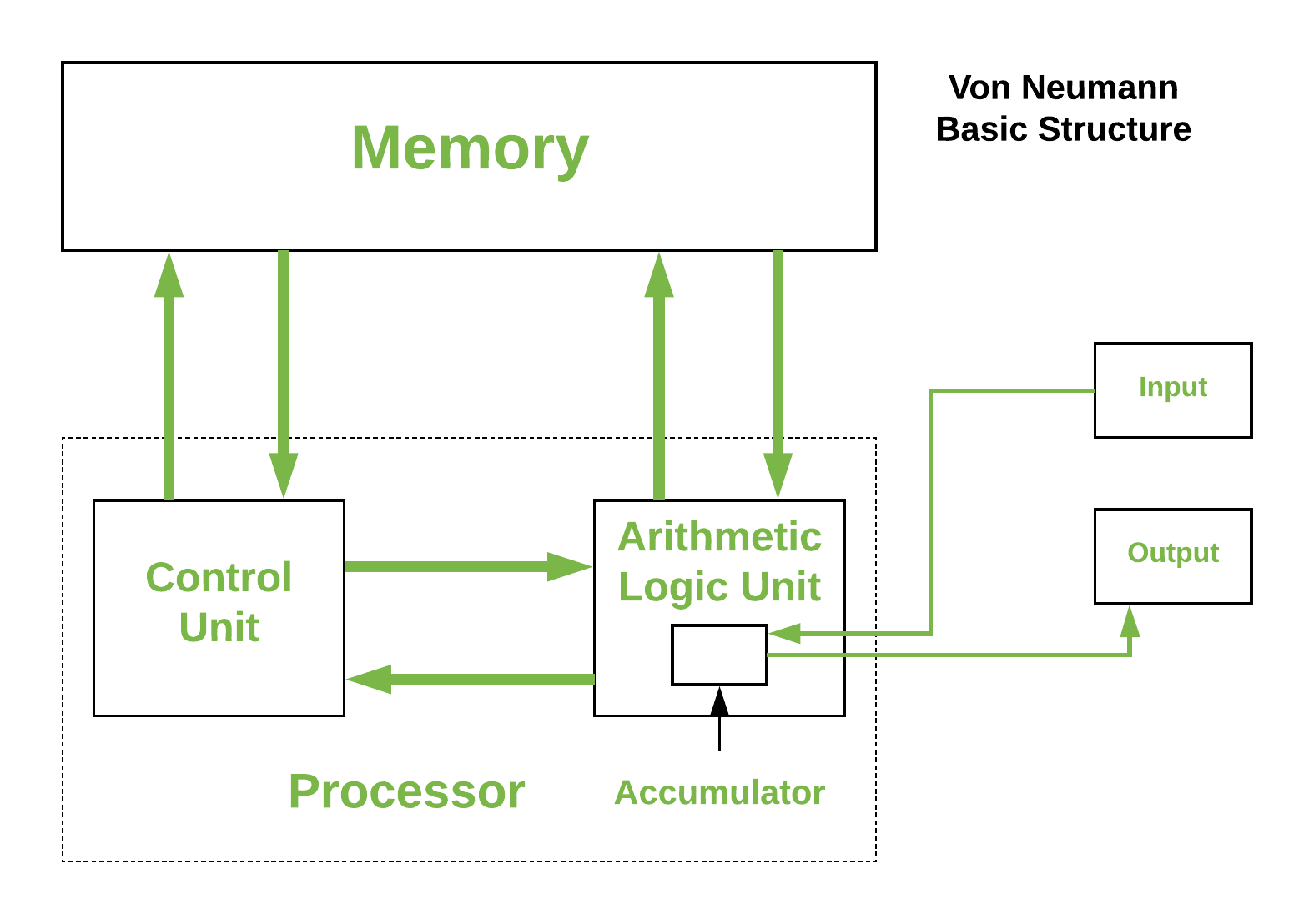
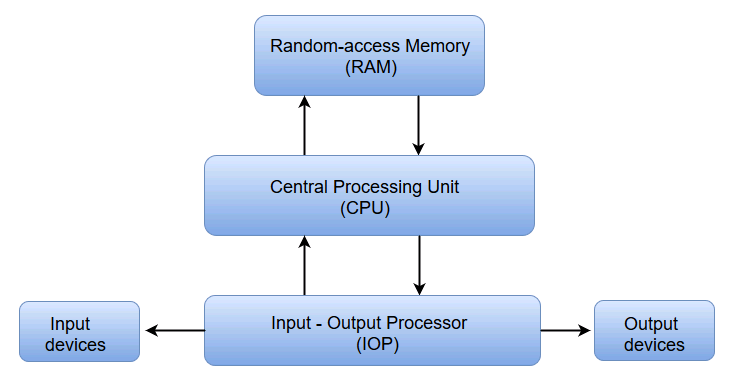
有著輸入、處理、輸出等概念和組成的計算機模型稱為馮·諾伊曼架構,它是一種將程式指令記憶體和資料記憶體合併在一起的電腦設計概念結構,是一種實現通用圖靈機的計算裝置,以及一種相對於平行計算的序列式結構參考模型(referential model)。馮·諾伊曼隱式指導了將儲存裝置與中央處理器分開的概念,也被稱為ISA(指令集架構)計算機。
馮·諾依曼1947年出版的《電子計算儀器問題的規劃和編碼》中的流程圖。
馮·諾依曼結構的抽象組成如下:
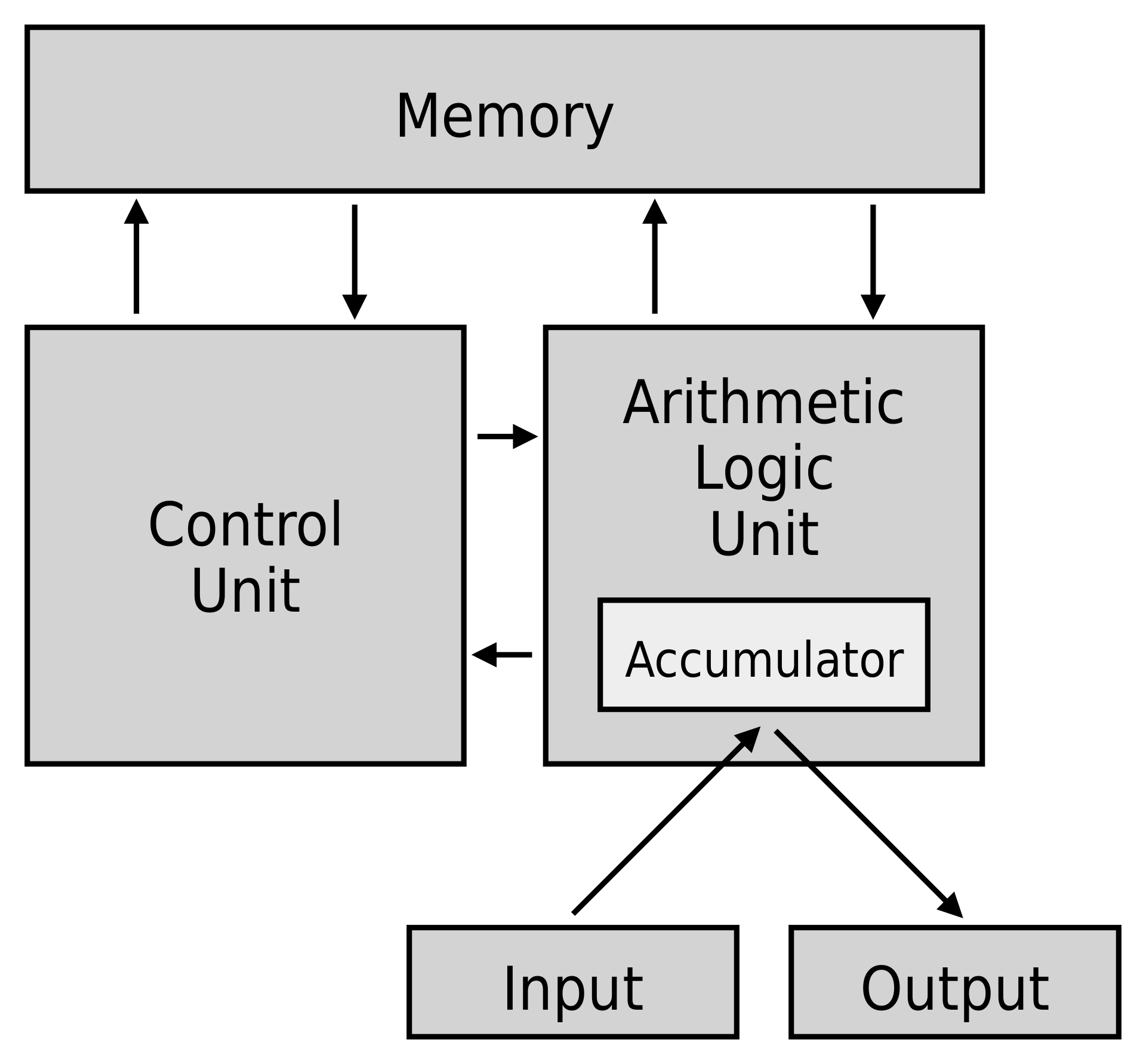
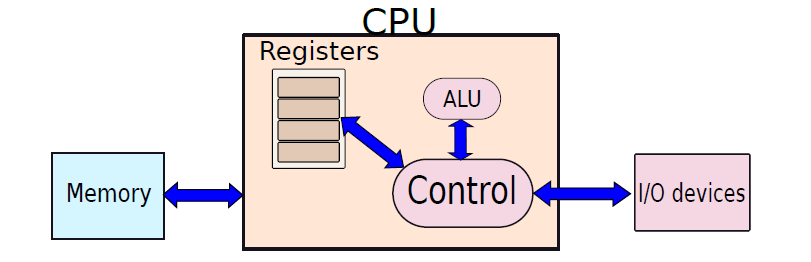
更進一步地,它約定了用二進位制進行計算和儲存,還定義計算機基本結構為5個部分,分別是中央處理器(CPU)、記憶體、輸入裝置、輸出裝置、匯流排。
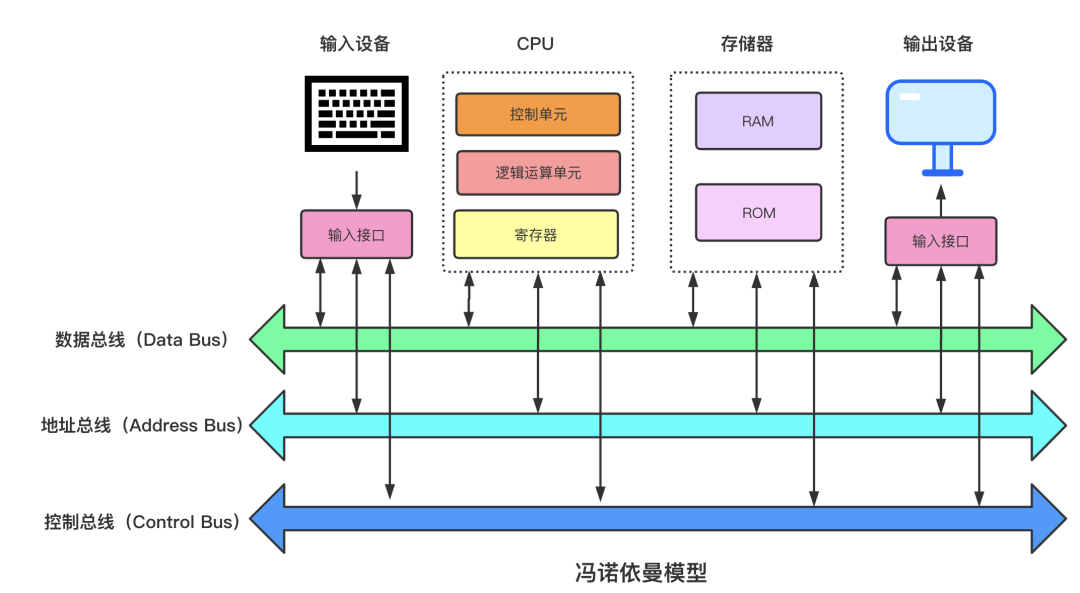
結合上圖,各部分結構的具體描述如下:
-
記憶體:程式碼跟資料在RAM跟ROM中是線性儲存, 資料儲存的單位是一個二進位制位,最小的儲存單位是位元組。
-
匯流排:匯流排是用於 CPU 和記憶體以及其他裝置之間的通訊,匯流排主要有三種:
-
地址匯流排:用於指定 CPU 將要操作的記憶體地址。
-
資料匯流排:用於讀寫記憶體的資料。
-
控制匯流排:用於傳送和接收訊號,比如中斷、裝置復位等訊號,CPU收到訊號後響應,這時也需要控制匯流排。
-
-
輸入/輸出裝置:輸入裝置向計算機輸入資料,計算機經過計算後,把資料輸出給輸出裝置。比如鍵盤按鍵時需要和CPU進行互動,這時就需要用到控制匯流排。
-
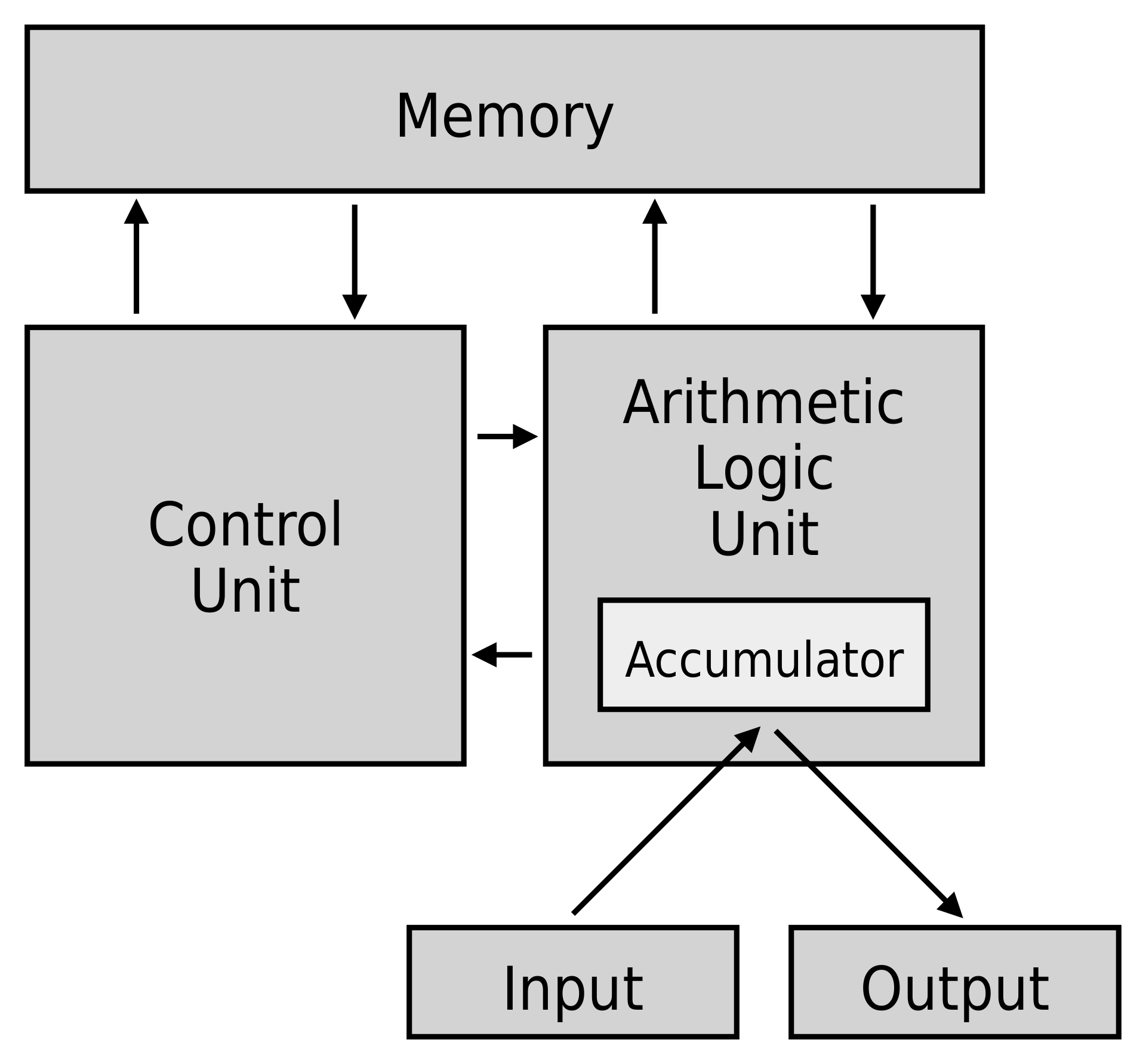
CPU:中央處理器,類比人腦,作為計算機系統的運算和控制核心,是資訊處理、程式執行的最終執行單元。它的結構如下所示:
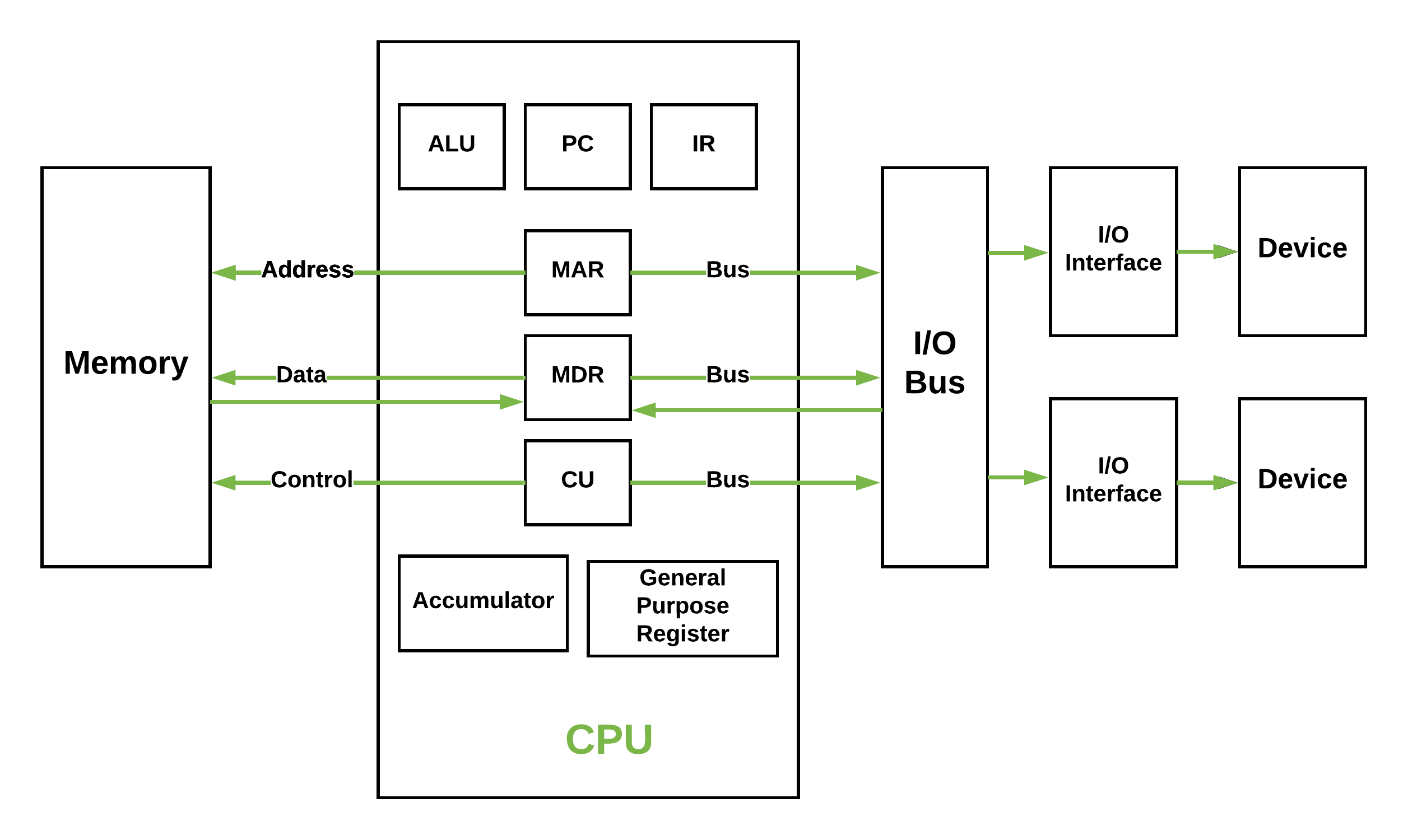
- 控制單元(CU):處理所有處理器控制訊號,指導所有輸入和輸出流,獲取指令程式碼,並控制資料在系統中的移動方式。
- 算術邏輯單元 (ALU) :處理CPU可能需要的所有計算(如加法、減法、比較),執行邏輯運算、位移運算和算術運算。
- 主記憶體儲器單元(暫存器):CPU用暫存器儲存計算時所需資料,暫存器一般有以下幾種:
- 累加器(Accumulator):儲存ALU的計算結果。
- 程式計數器(PC):跟蹤要處理的下一條指令的記憶體位置,然後PC將下一個地址傳遞給記憶體地址暫存器 (MAR)。
- 記憶體地址暫存器(MAR):儲存需要從記憶體中取出或儲存到記憶體中的指令的記憶體位置。
- 記憶體資料暫存器(MDR):儲存從記憶體中獲取的指令或任何要傳輸到記憶體並儲存在記憶體中的資料。
- 指令暫存器(IR):可分為兩種:
- 當前指令暫存器(CIR):在等待編碼和執行時儲存最近獲取的指令。
- 指令緩衝暫存器(IBR):不立即執行的指令放在指令緩衝暫存器IBR中。
- 通用暫存器(GPR):存放需要進行運算的資料,比如需進行加法運算的兩個資料。
在馮諾伊曼體系下計算機指令執行的簡要過程如下:
- CPU讀取程式計數器獲得指令記憶體地址,CPU控制單元操作地址匯流排從記憶體地址拿到資料,資料通過資料匯流排到達CPU被存入指令暫存器。
- CPU分析指令暫存器中的指令,如果是計算型別的指令交給邏輯運算單元,如果是儲存型別的指令交給控制單元執行。
- CPU 執行完指令後程式計數器的值通過自增指向下個指令,比如32位元CPU會自增4。
- 自增後開始順序執行下一條指令,不斷迴圈執行直到程式結束。
馮諾依曼瓶頸(Von Neumann bottleneck)是無論做什麼來提升效能,都無法擺脫這樣一個事實,即一次只能執行一條指令,並且只能按順序執行,這兩個因素都阻礙了CPU的能力。我們可以為馮諾依曼處理器提供更多快取、更多RAM或更快的元件,但如果要在CPU效能方面取得原始收益,則需要對CPU設定進行有影響力的檢查。 這種架構非常重要,用於PC乃至超級計算機。
19.3.4 多核結構
下圖是典型多核計算機主要部件的簡化檢視。大多數計算機,包括智慧手機和平板電腦中的嵌入式計算機,以及個人計算機、筆記型電腦和工作站,都安裝在主機板上。印刷電路板(PCB)是一種剛性的平板,用於固定和互連晶片和其他電子部件,該電路板由通常為兩到十層的層組成,這些層通過蝕刻到電路板中的銅路徑將元件互連。計算機中的主要印刷電路板稱為系統板或主機板,而插入主機板插槽的較小的印刷電路板則稱為擴充套件板。主機板上最突出的元素是晶片,晶片是一塊半導體材料,通常是矽,在其上製造電子電路和邏輯閘,所得產品稱為積體電路。
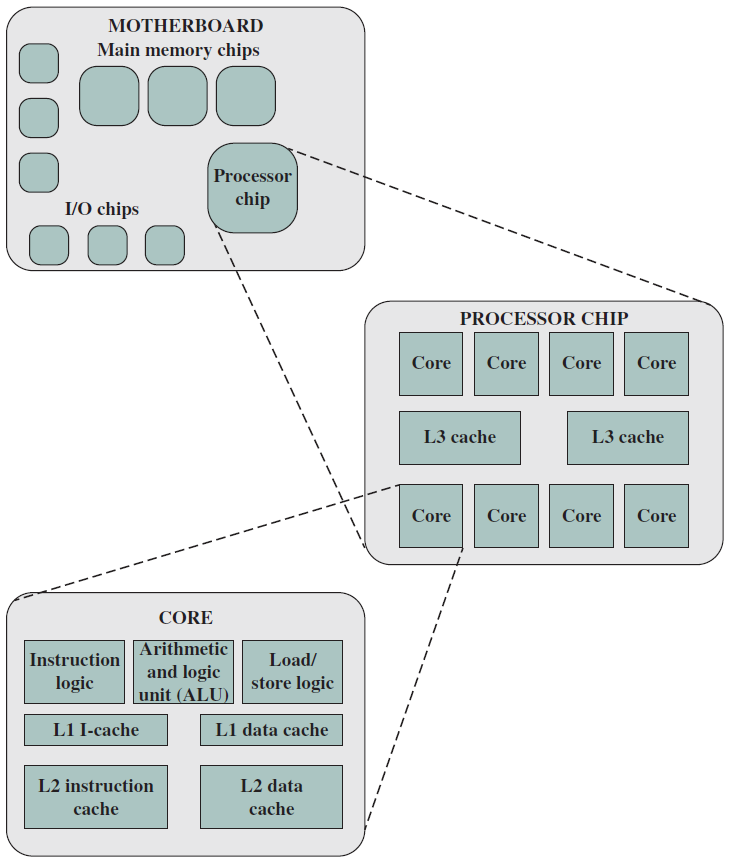
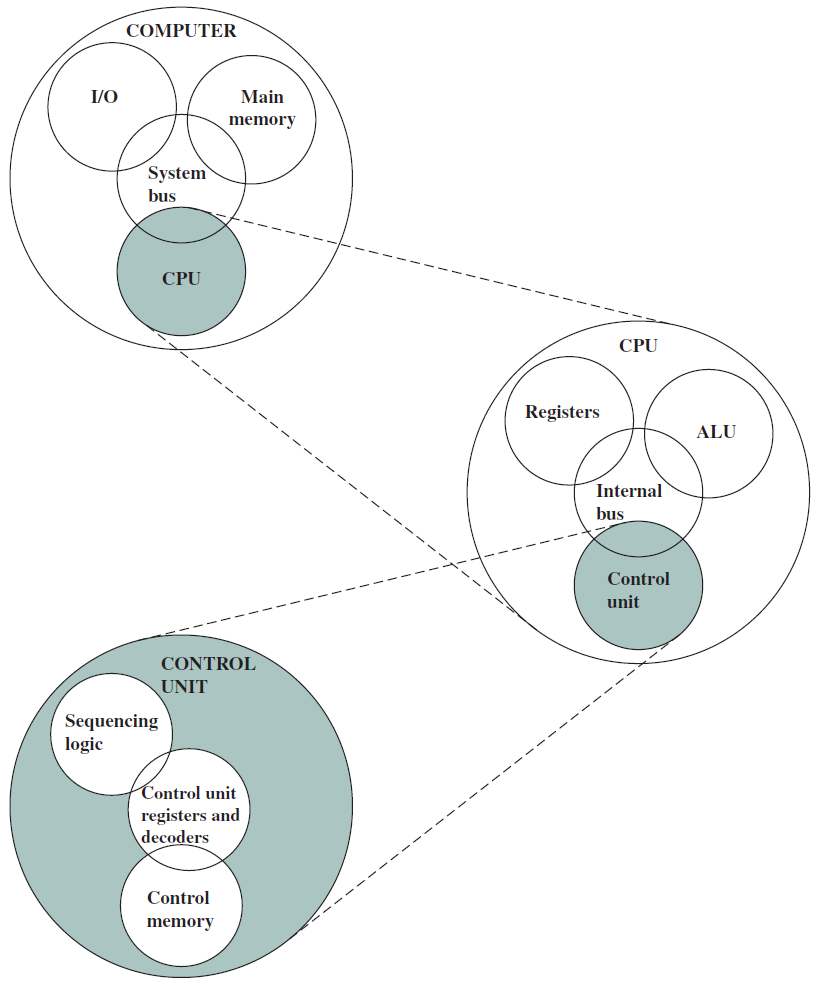
多核計算機主要元件的簡化檢視。
下圖左是IBM zEnterprise EC12大型計算機處理器晶片的照片,有27.5億個電晶體,有六個核心(處理器),還有兩個標記為L3快取的大區域,由所有六個處理器共用,L3控制邏輯控制L3快取記憶體和核心之間以及L3快取記憶體與外部環境之間的流量。此外,在核心和L3快取之間還有儲存控制(SC)邏輯,記憶體控制器(MC)功能控制對晶片外部記憶體的存取,GX I/O匯流排控制存取I/O的通道介面卡的介面。下圖右則展示了單個核的內部結構,只是構成單個處理器晶片的矽表面區域的一部分。
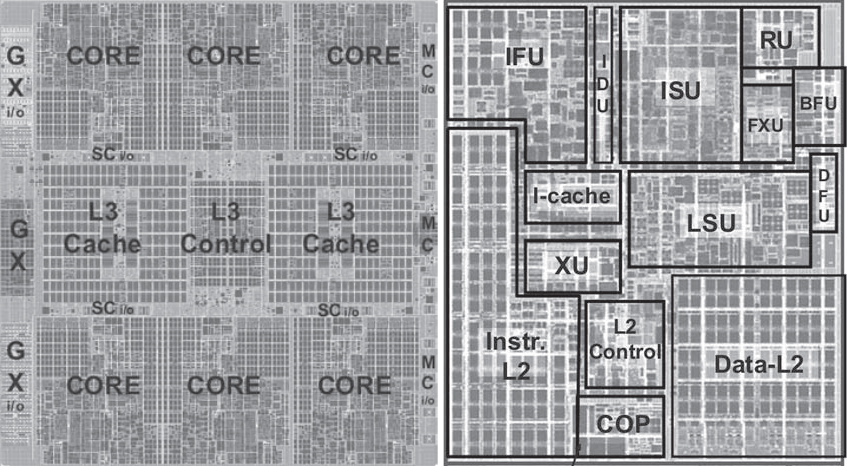
晶片(Wafer)、晶片(Chip)和門(Gate)之間的關係如下:
QPI(QuickPath Interconnect)是Intel於2008年推出的對等互連方法,QPI和其他對等互連方案的重要特徵是多個直接連線、分層協定架構和分組資料傳輸。
下圖說明了QPI在多核計算機上的典型使用。QPI鏈路(由圖中的綠色箭頭對錶示)形成了一個交換結構,使資料能夠在整個網路中移動,可以在每對核心處理器之間建立直接QPI連線。如果圖中的核心A需要存取核心D中的記憶體控制器,則它通過核心B或C傳送請求,後者必須將該請求轉發到核心D的記憶體控制器。同樣,具有八個或更多處理器的大型系統可以使用具有三個鏈路的處理器構建,並通過中間處理器路由流量。
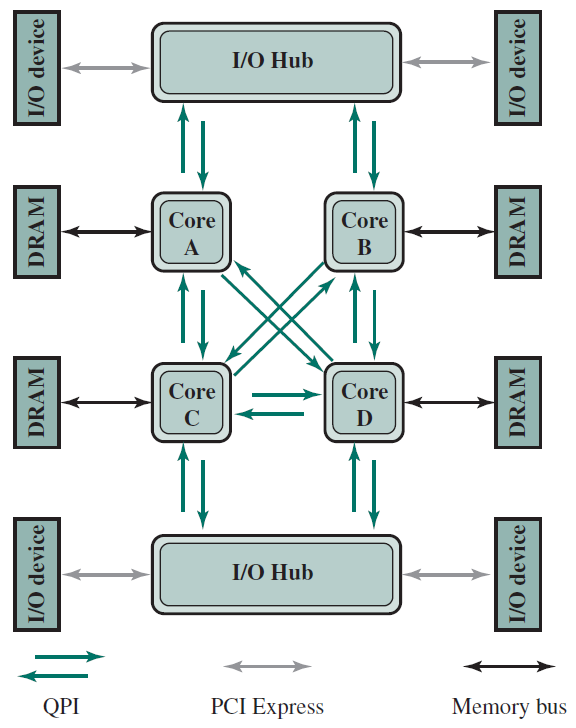
使用QPI的多核設定。
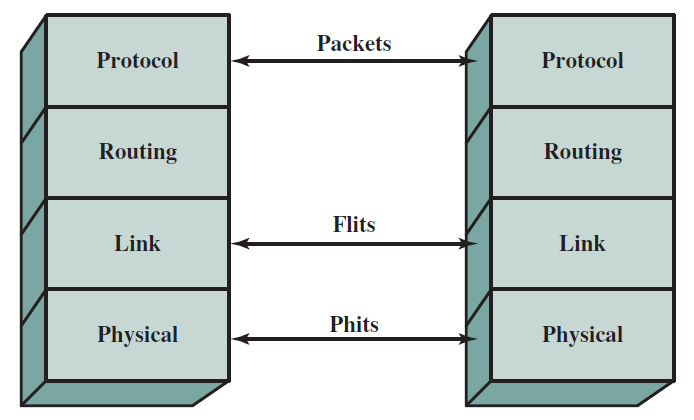
QPI層示意圖。
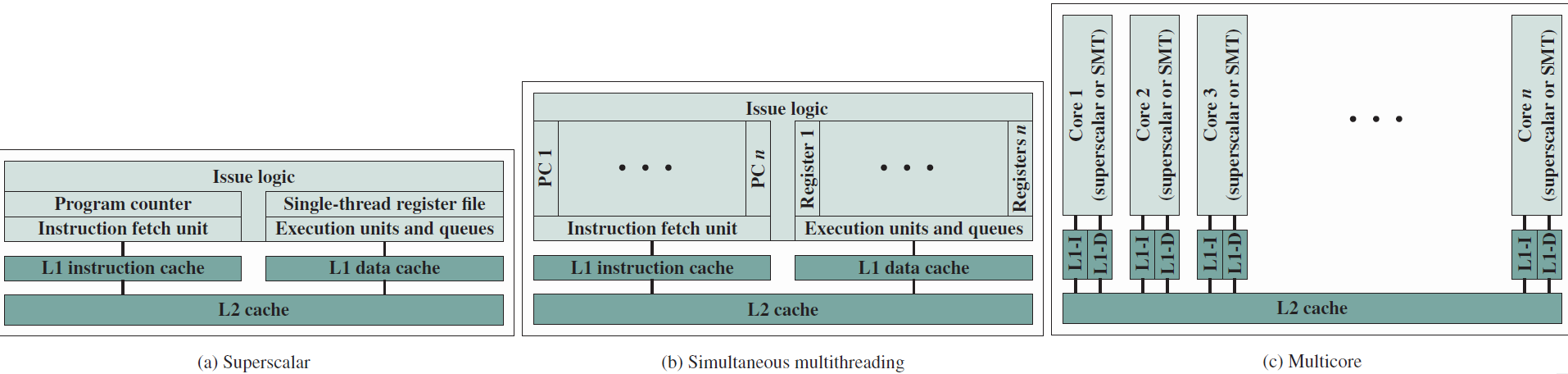
不同的晶片組織。
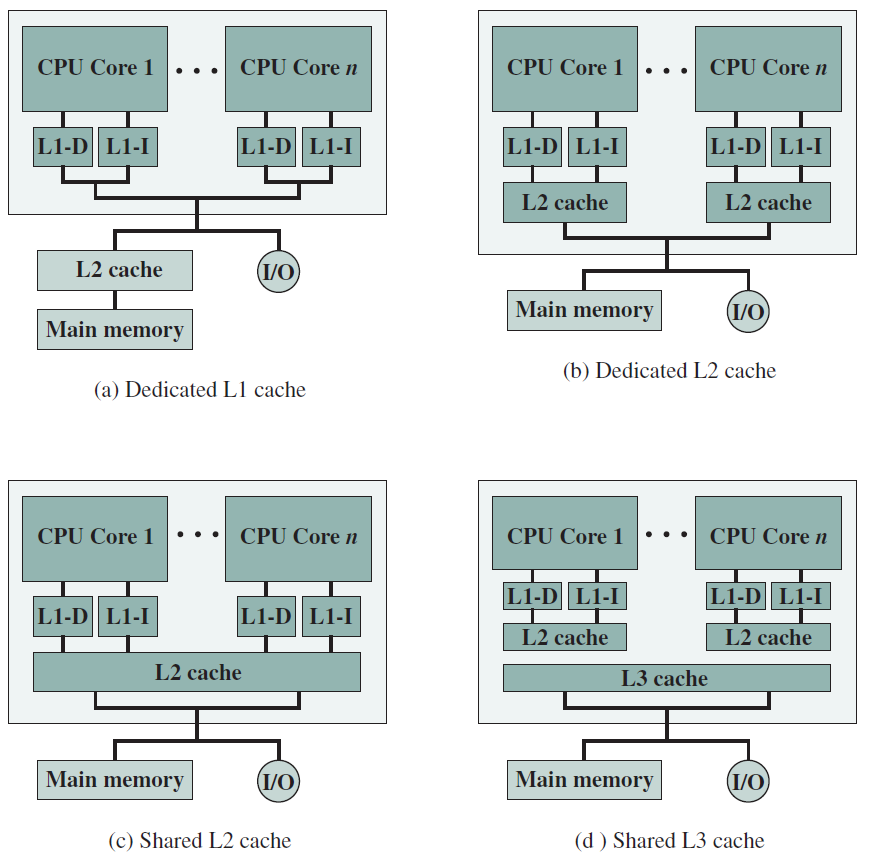
多核組織備選方案。
19.3.5 嵌入式系統
術語嵌入式系統是指在產品中使用電子裝置和軟體,而不是通用計算機,如平板電腦或桌上型電腦系統。每年售出數百萬臺電腦,包括筆記型電腦、個人電腦、工作站、伺服器、大型電腦和超級計算機,相比之下,每年生產數十億個嵌入大型裝置的計算機系統。如今,許多(也許是大多數)使用電力的裝置都有嵌入式計算系統,在不久的將來,幾乎所有這樣的裝置都將具有嵌入式計算系統。
具有嵌入式系統的裝置型別幾乎太多,無法列出,樣例包括手機、數碼相機、攝像機、計算器、微波爐、家庭安全系統、洗衣機、照明系統、恆溫器、印表機、各種汽車系統(如變速器控制、巡航控制、燃油噴射、防抱死制動和懸掛系統)、網球拍、牙刷以及自動化系統中的多種型別的感測器和致動器。
通常,嵌入式系統與其環境緊密耦合,導致與環境互動的需要所施加的實時約束。約束條件(如所需的運動速度、所需的測量精度和所需的持續時間)決定了軟體操作的時間,如果必須同時管理多個活動,會帶來更復雜的實時約束。
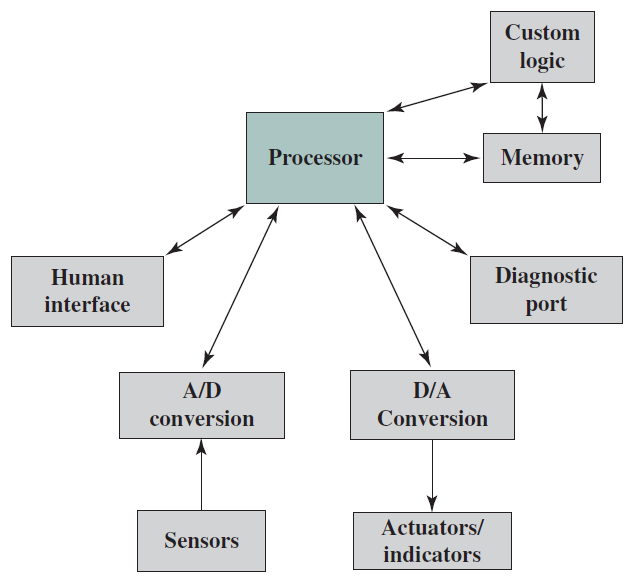
下圖概括地顯示了嵌入式系統組織,除了處理器和記憶體之外,還有許多元素與典型的桌上型電腦或筆記型電腦不同:
嵌入式系統的可能組織。
- 可能存在多種介面,使系統能夠測量、操作和以其他方式與外部環境互動。嵌入式系統通常通過感測器和致動器與外部世界互動(感知、操縱和通訊),因此通常是反應系統,反應系統與環境持續互動,並以該環境確定的速度執行。
- 人機介面可以像閃光燈一樣簡單,也可以像實時機器人視覺一樣複雜。在許多情況下,沒有人機介面。
- 診斷埠可用於診斷所控制的系統,而不僅僅用於診斷計算機。
- 可使用專用現場可程式化(FPGA)、專用(ASIC)或甚至非數位硬體來提高效能或可靠性。
- 軟體通常具有固定的功能,並且特定於應用程式。
- 效率對於嵌入式系統至關重要。需針對能量、程式碼尺寸、執行時間、重量、體積以及成本進行了優化。
與通用計算機系統也有幾個值得注意的相似之處:
- 即使使用名義上固定功能的軟體,現場升級以修復錯誤、提高安全性和新增功能的能力對於嵌入式系統來說也變得非常重要,而不僅僅是在消費類裝置中。
- 一個相對較新的發展是支援多種應用的嵌入式系統平臺,良好例子是智慧手機和音訊/視訊裝置(如智慧電視)。
19.3.5.1 微處理器與微控制器
早期的微處理器晶片包括暫存器、ALU和某種控制單元或指令處理邏輯。隨著電晶體密度的增加,有可能增加指令集架構的複雜性,最終增加記憶體和多個處理器,現代微處理器晶片包括多個核心和大量的快取記憶體。
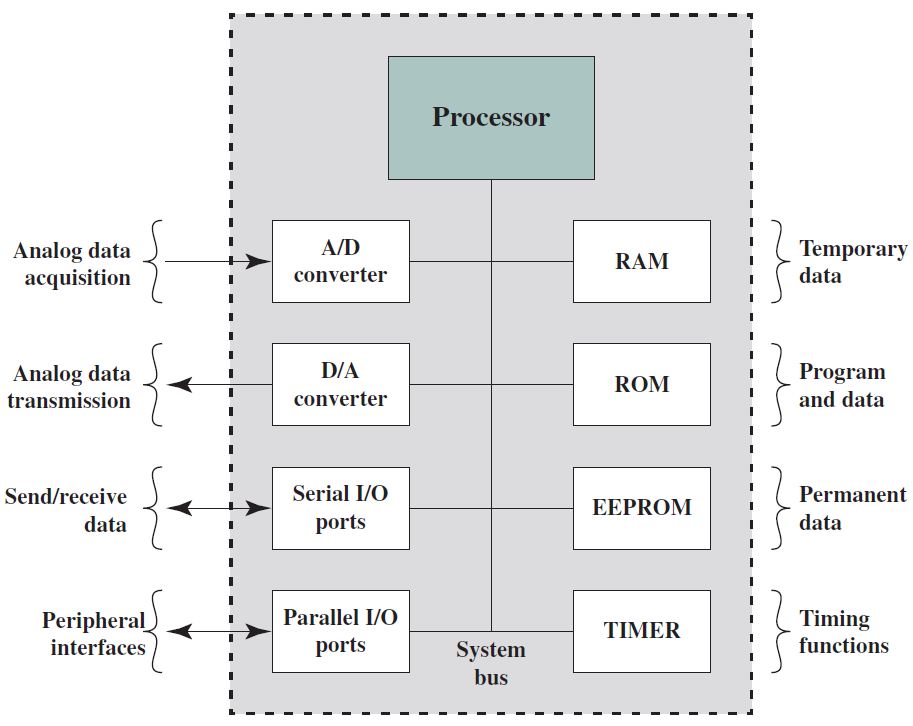
微控制器晶片對可用的邏輯空間進行了實質上不同的使用,下圖概括地顯示了微控制器晶片上常見的元件。微控制器是包含處理器、用於程式的非易失性記憶體(ROM)、用於輸入和輸出的易失性記憶體(RAM)、時鐘和I/O控制單元的單個晶片。微控制器的處理器部分具有比其他微處理器低得多的矽面積和高得多的能量效率。
也被稱為「晶片上的計算機」,每年數十億個微控制器單元被嵌入到從玩具到家電到汽車的各種產品中,比如單個車輛可以使用70個或更多個微控制器。通常,特別是對於更小、更便宜的微控制器,它們被用作特定任務的專用處理器,比如微控制器在自動化過程中被大量使用。通過提供對輸入的簡單反應,它們可以控制機器、開啟和關閉風扇、開啟和閉合閥門等,是現代工業技術的組成部分,是生產能夠處理極其複雜功能的機械的最廉價的方法之一。
微控制器具有多種物理尺寸和處理能力,處理器的範圍從4位元到32位元架構。微控制器往往比微處理器慢得多,通常工作在MHz範圍,而不是微處理器的GHz速度。微控制器的另一個典型特徵是它不提供人機互動,被程式設計用於特定任務,嵌入其裝置中,並在需要時執行。
19.3.5.2 嵌入式與深度嵌入式系統
嵌入式系統的一個子集,以及相當多的子集,被稱為深度嵌入式系統(Deeply embedded system)。儘管這個術語在技術和商業文獻中被廣泛使用,但你會在網際網路上無法明確地尋找一個直截了當的定義。通常,我們可以說,一個深度嵌入式系統有一個處理器,其行為很難被程式設計師和使用者觀察到。深度嵌入式系統使用微控制器而不是微處理器,一旦裝置的程式邏輯被燒錄到ROM(唯讀記憶體)中,就不可程式化,並且與使用者沒有互動。
深度嵌入式系統是專用的、單用途的裝置,可以檢測環境中的某些東西,執行基本級別的處理,然後對結果進行處理。深度嵌入式系統通常具有無線能力,並以聯網設定出現,例如部署在大面積(例如,工廠、農業領域)上的感測器網路,物聯網在很大程度上依賴於深度嵌入式系統。典型地,深度嵌入式系統在記憶體、處理器大小、時間和功耗方面具有極端的資源限制。
19.3.6 ARM架構
ARM架構是指從RISC設計原則演變而來的處理器架構,用於嵌入式系統。本節將簡述之。
ARM指令集是高度規則的,旨在高效實現處理器和高效執行。所有指令均為32位元長,遵循常規格式,使得ARM ISA適合在廣泛的產品上實現。
增強基本ARM ISA的是Thumb指令集,是ARM指令集的重新編碼子集。Thumb旨在提高使用16位元或更窄記憶體資料匯流排的ARM實現的效能,並允許比ARM指令集提供的程式碼密度更好的程式碼密度。Thumb指令集包含記錄為16位元指令的ARM 32位元指令集的子集。前些年定義的版本是Thumb-2。
ARM Holdings許可了許多專用微處理器和相關技術,但其產品線的大部分是Cortex系列微處理器架構。有三種Cortex架構,方便地用縮寫A、R和M標記。
-
Cortex-A和Cortex-A50:是應用處理器,適用於智慧手機和電子書閱讀器等移動裝置,以及數位電視和家庭閘道器(如DSL和有線網際網路資料機)等消費裝置。這些處理器以更高的時脈頻率(超過1GHz)執行,並支援記憶體管理單元(MMU),是全功能作業系統(如Linux、Android、MS Windows和行動作業系統)所需的。MMU是通過將虛擬地址轉換為實體地址來支援虛擬記憶體和分頁的硬體模組。這兩種架構同時使用ARM和Thumb-2指令集,主要區別在於Cortex-A是32位元機器,而Cortex-A50是64位元機器。
-
Cortex-R:設計用於支援實時應用程式,其中需要通過對事件的快速響應來控制事件的定時。它們可以在相當高的時脈頻率(例如200MHz到800MHz)下執行,並且具有非常低的響應延遲。Cortex-R包括對指令集和處理器組織的增強,以支援深度嵌入式實時裝置。這些處理器中的大多數沒有MMU,有限的資料需求和有限數量的同時處理消除了對虛擬記憶體的複雜硬體和軟體支援的需求。Cortex-R確實具有專為工業應用設計的記憶體保護單元(MPU)、快取和其他記憶體功能。MPU是一種硬體模組,它禁止記憶體中的一個程式意外存取分配給另一個活動程式的記憶體。使用各種方法,在程式周圍建立一個保護邊界,並且禁止程式內的指令參照該邊界之外的資料。使用Cortex-R的嵌入式系統包括汽車制動系統、大容量儲存控制器、網路和列印裝置。
-
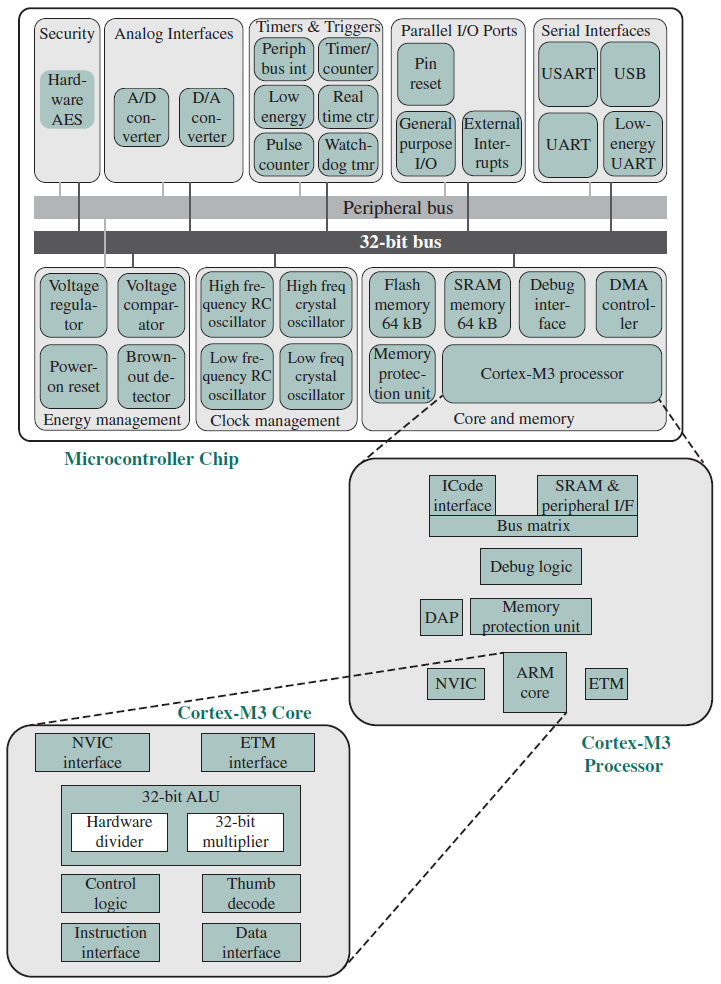
Cortex-M:主要是為微控制器領域開發的,在微控制器領域,快速、高確定性中斷管理的需求與極低門計數和最低可能功耗的需求相結合。與Cortex-R系列一樣,Cortex-M架構有一個MPU,但沒有MMU。Cortex-M僅使用Thumb-2指令集,其市場包括物聯網裝置、工廠和其他企業使用的無線感測器/致動器網路、汽車車身電子裝置等。Cortex-M系列包含Cortex-M0、Cortex-M0+、Cortex-M3、Cortex-M4等版本。下圖是基於Cortex-M3的典型微控制器晶片:
19.3.7 雲端計算
儘管雲端計算的一般概念可以追溯到20世紀50年代,但云端計算服務在2000年代初首次出現,尤其是針對大型企業。從那時起,雲端計算已經擴充套件到中小型企業,最近還擴充套件到了消費者。蘋果的iCloud於2012年推出,在推出一週內就擁有2000萬用戶,2008年推出的基於雲的筆記和歸檔服務Evernote在不到6年的時間內就接近了1億使用者。本節將簡要概述。
在許多組織中,越來越突出的趨勢是將大部分甚至所有資訊科技(IT)運營轉移到稱為企業雲端計算的網際網路連線基礎設施。與此同時,個人電腦和移動裝置的個人使用者越來越依賴雲端計算服務來備份資料、同步裝置和使用個人雲端計算進行共用。NIST在NIST SP-800-145(NIST雲端計算定義)中對雲端計算的定義如下:
雲端計算(Cloud computing):是一種模型,用於實現對可設定計算資源(例如,網路、伺服器、儲存、應用程式和服務)的共用池的無處不在、方便的按需網路存取,這些資源可以通過最小的管理工作量或服務提供商互動快速調配和釋出。
基本上,通過雲端計算,可以獲得規模經濟、專業網路管理和專業安全管理,這些功能對大小公司、政府機構以及個人電腦和移動使用者都有吸引力。個人或公司只需支付所需的儲存容量和服務費用,無論是公司還是個人,使用者都無需設定資料庫系統、獲取所需的硬體、進行維護和備份資料,所有這些都是雲服務的一部分。
理論上,使用雲端計算儲存資料並與其他人共用資料的另一大優勢是雲提供商負責安全。客戶並不總是受到保護,雲提供商之間出現了許多安全故障,例如Evernote在2013年初成為頭條新聞,當時它告訴所有使用者在發現入侵後重置密碼。
雲網路是指必須具備的網路和網路管理功能,以支援雲端計算。大多數雲端計算解決方案都依賴於網際網路,但這只是網路基礎設施的一部分。雲網路的一個範例是在提供商和訂戶之間提供高效能和/或高可靠性網路,在這種情況下,企業和雲之間的部分或全部流量繞過網際網路,使用雲服務提供商擁有或租用的專用專用網路設施。更一般地說,雲聯網是指存取雲所需的網路能力的集合,包括利用網際網路上的專門服務、將企業資料中心連結到雲,以及在關鍵點使用防火牆和其他網路安全裝置來強制執行存取安全政策。
我們可以將雲端儲存視為雲端計算的一個子集,本質上,雲端儲存由遠端託管在雲伺服器上的資料庫儲存和資料庫應用程式組成,使小型企業和個人使用者能夠利用可根據其需求擴充套件的資料儲存,並利用各種資料庫應用程式,而無需購買、維護和管理儲存資產。
雲端計算的基本目的是提供方便的計算資源租賃,雲服務提供商(CSP)維護通過網際網路或專用網路可用的計算和資料儲存資源,客戶可以根據需要租用這些資源的一部分。實際上,所有云服務都是使用三種模型之一提供的(下圖):SaaS、PaaS和IaaS。
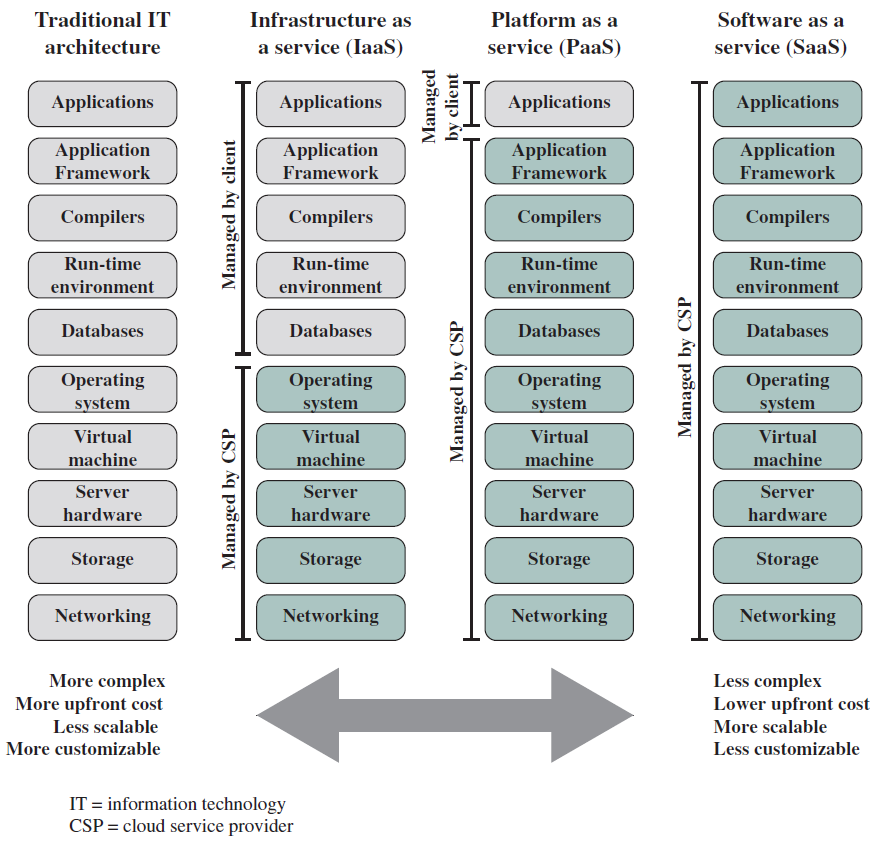
替代資訊科技架構。
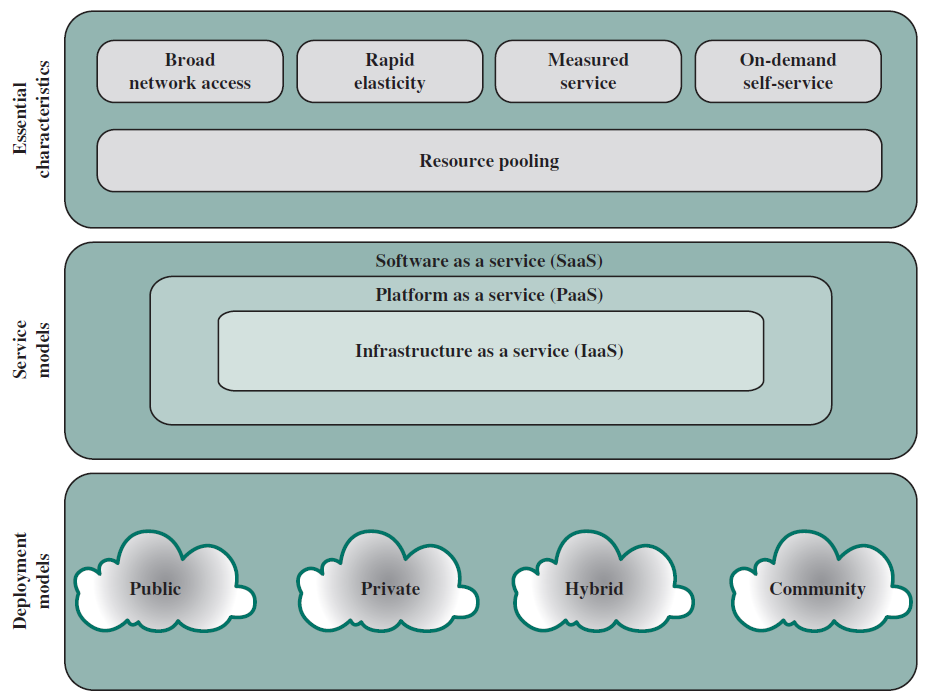
雲端計算元素。
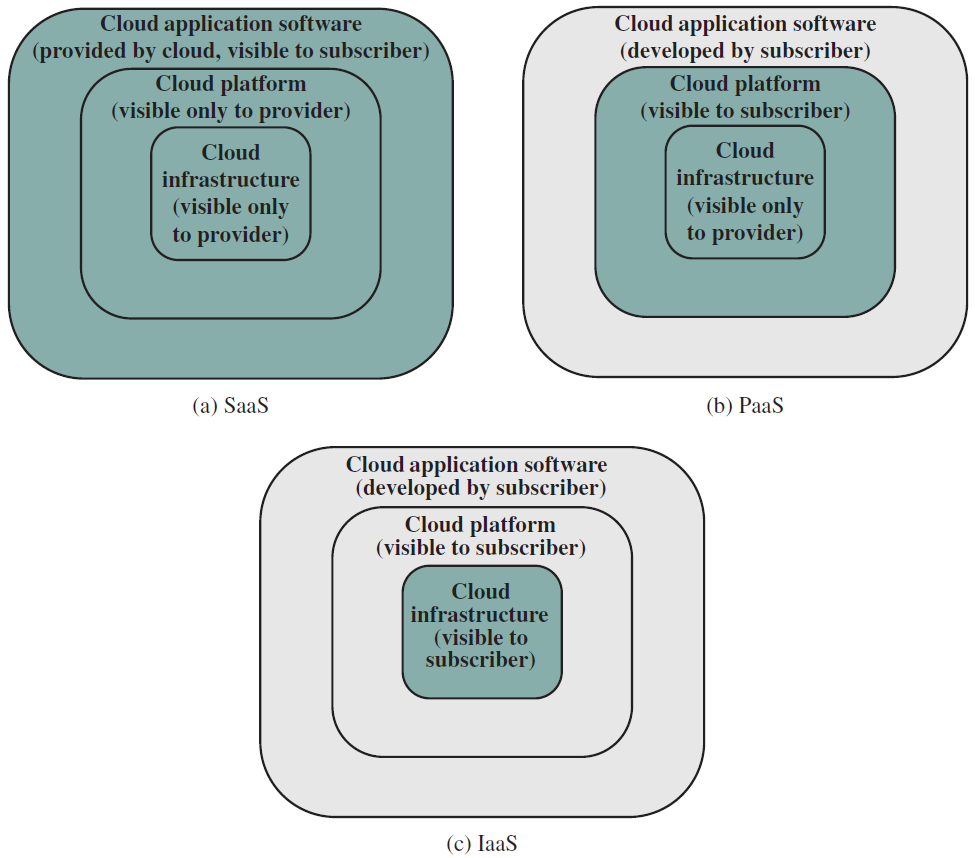
雲服務模型。
19.4 ISA
19.4.1 ISA定義
就像任何語言都有有限的單詞一樣,處理器可以支援的基本指令/基本命令的數量也必須是有限的,這組指令通常稱為指令集(instruction set),基本指令的一些範例是加法、減法、乘法、邏輯或和邏輯非。請注意,每條指令需要處理一組變數和常數,最後將結果儲存在變數中,這些變數不是程式設計師定義的變數,是計算機內的內部位置。我們將指令集架構定義為:
指令集架構(instruction set architecture,ISA)是處理器支援的所有指令的語意,包括指令本身及其運算元的語意,以及與外圍裝置的介面。
指令集架構是軟體感知硬體的方式,我們可以將其視為硬體輸出到外部世界的基本功能列表。Intel和AMD CPU使用x86指令集,IBM處理器使用PowerPC R指令集,HP處理器使用PA-RISC指令集,ARM處理器使用ARMR指令集(或其變體,如Thumb-1和Thumb-2)。因此,不可能在基於ARM的系統上執行為Intel系統編譯的二進位制檔案,因為指令集不相容,但在大多數情況下,可以重用C/C++程式。要在特定架構上執行C/C++程式,我們需要為該特定架構購買一個編譯器,然後適當地編譯C/C++程式。
19.4.2 基礎指令
基本計算機具有16位元指令暫存器 (IR),可以表示記憶體參照或暫存器參照或輸入輸出指令。一種簡單的指令格式可以是如下形式:

基礎指令可分為以下幾類:
- 記憶體參照
這些指令將記憶體地址稱為運算元,另一個運算元總是累加器。下圖為直接和間接定址指定12位元地址、3位元運算碼(111除外)和1位定址模式。

範例:IR暫存器內容是0001XXXXXXXXXXXX,即ADD指令取指譯碼後發現是ADD操作的記憶體參照指令,因此:
DR ← M[AR]
AC ← AC + DR, SC ← 0
- 暫存器參照
這些指令對暫存器而不是記憶體地址執行操作。下圖的IR(14 – 12) 為 111(將其與記憶體參照區分開),IR(15) 為 0(將其與輸入/輸出指令區分開),其餘12位元指定暫存器操作。

範例:IR暫存器內容是0111001000000000,即CMA在取指和解碼週期後發現它是二補數累加器的暫存器參照指令,因此:
AC ← ~AC
- 輸入/輸出
這些指令用於計算機和外部環境之間的通訊。下圖的IR(14 – 12) 為 111(將其與記憶體參照區分開來),IR(15) 為 1(將其與暫存器參照指令區分開),其餘 12 位指定 I/O 操作。

範例:IR暫存器內容是1111100000000000,即INP經過取指和解碼迴圈後發現它是用於輸入字元的輸入/輸出指令。因此,來自外圍裝置的INPUT字元。
包含在16位元IR暫存器中的指令集是:
- 算術、邏輯和移位指令(與、加、補、左迴圈、右迴圈等)。
- 將資訊移入和移出記憶體(儲存累加器,載入累加器)。
- 帶有狀態條件的程式控制指令(分支、跳過)。
- 輸入輸出指令(輸入字元、輸出字元)。
指令具體的描述如下表:
| 符號 | 16進位制碼 | 描述 |
|---|---|---|
| AND | 0xxx、8xxx | 與任意字到AC |
| ADD | 1xxx、9xxx | 累加任意字到AC |
| LDA | 2xxx、Axxx | 載入記憶體字到AC |
| STA | 3xxx、Bxxx | 儲存AC字到記憶體 |
| BUN | 4xxx、Cxxx | 無條件分支 |
| BSA | 5xxx、Dxxx | 分支並儲存返回地址 |
| ISZ | 6xxx、Exxx | 如果為0,則遞增並跳過 |
| CLA | 7800 | 清理AC |
| CLE | 7400 | 清除E(溢位位) |
| CMA | 7200 | 補充AC |
| CME | 7100 | 補充E |
| CIR | 7080 | 右迴圈AC和E |
| CIL | 7040 | 左迴圈AC和E |
| INC | 7020 | 遞增AC |
| SPA | 7010 | 如果AC>0,跳過下一條指令 |
| SNA | 7008 | 如果AC<0,跳過下一條指令 |
| SZA | 7004 | 如果AC=0,跳過下一條指令 |
| SZE | 7002 | 如果E=0,跳過下一條指令 |
| HLT | 7001 | 停止計算機 |
| INP | F800 | 輸入字元到AC |
| OUT | F400 | 輸出字元到AC |
| SKI | F200 | 跳過輸入標誌 |
| SKO | F100 | 跳過輸出標誌 |
| ION | F080 | 中斷開啟 |
| IOF | F040 | 中斷關閉 |
19.4.3 指令集設計準則
現在讓我們開始為處理器設計指令集的艱難過程,可以將指令集視為軟體和硬體之間的法律合同,雙方都需要履行各自的合同。軟體部分需要確保使用者編寫的所有程式都能成功有效地轉譯成基本指令,同樣,硬體需要確保指令集中的所有指令都是有效實現的。雙方都需要做出合理的假設,ISA需要具有一些必要的特性和一些有效性所需的特性。
-
完整。ISA應能夠實現所有使用者程式,是絕對必要的要求,我們希望ISA能夠代表使用者為其編寫的所有程式。例如,如果我們有一個ISA,只有一條ADD指令,那麼我們將無法減去兩個數位。為了實現迴圈,ISA應該有一些方法來一遍遍地重新執行同一段程式碼。如果沒有這種對和while迴圈的支援,C程式中的迴圈將無法運作。
請注意,對於通用處理器,我們正在檢視所有可能的程式。然而,許多用於嵌入式裝置的處理器功能有限,例如執行字串處理的簡單處理器不需要支援模擬點數(帶小數點的數位)。我們需要注意的是,不同的處理器被設計用於做不同的事情,因此它們的ISA可能不同。然而,底線是任何ISA都應該是完整的,因為它應該能夠用機器程式碼錶達使用者打算為其編寫的所有程式。
-
簡明。指令集的有限大小,最好不要有太多的指示。實現一條指令需要相當多的硬體,執行大量指令將不必要地增加處理器中電晶體的數量並增加其複雜性。因此,大多數指令集都有64到1000條指令。例如,MIPS指令集包含64條指令,而截至2012年,Intel x86指令集大約有1000條指令。請注意,對於ISA中的指令數量,1000條被認為是相當大的數位。
-
通用。指令應捕獲通用案例,程式中的大多數常見指令都是簡單的算術指令,如加法、減法、乘法、除法。最常見的邏輯指令是邏輯和、或、互斥或、和非。因此,為這些常見操作中的每一個指定一條指令是有意義的。
很少使用的計算的指令不是一個好主意。例如,實現計算\(\sin^{-1}(x)\)的指令可能沒有意義,可以提供使用現有的數學技術(如泰勒級數展開)實現的專用庫函數來計算\(\sin^{-1}(x)\)。由於大多數程式很少使用此函數,因此如果此函數執行時間相對較長,它們不會受到不利影響。
-
簡單。指令應該儘量簡單。假設有很多新增數位序列的程式,為了設計專門針對此類程式客製化的處理器,我們有幾個關於add指令的選項。我們可以實現一條將兩個數位相加的指令,也可以實現一個可以獲取運算元列表並生成列表和的指令。這裡的複雜性顯然存在差異,不能說哪種實現更快。前一種方法要求編譯器生成更多指令,但是,每個新增操作都執行得很快。後一種方法生成的指令數量更少,但是,每條指令執行的時間更長。前一種型別的ISA稱為精簡指令集(Reduced Instruction Set),後一種ISA稱為複雜指令集(Complex Instruction Set)。
精簡指令集計算機(reduced instruction set computer,RISC)實現具有簡單規則結構的簡單指令,指令的數量通常很小(64到128)。範例:ARM、IBM PowerPC、HP PA-RISC。
複雜指令集計算機(complex instruction set computer,CISC)實現高度不規則的複雜指令,採用多個運算元,並實現複雜功能。其次,指令的數量很大(通常為500+)。範例:Intel x86、VAX。
直到90年代末,RISC與CISC的爭論一直是一個非常有爭議的問題。然而,從那時起,設計師、程式設計師和處理器供應商一直傾向於RISC設計風格,共識似乎是採用少量相對簡單的、具有規則結構和格式的指令。值得注意的是,這一點仍有爭議,因為CISC指令有時更適合某些型別的應用。現代處理器通常使用混合方法,其中既有簡單的指令,也有一些複雜的指令。然而,在底層,CISC指令被轉譯成RISC指令。因此,我們認為行業稍微偏向RISC指令,認為有簡單的指示是一種可取的特性。
ISA需要完整、簡潔、通用和簡單,且必須完整,而其餘屬性是可取的(但附有爭議)。
19.4.4 圖靈機和指令完整性
如何驗證ISA的完整性?這是一個非常有趣、困難且理論上深刻的問題。確定給定ISA對於給定程式集是否完整的問題是一個相當困難的問題,一般情況要有趣得多。我們需要回答這個問題:給定ISA,它能代表所有可能的程式嗎?
假設有一個ISA,其中包含基本的加法和乘法指令,我們能用這個ISA執行所有可能的程式嗎?答案是否定的,因為我們不能用現有的基本指令減去兩個數位。如果我們將減法指令新增到指令庫中,我們可以計算一個數的平方根嗎?即使我們可以,是否可以保證我們可以進行所有型別的計算?要回答這些令人煩惱的問題,我們需要首先設計一臺通用機器。
通用機器(universal machine)是可以執行任何程式的機器。
它是一臺可以執行所有程式的機器,可以把這臺機器的每一個基本動作都當作一條指令。通用機器的一組動作就是它的ISA,而這個ISA是完整的。當說ISA是完整的時,相當於說可以專門基於給定的ISA構建通用機器,可以通過解決通用機器的設計問題來解決ISA的完整性問題。它們是雙重問題,就通用機器而言,推理更容易。
20世紀初,電腦科學家開始思考通用機器的設計,他們想知道什麼是可計算的,什麼不是,以及不同類別機器的能力。其次,能夠計算所有可能程式結果的理論機器的形式是什麼?電腦科學的這些基本結果構成了當今現代電腦架構的基礎。
阿蘭·圖靈(Alan Turing)是第一個提出一種極其簡單和強大的通用機器的人,這臺機器恰如其分地以他的名字命名,被稱為圖靈機器(Turing machine)。這只是一個理論實體,通常用作數學推理工具,可以建立圖靈機的硬體實現,然而極為困難,並且需要不成比例的資源。儘管如此,圖靈機構成了當今計算機的基礎,而現代ISA是從圖靈機的基本動作中派生出來的。因此,非常有必要研究它的設計。
下圖顯示了圖靈機的一般結構,它包含一個內部磁帶,磁帶是一個單元陣列,每個單元格可以包含有限字母表中的符號,有一個特殊符號$用作特殊標記,一個專用的磁帶頭指向磁帶中的一個單元。在一組狀態中,有一小塊記憶體可以儲存當前狀態,該儲存元件稱為狀態暫存器。
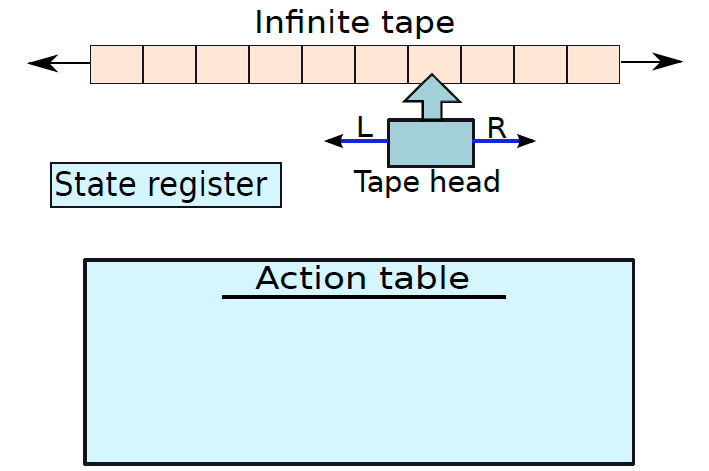
圖靈機的操作非常簡單。在每一步中,磁帶頭從狀態暫存器中讀取當前單元中的符號及其當前狀態,並查詢一個表,該表包含每個符號和狀態組合的操作集,這個專用表稱為轉換函數表或動作表。這個表中的每個條目都說明了三件事——是否將磁帶頭向左或向右移動一步、下一個狀態及應寫入當前單元格的符號。因此,在每一步中,磁帶頭都可以覆蓋單元格的值,改變狀態暫存器中的狀態,並移動到新單元格。唯一的限制是新單元格必須位於當前單元格的最左邊或最右邊。形式上,它的格式為:
其中\(L\)代表左邊,\(R\)代表右邊。
範例:設計一個圖靈機來判斷字串的形式是否為aaa...abb...bb。答案:讓我們定義兩個狀態\(\left(S_{a}, S_{b}\right)\)和兩個特殊狀態——exit和error。如果狀態等於退出或錯誤,則計算停止。圖靈機可以開始從右向左掃描輸入,開始於狀態\((S_b)\)。動作表如下:
以上只是圖靈機的簡單應用案例,但實際場景中,複雜程度遠遠不止於此。我們可以立即得出結論,為即使是簡單的問題設計圖靈機也是不可能的。因為動作表會包含很多狀態,並且很快就會超出大小,但基線是可以用這個簡單的裝置解決複雜的問題。事實上,這臺機器可以解決各種問題,如天氣建模、金融計算和微分方程的求解!
Church-Turing論文捕捉到了這一觀察結果,該論文說,任何物理計算裝置都可以計算的所有函數都可以由圖靈機計算。用外行的話說,任何可以在人類已知的任何計算機上用確定性演演算法計算的程式,也可以用圖靈機計算。
這篇論文在過去的半個世紀裡一直堅定不移。到目前為止,研究人員還無法找到比圖靈機器更強大的機器,意味著沒有程式可以由圖靈機之外的另一種機器計算。有一些程式可能需要很長時間才能在圖靈機上進行計算,但它們也會佔用所有其他計算機上的無限時間。我們可以用所有可能的方式擴充套件圖靈機,可以考慮多個磁帶、多個磁帶頭或每個磁帶中的多個磁軌。可以看出,這些機器中的每一個都像一個簡單的圖靈機一樣強大。
上面描述的圖靈機不是通用機器,因為它包含一個動作表,該動作表特定於機器正在計算的函數。一個真正的通用機器將具有相同的動作表、符號以及每個功能的相同狀態集。如果我們能設計一個能模擬另一個圖靈機的圖靈機,我們就能製造一個通用圖靈機——通用且不會特定於正在計算的函數。
讓被模擬的圖靈機被稱為M,通用圖靈機則被稱為U。讓我們首先為M的動作表建立一個通用格式,並將其儲存在U磁帶上的指定位置,每個動作都需要5個引數——舊狀態、舊符號、方向(左或右)、新狀態、新符號。我們可以使用一組常見的基本符號,可以是10位十進位制數位(0-9),如果一個函數需要更多的符號,那麼我們可以考慮將一個符號包含在一組由特殊分隔符劃分的連續單元中。讓這樣的符號稱為模擬符號。同樣,模擬動作表中的狀態也可以編碼為十進位制數。對於方向,我們可以使用0表示左側,1表示右側。因此,單個動作表條目可能看起來像(@1334@34@0@1335@10@),其中「@」是分隔符,該條目表示,如果遇到符號34,我們將從狀態1334移動到1335。我們向左移動(0),並寫一個值10。因此,我們找到了一種對用於計算某個函數的圖靈機的動作表、符號集和狀態進行編碼的方法。
類似地,我們可以指定磁帶的一個區域來包含M的狀態暫存器,稱之為模擬狀態暫存器。讓M的磁帶在U的磁帶中有一個專用的空間,我們把這個空間稱為工作區(work area)。這種組織如下圖所示。
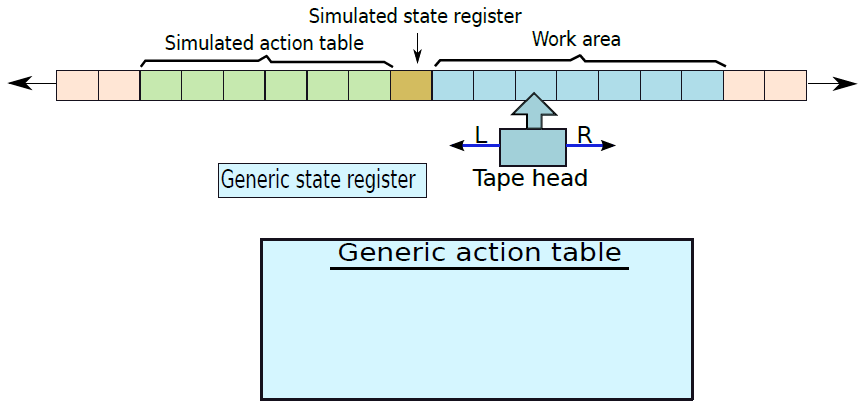
通用圖靈機的佈局。
磁帶因此分為三部分,第一部分包含模擬動作表,第二部分包含模擬狀態暫存器,最後一部分包含包含一組模擬符號的工作區。通用圖靈機(U)有一個非常簡單的動作表和一組狀態,其思想是在模擬動作表中查詢與模擬狀態暫存器中的值和磁帶頭下的模擬符號相匹配的正確條目。然後,通用圖靈機需要通過移動到新的模擬狀態來執行相應的動作,並在需要時覆蓋工作區中的模擬符號。為了做每一個基本動作,U需要做幾十次磁帶頭運動。然而,結論是我們可以構造一個通用的圖靈機。
可以構造一個通用的圖靈機,它可以模擬任何其他的圖靈機器。
自20世紀50年代以來,研究人員設計了更多型別的具有自己的狀態和規則集的假想機器,這些機器中的每一臺都已被證明至多與圖靈機一樣強大。所有機器和計算系統都有一個通用名稱,它們都像圖靈機一樣具有表達力和功能。這種系統可以說是圖靈完整的(Turing complete)。因此,任何通用機器和ISA都是圖靈完整的。
任何等同於圖靈機的計算系統都被稱為圖靈機。
因此,如果ISA是圖靈完整的,我們需要證明ISA是完整的或通用的。
現在考慮一個更適合實際實現的通用圖靈機的變體(下圖),讓它具有以下特性。請注意,這樣的機器已經被證明是圖靈完整的。
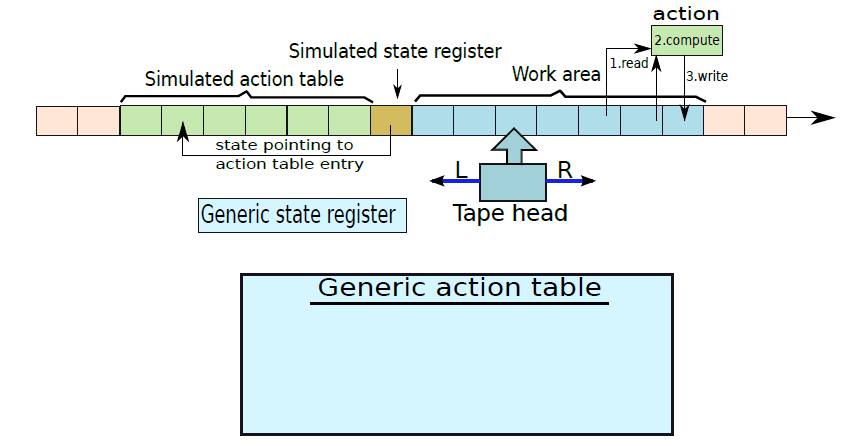
一種改進的通用圖靈機
1、磁帶為半無限(semi-infinite,僅在一個方向上延伸至無限)。
2、模擬狀態是指向模擬動作表中的條目的指標。
3、每個狀態的模擬動作表中有一個唯一的條目。在查詢模擬動作表時,我們不關心磁帶頭下的符號。
4、一個動作指示磁帶頭存取工作區中的一組位置,並根據它們的值使用簡單的算術函數計算一個新值。它將此新值寫入工作區中的新位置。
5、預設的下一個狀態是動作表中的後續狀態。
6、如果磁帶上某個位置的符號小於某個值,動作也可以任意改變狀態,意味著模擬磁帶頭將開始從模擬動作表中的新區域提取動作。
這臺圖靈機建議採用以下形式的機器組織。有大量指令(動作表),這個指令陣列通常被稱為程式。有一個狀態暫存器,用於維護指向陣列中當前指令的指標,稱為程式計數器,可以更改程式計數器以指向新指令。有一個大的工作區,可以儲存、檢索和修改符號,此工作區也稱為資料區。指令表(程式)和工作區(資料)儲存在我們改進的圖靈機的磁帶上。在實際的機器中,有限磁帶可被看作記憶體。記憶體是一個大的儲存單元陣列,其中儲存單元包含一個基本符號。記憶體的一部分包含程式,另一部分包含資料。
此外,每條指令都可以讀取記憶體中的一組位置,計算它們上的一個小算術函數,並將結果寫回記憶體,還可以根據記憶體中的值跳轉到任何其他指令。有一個專用單元來計算這些算術函數,寫入記憶體,並跳轉到其他指令,被稱為CPU(中央處理單元)。下圖顯示了該機器的概念組織。
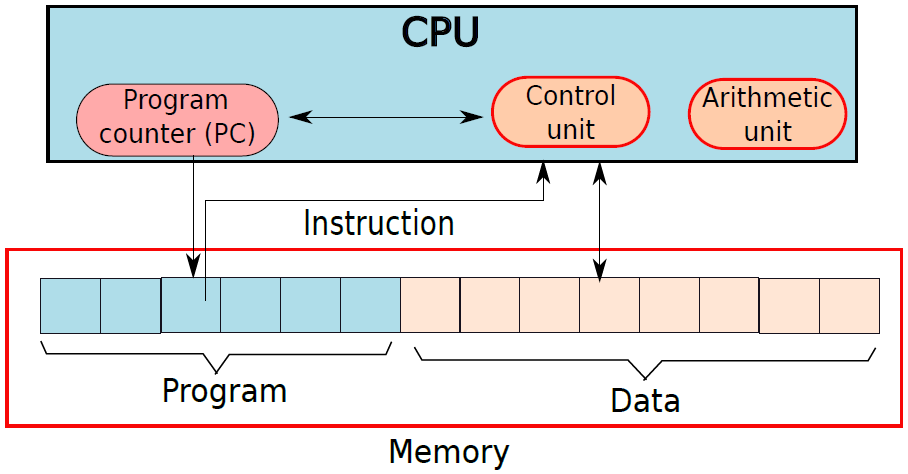
基本指令處理器。
上面我們已經捕獲了圖靈機的所有方面:狀態轉換、磁帶頭的移動、重寫符號以及基於磁帶頭下符號的決策。這種機器與馮·諾依曼機器非常相似,後者構成了當今計算機的基礎。
現在,讓我們嘗試為改進的圖靈機設計一個ISA,有可能有一個只包含一條指令的完整ISA,考慮一個與改進的圖靈機相容並且已經被證明是圖靈完備的指令。
sbn a, b, c
sbn表示減法,如果為負數則分支,此指令從a中減去b(a和b是記憶體位置),將結果儲存在a中。如果a<0,則跳轉到指令表中位置c處的指令,否則,控制轉移到下一條指令。例如,我們可以使用此指令將儲存在位置a和b中的兩個數位相加。請注意,退出是程式末尾的一個特殊位置。
1: sbn temp, b, 2
2: sbn a, temp, exit
這裡假設記憶體位置temp已經包含值0。第一條指令將\(-b\)儲存在temp中,不管結果的值如何,它都跳到下一條指令。請注意,識別符號(數位:)是指令的序列號。在第二條指令中,計算\(a = a + b = a - (-b)\)。因此,成功地相加了兩個數位,現在可以使用這段基本程式碼將數位從1加到10。我們假設變數計數器初始化為9,索引初始化為10,一初始化為1,和初始化為0。
1: sbn temp, temp, 2 // temp = 0
2: sbn temp, index, 3 // temp = -1 * index
3: sbn sum, temp, 4 // sum += index
4: sbn index, one, 5 // index -= 1
5: sbn counter, one, exit // loop is finished, exit
6: sbn temp, temp, 7 // temp = 0
7: sbn temp, one, 1 // (0 - 1 < 0), hence goto 1
我們觀察到,這個小的操作序列執行for迴圈。退出條件在第5行,迴圈返回發生在第7行。在每一次迭代中,它都計算\(-sum += index\)。
有許多類似的單指令ISA已經被證明是完整的,例如,如果小於等於,則進行減法和分支,如果借用(borrow),則進行反向減法和跳過,以及具有通用記憶體移動操作的計算機。
用一條指令編寫一個程式是非常困難的,而且程式往往很長。沒有理由吝嗇指令的數量,通過考慮大量的指令,可以使複雜程式的實現變得更加輕鬆。讓我們嘗試將基本的sbn指令分解為幾個指令:
- 算術指令。可以有一組算術指令,如加法、減法、乘法和除法。
- 移動指令。可以有移動指令,在不同的記憶體位置移動值,允許將常數值載入到記憶體位置。
- 分支指令。需要根據計算結果或儲存在記憶體中的值來改變程式計數器以指向新指令的分支指令。
記住這些基本原則,我們可以設計許多不同型別的完整ISA。需要注意的是,我們只需要三種型別的指令:算術(資料處理)、移動(資料傳輸)和分支(控制)。
在任何指令集中,至少需要三種型別的指令:
1、需要算術指令來執行加法、減法、乘法和除法等運算。大多數指令集也有這類專門的指令來執行邏輯運算,如邏輯OR和NOT。
2、需要資料傳輸指令,可以在記憶體位置之間傳輸值,並可以將常數載入到記憶體位置。
3、需要能夠根據指令運算元的值在程式中的不同點開始執行指令的分支指令。
暫存器機(register machine)是指包含無限數量的命名儲存位置,這些儲存位置稱為暫存器。暫存器可以隨機存取,所有指令都使用暫存器名作為運算元。CPU存取暫存器,獲取運算元,然後處理它們。還存在混合機器,它們可以增加儲存空間帶有暫存器的標準Von Neumann機器。暫存器是可以儲存符號的儲存位置。
記憶體通常是非常大的結構,在現代處理器中,整個記憶體可以包含數十億個儲存位置,這種大小的記憶體的任何實際實現在實踐中都相當緩慢。硬體中有一個一般的經驗法則,大則慢,小則快。因此,為了實現快速操作,每個處理器都有一組可以快速存取的暫存器,暫存器的數量通常在8到64之間。算術和分支操作中的大多數運算元都存在於這些暫存器中,由於程式傾向於在任何時間點重複使用一小組變數,因此使用暫存器可以節省許多記憶體存取。然而,有時需要將記憶體位置引入暫存器或將暫存器中的值寫回記憶體位置。在這些情況下,我們使用專用的載入和儲存指令,在記憶體和暫存器之間傳輸值。大多數程式都有大多數純暫存器指令,載入和儲存指令的數量通常約為已執行指令總數的三分之一。
假設我們要將數位的3次方加到儲存位置b和c中,並將結果儲存在儲存位置a中。帶有暫存器的機器需要以下指令,假設r1、r2和r3是暫存器的名稱,沒有使用任何特定的(通用的、概念性的)ISA。
1: r1 = mem[b] // load b
2: r2 = mem[c] // load c
3: r3 = r1 * r1 // compute b^2
4: r4 = r1 * r3 // compute b^3
5: r5 = r2 * r2 // compute c^2
6: r6 = r2 * r5 // compute c^3
7: r7 = r4 + r6 // compute b^3 + c^3
4: mem[a] = r7 // save the result
mem是表示記憶體的陣列,需要首先將值載入到暫存器中,然後執行算術計算,然後將結果儲存回記憶體。上面的程式碼通過使用暫存器來節省記憶體存取,如果增加計算的複雜性,將節省更多的記憶體存取,因此,使用暫存器的執行速度會更快。最終的處理器組織如下圖所示。
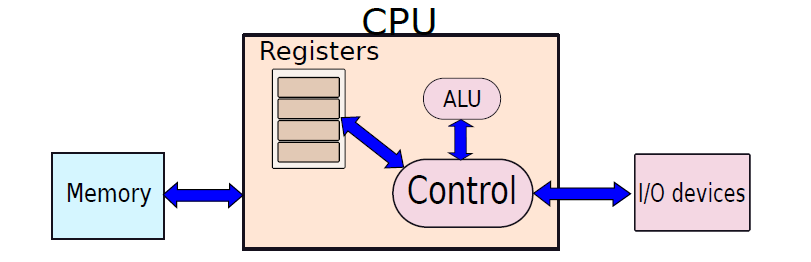
很明顯,安排計算在堆疊上工作是不可取的,將有許多冗餘負載和儲存。儘管如此,對於打算計算長數學表示式的機器,以及程式大小是一個問題的機器,通常會選擇堆疊。很少有基於堆疊的機器的實際實現,如Burroughs Large Systems、UCSD Pascal和HP 3000(經典)。Java語言在編譯過程中假設一臺基於堆疊的機器,由於基於堆疊的機器很簡單,Java程式實際上可以在任何硬體平臺上執行。當我們執行編譯後的Java程式時,Java虛擬機器器(JVM)會動態地將Java程式轉換為另一個可以在帶有暫存器的機器上執行的程式。
基於累加器的機器使用一個暫存器,稱為累加器(accumulator)。每條指令都將單個記憶體位置作為輸入運算元,例如,加法運算將累加器中的值與記憶體地址中的值相加,然後將結果儲存回累加器。早期無法容納暫存器的機器曾經有累加器,累加器能夠減少記憶體存取的次數並加速程式。
累加器的某些方面已經滲透到英特爾x86處理器組中,這些處理器是2012年桌上型電腦和筆記型電腦最常用的處理器。對於大數的乘法和除法,這些處理器使用暫存器eax作為累加器。對於其他通用指令,任何暫存器都可以指定為累加器。
19.4.5 常見ISA
目前市面上流行的指令集包含ARM指令集和x86指令集。ARM是高階RISC機器(Advanced RISC Machines),是一家總部位於英國劍橋的標誌性公司,截至2012年,包括蘋果iPhone和iPad在內的大約90%的移動裝置都執行在基於ARM的處理器上。同樣,截至2012年超過90%的桌上型電腦和筆記型電腦執行在基於Intel或AMD的x86處理器上。ARM是RISC指令集,x86是CISC指令集。
還有許多其他為各種處理器量身客製化的指令集,移動計算機的另一個流行指令集是MIPS指令集,基於MIPS的處理器也用於汽車和工業電子中的各種處理器。
對於大型伺服器,通常使用IBM(PowerPC)、Sun(如今的Oracle,UltraSparc)或HP(PA-RISC)處理器。每個處理器系列都有自己的指令集,這些指令集通常是RISC指令集,大多數ISA共用簡單的指令,如加法、減法、乘法、移位和載入/儲存指令。除了這個簡單的集合,他們使用了大量更專業的指令。在ISA中選擇正確的指令集取決於處理器的目標市場、工作負載的性質以及許多設計時間限制,下表顯示了流行的指令集列表。
| ISA | 型別 | 年份 | 廠商 | 位數 | 位元組順序 | 暫存器數 |
|---|---|---|---|---|---|---|
| VAX | CISC | 1977 | DEC | 32 | little | 16 |
| SPARC | RISC | 1986 | Sun | 32 | bi | 32 |
| SPARC | RISC | 1993 | Sun | 64 | bi | 32 |
| PowerPC | RISC | 1992 | Apple, IBM, Motorola | 32 | bi | 32 |
| PowerPC | RISC | 2002 | Apple, IBM | 64 | bi | 32 |
| PA-RISC | RISC | 1986 | HP | 32 | big | 32 |
| PA-RISC | RISC | 1996 | HP | 64 | big | 32 |
| m68000 | CISC | 1979 | Motorola | 16 | big | 16 |
| m68000 | CISC | 1979 | Motorola | 32 | big | 16 |
| MIPS | RISC | 1981 | MIPS | 32 | bi | 32 |
| MIPS | RISC | 1999 | MIPS | 64 | bi | 32 |
| Alpha | RISC | 1992 | DEC | 64 | bi | 32 |
| x86 | CISC | 1978 | Intel, AMD | 16 | little | 8 |
| x86 | CISC | 1985 | Intel, AMD | 32 | little | 8 |
| x86 | CISC | 2003 | Intel, AMD | 64 | 64 little | 16 |
| ARM | RISC | 1985 | ARM | 32 | bi (little default) | 16 |
| ARM | RISC | 2011 | ARM | 64 | bi (little default) | 31 |
19.4.6 指令實現機制
有一小組基本邏輯元件,可以以各種方式組合起來儲存二進位制資料,並對該資料執行算術和邏輯運算。如果要執行特定的計算,則可以構造專門為該計算設計的邏輯元件的設定。我們可以將以所需設定連線各種元件的過程視為程式設計的一種形式。生成的「程式」是硬體形式的,稱為硬連執行緒序(hardwired program)。
現在考慮這個替代方案。假設我們構造了算術和邏輯函數的通用設定,這組硬體將根據施加到硬體的控制訊號對資料執行各種功能。在客製化硬體的原始情況下,系統接受資料併產生結果(下圖a)。使用通用硬體,系統接受資料和控制訊號併產生結果,因此程式設計師只需要提供一組新的控制訊號,而不是為每個新程式重新佈線硬體。
硬體和軟體方法。
如何提供控制訊號?答案很簡單,但很微妙。整個程式實際上是一系列步驟,在每個步驟中,對一些資料執行一些算術或邏輯運算。對於每個步驟,都需要一組新的控制訊號。讓我們為每一組可能的控制訊號提供一個唯一的程式碼,並在通用硬體中新增一個可以接受程式碼並生成控制訊號的段(上圖b)。
程式設計現在更容易了。我們需要做的是提供一個新的程式碼序列,而不是為每個新程式重新佈線硬體。實際上,每個程式碼都是一條指令,部分硬體解釋每個指令並生成控制訊號。為了區分這種新的程式設計方法,一系列程式碼或指令被稱為軟體。
19.4.6.1 儲存指令
讓我們考慮載入指令:ld r1, 12[r2],此處將記憶體地址計算為r2和數位12的內容之和。ld指令存取此記憶體地址,獲取儲存的整數並將其儲存在r1中。假設計算的記憶體地址指向整數的第一個儲存位元組(即小端表示),所以記憶體地址包含LSB。詳情如下圖(a)所示。儲存操作則相反,將r1的值儲存到記憶體地址(r2+12)中,如下圖(b)所示。
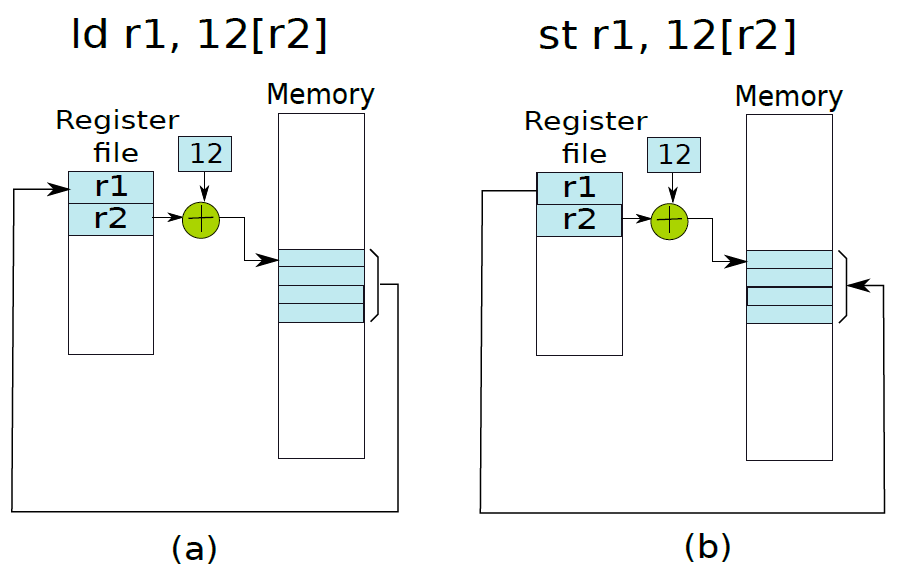
19.4.6.2 函數
回顧一下實現一個簡單函數的基本要求。假設地址為A的指令呼叫函數foo,在執行函數foo之後,需要立即返回A處指令之後的指令,該指令的地址為A+4(如果我們假設A處的指令長度為4位元組)。這個過程被稱為從函數返回,地址(a+4)被稱為返回地址。
返回地址(Return address)是程序在執行函數後需要分支到的指令的地址。
因此,實現函數有兩個基本方面:1、呼叫或呼叫函數的過程;2、涉及從函數返回。
函數本質上是一塊組合程式碼,呼叫一個函數本質上是讓PC指向這段程式碼的開頭。我們可以將標籤與每個函數相關聯,標籤應該與函數中的第一條指令相關聯,呼叫函數就像分支到函數開頭的標籤一樣簡單。然而,這只是故事的一部分,我們還需要實現返回功能。因此,我們不能使用無條件分支指令來實現函數呼叫。
因此,讓我們提出一個專用的函數呼叫指令,它分支到函數的開頭,同時儲存函數需要返回的地址(稱為返回地址)。讓我們考慮下面的C程式碼,並假設每個C語句對應於一行組合程式碼。
a = foo(); /* Line 1 */
c = a + b; /* Line 2 */
在這個小程式碼片段中,我們使用函數呼叫指令來呼叫foo函數,返回地址是第2行中指令的地址。呼叫指令必須將返回地址儲存在專用儲存位置,以便以後可以檢索。大多數RISC指令集都有一個專用暫存器,稱為返回地址暫存器(不妨稱為ra),用於儲存返回地址,返回地址暫存器由函數呼叫指令自動填充。當我們需要從函數返回時,我們需要分支返回地址暫存器中包含的地址。
如果foo呼叫另一個函數會發生什麼?在這種情況下,ra中的值將被覆蓋。我們稍後將討論這個問題。現在讓我們考慮將引數傳遞給函數並返回返回值的問題。
假設函數foo呼叫函數foobar。foo被稱為呼叫者(caller),foobar被稱為被呼叫者(callee)。請注意,呼叫方與被呼叫方的關係是不固定的。foo可以呼叫foobar,foobar也可以在同一個程式中呼叫foo。根據哪個函數呼叫另一個函數來決定單個函數呼叫的呼叫者和被呼叫者。
呼叫者和被呼叫者都看到相同的暫存器檢視。因此,我們可以通過暫存器傳遞引數,同樣也可以通過暫存器來傳遞返回值。然而,正如我們在下面列舉的,在這個簡單的想法中有幾個問題(假設我們有16個暫存器)。
1、一個函數可以接受16個以上的引數,比我們現有的通用暫存器數量還要多,因此需要新增額外的空間來儲存引數。
2、函數可以返回大量資料,例如C中的大型結構。這段資料可能不可能在暫存器中儲存。
3、被呼叫者可能會覆蓋呼叫者將來可能需要的暫存器。
因此,我們觀察到,通過暫存器傳遞引數和返回值只適用於簡單的情況,不是一個非常靈活和通用的解決方案。儘管如此,我們的討論提出了兩個要求:
- 空間問題。我們需要額外的空間來傳送和返回更多的引數。
- 覆蓋問題。我們需要確保被呼叫方不會覆蓋呼叫方的暫存器。
為了解決這兩個問題,需要更深入地瞭解函數是如何工作的。可以將函數foo想象成一個黑匣子,它接受一系列引數並返回一組值。要執行它的工作,foo可以花費一納秒、一週甚至一年的時間。foo可以呼叫其他函數來完成它的工作、將資料傳送到I/O裝置以及存取記憶體位置。下圖是函數foo的視覺化。
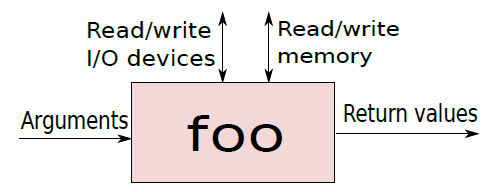
總而言之,通用函數處理引數,根據需要從記憶體和I/O裝置讀取和寫入值,然後返回結果。關於記憶體和I/O裝置,目前我們並不特別關心,有大量可用記憶體,空間不是主要限制,讀寫I/O裝置通常也與空間限制無關。主要問題是暫存器,因為它們供不應求。
讓我們先解決空間問題,可以通過暫存器和記憶體傳輸值。為了簡單起見,如果我們需要傳輸少量資料,我們可以使用暫存器,否則我們可以通過記憶體傳輸它們。類似地,對於返回值,我們可以通過記憶體傳輸值。如果我們使用記憶體傳輸資料,那麼我們不受空間限制。然而,這種方法缺乏靈活性,因為呼叫者和被呼叫者之間必須就要使用的記憶體位置達成嚴格的協定。請注意,我們不能使用一組固定的記憶體位置,因為被呼叫方可以遞迴呼叫自己。
void foobar()
{
...
foobar();
...
}
精明的讀者可能會認為,被呼叫方可以從記憶體中讀取引數並將其轉移到記憶體中的其他臨時區域,然後呼叫其他函數。然而,這種方法既不優雅,也不十分有效。稍後將研究更優雅的解決方案。
因此可以得出結論,我們已經部分解決了空間問題。如果需要在呼叫者和被呼叫者之間傳輸一些值,或者反之亦然,可以使用暫存器。但是,如果引數/返回值不在可用暫存器集中,那麼需要通過記憶體傳輸它們。對於通過記憶體傳輸資料,我們需要一個優雅的解決方案,它不需要呼叫者和被呼叫者之間就用於傳輸資料的記憶體位置達成嚴格的協定。
將暫存器儲存在記憶體中並隨後恢復的概念稱為暫存器溢位(register spilling)。
要解決覆蓋問題,有兩種解決方案:1、呼叫者可以將所需的暫存器集儲存在記憶體中的專用位置,可以在被呼叫方完成後檢索其暫存器集,並將控制權返回給呼叫方。2、讓被呼叫方儲存和恢復它需要的暫存器。這兩種方法都如下圖所示。這種將暫存器值儲存在記憶體中,然後再檢索的方法稱為溢位。
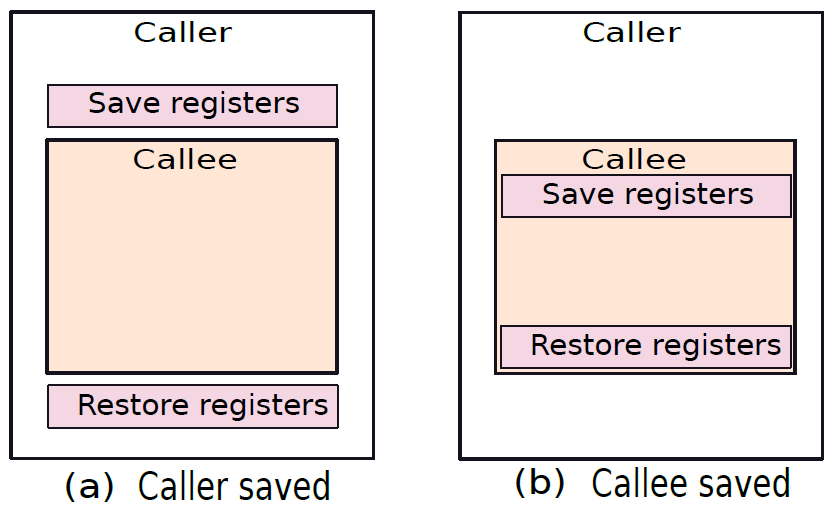
呼叫方儲存和被呼叫方儲存的暫存器。
我們又遇到了同樣的問題,即呼叫者和被呼叫者都需要就需要使用的記憶體位置達成嚴格的協定。現在讓我們一起努力解決這兩個問題。
我們簡化了向函數傳遞引數和從函數傳遞引數,以及使用記憶體中的專用位置儲存/恢復暫存器的過程。然而,該解決方案被發現是靈活的,對於大型現實世界程式來說,實現起來可能相當複雜。為了簡化這個想法,讓我們在函數呼叫中定義一個模式。
典型的C或Java程式從主函數開始。然後,該函數呼叫其他函數,這些函數可能反過來呼叫其他函數。最後,當主函數退出時,執行終止。每個函數定義一組區域性變數,並對這些變數和函數引數執行計算,它還可以呼叫其他函數。最後,函數返回一個值,很少返回一組值(C中的結構)。請注意,函數終止後,不再需要區域性變數和引數。因此,如果其中一些變數或引數儲存在記憶體中,我們需要回收空間。其次,如果函數溢位了暫存器,那麼這些記憶體位置也需要在它退出後釋放。最後,如果被呼叫方呼叫另一個函數,則需要將返回地址暫存器的值儲存在記憶體中,還需要在函數退出後釋放此位置。
最好將所有這些資訊連續儲存在一個記憶體區域中,被稱為函數的啟用塊(activation block),下圖顯示了啟用塊的記憶體對映。

啟用塊包含引數、返回地址、暫存器溢位區(對於呼叫方儲存和被呼叫方儲存的方案)和區域性變數。一旦函數終止,就可以完全擺脫啟用塊。一個函數如果想要返回一些值,那麼可以使用暫存器這樣做,但是它如果想要返回一個大的結構,那麼就可以將其寫入呼叫方的啟用塊中,呼叫方可以在其啟用塊中提供一個可以寫入該資料的位置。後面有可能更優雅地做到這一點,在解釋如何做到這一點之前,需要了解如何在記憶體中安排啟用塊。
我們可以有一個儲存區域,其中所有的啟用塊都儲存在相鄰的區域中。考慮一個例子,假設函數foo呼叫函數foobar,foobar又呼叫foobarbar。下圖顯示了4個記憶體狀態:(a)在呼叫foobar之前,(b)在呼叫foobarbar之前,(c)在呼叫foobarbar之後,(d)在foobarar返回之後。
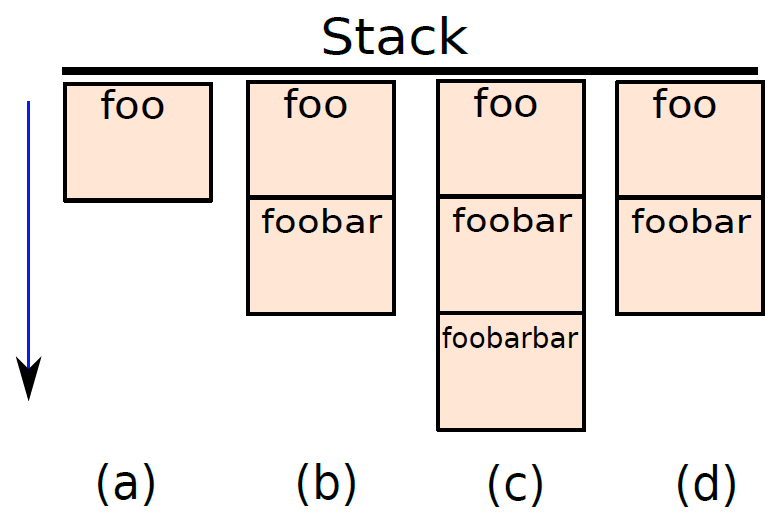
在這個記憶體區域中有一個後進先出的行為,最後呼叫的函數是要完成的第一個函數,這種後進先出的結構傳統上被稱為電腦科學中的堆疊(stack),因此專用於儲存啟用塊的儲存區域稱為堆疊。傳統上,堆疊被認為是向下增長的(向更小的記憶體地址增長),意味著主功能的啟用塊從非常高的位置開始,新的啟用塊被新增到現有啟用塊的正下方(朝向較低的地址)。堆疊的頂部實際上是堆疊中最小的地址,而堆疊的底部是最大的地址。堆疊的頂部表示當前正在執行的函數的啟用塊,堆疊的底部表示初始主函數。
堆疊(stack)是儲存程式中所有啟用塊的記憶體區域,一般情況是向下增長的。在呼叫函數之前,我們需要將其啟用塊推播到堆疊中,當函數完成執行時,需要將其啟用塊彈出到堆疊中。
堆疊指標暫存器(stack pointer register)儲存指向堆疊頂部的指標。
大多數架構將指向堆疊頂部的指標儲存在一個稱為堆疊指標的專用暫存器中,常被稱為sp。請注意,對於許多架構,堆疊是純軟體結構。對於他們來說,硬體不知道堆疊。但對於某些架構(如x86),硬體知道堆疊並使用它來推播返回地址或其他暫存器的值。即使在這種情況下,硬體也不知道每個啟用塊的內容,結構由程式集程式設計師或編譯器決定。在所有情況下,編譯器都需要顯式新增組合指令來管理堆疊。
為被呼叫方建立新的啟用塊涉及以下步驟。
1、將堆疊指標減小啟用塊的大小。
2、複製引數的值。
3、如果需要,通過寫入相應的記憶體位置來初始化任何區域性變數。
4、如果需要,溢位任何暫存器(儲存到啟用塊)。
從函數返回時,必須銷燬啟用塊,可以通過將啟用塊的大小新增到堆疊指標來完成。
通過使用堆疊,我們解決了所有問題。呼叫方和被呼叫方不能覆蓋彼此的區域性變數,區域性變數儲存在啟用塊中,兩個啟用塊不重疊。除了變數之外,還可以通過在啟用塊中顯式插入儲存暫存器的指令來阻止被呼叫方重寫呼叫方的暫存器。實現這一點有兩種方法:呼叫者儲存的方案和被呼叫方儲存的方案。其次,無需就將用於傳遞引數的記憶體區域達成明確協定,堆疊可以用於此目的,呼叫者可以簡單地將引數推播到堆疊上,這些引數將被推播到被呼叫方的啟用塊中,被呼叫方可以輕鬆使用它們。同樣,當從函數,被呼叫方可以通過堆疊傳遞返回值,需要先通過減少堆疊指標來銷燬其啟用塊,然後才能將返回值推播到堆疊上。呼叫方將知道被呼叫方的語意,因此在被呼叫方返回後,可以假定其啟用塊已被被呼叫方有效地放大,返回值佔用了額外的空間。
ARM使用B/BL/BX/BLX等語句呼叫函數和返回函數,而x86使用call等指令呼叫函數,此外,x86和ARM都可使用ret指令返回地址。下面是ARM的函數呼叫範例程式碼:
.globl main
.extern abs
.extern printf
.text
output_str:
.ascii "The answer is %d\n\0"
@ returns abs(z)+x+y
@ r0 = x, r1 = y, r2 = z
.align 4
do_something:
push {r4, lr}
add r4, r0, r1
mov r0, r2
bl abs ; 呼叫abs
add r0, r4, r0
pop {r4, pc}
main:
push {ip, lr}
mov r0, #1
mov r1, #3
mov r2, #-4
bl do_something ; 呼叫do_something
mov r1, r0
ldr r0, =output_str
bl printf
mov r0, #0
pop {ip, pc}
有趣的指令是pushpop和bl,只需獲取提供的暫存器列表並將其推到堆疊上,或者將其彈出並放入提供的暫存器中。bl只不過是帶連結的分支,分支後的下一條指令的地址被載入到連結暫存器lr中。
一旦我們正在呼叫的例程被執行,lr就可以被複制回pc,將使CPU能夠在bl指令之後從程式碼中繼續。在do_someting中,我們將連結暫存器推播到堆疊,這樣就可以再次將其彈出返回,即使對abs的呼叫將覆蓋連結暫存器的原始內容。程式儲存r4,因為Arm過程呼叫標準規定在函數呼叫之間必須保留r4-r11(下圖),並且被呼叫的函數負責該保留,意味著do_someting需要將r0+r1的結果儲存在一個不會被abs破壞的暫存器中,並且我們還必須儲存用於儲存該結果的任何暫存器的內容。當然,在這種特殊情況下,我們可以只使用r3,但是需要考慮的。我們推播並彈出暫存器,儘管我們不必保留它,因為過程呼叫標準要求堆疊64位元對齊。這在使用堆疊操作時提供了效能優勢,因為它們可以利用CPU內的64位元資料路徑。
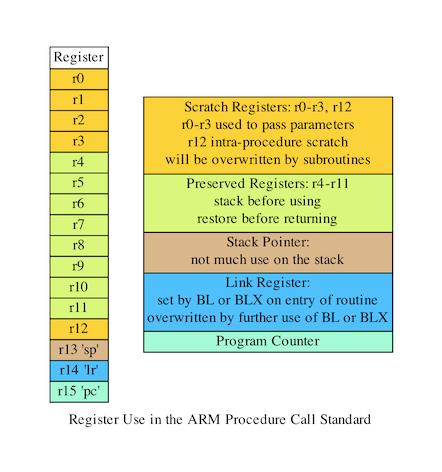
我們可以直接壓入高地址的值,畢竟如果abs需要註冊,那麼這就是它儲存值的方式。推播r4而不是我們知道需要的值有一個小的效能問題,但最有力的論點可能是,在函數的開始和結束時只推播/彈出所需的任何暫存器,就可以減少錯誤發生的可能性,提高程式碼的可讀性。此外,「main」函數還壓入和彈出lr的內容,因為雖然主程式碼可能是我的程式碼中要執行的第一件事,但它不是載入程式時要執行的第二件事。編譯器將在呼叫main之前插入對一些基本設定函數的呼叫,並在退出時進行一些最終清理呼叫。
現在讓我們嘗試將每條指令編碼為32位元值。假設有0、1、2和3地址格式的指令,其次,有些指令採用即時值,因此需要將32位元劃分為多個欄位。假設有21條指令,則需要5位來編碼指令型別,常規指令中的每個指令的程式碼如下表所示。我們可以使用32位元欄位中最重要的位來指定指令型別,指令的程式碼也稱為操作碼(opcode)。
| 指令 | 二進位制碼 |
|---|---|
| add | 00000 |
| sub | 00001 |
| mul | 00010 |
| div | 00011 |
| mod | 00100 |
| cmp | 00101 |
| and | 00110 |
| or | 00111 |
| not | 01000 |
| mov | 01001 |
| lsl | 01010 |
| lsr | 01011 |
| asr | 01100 |
| nop | 01101 |
| ld | 01110 |
| st | 01111 |
| beq | 10000 |
| bgt | 10001 |
| b | 10010 |
| call | 10011 |
| ret | 10100 |
現在,讓我們嘗試從0地址指令開始對每種型別的指令進行編碼。
我們擁有的兩條0地址指令是ret和nop。操作碼由五個最重要的位指定,在這種情況下,ret等於10100,b等於10010(參見上表)。它們的編碼如下圖所示,我們只需要在MSB位置指定5位元運算碼,其餘27位不需要。
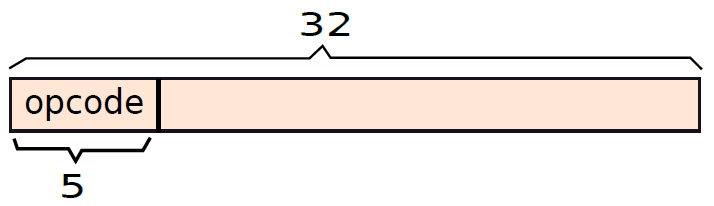
編碼ret指令。
我們擁有的1地址指令是call、b、beq和bgt,它們將標籤作為引數。在編碼指令時,我們需要指定標籤的地址作為引數,標籤的地址與它所指向的指令的地址相同。如果標籤後的行為空,那麼我們需要考慮下一條包含指令的組合語句。
這四條指令的操作碼需要5位,剩餘的27位可用於地址。請注意,記憶體地址是32位元長,不能用27位覆蓋地址空間,但可以進行兩個關鍵的優化。首先,可以假設PC相對定址,可以假設27位指定了相對於當前PC的偏移量(正負)。現代程式中的分支語句是因為for/while迴圈或if語句而生成的,對於這些構造,分支目標通常在幾百條指令的範圍內。如果有27位來指定偏移量,並且假設它是2的二補數,那麼任何方向(正或負)的最大偏移量都是226,對於幾乎所有的程式來說已足夠。
還有另一個重要的觀察。一條指令需要4個位元組。如果假設所有指令都與4位元組邊界對齊,那麼指令的所有起始記憶體地址都將是4的倍數,因此地址的至少兩個有符號二進位制數位將是00,沒有理由在試圖指定它們時浪費位元,可以假設27位指定包含指令的記憶體字(以4位元組記憶體字為單位)地址的偏移量。通過這種優化,從PC的位元組偏移量變為29位,即使是最大的程式,這個數位也應該足夠。以防萬一有極端的例子,其中分支目標距離超過228個位元組,那麼組合程式需要將分支連結起來,這樣一個分支將呼叫另一個分支,以此類推。這些指令的編碼如下圖所示。
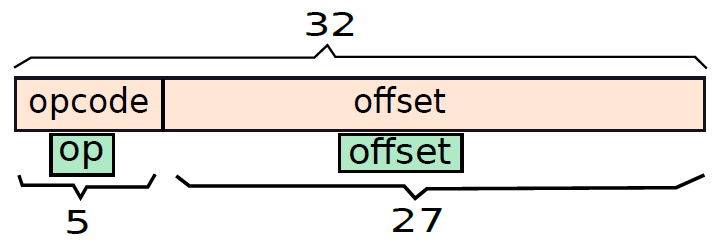
1地址指令的編碼(分支格式)。
請注意,1地址指令格式禁止使用0地址格式中未使用的位,可以將ret指令的0地址格式視為1地址格式的特例,1地址格式稱為分支格式。以這種格式命名欄位,將格式的操作碼部分稱為op,將偏移量稱為offset。操作欄位包含位置28-32的位,偏移欄位包含位置1-27的位。
接下來考慮3地址指令:add、sub、mul、div、mod和或、lsl、lsr和asr。
考慮一個通用的3地址指令,它有一個目標暫存器、一個輸入源暫存器和一個可以是暫存器或立即數的第二個源運算元。如果第二個源運算元是暫存器或立即數,需要將一位輸入和輸出。將其稱為I位,並在指令中的操作碼之後指定它。如果I=1,則第二個源運算元是立即數,如果I=0,則第二個源運算元是暫存器。
現在考慮將第二個源運算元作為暫存器(I=0)的3地址暫存器的情況。因為有16個暫存器,所以需要4位元來唯一地指定每個暫存器。暫存器ri可以編碼為i的無符號4位元二進位制等價物。因此,要指定目標暫存器和兩個輸入源暫存器,需要12位元。結構如下圖所示,此指令格式稱為暫存器格式。像分支格式一樣,不妨命名不同的欄位:op(操作碼,位:28-32)、I(立即數,位:27)、rd(目的暫存器,位:23-26)、rs1(源暫存器1,位:19-22)和rs2(源暫存器2,位:15-18)。
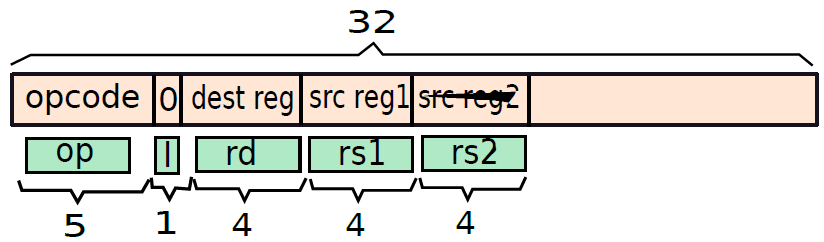
假設第二個源運算元是立即數,那麼需要將I設定為1,接下來計算指定立即數所剩的位數。現在已經為操作碼投入了5位,為I位投入了1位,為目標暫存器投入了4位元,為第一個源暫存器投入了四位,總共花費了14位元。因此,在32位元中,剩下18位元,可以使用它們來指定立即數。
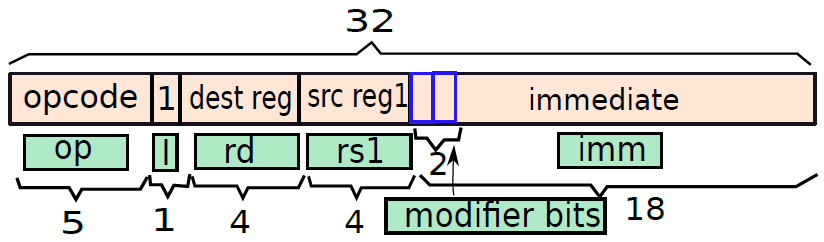
建議將18位元分為兩部分:2位(修改器)+16位元(立即數的常數部分),兩個修改位可以取三個值:00(預設值)、01(「u」)和10(「h」)。當使用預設修改器時,剩餘的16位元用於指定16位元2的二補數數。對於u和h修改器,假設立即欄位中的16位元常數是無符號數。假設立即欄位為18位元長,具有修改部分和常數部分,處理器根據修改器將立即數內部擴充套件為32位元值。
此編碼如下圖所示,可將此指令格式稱為立即數格式。像分支格式一樣,不妨命名不同的欄位:op(操作碼,位:28-32)、I(立即數,位:27)、rd(目標暫存器,位:23-26)、rs1(源暫存器1,位:19-22)和imm(立即數:1-18)。
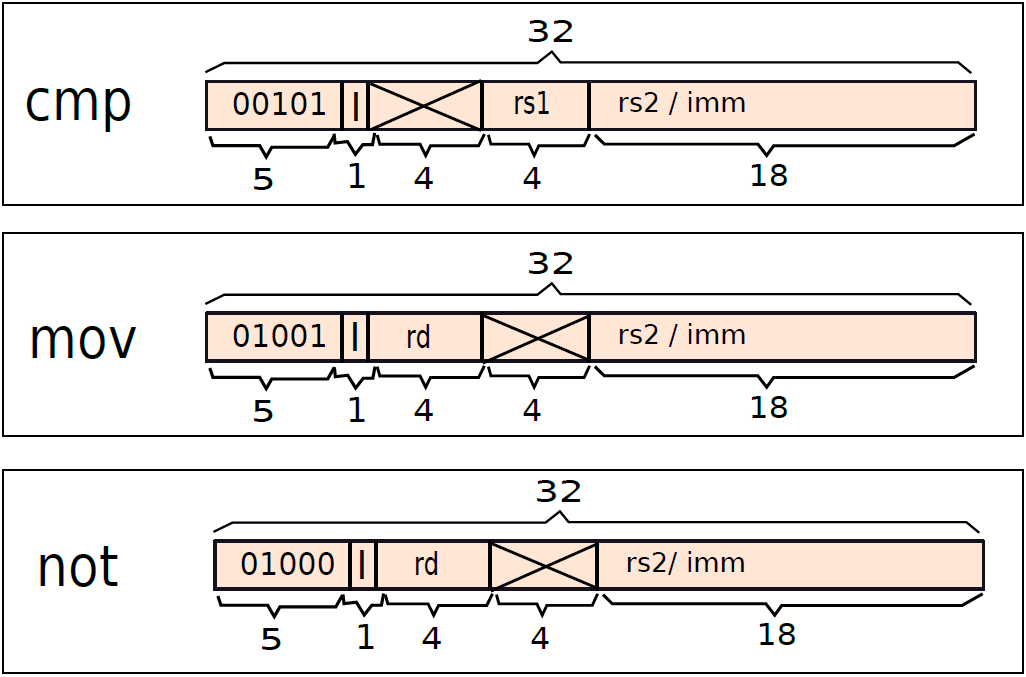
用類似的方式,可以用下圖所示的方式編碼cmp、not和mov指令:
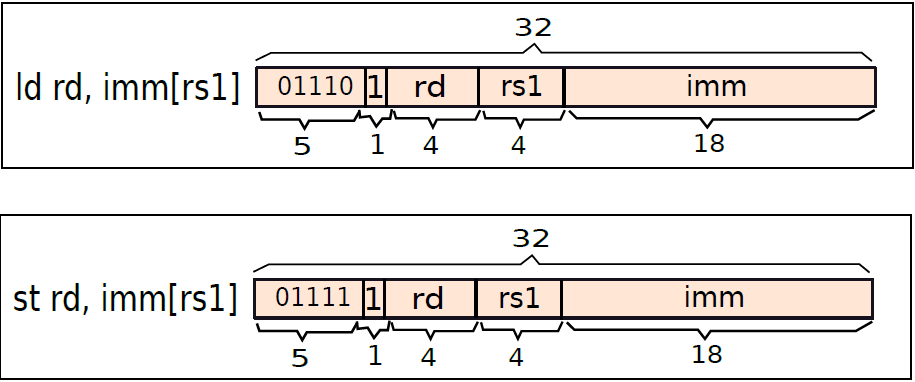
而載入指令的實現如下圖:
19.4.7 ARM指令編碼
ARM有四種型別的指令:資料處理(加/減/乘/比較)、載入/儲存、分支和其他,需要2位來表示這些資訊,這些位決定了指令的型別。下圖顯示了ARM中指令的通用格式。
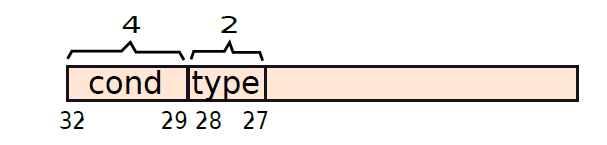
對於資料處理指令,型別欄位等於00,其餘26位需要包含指令型別、特殊條件和暫存器。下圖顯示了資料處理指令的格式。

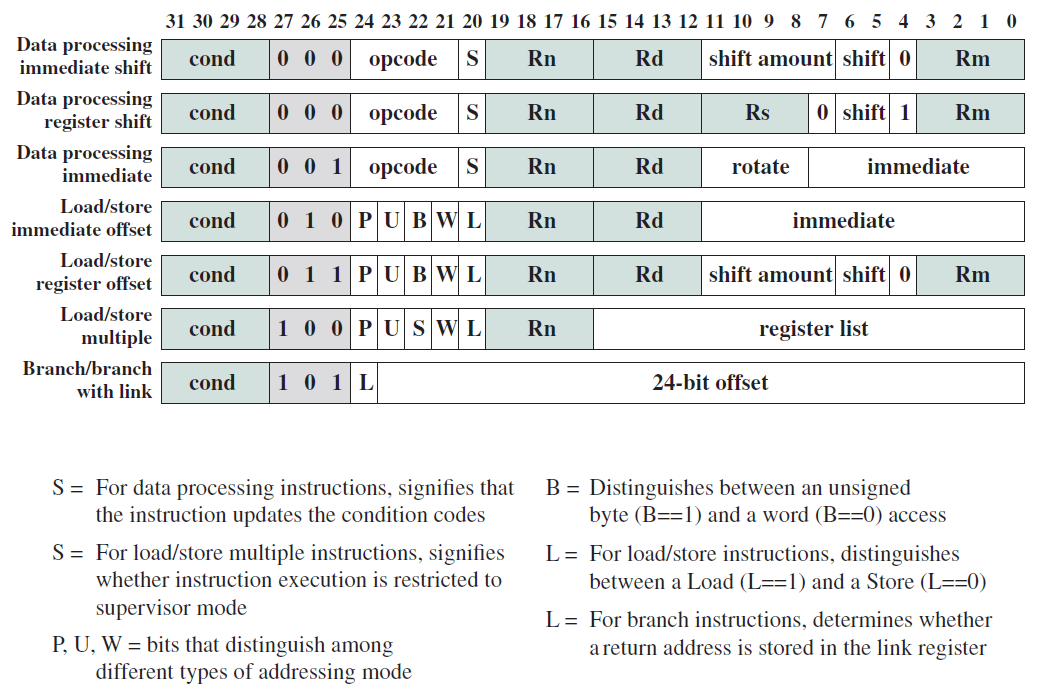
第26位稱為I(立即數)位,類似於前面所述的I位。如果將其設定為1,則第二個運算元是立即數,否則是暫存器。由於ARM有16條資料處理指令,需要4位元來表示它們,該資訊儲存在第22-25位。第21位儲存S位,如果開啟,則指令將設定CPSR。
其餘20位儲存輸入和輸出運算元。由於ARM有16個暫存器,需要4位元來編碼一個暫存器。第17-20位儲存第一個輸入運算元(rs)的識別符號,要求是一個暫存器。第13-16位元儲存目標暫存器(rd)的識別符號。
位1-12用於儲存立即數或移位器運算元,下面看看如何最好地利用這12位元。
ARM支援32位元立即數,然而實際上只有12位元來編碼它們。不可能對所有\(2^{32}\)個可能的值進行編碼,需要從中選擇一個有意義的子集,想法是使用12位元對32位元值的子集進行編碼,硬體預計將解碼這12位元,並在處理指令時將其擴充套件到32位元。
現在,12位元是一個相當不靈活的值,既不是1位元組,也不是2位元組。有必要想出一個非常巧妙的解決方案,想法是將12位元分為兩部分:4位元常數(rot)和8位元有效載荷(payload),參見下圖。

假設12位元中編碼的實際數位為n,有:
其中ror是右旋操作。通過將有效載荷右旋2倍於rot欄位中的值,獲得實際數位n。現在試著理解這樣做的邏輯。
數位n是32位元值。一個天真的解決方案是使用12位元來指定n的最小符號位,高階位可以是0。然而,程式設計師傾向於以位元組為單位存取資料和記憶體,因此1.5個位元組對我們毫無用處。更好的解決方案是使用1位元組的有效載荷,並將其放置在32位元欄位中的任何位置,其餘4位元用於此目的,它們可以對0到15之間的數位進行編碼。ARM處理器將該值加倍,以考慮0到30之間的所有偶數,將有效載荷向右旋轉該量。這樣做的好處是可以對更廣泛的數位集進行編碼,對於所有這些數位,有8位元對應於有效載荷,其餘24位元均為零。rot位僅確定32位元欄位中的哪8位元被有效載荷佔用。
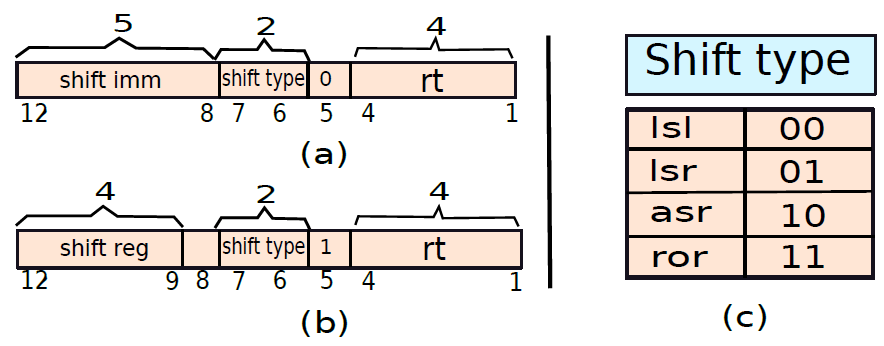
同樣地,通過合理地思考,可以得到以下的位移指令格式圖:
此外,載入、儲存指令格式如下:

而分支指令如下:

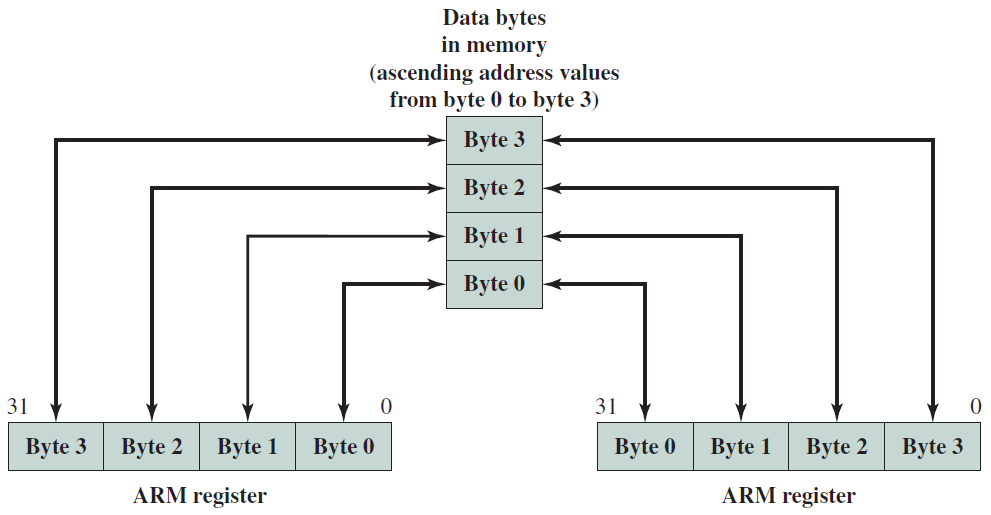
ARM Endian支援使用E-Bit載入/儲存字:
19.4.8 x86指令編碼
x86是真正的CISC指令集,其編碼過程更為規律,幾乎所有的指令都遵循標準格式。其次,x86中的操作碼通常有多種模式和字首。先看看編碼機器指令的廣泛結構,下圖顯示了二進位制編碼指令的結構。

x86二進位制指令格式。
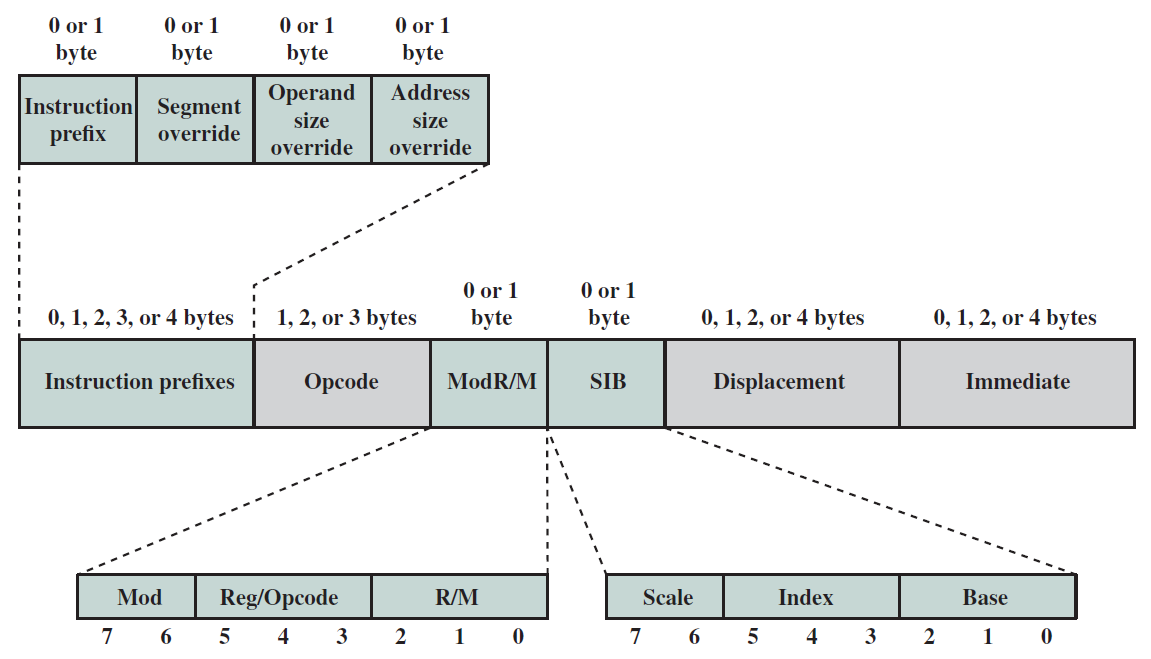
x86指令格式細節。
第一組1-4位元組用於編碼指令的字首,rep字首就是其中一個例子,還有許多其他型別的字首可以在第一組1-4位元組中編碼。
接下來的1-3個位元組用於對操作碼進行編碼,整個x86 ISA有數百條指令,操作碼還編碼運算元的格式。例如,加法指令可以將其第一個運算元作為記憶體運算元,也可以將其第二個運算元用作記憶體運算元。此資訊也是操作碼的一部分。
接下來的兩個位元組是可選的。第一個位元組被稱為ModR/M位元組,用於指定源暫存器和目標暫存器的地址,第二個位元組被稱作SIB(標度索引基)位元組,該位元組記錄基本縮放索引和基本縮放索引偏移定址模式的引數,記憶體地址可以可選地具有32位元的位移(在本書中也稱為偏移量)。因此,我們可以選擇在一條指令中多4個位元組來記錄位移值。最後,一些x86指令接受立即數作為運算元,立即數也可以大到32位元,因此,最後一個欄位(也是可選的)用於指定立即數運算元。
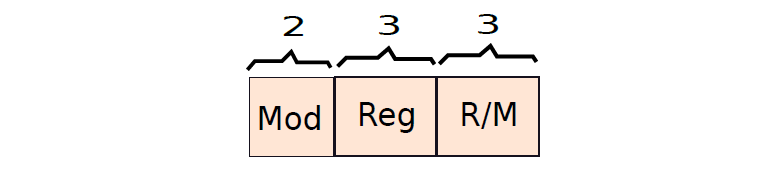
ModR/M位元組有三個欄位,如下圖所示:
SIB位元組的結構如下圖所示:

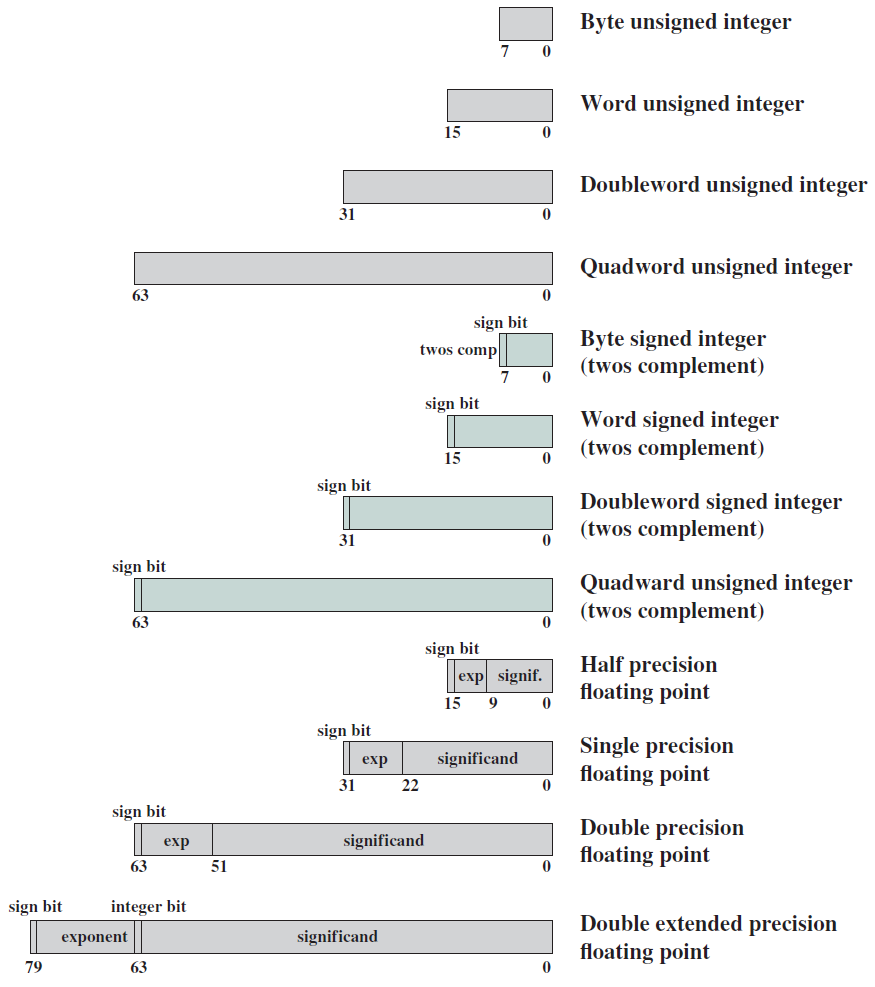
x86數位資料格式如下:
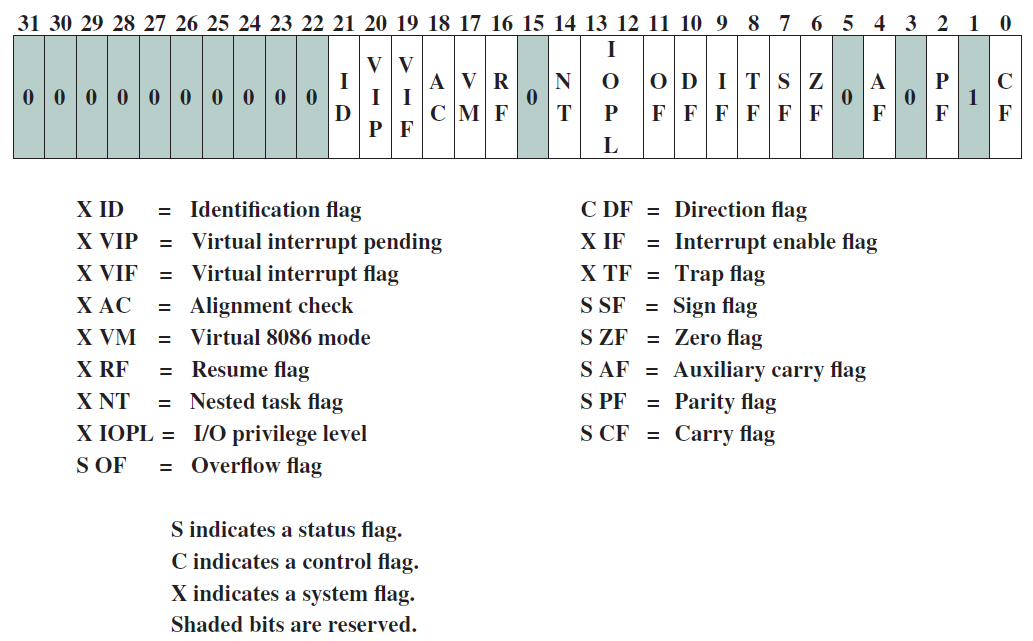
x86 EFLAGS暫存器:
x86控制暫存器:
MMX暫存器到浮點暫存器的對映:
19.5 處理器
19.5.1 指令處理概覽
我們可以將處理器的操作大致分為五個階段,如下圖所示。

指令處理的五個階段:指令獲取、運算元獲取、執行、記憶體存取、暫存器寫入。
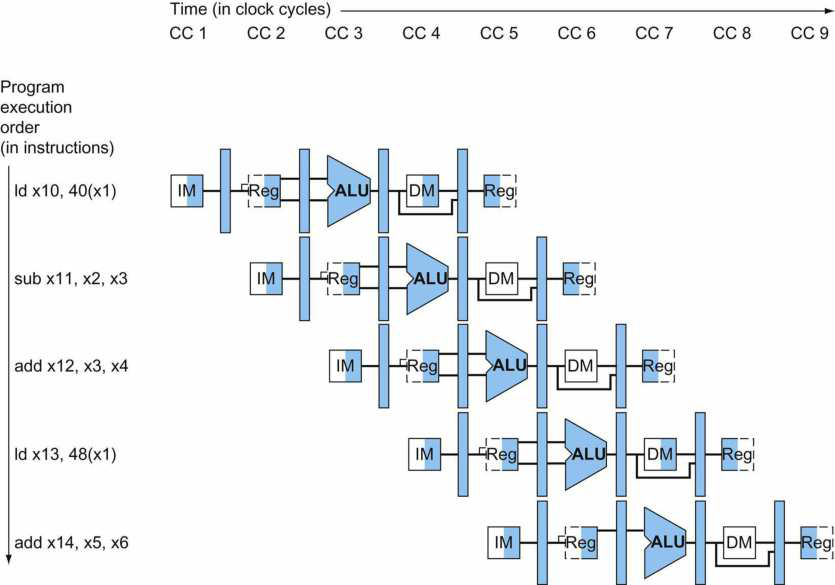
指令的多時鐘週期管線圖。圖中時間從左到右在頁面上前進,指令從頁面的頂部到底部前進。管線階段的表示沿指令軸放置在每個部分,佔據適當的時鐘週期。圖中顯示了每個階段之間的管線暫存器,資料路徑以圖形方式表示管線的五個階段,但命名每個管線階段的矩形也同樣有效。
第1步是從記憶體中獲取指令。機器的底層組織並不重要,該機器可以是馮·諾依曼機器(共用指令和資料記憶體),也可以是哈佛機器(專用指令記憶體)。提取階段有邏輯元件來計算下一條指令的地址,如果當前指令不是分支,那麼需要將當前指令的大小(4位元組)新增到儲存在PC中的地址。但如果當前指令是分支,那麼下一條指令的地址取決於分支的結果和目標。此資訊從處理器中的其他單元獲得。
第2步是解碼「指令並從暫存器中取出運算元。不同指令型別所需的處理非常不同,例如載入儲存指令使用專用的儲存單元,而算術指令則不使用。為了解碼指令,處理器有專用的邏輯電路,根據指令中的欄位生成訊號,這些訊號隨後被其他模組用來正確處理指令。像Intel處理器這樣的商用處理器有非常複雜的解碼單元,解碼x86指令集非常複雜。不管解碼的複雜程度如何,解碼過程通常包括以下步驟:
- 提取運算元的值,計算嵌入的立即數並將其擴充套件到32或64位元,以及生成關於指令處理的附加資訊。
- 生成關於指令的更多資訊的過程包括生成處理器專用訊號。例如,可以為載入/儲存指令生成「啟用記憶體單元」形式的訊號,對於儲存指令,可以生成一個禁用暫存器寫入功能的訊號。
第3步是執行算術和邏輯運算。它包含一個能夠執行所有算術和邏輯運算的算術和邏輯單元(ALU),ALU還需要計算載入儲存操作的有效地址,通常情況下處理器的這一部分也計算分支的結果。
ALU(算術邏輯單元)包含用於對資料值執行算術和邏輯計算的元素,通常包含加法器、乘法器、除法器,並具有計算邏輯位運算的單元。
第4步包含用於處理載入儲存指令的儲存單元。該單元與記憶體系統介面,並協調從記憶體載入和儲存值的過程。典型處理器中的記憶體系統相當複雜,其中一些複雜性是在處理器的這一部分中實現的。
第5步是將ALU計算的值或從記憶體單元獲得的載入值寫入暫存器檔案。
單個指令所需的處理稱為指令週期。使用前面給出的簡化的兩步描述,指令週期如下圖所示,這兩個步驟被稱為獲取週期和執行週期。只有在機器關閉、發生某種不可恢復的錯誤或遇到使計算機停止的程式指令時,程式執行才會停止。
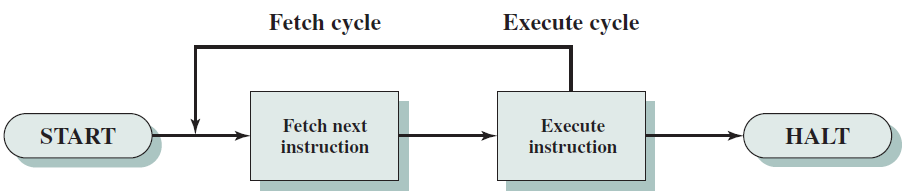
基本指令週期。
考慮一個使用假設機器的簡單範例,該機器包括下圖中列出的特性。處理器包含一個稱為累加器(AC)的資料暫存器,指令和資料都是16位元長,因此使用16位元字組織記憶體是方便的。指令格式為操作碼提供4位元,因此可以有多達\(2^4=16\)個不同的操作碼,並且可以直接定址多達\(2^{12}=4096\)(4K)個字的記憶體。
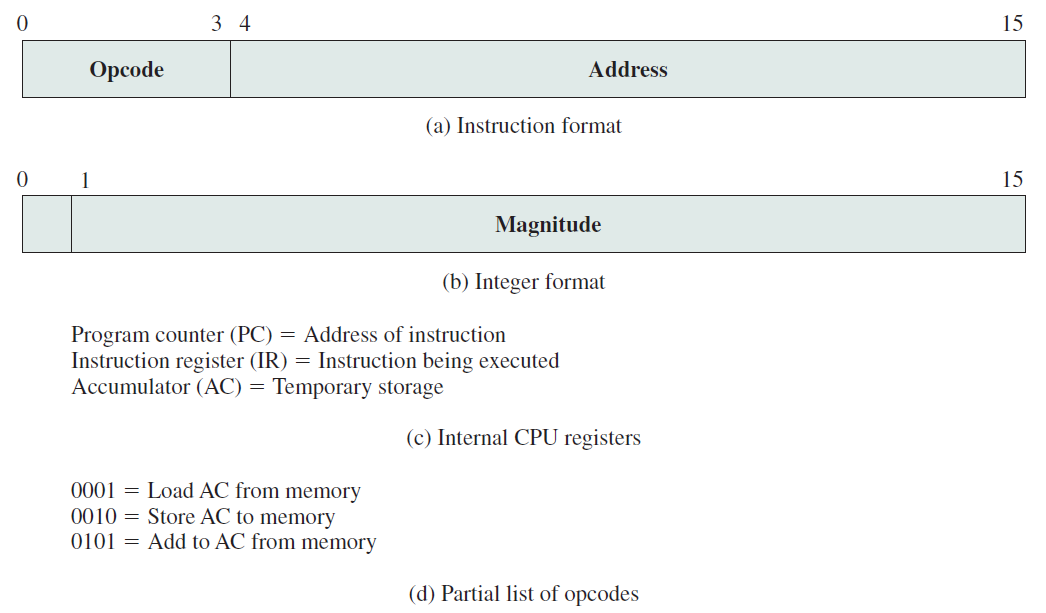
假想機器的特性。
下圖說明了部分程式執行,顯示了記憶體和處理器暫存器的相關部分。所示的程式片段將地址940處的儲存字的內容新增到地址941處的記憶體字的內容,並將結果儲存在後一位置。需要三條指令,可以描述為三個獲取和三個執行週期:
1、PC包含300,即第一條指令的地址。該指令(十六進位制值1940)被載入到指令暫存器IR中,PC遞增。注意,此過程涉及使用記憶體地址暫存器和記憶體緩衝暫存器。為了簡單起見,這些中間暫存器被忽略。
2、IR中的前4位元(第一個十六進位制數位)表示要載入AC,剩餘的12位元(三個十六進位制數位)指定要載入資料的地址(940)。
3、從位置301獲取下一條指令(5941),並且PC遞增。
4、新增AC的舊內容和位置941的內容,並將結果儲存在AC中。
5、從位置302取出下一條指令(2941),並且PC遞增。
6、AC的內容儲存在位置941中。
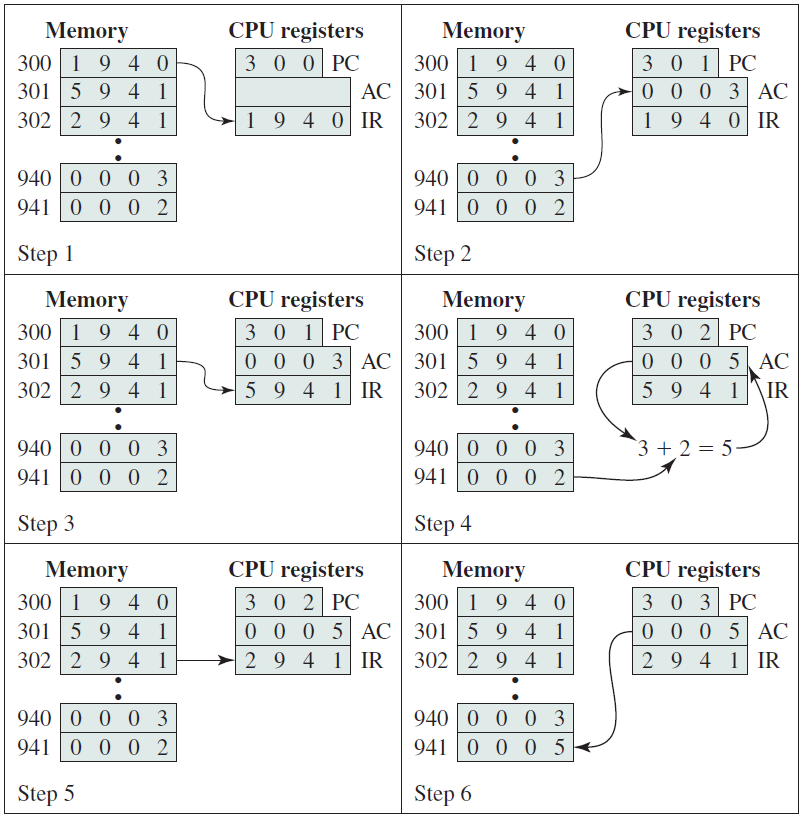
程式執行範例(記憶體和暫存器的內容為十六進位制)。
特定指令的執行週期可能涉及對記憶體的不止一次參照。此外,指令可以指定I/O操作,而不是記憶體參照。考慮到這些額外的考慮因素,圖下圖提供了基本指令週期的更詳細的檢視,該圖採用狀態圖的形式。對於任何給定的指令週期,某些狀態可能為空,而其他狀態可能被存取多次。
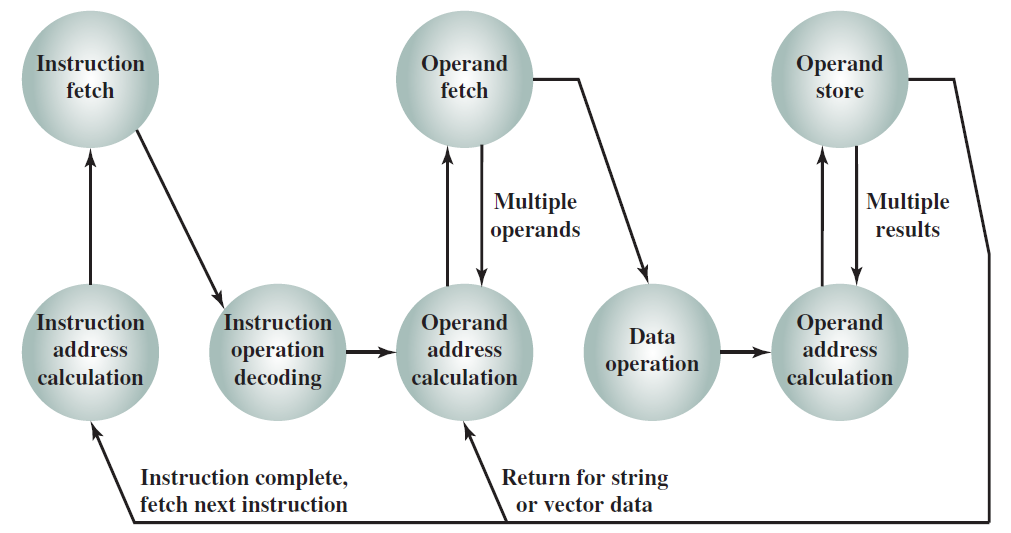
指令週期狀態圖。
狀態描述如下:
- 指令地址計算(iac):確定要執行的下一條指令的地址,通常需要在前一條指令的地址上新增一個固定的數位,例如如果每條指令的長度為16位元,並且記憶體被組織為16位元字,則在前一個地址上加1。相反,如果記憶體被組織為可單獨定址的8位元位元組,則在前一個地址上加2。
- 指令獲取(if):將指令從其記憶體位置讀入處理器。
- 指令操作解碼(iod):分析指令以確定要執行的操作型別和要使用的運算元。
- 運算元地址計算(oac):如果操作涉及對記憶體中的運算元的參照或通過I/O可用的運算元,則確定運算元的地址。
- 運算元獲取(of):從記憶體中獲取運算元或從I/O中讀取運算元。
- 資料操作(do):執行指令中指示的操作。
- 運算元儲存(os):將結果寫入記憶體或輸出到I/O。
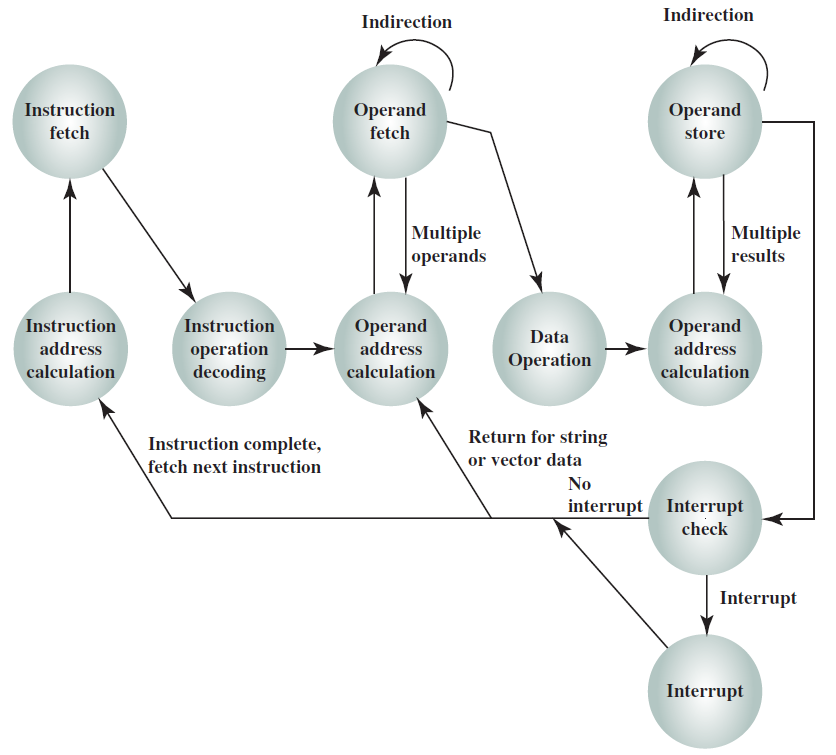
下圖顯示了包括中斷週期處理的修訂指令週期狀態圖:
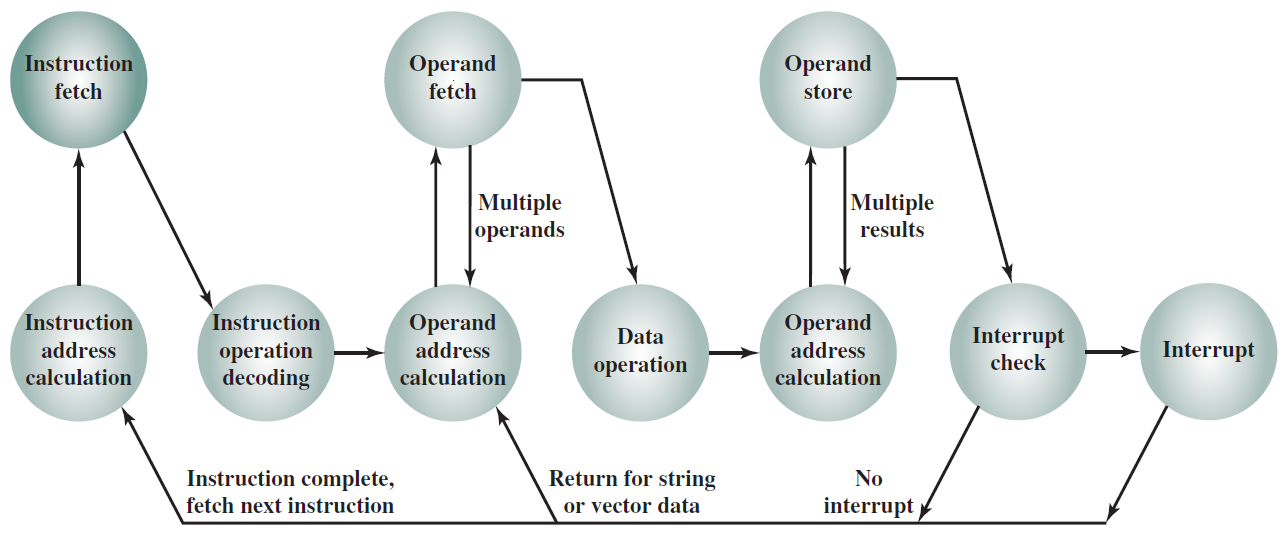
下圖左是非直接時鐘週期,右是中斷時鐘週期:
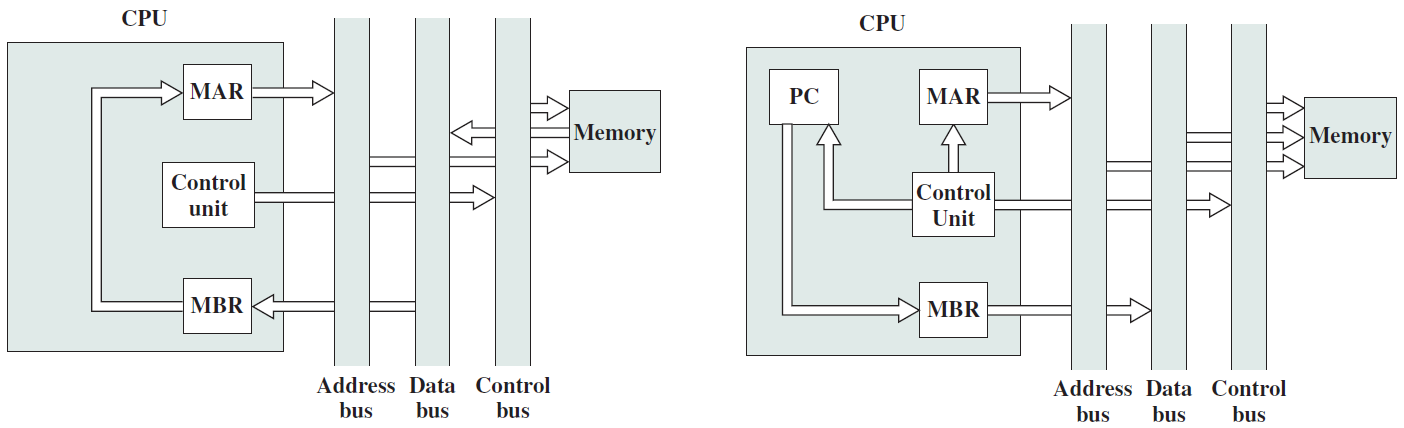
下圖通過指出每種模組型別的主要輸入和輸出形式,說明了所需的交換型別:

微處理器暫存器組織範例:
19.5.2 處理器結構
19.5.2.1 處理器單元
處理器內部包含了諸多單元,諸如獲取單元、資料路徑和控制單元、運算元獲取單元、執行單元(分支單元、ALU)、記憶體存取單元、暫存器回寫單元等等。
下圖顯示了獲取單元電路的實現。在一個週期中需要執行兩個基本操作:1、下一個PC(程式計數器)的計算;2、獲取指令。
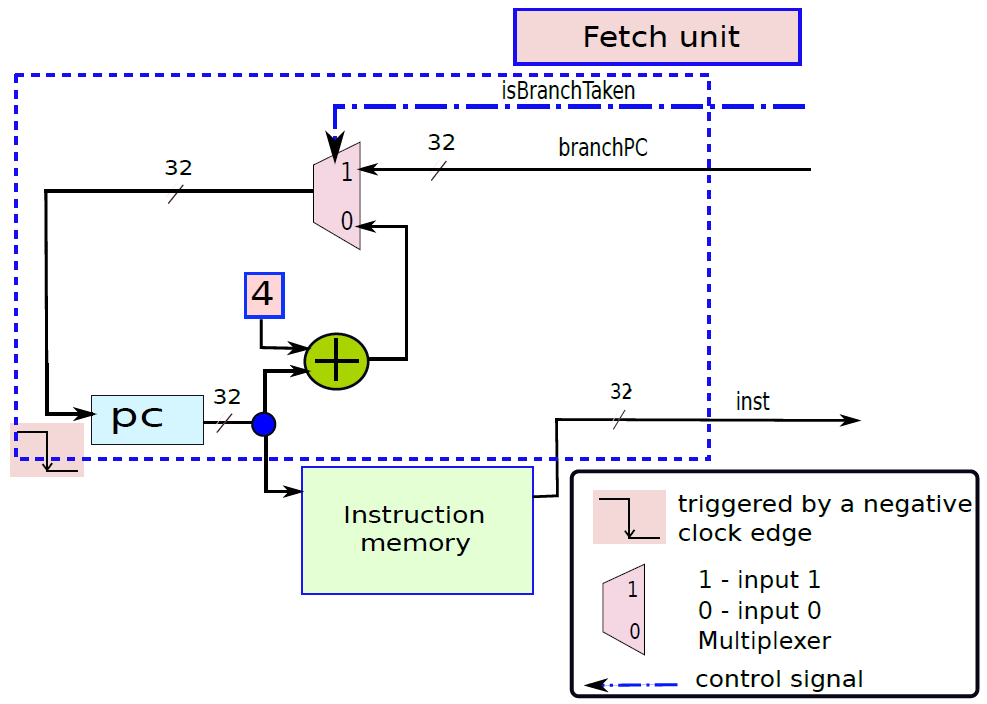
電路中有兩種元件:
- 第一類元件是暫存器、記憶體、算術和邏輯電路,用於處理資料值。
- 第二類元素是決定資料流方向的控制單元。處理器中的控制單元通常生成訊號以控制所有多路複用器(multiplexer),被稱為控制訊號(control signal),因為其作用是控制資訊流。
因此,我們可以從概念上認為處理器由兩個不同的子系統組成:
- 資料路徑(data path)。它包含儲存和處理資訊的所有元素。例如,資料記憶體、指令記憶體、暫存器檔案和ALU(算術邏輯單元)是資料路徑的一部分。記憶體和暫存器儲存資訊,而ALU處理資訊,例如,它將兩個數位相加,併產生和作為結果,或者它可以計算兩個數位的邏輯函數。
- 控制路徑(control path)。它通過生成訊號來引導資訊的正確流動,生成一個訊號,指示多路複用器在分支目標和預設下一個PC之間進行選擇。在這種情況下,多路複用器由訊號
isBranchTaken控制。
我們可以將控制路徑和資料路徑視為電路的兩個不同元件,就像城市的交通網路一樣。道路和紅綠燈類似於資料路徑,控制交通燈的電路構成了控制路徑,控制路徑決定燈光轉換的時間。在現代智慧城市中,控制城市中所有交通燈的過程通常是整合的。如果有可能智慧控制交通,使汽車繞過交通堵塞和事故現場。類似地,處理器的控制單元相當智慧,它的工作是儘可能快地執行指令。現代處理器的控制單元已經非常複雜。
資料路徑(data path):資料路徑由處理器中專用於儲存、檢索和處理資料的所有元素組成,如暫存器、記憶體和ALU。
控制路徑(control path):控制路徑主要包含控制單元,其作用是生成適當的訊號來控制資料路徑中指令和資料的移動。
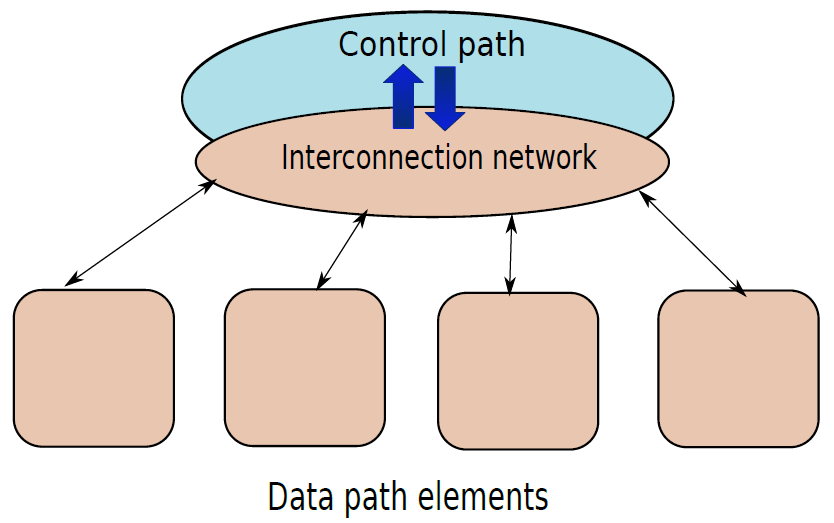
資料路徑和控制路徑之間的關係。
現在看看執行指令。首先將指令分為兩種型別:分支和非分支。分支指令由計算分支結果和最終目標的專用分支單元處理,非分支指令由ALU(算術邏輯單元)處理。分支單元的電路如下圖所示:
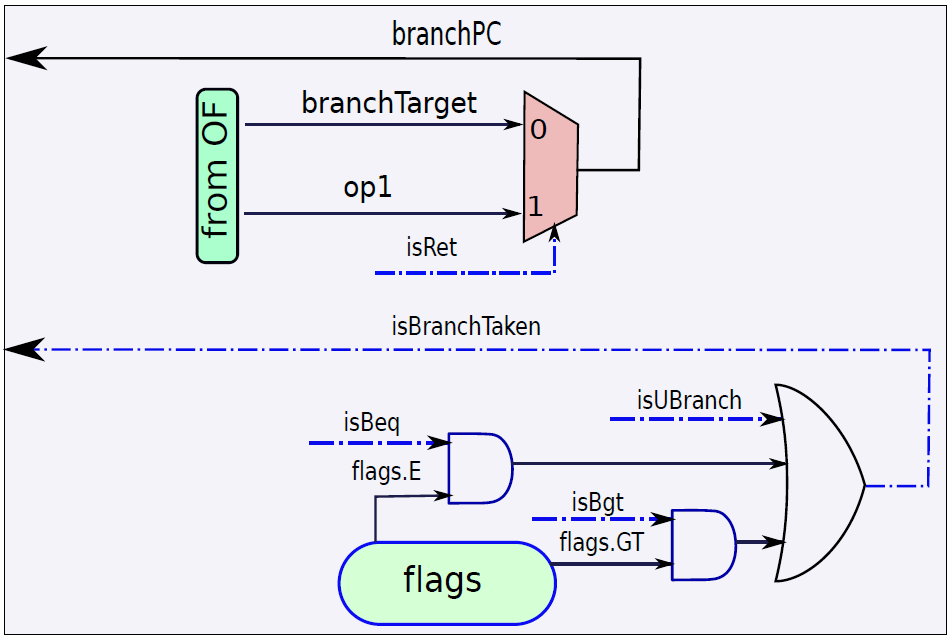
使用多路複用器在返回地址(op1)的值和指令中嵌入的branchT目標之間進行選擇。isRet訊號控制多路複用器,如果它等於1就選擇op1,否則選擇分支目標。多路複用器branchPC的輸出被傳送到提取單元。
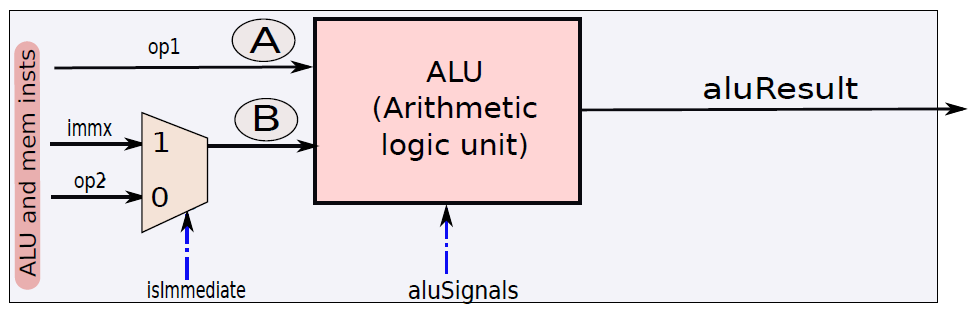
下圖顯示了包含ALU的執行單元部分。ALU的第一個運算元(A)始終為op1(從運算元獲取單元獲得),但第二個運算元(B)可以是暫存器或符號擴充套件立即數,由控制單元生成的isImmediate訊號決定,isImmediate訊號等於指令中立即數位的值,如果是1,則圖中的多路複用器選擇immx作為運算元,如果為0,則選擇op2作為運算元。ALU將一組訊號作為輸入,統稱為aluSignals,aluSignals由控制單元生成,並指定ALU操作的型別。ALU的結果稱為aluResult。
下圖顯示了ALU的一種設計。ALU包含一組模組,每個模組計算單獨的算術或邏輯函數,如加法或除法。其次,每個模組都有一個啟用或禁用它的專用訊號,例如,當我們想執行簡單的加法時,沒有理由啟用除法器。有幾種方法可以啟用或禁用單元,最簡單的方法是為每個輸入位使用一個傳輸門(transmission gate,見下下圖),如果訊號(S)開啟,則輸出反映輸入值。否則,它將保持其以前的值。因此,如果啟用訊號關閉,則模組不會看到新的輸入。因此,它不會耗散功率,並被有效禁用。
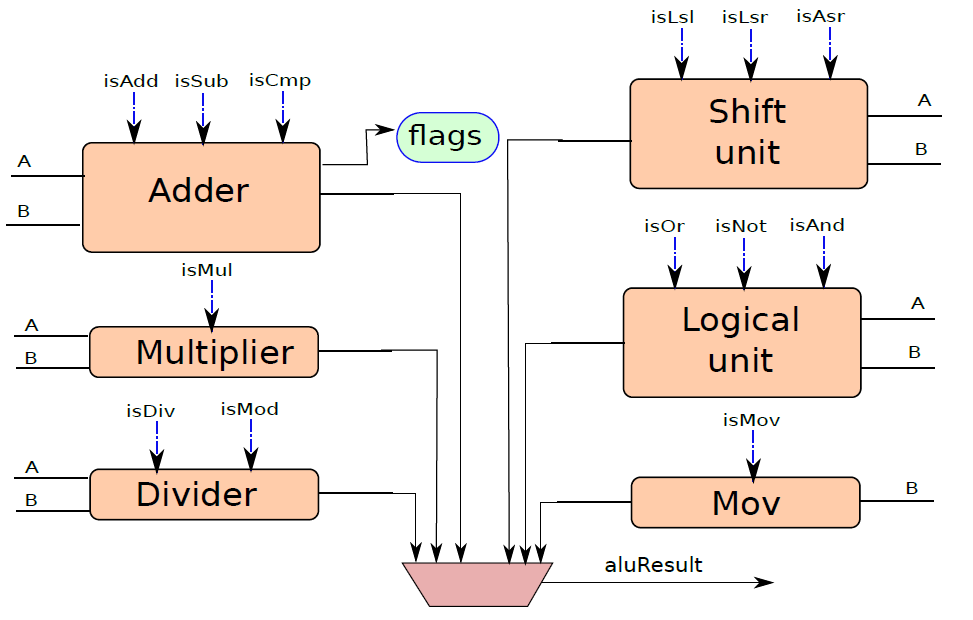
ALU。
傳輸門。
總之,下圖展示了執行單元(分支單元和ALU)的完整設計。要設定輸出(aluResult),需要一個多路複用器,可以從ALU中的所有模組中選擇正確的輸出,沒有在圖中顯示此多路複用器。
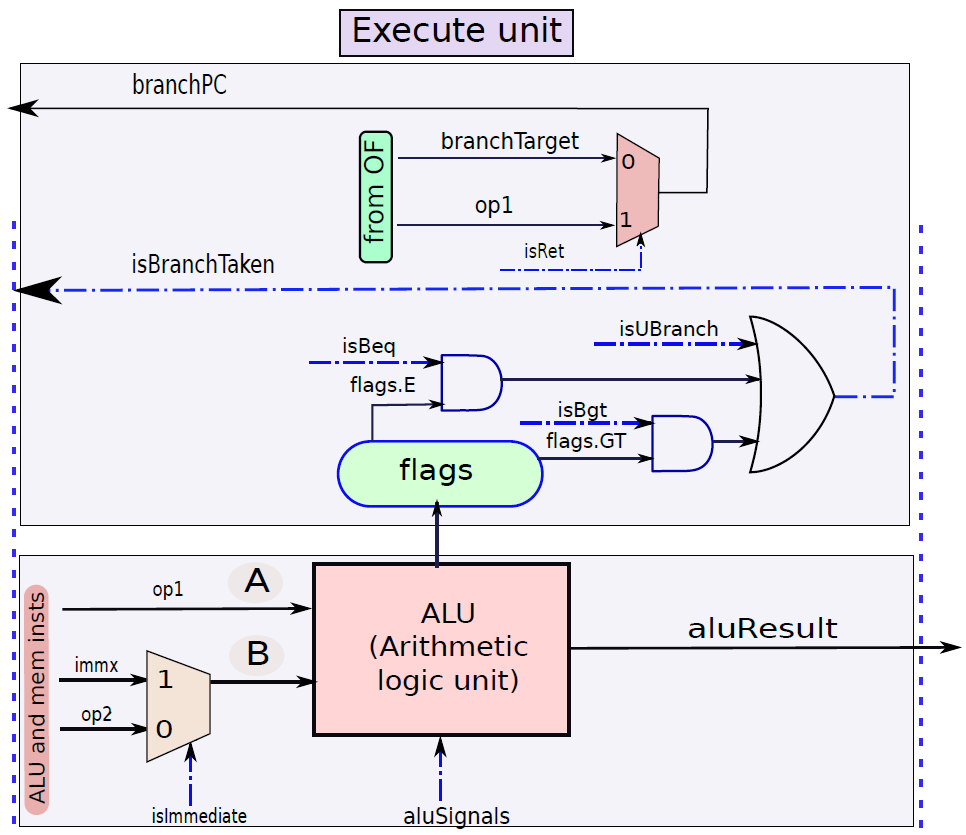
執行單元(分支和ALU單元)。
下圖顯示了記憶體存取單元。它有兩個輸入{資料和地址,地址由ALU計算,它等於ALU的結果(aluResult),載入和儲存指令都使用這個地址,地址儲存在傳統上稱為MAR(記憶體地址暫存器)的暫存器中。
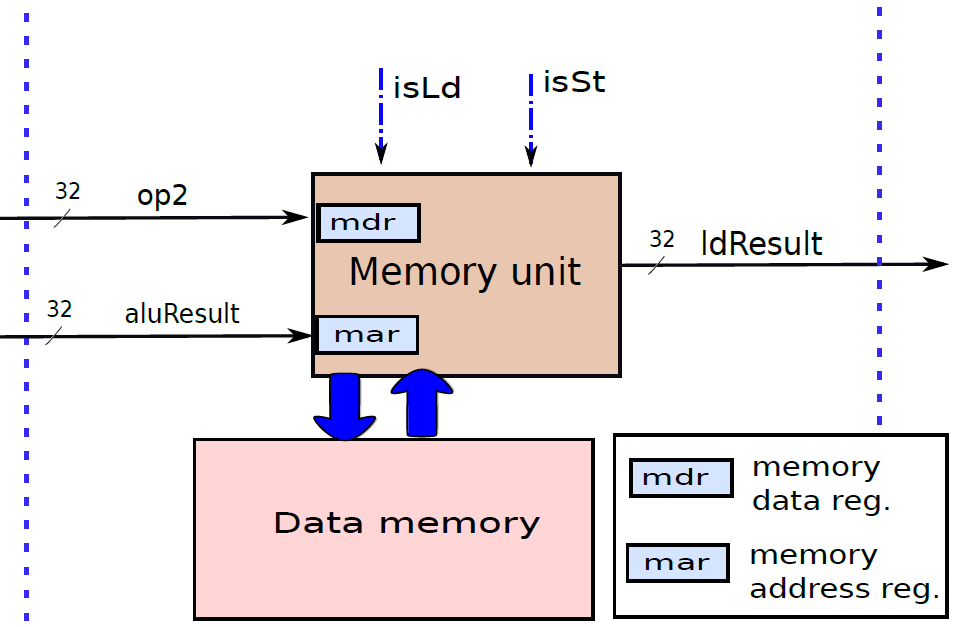
記憶體單元。
通過連線所有部分來形成整體。到目前為止,已經將處理器分為五個基本單元:指令獲取單元(IF)、運算元獲取單元(OF)、執行單元(EX)、記憶體存取單元(MA)和暫存器寫回單元(RW)。是時候把所有的部分結合起來,看看統一的圖片了(下圖,省略了詳細的電路,只關注資料和控制訊號的流動)。
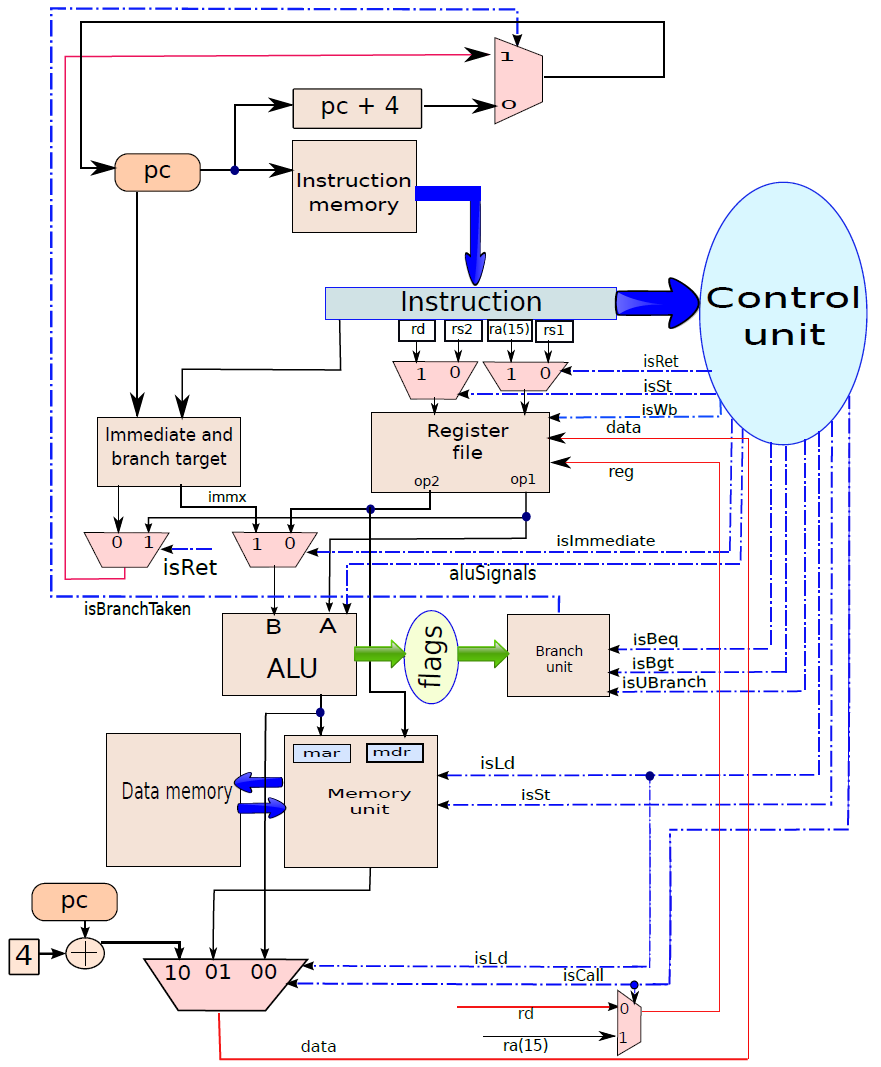
一個基礎處理器。
19.5.2.2 控制單元
一個簡單處理器的硬接線控制單元可以被認為是一個黑盒子,它以6位作為輸入(5個操作碼位和1個立即數位),併產生22個控制訊號作為輸出。如下圖所示。
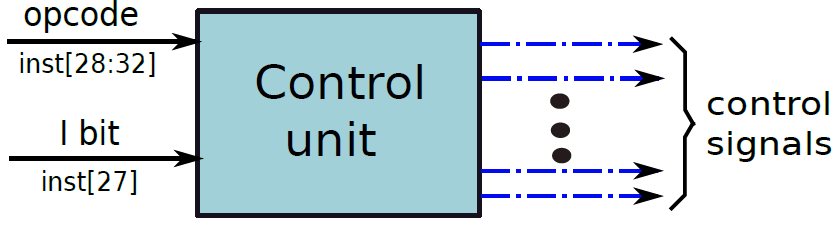
硬接線控制單元的抽象。
控制單元的結構圖。
硬接線控制單元快速高效,這就是今天大多數商用處理器使用硬接線控制單元的原因,但硬接線控制單元並不十分靈活,例如在處理器出廠後,不可能更改指令的行為,甚至不可能引入新指令。有時如果功能單元中存在錯誤,需要更改指令的執行方式,例如如果乘法器存在設計缺陷,那麼理論上可以使用加法器和移位單元執行布斯乘法演演算法。然而,我們需要一個非常複雜的控制單元來動態地重新設定指令的執行方式。
支援靈活的控制單元還有其他更實際的原因。某些指令集(如x86)具有重複指令給定次數的rep指令,它們還具有複雜的字串指令,可以處理大量資料,支援此類指令需要非常複雜的資料路徑。原則上,我們可以通過精心設計的控制單元來執行這些指令,而這些控制單元又有簡單的處理器來處理這些指令,這些子處理器可以生成用於實現複雜CISC指令的控制訊號。
資料路徑和控制訊號。
帶內部匯流排的CPU。
19.5.2.3 基於微程式的處理器
前面已經研究了帶有硬接線控制單元的處理器,設計了一個包含處理和執行指令所需的所有元素的資料路徑。在輸入運算元之間有選擇的地方,新增了一個多路複用器,它由來自控制單元的訊號控制。控制單元將指令的內容作為輸入,並生成所有控制訊號。現代高效能處理器通常採用這種設計風格。請注意,效率是有代價的,成本是靈活性。我們可能需要新增更多的多路複用器,併為每個新指令生成更多的控制訊號。其次,在處理器交付給客戶後,不可能向處理器新增新指令。有時候,我們渴望這樣的靈活性。
通過引入將ISA中的指令轉換為一組簡單微指令的轉換表,可以引入這種額外的靈活性。每個微指令都可以存取處理器的所有鎖存器和內部狀態元素。通過執行一組與指令關聯的微指令,我們可以實現該指令的功能,這些微指令或微程式碼儲存在微程式碼錶中。通常可以通過軟體修改該表的內容,從而改變硬體執行指令的方式。有幾個原因需要這種靈活性,允許我們新增新指令或修改現有指令的行為。其中一些原因如下:
- 處理器在執行某些指令時有時會出現錯誤。因為設計師在設計過程中犯下的錯誤,或者是由於製造缺陷,其中一個著名的例子是英特爾奔騰處理器中的除法錯誤,英特爾不得不召回它賣給客戶的所有奔騰處理器。如果可以動態地更改除法指令的實現,那麼就不必呼叫所有處理器。因此可以得出結論,處理器的某種程度的可重構性有助於解決在設計和製造過程的各個階段可能引入的缺陷。
- 英特爾奔騰4等處理器,以及英特爾酷睿i3和英特爾酷睿i7等更高版本的處理器,通過執行儲存在記憶體中的一組微指令來實現一些複雜的指令。通常使用微碼來實現資料串或指令的複雜操作,這些操作會導致一系列重複計算,意味著英特爾處理器在內部將複雜指令替換為包含簡單指令的程式碼段,使得處理器更容易實現複雜的指令。我們不需要對資料路徑進行不必要的更改,新增額外的狀態、多路複用器和控制訊號來實現複雜的指令。
- 當今的處理器只是晶片的一部分,有許多其他元件,被稱為片上系統(system-on-chip,SOC)。例如,手機中的晶片可能包含處理器、視訊控制器、相機介面、聲音和網路控制器。處理器供應商通常會硬連線一組簡單的指令,而與視訊和音訊控制器等外圍裝置介面的許多其他指令都是用微碼編寫的。根據應用程式域和外圍元件集,可以客製化微碼。
- 有時使用一組專用微指令編寫自定義診斷例程。這些例行程式在晶片執行期間測試晶片的不同部分,報告故障並採取糾正措施。這些內建自檢(BIST)例程通常是可客製化的,並以微碼編寫。例如,如果我們希望高可靠性,那麼我們可以修改在CPU上執行可靠性檢查的指令的行為,以檢查所有元件。但是,為了節省時間,可以壓縮這些例程以檢查更少的元件。
因此,我們觀察到,有一些令人信服的理由能夠以程式設計方式改變處理器中指令的行為,以實現可靠性、實現附加功能並提高可移植性。因此,現代計算系統,尤其是手機和平板電腦等小型裝置使用的晶片依賴於微碼。這種微碼序列通常被稱為韌體。
現代計算系統,尤其是手機、資料機、印表機和平板電腦等小型裝置,使用的晶片依賴於微碼。這種微碼序列通常被稱為韌體(firmware)。
因此,讓我們設計一個基於微程式的處理器,即使在處理器被製造並行送給客戶之後,它也能為我們提供更大的靈活性來客製化指令集。需要注意,常規硬接線處理器和微程式設計處理器之間存在著基本的權衡。權衡是效率與靈活性,不能指望有一個非常靈活的處理器,它既快速又省電。
19.5.2.4 微程式設計資料路徑
讓我們為微程式處理器設計資料路徑,修改處理器的資料路徑。處理器有一些主要單元,如提取單元、暫存器檔案、ALU、分支單元和記憶體單元。這些單元是用導線連線的,只要有可能有多個源運算元,我們就在資料路徑中新增一個多路複用器。控制單元的作用是為多路複用器生成所有控制訊號。
問題是多路複用器的連線是硬接線的,不能建立任意連線,例如,不能將儲存單元的輸出傳送到執行單元的輸入。因此我們希望有一個元件之間沒有固定互連的設計,理論上任何單位都可以向任何其他單位傳送資料。
最靈活的互連是基於匯流排的結構。匯流排是一組連線所有單元的普通銅線,支援一個寫入,在任何時間點支援多個讀者。例如,單元A可以在某個時間點寫入匯流排,所有其他單元都可以獲得單元A寫入的值。如果需要,可以將資料從一個單元傳送到另一個單元,或從一個裝置傳送到一組其他單元。控制單元需要確保在任何時間點,只有一個單元寫入匯流排,需要處理正在寫入的值的單元從匯流排讀取值。
現在讓我們繼續設計我們為硬連線處理器引入的所有單元的簡化版本,這些簡化版本可以適當地用於我們的微程式處理器的資料路徑。
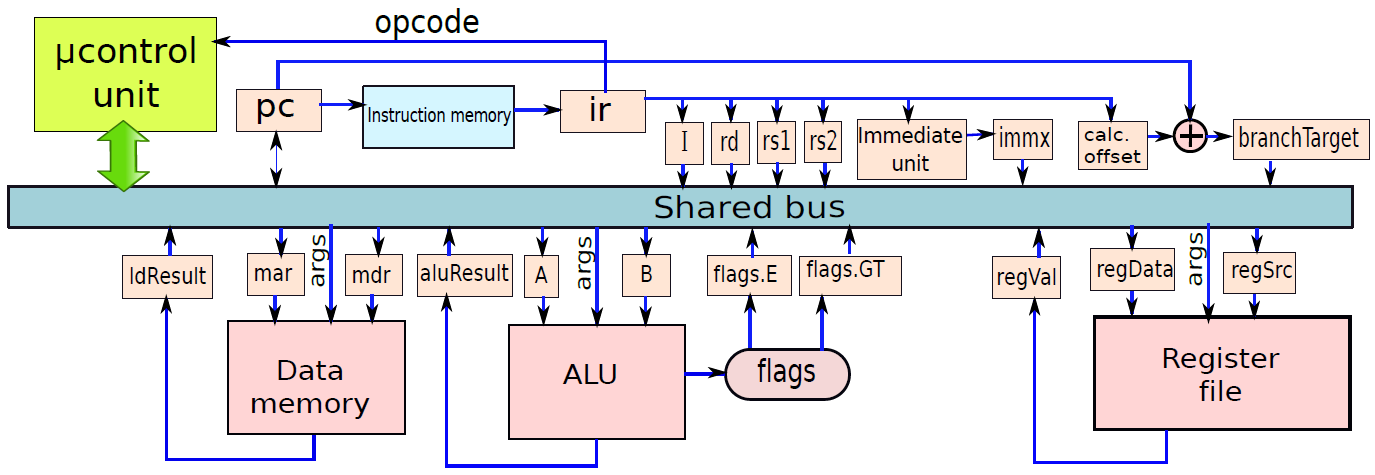
讓我們從解釋微程式處理器的設計原理開始。我們為每個單元新增暫存器,這些暫存器儲存特定單元的輸入資料,專用輸出暫存器儲存單元生成的結果,這兩組暫存器都連線到公共匯流排。與硬連線處理器不同的是,在不同的單元之間存在大量的耦合,微程式處理器中的單元是相互獨立的。他們的工作是執行一組操作,並將結果返回匯流排。每個單元就像程式語言中的一個函數,它有一個由一組暫存器組成的介面,用於讀取資料,通常需要1個週期來計算其輸出,然後該單元將輸出值寫入輸出暫存器。
根據上述原理,下圖中展示了提取單元的設計,它有兩個暫存器:pc(程式計數器)和ir(指令暫存器)。pc暫存器可以從匯流排讀取其值,也可以將其值寫入匯流排,沒有將ir連線到匯流排,因為沒有其他單位對指令的確切內容感興趣,其他單位只對指令的不同欄位感興趣。因此,有必要解碼指令並將其分解為一組不同的欄位,由解碼單元完成。
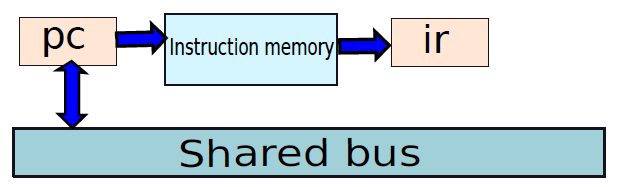
微程式處理器中的提取單元。
解碼單元在功能上類似於運算元獲取單元,但我們不在該單元中包含暫存器檔案,而將其視為微程式處理器中的一個獨立單元。下圖顯示了運算元獲取單元的設計。
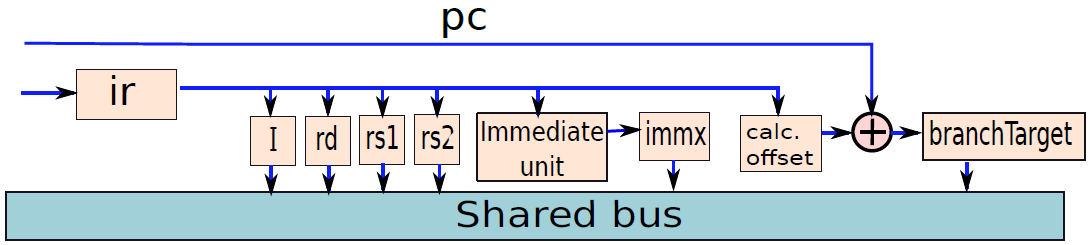
微程式處理器中的解碼單元。
我們將解碼單元和暫存器檔案組合成一個單元,稱為硬連線處理器的運算元獲取單元,但更期望在微程式處理器中保持暫存器檔案獨立,因為在硬連線處理器中,它在解碼指令後立即被存取。然而,微程式處理器可能不是這樣——在指令執行期間,可能需要多次存取它。
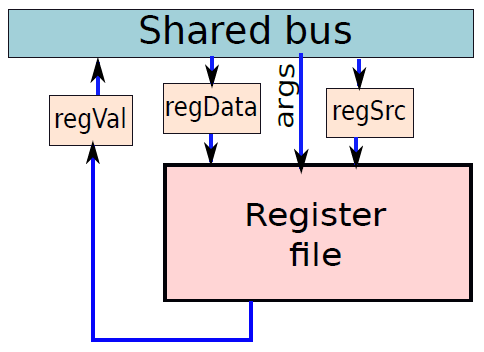
微程式處理器中的暫存器檔案。
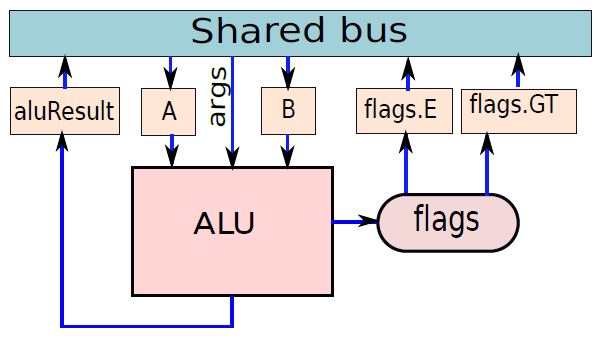
ALU的結構如下圖所示,有兩個輸入暫存器,A和B。ALU對暫存器A和B中包含的值執行操作,操作的性質由args值指定。例如,如果指定了加法運算,則ALU將暫存器A和B中包含的值相加。如果指定了減法運算,那麼將從A中包含的數值減去B中的值,對於cmp指令,ALU更新標誌。使用兩個標誌來指定相等和大於條件,分別儲存在暫存器標誌flags.E和標誌flags.GT中,然後ALU運算的結果儲存在暫存器aluResult中。此處還假設ALU在匯流排上指定args值後需要1個週期才能執行。
微程式處理器中的ALU。
記憶體單元如下圖所示。與硬連線處理器一樣,它有兩個源暫存器:mar(記憶體地址暫存器)和mdr(記憶體資料暫存器),mar緩衝記憶體地址,mdr緩衝需要儲存的值。還需要一組引數來指定記憶體操作的性質:載入或儲存,載入操作完成後,ldResult暫存器中的資料可用。
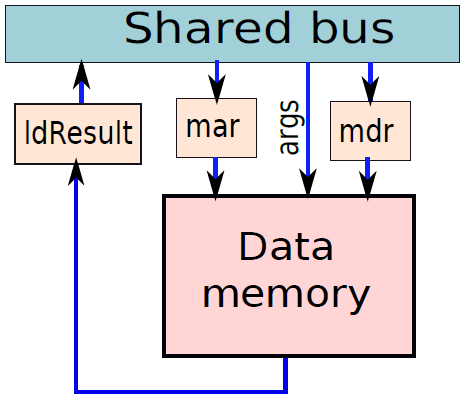
微程式處理器中的儲存單元。
綜上,微程式處理器中的資料路徑總覽如下:
19.5.3 管線處理器
19.5.3.1 管線概述
假設前面介紹的硬連線處理器需要一個週期來獲取、執行和將指令的結果寫入暫存器檔案或記憶體。在電氣層面上,是通過從提取單元經由其他單元流到暫存器寫回單元的訊號來實現的,而電訊號從一個單元傳播到另一個單元需要時間。
例如,從指令記憶體中獲取指令需要一些時間。然後需要時間從暫存器檔案讀取值,並用ALU計算結果。記憶體存取和將結果寫回暫存器檔案也是相當耗時的操作。需要等待所有這些單獨的子操作完成,然後才能開始處理下一條指令,意味著電路中有大量的空閒,當運算元獲取單元執行其工作時,所有其他單元都處於空閒狀態。同樣,當ALU處於活動狀態時,所有其他單元都處於非活動狀態。如果我們假設五個階段(IF、OF、EX、MA、RW)中的每一個都需要相同的時間,那麼在任何時刻,大約80%的電路都是空閒的!這代表了計算能力的浪費,空閒資源絕對不是一個好主意。
如果能找到一種方法讓晶片的所有單元保持忙碌,那麼就能提高執行指令的速度。
管線流程
不妨類比一下前面討論的簡單單週期處理器中的空閒問題。當一條指令在EX階段時,下一條指令可以在OF階段,而後續指令可以在IF階段。事實上,如果在處理器中有5個階段,簡單地假設每個階段花費的時間大致相同,可以假設同時處理5條指令,每條指令在處理器的不同單元中進行處理。類似於流水線中的汽車,指令在處理器中從一個階段移動到另一個階段。此策略確保處理器中沒有任何空閒單元,因為處理器中的所有不同單元在任何時間點都很忙。
在此方案中,指令的生命週期如下。它在週期n中進入IF階段,在週期n+1中進入OF階段,週期n+2中進入EX階段,迴圈n+3中進入MA階段,最後在週期n+4中完成RW階段的執行。這種策略被稱為流水線(pipelining,又名管線、管道),實現流水線的處理器被稱為流水處理器(pipelined processor)。五個階段(IF、OF、EX、MA、RW)的順序在概念上一個接一個地佈置,稱為流水線(pipeline,類似於汽車裝配線)。下圖顯示了流水線資料路徑的組織。

流水線資料路徑。
上圖中,資料路徑分為五個階段,每個階段處理一條單獨的指令。在下一個週期中,每條指令都會傳遞到下一個階段,如圖所示。
效能優勢
現在,讓我們考慮流水線處理器的情況,假設階段是平衡的,意味著執行每個階段需要相同的時間,大多數時候,處理器設計人員都會盡可能最大程度地實現這個目標。因此可以將r除以5,得出執行每個階段需要r/5納秒的結論,可以將回圈時間設定為r/5。迴圈結束後,流水線每個階段中的指令進入下一階段,RW階段的指令移出流水線並完成執行,同時,新指令進入IF階段。如下圖所示。
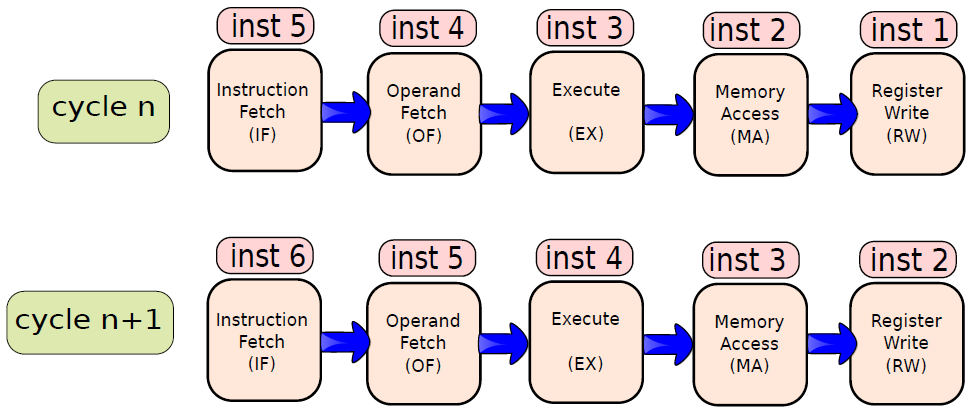
流水線中的指令。
如果我們可以用5階段流水線獲得5倍的優勢,那麼按照同樣的邏輯,應該可以用100階段流水線得到100倍的優勢。事實上,可以不斷增加階段的數量,直到一個階段只包含一個電晶體。但情況並非如此,流水線處理器的效能存在根本性的限制,不可能通過增加流水線階段的數量來任意提高處理器的效能。在一定程度上,增加更多的階段會適得其反。
下圖a描述了不使用流水線的指令序列的時序,顯然是一個浪費的過程,即使是非常簡單的流水線也可以大大提高效能。下圖b顯示了兩階段流水線方案,其中兩個不同指令的I級和E級同時執行。流水線的兩個階段是指令獲取階段和執行指令的執行/記憶體階段,包括暫存器到記憶體和記憶體到暫存器的操作,因此我們看到第二條指令的指令提取階段可以與執行/儲存階段的第一部分並行執行。然而,第二條指令的執行/儲存階段必須延遲,直到第一條指令清除流水線的第二階段。該方案的執行率可以達到序列方案的兩倍,兩個問題阻礙了實現最大加速。首先,我們假設使用單埠記憶體,並且每個階段只能存取一個記憶體,需要在某些指令中插入等待狀態。第二,分支指令中斷順序執行流,為了以最小的電路來適應這種情況,編譯器或組合器可以將NOOP指令插入到指令流中。
通過允許每個階段進行兩次記憶體存取,可以進一步改進流水線,產生了下圖c所示的序列。現在最多可以重疊三條指令,其改程序度為3倍,同樣,分支指令會導致加速比達不到可能的最大值,請注意資料依賴性也會產生影響。如果一條指令需要被前一條指令更改的運算元,則需要延遲,同樣可以通過NOOP實現。
由於RISC指令集的簡單性和規則性,分為三個或四個階段的設計很容易完成。下圖d顯示了4階段管線的結果,一次最多可以執行四條指令,最大可能的加速是4倍。再次注意,使用NOOP來解釋資料和分支延遲。
19.5.3.2 管線階段
流水線處理器使用的電子構造有所不同,下面是不同階段的一種設計:
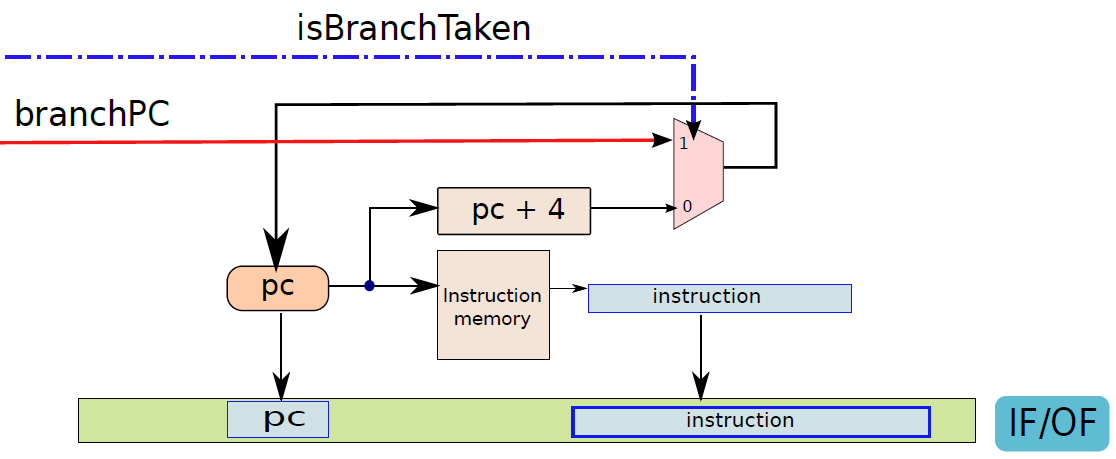
流水線處理器中的IF階段。
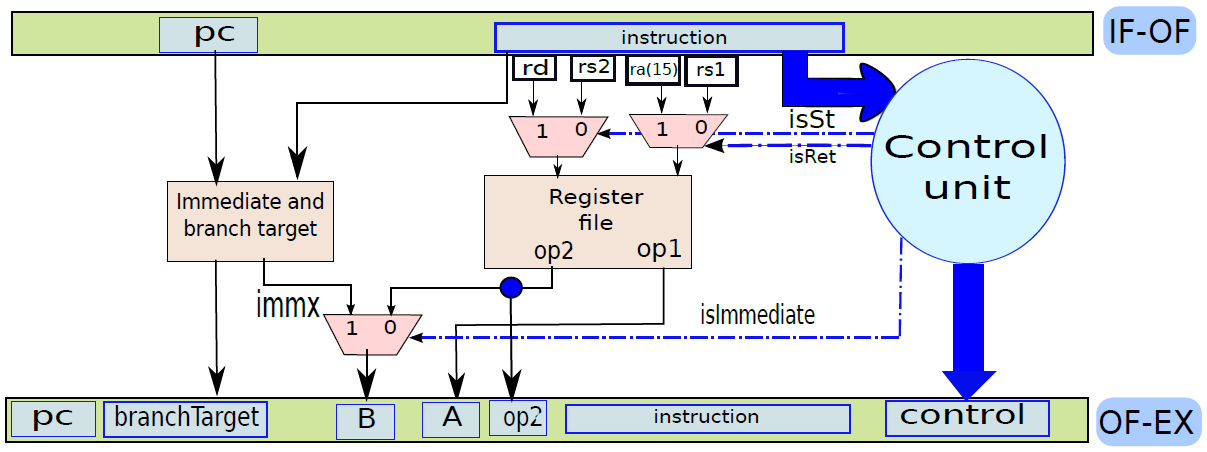
流水線處理器中的OF階段。
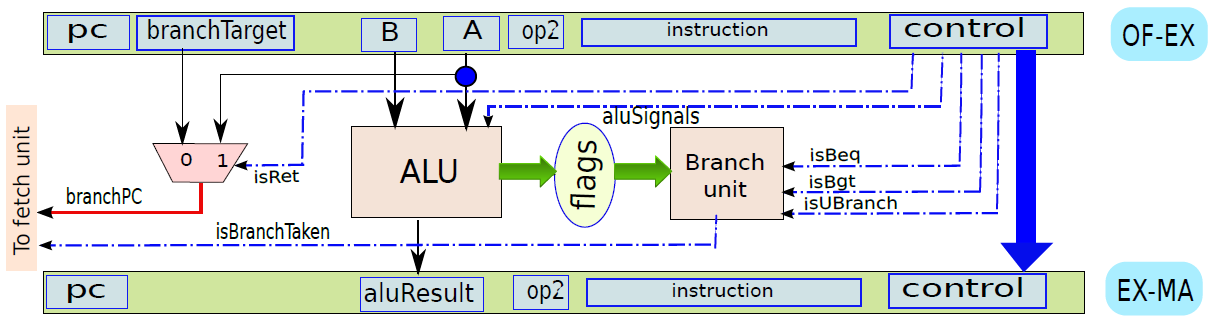
流水線處理器中的EX階段。
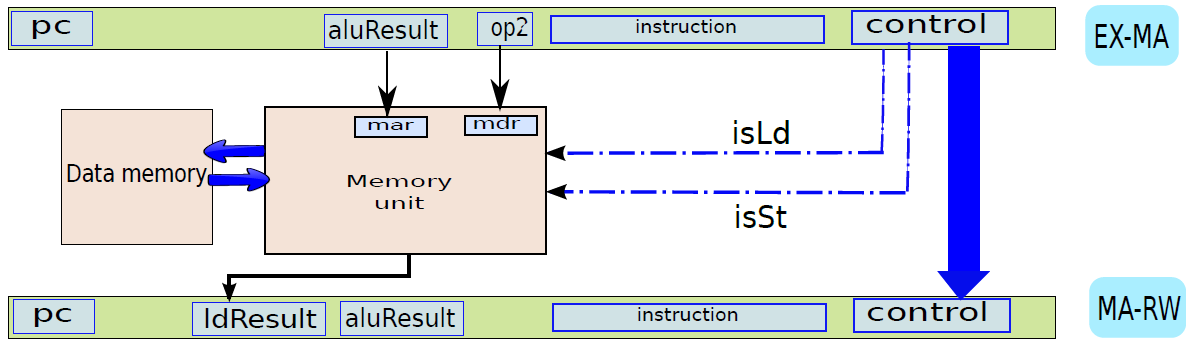
流水線處理器中的MA階段。
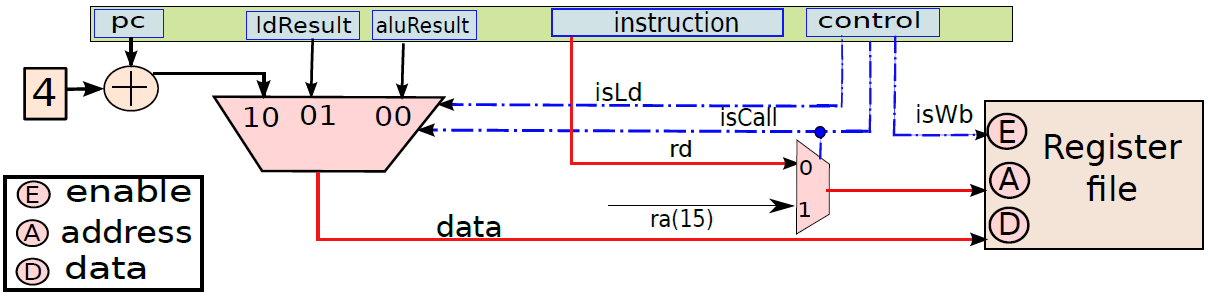
流水線處理器中的RW階段。
現在通過下圖顯示的帶有流水線暫存器的資料路徑來總結關於簡單流水線的討論。注意,我們的處理器設計已經變得相當複雜,圖表大小已經達到了一頁,不想引入更復雜的圖表。
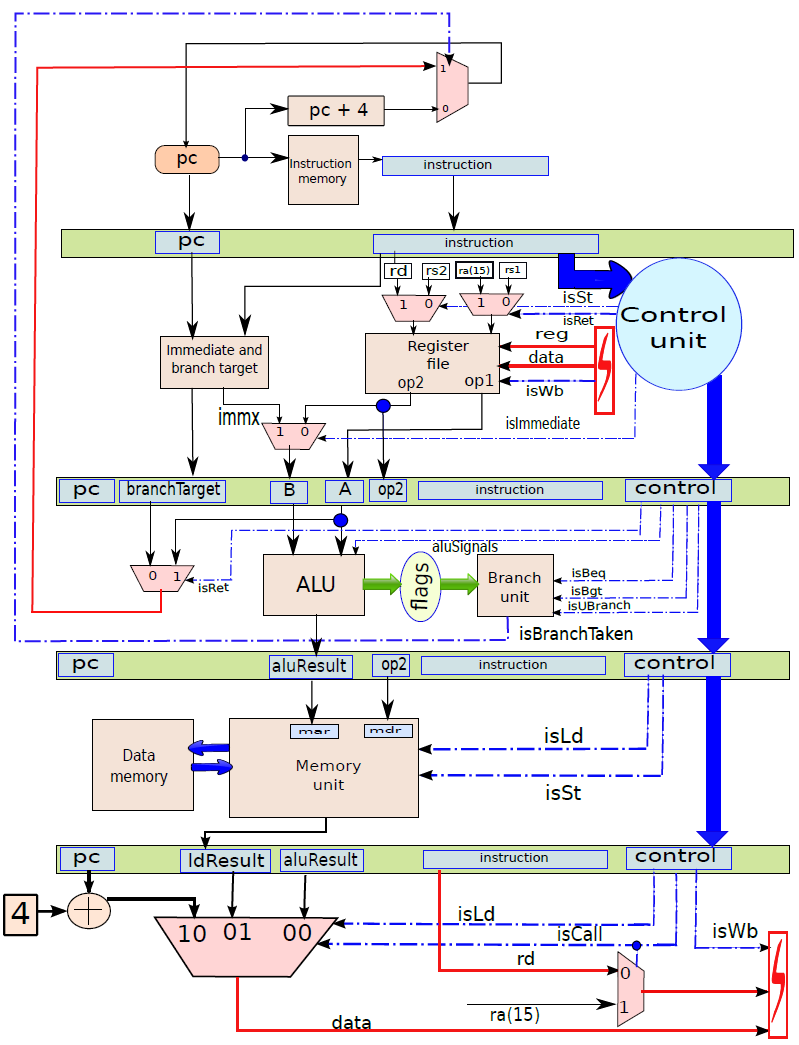
流水線資料路徑。
下圖顯示了流水線資料路徑的抽象。該圖主要包含不同單元的框圖,並顯示了四個流水線暫存器。我們將使用該圖作為討論先進流水線的基線。回想一下,rst暫存器運算元可以是指令的rs1欄位,也可以是ret指令的返回地址暫存器。在ra和rs1之間選擇多路複用器是基線流水線設計的一部分,為了簡單起見,沒有在圖中顯示它,假設它是暫存器檔案單元的一部分。類似地,選擇第二暫存器運算元(在rd和rs2之間)的多路複用器也被假定為暫存器檔案單元的一部分,因此圖中未示出,只顯示選擇第二個運算元(暫存器或立即數)的多路複用器。
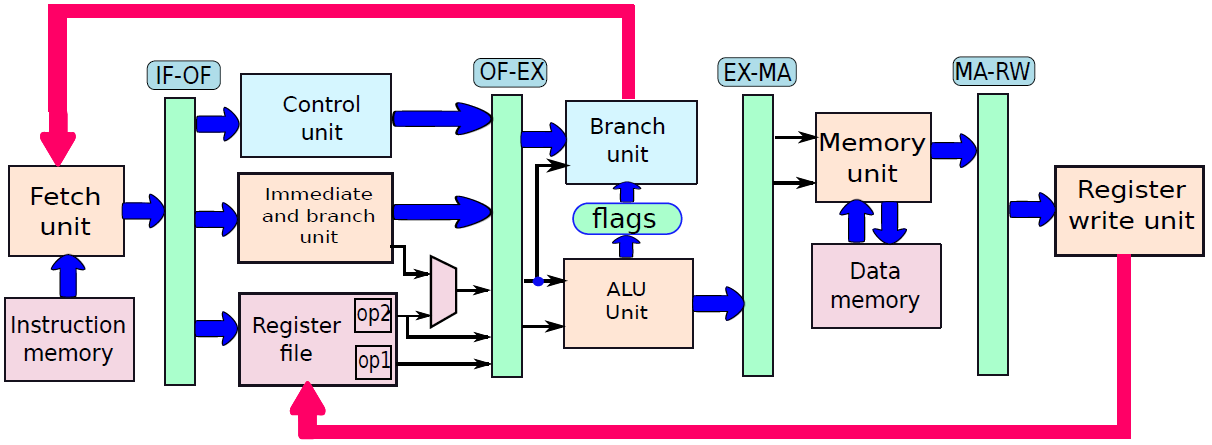
下圖顯示了三條指令通過管道時的流水線圖,每一行對應於每個流水線階段,列對應於時鍾週期。在範例程式碼中,有三條相互之間沒有任何依賴關係的指令,將這些指令分別命名為:[1]、[2]和[3]。最早的指令[1]在第一個週期進入流水線的IF階段,在第五個週期離開流水線。類似地,第二條指令[2]在第二個週期中進入流水線的IF階段,在第六個週期中離開流水線。這些指令中的每一條都會在每個迴圈中前進到流水線的後續階段,流水線圖中每條指令的軌跡都是一條朝向右下角的對角線。請注意,在考慮指令之間的依賴性之後,這個場景將變得相當複雜。
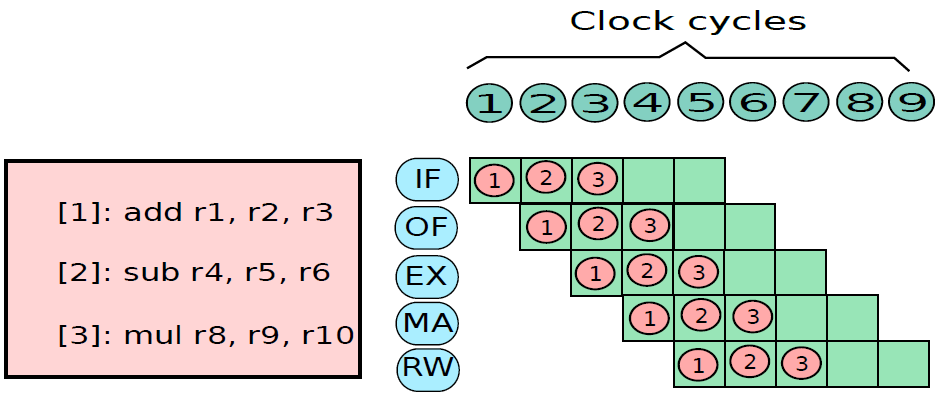
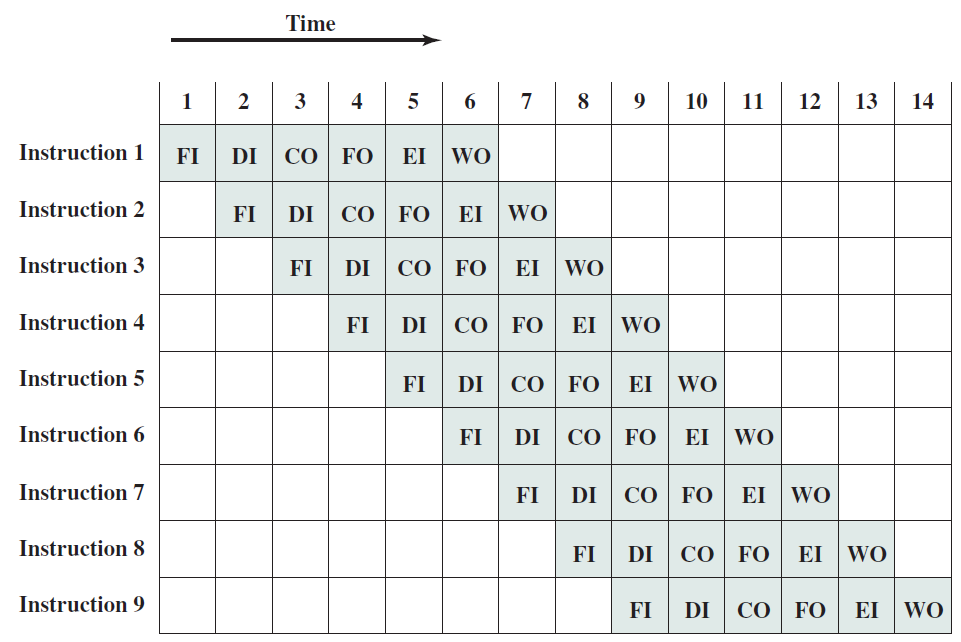
流水線示意圖。
下面是構建流水線圖的規則:
- 構建一個單元網格,該網格有5行和N列,其中N是希望考慮的時鐘週期總數,每5行對應於一個流水線階段。
- 如果指令([k])在週期m中進入流水線,那麼在第一行的第m列中新增一個與[k]對應的條目。
- 在第(m+1)個週期中,指令可以停留在同一階段(因為流水線可能會停頓,稍後將描述),也可以移動到下一行(OF階段)。在網格單元中新增相應的條目。
- 以類似的方式,指令按順序從IF級移動到RW級,它從不後退,但可以在連續的週期中保持在同一階段。
- 一個單元格中不能有兩個條目。
- 在指令離開RW階段後,最終將其從流水線圖中刪除。
根據以上規則舉個簡單的例子,假設有以下程式碼:
add r1, r2, r3
sub r4, r2, r5
mul r5, r8, r9
為上述程式碼段構建的流水線圖如下(假設第一條指令在週期1中進入流水線):
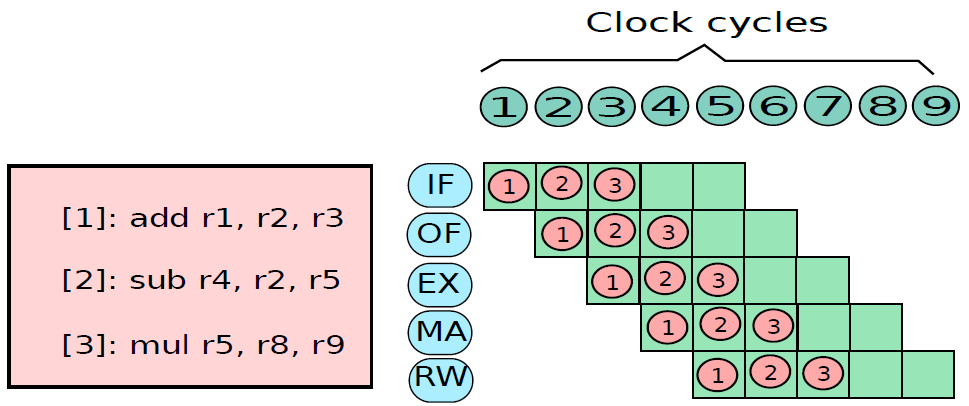
條件分支對指令流水線操作的影響:
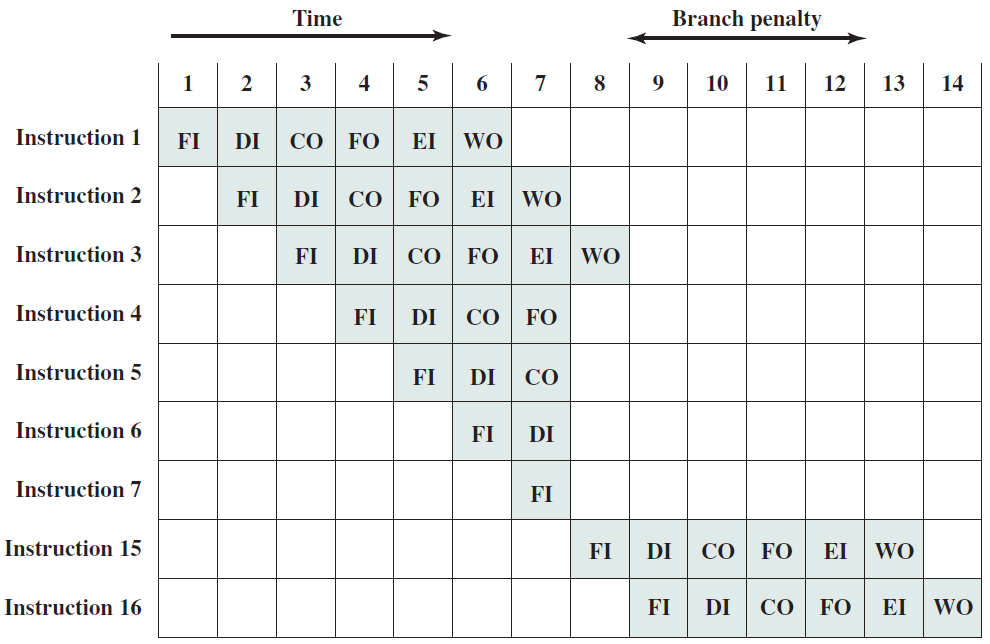
6階段的CPU指令管線:
一個備選的管線描述:
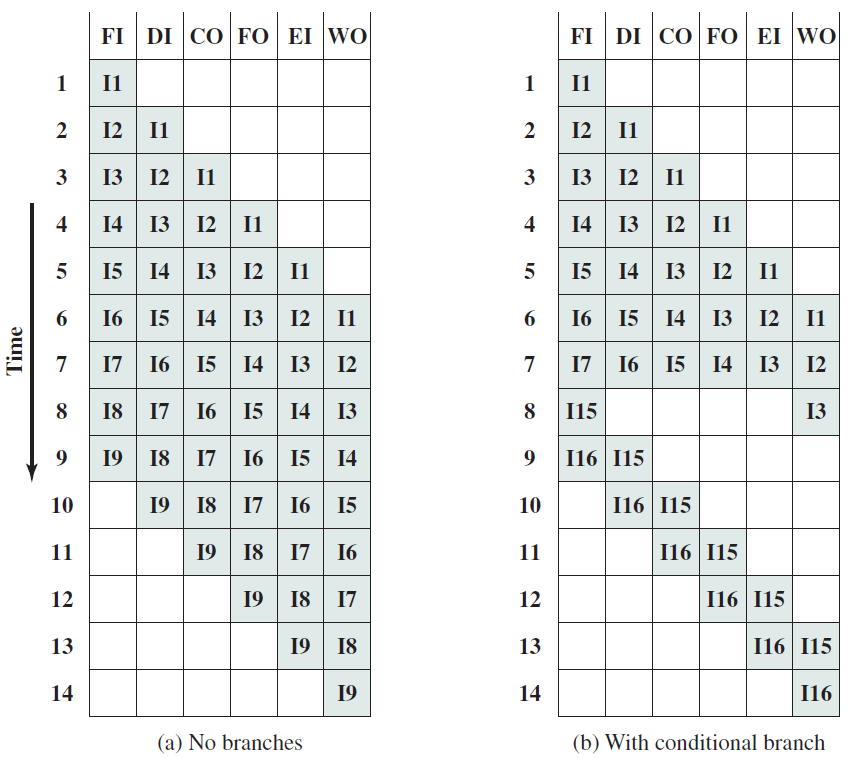
下圖a將加速因子繪製為在沒有分支的情況下執行的指令數的函數。正如可能預期的,在極限(n趨近正無窮),有k倍的加速。圖b顯示了作為指令管道中級數函數的加速因子。在這種情況下,加速因子接近可以在沒有分支的情況下饋送到管道中的指令數。因此,管線階段數越大,加速的可能性越大。然而,作為一個實際問題,額外管線階段的潛在收益會因成本增加、階段之間的延遲以及遇到需要重新整理管線的分支而抵消。
19.5.3.3 管線衝突
讓我們考慮下面的程式碼片段:
add r1, r2, r3
sub r3, r1, r4
此處的加法指令生成暫存器r1的值,子指令將其用作源運算元,這些指令構建一個流水線圖如下所示。
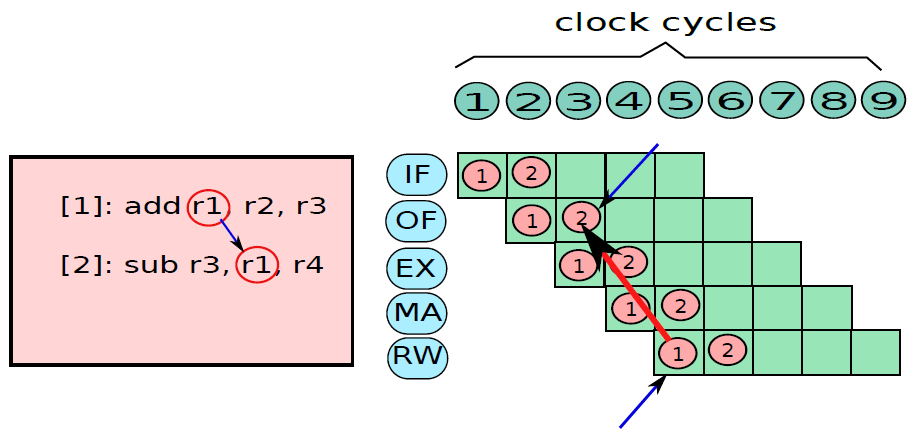
顯示RAW(寫入後讀取)危險的流水線圖。
顯示了有一個問題。指令1在第f個週期中寫入r1的值,指令2需要在第3個週期中讀取其值。這顯然是不可能的,我們在兩條指令的相關流水線階段之間新增了一個箭頭,以指示存在依賴關係。由於箭頭向左(時間倒退),我們無法在管道中執行此程式碼序列,被稱為資料衝突(亦稱資料危險,data hazard),衝突被定義為流水線中錯誤執行指令的可能性,這種特殊情況被歸類為資料衝突,除非採取適當措施,否則指令2可能會得到錯誤的資料。
衝突(hazard)被定義為流水線中錯誤執行指令的可能性,表示由於無法獲得正確的資料而導致錯誤執行的可能性。
這種特定型別的資料危險被稱為RAW(寫入後讀取)衝突。上面語句的減法指令試圖讀取r1,需要由加法指令寫入。在這種情況下,讀取會在寫入之後。
請注意,這不是唯一一種資料衝突,另外兩種型別的資料危害是WAW(寫入後寫入)和WAR(讀取後寫入)衝突,這些衝突在我們的流水線中不是問題,因為我們從不改變指令的順序,前一條指令總是在後一條指令之前。相比之下,現代處理器具有以不同順序執行指令的無序(out-of-order)流水線。
在有序流水線(如我們的流水線)中,前一條指令總是在流水線中的後一條指令之前。現代處理器使用無序(out-of-order)流水線來打破這一規則,並且可以讓後面的指令在前面的指令之前執行。
讓我們看看下面的組合程式碼段:
add r1, r2, r3
sub r1, r4, r3
指令1和指令2正在寫入暫存器r1。按照順序,流水線r1將以正確的順序寫入,因此不存在WAW危險。然而,在無序流水線中,我們有在指令1之前完成指令2的風險,因此r1可能會以錯誤的值結束。這便是WAW衝突的一個例子。讀者應該注意,現代處理器通過使用一種稱為暫存器重新命名(register renaming)的技術確保r1不會得到錯誤的值。
讓我們舉一個潛在WAR衝突的例子:
add r1, r2, r3
add r2, r5, r6
指令2試圖寫入r2,而指令1將r2作為源運算元。如果指令2先被執行,那麼指令1可能會得到錯誤的r2值。實際上,由於暫存器重新命名等方案,這在現代處理器中不會發生。我們需要理解,衝突是發生錯誤的理論風險,但不是真正的風險,因為採取了足夠的措施來確保程式不會被錯誤地執行。
本文將主要關注RAW危害,因為WAW和WAR危害僅與現代無序處理器相關。讓我們概述一下解決方案的性質,為了避免RAW危險,有必要確保流水線知道它包含一對指令,其中一條指令寫入暫存器,另一條指令按程式順序稍後從同一暫存器讀取。它需要確保使用者指令正確地從生產者指令接收運算元(在本例中為暫存器)的值,我們將研究硬體和軟體方面的解決方案。
現在看看當我們在流水線中有分支指令時會出現的另一種危險,假設有下面的程式碼片段:
[1]: beq .foo
[2]: mov r1, 4
[3]: add r2, r4, r3
...
...
.foo:
[100]: add r4, r1, r2
下圖展示了前三條指令的流水線圖:
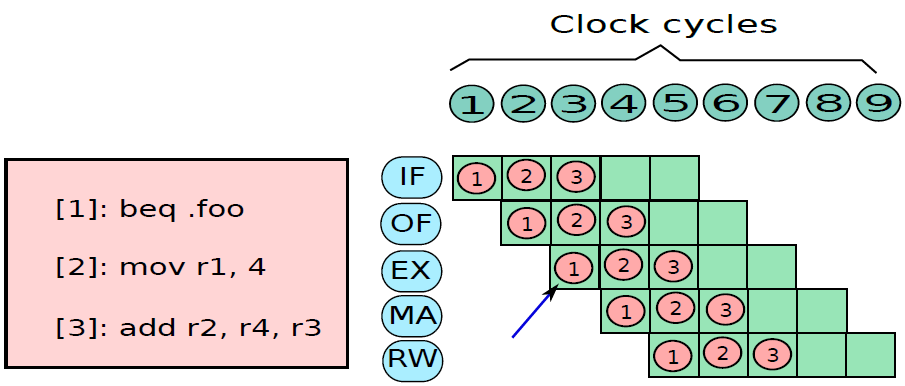
此處,分支的結果在迴圈3中被確定,並被傳送到提取單元,提取單元從週期4開始提取正確的指令。如果執行了分支,則不應執行指令2和3。可悲的是,在週期2和週期3中,無法知道分支的結果。因此,這些指令將被提取,並將成為流水線的一部分。如果執行分支,則指令2和3可能會破壞程式的狀態,從而導致錯誤,指令2和指令3被稱為錯誤路徑中的指令。這種情況稱為控制衝突(control hazard)。如果分支的結果與其實際結果不同,則會執行的指令被認為是錯誤的。例如,如果執行分支,則程式中分支指令之後的指令路徑錯誤。
控制衝突(control hazard)表示流水線中錯誤執行的可能性,因為分支錯誤路徑中的指令可能會被執行並將結果儲存在記憶體或暫存器檔案中。
為了避免控制衝突,有必要識別錯誤路徑中的指令,並確保其結果不會提交到暫存器檔案和記憶體。應該有一種方法使這些指令無效,或者完全避免它們。
當不同的指令試圖存取同一個資源,而該資源不能允許所有指令在同一週期記憶體取它時,就會出現結構衝突。讓我們舉個例子。假設我們有一條加法指令,可以從記憶體中讀取一個運算元,它可以具有以下形式:
add r1, r2, 10[r3]
結構衝突(structural hazard)是指由於資源限制,指令可能無法執行。例如,當多個指令試圖在同一週期記憶體取一個功能單元時,可能會出現這種情況,並且由於容量限制,該單元無法允許所有感興趣的指令繼續執行。在這種情況下,衝突中的一些指令需要暫停執行。
此處,有一個暫存器源運算元r2和一個記憶體源運算元10[r3],進一步假設流水線在OF階段讀取記憶體運算元的值。現在讓我們來看一個潛在的衝突情形:
[1]: st r4, 20[r5]
[2]: sub r8, r9, r10
[3]: add r1, r2, 10[r3]
請注意,這裡沒有控制和資料衝突,儘管如此,讓我們考慮流水線圖中儲存指令處於MA階段時的一點。此時,指令2處於EX階段,指令3處於OF階段。請注意,在此迴圈中,指令1和3都需要存取儲存單元。但如果我們假設記憶體單元每個週期只能服務一個請求,那麼顯然存在衝突情況,其中一條指令需要暫停執行。這種情況是結構衝突的一個例子。
由於具有典範性,後面我們把重點放在努力消除RAW和控制衝突上。
19.5.3.4 管線衝突解決
軟體方案
現在,讓我們找出一種避免RAW衝突的方法,假設有以下程式碼:
[1]: add r1, r2, r3
[2]: sub r3, r1, r4
指令2要求OF級中的r1值。然而,此時,指令1處於EX階段,它不會將r1的值寫回暫存器檔案,因此不能允許指令2在流水線中繼續。一個簡單的軟體解決方案是聰明的編譯器可以分析程式碼序列並意識到存在RAW衝突,它可以在這些指令之間引入nop指令,以消除任何RAW衝突。考慮以下程式碼序列:
[1]: add r1, r2, r3
[2]: nop
[3]: nop
[4]: nop
[5]: sub r3, r1, r4
當子指令到達OF階段時,加法指令將寫入其值並離開流水線,因此子指令將獲得正確的值。請注意,新增nop指令是一個成本高昂的解決方案,因為我們實際上是在浪費計算能力。在這個例子中,新增nop指令基本上浪費了3個週期。然而,如果考慮更長的程式碼序列,那麼編譯器可能會重新排序指令,這樣就可以最小化nop指令的數量。任何編譯器干預的基本目標都必須是在生產者和消費者指令之間至少有3條指令。
舉個具體的例子,重新排序以下程式碼段,並新增足夠數量的nop指令,以使其在流水線上正確執行:
add r1, r2, r3 ; 1
add r4, r1, 3 ; 2
add r8, r5, r6 ; 3
add r9, r8, r5 ; 4
add r10, r11, r12 ; 5
add r13, r10, 2 ; 6
答案是:
add r1, r2, r3 ; 1
add r8, r5, r6 ; 3
add r10, r11, r12 ; 5
nop
add r4, r1, 3 ; 2
add r9, r8, r5 ; 4
add r13, r10, 2 ; 6
我們需要理解這裡的兩個重要點:第一個是nop指令的能力,第二個是編譯器的能力,編譯器是確保程式正確性和提高效能的重要工具。在這種情況下,我們希望以這樣一種方式重新排序程式碼,即引入最小數量的nop指令。
接下嘗試使用相同的技術解決控制衝突。
如果再次檢視流水線圖,就會發現分支指令和分支目標處的指令之間至少需要兩條指令,這是因為在EX階段結束時得到分支結果和分支目標。此時,流水線中還有兩條指令。當分支指令分別處於OF和EX階段時,這些指令已被提取,它們可能執行錯了路徑。在EX階段確定分支目標和結果之後,我們可以繼續在IF階段獲取正確的指令。
現在考慮當不確定分支結果時提取的這兩條指令。如果分支的PC等於p1,則它們的地址分別為p1+4和p1+8。如果不採取行動,它們不會執行錯誤路徑。但是,如果執行分支,則需要從管道中丟棄這些指令,因為它們位於錯誤的路徑上。
讓我們看看一個簡單的軟體解決方案,其中硬體假設分支指令之後的兩條指令沒有在錯誤的路徑上,這兩條指令的位置稱為延遲時隙(delay slot)。通常可以通過在分支後插入兩條nop指令來確保延遲間隙中的指令不會引入錯誤,但這樣做不會獲得任何額外的效能,可以取而代之地對在分支指令之前執行的兩條指令進行繫結,並將它們移動到分支之後的兩個延遲時隙中。
請注意,我們不能隨意將指令移動到延遲時隙,不能違反任何資料依賴約束,還需要避免RAW衝突,另外,我們不能將任何比較指令移動到延遲時隙中。如果沒有適當的指令可用,那麼我們總是可以返回到普通的解決方案並插入nop指令。也有可能我們只需要找到一條可以重新排序的指令,然後只需要在分支指令之後插入一條nop指令。延遲分支方法是一種非常有效的方法,可以減少需要新增以避免控制衝突的nop指令的數量。
在簡單流水線資料路徑中,分支後獲取的兩條指令的PC分別等於p1+4和p1+8(p1是分支指令的PC)。由於編譯器確保這些指令始終在正確的路徑上,而不管分支的結果如何,因此我們不會通過獲取它們來提交錯誤。在確定分支的結果之後,如果不執行分支,則獲取的下一條指令的PC等於p1+12,或者如果執行分支,PC等於分支目標。因此,在這兩種情況下,在確定分支的結果後都會獲取正確的指令,可以得出結論,軟體解決方案在流水線版本的處理器上正確執行程式。
總之,軟體技術的關鍵是延遲時隙的概念。在分支之後需要兩個延遲時隙,因為不確定後續的兩條指令,它們可能在錯誤的路徑上。然而,使用智慧編譯器,可以設法將執行的指令移動到延遲時隙,而不管分支的結果如何。因此可以避免在延遲時隙中放置nop指令,從而提高效能。這種分支指令被稱為延遲分支指令(delayed branch instruction)。
如果處理器假定在其結果確定之前獲取的所有後續指令都在正確的路徑上,則分支指令稱為延遲分支(delayed branch)。如果處理器在提取分支指令的時間與確定其結果之間提取n條指令,那麼我們就說我們有n個延遲時隙。編譯器需要確保正確路徑上的指令佔用延遲時隙,並且不會引入額外的控制或RAW衝突。編譯器還可以在延遲時隙中引入nop指令。
現在舉個例子。重新排序下面的組合程式碼,以便在具有延遲分支的流水線處理器上正確執行,假設每個分支指令有兩個延遲時隙。
add r1, r2, r3 ; 1
add r4, r5, r6 ; 2
b .foo ; 3
add r8, r9, r10 ; 4
答案:
b .foo ; 3
add r1, r2, r3 ; 1
add r4, r5, r6 ; 2
add r8, r9, r10 ; 4
硬體方案
上面研究了消除RAW和控制衝突的軟體解決方案,但編譯器方法不是很通用,原因是:
- 首先,程式設計師總是可以手動編寫組合程式碼,並嘗試在處理器上執行它。在這種情況下,錯誤的可能性很高,因為程式設計師可能沒有正確地重新排序程式碼以消除衝突。
- 其次,還有可移植性問題。為一條流水線編寫的一段組合程式碼可能無法在遵循相同ISA的另一條流水線上執行,因為它可能具有不同數量的延遲時隙或不同數量的階段。如果我們的組合程式不能在使用相同ISA的不同機器之間移植,那麼引入組合程式的主要目標之一就失敗了。
讓我們嘗試在硬體層面設計解決方案,硬體應確保無論組合程式如何,都能正確執行,輸出應始終與單週期處理器產生的輸出相匹配。為了設計這樣的處理器,需要確保指令永遠不會接收錯誤的資料,並且不會執行錯誤的路徑指令。可以通過確保以下條件成立來實現:
- 資料鎖定(Data-Lock)。我們不能允許指令離開OF階段,除非它從暫存器檔案接收到正確的資料,意味著需要有效地暫停IF和OF階段,並讓其餘階段執行,直到OF階段中的指令可以安全地讀取其運算元。在此期間,從OF階段傳遞到EX階段的指令需要是nop指令。
- 分支鎖定(Branch-Lock)。我們從不在錯誤的路徑上執行指令,要麼暫停處理器直到結果已知,要麼使用技術確保錯誤路徑上的指令不能將其更改提交到記憶體或暫存器。
在流水線的純硬體實現中,有時需要阻止新指令進入流水線階段,直到某個條件停止保持。停止流水線階段接受和處理新資料的概念稱為流水線暫停(pipeline stall)或流水線互鎖(pipeline interlock)。其主要目的是確保程式執行的正確性。
如果我們確保資料鎖定和分支鎖定條件都成立,那麼流水線將正確執行指令。請注意,這兩種情況都要求管道的某些階段可能需要暫停一段時間,這些暫停也稱為流水線互鎖。換言之,通過保持流水線空閒一段時間,可以避免執行可能導致錯誤執行的指令。下表是純軟體和硬體方案實現流水線的整個邏輯的利弊。請注意,在軟體解決方案中,我們嘗試重新排序程式碼,然後插入最小數量的nop指令,以消除衝突的影響。相比之下,在硬體解決方案中,我們動態地暫停部分流水線,以避免在錯誤的路徑中執行指令,或使用錯誤的運算元值執行指令。暫停流水線相當於讓某些階段保持空閒,並在其他階段插入nop指令。
| 屬性 | 軟體 | 硬體(互鎖) |
|---|---|---|
| 可移植性 | 僅限於特定處理器 | 程式可以在任何處理器上執行 |
| 分支 | 通過使用延遲時隙,可能沒有效能損失 | 本文需要暫停流水線2個週期 |
| RAW衝突 | 可以通過程式碼排程消除它們 | 需要暫停流水線 |
| 效能 | 高度依賴於程式的特性 | 帶聯鎖的流水線的基本版本會比軟體慢 |
我們觀察到,軟體解決方案的效率高度依賴於程式的性質,可以對某些程式中的指令重新排序,以完全隱藏RAW衝突和分支的有害影響。然而,在某些程式中,我們可能沒有找到足夠的可以重新排序的指令,因此被迫插入大量nop指令,會降低效能。相比之下,一個遵守資料鎖和分支鎖條件的純硬體方案,只要檢測到可能錯誤執行的指令,就會暫停流水線。這是一種通用方法,比純軟體解決方案慢。
現在可以將硬體和軟體解決方案結合起來,重新排序程式碼,使其儘可能對流水線友好,然後在帶有互鎖的流水線上執行它。注意,在這種方法中,編譯器不保證正確性,只是將生產者指令和消費者指令儘可能分開,並在支援它們的情況下利用延遲分支。這減少了我們需要暫停流水線的次數,並確保了兩全其美。在設計帶互鎖的流水線前,下面藉助流水線圖來研究互鎖的性質。
現在繪製帶有互鎖的流水線圖,考慮下面的程式碼片段。
add r1, r2, r3
sub r4, r1, r2
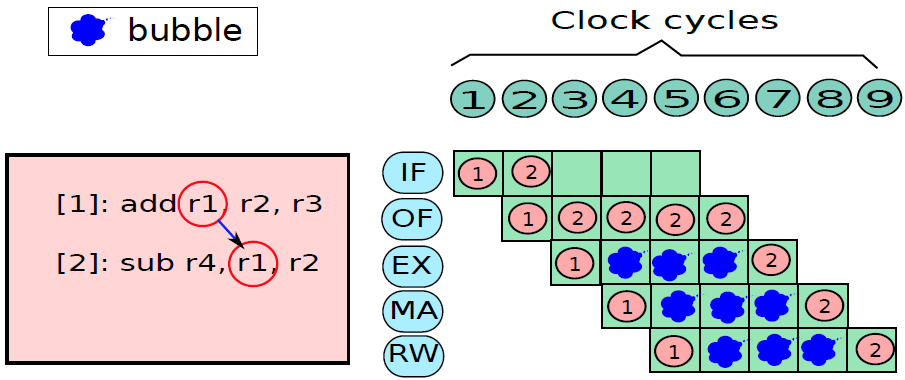
帶氣泡的流水線圖。
指令[1]寫入暫存器r1,指令[2]從r1讀取,顯然存在RAW依賴關係。為了確保資料鎖定條件,我們需要確保指令[2]僅在讀取了指令[1]寫入的r1值時才離開OF階段,僅在迴圈6中可行(上圖),然而指令[2]在週期3中到達OF階段。如果沒有衝突,則理想情況下它會在週期4中進入EX階段。由於我們有互鎖,指令[2]也需要在週期4、5和6中保持在OF階段中。問題是,當EX階段在週期4、5和6中沒有處理有效指令時,它會做什麼?類似地,MA階段在週期5、6和7中不處理任何有效的指令。我們需要有一種方法來禁用流水線階段,這樣我們就不會執行多餘的工作,標準方法是將nop指令插入階段。
再次參考上圖。在迴圈3結束時,知道需要引入互鎖,因此在週期4中,指令[2]保留在OF階段,將nop指令插入EX階段,該nop指令在週期5中移動到MA級,在週期6中移動到RW級。該nop命令稱為流水線氣泡。氣泡是由互鎖硬體動態插入的nop指令,在類似於正常指令的流水線階段中移動。同樣,在迴圈5和6中,我們需要插入管線氣泡。最後,在週期7中,指令[2]可以自由地進入EX和後續階段。氣泡不起任何作用,因此當階段遇到氣泡時,沒有任何控制訊號開啟。要注意的另一個微妙的點是,不能在同一個週期內對同一個暫存器進行讀寫,需要優先選擇寫入,因為它是較早的指令,而讀取需要暫停一個週期。
實現氣泡有兩種方法:
- 可以在指令包中有一個單獨的氣泡位。每當位為1時,該指令將被解釋為一個氣泡。
- 可以將指令的操作碼更改為nop的操作碼,並將其所有控制訊號替換為0。這種方法更具侵入性,但可以完全消除電路中的冗餘工作。在前一種方法中,控制訊號將開啟,由其啟用的單元將保持執行。硬體需要確保氣泡不能對暫存器或記憶體進行更改。
流水線氣泡(pipeline bubble)是由互鎖硬體動態插入流水線暫存器中的nop指令,氣泡以與正常指令相同的方式在流水線中傳播。
總之,通過在流水線中動態插入氣泡,可以避免資料衝突。
接下來闡述div和mod指令等慢指令的問題。在大多數流水線中,這些指令很可能需要n(n>1)個週期才能在EX階段執行。在n個週期的每個週期中,ALU完成div或mod指令的部分處理。每個這樣的迴圈被稱為T狀態(T State),通常一個階段具有1T狀態,但慢指令的EX階段有許多T狀態。因此,為了正確實現慢指令,需要暫停IF和OF階段(n-1)個週期,直到操作完成。
為了簡單起見,我們將不再討論這個問題,相反,繼續進行簡單的假設,即所有流水線階段都是平衡的,並且需要1個週期來完成它們的操作。現在看看控制衝突,首先考慮以下程式碼片段。
[1]: beq .foo
[2]: add r1, r2, r3
[3]: sub r4, r5, r6
....
....
.foo:
[4]: add r8, r9, r10
如果分支被執行,可以在流水線中插入氣泡,而不是使用延遲分支,否則不需要做任何事情。假設分支被去掉,這種情況下的流水線圖如下所示。
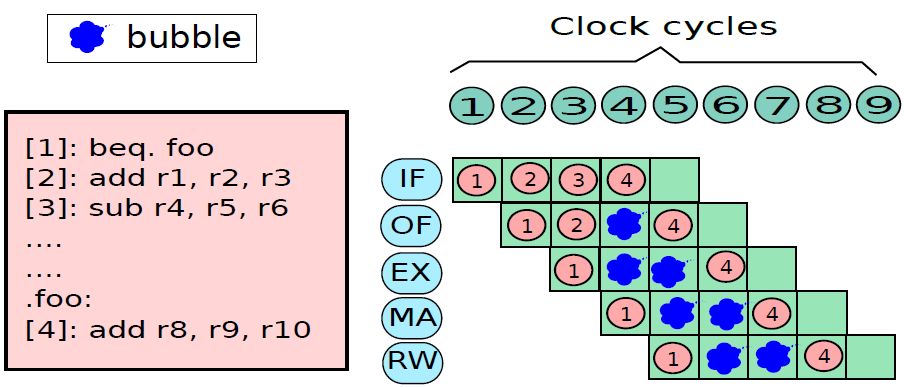
在這種情況下,指令[1]的分支條件的結果在迴圈3中決定。此時,指令[2]和[3]已經在流水線中(分別在IF和of階段)。由於分支條件求值為take,我們需要取消指令[2]和[3],否則它們將被錯誤執行。因此將它們轉換為氣泡,如上圖所示,指令[2]和[3]在迴圈4中轉換為氣泡。其次,在迴圈4從正確的分支目標(.foo)中提取,因此指令[4]進入流水線。兩個氣泡都經過所有流水線階段,最後分別在迴圈6和7中離開流水線。
因此可以通過在流水線中動態引入氣泡來確保這兩個條件(資料鎖定和分支鎖定)。下面更詳細地看看這些方法。
為了確保資料鎖定條件,需要確保OF階段中的指令與後續階段中的任何指令之間沒有衝突,衝突被定義為可能導致RAW衝突的情況。換句話說,如果後續階段的指令寫入由OF階段的指令讀取的暫存器,則存在衝突。因此需要兩個硬體來實現資料鎖定條件,第一步是檢查是否存在衝突,第二步是確保流水線停止。
首先看看衝突檢測硬體。衝突檢測硬體需要將OF階段中的指令的內容與其他三個階段(即EX、MA和RW)中的每個指令的內容進行比較,如果與這些指令中的任何一條發生衝突,可以宣告有衝突。讓我們關注檢測衝突的邏輯,簡要介紹一下衝突檢測電路的虛擬碼,設OF階段中的指令為[A],後續階段中的一條指令為[B]。檢測衝突的演演算法虛擬碼如下所示:
Data: Instructions: [A] and [B]
Result: Conflict exists (true), no conflict (false)
1 if [A].opcode 2 (nop,b,beq,bgt,call) then
/* Does not read from any register */
2 return false
3 end
4 if [B].opcode 2 (nop, cmp, st, b, beq, bgt, ret) then
/* Does not write to any register */
5 return false
6 end
/* Set the sources */
7 src1 [A]:rs1
8 src2 [A]:rs2
9 if [A].opcode = st then
10 src2 [A]:rd
11 end
12 if [A].opcode = ret then
13 src1 ra
14 end
/* Set the destination */
15 dest [B]:rd
16 if [B].opcode = call then
17 dest ra
18 end
/* Check if the first operand exists */
19 hasSrc1 true
20 if [A].opcode 2 (not,mov) then
21 hasSrc1 false
22 end
/* Check the second operand to see if it is a register */
23 hasSrc2 true
24 if [A].opcode =2 (st) then
25 if [A]:I = 1 then
26 hasSrc2 false
27 end
28 end
/* Detect conflicts */
29 if (hasSrc1 = true) and (src1 = dest) then
30 return true
31 end
32 else if (hasSrc2 = true) and (src2 = dest) then
33 return true
34 end
35 return false
用硬體實現上述演演算法很簡單,只需要一組邏輯閘和多路複用器,大多數硬體設計者通常用硬體描述語言(如Verilog或VHDL)編寫類似於上述演演算法的電路描述,並依靠智慧編譯器將描述轉換為實際電路。
我們需要三個衝突檢測器(\(\mathrm{OF} \leftrightarrow \mathrm{EX}, \mathrm{OF} \leftrightarrow \mathrm{MA}, \mathrm{OF} \leftrightarrow \mathrm{RW}\))。如果沒有衝突,則指令可以自由地進入EX階段,但如果至少有一個衝突,則需要暫停IF和OF階段。一旦指令通過OF階段,它就保證擁有所有的源運算元。
現在來看看流水線的暫停。我們基本上需要確保在發生衝突之前,沒有新的指令進入IF和OF階段,這可以通過禁用PC和IF-OF流水線暫存器的寫入功能來簡單地確保。因此,它們不能接受時鐘邊緣(clock edge)上的新資料,將繼續保持它們以前的值。
其次,還需要在流水線中插入氣泡,例如從OF傳遞到EX階段的指令需要是無效指令或氣泡,可以通過傳遞nop指令來確保。因此確保資料鎖定條件的電路是直接的,需要一個連線到PC的衝突檢測器和IF-OF暫存器。在發生衝突之前,這兩個暫存器將被禁用,無法接受新資料。我們強制OF-EX暫存器中的指令包含nop,流水線的增強電路圖如下圖所示。
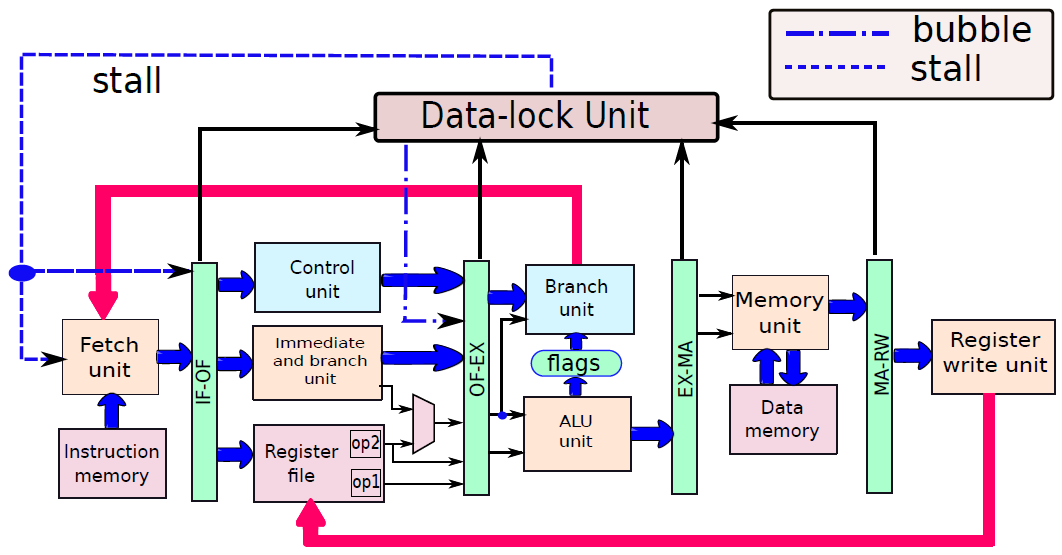
帶互鎖的流水線的資料路徑(實現資料鎖定條件)。
接下來闡述分支鎖定條件。
假設流水線中有一條分支指令(b、beq、bgt、call、ret)。如果有延遲時隙,那麼資料路徑與上圖所示的相同,不需要做任何更改,因為執行的整個複雜性已經載入到了軟體中。然而,將流水線暴露於軟體有其利弊,如果在管線中新增更多階段,那麼現有的可執行檔案可能會停止工作。為了避免這種情況,讓我們設計一個不向軟體暴露延遲時隙的流水線。
有兩個設計選項:
- 第一種:可以假設在確定結果之前不採取分支。我們可以繼續在分支之後獲取這兩條指令並進行處理,一旦在EX階段決定了分支的結果,就可以根據結果採取適當的行動。如果未執行分支,則在分支指令之後獲取的指令位於正確的路徑上,無需再執行任何操作。但是,如果執行了分支,則必須取消這兩條指令,並用流水線氣泡(nop指令)替換它們。
- 第二種:暫停流水線,直到分支的結果被確定,而不管結果如何。
顯然,第二種設計的效能低於假設不採用分支的第一種替代方案,例如,如果一個分支30%的時間沒有被佔用,那麼對於第一個設計,30%的時間都在做有用的工作。然而,對於第二個選項,我們在獲取分支指令後的2個週期中從未做過任何有用的工作。
因此,讓我們從效能的角度考慮第一個設計,只有在分支被佔用時,才取消分支後的兩個指令,這種方法為預測不採用(predict not
taken),因為實際上是在預測不採取的分支。稍後,如果發現此預測錯誤,則可以取消錯誤路徑中的指令。
如果分支指令的PC等於p,那麼選擇在接下來的兩個週期中在p+4和p+8處獲取指令。如果分支沒有被執行,那麼將繼續執行。但是,如果分支被執行,那麼將取消這兩條指令,並將它們轉換為流水線氣泡。
我們不需要對資料路徑進行任何重大更改,需要一個小型分支衝突單元,從EX階段接收輸入。如果執行分支,則在下一個週期中,它將If-OF和OF-EX階段中的指令轉換為流水線氣泡。帶有分支互鎖單元的擴充套件資料路徑如下圖所示。
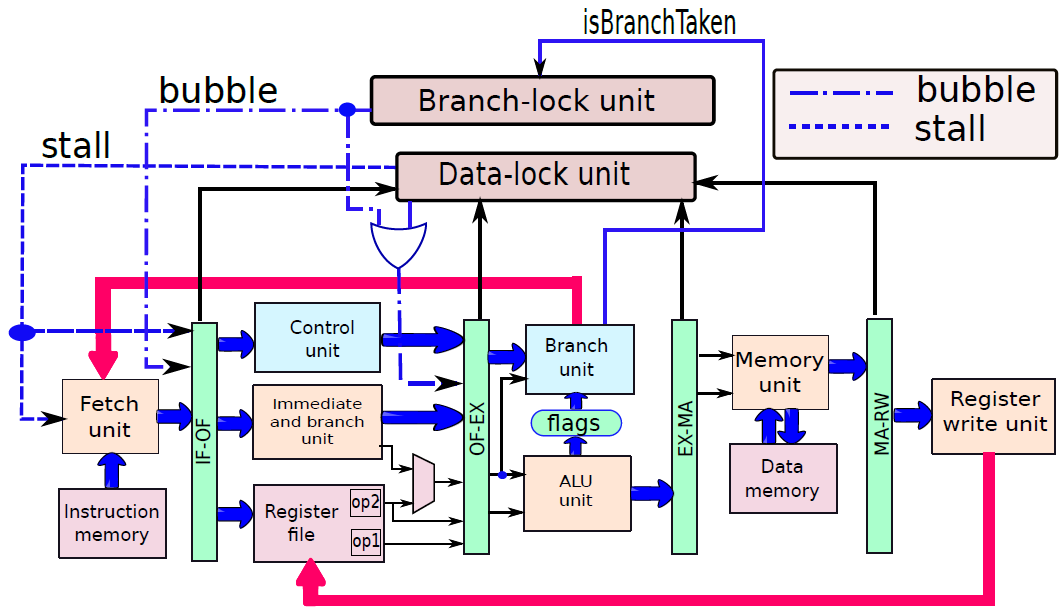
帶互鎖的流水線的資料路徑(實現資料鎖定和分支鎖定條件)。
接下來闡述帶轉發(Forwarding)的流水線。
上面已經實現了一個帶有互鎖的流水線。互鎖確保流水線正確執行,而不管指令之間的依賴性如何。對於資料鎖定條件,我們建議在流水線中新增互鎖,在暫存器檔案中有正確的值之前,不允許指令離開運算元獲取階段。然而,下面將看到,不必總是新增互鎖。事實上,在很多情況下,正確的資料已經存在於流水線暫存器中,儘管不存在於暫存器檔案中。可以設計一種方法,將資料從內部流水線暫存器正確地傳遞到適當的功能單元。考慮以下程式碼:
add r1, r2, r3
sub r4, r1, r2
下圖僅包含這兩條指令的流水線圖,(a)顯示了帶互鎖的流水線圖,(b)顯示了無互鎖和氣泡的流水線圖。現在嘗試論證不需要在指令之間插入氣泡。
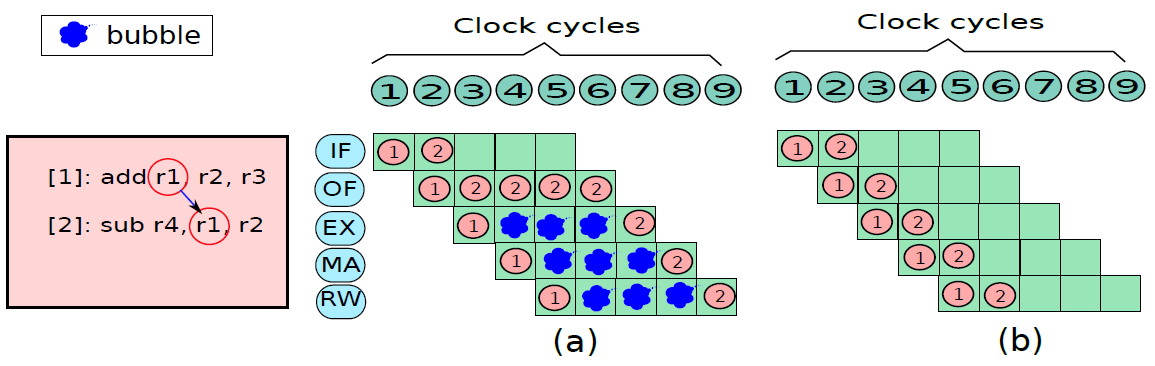
(a)帶互鎖的流水線圖,(b)無互鎖和氣泡的流水線圖。
讓我們深入檢視上圖(b)。指令1在EX階段結束時產生其結果,或者在週期3結束時產生結果,並在週期5中寫入暫存器檔案。指令2在週期3開始時需要暫存器le中的r1值,顯然是不可能的,因此建議新增流水線互鎖來解決此問題。
讓我們嘗試另一種解決方案,允許指令執行,然後在迴圈3中,[2]將獲得錯誤的值,允許它在週期4中進入EX階段。此時,指令[1]處於MA階段,其指令包包含正確的r1值。r1值是在前一個週期中計算的,存在於指令包的aluResult欄位中,[1] 的指令包在週期4中位於EX-MA暫存器中。現如果在EX-MA的aluResult欄位和ALU的輸入之間新增一個連線,那麼可以成功地將r1的正確值傳輸到ALU。我們的計算不會出錯,因為ALU的運算元是正確的,因此ALU運算的結果也將被正確計算。
下圖顯示了我們在流水線圖中的操作結果,將指令[1]的MA階段新增到指令[2]的EX階段。由於箭頭不會在時間上倒退,因此可以將資料(r1的值)從一個階段轉發(forward)到另一個階段。
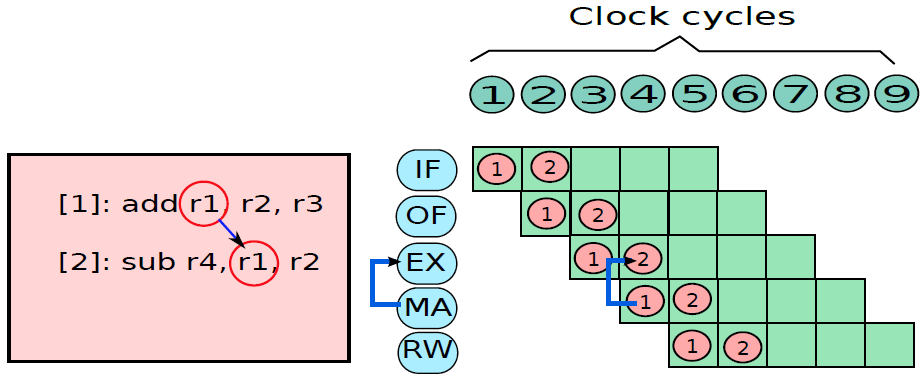
在流水線中轉發的範例。
轉發(Forwarding)是一種通過階段之間的直接連線在不同流水線階段中的指令之間傳輸運算元值的方法,不使用暫存器檔案跨指令傳輸運算元的值,從而避免昂貴的流水線互鎖。
我們剛剛研究了一種非常強大的技術,可以避免管線中的停頓,稱為轉發。本質上,我們允許運算元的值在指令之間流動,方法是跨階段直接傳遞它們,不使用暫存器檔案跨指令傳輸值。轉發的概念允許我們背靠背地(以連續的週期)執行指令[1]和[2],不需要新增任何暫停週期。因此,不需要重新排序程式碼或插入nop。
為了在指令[1]和[2]之間轉發r1的值,我們在MA級和EX級之間新增了一個連線,上圖9中通過在指令[1]和[2]的相應階段之間畫一個箭頭來顯示這種聯絡。這個箭頭的方向是垂直向上的,由於它沒有在時間上倒退,有可能轉發該值,否則是不可能的。
現在讓我們嘗試回答一個一般性問題——可以在所有指令對之間轉發值嗎?注意,不需要是連續的指令,即使生產者和消費者ALU指令之間有一條指令,我們仍然需要轉發值。現在嘗試考慮管線中各階段之間的所有可能的轉發路徑。
廣泛遵循的轉發基本原則如下:
- 在後期和早期之間新增了轉發路徑。
- 在管線中儘可能遲地轉發一個值。例如,如果給定階段不需要給定值,並且可以在稍後階段從生產者指令中獲取該值,那麼我們等待在稍後階段獲取轉發的值。
請注意,這兩個基本原則都不影響程式的正確性,它們只允許消除冗餘的轉發路徑。現在,系統地看看管道中需要的所有轉發路徑:
-
RW --> MA:MA階段需要來自RW階段的轉發路徑,考慮下圖所示的程式碼片段,指令[2]需要MA階段(週期5)中的r1值,而指令[1]在週期4結束時從記憶體中獲取r1值。因此,它可以在週期5中將其值轉發給指令[2]。
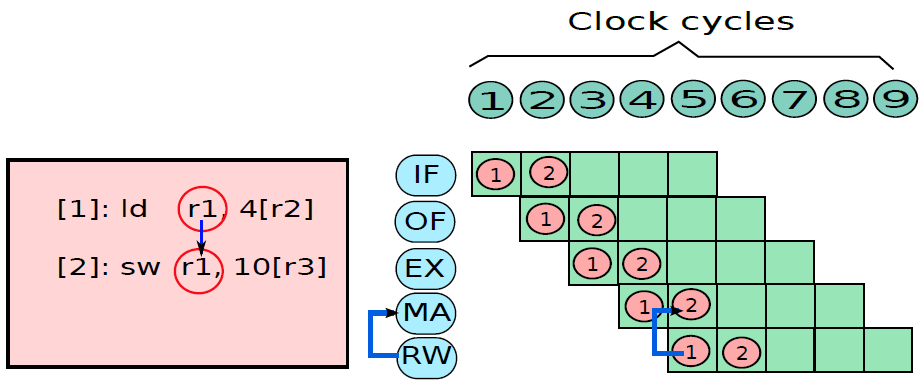
-
RW --> EX:下圖所示的程式碼段顯示了一條載入指令,它在週期4結束時獲取暫存器r1的值,以及一條後續的ALU指令,它需要週期5中的r1值。因為不會在時間上倒退,所以可以轉發該值。
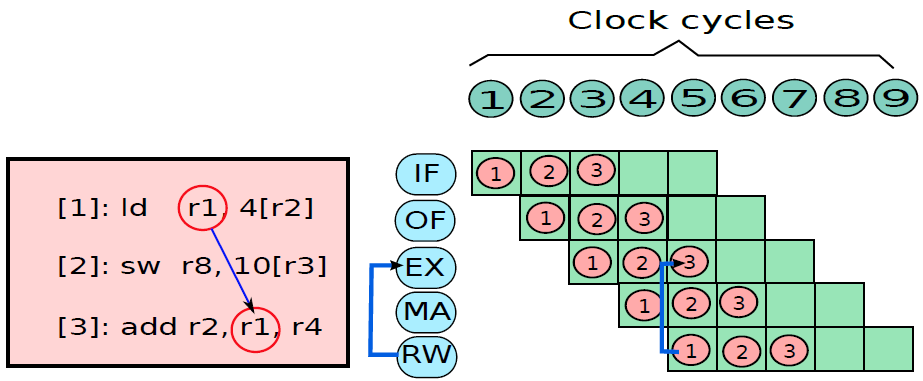
-
MA --> EX:下圖所示的程式碼段顯示了一條ALU指令,該指令在週期3結束時計算暫存器r1的值,以及一條連續的ALU指令在週期4中需要r1的數值。在這種情況下,還可以通過在MA和EX級之間新增互連(轉發路徑)來轉發資料。
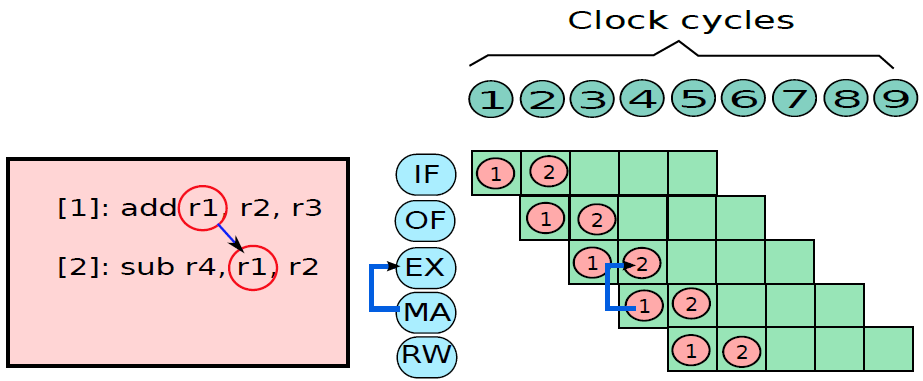
-
RW --> OF:通常OF階段不需要轉發路徑,因為它沒有任何功能單元,不需要立即使用值,可以稍後根據原則2轉發價值。然而,唯一的例外是從RW階段轉發,無法稍後轉發該值,因為指令將不在管線中。因此有必要新增從RW到OF級的轉發路徑,需要RW --> OF轉發的程式碼段範例如下圖所示。指令[1]通過在週期4結束時從記憶體中讀取r1的值來生成r1值,然後它在週期5中將r1值寫入暫存器檔案。同時,指令[4]嘗試在週期5的OF階段讀取r1值,不幸的是,這裡存在衝突。因此,我們建議通過在RW和OF階段之間新增轉發路徑來解決衝突。因此,禁止指令[4]讀取r1值的暫存器檔案。相反,指令[4]]使用RW --> OF轉發路徑從指令[1]獲取r1值。
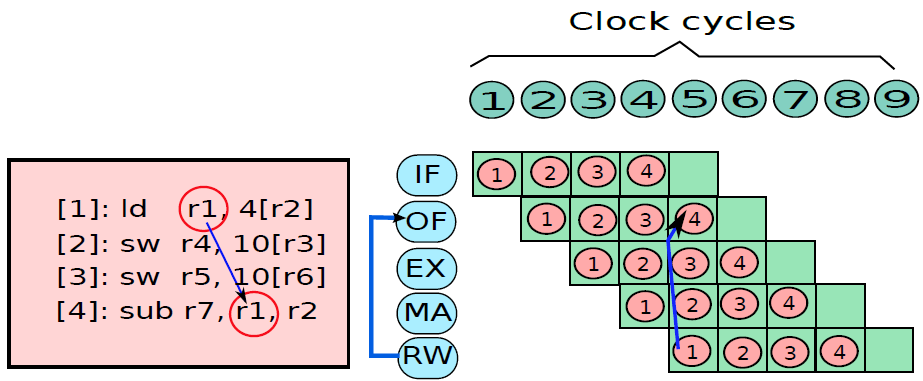
不需要新增以下轉發路徑:MA-->OF和EX-->OF,因為我們可以使用以下轉發路徑(RW-->EX)和(MA-->EX)。根據原則2,需要避免冗餘轉發路徑,因此不新增從MA和EX級到OF級的轉發路徑。我們不向IF階段新增轉發路徑,因為在這個階段,還沒有解碼指令,不知道其運算元。
現在又衍生了一個問題:轉發是否完全消除了資料衝突?
現在回答這個問題。先考量ALU指令,它們在EX階段產生結果,並準備在MA階段前進,任何後續的使用者指令都需要前一條ALU指令在EX階段最早生成的運算元的值。此時可以實現成功的轉發,因為運算元的值在MA階段已經可用。如果生產者指令已離開流水線,則任何後續指令都可以使用任何可用的轉發路徑或從暫存器檔案獲取值。如果生產者指令是ALU指令,那麼總是可以將ALU運算的結果轉發給消費者指令。為了證明這一事實,需要考慮所有可能的指令組合,並判斷是否可以將輸入運算元轉發給使用者指令。
唯一顯式生成暫存器值的其他指令是載入指令。請記住,儲存指令不會寫入任何暫存器。讓我們看看載入指令,載入指令在MA階段結束時產生其值,因此它準備在RW階段轉發其值。考慮下圖中的程式碼片段及其流水線圖。
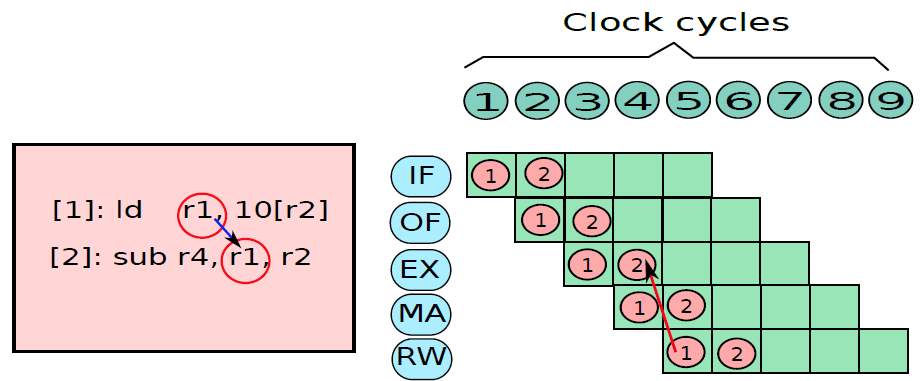
載入-使用衝突。
指令[1]是寫入暫存器r1的載入指令,指令[2]是使用暫存器r1作為源運算元的ALU指令,載入指令在週期5開始時準備好轉發。不幸的是,ALU指令在週期4開始時需要r1的值,故而需要在流水線圖中繪製一個箭頭,該箭頭在時間上向後流動。因此,在這種情況下,轉發是不可能的。
載入-使用衝突(Load-Use Hazard)是指載入指令將載入的值提供給在EX階段需要該值的緊隨其後的指令的情況。即使有轉發,管線也需要在載入指令之後插入一個暫停週期。
這是需要在管線中引入暫停迴圈的唯一情況,這種情況被稱為載入-使用衝突,載入指令將載入的值提供給在EX階段需要該值的緊隨其後的指令。消除載入-使用衝突的標準方法是允許管線插入氣泡,或者使用編譯器重新排序指令或插入nop指令。
總之,具有轉發的管線確實可能需要互鎖,唯一的特殊情況是載入-使用衝突。
請注意,如果在儲存載入值的載入指令之後有一個儲存指令,那麼我們不需要插入暫停迴圈,因為儲存指令需要MA階段的值。此時,載入指令處於RW階段,可以轉發該值。
如果要實現管線的轉發,需要根據不同的管線階段來實現。
支援轉發的OF階段如下圖所示,基線管道中沒有轉發的多路複用器用較淺的顏色著色,而為實現轉發而新增的附加多路複用器被著色為較深的顏色。
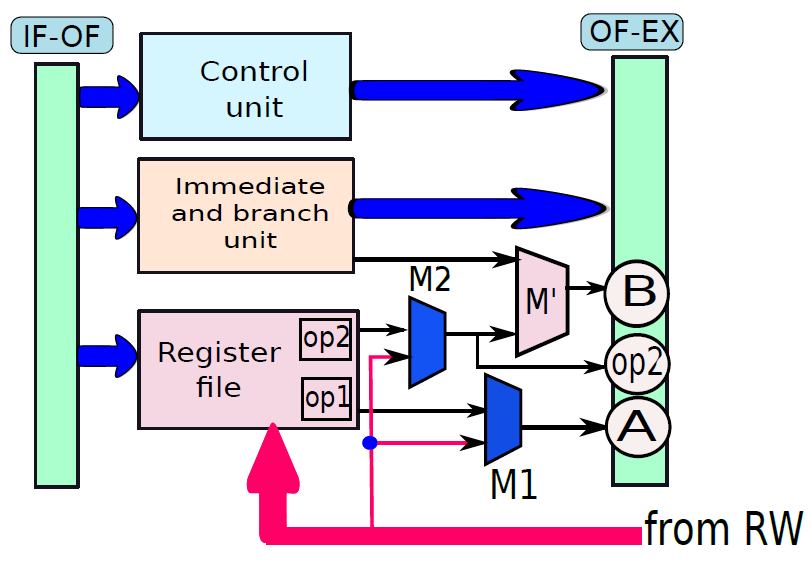
下圖顯示了修改後的EX階段。EX級從OF級獲得的三個輸入是A(第一個ALU運算元)、B(第二個ALU運算數)和op2(第二暫存器運算元)。對於A和B,我們新增了兩個複用器M3和M4,以在OF級中計算的值和分別從MA和RW級轉發的值之間進行選擇。對於可能包含儲存值的op2欄位,我們不需要MA --> EX轉發,因為在MA階段需要儲存值,因此我們可以使用RW --> MA轉發,從而減少一條轉發路徑。因此,多路複用器M5具有兩個輸入(預設值和從RW級轉發的值)。
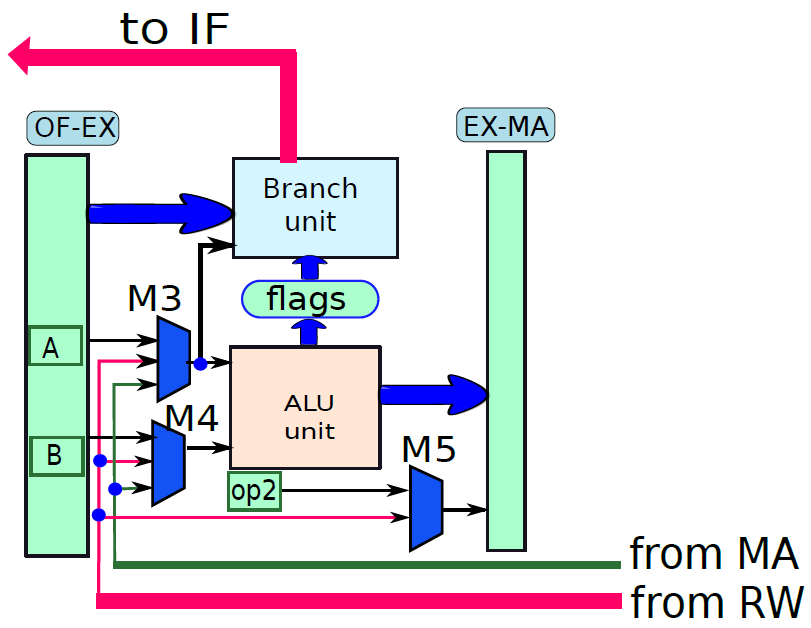
下圖顯示了具有額外轉發支援的MA階段。記憶體地址在EX階段計算,並儲存在指令包的aluResult欄位中,記憶體單元直接使用該值作為地址。然而,在儲存的情況下,需要儲存的值(op2)可以從RW階段轉發,因此新增了多路複用器M6,它在指令包中的op2欄位和從RW級轉發的值之間進行選擇。電路的其餘部分保持不變。
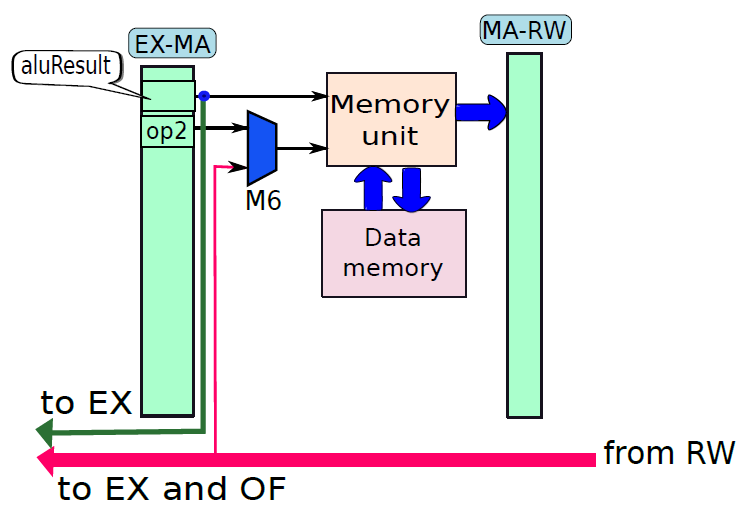
下圖顯示了RW階段。因為是最後一個階段,所以它不使用任何轉發值。但是,它將寫入暫存器le的值分別傳送到MA、EX和OF階段。
下圖將所有部分放在一起,並顯示了支援轉發的管線。總之,我們需要新增6個多路複用器,並在單元之間進行一些額外的互連,以傳遞轉發的值。我們設想一個專用的轉發單元,它為多路複用器(圖中未示出)計算控制訊號。除了這些小的更改,不需要對資料路徑進行其他重大更改。
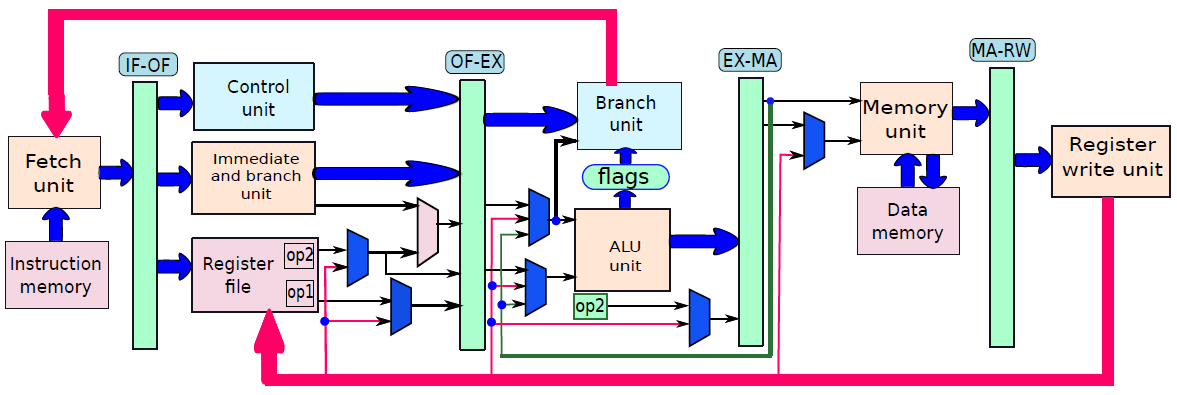
帶轉發的流水線資料路徑(簡圖)。
我們在討論轉發時使用了一個簡圖(上圖)。需要注意的是,實際電路現在變得相當複雜。除了對資料路徑的擴充套件,還需要新增一個專用轉發單元來為多路複用器生成控制訊號。詳細圖片如下圖所示。
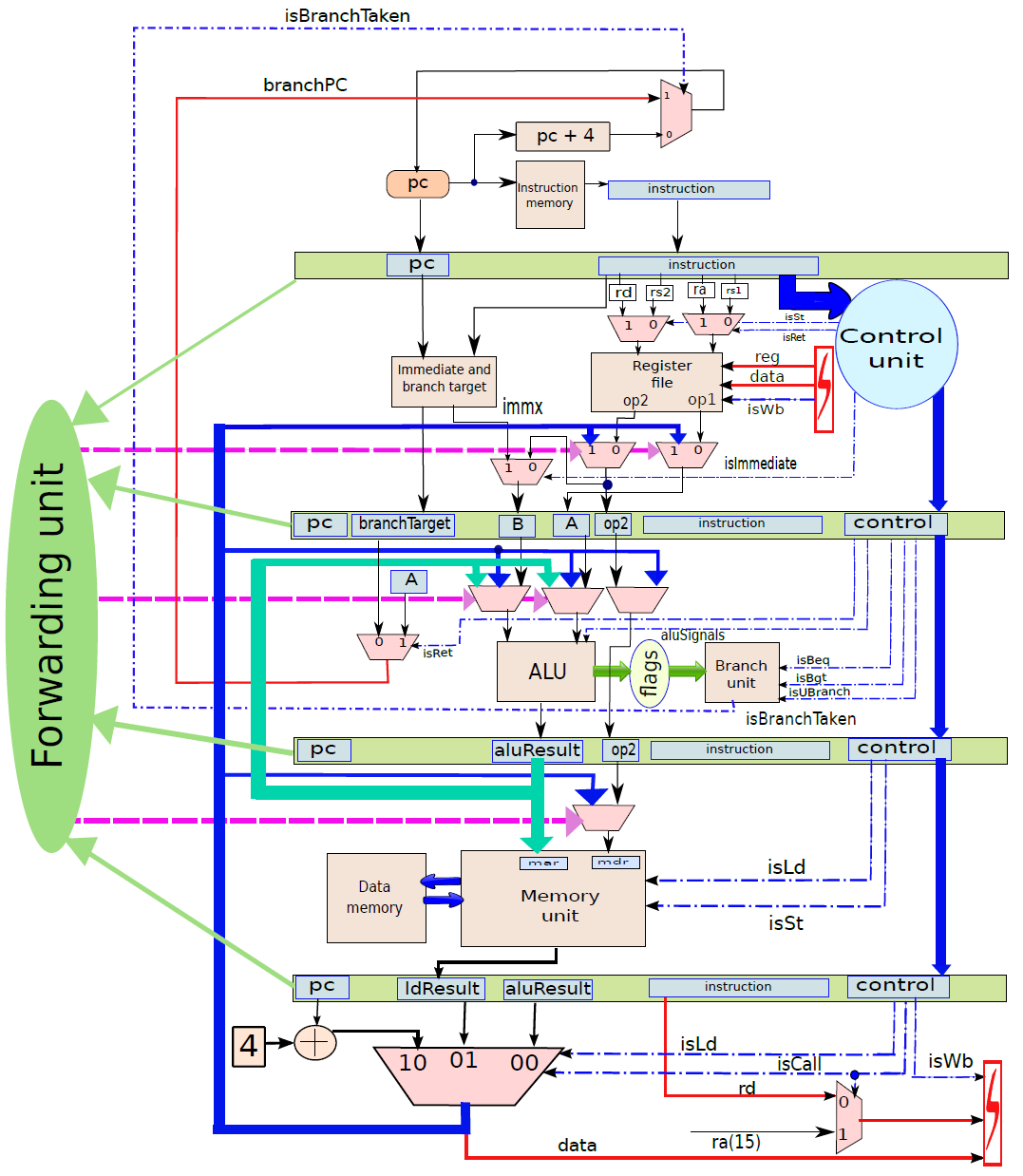
現在將互鎖邏輯新增到管線中,需要資料鎖定和分支鎖定條件的互鎖邏輯。請注意,現在已經成功處理了除載入-使用衝突以外的所有RAW衝突。在載入-使用衝突的情況下,只需要停止一個週期,大大簡化了資料鎖定電路。如果EX階段有載入指令,就需要檢查載入指令和OF階段的指令之間是否存在RAW資料依賴關係,不需要考慮的唯一RAW衝突是載入-儲存依賴性,即載入寫入包含儲存值的暫存器,我們不需要暫停,因為可以將要儲存的值從RW轉發到MA階段。對於所有其他資料依賴性,需要通過引入氣泡將管線暫停1個週期,此舉可以解決載入-使用衝突,確保分支鎖定條件的電路保持不變。還需要檢查EX階段中的指令,如果它是一個執行的分支,需要使if和OF階段的指令無效。最後應注意,互鎖始終優先於轉發。
19.5.3.5 效能標準和測量
本節討論流水線處理器的效能。
需要首先在處理器的上下文中定義效能的含義。大多數時候,當我們查詢筆記型電腦或智慧手機的規格時,會被大量的術語淹沒,比如時脈頻率、RAM和硬碟大小,遺憾的是,這些術語都不能直接表示處理器的效能。計算機標籤上從未明確提及效能的原因是「效能」一詞相當模糊,處理器的效能一詞總是指給定的程式或組合,因為處理器對不同程式的效能不同。
給定一個程式P,讓我們嘗試量化給定處理器的效能。如果P在A上執行P的時間比在B上執行P所需的時間短,那麼處理器A比處理器B效能更好。因此,量化給定程式的效能非常簡單,測量執行程式所需的時間,然後計算其倒數,這個數位可以解釋為與處理器相對於程式的效能成正比。
首先計算執行程式P所需的時間:
-
每秒的週期數是處理器的時脈頻率(f)。
-
每個指令的平均週期數稱為CPI(Cycles per instruction),其逆數(每個週期的指令數)稱為IPC(Instructions per cycle)。
-
最後一項是指令數(縮寫為#insts)。注意,是動態指令的數量,或者處理器實際執行的指令數量,不是程式可執行檔案中的指令數。
靜態指令是程式的二進位制或可執行檔案包含指令列表裡的每條指令。
動態指令是靜態指令的範例,當指令進入流水線時由處理器建立。
我們現在可以將效能P定義為與時間\(\tau\)成反比的量(稱為效能等式):
因此可以得出結論,處理器相對於程式的效能與IPC和頻率成正比,與指令數成反比。
現在看看單週期處理器的效能。對於所有指令,其CPI都等於1,效能與\(\cfrac{f}{\text{instsCount}}\)成正比,是一個相當微不足道的結果。當增加頻率時,單週期處理器會按比例變快。同樣,如果能夠將程式中的指令數量減少X倍,那麼效能也會增加X倍。讓我們考慮流水線處理器的效能,分析更為複雜,見解也非常深刻。
下面闡述效能方程中的三個項:
-
指令數量。程式中指令的數量取決於編譯器的智慧,真正智慧的編譯器可以通過從ISA中選擇正確的指令集並使用智慧程式碼轉換來減少指令。例如,程式設計師通常有一些歸類為死程式碼的程式碼,此程式碼對最終輸出沒有影響,聰明的編譯器可以刪除它能找到的所有死程式碼。附加指令的另一個來源是溢位和恢復暫存器的程式碼,編譯器通常對非常小的函數執行函數內聯,這種優化動態地移除這些函數,並將它們的程式碼貼上到呼叫函數的程式碼中。對於小函數,是一個非常有用的優化,可以擺脫溢位和恢復暫存器的程式碼。還有許多編譯器優化有助於減少程式碼大小,本節假設指令的數量是常數,只關注硬體方面。
-
計算週期總數。假設一個理想的管線不需要插入任何氣泡或停滯,它將能夠每個週期完成一條指令,因此CPI為1。假設一個包含n條指令的程式,並讓流水線有k個階段,讓我們計算所有n條指令離開流水線所需的週期總數。
第一條指令在週期1中進入流水線,在週期k中離開流水線,每個週期都會有一條指令離開流水線。在(n-1) 週期,所有指令都會離開流水線,迴圈總數為n+k- 1。CPI等於:
\[CPI = \cfrac{n+k-1}{n} \]請注意,CPI趨於1,因為n趨於正無窮。
-
與頻率的關係。讓指令在單週期處理器上完成執行所需的最大時間為\(t_{max}\),也稱為演演算法工作總量。我們在計算\(t_{max}\)時忽略了流水線暫存器的延遲。現在將資料路徑劃分為k個流水線階段,需要新增\(k-1\)個流水線暫存器。設流水線暫存器的延遲為\(l\),如果假設所有流水線階段都是平衡的(做同樣的工作,花費同樣的時間),那麼最慢的指令在一個階段完成工作所需的時間等於\(\cfrac{t_{max}}{k}\)。每階段的總時間等於電路延遲和流水線暫存器的延遲:
\[t_{stage} = \cfrac{t_{max}}{k} + 1 \]現在,最小時鐘週期時間必須等於流水線階段的延遲,因為設計流水線時的假設是每個階段只需要一個時鐘週期。因此,最小時鐘週期時間(\(t_{clk}\))或最大頻率(\(f\))等於:
\[t_{c l k}=\frac{1}{f}=\frac{t_{\max }}{k}+l \]
下面計算管線的效能。簡單地假設效能等於(f/CPI),因為指令數是常數(n)。
嘗試通過選擇正確的k值來最大化效能,有:
需要在CPI方程中納入停頓的影響,假設指令(n)的數量非常大。讓理想的CPI是\(CPI_{ideal}\),在本例,\(CPI_{ideal}=1\),有:
為了最大化效能,需要將分母最小化,得到:
為了確定管線階段的最佳數量的效能,假設n是正無窮,因此\((n + k- 1) / n\)趨近於1,因此有:
大多數時候,我們不會衡量處理器對一個程式的效能。考慮一組已知的基準程式,並測量處理器相對於所有程式的效能,以獲得統一的圖形。大多數處理器供應商通常總結其處理器相對於SPEC(Standard Performance Evaluation Corporation)的效能基準,釋出用於測量、總結和報告處理器和軟體系統效能的基準套件。
計算機架構通常使用SPEC CPU基準套件來衡量處理器的效能。SPEC CPU 2006基準有兩種程式型別:整數算術基準(SPECint)和浮點基準(SPECfp)有12個用C/C++編寫的SPECint基準測試。基準測試包含C編譯器、基因測序器、AI引擎、離散事件模擬器和XML處理器的部分,在類似的線路上,SPECfp套件包含17個程式,解決了物理、化學和生物學領域的不同問題。
大多數處理器供應商通常計算SPEC分數,代表處理器的效能,建議的過程是採用基準測試在參考處理器上花費的時間與基準測試在給定處理器上花費時間的比率,SPEC分數等於所有比率的幾何平均值。在電腦架構中,當我們報告平均相對效能(如SPEC分數)時,通常使用幾何平均值。對於報告平均執行時間(絕對時間),可以使用算術平均值。
有時報告的不是SPEC分數,而是平均每秒執行的指令數,而對於科學程式,則是平均每秒浮點運算數,這些指標提供了處理器或處理器系統的速度指示。通常使用以下術語:
- KIPS:每秒千(\(10^3\))條指令。
- MIPS:每秒百萬(\(10^6\))條指令。
- MFLOPS:每秒百萬(\(10^6\))次浮點運算。
- GFLOPS:每秒千兆(\(10^9\))次浮點運算。
- TFLOPS:每秒萬億(\(10^{12}\))次浮點運算。
- PFLOPS:每秒千萬億(\(10^{15}\))次浮點運算。
現在通過檢視效能、編譯器設計、處理器架構和製造技術之間的關係來總結討論。再次考慮效能等式:
如果最終目標是最大化效能,那麼需要最大化頻率(f)和IPC,同時最小化動態指令(#insts)的數量。有三個變數在我們的控制之下,即處理器架構、製造技術和編譯器。請注意,此處使用術語「構架」來指代處理器的實際組織和設計,然而文獻通常使用體系結構來指ISA和處理器的設計。下面詳細闡述每個變數。
- 編譯器
通過使用智慧編譯器技術,可以減少動態指令的數量,也可以減少暫停的數量,將改善IPC。下面範例通過重新排序add和ld指令來刪除一個暫停週期。在類似的行中,編譯器通常會分析數百條指令,並對它們進行最佳排序,以儘可能減少暫停。
; -----範例1-----
; 在不違反程式正確性的情況下重新排序以下程式碼,以減少暫停。
add r1, r2, r3
ld r4, 10[r5]
sub r1, r4, r2
;答案
ld r4, 10[r5]
add r1, r2, r3
sub r1, r4, r2
; 沒有載入-使用衝突,程式的邏輯保持不變。
; -----範例2-----
; 在不違反程式正確性的情況下重新排序以下程式碼,以減少暫停。假設有2個延遲時隙的延遲分支.
add r1, r2, r3
ld r4, 10[r5]
sub r1, r4, r2
add r8, r9, r10
b .foo
; 答案
add r1, r2, r3
ld r4, 10[r5]
b .foo
sub r1, r4, r2
add r8, r9, r10
; 消除了載入-使用風險,並最佳地使用了延遲時隙。
- 架構
我們使用流水線設計了一個高階架構。請注意,流水線本身並不能提高效能,由於暫停,與單週期處理器相比,流水線減少了程式的IPC。流水線的主要好處是它允許我們以更高的頻率執行處理器,最小週期時間從單迴圈流水線的\(t_{max}\)減少到k級流水線機器的\(t_{max}/k+l\)。由於每個週期都完成一條新指令的執行,除非出現暫停,所以可以在流水線機器上更快地執行一組指令,指令執行吞吐量要高得多。
流水線的主要好處是以更高的頻率執行處理器,可以確保更高的指令吞吐量(更多的指令每秒完成執行)。與單週期處理器相比,流水線本身減少了程式的IPC,也增加了處理任何單個指令所需的時間。
延遲分支和轉發等技術有助於提高流水線機器的IPC,我們需要專注於通過各種技術提高複雜管線的效能。需要注意的重要一點是,架構技術影響頻率(通過流水線階段的數量)和IPC(通過轉發和延遲分支等優化)。
- 製造工藝
製造工藝影響電晶體的速度,進而影響組合邏輯塊和鎖存器的速度,電晶體越小,速度越快。因此總演演算法工作量(\(t_{max}\))和鎖存延遲(l)也在穩步減少,可以在更高的頻率下執行處理器,從而提高效能。製造技術隻影響我們執行處理器的頻率,對IPC或指令數量沒有任何影響。
總之,可以用下圖總結這一段的討論。
效能、編譯器、架構和技術之間的關係。
請注意,總體情況並不像本節描述的那麼簡單,還需要考慮功率和複雜性問題。通常,由於複雜性的增加,實現超過20個階段的流水線非常困難。其次,大多數現代處理器都有嚴重的功率和溫度限制,這個問題也稱為功率牆(power wall,下圖)。通常不可能提高頻率,因為我們無法承受功耗的增加,根據經驗法則,功率隨頻率的立方而增加,將頻率增加10%會使功耗增加30%以上,非常之大。設計者越來越避免以非常高的頻率執行的深度流水線設計。
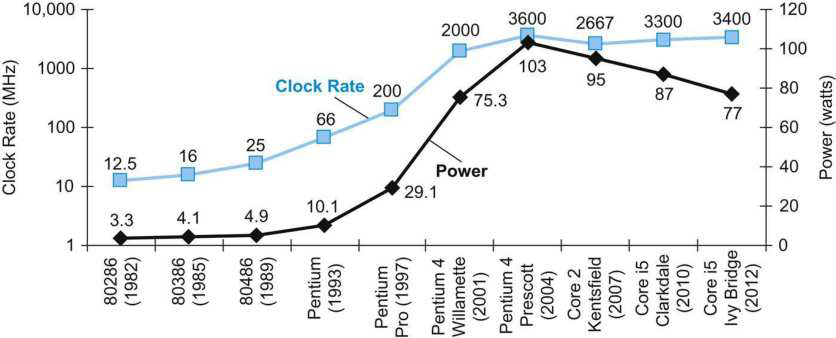
英特爾x86微處理器的時脈頻率和功耗超過八代30年。奔騰4在時脈頻率和功率上有了戲劇性的飛躍,但在效能上沒有那麼出色。Prescott的熱問題導致了奔騰4系列的報廢。Core 2系列恢復為更簡單的流水線,具有更低的時鐘速率和每個晶片多個處理器。Core i5管道緊隨其後。
關於效能,最後要進一步討論的是功率和溫度的問題。
功率和溫度問題在這些年變得越來越重要。高效能處理器晶片通常在正常操作期間消耗60-120W的功率。,如果在一臺伺服器級計算機中有四個晶片,那麼將大致消耗400W的功率。一般來說,計算機中的其他元件,如主記憶體儲器、硬碟、外圍裝置和風扇,也會消耗類似的電量,總功耗約為800W。如果增加額外的開銷,例如電源、顯示硬體的非理想效率,則功率需求將達到約1KW。一個擁有100臺伺服器的典型伺服器場將需要100千瓦的電力來執行計算機。此外還需要冷卻裝置(如空調),通常為了去除1W的熱量,需要0.5W的冷卻功率,因此伺服器農場的總功耗約為150千瓦。相比之下,一個典型的家庭的額定功率為6-8千瓦,意味著一個伺服器農場消耗的電力相當於20-25個家庭使用的電力,非常顯而易見。請注意,包含100臺機器的伺服器場是一個相對較小的設定,實際上,有更大的伺服器農場,包含數千臺機器,需要兆瓦的電力,足以滿足一個小鎮的需求。
現在考慮真正的小型裝置,比如手機處理器,由於電池壽命有限,功耗也是一個重要問題。所有人都會喜歡電池續航很長的裝置,尤其是功能豐富的智慧手機。現在考慮更小的裝置,例如嵌入身體內部的小型處理器,用於醫療應用,通常在起搏器等裝置中使用小型微晶片。在這種情況下,不想強迫患者攜帶重型電池,或經常給電池充電,從而給患者帶來不便。為了延長電池壽命,重要的是儘可能減少耗電。
此外,溫度是一個非常密切相關的概念。結合下圖中晶片的典型封裝圖,通常有一個200-400平方毫米的矽管芯(silicon die),管芯是指包含晶片電路的矩形矽塊。由於這一小塊矽耗散60-100W的功率(相當於6-10個CFL燈泡),除非採取額外措施冷卻矽管芯,否則其溫度可能會升至200攝氏度。首先在矽管芯上新增一塊5cm x 5cm的鍍鎳銅板,就是所謂的擴散器,擴散器通過傳播熱量,從而消除熱點,有助於在模具上形成均勻的溫度分佈。需要一個擴散器,因為晶片的所有部分都不會散發相同的熱量,例如ALU通常耗散大量熱量,而儲存元件相對較冷。其次,散熱取決於程式的性質,對於整數基準測試,浮點ALU是空閒的,會更冷。為了確保熱量正確地從矽管芯流到擴散器,通常新增一種導熱凝膠,稱為熱介面材料(TIM)。
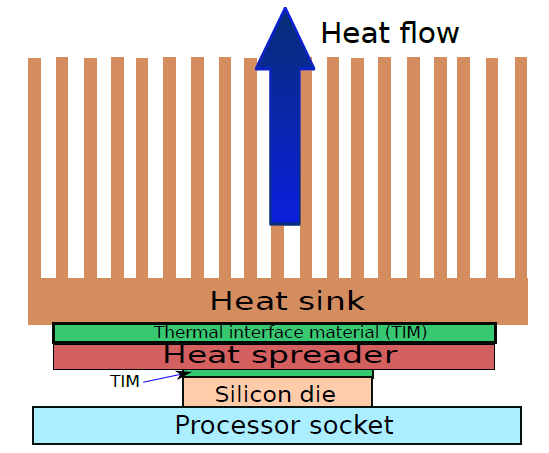
大多數晶片都有一種結構,即散熱器頂部的散熱器。它是一種銅基結構,具有一系列鰭片,如上圖所示。新增了一系列鰭片以增加其表面積,確保處理器產生的大部分熱量可以散發到周圍的空氣中。在桌上型電腦、筆記型電腦和伺服器中使用的晶片中,有一個風扇安裝在散熱器上,或者安裝在計算機機箱中,將空氣吹過散熱器,確保熱空氣被驅散,而來自外部的冷空氣流過散熱器。散熱器、散熱器和風扇的組合有助於散熱處理器產生的大部分熱量。
儘管採用了先進的冷卻技術,處理器仍能達到60-100攝氏度。在玩高度互動的電腦遊戲時,或者在執行天氣模擬等大量資料處理應用程式時,晶片上的溫度最高可達120攝氏度,足以燒開水、煮蔬菜,甚至在冬天溫暖一個小房間,我們不需要買加熱器,只需要執行一臺計算機!請注意,溫度有很多有害影響:
- 片上銅線和電晶體的可靠性隨著溫度的升高呈指數下降。由於一種被稱為NBTI(負偏置溫度不穩定性)的效應,晶片往往會隨著時間老化,老化有效地減緩了電晶體的速度。因此,有必要隨著時間的推移降低處理器的頻率,以確保正確的操作。
- 一些功耗機制(如洩漏功率)取決於溫度,意味著隨著溫度的升高,總功率的洩漏分量也隨之升高,進一步提高了溫度。
總之,為了降低電費、降低冷卻成本、延長電池壽命、提高可靠性和減緩老化,降低晶片上的功率和溫度非常重要。現在讓我們快速回顧一下主要的功耗機制。主要關注兩種機制,即動態和洩漏功率(leakage power),洩漏功率也稱為靜態功率。
先闡述動態功率。
可以把晶片的封裝看作一個封閉的黑盒子,有電能流入,熱量流出。在足夠長的時間段內,流入晶片的電能的量完全等於根據能量守恆定律作為熱量耗散的能量的量。此處忽略了沿I/O鏈路傳送電訊號所損失的能量,但與整個晶片的功耗相比,該能量可以忽略不計。
任何由電晶體和銅線組成的電路都可以被建模為具有電阻器、電容器和電感器的等效電路。電容器和電感器不散熱,但電阻器將流經電阻器的一部分電能轉換為熱量,這是電能在等效電路中轉化為熱能的唯一機制。
現在考慮一個小電路,它有一個電阻器和一個電容器,如下圖所示,電阻器代表電路中導線的電阻,電容器表示電路中電晶體的等效電容。需要注意的是,電路的不同部分,例如電晶體的柵極,在給定的時間點具有一定的電勢,意味著電晶體的柵極起著電容器的作用,從而儲存電荷。類似地,電晶體的漏極和源極具有等效的漏極電容和源極電容。通常不會在簡單的分析中考慮等效電感,因為大多數導線通常很短,並且它們不起電感器的作用。
具有電阻和電容的電路。
耗散的功率與頻率和電源電壓的平方成正比,請注意,該功耗表示由於輸入和輸出中的轉變而引起的電阻損耗,它被稱為動態功率。因此有:
動態功率(dynamic power)是由於電路中所有電晶體的輸入和輸出轉變而消耗的累積功率。
下面闡述靜態功率(洩露功率)。
請注意,動態功耗不是處理器中唯一的功耗機制,靜態或洩漏功率是高效能處理器功耗的主要組成部分,大約佔處理器總功率預算的20-40%。
到目前為止,我們一直假設電晶體在截止狀態時不允許任何電流流過,電容器的端子之間或NMOS電晶體的柵極和源極之間絕對沒有電流流過,所有這些假設都不是嚴格正確的。在實踐中,沒有任何結構是完美的絕緣體,即使在關閉狀態下,也有少量電流流過其端子。可以在理想情況下不應該通過電流的其他介面上有許多其他洩漏電源,這種電流源統稱為洩漏電流,相關的功率耗散稱為洩漏功率。
洩漏功率耗散有不同的機制,如亞閾值洩漏和柵極誘導漏極洩漏。研究人員通常使用BSIM3模型中的以下方程計算洩漏功率(主要捕獲亞閾值洩漏):
其中:
| 變數 | 定義 |
|---|---|
| $A $ | 面積相關比例常數 |
| $ \nu_{T}$ | 熱電壓 |
| $k $ | 波耳茲曼常數 |
| $q $ | \(1.6 \times 10^{-19}\) |
| $T $ | 溫度 |
| $V_{G S} $ | 柵極和源極之間的電壓 |
| $ V_{t h}$ | 閾值電壓,還取決於溫度 |
| $V_{o f f} $ | 殘餘電壓 |
| $n $ | 亞閾值擺動係數 |
| $ V_{D S}$ | 漏極和源極之間的電壓 |
注意,洩漏功率通過變數\(\nu T=k T / q\)取決於溫度。為了顯示溫度相關性,可以簡化方程以獲得以下方程:
上述公式中,A和B是常數。大約20年前,當電晶體閾值電壓較高時(約500 mV),洩漏功率與溫度呈指數關係,因此溫度的小幅度升高將轉化為洩漏功率的大幅度增加。然而,如今的閾值電壓在100-150 mV之間,因此溫度和洩漏之間的關係變得近似線性。
需要注意的是,洩漏功率始終由電路中的所有電晶體耗散,洩漏電流的量可能很小,但是當考慮數十億電晶體的累積效應時,洩漏功率耗散的總量是相當大的,甚至可能成為動態功率的很大一部分。由此,設計人員試圖控制溫度以控制洩漏功率。總功率由下式給出:
下面來建模溫度。
對晶片上的溫度建模是一個相當複雜的問題,需要大量的熱力學和傳熱背景知識,這裡陳述一個基本結果。讓我們把矽管芯的面積分成一個網格,將網格點編號為1 ... m,功率向量Ptot表示每個網格點耗散的總功率,類似地,讓每個網格點的溫度由向量T表示。對於大量網格點,功率和溫度通常由以下線性方程關聯:
- \(T_{amb}\)被稱為環境溫度,是周圍空氣的溫度。
- A是m * m矩陣,也稱為熱阻矩陣。根據公式,溫度(T)的變化和功耗彼此線性相關。
請注意,在\(\mathcal{P}_{\text {tot }}=\mathcal{P}_{\text {dyn }}+\mathcal{P}_{\text {leak }}\),\(\mathcal{P}_{\text {leak }}\)是溫度的函數,和上述公式形成反饋迴路。因此,我們需要假設溫度的初始值,計算洩漏功率,估計新的溫度,計算洩漏功耗,並不斷迭代直到值收斂。
19.5.4 高階技術
本節將簡要介紹實現處理器的高階技術。請注意,本節絕不是獨立的,其主要目的是為讀者提供額外學習的指導。本節將介紹幾個大幅度提高效能的廣泛範例,這些技術被最先進的處理器採用。
現代處理器通常使用非常深的流水線(12-20階段)在同一週期內執行多條指令,並採用先進技術消除流水線中的衝突。讓我們看看一些常見的方法。
19.5.4.1 分支預測
讓我們從IF階段開始,看看如何做得更好。如果在管線中有一個執行的分支,那麼IF階段尤其需要在管線中暫停2個週期,然後需要開始從分支目標中提取。隨著我們新增更多的線線階段,分支懲罰(branch penalty)從2個週期增加到20多個週期,使得分支指令非常昂貴,會嚴重限制效能。因此,有必要避免管線暫停,即使對於已採取的分支也是如此。
如果可以預測分支的方向,也可以預測分支目標,那會怎麼樣?在這種情況下,提取單元可以立即從預測的分支目標開始提取。如果在稍後的時間點發現預測錯誤,則需要取消預測錯誤的分支指令之後的所有指令,並將其從管線中丟棄,這種指令也稱為推測指令(speculative instruction)。
現代處理器通常根據預測執行大量指令集,例如預測分支的方向,並相應地從預測的分支目標開始提取指令,稍後執行分支指令時驗證預測。如果發現預測錯誤,則從管線中丟棄所有錯誤獲取或執行的指令,這些指令稱為推測指令(speculative instruction)。相反,正確獲取並執行的指令,或其預測已驗證的指令稱為非推測指令。
請注意,禁止推測性指令更改暫存器檔案或寫入記憶體系統是極其重要的,因此需要等待指令變得非推測性,然後才允許它們進行永久性的更改。第二,不允許它們在非推測之前離開管線,但如果需要丟棄推測指令,那麼現代管線採用更簡單的機制,通常會刪除在預測失敗的分支指令之後獲取的所有指令,而不是選擇性地將推測指令轉換為管線氣泡。這個簡單的機制在實踐中非常有效,被稱為管線重新整理(pipeline flush)。
現代處理器通常採用一種簡單的方法,即丟棄管線中的所有推測指令。它們完全完成所有指令的執行,直到出現預測失誤的指令,然後清理整個管線,有效地刪除在預測失誤指令之後獲取的所有指令。這種機制稱為管線重新整理(pipeline flush)。
現在概述分支預測中的主要挑戰:
- 如果一條指令是一個分支,需要在提取階段首先讀取,如果是分支,需要讀取分支目標的地址。
- 接下來,需要預測分支的預期方向。
- 有必要監測預測指令的結果。如果存在預測失誤,那麼需要在稍後的時間點執行管線重新整理,以便能夠有效地刪除所有推測指令。
在分支的情況下檢測預測失誤是相當直接的,將預測新增到指令包中,並用實際結果驗證預測。如果它們不同,那麼安排管線重新整理。主要的挑戰是預測分支指令的目標及其結果。
現代處理器使用稱為分支目標緩衝器(BTB)的簡單硬體結構,它是一個簡單的記憶體陣列,儲存最後N(從128到8192不等)條分支指令的程式計數器及其目標。找到匹配的可能性很高,因為程式通常表現出一定程度的區域性性,意味著它們傾向於在一段時間內重複執行同一段程式碼,例如迴圈,因此BTB中的條目往往會在很短的時間內被重複使用。如果存在匹配,那麼也可以自動推斷該指令是分支。
要有效地預測分支的方向要困難得多,但可以利用後面闡述的模式。程式中的大多數分支通常位於迴圈或if語句中,其中兩個方向的可能性不大,事實上,一個方向的可能性遠大於另一個方向,例如迴圈中的分支佔用了大部分時間。有時if語句僅在某個異常條件為真時才求值,大多數情況下,與這些if語句關聯的分支都不會被執行。類似地,對於大多數程式,設計者觀察到幾乎所有的分支指令都遵循特定的模式,它們要麼對一個方向有強烈的偏倚,要麼可以根據過去的歷史進行預測,要麼可以基於其它分支的行為進行預測。當然,這種說法沒有理論依據,只是處理器設計者的觀察結果,因此他們設計了預測器來利用程式中的這種模式。
本節討論一個簡單的2位分支預測器。假設有一個分支預測表,該表為表中的每個分支分配一個2位值,如下圖所示。
如果該值為00或01,則預測該分支不會被執行。如果它等於10或11,那麼預測分支被執行。此外,每次執行分支時,將相關計數器遞增1,每次不執行分支時將計數器遞減1。為了避免溢位,不將11遞增1以產生00,也不將00遞減以產生11。我們遵循飽和算術的規則,即(二進位制):\(11+1=11\)和\(00-1=00\)。這個2位值被稱為2位飽和計數器,其狀態圖如下圖所示。
預測分支有兩種基本操作:預測和訓練。為了預測分支,我們在分支預測表中查詢其程式計數器的值,在特定情況下,使用pc地址的最後n位來存取2n個條目的分支預測表。讀取2位飽和計數器的值,並根據其值預測分支,當得到分支的實際結果時,我們訓練通過使用飽和演演算法遞增或遞減計數器的值。
現在看看這個預測器的工作原理,考慮一段簡單的C程式碼及其等效的組合程式碼:
void main()
{
foo();
...
foo();
}
int foo()
{
int i, sum = 0
for(i=0; i < 10; i++)
{
sum = sum + i;
}
return sum;
}
.main:
call .foo
...
call .foo
.foo:
mov r0, 0 /* sum = 0 */
mov r1, 0 /* i = 0 */
.loop:
add r0, r0, r1 /* sum = sum + i */
add r1, r1, 1 /* i = i + 1 */
cmp r1, 10 /* compare i with 10 */
bgt .loop /* if(r1 > 10) jump to .loop */
ret
讓我們看看回圈中的分支語句bgt .loop,對於除最後一次之外的所有迭代,都會執行分支。如果在狀態10下啟動預測器,那麼第一次,分支預測正確(採取),計數器遞增並等於11,對於後續的每一次迭代,都會正確地預測分支。然而,在最後一次迭代中,需要將其預測為未採取,這裡有一個錯誤的預測,因此,2位計數器遞減,並設定為10。現在考慮一下再次呼叫函數foo時的情況,2位計數器的值為10,並且分支bgt .loop被正確預測為採用。
因此,2位計數器方案在預測方案中增加了一點延遲(或過去的歷史)。如果分支歷史上一直在一個方向,那麼一個異常不會改變預測。這個模式對於迴圈非常有用,正如在這個簡單的例子中看到的那樣,迴圈最後一次迭代中分支指令的方向總是不同的,但下一次進入迴圈時,分支的預測是正確的,正如本例所示。請注意,這只是其中一種模式,現代分支預測程式可以利用更多型別的模式。
程式優化提示:
- 為編譯器提供儘可能多的有關正在執行的操作的資訊。
- 儘可能使用常數和區域性變數。如果語言允許,請定義原型並宣告靜態函數。
- 儘可能使用陣列而不是指標。
- 避免不必要的型別轉換,並儘量減少浮點到整數的轉換。
- 避免溢位和下溢。
- 使用適當的資料型別(如float、double、int)。
- 考慮用乘法代替除法。
- 消除所有不必要的分支。
- 儘可能使用迭代而不是遞迴。
- 首先使用最可能的情況構建條件語句(例如if、switch、case)。
- 在結構中按尺寸順序宣告變數,首先宣告尺寸最大的變數。
- 當程式出現效能問題時,請在開始優化程式之前對程式進行概要分析。(評測是將程式碼分成小塊,並對每一小塊進行計時,以確定哪一塊花費的時間最多的過程。)
- 切勿僅基於原始效能放棄演演算法。只有當所有演演算法都完全優化時,才能進行公平的比較。
- 過程內聯(procedure inlining),用函數體替換對函數的呼叫,用呼叫者的引數替換過程的引數。
- 迴圈轉換(loop transformation),可以減少迴圈開銷,改善記憶體存取,並更有效地利用硬體。
- 迴圈展開(loop-unrolling)。在執行多次迭代的迴圈中,例如那些傳統上由For語句控制的迴圈,迴圈展開loop-unrolling的優化通常有用。迴圈展開包括進行迴圈,多次複製身體,並減少執行轉換後的迴圈的次數。迴圈展開減少了迴圈開銷,併為許多其他優化提供了機會。
- 複雜的迴圈轉換,如交換巢狀迴圈和阻塞回圈以獲得更好的記憶體行為。
- 區域性和全域性優化。在專用於區域性和全域性優化的過程中,執行以下優化:
- 區域性優化在單個基本塊內工作。區域性優化過程通常作為全域性優化的先導和後續執行,以在全域性優化前後「清理」程式碼。
- 全域性優化跨多個基本塊工作。
- 全域性暫存器分配為程式碼區域的暫存器分配變數。暫存器分配對於在現代處理器中獲得良好效能至關重要。
- 更具體地,有子表示式消除(Common subexpression elimination)、削減強度(Strength reduction)、常數傳播(Constant propagation)、拷貝傳播(Copy propagation)、死儲存消除(Dead store elimination)等操作。
如果使用兩個位,則可以使用它們來記錄相關指令執行的最後兩個範例的結果,或者以其他方式記錄狀態。下圖顯示了一種典型的方法,假設演演算法從流程圖的左上角開始。只要執行遇到的每個後續條件分支指令,決策過程就預測將執行下一個分支,如果單個預測錯誤,則演演算法繼續預測下一個分支被執行。只有在沒有采取兩個連續分支的情況下,演演算法才會轉移到流程圖的右側,隨後該演演算法將預測在一行中的兩個分支被取下之前不會取下分支,因此該演演算法需要兩個連續的錯誤預測來改變預測決策。

分支預測流程圖。
預測過程可以用有限狀態機更緊湊地表示,如下圖所示,許多文獻通常使用有限狀態機表示。
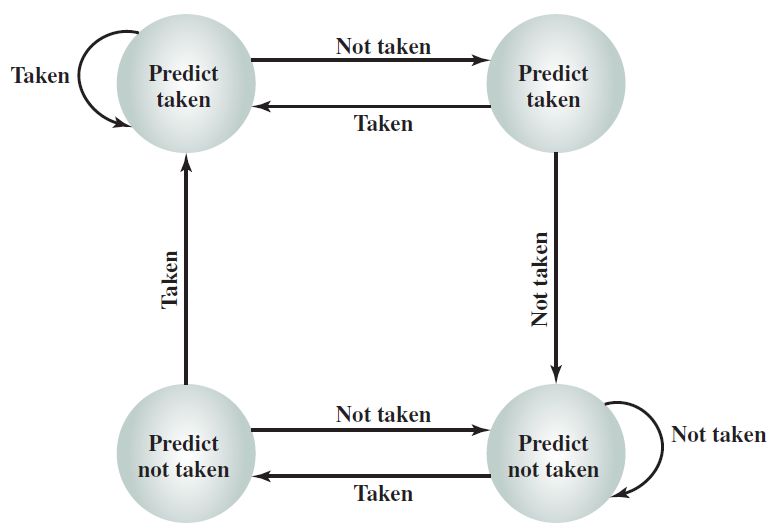
分支預測狀態圖。
下圖將該方案與從未採取的預測策略進行了對比。使用前一種策略,指令獲取階段總是獲取下一個順序地址。如果執行了分支,處理器中的某些邏輯會檢測到這一點,並指示從目標地址提取下一條指令(除了重新整理管道之外)。分支歷史表被視為快取,每個預取都會觸發分支歷史表中的查詢。如果未找到匹配項,則使用下一個順序地址進行提取,如果找到匹配,則根據指令的狀態進行預測:下一個順序地址或分支目標地址被饋送到選擇邏輯。
為了彌補依賴性,已經開發了程式碼重組技術,首先考慮分支指令。延遲分支(Delayed branch)是一種提高流水線效率的方法,它使用的分支在執行以下指令後才生效(因此稱為延遲),緊接在分支之後的指令位置被稱為延遲槽(delay slot)。這個奇怪的過程如下表所示。在標記為「正常分支」的列中,有一個正常的符號指令機器語言程式。執行102之後,下一條要執行的指令是105。為了規範流水線,在這個分支之後插入一個NOOP。但是,如果在101和102處的指令互換,則可以實現提高的效能。
下圖顯示了結果。圖a顯示了傳統管線方法。JUMP指令在時間4被獲取,在時間5,JUMP指令與指令103(ADD指令)被獲取的同時被執行。因為發生了JUMP,它更新了程式計數器,所以必須清除流水線中的指令103,在時間6,作為JUMP的目標的指令105被載入。
圖b顯示了典型RISC組織處理的相同管線,時間是一樣的,但由於插入了NOOP指令,不需要特殊的電路來清除管線,NOOP簡單地執行而沒有效果。
圖c顯示了延遲分支的使用。JUMP指令在ADD指令之前的時間2獲取,ADD指令在時間3獲取。但請注意,ADD指令是在執行JUMP指令有機會改變程式計數器之前獲取的。因此,在時間4期間,在獲取指令105的同時執行ADD指令,保留了程式的原始語意,但執行需要兩個更少的時鐘週期。
19.5.4.2 延遲載入
類似延遲分支的策略稱為延遲載入(delayed load),可以用於載入指令。在LOAD指令中,將成為載入目標的暫存器被處理器鎖定。然後,處理器繼續執行指令流,直到它到達需要該暫存器的指令為止,此時它將空閒,直到載入完成。如果編譯器可以重新排列指令,以便在載入過程中完成有用的工作,那麼效率就會提高。
19.5.4.3 迴圈展開
另一種提高指令並行性的編譯器技術是迴圈展開(loop unrolling)。展開會多次複製迴圈體,稱為展開因子(u),並按步驟u而不是步驟1進行迭代:
- 減少環路開銷
- 通過提高流水線效能提高指令並行性
- 改進暫存器、資料快取或TLB位置
下圖在一個範例中說明了所有三種改進。迴圈開銷減少了一半,因為在測試之前執行了兩次迭代,並在迴圈結束時分支。由於可以在儲存第一次賦值的結果和更新迴圈變數的同時執行第二次賦值,因此提高了指令並行性。如果將陣列元素分配給暫存器,暫存器區域性性將得到改善,因為在迴圈體中使用了兩次a[i]和a[i+1],從而將每次迭代的載入次數從三次減少到兩次。

指令流水線的設計不應與應用於系統的其他優化技術分離,例如流水線的指令排程和暫存器的動態分配應該一起考慮,以實現最大的效率。
19.5.4.4 順序管線的問題
在簡單管線中,每個週期只執行一條指令,但並非絕對必要。我們可以設計一個處理器,比如最初的英特爾奔騰,它有兩條並行管線。該處理器可以在一個週期內同時執行兩條指令。這些管道具有額外的功能單元,因此兩條管線中的指令都可以在沒有任何重大結構衝突的情況下執行。該策略增加了IPC,但也使處理器更加複雜。這樣的處理器被稱為包含多個順序執行管線,因為可以在同一個週期內向執行單元釋出多條指令。每個週期可以執行多條指令的處理器也稱為超標量處理器(superscalar processor)。
其次,這種處理器被稱為有序處理器(in-order processor),因為它按程式順序執行指令,程式順序是指令的動態範例在程式中出現時的執行順序。例如,單週期處理器或流水線處理器按程式順序執行指令。
每個週期可以執行多條指令的處理器稱為超標量處理器(superscalar processor)。
有序處理器按程式順序執行指令。程式順序被定義為指令的動態範例的順序,與順序執行程式的每條指令時所感知的順序相同。
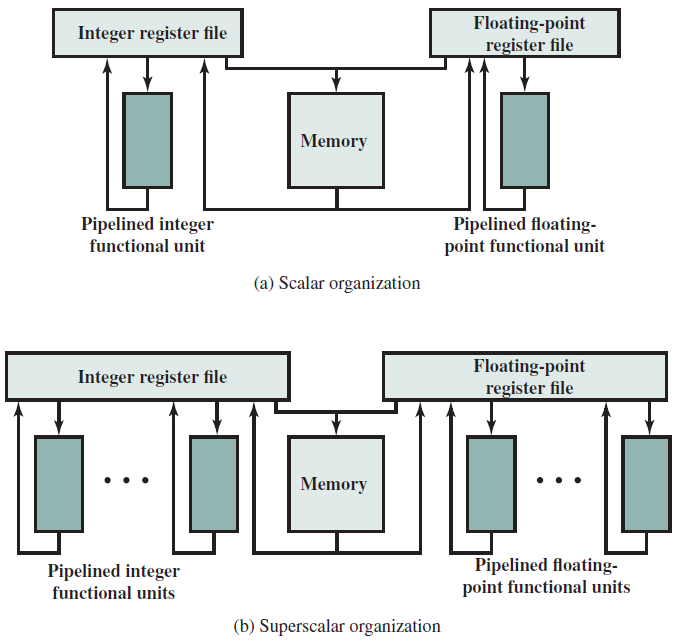
超標量組織與普通標量組織的比較。
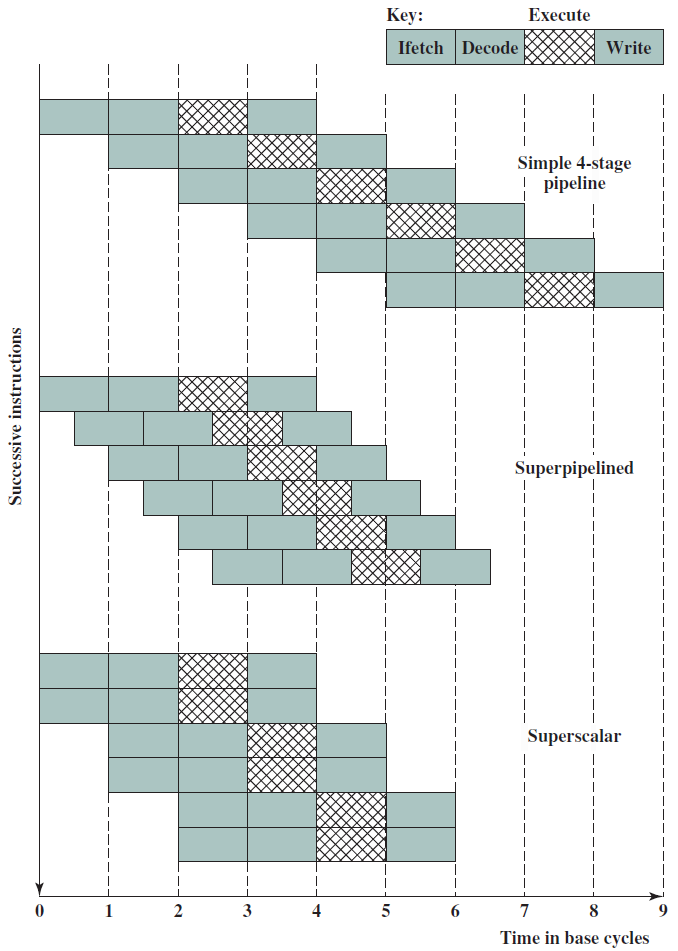
超標量和超流水線方法的比較。
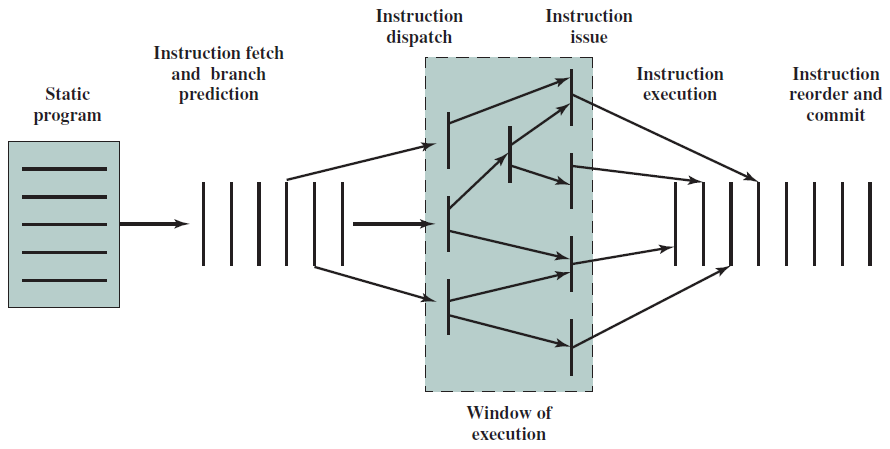
超標量處理的概念描述。
現在,我們需要尋找兩條管線的依賴性和潛在衝突。其次,轉發邏輯也要複雜得多,因為結果可以從任一管線轉發。英特爾釋出的原始奔騰處理器有兩條管線,即U管線和V管線。U管線可以執行任何指令,而V管線僅限於簡單指令。指令作為2-指令束(2-instruction bundle)獲取,指令束中的前一條指令被傳送到U管線,後一條指令則被傳送到V管線。這種策略允許並行地執行這些指令。
讓我們嘗試在概念上設計一個簡單的處理器,它採用了原始奔騰處理器的兩條流水線:U和V。我們設想了一個組合的指令和運算元獲取單元,它形成2-指令束,並被傳送到兩個流水線以同時執行。但如果指令不滿足某些約束,則該單元形成1-指令束並將其傳送到U流水線。無論何時,我們生成這樣的束,都可以廣泛遵守一些通用規則,應該避免具有RAW依賴性的兩條指令,在這種情況下,管線將暫停。
其次,需要特別注意記憶體指令,因為它們之間的依賴關係在EX階段結束之前無法發現。假設指令束中的第一條指令是儲存指令,第二條指令是載入指令,並且它們碰巧存取相同的記憶體地址。需要在EX階段結束時檢測這種情況,並將值從儲存轉發到載入。對於相反的情況,當第一條指令是載入指令,第二條指令是儲存到相同地址時,需要暫停儲存指令,直到載入完成。如果指令束中的兩條指令都儲存到同一地址,那麼前面的指令是冗餘的,可以轉換為nop。因此,需要設計一個符合這些規則的處理器,並具有複雜的互鎖和轉發邏輯。
下面展示一個簡單的例子。為以下組合程式碼繪製一個流水線圖,假設流水線中存在2個問題。
[1]: add r1, r2, r3
[2]: add r4, r5, r6
[3]: add r9, r8, r8
[4]: add r10, r9, r8
[5]: add r3, r1, r2
[6]: ld r6, 10[r1]
[7]: st r6, 10[r1]
此處,流水線圖包含每個階段的兩個條目,因為兩個指令可以同時在一個階段中。我們首先觀察到可以並行執行指令[1]和[2],但不能並行執行指令[3]和[4],因為指令[3]寫入r9,而指令[4]將r9作為源運算元。我們不能在同一個週期內執行這兩條指令,因為r9的值是在EX階段產生的,也是EX階段需要的。我們繼續並行執行[4]和[5],在指令[4]的情況下,可以使用轉發來獲得r9的值。最後,我們不能並行執行指令[6]和[7],它們存取相同的記憶體地址,載入需要在儲存開始之前完成,因此插入了另一個氣泡。管線圖如下:
19.5.4.5 EPIC和VLIW處理器
現在,我們可以用軟體(而不是用硬體)準備指令束。編譯器對程式碼的可見性要高得多,並且可以執行廣泛的分析以建立多指令束。英特爾和惠普設計的安騰處理器是一款基於類似原理的非常經典的處理器。讓我們首先從定義術語開始:EPIC和VLIW。
VLIW(Very Long Instruction Word,超長指令字):編譯器建立的指令束之間沒有依賴關係,硬體並行執行每個包中的指令,正確性的全部責任在於編譯器。
EPIC(Explicitly Parallel Instruction Computing,顯式並行指令計算):這種範例擴充套件了VLIW計算,但在這種情況下,無論編譯器生成什麼程式碼,硬體都會確保執行正確。
EPIC/VLIW處理器需要非常聰明的編譯器來分析程式並建立指令包,例如如果一個處理器有4條流水線,那麼每個束包含4條指令。編譯器建立束,以便束中的指令之間不存在依賴關係。設計EPIC/VLIW處理器的更廣泛的目標是將所有的複雜性轉移到軟體上,編譯器以這樣一種方式排列束,可以最大限度地減少處理器中所需的互鎖、轉發和指令處理邏輯。
但事後看來,這類處理器未能兌現承諾,因為硬體無法像設計者最初計劃的那樣簡單。高效能處理器仍然需要相當複雜的硬體,並且需要一些複雜的架構特性。這些特性增加了硬體的複雜性和功耗。
19.5.4.6 亂序管線
到目前為止,我們一直在主要考慮有序管線,這些管線按照指令在程式中出現的順序執行指令,但並不是絕對必要的。考慮下面的程式碼片段:
[1]: add r1, r2, r3
[2]: add r4, r1, r1
[3]: add r5, r4, r2
[4]: mul r6, r5, r2
[5]: div r8, r9, r10
[6]: sub r11, r12, r13
上面程式碼中,由於資料依賴性,我們被限制按順序執行指令1到4。然而,可以並行執行指令5和6,因為它們不依賴於指令1-4。如果無序執行指令5、6,不會犧牲正確性,例如如果可以在一個週期內發出兩條指令,那麼可以一起提交(1,5),然後提交(2,6),最後提交指令3和4。在這種情況下,可以通過在前兩個週期內執行2條指令,在4個週期中執行6條指令的序列。這種可能在每個週期執行多條指令的處理器正是超標量處理器。
可以按照與其程式順序不一致的順序執行指令的處理器稱為亂序(Out-Of-Order,OOO,亦稱無序)處理器。
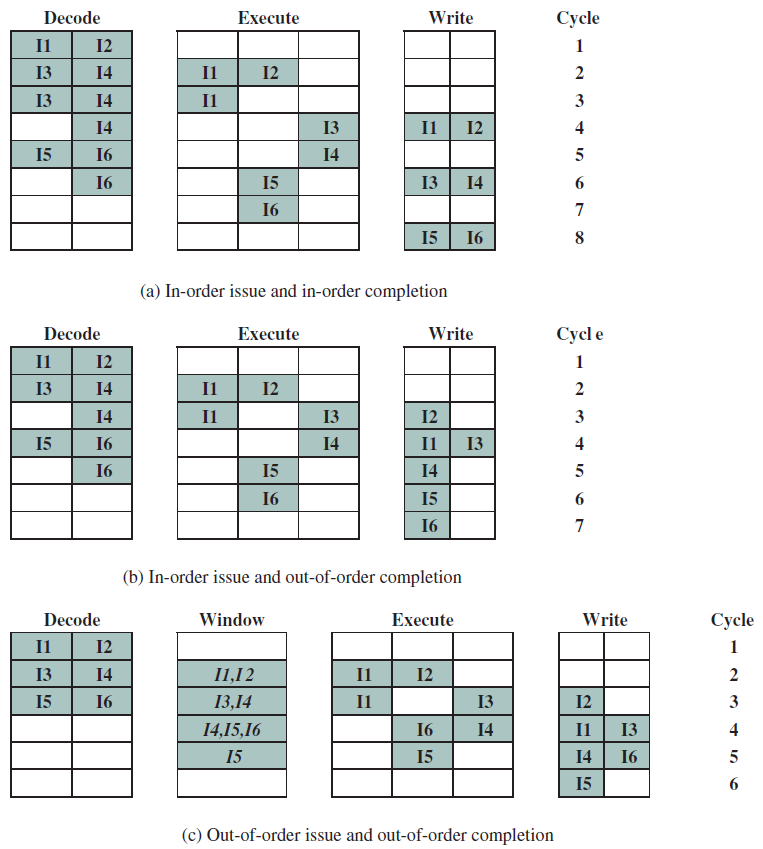
超標量指令執行和完成策略。
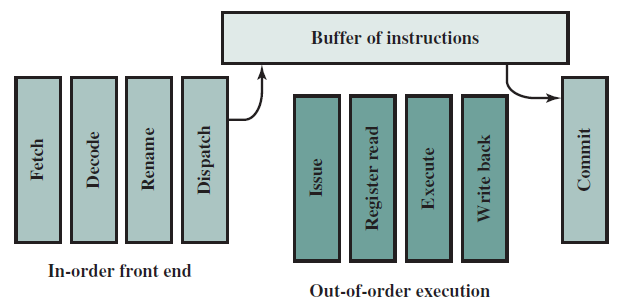
具備亂序完備的亂序執行組織。
亂序(OOO)處理器按順序獲取指令,在提取階段之後,它繼續解碼指令。大多數真實世界的指令需要一個以上的解碼週期,這些指令同時按程式順序新增到稱為重新排序緩衝區(reorder buffer,ROB)的佇列中。解碼指令後,需要執行一個稱為暫存器重新命名(register renaming)的步驟。大致思路是:由於執行的指令是無序的,可能會有WAR和WAW衝突。考慮下面的程式碼片段:
[1]: add r1, r2, r3
[2]: sub r4, r1, r2
[3]: add r1, r5, r6
[4]: add r9, r1, r7
如果在指令[1]之前執行指令[3]和[4],那麼就有潛在的WAW衝突,因為指令[1]可能會覆蓋指令[3]寫入的r1的值,將導致錯誤的執行。因此,我們嘗試重新命名暫存器,以便消除這些衝突。大多數現代處理器都設計了一組架構暫存器(architectural register),這些暫存器與暴露於軟體(組合程式)的暫存器相同。此外,它們還有一組僅在內部可見的物理暫存器(physical register),重新命名階段將架構暫存器名轉換為物理暫存器名,以消除WAR和WAW衝突。上面程式碼中僅存的衝突是RAW衝突,表明存在真正的資料依賴性。因此,重新命名後的程式碼段將如下所示,假設物理暫存器的範圍為p1 … p128。
[1]: add p1, p2, p3 /* p1 contains r1 */
[2]: sub p4, p1, p2
[3]: add p100, p5, p6 /* r1 is now begin saved in p100 */
[4]: add p9, p100, p7
我們通過將指令3中的r1對映到p100,消除了WAW衝突,唯一存在的依賴關係是指令之間的RAW依賴關係[1] --> [2] 和[3] --> [4],重新命名後的指令進入指令視窗。請注意,到目前為止,指令一直在按順序處理。
指令視窗或指令佇列通常包含64-128個條目(參見下圖),每條指令都監視其源運算元,只要一條指令的所有源運算元都準備好了,該指令就可以提交到其相應的功能單元。指令不必總是存取物理暫存器檔案,還可以從轉發路徑中獲取值。指令完成執行後,將結果的值廣播給指令視窗中的等待指令。等待結果的指令,將其相應的源運算元標記為就緒,此過程稱為指令喚醒(instruction wakeup)。現在,有可能在同一週期內準備好多條指令,為了避免結構衝突,指令選擇單元選擇一組指令執行。
我們需要另一種用於載入和儲存指令的結構,稱為載入-儲存(load-store)佇列,它按程式順序儲存載入和儲存列表,允許載入通過內部轉發機制獲取其值,如果同一地址有較早的儲存。
指令完成執行後,我們在重新排序緩衝區中標記其條目,指令按程式順序離開重新排序緩衝區。如果一條指令由於某種原因不能快速完成,那麼重新排序緩衝區中的所有指令都需要暫停。回想一下,重新排序緩衝區中的指令條目是按程式順序排序的,指令需要按程式順序保留重新排序緩衝區,以便我們能夠確保精確的異常。
綜上所述,無序處理器(OOO)的主要優點是它可以並行執行指令,這些指令之間沒有任何RAW依賴關係。大多數程式通常在大多數時間點都有這樣的指令集。此屬性稱為指令級並行(instruction level parallelism,ILP),現代OOO處理器旨在儘可能地利用ILP。
19.5.4.7 微操作
在執行程式時,計算機的操作由一系列指令週期組成,每個週期有一條機器指令。由於分支指令的存在,這個指令週期序列不一定與組成程式的指令序列相同,這裡所指的是指令的執行時間序列。
每個指令週期都由一些較小的單元組成,其中一種方便的細分是獲取、間接、執行和中斷,只有獲取和執行週期總是發生。然而,要設計控制單元,需要進一步細分描述,而進一步的細分是可能的。事實上,我們將看到每個較小的週期都涉及一系列步驟,每個步驟都涉及處理器暫存器。這些步驟稱為微操作(micro-operation)。
字首micro指的是每個步驟都非常簡單,完成的很少,下圖描述了各種概念之間的關係。總之,程式的執行包括指令的順序執行,每個指令在由較短子週期(如獲取、間接、執行、中斷)組成的指令週期內執行。每個子週期的執行涉及一個或多個較短的操作,即微操作。
程式執行的組成要素。
微操作是處理器的功能操作或原子操作。本節將研究微操作,以瞭解如何將任何指令週期的事件描述為此類微操作的序列。將使用一個簡單的範例,並展示微操作的概念如何作為控制單元設計的指南。
先闡述獲取週期(Fetch Cycle)。
獲取週期發生在每個指令週期的開始,並導致從記憶體中獲取指令,涉及四個暫存器:
- 記憶體地址暫存器(MAR):連線到系統匯流排的地址線。它為讀或寫操作指定記憶體中的地址。
- 記憶體緩衝暫存器(MBR):連線到系統匯流排的傳輸線。它包含要儲存在記憶體中的值或從記憶體中讀取的最後一個值。
- 程式計數器(PC):儲存要獲取的下一條指令的地址。
- 指令暫存器(IR):儲存獲取的最後一條指令。
讓我們從獲取週期對處理器暫存器的影響的角度來看獲取週期的事件序列。下圖中顯示了一個範例,在提取週期開始時,要執行的下一條指令的地址在程式計數器(PC)中,其中地址是1100100。
- 第一步是將該地址移動到記憶體地址暫存器(MAR),因為這是連線到系統匯流排地址線的唯一暫存器。
- 第二步是引入指令,所需地址(在MAR中)被放置在地址匯流排上,控制單元在控制匯流排上發出READ命令,結果出現在資料匯流排上,並被複制到記憶體緩衝暫存器(MBR)中。我們還需要將PC增加指令長度,以便為下一條指令做好準備。這兩個動作(從記憶體中讀取字,遞增PC)互不干擾,所以可以同時執行它們以節省時間。
- 第三步是將MBR的內容移動到指令暫存器(IR),將釋放MBR,以便在可能的間接回圈期間使用。

事件順序,獲取週期。
因此,簡單的提取週期實際上由三個步驟和四個微操作組成。每個微操作都涉及將資料移入或移出暫存器。只要這些動作不相互干擾,一步中就可以進行幾個動作,從而節省時間。象徵性地,我們可以將這一系列事件寫成如下:

其中I是指令長度。需要對這個序列做幾點評論,假設時鐘可用於定時目的,並且它發出規則間隔的時鐘脈衝。每個時鐘脈衝定義一個時間單位,因此所有時間單位都具有相同的持續時間。每個微操作可以在單個時間單位的時間內執行,符號(t1、t2、t3)表示連續的時間單位。換句話說,我們有:
- 第一時間單位:將PC的內容移動到MAR。
- 第二時間單位:將MAR指定的記憶體位置的內容移動到MBR。按I遞增PC的內容。
- 第三時間單位:將MBR的內容移動到IR。
注意,第二和第三微操作都發生在第二時間單位期間,第三個微操作可以與第四個微操作分組,而不影響提取操作:

微操作的分組必須遵循兩個簡單的規則:
- 必須遵循正確的事件順序。因此,(MAR <--(PC))必須在(MBR <-- Memory)之前,因為記憶體讀取操作使用MAR中的地址。
- 必須避免衝突。不應試圖在一個時間單位內對同一暫存器進行讀寫,因為結果是不可預測的,例如微操作(MBR dMemory)和(IR dMBR)不應在同一時間單位內發生。
最後一點值得注意的是,其中一個微操作涉及相加。為了避免電路重複,可以由ALU執行此相加。ALU的使用可能涉及額外的微操作,取決於ALU的功能和處理器的組織。
此外,在非直接週期(Indirect Cycle)、中斷週期(Interrupt Cycle)、執行週期(Execute Cycle)、指令週期(Instruction Cycle)等也涉及了類似的機制和原理。
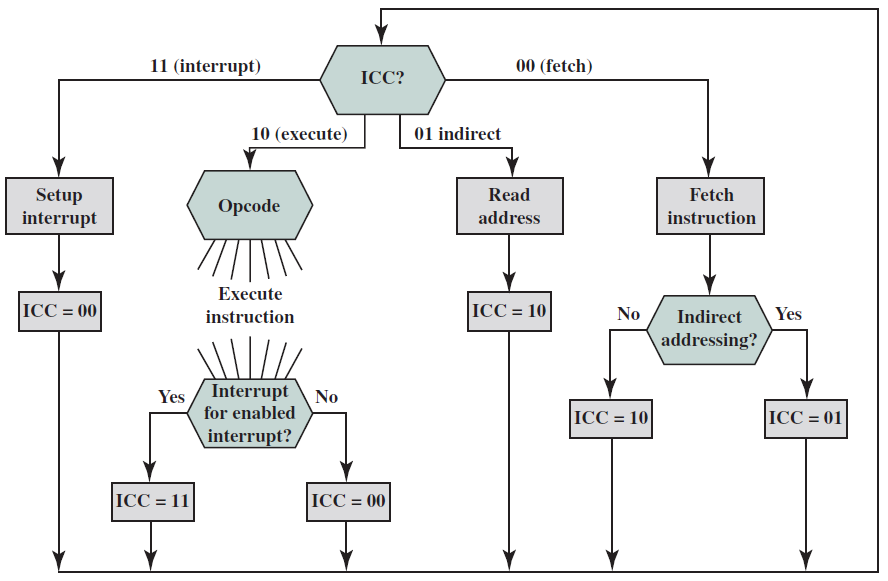
指令週期流程圖。
19.5.5 商業處理器案例
現在來看看一些真正的處理器的設計,這樣就可以將迄今為止所學的所有概念放在實際的角度。後面將研究ARM、AMD和Intel三大處理器公司的嵌入式(用於小型移動裝置)和伺服器處理器。本節的目的不是比較和對比三家公司的處理器設計,甚至是同一家公司的不同型號。每一個處理器都是針對特定的細分市場進行優化設計的,並考慮到某些關鍵業務決策。因此,本節的重點是從技術角度研究設計,並瞭解設計的細微差別。
在對RISC機器的最初熱情之後,人們越來越認識到:
- RISC設計可能會從包含一些CISC功能中受益。
- CISC設計可能從包含一些RISC功能中獲益。結果是,較新的RISC設計,特別是PowerPC,不再是「純」RISC,而較新的CISC設計,尤其是奔騰II和更高版本的奔騰型號,確實包含了一些RISC特性。
下表列出了一些處理器,並對它們進行了多個特性的比較。為了進行比較,以下是典型的RISC:
- 單個指令大小。
- 該大小通常為4位元組。
- 少量資料定址模式,通常少於五種,很難確定。在表中,暫存器和文字模式不計算在內,具有不同偏移量大小的不同格式分別計算在內。
- 無需進行一次記憶體存取以獲取記憶體中另一個運算元的地址的間接定址。
- 沒有將載入/儲存與算術相結合的操作(如從記憶體新增、新增到記憶體)。
- 每條指令不超過一個記憶體定址運算元。
- 不支援載入/儲存操作的資料任意對齊。
- 記憶體管理單元(MMU)對指令中的資料地址的最大使用次數。
- 整數暫存器說明符的位數等於或大於5,意味著一次至少可以顯式參照32個整數暫存器。
- 浮點暫存器說明符的位數等於或大於4,意味著一次至少可以顯式參照16個浮點暫存器。
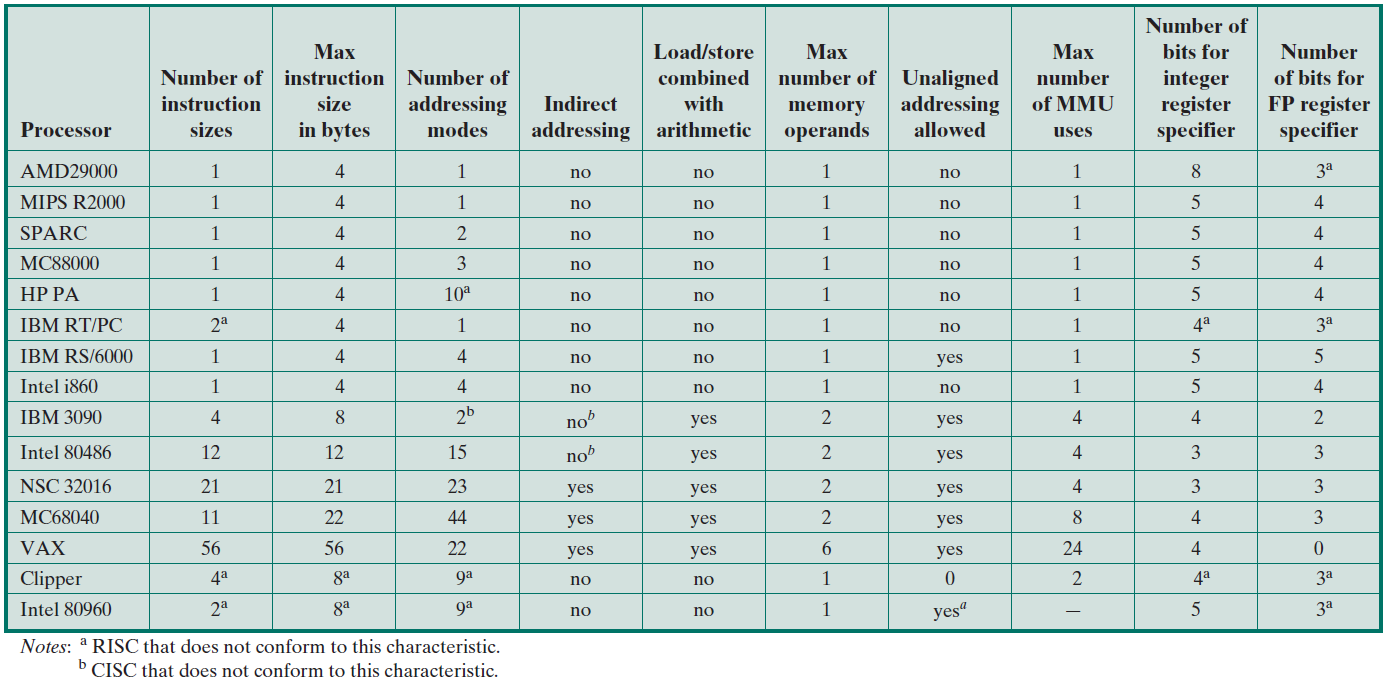
19.5.5.1 ARM處理器
ARM最初是Acorn計算機的處理器,因此其原名為Acorn RISC Machine,伯克利RISC論文影響了其架構。最重要的早期應用之一是16位元微處理器AM 6502的模擬,該模擬旨在為Acorn計算機提供大部分軟體。由於6502有一個可變長度的指令集,是位元組的倍數,因此6502模擬有助於解釋ARMv7指令集中對移位和遮蔽的強調。它作為一款低功耗嵌入式計算機的流行始於它被選為命運多舛的Apple Newton個人數位助理的處理器。
雖然Newton並沒有蘋果希望的那麼受歡迎,但蘋果的祝福讓早期的ARM指令集變得引人注目,隨後它們在包括手機在內的幾個市場上流行起來。與Newton的經歷不同,手機的非凡成功解釋了2014年出貨120億ARM處理器的原因。ARM歷史上的一個重大事件是稱為版本8的64位元地址擴充套件,ARM藉此機會重新設計了指令集,使其看起來更像MIPS,而不像早期的ARM版本。
ARM處理器(通常稱為ARM核心)最重要的一點是ARM設計處理器,然後將設計許可給客戶。與英特爾或IBM等其他供應商不同,ARM不生產矽片。相反,德州儀器(Texas Instruments)和高通(Qualcomm)等供應商購買了使用ARM核心設計的許可證,並新增了額外的元件。然後,他們將合同交給半導體制造公司,或使用自己的製造設施在矽上製造整個SOC(片上系統)。
ARM的最新(截至2012年)ARMv8架構有三條處理器線:
- 第1系列處理器被稱為ARM Cortex-M系列。這些處理器主要設計用於醫療裝置、汽車和工業電子等嵌入式應用中的微控制器,其設計背後的主要關注點是功率效率和成本。本節將描述具有三階段流水線的ARM Cortex-M3處理器。
- 第2系列處理器被稱為ARM Cortex-R系列。這些處理器是為實時應用而設計的,主要重點是可靠性、高速和實時響應。它們不適用於智慧手機等消費電子裝置,不支援執行使用虛擬記憶體的作業系統。
- 第3系列處理器被稱為ARM Cortex-A系列。這些處理器設計用於在智慧手機、平板電腦和一系列高階嵌入式裝置上執行常規使用者應用程式。這些ARM核心通常具有複雜的管線,支援向量操作,並且可以執行需要虛擬記憶體硬體支援的複雜作業系統。
ARM Cortex-M3
讓我們從主要為嵌入式處理器市場設計的ARM Cortex-M系列處理器開始。對於這樣的嵌入式處理器,能效和成本比原始效能更重要。因此,ARM工程師設計了一個3執行的流水線,沒有非常複雜的功能。
Cortex-M3支援ARMv7-M指令集的基本版本,通常使用ARM AMBA匯流排連線到其他元件,如下圖所示。
連線到AMBA匯流排的ARM Cortex-M3以及其他元件。
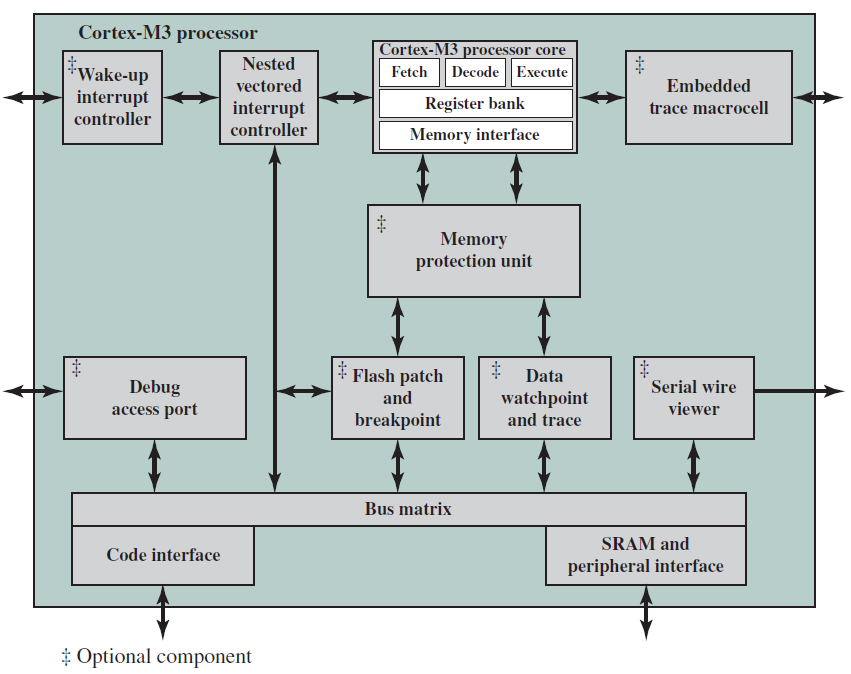
ARM Cortex-M3架構圖。
AMBA(高階微控制器匯流排體系結構)是一種由ARM設計的匯流排體系結構,它用於將ARM核心與基於SOC的系統中的其他元件連線。例如,智慧手機和移動裝置中的大多數處理器使用AMBA匯流排通過橋接裝置連線到高速記憶體裝置、DMA引擎和其他外部匯流排。一種這樣的外部匯流排是APB匯流排(高階外圍匯流排),用於連線到外圍裝置,例如鍵盤、UART控制器(通用非同步收發器協定)、計時器和PIO(並行輸入輸出)介面。
下圖顯示了ARM Cortex-M3的流水線。它有三個階段:獲取(F)、解碼(D)和執行(E)。提取階段從記憶體中提取指令,是所有三個階段中最小的階段。
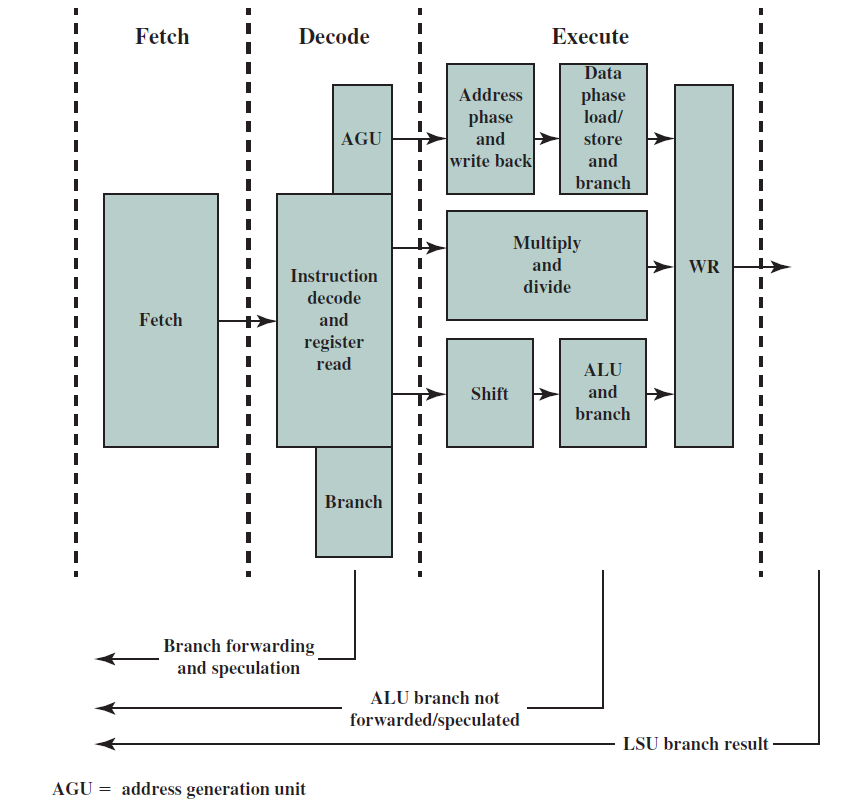
ARM Cortex-M3的流水線。
解碼階段(D階段)有三個不同的子單元,如上圖所示。D階段有一個指令解碼和暫存器讀取單元,解碼指令,並形成指令包,同時讀取指令中嵌入的運算元的值,也從暫存器檔案中讀取值。AGU(地址生成單元)提取指令中的所有欄位,並在流水線的下一階段排程載入或儲存指令的執行。它在處理ldm(載入多個)和stm(儲存多個)指令時扮演著特殊的角色。這些指令可以同時讀取或寫入多個暫存器,AGU使用管線中的單個ldm或stm指令建立多個操作。分支單元用於分支預測,它預測分支結果和分支目標。
執行階段在功能方面相當繁重,有些指令需要2個週期才能執行,先看看常規ALU和分支指令。ARM指令可以有一個移位器運算元,其次,從其12位元編碼計算32位元立即數的值本質上是移位(旋轉是移位的一種型別)操作,這兩種操作都由具有稱為桶形移位器的硬體結構的移位單元執行。一旦運算元就緒,它們就被傳遞給ALU和分支單元,後者計算分支結果/目標和ALU結果。
ARM有兩種分支:直接分支和間接分支。對於直接分支,分支目標與當前PC的偏移量嵌入指令中,比如到標籤的分支是直接分支的範例,可以在解碼階段計算直接分支的分支目標。ARM還支援間接分支,其中分支目標是ALU或記憶體指令的結果,例如,指令ldr-pc, [r1, #10]是間接分支的一個範例,此處的分支目標的值等於載入指令從記憶體載入的值,通常很難預測間接分支的目標。在Cortex-M3處理器中,每當出現分支預測失誤(目標或結果)時,在分支後提取的兩條指令都會被取消,處理器開始從正確的分支目標獲取指令。
除了基本的ALU,Cortex-M3還有一個乘除單元,可以執行有符號和無符號、乘法和除法。Cortex-M3支援兩條指令sdiv和udiv,分別用於有符號和無符號除法。除了這些指令外,它還支援乘法和乘法累加操作。
載入和儲存指令通常需要兩個週期,它們具有地址生成階段和記憶體存取階段。載入指令需要2個週期才能執行,注意,在第二個週期中,其他指令不可能在E階段執行。管線因此停滯一個週期,這種特殊特性降低了管線的效能,ARM在其高效能處理器中消除了這一限制。儲存指令也需要2個週期才能執行,但存取記憶體的第二個週期不會使管線停止。處理器將值寫入儲存緩衝器(類似於寫入緩衝器),然後繼續執行。還可以發出背靠背(連續迴圈)儲存和載入指令,其中載入讀取儲存寫入的值。管線不需要為載入指令暫停,因為它從儲存緩衝區讀取儲存寫入的值。
ARM Cortex-A8
與Cortex-M3(嵌入式處理器)相比,Cortex-A8被設計為可以在複雜的智慧手機和平板電腦處理器上執行的全邊緣處理器。A代表應用程式,ARM的意圖是使用該處理器在移動裝置上執行常規應用程式。其次,這些處理器被設計為支援虛擬記憶體,並且還包含專用浮點和SIMD單元。
Cortex-A8核心流水線的設計特點是它是一個雙問題超標量處理器,但並不是一個完全亂序的處理器。問題的邏輯是無序的Cortex-A8有一個13階段整數流水線,帶有複雜的分支預測邏輯。由於它使用深度管線,因此可以以比其他具有較淺管線的ARM處理器更高的頻率對其進行計時。Cortex-A8核心的時脈頻率在500MHz和1GHz之間,在嵌入式領域是相當快的時鐘速度。
除了整數管線,Cortex-A8還包含一個專用浮點和SIMD單元。浮點單元實現ARM的VFP(向量浮點)ISA擴充套件,SIMD單元實現ARM NEON指令集。該單元也是流水線式的,有10個階段。此外,ARM Cortex-A8處理器具有單獨的指令和資料快取,可以選擇連線到大型共用二級快取。
下圖顯示了ARM Cortex-A8處理器的流水線設計。提取單元在兩個階段之間進行流水線處理,主要目的是獲取指令並更新PC,它還內建了指令預取器、ITLB(指令TLB)和分支預測器,指令隨後傳遞到解碼單元。
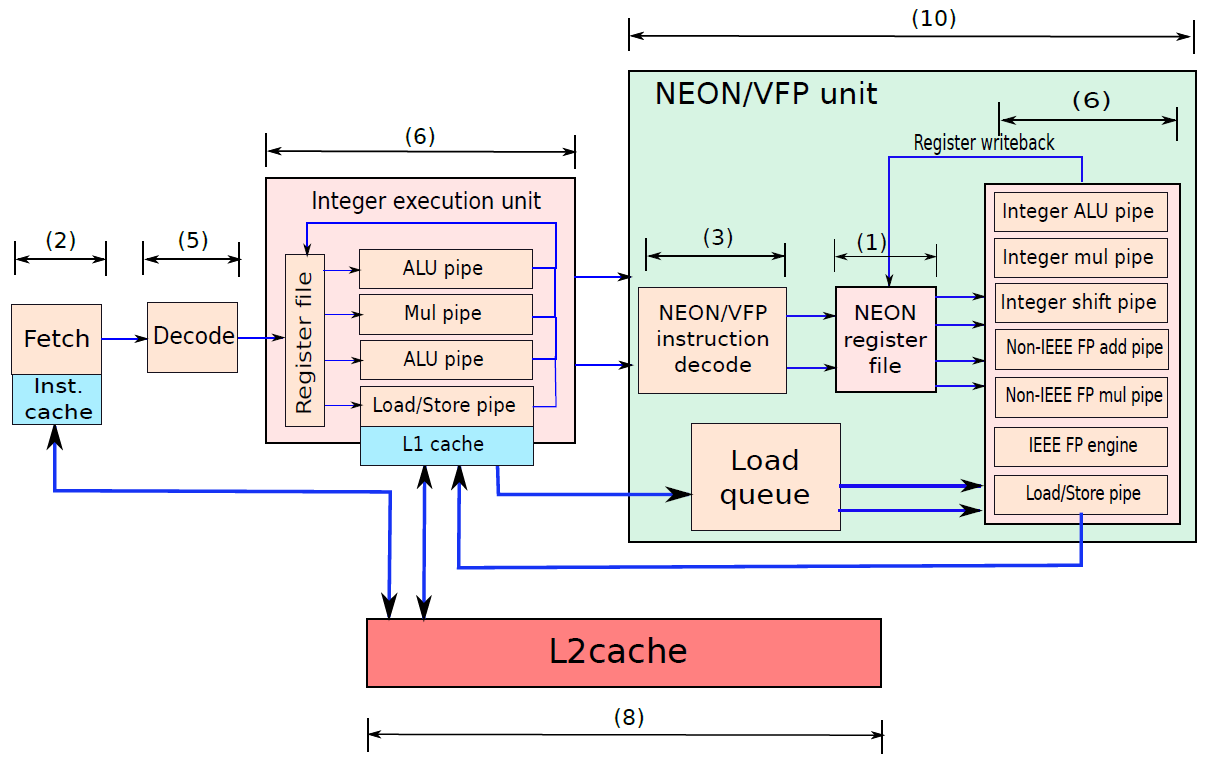
ARM Cortex-A8處理器的流水線。
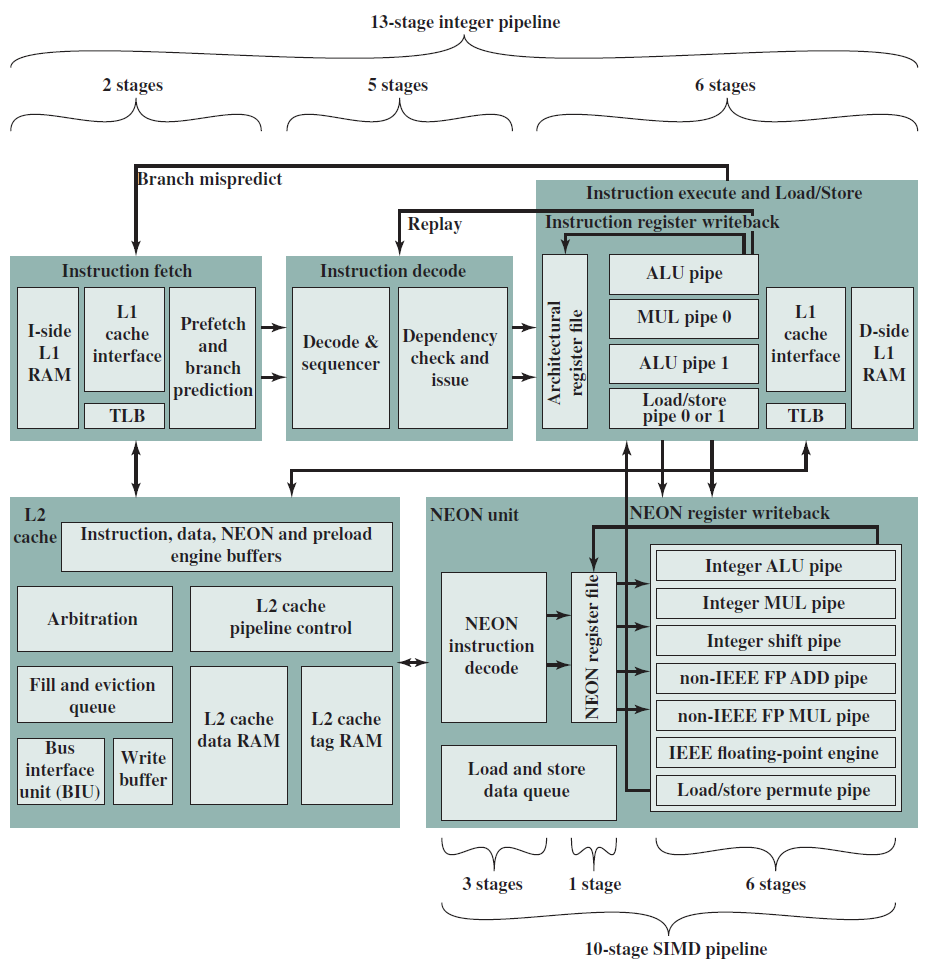
ARM Cortex-A8架構圖。
解碼單元在5階段之間進行流水線處理。Cortex-A8處理器中的解碼單元比Cortex-M3更復雜,因為它有額外的責任檢查指令之間的相關性,並一起發出兩條指令。因此,轉發、暫停和互鎖邏輯要複雜得多。讓我們對兩個指令執行槽0和1進行編號,如果解碼階段找到兩個不具有任何相關性的指令,那麼它會用指令填充兩個執行槽,並將它們傳送到執行單元。否則,解碼階段只發出一個時隙。
執行單元跨6個階段進行流水線處理,它包含4個獨立的流水線,有兩個ALU管道,兩個指令都可以使用。它有一個乘法管線,只能由插槽0中發出的指令使用。最後,它有一個載入/儲存管線,可以再次被兩個釋出槽中發出的指令使用。
NEON和VFP指令傳送到NEON/VFP單元,NEON/VFP指令的解碼和排程需要三個週期,NEON/VFP單元從包含32個64位元暫存器的NEON暫存器檔案中取出運算元。NEON指令還可以將暫存器檔案視為十六個128位元暫存器,NEON/VFP單元有六個6級流水線用於算術運算,還有一個6階段管道用於載入/儲存操作,載入向量資料是SIMD處理器中非常關鍵的效能操作。因此,ARM在NEON單元中有一個專用的載入佇列,用於通過從L1快取載入資料來填充NEON暫存器檔案。為了儲存資料,NEON單元將資料直接寫入L1快取。
每個一級快取(指令/資料)的塊大小為64位元組,關聯性為4,可以是16KB或32KB。其次,每個L1快取有兩個埠,每個週期可以為NEON和浮點操作提供4個字。需要注意的是,NEON/VFP單元和整數管線共用L1資料快取。L1快取可選地連線到大型L2快取,它的塊大小為64位元組,是8路集關聯的,最大可達1MB,二級快取分為多個儲存庫。可以同時查詢兩個標記,資料陣列存取並行進行。

ARM Cortex-A8 NEON和浮點管線。
ARM Cortex-A15
ARM Cortex-A15是2013年初發布的最新ARM處理器,面向高效能應用。
Cortex-A5處理器比Cortex-M3和Cortex-A8複雜得多,功能也更強大。它沒有使用亂序核心,而是使用了3執行的超標量無序核心。它還有一條更深的管線,具體來說,它有一個15階段整數管線和一個17-25階段浮點管線。更深的管線允許它以更高的頻率(1.5-2.5GHz)執行。此外,它在核心上完全整合了VFP和NEON單元,而不是將它們作為單獨的執行單元。與伺服器處理器一樣,它被設計為存取大量記憶體,可以支援40位實體地址,意味著它可以使用支援系統級一致性的最新AMBA匯流排協定來定址多達1 TB的記憶體。Cortex-A15旨在執行現代作業系統和虛擬機器器,虛擬機器器是可以幫助在同一處理器上同時執行多個作業系統的特殊程式,用於伺服器和雲端計算環境,以支援具有不同軟體需求的使用者。Cortex-A15採用了先進的電源管理技術,可在不使用處理器時動態關閉部分處理器。
Cortex-A15處理器的另一個標誌性特點是它是一個多核處理器,為每個叢集組織4個核心,每個晶片可以有多個叢集。Snoop控制單元提供叢集內的一致性,AMBA4規範定義了跨叢集支援快取和系統級一致性的協定,AMBA4匯流排還支援同步操作。記憶體系統也更快、更可靠,Cortex-A15的記憶體系統使用SECDED(單錯誤糾正,雙錯誤檢測)錯誤控制程式碼。
下圖顯示了Cortex-A15核心的管線概覽。有5個提取階段,fetch更復雜,因為Cortex-A15有一個複雜的分支預測器,可以處理多種型別的分支指令。解碼、重新命名和指令分派單元在7個階段之間進行流水線處理。暫存器重新命名單元和指令視窗對無序處理器的效能至關重要,它們的作用是在給定的週期內發出準備執行的指令集。
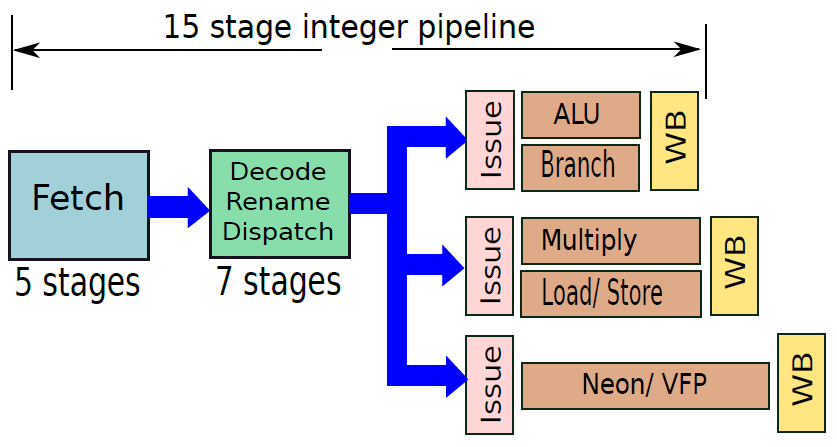
ARM Cortex-A15處理器的概覽。
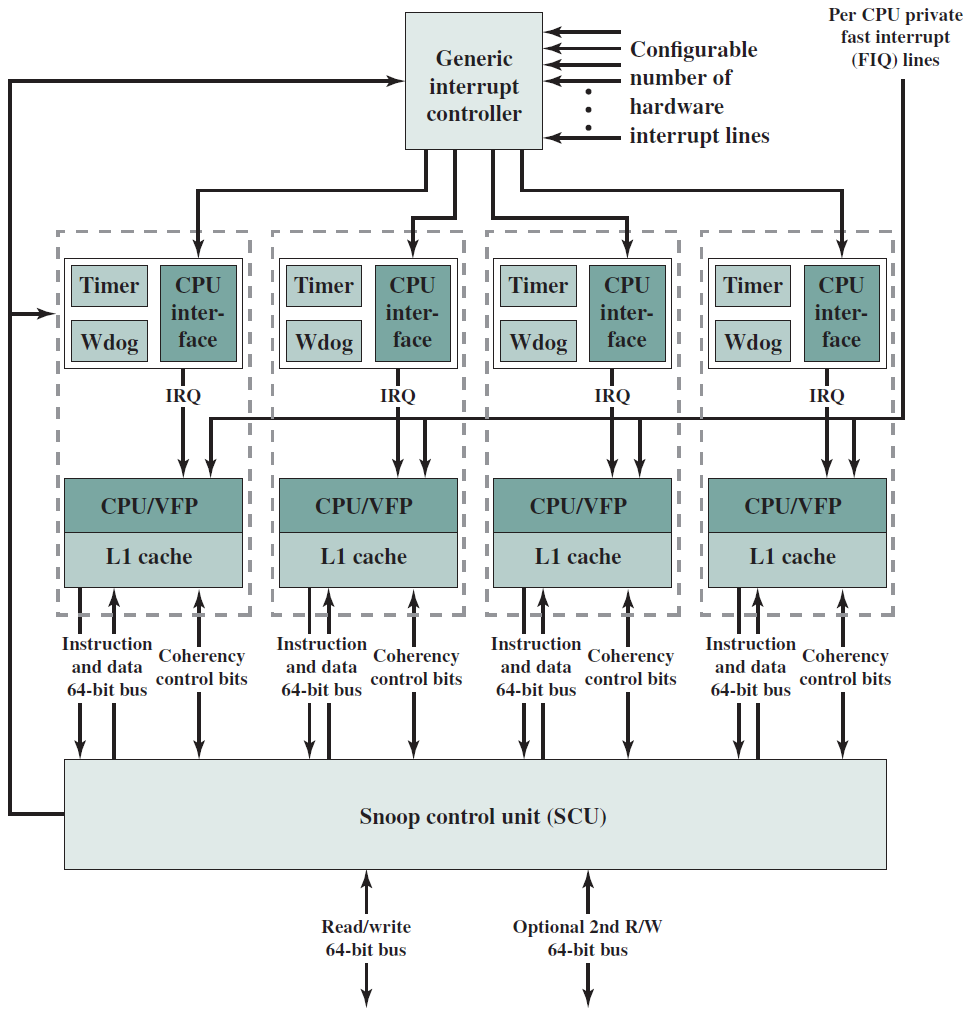
ARM Cortex-A15 MPCore晶片結構圖。
Cortex-A15有幾個執行管線。整數ALU和分支管線各需要3個週期,但乘法和載入/儲存管線更長。與其他將NEON/VFP單元視為物理獨立單元的ARM處理器不同,Cortex-A15將其整合在核心上,是亂序管線的一部分。現在更詳細地看一下管線(參見下圖)。
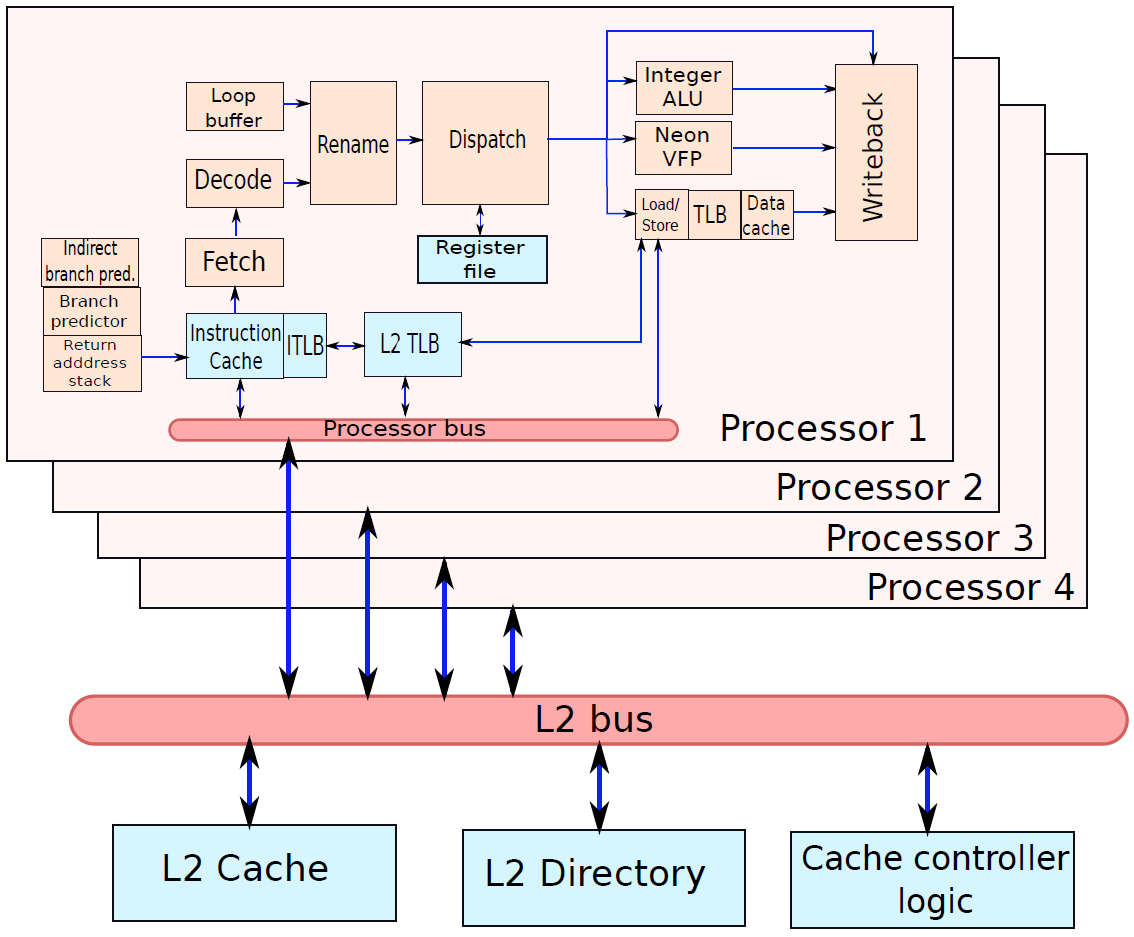
ARM Cortex-A15處理器的管線。
Cortex-A5核心(Cortex-A8的分支預測器也具有相同的功能)分支預測器包含直接分支預測器、間接分支預測器和預測返回地址的預測器。間接分支預測器嘗試基於分支指令的PC來預測分支目標,有一個256個條目,由給定分支的歷史及其PC索引。實際上不需要複雜的分支預測邏輯來預測返回指令的目標,一個更簡單的方法是每當呼叫函數時記錄返回地址,並將其推播到堆疊(稱為返回地址堆疊,RAS)。由於函數呼叫表現出後進先出的行為,因此需要簡單地彈出RAS並在從函數返回時獲取返回地址的值。最後,為了支援更寬的問題寬度,提取單元被設計為一次從指令快取中提取128位元。
迴圈緩衝區(也存在於Cortex-A8中)是解碼階段的一個非常有趣的補充。假設在迴圈中執行一組指令,在任何其他處理器中,都需要在迴圈中重複獲取指令,並對其進行解碼,這個過程浪費了能量和記憶體頻寬。可以通過將所有解碼的指令包儲存在迴圈緩衝區中來優化此過程,以便在執行迴圈時完全繞過提取和解碼單元,暫存器重新命名階段因此可以從解碼單元或迴圈緩衝器獲得指令。
核心維護一個包含所有指令結果的重新排序緩衝區(ROB),ROB中的條目是按程式順序分配的。重新命名階段將運算元對映到ROB中的條目(在ARM檔案中稱為結果佇列),例如,如果指令3需要一個將由指令1產生的值,則相應的運算元被對映到指令1的ROB條目。所有指令隨後進入指令視窗,等待其源運算元就緒。一旦準備就緒,它們就會被傳送到相應的管線。Cortex-A15具有2個整數ALU、1個分支單元、1個乘法單元和2個載入/儲存單元,NEON/VFP單元每個週期可接受2條指令。
載入/儲存單元具有4階段管線。為了確保精確的異常儲存,只有當指令到達ROB的頭部時(管線中沒有更早的指令),才會向記憶體系統發出儲存。同時,對管線中相同地址執行儲存操作的任何載入操作都會通過轉發路徑獲取其值。兩個L1快取(指令和資料)通常各為32KB。
Cortex-A15處理器支援大型二級快取(高達4 MB),它是一個帶有主動預取器的16路集合關聯快取。L1快取和L2快取是快取一致性協定的一部分,Cortex-A55使用基於目錄的MESI協定,二級快取包含一個窺探標記陣列,該陣列維護一級所有目錄的副本。如果I/O操作希望修改某一行,則二級快取使用窺探標記陣列來查詢該行是否位於任何一級快取中。如果任何一級快取包含該行的副本,則該副本無效。同樣,如果存在DMA讀取操作,則L2控制器從包含其副本的L1快取中取出該行。此外,還可以擴充套件此協定以支援L3快取和一系列外圍裝置。
Cortex-A53是一個可設定核心,支援ARMv8指令集架構,作為IP(智慧財產權)核心交付。IP核心是嵌入式、個人移動裝置和相關市場的主要技術交付形式,數十億的ARM和MIPS處理器已經從這些IP核中建立出來。
注意,IP核與Intel i7多核計算機中的核不同。IP核(其本身可能是多核)被設計為與其他邏輯結合(因此它是晶片的「核心」),包括專用處理器(例如視訊編碼器或解碼器)、I/O介面和記憶體介面,然後被製造為針對特定應用優化的處理器。雖然處理器核心在邏輯上幾乎相同,但最終產生的晶片有很多不同。一個引數是二級快取的大小,它可以變化16倍。
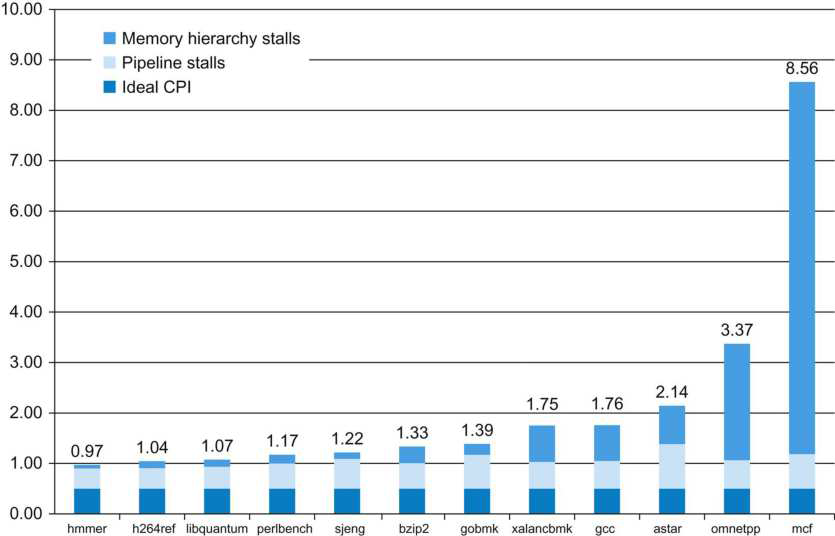
SPEC2006整數基準的ARM Cortex-A53上的CPI。
19.5.5.2 AMD處理器
現在來研究AMD處理器的設計。AMD處理器實現x86指令集,為移動裝置、小筆電、筆記型電腦、桌上型電腦和伺服器製造處理器。本節將研究設計頻譜兩端的兩個處理器。AMD Bobcat處理器適用於移動裝置、平板電腦和小筆電,它實現了x86指令集的一個子集,其設計的主要目標是功率效率和可接受的效能水平。AMD Bulldozer處理器處於另一端,專為高階伺服器設計,它針對效能和指令吞吐量進行了優化,也是AMD的第一個多執行緒處理器,使用了一種稱為聯合核心的新型核心來實現多執行緒。
AMD Bobcat
Bobcat處理器設計為在10-15W功率預算內執行,在這個功率預算內,Bobcat的設計者能夠在處理器中實現大量複雜的架構特性,如Bobcat使用了一個相當複雜的2執行亂序管線。Bobcat的流水線使用了一個複雜的分支預測器,設計用於在同一週期內獲取2條指令。它隨後可以以該速率解碼它們,並將它們轉換為複雜的微操作(Cop)。AMD術語中的複雜微操作是一種類似CISC的指令,可以讀取和寫入記憶體,這組Cop隨後被傳送到指令佇列、重新命名引擎和排程器。
排程器按順序選擇指令,並將它們分派給ALU、記憶體地址生成單元和載入/儲存單元。為了提高效能,載入/儲存單元還無序地向記憶體系統傳送請求。因此很容易地得出結論,Bobcat支援弱記憶體模型,除了複雜的微架構功能外,Bobcat還支援SIMD指令集(最高SSE 4)、自動將處理器狀態儲存在記憶體中的方法以及64位元指令。為了確保處理器的功耗在限制範圍內,Bobcat包含大量節能優化,其中一個突出的機制被稱為時鐘門控( clock gating),對於未使用的單元,時鐘訊號被設定為邏輯0,確保了在未使用的單元中沒有訊號轉換,因此沒有動態功率的耗散。Bobcat處理器還儘可能使用指向資料的指標,並儘量減少在處理器中不同位置複製資料。
下圖顯示了AMD Bobcat處理器的流水線框圖。Bobcat處理器的一個顯著特點是相當複雜的分支預測器,需要首先預測指令是否是分支,因為在x86 ISA中沒有辦法快速解決這個問題。如果一條指令被預測為分支,需要計算其結果(執行/未執行)和目標。AMD使用基於高階模式匹配的專有演演算法進行分支預測,在分支預測之後,提取引擎一次從I快取中提取32個位元組,並將其傳送到指令緩衝區。
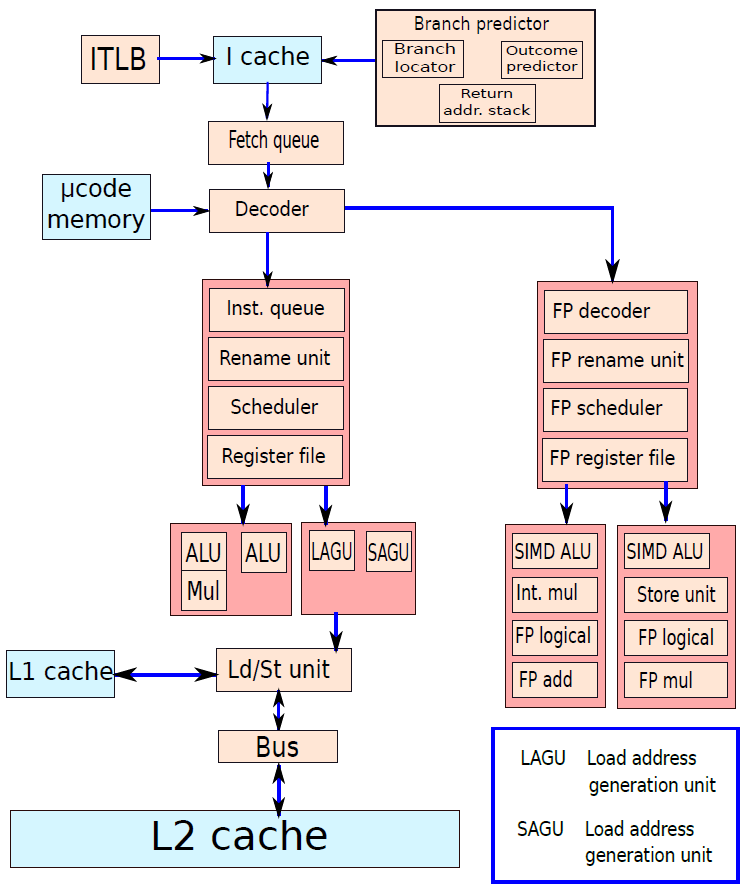
AMD Bobcat處理器的流水線。
解碼器一次考慮22個指令位元組,並試圖劃分指令邊界。這是一個緩慢且計算密集的過程,因為x86指令長度可能具有很大的可變性。較大的處理器通常快取該資訊,以便第二次解碼指令更容易。由於Bobcat的解碼吞吐量僅限於2條指令,因此它沒有此功能。現在,大多數x86指令對在22位元組內,因此解碼器可以在大多數時間提取這兩個x86指令的內容。解碼器通常將每個x86指令轉換為1-2個Cop,對於一些不常用的指令,它用微碼序列替換指令。
隨後,Cop被新增到56條目重新排序緩衝區(ROB)中。Bobcat有兩個排程程式,整數排程器有16個條目,浮點排程器有18個條目。整數排程器在每個週期選擇兩條指令執行,整數管線有兩個ALU和兩個地址生成單元(1個用於載入,1個用於儲存),浮點管線也可以在每個週期執行兩次Cop,但有一些限制。
處理器中的載入儲存單元將值從儲存轉發到流水線中的載入指令。Bobcat擁有32KB(8路關聯)的L1 D和I快取,它們連線到512 KB的二級快取(16路集合關聯),匯流排介面將二級快取連線到主記憶體和系統匯流排。
現在考慮一下管線的時間排程。Bobcat整數管道分為16個階段,由於管線較深,可以在1-2GHz之間的頻率對核心進行時鐘控制。Bobcat管線有6個提取週期和3個解碼週期,最後3個提取週期與解碼週期重疊,重新命名引擎和排程程式需要4個週期。對於大多數整數指令,需要1個週期讀取暫存器檔案,1個週期存取ALU,以及1個週期將結果寫回暫存器檔案。浮點流水線有7個附加階段,載入儲存單元需要3個附加階段用於地址生成和資料快取存取。
AMD Bulldozer
顧名思義,Bulldozer核心位於頻譜的另一端,主要用於高階桌上型電腦、工作站和伺服器。除了是一個激進的無序機器之外,它還具有多執行緒功能。Bulldozer實際上是多核、單粒度多執行緒處理器和SMT的組合,其核心實際上是一個「聯合核心」,由兩個共用功能單元的較小核心組成。
兩個Bulldozer執行緒共用獲取引擎(參見下圖)和解碼邏輯。管線的這一部分(稱為前端)在兩個執行緒之間每一個週期或幾個週期切換一次,然後將整數、載入儲存和分支指令分派到兩個核心中的一個。每個核心包含一個指令排程器、暫存器檔案、整數執行單元、L1快取和一個載入儲存單元,每個核心可被視為一個沒有指令獲取和解碼功能的自我支援的核心。兩個核心共用在SMT模式下執行的浮點單元,它有專用的排程器和執行單元Bulldozer處理器設計用於在3-4GHz下執行伺服器和數位工作負載,最大功耗限制為125-140W。
Bulldozer處理器概覽。
現在考慮下圖中處理器的更詳細檢視。
Bulldozer處理器的讀取寬度是Bobcat處理器的兩倍。它每個週期最多可以提取和解碼4條x86指令,與Bobcat類似,Bulldozer處理器具有複雜的分支預測邏輯,可以預測指令是否為分支、分支結果和分支目標。它有一個多級分支目標緩衝區,可以儲存大約5500條分支指令的預測分支目標。
解碼引擎將x86指令轉換為Cop。AMD中的一個Cop是CISC指令,儘管有時比原始的x86指令簡單,大多數x86指令只轉換為一個Cop。然而,有些指令被轉換為多個Cop,有時需要使用微碼記憶體進行指令轉換。解碼引擎的一個有趣的方面是它可以動態地合併指令以生成更大的指令,例如,它可以將比較指令和後續分支指令合併到一個Cop中。這被稱為宏指令融合。
隨後,整數指令被分派到核心執行。每個核心都有一個重新命名引擎、指令排程器(40個條目)、一個暫存器檔案和一個128個條目的ROB。核心的執行單元由4個獨立的管線組成,兩個管線具有ALU,另外兩個管道專用於記憶體地址生成。載入儲存單元協調對記憶體的存取,將儲存之間的資料轉發給載入,並使用跨步預取器執行積極的預取。跨步預取器可以自動推斷陣列存取,並從將來最可能存取的陣列索引中提取。
兩個核心共用一個64KB的指令快取,而每個核心都有一個16KB的一級寫快取,每次載入存取需要4個週期。L1快取連線到不同大小的L2快取,在核心之間共用,具有18個週期的延遲。
浮點單元在兩個核心之間共用,不僅僅是一個功能單元,可被看作是一個SMT處理器,同時排程和執行兩個執行緒的指令。它有自己的指令視窗、暫存器檔案、重新命名和喚醒選擇(無序排程)邏輯。Bulldozer的浮點單元有4條處理SIMD指令(整數和浮點)和常規浮點指令的流水線。前兩條管線具有128位元浮點ALU,稱為FMAC單元,FMAC(浮點乘法累加)單元可以執行形式(a <-- a+b*c)的運算,以及常規浮點運算。最後兩條管線具有128位元整數SIMD單元,另外,最後一條管線還用於將結果儲存到記憶體中。浮點單元有一個專用的載入儲存單元來存取核心中的快取。
19.5.5.3 Intel處理器
前些年的英特爾處理器在筆記型電腦和桌上型電腦市場佔據主導地位,本節將介紹兩種設計非常不同的英特爾處理器的設計。第一個處理器是Intel Atom,專為手機、平板電腦和嵌入式計算機設計。另一端是Sandy Bridge多核處理器,它是Intel Core i7系列處理器的一部分,這些處理器用於高階桌上型電腦和伺服器。這兩個處理器都有非常不同的業務需求,導致了兩種截然不同的設計。
x86的祖先是1972年開始生產的第一批微處理器。Intel 4004和8008是極其簡單的4位元和8位元累加器式架構,Morse等人將8086從上世紀70年代末的8080演變為具有更好吞吐量的16位元架構。當時幾乎所有微處理器的程式設計都是用組合語言完成的,記憶體和編譯器都很短缺。英特爾希望保持8080使用者的基礎,因此8086被設計為與8080「相容」。8086從來都不是與8080相容的目的碼,但其架構足夠接近,可以自動完成組合語言程式的翻譯。
1980年初,IBM選擇了一個帶有8位元外部匯流排的8086版本,稱為8088,用於IBM PC。他們選擇了8位元版本以降低體系結構的成本,這一選擇,加上IBM PC的巨大成功,使得8086體系結構無處不在。IBM PC的成功部分歸因於IBM開放了PC的體系結構,並使PC克隆產業蓬勃發展。80286、80386、80486、奔騰、奔騰Pro、奔騰II、奔騰III、奔騰4和AMD64擴充套件了體系結構並提供了一系列效能增強。
雖然68000被選擇用於Macintosh,但Mac從未像PC那樣普及,部分原因是蘋果不允許基於68000的Mac克隆,68000也沒有獲得8086所享受的軟體。摩托羅拉68000在技術上可能比8086更重要,但IBM的選擇和開放架構策略的影響主導了68000在市場上的技術優勢。
一些人認為,x86指令集的不雅是不可避免的,是任何架構取得巨大成功所必須付出的代價。我們拒絕這種觀點。顯然,沒有一個成功的架構可以拋棄以前實現中新增的特性,隨著時間的推移,一些特性可能會被視為不可取的。x86的尷尬始於8086指令集的核心,並因8087、80286、80386、MMX、SSE、SSE2、SSE3、SSE4、AMD64(EM64T)和AVX中發現的架構不一致擴充套件而加劇。
一個反例是IBM 360/370體系結構,它比x86老得多,主宰了大型電腦市場,就像x86主宰了PC市場一樣。毫無疑問,由於有了更好的基礎和更相容的增強功能,該指令集在首次實現50年後比x86更有意義。將x86擴充套件到64位元定址意味著該體系結構可能會持續幾十年,未來的指令集人類學家將從這樣的架構中一層又一層地剝離,直到他們從第一個微處理器中發現人工製品。鑑於這樣的發現,他們將如何判斷當今的計算機架構?
Intel核心微架構
儘管超標量設計的概念通常與RISC架構相關聯,但同樣的超標量原理也可以應用於CISC機器,其中值得注意的例子是Intel x86架構。Intel系列中超標量概念的演變值得注意,386是一種傳統的CISC非管線機器,486引入了第一個管線x86處理器,將整數運算的平均延遲從兩到四個週期減少到一個週期,但仍限於每個週期執行一條指令,沒有超標量元素。最初的奔騰有一個適度的超標量元件,由兩個獨立的整數執行單元組成,奔騰Pro推出了全面的超標量設計,亂序執行。隨後的x86型號改進並增強了超標量設計。
下圖顯示了x86管線架構的版本。Intel將流水線架構稱為微架構(microarchitecture),微架構是機器指令集體系結構的基礎和實現,也稱為Intel核心微架構。它在Intel core 2和Intel Xeon處理器系列的每個處理器核上實現,還有一個增強型Intel核心微架構。兩種微架構之間的一個關鍵區別是,後者提供了第三級快取。
Intel核心微架構。
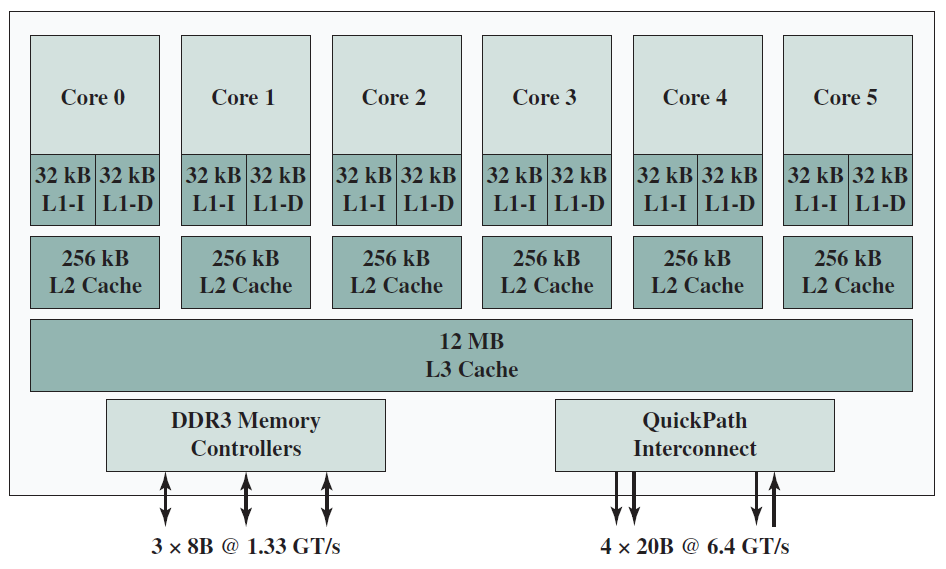
Intel Core i7-990X結構圖。
Intel 8085 CPU結構圖。
下表顯示了快取架構的一些引數和效能特徵。所有快取都使用寫回更新策略,當指令從記憶體位置讀取資料時,處理器會按以下順序在快取和主記憶體中查詢包含此資料的快取行:
- 發起核心的L1資料快取。
- 其他核心的L1資料快取和L2快取。
- 系統記憶體。
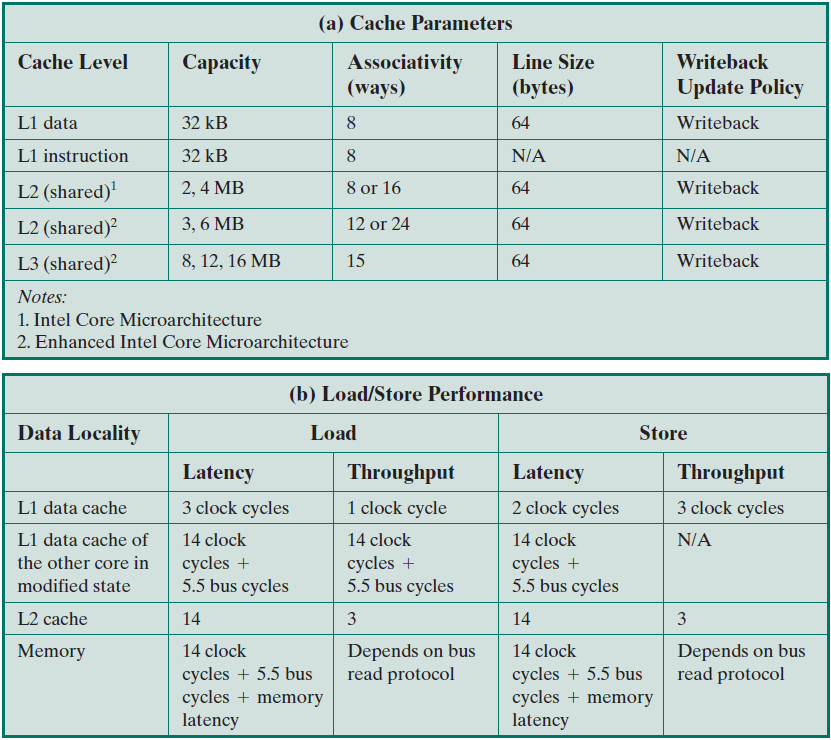
基於Intel Core微架構的處理器的快取/記憶體引數和效能。
僅當快取行被修改時,快取行才會從另一個核心的一級資料快取中取出,而忽略二級快取中的快取行可用性或狀態。上表b顯示了從記憶體叢集中獲取不同位置的前四個位元組的特性,延遲列提供存取延遲的估計值,然但實際延遲可能會因快取負載、記憶體元件及其引數而異。
Intel Core微架構的管線包含:
- 一種有序提交前端,從記憶體中獲取指令流,具有四個指令解碼器,將解碼後的指令提供給無序執行核心。每個指令都被翻譯成一個或多個固定長度的RISC指令,稱為微操作(micro-operation或micro-ops)。
- 一個無序的超標量執行核心,每個週期最多可以發出6個微操作,並在源就緒且執行資源可用時重新排序微操作以執行。
- 一種有序的引退單元,確保微操作的執行結果得到處理,架構狀態和處理器的暫存器集根據原始程式順序進行更新。
實際上,Intel核心微架構在RISC微架構上實現了CISC指令集架構。內部RISC微操作通過至少14階段的流水線,在某些情況下,微操作需要多個執行階段,從而導致更長的管線,與早期Intel x86處理器和Pentium上使用的5階段流水線形成了鮮明對比。
接下來闡述前端(Front End)。
先闡述分支預測單元。前端需要提供解碼的指令(微操作),並將流維持到一個6階段的無序引擎,該引擎由三個主要部件組成:分支預測單元(BPU)、指令提取和預譯碼單元、指令佇列和譯碼單元。
分支預測單元此單元通過預測各種分支型別(條件、間接、直接、呼叫和返回),幫助指令獲取單元獲取最可能執行的指令,BPU為每種分支型別使用專用硬體,分支預測使處理器能夠在決定分支結果之前很久就開始執行指令。
微架構使用基於最近執行分支指令的歷史的動態分支預測策略。維護分支目標緩衝區(BTB),該緩衝區快取關於最近遇到的分支指令的資訊。每當在指令流中遇到分支指令時,都會檢查BTB,如果BTB中已經存在條目,則指令單元在確定是否預測分支被採取時由該條目的歷史資訊引導。如果預測到分支,則與該條目關聯的分支目標地址用於預取分支目標指令。
一旦指令被執行,相應條目的歷史部分被更新以反映分支指令的結果。如果此指令未在BTB中表示,則將此指令的地址載入到BTB中的條目中,如果需要,將刪除較舊的條目。
前兩段的描述大體上適用於原始奔騰機型以及後來的奔騰機型(包括後續的Intel機型)上使用的分支預測策略,但在奔騰的情況下,使用了相對簡單的2位歷史方案。後來的型號具有更長的流水線(Intel核心微架構為14階段,奔騰為5階段),因此預測失誤的懲罰更大。所以後面的模型使用了更復雜的分支預測方案,具有更多的歷史位元,以降低預測失誤率。
根據以下規則,使用靜態預測演演算法預測在BTB中沒有歷史的條件分支:
- 對於與指令指標(IP)無關的分支地址,如果分支是返回,則預測執行,否則不執行。
- 對於IP相對後向條件分支,請進行預測。此規則反映了迴圈的典型行為。
- 對於IP相對前向條件分支,預測不執行。
再闡述指令獲取和預譯碼單元。指令獲取單元包括指令翻譯後備緩衝器(ITLB)、指令預取器、指令快取和預譯碼邏輯。
指令獲取是從一級指令快取執行的。當發生一級快取未命中時,有序前端將新指令從二級快取一次64位元組送入一級快取。預設情況下,指令是按順序提取的,因此每個二級快取行提取都包含下一條要提取的指令,經由分支預測單元的分支預測可以改變該順序提取操作。ITLB將給定的線性IP地址轉換為存取二級快取所需的實體地址,前端的靜態分支預測用於確定下一個要獲取的指令。
預譯碼單元接受來自指令快取記憶體或預取緩衝器的十六個位元組,並執行以下任務:
- 確定指令的長度。
- 解碼與指令相關的所有字首。
- 標記解碼器指令的各種屬性(如「is branch」)。
預編碼單元每個週期最多可將六條指令寫入指令佇列。如果一個提取包含六條以上的指令,則預解碼器在每個週期繼續解碼多達六條指令,直到提取中的所有指令都寫入指令佇列。後續提取只能在當前提取完成後進入預編碼。
最後闡述指令佇列和解碼單元。提取的指令被放置在指令佇列中,從那裡,解碼單元掃描位元組以確定指令邊界,由於x86指令的長度可變,是一個必要的操作。解碼器將每個機器指令翻譯成一到四個微操作,每個微操作都是118位元RISC指令。請注意,大多數純RISC機器的指令長度僅為32位元,需要更長的微操作長度來適應更復雜的x86指令。儘管如此,微操作比它們派生的原始指令更容易管理。
一些指令需要四個以上的微操作,這些指令被傳送到微碼ROM,其中包含與複雜機器指令相關的一系列微操作(五個或更多),例如一個字串指令可以轉換為一個非常大(甚至數百個)的重複微操作序列。因此,微碼ROM是一個微程式控制單元。
生成的微操作序列被傳遞到重新命名/分配器模組。
上面闡述完前端的三個部件,接下來闡述亂序執行邏輯。
處理器的這一部分對微操作進行重新排序,以允許它們在輸入運算元就緒時儘快執行。分配階段分配執行所需的資源,它執行以下功能:
- 如果在一個時鐘週期內到達分配器的三個微操作中的一個無法使用所需的資源(如暫存器),則分配器會暫停管線。
- 分配器分配一個重新排序緩衝區(ROB)條目,該條目跟蹤隨時可能正在進行的126個微操作之一的完成狀態。
- 分配器為微操作的結果資料值分配128個整數或浮點暫存器項中的一個,並且可能分配一個用於跟蹤機器流水線中48個載入或24個儲存之一的載入或儲存緩衝區。
- 分配器在指令排程器前面的兩個微操作佇列之一中分配一個條目。
ROB是一個迴圈緩衝區,最多可容納126個微操作,還包含128個硬體暫存器。每個緩衝區條目由以下欄位組成:
- 狀態:指示此微操作是否計劃執行、是否已排程執行,或是否已完成執行並準備好退出。
- 記憶體地址:生成微操作的奔騰指令的地址。
- 微操作:實際操作。
- 別名暫存器:如果微操作參照了16個架構暫存器中的一個,則此條目將該參照重定向到128個硬體暫存器中的其中一個。
微操作按順序進入ROB,然後微操作從ROB無序地傳送到排程/執行單元,排程的標準是適當的執行單元和此微操作所需的所有必要資料項可用,最後微操作按順序從ROB中退出。為了實現有序清理,在每個微操作被指定為準備清理後,微操作首先被清理。
重新命名階段將對16個架構暫存器(8個浮點暫存器,外加EAX、EBX、ECX、EDX、ESI、EDI、EBP和ESP)的參照重新對映到一組128個物理暫存器中。該階段消除了由有限數量的架構暫存器引起的錯誤依賴,同時保留了真實的資料依賴(寫入後讀取)。
在資源分配和暫存器重新命名之後,微操作被放置在兩個微操作佇列中的一個佇列中,在那裡它們被儲存,直到排程器中有空間為止。兩個佇列中的一個用於記憶體操作(載入和儲存),另一個用於不涉及記憶體參照的微操作。每個佇列都遵循FIFO(先進先出)規則,但佇列之間不保持順序。也就是說,相對於另一個佇列中的微操作,微操作可能會被無序地從一個佇列讀取。此舉為排程器提供了更大的靈活性。
排程器負責從微操作佇列中檢索微操作,並分派這些微操作以供執行。每個排程程式查詢狀態指示微操作具有其所有運算元的微操作,如果該微操作所需的執行單元可用,則排程器獲取該微操作並將其分派給適當的執行單元。一個週期內最多可排程六個微操作,如果給定的執行單元有多個微操作可用,那麼排程器會從佇列中按順序分派它們。這是一種FIFO規則,有利於按順序執行,但此時指令流已被依賴項和分支重新排列,基本上已亂序。
四個埠將排程器連線到執行單元,埠0用於整數和浮點指令,但分配給埠1的簡單整數操作和處理分支預測失誤除外。此外,MMX執行單元在這兩個埠之間分配,其餘埠用於記憶體載入和儲存。
接下來闡述整數和浮點執行單元。
整數和浮點暫存器檔案是執行單元掛起操作的源,執行單元從暫存器檔案以及L1資料快取中檢索值。單獨的管道階段用於計算標誌(如零、負),通常是分支指令的輸入。
隨後的管線階段執行分支檢查,此函數將實際分支結果與預測結果進行比較。如果分支預測被證明是錯誤的,那麼在處理的各個階段都存在必須從管道中刪除的微操作。然後,在驅動階段將正確的分支目標提供給分支預測器,該階段將從新的目標地址重新啟動整個管線。
Intel Atom
Intel Atom處理器一開始就有一套獨特的要求。設計者必須設計一個非常節能的核心,具有足夠的功能來執行商業作業系統和web瀏覽器,並且完全相容x86。一種降低功耗的粗略方法是實現x86 ISA的一個子集,這種方法將導致更簡單和更節能的解碼器。由於已知解碼邏輯在x86處理器中是耗電的,因此降低其複雜性是降低功耗的最簡單方法之一,但完全的x86相容性排除了此選項。
因此,設計師不得不考慮非常節能且不影響效能的新穎設計,決定簡化管線,只考慮兩個問題。亂序管線具有複雜的結構,用於確定指令之間的依賴關係,以及無序執行指令。其中一些結構是指令視窗、重新命名邏輯、排程器和喚醒選擇邏輯,它們增加了處理器的複雜性,並增加了其功耗。
其次,大多數英特爾處理器通常將CISC指令轉換為類似RISC的微操作,這些微操作像流水線中的普通RISC指令一樣執行。指令翻譯過程消耗大量的能量,Intel Atom的設計者決定放棄指令翻譯,Atom管線直接處理CISC指令。對於一些非常複雜的指令,Atom處理器確實使用微碼ROM將它們轉換為更簡單的CISC指令。然而,這更多的是一種例外,而不是一種常態。
與RISC處理器相比,CISC處理器的提取和解碼階段更加複雜,因為指令具有可變的長度,劃分指令邊界是一個乏味的過程。其次,解碼的過程也更加複雜。Atom將其16階段流水線中的6個階段用於指令獲取和解碼,如下圖所示,其餘階段執行暫存器存取、資料快取存取和指令執行等傳統功能。除了更簡單的流水線之外,Intel Atom處理器的另一個顯著特點是它支援雙向多執行緒,現代移動裝置通常執行多工作業系統,使用者同時執行多個程式。多執行緒可以支援這一需求,實現額外的並行性,並減少處理器管線中的空閒時間。管線中的最後3個階段專門用於處理異常、處理與多執行緒相關的事件以及將資料寫回暫存器或記憶體。與所有現代處理器一樣,儲存指令不在關鍵路徑上。通常,不遵守順序一致性的處理器將其儲存值寫入寫入緩衝區並繼續執行後續指令。

Intel Atom處理器的流水線。
現在更詳細地描述其設計。從提取和解碼階段開始(見下圖)。在提取階段,Atom處理器預測分支的方向和目標,並將一個位元組流提取到指令預取緩衝區。下一個任務是在獲取的位元組流中劃分指令,x86指令的邊界是這部分流水線執行的最複雜的任務之一,因此Atom處理器有一個2級預解碼步驟,在第一次解碼指令後,在指令之間新增1位標記,該步驟由ILD(指令長度解碼器)單元執行,然後將指令儲存在I快取中。隨後,從I快取中提取的預解碼指令可以繞過預解碼步驟,並直接進入解碼步驟,因為其長度是已知的。儲存這些附加標記會減少I快取的有效大小,I快取的大小為36KB,但在新增標記之後,它實際上是32KB。解碼器不會將大多數CISC指令轉換為類似RISC的微操作。但對於一些複雜的x86指令,有必要通過存取微碼記憶體將它們轉換為更簡單的微操作。
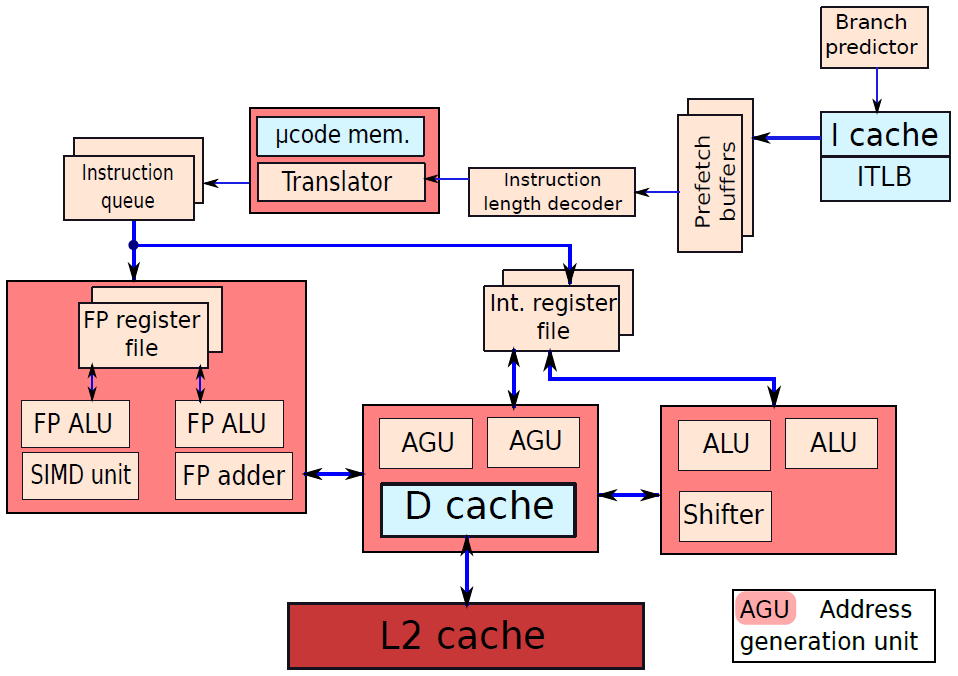
Intel Atom處理器內部結構圖。
隨後,整數指令被分派到整數執行單元,FP指令被分派給FP執行單元,Atom有兩個整數ALU、兩個FP ALU和兩個用於記憶體操作的地址生成單元。為了支援多執行緒,需要有兩個指令佇列副本(每個執行緒1個),以及兩個整數和FP暫存器檔案副本。英特爾沒有像指令佇列那樣建立硬體結構的副本,而是採用了不同的方法,例如在Atom處理器中,32個條目的指令佇列被分成兩個部分(每個部分有16個條目),每個執行緒都使用其部分的指令佇列。
現在討論一下關於多執行緒的一般觀點。多執行緒通過減少晶片上的資源閒置時間來提高其利用率,因此理想情況下,多執行緒處理器應該具有更高的功率開銷(因為活動更高),並且具有更好的指令吞吐量。需要注意的是,除非處理器設計得很明智,否則吞吐量可能無法預測地增加。多執行緒增加了共用資源(如快取、TLB和指令排程/排程邏輯)中的爭用,特別是,快取線上程之間進行分割區,預計未命中率會增加,TLB的情況也類似。另一方面,流水線不需要在二級未命中的陰影下或在程式的低ILP(指令級並行性)階段保持空閒。因此,多執行緒有其優點和缺點,只有當好的效果(效能提高效果)大於壞的效果(爭用增加效果)時,才能獲得效能優勢。
Intel Sandy Bridge
現在討論一款名為Sandy Bridge處理器的高效能Intel處理器的設計,該處理器是市場上Intel Core i7處理器的一部分。設計Sandy Bridge處理器的主要目的是支援新興的多媒體工作負載、數位密集型應用程式和多核友好並行應用程式。
Sandy Bridge處理器最顯著的特點是它包含一個片上圖形處理器。圖形處理器裝有專門的單元,用於執行影象渲染、視訊編碼/解碼和自定義影象處理,CPU和GPU通過大型共用片上L3快取進行通訊。Sandy Bridge處理器概覽如下圖所示。
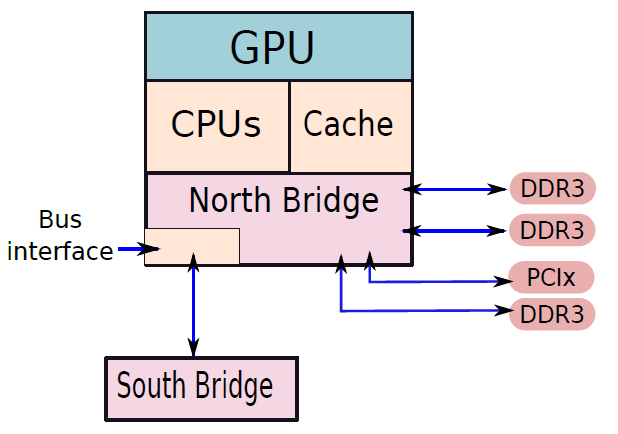
隨著晶片上元件的增加,CPU也進行了大量修改。Sandy Bridge處理器完全支援新的AVX指令集,AVX指令集是一個256位SIMD指令集,對於每個SIMD單元,可以同時執行4個雙精度操作或8個單精度操作。由於新增了這麼多高效能功能,因此也有必要新增許多節能功能。對於未使用的單元,諸如DVFS(動態電壓頻率縮放)、時鐘門控(關閉時鐘)和電源門控(關閉一組功能單元的電源)等技術已然常見。此外,Sandy Bridge的設計人員修改了核心的設計,以儘可能減少單元之間的複製值(AMD Bobcat的設計人員也做出了類似的設計決策),並對一些核心結構的設計進行了基本更改,如分支預測器和分支目標緩衝器,以提高功率效率。
需要注意的是,Intel Sandy Bridge等處理器設計為支援多核(4-8),每個核心支援雙向多執行緒,因此可以在8核機器上執行16個執行緒,這些執行緒可以在彼此、三級快取組、GPU和片上北橋控制器之間進行主動通訊。有這麼多通訊實體,需要設計靈活的片上網路,以促進高頻寬和低延遲通訊。
Sandy Bridge的設計者選擇了基於環的互連,而不是傳統的匯流排。Sandy Bridge處理器設計用於32納米1半導體工藝,它的繼任者是Intel Ivy Bridge處理器,該處理器具有相同的設計,但設計用於22納米工藝。
現在考慮下圖中Sandy Bridge核心的詳細設計。它有一個32KB的指令快取,每個週期可以提供4條x86指令。解碼x86指令流的第一步是劃定它們的邊界(稱為預譯碼),一旦4條指令被預先編碼,它們就被傳送到解碼器。Sandy Bridge有4個解碼器,其中三個是簡單的解碼器,一個解碼器被稱為使用微程式記憶體的複雜解碼器,所有解碼器都將CISC指令轉換為類似RISC的微操作。Sandy Bridge有一個用於微操作的L0快取,可以儲存大約1500個微操作,L0微操作快取在效能和功耗方面都具有效能優勢。如果分支目標處的指令在L0快取中可用,則可以減少分支預測失誤延遲。由於程式中的大多數分支都在分支附近,因此預計L0快取的命中率會很高,還可以節省電力。如果一條指令的微操作在L0快取中可用,就不需要再次獲取、預編碼和解碼該指令,從而避免了這些耗電的操作。
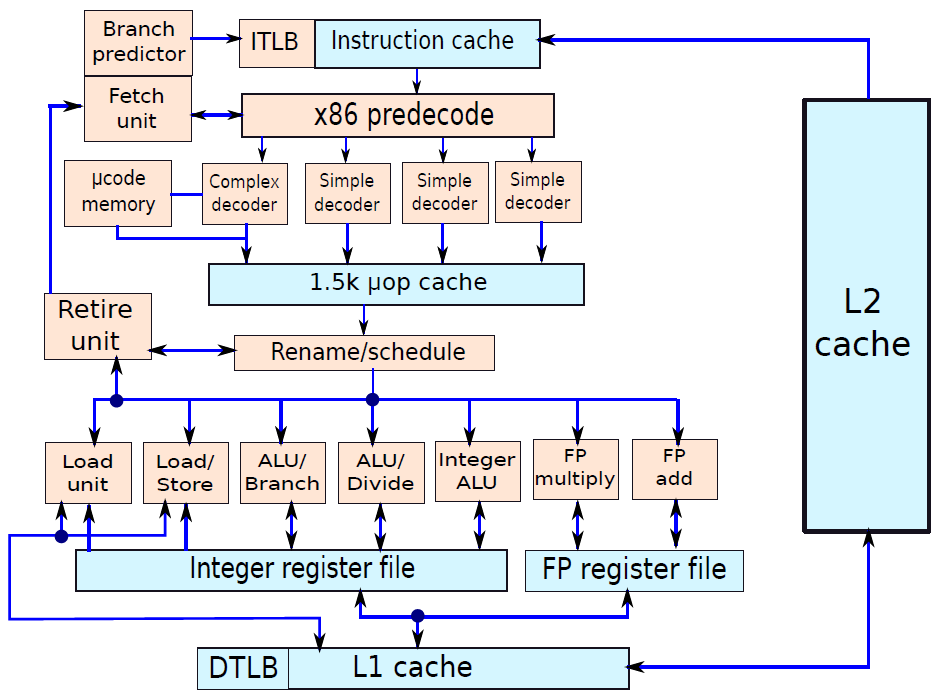
Sandy Bridge處理器的內部結構。
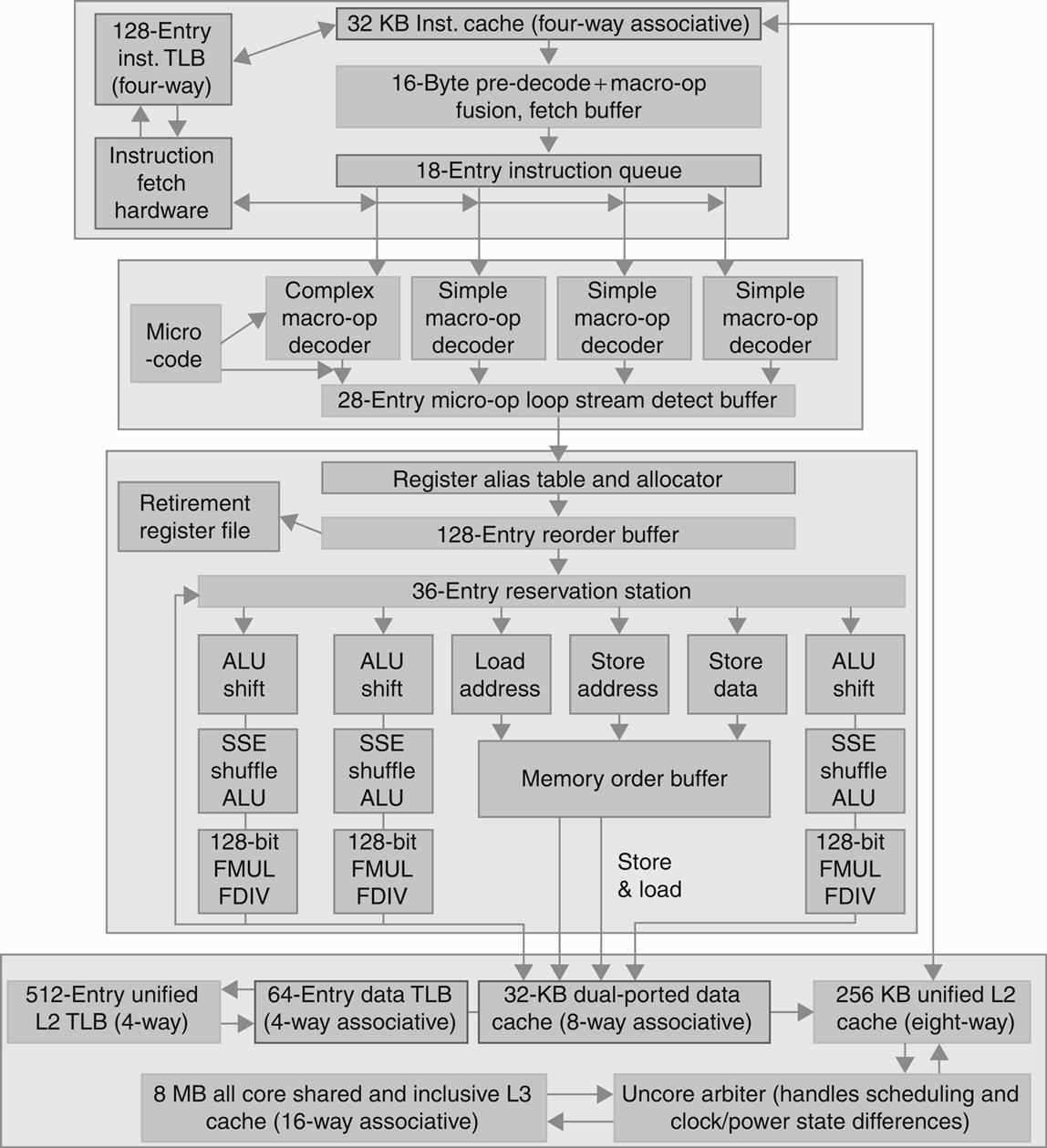
帶有記憶體元件的Core i7管線。
一個有趣的設計決策是設計者針對分支預測器做出的,代表了電腦架構中的許多類似問題:應該用複雜的條目設計一個小結構,還是應該用簡單的條目設計大結構?例如,應該使用4路16 KB關聯快取,還是2路32 KB關聯快取?一般來說,這種性質的問題沒有明確的答案,它們高度依賴於目標工作負載的性質。對於Sandy Bridge處理器,設計者有一個選擇,可以選擇具有2位飽和計數器的分支預測器,或者具有更多條目的預測器和1位飽和計數器。發現後一種設計的功率和效能權衡更好,因此他們選擇了1位計數器。
隨後,4個微操作被傳送到執行無序排程的重新命名和排程單元。在早期的處理器(如Nehalem處理器)中,正在執行的指令的臨時結果儲存在ROB中,一旦指令完成,它們就被複制到暫存器中,該操作涉及複製資料,從功率的角度來看效率不高。Sandy Bridge避免了這一點,並將結果直接儲存在物理暫存器中,類似於高效能RISC處理器。當一條指令到達重新命名階段時,檢查重新命名錶中的對映,並查詢包含源運算元值的物理暫存器的ID,或者在將來的某個時間點應該包含這些值。隨後,要麼讀取物理暫存器檔案,要麼等待生成它們的值。使用物理暫存器檔案是一種比使用其他方法更好的方法,這些方法將未完成指令的結果儲存在ROB中,然後將結果複製回暫存器檔案,使用物理暫存器是快速、簡單和節能的。通過在Sandy Bridge處理器中使用這種方法,ROB得到了簡化,在任何時間點都有可能有168條正在執行的指令。
Sandy Bridge處理器有3個整數ALU、1個載入單元和1個載入/儲存單元,整數單元從160個入口暫存器檔案讀取和寫入其運算元。為了支援浮點運算,它有一個FP加法單元和一個FP乘法單元,它們支援AVX SIMD指令集(對單精度和雙精度數位集執行256位元運算)。此外,為了支援256位元運算,Intel在x86 AVX ISA中新增了新的256位向量暫存器(YMM暫存器)。
要實現AVX指令集,必須支援來自32KB資料快取的256位傳輸。Sandy Bridge處理器可以執行兩個128位元載入,每個週期執行一個128位元儲存。在載入YMM(256位)暫存器的情況下,兩個128位元載入操作被融合為一個(256位的)載入操作。Sandy Bridge有一個256 KB的二級快取和一個大的(1-8 MB)三級快取,三級快取分為多個組,三級組、核心、GPU和北橋控制器使用基於單向環的互連進行連線。注意,單向環的直徑是(N-1),因為只能在一個方向上傳送訊息。為了克服這個限制,每個節點實際上連線到環上的兩個點,這些點彼此正好相反,因此有效直徑接近N=2。
Sandy Bridge處理器有一個獨特功能,稱為turbo(渦輪)模式,想法如下。假設處理器有一段靜止期(活動較少),所有芯的溫度將保持相對較低。再假設使用者決定執行計算密集型活動,需要數位密集型的計算,也需要大量的功率。每個處理器都有額定熱設計功率(TDP),是處理器允許消耗的最大功率。在turbo模式下,允許處理器在短時間內(20-25秒)消耗比TDP更多的功率,亦即允許處理器以高於標稱值的頻率執行所有單元。一旦溫度達到某個閾值,turbo模式將自動關閉,處理器將恢復正常執行。需要注意的主要點是,在短時間內消耗大量電力不是問題,但即使在短時間裡也不允許出現非常高的溫度,因為高溫會永久損壞晶片,比如如果一根電線熔化,整個晶片就會被破壞。由於處理器需要幾秒鐘才能加熱,因此可以利用這一效應,使用高頻率和高功率的相位來快速完成零星的工作。請注意,turbo模式對於耗時數小時的長時間執行作業不適用。
Intel CPU架構
Intel架構指令擴充套件的軟體程式設計介面以及未來幾代Intel處理器可能包含的功能。指令集擴充套件涵蓋了各種應用領域和程式設計用途。512位元
SIMD向量SIMD擴充套件,稱為Intel Advanced vector extensions 512(Intel AVX-512)指令,與向量擴充套件(IntelAVX)和IntelAdvanced vector Extension(IntelAVX2)指令相比,可提供全面的功能和更高的效能。
512位元SIMD指令擴充套件的基礎稱為Intel AVX-512 Foundation指令,包括Intel AVX和Intel AVX2系列SIMD指令的擴充套件,但使用新的編碼方案編碼,支援512位元向量暫存器、64位元模式下最多32個向量暫存器以及使用opmask暫存器的條件處理。Intel處理器相關的特性包含但不限於:高階矩陣擴充套件(AMX)、ENQCMD/ENWCMDS指令和虛擬化支援、TSX掛起載入地址跟蹤、線性地址轉換、架構最後分支記錄(LBRS)、非回寫鎖定禁用架構、匯流排鎖定和VM通知功能、資源管理器技術、增強型硬體反饋介面(EHFI)、線性地址遮蔽(LAM)、基於Sapphire Rapids微架構的處理器的機器錯誤程式碼、IPI虛擬化等等。關於它們的具體描述可參閱Intel的說明檔案:Intel Architecture Instruction Set Extensions and Future Feature。
Xeon E5-2600/4600的晶片架構如下:
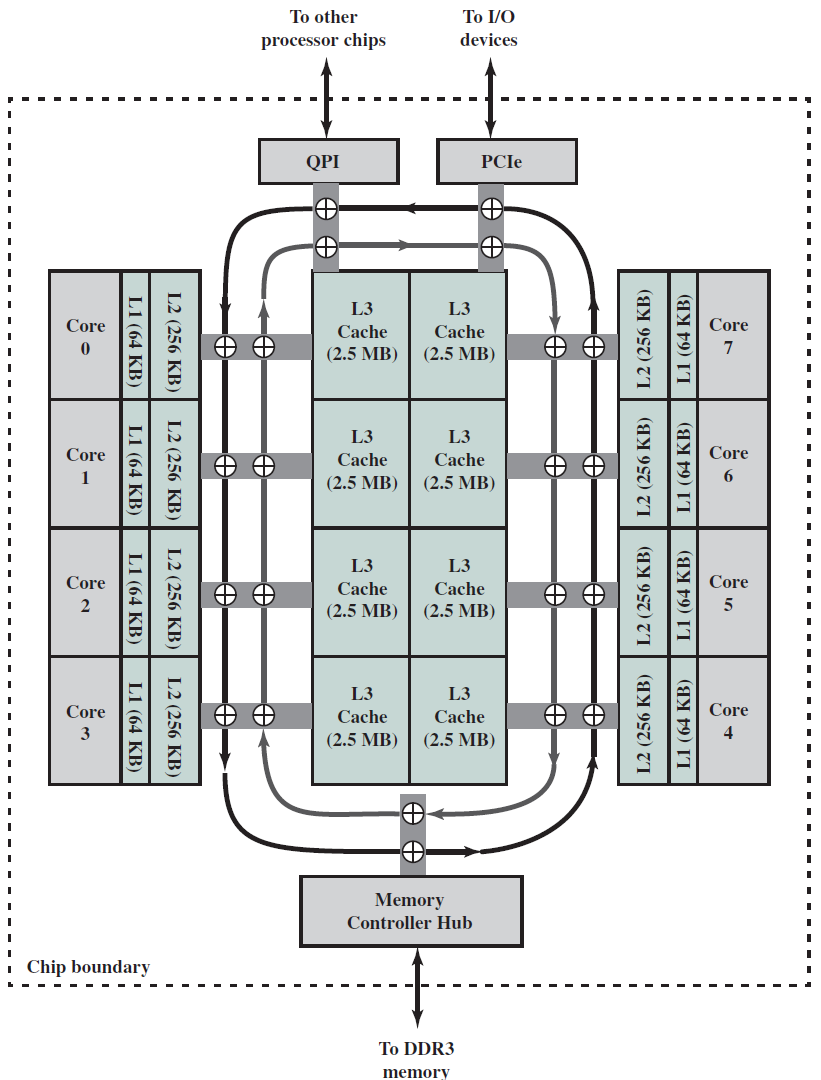
2021年的Intel架構支援標量、向量、矩陣和空間的混合計算:
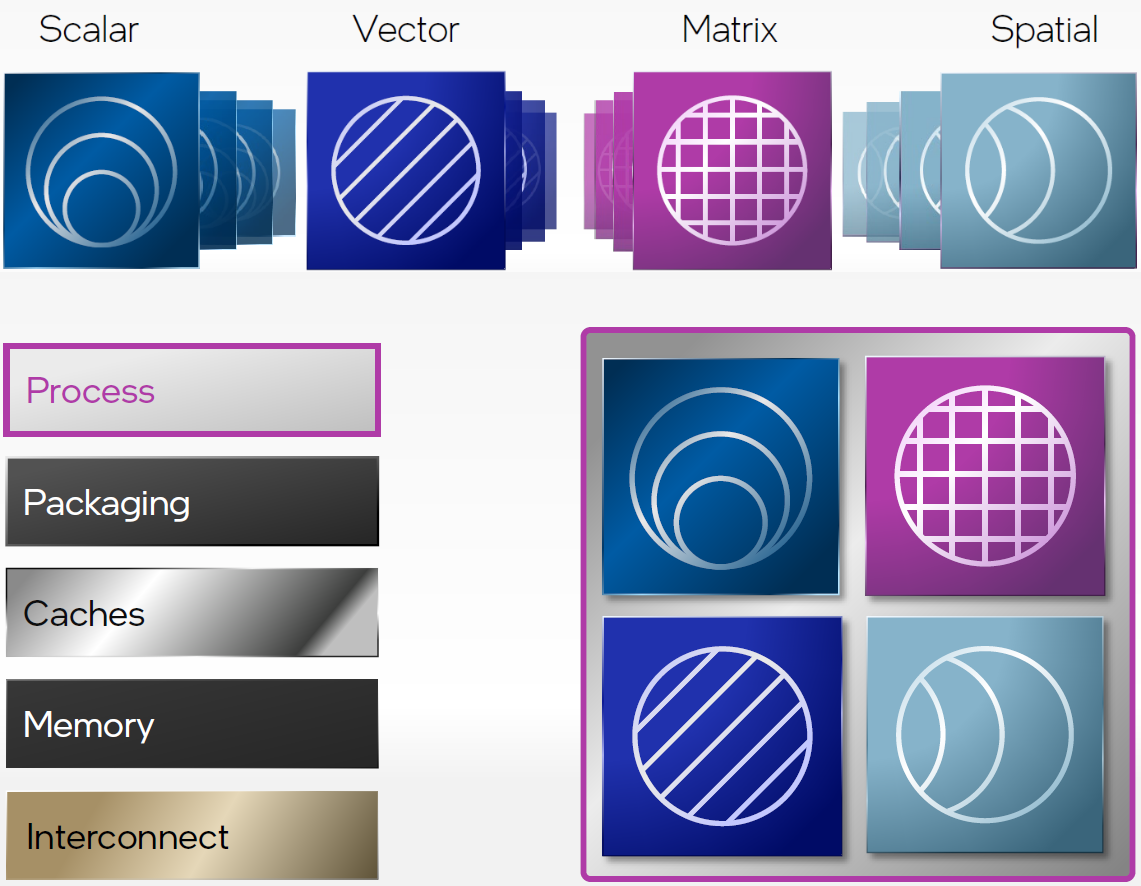
單個包中整合了混合計算叢集:

新架構的基礎元件如下,包含了各類高效能且節能的核心:
對於高效的x86核心而言,其具備高度可延伸的體系結構,以滿足下一個計算十年的吞吐量效率需求:

專為吞吐量而設計,為現代多工實現可伸縮的多執行緒效能。針對功率和密度高效吞吐量進行了優化,具有:
- 深度前端,按需長度解碼。
- 具有許多執行埠的寬頻後端。
- 針對最新電晶體技術的優化設計。

對於指令控制,帶有按需指令長度解碼器的大型指令快取(64KB)加快了現代工作負載的速度,佔用了大量程式碼。通過深度的分支歷史和大結構尺寸精確預測分支。

雙三寬亂序解碼器,每個週期最多可解碼6條指令,同時保持功率和延遲:

對於資料執行,五寬分配,八寬回收,256項亂序視窗發現資料並行性,17個執行埠執行資料並行。

資料執行涉及的硬體部件、數量和佈局如下:
在記憶體子系統方面:
- 雙過載入+雙重儲存。
- 高達4MB的L2快取:四個核心之間共用L2,在17個延遲週期內具有64位元組/週期頻寬。
- 高階預取器:在所有快取級別檢測各種流。
- 深度緩衝(Deep buffering,注意不是Depth Buffer):支援64次未命中。
- 英特爾資源管理器(Resource Director)技術:使軟體能夠控制核心之間以及不同軟體執行緒之間的公平性。

具備現代的指令級:
- 安全。
- 浮點乘法累加(FMA)指令,吞吐量為2倍。
- 新增關鍵指令以實現整數AI吞吐量(VNNI)。
- 寬向量。指令集架構。
- 支援Intel VT-rp(虛擬化技術重定向保護)。
- 高階推測執行驗證方法。
- Intel Control flow Enforcement Technology旨在提高防禦深度。
- 支援具有AI擴充套件的高階向量指令。
每個電晶體的功率和效能效率:
- 高度關注功能選擇和設計實現成本,以最大限度地提高面積效率,從而實現核心數量的擴充套件。
- 每個指令的低切換能量可最大化受功率限制的吞吐量,是當今吞吐量驅動工作負載的關鍵。
- 在擴充套件效能範圍的同時,降低了所有頻率傳輸功率所需的工作電壓。

處理器功率計算公式。
在延遲效能方面,ISO功率下提升40%以上的效能,在ISO效能下降低功率40%以上。
在吞吐量效能方面,提升80%的效能,降低80%的功率。
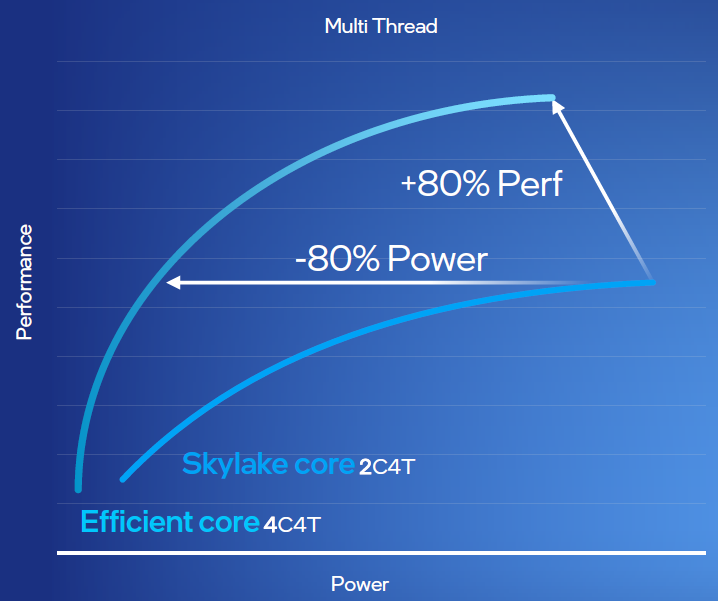
專為吞吐量而設計,為現代多工實現可伸縮的多執行緒效能。針對功率和密度高效吞吐量進行了優化,具有:
- 深度前端,按需長度解碼。
- 寬後端,具有許多執行埠。
- 針對最新電晶體技術的優化設計。
接下來闡述x86核心的效能。架構的目標是:
- 提供通用CPU效能的步進函數。
- 使用新功能改進Arch/uArch,以適應不斷變化的工作負載模式的趨勢。
- 在人工智慧效能加速方面實現創新。
新的x86架構專為速度而設計,通過以下方式突破低延遲和單執行緒應用程式效能的限制:
- 更寬。
- 更深。
- 更智慧。
使用大程式碼佔用和巨量資料集加速工作負載,通過協處理器實現矩陣乘法的新型AI加速技術,用於細粒度電力預算管理的新型智慧PM控制器。
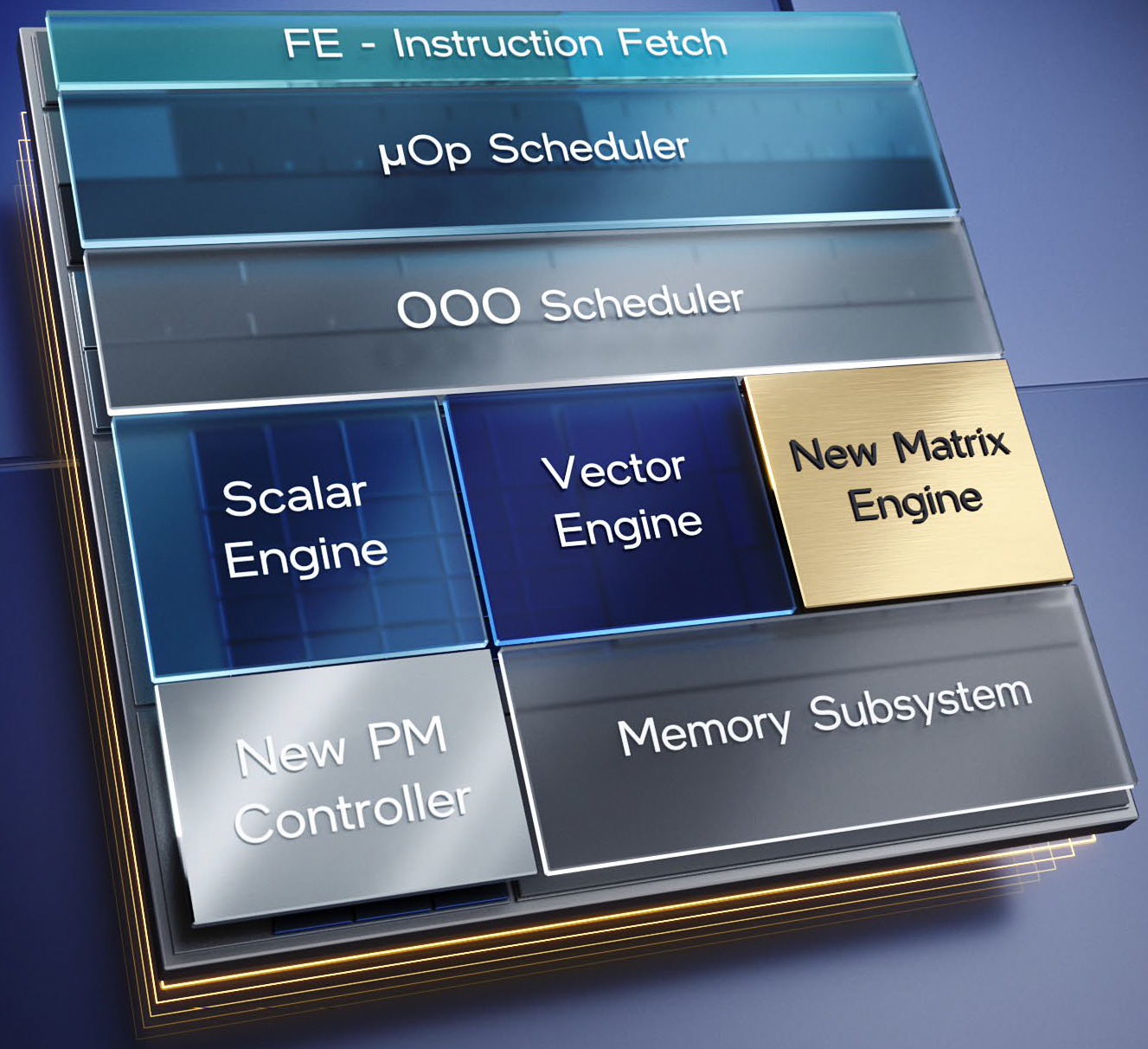
前端獲取指令並將其解碼到\(\mu\)級別的操作:
- 更大的程式碼:從128提升到256個4K iTLB,從16提升到32個2M/4M iTLB。
- 更寬:解碼長度從16B提升到32B。
- 更智慧:提高分支預測精度,更智慧的程式碼預取機制。
- \(\mu\)佇列:每執行緒條目從70提升到72,單個執行緒從70提升到144。
- \(\mu\)操作:2.25K提升到4K,提升命中率,提升前端頻寬。

亂序引擎跟蹤\(\mu\)操作依賴性並將準備好的\(\mu\)操作分派給執行單元:
- 更寬:分配寬度從5提到到6,執行埠從10提升到12。
- 更深:512項重新排序緩衝區和更大的排程器大小。
- 更智慧:在重新命名/分配階段「執行」更多指令。

整數執行單元新增了第5代整數執行埠/ALU,所有5個埠上的1週期LEA也用於算術計算:

向量運算單元具有新的快速加法器(FADD):節能、低延遲,以及FMA單元支援FP16資料型別:FP16新增到Intel AVX512,包括複數支援。

L1快取和記憶體子系統的特性有:
- 更寬:載入埠從2提升到3:3x256 bit的載入,2x512 bit的載入。
- 更深:更深入的載入緩衝區和儲存緩衝區暴露了更多的記憶體並行性。
- 更智慧:降低有效負載延遲,更快的記憶體消除分支。
- 更巨量資料:DTLB(資料快表)從64提升到96,L1資料快取從12提升到16且具有增強型預取器,頁面遍歷器(page walker)從2提升到4。
L2快取和記憶體子系統的特性有:
- 更大:1.25M(使用者端)或2M(資料中心)。
- 更快:最大需求未命中從32提升到48。
- 更智慧:基於L2快取模式的多路徑預取器,基於反饋的預取限制(throttling),全線寫入預測頻寬優化以減少DRAM讀取。
通用效能與第11代Intel Core,ISO頻率下效能提高19%:
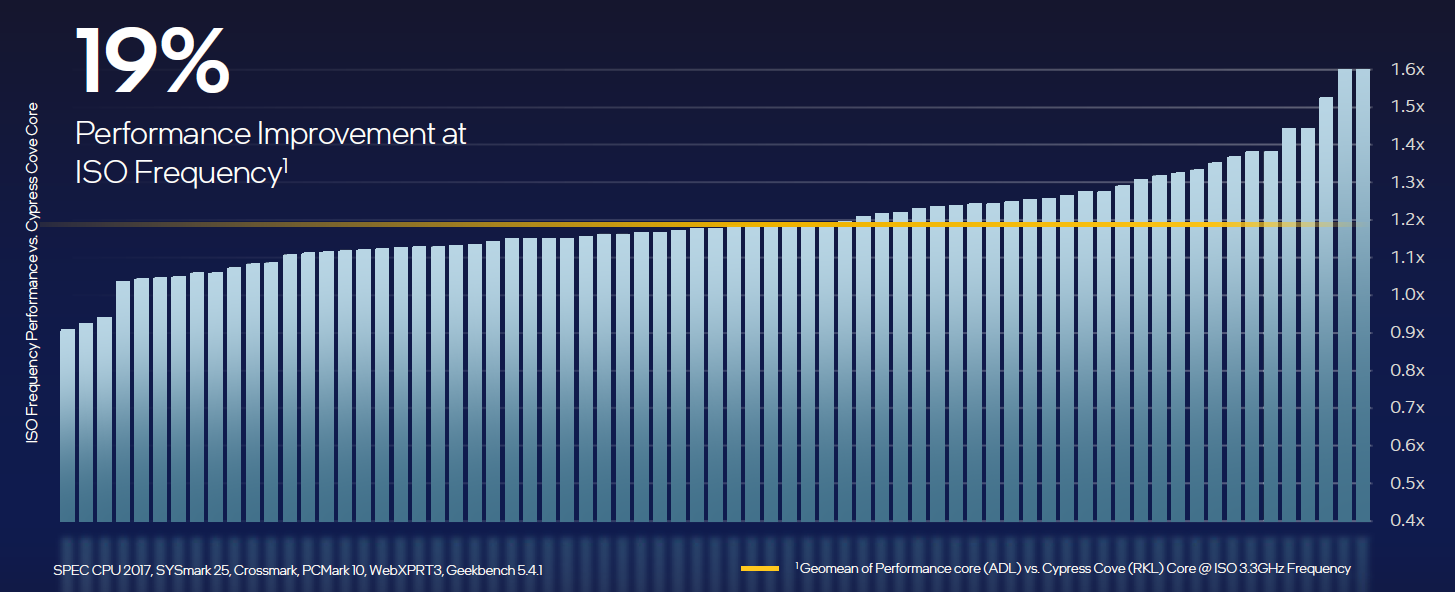
英特爾高階矩陣擴充套件(英特爾AMX),分塊矩陣乘法加速器——資料中心,VNNI從256 int8提升至AMX的2048 int8,提升了8倍的操作、時鐘週期、核心。

AMX架構有兩個元件:
- 分塊(Tile):
- 新的可延伸2D暫存器檔案——8個新暫存器,每個1Kb:T0-T7。
- 暫存器檔案支援基本資料運運算元——載入/儲存、清除、設定為常數等。
- 分塊宣告狀態並由XSAVE體系結構管理作業系統。
- TMUL:
- 矩陣乘法指令集,TILE上的第一個運運算元。
- MAC計算網格計算資料的「分塊」。
- TMUL使用三個分塊暫存器(
T2=+T1*T0)執行矩陣加法乘法(C=+A*C)。 - TMUL要求分塊已被呈現。
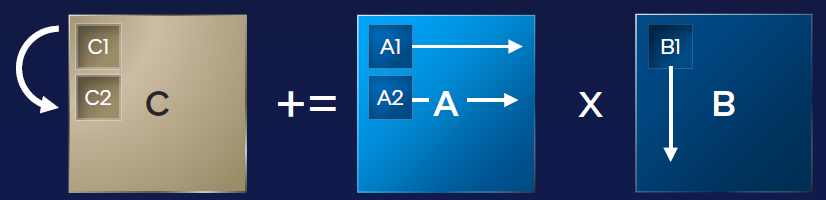
英特爾高階矩陣擴充套件(英特爾AMX)架構如下:
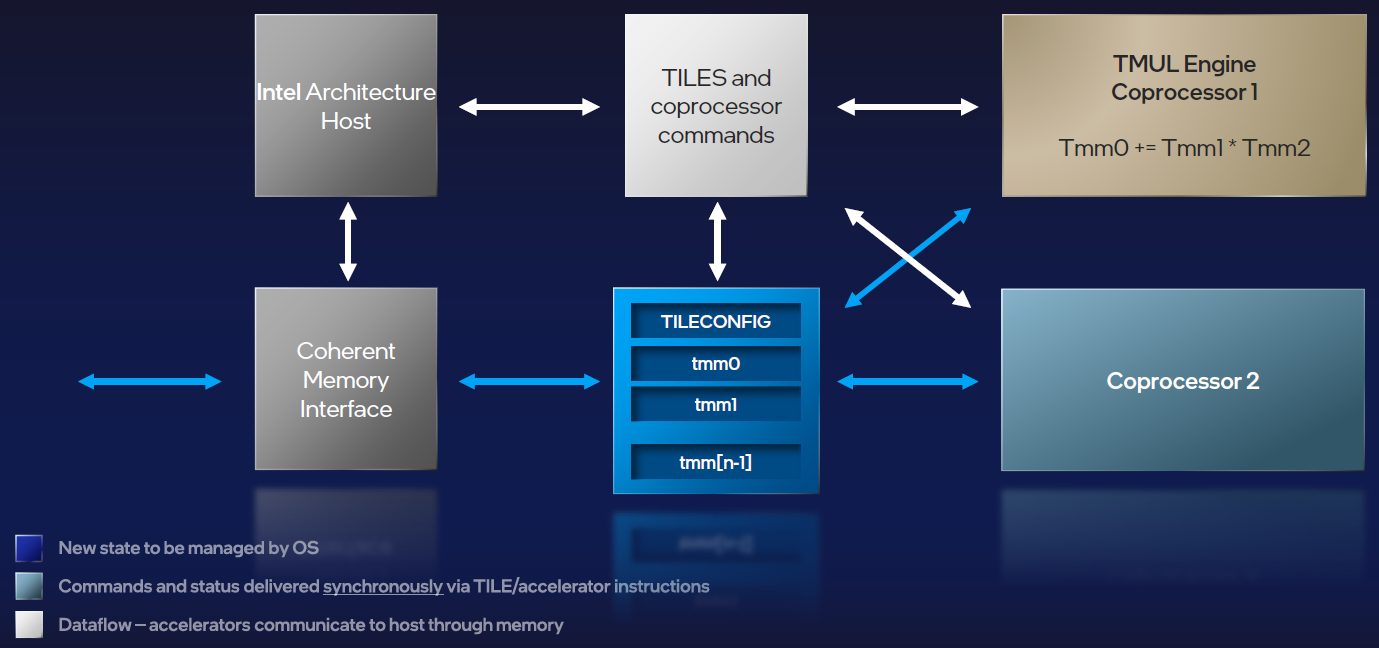
x86核心是下一個計算十年CPU架構效能的階梯函數,在高功率效率下顯著提高IPC,具備更寬、更深、更智慧的特點。更好地支援大型資料集和大型程式碼佔用應用程式,機器學習技術:Intel AMX的分塊乘法,增強的電源管理可提高頻率和功率。所有這些都採用量身客製化的可延伸架構,可為從筆記型電腦到桌上型電腦再到資料中心的全系列產品提供服務。
Intel標量架構的路線圖如下:

單執行緒/延遲和多執行緒效能/吞吐量的二維關係如下:
Intel執行緒管理器(Thread Director):
- 排程的目標是:軟體透明、實時自適應、從行動端到桌面的可延伸性。
- 直接內建於核心的智慧,基於熱設計點、執行條件和功率設定動態調整指導,無需任何使用者輸入。
- 向作業系統提供執行時反饋,以便為任何工作負載或工作流做出最佳排程決策。
- 以納秒級精度監控每個執行緒的執行時指令組合以及每個核心的狀態。
Thread Director排程案例如下:
1:在P核上排程的優先任務。
2:在E核上排程的後臺任務。
3:新的AI執行緒就緒。
4:AI執行緒優先排程於P核。
5-7:自旋等待從P核移動到E核。
接下來介紹多核架構Alder Lake。Alder Lake的特點是:
- 單一可延伸SoC架構。所有使用者端段,從9W至125W,基於Intel 7程序構建。
- 全新核心設計。與Intel執行緒控制器的效能混合。
- 業界領先的記憶體和I/O。支援DDR5、PCIe Gen5、Thunderbolt 4、Wi-Fi 6E等。
可延伸的使用者端架構:

架構積木:

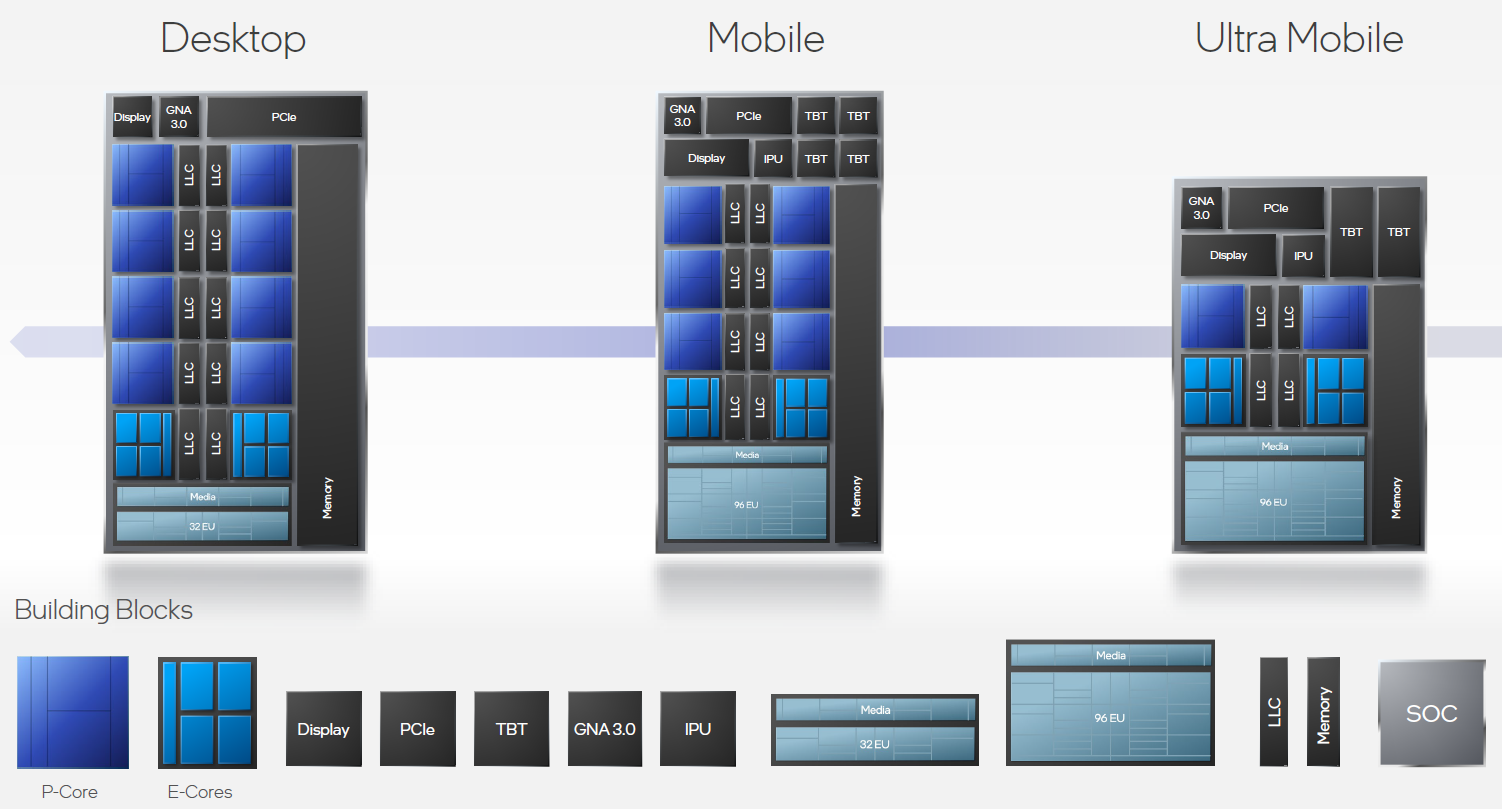
Alder Lake的核心和快取資料如下:
- 高達16核,8效能核,8效率核。
- 高達24執行緒,每個P核2個執行緒,每個E核1個執行緒。
- 高達30M快取,非包容性,LL快取。
Alder Lake的記憶體引領行業向DDR5過渡,支援所有四種主要記憶體技術,動態電壓頻率縮放,增強的超頻支援。

PCIe引領行業向PCIe Gen5過渡,與Gen4相比,頻寬高達2倍,最高64GB/s,x16通道。
內部連線(Interconnect)的特點:
- 計算結構:高達1000 GB/s,動態延遲優化。
- I/O結構:高達64GB/s,實時、基於需求的頻寬控制。
- 記憶體結構:高達204 GB/s,動態匯流排寬度和頻率。
Intel的整合圖形晶片\(X^e\) HPG的Render Slice架構如下圖,包含核心、取樣器、光線追蹤單元各4個,幾何處理、光柵化、HiZ等各1個,畫素後端2個:

\(X^e\) HPG具有可延伸的圖形引擎,包含8個Render Slice,其效能和功率關係如下:
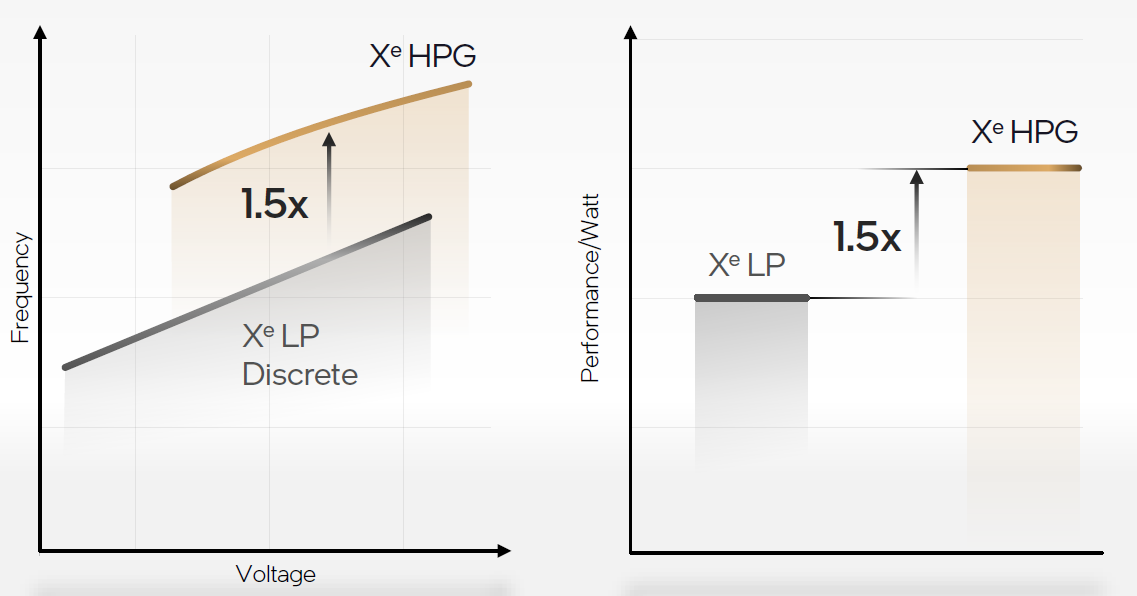
基於\(X^e\) HPC的GPU的計算構建塊:

向量引擎和矩陣引擎的引數及所處的位置如下:

單個切片結構如下:

多個切片組成的棧(stack)如下:

當然多個棧還可以組成更大的結構。連線具有高度伸縮性,支援2點互聯、4點互聯、6點互聯甚至8點和互聯:
Sapphire Rappids是下一代Intel Xeon可延伸處理器,資料中心體系結構的新標準,專為微服務和AI工作負載設計,開創性的高階記憶體和IO轉換。Intel Xeon的節點效能表現在標量效能、資料並行效能、快取和記憶體子系統架構,以及通訊端內/通訊端間縮放等方面:

Intel Xeon的資料中心效能表現在整合和業務流程、效能一致性、彈性和高效的資料中心利用率、基礎設施和框架開銷等方面:

通過模組化架構,利用單片CPU的現有軟體範例(如Ice Lake),提供可延伸、平衡的架構(如Sapphire Rapids):

Sapphire Rapids是多片、單CPU架構,每個執行緒都可以完全存取所有分塊的快取、記憶體、IO…在整個SoC中提供一致的低延遲和高橫截面的頻寬。Sapphire Rapids的SoC的物理架構如下:

Sapphire Rapids的關鍵構建塊如下:
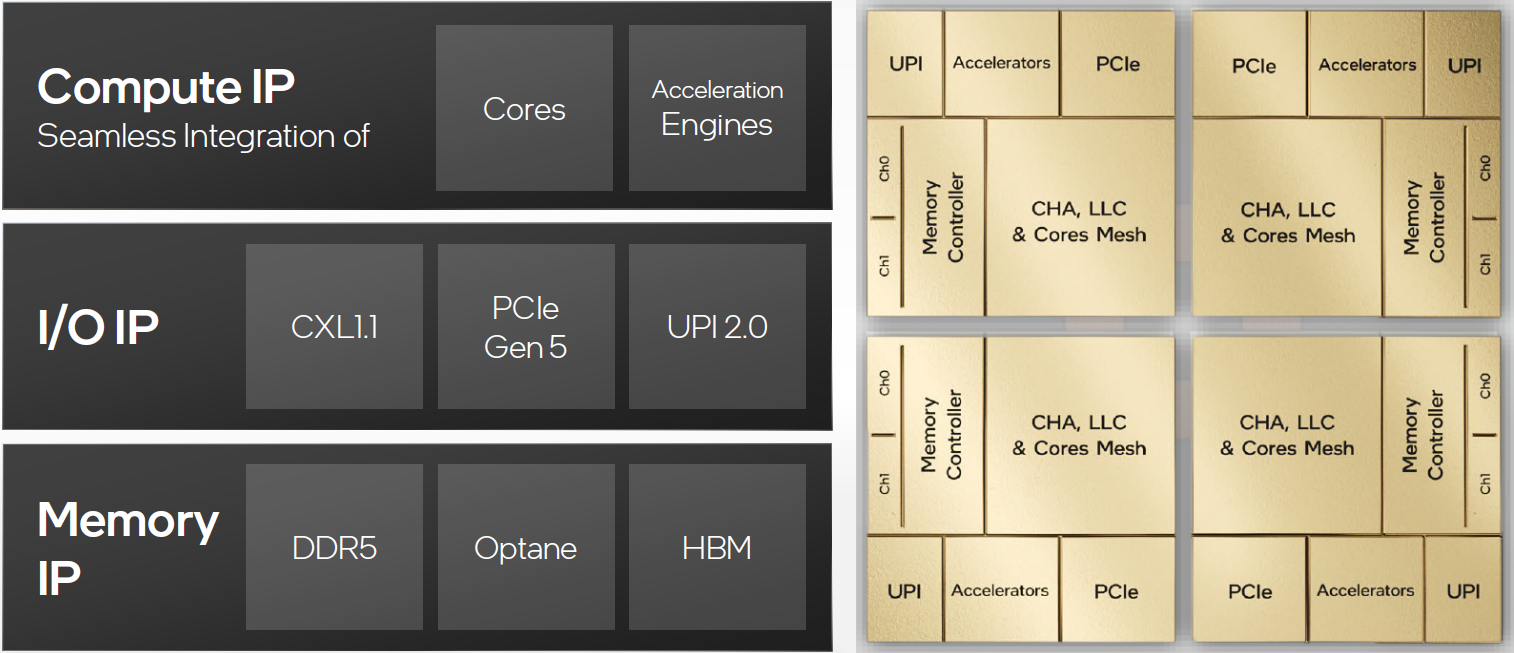
為資料中心構建的效能核心,主要微架構和IPC改進,改進了對大程式碼/資料佔用的支援,高頻自動/快速PM。

效能核心,DC工作負載和使用的架構改進:
- AI:英特爾高階矩陣擴充套件-AMX,用於推理和訓練加速的平鋪矩陣運算。
- 連線裝置:加速器介面架構-AiA,使用者級的高效排程、信令和同步。
- FP16:半精度,支援更高的吞吐量和更低的精度。
- 快取管理:CLDEMOTE,主動放置快取內容。
Sapphire Rapids加速引擎,通過無縫整合的加速引擎實現共模任務的解除安裝以提高核心的效率,原生排程、來自使用者空間的信令和同步、加速器介面架構,核心與加速引擎之間的相干共用儲存空間,可並行共用的程序、容器和VM。
Intel Data Streaming加速引擎優化流資料移動和轉換操作,每個通訊端最多4個範例,低延遲呼叫,無記憶體固定開銷,DSA解除安裝後獲得額外39%的CPU核心週期。
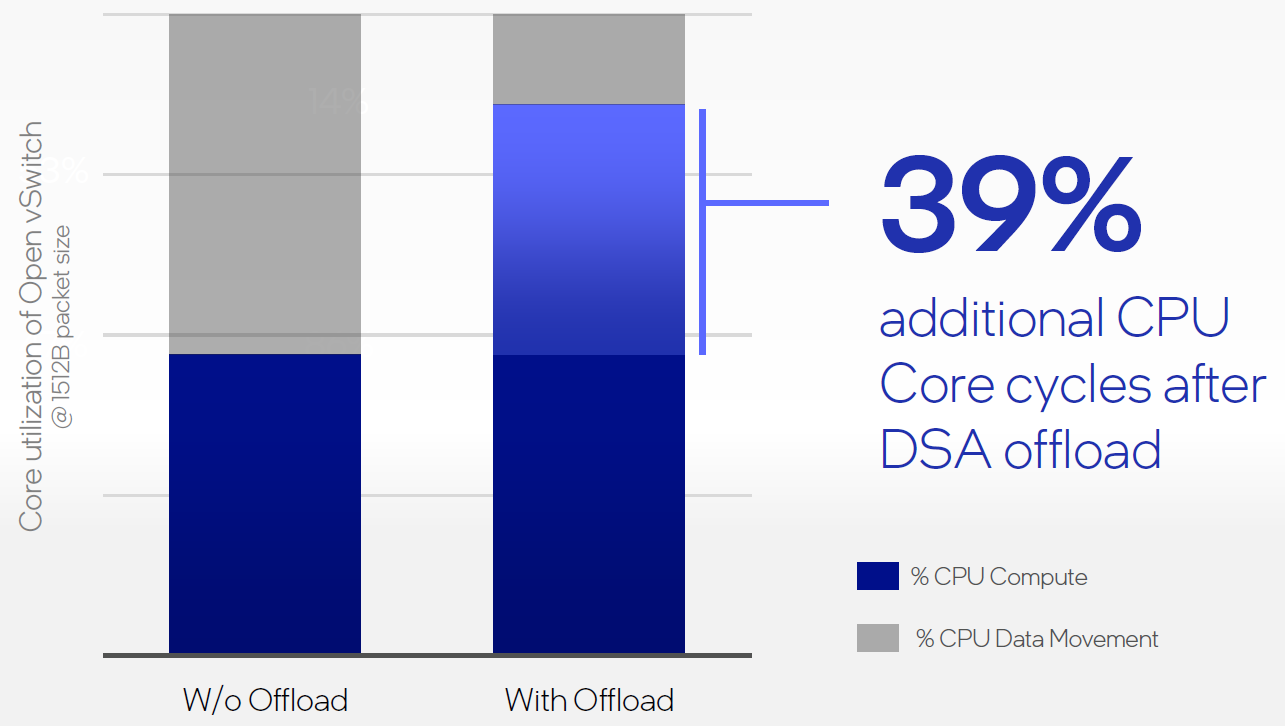
Intel Quick Assist Technology加速引擎加快加密和資料消除/壓縮,高達400Gb/s對稱加密,高達160Gb/s壓縮+160Gb/s解壓縮,融合操作,QAT解除安裝後增加98%的工作負載容量。
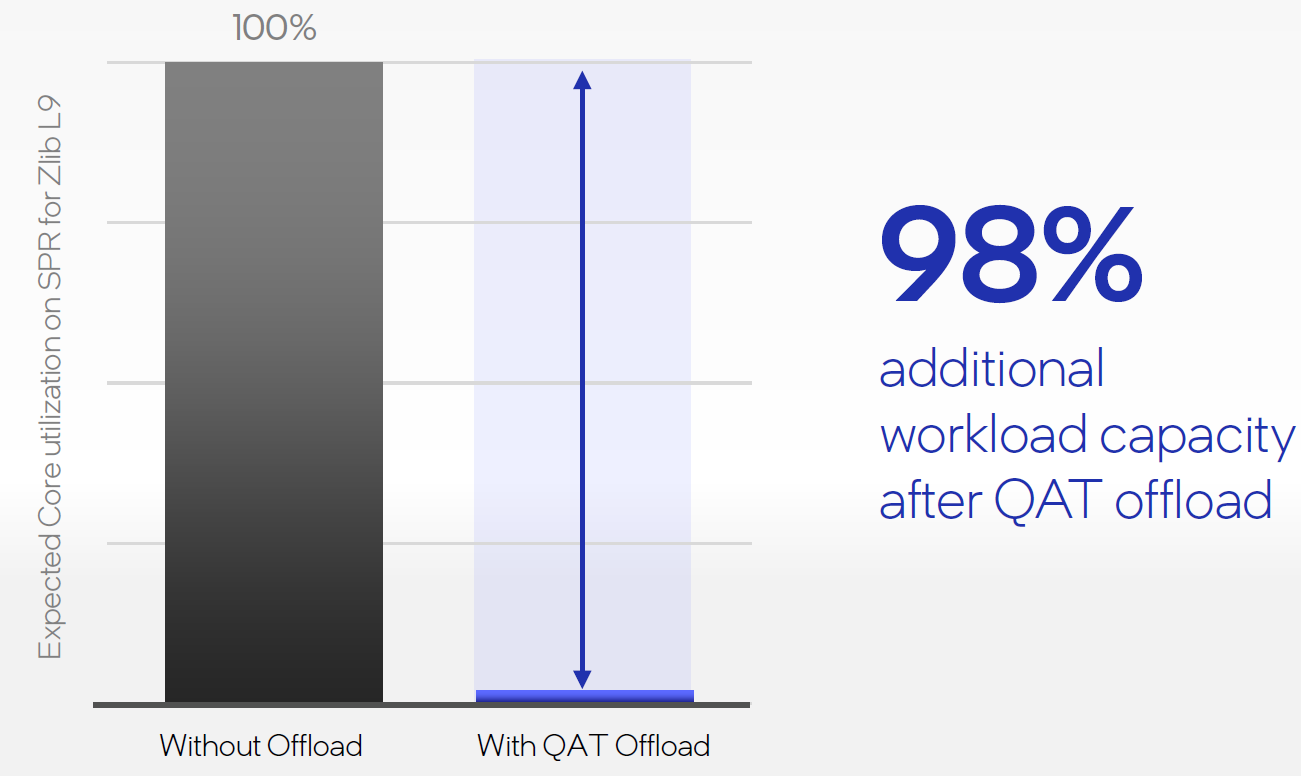
Sapphire Rapids的I/O高階特性:
- Compute ePressLink(CXL)1.1簡介,資料中心中的加速器和記憶體擴充套件。
- 通過PCIe 5.0和連線擴充套件裝置效能,通過Intel®Ultra Path Interconnect(UPI)2.0改進多插槽擴充套件。
- 最多4 x24 UPI鏈路以16 GT/s的速度執行,新的8S-4UPI效能優化拓撲,改進的DDIO和QoS功能。
Sapphire Rapids的記憶體和最後一級快取:
- 增加的共用最後一級快取(LLC),在所有核心中共用的最大容量超過100 MB LLC。
- 通過DDR 5記憶體提高頻寬、安全性和可靠性,4個記憶體控制器,支援8個通道。
- Intel Optane永久記憶體300系列。
Sapphire Rapids具有高頻寬記憶體:
- 與8通道DDR 5的基線Xeon SP相比,記憶體頻寬顯著提高。
- 增加容量和頻寬,某些用途可以完全消除對DDR的需求。
- 2種模式:
- HBM扁平模式。帶HBM和DRAM的扁平記憶體區域。
- HBM快取模式。DRAM備份快取。
Sapphire Rapids為彈性計算模型構建微服務,80%以上的新雲原生和SaaS應用程式預計將作為微服務構建。其目標是:實現更高的吞吐量,同時滿足延遲要求,並減少執行、監控和協調數千個微服務的基礎架構開銷;提高效能和服務質量,減少基礎設施開銷,更好的分散式通訊。微服務效能的對比如下:
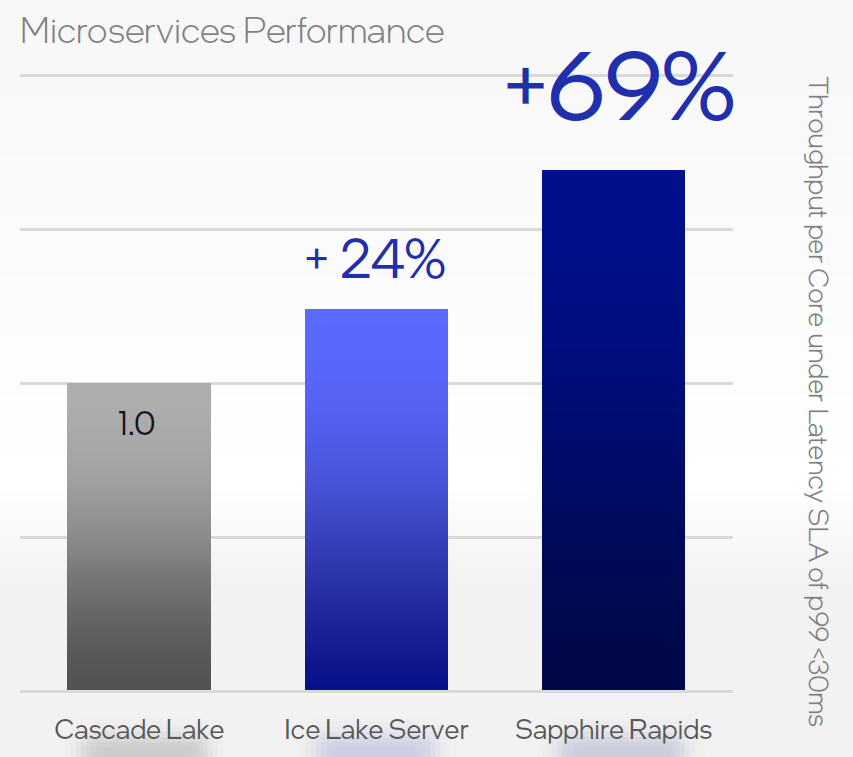
Ponte Vecchio具有:
- 新的驗證方法。
- 新的SOC架構。
- 新的IP架構。
- 新記憶體體系結構。
- 新的I/O體系結構。
- 新的包裝技術。
- 新的電力輸送技術。
- 新的互連。
- 新的訊號完整性技術。
- 新的可靠性方法。
- 新的軟體。
Ponte Vecchio SoC擁有1000億以上電晶體,47活動分塊,5個程序節點。其內部結構圖如下:

具有不同加速比的加速計算系統:

克服分離的CPU和GPU軟體堆疊,囊括了CPU優化堆疊和GPU優化堆疊:
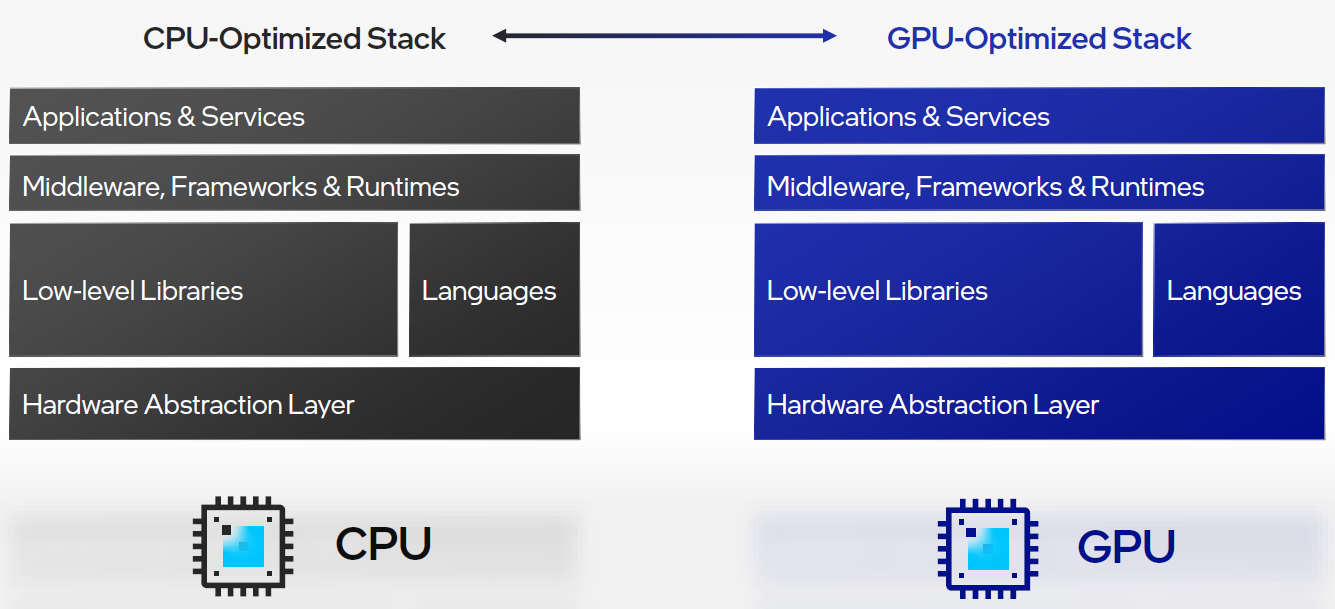
19.6 記憶體系統
到目前為止,我們已經將記憶體系統視為一個大的位元組陣列,這種抽象對於設計指令集、學習組合語言,甚至對於設計具有複雜流水線的基本處理器來說,都已經足夠好了。然而,從實際角度來看,這種抽象需要進一步重新定義,以設計一個快速記憶體系統。在前面章節介紹的基礎流水線中,假設存取資料和指令記憶體需要1個週期,在本章並不總是正確的。事實上,需要對記憶體系統進行重大優化,以接近1個週期的理想延遲,需要引入「快取」和分層記憶體系統的概念,以解決具有大記憶體容量和低延遲的雙重問題。
其次,到目前為止,一直假設只有一個程式在系統上執行,但大多數處理器通常在分時基礎上執行多個程式,例如,如果有兩個程式A和B,現代桌上型電腦或筆記型電腦通常會執行程式A幾毫秒,執行程式B幾毫秒,然後來回切換。事實上,系統執行著許多其他程式,比如網頁瀏覽器、音訊播放器和日曆應用程式。一般來說,使用者不會感知到任何中斷,因為中斷髮生的時間尺度遠低於人腦所能感知的時間尺度。例如,一個典型的視訊每秒顯示30次新圖片,或者每隔33毫秒顯示一張新圖片。人腦通過將圖片拼接在一起,產生一個平穩移動的物體的錯覺。如果處理器在33毫秒之前完成處理視訊序列中下一張圖片的工作,那麼它可以執行另一個程式的一部分。人腦將無法分辨差異。這裡的重點是,在我們不知情的情況下,處理器與作業系統合作,在多個程式之間每秒切換多次。作業系統本身就是一個專門的程式,可以幫助處理器管理自己和其他程式。Windows和Linux是流行作業系統的範例。
我們需要記憶體系統中的特殊支援來支援多個程式,如果沒有這種支援,那麼多個程式會覆蓋彼此的資料,這是不希望的行為。第二,我們一直假設擁有無限的記憶體,這也不是事實,我們擁有的記憶體量是零,而且它可能會被大型記憶體密集型程式耗盡。因此,我們應該有一個機制來繼續執行這樣大的程式,將引入虛擬記憶體的概念來解決這兩個問題:執行多個程式和處理大型記憶體密集型程式。
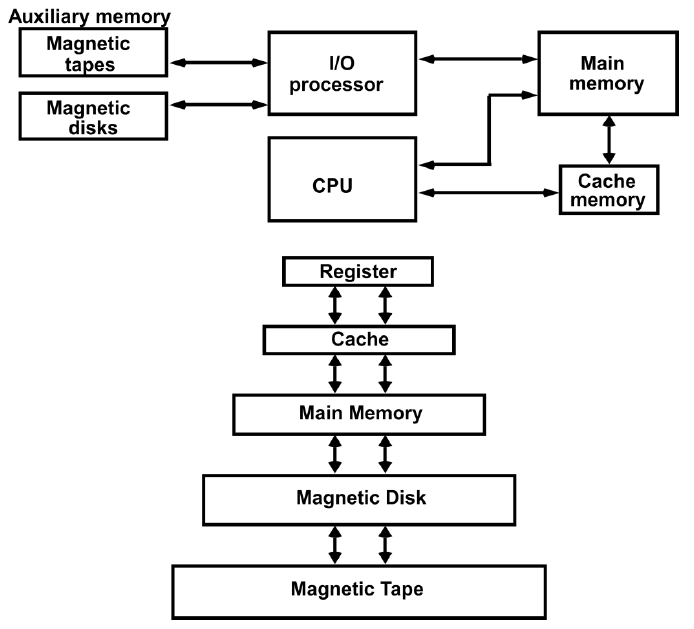
計算機系統中的記憶體層次結構。
如果根據記憶體系統的關鍵特性對其進行分類,那麼計算機記憶體這一複雜的主題就更容易管理。其中最重要的列於下表。
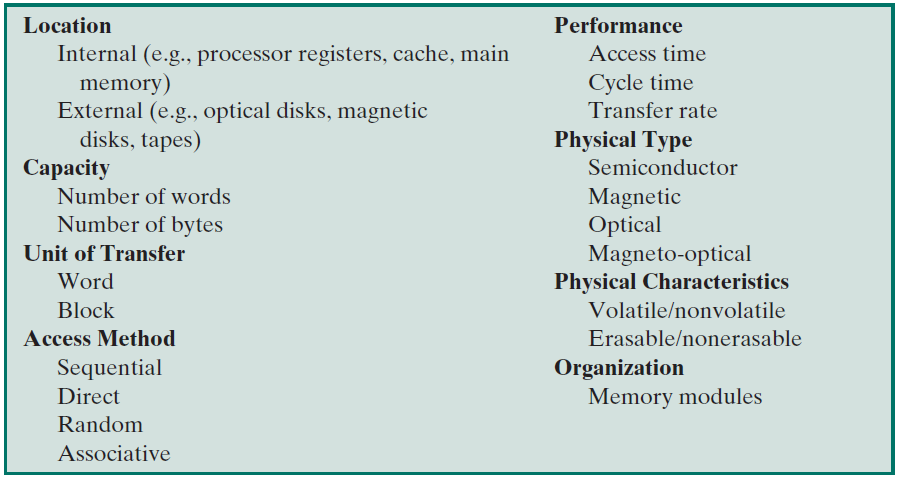
表中的術語位置是指記憶體是計算機內部還是外部,內部記憶體通常等同於主記憶體,但也有其他形式的內部記憶體。處理器需要自己的區域性記憶體,以暫存器的形式,處理器的控制單元部分也可能需要其自己的內部記憶體,快取是記憶體的另一種形式。外部記憶體由外圍儲存裝置(如磁碟和磁帶)組成,處理器可以通過I/O控制器存取這些裝置。
記憶體的一個明顯特徵是它的容量。對於內部記憶體,通常以位元組(1位元組=8位元)或字表示,常見的字長為8、16和32位元。外部記憶體容量通常以位元組表示。
一個相關的概念是傳輸單位(unit of transfer)。對於內部記憶體,傳輸單位等於進出儲存模組的電線數量,可能等於字長,但通常更大,例如64、128或256位。為了闡明這一點,請考慮內部記憶體的三個相關概念:
- 字(Word):記憶體組織的「自然」單位,字的大小通常等於用於表示整數的位數和指令長度。不幸的是,有很多例外,例如CRAY C90(一種老式CRAY超級計算機)具有64位元的字長,但使用46位整數表示。Intel x86體系結構具有多種指令長度,以位元組的倍數表示,字大小為32位元。
- 可定址單元(Addressable unit):在某些系統中,可定址單元是字,但許多系統允許在位元組級別定址。在任何情況下,地址的位A長度與可定址單元的數量N之間的關係是\(2^A=N\)。
- 傳輸單位(Unit of transfer):對於主記憶體,是一次從記憶體中讀出或寫入的位數,傳輸單位不必等於字或可定址單位。對於外部記憶體,資料通常以比字大得多的單位傳輸,這些單位被稱為塊。
記憶體型別的另一個區別是存取資料單元的方法,其中包括以下內容:
- 順序存取:記憶體被組織成資料單元,稱為記錄,存取必須按照特定的線性順序進行,儲存的定址資訊用於分離記錄並協助檢索過程。使用共用讀寫機制,必須將其從當前位置移動到所需位置,傳遞和拒絕每個中間記錄,因此存取任意記錄的時間是高度可變的。
- 直接存取:與順序存取一樣,直接存取涉及共用的讀寫機制,但單個塊或記錄具有基於物理位置的唯一地址。存取是通過直接存取來實現的,以到達一般鄰近位置,再加上順序搜尋、計數或等待到達最終位置。同樣,存取時間是可變的。
- 隨機存取:記憶體中的每個可定址位置都有一個獨特的物理連線定址機制,存取給定位置的時間與先前存取的順序無關,並且是恆定的。因此,可以隨機選擇任何位置,並直接定址和存取。主記憶體和一些快取系統是隨機存取的。
- 關聯(Associative):是一種隨機存取型別的記憶體,使我們能夠對一個字內的所需位位置進行比較,以獲得指定的匹配,並同時對所有字進行比較。因此,一個字是基於其內容的一部分而不是其地址來檢索的。與普通隨機存取記憶體一樣,每個位置都有自己的定址機制,檢索時間與位置或先前的存取模式無關。快取記憶體記憶體可以採用關聯存取。
從使用者的角度來看,記憶體的兩個最重要的特性是容量和效能,效能涉及三個引數:
-
存取時間(延遲):對於隨機存取記憶體,是執行讀取或寫入操作所需的時間,即從地址呈現到記憶體的那一刻到資料被儲存或可供使用的那一瞬間的時間。對於非隨機存取記憶體,存取時間是將讀寫機制定位在所需位置所需的時間。
-
記憶體週期時間:主要應用於隨機存取記憶體,包括存取時間加上第二次存取開始前所需的任何額外時間。如果訊號線上的瞬變消失(die out)或資料被破壞性讀取,則可能需要額外的時間來重新生成資料。注意,記憶體週期時間與系統匯流排有關,與處理器無關。
-
傳輸速率:是資料可以傳輸到記憶體單元或從記憶體單元傳輸出去的速率。對於隨機-存取記憶體,它等於1/(迴圈時間),對於非隨機存取記憶體,以下關係成立:
\[T_{n}=T_{A}+\frac{n}{R} \]其中:
- \(T_n\)=讀取或寫入n位的平均時間。
- \(T_A\)=平均存取時間。
- \(n\)=位數。
- \(R\)=傳輸速率,單位為位元/秒(bps)。
已經闡述了各種物理型別的記憶體。當今最常見的是半導體記憶體、用於磁碟和磁帶的磁表面記憶體、光學和磁光記憶體。
19.6.1 記憶體系統概論
19.6.1.1 快速記憶體系統需求
現在看看構建快速儲存系統的技術要求。我們可以用四種基本電路設計記憶體元件:鎖存器、SRAM單元、CAM單元和DRAM單元。這裡有一個權衡,鎖存器和SRAM單元比DRAM或CAM單元快得多,但與DRAM單元相比,鎖存器、CAM或SRAM單元的面積要大一個數量級,而且功耗也要大得多。鎖存器被設計為在負時鐘邊沿讀取和讀出資料,是一個快速電路,可以在時鐘週期的一小部分記憶體儲和檢索資料。另一方面,SRAM單元通常被設計為與解碼器和感測放大器一起用作SRAM單元的大陣列的一部分。由於這種額外的開銷,SRAM單元通常比典型的邊緣觸發鎖存器慢。相比之下,CAM單元最適合與內容相關的記憶體,而DRAM單元最適合容量非常大的記憶體。
現在,管線假定記憶體存取需要1個週期,為了滿足這一要求,需要用鎖存器或SRAM單元的小陣列構建整個記憶體。下表顯示了截至2012年的典型鎖存器、SRAM單元和DRAM單元的尺寸。
| 單元型別 | 面積 | 典型延遲 |
|---|---|---|
| 主從D觸發器 | 0.8 \(\mu m^2\) | 一個時鐘週期內的分數 |
| SRAM單元 | 0.08 \(\mu m^2\) | 1-5時鐘週期 |
| DRAM單元 | 0.005 \(\mu m^2\) | 50-200時鐘週期 |
典型的鎖存器(主從D觸發器)比SRAM單元大10倍,而SRAM單元又比DRAM單元大約16倍,意味著,給定一定量的矽,如果使用DRAM單元,可以儲存160倍的資料,但也慢200倍(如果考慮DRAM單元的代表性陣列)。顯然,容量和速度之間存在權衡,但我們實際上需要兩者。
讓我們首先考慮儲存能力問題。由於技術和可製造性方面的若干限制,截至2012年,無法制造面積超過400-500平方毫米的晶片,因此在晶片上擁有的記憶體總量是有限的,但用專門包含儲存單元的附加晶片來補充可用記憶體的數量是完全可能的。請記住,片外記憶體速度較慢,處理器存取此類記憶體模組需要數十個週期。為了實現1週期記憶體存取的目標,我們需要在大多數時間使用相對更快的片上記憶體,但選擇也是有限的,無法承受只由鎖存器組成的儲存系統。對於大量程式,無法將所有資料儲存在記憶體中,例如,現代程式通常需要數百兆位元組的記憶體,一些大型科學程式需要千兆位元組的記憶體。其次,由於技術限制,很難在同一晶片上整合大型DRAM陣列和處理器,設計者不得不將大型SRAM陣列用於片上記憶體。如上表所示,SRAM單元(陣列)比DRAM單元(陣列)大得多,因此容量小得多。
但是,延遲要求存在衝突。假設我們決定最大化儲存,並使記憶體完全由DRAM單元組成,存取DRAM的等待時間為100個週期。如果假設三分之一的指令是記憶體指令,那麼完美的5階段處理器管線的有效CPI計算為:\(1+1/3 \times (100-1)=34\)。需要注意的是,CPI增加了34倍,完全不能接受!
因此,我們需要在延遲和儲存之間進行公平的權衡,希望儲存儘可能多的資料,但不能以非常低的IPC為代價。不幸的是,如果假設記憶體存取是完全隨機的,那麼就沒有辦法擺脫這種情況。如果記憶體存取中存在某種模式,那麼會做得更好,這樣就可以做到兩全其美:高儲存容量和低延遲。
19.6.1.2 記憶體存取模式
記憶體存取模式有兩種:
- 時間區域性性(Temporal Locality)。如果某個資源在某個時間點被存取,那麼很可能會在很短的時間間隔內再次被存取。
- 空間區域性性(Spatial Locality)。如果某個資源在某個時間點被存取,那麼很可能在不久的將來也會存取類似的資源。
記憶體存取中是否存在時間和空間區域性性?
如果存在一定程度的時間和空間區域性性,那麼可以進行一些關鍵的優化,以幫助解決大記憶體需求和低延遲這兩個問題。在計算機架構中,通常利用諸如時間和空間區域性性之類的特性來解決問題。
19.6.1.3 指令存取的時空區域性性
解決這一問題的標準方法是在一組具有代表性的專案中測量和描述區域性性,如SPEC基準。可將將記憶體存取分為兩大類:指令和資料,指令存取更容易進行非正式分析,因此先來看看它。
一個典型的程式有賦值語句、分支語句(if、else)和迴圈,大型程式中的大部分程式碼都是迴圈的一部分或一些通用程式碼。計算機架構中有一個標準的經驗法則,它表明90%的程式碼執行10%的時間,10%的程式碼執行90%的時間。對於一個文書處理器,處理使用者輸入並在螢幕上顯示結果的程式碼比顯示幫助螢幕的程式碼執行得更頻繁。同樣,對於科學應用,大部分時間都花在程式中的幾個迴圈中。事實上,對於大多數常見的應用程式,我們使用這種模式。因此,計算機架構師得出結論,指令存取的時間區域性性適用於絕大多數程式。
現在考慮指令存取的空間區域性性。如果沒有分支語句,那麼下一個程式計數器是當前程式計數器加上ISA的4個位元組(常規ISA而言)。如果兩個存取的記憶體地址彼此接近,我們認為這兩個存取「相似」,很明顯,此處具有空間區域性性。程式中的大多數指令是非分支的,空間區域性性成立。此外,在大多數程式中,分支的一個很好的模式是,分支目標實際上並不遠。如果我們考慮一個簡單的If-else語句或for迴圈,那麼分支目標的距離等於迴圈的長度或語句的If部分。在大多數程式中,通常是10到100條指令長,而不是數千條指令長。因此,架構師得出結論,指令記憶體存取也表現出大量的空間區域性性。
資料存取的情況稍微複雜一些,但差別不大。對於資料存取,我們也傾向於重用相同的資料,並存取類似的資料項。
19.6.1.4 時間區域性性特徵
讓我們描述一種稱為堆疊距離(stack distance)方法的方法,以表徵程式中的時間區域性性。
我們維護一個存取的資料地址堆疊。對於每個記憶體指令(載入/儲存),在堆疊中搜尋相應的地址,找到條目的位置(如果找到)稱為「堆疊距離」。距離是從堆疊頂部開始測量的,堆疊頂部的距離等於零,而第100個條目的堆疊距離等於99。每當我們檢測到堆疊中的條目時,我們就會將其移除,並將其推到堆疊頂部。
如果找不到記憶體地址,那麼建立一個新條目並將其推到堆疊的頂部。通常,堆疊的深度是有界的,它的長度為L。如果由於新增了一個新條目,堆疊中的條目數超過了L,那麼需要刪除堆疊底部的條目。其次,在新增新條目時,堆疊距離沒有定義。注意,由於我們考慮有界堆疊,因此無法區分新條目和堆疊中的條目,但必須將其刪除,因為它位於堆疊的底部。因此,在這種情況下,我們將堆疊距離設為等於L(以堆疊深度為界)。
請注意,堆疊距離的概念為我們提供了時間區域性性的指示。如果存取具有高的時間區域性性,那麼平均堆疊距離預計會更低。相反,如果記憶體存取具有低的時間區域性性,那麼平均堆疊距離將很高,因此可以使用堆疊距離的分佈來衡量程式中的時間區域性性。
我們可以使用SPEC2006基準測試Perlbench進行了一個簡單的實驗,它執行不同的Perl程式,我們維護計數器以跟蹤堆疊距離。第一百萬次記憶體存取是一個預熱期(warm-up period),在此期間,堆疊保持不變,但計數器不遞增。對於接下來的一百萬次記憶體存取,堆疊將保持不變,計數器也將遞增。下圖顯示了堆疊距離的直方圖,堆疊的大小限制為1000個條目,足以捕獲絕大多數的記憶體存取。
堆疊距離分佈圖。
以上可知,大多數存取具有非常低的堆疊距離,0-9之間的堆疊距離是最常見的值,大約27%的所有存取都在這個箱中。事實上,超過三分之二的記憶體存取的堆疊距離小於100。超過100,分佈逐漸減少,但仍然相當穩定。堆疊距離的分佈通常被稱為遵循重尾分佈(heavy tailed distribution),意味著分佈嚴重偏向於較小的堆疊距離,但大的堆疊距離並不少見。對於大的堆疊距離,分佈的尾部仍然是非零的,上圖顯示了類似的行為。
研究人員試圖使用對數正態分佈來近似堆疊距離:
\[f(x)=\frac{1}{x \sigma \sqrt{2 \pi}} e^{-\frac{(\ln (x)-\mu)^{2}}{2 \sigma^{2}}} \]
19.6.1.5 空間區域性性特徵
關於堆疊距離,我們定義了術語地址距離,第i個地址距離是第i次記憶體存取的記憶體地址與最後K次記憶體存取集合中最近的地址之間的差,記憶體存取可以是載入或儲存。以這種方式消除不良地址距離有一個直觀的原因,程式通常在同一時間間隔記憶體取主記憶體的不同區域,例如,對陣列執行操作,存取陣列項,然後存取一些常數,執行操作,儲存結果,然後使用For迴圈移動到下一個陣列條目。這裡顯然存在空間區域性性,即迴圈存取的連續迭代接近陣列中的地址。但為了量化它,需要搜尋最近K次存取中最近的存取(以記憶體地址表示),其中K是封閉迴圈每次迭代中的記憶體存取數。在這種情況下,地址距離被證明是一個小值,並且表示高空間區域性性。但K需要精心選擇,不應該太小,也不應該太大,根據經驗,K=10對於一組大型程式來說是一個合適的值。
總之,如果平均地址距離很小,意味著程式具有較高的空間區域性性,該程式傾向於在相同的時間間隔內以高可能性存取附近的記憶體地址。相反,如果地址距離很高,則存取彼此相距很遠,程式不會表現出空間區域性性。
使用SPEC2006基準Perlbench重複前面描述的實驗,為前100萬次存取提供了地址距離分佈,見下圖。
四分之一以上的存取的地址距離在-5和+5之間,三分之二以上的存取地址距離在-25和+25之間。超過\(\pm 50\),地址距離分佈逐漸減小。從經驗上看,這種分佈也具有重尾性質。
19.6.1.6 利用時空區域性性
前面小節展示了範例程式的堆疊和地址距離分佈。使用者在日常生活中使用的數千個程式也進行了類似的實驗,包括計算機遊戲、文書處理器、資料庫、電子試算表應用程式、天氣模擬程式、金融應用程式和在移動計算機上執行的軟體應用程式。幾乎所有這些都表現出非常高的時間和空間區域性性,換句話說,時間和空間的區域性性是人類的基本特徵,無論我們做什麼(如拿取書本或編寫程式)都會保持不變。請注意,這些只是經驗觀察,依然可以編寫一個不顯示任何形式的時間和空間區域性性的程式,在商業程式中也可以找到不顯示這些特徵的程式碼區域。但這些是例外,不是常態。我們需要為常規而不是特例設計計算機系統,這就是我們如何提高大多數使用者期望執行的程式的效能。
從現在起,將時間和空間的區域性性視為理所當然,看看可以做些什麼來提高記憶體系統的效能,而不影響儲存容量。讓我們先看看時間區域性性。
利用時間區域性性:分層記憶體系統
我們可以為記憶體設計一個儲存位置,稱之為快取,快取中的每個條目在概念上都包含兩個欄位:記憶體地址和值,並定義一個快取層次結構,如下圖所示。
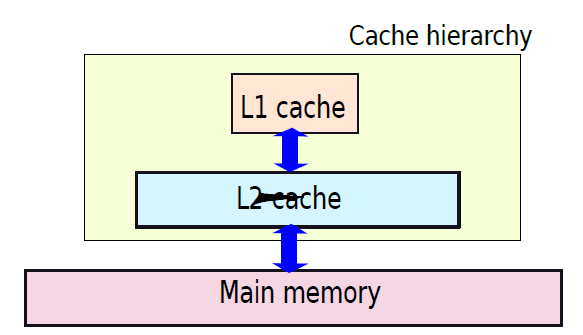
記憶體層次。
主記憶體(實體記憶體)是一個大型DRAM陣列,包含處理器使用的所有記憶體位置的值。
L1快取通常是一個小型SRAM陣列(8 - 64KB),L2快取是一個更大的SRAM陣列(128KB - 4 MB)。一些處理器(如Intel Sandybridge處理器)有另一級快取,稱為L3快取(4MB+)。在L2/L3快取記憶體下面,有一個包含所有記憶體位置的大型DRAM陣列,被稱為主記憶體或實體記憶體。在L1快取中維護L2快取的值子集更容易,以此類推,稱為具有包含式快取(inclusive cache)的系統。因此,對於包含性快取層次結構,我們有:\(\text { values }(L 1) \subset \text { values }(L 2) \subset \text { values }(\text { main memory })\)。或者,我們可以使用獨佔快取(exclusive cache),其中較高階別的快取不一定包含較低階別快取中的值子集。到目前為止,所有處理器都普遍使用非獨佔快取,因為其設計的簡單性、簡單性和一些微妙的正確性問題。然而,截至2012年,通用處理器的實用性尚未確定。
第n級快取中包含的一組記憶體值是第(n+1)級快取中所有值的子集的記憶體系統稱為包含式快取(inclusive cache)層次結構。不遵循嚴格包含的記憶體系統稱為獨佔快取(exclusive cache)層次結構。
現在再次檢視上圖所示的快取層次結構。由於L1快取較小,所以存取速度更快,存取時間通常為1-2個週期。L2快取更大,通常需要5-15個週期才能存取。主記憶體由於其大尺寸和使用DRAM單元,速度要慢得多,存取時間通常非常高,在100-300個週期之間。記憶體存取協定類似於作者存取書籍的方式。
記憶體存取協定如下。每當有記憶體存取(載入或儲存)時,處理器都會首先檢查一級快取。請注意,快取中的每個條目在概念上都包含記憶體地址和值。如果資料項存在於一級快取中,則快取命中(cache hit),否則快取未命中(cache miss)。如果存在快取命中,並且記憶體請求是讀取,那麼只需將值返回給處理器,如果記憶體請求是寫入,則處理器將新值寫入快取條目。然後,它可以將更改傳播到較低階別,或恢復處理。後面章節會討論不同的寫入策略和執行快取寫入的不同方法。但是,如果存在快取未命中,則需要進一步處理。
快取命中(cache hit):當快取中存在記憶體位置時,該事件稱為快取命中。
快取未命中(cache miss):當快取中不存在記憶體位置時,該事件稱為快取未命中。
在一級快取未命中的情況下,處理器需要存取二級快取並搜尋資料項。如果找到專案(快取命中),則協定與一級快取相同,由於本文考慮了包含性快取,所以有必要將資料項提取到一級快取。如果存在L2未命中,則需要存取較低階別,較低階別可以是另一個L3快取,也可以是主記憶體。在最低階別(即主記憶體),我們保證不會發生未命中,因為我們假設主記憶體包含所有記憶體位置的條目。
處理器使用分層記憶體系統來最大化效能,而不是使用單一的平面儲存系統,分層儲存系統旨在提供具有理想單週期延遲的大記憶體的錯覺。
舉個具體的例子,查詢以下設定的平均記憶體存取延遲。
| 級別 | 未命中率(%) | 延遲 |
|---|---|---|
| L1 | 10 | 1 |
| L2 | 10 | 10 |
| 主記憶體 | 0 | 100 |
記憶體系統設定1。
| 級別 | 未命中率(%) | 延遲 |
|---|---|---|
| 主記憶體 | 0 | 100 |
記憶體系統設定2。
答案:讓我們先考慮設定1,90%的存取都發生在一級快取中,這些命中的記憶體存取時間是1個週期。請注意,即使在一級快取中未命中的存取仍會導致1個週期的延遲,因為我們不知道存取是否會在快取中命中或未命中。隨後,90%到二級快取的存取都會在快取中命中,它們會產生10個週期的延遲。最後,剩餘的存取(1%)命中了主記憶體,並導致了額外的延遲。因此,平均記憶體存取時間(T)為:
因此,設定1的分層記憶體系統的平均記憶體延遲是3個週期。
設定2是一個平面層次結構,使用主記憶體進行所有存取,平均記憶體存取時間為100個週期。因此,使用分層記憶體系統可以將速度提高\(100/3=33.3\)倍。
上面的範例表明,使用分層記憶體系統的效能增益是具有單層分層結構的平面記憶體系統的33.33倍,效能改進是不同快取的命中率及其延遲的函數。此外,快取的命中率取決於程式的堆疊距離分佈和快取管理策略,同樣,快取存取延遲取決於快取製造技術、快取設計和快取管理方案。在過去二十年中,優化快取存取一直是電腦架構研究中的一個非常重要的主題,研究人員在這方面發表了數千篇論文。本文只討論其中的一些基本機制。
利用空間區域性性:快取塊
現在考慮空間區域性性,上上圖揭示了大多數存取的地址距離在\(\pm 25\)位元組內。地址距離分佈表明,如果將一組記憶體位置分組到一個塊中,並從較低階別一次性獲取,那麼可以增加快取命中數,因為存取中存在高度的空間區域性性。
因此,幾乎所有處理器都建立連續地址塊,快取將每個塊視為一個原子單元。一次從較低階別獲取整個塊,如果需要,也會從快取中逐出整個塊。快取塊也稱為快取行,一個典型的快取塊或一行是32-128位元組長,為了便於定址,它的大小必須是2的嚴格冪。
快取塊(cache block)或快取行(cache line)是一組連續的記憶體位置,被視為快取中的原子資料單元。
因此,我們需要稍微重新定義快取條目(cache entry)的概念,沒有為每個記憶體地址建立一個條目,而是為每個快取行建立一個單獨的條目。請注意,本文將同義地使用術語快取行和塊,還要注意,L1快取記憶體和L2快取記憶體中不必具有相同的快取記憶體行大小,它們可以不同。然而,為了保持快取記憶體的包容性,並最小化額外的記憶體存取,通常需要在L2使用與L1相同或更大的塊大小。
迄今所學到的要點:
- 時間和空間區域性性是大多數人類行為固有的特性,它們同樣適用於閱讀書籍和編寫計算機程式。
- 時間區域性性可以由堆疊距離量化,空間區域性性可以通過地址距離量化。
- 我們需要設計記憶體系統,以利用時間和空間的區域性性。
- 為了利用時間區域性性,我們使用由一組快取組成的分層記憶體系統。L1快取記憶體通常是一種小而快的結構,旨在快速滿足大多數記憶體存取。較低階別的快取儲存的資料量較大,存取頻率較低,存取時間較長。
- 為了利用空間區域性性,我們將連續的記憶體位置集合分組為塊(也稱為行),塊被視為快取中的原子資料單元。
前面已經定性地研究了快取的需求,後面將繼續討論快取的設計。
19.6.2 快取
19.6.2.1 快取綜述
快取記憶體的設計是為了將昂貴的高速記憶體的記憶體存取時間與較便宜的低速記憶體的大記憶體大小相結合,如下圖a所示。下圖b描述了多級快取的使用,L2快取記憶體比L1快取記憶體慢且通常更大,而L3快取記憶體比L2快取記憶體慢並且通常更大。
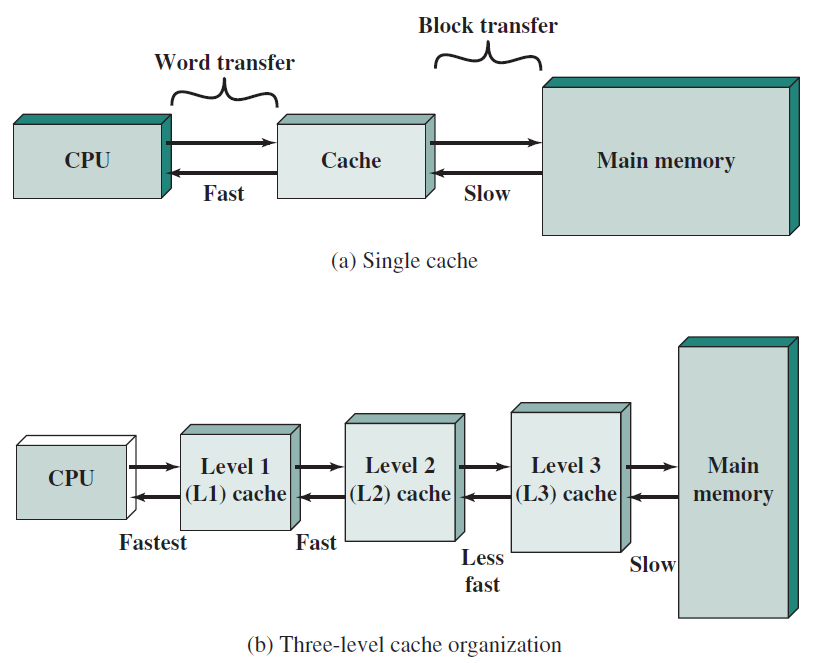
下圖描述了快取/主記憶體系統的結構。主記憶體由多達\(2^n\)個可定址字組成,每個字具有唯一的n位地址。出於對映的目的,該記憶體被認為由多個固定長度的塊組成,每個塊包含K個字,也就是說,主記憶體中有\(M=2^n/K\)個塊。快取由m個塊組成,稱為行(line),每行包含K個字,加上幾個位的標記。每一行還包括控制位(未示出),例如指示該行自從被載入到快取中以來是否已被修改的位,行的長度(不包括標記和控制位)是行大小。
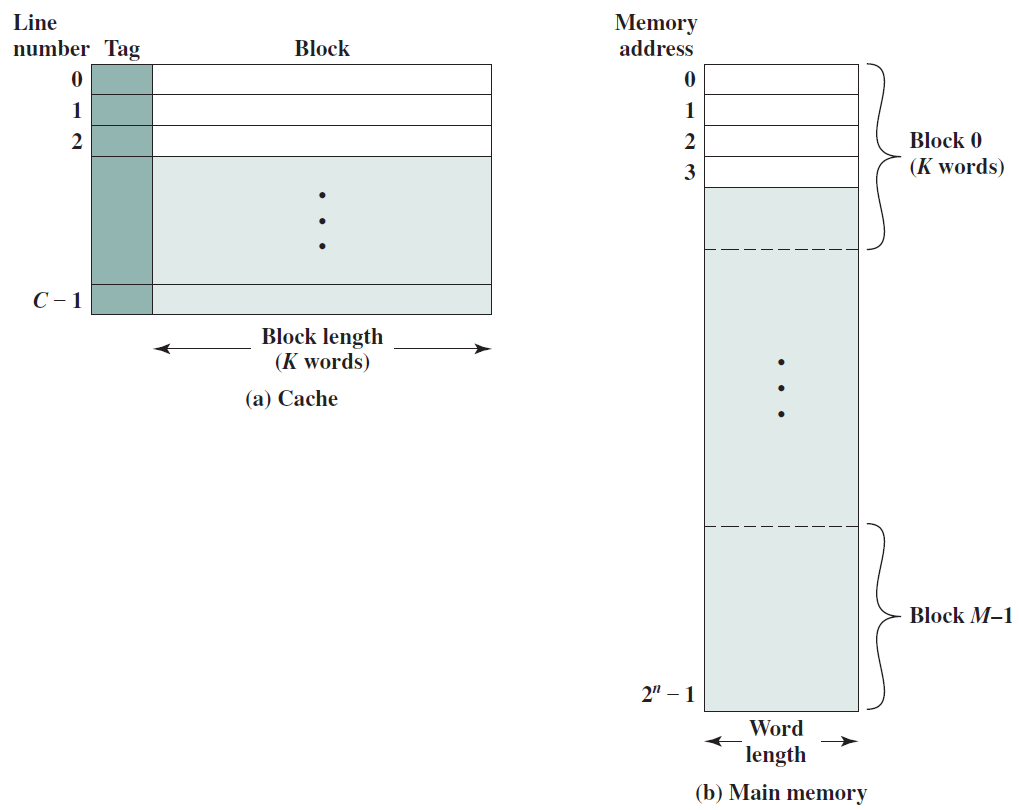
下圖說明了讀取操作。處理器生成要讀取的字的讀取地址(RA),如果該單詞包含在快取中,則將其傳遞給處理器。否則,包含該字的塊被載入到快取中,並且該字被傳遞到處理器。圖中顯示了並行發生的最後兩個操作,並反映了下下圖所示的當代快取組織的典型。在這種組織中,快取通過資料、控制和地址線連線到處理器。資料和地址線還連線到資料和地址緩衝區,這些緩衝區連線到系統匯流排,從該匯流排可以存取主記憶體。當快取命中時,資料和地址緩衝區將被禁用,並且只有處理器和快取之間的通訊,沒有系統匯流排通訊。當發生快取未命中時,所需的地址被載入到系統匯流排上,資料通過資料緩衝區返回到快取和處理器。在其他組織中,快取物理地插入處理器和主記憶體之間,用於所有資料、地址和控制線。在後一種情況下,對於快取未命中,所需的字首先被讀取到快取中,然後從快取傳輸到處理器。
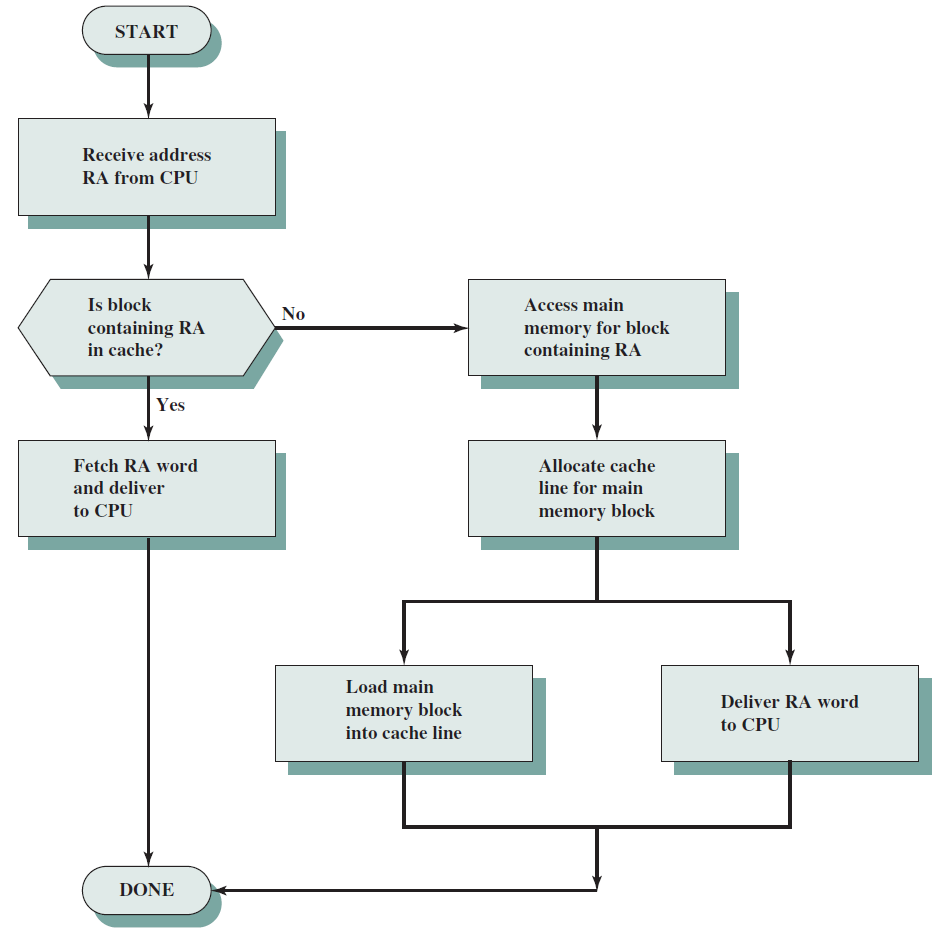
快取讀取操作。
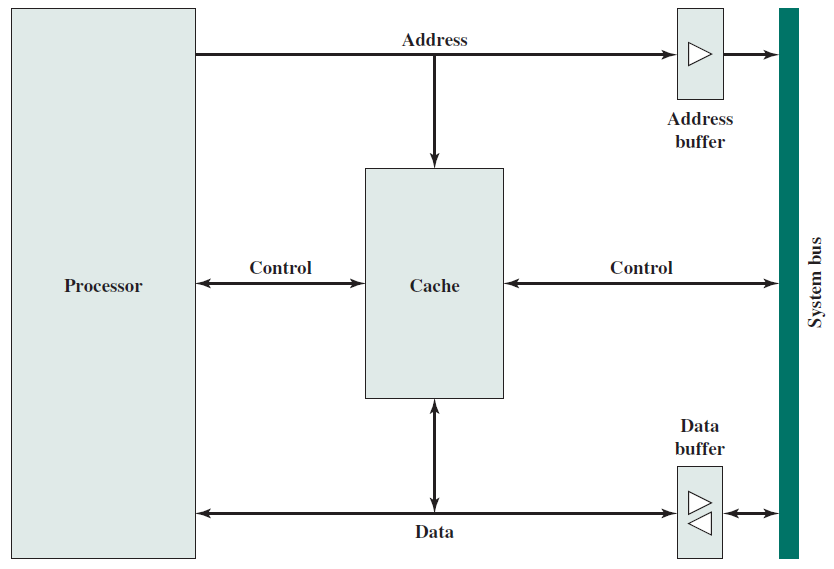
典型的快取組織。
當使用虛擬地址時,系統設計者可以選擇在處理器和MMU之間或MMU和主記憶體之間放置快取(下圖)。邏輯快取(也稱為虛擬快取)使用虛擬地址儲存資料,處理器直接存取快取,而不經過MMU,物理快取則使用主記憶體實體地址儲存資料。
下圖a顯示了快取的直接對映方式,其中前m個主記憶體塊的對映,每個主記憶體塊對映到快取的一個唯一行中,接下來的m個主記憶體塊以相同的方式對映到快取中。
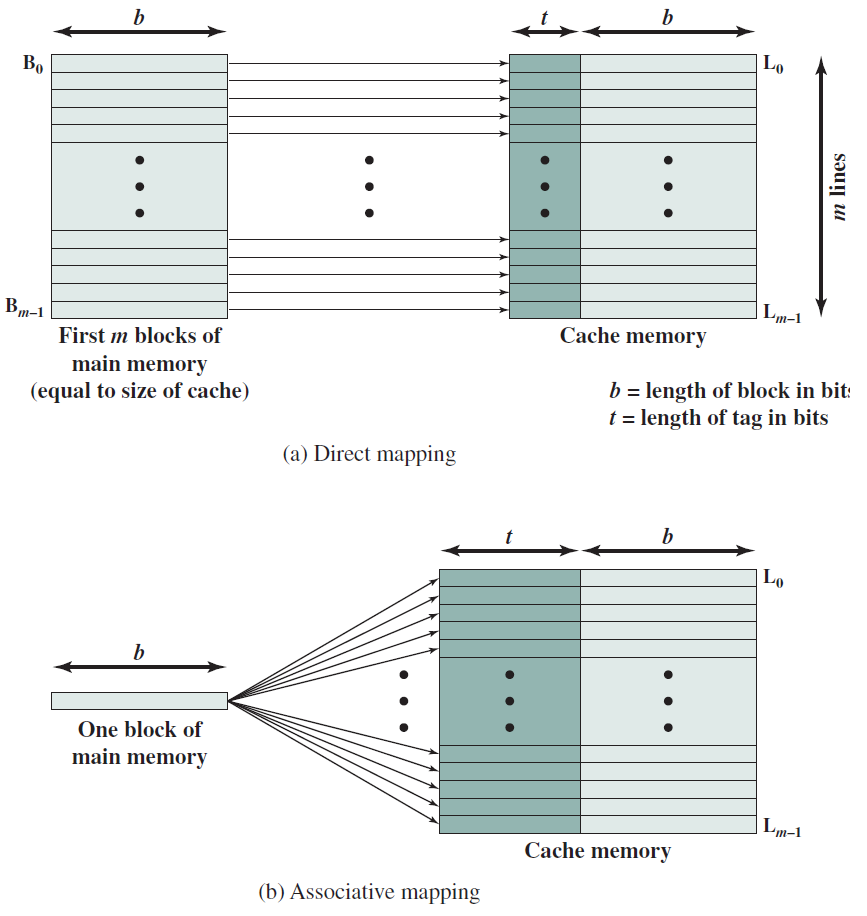
快取的直接和關聯對映。
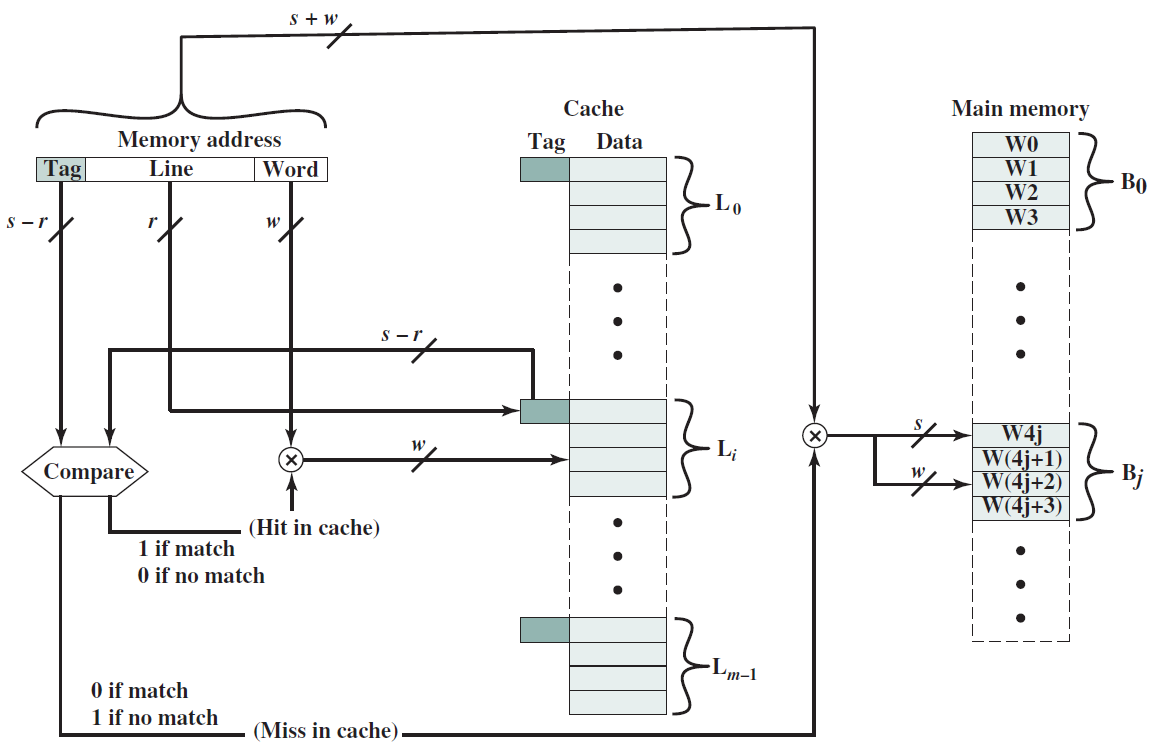
直接對映快取組織。
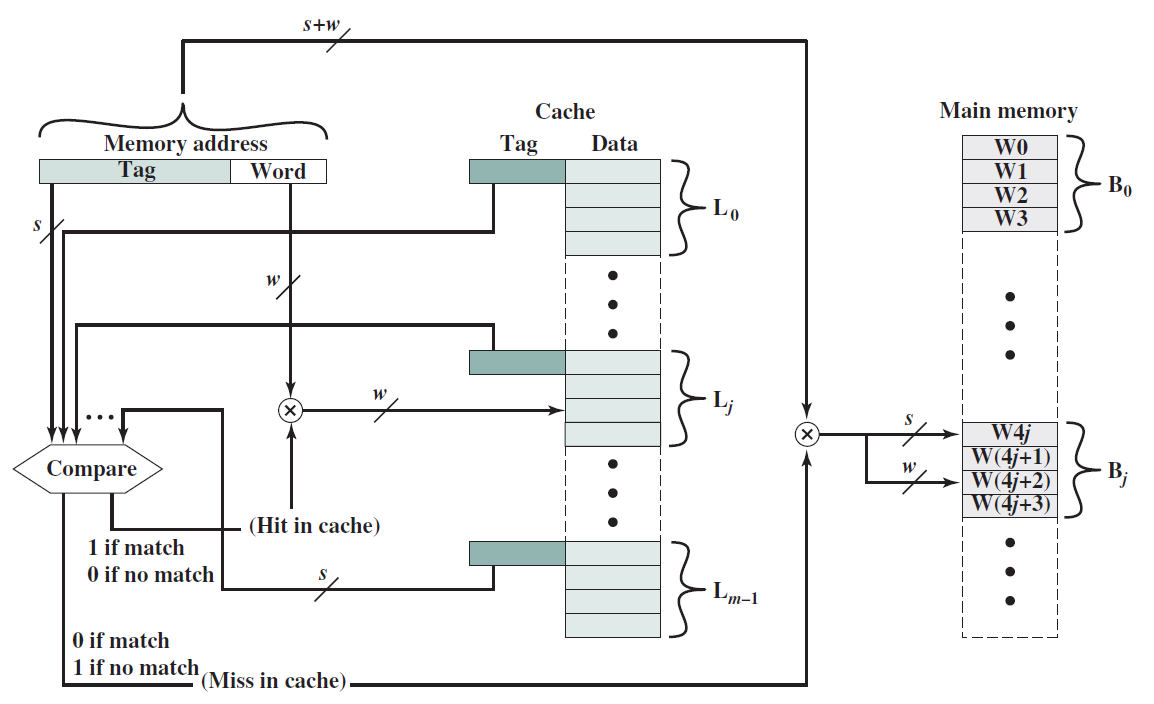
完全的關聯對映快取組織。
此處之外,還存在K路(如2、4、8、16路)的快取對映方式,參見下圖。
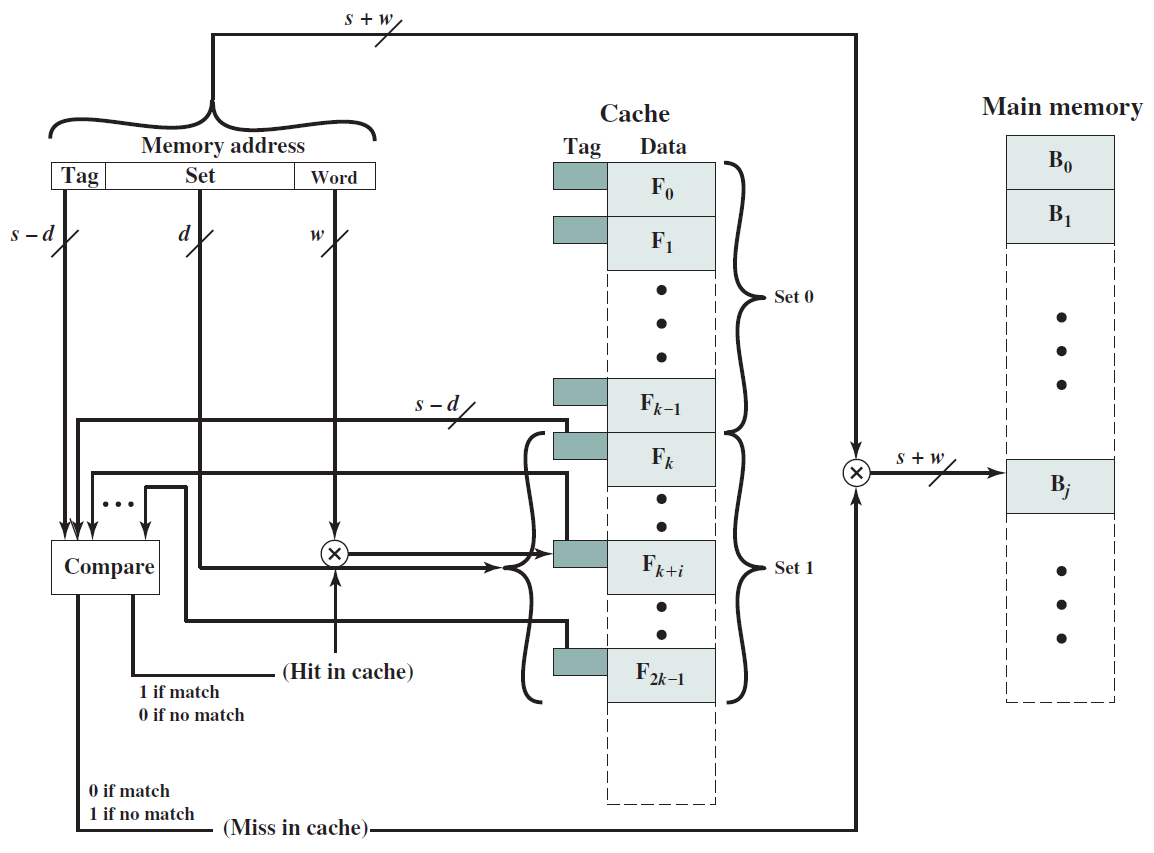
k路集關聯快取組織。
不同對映方式隨著快取大小改變關聯性的曲線如下:
下圖是曾經風靡一時具有代表性的奔騰4的結構圖,清晰地展示了快取的結構:
19.6.2.2 基本快取操作
讓我們將快取視為一個黑盒子,如下圖所示。在載入操作的情況下,輸入是記憶體地址,如果快取命中,輸出是記憶體位置的值。我們設想快取有一個狀態行,指示請求是命中還是未命中。如果操作是儲存,則快取接受兩個輸入:記憶體地址和值。如果快取命中,則快取將值儲存在與記憶體位置相對應的條目中,否則,表示快取未命中。
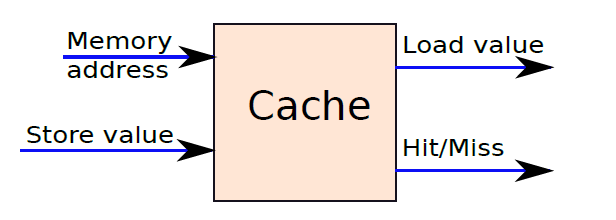
作為黑盒子的快取。
現在看看實現這個黑盒子的方法,將使用SRAM陣列作為構建塊。
為了啟發設計,考慮一個例子,有一個塊大小為64位元組的32位元機器,在這臺機器中,有\(2^{26}\)個塊。一級快取的大小為8 KB,包含128個塊。因此,可以在任何時間點將一級快取視為整個記憶體地址空間的非常小的子集,最多包含\(2^{26}\)個塊中的128個。為了確定一級快取中是否存在給定的塊,需要檢視128個條目中是否有任何一個包含該塊。
假設一級快取是記憶體層次結構的一部分,記憶體層次結構作為一個整體支援兩個基本請求:讀和寫。然而,在快取級別需要許多基本操作來實現這兩個高階操作。
類似於記憶體地址,將塊地址定義為記憶體地址的26個MSB位。第一個問題是判斷快取中是否存在具有給定塊地址的塊,需要執行一個查詢(lookup)操作。如果塊存在於快取中(即快取命中),則返回指向該塊的指標,需要兩個基本操作來服務請求,即資料讀取(data read)和資料寫入(data write)——讀取或寫入塊的內容,並需要指向塊的指標作為引數。
如果有快取未命中,那麼需要從記憶體層次結構的較低階別獲取塊並將其插入快取。從記憶體層次結構的較低階別獲取塊並將其插入快取的過程稱為填充(fill)操作,填充操作是一個複雜的操作,並使用許多原子子操作。需要首先向較低階別的快取傳送載入請求以獲取塊,然後插入L1快取。
插入過程也是一個複雜的過程。首先需要檢查在一組給定的塊中是否有空間插入一個新塊,如果有足夠的空間,那麼可以使用插入(insert)操作填充其中一個條目。但是,如果要在快取中插入塊的所有位置都已經被佔用,那麼需要從快取中移除一個已經存在的塊。因此,需要呼叫一個替換(replace)操作來結束需要收回的快取塊。一旦找到了合適的替換候選塊,需要使用逐出(evict)操作將其從快取中逐出。
總之,實現快取廣泛地需要這些基本操作:查詢、資料讀取、資料寫入、插入、替換和逐出。填充操作只是記憶體層次結構不同級別的查詢、插入和替換操作的序列,同樣,讀取操作主要是查詢操作,或者是查詢和填充操作的組合。
19.6.2.3 快取查詢和快取設計
假設為32位元系統設計一個塊大小為64位元組的8KB快取。為了進行高效的快取記憶體查詢,需要找到一種高效的方法來查詢快取記憶體中128個條目中是否存在26位塊地址。存在兩個問題:第一個問題是快速找到給定的條目,第二個問題是執行讀/寫操作。與其使用單個SRAM陣列來解決這兩個問題,不如將其拆分為兩個陣列,如下圖所示。
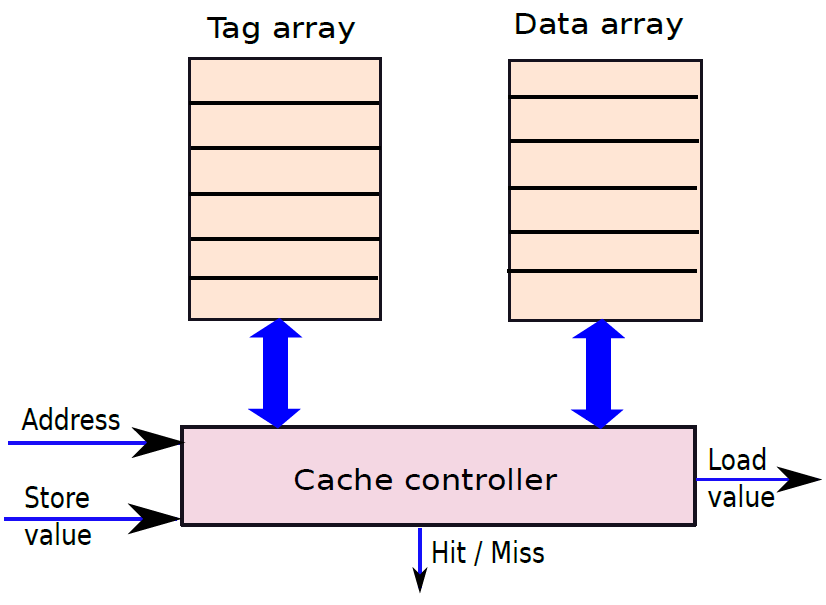
快取結構。
完全關聯(FA)快取
在典型的設計中,快取條目儲存在兩個基於SRAM的陣列中,一個稱為標記陣列的SRAM陣列包含與塊地址有關的資訊,另一個稱稱為資料陣列的SRRAM陣列包含塊的資料。標記陣列包含唯一標識塊的標記,標記通常是塊地址的一部分,並取決於快取的型別。除了標籤和資料陣列之外,還有一個專用的快取記憶體控制器,用於執行快取記憶體存取演演算法。
首先考慮一種非常簡單的定位塊的方法。我們可以同時檢查快取中128個條目中的每一個,以檢視塊地址是否等於快取條目中的塊地址。此快取稱為完全關聯快取(fully associative cache)或內容可定址快取(content addressable cache),「完全關聯」表示給定塊可以與快取中的任何條目關聯。
因此,全關聯(FA)快取中的每個快取條目都需要包含兩個欄位:標籤(tag)和資料(data)。在這種情況下,可以將標記設定為等於塊地址,由於塊地址對於每個塊都是唯一的,因此它適合標記的定義。塊資料指的是塊的內容(在這種情況中為64位元組)在我們的範例中,塊地址需要26位,塊資料需要64位元組。搜尋操作需要跨越整個快取,一旦找到條目,我們需要讀取資料或寫入新值。
先看看標籤陣列。在這種情況下,每個標籤都等於26位塊地址,記憶體請求到達快取後,第一步是通過提取26個最重要的位來計算標籤,然後,需要使用一組比較器將提取的標籤與標籤陣列中的每個條目進行匹配。如果沒有匹配,可以宣告快取未命中並進一步處理,如果有快取命中,需要使用與標記匹配的條目編號來存取資料條目,例如,在包含128個條目的8KB快取中,標籤陣列中的第53個條目可能與標籤匹配。在這種情況下,快取記憶體控制器需要在讀取存取的情況下從資料陣列中取出第53個條目,或者在寫入存取的情況中寫入第53個條目的。
有兩種方法可以在完全關聯快取中實現標記陣列,或者可以將其設計為一個普通的SRAM陣列,其中快取控制器迭代每個條目,並將其與給定的標記進行比較,或者可以使用每行都有比較器的CAM陣列。它們可以將標籤的值與儲存在行中的資料進行比較,並根據比較結果生成輸出(1或0)。CAM陣列通常使用編碼器來計算與結果匹配的行數,完全關聯快取的標記陣列的CAM實現更為常見,主要是因為順序迭代陣列非常耗時。
下圖說明了這一概念。通過將對應的字線設定為1來啟用CAM陣列的每一行,隨後,CAM單元中的嵌入式比較器將每一行的內容與標籤進行比較,並生成輸出。我們使用OR門來確定是否有任何輸出等於1,如果有任何輸出為1,則表示快取命中,否則表示快取未命中。這些輸出線中的每一條還連線到編碼器,該編碼器生成匹配行的索引,我們使用此索引存取資料陣列並讀取塊的資料。在寫入的情況下,我們寫入塊,而不是讀取它。
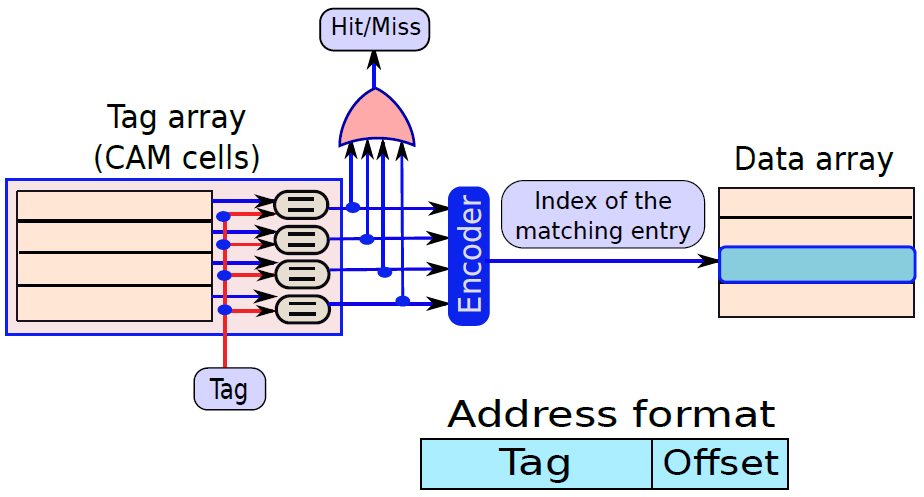
完全關聯快取。
全關聯快取對於小型結構(通常為2-32)條目非常有用,但不可能將CAM陣列用於更大的結構,比較和編碼的面積和功率開銷非常高。也不可能順序地遍歷標籤陣列的SRAM實現的每個條目,非常耗時。因此,我們需要找到一種更好的方法來定位更大結構中的資料。
直接對映(DM)快取
在完全關聯的快取中,可以將任何塊儲存在快取中的任何位置。這個方案非常靈活,但是,當快取有大量條目時,它不能使用,主要是因為面積和電源開銷太大。我們不允許將塊儲存在快取中的任何位置,而是隻為給定塊指定一個固定位置。可以按如下方式進行。
在範例中,有一個8 KB的快取,包含128個條目,不妨限制64位元組塊在快取中的位置。對於每個塊,在標記陣列中指定一個唯一的位置,在該位置可以儲存與其地址對應的標記,可以生成這樣一個獨特的位置,如下所示。讓我們考慮塊a的地址和快取中的條目數(128),並計算a%128,%運運算元計算a除以128的餘數,由於a是二進位制值,128是2的冪,因此計算餘數非常容易。我們只需要從26位塊地址中提取7個LSB位,這7位可用於存取標籤陣列,就可以將儲存在標記陣列中的標記值與根據塊地址計算的標記值進行比較,以確定是否命中或未命中。
還可以稍微優化它的設計,而不是像完全關聯快取那樣將塊地址儲存在標記陣列中。塊地址中的26位中有7位用於存取標籤陣列中的標籤,意味著所有可能被對映到標籤陣列中給定條目的塊都將有其最後7位共用,因此這7位不需要明確地儲存為標籤的一部分,只需要儲存塊地址的剩餘19位,這些位可以在塊之間變化。因此,快取記憶體的直接對映實現中的標籤只需要包含19位。
下圖以圖形方式描述了這一概念。將32位元地址分成三部分,最重要的19位包括標記,接下來的7位稱為索引(標記陣列中的索引),其餘6位指向塊中位元組的偏移,存取協定的其餘部分在概念上類似於完全關聯快取。在這種情況下,我們使用索引來存取標記陣列中的相應位置,讀取內容並將其與計算標記進行比較。如果它們相等,則我們宣告快取命中,否則,快取未命中。在快取命中的情況下,使用索引存取資料陣列,使用快取命中/未命中結果來啟用/禁用資料陣列。
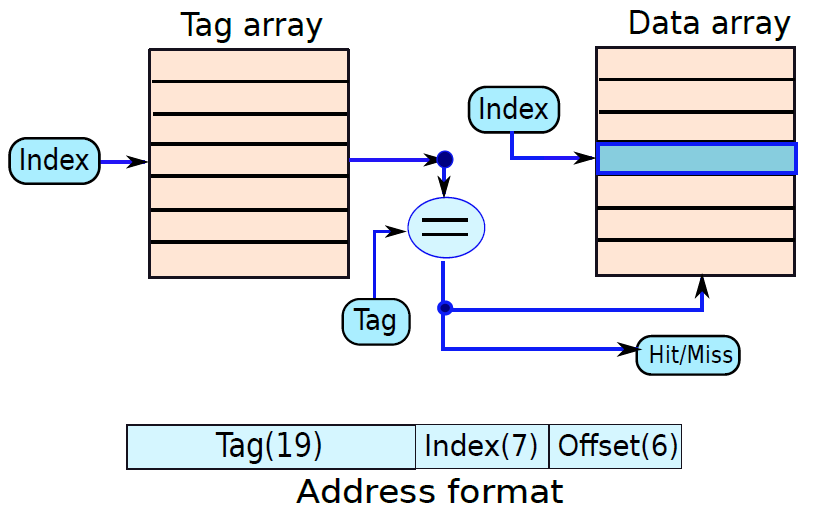
直接對映快取。
到目前為止,我們已經研究了完全關聯和直接對映快取:
- 全關聯快取是一種非常靈活的結構,因為塊可以儲存在快取中的任何條目中,但具有更高的延遲和功耗。由於給定的塊可能被分配到快取的更多條目中,因此它的命中率高於直接對映快取。
- 直接對映快取是一種速度更快、功耗更低的結構。一個塊只能駐留在快取中的一個條目中,此快取的預期命中率小於完全關聯快取的命中率。
在完全關聯和直接對映快取之間,在功率、延遲和命中率之間存在折衷。
集合相聯快取
全關聯快取更耗電,因為需要在快取的所有條目中搜尋塊。相比之下,直接對映快取更快、更高效,因為只需要檢查一個條目,但命中率較低,也是不可接受的。因此,嘗試將這兩種正規化結合起來。
讓我們設計一個快取,其中一個塊可以潛在地駐留在快取中多個條目的集合中的任何一個條目中,將快取中的一組條目與塊地址相關聯,像完全關聯快取一樣,必須在宣告命中或未命中之前檢查集合中的所有條目,這種方法結合了完全關聯和直接對映方案的優點。如果一個集合包含4或8個條目,那麼就不必使用昂貴的CAM結構,也不必依次迭代所有條目,可以簡單地從標記陣列中並行讀取集合的所有條目,並將所有條目與塊地址的標記部分進行並行比較。如果存在匹配,那麼我們可以從資料陣列中讀取相應的條目。由於多個塊可以與一個集合相關聯,因此將此設計稱為集合關聯(set associative)快取。集合中的塊數稱為快取的關聯性,集合中的每個條目都被稱為一個路(way)。
關聯性(Associativity):集合中包含的塊數定義為快取的關聯性。
路(Way):集合中的每個條目都被稱為路。
讓我們描述一個簡單的方法,將快取項分組為集合,考慮了一個32位元記憶體系統,其中有一個8 KB的快取和64位元組的塊。如下圖所示,首先從32位元地址中刪除最低的6位,因為它們指定了塊中位元組的地址,剩餘的26位指定塊地址,8-KB快取總共有128個條目。如果想建立每個包含4個條目的集合,那麼我們需要將所有快取條目分成4個條目,將有32(\(2^5\))個這樣的集合。
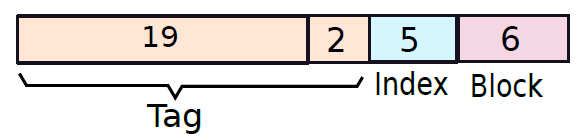
在直接對映快取中,我們使用26位塊地址中的最低7位來指定快取中條目的索引,現在可以將這7個位元分成兩部分,如上圖所示。一部分包含5個位元並指示集合的地址,而第二部分包含2個位元則被忽略,指示集合地址的5位組稱為集合索引。
在計算集合索引\(i\)之後,需要存取標籤陣列中屬於集合的所有元素。可以按有以下方式排列標籤陣列,如果一個集合中的塊數是S,那麼可以對屬於一個集合的所有條目進行連續分組。對於第\(i\)個集合,我們需要存取元素\(iS\)、$(iS+1) $ ... $(iS+S - 1) $在標籤陣列中。
對於標記陣列中的每個條目,需要將條目中儲存的標記與塊地址的標記部分進行比較。如果有匹配,那麼我們可以宣佈命中。集合關聯快取中標記的概念相當棘手。如上圖所示,它由不屬於索引的位組成,是塊地址的\((21=26-5)\)MSB位,用於確定標籤位元數的邏輯如下。
每個集合由5位集合索引指定,這5個位元對於可能對映到給定集合的所有塊都是公用的,需要使用其餘的位元\((21=26-5)\)來區分對映到同一集合的不同塊。因此,集合關聯快取記憶體中的標籤的大小介於直接對映快取記憶體(19)和完全關聯快取記憶體(26)的大小之間。
下圖顯示了集合關聯快取的設計。首先從塊的地址計算集合索引,使用位7-11,使用集合索引來使用標籤陣列索引生成器生成標籤陣列中相應四個條目的索引。然後,並行存取標記陣列中的所有四個條目,並讀取它們的值。此處無需使用CAM陣列,可以使用單個多埠(多輸入、多輸出)SRAM陣列。接下來,將每個元素與標記進行比較,並生成一個輸出(0或1)。如果任何一個輸出等於1(由或門確定),快取命中,否則快取未命中。我們使用編碼器對匹配的集合中的標記進行索引,因為假設4路關聯快取,編碼器的輸出在00到11之間。隨後,使用多路複用器來選擇標籤陣列中匹配條目的索引,這個索引可以用來存取資料陣列,資料陣列中的相應條目包含塊的資料,可以讀或寫它。
可以對讀取操作進行一個小優化。請注意,在讀取操作的情況下,對資料陣列和標記陣列的存取可以並行進行。如果一個集合有4路,那麼當計算標籤匹配時,可以讀取與該集合的4路對應的4個資料塊。隨後,在快取命中的情況下,在計算了標記陣列中的匹配條目之後,我們可以使用多路複用器選擇正確的資料塊。在這種情況下,實際上將從資料陣列讀取塊所需的部分或全部時間與標記計算、標記陣列存取和匹配操作重疊。
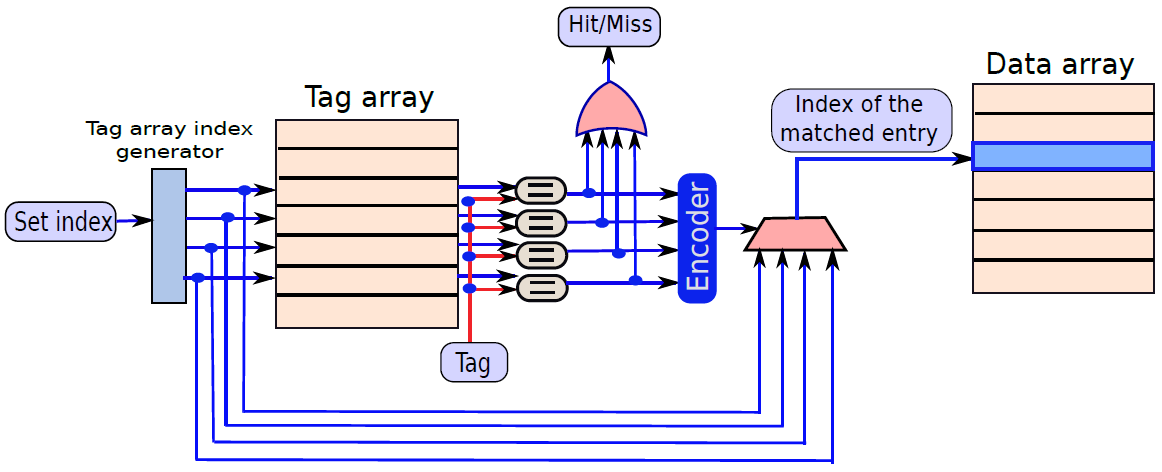
集合關聯快取。
總之,集合關聯快取是目前最常見的快取設計,即使是非常大的快取,它也具有可接受的功耗值和延遲。集合關聯快取的關聯性通常為2、4或8,關聯性為K的集合也稱為K路關聯快取。
在設計集合關聯快取時,我們需要回答一個深刻的問題。設定索引位和忽略位的相對順序應該是什麼?被忽略的位應該朝向索引位的左側(MSB),還是朝向索引位右側(LSB)?上上圖選擇了MSB,背後的邏輯是什麼?
答案:
如果索引位的左邊(MSB)有被忽略的位,那麼相鄰的塊對映到不同的集合。然而,對於被忽略的位在索引位的右側(LSB)的相反情況,連續塊對映到同一集合。前一種方案稱為非CONT,後一種方案為CONT,在設計中選擇了非CONT。
考慮兩個陣列A和B,讓A和B的大小明顯小於快取的大小,讓它們的一些組成塊對映到同一組集合。下圖顯示了儲存CONT和NON-CONT方案陣列的快取區域的概念圖。我們觀察到,即使快取中有足夠的空間,也不可能使用CONT方案同時儲存快取中的兩個陣列。它們的記憶體佔用在快取的一個區域中重疊,因此不可能在快取中同時儲存兩個程式的資料。然而,NON-CONT方案試圖將塊均勻分佈在所有集合上。因此,可以同時將兩個陣列儲存在快取中。
這是程式中經常出現的模式。CONT方案保留快取的整個區域,因此不可能容納對映到衝突集的其他資料結構。然而,如果將資料分佈在快取中,那麼可以容納更多的資料結構並減少衝突。
舉個具體的範例,在32位元系統中,快取具有以下引數:
| 引數 | 值 |
|---|---|
| 尺寸 | \(N\) |
| 關聯性 | \(K\) |
| 塊尺寸 | \(B\) |
那麼,標籤的尺寸是多數?答案:
- 指定塊內的位元組所需的位數為\(\log(B)\)。
- 塊數等於\(N=B\),集合數等於\(N/(BK)\)。
- 設定的索引位數等於:\(\log(N)-\log(B)-\log(K)\)。
- 剩餘的位數是標籤位,等於:\(32-(\log (N)-\log (B)-\log (K)+\log (B))=32-\log (N)+\log (K)\)。
19.6.2.4 資料讀取和寫入操作
一旦我們確定給定的塊存在於快取中,我們就使用基本的讀取操作從資料陣列中獲取記憶體位置的值。如果查詢操作返回快取命中,將確定快取中是否存在塊。如果快取中存在未命中,則快取控制器需要向較低階別的快取發出讀取請求,並獲取塊。資料讀取操作可以在資料可用時立即開始。
第一步是讀取資料陣列中對應於匹配標記條目的塊,然後從塊中的所有位元組中選擇合適的位元組集,可以使用一組多路複用器來實現之。在查詢操作之後,不必嚴格開始資料讀取操作,可以在兩次行動之間有明顯的重疊,例如,可以並行讀取標記陣列和資料陣列。在計算出匹配標記之後,可以使用多路複用器選擇正確的值集合。
在寫入值之前,需要確保整個塊已經存在於快取中,這點非常重要。請注意,我們不能斷言,因為正在建立新資料,所以不需要塊的前一個值。原因是:對於單個記憶體存取,通常寫入4個位元組或最多8個位元組,但一個塊至少有32或64位元組長,塊是快取中的原子單元,因此不能在不同的地方擁有它的不同部分。例如,不能將一個塊的4個位元組儲存在一級快取中,其餘的位元組儲存在二級快取中。其次,為了做到這一點,需要維護額外的狀態,以跟蹤已被寫入更新的位元組。因此,為了簡單起見,即使希望只寫入1個位元組,也需要用整個塊填充快取。
之後,需要通過啟用適當的一組字行(word line)和位行(bit line)將新值寫入資料陣列,可以使用一組解複用器的電路來簡單實現。
執行資料寫入有兩種方法:
- 直寫(write-through)。直寫是一種相對簡單的方案,在這種方法中,每當將值寫入資料陣列時,也會向較低階別的快取傳送寫操作。這種方法增加了快取流量,但實現快取更簡單,因為不必在將塊放入快取後跟蹤已修改的塊。因此,如果需要,可以無縫地從快取中逐出一行。快取收回和替換也很簡單,但以寫入為代價。如果L1快取遵循直寫協定,那麼很容易為多處理器實現快取。
- 回寫(write-back)。此方案明確地跟蹤已使用寫操作修改的塊,可以通過在標記陣列中使用額外的位來維護此資訊,該位通常稱為修改位,每當從記憶體層次結構的較低階別獲得一個塊時,修改位為0,然而,當進行資料寫入並更新資料陣列時,將標記陣列中的修改位設定為1。逐出一行需要額外的處理。對於寫回協定,寫入成本較低,逐出操作成本較高。這裡的折衷與直寫快取中的折衷相反。
帶有附加修改位的標籤陣列中的條目結構如下圖所示。
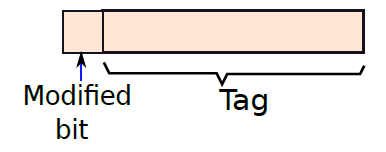
帶有修改位的標籤陣列中的條目。
19.6.2.5 插入操作
本節將討論在快取中插入塊的協定。當塊從較低階別到達時,將呼叫此操作。需要首先檢視給定塊對映到的集合的所有方式,並檢視是否有空條目。如果存在空條目,那麼可以任意選擇其中一個條目,並用給定塊的內容填充它。如果沒有結束任何空條目,需要呼叫替換和逐出操作來從集合中選擇和刪除一個已經存在的塊。
需要維護一些額外的狀態資訊,以確定給定條目是空的還是非空的。在電腦架構中,這些狀態也分別被稱為無效(invalid)和有效(valid)。只需要在標記陣列中儲存一個額外的位,以指示塊的狀態,被稱為有效位(valid bit)。使用標籤陣列來儲存關於條目的附加資訊,因為它比資料陣列更小,通常更快。新增了有效位的標籤陣列中的條目結構如下圖所示。
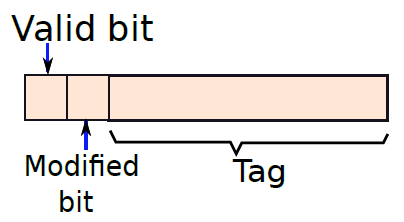
標籤陣列中的一個條目,包含修改後的有效位。
快取控制器需要在搜尋無效條目時檢查每個標籤的有效位。快取的所有條目最初都是無效的,如果發現無效條目,則可以用塊的內容填充資料陣列中的相應條目,該條目隨後生效。但是,如果沒有無效條目,那麼需要用需要插入快取的給定塊替換一個條目。
19.6.2.6 替換操作
這裡的任務是在集合中查詢一個可以被新條目替換的條目。我們不希望替換頻繁存取的元素,因為會增加快取未命中的數量。理想情況下,希望替換將來被存取的可能性最小的元素,但是,很難預測未來的事件。需要根據過去的行為做出合理的猜測,可以有不同的策略來替換快取中的塊。這些被稱為替換方案或替換策略。
快取替換方案(replacement scheme)或替換策略(replacement policy)是用新條目替換集合中的條目的方法。
常用的替換策略有:
-
隨機替換策略。此策略最簡單和普通,隨機選取一個塊並替換它。但是,它在效能方面並不是很理想,因為沒有考慮程式的行為和記憶體存取模式的性質。該方案最終經常替換非常頻繁存取的塊。
-
FIFO替換策略。FIFO(先入先出)替換策略的假設是,在最早的時間點被帶入快取的塊在將來被存取的可能性最小。為了實現FIFO替換策略,需要在標記陣列中新增一個計數器。每當引入一個塊時,都會給它分配一個等於0的計數器值,為其餘的塊增加計數器值。計數器越大,塊越早進入快取。
此外,要查詢替換的候選項,我們需要查詢計數器值最大的條目,一定是最早的區塊。不幸的是,FIFO方案並不嚴格符合時間區域性性原則。它會懲罰快取中長期存在的塊,而實際上,這些塊也可能是非常頻繁存取的塊,不應該首先被逐出。
現在考慮實施FIFO替換策略的實際方面。計數器的最大大小需要等於集合中元素的數量,即快取的關聯性。例如,如果快取的關聯性為8,則需要有一個3位計數器,需要替換的條目應具有最大的計數器值。
請注意,在這種情況下,將新值引入快取的過程相當昂貴,我們需要增加集合中除一個元素外的所有元素的計數器。然而,與快取命中相比,快取未命中更為罕見。因此,開銷實踐上並不顯著,並且該方案可以在沒有較大效能開銷的情況下實現。
-
LRU替換策略。LRU(最近最少使用的)更換策略被認為是最有效的方案之一。LRU方案直接從堆疊距離的定義開始,理想情況下,我們希望替換將來被存取的機會最低的塊,根據堆疊距離的概念,未來被存取的概率與最近存取的概率有關。如果處理器在n次(n不是很大的數目)存取的最後一個視窗中頻繁地存取一個塊,那麼該塊很有可能在不久的將來被存取。然而,如果上一次存取一個塊是很久以前的事了,那麼它很快就不太可能被存取了。
在LRU更換策略中,我們保留塊最後一次存取的時間,選擇在最早的時間點最後存取的塊作為替換的候選。此策略為每個塊維護一個時間戳,每當存取一個塊時,它的時間戳都會被更新以匹配當前時間。要查詢合適的替換候選項,需要查詢集合中時間戳最小的條目。
實現LRU策略最大的問題是需要為對快取的每次讀寫存取做額外的工作,對效能產生重大影響,因為通常三分之一的指令是記憶體存取。其次,需要專用位元來儲存足夠大的時間戳,否則需要頻繁地重置集合中每個塊的時間戳,此過程導致快取控制器的進一步減速和額外複雜性。因此,實現儘可能接近理想的LRU方案且沒有顯著的開銷是一項艱鉅的任務。
可以嘗試設計使用小時間戳(通常為1-3位)並大致遵循LRU策略的LRU方案,稱為偽LRU(pseudo-LRU)方案。下面概述實現基本偽LRU的簡單方法。與其嘗試顯式標記最近最少使用的元素,不如嘗試標記最近使用的元素。未標記的元素將自動分類為最近最少使用的元素。
讓我們從將計數器與標記陣列中的每個塊相關聯開始。每當存取一個塊(讀/寫)時,都遞增計數器,一旦計數器達到最大值,就停止遞增。例如,如果使用一個2位計數器,那麼避免將計數器遞增到3以上。為了實現與每個塊關聯的計數器將最終達到3並保持值,可以週期性地將集合中每個塊的計數器遞減1,甚至可以將它們重置為0。隨後,一些計數器將再次開始增加。
此舉確保大多數情況下,可以通過檢視計數器的值來識別最近最少使用的塊。與計數器的最低值相關聯的塊是最近最少使用的塊之一,最有可能、最近最少使用的塊。請注意,這種方法確實涉及每次存取的一定活動量,但是遞增一個小計數器幾乎沒有額外開銷。其次,它在計時方面不在關鍵路徑上,可以並行執行,也可以稍後執行。尋找替換的候選項包括檢視一組中的所有計數器,並查詢計數器值最低的塊。用新塊替換塊後,大多數處理器通常會將新塊的計數器設定為最大可能值。這向快取記憶體控制器指示,相對於替換的候選,新塊應該具有最低優先順序。
19.6.2.7 逐出操作
如果快取遵循直寫策略,則無需執行任何操作,該塊可以簡單地丟棄。然而,如果快取遵循寫回策略,那麼需要檢視修改後的位。如果資料沒有被修改,那麼它可以被無縫地收回。但是,如果資料已被修改,則需要將其寫回較低階別的快取。
19.6.2.8 綜合操作
快取讀取操作的步驟序列如下圖所示,從查詢操作開始,可以在查詢和資料讀取操作之間有部分重疊。如果有快取命中,則快取將值返回給處理器或更高階別的快取(無論是哪種情況)。但是,如果快取未命中,則需要取消資料讀取操作,並向較低階別的快取傳送請求。較低階別的快取將執行相同的存取序列,並返回整個快取塊(不僅僅是4個位元組)。然後,快取記憶體控制器可以從塊中提取所請求的資料,並將其傳送到處理器,同時快取控制器呼叫插入操作將塊插入快取。如果集合中有一個無效的條目,那麼可以用給定的塊替換它,但如果集合中的所有方法都有效,則需要呼叫替換操作來查詢替換的候選。該圖為該操作附加了一個問號,因為該操作並非一直被呼叫(僅當集合的所有路徑都包含有效資料時)。然後,需要收回塊,如果修改了行,可能會將其寫入較低階別的快取,並且正在使用寫回快取。然後快取控制器呼叫插入操作,這次肯定會成功。
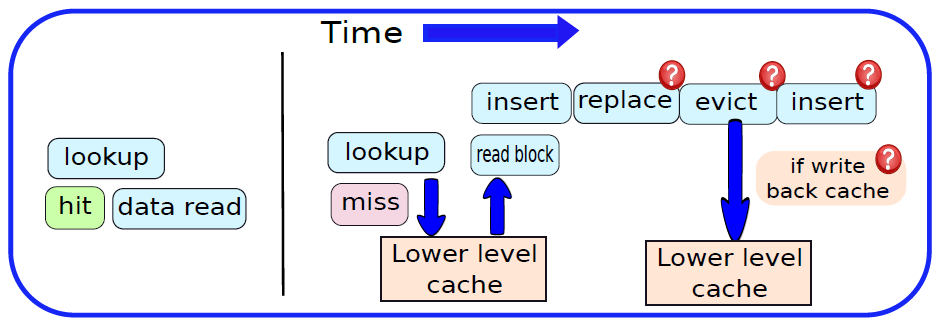
讀取操作。
下圖顯示了回寫快取的快取寫入操作的操作序列,操作順序大致類似於快取讀取。如果快取命中,將呼叫資料寫入操作,並將修改後的位設定為1,否則將向較低階別的快取發出塊的讀取請求。塊到達後,大多數快取控制器通常將其儲存在一個小的臨時緩衝區中,此時將4個位元組寫入緩衝區,然後返回。在某些處理器中,快取控制器可能會等待所有子操作完成。寫入臨時緩衝區後(上圖中的寫入塊操作),呼叫插入操作來寫入塊的內容(修改後),如果此操作不成功(因為所有方法都有效),那麼將遵循與讀取操作相同的步驟順序(替換、逐出和插入)。
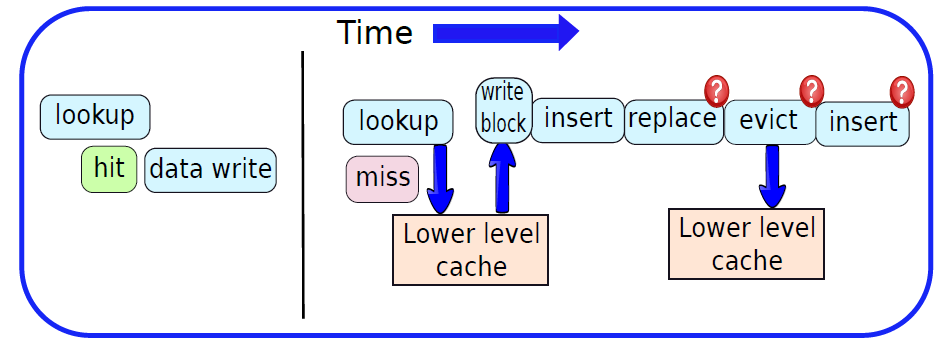
寫操作(回寫快取)。
下圖顯示了直寫快取的操作序列。第一個不同點是,即使請求在快取中命中,也會將塊寫入較低階別。第二個不同點是,在將值寫入臨時緩衝區之後(在未命中之後),還將塊的新內容寫回較低階別的快取。其餘步驟類似於為回寫快取所遵循的步驟序列。
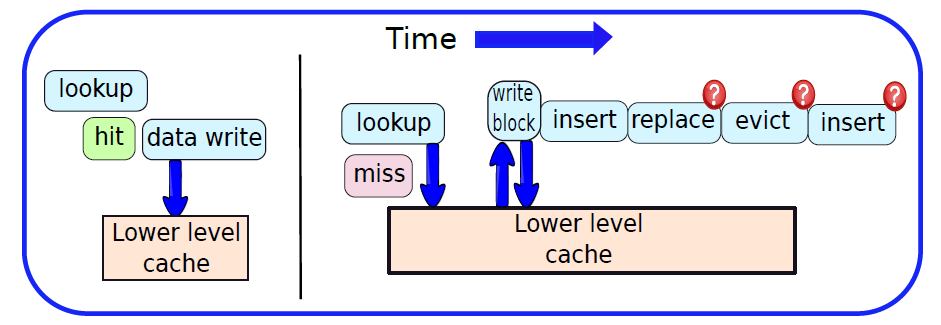
寫入操作(直寫快取)。
19.6.3 記憶體系統機制
我們已經對快取的工作及其所有組成操作有了一個合理的理解,使用快取層次結構構建記憶體系統。記憶體系統作為一個整體支援兩種基本操作:讀取和寫入,或者載入和儲存。
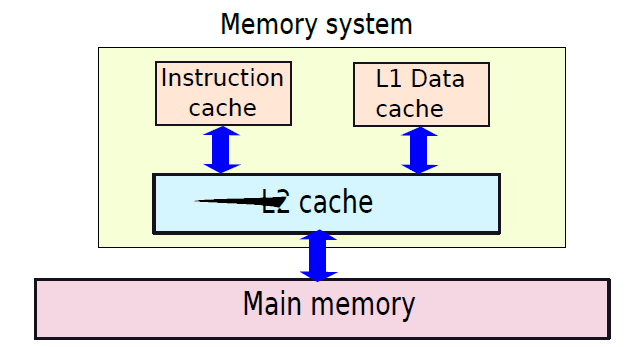
有兩個最高階別的快取:資料快取(也稱為一級快取)和指令快取(也稱I快取)。幾乎所有時候,它們都包含不同的記憶體位置集。用於存取I快取和L1快取的協定相同,為了避免重複,後面只關注一級快取。我們只需要記住,對指令快取的存取遵循相同的步驟順序。
處理器通過存取一級快取啟動。如果存在L1命中,則它通常在1-2個週期內接收該值。否則,請求需要轉到二級快取,或者甚至更低階別的快取,如主記憶體。在這種情況下,請求可能需要數十或數百個週期。本節將從整體上看快取系統,並將它們視為一個稱為記憶體系統的黑盒子。
如果考慮包含性快取,那麼記憶體系統的總大小等於主記憶體的大小。例如,如果一個系統有1 GB的主記憶體,那麼記憶體系統的大小等於1 GB。記憶體系統內部可能有一個用於提高效能的快取層次結構,但不會增加總儲存容量,因為只包含主記憶體中包含的資料子集。此外,處理器的記憶體存取邏輯還將整個記憶體系統視為單個單元,概念上被建模為一個大的位元組陣列。這也稱為實體記憶體系統或實體地址空間。
實體地址空間包括快取記憶體和主記憶體中包含的所有記憶體位置的集合。
19.6.3.1 記憶體系統的數學模型
效能
記憶體系統可以被認為是一個只服務於讀寫請求的黑盒子,請求所用的時間是可變的,取決於請求到達的記憶體系統的級別。管線在記憶體存取(MA)階段連線到記憶體系統,並向其發出請求。如果回覆不在一個週期內,那麼需要在5階段順序流水線中引入額外的氣泡。
設平均記憶體存取時間為AMAT(以週期測量),載入/儲存指令的分數為\(f_{mem}\),那麼CPI可以表示為:
\(CPI_{ideal}\)是假定完美的記憶體系統對所有存取具有1個週期延遲的CPI。請注意,在5階段順序流水線中,理想的指令吞吐量是每個週期1條指令,記憶體級分配1個週期。在實踐中,如果一次記憶體存取需要n個週期,那麼我們有n-1個暫停週期,它們需要上述公式來解釋。在此公式中,我們隱式地假設每次記憶體存取都會經歷AMAT-1個週期的暫停。實際上,情況並非如此,因為大多數指令將在一級快取中命中,並且一級快取通常具有1個週期的延遲。因此,命中一級快取的存取不會停止。但是,L1和L2快取中的存取失敗會導致長的暫停週期。
儘管如此,上述公式仍然成立,因為我們只對大量指令的平均CPI感興趣,可以通過考慮大量指令,對所有記憶體暫停週期求和,並計算每條指令的平均週期數來推匯出這個方程。
平均記憶體存取時間
在上述公式中,\(CPI_{ideal}\)由程式的性質和管線的其他階段(MA除外)的性質決定,\(f_{mem}\)也是處理器上執行的程式的固有屬性。我們需要一個公式來計算AMAT,可以用類似於上面公式的方法計算它。假設一個具有L1和L2快取的記憶體系統,有:
所有記憶體存取都需要存取L1快取,而不管命中還是未命中,因此它們需要產生等於L1命中時間的延遲。一部分存取(\(L1_{\text {miss rate}}\))將在L1快取中丟失,並移動到L2快取。此外,無論命中還是未命中,都需要產生\(L2_{\text {hit time}}\)週期的延遲。如果L2快取中有一部分存取(\(L2_{\text {miss rate}}\))未命中,則需要繼續存取主記憶體儲器。我們假設所有的存取都發生在主記憶體中。因此,\(L2_{\text {miss penalty}}\)懲罰等於主記憶體儲器存取時間。
假設有一個n級記憶體系統,其中第一級是L1快取,最後一級是主記憶體儲器,那麼可以使用類似的公式:
需要注意的是,這些等式中針對某一級別\(i\)使用的未命中率等於該級別未命中的存取數除以該級別的存取總數,被稱為區域性未命中率(local miss rate)。相比之下,我們可以定義第\(i\)級的全域性未命中率(global miss rate),它等於第\(i\)級未命中數除以記憶體存取總數。
區域性未命中率(local miss rate):它等於第\(i\)級快取中的未命中數除以第\(i\)級的存取總數。
全域性未命中率(global miss rate):它等於\(i\)級快取中的未命中數除以記憶體存取總數。
可以通過降低未命中率、未命中懲罰或減少命中時間來提高系統的效能。後面先看看未命中率。
19.6.3.2 快取未命中
快取未命中分類
讓我們首先嚐試對快取中不同型別的未命中進行分類。
- 強制未命中或冷未命中。當資料第一次載入到快取中時,由於資料值不在快取中,必然會發生此類未命中。
- 容量未命中。當一個程式所需的記憶體量大於快取大小時,會發生容量未命中。例如,假設一個程式重複存取陣列的所有元素,陣列的大小等於1 MB,二級快取的大小為512 KB。在這種情況下,二級快取中會有容量未命中,因為它太小,無法容納所有資料。
- 衝突未命中。程式在一個典型的時間間隔記憶體取的一組塊稱為其工作集,也可以說,當快取的大小小於程式的工作集時,會發生衝突未命中。請注意,工作集的定義有點不精確,因為間隔的長度是主觀考慮的。然而,時間間隔的內涵是,與程式執行的總時間相比,它是一個很小的間隔。只要它足夠大,以確保系統的行為達到穩定狀態,此類未命中發生在直接對映和集關聯快取中。例如,考慮一個4路集合關聯快取,如果一個程式的工作集中有5個塊對映到同一個集,必然會有快取未命中,因為存取的塊的數量大於可以作為集合一部分的最大條目數。
程式在短時間間隔記憶體取的記憶體位置包括程式在該時間點的工作集。
由此,可將未命中分為三類:強制、容量和衝突,也稱為三「C」。
降低未命中率
為了維持高IPC,有必要降低快取未命中率。我們需要採取不同的策略來減少不同型別的快取未命中。
讓我們從強制性失誤開始。我們需要一種方法來預測未來將存取的塊,並提前獲取這些塊。通常,利用空間區域性性的方案是有效的預測因素。因此,增加塊大小對於減少強制未命中的數量應該是有益的。然而,將塊大小增加到超過某個限制也會產生負面後果。它減少了可以儲存在快取中的塊的數量,其次,額外的好處可能是微不足道的。最後,從記憶體系統的較低階別讀取和傳輸較大的塊將需要更多的時間。因此,設計師避免過大的塊尺寸。32-128位元組之間的任何值都是合理的。
現代處理器通常具有複雜的預測器,這些預測器試圖根據當前的存取模式預測將來可能存取的塊的地址。他們隨後從記憶體層次結構的較低階別獲取預測的塊,試圖降低未命中率。例如,如果我們按順序存取一個大陣列的元素,那麼可以根據存取模式預測未來的存取。有時我們存取陣列中的元素,其中的索引相差固定值。例如,我們可能有一個存取陣列中每四個元素的演演算法。在這種情況下,也可以分析模式並預測未來的存取,因為連續存取的地址相差相同的值。這種單元被稱為硬體預取器。它存在於大多數現代處理器中,並使用複雜的演演算法來「預取」塊,從而降低未命中率。請注意,硬體預取器不應非常激進。否則,它將傾向於從快取中移出比它帶來的更有用的資料。
硬體預取器(hardware prefetcher)是一個專用的硬體單元,它預測在不久將來的記憶體存取,並從記憶體系統的較低階別獲取它們。
先闡述容量未命中。唯一有效的解決方案是增加快取的大小,不幸的是,本文介紹的快取設計要求快取的大小等於2的冪(以位元組為單位),使用一些高階技術可能會違反這一規則。然而,大體上,商業處理器中的大多數快取的大小都是2的冪。因此,增加快取的大小等於至少使其大小加倍,將快取的大小加倍需要兩倍的面積,使其速度減慢,並增加功耗。如果明智地使用預取,也會有所幫助。
減少衝突未命中數的經典解決方案是增加快取的關聯性,但也會增加快取的延遲和功耗,設計者有必要仔細平衡集合關聯快取的額外命中率和額外延遲。有時,快取中的一些集合中會出現衝突未命中,在這種情況下,可以用一個小型的全關聯快取,稱為犧牲快取(victim cache)和主快取。從主快取移位的任何塊都可以寫入犧牲快取,快取控制器需要首先檢查主快取,如果有未命中,則需要檢查犧牲快取,然後再繼續進行下一級。因此,級別i的犧牲快取可以過濾掉一些到達級別(i+1)的請求。
注意,與硬體技術一起,以「快取友好」的方式編寫程式是可行的,可以最大化時間和空間的區域性性,編譯器也可以優化給定記憶體系統的程式碼。其次,編譯器可以插入預取程式碼,以便在實際使用之前將塊預取到快取中。
現在快速提及兩條經驗法則,這些規則被發現在經驗上大致成立,並且在理論上並非完全正確。
第一個被稱為平方根規則(Square Root Rule),它表示未命中率與快取大小的平方根成正比:
哈特斯坦等人[Hartstein等人,2006]試圖為該規則找到理論依據,並利用概率論的結果解釋該規則的基礎。根據他們的實驗結果,得出了該規則的通用版本,該規則表示平方根規則中快取大小的指數從-0.3到-0.7不等。
第二個規則被稱為關聯性規則(Associativity Rule),它表明將關聯性加倍的效果幾乎與將快取大小與原始關聯性加倍相同,例如64 KB 4路關聯快取的未命中率幾乎與128 KB 2路關聯快取相同。
注意,關聯性規則和平方根規則只是經驗規則,並不完全成立,僅僅用作概念輔助工具,我們總是可以構造違反這些規則的範例。
減少命中時間和未命中不利
還可以通過減少命中時間和未命中不利(Miss Penalty)來減少平均記憶體存取時間。為了減少命中時間,需要使用小而簡單的快取,但也增加了未命中率。
現在討論一下減少不利的方法。請注意,級別i處的未命中不利等於從級別(i+1)開始的記憶體系統的記憶體延遲。傳統的減少命中時間和未命中率的方法總是可以用於在給定的水平上減少未命中不利,現在研究專門針對減少未命中不利的方法。首先看看一級快取中的寫入未命中。在這種情況下,必須將整個塊從L2快取記憶體帶入快取記憶體,需要時間(>10個週期),其次,除非寫入完成,否則管線無法恢復。處理器設計人員使用一個稱為寫緩衝區的小集合關聯快取,如下圖所示。處理器可以將值寫入寫緩衝區,然後恢復,或者,只有在L1快取中未命中時(假設),它才可以寫入寫緩衝。任何後續讀取都需要在存取一級快取的同時檢查寫入緩衝區,該結構通常非常小且快速(4-8個條目)。
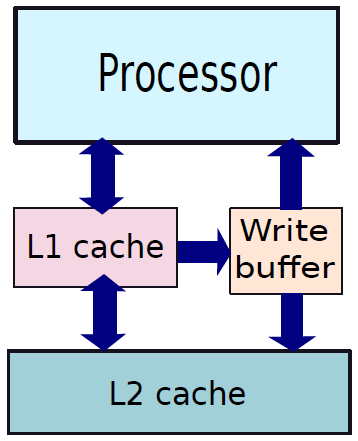
一旦資料到達一級快取,就可以從寫緩衝器中刪除相應的條目。注意,如果寫緩衝區中沒有可用的空閒條目,則管線需要暫停。其次,在從較低階別的快取記憶體服務寫入未命中之前,可能存在對同一地址的另一次寫入,可以通過寫入寫入緩衝區中給定地址的分配條目來無縫處理。
現在看看讀取未命中。處理器通常只對每次記憶體存取最多4個位元組感興趣,如果提供了這些關鍵的4位元組,管線可以恢復。然而,在操作完成之前,記憶體系統需要填充整個塊,塊的大小通常在32-128位元組之間。因此,如果記憶體系統知道處理器所需的確切位元組集,則可以在此引入優化。在這種情況下,記憶體系統可以首先獲取所需的記憶體字(4位元組),隨後或者並行地獲取塊的其餘部分。這種優化被稱為關鍵詞優先(critical word first)。然後,可以將這些資料快速傳送到管線,以便恢復其操作。這種優化被稱為提前重啟(early restart)。實現這兩種優化增加了記憶體系統的複雜性。然而,關鍵詞語優先和提前重啟在減少未命中不利方面相當有效。
記憶體系統優化技術概述
下表總結了我們為優化儲存系統而引入的不同技術。請注意,每種技術都有一些負面影響,如果一種技術在一個方面改進了記憶體系統,那麼在另一個方面是有害的。例如,通過增加快取大小,我們可以減少容量未命中的數量,但也增加了面積、延遲和功率。
| 技術 | 應用 | 劣勢 |
|---|---|---|
| 大塊尺寸 | 強制未命中 | 減少快取的塊數 |
| 預獲取 | 強制未命中、容量未命中 | 額外的複雜性和從快取中替換有用資料的風險 |
| 大快取大小 | 容量未命中 | 高延遲、高功率、更大面積 |
| 關聯性增強 | 衝突未命中 | 高延遲、高功率 |
| 犧牲快取 | 衝突未命中 | 額外複雜性 |
| 基於編譯器的技術 | 所有型別的未命中 | 不是很通用 |
| 小而簡單的快取 | 命中時間 | 高未命中率 |
| 寫入緩衝器 | 未命中不利 | 額外複雜性 |
| 關鍵詞優先 | 未命中不利 | 額外的複雜性和狀態 |
| 提前重啟 | 未命中不利 | 額外複雜性 |
總而言之,必須非常仔細地設計記憶體系統。目標工作量的要求必須與設計師設定的限制和製造技術的限制仔細平衡,需要最大化效能,同時注意功率、面積和複雜性限制。
19.6.4 虛擬記憶體
一個處理器可以通過在不同的程式之間快速切換來執行多個程式。例如,當用戶玩遊戲時,他的處理器可能正在接收電子郵件,之所以感覺不到任何中斷,是因為處理器在程式之間來回切換的時間尺度(通常為幾毫秒)比人類所能感知的要小得多。
到目前為止,我們假設程式所需的所有資料都駐留在主記憶體中,這種假設是不正確的。在過去,主記憶體的大小曾經是幾兆位元組,而使用者可以執行需要數百兆位元組資料的非常大的程式。即使現在,也可以處理比主記憶體量大得多的資料。使用者可以通過編寫一個C程式來輕鬆驗證這一語句,該程式建立的資料結構大於機器中包含的實體記憶體量。在大多數系統中,此C程式將成功編譯並執行。
本節通過對記憶體系統進行少量更改,可以滿足以上要求。閱讀本節需要一定的作業系統知識(如程序、執行緒、記憶體等),可參閱剖析虛幻渲染體系(18)- 作業系統。
19.6.4.1 記憶體的虛擬檢視
因為多個程序在同一時間點處於活動狀態,有必要在程序之間劃分記憶體,如果不這樣做,那麼程序可能最終會修改彼此的值,同時也不希望程式設計師或編譯器知道多個程序的存在。否則,會引入不必要的複雜性,其次,如果給定的程式是用某個記憶體對映編譯的,那麼它可能不會在另一臺具有重疊記憶體對映的程序的機器上執行,更糟糕的是,不可能執行同一程式的兩個副本。因此,每個程式都必須看到記憶體的虛擬檢視,在該檢視中,它假定自己擁有整個記憶體系統。
這兩個要求出現了相互的矛盾——記憶體系統和作業系統希望不同的程序存取不同的記憶體地址,而程式設計師和編譯器不希望知道這一要求。此外,程式設計師希望根據自己的意願佈局記憶體對映。事實證明,有一種方法可以讓程式設計師和作業系統都感到滿意。
我們需要定義記憶體的虛擬和物理檢視。在記憶體的物理檢視中,不同的程序在記憶體空間的非重疊區域中操作。然而,在虛擬檢視中,每個程序都存取它希望存取的任何地址,並且不同程序的虛擬檢視可以重疊。解決方案是分頁。記憶體的虛擬檢視也稱為虛擬記憶體,它被定義為一個假設的記憶體系統,其中一個程序假定它擁有整個記憶體空間,並且沒有任何其它程序的干擾。
虛擬記憶體系統被定義為一個假設的記憶體系統,其中一個程序假定它擁有整個記憶體空間,並且沒有任何其他程序的干擾。記憶體的大小與系統的總可定址記憶體一樣大。例如,在32位元系統中,虛擬記憶體的大小為\(2^{32}\)位元組(4 GB)。虛擬記憶體中所有記憶體位置的集合稱為虛擬地址空間。
下圖顯示了32位元Linux作業系統中程序的記憶體對映的簡化檢視。讓我們從底部(最低地址)開始。第一段包含檔頭,從程序、格式和目標機器的詳細資訊開始。檔頭包含記憶體對映中每段的詳細資訊,例如,它包含包含程式程式碼的文字部分的詳細資訊,包括其大小、起始地址和其他屬性。文欄位從檔頭之後開始,載入程式時,作業系統將程式計數器設定為文欄位的開始。程式中的所有指令通常都包含在文欄位中。
Linux作業系統中程序的記憶體對映(32位元)。
文欄位後面是另外兩個段,用於包含靜態變數和全域性變數。可選地,一些作業系統也有一個額外的區域來包含唯讀資料,如常數。文欄位之後通常是資料部分,包含所有由程式設計師初始化的靜態/全域性變數。讓我們考慮以下形式的宣告(在C或C++中):
static int val = 5;
與變數val對應的4個位元組儲存在資料段中。
資料段後面是bss段,bss段儲存程式設計師未明確初始化的靜態變數和全域性變數。大多數作業系統,所有與bss段對應的記憶體區域都為零。為了安全起見,必須這樣做。讓我們假設程式A執行並將其值寫入bss段,隨後程式B執行。在寫入bss段中的變數之前,B總是可以嘗試讀取其值。在這種情況下,它將獲得程式A寫入的值,但這不是理想的行為,程式A可能在bss段儲存了一些敏感資料,例如密碼或信用卡號。因此,程式B可以在程式A不知情的情況下存取這些敏感資料,並可能濫用這些資料。因此,有必要用零填充bss段,這樣就不會發生此類安全錯誤。
bss段後面是一個稱為堆的記憶體區域,堆區域用於在程式中儲存動態分配的變數。C程式通常使用malloc呼叫分配新資料,Java和C++使用new運運算元。讓我們看看一些例子:
int *intarray = (int*) malloc(10 * sizeof(int)); // [C]
int *intarray = new int[10]; // [C++]
int[] intarray = new int[10]; // [Java]
請注意,在這些語言中,動態分配陣列非常有用,因為它們的大小在編譯時是未知的。堆中有資料的另一個優點是它們可以跨函數呼叫生存。堆疊中的資料僅在函數呼叫期間保持有效,隨後被刪除。然而,堆中的資料會在程式的整個生命週期中保留,它可以由程式中的所有函數使用,指向堆中不同資料結構的指標可以跨函數共用。請注意,堆向上增長(朝向更高的地址)。其次,在堆中管理記憶體是一項相當困難的任務,因為在高階語言中,堆的區域動態地被分配了malloc/new呼叫,並被釋放了free/delete呼叫。一旦釋放了分配的記憶體區域,就會在記憶體對映中形成一個孔洞。如果孔的大小小於孔的大小,則可以在孔中分配一些其他資料結構。在這種情況下,將在記憶體對映中建立另一個較小的孔。隨著時間的推移,隨著越來越多的資料結構被分配和取消分配,孔洞的數量往往會增加,這就是所謂的碎片化。因此,有必要擁有一個高效的記憶體管理器,以減少堆中的孔數。下圖顯示了帶有孔和分配記憶體的堆的檢視。
堆的記憶體對映。
下一段用於儲存與記憶體對映的檔案和動態連結的庫相對應的資料。大多數情況下,作業系統將檔案的內容(如音樂、文字或視訊檔)傳輸到記憶體區域,並將檔案的屬性視為常規陣列,該存記憶體區域被稱為記憶體對映檔案。其次,程式可能偶爾會動態讀取其他程式(稱為庫)的內容,並將其文欄位的內容傳輸到記憶體對映中,這種庫稱為動態連結庫(dll)。這種記憶體對映結構的內容儲存在程序的記憶體對映中的專用段中。
下一段是堆疊,它從記憶體對映的頂部開始向下增長(朝向更小的地址),堆疊根據程式的行為不斷增長和收縮。請注意,上上圖未按比例繪製。如果我們考慮32位元記憶體系統,那麼虛擬記憶體的總量是4 GB,但程式可能使用的記憶體總量通常限制在數百兆位元組。因此,在堆的開始部分和堆疊部分之間的對映中有一個巨大的空區域。
請注意,作業系統需要非常頻繁地執行,需要為裝置請求提供服務,並執行程序管理。從一個程序到另一個程序更改記憶體的虛擬檢視稍微有些昂貴,因此,大多數作業系統在使用者程序和核心之間劃分虛擬記憶體,例如,Linux為使用者程序提供了較低的3GB,為核心保留了較高的1GB。類似地,Windows為核心保留較高的2GB,為使用者程序保留較低的2GB。當處理器從使用者程序轉換到核心時,不需要更改記憶體檢視。其次,這種小的修改不會極大地降低程式的效能,因為2GB或3GB遠遠超過程式的典型記憶體佔用量。此外,這個技巧也與虛擬記憶體概念不衝突,一個程式只需要假設它的記憶體空間減少了(在Linux的情況下,從4GB減少到3GB),參考下圖。
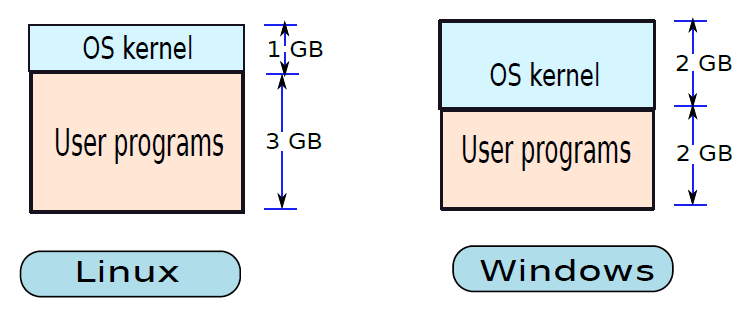
Linux和Windows的使用者、核心的記憶體對映。
19.6.4.2 重疊和尺寸問題
我們需要解決兩個虛擬記憶體的問題:
- 重疊問題。程式設計師和編譯器編寫程式時假定他們擁有整個記憶體空間,並且可以隨意寫入任何位置。不幸的是,所有同時處於活動狀態的程序都做出了相同的假設。除非採取措施,否則它們可能會在不經意間寫入對方的記憶體空間並破壞對方的資料。事實上,考慮到它們使用相同的記憶體對映,在粗略的系統中發生這種情況的可能性非常高,硬體需要確保不同的程序相互隔離。這就是重疊問題。
- 尺寸問題。有時我們需要執行需要比可用實體記憶體更多記憶體的程序。如果其他儲存媒介(例如硬碟)中的一些空間可以重新用於儲存程序的記憶體佔用,便是理想的,這就是所謂的尺寸問題。
任何虛擬記憶體的實現都需要有效地解決尺寸和重疊問題。
19.6.4.3 分頁
本小節涉及到的概念解析如下:
- 虛擬地址:程式在虛擬地址空間中指定的地址。
- 實體地址:地址轉換後呈現給記憶體系統的地址。
- 頁(page):是虛擬地址空間中的一塊記憶體。
- 幀(frame):是實體地址空間中的一塊記憶體,頁和幀大小相同。
- 頁表(page table):是一個對映表,將每個頁面的地址對映到幀的地址。每個程序都有自己的頁表。
為了平衡處理器、作業系統、編譯器和程式設計師的需求,需要設計一個轉譯系統,將程序生成的地址轉譯成記憶體系統可以使用的地址。通過使用轉譯器,可以滿足需要虛擬記憶體的程式設計師/編譯器和需要實體記憶體的處理器/記憶體系統的需求。轉譯系統類似於現實生活中的翻譯人員,例如,如果我們有一個俄羅斯代表團存取迪拜,那麼我們需要一個能將俄語翻譯成阿拉伯語的翻譯。然後雙方都可以說自己的語言,從而感到高興。轉譯系統的概念圖如下圖所示。

考慮一個32位元記憶體地址,現在可以把它分成兩部分。如果考慮一個4KB的頁面,那麼低12位元指定頁面中位元組的地址(原因:\(2^{12}\)=4096=4KB),稱為偏移,高20位指定頁碼(下圖)。同樣,可以將實體地址分為兩部分:幀號和偏移。下圖的轉換過程首先將20位頁碼替換為等效的20位幀號,然後將12位元偏移量附加到物理幀號。
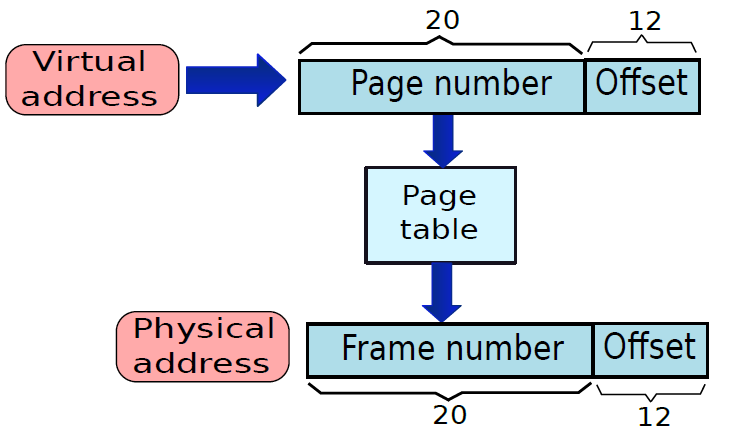
將虛擬地址轉換為實體地址。
在實現的方案中,按照頁表的層級,有1級和2級頁表,它們的示意圖如下:
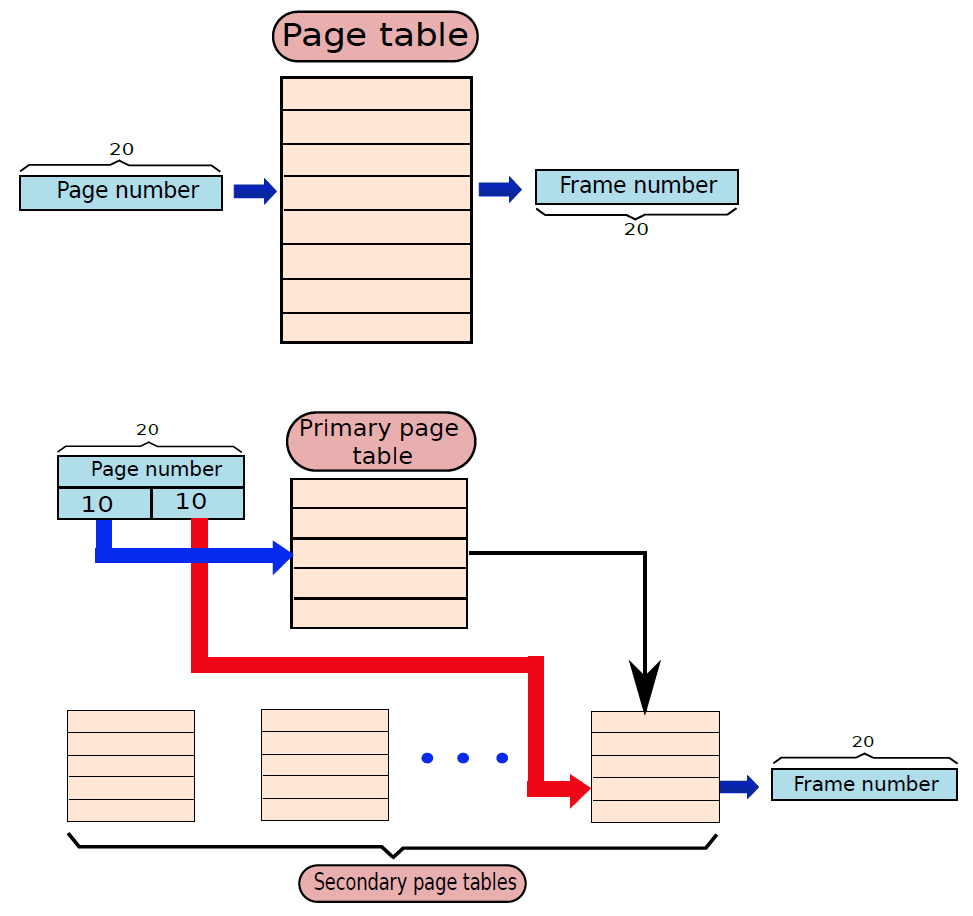
上:1級頁表;下:2級頁表。
一些處理器,如英特爾安騰和PowerPC 603,對頁表使用不同的設計。它們不是使用頁碼來定址頁表,而是使用幀號來定址頁。在這種情況下,整個系統只有一個頁面表。由於一個幀通常被唯一地對映到程序中的一個頁面,所以這個反向頁面表中的每個條目都包含程序id和頁碼。下圖(a)顯示了反轉頁表的結構,其主要優點是不需要為每個程序保留單獨的頁表。如果有很多程序,並且實體記憶體的大小很小,可以節省空間。
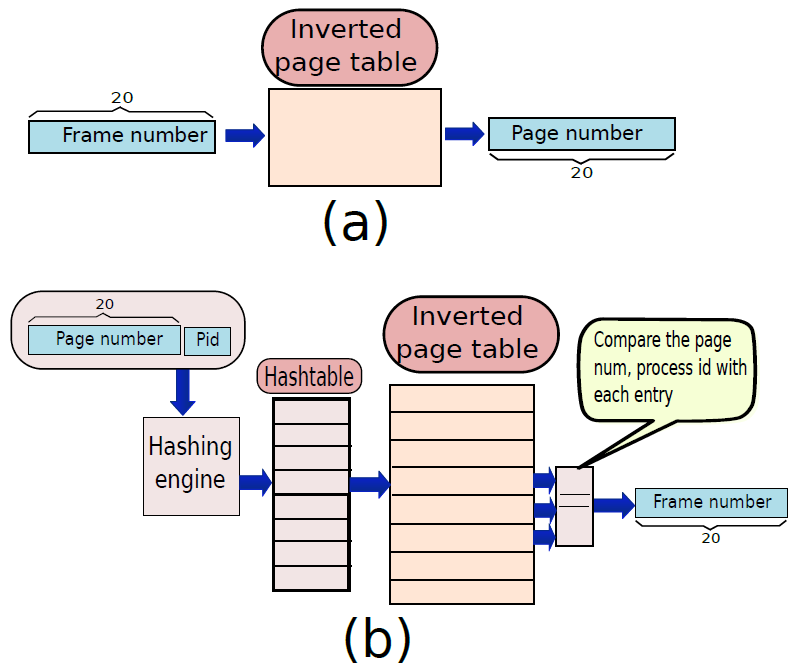
反轉頁表。
反向頁表的主要困難在於查詢虛擬地址。掃描所有條目是一個非常緩慢的過程,因此不實用。因此,需要一個雜湊函數,將(程序id,頁碼)對對映到雜湊表中的索引,雜湊表中的這個索引需要指向反向頁表中的一個條目。由於多個虛擬地址可以指向雜湊表中的同一條目,因此有必要驗證(程序id、頁碼)與儲存在反向頁表中的條目中的匹配。
上圖(b)中展示了一種使用反向頁表的方案。在計算頁碼和程序id對的雜湊之後,存取一個由雜湊內容索引的雜湊表,雜湊表條目的內容指向可能對映到給定頁面的幀f。然而,我們需要驗證,因為雜湊函數可能將多個頁面對映到同一幀。隨後存取反向頁表,並存取條目f。反向頁表的一個條目包含對映到給定條目(或給定幀)的頁碼、程序id對。如果發現內容不匹配,就繼續在隨後的K個條目中搜尋頁碼、程序id對。這種方法被稱為線性探測(linear probing),在目標資料結構中不斷搜尋,直到找到匹配。如果沒有在K個條目中找到匹配項,就可能會得出頁面沒有對映的結論。然後,需要建立一個對映,方法是逐出一個條目(類似於快取),並將其寫入主記憶體中的一個專用區域,該區域儲存從反向頁表中逐出的所有條目,需要始終確保雜湊表指向的條目和包含對映的實際條目之間的差異不超過K個條目。如果沒有找到任何空閒插槽,那麼就需要收回一個條目。
有人可能認為,可以直接使用雜湊引擎的輸出來存取反向頁表。通常,我們新增存取雜湊表作為中間步驟,因為它允許更好地控制實際使用的幀集。使用此過程,可以禁止某些幀的對映,這些幀可用於其他目的。最後需要注意的是,維護和更新雜湊表的開銷大於擁有全系統頁面表的收益。因此,反轉頁表通常不用於商業系統。
虛擬記憶體還涉及TLB、空間替換、MMU、頁面錯誤等概念和機制,這些可在虛擬記憶體中尋得支援,本文不再累述。
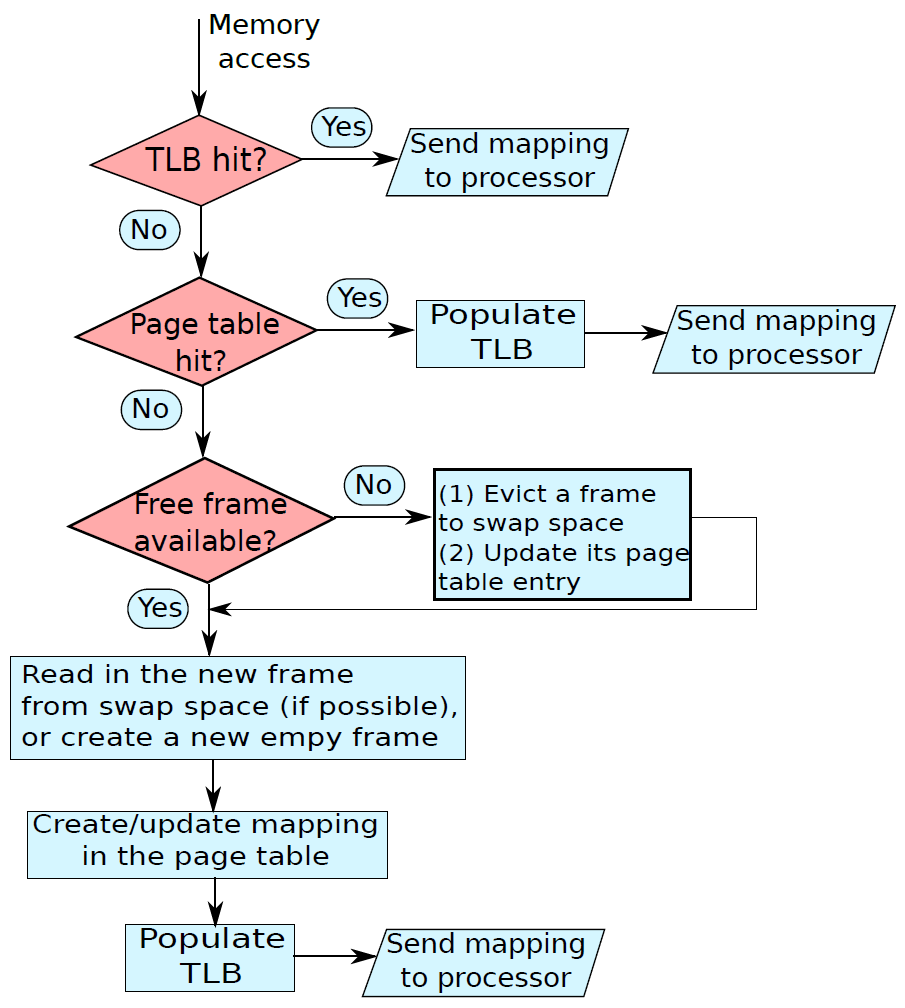
地址轉譯過程。
19.6.4.4 分頁系統高階功能
事實證明,我們可以用頁表機制做一些有趣的事情,下面看看幾個例子。
- 共用記憶體
假設兩個程序希望在彼此之間共用一些記憶體,以便它們交換資料,每個程序都需要讓核心知道這一點。核心可以將兩個虛擬地址空間中的兩個頁面對映到同一幀,之後,每個程序都可以在自己的虛擬地址空間中寫入頁面,神奇的是,資料將反映在另一個程序的虛擬地址中。有時需要幾個程序相互通訊,共用記憶體機制是最快的方法之一。
- 保護
計算機病毒通常會更改正在執行的程序的程式碼,以便它們可以執行自己的程式碼,通常通過向程式提供一個特定的錯誤輸入序列來實現。如果沒有進行適當的檢查,那麼程式中特定變數的值將被覆蓋。一些變數可以更改為指向文欄位的指標,並且可以利用此機制更改文字部分段中的指令。可以通過將文欄位中的所有頁面標記為唯讀來解決此問題,無法在執行時修改它們的內容。
- 分段
我們一直假設程式設計師可以根據自己的意願自由佈局記憶體對映,例如,程式設計師可能決定在非常高的地址(例如0xFFFFFFF8)啟動堆疊,然而,即使程式的記憶體佔用非常小,該程式碼也可能無法在使用16位元地址的機器上執行。其次,某個系統可能保留了虛擬記憶體的某些段,並使其無法用於程序。例如,作業系統通常為核心保留較高的1或2 GB。為了解決這些問題,我們需要在虛擬記憶體之上建立另一個虛擬層。
在分段記憶體(用於x86系統)中,有用於文字、資料和堆疊段的特定段暫存器。每個虛擬地址指定為特定段暫存器的偏移量。預設情況下,指令使用程式碼段暫存器,資料使用資料段暫存器。管線的記憶體存取(MA)階段將偏移量新增到儲存在段暫存器中的值以生成虛擬地址。隨後,MMU使用該虛擬地址來生成實體地址。
19.7 多處理器系統
前面已經詳細討論了處理器的設計和實現,以及優化其效能的幾種方法,如管線。通過優化處理器和記憶體系統,可以顯著提高程式的效能。問題是,這足夠了嗎?有沒可能做得更好?
簡短答案:也許不是。從處理器效能有其侷限性開始說起。不可能單獨提高處理器的速度,即使是非常複雜的超標量處理器和高度優化的記憶體系統,通常不可能將IPC增加超過50%。其次,由於功率和溫度的考慮,很難將處理器頻率提高到3 GHz以上。在過去相當多年中,處理器頻率基本保持不變,由此CPU效能的增長也非常緩慢。
下面兩圖中證明了以上論述。下圖顯示了英特爾、AMD、Sun、高通和富士通等多家供應商從2001年到2010年釋出的處理器的峰值頻率。我們觀察到,頻率或多或少保持不變(大多在1 GHz到2.5 GHz之間),這些趨勢表明頻率沒有逐漸增加。預計在不久的將來,處理器的頻率也將限制在3 GHz。
CPU頻率。
下圖顯示了2001年至2010年同一組處理器的Spec Int 2006平均得分。我們觀察到,隨著時間的推移,CPU效能逐漸飽和,提高效能變得越來越困難。
CPU效能。
儘管單個處理器的效能預計在未來不會顯著提高,但計算機架構的未來並不黯淡,因為處理器製造技術正在穩步進步,導致更小更快的電晶體。直到20世紀90年代末,處理器設計者一直在利用電晶體技術的進步,通過實現更多功能來增加處理器的複雜性。然而,由於複雜度和功耗的限制,2005年後,設計師們轉而使用更簡單的處理器。供應商沒有在處理器中實現更多功能,而是決定在單個晶片上安裝多個處理器,有助於同時執行多個程式。或者,可以將單個程式拆分為多個部分,並行執行所有部分。
這種使用多個並行執行的計算單元的範例稱為多處理(multiprocessing)。多處理是一個相當通用的術語,可以指同一晶片中的多個處理器並行工作,也可以指跨晶片的多個並行處理器。多處理器是一種支援多處理的硬體,當我們在一個晶片中有多個處理器時,每個處理器都被稱為一個核心,而這個晶片被稱為多核(multicore)處理器。
我們正處於多處理器(multiprocessors)時代,尤其是多核(multicore)系統。每個晶片的核數大約每兩年增加兩倍,正在編寫新的應用程式來利用這些額外的硬體。大多數專家認為計算的未來在於多處理器系統。
在開始設計不同型別的多處理器之前,讓我們先來看看多處理器的背景和歷史。
19.7.1 多處理器背景
在60年代和70年代,大型計算機主要被銀行和金融機構使用。他們擁有越來越多的消費者,因此需要能夠每秒執行越來越多事務的計算機。通常,只有一個處理器被證明不足以提供所需的計算吞吐量。因此,早期的計算機設計師決定在一臺計算機中安裝多個處理器。處理器可以共用計算負載,從而增加整個系統的計算吞吐量。
最早的多處理器之一是Burroughs 5000,它有兩個處理器:A和B。A是主處理器,B是輔助處理器。當負載很高時,處理器A給處理器B一些工作要做。當時幾乎所有其他主要供應商都有多處理器產品,如IBM 370、PDP 11/74、VAX-11/782和Univac 1108-II,這些計算機支援第二個CPU晶片,已連線到主處理器。在所有這些早期機器中,第二個CPU位於第二個晶片上,該晶片通過導線或電纜與第一個CPU物理連線。它們有兩種型別:對稱和不對稱。對稱多處理器由多個處理器組成,每個處理器都是相同型別的,並且可以存取作業系統和外圍裝置提供的服務。非對稱多處理器為不同的處理器分配不同的角色,通常有一個獨特的處理器來控制作業系統和外圍裝置,其餘的處理器都是從機,它們從主處理器獲取工作,並返回結果。
對稱多處理器(Symmetric Multiprocessing):此範例將多處理器系統中的所有組成處理器視為相同的,每個處理器都可以平等地存取作業系統和I/O外圍裝置,也稱為SMP系統。
非對稱多處理器(Asymmetric Multiprocessing):此範例並不將多處理器系統中的所有組成處理器視為相同的,通常有一個主處理器獨佔控制作業系統和I/O裝置,將工作分配給其他處理器。
早期,第二個處理器使用一組電纜連線到主處理器,通常位於主計算機的不同區域。請注意,在那個年代,電腦曾經有一個房間那麼大。隨著小型化程度的提高,兩個處理器逐漸接近。在80年代末和90年代初,公司開始在同一主機板上安裝多個處理器。主機板是一塊印刷電路板,包含計算機使用的所有晶片,帶有晶片和金屬線的大型綠色電路板是主機板。到了90年代末,在一塊主機板上可以有四到八個處理器,它們通過專用高速匯流排相互連線。
漸漸地,多核處理器的時代開始了,同一晶片中有多個處理器。2001年,IBM率先推出了名為Power 4的雙核(2核)多核處理器,2005年,英特爾和AMD也推出了類似產品。截至2022年,有16、32、64甚至更多核心的多核處理器可供選擇。
現在更深入地瞭解一下1960年至2012年間處理器世界發生了什麼。在六十年代,一臺電腦通常只有一個房間那麼大,而今,口袋裡裝著一臺電腦。在60年代早期,手機中的處理器比IBM 360機器快約160萬倍,它的功率效率也提高了幾個數量級。計算機技術持續發展的主要驅動因素是電晶體的小型化,電晶體在六十年代曾經有幾毫米的溝道長度,現在大約有20-30納米長。1971年,一個典型的晶片曾經有2000-3000個電晶體,如今的一個晶片有數十億個電晶體。
在過去的四十到五十年中,每個晶片的電晶體數量大約每1-2年翻一番。事實上,英特爾的聯合創始人戈登·摩爾(Gordon Moore)在1965年就預測到了這一趨勢。摩爾定律預測,晶片上的電晶體數量預計每一到兩年就會翻一番。最初,摩爾曾預測每年翻倍的時間,隨著時間的推移,這段時間已經變成了大約2年。由於製造技術、新材料和製造技術的穩步發展,這種情況預計會發生。
摩爾定律自20世紀60年代中期提出以來,幾乎一直成立。如今,幾乎每兩年,電晶體的尺寸就會縮小\(\sqrt{2}\)倍,確保了電晶體的面積縮小一倍,從而可以使晶片上的電晶體數量增加一倍。讓我們將特徵尺寸(feature size)定義為可以在晶片上製造的最小結構的尺寸。下表顯示了過去10年英特爾處理器的功能大小,我們觀察到特徵大小每兩年大約減少\(\sqrt{2}\)(1.41)倍,導致電晶體數量加倍。
| 年份 | 特徵尺寸 |
|---|---|
| 2001 | 130 nm |
| 2003 | 90 nm |
| 2005 | 65 nm |
| 2007 | 45 nm |
| 2009 | 32 nm |
| 2011 | 22 nm |
請注意,摩爾定律是一個經驗定律。然而,由於它在過去四十年中正確預測了趨勢,因此在技術文獻中被廣泛參照。它直接預測了電晶體尺寸的小型化,更小的電晶體更省電、更快。傳統上,設計師們利用這些優勢來設計具有額外電晶體的更大處理器,他們使用額外的電晶體預算來增加不同單元的複雜性,增加快取大小,增加問題寬度和功能單元的數量。其次,管線階段的數量也在穩步增加,直到2002年左右,時脈頻率也隨之增加。然而,2002年之後,計算機架構的世界發生了根本性的變化。突然間,電力和溫度成了主要問題。處理器功耗曲線開始超過100瓦,晶片溫度開始超過100攝氏度,這些限制顯著地結束了處理器複雜性和時脈頻率的擴充套件。
相反,設計師開始在不改變其基本設計的情況下,為每個晶片封裝更多的核心,確保了每個核的電晶體數量保持不變。根據摩爾定律,核的數量每兩年翻一番,開啟了多核處理器的時代,處理器供應商開始將晶片上的核數量增加一倍。在未來不久,每個晶片的核數預計普遍達到64、128個甚至更多。
除了常規的多核處理器,還有另一個重要的發展。除了每個晶片有4個大核心,還有一些架構在晶片上有64-256個非常小的核心,例如圖形處理器。這些處理器也遵循摩爾定律,每2年將其核心翻倍,被越來越多地用於計算機圖學、數值計算和科學計算。也可以拆分處理器的資源,使其支援兩個程式計數器,並同時執行兩個程式,這些特殊型別的處理器被稱為多執行緒處理器。
本章讓讀者瞭解多處理器設計的廣泛趨勢,首先從軟體的角度來看多處理,一旦確定了軟體需求,將著手設計支援多處理的硬體,將廣泛考慮多核、多執行緒和向量處理器。
19.7.2 多處理器系統軟體
19.7.2.1 強和鬆散耦合多處理
鬆散耦合多處理(Loosely Coupled Multiprocessing)是在多處理器上並行執行多個不相關的程式。
強耦合多處理(Strongly Coupled Multiprocessing)是在多處理器上並行執行一組共用記憶體空間、資料、程式碼、檔案和網路連線的程式。
本文將主要研究強耦合多處理,並主要關注通過共用大量資料和程式碼來允許一組程式協同執行的系統。
19.7.2.2 共用記憶體與訊息傳遞
計算機架構師按照不同的模式為多處理器設計了一套協定。第一個範例被稱為共用記憶體,所有單獨的程式都看到記憶體系統的相同檢視,如果程式A將x的值更改為5,則程式B立即看到更改。第二種設定稱為訊息傳遞,多個程式通過傳遞訊息相互通訊。共用記憶體範例更適合強耦合多處理器,訊息傳遞範例更適合鬆散耦合多處理器。請注意,可以在強耦合多處理器上實現訊息傳遞。同樣,也可以在鬆散耦合的多處理器上實現共用記憶體的抽象,被稱為分散式共用記憶體(distributed shared memory),但通常不是常態。
共用記憶體
讓我們嘗試使用多處理器並行新增n個數位,它的程式碼如下所示,使用OpenMP語言擴充套件用C++編寫了程式碼。假設所有的數位都已經儲存在一個稱為numbers.的陣列中,陣列編號有SIZE個條目,假設可以啟動的並行子程式的數量等於N。
/* 變數宣告 */
int partialSums[N];
int numbers[SIZE];
int result = 0;
/* 初始化陣列 */
(...)
/* 並行程式碼 */
#pragma omp parallel
{
/* get my processor id */
int myId = omp_get_thread_num();
/* add my portion of numbers */
int startIdx = myId * SIZE/N;
int endIdx = startIdx + SIZE/N;
for(int jdx = startIdx; jdx < endIdx; jdx++)
partialSums[myId] += numbers[jdx];
}
/* 順序程式碼 */
for(int idx=0; idx < N; idx++)
result += partialSums[idx];
除了指令#pragma omp parallel之外,很容易將程式碼誤認為是常規順序程式,這是在並行程式中新增的唯一額外語意差異,它將此迴圈的每個迭代作為單獨的子程式啟動,每個這樣的子程式都被稱為執行緒。執行緒通過修改共用記憶體空間中記憶體位置的值與它們通訊,每個執行緒都有自己的一組區域性變數,其他執行緒無法存取這些變數。
迭代次數或啟動的並行執行緒數是預先設定的系統引數,通常等於處理器的數量,上述程式碼中等於N。因此,並行啟動程式碼的並行部分的N個副本,每個副本在單獨的處理器上執行。請注意,程式的每個副本都可以存取在呼叫並行部分之前宣告的所有變數,例如,可以存取partialSums和numbers陣列。每個處理器都呼叫函數omp_get_thread_num,該函數返回執行緒的id。每個執行緒都使用執行緒id來查詢需要新增的陣列範圍,在陣列的相關部分中新增所有條目,並將結果儲存在partialSums陣列中相應的條目中。一旦所有執行緒都完成了它們的工作,順序部分就開始了,這段順序程式碼可以在任何處理器上執行,是由作業系統或並行程式設計框架在執行時動態做出的。為了得到最終結果,必須將順序部分中的所有部分和相加。
計算的圖形表示如下圖所示。父執行緒生成一組子執行緒,做各自的工作,完成後最終連線,父執行緒接管並聚合並行結果。此例也是Fork-Join範例的一個具體範例。
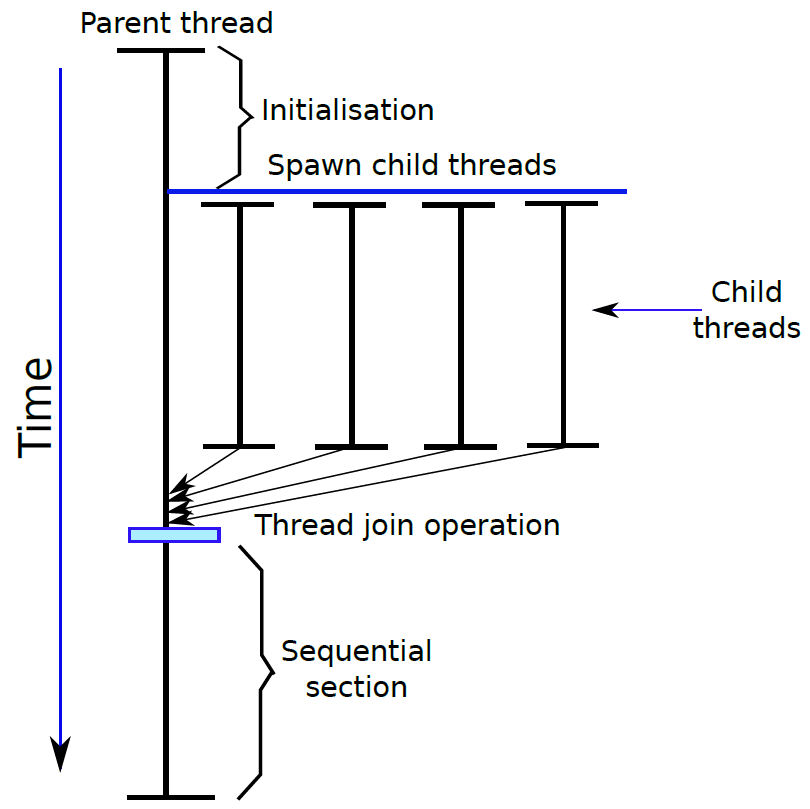
並行加法程式的圖形表示。
有幾個要點需要注意。每個執行緒都有自己的堆疊,可以使用其堆疊宣告其區域性變數。一旦完成,堆疊中的所有區域性變數都將被銷燬。要在父執行緒和子執行緒之間傳遞資料,必須使用兩個執行緒都可以存取的變數,所有執行緒都需要全域性存取這些變數,子執行緒可以自由地修改這些變數,甚至可以使用它們相互通訊。此外,它們還可以自由呼叫作業系統,並寫入外部檔案和網路裝置。一旦所有執行緒完成執行,它們就執行一個聯接操作,並釋放它們的狀態,父執行緒接管並完成聚合結果的角色。join是執行緒之間同步操作的一個範例,執行緒之間可以有許多其他型別的同步操作。有一組複雜的結構,執行緒可以用來協同執行非常複雜的任務,新增一組數位是一個非常簡單的例子。多執行緒程式可以用於執行其他複雜任務,如矩陣代數,甚至可以並行求解微分方程。
訊息傳統
接下來簡單地看看訊息傳遞,只給讀者一個訊息傳遞程式的概況,在這種情況下,每個程式都是一個單獨的實體,不與其他程式共用程式碼或資料。它是一個程序,其中程序被定義為程式的執行範例,通常不與任何其他程序共用其地址空間。
現在快速定義訊息傳遞語意,主要使用兩個函數:send和receive,如下表所示。send(pid, val)函數用於向id等於pid的程序傳送整數(val),receive(pid)用於接收id等於pid的程序傳送的整數。如果pid等於ANYSOURCE,那麼接收函數可以返回任何程序傳送的值。我們的語意基於流行的並行程式設計框架MPI(訊息傳遞介面),MPI呼叫有更多的引數,語法相對複雜。
| 函數 | 語意 |
|---|---|
| send(pid, val) | 將整數val傳送給id等於pid的程序。 |
| receive(pid) | 1、 從程序pid接收整數。 2、 函數會一直阻塞,直到它得到值。 3、 如果pid等於ANYSOURCE,則接收函數返回任何程序傳送的值。 |
現在考慮以下範例並行新增n個數位的相同範例。假設所有的數位都儲存在numbers陣列中,並且這個陣列可用於所有N個處理器,numbers元素數為SIZE。為了簡單起見,假設SIZE可被N整除。
/* start all the parallel processes */
SpawnAllParallelProcesses();
/* For each process execute the following code */
int myId = getMyProcessId();
/* 計算部分和 */
int startIdx = myId * SIZE/N;
int endIdx = startIdx + SIZE/N;
int partialSum = 0;
for(int jdx = startIdx; jdx < endIdx; jdx++)
partialSum += numbers[jdx];
/* 所有非根節點將其部分和傳送到根 */
if(myId != 0)
{
send (0, partialSum);
}
else
{
/* 處理根節點 */
int sum = partialSum;
for (int pid = 1; pid < N; pid++)
{
sum += receive(ANYSOURCE);
}
/* 關閉所有程序 */
shutDownAllProcesses();
return sum;
}
19.7.3 多處理器的設計空間
邁克爾·弗林(Michael J.Flynn)在1966年提出了著名的弗林對多處理器的分類,他從觀察到不同處理器的整合可能共用程式碼、資料或兩者兼而有之開始。有四種可能的選擇:SISD(單指令單資料)、SIMD(單指令多資料)、MISD(多指令單資料)和MIMD(多指令多資料),下面描述這些型別的多處理器:
-
SISD:是一個標準的單處理器,具有單個流水線。SISD處理器可以被看作是一組只有單個處理器的多處理器的特例。
-
SIMD:SIMD處理器可以在一條指令中處理多個資料流,例如SIMD指令可以用一條指令將4組數位相加。現代處理器將SIMD指令納入其指令集,並具有特殊的SIMD執行單元,例如包含SIMD指令集的SSE集的x86處理器。圖形處理器和向量處理器是高度成功的SIMD處理器的特殊例子。
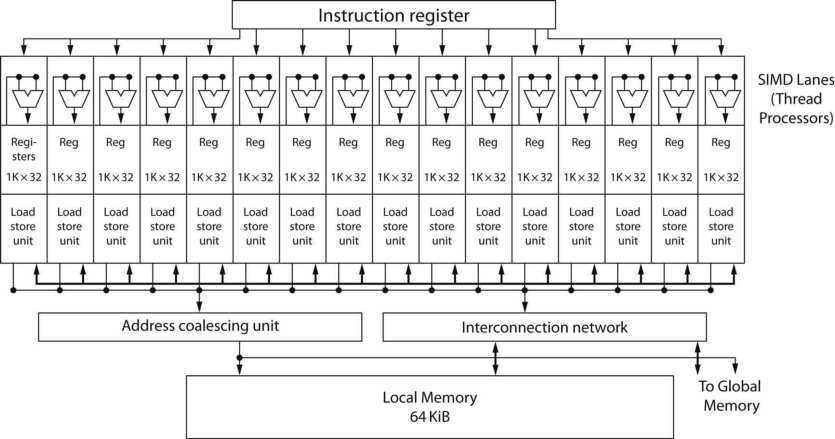
多執行緒SIMD處理器資料路徑的簡化框圖。。
-
MISD:MISD系統在實踐中非常罕見,主要用於可靠性要求非常高的系統中。例如,大型商用飛機通常有多個處理器執行同一程式的不同版本,最終結果由表決(voting)決定。例如,一架飛機可能有一個MIPS處理器、一個ARM處理器和一個x86處理器,每個處理器都執行著相同程式的不同版本,如自動駕駛系統,它們有多個指令流,但只有一個資料來源。專用投票電路(dedicated voting circuit)計算三個輸出的多數投票。例如,由於程式或處理器中的錯誤,其中一個系統可能錯誤地決定左轉,而其他兩個系統都可能做出正確的右轉決定,在這種情況下,投票電路將決定右轉。由於MISD系統幾乎從未在實踐中使用過,除了特殊的例子,本文不再討論它們。
-
MIMD:MIMD系統是目前最流行的多處理器系統,它們有多個指令流和多個資料流,多核處理器和大型伺服器都是MIMD系統。多個指令流意味著指令來自多個來源,每個源都有其唯一的位置和相關的程式計數器。MIMD正規化的兩個重要分支在過去幾年中形成。
第一個是SPMD(單程式多資料),第二個是MPMD(多程式多資料),大多數並行程式以SPMD風格編寫。同一程式的多個副本在不同的核心或獨立的處理器上執行,然而,每個單獨的處理單元都有單獨的程式計數器,因此可以感知不同的指令流。有時,SPMD程式的編寫方式會根據執行緒ID執行不同的操作,SPMD的優點是我們不必為不同的處理器編寫不同的程式。同一程式的部分可以在所有處理器上執行,儘管它們的行為可能不同。
一個對比的範例是MPMD,在不同處理器上執行的程式實際上是不同的,它們對於具有異構處理單元的專用處理器更有用。通常只有一個主程式將工作分配給從程式,從屬程式完成分配給它們的工作量,然後將結果返回給主程式。這兩個程式的工作性質實際上非常不同,通常不可能將它們無縫地組合到一個程式中。
在MIMD組織中,處理器是通用的,每個處理器都能夠處理執行適當資料轉換所需的所有指令。MIMD可以通過處理器通訊的方式進一步細分(下圖)。
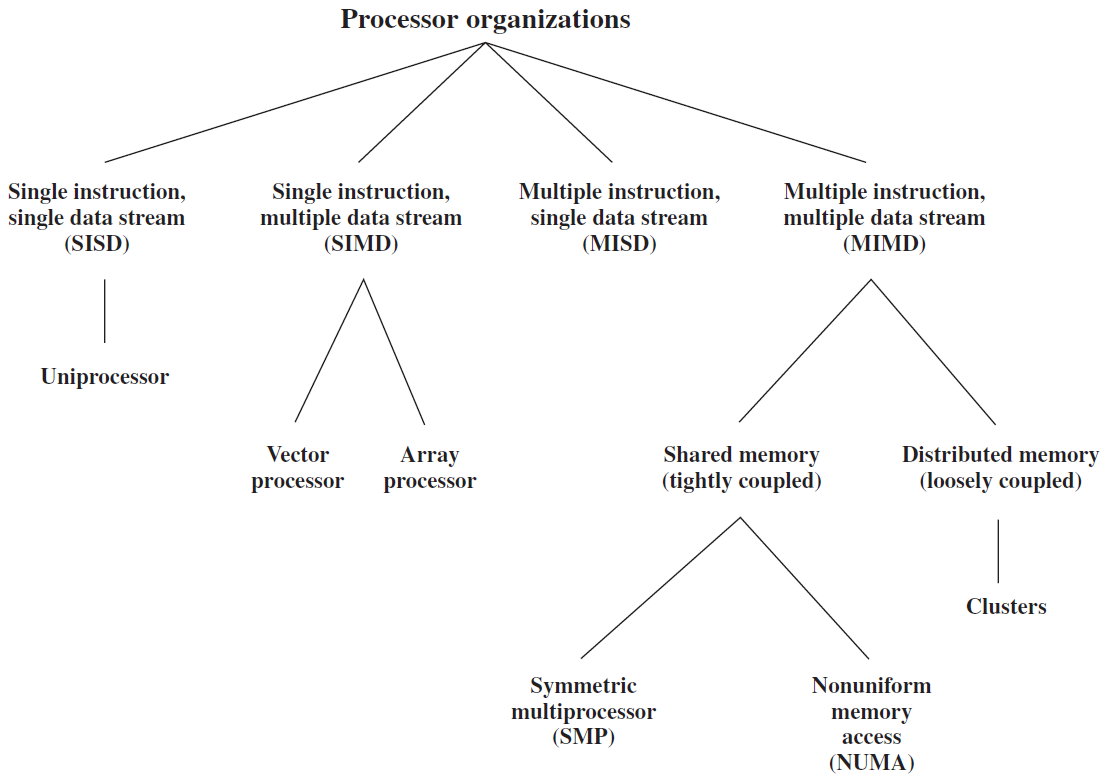
如果處理器共用一個公共記憶體,則每個處理器存取儲存在共用記憶體中的程式和資料,處理器通過該記憶體相互通訊,這種系統最常見的形式是對稱多處理器(SMP)。在SMP中,多個處理器通過共用匯流排或其他互連機制共用單個記憶體或記憶體池,區別特徵在於,對於每個處理器,對任何記憶體區域的記憶體存取時間大致相同。前些年的一個發展是非均勻記憶體存取(NUMA)組織,如下圖所述。顧名思義,NUMA處理器對不同記憶體區域的記憶體存取時間可能不同。
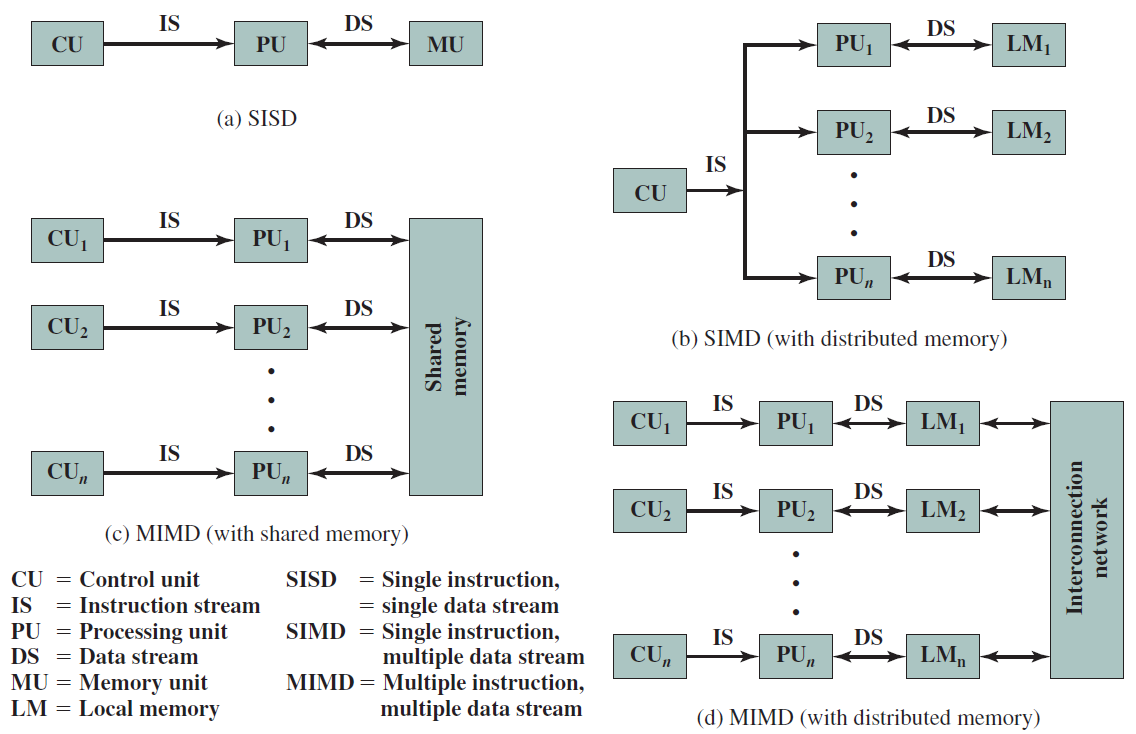
從上面的描述可以清楚地看出,我們需要關注的系統是SIMD和MIMD。由於MISD系統很少使用,不再討論,下面首先討論MIMD多處理,注意只描述MIMD多處理的SPMD變體,因為SPMD是最常見的方法。
19.7.4 MIMD多處理器
現在讓我們更深入地研究基於強耦合共用記憶體的MIMD機器,首先從軟體的角度來看它們,從軟體的角度制定了這些機器的廣泛規格之後,可以繼續對硬體的設計進行簡要概述。請注意,並行MIMD機器的設計可能需要一整本書來描述。
將共用記憶體MIMD機器的軟體介面稱為邏輯角度(logical point of view),並將多處理器的實際物理設計稱為物理角度(physical point of view)。當描述邏輯角度時,主要關心的是多處理器相對於軟體的行為,硬體對其行為有什麼保證,軟體可以期待什麼,包括正確性、效能,甚至是故障恢復能力。物理角度與多處理器的實際設計有關,包括處理器、儲存系統和互連網路的物理設計。請注意,物理角度必須符合邏輯角度。此處採用了與單處理器類似的方法,首先通過檢視組合程式碼來解釋軟體檢視(架構),然後通過描述流水線處理器(組織)為組合程式碼提供了一個實現。
19.7.4.1 邏輯視角
下圖顯示了共用記憶體MIMD多處理器的邏輯檢視。每個處理器都連線到儲存程式碼和資料的記憶體系統,其程式計數器指向它正在執行的指令的位置,即在記憶體的程式碼段,此段通常是唯讀的,因此不受我們有多處理器這一事實的影響。
多處理器系統的邏輯檢視。
實現共用記憶體多處理器的主要挑戰是正確處理資料存取。上圖顯示了一種方案,其中每個計算處理器都連線到記憶體,並將其視為一個黑盒。如果考慮具有不同虛擬地址空間的程序系統,就沒有問題。每個處理器都可以處理其資料的私有副本,由於記憶體佔用實際上是不相交的,可以很容易地在這個系統中執行一組並行程序。然而,當研究具有多個執行緒的共用記憶體程式,並且存在跨執行緒的資料共用時,主要的複雜性就出現了。請注意,我們還可以通過將不同的虛擬頁面對映到同一物理幀來跨程序共用記憶體,把這種情況視為並行多執行緒軟體的一種特殊情況。
一組並行執行緒通常共用其虛擬和實體地址空間,但執行緒也有私有資料,這些資料儲存在它們的堆疊中。有兩種方法可以實現不相交的堆疊。第一,所有執行緒都可以有相同的虛擬地址空間,不同的堆疊指標可以從虛擬地址空間中的不同點開始,需要進一步確保執行緒堆疊的大小不足以與另一個執行緒的堆疊重疊。另一種方法是將不同執行緒的虛擬地址空間的堆疊部分對映到不同的記憶體幀,每個執行緒可以在其頁面表中為堆疊部分有不同的條目,但對於虛擬地址空間的其餘部分(如程式碼、唯讀資料、常數和堆變數)有共同的條目。
在任何情況下,並行軟體複雜性的主要問題都不是因為程式碼是唯讀的,也不是因為執行緒之間不共用的區域性變數,主要問題是由於資料值可能在多個執行緒之間共用。這就是並行程式的強大之處,也使它們變得非常複雜。在前面展示的並行新增一組數位的範例中,我們可以清楚地看到通過共用記憶體共用值和計算結果所獲得的優勢。
然而,跨執行緒共用值並不是那麼簡單,是一個相當深刻的話題,本文簡要地看一下其中的兩個重要主題,即連貫性(coherence)和記憶體一致性(memory consistency)。當在快取上下文中提到一致性時,一致性也稱為快取一致性。然而,一致性不僅僅限於快取,它是一個通用術語。
一致性
記憶體系統中的一致性是指多個執行緒存取同一位置的方式。當多個執行緒存取同一記憶體位置時,許多不同的行為都是可能的,有些行為直覺上是錯誤的,但也有可能。在研究一致性之前,需要注意,在記憶體系統中,有許多不同的實體,如快取、寫入緩衝區和不同型別的臨時緩衝區。處理器通常將值寫入臨時緩衝區,然後恢復其操作。記憶體系統的工作是將資料從這些緩衝區傳輸到快取子系統中的某個位置。因此,在內部,給定的記憶體地址可能在給定的時間點與許多不同的物理位置相關聯。其次,將資料從處理器傳輸到記憶體系統中的正確位置(通常是快取塊)的過程不是瞬時的,記憶體讀取或寫入請求有時需要超過幾十個週期才能到達其位置。如果記憶體流量很大,這些記憶體請求訊息可能會等待更長時間,訊息也可以與之後傳送的其他訊息重新排序。
讓我們假設記憶體對於所有處理器來說都像一個大的位元組陣列,儘管在內部,它是一個由不同元件組成的複雜網路,這些元件努力為讀/寫操作提供簡單的邏輯抽象。多處理器記憶體系統的內部複雜性導致了存取同一組共用變數的程式的幾種有趣行為。
讓我們考慮一組範例。在每個範例中,所有共用值都被初始化為0,所有區域性變數都以t開頭,如t1、t2和t3。假設執行緒1寫入跨執行緒共用的變數x,緊接著,執行緒2嘗試讀取其值。
// Thread 1:
x = 1
// Thread 2:
t1 = x
執行緒2是否保證讀取1?或者,它可以得到以前的值0嗎?如果執行緒2在2 ns甚至10 ns後讀取x的值,該怎麼辦?一個執行緒中的寫入傳播到其他執行緒所需的時間是多少?這些問題的答案取決於記憶體系統的實現。如果記憶體系統有快速匯流排和快速快取,那麼寫操作可以很快地傳播到其他執行緒。但是,如果匯流排和快取很慢,那麼其他執行緒可能需要更多時間才能看到對共用變數的寫入。
現在,把這個例子進一步複雜化,假設執行緒1寫入x兩次:
// Thread 1:
x = 1
x = 2
// Thread 2:
t1 = x
t2 = x
現在讓我們看看一系列可能的結果:(t1,t2)=(1,2)、(t1,t2) = (0,1)都是可能的,當t1線上程1啟動之前寫入,而t2線上程1的rst語句完成之後寫入時,這是可能的。同樣,可以系統地列舉所有可能結果的集合,這些結果是:(0,0)、(0,1)、(0,2)、(1,1)、(1,2)和(2,2)。有趣的問題是,結果(2,1)是否可能?如果對x的第一次寫入在記憶體系統中被延遲,而第二次寫入超過了它,這也許是可能的,但問題是我們是否應該允許這種行為。
答案是否定的。如果我們允許這種行為,那麼實現多處理器記憶體系統無疑會變得更簡單,但編寫和推理並行程式將變得非常困難。因此,大多數多處理器系統都不允許這種行為。
現在稍微正式地看看多個執行緒存取同一記憶體位置的問題。我們理想地希望記憶體系統是連貫的,意味著在處理對同一記憶體地址的不同存取時,它應該遵守一組規則,以便更容易編寫程式。
記憶體存取同一記憶體地址的行為稱為一致性(coherence)。
通常,一致性有兩個公理:
- 完成(Completion):寫入必須最終完成。此公理表示,記憶體系統中永遠不會丟失任何寫入,例如不可能將值10寫入變數x,而寫入請求會被記憶體系統丟棄,它需要到達x對應的記憶體位置,然後需要更新其值,稍後可能會被另一個寫入請求覆蓋。然而,底線是寫請求需要在將來的某個時間點更新記憶體位置。
- 順序(Order):對同一記憶體地址的所有寫入都需要被所有執行緒以相同的順序看到。此公理表示,所有執行緒都認為對記憶體位置的所有寫入順序相同,意味著不可能讀取上面案例中的(2,1),因為執行緒1知道2是在1之後寫入到儲存位置x的,根據順序公理,所有其他執行緒都需要感知到寫入x的相同順序,它們對x的感知不能與執行緒1的感知不同,因此,它們不能在1之後讀取2。一致性的公理具有直觀的意義,基本上意味著所有的寫入最終都會完成,單處理器系統也是如此。其次,所有處理器都看到單個記憶體位置的相同檢視,如果其值從0變為1變為2,則所有處理器都會看到相同的變化順序(0-1-2),沒有處理器以不同的順序看到更新。這進一步意味著,無論記憶體系統如何在內部實現,在外部,每個記憶體位置都被視為可全域性存取的單個位置。
記憶體一致性
一致性是指對同一記憶體位置的存取,如何存取不同的儲存位置?可用一系列例子來解釋。
// Thread 1:
x = 1;
y = 1;
// Thread 2:
t1 = y;
t2 = x;
現在從直觀的角度來看t1和t2的允許值,總是可以獲得(t1,t2)=(0,0),當執行緒2線上程1之前排程時,可能會發生這種情況。還可能獲得(t1,t2)=(1,1),當執行緒2線上程1完成後排程時,會發生這種情況。同樣,可以讀取(t1,t2)=(0,1)。下圖顯示瞭如何獲得所有三種結果。
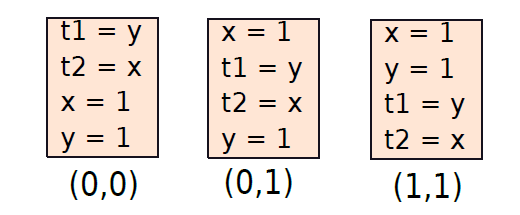
所有可能結果的示意圖。
有趣的問題是(t1,t2)=(1,0)是否被允許?當對x的寫入被記憶體系統以某種方式延遲,而對y的寫入很快完成時,就會發生這種情況。在這種情況下,t1將獲得y的更新值,t2將獲得x的舊值。是否允許這種行為?很明顯,如果允許這種行為,就很難對軟體和並行演演算法的正確性進行推理,程式設計也將變得困難。然而,如果允許這種行為,那麼硬體設計就會變得更簡單,因為不必為軟體提供強有力的保證。
答案顯然沒有對錯之分?完全取決於我們想要如何程式設計軟體,以及硬體設計師想要為軟體編寫人員構建什麼。但是,這個例子仍然有一些非常深刻的東西,(t1,t2)=(1,0)的特例。為了找出原因,再次檢視上圖,我們已經能夠通過在兩個執行緒的指令之間建立交錯來推理三個結果。在這些交錯中,同一執行緒中的指令順序與程式中指定的順序相同,稱為程式順序(program order)。
與每個組成執行緒的控制流語意一致的指令順序(可能屬於多個執行緒)稱為程式順序(program order)。執行緒的控制流語意被定義為一組規則,用於確定在給定指令之後可以執行哪些指令,例如,單週期處理器執行的指令集總是按程式順序執行。
很明顯,我們不能通過按程式順序交錯執行緒來生成結果(t1,t2)=(1,0)。
如果我們能從可能的輸出集合中排除輸出(1,0),那就好了,將允許編寫並行軟體,很容易地預測可能的結果。確定並行程式可能結果集的記憶體系統模型稱為記憶體模型(memory model)。
確定並行程式可能結果集的記憶體系統模型稱為記憶體模型(memory model)。
順序一致性(Sequential Consistency)
我們可以有不同型別的記憶體模型,對應於不同型別的處理器,最重要的記憶體模型之一是順序一致性(Sequential Consistency,SC)。順序一致性表示,只允許通過按程式順序交錯執行緒生成那些結果,意味著上圖所示的所有結果都是允許的,因為它們是通過以所有可能的方式交錯執行緒1和執行緒2生成的,而不會違反它們的程式順序。然而,結果(t1,t2)=(1,0)是不允許的,因為它違反了程式順序,在順序一致的記憶體模型中是不允許的。請注意,一旦我們按照程式順序交錯多個執行緒,就等於說我們有一個處理器在一個週期中執行一個執行緒的指令,可能在下一個週期執行另一個其他執行緒的指令。因此,處理多個執行緒的單處理器產生SC執行。事實上,如果我們考慮模型的名稱,「sequential」一詞來源於這樣一個概念,即執行等同於單處理器以某種順序順序執行所有執行緒的指令。
如果一組並行執行緒的執行結果等同於單個處理器以某種順序執行來自所有執行緒的指令的結果,則記憶體模型是順序一致的。或者,可以將序列一致性定義為一個記憶體模型,其一組可能的結果是可以通過按程式順序交錯一組執行緒來生成的結果。
序列一致性是一個非常重要的概念,在電腦架構和分散式系統領域得到了廣泛的研究。它通過將並行系統上的執行等同於順序系統上的執行,將並行系統簡化為具有一個處理器的序列系統。需要注意的一點是,SC並不意味著一組並行程式的執行結果始終相同,取決於執行緒的交錯方式以及執行緒到達的時間,但某些結果是不允許的。
弱一致性(Weak Consistency)
SC的實施是有代價的,使軟體變得簡單,但使硬體變得非常慢。為了支援SC,通常需要等待讀取或寫入完成,然後才能將下一次讀取或寫入傳送到記憶體系統。當任何處理器的所有後續讀取都將獲得W已寫入的值或稍後寫入同一位置的值時,寫入請求W完成。讀取資料後,讀取請求完成,而最初寫入資料的寫入請求完成。
這些要求/限制成為高效能系統的瓶頸,因此計算機架構社群已經轉向違反SC的弱記憶體模型。弱記憶體模型將允許以下多執行緒程式碼段中的結果(t1,t2)=(1,0)。
// Thread 1:
x = 1
y = 1
// Thread 2:
t1 = y
t2 = x
弱一致性(weakly consistent ,WC)記憶體模型不符合SC,通常允許任意記憶體排序。
弱記憶體模型有不同的型別,一個通用的變體是弱一致性(WC)。現在嘗試找出為什麼WC允許(1,0)結果,假設執行緒1在核心1上執行,執行緒2在核心2上執行。此外,假設對應於x的記憶體位置在核心2附近,對應於y的記憶體位置位於核心1附近。還假設從核心1附近向核心2傳送請求需要數十個週期,並且延遲是可變的。
首先研究核心1的流水線的行為。從核心1流水線的角度來看,一旦將記憶體寫入請求移交給記憶體系統,則認為記憶體寫入指令已完成,指令進入RW階段。因此,在這種情況下,處理器將在第-n個週期中將對x的寫入移交給記憶體系統,然後在第(n+1)個週期中將寫入傳遞給y。對y的寫入將很快到達y的記憶體位置,而對x的寫入將需要很長時間。
同時,核心2將嘗試讀取y的值。假設讀取請求在寫入請求(到y)到達y之後到達y的記憶體位置,將得到y的新值,該值等於1。隨後,核心2將對x發出讀操作,對x的讀操作可能在對x的寫操作到達x之前到達x的記憶體位置。在這種情況下,它將獲取x的舊值,即0。因此,結果(1,0)在弱記憶體模型中是可能的。
為了避免這種情況,我們可以等待對x的寫入完全完成,然後再向y發出寫入請求,這樣做雖然是正確的,但是一般來說,當我們寫入共用記憶體位置時,其他執行緒不會在完全相同的時間點讀取它們。我們無法在執行時區分這兩種情況,因為處理器之間不共用它們的記憶體存取模式。為了提高效能,將每個記憶體請求延遲到前一個記憶體請求完成是不值得的。因此,高效能實現更喜歡允許來自同一執行緒的記憶體存取由記憶體系統重新排序的記憶體模型。我們將在後續小節中研究避免(1,0)結果的方法。
大多數處理器都假定記憶體請求在離開管線後的某個時間點瞬間完成,此外,所有執行緒都假定記憶體請求在完全相同的時間點瞬間完成。記憶體請求的這個屬性稱為原子性(atomicity)。其次,需要注意,記憶體請求的完成順序可能與它們的程式順序不同。當完成順序與每個執行緒的程式順序相同時,記憶體模型遵循SC,如果完成順序與程式順序不同,則記憶體模型是WC的變體。
當記憶體請求在發出後的某個時間點被所有執行緒感知為瞬時執行時,稱其為原子的(atomic)或觀察原子性(observe atomicity)。
準確地說,對於每個記憶體請求,都有三個感興趣的事件,即開始、結束和完成。讓我們考慮一個寫請求。當指令將請求傳送到MA階段的L1快取時,請求開始。當指令移動到RW階段時,請求完成。在現代處理器中,無法保證在記憶體請求完成時寫入會到達目標記憶體位置,寫入請求到達記憶體位置且寫入對所有處理器可見的時間點稱為完成時間。在簡單的處理器中,完成請求的時間介於開始時間和結束時間之間。然而,在高效能處理器中,情況並非如此。此概念如下圖所示。

讀請求怎麼樣?大多數人會天真地認為讀取的完成時間介於開始時間和結束時間之間,因為它需要返回記憶體位置的值。然而,這並不完全正確,因為讀取可能會返回尚未完成的寫入的值。在要求寫入原子性(寫入瞬間完成的錯覺)的記憶體模型中,只有當相應的寫入請求完成時,讀取才完成。所有假定寫原子性的記憶體一致性模型都是使用記憶體存取完成順序的屬性來定義的。
在弱記憶體模型中,不遵循同一執行緒中獨立記憶體操作之間的順序。例如,當我們寫到x,然後寫到y時,執行緒2發現它們的順序相反。然而,屬於同一執行緒的從屬記憶體指令的操作順序始終受到遵循。例如,如果將變數x的值設定為1,然後在同一執行緒中讀取它,我們將得到1或稍後寫入x的值,所有其他執行緒都會感知記憶體請求的順序相同。在由同一執行緒進行的從屬記憶體存取之間,絕不存在任何記憶體順序衝突(參見下圖)。
多執行緒程式中記憶體請求的實際完成時間。
現在說明使用不遵守任何順序規則的弱記憶體模型的困難。假設一個順序一致的系統,讓我們編寫並行加法程式。請注意,不使用OpenMP,因為OpenMP在幕後做了很多工作,以確保程式在記憶體模型較弱的機器上正確執行。讓我們定義一個並行構造,它並行執行一個程式碼塊,以及一個getThreadId()函數,它返回執行緒的識別符號,執行緒id的範圍是從0到N-1。並行加法函數的程式碼如下所示。假設在並行部分開始之前,所有陣列都被初始化為0,在並行部分中,每個執行緒將其部分數位相加,並將結果寫入陣列中相應的條目partialSums。完成後,它將完成陣列中的條目設定為1。
/* variable declaration */
int partialSums[N];
int finished[N];
int numbers[SIZE];
int result = 0;
int doneInit = 0;
/* initialise all the elements in partialSums and finished to 0 */
(...)
doneInit = 1;
/* parallel section */
parallel
{
/* wait till initialisation */
while (!doneInit()){};
/* compute the partial sum */
int myId = getThreadId();
int startIdx = myId * SIZE/N;
int endIdx = startIdx + SIZE/N;
for(int jdx = startIdx; jdx < endIdx; jdx++)
partialSums[myId] += numbers[jdx];
/* set an entry in the finished array */
finished[myId] = 1;
}
/* wait till all the threads are done */
do
{
flag = 1;
for (int i=0; i < N; i++)
{
if(finished[i] == 0)
{
flag = 0;
break;
}
}
} while (flag == 0);
/* compute the final result */
for(int idx=0; idx < N; idx++)
result += partialSums[idx];
現在闡述需要聚合結果的執行緒,它需要等待所有執行緒完成計算部分和的工作,通過等待完成的陣列中的所有條目都等於1來實現這一點。一旦確定完成的陣列的所有條目均等於1,它就繼續將所有部分和相加,以獲得最終結果。可以很容易驗證,如果假設一個順序一致的系統,那麼這段程式碼會正確執行。她需要注意的是,只有當讀取陣列中的所有條目完成為1時,才計算結果。如果計算部分和並寫入partialSums陣列,則完成陣列中的條目等於1。由於我們新增了partialSums陣列的元素來計算最終結果,因此可以得出結論,它是正確計算的。
現在考慮一個弱記憶體模型,在上面的範例中以順序一致性隱式假設,當最後一個執行緒讀取finished[i]為1時,partialSums[i]包含部分和的值。然而,如果假設弱記憶體模型,則此假設不成立,因為記憶體系統可能會將寫入重新排序為finished[i]和partialSums[i]。因此,在具有弱記憶體模型的系統中,寫入完成的陣列可能發生在寫入partialSums陣列之前。在這種情況下,finished[i]等於1的事實並不保證partialSums[i]包含更新的值。這種區別正是順序一致性對程式設計師非常友好的原因。
在弱記憶體模型中,同一執行緒發出的記憶體存取總是被該執行緒認為是按程式順序進行的。但是,其它執行緒可以不同地感知記憶體存取的順序。
回到確保並行加法範例正確執行的問題上。擺脫困境的唯一方法是有一種機制,確保在另一個執行緒讀取完成[i]為1之前完成對partialSums[i]的寫入。我們可以使用一種稱為柵欄(fence)的通用指令,此指令確保在柵欄開始後的任何讀取或寫入之前完成柵欄之前發出的所有讀取和寫入。簡單地說,我們可以通過在每條指令後插入柵欄,將弱記憶體模型轉換為順序一致的模型。然而,這可能會導致大量開銷,最好在需要時引入最少數量的柵欄指令。下面通過新增圍欄指令,為弱記憶體模型並行新增一組數位。
/* variable declaration */
int partialSums[N];
int finished[N];
int numbers[SIZE];
int result = 0;
/* initialise all the elements in partialSums and finished to 0 */
(...)
/* fence */
/* 確保並行部分可以讀取初始化的陣列 */
fence();
/* All the data is present in all the arrays at this point */
/* parallel section */
parallel
{
/* get the current thread id */
int myId = getThreadId();
/* compute the partial sum */
int startIdx = myId * SIZE/N;
int endIdx = startIdx + SIZE/N;
for(int jdx = startIdx; jdx < endIdx; jdx++)
partialSums[myId] += numbers[jdx];
/* fence */
/* 確保在partialSums[i]之後寫入finished[i] */
fence();
/* set the value of done */
finished[myId] = 1;
}
/* wait till all the threads are done */
do
{
flag = 1;
for (int i=0; i < N; i++)
{
if(finished[i] == 0)
{
flag = 0;
break;
}
}
} while (flag == 0) ;
/* sequential section */
for(int idx=0; idx < N; idx++)
result += partialSums[idx];
上述程式碼顯示了弱記憶體模型的程式碼,程式碼與順序一致記憶體模型的程式碼大致相同,唯一的區別是我們增加了兩個額外的柵欄指令。我們假設一個名為fence()的函數在內部呼叫fence指令,在呼叫所有並行執行緒之前,首先呼叫fence(),確保初始化資料結構的所有寫入都已完成。隨後開始並行執行緒,並行執行緒完成計算和寫入部分和的過程,然後再次呼叫fence操作,以確保在完成[myId]設定為1之前,所有部分和都已計算並寫入記憶體中各自的位置。其次,如果最後一個執行緒讀取finished[i]為1,就可以確定partialSums[i]的值是最新的並且正確的。因此,儘管記憶體模型較弱,該程式仍能正確執行。
因此,如果程式設計師意識到弱記憶體模型並在正確的位置插入柵欄,那麼弱記憶體模型不會影響正確性。儘管如此,程式設計師有必要理解弱記憶體模型,否則,會因為程式設計師沒有考慮底層記憶體模型,導致並行程式中會出現很多細微的錯誤。弱記憶體模型目前被大多數處理器使用,因為它們允許我們構建高效能記憶體系統。相比之下,順序一致性非常有限,除了MIPS R10000,沒有其他主要供應商提供具有順序一致性的機器,目前所有基於x86和ARM的機器都使用不同版本的弱記憶體模型。
19.7.4.2 物理視角
我們研究了多處理器記憶體系統邏輯檢視的兩個重要方面,即連貫性和一致性,需要實現一個兼顧這兩個屬性的記憶體系統。本節將研究多處理器記憶體系統的設計空間,並提供設計備選方案的概述。為多處理器記憶體系統設計快取記憶體有兩種方法:第一種設計稱為共用快取,其中單個快取在多個處理器之間共用。第二種設計使用一組專用快取,其中每個處理器或一組處理器通常都有一個專用快取。所有的私有快取共同作業提供共用快取的錯覺,這就是所謂的快取一致性(cache coherence)。
本節將研究共用快取的設計和私有快取的設計,介紹確保記憶體一致性的問題,最終將得出結論,有效實現給定的一致性模型(如順序一致性或弱一致性)是困難的,並且是高階電腦架構課程中的一個研究主題,本文提出了一個簡單的解決方案。
多處理器記憶體系統:共用和私有快取
首先考慮一級快取。可以給每個處理器單獨的指令快取,指令表示唯讀資料,通常在程式執行期間不會改變。由於共用不是問題,所以每個處理器都可以從其小型專用指令快取中受益,主要問題是資料快取。設計資料快取有兩種可能的方法,可以有共用快取,也可以有私有快取。共用快取是所有處理器都可以存取的單個快取,私有快取只能由一個處理器或一組處理器存取。可以有共用快取的層次結構,也可以有私有快取的層次結構,甚至可以在同一系統中有共用和私有快取的組合,如下圖所示。
具有共用和私有快取的系統範例。
現在評估一下共用快取和私有快取之間的權衡。共用快取可供所有處理器存取,並且包含快取記憶體位置的單個條目,通訊協定很簡單,就像任何常規快取存取一樣。額外的複雜性主要是因為我們需要正確地排程來自不同處理器的請求。然而,以簡單為代價,共用快取也有其問題,為了服務來自所有處理器的請求,共用快取需要有大量的讀寫埠來同時處理請求。不幸的是,快取的大小大約是埠數的平方。此外,共用快取需要容納當前執行的所有執行緒的工作集,因此,共用快取往往變得非常大和緩慢。由於物理限制,很難在所有處理器附近放置共用快取。相比之下,私有快取通常要小得多,服務請求的核心更少,讀/寫埠數量更少。因此,它們可以放置在與其關聯的處理器附近。因此,私有快取的速度要快得多,因為它可以放在離處理器更近的地方,而且大小也要小得多。
為了解決共用快取的問題,設計者經常使用私有快取,尤其是在記憶體層次結構的更高層。私有快取只能由一個處理器或一小組處理器存取,它們體積小,速度快,耗電量小。私有快取的主要問題是它們需要為程式設計師提供共用快取的假象,例如,一個具有兩個處理器的系統,以及與每個處理器關聯的專用資料快取。如果一個處理器寫入記憶體地址x,則另一個處理器需要知道該寫入。然而,如果它只存取其私有快取,那麼它將永遠不會知道寫入地址x,意味著寫入地址x丟失,因此係統不一致。因此,需要繫結所有處理器的私有快取,使它們看起來像一個統一的共用快取,並遵守一致性規則。快取上下文中的一致性通常稱為快取一致性(cache coherence)。保持快取一致性是私有快取的另一個複雜性來源,並限制了其可延伸性。它適用於小型私人快取,然而,對於更大的私有快取,維護一致性的開銷變得令人望而卻步。對於大型低階別快取,共用快取更合適。其次,通常會跨多個私有快取進行一些資料複製,但會浪費空間。
一組私有快取上下文中的一致性稱為快取一致性(cache coherence)。
通過實現快取一致性協定,可以將一組不相交的私有快取轉換為軟體共用快取。下表概述共用快取和私有快取之間的主要權衡。
| 屬性 | 私有快取 | 共用快取 |
|---|---|---|
| 面積 | 低 | 高 |
| 速度 | 快 | 慢 |
| 接近處理器 | 近 | 遠 |
| 尺寸擴充套件性 | 低 | 高 |
| 資料複製 | 是 | 否 |
| 複雜度 | 高(需快取一致性) | 低 |
從表中可以清楚地看出,一級快取最好是私有的,因為可獲得低延遲和高吞吐量。然而,較低階別需要更大的尺寸,並且服務的請求數量要少得多,因此它們應該包括共用快取。接下來描述一致的私有快取和大型共用快取的設計。為了簡單起見,只考慮單層私有快取,而不考慮分層私有快取,它們會引入額外的複雜性。先討論共用快取的設計,因為它們更簡單。
19.7.4.3 共用快取
在共用快取的最簡單實現案例中,可以將其實現為單處理器中的常規快取,但在實踐中它被證明是一種非常糟糕的方法,原因是在單處理器中,只有一個執行緒存取快取;然而在多處理器中,多個執行緒可能會存取快取,因此我們需要提供更多的頻寬。如果所有執行緒都需要存取相同的資料和標記陣列,那麼要麼請求必須暫停,要麼必須增加陣列中的埠數,導致面積和功率產生非常負面的後果。最後,根據摩爾定律,快取大小(尤其是L2和L3)大致加倍,如今片上快取的大小可達4-16 MB甚至更多。如果對整個快取使用單個標籤陣列,那麼它將非常大且速度很慢。術語最後一級快取(last level cache,LLC)定義為在記憶體層次結構中位置最低的片上快取(主記憶體最低),例如,如果多核處理器有一個連線到主記憶體的片上L3快取記憶體,那麼LLC就是L3高速緩衝記憶體。後面會經常使用術語LLC。
要建立一個可以同時支援多個執行緒的多兆位元組LLC,需要將其拆分為多個子快取。假設有一個4 MB的LLC,在一個典型的設計中,它將被分成8-16個更小的子快取(subcache),每個子快取的大小為256-512 KB,這是可接受的大小。每個子快取本身就是一個快取,稱為快取庫(cache bank)。因此,實際上將一個大型快取拆分為一組快取庫,快取庫可以是直接對映的,也可以設定為關聯的。存取多庫快取有兩個步驟:首先計算庫地址,然後在庫執行常規快取存取。用一個例子來解釋,考慮一個16組、4 MB的快取,每個庫包含256KB的資料,4 MB=\(2^{22}\)位元組,可以將位19-22專用於選擇存地址。注意,在這種情況下,庫選擇與關聯性無關。選擇一個庫後,可以在塊內的偏移量、集合索引和標籤之間分割剩餘的28位元。
將快取劃分為多個庫有兩個優點。第一,減少了每個庫的爭用量。如果我們有4個執行緒和16個庫,那麼2個執行緒存取同一庫的概率很低。其次,由於每個庫都是一個較小的快取,因此它更省電、更快。因此,我們實現了支援多執行緒和設計快速快取的雙重目標。
19.7.4.4 私有快取
我們的目的是使一組私有快取的行為就像是一個大型共用快取,從軟體的角度來看,我們不應該知道快取是私有的還是共用的。系統的概念圖如下圖所示,它顯示了一組處理器及其相關快取,這組快取形成一個快取組,整個快取組需要顯示為一個快取。
具有許多處理器及其私有快取的系統。其中左側是軟體視角,而右側是硬體視角。
這些快取通過內部網路連線,內部網路可以從簡單的共用匯流排型別拓撲到更復雜的拓撲。假設所有快取都連線到共用匯流排,共用匯流排允許在任何時間點使用單個寫入器和多個讀取器。如果一個快取將訊息寫入匯流排,那麼所有其他快取都可以讀取該訊息。拓撲結構如下圖所示。請注意,匯流排在寫入訊息的任何時間點只提供對一個快取的獨佔存取,因此所有快取都感知到相同的訊息順序。一種與連線在共用匯流排上的快取實現快取一致性的協定稱為監聽協定(snoopy protocol)。
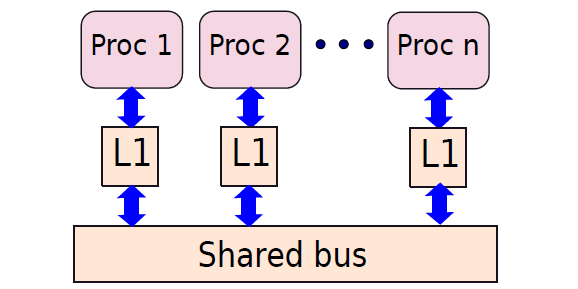 ng)
ng)
與共用匯流排連線的快取。
現在讓我們從一致性的兩個公理的角度來考慮史努比協定的操作:寫入總是完成(完成公理),並且所有處理器都以相同的順序看到對同一塊的寫入(順序公理)。如果快取i希望對一個塊執行寫入操作,那麼該寫入需要最終對所有其他快取可見。我們需要這樣做來滿足完成公理,因為不允許丟失寫請求。其次,對同一塊的不同寫入需要以相同的順序到達可能包含該塊的所有快取(順序公理),以確保對於任何給定的塊,所有快取感知到相同的更新順序。共用匯流排自動滿足順序公理的要求。
下面給出兩個監聽協定的設計:寫更新(write-update)和寫無效(write-invalidate)。
寫更新協定
現在讓我們設計一個協定,假設一個私有快取儲存一個寫請求的副本,並將寫請求廣播到所有快取。此策略確保寫入永遠不會丟失,並且所有快取都以相同的順序感知到同一塊的寫入訊息。此策略要求無論何時寫入都要廣播,是一個很大的額外開銷,然而,這一策略依然奏效。
現在將讀取納入協定。對位置x的讀取可以首先檢查私有快取,以檢視其副本是否已經可用。如果有效副本可用,則可以將該值轉發給請求處理器。但是,如果存在快取未命中,那麼它可能與快取組中的另一個姐妹快取一起存在,或者可能需要從較低階別獲取。首先檢查該值是否存在於姐妹快取中,此處遵循相同的流程,快取向所有快取廣播讀取請求,如果任何一個快取具有該值,則它會進行回覆,並將該值傳送到請求快取。請求快取插入該值,並將其轉發給處理器。但是,如果它沒有從任何其他快取獲得任何回覆,那麼它將啟動對較低階別的讀取。
該協定稱為寫更新(write-update)協定。每個快取塊需要保持三種狀態:M、S和I。M表示修改後的狀態,表示快取已經修改了塊,S(共用)表示快取未修改塊,I(無效)表示塊不包含有效資料。
下圖顯示了每個快取塊的有限狀態機(FSM),該FSM由快取記憶體控制器執行,狀態轉換的格式是:事件/動作。如果快取控制器被傳送了一個事件,那麼它會採取相應的動作,可能包括狀態轉換。請注意,在某些情況下,動作欄位為空,意味著在這些情況下,不採取任何行動。請注意,快取塊的狀態是其在標記陣列中的條目的一部分,如果快取中不存在塊,則其狀態被假定為無效(I)。值得一提的是,下圖顯示了處理器生成的事件的轉換,它不顯示快取組中其他快取通過匯流排傳送的事件的操作。
寫更新協定中的狀態轉換圖。
所有塊最初都處於I狀態。如果存在讀取未命中,則它將移動到S狀態,還需要向快取組中的所有快取廣播讀未命中,並從姊妹快取或較低階別獲取值。請注意,我們首先優先考慮姊妹快取,因為它可能修改了塊而沒有將其寫回較低階別。類似地,如果在I狀態中存在寫入未命中,那麼需要從另一個姊妹快取中讀取塊(如果它可用),並移動到M狀態。如果沒有其他姐妹快取具有該塊,那麼需要從記憶體層次結構的較低階別讀取該塊。
如果在S狀態下有讀取命中,就可以無縫地將資料傳遞給處理器。但如果要寫入S狀態的塊,就需要將寫入廣播到所有其他快取,以便它們獲得更新的值。一旦快取從匯流排獲取了其寫入請求的副本,它就可以將值寫入塊,並將其狀態更改為M。要將處於S狀態的塊逐出,只需要將其從快取中逐出,此時沒有必要寫回其值,因為塊尚未修改。
現在考慮M狀態。如果需要讀取M狀態的塊,那麼可以從快取中讀取它,並將值傳送給處理器。沒有必要傳送任何訊息,但如果希望寫入它,則需要在匯流排上傳送寫入請求。一旦快取看到自己的寫入請求到達共用匯流排,它就可以將其值寫入其專用快取中的記憶體位置。要回收M狀態的塊,需要將其寫回記憶體層次結構中的較低階別,因為它已被修改。
每個匯流排都有一個稱為仲裁器(arbiter)的專用結構,它接收來自不同快取的使用匯流排的請求,按FIFO順序將匯流排分配給快取。匯流排仲裁器的示意圖如下圖所示,是一個非常簡單的結構,包含一個在匯流排上傳輸的請求佇列。每個週期它從佇列中提取一個請求,並向相應的快取授予在匯流排上傳輸訊息的許可權。
匯流排仲裁器結構。
現在考慮一個姐妹快取。每當它從匯流排收到一條未命中訊息時,它就會檢查快取以確定是否有該塊。如果有快取命中,它就將塊傳送到匯流排上,或直接傳送到請求快取。它如果接收到另一個快取的寫入通知,就會更新其快取中存在的塊的內容。
目錄協定
請注意,在監聽協定中,我們總是廣播寫入、讀取未命中或寫入未命中,實際上只需要向那些包含塊副本的快取傳送訊息。目錄協定(directory protocol)使用稱為目錄的專用結構來維護此資訊,對於每個塊地址,目錄維護一個共用者列表。共用者是可能包含該塊的快取的id,共用者列表通常是可能包含給定塊的快取的超集。我們可以將共用者列表保持為位向量(每個共用者1位),如果位為1,則快取包含一個副本,否則不包含。
帶有目錄的寫更新協定修改如下。快取不是在匯流排上廣播資料,而是將其所有訊息傳送到目錄。對於讀或寫未命中,目錄從姊妹快取中獲取塊(如果它有副本),然後它將塊轉發到請求快取。類似地,對於寫入,目錄只將寫入訊息傳送到那些可能有塊副本的快取,當快取插入或回收塊時,需要更新共用者列表。最後,為了保持一致性,目錄需要確保所有快取以相同的順序獲取訊息,並且不會丟失任何訊息。目錄協定最大限度地減少了需要傳送的訊息的數量,因此更具可延伸性。
監聽協定(Snoopy Protocol):在監聽協定中,所有快取都連線到共用匯流排。快取將每條訊息廣播到其他快取。
目錄協定(Directory Protocol):在目錄協定中,通過新增一個稱為目錄的專用結構來減少訊息的數量。該目錄維護可能包含塊副本的快取列表,只向列表中的快取傳送給定塊地址的訊息。
為什麼需要等待匯流排的廣播來執行寫入?
答:讓我們假設情況並非如此,處理器1希望將1寫入x,處理器2希望將2寫入x。然後,它們將首先分別將1和2寫入x的副本,然後廣播寫入,因此兩個處理器將以不同的順序看到對x的寫入。這違反了秩序公理。但是,如果它們等待寫入請求的副本從匯流排到達,那麼它們將以相同的順序寫入x。匯流排有效地解決了處理器1和2之間的衝突,並對一個請求進行排序。
寫無效協定
我們需要注意的是,為每次寫入廣播寫入請求是不必要的開銷,有可能大多數塊在一開始就不共用,所以不需要在每次寫入時傳送額外的訊息。讓我們嘗試通過提出寫無效協定來減少寫更新協定中的訊息數量,此處可以使用監聽協定,也可以使用目錄協定。下面展示一個監聽協定的範例。
為每個塊保持三個狀態:M、S和I,但改變狀態的含義:
- 無效狀態(I)保留相同含義,意味著該條目實際上不存在於快取中。
- 共用狀態(S)意味著快取可以讀取塊,但不能寫入塊,在共用狀態下,可以在不同的快取中擁有同一塊的多個副本。由於共用狀態假定塊是唯讀的,因此具有塊的多個副本不會影響快取一致性。
- M(已修改)狀態表示快取可以寫入塊。如果一個塊處於M狀態,那麼快取組中的所有其他快取都需要使該塊處於I狀態。不允許任何其他快取具有S或M狀態的塊的有效副本,這就是寫無效協定不同於寫更新協定的地方。它一次只允許一個寫入,或者一次允許多個讀取,絕不允許讀和寫同時共存。通過限制在任何時間點對塊具有寫存取許可權的快取數量,可以減少訊息的數量。
內部機制如下。寫更新協定不必在讀命中時傳送任何訊息,所以當寫命中時傳送了額外的訊息,我們希望消除之。它需要傳送額外的訊息,因為多個快取可以同時讀取或寫入一個塊。寫無效協定已經消除了這種行為,如果一個塊處於M狀態,那麼沒有其他快取包含該塊的有效副本。
下圖顯示了由於處理器的動作而導致的狀態轉換圖,狀態轉換圖與寫更新協定的狀態轉換圖基本相同。讓我們看看差異。第一種是,我們定義了三種型別的訊息放在匯流排上,即寫入、寫入未命中和讀取未命中。當從I狀態轉換到S狀態時,將讀取未命中放在匯流排中。如果姊妹快取記憶體沒有回覆資料,則快取記憶體控制器從較低階別讀取塊。S狀態的語意保持不變,要寫入S狀態的塊,我們需要在匯流排上寫入寫入訊息後轉換到M狀態。現在,當一個塊處於M狀態時,可以確信沒有其他快取包含有效副本,可以自由地讀寫M狀態的塊,沒有必要在匯流排上傳送任何資訊。如果處理器決定將M狀態的塊逐出,則需要將其資料寫入較低階別。
由於處理器的動作導致的塊的狀態轉換圖。
下圖顯示了由於匯流排上接收到的訊息而導致的狀態轉換。在S狀態下,如果我們得到一個讀未命中,那麼這意味著另一個快取想要對該塊進行讀存取。包含該塊的任何快取都會將該塊的內容傳送給它。這個過程可以按如下方式編排。所有具有塊副本的快取都試圖存取匯流排。存取匯流排的rst快取將塊的副本傳送到請求快取。其餘的快取立即知道塊的內容已被傳輸。他們隨後停止了嘗試。如果我們在S狀態下收到寫入或寫入未命中訊息,那麼塊將轉換到I狀態。
現在讓我們考慮M狀態。如果某個其他快取傳送寫入未命中訊息,則包含該塊的快取的快取控制器將向其傳送塊的內容,並轉換為I狀態。但是,如果發生讀取未命中,則需要執行一系列步驟,假設可以無縫地回收處於S狀態的塊,因此,有必要在移動到S狀態之前將資料寫入較低階別。隨後,原本具有塊的快取記憶體也將塊的內容傳送到請求快取記憶體,並將塊的狀態轉換為S狀態。
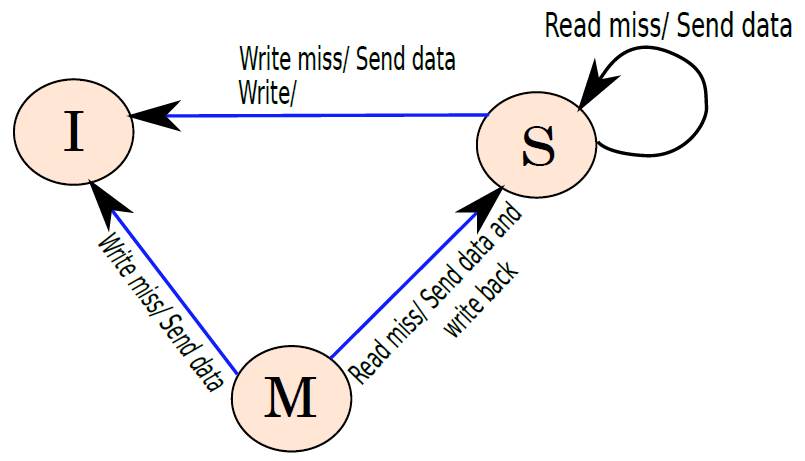
由於匯流排上的訊息導致的塊狀態轉換圖。
使用目錄的寫無效協定
使用目錄實現寫無效協定相當簡單。狀態轉換圖幾乎保持不變,沒有廣播訊息,而是將其傳送到目錄,目錄將訊息傳送給塊的共用者。
現在闡述塊的生命週期。每當從較低階別引入塊時,都會初始化一個目錄條目,它只有一個共用者,是從較低階別帶來它的快取。現在,如果塊中存在讀取未命中,則目錄會繼續新增共用程式。但如果存在寫入未命中,或者處理器決定寫入塊,則會向目錄傳送寫入或寫入未命中訊息。該目錄清理共用者列表,並只保留一個共用者,即執行寫存取的處理器。當一個塊被逐出時,它的快取會通知目錄,目錄會刪除一個共用程式。當共用者集變空時,可以刪除目錄條目。
可以通過新增一個稱為獨佔(Exclusive,E)狀態的附加狀態來改進寫無效和更新協定,E狀態可以是從記憶體層次結構的較低階別獲取的每個快取塊的初始狀態,此狀態儲存塊獨佔地屬於快取的事實。但是,快取對其具有唯讀存取許可權,而沒有寫存取許可權。對於E到M的轉換,不必在匯流排上傳送寫未命中或寫訊息,因為塊只由一個快取擁有。如果需要,可以無縫地將資料從E狀態中逐出。
19.7.4.5 MESI協定
為了在SMP上提供快取一致性,資料快取通常支援稱為MESI的協定。對於MESI,資料快取包含每個標記的兩個狀態位,因此每行可以處於四種狀態之一:
- 已修改(Modified,M):快取中的行已被修改(與主記憶體不同),僅在此快取中可用。
- 獨佔(Exclusive,E):快取中的行與主記憶體中的行相同,不存在於任何其他快取中。
- 共用(Shared,S):快取中的行與主記憶體中的行相同,可能存在於另一個快取中。
- 無效(Invalid,I):快取中的行不包含有效資料。
下表總結了四種狀態的含義。
| M Modified |
E Exclusive |
S Shared |
I Invalid |
|
|---|---|---|---|---|
| 此快取行有效嗎? | 是 | 是 | 是 | 否 |
| 記憶體副本是… | 過期 | 有效 | 有效 | - |
| 副本是否存在於其他快取中? | 否 | 否 | 可能 | 可能 |
| 一個寫入到此行… | 不進入匯流排 | 不進入匯流排 | 進入匯流排且更新快取 | 直接進入匯流排 |
下圖顯示了MESI協定的狀態圖,快取的每一行都有自己的狀態位,因此狀態圖也有自己的實現。圖a顯示了由於連線到此快取的處理器啟動的操作而發生的轉換,圖b顯示了由於在公共匯流排上窺探的事件而發生的轉換。處理器啟動和匯流排啟動動作的單獨狀態圖有助於闡明MESI協定的邏輯。任何時候,快取行都處於單一狀態,如果下一個事件來自所連線的處理器,則轉換由圖a指示,如果下一事件來自匯流排,則轉換則由圖b指示。
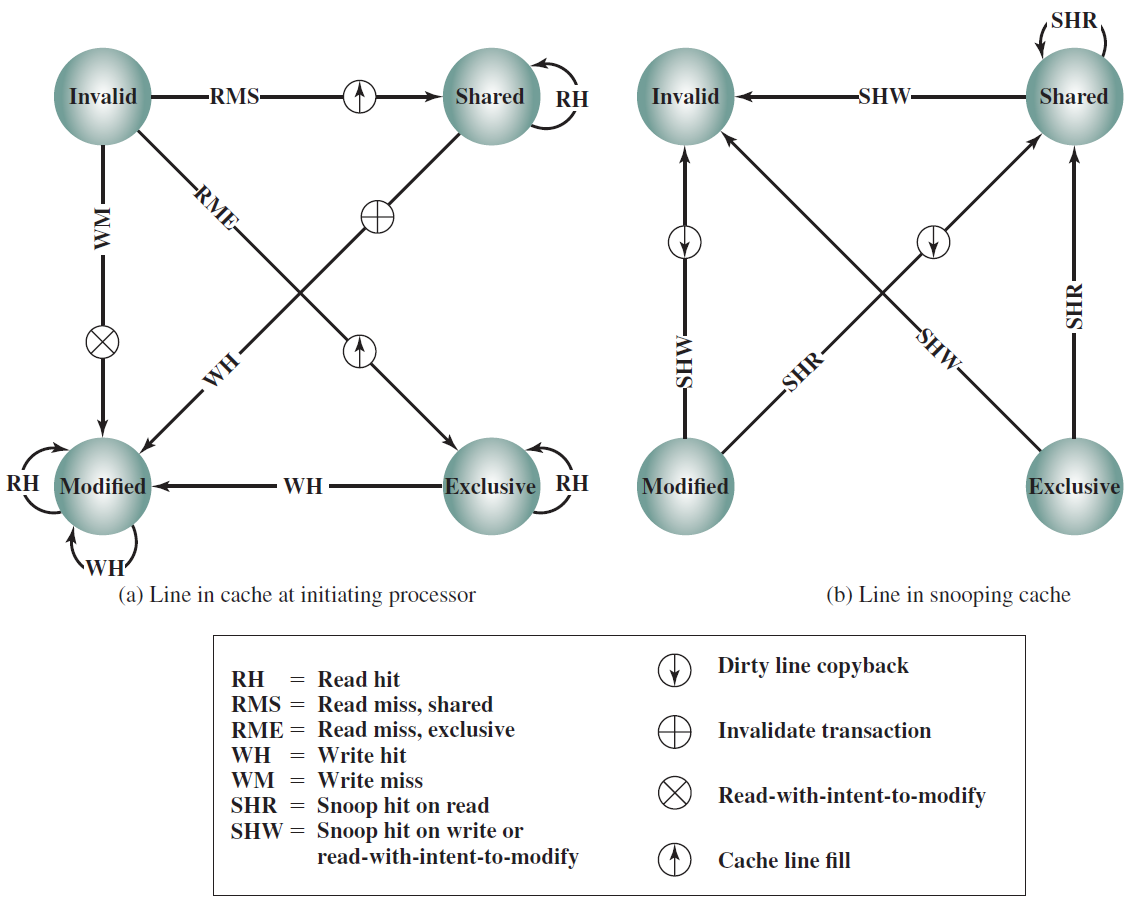
MESI狀態轉換圖。
讀未命中(read miss):當本地快取中發生讀未命中時,處理器啟動記憶體讀取以讀取包含丟失地址的主記憶體行。處理器在匯流排上插入一個訊號,提醒所有其他處理器/快取單元窺探事務。有許多可能的結果:
- 如果另一個快取具有獨佔狀態的行的乾淨(自記憶體讀取以來未修改)副本,則它將返回一個訊號,指示它共用該行。然後,響應處理器將其副本的狀態從獨佔轉換為共用,啟動處理器從主記憶體讀取該行,並將其快取中的行從無效轉換為共用。
- 如果一個或多個快取具有處於共用狀態的行的乾淨副本,則每個快取都會發出共用該行的訊號。啟動處理器讀取該行並將其快取中的行從無效轉換為共用。
- 如果另一個快取具有該行的修改副本,則該快取將阻止記憶體讀取,並通過共用匯流排將該行提供給請求快取,然後響應快取將其行從修改更改為共用。傳送到請求快取的行也由記憶體控制器接收和處理,該控制器將塊儲存在記憶體中。
- 如果沒有其他快取具有該行的副本(清除或修改),則不會返回任何訊號。啟動處理器讀取該行並將其快取中的行從無效轉換為獨佔。
讀命中(read hit):當讀命中發生在本地快取中的當前行上時,處理器只需讀取所需的項。沒有狀態更改:狀態保持修改、共用或獨佔狀態。
寫未命中(write miss):當本地快取中發生寫未命中時,處理器啟動記憶體讀取以讀取包含丟失地址的主記憶體行。為此,處理器在匯流排上發出一個訊號,表示讀取意圖修改(read-with-intent-to-modify,RWITM)。載入該行後,將立即標記為已修改。對於其他快取,載入資料行之前有兩種可能的情況:
- 首先,某些其他快取可能具有該行的已修改副本(狀態=修改)。在這種情況下,報警處理器向啟動處理器發出訊號,表示另一個處理器具有該行的修改副本,發起處理器放棄匯流排並等待。另一個處理器獲得對匯流排的存取權,將修改後的快取線寫回主記憶體儲器,並將快取行的狀態轉換為無效(因為啟動的處理器將修改此線)。隨後,啟動處理器將再次向RWITM的匯流排發出訊號,然後從主記憶體儲器讀取該行,修改快取中的行,並將該行標記為修改狀態。
- 其次,沒有其他快取具有請求行的修改副本。在這種情況下,不返回任何訊號,啟動處理器繼續讀入該行並修改它。同時,如果一個或多個快取具有處於共用狀態的行的乾淨副本,則每個快取都會使其行副本無效,如果一個快取具有排他狀態的行副本,則其行副本將無效。
寫命中(write hit):當本地快取中當前行發生寫命中時,效果取決於本地快取中該行的當前狀態:
- 共用:在執行更新之前,處理器必須獲得該行的獨佔所有權,處理器在匯流排上發出訊號,在其快取中具有行的共用副本的每個處理器將磁區從共用轉換為無效,然後發起處理器執行更新並將其行副本從共用轉換為修改。
- 獨佔:處理器已經對該行具有獨佔控制權,因此它只需執行更新並將該行的副本從獨佔轉換為已修改。
- 已修改:處理器已經對該行具有獨佔控制權,並將該行標記為已修改,因此它只需執行更新。
L1-L2快取一致性:到目前為止,我們已經根據連線到同一匯流排或其他SMP互連設施的快取之間的共同作業活動描述了快取一致性協定。通常,這些快取是L2快取,每個處理器還具有一個L1快取,該快取不直接連線到匯流排,因此不能參與窺探協定,因此需要某種方案來維護兩級快取和SMP設定中所有快取的資料完整性。
策略是將MESI協定(或任何快取一致性協定)擴充套件到L1快取,L1快取記憶體中的每一行包括指示狀態的位,目標如下:對於L2快取及其對應的L1快取中存在的任何行,L1行狀態應跟蹤L2行的狀態。一種簡單的方法是在L1快取中採用直寫策略;在這種情況下,寫入是到L2快取記憶體而不是到記憶體。L1直寫策略強制對L2快取的L1行進行任何修改,從而使其對其他L2快取可見。使用L1直寫策略要求L1內容必須是L2內容的子集。這反過來表明,二級快取的關聯性應等於或大於一級快取的關聯性。L1直寫策略用於IBM S/390 SMP。
如果一級快取具有回寫策略,則兩個快取之間的關係更為複雜。有幾種維護方法,但超出了本文的範圍。
19.7.4.6 記憶體一致性模型
典型的記憶體一致性模型指定了同一執行緒發出的記憶體操作之間允許的重新排序型別。例如,在順序一致性中,所有讀/寫存取都按程式順序完成,所有其他執行緒也按程式順序感知任何執行緒的記憶體存取。
讓我們構建一個連貫的記憶體系統,並提供一定的保證。假設所有的寫操作都與完成時間相關聯,並在完成時立即執行,任何讀取操作都不可能在完成之前獲取寫入的值。寫操作完成後,對同一地址的所有讀操作要麼得到寫操作寫入的值,要麼得到更新的寫操作。由於假設一個一致性記憶體,所以所有處理器都會以相同的順序看到對同一記憶體地址的所有寫入操作。其次,每次讀取操作都會返回最近完成的寫入操作寫入該地址的值。現在考慮處理器1向地址x發出寫入請求,同時處理器2向同一地址x發出讀取請求的情況。這種行為沒有定義,讀取可以獲取並行寫入操作設定的值,也可以獲取先前的值。但是,如果讀取操作獲得了並行寫入操作設定的值,那麼任何處理器發出的所有後續讀取都需要獲得該值或更新的值。一旦完成讀取記憶體位置的值,讀取操作就完成了,生成其資料的寫入也完成了。
現在,讓我們設計一個多處理器,其中每個處理器在完成之前發出的所有記憶體請求之後發出一個記憶體請求,意味著在發出記憶體請求(讀/寫)之後,處理器會等待它完成,然後再發出下一個記憶體請求。具有這種特性的處理器的多處理器是順序一致的。
現在概述一個簡短的非正式證明,首先介紹一個稱為存取圖(access graph)的理論工具。
存取圖
下圖顯示了兩個執行緒的執行及其相關的記憶體存取序列。對於每個讀或寫存取,我們在存取圖中建立一個圓或節點(見圖(c))。在這種情況下,如果一個存取按程式順序跟隨另一個存取,或者如果來自不同執行緒的兩個存取之間存在讀寫依賴關係,將在兩個節點之間新增一個箭頭(或邊)。例如,如果線上程1中將x設定為5,而執行緒2中的讀取操作讀取x的這個值,那麼x的讀取和寫入之間存在相關性,因此在存取圖中新增了一個箭頭,箭頭表示目標請求必須在源請求之後完成。
記憶體存取的圖形表示。
定義節點a和b之間的發生-之前(happens-before)關係,如果存取圖中存在從a到b的路徑。
發生-之前(happens-before)關係表示存取圖中存在從a到b的路徑。此關係表示b必須在a完成後完成其執行。
存取圖是一種通用工具,用於對並行系統進行推理,由一組節點組成,其中每個節點都是指令的動態範例(通常是記憶體指令),節點之間有邊節點之間有邊,來自A-->B的邊意味著B需要在A之後完成執行。在上圖中,新增了兩種邊,即程式順序邊(program order edge)和因果關係邊(causality edge)。程式順序邊表示同一執行緒中記憶體請求的完成順序,當等待一條指令完成時,在執行下一條指令之前,同一執行緒的連續指令之間存在邊。
因果邊位於執行緒之間的載入和儲存指令之間。例如,如果一條給定的指令寫入一個值,而另一條指令在另一個執行緒中讀取該值,我們將從儲存到載入新增一條邊。
為了證明順序一致性,需要向存取圖新增額外的邊,見下面闡述。首先假設有一個聖人(一個知道一切的假設實體),由於假設一致性記憶體,所以對同一記憶體位置的所有儲存都是按順序排序的。此外,載入和儲存到同一記憶體位置之間存在順序。例如,如果將x設定為1,然後將x設定成3,然後讀取t1=x,然後將x=5,則位置x有一個儲存-儲存-載入-儲存的順序。聖人知道每個記憶體位置的載入和儲存之間的這種順序,假設聖人將相應的發生在邊之前新增到存取圖中,在這種情況下,儲存和載入之間的邊是因果關係邊,儲存-儲存和載入-儲存邊是一致性邊的範例。
接下來描述如何使用存取圖來證明系統的屬性。首先,需要基於給定的程式執行,為給定的記憶體一致性模型M構建程式的存取圖,基於記憶體存取行為新增了一致性和因果關係邊。其次,基於一致性模型在同一執行緒中的指令之間新增程式順序邊。對於SC,在連續指令之間新增邊,對於WC,在從屬指令之間、常規指令之間和柵欄之間新增邊。理解存取圖是一個理論工具,但它通常不是一個實用工具,這點非常重要。我們將對存取圖的屬性進行推理,而不必為給定的程式或系統實際地構建存取圖。
如果存取圖不包含迴圈,就可以按順序排列節點。現在來證明這一事實。在存取圖中,如果存在從a到b的路徑,那麼讓a稱為b的祖先。可以通過遵循迭代過程來生成順序,首先找到一個沒有祖先的節點,必然有這樣的一個節點,因為某些操作必須是第一個完成的(否則會有一個迴圈)。將其從存取圖中刪除,然後繼續查詢另一個沒有任何祖先的節點,按照順序新增每個這樣的節點,如上圖(d)所示。在每一步中,存取圖中的節點數減少1,直到最後只剩下一個節點,它成為順序中的最後一個節點。現在考慮這樣一種情況,即沒有在存取圖中查詢任何沒有祖先的節點,只有在存取圖中存在迴圈時才可能,因此正常情況下不可能。
按順序排列節點相當於證明存取圖符合其設計的記憶體模型。事實上,我們可以按順序列出節點,而不違反任何happens-before關係,意味著執行等同於單處理器按順序依次執行每個節點,正是一致性模型的定義。任何一致性模型都由記憶體指令之間的排序約束以及一致性假設組成,該定義還意味著,單處理器應該可以按順序執行指令,而不違反任何happens-before關係。
這正是我們通過將存取圖轉換為等效的節點順序列表所實現的。現在,程式順序、因果關係和一致性邊緣足以指定一致性模型的事實更加深刻。
因此,如果一個存取圖(對於記憶體模型,M)不包含迴圈,可以得出一個給定的執行遵循M的結論。如果可以證明一個系統可以生成的所有可能的存取圖都是非迴圈的,就可以得出整個系統遵循M的結果。
順序一致性的證明
讓我們證明,在發出後續記憶體請求之前等待記憶體請求完成的簡單系統可以生成的所有可能的存取圖(假設為SC)都是非迴圈的。考慮任意一個存取圖G,我們必須證明,可以按順序寫入G中的所有記憶體存取,這樣,如果節點b位於節點a之後,那麼G中就沒有從b到a的路徑。換句話說,我們的順序遵循存取圖中所示的存取順序。
假設存取圖有一個迴圈,它包含一組屬於同一執行緒t1的節點S,其中a是S中程式順序中最早的節點,b是S中最晚的節點,顯然a發生在b之前,因為按照程式順序執行記憶體指令,在同一執行緒中啟動下一個請求之前等待請求完成。對於由於因果邊而形成的迴圈,b需要寫入另一個記憶體讀取請求(節點)讀取的值,c屬於另一個執行緒。或者,在b和屬於另一執行緒的節點c之間可以存在相干邊(coherence edge)。現在,為了存在一個迴圈,c需要發生在a之前。假設c和a之間有一個節點鏈,節點鏈中的最後一個節點是d,根據定義,\(d \notin t_{1}\),意味著d寫入一個儲存位置,節點a從中讀取,或者有一條從d到a的相干邊。因為有一條路徑從節點b到節點a(通過c和d),與節點b相關聯的請求必須發生在節點a的請求之前。這是不可能的,因為在節點a請求完成之前,無法執行與節點b關聯的記憶體請求。因此,存在一個矛盾,在存取圖中迴圈是不可能的。因此,執行在SC中。
現在澄清聖人的概念。這裡的問題不是生成順序,而是證明順序存在,因為正在解決後一個問題,所以總是可以假設一個假設實體向存取圖新增了額外的邊。產生的順序次序(sequential order)遵循每個執行緒的程式順序、因果關係和基於happens-before關係的連貫性。因此,這是一個有效的順序。
因此,可以得出結論,在我們的系統中始終可以為執行緒建立順序,因此多處理器是在SC中。既然已經證明了我們的系統是順序一致的,那麼讓我們描述一種用所做的假設實現多處理器的方法,可以實現如下圖所示的系統。
一個簡單的順序一致的系統。
簡單順序一致機器
上圖顯示了一種設計,它在多處理器的所有處理器上都有一個大的共用L1快取,每個記憶體位置只有一個副本,在任何單個時間只能支援一次讀或寫存取,確保了一致性。其次,當一次寫入更改其在一級快取中的記憶體位置的值時,寫入完成。同樣,當讀取L1快取中的記憶體地址值時,讀取完成。我們需要修改前面章節描述的簡單有序RISC流水線,以便指令僅在完成讀/寫存取後才離開記憶體存取(MA)階段。如果存在快取未命中,則指令等待直到塊到達一級快取,並且存取完成。這個簡單的系統確保來自同一執行緒的記憶體請求按程式順序完成,因此順序一致。
請注意,上圖描述的系統做出了一些不切實際的假設,因此不實用。如果我們有16個處理器,並且記憶體指令的頻率是1/3,那麼每個週期都需要5-6條指令存取一級快取。因此,一級快取需要至少6個讀/寫埠,使得結構太大和太慢。此外,L1快取需要足夠大以容納所有執行緒的工作集,進一步使得L1快取非常大且速度慢。因此,具有這種快取記憶體的多處理器系統在實踐中將非常緩慢,而現代處理器選擇了更高效能的實現,其記憶體系統更復雜,有很多更小的快取。這些快取相互共同作業,以提供更大快取的錯覺。
很難證明一個複雜系統遵循順序一致性(SC),設計師選擇設計具有弱記憶體模型的系統。在這種情況下,我們需要證明柵欄指令正確工作,如果考慮複雜設計中可能出現的所有細微角落情況,也是一個相當具有挑戰性的問題。
實現弱一致性模型
考慮弱一致系統的存取圖,沒有邊來表示同一執行緒中節點的程式順序。相反,對於同一執行緒中的節點,在常規讀/寫節點和柵欄操作之間有邊緣,需要將因果關係和相干邊新增到存取圖中,就像對SC的情況所做的那樣。
弱一致機器的實現需要確保該存取圖沒有迴圈。我們可以證明,下面的實現沒有向存取圖引入迴圈,確保在給定執行緒的程式順序中的所有先前指令完成後,柵欄指令開始。fence指令是一條偽指令,只需要到達管線的末端,僅用於計時目的。我們在MA階段暫停柵欄指令,直到前面的所有指令完成,該策略還確保沒有後續指令到達MA階段。一旦所有先前的指令完成,圍欄指令進入RW階段,隨後的指令可以向記憶體發出請求。
總結一下實現記憶體一致性模型的內容。通過修改處理器的流水線,並確儲儲存器系統一旦完成對記憶體請求的處理就向處理器傳送確認,可以實現諸如順序一致性或弱一致性的記憶體一致性模型。在高效能實現中,許多細微的角落情況是可能的,確保它們實現給定的一致性模型相當複雜。
關於記憶體屏障的應用和UE的實現,可參閱1.4.5 記憶體屏障。
19.7.4.7 多執行緒處理器
現在看看設計多處理器的另一種方法。到目前為止,我們一直堅持需要有物理上分離的管線來建立多處理器,研究了為每個管線分配單獨程式計數器的設計。然而,讓我們看看在同一管線上執行一組執行緒的不同方法,這種方法被稱為多執行緒(multithreading)。不在單獨的管線上執行單獨的執行緒,而是在同一管道上執行它們。通過討論稱為粗粒度多執行緒的最簡單的多執行緒變體來說明這個概念。
多執行緒(multithreading)是一種設計正規化,在同一管線上執行多個執行緒。
多執行緒處理器(multithreaded processor)是實現多執行緒的處理器。
粗粒度多執行緒
假設我們希望在單個管線上執行四個執行緒。屬於同一程序的多個執行緒有各自的程式計數器、堆疊和暫存器,然而,它們對記憶體有著共同的檢視,所有這四個執行緒都有各自獨立的指令流,因此有必要提供一種錯覺,即這四個程序是單獨執行的。軟體應該忽略執行緒在多執行緒處理器上執行的事實,它應該意識到每個執行緒都有其專用的CPU。除了傳統的一致性和一致性保證之外,還需要提供一個額外的保證,即軟體應該忽略多執行緒。
考慮一個簡單的方案,如下圖所示,執行緒1執行n個迴圈,然後切換到執行緒2並執行n個週期,然後切換至執行緒3,以此類推。在執行執行緒4 n個迴圈後,再次開始執行執行緒1。要執行執行緒,需要載入其狀態或上下文。程式的上下文包括標誌暫存器、程式計數器和一組暫存器,沒有必要跟蹤主記憶體,因為不同程序的記憶體區域不重疊,在多個執行緒的情況下,明確希望所有執行緒共用相同的記憶體空間。
可以採用更簡單的方法,而不是顯式地載入和解除安裝執行緒的上下文,可以在管線中儲存執行緒的上下文,例如,如果望支援粗粒度多執行緒,就可以有四個獨立的標誌暫存器、四個程式計數器和四個獨立暫存器(每個執行緒一個),還可以有一個包含當前執行執行緒的id的專用暫存器。例如,如果正在執行執行緒2,就使用執行緒2的上下文,如果在執行執行緒3,就使用執行緒3的上下文。以這種方式,多個執行緒不可能覆蓋彼此的狀態。
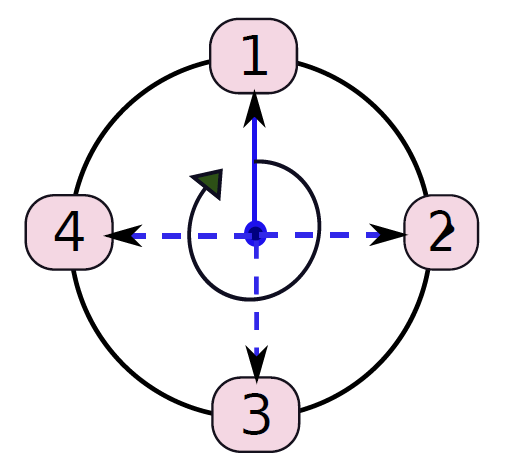
粗粒度多執行緒的概念圖
可以採用更簡單的方法,而不是顯式地載入和解除安裝執行緒的上下文。我們可以在管道中儲存執行緒的上下文。例如,如果我們希望支援粗粒度多執行緒,那麼我們可以有四個獨立的標誌暫存器、四個程式計數器和四個獨立暫存器檔案(每個執行緒一個)。此外,我們可以有一個包含當前執行執行緒的id的專用暫存器。例如,如果我們正在執行執行緒2,那麼我們使用執行緒2的上下文,如果我們在執行執行緒3,我們使用執行緒3的上下文。以這種方式,多個執行緒不可能覆蓋彼此的狀態。
現在看看一些微妙的問題。可能在管線中的同一時間點擁有屬於多個執行緒的指令,當從一個執行緒切換到下一個執行緒時,可能會發生這種情況。讓我們將執行緒id欄位新增到指令包中,並進一步確保轉發和互鎖邏輯考慮到執行緒的id,我們從不跨執行緒轉發值。以這種方式,可以在管線上執行四個獨立的執行緒,而執行緒之間的切換開銷可以忽略不計。我們不需要使用例外處理程式來儲存和恢復執行緒的上下文,也不需要呼叫作業系統來排程執行緒的執行。
現在整體來看一下粗粒度多執行緒。我們快速連續執行n個執行緒,並按回圈順序執行,此外,有一種線上程之間快速切換的機制,執行緒不會破壞彼此的狀態,但仍然不會同時執行四個執行緒。那麼,這個方案的優點是什麼?
考慮一下記憶體密集型執行緒的情況,這些執行緒對記憶體有很多不規則的存取,它們將經常在二級快取中發生未命中,其管線需要暫停100-300個週期,直到值從記憶體中返回。無序管線可以通過執行一些不依賴於記憶體值的其他指令來隱藏某些延遲,儘管如此,它也將暫停很長一段時間。然而,如果我們可以切換到另一個執行緒,那麼它可能有一些有用的工作要做。如果該執行緒也來自L2快取中的未命中,那麼我們可以切換到另一個執行緒並完成其部分工作,這樣可以最大化整個系統的吞吐量。可以設想兩種可能的方案:可以每n個週期週期性地切換一次,或者在發生二級快取未命中等事件時切換到另一個執行緒;其次,如果執行緒正在等待高延遲事件(如二級快取丟失),不需要切換到該執行緒,需要切換到一個具有準備好執行指令池的執行緒。可以設計大量的啟發式演演算法來優化粗粒度多執行緒機器的效能。
軟體執行緒和硬體執行緒的區別:
- 軟體執行緒是一個子程式,與其他軟體執行緒共用一部分地址空間,這些執行緒可以相互通訊以共同作業實現共同目標。
- 硬體執行緒被定義為在管線上執行的軟體執行緒或單執行緒程式及其執行狀態的範例。
多執行緒處理器通過跨執行緒分配資源來支援同一處理器上的多個硬體執行緒。軟體執行緒可以物理地對映到單獨的處理器或硬體執行緒,與用於執行它的實體無關。需要注意的重要一點是,軟體執行緒是一種程式語言概念,而硬體執行緒在物理上與管線中的資源相關聯。
本文使用「執行緒」一詞來表示軟體和硬體執行緒,需要根據上下文推斷正確的用法。
細粒度多執行緒
細粒度多執行緒是粗粒度多執行緒的一種特殊情況,其中切換間隔n非常小,通常為1或2個迴圈,意味著可以線上程之間快速切換。我們可以利用粒度多執行緒來執行記憶體密集型執行緒,然而,否定多執行緒對於執行一組執行緒(例如具有長算術運算,如除法)也很有用。在典型的處理器中,除法運算和其他特殊運算(如三角運算或超越運算)很慢(3-10個週期)。在這段時間內,當原始執行緒等待操作完成時,可以切換到另一個執行緒,並在管線階段中執行它的一些未使用的指令。因此,我們可以利用線上程之間快速切換的能力來減少具有大量數學運算的科學程式中的空閒時間。
因此,我們可以將細粒度多執行緒視為更靈活的粗粒度多執行緒形式,線上程之間快速切換,並利用空閒階段執行有用的工作。請注意,這個概念並不像聽起來那麼簡單。需要在常規有序或無序管線中的所有結構中為多執行緒提供詳細的支援,需要非常仔細地管理每個執行緒的上下文,並確保不會遺漏指令,也不會引入錯誤。
執行緒之間切換的邏輯不是普通的。大多數時候,線上程之間切換的邏輯是基於時間的標準(週期數)和基於事件的標準(高延遲事件,如二級快取未命中或頁面錯誤)的組合。為了確保多執行緒處理器在一系列基準測試中表現良好,必須仔細調整啟發式。
並行多執行緒
對於單個執行管線,如果可以通過使用複雜的邏輯線上程之間切換來確保每個階段都保持忙碌,就可以實現高效率。單個執行管線中的任何階段每個週期只能處理一條指令。相比之下,多執行流水線每個週期可以處理多個指令,此外,將執行槽的數量設計為等於流水線每個週期可以處理的指令數量。例如,一個3執行處理器,每個週期最多可以獲取、解碼並最終執行3條指令。
為了在多執行管線中實現多執行緒,還需要考慮執行緒中指令之間的依賴性。細粒度和粗粒度方案可能無法很好地執行,因為執行緒無法為所有執行槽向功能單元執行指令,這種執行緒可描述成具有低指令級並行性。如果我們使用4個執行流水線,並且由於程式中的依賴性,每個執行緒的最大IPC為1,那麼每個週期中有3個執行槽將保持空閒。因此,4執行緒系統的總體IPC將為1,多執行緒的好處將受到限制。
因此,有必要利用額外的執行時段,以便我們能夠增加整個系統的IPC。一種簡單的方法是為每個執行緒分配一個執行槽。其次,為了避免結構衝突,可以有四個ALU,併為每個執行緒分配一個ALU。然而,這是對管線的次優利用,因為執行緒可能沒有執行每個週期的指令。最好有一個更靈活的方案,可以線上程之間動態地劃分執行槽,這種方案被稱為並行多執行緒(simultaneous multithreading,SMT)。例如,在給定的週期中,我們可能會從執行緒2執行2條指令,從執行緒3和4執行1條指令,這種情況可能在下一個週期中發生逆轉。下圖說明這個概念,同時還將SMT方法與細粒度和粗粒度多執行緒進行比較。
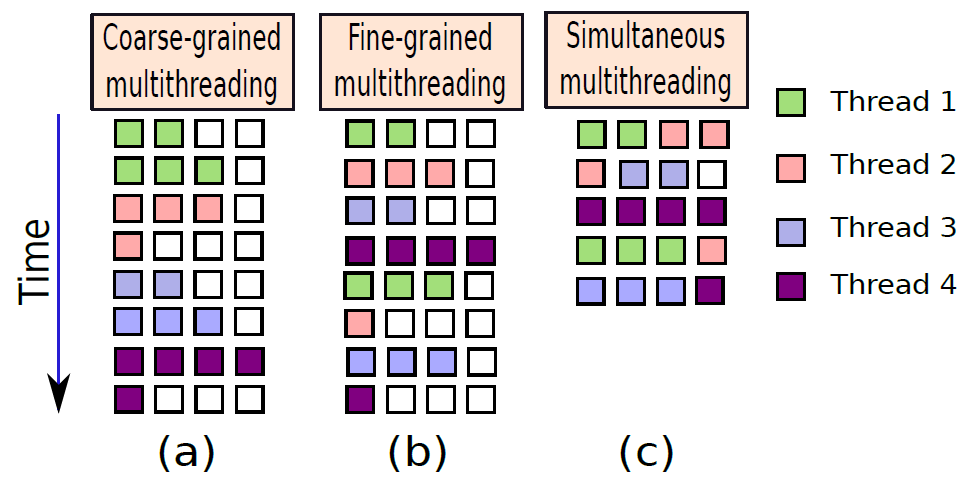
多執行緒處理器中的指令執行。
上圖中的列表示多執行機器的執行槽,行表示週期,屬於不同執行緒的指令有不同的顏色。圖(a)顯示了粗粒度機器中指令的執行情況,其中每個執行緒執行兩個連續的週期。由於沒有找到足夠數量的可執行指令,所以很多執行槽都是空的,細粒度多執行緒(圖(b))也有同樣的問題。然而,在SMT處理器中,通常能夠使大多數執行槽保持忙碌,因為總是從準備執行的可用執行緒集中找到指令。如果一個執行緒由於某種原因被暫停,其他執行緒會通過執行更多的指令進行補償。實際上,所有執行緒不同時具有低ILP(Instruction Level Parallelism,指令級並行)階段,因此,SMT方法已被證明是一種非常通用且有效的方法,可以利用多個執行處理器的能力。自從奔騰4(90年代末釋出)以來,大多數英特爾處理器都支援不同版本的同時多執行緒,在英特爾的術語中,SMT被稱為超執行緒,而IBM Power 7處理器有8個核心,每個核心都是4路SMT(每個核心可以執行4個執行緒)。
請注意,選擇要執行的正確指令集的問題對SMT處理器的效能至關重要。其次,n路SMT處理器的記憶體頻寬要求高於等效單處理器,提取邏輯也要複雜得多,因為需要在同一週期內從四個獨立的程式計數器中提取。最後,保持連貫性和一致性的問題使情況更加複雜。
執行多個執行緒的更多方法如下:
它們的說明如下:
- 超標量(Superscalar):是沒有多執行緒的基本超標量方法,直到前些年,依舊是在處理器內提供並行性的最強大的方法。注意,在某些週期中,並非使用所有可用的執行槽(issue slot),在這些週期中,發出的指令數少於最大指令數,被稱為水平損耗(horizontal loss)。在其他指令週期中,不使用執行槽,是無法發出指令的週期,被稱為垂直損耗(vertical loss)。
- 交錯多執行緒超標量(Interleaved multithreading superscalar):在每個週期中,從一個執行緒發出儘可能多的指令。如前所述,通過這種技術,消除了由於執行緒切換導致的潛在延遲,但在任何給定週期中發出的指令數量仍然受到任何給定執行緒中存在的依賴性的限制。
- 阻塞的多執行緒超標量(Blocked multithreaded superscalar):同樣,在任何週期中,只能發出來自一個執行緒的指令,並且使用阻塞多執行緒。
- 超長指令字(Very long instruction word,VLIW):VLIW架構(如IA-64)將多條指令放在一個字中,通常由編譯器構建,它將可以並行執行的操作放在同一個字中。在一個簡單的VLIW機器(上圖g)中,如果不可能用並行發出的指令完全填充單詞,則不使用操作。
- 交錯多執行緒VLIW(Interleaved multithreading VLIW):提供與超標量架構上交錯多執行緒所提供的效率類似的效率。
- 阻塞多執行緒VLIW(Blocked multithreaded VLIW):提供與超標量架構上的阻塞多執行緒所提供的效率類似的效率。
- 同時多執行緒(Simultaneous multithreading):上圖j顯示了一個能夠一次發出8條指令的系統。如果一個執行緒具有高度的指令級並行性,則它可能在某些週期內能夠填滿所有的水平槽。在其他週期中,可以發出來自兩個或多個執行緒的指令。如果有足夠的執行緒處於活動狀態,則通常可以在每個週期中發出最大數量的指令,從而提供較高的效率。
- 晶片多處理器(Chip multiprocessor),亦即多核(multicore):上圖k顯示了一個包含四個核的晶片,每個核都有一個兩個問題的超標量處理器。每個核心都分配了一個執行緒,每個週期最多可以發出兩條指令。
19.7.5 SIMD多處理器
本節討論SIMD多處理器。SIMD處理器通常用於科學應用、高強度遊戲和圖形,它們沒有大量的通用用途。然而,對於一類有限的應用,SIMD處理器往往優於MIMD處理器。
SIMD處理器有著豐富的歷史。在過去的好日子裡,我們把處理器排列成陣列,資料通常通過處理器的第一行和第一列輸入,每個處理器對輸入訊息進行操作,生成一條輸出訊息,並將該訊息傳送給其鄰居。這種處理器被稱為收縮陣列(systolic array)。收縮陣列用於矩陣乘法和其他線性代數運算。隨後的幾家供應商,尤其是Cray,在他們的處理器中加入了SIMD指令,以設計更快、更節能的超級計算機。如今,這些早期的努力大多已經隱退,然而,經典SIMD計算機的某些方面,即單個指令對多個資料流進行操作,已經滲透到現代處理器的設計中。
我們將討論現代處理器設計領域的一個重要發展,即在高效能處理器中加入SIMD功能單元和指令。
19.7.5.1 SIMD:向量處理器
讓我們考慮新增兩個n元素陣列的問題。在單執行緒實現中,需要從記憶體載入運算元,新增運算元,並將結果儲存在記憶體中。因此,為了計算目標陣列的每個元素,需要兩條載入指令、一條加法指令和一條儲存指令。傳統處理器試圖通過利用可以平行計算(c[i]=a[i]+b[i])和(c[j]=a[j]+b[j])的事實來實現加速,因為這兩個運算之間沒有任何依賴關係,可以通過並行執行許多這樣的操作來增加IPC。
現在讓我們考慮超標量處理器。如果它們每個週期可以執行4條指令,那麼它們的IPC最多可以是單週期處理器的4倍。在實踐中,對於4執行的處理器,我們可以通過這種固有的並行陣列處理操作在單週期處理器上實現的峰值加速大約是3到3.5倍。其次,這種通過寬執行寬度來增加IPC的方法是不可延伸的。在實踐中沒有8或10個執行處理器,因為流水線的邏輯變得非常複雜,並且面積/功率開銷變得令人望而卻步。
因此,設計人員決定對對大型資料向量(陣列)進行操作的向量操作提供特殊支援,這種處理器被稱為向量處理器,主要思想是一次處理整個資料陣列。普通處理器使用常規標量資料型別,如整數和浮點數;而向量處理器使用向量資料型別,本質上是標量資料型別的陣列。
向量處理器(vector processor)將原始資料型別(整數或浮點數)的向量視為其基本資訊單位。它可以一次載入、儲存和執行整個向量的算術運算,這種對資料向量進行操作的指令稱為向量指令(vector instruction)。
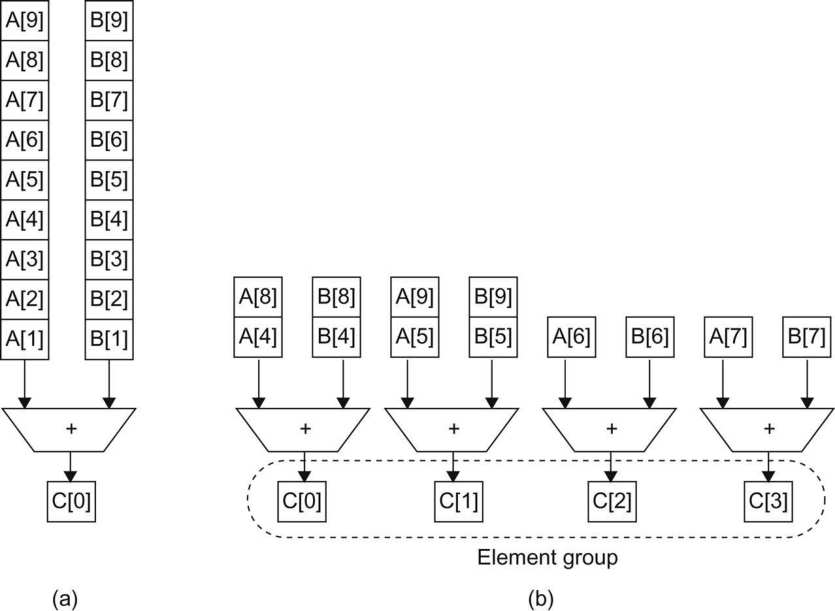
使用多個功能單元來提高單個向量加法C=A+B指令的效能。
包含四通道的向量單元的結構。
主要使用向量處理器的最具標誌性的產品之一是Cray 1超級計算機,這種超級計算機主要用於主要由線性代數運算組成的科學應用,這樣的操作適用於資料和矩陣的向量,因此非常適合在向量處理器上執行。可悲的是,在高強度科學計算領域之外,向量處理器直到90年代末才進入通用市場。
90年代末,個人計算機開始用於研究和執行科學應用。其次,設計師們開始使用普通商品處理器來建造超級計算機,而不是為超級計算機設計客製化處理器。從那時起,這一趨勢一直持續到圖形處理器的發展。1995年至2010年間,大多數超級計算機由數千個商品處理器組成。在常規處理器中使用向量指令的另一個重要原因是支援高強度遊戲,遊戲需要大量的圖形處理,例如,現代遊戲渲染具有多個角色和數千個視覺效果的複雜場景。大多數視覺效果,如照明、陰影、動畫、深度和顏色處理,都是對包含點或畫素的矩陣進行基本線性代數運算的核心。由於這些因素,常規處理器開始引入有限的向量支援,特別是,英特爾處理器提供了MMX、SSE 1-4向量指令集,AMD處理器提供了3DNow!向量擴充套件,ARM處理器提供ARM Neon向量ISA。這些ISA之間有很多共性,因此我們不用關注任何特定的ISA。讓我們轉而討論向量處理器設計和操作背後的廣泛原則。
19.7.5.2 軟體介面
讓我們先考慮一下機器的型號,需要一組向量暫存器,例如,x86 SSE(資料流單指令多資料擴充套件指令集)指令集定義了16個128位元暫存器(XMM0...XMM15),每個這樣的暫存器可以包含四個整數或四個浮點值,或者也可以包含八個2位元組短整數或十六個1位元組字元。在同一行上,每個向量ISA都需要比普通暫存器寬的附加向量暫存器。通常,每個暫存器可以包含多個浮點值。此處不妨讓我們定義八個128位元向量暫存器:vr0...vr7。
現在,我們需要指令來載入、儲存和操作向量暫存器。對於載入向量暫存器,有兩個選項,可以從連續記憶體位置載入值,也可以從非連續記憶體位置裝載值。前一種情況更為特殊,通常適用於基於陣列的應用程式,其中所有陣列元素都儲存在連續的記憶體位置。ISA的大多數向量擴充套件都支援載入指令的這種變體,因為它的簡單性和規則性。此處不妨將ISA設計這樣一個向量載入指令v:ld,考慮下圖中所示的語意。此處,v:ld指令將記憶體位置([r1+12]、[r1/16]、[r2+20]、[r 1+24])的內容讀入向量暫存器vr1。在下表中,請注意
| 範例 | 語法 | 解釋 |
|---|---|---|
| v.ld vr1, 12[r1] | v.ld |
vr1 <-- ([r1+12], [r1+16], [r1+20], [r1+ 24]) |
現在考慮矩陣的情況。假設有一個10000元素矩陣a[100][100],並假設資料是按行主順序儲存的,且要對矩陣的兩列進行運算。在這種情況下,我們遇到了一個問題,因為列中的元素沒有儲存在相鄰的位置。因此,依賴於輸入運算元儲存在連續記憶體位置的假設的向量載入指令將停止工作,需要有專門的支援來獲取列中位置的所有資料,並將它們儲存在向量暫存器中。這種操作稱為分散-聚集(catter-gather)操作,因為輸入運算元基本上分散在主記憶體中。
我們需要收集,並將它們放在一個叫向量暫存器的地方。讓我們考慮向量載入指令的分散-聚集變體,並將其稱為v.sg.ld。處理器讀取另一個包含元素地址的向量暫存器,而不是假設陣列元素的位置(語意見下表)。在這種情況下,專用向量載入單元讀取儲存在vr2中的記憶體地址,從記憶體中提取相應的值,並將它們順序寫入向量暫存器vr1。
| 範例 | 語法 | 解釋 |
|---|---|---|
| v.sg.ld vr1, 12[r1] | v.sg.ld |
vr1 <-- ([vr2[0]], [vr2[1]], [vr2[2]], [vr2[3]]) |
一旦在向量暫存器中載入了資料,就可以直接對兩個這樣的暫存器進行操作。例如,考慮128位元向量暫存器vr1和vr2,那麼,組合語句v.add vr3, vr1, vr2,將儲存在輸入向量暫存器(vr1和vr2)中的每對對應的4位元組浮點數相加,並將結果儲存在輸出向量暫存器(vr3)中的相關位置。注意,這裡使用向量加法指令(v.add)。下圖顯示了向量加法指令的範例。

向量ISA為向量乘法、除法和邏輯運算定義了類似的操作。向量指令不必總是有兩個輸入運算元,即向量,可以將一個向量與一個標量相乘,也可以有一條只對一個向量運算元進行運算的指令。例如,SSE指令集有專門的指令,用於計算向量暫存器中的一組浮點數的三角函數,如sin和cos。如果一條向量指令可以同時對n個運算元執行操作,就說有n個資料通道,而向量指令同時對所有n個資料路徑執行操作。
如果一條向量指令可以同時對n個運算元執行操作,那麼就表示有n個資料通道(lane),而向量指令同時對所有n個資料路徑執行操作。
最後一步是將向量暫存器儲存在記憶體中,有兩種選擇:可以儲存到相鄰的記憶體位置,也可以儲存到非相鄰的位置。可以在向量載入指令的兩個變體(v.ld和v.sg.ld)的行上設計向量儲存指令的兩種變體(連續和非連續)。有時需要引入在標量暫存器和向量暫存器之間傳輸資料的指令。
19.7.5.3 SSE指令範例
現在考慮一個使用基於x86的SSE指令集的實際範例,不使用實際的組合指令,改為使用gcc編譯器提供的函數,這些函數充當組合指令的封裝器,稱為gcc內建函數。
現在讓我們解決新增兩個浮點數陣列的問題,希望對i的所有值計算c[i]=a[i]+b[i]。
SSE指令集包含128位元暫存器,每個暫存器可用於儲存四個32位元浮點數。因此,如果有一個N個數位的陣列,需要進行N/4次迭代,因為在每個迴圈中最多可以新增4對數位。在每次迭代中,需要載入向量暫存器,累加它們,並將結果儲存在記憶體中。這種基於向量暫存器大小將向量計算分解為迴圈迭代序列的過程稱為條帶開採(strip mining)。
用C/C++編寫一個函數,將陣列a和b中的元素成對相加,並使用x86 ISA的SSE擴充套件將結果儲存到陣列C中。假設a和b中的條目數相同,是4的倍數。一種實現的程式碼如下:
void sseAdd (const float a[], const float b[], float c[], int N)
{
/* strip mining */
int numIters = N / 4;
/* iteration */
for (int i = 0; i < numIters; i++)
{
/* load the values */
__m128 val1 = _mm_load_ps(a);
__m128 val2 = _mm_load_ps(b);
/* perform the vector addition */
__m128 res = _mm_add_ps(val1, val2);
/* store the result */
_mm_store_ps(c, res);
/* increment the pointers */
a += 4 ; b += 4; c+= 4;
}
}
上述的程式碼解析:先計算迭代次數,在每次迭代中,考慮一個由4個陣列元素組成的塊,將一組四個浮點數載入到128位元向量變數中,val1.val1由編譯器對映到向量暫存器,使用函數_mm_load_ps從記憶體中載入一組4個連續的浮點值。例如,函數_mm_load_ps(a)將位置a、a+4、a+8和a+12中的四個浮點值載入到向量暫存器中。類似地,載入第二個向量暫存器val2,從記憶體地址b開始的四個浮點值。隨後執行向量加法,並將結果儲存在與變數res關聯的128位元向量暫存器中。為此,使用內建函數_mm_add_ps,隨後將變數res儲存在記憶體位置,即c、c+4、c+8和c+12。
在繼續下一次迭代之前,需要更新指標a、b和c。因為每個週期處理4個連續的陣列元素,所以用4個(4個陣列元素)更新每個指標。
可以很快得出結論,向量指令有助於批次計算,例如批次載入/儲存,以及一次性成對新增一組數位。將此函數的效能與四核Intel core i7機器上不使用向量指令的函數版本進行了比較,帶有SSE指令的程式碼對百萬元素陣列的執行速度快2-3倍。如果有更廣泛的SSE暫存器,那麼可以獲得更多的加速,x86處理器上最新的AVX向量ISA支援256和512位元向量暫存器。
19.7.5.4 判斷指令
到目前為止,我們已經考慮了向量載入、儲存和ALU操作。分支呢?通常,分支在向量處理器的上下文中具有不同的含義。例如,一個具有向量暫存器的處理器,其寬度足以容納32個整數,有一個程式要求僅對18個整數進行成對相加,然後將它們儲存在記憶體中。在這種情況下,無法將整個向量暫存器儲存到記憶體中,因為有覆蓋有效資料的風險。
讓我們考慮另一個例子。假設想對陣列的所有元素應用函數inc10(x),在這種情況下,如果輸入運算元x小於10,希望將其加10。在向量處理器上執行的程式中,這種模式非常常見,因此需要向量ISA中的額外支援來支援它們。
function inc10(x):
if (x < 10)
x = x + 10;
讓我們新增一個規則指令的新變體,並將其稱為判斷指令(predicated instruction,類似於ARM中的條件指令)。例如,我們可以建立常規載入、儲存和ALU指令的判斷變體。判斷指令在特定條件為真時執行,否則根本不執行,如果條件為false,則判斷指令等同於nop。
判斷指令(predicated instruction)是正常載入、儲存或ALU指令的變體。如果某個條件為真,它將正常執行;如果關聯條件為false,那麼它將轉換為nop。
例如,如果最後一次比較結果相等,則ARM ISA中的
addeq指令會像正常的加法指令一樣執行。但是,如果不是這樣,則add指令根本不執行。
現在讓新增對判斷的支援。首先建立cmp指令的向量形式,並將其稱為v.cmp。它對兩個向量進行成對比較,並將比較結果儲存在v.flags暫存器中,該暫存器是標誌暫存器的向量形式。v.flags暫存器的每個元件都包含一個E和GT欄位,類似於常規處理器中的標誌暫存器。
v.cmp vr1, vr2
上述語句比較vr1和vr2,並將結果儲存在v.flags暫存器中。我們可以使用此指令的另一種形式,將向量與標量進行比較。
v.cmp vr1, 10
現在,讓我們定義向量加法指令的謂詞形式。如果v.flags[i]暫存器滿足某些屬性,則此指令將兩個向量的第i元素相加,並更新目標向量暫存器的第i個元素。否則,它不會更新目標暫存器的第i個元素。假設判斷向量add指令的一般形式為:v.p.add,p是判斷條件。下表列出了p可以取的不同值。
| 判斷條件 | 解析 |
|---|---|
| lt | < |
| gt | > |
| le | <= |
| ge | >= |
| eq | = |
| ne | != |
現在考慮下面的程式碼片段:
v.lt.add vr3, vr1, vr2
此處,向量暫存器vr3的值是由vr1和vr2表示的向量之和,預測條件小於(lt),意味著,如果在v.flags暫存器中元素i的E和GT標誌都為假,那麼只有我們對第i個元素執行加法,並在vr3暫存器中設定其值,vr3暫存器中未被加法指令設定的元素保持其先前的值。因此,實現函數inc10(x)的程式碼如下,假設vr1包含輸入陣列的值。
v.cmp vr1, 10
v.lt.add vr1, vr1, 10
同樣,我們可以定義載入/儲存指令和其他ALU指令的判斷版本。
19.7.6 互連網路
19.7.6.1 網際網路絡概述
現在考慮互連不同處理和儲存元件的問題。通常,多核處理器使用棋盤設計,但此處我們將處理器集劃分為塊(tile,亦稱瓦片),塊通常由一組2-4個處理器組成,具有其專用快取(L1和可能的L2),它還包含共用的最後一級快取(L2或L3)的一部分。共用的最後一級快取的一部分是給定分片的一部分,稱為分片(slice),分片由2-4個儲存庫(bank)組成。此外,在現代處理器中,一個塊或一組塊可能共用一個記憶體控制器,記憶體控制器的作用是協調片上快取記憶體和主記憶體之間的資料傳輸。下圖顯示了32核多處理器的代表性佈局,與快取組相比,核心的顏色更深。我們使用2個塊大小(2個處理器和2個快取組),並假設共用L2快取具有32個均勻分佈在塊上的快取組。此外,每個塊都有一個專用的記憶體控制器和一個稱為路由器(router)的結構。
多核處理器的佈局。
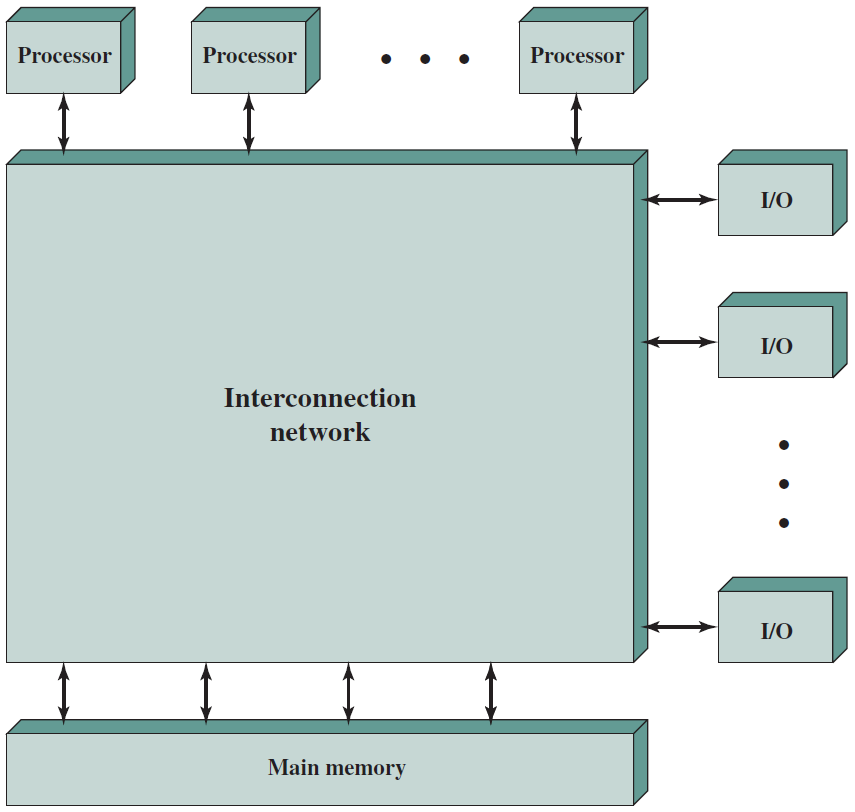
緊密耦合多處理器的通用架構圖。
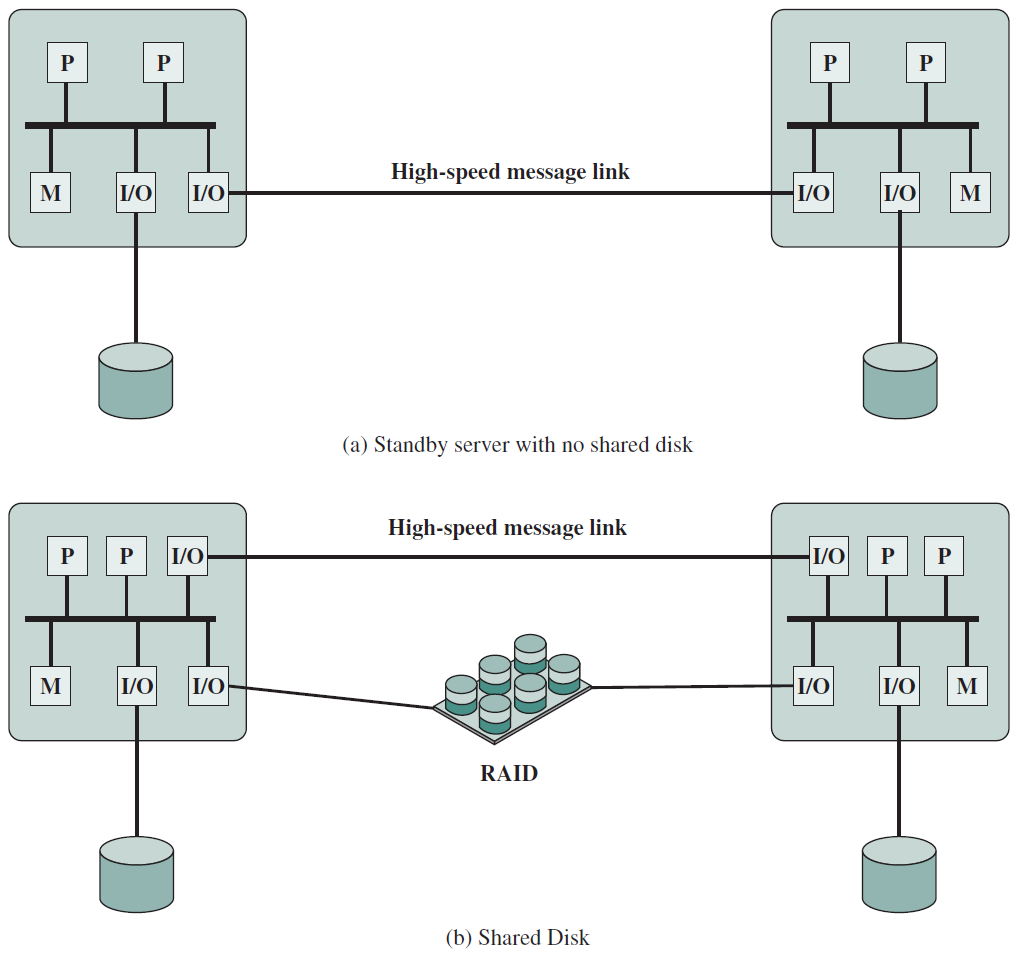
叢集設定。
路由器是一個專用單元,定義如下。
1、路由器通過片上網路將源自其瓦片中的處理器或快取的訊息傳送到其他瓦片。
2、路由器通過片上網路相互連線。
3、訊息通過一系列路由器從源路由器傳送到(遠端瓦片的)目的路由器。途中的每一個路由器都會將訊息轉發到另一個離目的地更近的路由器。
4、最後,與目的地磚相關聯的路由器將訊息轉發到遠端磚中的處理器或快取記憶體。
5、相鄰路由器通過鏈路連線,鏈路是一組用於傳輸訊息的無源銅線。
6、路由器通常有許多傳入鏈路和許多傳出鏈路。一組傳入和傳出連結將其連線到處理器,並在其瓦片中快取。每個連結都有一個唯一的識別符號。
7、路由器具有相當複雜的結構,通常由3至5級管線組成。大多數設計通常將管線階段用於緩衝訊息、計算傳出鏈路的id、仲裁鏈路以及通過傳出鏈路傳送訊息。
8、路由器和鏈路的佈置被稱為片上網路或片上網路,縮寫為NOC。
9、將連線到NOC的每個路由器稱為節點,節點通過傳送訊息相互通訊。
在程式執行過程中,它通過NOC傳送數十億條訊息,NOC攜帶一致性訊息、LLC(最後一級快取)請求/響應訊息以及快取和記憶體控制器之間的訊息。作業系統還使用NOC向核心傳送訊息以載入和解除安裝執行緒,由於資訊量大,大部分NOC經常遇到相當大的擁堵。因此,設計儘可能減少擁堵、易於設計和製造並確保資訊快速到達目的地的NOC至關重要。讓我們定義NOC的兩個重要特性:等分頻寬(bisection bandwidth)和直徑(diameter)。
對稱多處理器組織如下:
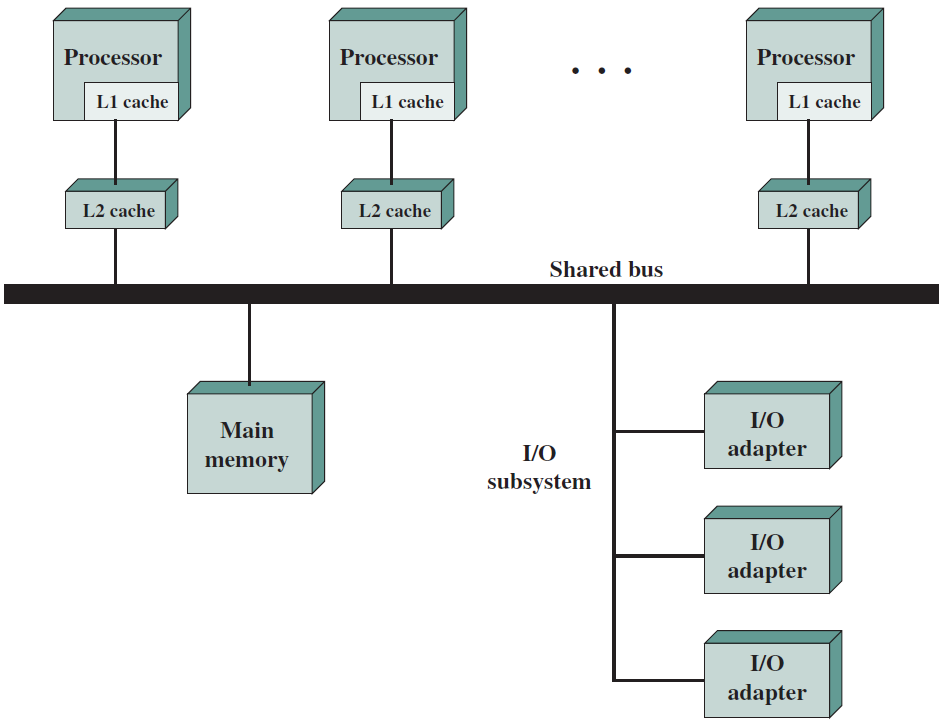
19.7.6.2 等分頻寬和網路直徑
讓我們考慮一個網路拓撲,其中頂點是節點,頂點之間的邊是連結。假設存在鏈路故障,或者由於擁塞等其他原因,鏈路不可用,那麼應該可以通過備用路徑路由訊息。例如,考慮一個佈置為環的網路,如果一個鏈路失敗,那麼總是可以通過環的另一端傳送訊息。如果以順時針方式傳送訊息,可以以逆時針方式傳送。然而,如果存在兩個鏈路故障,則網路可能會斷開成兩個相等的部分。因此,我們希望最大限度地減少將網路完全斷開成相當大的部分(可能相等)所需的鏈路故障數量。將此類故障的數量稱為等分頻寬(bisection bandwidth),等分頻寬是衡量網路可靠性的指標,它精確地定義為需要將網路劃分為兩個相等部分的最小鏈路數。
可以對等分頻寬進行另一種解釋。假設一半網路中的節點正在嘗試向另一半網路中節點傳送訊息,那麼可以同時傳送的訊息數量至少等於等分頻寬。因此,等分頻寬也是網路頻寬的度量。
等分頻寬(bisection bandwidth)被定義為將網路分成兩個相等部分所需的最小鏈路故障數。
我們已經討論了可靠性和頻寬,現在轉向關注延遲。考慮網路中的節點對,接下來考慮每對節點之間的最短路徑,在所有這些最短路徑中,考慮具有最大長度的路徑,該路徑的長度是網路中節點接近度的上限,稱為網路直徑(Network Diameter)。或者,可以將網路的直徑解釋為任何一對節點之間最壞情況下延遲的估計。
讓我們考慮所有節點對,並計算每對節點之間的最短路徑,最長路徑的長度稱為網路直徑(Network Diameter),它是網路最壞情況下延遲的度量。
19.7.6.3 網路拓撲
本節回顧一些最常見的網路拓撲,其中一些拓撲用於多核處理器。然而,大多數複雜的拓撲結構用於使用常規乙太網鏈路連線處理器的鬆散耦合多處理器。對於每個拓撲,假設它有N個節點,為了計算等分頻寬,可以進一步簡化N可被2整除的假設。請注意,等分頻寬和直徑等度量都是近似度量,僅表示廣泛的趨勢。因此,我們有餘地做出簡單的假設,從考慮適用於多核的更簡單拓撲開始,要以高的等分頻寬和低的網路直徑為目標。
鏈和環
下圖左顯示了一個節點鏈,它的等分頻寬為1,網路直徑為N-1,是最糟糕的設定。可以通過考慮一個節點環來改進這兩個指標(下圖右),此時等分頻寬為2,網路直徑為N=2。這兩種拓撲都相當簡單,已被其他拓撲所取代。現在考慮一種稱為胖樹的拓撲結構,它通常在叢集計算機中使用,叢集計算機是指由通過區域網連線的多個處理器組成的鬆散耦合的多處理器。
叢集計算機(cluster computer)是指由通過區域網連線的多個處理器組成的鬆散耦合計算機。
左:鏈;右:環。
胖樹
下圖顯示了一棵胖樹(fat tree),所有節點都在葉子上,樹的所有內部節點都是專用於路由訊息的路由器,將這些內部節點稱為交換機。從節點A到節點b的訊息首先傳播到最近的節點,該節點是A和b的共同祖先,然後它向下傳播到b。請注意,訊息的密度在根附近最高,為了避免爭用和瓶頸,當向根節點移動時,逐漸增加連線節點及其子節點的連結數。該策略減少了根節點處的訊息擁塞。
在範例中,兩個子樹連線到根節點,每個子樹有4個節點,根最多可以從每個子樹接收4條訊息。其次,它最多需要向每個子樹傳送4條訊息。假設一個雙工連結,根需要有4個連結將其連線到其每個子級。同樣,下一級節點需要它們與其每個子節點之間的2個連結,每個葉子需要一個連結。因此,當向根部前進時,可以看到這棵樹越來越胖,因此它被稱為胖樹。
網路直徑等於\(2log(N)\),等分頻寬等於將根節點連線到其每個子節點的最小鏈路數。假設樹的設計是為了確保根上的連結絕對沒有爭用,那麼需要用N=2個連結將根連線到每個子樹,這種情況下的等分頻寬為N=2。請注意,在大多數實際情況下,不會在根及其子級之間分配N=2個鏈路,因為子樹中所有節點同時傳送訊息的概率很低,因此在實踐中可以減少每個級別的連結數。
網格和圓環
左:網格;右:圓環。
現在看看更適合多核的拓撲,最常見的拓撲之一是網格(mesh),其中所有節點都以類似矩陣的方式連線(上圖左)。拐角處的節點有兩個鄰居,邊緣上的節點有三個鄰居,其餘節點有四個鄰居。現在計算網格的直徑和等分頻寬,最長的路徑在兩個角節點之間,直徑等於(\(2 \sqrt{N}-2\))。要將網路分成兩個相等的部分,需要在中間(水平或垂直)分割網格,因為在一行或一列中有\(\sqrt{N}\)個節點,所以等分頻寬等於\(\sqrt{N}\)。就這些引數而言,網格優於鏈和環。
不幸的是,網格拓撲本質上是不對稱的,位於網格邊緣的節點彼此遠離,可以通過每行和每列的末端之間的交叉連結來增加網格,所得結構稱為圓環(torus),如上圖右所示。現在看看圓環的性質,網路邊緣兩側的節點只相隔一跳,最長的路徑位於任何角節點和圓環中心的節點之間,直徑再次等於(忽略小的相加常數)\(\sqrt{N} / 2+\sqrt{N} / 2=\sqrt{N}\)。回想一下,圓環每邊的長度等於\(\sqrt{N}\)。
現在,將網路分成兩個相等的部分,將其水平拆分。因此,需要捕捉\(\sqrt{N}\)個垂直連結,以及\(\sqrt{N}\)條交叉連結(每列末端之間的連結)。因此,等分頻寬等於\(2 \sqrt{N}\)。
通過新增\(2\sqrt{N}\)個交叉連結(行為\(\sqrt{N}\),列為\(\sqrt{N}\)),將直徑減半,並將圓環的等分頻寬加倍。然而,這個方案仍然存在一些問題,後面詳細說明。
在確定直徑時,我們做了一個隱含的假設,即每個鏈路的長度幾乎相同,或者訊息穿過鏈路所需的時間對於網路中的所有鏈路幾乎相同,由此根據訊息經過的連結數來定義直徑。這種假設並不十分不切實際,因為與沿途路由器的延遲相比,通常通過鏈路的傳播時間很短。然而,鏈路的延遲是有限制的,如果連結很長,對直徑的定義需要修改,就圓環來說,有這樣的情況。交叉鏈路在物理上比相鄰節點之間的常規鏈路長\(\sqrt{N}\)倍。因此,與網格相比,我實踐中沒有顯著減小直徑,因為一行末端的節點仍然相距很遠。
幸運的是,可以通過使用一種稍加修改的稱為摺疊圓環(Folded Torus)的結構來解決這個問題,如下圖所示。每一行和每一列的拓撲結構都像一個環,環的一半由原本是網格拓撲的一部分的規則連結組成,另一半由新增的交叉連結組成,這些交叉連結用於將網格轉換為圓環,交替地將節點放置在常規連結和交叉連結上。該策略確保摺疊環面中相鄰節點之間的距離是規則環面中的相鄰節點之間距離的兩倍,但避免了行或列兩端之間的長交叉連結(\(\sqrt{N}\)跳長)。
網路的等分頻寬和直徑與圓環保持相同。在這種情況下,有幾個路徑可以作為最長路徑,但從拐角到中心的路徑不是最長的,最長的路徑之一是在兩個相對的角落之間。摺疊圓環通常是多核處理器中的首選設定,因為它避免了長的交叉鏈路。
超立方體
現在考慮一個具有\(O(log(N))\)直徑的網路,這些網路使用大量連結,因此它們不適用於多核,通常用於大型叢集計算機。這個網路被稱為超立方體(hypercube)。超立方體實際上是一個網路族,每個網路都有一個階(order),k階的超立方體稱為\(H_k\)。它有著下圖所示的幾種拓撲結構。
蝴蝶
最後一個叫做蝴蝶的網路,它也有\(O(log(N))\)的直徑,但它適合於多核。下圖顯示了8個節點的蝶形網路,每個節點由一個圓表示。除了節點之外,還有一組交換機或內部節點(以矩形顯示),用於在節點之間路由訊息。訊息從左側開始,經過交換機,到達圖表的右側。請注意,圖最左側和最右側的節點實際上是相同的節點集。沒有新增從左到右的交叉連結,以避免使圖表複雜化,圖中顯示了兩個節點的集合。
拓撲結構對比
下表用四個引數:內部節點(或交換機)數量、鏈路數量、直徑和二等分頻寬來比較拓撲結構。在所有情況下,假設網路有N個節點可以傳送和接收訊息,N是2的冪。
| 拓撲 | 節點數 | 連結數 | 直徑 | 等分網路 |
|---|---|---|---|---|
| 鏈 | 0 | \(N-1\) | \(N-1\) | 1 |
| 環 | 0 | \(N\) | \(N/2\) | 2 |
| 胖樹 | \(N-1\) | \(2N-2\) | \(2 \log(N)\) | \(N/2\) |
| 網格 | 0 | \(2N-\sqrt{N}\) | \(2\sqrt{N}-2\) | \(\sqrt{N}\) |
| 圓環 | 0 | \(2N\) | \(\sqrt{N}\) | \(2\sqrt{N}\) |
| 摺疊圓環 | 0 | \(2N\) | \(\sqrt{N}\) | \(2\sqrt{N}\) |
| 超立方體 | 0 | \(N\log(N)/2\) | \(\log(N)\) | \(N/2\) |
| 蝴蝶 | \(N\log(N)/2\) | \(N + N\log(N)\) | \(\log(N)+1\) | \(N/2\) |
除此之外,還有以下型別的網路拓撲:
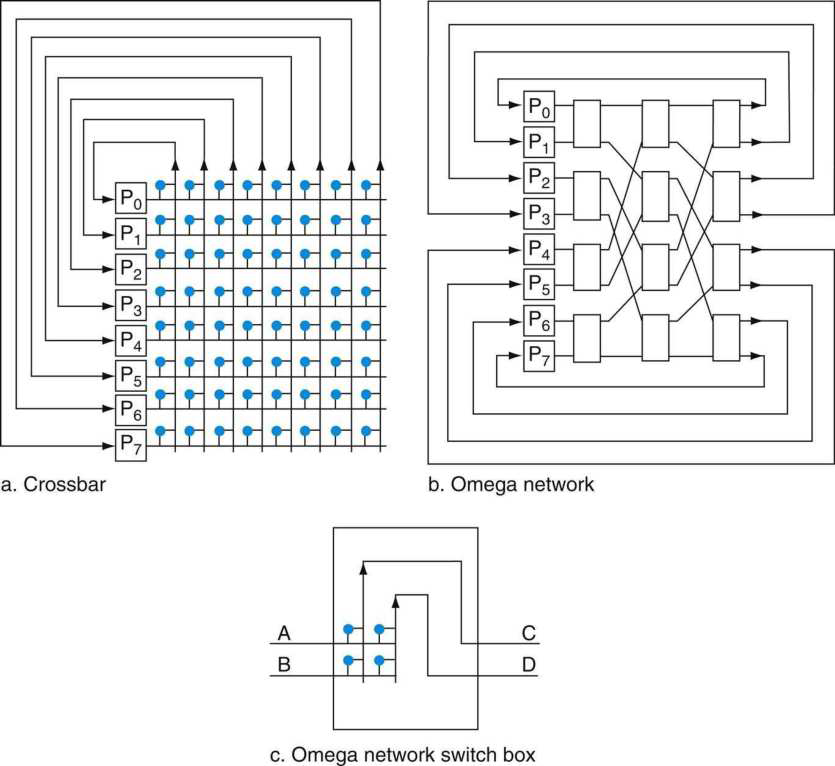
19.8 I/O和儲存裝置
計算機中需要I/O(輸入/輸出)系統,下圖是典型計算機的結構。
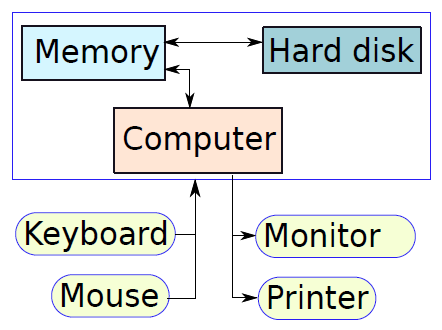
典型的計算機系統。
I/O通道的兩種架構。
處理器是計算機的核心,它連線到一系列I/O裝置,用於處理使用者輸入和顯示結果。這些I/O裝置稱為外圍裝置,最常見的使用者輸入裝置是鍵盤和滑鼠,而最常見的顯示裝置是監視器和印表機。計算機還可以通過一組通用I/O埠與許多其他裝置進行通訊,如相機、掃描器、mp3播放器、攝像機、麥克風和揚聲器。I/O埠包括:
- 一組金屬引腳,用於幫助處理器與外部裝置連線。
- 一個埠控制器,用於管理與外圍裝置的連線。計算機還可以通過一種稱為網路卡的特殊外圍裝置與外界通訊,網路卡包含通過有線或無線連線與其他計算機通訊的電路。
I/O埠(I/O port)由一組金屬引腳組成,用於連線外部裝置提供的聯結器。每個埠都與協調通訊鏈路上資料交換的埠控制器相關聯。
本章特別優先考慮一類特定的裝置,即儲存裝置。硬碟和快閃記憶體驅動器等儲存裝置可以幫助我們永久地儲存資料,即使系統斷電後亦是如此。本章強調儲存裝置的原因是因為它們是電腦架構的組成部分,跨計算機的外圍裝置的性質各不相同。但是,從小型手持電話到大型伺服器,所有計算機都有某種形式的永久儲存,此儲存用於在程式執行期間儲存檔案、系統設定資料和交換空間。因此,架構師特別關注儲存系統的設計和優化。
19.8.1 I/O系統概述
現在遠離I/O裝置的確切細節,在設計計算機系統時,設計者不可能考慮所有可能型別的I/O裝置,即使這樣做,也有可能在電腦售出後出現一類新的裝置,例如蘋果iPad等平板電腦在2005年就不存在了。儘管如此,在iPad和舊電腦之間傳輸資料仍然是可能的,因為大多數設計師都在他們的計算機系統中提供標準介面,例如,典型的桌上型電腦或筆記型電腦有一組USB埠,任何符合USB規範的裝置都可以連線到USB埠,然後可以與主機通訊。類似地,幾乎可以將任何監視器或投影儀與任何筆記型電腦相連,因為筆記型電腦有一個通用的DVI埠,可以連線到任何顯示器。筆記型電腦公司通過實現DVI埠來遵守其DVI規範,DVI埠可以在處理器和埠之間無縫傳輸資料。在類似的線路上,監視器公司通過確保其監視器可以無縫顯示DVI埠上傳送的所有資料來遵守其的DVI規範部分。因此,我們需要確保計算機能夠支援與外圍裝置的一組固定介面,且可以在執行時連線任何外圍裝置。
注意,僅僅因為可以通過實現埠的規範來連線通用I/O裝置,並不意味著I/O裝置可以工作。例如,可以始終將印表機連線到USB埠,但是印表機可能無法列印頁面,原因是需要軟體層面的額外支援來操作印表機。此支援內建於作業系統中的印表機裝置驅動程式中,可以有效地將資料從使用者程式傳輸到印表機。
因此需要明確區分軟體和硬體的角色。先看軟體,大多數作業系統都需要一個非常簡單的使用者介面來存取I/O裝置,例如Linux作業系統有兩個系統呼叫,即讀和寫,具體如下。
read(int file_descriptor, void *buffer, int num_bytes)
write(int file_descriptor, void *buffer, int num_bytes)
Linux將所有裝置視為檔案,併為它們分配一個檔案描述符,檔案描述符是第一個引數,指定了裝置的id。第二個引數指向記憶體中包含資料來源或目標的區域,最後一個參數列示需要傳輸的位元組數。從使用者的角度來看,這就是所有需要做的事情。這些正是作業系統的裝置驅動程式的工作,以及協調其餘過程的硬體,此法已被證明是存取I/O裝置的一種非常通用的方法。
不幸的是,作業系統需要做更多的工作。對於每個I/O呼叫,它需要找到適當的裝置驅動程式並傳遞請求,可能有多個程序試圖存取同一I/O裝置,在這種情況下,需要正確地排程不同的請求。
裝置驅動程式的工作是與本地硬體介面並執行所需操作,通常使用組合指令與硬體裝置通訊。它首先評估自己的狀態,如果是空閒的,就要求外圍裝置執行所需的操作,啟動儲存系統和外圍裝置之間的資料傳輸過程。
下圖概括了上述的討論。圖的上部顯示了軟體模組(應用程式、作業系統、裝置驅動程式),圖的下部顯示了硬體模組。裝置驅動程式使用I/O指令與處理器通訊,然後處理器將命令路由到適當的I/O裝置。當I/O裝置有一些資料要傳送給處理器時,它傳送一箇中斷,然後中斷服務例程讀取資料,並將其傳遞給應用程式。
I/O系統(硬體和軟體)。
實際上,整個I/O過程是一個極其複雜的過程,本章致力於研究和設計裝置驅動程式,僅討論I/O系統的硬體部分,並粗略地瞭解所需的軟體支援。I/O系統的軟體和硬體元件之間的重要差異點如下:
- I/O系統的軟體元件由應用程式和作業系統組成。應用程式通常被提供一個非常簡單的介面來存取I/O裝置,作業系統的作用是整理來自不同應用程式的I/O請求,適當地排程它們,並將它們傳遞給相應的裝置驅動程式。
- 裝置驅動程式通過特殊的組裝指令與硬體裝置通訊。它們協調處理器和I/O裝置之間的資料、控制和狀態資訊的傳輸。
- 硬體(處理器和相關電路)的作用只是充當作業系統和連線到專用I/O埠的I/O裝置之間的信使。例如,如果我們將數碼相機連線到USB埠,則處理器不知道所連線裝置的詳細資訊,它的唯一作用是確保相機的裝置驅動程式和連線到相機的USB埠之間的無縫通訊。
- I/O裝置可以通過傳送中斷來啟動與處理器的通訊,會中斷當前正在執行的程式,並呼叫中斷服務例程。中斷服務例程將控制傳遞給相應的裝置驅動程式,然後裝置驅動程式處理中斷,並採取適當的操作。
下面將細討論I/O系統的硬體元件的架構。
19.8.1.1 I/O系統要求
現在嘗試設計I/O系統的架構,下表列出想要支援的所有裝置及其頻寬要求。需要最大頻寬的元件是顯示裝置(監視器、投影儀、電視),它連線到圖形卡,包含處理影象和視訊資料的圖形處理器。
| 裝置 | 匯流排技術 | 頻寬 | 典型值 |
|---|---|---|---|
| 顯示裝置 | PCI Express(版本4) | 高 | 1-10 GB/s |
| 硬碟 | ATA/SCSI/SAS | 中 | 150-600 MB/s |
| 網路卡(有線/無線) | PCI Express匯流排 | 中 | 10-100 MB/s |
| USB裝置 | USB(通用串列埠匯流排) | 中 | 60-625 MB/s |
| DVD音訊/視訊 | PCI(個人計算機介面) | 中 | 1-4 MB/s |
| 揚聲器/麥克風 | AC'97/Intel High. Def. Audio | 低 | 100 KB/s至3 MB/s |
| 鍵盤/滑鼠 | USB、PCI | 非常低 | 10-100 B/s |
請注意,在討論I/O裝置時,經常使用術語卡(card)。卡是一塊印刷電路板(PCB),可以連線到計算機的I/O系統以實現特定功能,例如,圖形卡可以幫助我們處理影象和視訊,音效卡可以幫助處理高清晰度音訊,網路卡可以幫助連線到網路。網路卡的圖片如下圖所示,可以看到印刷電路板上互連的一組晶片,有一組埠用於將外部裝置連線到卡。

除了圖形卡,另一個需要連線到CPU的高頻寬裝置是主記憶體,其頻寬大約為10-20 GB/s。因此,我們需要設計一個對主記憶體和圖形卡進行特殊處理的I/O系統。
其餘裝置的頻寬相對較低,硬碟、USB裝置和網路卡的頻寬要求限制在500-600 MB/s,鍵盤、滑鼠、CD-DVD驅動器和音訊外圍裝置的頻寬要求極低(小於4 MB/s)。
19.8.1.2 I/O系統設計
結合上表,可以注意到有不同種類的匯流排技術,如USB、PCI Express和SATA,匯流排(bus)被定義為I/O系統中兩個或兩個以上元件之間的鏈路。我們使用不同型別的匯流排來連線不同型別的I/O裝置,例如,使用USB匯流排連線USB裝置(如筆驅動器和相機),使用SATA或SCSI匯流排連線到硬碟。需要使用這麼多不同型別的匯流排的原因有:
- 不同I/O裝置的頻寬要求非常不同。圖形卡需要使用非常高速的匯流排,而鍵盤和滑鼠只需更簡單的匯流排技術,因為總頻寬需求最小。
- 歷史原因。歷史上,硬碟供應商一直使用SATA或IDE匯流排,而圖形卡供應商一直使用AGP匯流排,2010年後,圖形卡供應商轉而使用PCI Express匯流排。
由於多種因素的組合,I/O系統設計者需要支援多種匯流排。
匯流排(bus)是一組用於並聯連線多個裝置的導線。裝置可以使用匯流排在彼此之間傳輸資料和控制訊號。
現在深入研究匯流排的結構。匯流排不僅僅是兩個端點之間的一組銅線,實際上是一個非常複雜的結構,其規格通常長達數百頁。我們需要關注它的電氣特性、誤差控制、發射機(transmitter)和接收機電路、速度、功率和頻寬,本章將有充分的機會討論高速匯流排。連線到匯流排的每個節點(源或目的地)都需要匯流排控制器來傳送和接收資料,儘管匯流排的設計相當複雜,但我們可以將其抽象為一個邏輯鏈路,可以無縫可靠地將位元組從單個源傳輸到一組目的地。
為了設計計算機的I/O系統,首先需要提供由一組金屬引腳或插座組成的外部I/O埠,這些I/O埠可用於連線外部裝置,每個埠都有一個與裝置介面的專用埠控制器,然後埠控制器需要使用上表列出的匯流排之一將資料傳送到CPU。
這裡主要的設計問題是不可能通過I/O匯流排將CPU連線到每個I/O埠,有幾個原因:
1、如果將CPU連線到每個I/O埠,那麼CPU需要為每種匯流排型別配備匯流排控制器,會增加CPU的複雜性、面積和功耗。
2、CPU的輸出引腳的數量是有限的。如果CPU連線到一個I/O裝置主機,那麼它需要大量額外的引腳來支援所有I/O匯流排,大多數CPU通常沒有足夠的引腳來支援此功能。
3、從商業角度來看,將CPU的設計與I/O系統的設計分開是一個好主意,這樣就可以在各種各樣的計算機中使用CPU。
因此,大多數處理器僅連線到一條匯流排,或最多連線到2到3條匯流排。我們需要使用輔助晶片將處理器連線到不同的I/O匯流排主機,它們需要聚合來自I/O裝置的流量,並將CPU生成的資料正確路由到正確的I/O裝置,反之亦然。這些額外的晶片包括給定處理器的晶片組,晶片組的晶片在被稱為主機板的印刷電路板上相互連線。
晶片組(Chipset):是主CPU連線到主記憶體、I/O裝置和執行系統管理功能所需的一組晶片。
主機板(Motherboard):晶片組中的所有晶片都在一塊稱為主機板的印刷電路板上相互連線。
大多數處理器的晶片組中通常有兩個重要的晶片:北橋(North Bridge)和南橋(South Bridge),如下圖所示。CPU使用前端匯流排(FSB)連線到北橋晶片,北橋晶片連線到DRAM記憶體模組、圖形卡和南橋晶片。相比之下,南橋晶片旨在處理速度慢得多的I/O裝置,連線到所有USB裝置,包括鍵盤和滑鼠、音訊裝置、網路卡和硬碟。
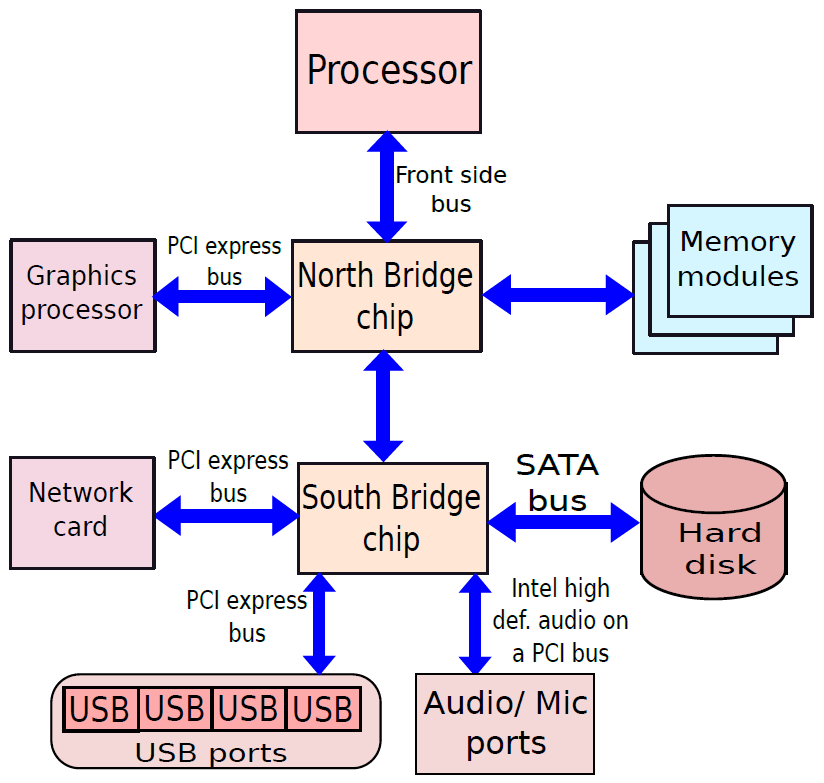
I/O系統架構。
為了完整起見,先闡述計算機系統中其他兩種常見型別的匯流排:
-
後端匯流排(back side bus)。它用於將CPU連線到二級快取。早期的處理器使用晶片外L2快取,通過後端匯流排進行交流,如今的L2快取記憶體已移動到晶片上,因此後端匯流排也在晶片上。它通常以核心頻率計時,是一種非常快的匯流排。
-
背板匯流排(backplane bus)。它用於大型計算機或儲存系統,通常具有多個主機板和外圍裝置,如硬碟。所有這些實體都並聯連線到單個背板匯流排,背板匯流排本身由多條平行銅線和一組可用於連線裝置的聯結器組成。
前端匯流排(front side bus):一種將CPU連線到記憶體控制器的匯流排,或者在Intel系統中連線到北橋晶片。
後端匯流排(back side bus):將CPU連線到二級快取的匯流排。
背板匯流排(backplane bus):連線到多個主機板、儲存和外圍裝置的系統範圍匯流排。
北橋和南橋晶片都需要為它們所連線的所有匯流排配備匯流排控制器,每個匯流排控制器協調對其相關匯流排的存取。成功接收封包後,它將封包傳送到目的地(朝向CPU或I/O裝置)。由於這些晶片互連各種型別的匯流排,並在目標匯流排繁忙時臨時緩衝資料值,因此它們被稱為橋(匯流排之間的橋)。
記憶體控制器是北橋晶片的一部分,實現對主記憶體儲器的讀/寫請求。在過去的幾年裡,處理器供應商已經開始將記憶體控制器轉移到主CPU晶片中,並使其更加複雜,對記憶體控制器的大多數增強都集中在降低主記憶體功率、減少重新整理週期數和優化效能上。從Intel Sandybridge處理器開始,圖形處理器也移動到晶片上。把它們放入CPU晶片的原因是:
- 有額外的電晶體可用。
- 晶片內通訊比晶片外通訊快得多。許多嵌入式處理器還將南橋晶片的大部分、埠控制器以及CPU整合在一個晶片中,有助於減小主機板的尺寸,並允許I/O控制器和CPU之間更有效的通訊。這種型別的系統被稱為SOC(System on Chip,片上系統)。
SOC(System on Chip,片上系統)通常將計算系統的所有相關部分封裝到單個晶片中,包括主處理器和I/O系統中的大部分晶片。
19.8.1.3 I/O系統中的層
大多數複雜的架構通常被分為多個層(layer),猶如網際網路架構,一層基本上獨立於另一層。因此,我們可以選擇以任何方式實現它,只要它符合標準介面。現代計算機的I/O架構也相當複雜,有必要將其功能劃分為不同的層。
我們可以將I/O系統的功能大致分為四個不同的層。請注意,我們將I/O系統的功能劃分為多個層,主要是受7層OSI模型(用於劃分廣域網的功能層)的啟發:
-
物理層:匯流排的物理層主要定義匯流排的電氣規格。它分為兩個子層,即傳輸子層(transmission sublayer)和同步子層(synchronisation sublayer)。
傳輸子層定義了傳輸位元的規範。例如,一條匯流排可以為高電平有效(如果電壓為高電平,則邏輯1),另一條匯流排可為低電平有效(電壓為零電平,則為邏輯1)。今天的高速匯流排使用高速差分訊號,可以使用兩根銅線來傳輸單個位元,通過監測兩條導線之間電壓差的符號來推斷邏輯0或1(類似於SRAM單元中位線的概念)。現代匯流排擴充套件了這一思想,並使用電訊號組合對邏輯位進行編碼。
同步子層規定了訊號的定時,以及恢復接收器在匯流排上傳送的資料的方法。
-
資料鏈路層:資料鏈路層主要用於處理物理層讀取的邏輯位,將位元集分組為幀,執行錯誤檢查,控制對匯流排的存取,並幫助實現I/O事務。具體而言,它確保在任何時間點只有一個實體可以在匯流排上傳輸訊號,並且實現了利用公共訊息模式的特殊功能。
-
網路層:該層主要涉及通過晶片組中的各種晶片將一組幀從處理器成功傳輸到I/O裝置,反之亦然。我們唯一地定義了I/O裝置的地址,並考慮了在I/O指令中嵌入I/O裝置地址的方法。大體上討論兩種方法:基於I/O埠的定址和記憶體對映定址,在後一種情況下,將對I/O裝置的存取視為對指定記憶體位置的常規存取。
-
協定層:最頂層稱為協定層,負責端到端執行I/O請求,包括處理器和I/O裝置之間在訊息語意方面進行高階通訊的方法。例如,I/O裝置可以中斷處理器,或者處理器可以明確請求每個I/O裝置的狀態。其次,為了在處理器和裝置之間傳輸資料,可以直接傳輸資料,也可以將資料傳輸的責任委託給稱為DMA控制器的晶片組中的專用晶片。
下圖總結了典型處理器的4層I/O架構。
I/O系統中的4個層。
19.8.2 物理層:傳輸子層
物理層是I/O系統的最下層,涉及源和接收器之間訊號的物理傳輸。它又可以被分成兩個子層,第一個子層是傳輸子層,它處理從源到目的地的位元傳輸,該子層涉及鏈路的電特性(電壓、電阻、電容),以及使用電訊號表示邏輯位(0或1)的方法。
第二個子層稱為同步子層,涉及從物理鏈路讀取整個位元幀,其中幀被定義為一組由特殊標記劃分的位元。由於I/O通道受到抖動(不可預測的訊號傳播時間)的困擾,因此有必要正確地同步資料到達接收器,並正確讀取每一幀。
本節將討論傳輸子層,下一節討論同步子層。
請注意,建立多個子層而不是建立多個層的原因是因為子層不需要彼此獨立。理論上,可以使用任何物理層和任何其他資料鏈路層協定,理想情況下,它們應該完全忘記對方。但是,傳輸子層和同步子層具有很強的聯絡,因此不可能將它們分離成單獨的層。
下圖顯示了I/O鏈路的一般檢視。源(發射機)向目的地(接收機)傳送一系列位元,在傳輸時,資料始終與源的時鐘同步,意味著,如果源以1GHz執行,那麼它以1GHZ的速率傳送位元。請注意,源的頻率不一定等於傳送資料的處理器或I/O元件的頻率。傳輸電路通常是一個單獨的子模組,它有一個時鐘,該時鐘是從作為其一部分的模組的時鐘中匯出的,例如,處理器的傳輸電路可能以500MHz傳輸資料,而處理器可能以4GHz執行。在任何情況下,我們假設發射機以其內部時鐘速率傳輸資料,該時鐘速率也稱為匯流排頻率(bus frequency),該頻率通常低於處理器或晶片組中其他晶片的時脈頻率。接收器可以以相同的頻率執行,也可以使用更快的頻率,除非明確說明,否則不會假設源和目的地具有相同的頻率。最後要注意,我們將互換使用傳送器、源和傳送器這三個術語,同樣將互換使用「目標」和「接收者」這兩個術語。

I/O鏈路的通用檢視。
19.8.2.1 單端訊號
現在考慮一種簡單的方法,通過從源向目的地傳送脈衝序列來傳送1和0的序列,這種信令方法稱為單端訊號(single ended signalling),是最簡單的方法。
在特定情況下,可以將高電壓脈衝與1相關聯,將低電壓脈衝與0相關聯,這種約定被稱為高電平有效(active high)。或者,可以將低壓脈衝與邏輯1相關聯,將高壓脈衝與邏輯0相關聯,相反,這種約定被稱為低電平有效(active low)。這兩種約定如下圖所示。
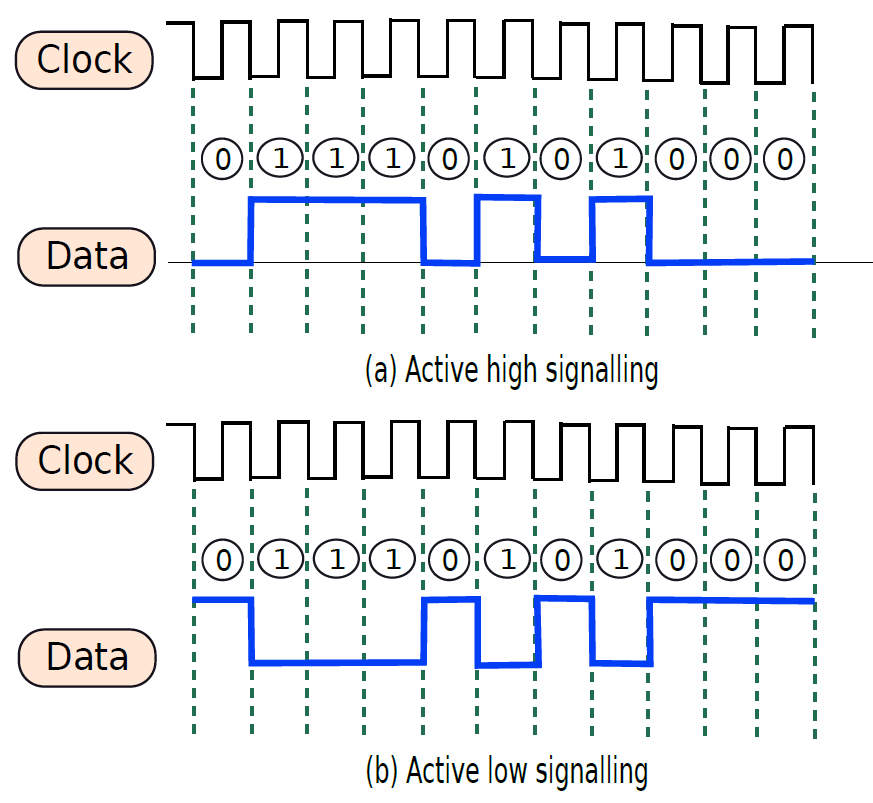
高電平有效和低電平有效的訊號傳送方法。
可悲的是,這兩種方法都極其緩慢和過時。回顧之前章節對SRAM單元的討論,快速I/O匯流排需要將邏輯0和1之間的電壓差降低到儘可能低的值,因為電壓差在對具有內部電容的檢測器充電之後被檢測到。所需電壓越高,電容器充電所需時間越長。如果電壓差為1伏,則需要很長時間才能檢測到從0到1的轉換,將限制匯流排的速度。然而,如果電壓差為30mV,就可以更快地檢測到電壓的轉變,從而可以提高匯流排的速度。
因此,現代匯流排技術試圖將邏輯0和1之間的電壓差降至儘可能低的值。請注意,為了提高匯流排速度,不能任意減小邏輯0和1之間的電壓差。例如,不能讓所需的電壓差為0.001 mV,因為系統中存在一定量的電噪聲,是由幾個因素引起的。如果手機在汽車或電腦的揚聲器開啟時開始響起,那麼揚聲器中也會有一定的噪音。如果把一部手機放在微波爐旁邊,而它正在執行,那麼手機的音質就會下降,因為有電磁干擾。同樣,處理器中也可能存在電磁干擾,並可能引入電壓尖峰。假設這種電壓尖峰的最大振幅為20mV,那麼0和1之間的電壓差需要大於20mV。否則,由於干擾引起的電壓尖峰可能會翻轉訊號的值,從而導致錯誤。下一節簡單地闡述一下片上信令最常見的技術之一,即LVDS。
19.8.2.2 低壓差分訊號(LVDS)
LVDS使用兩根導線傳輸單個訊號。監測這些導線的電壓差。從電壓差的符號推斷出傳遞的值。
基本LVDS電路如下圖所示。有一個3.5 mA的固定電流源。根據輸入a的值,電流通過線路1或線路2流向目的地。例如,如果a為1,則電流流經線路1,因為電晶體T1開始導通,而T2截止。在這種情況下,電流到達目的地,通過電阻器Rd,然後通過線路2流回。通常,當沒有電流流動時,兩條線路的電壓保持在1.2V。當電流流過時,存在電壓擺動。電壓擺動等於3.5mA乘以Rd。Rd通常為100歐姆。因此,總差分電壓擺動為350 mV。檢測器的作用是檢測電壓差的符號。如果是肯定的,它可以宣告邏輯1。否則,它可以宣佈邏輯0。由於擺動電壓低(350 mV),LVDS是一種非常快速的物理層協定。
LVDS電路。
19.8.2.3 多位傳輸
現在考慮按順序傳送多個位元的問題。大多數I/O通道不是一直都很忙,只有在傳輸資料時才忙,因此它們的佔空比(裝置執行時間的百分比)往往是高度可變的,而且大多數時間都不是很高。然而,檢測器幾乎一直處於開啟狀態,一直在檢測匯流排的電壓,可能會影響功耗和正確性。功率是一個問題,因為檢測器在每個週期都會檢測到邏輯1或0,更高階別的層有必要處理資料。為了避免這種情況,大多數系統通常都有一條額外的線來指示資料位是有效還是無效,這條線路傳統上被稱為閃控(strobe)。傳送器可以通過設定閃控的值來向接收器指示資料的有效期,同樣地,有必要同步傳輸線和閃控。對於高速I/O匯流排來說,變得越來越困難,因為傳輸線上的訊號和閃控可能會受到不同延遲量的影響。因此,這兩條線路可能會不同步,最好定義三種型別的訊號:0、1和空閒,其中0和1表示匯流排上邏輯0和1的傳輸,而空閒狀態是指沒有訊號被傳送的事實。這種信令模式也稱為三元信令(ternary signalling),因為使用了三種狀態。
我們可以使用LVDS輕鬆實現三元信令。不妨將LVDS中的導線分別稱為A和B,VA是A線的電壓,VB是B線的電壓。分為以下幾種情況:
- 如果\(\left|V_{A}-V_{B}\right|<\tau\),其中\(\tau\)是檢測閾值,就推斷線路是空閒的,沒有傳輸任何內容。
- 如果\(\left|V_{A}-V_{B}\right|>\tau\),表示正在傳輸邏輯1。
- 如果\(\left|V_{B}-V_{A}\right|>\tau\),表示正在傳輸邏輯0。因此,不需要對基本LVDS協定進行任何更改。
後面闡述一組優化用於在物理層中傳輸多個位元的技術。
19.8.2.4 歸零(RZ)協定
此協定會傳送一個脈衝(正或負),然後在一個位元週期內暫停一段時間。此處可將位元週期定義為傳輸位元所需的時間,大多數I/O協定假設位元週期獨立於正在傳輸的位元(0或1)的值,通常,1位週期等於一個I/O時鐘週期的長度,I/O時鐘是I/O系統元件使用的專用時鐘。我們將互換使用術語時鐘週期(clock cycle)和位週期(bit period),不強調術語之間的差異。
在RZ協定中,如果希望傳送邏輯1,就在鏈路上傳送一個正電壓脈衝,持續一個位元週期的一小部分,隨後停止傳送脈衝,並確保鏈路上的電壓恢復到空閒狀態。類似地,當傳輸邏輯0時,沿著線路傳送一個負電壓脈衝,持續一個週期的一小部分,隨後等待直到線路返回空閒狀態。這可通過允許電容器放電,或通過施加反向電壓使線路進入空閒狀態來實現。在任何情況下,關鍵點是,當在傳輸時,傳輸位元週期的某一部分的實際值,然後允許線路返回到預設狀態,不妨假設為空閒狀態。返回到空閒狀態有助於接收器電路與傳送器的時鐘同步,從而正確讀取資料,這裡隱含的假設是,傳送方每個週期(傳送方週期)傳送一個位元。注意,傳送器和接收器的時鐘週期可能不同。
下圖顯示了帶有三元信令的RZ協定範例。如果要使用二進位制信令,就可以有如下的替代方案:
- 對於邏輯1,我們可以在一個週期內傳送一個短脈衝。
- 對於邏輯0,則不傳送任何訊號。
主要問題是,通過檢視傳送邏輯1後的暫停長度,來判斷是否正在傳送邏輯0,需要在接收器末端設定複雜的電路。
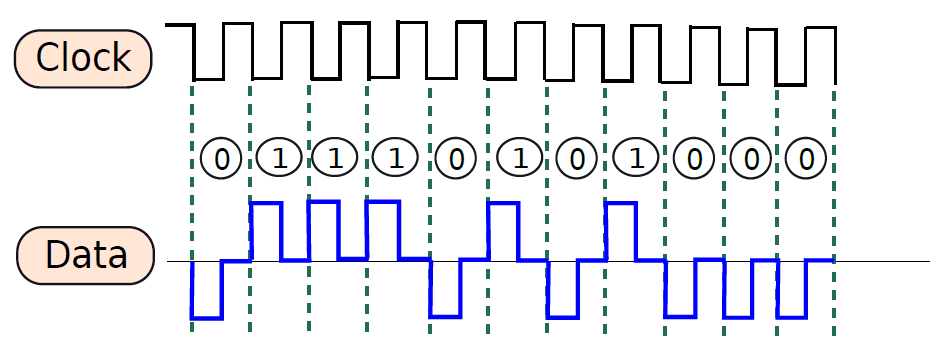
歸零(RZ)協定(範例)。
然而,RZ(歸零)方法的主要缺點是浪費頻寬,需要在傳輸邏輯0或1之後引入一個短暫的暫停(空閒期)。事實證明,我們可以設計不受此限制的協定。
19.8.2.5 曼徹斯特編碼
在討論曼徹斯特編碼之前,讓我們區分物理位(physical bit)和邏輯位(logical bit)。到目前為止,我們一直認為它們的意思是一樣的,然而從現在起,將不再如此。物理位(如物理1或0)表示鏈路兩端的電壓,例如,在有效高電平信令方法中,高電壓指示正在傳輸位1,而低電壓(物理位0)指示正在傳送0位。然而,現在情況不再如此,因為我們假設邏輯位(邏輯0或1)是物理位值的函數,比如當前和前一個物理位等於10,可以推斷邏輯0,同樣,可以有不同的規則來推斷邏輯1。接收器的工作是將物理訊號(或者更確切地說是物理位)轉換為邏輯位,並將其傳遞到I/O系統的更高層。下一層(資料鏈路層)接受來自物理層的邏輯位,它忽略了信令的性質,以及鏈路上傳輸的物理位元的含義。
現在討論曼徹斯特編碼(Manchester Encoding)的機制。這裡將邏輯位編碼為物理位的轉換,下圖顯示了一個範例。物理位的\(0\rightarrow 1\)轉換編碼邏輯1,相反,物理位的\(1\rightarrow 0\)轉換編碼邏輯0。
曼徹斯特程式碼(範例)。
曼徹斯特碼總是有一個轉換來編碼資料。大多數時候,在一段時間的中間,有一個轉換。如果沒有轉換,可以得出結論,沒有訊號被傳輸,鏈路是空閒的。曼徹斯特編碼的一個優點是很容易解碼在鏈路上傳送的資訊,只需要檢測轉換的性質,另外,不需要外部閃控訊號來同步資料。資料被稱為是自計時的(self clocked),意味著可以從資料中提取傳送方的時鐘,並確保接收方以傳送方傳送資料的相同速度讀取資料。
曼徹斯特編碼用於IEEE 802.3通訊協定,該協定構成了今天區域網乙太網協定的基礎。批評者認為,由於每一個邏輯位都與一個轉換相關聯,我們最終不必要地消耗了大量的能量。每一次轉換都需要我們對與鏈路、驅動器和相關電路相關的一組電容器進行充電/放電。相關的電阻損失作為熱量消散,因此讓我們嘗試減少轉換次數。
19.8.2.6 不歸零(NRZ)協定
此方法利用了1和0的執行。對於傳輸邏輯1,將鏈路的電壓設定為高。類似地,對於傳輸邏輯0,將鏈路的電壓設定為低。現在考慮兩個1位的執行。對於第二位,不會在鏈路中引起任何躍遷,並且將鏈路的電壓保持為高。類似地,如果有n個0。然後,對於最後的(n-1)0,保持鏈路的低電壓,因此沒有躍遷。
下圖顯示了一個範例,我們觀察到,當需要傳輸的邏輯位的值保持不變時,通過完全避免電壓轉換,已經最小化了轉換次數。該協定速度快,因為沒有浪費任何時間(例如RZ協定),並且功率效率高,因為消除了相同位執行的轉換(與RZ和曼徹斯特碼不同)。
不歸零協定(範例)。
然而,增加的速度和功率效率是以複雜性為代價的。假設要傳輸一個100個1的字串,在這種情況下,只對第一位和最後一位進行轉換。由於接收方沒有傳送方的時鐘,因此無法知道位元週期的長度。即使傳送器和接收器共用相同的時鐘,由於鏈路中引起的延遲,接收器可能會得出結論,有99或101位的執行,概率為零。因此,必須傳送額外的同步資訊,以便接收器能夠正確讀取在鏈路上傳送的所有資料。
不歸零(NRZI)反轉協定
不歸零(NRZI)反轉協定是NRZ協定的變體。當希望編碼邏輯1時,有一個從0到1或1到0的轉換,而對於邏輯0,沒有轉換。下圖顯示了一個範例。
19.8.3 物理層:同步子層
傳輸子層確保脈衝序列從發射機成功地傳送到一個接收機或一組接收機。然而還不夠,接收機需要在正確的時間讀取訊號,並且需要假定正確的位元週期。它如果讀取訊號太早或太晚,就有可能獲得錯誤的訊號值。其次,如果它假設了錯誤的位元週期值,那麼NRZ協定可能不起作用,因此,需要保持源和目的地之間的時間概念。目標需要確切地知道何時將值傳輸到鎖存器中。讓我們考慮針對單一來源和目的地的解決方案。
總之,同步子層從傳輸子層接收邏輯位元序列,而沒有任何定時保證。它需要計算出位元週期的值,並讀入傳送方傳送的整個資料框(固定大小的塊),然後將其傳送到資料鏈路層。請注意,找出幀邊界和在幀中放置位元集的實際工作是由資料鏈路層完成的。
19.8.3.1 同步匯流排
首先考慮同步系統的情況,其中傳送方和接收方共用相同的時鐘,並且將資料從傳送方傳輸到接收方只需一個週期的一小部分,此外,假設傳送方一直在傳送。讓我們把這個系統稱為一個簡單的同步匯流排(synchronous bus)。
在這種情況下,傳送方和接收方之間的同步任務相當簡單。我們知道資料是在時鐘的負邊緣傳送的,在不到一個週期的時間內就到達了接收器,需要避免的最重要的問題是亞穩態。當資料在時鐘負邊緣附近的一個小時間視窗內發生轉變時,觸發器進入亞穩態。具體而言,我們希望資料在時鐘邊緣之前的設定時間間隔內保持穩定,而資料需要在時鐘邊緣之後的保持時間間隔內穩定。由設定和保持間隔組成的間隔被稱為時鐘的禁止區域(keep-out region)。
在這種情況下,假設資料在少於\(t_{clk}-t_{setup}\)時間單位的時間內到達接收器,因此不存在亞穩態問題,我們可以將資料讀取到接收器的觸發器中。由於數位電路通常以較大的塊(位元組或字)處理資料,在接收器處使用串入——並行地從暫存器出,序列讀入n位,並一次性讀出n位塊。由於傳送器和接收器時鐘相同,因此沒有速率不匹配。接收器的電路如下圖所示。
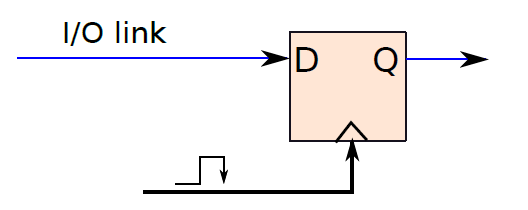
簡單同步匯流排的接收器。
在中時系統中,訊號和時鐘之間的相位差是一個常數。由於鏈路中的傳播延遲以及傳送器和接收器的時鐘中可能存在相位差,所以可以在訊號中引入相位差。在這種情況下,我們可能會出現亞穩態問題,因為資料可能會到達接收器時鐘的關鍵禁區,因此需要新增一個延遲元件,該延遲元件可以將訊號延遲一個固定的時間量,使得在接收器時鐘的禁止區域中沒有轉變。電路的其餘部分與用於簡單同步匯流排的電路保持相同。電路設計如下圖所示。
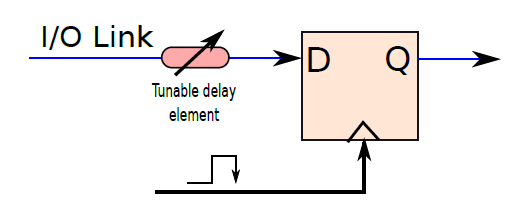
中型匯流排的接收器。
延遲元件可以通過使用延遲鎖定環(DLL)來構造,DLL可以有不同的設計,其中一些設計可能相當複雜,一個簡單的DLL由一系列反相器組成。注意,我們需要有偶數個反相器,以確保輸出等於輸入。為了建立一個可調延遲元件,可以在每對反相器之後抽頭訊號。這些訊號在邏輯上等同於輸入,但由於反相器的傳播延遲而具有漸進相位延遲,然後可以使用多路複用器選擇具有特定相位延遲量的訊號。
現在考慮一個更現實的情景。在這種情況下,傳送方和接收方的時鐘可能不完全相同,可能有少量的時鐘漂移(drift),可以假設在幾十或幾百個週期內,它是最小的,然而可以在數百萬個週期中有幾個週期的漂移。第二,假設傳送方不總是傳輸資料,匯流排中有空閒時間。這種匯流排在伺服器計算機中可以找到,在伺服器計算機上,有多個主機板,理論上以相同的頻率執行,但不共用一個公共時鐘。當考慮數百萬週期量級的時間尺度時,處理器之間存在一定的時鐘漂移。
現在做一些簡單的假設。通常,給定的資料框包含100或可能1000位。當傳輸幾位(<100)時,不必擔心時鐘漂移。然而,對於更多的位元(>100),需要週期性地重新同步時鐘,以便不會丟失資料。此外,確保接收器時鐘的禁止區域中沒有躍遷是一個非常重要的問題。
為了解決這個問題,我們使用了一個稱為閃控的附加訊號,該訊號與傳送器的時鐘同步。在幀傳輸開始時(或者可能在傳送第一個資料位元之前的幾個週期)觸發閃控脈衝,然後每n個週期週期性地切換閃控脈衝一次。在這種情況下,接收機使用可調諧延遲元件,它根據接收閃控脈衝的時間和時鐘轉換之間的間隔來調整其延遲。傳送閃控脈衝幾個週期後,開始傳輸資料。由於時鐘會漂移,需要重新調整或重新調整延遲元件,所以有必要週期性地向接收機傳送閃控脈衝。下圖顯示了資料和閃控的時序圖。
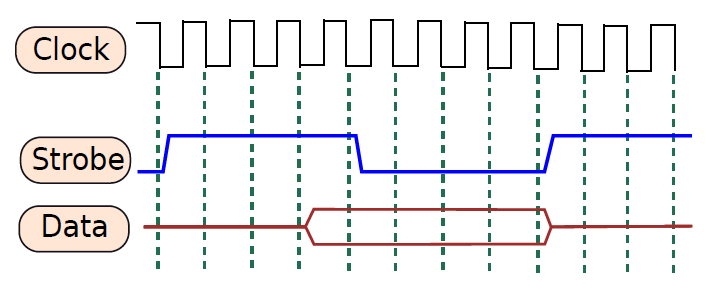
準同步匯流排的時序圖。
與中型匯流排的情況類似,每n個週期,接收機可以使用序列輸入——並行輸出暫存器並行讀出所有n位。接收器的電路如下圖所示。我們有一個延遲計算器電路,將閃控脈衝和接收器時鐘(rclk)作為輸入。基於相位延遲,它調諧延遲元件,使得來自源的資料到達接收機時鐘週期的中間。由於以下原因,需要這樣做:由於傳送方和接收方時鐘週期不完全相同,因此可能存在速率不匹配的問題。我們可能在一個接收機時鐘週期內得到兩個有效資料位,或者根本沒有得到位。當一位到達時鐘週期的開始或結束時,就會發生這種情況。因此,我們希望確保位元在時鐘週期的中間到達,此外,還存在亞穩態避免問題。
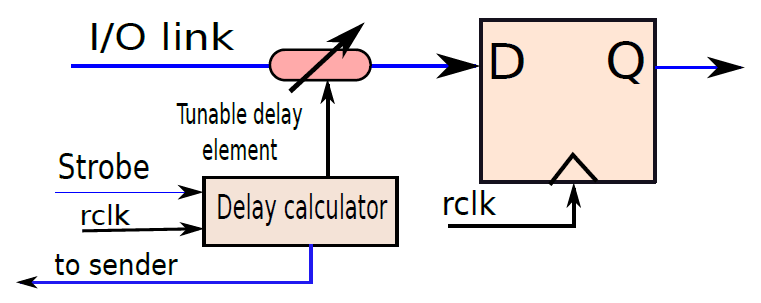
準同步匯流排的接收器。
不幸的是,相位會逐漸改變,位元可能會在時鐘週期開始時到達接收器,然後可以在同一週期中接收兩個位元。在這種情況下,專用電路需要預測該事件,並預先向傳送方傳送訊息以暫停傳送位元。同時,延遲元件應該被重新調諧,以確保位元到達週期的中間。
19.8.3.2 源同步匯流排
可悲的是,即使是準同步匯流排也很難製造。在傳輸訊號時,經常會有很大且不可預測的延遲,甚至很難確保緊密的時鐘同步。例如,用於在同一主機板上的不同處理器之間提供快速I/O路徑的AMD超傳輸協定不採用同步或準同步時鐘。其次,該協定假設了高達1個週期的額外抖動(訊號傳播時間的不可預測性)。
在這種情況下,需要使用更復雜的閃控訊號。在源同步匯流排中,通常將傳送器時鐘作為選通訊號傳送,如果在訊號傳播時間中引入延遲,那麼訊號和閃控脈衝將受到同等影響。這是一個非常現實的假設,截至2013年,大多數高效能I/O匯流排都使用源同步匯流排。源同步匯流排的電路也不是很複雜,我們使用傳送器的時鐘(作為閃控訊號傳送)將資料輸入序列輸入——並行輸出暫存器,它被稱為xclk。我們使用接收器的時鐘讀取資料,如下圖所示。通常,每當訊號跨越時鐘邊界時,都需要一個可調諧的延遲元件來將躍遷保持在禁止區域之外。因此有一個延遲計算器電路,它根據作為閃控脈衝接收的傳送器時鐘(xclk)和接收器時鐘(rclk)之間的相位差來計算延遲元件的引數。
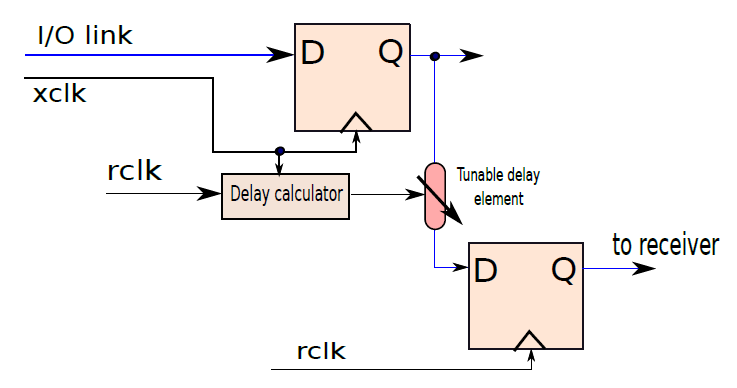
源同步匯流排的接收器。
注意,可以具有多個並行資料鏈路,從而可以同時傳送一組位元,所有傳輸線可以共用攜帶同步時鐘訊號的閃控脈衝。
19.8.3.3 非同步匯流排
現在考慮最通用的匯流排類,即非同步匯流排。在此,不保證傳送方和接收方的時鐘同步,也不會將傳送器的時鐘與訊號一起傳送。接收器的工作是從訊號中提取傳送器的時鐘,並正確讀取資料。讓我們看看下圖所示的資料讀取電路。
非同步匯流排中的接收器電路。
為了便於解釋,假設使用NRZ編碼位的方法,將設計擴充套件到其他型別的編碼相當容易。由傳輸子層傳遞的邏輯位元流被傳送到第一D觸發器,同時被傳送到時鐘檢測器和恢復電路,這些電路檢查I/O訊號中的轉變,並嘗試猜測傳送器的時鐘。具體而言,時鐘恢復電路包含PLL(鎖相環),PLL是一種振盪器,它生成時鐘訊號,並試圖調整其相位和頻率,使其儘可能接近輸入訊號中的轉變序列。請注意,這是一個相當複雜的操作。
在RZ或曼徹斯特編碼的情況下,有周期性躍遷,因此更容易在接收機處同步PLL電路。然而,對於NRZ編碼,沒有周期性躍遷,因此接收機處的PLL電路可能會失去同步。許多使用NRZ編碼的協定(特別是USB協定)在訊號中插入週期性轉換或偽位元,以使接收器處的PLL重新同步。其次,時鐘恢復電路中的PLL還需要處理匯流排中長時間不活動的問題,在此期間,它可能會失去同步。有先進的方案可以確保從非同步訊號中正確恢復時鐘,本節只粗略地闡述,並假設時鐘恢復電路正確地完成其工作。
我們將時鐘檢測和恢復電路的輸出連線到第一個D觸發器的時鐘輸入,因此根據傳送者的時鐘對資料進行計時。為了避免亞穩態問題,在兩個D觸發器之間引入了延遲元件,第二個D觸發器在接收器的時鐘域中。這部分電路與源同步匯流排的電路相似。
注意,在三元信令的情況下,很容易發現匯流排何時處於活動狀態(當在匯流排上看到物理0或1時)。然而在二進位制信令的情況下,不知道匯流排何時處於活動狀態,因為原則上一直在傳輸0或1位,因此有必要使用附加閃控訊號來指示資料的可用性。現在來看看使用閃控訊號來指示匯流排上資料可用性的協定,閃控訊號也可以可選地由三元匯流排用於指示I/O請求的開始和結束。在任何情況下,使用閃控訊號提出的兩種方法都是相當基本的,已經被更先進的方法所取代。
假設源希望向目標傳送資料。它首先將資料放置在匯流排上,在一個小的延遲後設定(設定為1)閃控,如下圖中的時序圖所示。這樣做是為了確保在接收器感知到要設定的選通之前,資料在匯流排上是穩定的。接收器立即開始讀取資料值,直到閃控開啟,接收器繼續讀取資料,將其放入暫存器,並將資料塊傳輸到更高層。當源決定停止傳送資料時,它重置(設定為0)閃控。注意,這裡的時機很重要,通常在停止傳送資料之前重置閃控。需要等待完成,因為希望接收器在選通復位後將匯流排內容視為最後一位。一般而言,希望資料訊號在讀取後保持其值一段時間(對於亞穩態約束)。
基於閃控的非同步通訊系統的時序圖。
注意,在使用閃控訊號的簡單非同步通訊中,源無法知道接收器是否讀取了資料。因此,引入了一種握手協定,其中源明確地知道接收器已經讀取了其所有資料。相關的時序圖如圖下圖所示。
基於閃控的非同步通訊系統的時序圖。
一開始,傳送方將資料放在匯流排上,然後設定閃控。接收器一觀察到要設定的閃控脈衝,就開始從匯流排上讀取資料。讀取資料後,它將ack線設定為1。在發射機觀察到ack線設定設定為1後,可以確定接收機已讀取資料。因此,發射機重置閃控脈衝,並停止傳送資料。當接收機觀察到閃控脈衝已復位時,它將復位確認線。隨後,發射機準備使用相同的步驟序列再次發射。
這一系列步驟確保發射器知道接收器已讀取資料的事實。注意,當接收機能夠確定它已經讀取了發射機希望傳送的所有資料時,該圖是有意義的,因此設計者大多使用該協定來傳輸單個位元。在這種情況下,在接收器讀取位之後,它可以斷言ack線。其次,該方法也與RZ和曼徹斯特編碼方法更相關,因為發射機需要在傳送新位元之前返回到預設狀態。收到確認後,發射機可以開始返回預設狀態的過程,如上上圖所示。
為了並行傳輸多個位元,需要為每條傳輸線設定一個閃控脈衝,然而可以有一條共同的確認線,需要在所有接收器都已讀取其位時設定ack訊號,並且需要在所有閃控線都已重置時重置ack線。最後,該協定中有四個獨立的事件(如圖所示)。因此,該協定被稱為4階段握手協定(4-phase handshake protocol)。
如果使用NRZ協定,就不需要返回預設狀態,可以在收到確認後立即開始傳送下一個位元。然而,在這種情況下,需要稍微改變閃控和確認訊號的語意。下圖顯示了時序圖。
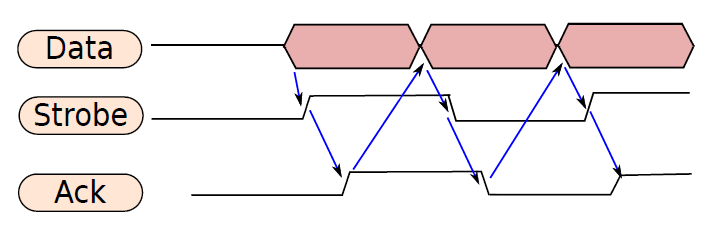
具有2相握手的基於閃控的非同步通訊系統的時序圖。
在這種情況下,在將資料放在匯流排上之後,發射機切換閃控脈衝的值。隨後,在讀取資料後,接收器切換確認行的值。發射機檢測到確認線已切換後,開始傳送下一位。短時間後,它切換閃控脈衝的值以指示資料的存在。再次,在讀取位之後,接收器切換ack線,因此協定繼續。注意,在這種情況下,我們不是設定和重置ack和閃控線,而是切換它們,以減少需要在匯流排上跟蹤的事件數量,然而,需要在傳送方和接收方保持一些額外的狀態。這是微不足道的開銷,因此,4相協定得到了顯著簡化。NRZ協定更適合這種方法,因為它們具有連續的資料傳輸,沒有任何中間的暫停週期。
簡單同步匯流排:一種簡單的同步匯流排,假設發射機和接收機共用相同的時鐘,並且時鐘之間沒有偏差。
中時匯流排(Mesochronous Bus):發射器和接收器具有相同的時脈頻率,但時鐘之間可能存在相位延遲。
準同步匯流排(Plesiochronous Bus):發射器和接收器的時脈頻率之間存在少量不匹配。
源同步匯流排(Source Synchronous Bus):發射器和接收器的時鐘之間沒有關係。因此將發射機的時鐘與訊息一起傳送給接收機,以便它可以使用它來對訊息中的位元進行取樣。
非同步匯流排(Asynchronous Bus):非同步匯流排不假定發射機和接收機的時鐘之間有任何關係,通常具有複雜的電路,通過分析訊息中的電壓轉變來恢復發射機的時鐘。
19.8.4 資料鏈路層
資料鏈路層從物理層獲取邏輯位序列。如果序列輸入-並行輸出暫存器的寬度是n位,那麼保證一次獲得n位。資料鏈路層的工作是將資料分成幀,並緩衝幀,以便在其他傳出鏈路上傳輸。其次,它執行基本的錯誤檢查和糾正。由於電磁干擾,可能會在訊號中引起誤差,例如,邏輯1可能會翻轉為邏輯0,反之亦然。可以在資料鏈路層中糾正這種單位元錯誤,如果存在大量錯誤,並且不可能糾正錯誤,那麼在這個階段,接收機可以向發射機傳送請求重傳的訊息。錯誤檢查後,如果需要,可以在另一條鏈路上轉發該幀。
可能有多個傳送者同時試圖存取一條匯流排。在這種情況下,需要在請求之間進行仲裁,並確保在任何一個時間點只有一個傳送方可以傳送資料。此過程稱為仲裁(arbitration),通常也在資料鏈路層中執行。最後,仲裁邏輯需要對處理作為事務一部分的請求提供特殊支援,比如到記憶體單元的匯流排可能包含作為記憶體事務一部分的載入請求。作為響應,記憶體單元傳送包含記憶體位置的內容的響應訊息。我們需要在匯流排控制器級別提供一些額外的支援,以支援這樣的訊息模式。
概括而言,資料鏈路層將從物理層接收到的資料分解為幀,執行錯誤檢查,通過允許在單個時間使用單個發射機來管理匯流排,並優化常見訊息模式的通訊。
19.8.4.1 分幀和快取
資料鏈路層中的處理開始於從物理層讀取位元集,可以有一個序列鏈路,也可以有同時傳輸位元的多個序列鏈路。一組多個序列鏈路稱為並行鏈路。在這兩種情況下,我們讀入資料,將它們序列儲存在——並行輸出移位暫存器,並將位元塊傳送到資料鏈路層,資料鏈路層的作用是根據從物理層獲得的值建立位元幀。對於從鍵盤和滑鼠傳輸資料的鏈路,幀可能是一個位元組,對於在處理器和主記憶體或主記憶體和圖形卡之間傳輸資料的鏈路,幀可能高達128個位元組。在任何情況下,每個匯流排控制器的資料鏈路層都知道幀大小,主要問題是劃定幀的邊界。幀劃分方法有:
- 通過插入長暫停進行劃分。在兩個連續幀之間,匯流排控制器可以插入長暫停。通過檢查這些暫停的持續時間,接收機可以推斷幀邊界。但是,由於I/O通道中的抖動,這些暫停的持續時間可能會發生變化,並且可能會引入新的暫停。此法不是一種非常可靠的方法,而且還浪費寶貴的頻寬。
- 位元計數。可以先驗地乘以一幀中的位元數,簡單地計算傳送的位元數,並在所需的位元數到達接收器後宣佈一幀結束。主要問題是,有時由於訊號失真,脈衝會被刪除,並且很容易失去同步。
- 位/位元組填充。是最靈活的方法,用於大多數商業I/O匯流排實現。此法使用預先指定的位元序列來指定幀的開始和結束,例如,我以使用模式0xDEADBEF指示幀的開始,使用0x12345678指示幀的結束。幀中任何32位元序列在開始和結束時與特殊序列匹配的概率很小,概率等於\(2^{-32}\)或\(2:5e-10\)。不幸的是,概率仍然是非零,因此可以採用一個簡單的解決方案來解決這個問題。如果序列0xDEADBEF出現在幀的內容中,就再新增32個虛位並重復此模式,比如將位元型樣0xDEADBEF替換為0xDEADEEFDEADBEF。接收機的鏈路層可以發現該模式重複偶數次。模式中的一半位是幀的一部分,其餘的是偽位,然後接收機可以繼續去除偽位元。這種方法是靈活的,它可以對抖動和可靠性問題非常有彈性。這些序列也稱為逗點(commas)。
一旦資料鏈路層建立了一個幀,它就將其傳送到錯誤檢查模組,並對其進行緩衝。
19.8.4.2 檢錯和糾錯
由於各種原因,在訊號傳輸中可能引入誤差。由於附近執行的其他電子裝置,可能會受到外部電磁干擾,比如開啟微波爐等電子裝置後,可能會注意到手機的音質下降,因為電磁波耦合到I/O通道的銅線並引入電流脈衝。還可能受到附近電線的額外干擾(稱為串擾),以及電線傳輸延遲因溫度而發生的變化。累積起來,干擾會引起抖動(在訊號的傳播時間中引入變化),並引入失真(改變脈衝的形狀)。因此,可能錯誤地將0解釋為1,反之亦然。因此,有必要新增冗餘資訊,以便能夠恢復正確的值。
注意,在實踐中出錯的概率很低,主機板上互連的傳輸率通常不到百萬分之一,但也不是一個很小的數位。如果每秒有一百萬次I/O操作,通常每秒就會有一次錯誤,實際上是一個非常高的錯誤率。因此需要向位新增額外的資訊,以便檢測錯誤並從錯誤中恢復。這種方法被稱為向前錯誤更正(forward error correction)。相比之下,在反向糾錯(backward error correction)中,我們檢測錯誤,丟棄訊息,並請求傳送方重新傳送。下面討論流行的錯誤檢測和恢復方案。
單個錯誤檢測
由於單位元錯誤是相當不可能的,因此在同一幀中出現兩個錯誤的可能性極低。因此,讓我們專注於檢測單個錯誤,並假設只有一位由於錯誤而翻轉其狀態。
讓我們簡化問題。假設一幀包含8位元,我們希望檢測是否存在單位錯誤。讓我們將幀中的位元編號為D1;D2;::;D8。現在讓我們新增一個稱為奇偶校驗位的附加位。奇偶校驗位P等於:
這裡,\(\oplus\)操作是XOR運運算元,簡而言之,奇偶校驗位表示所有資料位(D1 ... D8)的XOR。對於每8位元,我們傳送一個額外的位,即奇偶校驗位(parity bit),因此將8位元訊息轉換為等效的9位訊息。在這種情況下,以更高的可靠性為代價,有效地增加了可用頻寬12.5%的開銷。下圖顯示了使用8位元奇偶校驗方案的幀或訊息的結構。注意,還可以通過將單獨的奇偶校驗位與8個資料位的每個序列相關聯來支援更大的幀大小。
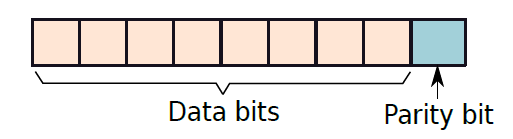
帶有奇偶校驗位的8位元訊息。
當接收器接收到訊息時,它通過計算8個資料位的XOR來計算奇偶性。如果該值與奇偶校驗位匹配,就可以斷定沒有錯誤,但如果訊息中的奇偶校驗位與計算出的奇偶校驗位元的值不匹配,就可以得出結論,存在單個位元錯誤。錯誤可能出現在訊息中的任何資料位中,甚至可能出現在奇偶校驗位中。在這種情況下,無從得知,所能檢測到的只是存在一個位錯誤。現在嘗試糾正錯誤。
單個錯誤校正
要糾正單個位錯誤,如果有錯誤,需要知道已丟棄的位的索引,現在統計一下可能的結果。對於n位塊,需要知道有錯誤的位的索引,此種情況下,可以有n個可能的索引,沒有錯誤,因此對於單個糾錯(SEC)電路,總共有n+1個可能結果(n個結果有錯誤,一個結果無錯誤)。因此從理論角度來看,需要\([\log(n+1)]\)個額外的位元,比如對於8位元幀,需要\([\log(8+1)]=4\)位。讓我們設計一個(8,4)程式碼,每8位元資料字有四個附加位。
讓我們從擴充套件奇偶校驗方案開始。假設四個附加位元中的每一個都是奇偶校驗位元,但它們不是整個資料位集合的奇偶校驗函數,相反,每個位元是資料位元子集的奇偶校驗。四個奇偶校驗位分別命名為P1、P2、P3和P4,此外,排列8個資料位和4個奇偶校驗位元,如下圖所示。
資料和奇偶校驗位的排列。
將奇偶校驗位P1、P2、P3和P4分別保持在位置1、2、4和8,將資料位D1...D8分別排列在位置3、5、6、7、9、10、11和12,下一步是為每個奇偶校驗位分配一組資料位。用二進位制表示每個資料位的位置,在這種情況下,需要4個二進位制位,因為需要表示的最大數位是12。現在將第一個奇偶校驗位P1與其位置(以二進位制表示)的LSB為1的所有資料位相關聯,在這種情況下,以1作為LSB的資料位是D1(3)、D2(5)、D4(7)、D5(9)和D7(11)。因此,將奇偶校驗位P1計算為:
類似地,將第二奇偶校驗位P2與在其第二位置具有1的所有資料位相關聯(假設LSB位於第一位置),對第3和第4奇偶校驗位使用類似的定義。
下表顯示了資料和奇偶校驗位之間的關聯。「X」表示給定的奇偶校驗位是資料位的函數。基於此表,我們得出以下等式來計算奇偶校驗位。
 )
)
資料和奇偶校驗位的關係。
訊息傳輸的演演算法如下。根據下面的等式計算奇偶校驗位,然後將奇偶校驗位分別插入位置1、2、4和8,並根據上上圖通過新增資料位形成訊息。一旦接收機的資料鏈路層收到訊息,它首先提取奇偶校驗位,並形成由四個奇偶校驗位組成的形式為\(P=P_4P_3P_2P_1\)的數位,例如如果P1=0,P2=0,P3=1,P4=1,則P=1100。隨後,接收器處的錯誤檢測電路從接收到的資料位中計算出一組新的奇偶校驗位(\(P'_1,P'_2,P'_3,P'_4\)),並形成形式為\(P^{\prime}=P_{4}^{\prime} P_{3}^{\prime} P_{2}^{\prime} P_{1}^{\prime}\)的另一個數。理想情況下,P應該等於P0,但如果資料或奇偶校驗位中存在錯誤,則情況不會如此。讓我們計算\(P\oplus P'\),這個值也稱為伴隨式(syndrome)。
現在嘗試將伴隨式的值與錯誤位的位置相關聯。首先假設奇偶校驗位中存在錯誤,在這種情況下,下表中的前四個條目顯示了訊息中錯誤位的位置和伴隨式的值,伴隨式的值等於訊息中錯誤位的位置。奇偶校驗位分別位於位置1、2、4和8,因此如果任何奇偶校驗位有錯誤,其校正子中的對應位被設定為1,其餘位保持為0。因此,校正子匹配錯誤位的位置。
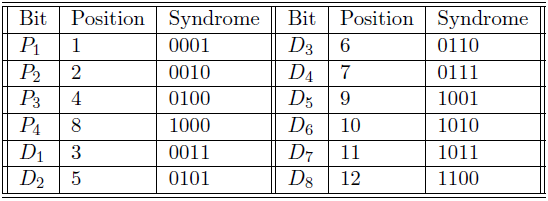
錯誤位置與伴隨式之間的關係。
現在考慮資料位中的單位錯誤的情況。再次從上表中可以得出結論,伴隨式與資料位的位置相匹配,因為一旦資料位出現錯誤,所有相關的奇偶校驗位都會被翻轉。例如,如果D5有錯誤,則奇偶校驗位P1和P4被翻轉。回想一下,將P1和P4與D5關聯的原因是因為D5是位號9(1001),而9的二進位制表示中的兩個1分別位於位置1和4。隨後,當D5中存在錯誤時,校正子等於1001,這也是訊息中位的索引。同樣,每個資料和奇偶校驗位都有一個獨特的校正子(參見上上表)。
因此可以得出結論,如果存在錯誤,則伴隨式指向錯誤位(資料或奇偶校驗)的索引。如果沒有錯誤,則伴隨式等於0。因此有了檢測和糾正單個錯誤的方法。這種用附加奇偶校驗位編碼訊息的方法稱為SEC(single error correction,單糾錯)碼。
單錯誤校正,雙錯誤檢測(SECDED)
現在嘗試使用SEC程式碼來額外檢測雙重錯誤(兩位錯誤)。舉一個反例,證明基於伴隨式的方法是行不通的。假設位D2和D3中存在錯誤,伴隨式將等於0111,但如果D4中存在錯誤,伴隨式也將等於0112。因此,無法知道是否存在單位錯誤(D4)或雙位錯誤(D2和D3)。
稍微擴充一下演演算法來檢測雙重錯誤。新增一個額外的奇偶校驗位P5,它計算SEC程式碼中使用的所有資料位(D1…D8)和四個奇偶校驗位(P1…P4)的奇偶校驗,然後將P5新增到訊息中。將其儲存在資訊的第13位,並將其排除在計算伴隨式的過程中。新演演算法如下。首先使用與SEC(單一錯誤校正)程式碼相同的過程來計算伴隨式。如果伴隨式為0,則不會有錯誤(單或雙)。通過檢視上上表,可以很容易地驗證單個錯誤的證明。對於雙重錯誤,假設兩個奇偶校驗位被翻轉,在這種情況下,伴隨式將有兩個1。類似地,如果兩個資料位被翻轉,則伴隨式將至少有一個1位,因為上上表中沒有兩個資料位元具有相同的列。現在,如果一個資料和一個奇偶校驗位被翻轉了,那麼伴隨式也將為非零,因為一個資料位元與多個奇偶校驗位元相關聯。正確的奇偶校驗位將指示存在錯誤。
因此,如果伴隨式是非零的,就可以懷疑有錯誤;否則假設沒有錯誤。如果有錯誤,檢視訊息中的位P5,並在接收器處重新計算。讓我們將重新計算的奇偶校驗位指定為P'5。現在,如果P5=P'5,那麼我們可以得出結論,存在雙位錯誤。在計算最終奇偶校驗時,兩個單位元錯誤基本上是相互抵消的。相反,如果P5不等於P'5,則意味著有一個位錯誤。可以使用此檢查來檢測兩位或一位是否有錯誤,如果有一個位錯誤,那麼也可以糾正它。然而,對於雙位錯誤,只能檢測它,並可能要求源重新傳輸。該程式碼通常稱為SECDED程式碼。
漢明碼(Hamming Code)
迄今為止描述的所有程式碼都被稱為漢明程式碼,因為它們隱含地依賴於漢明距離,漢明距離是兩個二進位制位元序列之間不同的對應位元數。例如,0011和1010之間的漢明距離為2(MSB和LSB不同)。
現在考慮一個4位元奇偶校驗碼。如果訊息為0001,則奇偶校驗位等於1,且奇偶校驗位位於MSB位置的傳送訊息為10001。不妨將傳送訊息稱為碼字(code word)。注意,00001不是一個有效的碼字,接收者將依靠這個事實來判斷是否存在錯誤,事實上,在有效碼字的漢明距離1內沒有其他有效碼字。同樣,對於SEC程式碼,碼字之間的最小漢明距離為2,對於SECDED程式碼,最小漢明距離為3。現在考慮一種同樣非常流行的不同型別的程式碼。
漢明糾錯碼。
漢明SEC-DEC碼。
迴圈冗餘校驗(CRC)碼
CRC(yclic Redundancy Check,迴圈冗餘校驗)碼主要用於檢測錯誤,即使在大多數情況下它們可以用於糾正單位元錯誤。為了激勵CRC碼的使用,讓我們看看實際I/O系統中的錯誤模式。通常在I/O通道中,干擾持續時間比位週期長。例如,如果有一些外部電磁干擾,那麼它可能會持續幾個週期,並且可能會有幾個位元被翻轉。這種錯誤模式稱為突發錯誤(burst error)。例如,32位元CRC碼可以檢測長達32位元的突發錯誤,它通常可以檢測大多數2位錯誤和所有單位錯誤。
CRC碼背後的數學十分複雜,感興趣的讀者可以參考有關編碼理論的文字,下面展示一個小范例。
假設我們希望為8位元訊息計算4位元CRC碼。讓訊息等於二進位制的101100112,第一步是將訊息填充4位元,即CRC碼的長度,因此新訊息等於10110011 0000(增加了一個空格以提高可讀性)。CRC碼需要另一個5位數位,即生成多項式或除數。原則上,需要將訊息表示的數位除以除數表示的數位,剩餘部分是CRC碼。然而這種劃分不同於常規劃分,它被稱為模2除法。在這種情況下,假設除數是110012。對於n位CRC碼,除數的長度是n+1位。
現在闡述演演算法。首先將除數的MSB與訊息的MSB對齊,如果訊息的MSB等於1,就計算第一個n+1位和除數的XOR,並用結果替換訊息中的相應位。否則,如果MSB為0,則不執行任何操作。在下一步中,將除數向右移動一步,將訊息中與除數的MSB對齊的位視為訊息的MSB,然後重複相同的過程。繼續這一系列步驟,直到除數的LSB與訊息的LSB對齊。最後,最小有效n(4位元)包含CRC碼。對於傳送訊息,在訊息中附加CRC碼。接收機重新計算CRC碼,並將其與訊息附加的碼匹配。
具體範例,顯示計算4位元CRC碼的步驟,其中訊息等於10110011,除數等於11001。演演算法過程示意圖如下:
此圖忽略了訊息相關部分的MSB為0的步驟,因為在這些情況下,無需執行任何操作。
Reed-Solomon
漢明碼在人們可以合理預期錯誤是罕見事件的情況下工作得很好,固定磁碟驅動器的錯誤率約為1億分之一,3位漢明碼將很容易糾正這種錯誤,但漢明碼在多個相鄰位元可能被損壞(即突發錯誤)的情況下是無用的。由於它們暴露於處理不當和環境壓力,在磁帶和光碟等可移動媒介上,突發錯誤很常見。
如果期望錯誤發生在塊中,就應該使用基於塊級(block level)操作的糾錯碼,而不是位元級(bit level)操作的漢明碼。Reed-Solomon(所羅門,RS)碼可以被認為是一種CRC,它在整個字元上執行,而不僅僅是幾個位元。RS碼和CRC一樣,都是系統化的:奇偶校驗位元組被附加到一個資訊位元組塊上。使用以下引數定義\(RS(n, k)\)碼:
- \(s\) = 字元(或「符號」)中的位數。
- \(k\) = 構成資料塊的s位字元數。
- \(n\) = 碼字中的位數。
\(RS(n, k)\)可以校正k個資訊位元組中的\(\cfrac{n-k}{2}\)個錯誤。因此,流行的\(RS(255, 223)\)碼使用223個8位元資訊位元組和32個伴隨式位元組來形成255位元組的碼字,它將糾正資訊塊中多達16個錯誤位元組。RS碼的生成多項式由一個定義在抽象數學結構(稱為Galois域)上的多項式給出,RS生成多項式為:
其中\(t=n− k\)和\(x\)是整個位元組(或符號),並且\(g(x)\)在欄位\(GF(2^S)\)上操作。注意,這個多項式在Galois域上展開,與普通代數中使用的整數域有很大不同。使用以下等式計算\(n\)位元組\(RS\)碼字:
其中\(i(x)\)是資訊塊。儘管RS糾錯演演算法背後有令人望而生畏的代數,但它很適合在計算機硬體中實現,在大型計算機的高效能磁碟驅動器以及用於音樂和資料儲存的光碟中實現。
19.8.4.3 仲裁
現在闡述匯流排仲裁(arbitration)的問題,「仲裁」一詞的字面意思是「解決爭端」。考慮一種多點匯流排,那裡可能有多個發射機。如果多個發射機有興趣通過匯流排傳送值,需要確保在任何時間點只有一個發射機可以在匯流排上傳送值。因此,需要一個仲裁策略來選擇可以通過匯流排傳送資料的裝置。如果有對等匯流排,其中有一個傳送器和一個接收器,那麼不需要仲裁。如果有不同型別的訊息等待傳輸,就需要根據一些最優性標準來排程鏈路上的訊息傳輸。
設想了一種稱為仲裁器(arbiter)的專用結構,它執行匯流排仲裁的任務。所有裝置都連線到匯流排和仲裁器,它們通過向仲裁器傳送訊息來表示它們願意傳輸資料。仲裁器選擇其中一個裝置,有兩種拓撲用於將裝置連線到仲裁器。可以使用星形(star like)拓撲,也可以使用菊花鏈拓撲(daisy chain)。接下來的小節中討論這兩種方案。
星形拓撲
在這個集中式協定中,有一個稱為仲裁器的中央實體,它是一個專用電路,接受來自所有希望在匯流排上傳輸的裝置的匯流排請求。它強制執行優先順序和公平性政策,並授予單個裝置在匯流排上傳送資料的權利。具體來說,在請求完成後,仲裁器檢視所有當前請求,然後為選擇傳送資料的裝置斷言匯流排授權訊號。所選裝置隨後成為匯流排主控器並獲得匯流排的獨佔控制,然後它可以適當地設定匯流排,並傳輸資料。系統概述如下圖所示。
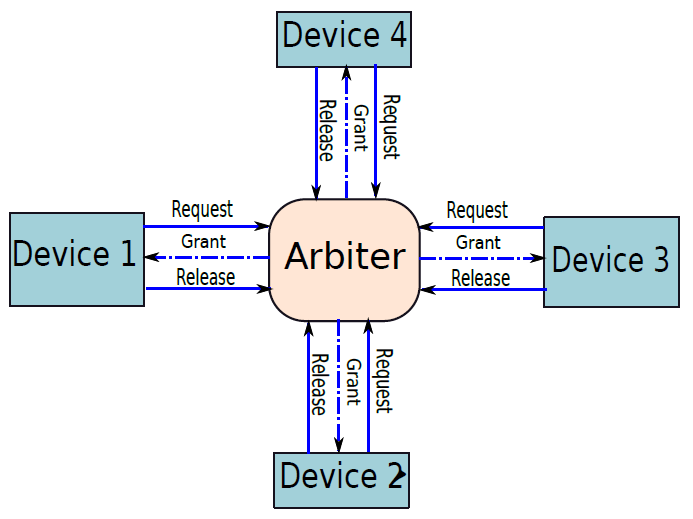
集中的基於仲裁者的架構。
我們可以採用兩種方法來確定當前請求何時完成。第一種方法是,連線到匯流排的每個裝置在給定的週期數n內進行傳輸,在這種情況下,在經過n個週期後,仲裁器可以自動假設匯流排是空閒的,並且可以排程另一個請求。然而,情況可能並不總是這樣,可能有不同的傳輸速度和不同的訊息大小,在這種情況下,每個傳送裝置都有責任讓仲裁器知道這已經完成。我們設想了一個額外的訊號匯流排釋放,每個裝置都有一條到仲裁器的專用線路,用於傳送匯流排釋放訊號。一旦完成了傳輸過程,它就斷言這條線(將其設定為1)。隨後,仲裁器將匯流排分配給另一個裝置。它通常遵循標準策略,如迴圈或FIFO。
基於菊花鏈的仲裁
如果有多個裝置連線到一條匯流排,仲裁器需要知道所有裝置及其相對優先順序。此外,當增加連線到匯流排的裝置數量時,仲裁器開始出現高爭用,並且變得緩慢。因此,希望有一個方案,可以容易地執行優先順序,保證一定程度的公平性,並且不會在增加連線裝置的數量時導致匯流排分配決策的緩慢。菊花鏈匯流排是考慮到所有這些要求而提出的。
下圖顯示了基於菊花鏈的匯流排的拓撲結構。該拓撲結構類似於線性鏈,一端有仲裁器。除最後一個裝置外,每個裝置都有兩個連線。協定開始如下。一個裝置從斷言其匯流排請求線開始,所有裝置的匯流排請求線以有線或方式連線,到仲裁器的請求線本質上計算所有匯流排請求線的邏輯或。隨後,如果仲裁器具有令牌,則仲裁器將令牌傳遞給與其連線的裝置,否則需要等待仲裁器獲得釋放訊號。一旦裝置獲得令牌,它就成為匯流排主機,如果需要,它可以在匯流排上傳輸資料。傳送訊息後,每個裝置將令牌傳遞給鏈上的下一個裝置,該裝置也遵循相同的協定。如果需要,它會傳輸資料,否則只傳遞令牌。最後,令牌到達鏈的末端。鏈上的最後一個裝置斷言匯流排釋放訊號,並銷燬令牌,釋放訊號是所有匯流排釋放訊號的邏輯或。一旦仲裁器觀察到要斷言的釋放訊號,它就會建立一個令牌。在看到請求行設定為1後,它會將此令牌重新插入菊花鏈。
菊花鏈架構。
這個方案有幾個微妙的優點。首先,有一個隱含的優先權概念,連線到仲裁器的裝置具有最高優先順序。漸漸地,當離開仲裁器時,優先順序會降低。其次,該協定具有一定程度的公平性,因為在高優先順序裝置放棄令牌之後,它無法再次取回令牌,直到所有低優先順序裝置都獲得令牌,所以裝置不可能單獨等待。其次,很容易將裝置插入和移除到匯流排,我們從不維護裝置的任何單獨狀態,所有到仲裁器的通訊都是聚合的,我們只計算匯流排請求和匯流排釋放線的OR函數。裝置必須保持的唯一狀態是關於其在菊花鏈中的相對位置以及其近鄰的地址的資訊。
我們也可以有完全避免中央仲裁器的純分散式方案。在這種方案中,所有節點都獨立地做出決策,但這種方案很少使用。
19.8.4.4 面向事務的匯流排
到目前為止,我們只關注單向通訊,在任何一個時間點,只有一個節點可以向其他節點進行傳輸。現在考慮更現實的匯流排,實際上大多數高效能I/O匯流排都不是多點匯流排。多點匯流排可能允許多個發射機,儘管不是在同一時間點,現代I/O匯流排是對等匯流排,通常有兩個端點。其次,I/O匯流排通常由兩條物理匯流排組成,因此可以進行雙向通訊。例如,如果有一條連線節點A和B的I/O匯流排,就可以同時向彼此傳送訊息。
一些早期的系統有一條匯流排,將處理器直接連線到記憶體。在這種情況下,處理器被指定為主處理器,因為它只能啟動匯流排訊息的傳輸。記憶體被稱為從屬記憶體,它只能響應請求。如今,主和從的概念已經淡化,但並行雙向通訊的概念仍然很普遍。雙向匯流排被稱為雙工匯流排(duplex bus)或全雙工匯流排(full duplex bus)。相比之下,可以使用半雙工匯流排(half duplex bus),它只允許一方在任何時間點進行傳輸。
下圖中的記憶體控制器晶片和DRAM模組之間的雙工通訊的典型場景,顯示了記憶體讀取操作的訊息順序和時序。實際上有兩條匯流排。第一匯流排將記憶體控制器連線到DRAM模組,它由地址線(承載記憶體地址的線)和承載專用控制訊號的線組成,控制訊號指示操作的定時以及需要在DRAM陣列上執行的操作的性質。第二匯流排將DRAM模組連線到記憶體控制器,包括傳輸線(承載從DRAM讀取的資料的線)和定時線(傳送定時資訊的線)。
DRAM讀取時序。
協定如下。記憶體控制器通過斷言RAS(行地址選通)訊號開始,RAS訊號啟用設定字線值的解碼器。同時,記憶體控制器將行的地址放置在地址線上,它估計了DRAM模組讀取行地址所需的時間(\(t_{row}\))。在\(t_{row}\)時間單位後,它斷言CAS訊號(列地址選通),並將列的地址放在匯流排上的DRAM陣列中,它還使能向DRAM模組指示它需要執行讀存取的讀訊號。隨後,DRAM模組讀取記憶體位置的內容並將其傳輸到其輸出緩衝器。然後它斷言就緒訊號,並將資料放在匯流排上。但此時記憶體控制器不是空閒的,它開始在匯流排上放置下一個請求的行地址。注意,DRAM存取的時序非常複雜,連續訊息的處理通常是重疊的,例如當第n個請求正在傳輸其資料時,我們可以繼續解碼第(n+1)個請求的行地址,可減少DRAM延遲,但為了支援這一功能,需要雙工匯流排和複雜的訊息序列。
讓注意上圖所示的基本DRAM存取協定的一個顯著特徵,請求和響應彼此之間的耦合非常強,源(記憶體控制器)知道目的地(DRAM模組)的複雜性,並且源和目的地傳送的訊息的性質和定時之間存在強烈的相互關係。其次,在請求期間,記憶體控制器和DRAM模組之間的I/O鏈路被鎖定,我們無法為原始請求和響應之間的任何干預請求提供服務。這種訊息序列被稱為匯流排事務(bus transaction)。
面向事務的匯流排有利弊。首先是複雜性,它們對接收機的定時做了很多假設,因此訊息傳輸協定對於每種型別的接收機都非常特殊,對可移植性不利,插入具有不同訊息語意的裝置變得非常困難。此外,匯流排可能會被鎖定很長一段時間,並有空閒時間,會浪費頻寬。然而,在一些場景中,例如我們所展示的範例中,面向事務的匯流排表現非常好,並且優於其他型別的匯流排。
19.8.4.5 拆分事務匯流排
現在看一下試圖糾正面向事務匯流排缺點的拆分事務匯流排,我們不假設不同節點之間的訊息序列是嚴格的,比如對於DRAM和記憶體控制器範例,將訊息傳輸分成兩個較小的事務。首先,記憶體控制器向DRAM傳送記憶體請求,DRAM模組緩衝訊息,並繼續進行記憶體存取。隨後,它向記憶體控制器傳送一個單獨的訊息,其中包含來自記憶體的資料,兩個訊息序列之間的間隔可以任意大。這種匯流排被稱為拆分事務匯流排(split transaction bus),它將一個較大的事務拆分為更小、更短的單個訊息序列。
這裡的優點是簡單性和可移植性,所有的傳輸基本上都是單向的。我們傳送一條訊息,然後不通過鎖定匯流排來等待它的回覆,傳送者繼續處理其他訊息。每當接收器準備好響應時,它都會傳送一條單獨的訊息。除了簡單,這種方法還允許我們將各種接收器連線到匯流排,只需要定義一個簡單的訊息語意,任何符合該語意的接收器電路都可以連線到匯流排。我們不能使用此匯流排執行復雜的操作,例如重疊多個請求和響應,以及細粒度的定時控制。對於此類需求,可以始終使用支援事務的匯流排。
19.8.5 網路層
前面小節研究瞭如何設計全雙工匯流排,具體來說,研究了信令、訊號編碼、定時、分幀、錯誤檢查和事務相關問題。現在可以假設I/O匯流排在端點之間正確地傳遞訊息,並確保及時和正確的傳遞。現在看看整個晶片組,它本質上是一個大型I/O匯流排網路。
本節解決的問題與I/O定址有關。例如,如果處理器希望向USB埠傳送訊息,則需要有一種唯一定址USB埠的方法。隨後,晶片組需要確保將訊息正確路由到適當的I/O裝置。類似地,如果鍵盤等裝置需要將按鍵的ASCII碼傳送給處理器,則需要有一種定址處理器的方法。本節將檢視晶片組中的路由訊息。
19.8.5.1 I/O埠定址
硬體I/O埠稱為外部連線裝置的連線端點。現在考慮一個軟體埠,將其定義為一個抽象實體,它對軟體來說是一個暫存器或一組暫存器,例如USB埠物理上包含一組金屬管腳及執行USB協定的埠控制器。然而USB埠的軟體版本,是一組可定址的暫存器,如果希望寫入USB裝置,就將寫入由USB埠暴露給軟體的一組暫存器,USB埠控制器通過將處理器傳送的資料物理寫入連線的I/O裝置來實現軟體抽象。同樣,為了讀取I/O裝置通過USB埠傳送的值,處理器發出讀取相應的埠控制器將I/O裝置的輸出轉發給處理器。
下圖說明這個概念。圖中有一個物理硬體埠,它有一組金屬引腳,以及實現物理和資料鏈路層的相關電路。埠控制器通過處理器傳送的完整請求實現網路層,它還公開了一組8到32位元暫存器,這些暫存器可以是唯讀、唯讀或讀寫的,例如,顯示器等顯示裝置的埠包含唯讀暫存器,因為無法從中獲取任何輸入。類似地,滑鼠的埠控制器包含唯讀暫存器,而掃描器的埠控制器則包含讀寫暫存器,因為通常向掃描器傳送設定資料和命令,並從掃描器讀取檔案的影象。
I/O埠的軟體介面。
例如,Intel處理器需要64K(216)個8位元I/O埠,可以將4個連續埠融合為32位元埠,這些埠相當於組合程式碼可存取的暫存器。其次,諸如乙太網埠或USB埠的給定物理埠可以具有分配給它們的多個這樣的軟體埠,例如,如果希望一次性將大量資料寫入乙太網,就可能會使用數百個埠。Intel處理器中的每個埠都使用從0到0xFFFF不等的16位元數位進行定址,類似地,其他架構定義了一組I/O埠,這些埠充當實際硬體埠的軟體介面。
讓我們將術語I/O地址空間定義為作業系統和使用者程式可存取的所有I/O埠地址的集合。I/O地址空間中的每個位置對應於一個I/O埠,該埠是物理I/O埠控制器的軟體介面。
大多數指令集架構有兩條指令:輸入和輸出。指令的語意如下。
| 指令 | 語意 |
|---|---|
| in r1, <I/O port> | I/O埠的內容傳輸到r1暫存器。 |
| out r1, <I/O port> | r1暫存器的內容傳輸到I/O埠。 |
in指令將資料從I/O埠傳輸到暫存器。相反,out指令將資料從暫存器傳輸到I/O埠,是一種用於程式設計I/O裝置的通用通用機制。例如,如果想要列印一頁,就可以將整個頁面的內容傳輸到印表機的I/O埠,最後將列印命令寫入接受印表機命令的I/O埠,隨後印表機可以開始列印。
現在讓我們執行輸入和輸出指令。第一個任務是確保訊息到達適當的埠控制器,第二個任務是在輸出指令的情況下將響應路由回處理器。
讓我們再次看看之前章節涉及的主機板架構。CPU通過前端匯流排連線到北橋晶片,DRAM記憶體模組和圖形卡也連線到北橋晶片,北橋晶片連線到處理速度較慢的裝置的南橋晶片,南橋晶片連線到USB埠、PCI Express匯流排(及其連線的所有裝置)、硬碟、滑鼠、鍵盤、揚聲器和網路卡。這些裝置中的每一個都有一組相關的I/O埠和I/O埠號。
通常,主機板設計者有分配I/O埠的方案。讓我們嘗試構建一個這樣的方案,假設有64K個8位元I/O埠,就像Intel處理器一樣,I/O埠的地址範圍從0到0xFFFF。首先,將I/O埠分配給連線到北橋晶片的高頻寬裝置,給他們0到0x00FF範圍內的埠地址,為連線到南橋晶片的裝置劃分其餘地址,假設硬碟的埠範圍為0x0100到0x0800,讓USB埠的範圍為0x0801到0x0FFF,為網路卡分配以下範圍:0x1000到0x4000,將剩餘的幾個埠分配給其他裝置,併為以後可能要連線的任何新裝置保留一部分空白。
現在,當處理器發出I/O指令(輸入或輸出)時,處理器識別出這是一條I/O指令,通過FSB(前端匯流排)向北橋晶片傳送I/O埠地址和指令型別,北橋晶片為每種I/O埠型別及其位置維護一個範圍表。一旦它看到來自處理器的訊息,它就會存取這個表並找出目標的相對位置。如果目的地是直接連線到它的裝置,則北橋晶片將訊息轉發到目的地。否則,它將請求轉發到南橋晶片,南橋晶片維護I/O埠範圍和裝置位置的類似表。在該表中執行查詢後,它將接收到的訊息轉發到適當的裝置。這些表稱為I/O路由表(I/O routing table),I/O路由表在概念上類似於大型網路和網際網路使用的網路路由表。
對於反向路徑,通常將響應傳送到處理器。我們為處理器分配了一個唯一的識別符號,訊息由北橋和南橋晶片適當地路由。有時需要將訊息路由到記憶體模組,使用類似的定址方案。
該方案本質上將物理I/O埠集對映到I/O地址空間中的位置,專用I/O指令使用埠地址與它們通訊。這種存取和定址I/O裝置的方法通常稱為I/O對映I/O( I/O mapped I/O)。
19.8.5.2 記憶體對映定址
現在再次檢視輸入和輸出I/O指令。執行程式需要了解I/O埠的命名方案,不同的晶片組和主機板可能使用不同的I/O埠地址,例如,一塊主機板可能會為USB埠分配I/O埠地址範圍0xFF80到0xFFC0,另一塊主機板則可能會分配範圍0xFEA0到0xFFB0。因此,在第一塊主機板上執行的程式可能無法在第二塊主機板上工作。
為了解決這個問題,需要在I/O埠和軟體之間新增一個附加層,提出一種類似於虛擬記憶體的解決方案。事實上,虛擬化是解決計算機架構中各種問題的標準技術,後續繼續設計使用者程式和I/O地址空間之間的虛擬層。
假設在作業系統中有一個專用的裝置驅動程式,該驅動程式專用於晶片組和主機板。它需要了解I/O埠的語意,以及它們到實際裝置的對映。考慮一個希望存取USB埠的程式(使用者程式或作業系統),一開始,它不知道USB埠的I/O埠地址,因此它需要首先請求作業系統中的相關模組將其虛擬地址空間中的記憶體區域對映到I/O地址空間的相關部分。例如,如果USB裝置的I/O埠在0xF000到0xFFFF之間,那麼I/O地址空間中的這個4 KB區域可以對映到程式虛擬地址空間中一個頁面。需要在TLB和頁表條目中新增一個特殊的位,以指示該頁實際上對映到I/O埠。其次,需要儲存I/O埠地址,而不是儲存物理幀的地址。主機板驅動程式的角色是作業系統的一部分,用於建立此對映。在作業系統將I/O地址空間對映到程序的虛擬地址空間之後,程序可以繼續進行I/O存取。注意,在建立對映之前,需要確保程式具有足夠的許可權來存取I/O裝置。
建立對映後,程式可以自由存取I/O埠。它使用常規載入和儲存指令來寫入虛擬地址空間中的位置,而不是使用I/O指令(如in和out)。在這樣的指令到達流水線的記憶體存取(MA)階段之後,有效地址被傳送到TLB以進行轉換。如果有TLB命中,那麼管線也會意識到虛擬地址對映到I/O地址空間而不是實體地址空間的事實。其次,TLB還將虛擬地址轉換為I/O埠地址,注意,在這個階段不需要使用TLB,可以使用另一個專用模組來轉換地址。在任何情況下,處理器在MA階段接收等效的I/O埠地址。隨後,它建立一個I/O請求並將該請求分派到I/O埠。
記憶體對映I/O是一種通過將I/O地址空間中的每個地址分配給程序虛擬地址空間中唯一的地址來定址和存取I/O裝置的方案。對於存取I/O埠,該過程使用常規載入和儲存指令。
這種方案稱為記憶體對映I/O,其主要優點是它使用常規載入和儲存指令來存取I/O裝置,而不是專用的I/O指令。其次,程式設計師不需要知道I/O地址空間中I/O埠的實際地址。由於作業系統和記憶體系統中的專用模組在I/O地址空間和程序的虛擬地址空間之間建立了對映,因此程式可以完全忽略定址I/O埠的語意。
19.8.6 協定層
現在討論I/O系統中的最後一層。前三層確保訊息從I/O系統中的一個裝置正確傳遞到另一個裝置,現在看看完整I/O請求的級別,例如列印整個頁面、掃描整個檔案或從硬碟讀取一大塊資料。以列印檔案為例。
假設印表機連線到USB埠。印表機裝置驅動程式首先指示處理器將檔案的內容傳送到與USB埠關聯的緩衝區,假設每個這樣的緩衝區都分配了唯一的埠地址,並且整個檔案都在緩衝區集中,此外假設裝置驅動程式知道緩衝區是空的。要傳送檔案內容,裝置驅動程式可以使用一系列輸出指令,也可以使用記憶體對映的I/O。傳輸檔案內容後,最後一步是將PRINT命令寫入預先指定的I/O埠。USB控制器管理與其相關的所有I/O埠,並確保傳送到這些埠的訊息傳送到連線的印表機,印表機在從USB控制器接收到PRINT命令後開始列印作業。
假設使用者單擊另一個檔案的列印按鈕。在將新檔案傳送到印表機之前,驅動程式需要確保印表機已完成前一檔案的列印。此處的假設是,有一個簡單的印表機,一次只能處理一個檔案。因此,應該有一種方法讓驅動程式知道印表機是否空閒。
在研究印表機與其驅動程式通訊的不同機制之前,考慮一個類比場景,在這個場景中,Sofia正在等待一封信送達。如果這封信是通過Sofia的一個朋友寄來的,那麼Sofia可以繼續給她的朋友打電話,詢問她何時會回來,一旦她回來,Sofia就可以去她家收信了。或者,發件人可以通過快遞服務傳送信件,在這種情況下,Sofia只需要等待快遞員來送信。前者接收訊息的機制稱為輪詢(polling),後者稱為中斷(interrupt)。後續小節會詳細說明。
19.8.6.1 輪詢
假設印表機中有一個名為狀態暫存器的專用暫存器,用於維護印表機的狀態。每當印表機的狀態發生變化時,它都會更新狀態暫存器的值。假設狀態暫存器可以包含兩個值,即0(空閒)和1(忙),當印表機列印檔案時,狀態暫存器的值為1(忙碌),當印表機完成檔案列印時,它將狀態暫存器的值設定為0(空閒)。
現在假設印表機驅動程式希望讀取印表機的狀態暫存器的值。它向印表機傳送一條訊息,要求它獲取狀態暫存器的數值。傳送訊息的第一步是向USB埠控制器的相關I/O埠傳送位元組序列,埠控制器依次將位元組傳送到印表機。如果它使用拆分事務匯流排,那麼它將等待響應到達。同時,印表機解釋訊息,並將狀態暫存器的值作為響應傳送,USB埠控制器通過I/O系統將其轉發給處理器。
如果印表機空閒,則裝置驅動程式可以繼續列印下一個檔案,否則,它需要等待印表機完成。它可以繼續向印表機請求狀態,直到印表機空閒。這種反覆查詢裝置狀態直到其狀態具有特定值的方法稱為輪詢(polling)。
輪詢(polling)是一種等待I/O裝置達到給定狀態的方法,是通過在迴圈中重複查詢裝置的狀態來實現的。
下面展示一段在假設系統中實現輪詢的組合程式碼,假設獲取印表機狀態的訊息是0xDEADBEEF,需要首先將訊息傳送到I/O埠0xFF00,然後從I/O埠0xFF04讀取響應。
/* 載入DEADBEEF到r0 */
movh r0, 0xDEAD
addu r0, r0, 0xBEEF
/* 輪詢的迴圈 */
.loop:
out r0, 0xFF00
in r1, 0xFF04
cmp r1, 1
beq .loop /* 保持迴圈,直到status = 1 */
19.8.6.2 中斷
基於輪詢的方法有幾個缺點。它使處理器保持忙碌,浪費電力,並增加I/O流量,可以改用中斷。想法是向印表機傳送訊息,通知處理器何時空閒。印表機空閒後,或者如果印表機已經空閒,印表機會向處理器傳送中斷。I/O系統通常將中斷視為常規訊息,然後它將中斷傳遞給處理器或專用中斷控制器,這些實體意識到中斷來自I/O系統。隨後,處理器停止執行當前程式,並跳轉到中斷處理程式。
請注意,每個中斷都需要標識自己或生成它的裝置,主機板上的每個裝置通常都有一個唯一的程式碼,此程式碼是中斷的一部分。在某些情況下,當我們將裝置連線到通用埠(如USB埠)時,中斷程式碼包含兩部分,其中一部分是主機板上連線到外部裝置的埠的地址,另一部分是由主機板上的I/O埠分配給裝置的id。這種包含唯一程式碼的中斷稱為向量中斷(vectored interrupt)。
在某些系統(如x86機器)中,中斷處理的第一階段由可程式化中斷控制器(PIC)完成,這些中斷控制器在x86處理器中稱為APIC(高階可程式化中斷控制器),其作用是緩衝中斷訊息,並根據一組規則將它們傳送給處理器。
現在看看PIC遵循的一套規則。大多數處理器在計算的某些關鍵階段禁用中斷處理,例如,當中斷處理程式儲存原始程式的狀態時,我們不能允許處理器中斷。成功儲存狀態後,中斷處理程式可能會重新啟用中斷。在某些系統中,每當中斷處理程式執行時,中斷都會被完全禁用。一個密切相關的概念是中斷遮蔽,它選擇性地啟用一些中斷,並禁用一些其他中斷,例如,我們可以在處理中斷處理程式期間允許溫度控制器的高優先順序中斷,並選擇暫時忽略硬碟的低優先順序中斷。PIC通常有一個向量,每個中斷型別有一個條目。它被稱為中斷掩碼向量(interrupt mask vector)。對於中斷,如果中斷掩碼向量中的對應位為1,則中斷被啟用,否則被禁用。
最後,如果在同一時間視窗內有多箇中斷到達,PIC需要尊重中斷的優先順序,比如來自具有實時約束的裝置(如連線的高速通訊裝置)的中斷具有較高的優先順序,而鍵盤和滑鼠中斷具有較低的優先順序。PIC使用考慮到其優先順序和到達時間的啟發式方法對中斷進行排序,並按照該順序將其呈現給處理器。隨後,處理器根據前述章節說明的方法處理中斷。
向量中斷(Vectored Interrupt):包含生成中斷的裝置id或連線到外部裝置的I/O埠地址的中斷。
可程式化中斷控制器(Programmable Interrupt Controller,PIC):用來緩衝、替換和管理傳送給處理器的中斷。
中斷遮蔽(Interrupt Masking):使用者或作業系統可以選擇在程式的某些關鍵階段(如執行裝置驅動程式和中斷處理程式時)選擇性地禁用一組中斷。這種機制被稱為中斷遮蔽。PIC中的中斷掩碼向量通常是位向量(每種中斷型別一位),如果位設定為1,則中斷被啟用,否則被禁用,中斷將被忽略,或在PIC中緩衝並稍後處理。
19.8.6.3 DMA
對於存取I/O裝置,可以同時使用輪詢和中斷。在任何情況下,對於每個I/O指令,通常一次傳輸4個位元組,意味著,如果需要將4KB塊傳輸到I/O裝置,就需要發出1024條輸出指令。類似地,如果希望讀入4KB的資料,就需要發出1024個指令。每個I/O指令通常需要十多個週期,因為它在經過幾個級別的間接定址後到達一個I/O埠。其次,I/O匯流排的頻率通常是處理器頻率的三分之一到四分之一。因此,巨量資料塊的I/O是一個相當緩慢的過程,會使處理器長時間處於忙碌狀態。目標是儘可能縮短裝置驅動程式和中斷處理程式等敏感程式碼。
因此,嘗試設計一種可以載入處理器部分工作的解決方案。考慮一個類比場景,假設一位教授教授的班級有100多名學生,考試後需要給100多個劇本打分,這種情況將使她忙碌至少一週,而給劇本打分的過程是一個非常累和耗時的過程。因此,她可以將考試指令碼評分的工作交給助教,確保教授有空閒時間,可以專注於解決最先進的研究問題。我們可以從這個例子中得到線索,併為處理器設計一個類似的方案。
設想一個稱為DMA(直接記憶體存取)引擎的專用單元,它可以代表處理器做一些工作。具體而言,如果處理器希望將記憶體中的大量資料傳輸到I/O裝置,反之亦然,那麼DMA引擎可以代替發出大量I/O指令來承擔責任。使用DMA引擎的過程如下:
- 裝置驅動程式確定有必要在記憶體和I/O裝置之間傳輸大量資料。
- 它將記憶體區域的細節(位元組範圍)和I/O裝置的細節(I/O埠地址)傳送到DMA引擎,進一步規定了資料傳輸是從記憶體到I/O還是反向。
- 裝置驅動程式掛起自己,處理器可以自由執行其他程式。同時,DMA引擎或DMA控制器開始在主記憶體儲器和I/O裝置之間傳輸資料的過程。根據傳輸的方向,它會讀取資料,暫時儲存資料,然後將其傳送到目的地。
- 一旦傳輸結束,它將向處理器傳送一箇中斷,指示傳輸結束。
- I/O裝置的裝置驅動程式準備好恢復操作並完成所有剩餘步驟。
現代處理器通常使用基於DMA的方法在主記憶體、硬碟或網路卡之間傳輸大量資料。資料傳輸是在後臺完成的,處理器基本上不會注意這個過程。其次,大多數作業系統都有庫來程式設計DMA引擎以執行資料傳輸。
需要在DMA引擎的上下文中討論兩個微妙的點:
- 第一個是DMA控制器需要偶爾成為匯流排主控器。在大多數設計中,DMA引擎通常是北橋晶片的一部分,在需要時成為匯流排到記憶體的匯流排主控器,以及到南橋晶片的匯流排。它可以一次性傳輸所有資料,此法稱為突發(burst)模式;或者,它等待匯流排中的空閒週期,並使用這些週期來排程自己的傳輸,此法稱為週期竊取(cycle stealing)模式。
- 第二個微妙的問題是,如果不小心,可能會出現正確性問題。例如,可能在快取中有一個給定的位置,同時DMA引擎正在向主記憶體中的位置寫入資料。在這種情況下,快取中的值將變得過時,而遺憾的是,處理器將無法知道這一事實。因此,確保DMA控制器存取的位置不在快取中是很重要的。通常是通過一個稱為DMA監聽電路(snoop circuit)的專用邏輯塊實現的,如果DMA引擎寫入了快取中的位置,則該邏輯塊會動態逐出快取中存在的位置。
DMA機制可以以多種方式設定,下圖顯示了一些可能性。在第一個範例中,所有模組共用相同的系統匯流排,DMA模組充當代理處理器,使用程式設計的I/O通過DMA模組在記憶體和I/O模組之間交換資料,這種設定雖然可能很便宜,但顯然效率很低。與處理器控制的程式設計I/O一樣,每個字的傳輸消耗兩個匯流排週期。
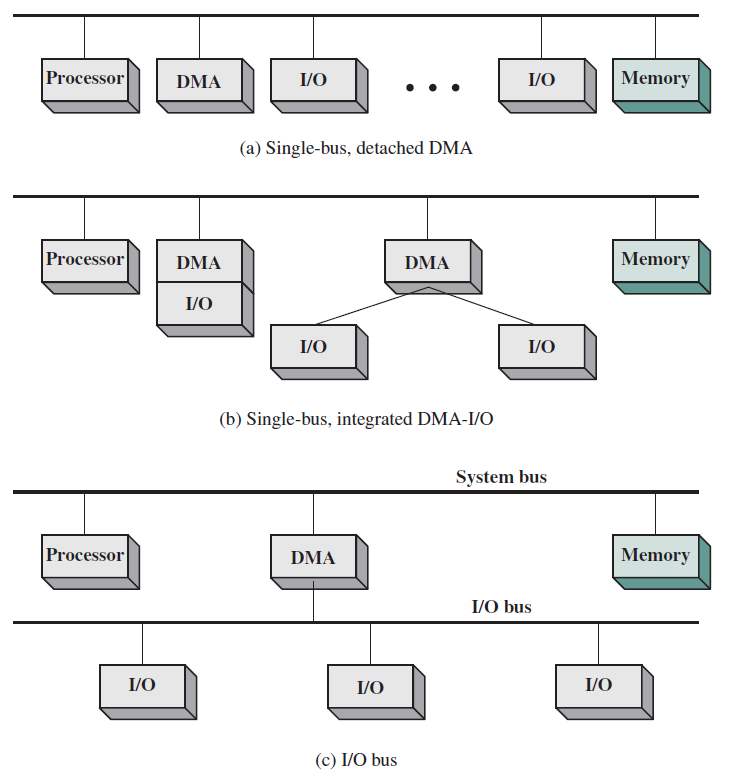
19.8.7 I/O協定
本節將描述幾種最先進的I/O協定的操作,簡要概述之。為了進行詳細的研究,或者在有疑問的地方,可以檢視網上釋出的正式規範。正式規範通常由支援I/O協定的公司聯盟釋出,本節提供的大多數材料都來自於此。
19.8.7.1 PCI Express
大多數主機板需要可用於將專用音效卡、網路卡和圖形卡等裝置連線到北橋或南橋晶片的本地匯流排。為了響應這一要求,1993年,一個公司聯盟建立了PCI(外圍元件互連)匯流排規範。
1996年,Intel建立了用於連線圖形卡的AGP(加速圖形埠)匯流排。在90年代末,許多新的匯流排型別被提出用於將各種硬體裝置連線到北橋和南橋晶片。設計者很快意識到,擁有許多不同的匯流排協定會阻礙標準化工作,並迫使裝置供應商支援多種匯流排協定。因此,一個公司聯盟開始了標準化工作,並於2004年建立了PCI Express匯流排標準。該技術取代了大多數早期技術,迄今為止,它是主機板上最流行的匯流排。
PCI express匯流排的基本思想是它是一種高速對等序列(單位)互連。對等互連只有兩個端點,為了將多個裝置連線到南橋晶片,建立了PCI express裝置樹。樹的內部節點是PCI express交換機,可以多路複用來自多個裝置的流量。其次,與舊協定相比,每個PCI Express匯流排在單個位線上序列傳送位。通常高速匯流排避免使用多條銅線並行傳輸多個位元,因為不同的鏈路經歷不同程度的抖動和訊號失真。要保持不同導線中的所有訊號彼此同步變得非常困難,因此,現代匯流排大多是序列的。
單個PCI Express匯流排實際上由許多單獨的序列匯流排(稱為通道)組成,每個通道都有其單獨的物理層,PCI Express封包在通道上分條(striped)。條帶化意味著將一個資料塊(封包)劃分為更小的資料塊,並將它們分佈在各個通道上,例如,在具有8個通道和8位元封包的匯流排中,可以在單獨的通道上傳送封包的每一位。注意,在不同的通道上並行傳送多個位元與具有多條線路傳送資料的並行匯流排不同,因為並行匯流排對所有銅線都有一個物理層電路,而在這種情況下,每條通道都有其單獨的同步和定時。資料鏈路層通過聚合從不同通道收集的每個封包的子部分來完成成幀(framing)工作。
條帶化(striping)過程是指將一個資料塊劃分為更小的資料塊,並將它們分佈在一組實體上。
通道由兩條基於LVDS的導線組成,用於全雙工信令。一根導線用於從第一個端點向第二個端點傳送訊息,第二根導線用於反向傳送訊號。一組通道被分組在一起以形成一個I/O鏈路,該鏈路被假定為傳輸完整的封包(或幀)。然後,物理層將封包傳輸到資料鏈路層,資料鏈路層執行糾錯、流控制和實現事務。PCI Express協定是一種分層協定,其中每一層的功能大致類似於我們定義的I/O層。它沒有將事務視為資料鏈路層的一部分,而是有一個單獨的事務層。但是,除非另有說明,否則我們將使用本章中定義的術語來解釋所有I/O協定。
PCI Express協定的規格彙總如下表所示,有1-32個通道,每條通道都是一條非同步匯流排,它使用一種稱為8bit/10bit編碼的複雜資料編碼。8bit/10bit編碼在概念上可以被認為是NRZ協定的擴充套件,它將8個邏輯位的序列對映到10個物理位的序列,確保連續不超過五個1或0,可以有效地恢復時鐘。回想一下,接收器通過分析資料中的轉換來恢復傳送器的時鐘。其次,編碼確保我們在傳輸訊號中具有幾乎相同數量的物理1和0。在資料鏈路層中,PCI Express協定實現了具有1-128位元組幀和基於32位元CRC的糾錯的分割事務匯流排。
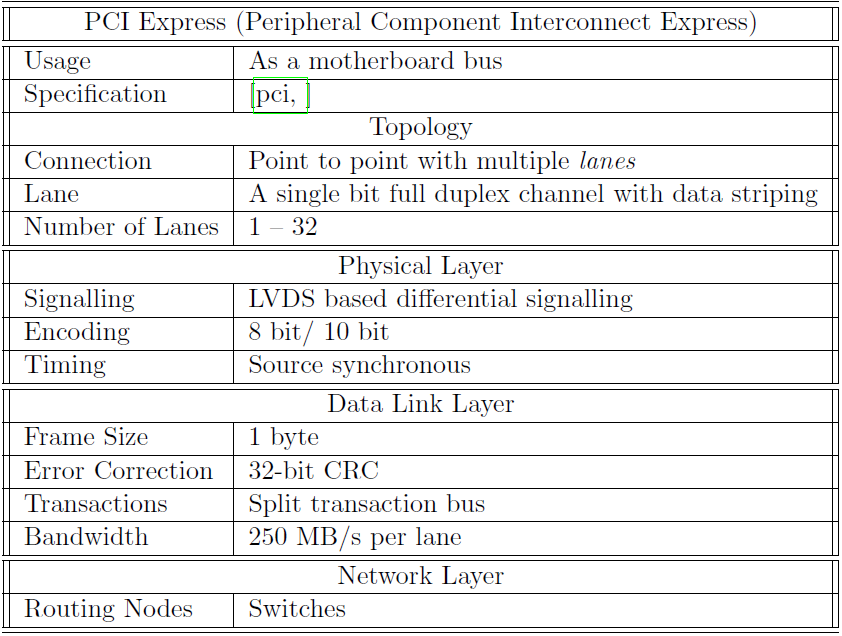
PCI Express匯流排通常用於連線通用I/O裝置。有時有些插槽未使用,這樣使用者以後就可以為其特定應用程式連線卡,例如,如果使用者對使用專用醫療裝置感興趣,那麼她可以連線一個I/O卡,該卡可以從外部與醫療裝置連線,也可以從內部連線到PCI Express匯流排。這種免費的PCI Express插槽稱為擴充套件插槽(expansion slot)。
與QPI類似,PCIe是對等架構,每個PCIe埠由多個雙向通道組成(注意,QPI的通道僅指單向傳輸)。通過一對電線上的差分訊號,在通道的每個方向上進行傳輸,PCI埠可以提供1、4、6、16或32個通道。
與QPI一樣,PCIe使用多通道分發技術。下圖顯示了由四個通道組成的PCIe埠的範例。使用簡單的迴圈方案將資料一次分配到四個通道1個位元組,在每個物理通道上,每次緩衝和處理16位元組(128位元)的資料。128位元的每個塊被編碼成用於傳輸的唯一130位碼字,被稱為128b/130b編碼。因此,單個通道的有效資料速率降低了128/130倍。
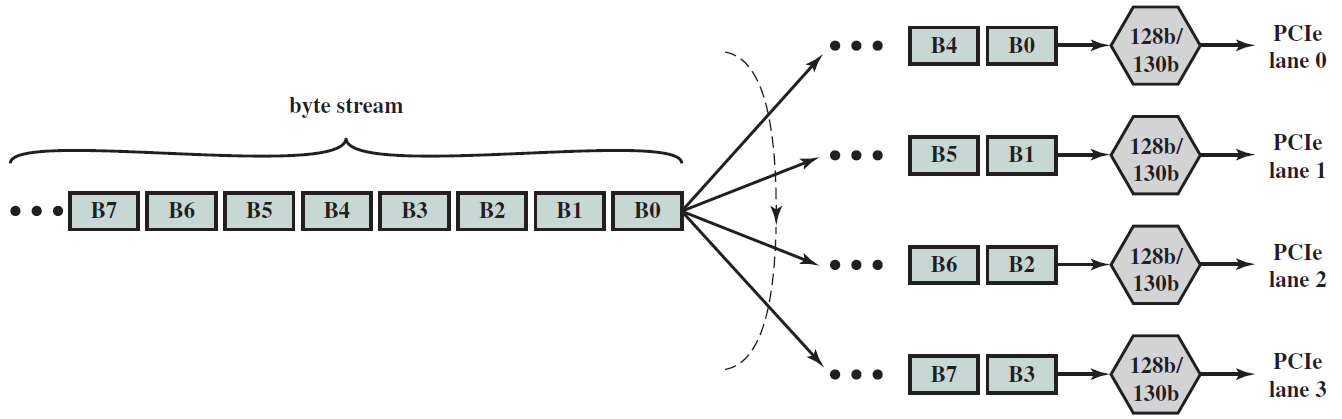
PCIe多層配線。
下圖說明了加擾(scrambling)和編碼的使用。要傳輸的資料被送入擾頻器,然後將加擾的輸出饋送到128b/130b編碼器,該編碼器緩衝128位元,然後將128位元塊對映到130位塊。然後,該塊通過並行到序列轉換器,並使用差分信令一次傳輸一位。
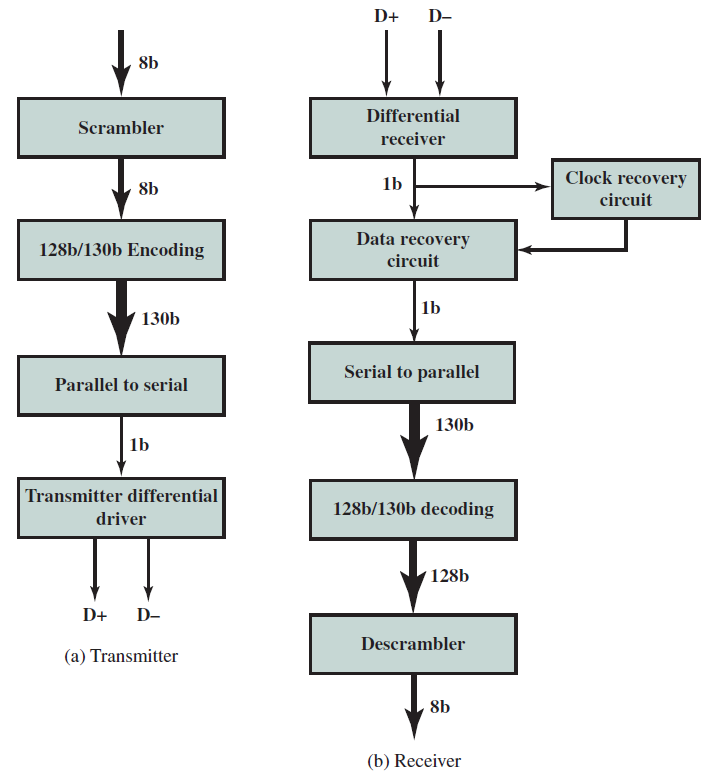
19.8.7.2 SATA
現在看一下匯流排,它主要是為連線硬碟和光碟等儲存裝置而開發的。從80年代中期開始,設計師和儲存供應商開始設計這種匯流排。隨著時間的推移,開發了幾種這樣的匯流排,例如IDE(整合驅動電子)和PATA(並行高階技術附件)匯流排。這些匯流排主要是並行匯流排,其組成通訊鏈路受到不同程度的抖動和失真。因此,這些技術被稱為SATA(序列ATA)的序列標準所取代,是一種像PCI Express一樣的對等鏈路。
用於存取儲存裝置的SATA協定現在在絕大多數筆記型電腦和桌上型電腦處理器中使用,它已成為事實上的標準。SATA協定有三層:物理層、資料鏈路層和傳輸層。我們將SATA協定的傳輸層對映到協定層,每個SATA鏈路包含一對使用LVDS信令的單位鏈路。與PCI Express不同,SATA協定中的端點不可能同時讀取和寫入資料。在任何時間點只能執行其中一個操作,因此,它是一條半雙工匯流排,使用8b/10b編碼,並且是非同步匯流排。資料鏈路層完成分幀工作。現在討論網路層。由於SATA是一種對等協定,因此可以以樹結構連線一組SATA裝置。樹的每個內部節點都被稱為乘數,它將請求從父級路由到其子級,或從其子級路由到父級。最後,協定層作用於幀並確保它們以正確的順序傳輸,並實現SATA命令。具體來說,它實現DMA請求,存取儲存裝置,緩衝資料,並按預定順序將其傳送給處理器。
下表顯示了SATA協定的規格。需要注意,SATA協定具有非常豐富的協定層,為基於儲存的裝置提供了多種命令,比如有專用命令來執行DMA存取、執行直接硬碟存取、編碼和加密資料以及控制儲存裝置的內部。SATA匯流排是分離事務匯流排,資料鏈路層區分命令及其響應。協定層實現所有命令的語意。
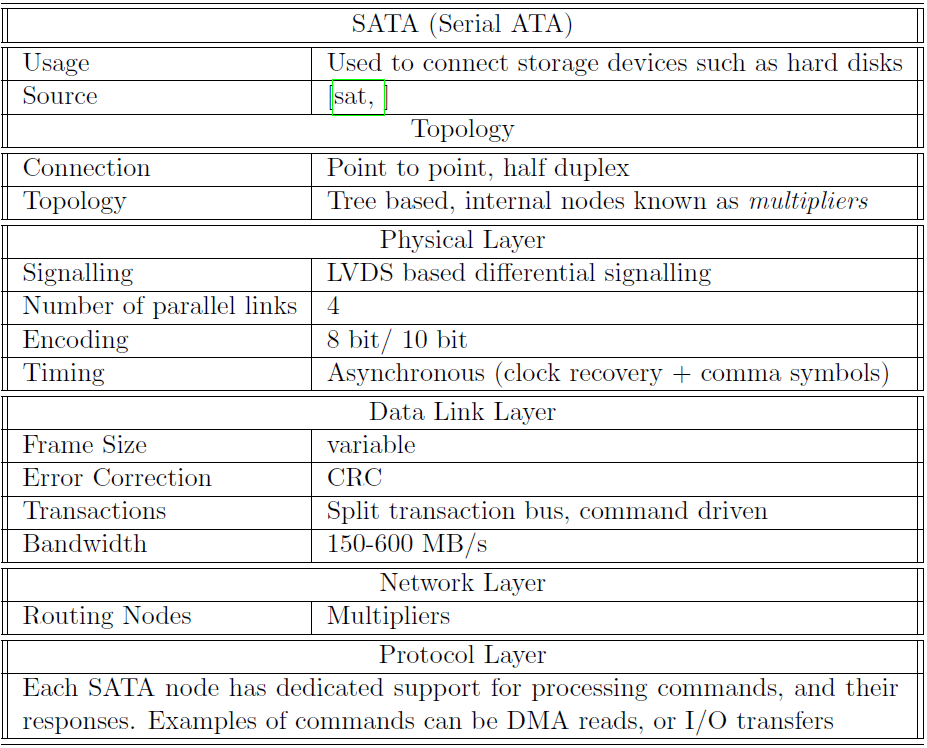
19.8.7.3 SCSI和SAS
SCSI概述
現在討論另一種適用於外圍裝置的I/O協定,即SCSI(發音為「scuzzy」)協定。SCSI最初是PCI的競爭對手,但隨著時間的推移,它轉變為連線儲存裝置的協定。
最初的SCSI匯流排是多點並行匯流排,可以有8到16個連線。SCSI協定區分主機和外圍裝置,例如南橋晶片是主機,而CD驅動器的控制器是外圍裝置,任何一對節點(主機或外圍裝置)都可以相互通訊。與當今的高速匯流排相比,最初的SCSI匯流排是同步的,執行頻率相對較低。SCSI至今仍然存在,最先進的SCSI匯流排使用80-160 MHz時鐘並行傳輸16位元,因此它們的理論最大頻寬為320-640MB/s。請注意,序列匯流排可以達到1GHz,更通用,並且可以支援更大的頻寬。
考慮到多點並行匯流排存在問題,設計人員開始將SCSI協定重新定位為對等序列匯流排。回想一下,PCI Express和SATA匯流排也是出於同樣的原因建立的。因此,設計者提出了一系列擴充套件了原始SCSI協定的匯流排,但本質上是對等序列匯流排。兩種這樣重要的技術是SAS(序列連線SCSI)和FC(雙連結)匯流排。FC匯流排主要用於超級計算機等非常高階的系統,SAS匯流排更常用於企業和科學應用。
因此,讓我們主要關注SAS協定,因為它是當今使用的SCSI協定的最流行變體。SAS是一種序列對等技術,也與以前版本的基於SATA的裝置相容,其規格與SATA規格非常接近。
SAS概述
SAS被設計為與SATA向後相容,因此這兩種協定在物理層和資料鏈路層上沒有很大不同,但仍然存在一些差異。最大的區別是SAS允許全雙工傳輸,而SATA僅允許半雙工傳輸。其次,SAS通常可以支援更大的機架尺寸,並且與SATA相比,SAS支援端點之間更大的電纜長度(SAS為8米,SATA為1米)。
網路層與SATA不同。SAS沒有使用乘法器(用於SATA),而是使用一種更復雜的結構,稱為擴充套件器,用於連線多個SAS目標。傳統上,SAS匯流排的匯流排主節點稱為啟動器,而另一個節點稱為目標節點。有兩種擴充套件器:邊緣擴充套件器和扇出擴充套件器,邊緣擴充套件器最多可用於連線255個SAS裝置,扇出擴充套件器最多可連線255個邊緣擴充套件器。我們可以使用根節點和一組擴充套件器在基於樹的拓撲中新增大量裝置,啟動時為每個裝置分配一個唯一的SCSI id,裝置可以進一步細分為幾個邏輯分割區,例如,寫入者目前正在處理一個被劃分為兩個邏輯分割區的儲存系統,每個分割區都有一個邏輯單元號(LUN)。路由演演算法如下:如果存在直接連線,啟動器會直接向裝置傳送命令,或者向擴充套件器傳送命令。擴充套件器有一個詳細的路由表,根據其SCSI id維護裝置的位置,它查詢此路由表並將封包轉發到裝置或邊緣擴充套件器。此邊緣擴充套件器具有另一個路由表,用於將命令轉發到適當的SCSI裝置,然後SCSI裝置將該命令轉發到相應的LUN。對於向另一個SCSI裝置或處理器傳送訊息,請求遵循反向路徑。
最後,協定層對於SAS匯流排非常靈活。它支援三種協定,可以使用SATA命令、SCSI命令或SMP(SAS管理協定)命令。SMP命令是用於設定和維護SAS裝置網路的專用命令。SCSI命令集非常廣泛,旨在控制一系列裝置(主要是儲存裝置),請注意,在向裝置傳送SCSI命令之前,裝置必須與SCSI協定層相容。如果裝置不理解某個命令,那麼可能會發生災難性的事情,例如如果想讀取CD,但CD驅動程式不理解該命令,那麼它可能會彈出CD。更糟糕的是,它可能永遠不會彈出CD,因為它不理解彈出命令。同樣的論點也適用於SATA的情況。如果希望使用SATA命令,需要SATA相容裝置,如SATA相容硬碟機和SATA相容光碟驅動器。由於協定層的靈活性,SAS匯流排在設計上與SATA裝置和SAS/SSCSI裝置相容。對於協定層,SAS啟動器向SAS/SSCSI裝置傳送SCSI命令,向SATA裝置傳送SATA命令。
近線SAS(NL-SAS)驅動器本質上是SATA驅動器,但具有將SCSI命令轉換為SATA命令的SCSI介面。因此,NL-SAS驅動器可以在SAS匯流排上無縫使用。由於SCSI命令集更具表現力和效率,NL-SAS驅動器的速度比純SATA驅動器快10-20%。
現在用4句話來簡單描述SCSI命令集。啟動器首先向目標傳送命令,每個命令都有一個1位元組的檔頭,並且具有可變長度的有效負載。然後,目標傳送帶有命令執行狀態的回覆,SCSI規範為裝置控制和資料傳輸提供了至少60種不同的命令。
19.8.7.4 USB
概述
USB協定主要用於將外部裝置連線到筆記型電腦或臺式電腦,如鍵盤、滑鼠、揚聲器、網路攝像頭和印表機。在90年代中期,供應商意識到存在多種I/O匯流排協定和聯結器,主機板設計者和裝置驅動程式編寫者很難支援大量裝置。因此需要標準化,一個公司聯盟(DEC、IBM、Intel、Nortel、NEC和Microsoft)構想了USB協定(通用序列匯流排)。
USB協定的主要目的是為各種裝置設計一個標準介面。設計者一開始將裝置分為三種型別,即低速(鍵盤、滑鼠)、全速(高速音訊)和高速(掃描器和攝像機)。截至2012年,已經提出了三個版本的USB協定,即版本1.0、2.0和3.0。基本USB協定大致相同,協定向後相容,意味著具有USB 3.0埠的現代計算機支援USB 1.0裝置。與為特定硬體集設計的SAS或SATA協定不同,USB協定的設計非常通用,因此可以對目標裝置的行為進行大量假設。因此,設計者需要為作業系統提供廣泛的支援,以發現裝置的型別、需求,並對其進行適當設定。其次,許多USB裝置沒有電源,例如鍵盤和滑鼠。有必要在USB電纜中包括用於執行連線的裝置的電源線。USB協定的設計者牢記了所有這些要求。
從一開始,設計者就希望USB成為一種快速協定,能夠在未來支援高速裝置,如高清視訊。因此,他們決定使用對等序列匯流排(類似於PCI Express、SATA和SAS)。每檯筆記型電腦、桌上型電腦和中型伺服器的前面板或後面板上都有一系列USB埠,每個USB埠都被視為可以與一組USB裝置連線的主機。由於使用序列連結,可以建立一個類似於PCI Express和SAS裝置樹的USB裝置樹。大多數時候,只將一個裝置連線到USB埠。但不是唯一的設定,也可以連線一個USB集線器,它就像樹的內部節點。USB集線器原則上類似於SATA乘法器和SAS擴充套件器。
USB集線器大部分時間是被動裝置,通常有四個埠連線到下游的其他裝置和集線器,集線器最常見的設定包括一個上游埠(連線到父節點)和四個下游埠。我可以用這種方式建立一個USB集線器樹,並將多個裝置連線到主機板上的單個USB主機。USB協定支援每個主機127個裝置,最多可以序列連線5個集線器。集線器可以由主機供電,也可以自供電,如果集線器是自供電的,它可以連線更多裝置,因為USB協定對其可以傳輸到任何單個裝置的電流量有限制,目前,它被限制為500 mA,並且功率以100 mA的塊分配。因此,由主機供電的集線器最多可以有4個埠,因為它可以給每個裝置100 mA,並保持100 mA。有時,集線器需要成為活動裝置,每當USB裝置與集線器斷開連線時,集線器就會檢測到此事件,並向處理器傳送訊息。
USB協定的層
- 物理層
現在更詳細地討論協定,並從物理層開始。標準USB聯結器有4個引腳,第一個引腳是提供固定5V DC電壓的電源線,通常被稱為Vbus的Vcc。差分訊號有兩個引腳,即D+和D-,其預設電壓設定為3.3V。第四個引腳是接地引腳(GND),迷你和微型USB聯結器有一個稱為ID的附加引腳,有助於區分與主機和裝置的連線。
USB協定使用差分信令,它使用NRZI協定的變體。對於編碼邏輯位,它假設邏輯0由物理位中的轉換表示,而邏輯1由無轉換表示(與傳統NRZI協定相反)。USB匯流排是一種恢復時鐘的非同步匯流排,為了幫助時鐘恢復,如果資料中沒有轉換,則同步子層引入虛擬轉換。例如,如果我們有1的連續執行,那麼傳輸的訊號中就不會有躍遷。在這種情況下,USB協定在每次執行6個1後引入0位。該策略確保了訊號中有一些保證的過渡,並且接收機可以恢復發射機的時鐘而不失同步。USB聯結器只有一對用於差分訊號的導線,因此全雙工信令是不可能的,相反,USB鏈路使用半雙工信令。
- 資料連結層
對於資料鏈路層,USB協定使用基於CRC的錯誤檢查和可變幀長度,它使用位填充(專用幀開始和結束符號)來劃分幀邊界。仲裁在USB集線器中是一個相當複雜的問題,因為有很多種流量和很多種裝置。USB協定定義了四種流量:
- 控制:用於設定裝置的控制訊息。
- 中斷:需要緊急傳送到裝置的少量資料。
- 大量(Bulk):大量資料,沒有任何延遲和頻寬保證。如掃描器中的影象資料。
- 同步(Isochronous):具有延遲和頻寬保證的固定速率資料傳輸。 如網路攝像機中的音訊/視訊。
隨著流量的不同,我們有不同種類的USB裝置,即低速裝置(192 KB/s)、全速裝置(1.5 MB/s)和高速裝置(60 MB/s),USB 3.0協定引入了需要384 MB/s的高速裝置。
現在,有可能將高速和低速裝置連線到同一個集線器。假設高速裝置正在進行批次傳輸,而低速裝置正在傳送中斷。在這種情況下,需要優先考慮樞紐上游鏈路的接入。仲裁很難,因為需要符合每類流量和每類裝置的規範,在執行批次傳輸和傳送中斷之間陷入了兩難境地。理想情況下,希望通過使用不同的流量優先順序啟發式方法,在衝突的需求之間取得平衡。有關仲裁機制的詳細說明,可參閱USB規範。
現在考慮事務問題。假設高速集線器連線到主機,高速集線器(hub)還連線到下游的全速和低速裝置,在這種情況下,如果主機通過高速集線器啟動到低速裝置的事務,那麼它必須等待從裝置獲得回覆,因為高速集線器和裝置之間的連結很慢。在這種情況下,沒有理由鎖定主機和集線器之間的匯流排。可以改為實現拆分事務,拆分事務的第一部分將命令傳送到低速裝置,拆分事務的第二部分包括從低速裝置到主機的訊息。在拆分事務之間的間隔內,主機可以與其他裝置通訊。USB匯流排為許多其他型別的場景實現了類似的拆分事務(請參閱USB規範)。
- 網路層
現在考慮網路層。包括集線器的每個USB裝置都由主機分配一個唯一的ID,由於每個主機最多可以支援127個裝置,因此需要一個7位裝置id。其次,每個裝置都有多個I/O埠,每個這樣的I/O埠都稱為端點。我們可以有資料端點(中斷、批次或同步),也可以有控制端點。此外,可以將端點分類為IN或OUT,IN端點表示只能向處理器傳送資料的I/O埠,OUT端點接受來自處理器的資料。每個USB裝置最多可以有16個IN端點和16個OUT端點,任何USB請求都明確規定了它需要存取的端點型別(IN或OUT)。考慮到端點的型別由請求固定,只需要4位元就可以指定端點的地址。
所有USB裝置都有一組預設的IN和OUT端點,其id等於0,這些端點用於啟用裝置並與其建立通訊,隨後每個裝置定義其自定義端點集。簡單的裝置,如滑鼠或鍵盤,通常只需一個IN端點即可將資料傳送到處理器。然而更復雜的裝置(如網路攝像頭)需要多個端點。一個端點用於視訊饋送,一個端點是音訊饋送,並且可以有多個端點用於交換控制和狀態資料。
集線器負責將訊息路由到正確的USB裝置,集線器維護將USB裝置與本地埠ID關聯的路由表。一旦訊息到達裝置,它就會將其路由到正確的端點。
- 協定層
USB協定層相當複雜。首先,在端點之間定義兩種連線,稱為管道,它將流管道定義為沒有任何特定訊息結構的資料流。相比之下,訊息管道更加結構化,並且定義了傳送方和接收方都必須遵循的訊息序列,訊息管道中的典型訊息由三種封包組成。通訊以令牌包開始,令牌包包含裝置id、端點id、通訊性質和有關連線的附加資訊。路徑上的集線器將令牌分組路由到目的地,從而建立連線。然後,根據傳輸的方向(主機到裝置或裝置到主機),主機或裝置傳送一系列封包。最後,在資料分組序列的末尾,分組的接收器傳送握手分組以指示I/O請求的成功完成。
總結
下表總結了USB的討論,可以參考USB協定的規範以獲取更多資訊。
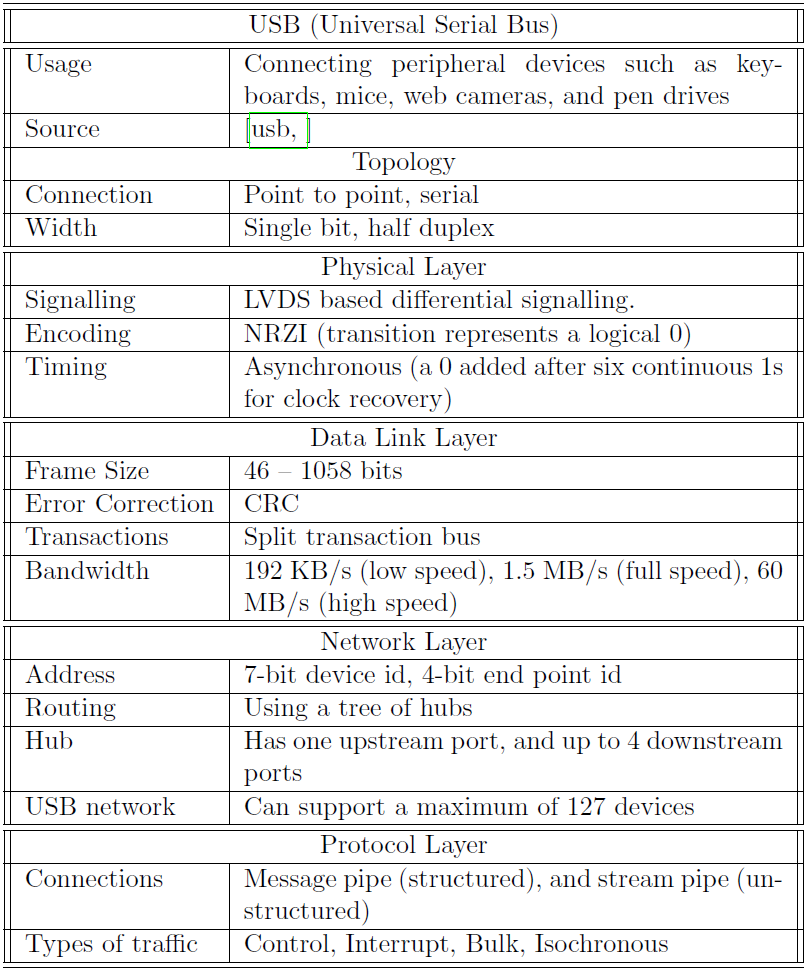
19.8.8 儲存
在所有通常連線到處理器的外圍裝置中,儲存裝置有一個特殊的位置,主要是因為它們是計算機系統功能的組成部分。
儲存裝置保持持久狀態。持久狀態指的是計算機系統中儲存的所有資料,即使它通電時也是如此。值得注意的是,儲存系統儲存作業系統、所有程式及其相關資料,包括所有檔案、歌曲、影象和視訊。從計算機架構師的角度來看,儲存系統在引導過程中扮演著積極的角色,儲存檔案和資料以及虛擬記憶體。讓我們逐一討論這些角色。
當處理器啟動時(該過程稱為引導),它需要載入作業系統的程式碼。通常作業系統的程式碼在主硬碟的地址空間的開頭可用,然後處理器將作業系統的程式碼載入到主記憶體儲器中,並開始執行它。在引導過程之後,使用者可以使用作業系統來執行程式和存取資料。程式在儲存系統中儲存為常規檔案,資料也儲存在檔案中。檔案本質上是硬碟或類似儲存裝置中的資料塊,這些資料塊需要讀入主記憶體,以便處理器可以存取。
最後,儲存裝置在實現虛擬記憶體方面發揮著非常重要的作用,它們儲存交換空間,交換空間包含主記憶體中無法包含的所有幀,有效地幫助擴充套件實體地址空間以匹配虛擬地址空間的大小。一部分幀儲存在主記憶體中,其餘幀儲存在交換空間中。當出現頁面錯誤時,它們被引入(交換)。
幾乎所有型別的計算機都連線了儲存裝置,但也有一些例外,某些機器,特別是在實驗室環境中,可能通過網路存取硬碟。它們通常使用網路啟動協定從遠端硬碟啟動,並通過網路存取包括交換空間在內的所有檔案。從概念上講,它們仍然有一個連線的儲存裝置。它只是沒有物理連線到主機板,儘管如此,仍然可以通過網路存取。
現在看看主要的儲存技術。傳統上,磁儲存一直是主導技術,這種儲存技術記錄了大型鐵磁磁碟微小區域中的位值。根據磁化狀態,可以推斷邏輯0或1。可以使用光碟技術,如CD/DVD/藍光碟機動器,而不是磁碟技術。CD/DVD/藍光光碟包含一系列凹坑(表面像差),這些凹坑編碼一系列二進位制值,光碟驅動器使用鐳射讀取儲存在磁碟上的值。計算機的大多數操作通常存取硬碟,而光碟主要用於存檔視訊和音樂,但從光碟驅動器啟動並不罕見。
固態驅動器是磁碟和光碟的快速替代品。與具有移動部件的磁性和光學驅動器不同,固態驅動器由半導體制成。固態驅動器中最常用的技術是快閃記憶體,快閃記憶體裝置使用儲存在半導體中的電荷來表示邏輯0或1,它們比傳統硬碟機快得多,但可以儲存的資料要少得多,截至2012年,其成本要高出5-6倍。因此,高階伺服器選擇混合解決方案,有一個快速的SSD驅動器,可以作為更大硬碟的快取。
19.8.8.1 硬碟
從筆記型電腦到伺服器,硬碟是大多數計算機系統的組成部分。它是一種由鐵磁材料和機械部件製成的儲存裝置,可以以低成本提供大量儲存容量。因此,在過去三十年中,硬碟一直被專門用於儲存個人計算機、伺服器和企業級系統中的持久狀態。
令人驚訝的是,資料儲存的基本物理原理非常簡單,在一系列磁鐵中儲存0和1,現在快速回顧一下硬碟中資料儲存的基本物理。
硬碟資料儲存物理學
考慮一個典型的磁體,它有北極和南極,同極相互排斥,相反極相互吸引。除了機械效能外,磁體還具有電學效能,例如,當通過電線線圈的磁場由於磁體和線圈之間的相對運動而改變時,根據法拉第定律,電線兩端會感應出EMF(電壓)。硬碟使用法拉第定律作為其操作的基礎。
硬碟的基本元素是一個小磁鐵。硬碟中使用的磁體通常由氧化鐵製成,具有永久磁性,意味著它們的磁性一直保持不變。它們被稱為永磁體或鐵磁體(因為氧化鐵)。相比之下,可以擁有由纏繞在鐵棒上的載流電線線圈組成的電磁鐵,電流切斷後,電磁鐵失去磁性。
現在考慮一組串聯的磁體,如下圖所示。它們的相對方向有兩種選擇,即N-S(北-南)或S-N(南-北)。現在在磁鐵的排列上移動一小圈電線,每當它穿過兩個方向相反的磁體的邊界時,磁場就會發生變化。因此,作為法拉第定律的直接結果,線圈兩端感應出EMF。然而,當磁場方向沒有變化時,線圈兩端感應的EMF可以忽略不計。微小磁體方向的轉變對應於邏輯1位,而沒有轉變表示邏輯0位。因此,圖中的磁體表示位元型樣0101,類似於I/O通道的NRZI編碼。

硬碟表面的一系列微小磁鐵。
由於在轉換中編碼資料,因此需要儲存資料塊,硬碟在磁區中儲存一塊資料。硬碟磁區的大小在512位元組之間,它被視為一個原子塊,通常一次讀取或寫入整個磁區,包含小線圈並穿過磁鐵的結構稱為讀取頭。
現在看看將資料寫入硬碟。在這種情況下,任務是設定磁鐵的方向,還有一種叫做寫頭的結構,它包含一個微型電磁鐵。如果電磁鐵經過永久磁鐵,它會引起永久磁鐵的磁化。其次,磁化方向取決於電流的方向,如果改變電流的方向,磁化的方向就會改變。
為了簡潔起見,將讀磁頭和寫磁頭的組合元件稱為磁頭。
碟片結構
硬碟通常由一組碟片組成。碟片是一箇中間有孔的圓形圓盤,一個主軸通過中間的圓孔連線到碟片上。碟片被分成一組稱為軌道(track,亦稱磁軌)的同心環,軌道被進一步劃分為固定長度的磁區(sector),如下圖所示。
硬碟由多個碟片組成。碟片是一個固定在主軸上的圓盤,碟片還包括一組稱為磁軌的同心環,每個磁軌由一組磁區組成。磁區通常包含固定數量的位元組,而與磁軌無關。
現在概述一下硬碟的基本操作。碟片連線到主軸上。在硬碟操作過程中,主軸及其連線的碟片不斷旋轉。為了簡單起見,假設一個單盤磁碟。第一步是將磁頭定位在包含所需資料的磁軌上。接下來,磁頭需要在此位置等待,直到所需磁區到達磁頭下方。由於碟片以恆定的速度旋轉,可以根據頭部的當前位置計算需要等待的時間。一旦所需磁區到達頭部下方,就可以繼續讀取或寫入資料。
這裡需要考慮一個重要問題。每個軌道的磁區數是相同的還是不同的?請注意,每個磁軌可以儲存的位數存在技術限制。因此,如果每個磁軌的磁區數相同,那麼實際上是在向外圍浪費磁軌中的儲存容量,因為受限於最接近中心的磁軌中可以儲存的位數。因此,現代硬碟避免了這種方法。
嘗試為每個軌道儲存可變數量的磁區。朝向中心的軌道包含更少的磁區,而朝向外圍的軌道包含更多的磁區。這一計劃也有其自身的問題。比較最內側和最外側軌道,並假設最內側軌道包含N個磁區,最外側軌道包含2N個磁區。如果假設每分鐘的旋轉數是恆定的,那麼需要在最外層軌道上讀取資料的速度是最內層軌道的兩倍。事實上,每一條軌道的資料檢索率都是不同的,使得磁碟中的電子電路複雜化。可以探索另一種選擇,即以不同的速度為每個磁軌旋轉磁碟,以使資料傳輸速率保持恆定。在這種情況下,電子電路更簡單,但以各種不同速度執行主軸電機所需的複雜程度令人望而卻步。因此,這兩種解決方案都是不切實際的。
怎麼樣,把兩個不切實際的解決方案結合起來,讓它變得實用!將這組軌跡劃分為一組區域,每個區域由一組連續的m條軌道組成。如果碟片中有n個軌道,那麼有n=m個區域。在每個區域中,每個磁軌的磁區數是相同的,碟片以恆定的角速度旋轉一個區域中的所有軌道。在一個區域中,與朝向碟片外圍的磁軌相比,更靠近中心的磁軌的資料更密集。換言之,磁區在一個區域中的磁軌具有物理上不同的大小。這不是問題,因為磁碟驅動器假設在一個區域中通過每個磁區所需的時間相同,並且以恆定的角速度旋轉可以確保這一點。
下圖顯示了將碟片劃分為區域的概念圖,請注意,每個磁軌的磁區數因區域而異。這種方法被稱為分割區位記錄(Zoned-Bit Recording,ZBR)。我們沒有考慮的兩個不切實際的設計是ZBR的特例。第一種設計假設我們有一個區域,第二種設計假設每個軌道屬於不同的區域。
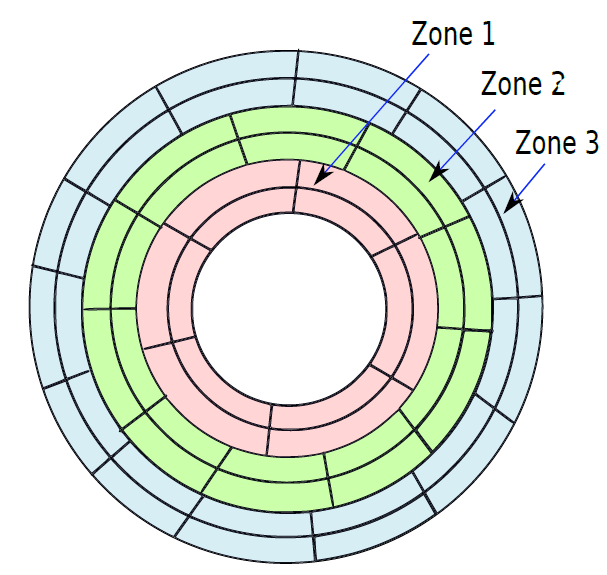
分割區位記錄。
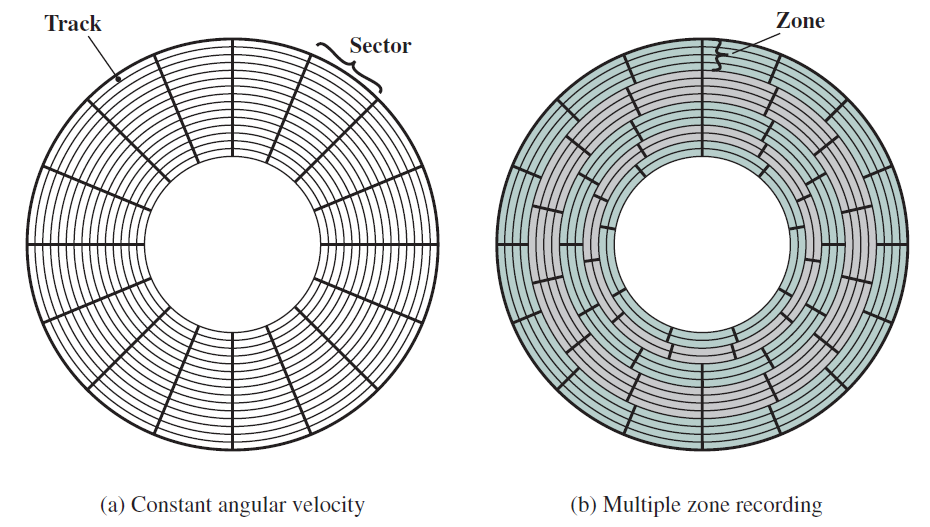
磁碟佈局方法的比較:(a) 恆定角速度,(b)多區記錄。
現在看看這個方案為什麼有效。由於有多個分割區,因此浪費的儲存空間不如僅使用單個分割區的設計高。其次,由於區域的數量通常不是很大,因此主軸的電機不需要頻繁地重新調整其速度。事實上,由於空間位置的原因,留在同一區域的可能性相當高。
硬碟結構
現在將所有部件放在一起,看看下面兩圖的硬碟結構。有一組連線到單個旋轉主軸(spindle)的碟片(platter),以及一組碟片臂(disk arm,碟片的每一側一個),其末端包含一個磁頭(head)。通常,所有臂一起移動,所有頭部在同一圓柱體上垂直對齊。在這裡,圓柱體(cylinder)被定義為來自多個碟片的一組軌道,這些碟片具有相同的半徑。在大多數硬碟中,一個時間點只有一個磁頭被啟用,它對給定磁區執行讀或寫存取。在讀取存取的情況下,資料被傳輸回驅動電子裝置進行後處理(成幀、糾錯),然後通過匯流排介面在匯流排上傳送到處理器。

硬碟結構。
現在考慮一下硬碟設計中的一些細微之處(參見下圖)。它顯示了連線到主軸的兩個碟片,每個碟片都有兩個記錄表面。主軸連線到電機(motor,稱為主軸電機),該電機根據我們希望存取的區域調整其速度。所有臂組一起移動,並使用心軸連線到致動器(actuator)。致動器是一個小型電機,用於順時針或逆時針移動臂。致動器的作用是通過順時針或逆時針旋轉給定的角度,將臂的頭部定位在指定的軌道上。
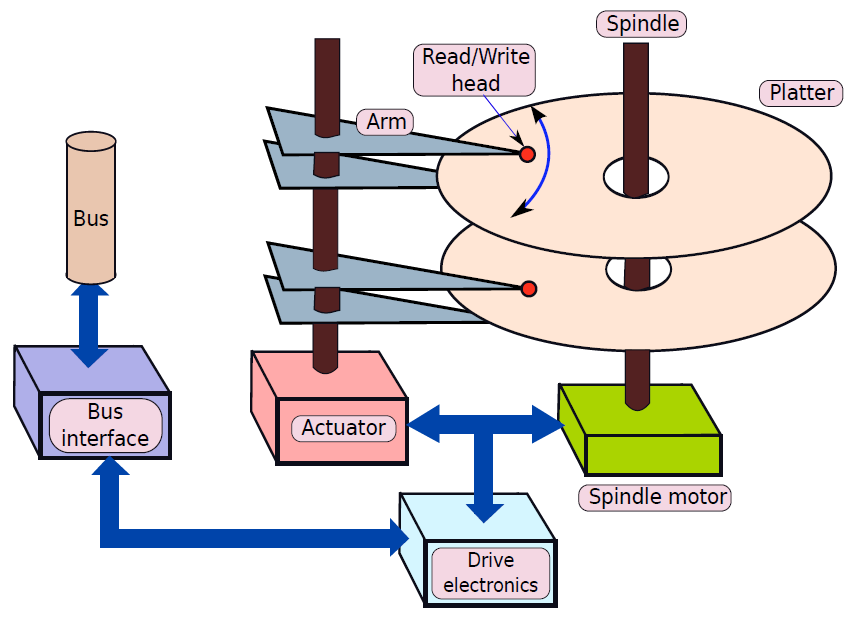
硬碟內部結構。
桌面處理器中的典型磁碟驅動器的磁軌密度約為每英寸10000個磁軌,意味著軌道之間的距離為2.5微米,因此致動器必須非常精確。通常,磁區上有一些標記,指示軌道的編號,致動器通常需要進行輕微調整以達到準確的點。這種控制機制被稱為伺服控制(servo control)。致動器和主軸電機均由硬碟機箱內的電子電路控制,一旦致動器將磁頭放置在正確的軌道上,它需要等待所需的磁區到達磁頭下方,軌道上有標記以指示磁區的編號。磁頭放置在軌道上後,會繼續讀取標記。根據這些標記,它可以準確預測所需磁區何時位於頭部下方。
除了機械部件外,硬碟還具有包括小型處理器在內的電子部件。它們在匯流排上接收和傳輸資料,在硬碟上排程請求,並執行糾錯。硬碟是人類工程學的一項令人難以置信的成就。硬碟可以在大多數時間無縫地容忍錯誤,動態地使壞磁區(有故障的磁區)無效,並將資料重新對映到好磁區。
下圖說明了與任何SSD系統相關的通用體系結構系統元件的一般檢視。在主機系統上,作業系統呼叫檔案系統軟體來存取磁碟上的資料,檔案系統反過來呼叫I/O驅動程式軟體,I/O驅動程式軟體提供對特定SSD產品的主機存取。圖中的介面元件是指主機處理器和SSD外圍裝置之間的物理和電氣介面,如果裝置是內部硬碟機,則通用介面為PCIe。對於外部裝置,一個通用介面是USB。
固態驅動器架構。
硬碟存取的數學模型
現在,讓我們為請求完成對硬碟的存取所需的時間構建一個快速的數學模型。可以把花費的時間分成三部分:
- 第一個是尋道時間,定義為磁頭到達正確軌道所需的時間。
- 頭部需要等待所需磁區到達其下方,該時間間隔稱為旋轉延遲。
- 磁頭需要讀取資料,處理資料以消除錯誤和冗餘資訊,然後在匯流排上傳輸資料,被稱為傳輸時間。
因此,有一個簡單的方程式描述之:
除此之外,還有RAID陣列、光碟、快閃記憶體盤等媒介,更多可參閱:18.11 檔案和I/O。
19.9 GPU
19.9.1 概述
高強度圖形是當代計算機系統的標誌。今天的計算機,從智慧手機到高階桌上型電腦,都使用各種複雜的視覺效果來增強使用者體驗。此外,使用者還可以使用計算機玩圖形密集型遊戲、觀看高清視訊,以及進行計算機輔助工程設計,所有這些應用程式都需要大量的圖形處理。
在早期,計算機中的圖形支援非常初級,程式設計師需要指定螢幕上繪製的每個形狀的座標,例如要繪製一條線,程式設計師需要明確提供該線的座標,並指定其顏色。顏色的範圍非常有限,而且幾乎沒有用於解除安裝圖形密集型任務的硬體。由於在螢幕上繪製的每一條線或圓都需要幾個組合語句,因此建立和使用計算機圖形的過程非常緩慢。漸漸地,需要在硬體中對圖形進行一些支援。
由於GPU和CPU是為兩種截然不同的應用程式而設計和優化的,因此它們的體系結構存在顯著差異,可以通過比較兩種處理器技術專用於快取記憶體、控制邏輯和處理邏輯的管芯面積(電晶體計數)的相對數量來看出(下圖)。
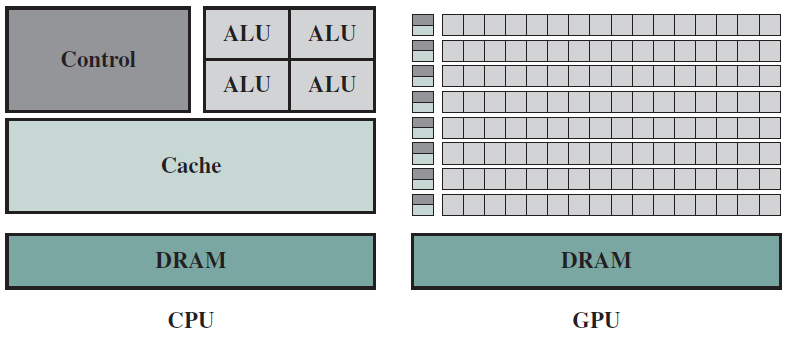
CPU和GPU在快取、ALU、控制器等硬體單元的對比圖。
19.9.1.1 圖形應用
我們可以將現代圖形應用程式分為兩種型別。第一類是自動影象合成。例如考慮遊戲中的一個複雜場景,其中一個角色在月明的夜晚拿著機槍奔跑。在這種情況下,程式設計師不是手動將每個畫素的值設定為給定的顏色,此過程太慢且耗時。如果使用這種方法,互動遊戲都不會起作用。相反,程式設計師在高階物件級別編寫程式,例如他可以用道路、植物和障礙物等一組物件來定義場景,可以塑造一個角色,以及隨身攜帶的諸如機關槍、小刀和斗篷等工藝品,程式設計師根據這些物件編寫程式。此外,他還可指定了一組規則來定義這些物件的互動,例如,如果角色與牆發生碰撞,則該角色會轉身並朝另一個方向執行。除了定義物件和物件的語意外,還必須定義場景中的光源。在這種情況下,程式設計師需要指定月光下夜晚的光線強度。然後,通過專用圖形軟體和硬體自動計算角色和背景的照度。
遺憾的是,圖形硬體不理解複雜物件和字元的語言。因此,大多數圖形工具包都有圖形庫來將複雜結構分解為一組基本形狀,計算機圖形應用程式中的大多數形狀都被分解為一組三角形,所有操作(如物件碰撞、移動、照明、陰影和照明)都轉換為三角形上的基本操作。然而,圖形庫不使用常規處理器來處理這些三角形,並最終建立要在計算機螢幕上顯示的畫素陣列。一旦程式設計師的意圖轉化為對基本形狀的操作,圖形庫就會將程式碼傳送到專用圖形處理器,該處理器完成其餘的處理。圖形處理器根據使用者提供的資料和規則生成複雜場景,對由邊和頂點指定的形狀進行操作。大多數時候,這些形狀是二維空間中的三角形,或者三維空間中的四面體。圖形處理器還在生成最終影象時計算照明、物件位置、深度和透視的效果,一旦圖形處理器生成了最終影象,它就會將其傳送到顯示裝置。如果我們在玩電腦遊戲,那麼這個過程需要每秒至少進行50-100次。
總之,由於生成複雜的圖形場景既困難又緩慢,因此程式設計師對物件進行高階描述。隨後,圖形庫將程式設計師的指令轉換為對基本形狀的操作,並將一組形狀和對其進行操作的規則傳送給圖形處理器。圖形處理器通過對基本形狀進行操作,然後將其轉換為畫素陣列來生成最終場景。
圖形處理器的第二個重要應用是顯示視訊等動畫內容,高清晰度視訊每個場景有數百萬畫素。為了減少儲存需求,大多數高清晰度視訊都經過了嚴格壓縮(編碼)。因此,計算機需要解碼或解壓縮視訊,每秒計算50-100次畫素陣列,並在螢幕上顯示它們。這是一個非常計算密集的過程,可能佔用CPU的資源。因此,視訊解碼通常也被載入到圖形處理器,該處理器包含處理視訊的專用單元。
幾乎所有現代計算機系統都包含圖形處理器,它被稱為GPU(Graphics Processing Unit,圖形處理單元)。現代GPU包含超過64-128個核心,因此設計用於廣泛的並行處理。
19.9.1.2 圖形管線
現在讓我們看看下圖中的典型圖形處理器的流水線。

圖形管線。
第一階段稱為頂點處理。在此階段,將處理一組頂點、形狀和三角形。GPU執行復雜的操作,例如物件旋轉和平移。程式設計師可能會指定給定的物件以一定的速度朝向另一個物件移動,因此有必要以給定的速率平移形狀的位置,這種操作也在這個階段進行。此階段的輸出是2D平面中的一組簡單三角形。
第二階段稱為光柵化。光柵化過程將每個三角形轉換為一組畫素,稱為片元(或片段)。此外,它將片元中的每個畫素與一組引數相關聯,這些引數稍後用於插值顏色的值。
第三階段是片元處理。該階段使用前一階段計算的中間結果根據一組固定規則對片元的畫素進行著色,或者將給定紋理對映到片元。例如,如果一塊片元代表一張木製桌子的表面,那麼這個階段將木材的紋理對映到畫素的顏色。此階段還用於合併陰影和照明等效果。
注意,到目前為止,我們已經計算了場景中所有物件的片元顏色。然而,一個物件可能位於另一個物件的前面,因此第二個物件的一部分可能被隱藏。
第四階段聚合來自第三階段的所有片元,並執行稱為幀緩衝處理的操作。幀緩衝區是一個大陣列,包含每個畫素的顏色值,圖形卡每秒向顯示裝置傳送50-100次幀緩衝器。在此階段執行的操作之一稱為深度緩衝,它通過隱藏部分物件,以一定角度計算3D空間的2D檢視。建立最終場景後,圖形管線將影象傳輸到幀緩衝區。
以上就是圖形處理器渲染複雜遊戲,甚至是最小化或最大化視窗等標準操作的方式。渲染被定義為通過根據物件、規則和視覺效果處理場景的高階描述,以畫素為單位生成場景的過程。渲染過程本質上涉及很多線性代數運算,包含物件旋轉或平移都等矩陣運算。這些操作處理大量浮點值,並且本質上是並行的。
19.9.1.3 高效能運算與圖形計算的融合
到了90年代末,計算機圖學領域迅速發展。計算機遊戲、桌面視覺效果和先進的工程軟體激增,需要複雜的計算機圖形硬體加速器。因此,設計師越來越需要創造更生動的場景和更逼真的物體。我們可以比較80年代後期製作的動畫電影和今天的好萊塢電影,今天的動畫電影有非常逼真的人物,面部表情非常細緻。多虧了圖形硬體,所有這些都成為可能。為了創造這種身臨其境的體驗,有必要在圖形處理器中增加很大程度的靈活性,以結合不同型別的視覺效果。因此,圖形處理器設計者將處理器的許多內部部件暴露給低階軟體,並允許程式設計師更靈活地使用處理器。一組名為著色器的程式誕生於2000年初,它們允許程式設計師建立靈活的片段和畫素處理例程。
到2006年,主要GPU供應商已經認識到圖形管道也可以用於通用計算,例如大量數值化的科學程式碼在概念上類似於片元或畫素處理操作。我們如果允許常規使用者程式存取圖形處理器以執行其任務,就可以在圖形處理器上執行大量科學程式。為了響應這一要求,NVIDIA釋出了CUDA API,允許C程式設計師用C語言編寫程式碼,並在圖形處理器上執行,GPGPU(通用GPU)一詞就此誕生了。
GPGPU代表通用圖形處理單元,本質上是一個圖形處理器,允許普通使用者在其上編寫和執行程式碼。使用者通常使用專用語言或標準語言的擴充套件來生成與GPGPU相容的程式碼。
後面將討論NVIDIA Tesla GPU架構的設計,具體來說,將討論GeForce 8800 GPU的設計。GPU最快的部分(核心)通常工作在1.5GHz或更高,其他部件的工作頻率為600 MHz、750 MHz或以上。
19.9.2 GPU系統架構
當今常用的GPU系統架構有幾種,下面將闡述它們的系統設定、GPU功能和服務、標準程式設計介面以及基本的GPU內部架構。
19.9.2.1 異構CPU–GPU系統架構
使用GPU和CPU的異構計算機系統架構可以通過兩個主要特徵在高層次上描述:第一,使用了多少功能子系統和/或晶片,以及它們的互連技術和拓撲結構;第二,哪些記憶體子系統可用於這些功能子系統。
下圖顯示了大約1990年遺留PC的高階結構圖。北橋包含連線CPU、記憶體和PCI匯流排的高頻寬介面,南橋包含傳統的介面和裝置:ISA匯流排(音訊、LAN)、中斷控制器;DMA控制器;時間/計數器。在該系統中,顯示器由一個簡單的幀緩衝子系統驅動,該子系統被稱為VGA(視訊圖形陣列),它連線到PCI匯流排。具有內建處理元件(GPU)的圖形子系統在1990年的PC環境中並不存在。
下圖說明了目前常用的兩種設定。它們的特點是具有各自記憶體子系統的獨立GPU(離散GPU)和CPU。在圖a中,對於Intel CPU,GPU通過16通道PCI Express 2.0鏈路連線,以提供峰值16 GB/s傳輸速率(每個方向的峰值為8 GB/s)。類似地,在圖b中,對於AMD CPU,GPU也通過具有相同可用頻寬的PCI Express連線到晶片組。在這兩種情況下,GPU和CPU可以存取彼此的記憶體,儘管可用頻寬比它們存取更直接連線的記憶體的頻寬要少。在AMD系統的情況下,北橋或記憶體控制器與CPU整合在同一晶片中。
PCI Express(PCIe):使用對等鏈路的標準系統I/O互連,鏈路具有可設定的通道數和頻寬。
統一記憶體架構(unified memory architecture,UMA):CPU和GPU共用公共系統記憶體的系統架構。
這些系統上的一種低成本變體,即統一記憶體架構系統,僅使用CPU系統記憶體,而省略了系統中的GPU記憶體。這些系統具有相對較低的效能GPU,因為它們實現的效能受到可用系統記憶體頻寬和增加的記憶體存取延遲的限制,而專用GPU記憶體提供高頻寬和低延遲。
高效能系統變體使用多個連線的GPU,通常兩到四個並行工作,其顯示器呈菊花鏈,如NVIDIA SLI(可延伸連結互連)多GPU系統,專為高效能遊戲和工作站而設計。
下一個系統類別將GPU與北橋(Intel)或晶片組(AMD)整合在一起,無論有無專用圖形記憶體。
前述章節解釋了快取如何在共用地址空間中保持一致性。對於CPU和GPU,有多個地址空間,GPU可以使用由GPU上的MMU轉換的虛擬地址存取自己的物理本地記憶體和CPU系統的實體記憶體。作業系統核心管理GPU的頁表,可以使用一致或非一致的PCI Express事務存取系統物理頁面,取決於GPU頁面表中的屬性。CPU可以通過PCI Express地址空間中的地址範圍(也稱為開口,aperture)存取GPU的本地記憶體。
諸如Sony PlayStation 3和Microsoft Xbox 360的控制檯系統類似於前面描述的PC系統架構,控制檯系統設計為在使用壽命長達五年或更長的時間內提供相同的效能和功能。在此期間,可以多次重新實現系統以開發更先進的矽製造工藝,從而以更低的成本提供恆定的能力。控制檯系統不需要像PC系統那樣擴充套件和升級其子系統,因此主要的內部系統匯流排傾向於客製化而非標準化。
在如今的PC中,GPU通過PCI Express連線到CPU,前幾代使用AGP。圖形應用程式呼叫OpenGL或Direct3DAPI函數,將GPU用作協處理器,API通過為特定GPU優化的圖形裝置驅動程式向GPU傳送命令、程式和資料。
AGP:原始PCI I/O匯流排的擴充套件版本,為單個卡插槽提供了高達原始PCI匯流排八倍的頻寬。其主要目的是將圖形子系統連線到PC系統中。
19.9.2.2 基礎統一GPU架構
統一GPU架構基於許多可程式化處理器的並行陣列。它們將頂點、幾何體和畫素著色器處理和平行計算統一在同一處理器上,與早期GPU不同,早期GPU具有專用於每種處理型別的單獨處理器。可程式化處理器陣列與固定功能處理器緊密整合,用於紋理過濾、光柵化、光柵操作、抗鋸齒、壓縮、解壓縮、顯示、視訊解碼和高清視訊處理。儘管固定功能處理器在受面積、成本或功率預算限制的絕對效能方面明顯優於更一般的可程式化處理器,本小節重點介紹可程式化處理器。
與多核CPU相比,多核GPU具有不同的架構設計點,其重點是在多個處理器核上高效地執行多個並行執行緒。通過使用許多更簡單的核心並優化執行緒組之間的資料並行行為,每個晶片的電晶體預算更多地用於計算,而更少地用於片上快取和開銷。
統一的GPU處理器陣列包含許多處理器核心,通常組織為多執行緒多處理器。下圖顯示了具有112個流處理器(SP)核心陣列的GPU,這些核心被組織為14個多執行緒流多處理器(SM)。每個SP核心都是高度多執行緒的,在硬體中管理96個並行執行緒及其狀態。處理器通過互連網路與四個64位元寬的DRAM分割區連線,每個SM有八個SP核、兩個特殊功能單元(SFU)、指令和常數快取、一個多執行緒指令單元和一個共用記憶體。這是NVIDIA GeForce 8800實現的基本Tesla架構,具有統一的架構,其中用於頂點、幾何和畫素著色的傳統圖形程式在統一的SM及其SP核心上執行,計算程式在相同的處理器上執行。
通過縮放多處理器的數量和記憶體分割區的數量,處理器陣列架構可延伸到更小和更大的GPU設定。上圖顯示了共用紋理單元和紋理L1快取的兩個SM的七個叢集,紋理單元將過濾後的結果傳遞給SM,並將一組座標轉換為紋理圖。由於連續紋理請求的支援過濾器區域經常重疊,因此小型流式L1紋理快取可有效減少對記憶體系統的請求數量。處理器陣列通過GPU範圍的互連網路與光柵操作處理器(ROP)、二級紋理快取、外部DRAM記憶體和系統記憶體連線。處理器的數量和記憶體的數量可以進行擴充套件,以針對不同的效能和市場細分設計平衡的GPU系統。
下圖顯示了NVIDIA Fermi架構GPU的總體佈局。如圖所示,L2快取位於16個SM(上下8個SM)的中心,每個SM由2個相鄰列和16行矩形(GPU處理器核心)以及一列16個載入/儲存單元和一列4個特殊功能單元(SFU)表示。SM模組的更詳細圖示如下下圖所示。下圖中SM頭部和底部的矩形是暫存器和L1/共用記憶體所在的位置,6個DRAM I/O介面中的每一個都具有64位元記憶體介面(DRAM介面電路在最外側的左側和右側以深藍色矩形顯示)。因此,總體而言,GPU的GDDR5(圖形雙倍資料速率,專為圖形處理而設計的DDR記憶體)DRAM具有384位元介面,允許支援總計6 GB的SM片外記憶體(即全域性、固定、紋理和區域性)。此外,下圖所示為主機介面,可在GPU佈局圖的左側找到,主機介面允許GPU和CPU之間的PCIe連線。最後,GigaThread全域性排程器(位於主機介面旁邊)負責將執行緒塊分配給所有SM的warp排程器。

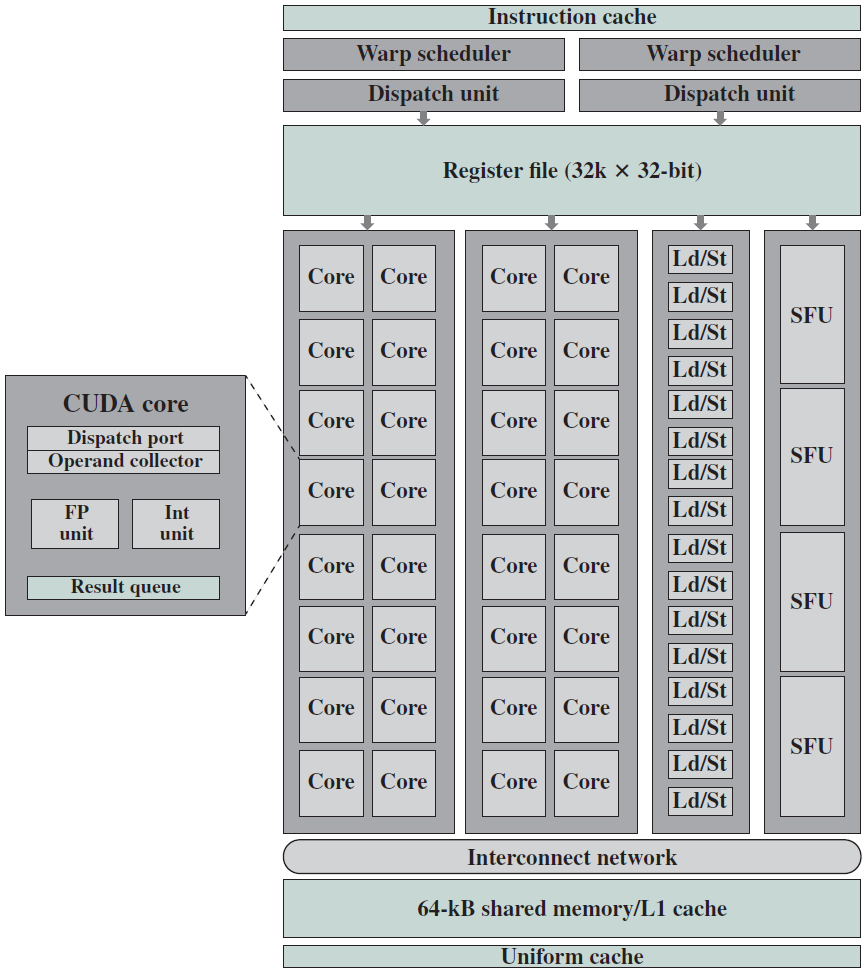
19.9.3 多執行緒多處理器架構
為了解決不同的市場細分,GPU實現了可延伸的多處理器數量,實際上GPU是由多處理器組成的多處理器,此外,每個多處理器都是高度多執行緒的,可以高效地執行許多細粒度頂點和畫素著色器執行緒。一個高質量的基本GPU有兩到四個多處理器,而遊戲愛好者的GPU或計算平臺有幾十個。本節將介紹一個這樣的多執行緒多處理器的架構,是前面描述的NVIDIA Tesla流式多處理器(SM)的簡化版本。
為什麼要使用多處理器,而不是幾個獨立的處理器?每個多處理器內的並行性提供了在地化的高效能,並支援細粒度並行程式設計模型的廣泛多執行緒,執行緒塊的各個執行緒在多處理器內一起執行以共用資料。這裡描述的多執行緒多處理器設計在緊密耦合的架構中有八個標量處理器核心,最多執行512個執行緒。為了提高面積和功率效率,多處理器在八個處理器核心中共用大型複雜單元,包括指令快取、多執行緒指令單元和共用記憶體RAM。
GPU處理器高度多執行緒,可實現以下幾個目標:
- 覆蓋DRAM記憶體載入和紋理提取的延遲
- 支援細粒度並行圖形著色器程式設計模型
- 支援細粒度平行計算程式設計模型
- 將物理處理器虛擬化為執行緒和執行緒塊,以提供透明的可延伸性
- 將並行程式設計模型簡化為為一個執行緒編寫序列程式
記憶體和紋理提取延遲可能需要數百個處理器時鐘,因為GPU通常具有小型流快取,而不像CPU這樣的大型工作集快取,提取請求通常需要完整的DRAM存取延遲加上互連和緩衝延遲。當一個執行緒等待載入或紋理獲取完成時,多執行緒有助於利用有用的計算來覆蓋延遲,處理器可以執行另一個執行緒。細粒度並行程式設計模型提供了數千個獨立的執行緒,儘管單個執行緒的記憶體延遲很長,但這些執行緒仍能讓許多處理器保持忙碌。
圖形頂點或畫素著色器程式是用於處理頂點或畫素的單個執行緒的程式,類似地,CUDA程式是用於計算結果的單個執行緒的C程式。圖形和計算程式範例化許多並行執行緒,以渲染複雜影象並計算大型結果陣列。為了動態平衡移動頂點和畫素著色器執行緒工作負載,每個多處理器同時執行多個不同的執行緒程式和不同型別的著色器程式。
為了支援圖形著色語言的獨立頂點、圖元和畫素程式設計模型以及CUDA C/C++的單執行緒程式設計模型,每個GPU執行緒都有自己的專用暫存器、專用每執行緒記憶體、程式計數器和執行緒執行狀態,並且可以執行獨立的程式碼路徑。為了有效地執行數百個並行輕量級執行緒,GPU多處理器是硬體多執行緒的,在硬體中管理和執行數百個並行執行緒,而無需排程開銷。執行緒塊中的並行執行緒可以在一個屏障處與單個指令同步,輕量級執行緒建立、零開銷執行緒排程和快速屏障同步有效地支援非常細粒度的並行性。
19.9.3.1 海量執行緒
GPU處理器高度多執行緒化,可實現以下幾個目標:
- 覆蓋DRAM記憶體載入和紋理提取的延遲。
- 支援細粒度並行圖形著色器程式設計模型。
- 支援細粒度平行計算程式設計模型。
- 將物理處理器虛擬化為執行緒和執行緒塊,以提供透明的可延伸性。
- 將並行程式設計模型簡化為為一個執行緒編寫序列程式。
記憶體和紋理提取延遲可能需要數百個處理器時鐘,因為GPU通常具有小型流快取,而不像CPU的大型工作集快取。提取請求通常需要完整的DRAM存取延遲加上互連和緩衝延遲,當一個執行緒等待載入或紋理獲取完成時,多執行緒有助於利用有用的計算來覆蓋延遲,處理器可以執行另一個執行緒(下圖)。細粒度並行程式設計模型提供了數千個獨立的執行緒,儘管單個執行緒的記憶體延遲很長,但這些執行緒仍能讓許多處理器保持忙碌。
GPU利用多個Context切換來覆蓋記憶體存取延遲。
圖形頂點或畫素著色器程式是用於處理頂點或畫素的單個執行緒的程式,類似地,CUDA程式是用於計算結果的單個執行緒的C程式,圖形和計算程式範例化許多並行執行緒以渲染複雜的影象並計算大型結果陣列。為了動態平衡移動頂點和畫素著色器執行緒工作負載,每個多處理器同時執行多個不同的執行緒程式和不同型別的著色器程式。
為了支援圖形著色語言的獨立頂點、圖元和畫素程式設計模型以及CUDA C/C++的單執行緒程式設計模型,每個GPU執行緒都有自己的專用暫存器、專用逐執行緒記憶體、程式計數器和執行緒執行狀態,並且可以執行獨立的程式碼路徑。為了有效地執行數百個並行輕量級執行緒,GPU多處理器是硬體多執行緒的,它在硬體中管理和執行數百個並行執行緒,而無需排程開銷。執行緒塊中的並行執行緒可以在一個屏障處與單個指令同步,輕量級執行緒建立、零開銷執行緒排程和快速屏障同步有效地支援非常細粒度的並行性。
19.9.3.2 多處理器架構
統一的圖形和計算多處理器執行頂點、幾何體和畫素片段著色器程式以及平行計算程式。如下圖所示,範例多處理器由八個標量處理器(SP)核心組成,每個核心具有一個大型多執行緒暫存器檔案(RF)、兩個特殊功能單元(SFU)、一個多執行緒指令單元、一個指令快取、一個唯讀常數快取和一個共用記憶體。
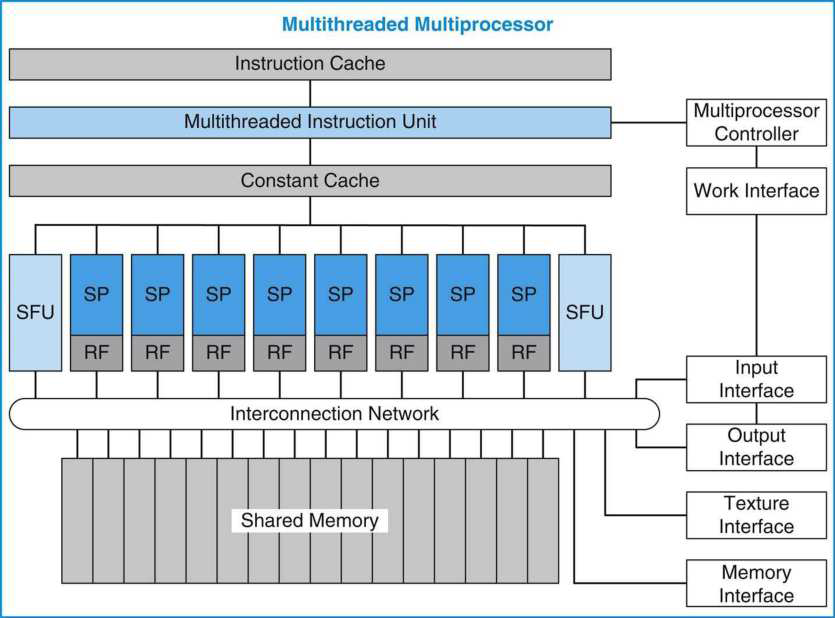
具有八個標量處理器(SP)核的多執行緒多處理器。八個SP核每個都有一個大型多執行緒暫存器檔案(RF),並共用一個指令快取、多執行緒指令釋出單元、常數快取、兩個特殊功能單元(SFU)、互連網路和一個多組共用記憶體。
16KB的共用記憶體儲存圖形資料緩衝區和共用計算資料,宣告為__shared__的CUDA變數駐留在共用記憶體中。為了通過多處理器多次對映邏輯圖形管道工作負載,頂點、幾何體和畫素執行緒具有獨立的輸入和輸出緩衝區,工作負載的到達和離開與執行緒執行無關。
每個SP核心包含執行大多數指令的標量整數和浮點算術單元。SP是硬體多執行緒的,最多支援64個執行緒。每個流水線SP核心每時鐘每個執行緒執行一個標量指令,在不同的GPU產品中,其範圍從1.2 GHz到1.6 GHz。每個SP核心都有一個1024個通用32位元暫存器的大RF,在其分配的執行緒之間進行分割區。程式宣告其暫存器需求,通常每個執行緒16到64個標量32位元暫存器。SP可以同時執行使用少量暫存器的多個執行緒或使用更多暫存器的更少執行緒,編譯器優化暫存器分配,以平衡溢位暫存器的成本與更少執行緒的成本。畫素著色器程式通常使用16個或更少的暫存器,使每個SP能夠執行多達64個畫素著色器執行緒,以覆蓋長延遲紋理提取。編譯的CUDA程式通常每個執行緒需要32個暫存器,將每個SP限制為32個執行緒,限制了該範例多處理器上的核心程式每個執行緒塊只能有256個執行緒,而不是最多512個執行緒。
流水線SFU執行執行緒指令,這些指令計算特殊函數,並從原始頂點屬性插值畫素屬性,可以與SP上的指令同時執行。
多處理器通過紋理介面在紋理單元上執行紋理提取指令,並使用記憶體介面執行外部記憶體載入、儲存和原子存取指令,這些指令可以與SP上的指令同時執行。共用記憶體存取使用SP處理器和共用記憶體組之間的低延遲互連網路。
19.9.3.3 單指令多執行緒(SIMT)
為了高效地管理和執行執行多個不同程式的數百個執行緒,多處理器採用了單指令多執行緒(SIMT)架構,它在稱為warp的並行執行緒組中建立、管理、排程和執行並行執行緒。「warp」一詞起源於第一種平行線技術——編織,下圖中的照片顯示了織機上出現的平行線的warp,此範例多處理器使用32個執行緒的SIMT warp大小,在四個時鐘上在八個SP核中的每一箇中執行四個執行緒。Tesla SM多處理器還使用32個並行執行緒的warp大小,每個SP核心執行四個執行緒,以提高大量畫素執行緒和計算執行緒的效率。執行緒塊由一個或多個warp組成。
SIMT多執行緒warp排程。排程器選擇一個準備好的warp,並向組成warp的並行執行緒同步發出指令。因為warp是獨立的,所以排程器每次都可以選擇不同的warp。
單指令多執行緒(single-instruction multiple-thread,SIMT):一種並行地將一條指令應用於多個獨立執行緒的處理器架構。
經線(warp):在SIMT體系結構中一起執行同一指令的一組並行執行緒。
此範例SIMT多處理器管理一個包含16個warp的池,總共512個執行緒。組成warp的單個並行執行緒是相同的型別,並在相同的程式地址一起開始,但在其他情況下可以自由分支並獨立執行。在每次指令發出時,SIMT多執行緒指令單元選擇一個準備好執行其下一條指令的warp,然後將該指令發出給該warp的活動執行緒。SIMT指令被同步廣播到warp的活動並行執行緒,由於獨立的分支或預測,各個執行緒可能處於非活動狀態。在該多處理器中,每個SP標量處理器核心使用四個時鐘為一個warp的四個單獨執行緒執行一條指令,反映了warp執行緒與核心的4:1比率。
SIMT處理器架構類似於單指令多資料(SIMD)設計,它將一條指令應用於多個資料通道,但不同之處在於,SIMT將一條命令並行應用於多條獨立執行緒,而不僅僅是多條資料通道。用於SIMD處理器的指令一起控制多個資料通道的向量,而用於SIMT處理器的指令控制單個執行緒,並且SIMT指令單元向獨立並行執行緒的warp發出指令以提高效率。SIMT處理器在執行時發現執行緒之間的資料級並行性,類似於超標量處理器在執行時間發現指令之間的指令級並行性。
當warp的所有執行緒採用相同的執行路徑時,SIMT處理器實現了充分的效率和效能。如果warp的執行緒通過依賴於資料的條件分支分叉,則執行會對所採用的每個分支路徑進行序列化,並且當所有路徑完成時,執行緒會匯聚到同一執行路徑。對於等長路徑,發散的if-else程式碼塊的效率為50%,多處理器使用分支同步堆疊來管理髮散和聚合的獨立執行緒。不同的warp以全速獨立執行,而不管它們是執行公共的還是不相交的程式碼路徑。因此,與早期GPU相比,SIMT GPU在分支程式碼上的效率和靈活性顯著提高,因為它們的warp比現有GPU的SIMD寬度窄得多。
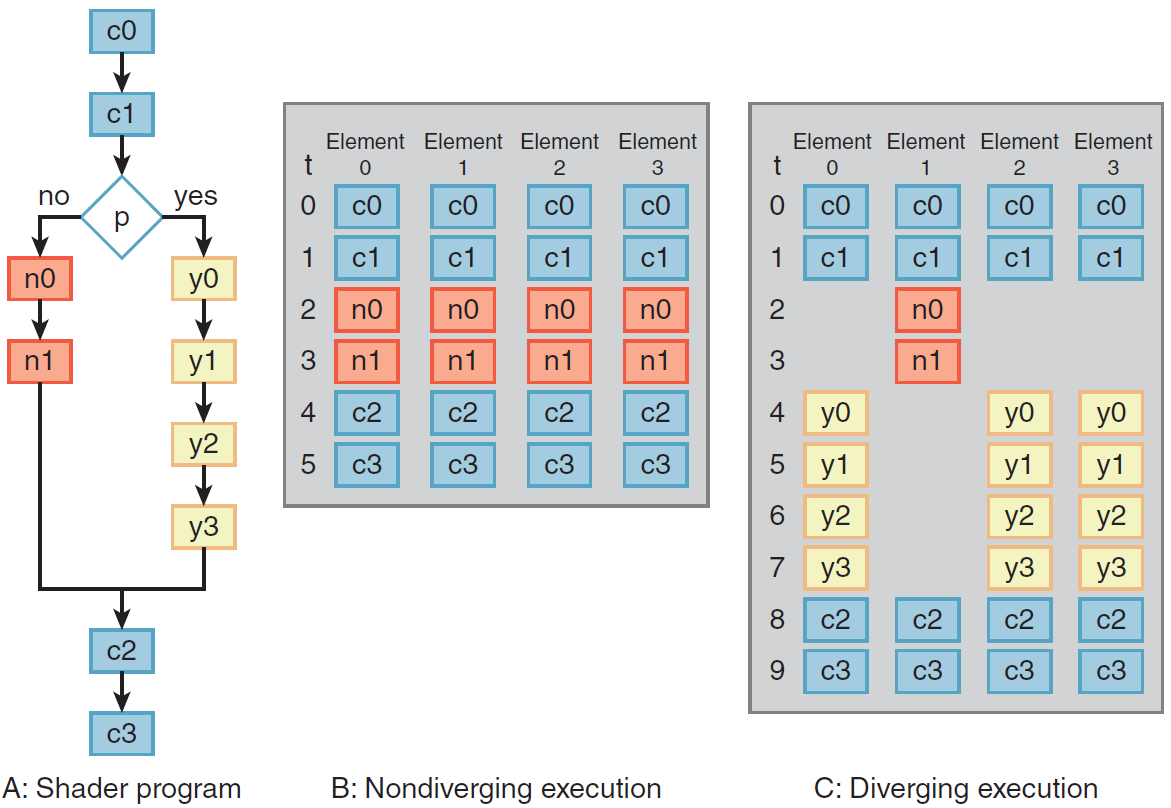
四元素預測向量核上的分支和非分支執行。每個元素執行在判斷p上分支的十個操作著色器A。在情況B中,所有四個元素都採用無分支,沒有發散,只需要六個執行步驟。在情況C中,元素1採用no分支,但其他三個元素採用yes分支。判斷通過分別執行no和yes操作來處理這種差異,因此需要所有十個執行步驟。
與SIMD向量架構相比,SIMT使程式設計師能夠為單個獨立執行緒編寫執行緒級並行程式碼,以及為許多協調執行緒編寫資料並行程式碼。對於程式的正確性,程式設計師基本上可以忽略warp的SIMT執行屬性,但通過注意程式碼很少需要warp中的執行緒來發散,可以實現顯著的效能改進。實際上,這與傳統程式碼中快取線的作用類似:在設計正確性時可以安全地忽略快取行大小,但在設計峰值效能時必須在程式碼結構中考慮快取行大小。
19.9.3.4 SIMT Warp執行和發散
排程獨立warp的SIMT方法比先前GPU架構的排程更靈活。warp包含相同型別的並行執行緒:頂點、幾何體、畫素或計算。畫素片段著色器處理的基本單元是實現為四個畫素著色器執行緒的2*2畫素四邊形,多處理器控制器將畫素四邊形打包為warp,它類似地將頂點和圖元分組為warp,並將計算執行緒打包為warp,執行緒塊包括一個或多個warp。SIMT設計在一個warp的並行執行緒之間有效地共用指令獲取和發出單元,但需要一個完整的活動執行緒warp來獲得充分的效能效率。
這種統一的多處理器同時排程和執行多個warp型別,允許它同時執行頂點和畫素warp。它的warp排程器以低於處理器時鐘速率的速度執行,因為每個處理器核心有四個執行緒通道。在每個排程週期中,它選擇一個warp來執行SIMT warp指令,如上圖所示。發出的warp指令在四個處理器吞吐量週期內作為四組八個執行緒執行,處理器流水線使用幾個延遲時鐘來完成每個指令。如果活動warp次數乘以每個warp的時鐘數超過了管線延遲,程式設計師可以忽略管線延遲。對於該多處理器,八個warp的迴圈排程在同一個warp的連續指令之間有32個週期。如果程式可以保持每個多處理器256個執行緒處於活動狀態,那麼單個連續執行緒可以隱藏多達32個週期的指令延遲。然而,由於很少有活動warp,處理器管線深度變得可見,可能會導致處理器停滯。
一個具有挑戰性的設計問題是為不同warp程式和程式型別的動態混合實現零開銷warp排程。指令排程程式必須每四個時鐘選擇一個warp,以便每個執行緒每個時鐘發出一條指令,相當於每個處理器核心1.0的IPC。因為warp是獨立的,所以唯一的依賴關係是來自同一warp的順序指令。排程器使用暫存器相關性記分板來限定活動執行緒準備好執行指令的warp,它會優先考慮所有這些準備好的warp,併為問題選擇最高優先順序的warp。優先順序必須考慮warp型別、指令型別以及對所有活動warp公平的願望。
19.9.3.5 管理執行緒和執行緒塊
多處理器控制器和指令單元管理執行緒和執行緒塊。控制器接受工作請求和輸入資料,並仲裁對共用資源的存取,包括紋理單元、記憶體存取路徑和I/O路徑。對於圖形工作負載,它同時建立和管理三種型別的圖形執行緒:頂點、幾何體和畫素。每種圖形工作型別都有獨立的輸入和輸出路徑。它將這些輸入工作型別中的每一種累積並打包為執行同一執行緒程式的並行執行緒的SIMT warp,它分配一個自由的warp,為warp執行緒分配暫存器,並在多處理器中開始warp執行。每個程式都宣告其每執行緒暫存器需求,只有當控制器可以為warp分配請求的暫存器計數時,控制器才啟動warp。當warp的所有執行緒退出時,控制器將解開打包結果並釋放warp暫存器和資源。
控制器建立共同作業執行緒陣列(cooperative thread array,CTA),將CUDA執行緒塊實現為一個或多個並行執行緒warp,當它可以建立所有CTA warp並分配所有CTA資源時,它會建立CTA。除了執行緒和暫存器,CTA還需要分配共用記憶體和障礙。程式宣告所需的容量,控制器等待,直到可以分配這些容量,然後啟動CTA。隨後,它以warp排程速率建立CTA warp,從而使CTA程式立即以完全的多處理器效能開始執行。控制器監控CTA的所有執行緒何時退出,並釋放CTA共用資源及其warp資源。
協同執行緒陣列(cooperative thread array,CTA):一組並行執行緒,它們執行相同的執行緒程式,並可以共同作業計算結果。GPU CTA實現CUDA執行緒塊。
19.9.3.6 執行緒指令
SP執行緒處理器為單個執行緒執行標量指令,與早期的GPU向量指令架構不同,後者為每個頂點或畫素著色器程式執行四個分量向量指令。頂點程式通常計算(x,y,z,w)位置向量,而畫素著色器程式計算(紅、綠、藍、Alpha)顏色向量。然而,著色器程式變得越來越長,越來越標量化,甚至很難完全佔據傳統GPU四分量向量架構的兩個元件。實際上,SIMT架構跨32個獨立的畫素執行緒進行並行化,而不是並行化一個畫素內的四個向量元件。CUDA C/C++程式主要具有每個執行緒的標量程式碼,以前的GPU使用向量打包(例如,組合工作的子向量以獲得效率),但會使得排程硬體和編譯器複雜化。標量指令更簡單且編譯器友好,紋理指令仍然基於向量,獲取源座標向量並返回過濾後的顏色向量。
為了支援具有不同二進位制微指令格式的多個GPU,高階圖形和計算語言編譯器生成中間組合程式級指令(例如Direct3D向量指令或PTX標量指令),然後將其優化並轉換為二進位制GPU微指令。NVIDIA PTX(並行執行緒執行)指令集定義為編譯器提供了穩定的目標ISA,並提供了幾代GPU與不斷髮展的二進位制微指令集架構的相容性,優化器很容易將Direct3D向量指令擴充套件為多個標量二進位制微指令。儘管一些PTX指令擴充套件為多個二進位制微指令,並且多個PTX指令可以摺疊成一個二進位制微命令,但PTX標量指令幾乎可以用標量二進位制微指令進行一對一轉換。由於中間組合程式級指令使用虛擬暫存器,優化器分析資料相關性並分配實際暫存器。優化器消除了死程式碼,在可行時將指令摺疊在一起,並優化了SIMT分支的分叉點和聚合點。
指令集體系結構(ISA)
這裡描述的執行緒ISA是Tesla架構PTX ISA的簡化版本,是一個基於暫存器的標量指令集,包括浮點、整數、邏輯、轉換、特殊函數、流控制、記憶體存取和紋理操作。下圖列出了基本的PTX GPU執行緒指令,有關詳細資訊,請參閱NVIDIA PTX規範。
其指令格式為:
opcode.type d, a, b, c;
其中d是目標運算元,a、b、c是源運算元,.type是以下之一:
| 型別 | .type特定值 |
|---|---|
| 無型別的位8、16、32和64位元 | .b8、.b16、.b32、.b64 |
| 無符號整數8、16、32和64位元 | .u8、.u16、.u22、.u64 |
| 有符號整數8、16、32和64位元 | .s8、.s16、.s32、.s64 |
| 浮點16、32和64位元 | .16、.f32、.f64 |
源運算元是暫存器中的標量32位元或64位元值、立即數或常數,判斷運算元是1位布林值。目的地是暫存器,儲存到記憶體除外。指令是通過在它們前面加上@p或@!p、 其中p是判斷暫存器。記憶體和紋理指令傳輸兩到四個分量的標量或向量,總計最多128位元。PTX指令指定一個執行緒的行為。
PTX算術指令對32位元和64位元浮點、有符號整數和無符號整數型別進行操作。當前GPU支援64位元雙精度浮點,PTX 64位元整數和邏輯指令被轉換為兩個或多個執行32位元操作的二進位制微指令,GPU特殊功能指令僅限於32位元浮點。執行緒控制流指令包括條件分支、函數呼叫和返回、執行緒退出和bar.sync(屏障同步)。條件分支指令@p bra target使用判斷暫存器p(或!p)來確定執行緒是否執行分支,該判斷暫存器p先前由比較和設定判斷setp指令設定,其他指令也可以基於判斷暫存器為真或假。
19.9.3.7 記憶體存取指令
tex指令通過紋理子系統從記憶體中的1D、2D和3D紋理陣列中提取並過濾紋理樣本。紋理提取通常使用插值浮點座標來處理紋理。一旦圖形畫素著色器執行緒計算其畫素片段顏色,光柵操作處理器將其與指定(x,y)畫素位置的畫素顏色混合,並將最終顏色寫入記憶體。
為了支援計算和C/C++語言需求,Tesla PTX ISA實現了記憶體載入/儲存指令。它使用整數位節定址和暫存器加偏移地址演演算法,以促進常規編譯器程式碼優化。記憶體載入/儲存指令在處理器中很常見,但在Tesla架構GPU中是一項重要的新功能,因為以前的GPU只提供圖形API所需的紋理和畫素存取。
對於計算,載入/儲存指令存取實現第B.3節中相應CUDA儲存空間的三個讀/寫儲存空間:
- 逐執行緒專用可定址臨時資料的區域性記憶體(在外部DRAM中實現)。
- 共用記憶體,用於低延遲存取同一個CTA/執行緒塊中共同作業執行緒共用的資料(在片上SRAM中實現)。
- 由計算應用程式的所有執行緒共用的大型資料集的全域性記憶體(在外部DRAM中實現)。
記憶體載入/儲存指令ld.global、st.global、ld.shared、st.shared、ld.local和st.local分別存取全域性、共用和區域性記憶體空間。計算程式使用快速屏障同步指令bar.sync以同步CTA/執行緒塊內通過共用和全域性記憶體彼此通訊的執行緒。
為了提高記憶體頻寬並減少開銷,當地址落在同一塊中並滿足對齊標準時,區域性和全域性載入/儲存指令將來自同一SIMT warp的單個並行執行緒請求合併為單個記憶體塊請求。與來自單個執行緒的單獨請求相比,合併記憶體請求可顯著提高效能。多處理器的大量執行緒數,加上對許多未完成的負載請求的支援,有助於覆蓋負載,從而使用外部DRAM中實現的區域性和全域性記憶體的延遲。
Tesla架構GPU還通過atom.op.u32指令在記憶體上提供高效的原子記憶體操作,包括整數操作add、min、max、and、or、xor、exchange和cas(比較和交換)操作,有助於並行縮減和並行資料結構管理。
19.9.3.8 執行緒通訊的屏障同步
快速屏障同步允許CUDA程式通過簡單呼叫__syncthreads(),通過共用記憶體和全域性記憶體頻繁通訊,作為每個執行緒間通訊步驟的一部分。同步內建函數生成單個bar.sync指令,但在每個CUDA執行緒塊最多512個執行緒之間實現快速屏障同步是一個挑戰。
將執行緒分組為32個執行緒的SIMT warp將同步難度降低了32倍。執行緒在SIMT執行緒排程程式中的一個屏障處等待,因此它們在等待時不會消耗任何處理器週期。當執行緒執行一條bar.sync指令,它遞增屏障的執行緒到達計數器,排程器將執行緒標記為在屏障處等待。一旦所有CTA執行緒到達,屏障計數器與預期的終端計數相匹配,排程器釋放在屏障處等待的所有執行緒並恢復執行執行緒。
19.9.3.9 流式多處理器(SM)
紋理/處理器叢集。
上圖顯示了具有兩個SM的TPC的結構。幾何控制器在單個核上協調頂點和形狀處理,它從記憶體層次結構中引入頂點資料,指導核心處理它們,然後協調將輸出儲存到記憶體層次結構的過程。此外,它還有助於將輸出轉發到下一個處理階段。SMC(SM控制器)排程對外部資源的請求,例如,SM中的多個核心可能希望寫入DRAM記憶體或存取紋理單元。在這種情況下,SMC對請求進行仲裁。
現在看看SM的結構。每個SM都有一個I快取(指令快取)、一個C快取(常數快取)和一個用於多執行緒工作負載的內建執行緒排程器(MT Issue Unit)。8個SP核可以存取嵌入在SM中的共用記憶體單元,以便在它們之間進行通訊。SP核心具有符合IEEE 754的浮點ALU,可以執行常規浮點運算,如加法、減法和乘法。它還支援稱為乘法加法的特殊指令,這在圖形計算中是非常常見的,此指令計算表示式的值:a*b+c。與FP ALU一起,每個SP都有一個整數ALU,可以執行常規整數指令和邏輯指令,此外,SP核心可以執行記憶體指令和分支指令。與向量處理器類似,SP核心實現預測指令,意味著他們將執行槽專用於錯誤路徑中的指令,儘管它們被nop指令取代。SP針對速度進行了優化,是整個GPU中速度最快的單元,因為它們實現了一個非常簡單的類似RISC的指令集,它主要由基本指令組成。
為了計算更復雜的數學函數,例如超越函數或三角函數,每個SM中有兩個特殊的函數單元(SFU)。SFU還具有專門的單元,用於插值片元內的顏色值,GPU使用此功能為每個三角形片段的內部著色。除了專用單元外,SFU還具有用於執行通用程式碼的常規整數/浮點ALU。
TPC中的兩個SM共用一個紋理單元,紋理單元可以同時處理四個執行緒,並將光柵化後生成的所有三角形與與三角形關聯的曲面紋理進行處理。紋理資訊儲存在紋理單元內的小快取中,在快取未命中時,紋理單元可以從相關的二級快取或從主DRAM記憶體獲取資料。
現在討論如何在GPU上執行計算。SM中的每個執行緒(對映到SP)可以存取逐執行緒區域性記憶體(儲存在外部DRAM上)、共用記憶體(在SM中的所有執行緒之間共用,並儲存在晶片上)或全域性DRAM記憶體。程式設計師可以明確指示GPU使用某種記憶體。
更詳細的單個SM結構如下圖所示。
單個SM架構。
上圖右側將NVIDIA費米體系結構分解為單個SM的基本元件,這些元件是:
- GPU處理器核心(共32個CUDA核心)。
- Warp排程程式和排程埠。
- 16個載入/儲存單元。
- 四個SFU。
- 32k*32位元暫存器。
- 共用記憶體和一級快取(共64 kB)。
下面詳細闡述SM內的各個部件。先闡述雙warp排程器(dual warp scheduler)。
如前所述,GPU晶片上的GigaThread全域性排程器單元將執行緒塊分配給SM,然後雙warp排程器將其處理的每個執行緒塊分解為warp,其中warp是由32個執行緒組成的束,這些執行緒從相同的起始地址開始,其執行緒ID是連續的。一旦發出warp,每個執行緒都會有自己的指令地址計數器和暫存器集,以允許SM中每個執行緒的獨立分支和執行。
GPU在處理儘可能多的warp以最大限度地利用CUDA核心時效率最高。如下圖所示,當雙warp排程器和指令排程單元能夠每兩個時鐘週期發出兩次warp(Fermi架構)時,SM硬體利用率將達到最大值。如下文所述,結構衝突是SM無法達到最大處理速率的主要原因,而片外記憶體存取延遲則更容易隱藏。
如果元件列不存在結構衝突,則每個劃分的列由16個CUDA核心(*2)、16個載入/儲存單元和4個SFU(上圖)組成,每個時鐘週期可以從兩個warp排程器/排程單元中的每一個分配半個warp(16個執行緒)進行處理。結構衝突由有限的SFU、雙精度乘法和分支引起,但是,warp排程程式有一個內建的記分板(scoreboard)來跟蹤可用於執行的warp以及結構衝突,使得SM既能避免結構衝突,又能儘可能地隱藏晶片外記憶體存取延遲。
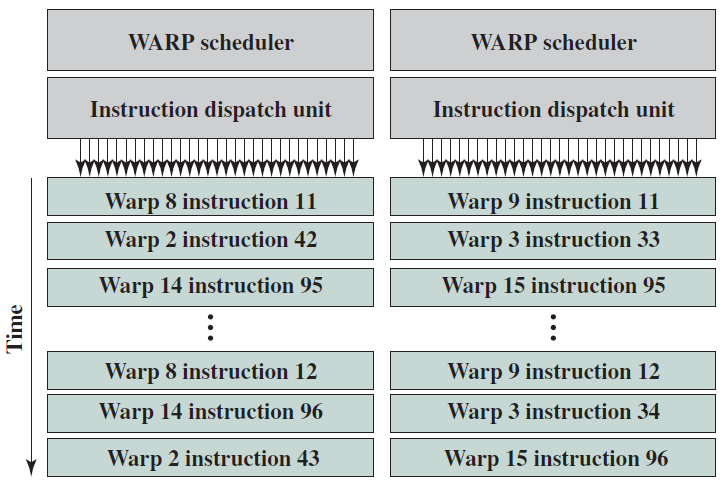
雙warp排程器和指令排程單元執行範例。
因此,程式設計師必須將執行緒塊大小設定為大於SM中CUDA核心的總數,但小於每個塊允許的最大執行緒數,並確保執行緒塊大小(在x和/或y維度)為32的倍數(warp大小),以實現SM的接近最佳利用率。
闡述完雙warp排程器,再闡述CUDA核心。
NVIDIA GPU處理器核心也稱為CUDA核心,在Fermi架構中,共有32個CUDA核專用於每個SM。每個CUDA核心都有兩個獨立的管線或資料路徑:一個整數(INT)單元管線和一個浮點(FP)單元管線(見上上圖),在一個時鐘週期內只能使用這些資料路徑中的一個。INT單元能夠進行32位元、64位元和擴充套件精度的整數和邏輯/位運算,FP單元可以執行單精度FP運算,而雙精度FP運算需要兩個CUDA核。因此,與單精度FP執行緒相比,僅執行雙精度FP操作的執行緒執行所需的時間是其兩倍。通過在每個SM中包含專用的雙精度單元以及大多數單精度單元,Kepler架構解決了雙精度FP演演算法的效能影響。幸運的是,CUDA程式設計師隱藏了執行緒級FP單精度和雙精度操作的管理,但程式設計師應該意識到使用基於所用GPU的兩種精度型別之間可能產生的潛在效能影響。
Fermi架構為CUDA核心的FP單元增加了一項改進,從IEEE 754-1985浮點算術標準升級為IEEE 754-2008標準,是通過使用融合乘法加法(FMA)指令提高乘法加法指令(MAD)的精度來實現的。FMA指令對單精度和雙精度算術都有效,Fermi架構僅在FMA指令末尾執行一次舍入,此舉不僅提高了結果的準確性,而且執行FMA指令也被壓縮到單處理器時鐘週期中。因此,每個SM在一個處理器時鐘週期內可以進行32次單精度或16次雙精度FMA操作。
其它部件說明如下:
-
特殊函數單元(special function unit):每個SM有四個SFU。SFU在一個時鐘週期內執行超越運算,如餘弦、正弦、倒數和平方根。由於一個SM中只有4個SFU,而一個warp中只有一條指令的32個並行執行緒,因此完成一個需要SFU的warp需要8個時鐘週期,但CUDA處理器以及載入和儲存單元仍然可以同時使用。
-
載入和儲存單位:SM的16個載入和儲存單元中的每一個計算每個時鐘週期單個執行緒的源地址和目標地址,這些地址用於執行緒希望寫入資料或從中讀取資料的快取或DRAM。
-
暫存器、共用記憶體和L1快取:每個SM都有自己的(片上)專用暫存器集和共用記憶體/l1快取塊。關於低延遲片上記憶體的詳細資訊和優點如下表。
記憶體型別 相對存取時間 存取型別 範圍 資料生存期 暫存器 最快,晶片內 R/W 單執行緒 執行緒 共用 快,晶片內 R/W 塊上的所有執行緒 塊 區域性 比共用和暫存器慢100到150倍,晶片外 R/W 單執行緒 執行緒 全域性 比共用和暫存器慢100到150倍,晶片外 R/W 所有執行緒和主機 應用程式 固定 比共用和暫存器慢100到150倍,晶片外 R 所有執行緒和主機 應用程式 紋理 比共用和暫存器慢100到150倍,晶片外 R 所有執行緒和主機 應用程式
儘管Fermi架構每個SM有一個令人印象深刻的32k x 32位元暫存器,但每個執行緒最多分配64x32位元的暫存器,如CUDA計算能力2.x版所定義的,這是每個SM允許的最大活動warp數以及每個SM的暫存器數的函數。如上表所示,暫存器和共用記憶體的最快存取時間只有幾納秒(ns)。如果有任何臨時暫存器溢位,資料將首先移動到L1快取,然後再傳送到L2快取,然後是長存取延遲本地記憶體(見下圖a)。使用一級快取有助於防止發生資料讀/寫衝突,因此分配給執行緒的暫存器中的資料的壽命僅與執行緒的壽命相同。
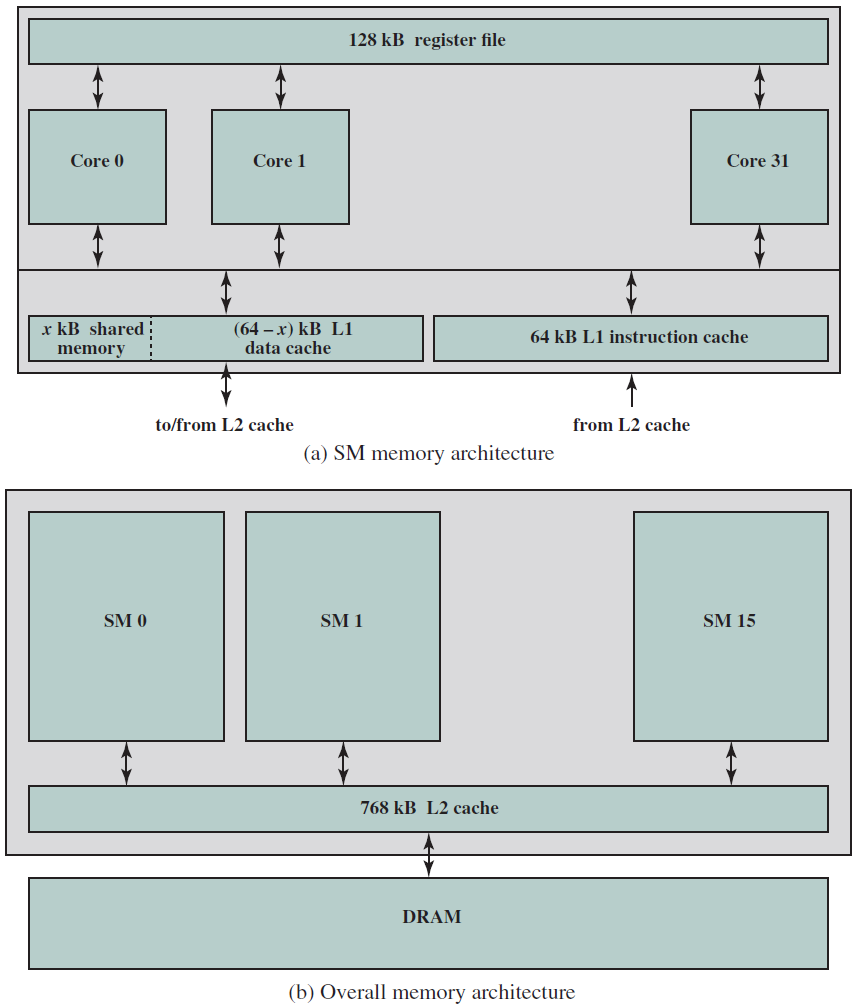
Fermi記憶體架構。
與當代多核微處理器(如CPU)相比,專用於SM的GPU處理器核心的可定址片上共用記憶體是一種獨特的設定,這些當代架構具有專用的片上L1快取和每個核心一組暫存器,但它們通常沒有片上可定址記憶體。相反,專用記憶體管理硬體在沒有程式設計師控制的情況下調節快取記憶體和主記憶體之間的資料移動,與GPU架構有很大不同。
共用記憶體被新增到GPU架構中,專門用於輔助GPGPU應用程式。優化共用記憶體的使用可以通過消除對片外記憶體的不必要的長延遲存取,顯著提高GPGPU應用程式的速度和效能。儘管每個SM的共用記憶體大小很小(最大設定為48 kB),但它的存取延遲非常低,比全域性記憶體少100到150倍(見上表)。因此,共用記憶體可以通過三種主要方式加速並行處理任務:
- 塊的所有執行緒多次重複使用共用記憶體資料(如用於矩陣-矩陣乘法的資料塊)。
- 使用塊的選擇執行緒(基於特定ID)將資料從全域性記憶體傳輸到共用記憶體,從而消除了對相同記憶體位置的冗餘讀取和寫入。
- 如果可能,使用者可以通過確保存取被合併來優化對全域性記憶體的資料存取。
所有這些點也有助於減少片外記憶體頻寬限制問題。SM共用記憶體中資料的生命週期與在其上處理的執行緒塊的生命週期一樣長。因此,一旦塊的所有執行緒完成,SM共用記憶體中的資料就不再有效。
儘管共用記憶體的使用將提供最佳執行時間,但在某些應用程式中,在程式設計階段記憶體存取是未知的,擁有更多可用的L1快取(最大設定為48 kB)將獲得最佳結果。此外,L1快取有助於防止暫存器溢位,而不是直接進入本地(片外)DRAM記憶體。兩級快取層次結構每個SM一個L1快取,以及跨晶片、SM共用的L2快取提供了與傳統多核微處理器相同的好處。
我們需要認識到,在GPU程式設計中,理解記憶體型別具有舉足輕重的作用。
程式設計師必須瞭解各種GPU記憶體的細微差別,特別是每種記憶體型別的可用大小、相對存取時間和可存取性限制,以使用CUDA進行正確高效的程式碼開發。GPGPU程式設計所需的方法與針對CPU的程式開發方法大不相同,其中所使用的特定資料儲存硬體(檔案I/O除外)對程式設計師來說是隱藏的。
例如,在GPU架構中,分配給CUDA核心的每個執行緒都有自己的暫存器集,因此一個執行緒無法存取另一個執行緒的暫存器,無論是否在同一個SM中。特定SM中的執行緒可以相互共同作業(通過資料共用)的唯一方式是通過共用記憶體(下圖),通常通過程式設計師僅分配SM的某些執行緒來寫入其共用記憶體的特定位置來實現,從而防止寫入衝突或浪費週期(例如許多執行緒從全域性記憶體讀取相同的資料並將其寫入相同的共用記憶體地址)。在特定SM的所有執行緒被允許從剛剛寫入的共用記憶體中讀取之前,需要對該SM的所有的執行緒進行同步,以防止寫入後讀取(RAW)資料衝突。
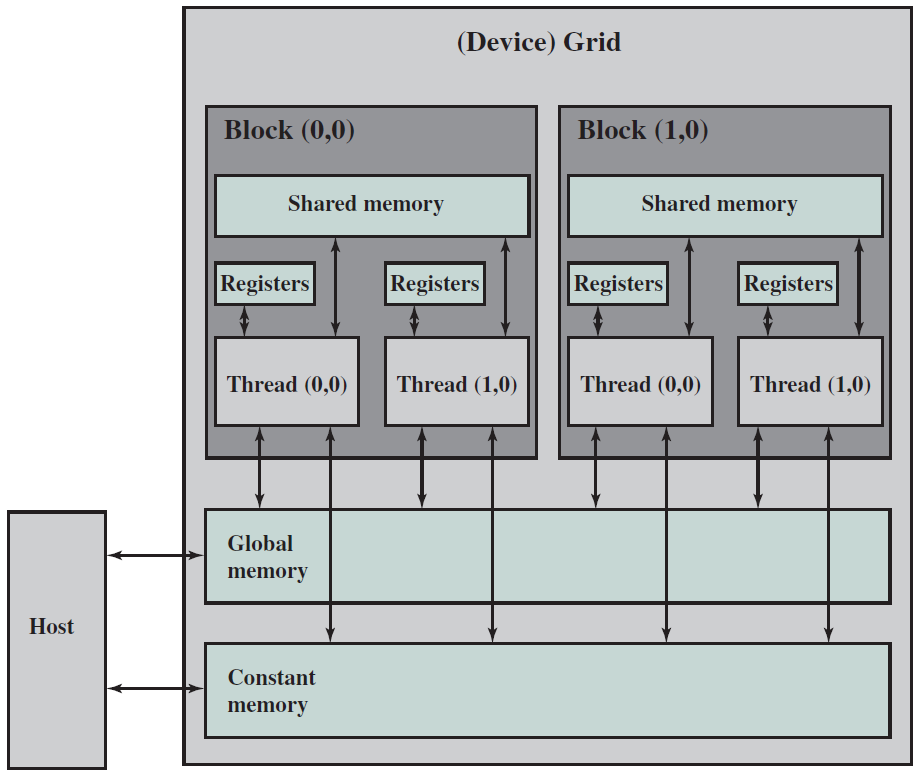
GPU基本架構的CUDA表示。
19.9.3.10 流處理器(SP)
多執行緒流處理器(SP)核心是多處理器中的主要執行緒指令處理器,其暫存器檔案(RF)為多達64個執行緒提供1024個標量32位元暫存器。它執行所有基本的浮點運算,包括add.f32、mul.f32、mad.f32(浮動乘加)、min.f32, max.f32和setp.f32(浮動比較和設定判斷)。浮點加法和乘法運算與IEEE 754標準相容,適用於單精度FP數,包括非整數(NaN)和無窮大值。SP核心還實現了所有32位元和64位元整數運算、比較、轉換和邏輯PTX指令。
浮點加法和乘法運算採用IEEE舍入調,甚至作為預設舍入模式。mad.f32浮點乘法加法運算執行帶截斷的乘法,然後執行帶舍入到最接近偶數的加法。SP將輸入非正規運算元重新整理為符號保留零,舍入後,將目標輸出指數範圍下溢的結果重新整理為符號保留零。
19.9.3.11 特殊功能單元(SFU)
某些執行緒指令可以與SP上執行的其他執行緒指令同時在SFU上執行。SFU實現了特殊函數指令,該指令計算32位元浮點逼近的倒數、倒數平方根和關鍵超越函數,它還為畫素著色器實現32位元浮點平面屬性插值,提供顏色、深度和紋理座標等屬性的精確插值。
每個流水線SFU每個週期生成一個32位元浮點特殊函數結果,每個多處理器的兩個SFU以八個SP的簡單指令速率的四分之一執行特殊功能指令。SFU還與八個SP同時執行mul.f32乘法指令,將具有適當指令混合的執行緒的峰值計算率提高到50%。
對於功能評估,Tesla架構SFU採用基於增強的最小極大近似的二次插值來逼近倒數、倒數平方、\(\log_2x\)、2x和sin/cos函數,函數計算的精度範圍從22到24個尾數位。
19.9.3.12 與其他多處理器相比
與x86 SSE等SIMD向量體系結構相比,SIMT多處理器可以獨立執行單個執行緒,而不是總是在同步組中一起執行它們。SIMT硬體在獨立執行緒之間找到資料並行性,而SIMD硬體要求軟體在每個向量指令中明確表示資料並行性。當執行緒採用相同的執行路徑時,SIMT機器同步執行32個執行緒的warp,但當它們分開時,可以獨立執行每個執行緒。這一優勢非常明顯,因為SIMT程式和指令只描述單個獨立執行緒的行為,而不是四個或更多資料通道的SIMD資料向量。然而,SIMT多處理器具有類似於SIMD的效率,將一個指令單元的面積和成本擴充套件到32個warp執行緒和8個流處理器核心。SIMT提供了SIMD的效能和多執行緒的生產力,避免了為邊緣條件和部分發散顯式編碼SIMD向量的需要。
SIMT多處理器的開銷很小,因為它是帶有硬體屏障同步的硬體多執行緒,允許圖形著色器和CUDA執行緒表達非常細粒度的並行性。圖形和CUDA程式使用執行緒來表示每執行緒程式中的細粒度資料並行性,而不是強迫程式設計師將其表示為SIMD向量指令。與向量程式碼相比,開發標量單執行緒程式碼更簡單、更高效,SIMT多處理器以類似SIMD的效率執行程式碼。
將八個流處理器核心緊密耦合到一個多處理器中,然後實現可延伸數量的多處理器,從而形成由多處理器組成的兩級多處理器。CUDA程式設計模型通過為細粒度平行計算提供單個執行緒,併為粗粒度並行操作提供執行緒塊網格,從而利用了兩級層次結構,同一執行緒程式可以提供細粒度和粗粒度操作。相反,具有SIMD向量指令的CPU必須使用兩種不同的程式設計模型來提供細粒度和粗粒度操作:不同核心上的粗粒度並行執行緒,以及用於細粒度資料並行的SIMD向量。
19.9.3.13 多執行緒多處理器結論
基於Tesla架構的範例GPU多處理器是高度多執行緒的,同時執行多達512個輕量級執行緒,以支援細粒度畫素著色器和CUDA執行緒。它使用了SIMD架構和多執行緒的一種變體,稱為SIMT(單指令多執行緒),以有效地將一條指令廣播到32個並行執行緒的warp中,同時允許每個執行緒獨立地分支和執行。每個執行緒在八個流處理器(SP)核心之一上執行其指令流,這些核心最多有64個執行緒。
PTX ISA是一種基於暫存器的載入/儲存標量ISA,用於描述單個執行緒的執行。由於PTX指令被優化並轉換為特定GPU的二進位制微指令,因此硬體指令可以快速發展,而不會中斷生成PTX指令的編譯器和軟體工具。
19.9.3.14 分塊渲染(Binned Rendering)
我們通常將光柵化定義為將螢幕座標幾何圖元直接轉換為畫素片段的過程,但是,也可以將光柵化到更大的螢幕區域,例如n×n畫素塊。GeForce 9800 GTX光柵化器就是一個例子,它輸出2×2個四邊形片段以簡化紋理重對映計算。分塊渲染(Binned Rendering,亦稱裝箱渲染)將光柵化分為兩個階段:第一階段輸出中等大小的分塊片段,每個片段對應於螢幕座標中的8×8、16×16或32×32畫素網格,隨後是第二階段,該第二階段將每個分塊片段減少為畫素片段。當然,平鋪片段包括從螢幕座標圖元匯出的資訊,以便第二階段光柵化可以產生正確的畫素片段。
分塊渲染實際上將整個渲染過程分為兩個階段,對應於光柵化的兩個階段。在第一階段,通過分塊光柵化處理場景,並將生成的分塊片段分類到各個分格中,每個分格對應於每個螢幕分塊。只有在第一階段完成之後(即在生成了整個場景的分塊片段並將其分類到箱子中之後),第二階段才開始。在第二階段,每個bin都被單獨處理,直到完成,產生一個n×n的畫素塊,並將其儲存在幀緩衝區中。
分塊渲染有幾個吸引人的特性:
- 區域性記憶體:幀緩衝區資料一致性的絕對保證,僅存取分塊中的畫素,允許在區域性記憶體中處理畫素,而不是從主記憶體快取。功耗和主記憶體週期都可節省,使得分塊渲染成為移動裝置的一個有吸引力的解決方案。
- 全場景抗鋸齒:回想一下,多取樣抗鋸齒需要在每個畫素儲存多個顏色和深度取樣。由於通過增加取樣數提高了質量,因此當渲染到整個幀緩衝區時,儲存和頻寬都變得非常昂貴,但當渲染僅限於一小塊畫素時,它們仍然很經濟。甚至更高階的渲染演演算法,如透明表面的順序無關渲染,都可以通過巧妙地使用區域性記憶體來支援。
- 延遲著色:將渲染限制在一小塊畫素上解決了延遲著色的關鍵限制:需要過多的記憶體儲存和頻寬,以及與多樣本抗鋸齒不相容。
分塊渲染的優點是引人注目的,但目前還沒有PC級GPU實現它。最根本的原因是,分塊渲染與管線Direct3D和OpenGL架構的差異太大,我們說抽象距離太大。通常,過度的抽象距離會導致產品具有混雜的效能特徵(預期快的操作是慢的,預期慢的操作是快的)或與指定操作的細微偏差。遇到的實際問題包括:
- 過度延遲:以前的分塊渲染系統,如北卡羅來納大學教堂山分校開發的PixelPlanes 5系統,增加了全幀延遲時間。
- 較差的多pass操作:Direct3D和OpenGL鼓勵先進的多pass渲染技術,在分塊實現中,每個最終幀需要多次兩遍操作。例如,通過1)渲染在反射中可見的場景,2)將該影象載入為紋理,3)使用適當扭曲的紋理影象渲染表面來渲染來自表面的反射。一些分塊渲染系統無法支援此類操作,其他的雖支援但表現不佳。
- 無邊界記憶體需求:雖然分塊渲染將畫素儲存限制為單個塊所需的儲存,但分塊本身所需的記憶體會隨著場景複雜性而增加。OpenGL和Direct3D都沒有場景複雜度限制,因此完全確認的實現需要無限的記憶體(顯然不可能),或者必須引入複雜度來處理有限塊儲存不足的情況。
這些複雜性已經足以將binned渲染排除在主流PC GPU之外。但是最近的實現趨勢,特別是使用時間共用的單個計算引擎來實現所有管線著色階段,可能會克服一些困難。
19.9.4 並行記憶體系統
在GPU本身之外,記憶體子系統是圖形系統效能的最重要決定因素,圖形工作負載需要非常高的記憶體傳輸速率。畫素寫入和混合(讀取-修改-寫入)操作、深度緩衝區讀取和寫入、紋理貼圖讀取,以及命令和物件頂點和屬性資料讀取,構成了大部分記憶體流量。
現代GPU是高度並行的,例如GeForce 8800可以在600 MHz下處理每個時鐘32個畫素,每個畫素通常需要4位元組畫素的顏色讀寫和深度讀寫。通常讀取平均兩個或三個四位元組的紋素,以生成畫素的顏色,對於典型情況,每個時鐘需要28位元組乘以32畫素=896位元組,顯然對記憶體系統的頻寬需求是巨大的。
為了滿足這些要求,GPU記憶體系統具有以下特點:
- 它們很寬,意味著GPU和它的記憶體裝置之間有大量的引腳來傳輸資料,而記憶體陣列本身包括許多DRAM晶片來提供全部的資料匯流排寬度。
- 它們速度很快,意味著使用積極的信令技術來最大化每引腳的資料速率(位元/秒)。
- GPU尋求使用每個可用週期來向或從記憶體陣列傳輸資料。為了實現這一點,GPU特別不以最小化記憶體系統的延遲為目標。高吞吐量(利用效率)和短延遲從根本上來說是相沖突的。
- 使用的壓縮技術既有程式設計師必須意識到的有失真壓縮技術,也有應用程式不可見的無失真壓縮技術。
- 快取和工作合併結構用於減少所需的片外流量,並確保儘可能充分地使用行動資料所花費的週期。
19.9.4.1 視訊記憶體結構
雖然DRAM通常被視為一個扁平的位元組陣列,但其內部結構要複雜得多。對於像GPU這樣的高效能應用程式,非常有必要深入地理解它。從下往上大致看,VRAM由以下部分組成:
-
R行乘以C列的記憶體平面(memory plane),每個單元為一位。
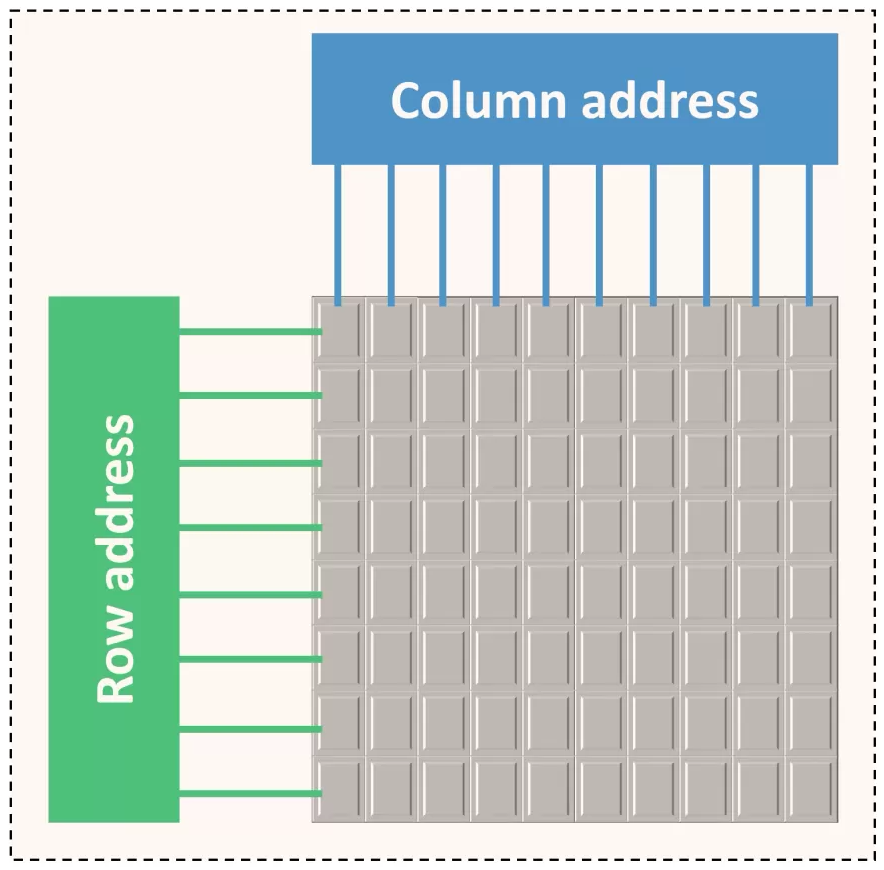
-
由32、64或128個並行使用的記憶體平面組成的記憶體體(memory bank)——這些平面通常分佈在多個晶片上,其中一個晶片包含16或32個記憶體平面。bank中的所有頁面都連線到行定址系統(列也是如此),並且這些頁面由命令訊號和每行/列的地址控制。bank中的行和列越多,地址中需要使用的位就越多。
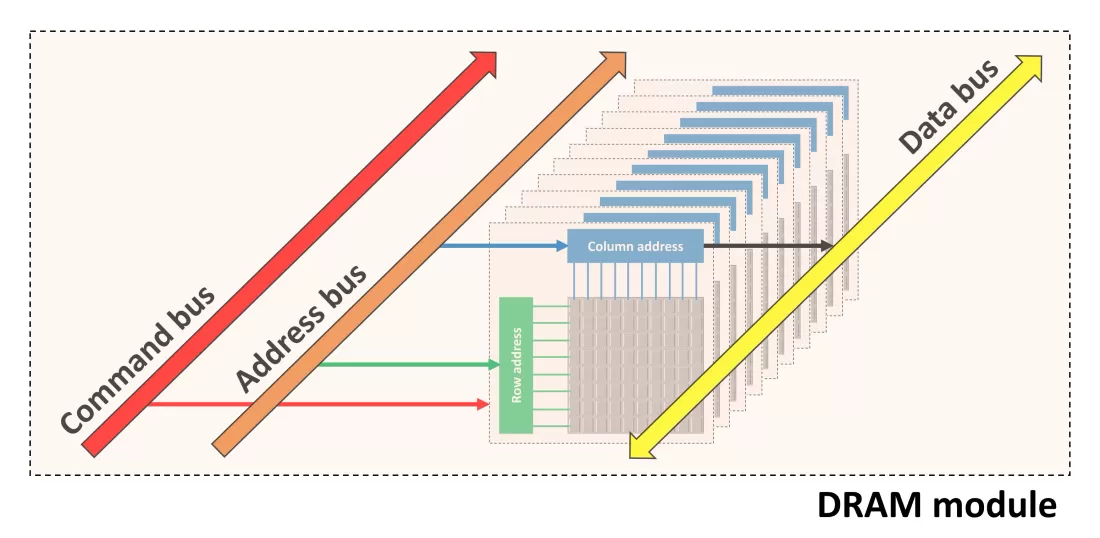
-
由若干個[2、4或8]個memory bank連線在一起並由地址位選擇的記憶體排(memory rank)——給定記憶體平面的所有memory bank位於同一晶片中。
-
由一個或兩個連線在一起並由晶片選擇線選擇的memory rank組成的記憶體子分割區(memory subpartition)——rank的行為類似於bank,但不必具有統一的幾何結構,而是在單獨的晶片中。
-
由一個或兩個稍微獨立的memory subpartition組成了記憶體分割區(memory partition)。
-
整個VRAM由幾個[1-8]個memory partition組成。
以上數量會因不同的GPU架構和家族而不同。
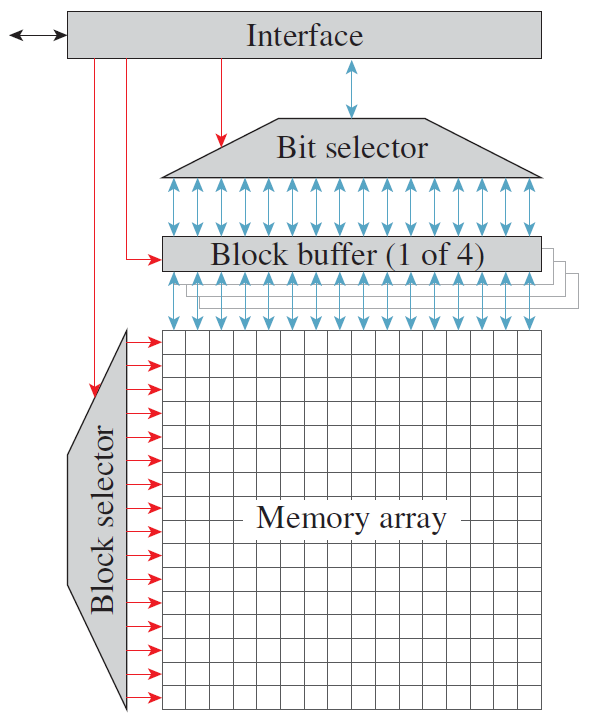
簡化GDDR3記憶體電路的結構圖。為了提高清晰度,實際儲存容量(十億位)減少到256位,實現為16個16位元塊(也稱為行)的陣列。到達塊左邊緣的紅色箭頭表示控制路徑,而到達塊頂部和底部的藍色箭頭表示資料路徑。
DRAM最基本的單元是記憶體平面,它是按所謂的列和行組織的二維位陣列:
column
row 0 1 2 3 4 5 6 7
0 X X X X X X X X
1 X X X X X X X X
2 X X X X X X X X
3 X X X X X X X X
4 X X X X X X X X
5 X X X X X X X X
6 X X X X X X X X
7 X X X X X X X X
buf X X X X X X X X
記憶體平面包含一個緩衝區,該緩衝區可容納整個行。在內部,DRAM通過緩衝區以行為單位進行讀/寫。因此有幾個後果:
- 在對某個位進行操作之前,必須將其行載入到緩衝區中,會很慢。
- 處理完一行後,需要將其寫回記憶體陣列,也很慢。
- 因此,存取新行的速度很慢,如果已經有一個活動行,存取速度甚至更慢。
- 在一段不活動時間後,搶先關閉一行通常很有用——這種操作稱為precharging(預充電?)一個bank。
- 但是,可以快速存取同一行中的不同列。
由於載入列地址本身比實際存取活動緩衝區中的位花費更多的時間,所以DRAM是以突發方式存取的,即對活動行中1-8個相鄰位的一系列存取,通常突發中的所有位都必須位於單個對齊的8位元組中。記憶體平面中的行和列的數量始終是2的冪,並通過行選擇和列選擇位的計數來衡量[即行/列計數的log2],通常有8-10列位和10-14行位。記憶體平面被組織在bank中,bank由兩個記憶體平面的冪組成。記憶體平面是並行連線的,共用地址和控制線,只有資料/資料啟用線是分開的。這有效地使記憶體bank類似於由32位元/64位元/128位元記憶體單元組成的記憶體平面,而不是單個位——適用於平面的所有規則仍然適用於bank,但操作的單元比位大。單個儲存晶片通常包含16或32個儲存平面,用於單個bank,因此多個晶片通常連線在一起以形成更寬的bank。
一個記憶體晶片包含多個[2、4或8]個bank,使用相同的傳輸線,並通過bank選擇線進行多路複用。雖然在bank之間切換比在一行中的列之間切換要慢一些,但要比在同一bank中的行之間切換快得多。因此,一個記憶體bank由(MEMORY_CELL_SIZE / MEMORY_CELL_SIZE_PER_CHIP)記憶體晶片組成。一個或兩個通過公共線(包括資料)連線的記憶體列,晶片選擇線除外,構成記憶體子分割區。在rank之間切換與在bank中的列組之間切換具有基本相同的效能後果,唯一的區別是物理實現和為每個rank使用不同數量行選擇位的可能性(儘管列計數和列計數必須匹配)。存在多個bank/rank的後果:
- 確保一起存取的資料要麼屬於同一行,要麼屬於不同的bank,這一點很重要(以避免行切換)。
- 分塊記憶體佈局的設計使分塊大致對應於一行,相鄰的分塊從不共用一個bank。
記憶體子分割區在GPU上有自己的DRAM控制器。1或2個子分割區構成一個記憶體分割區,它是一個相當獨立的實體,具有自己的記憶體存取佇列、自己的ZROP和CROP單元,以及更高版本卡上的二級快取。所有記憶體分割區與crossbar邏輯一起構成了GPU的整個VRAM邏輯,分割區中的所有子分割區必須進行相同的設定,GPU中的分割區通常設定相同,但在較新的卡上則不是必需的。子分割區/分割區存在的後果:
- 與bank一樣,可以使用不同的分割區來避免相關資料的行衝突。
- 與bank不同,如果(子)分割區沒有得到同等利用,頻寬就會受到影響。因此,負載平衡非常重要。
雖然記憶體定址高度依賴於GPU系列,但這裡概述了基本方法。記憶體地址的位按順序分配給:
- 識別記憶體單元中的位元組,因為無論如何都必須存取整個單元。
- 多個列選擇位,以允許突發(burst)。
- 分割區/子分割區選擇-以低位進行,以確保良好的負載平衡,但不能太低,以便在單個分割區中保留相對較大的tile,以利於ROP。
- 剩餘列選擇位。
- 所有/大部分bank選擇位,有時是排名選擇位,以便相鄰地址不會導致行衝突。
- 行位(row bit)。
- 剩餘的bank位或rank位,有效地允許將VRAM拆分為兩個區域,在其中一個區域放置顏色緩衝區,在另一個區域放置zeta緩衝區,這樣它們之間就不會有行衝突。
GPU必須考慮DRAM的獨特特性。DRAM晶片在內部被佈置為多個(通常為四到八個)儲存體(bank),其中每個bank包括2次冪數的行(通常為16384),並且每行包含2次冪位數的位(通常為8192)。DRAM對其控制處理器施加了各種時序要求,例如啟用一行需要幾十個週期,但一旦啟用,該行內的位可以每四個時鐘隨機存取一個新的列地址。雙倍資料速率(DDR)同步DRAM在介面時鐘的上升沿(rising edge)和下降沿(falling edge)傳輸資料(下面兩圖),因此1GHz時鐘DDR DRAM以每資料引腳每秒2千兆位元的速度傳輸資料。圖形DDR DRAM通常有32個雙向資料引腳,因此每個時鐘可以從DRAM讀取或寫入8個位元組。
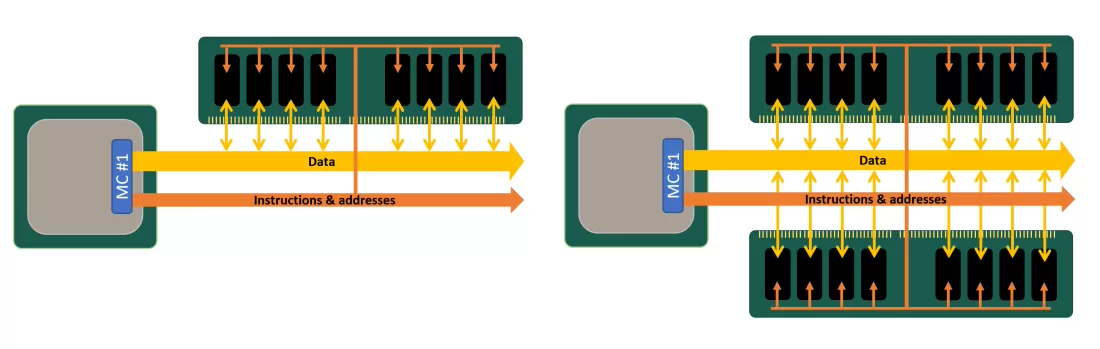
單ank和雙rank對比。
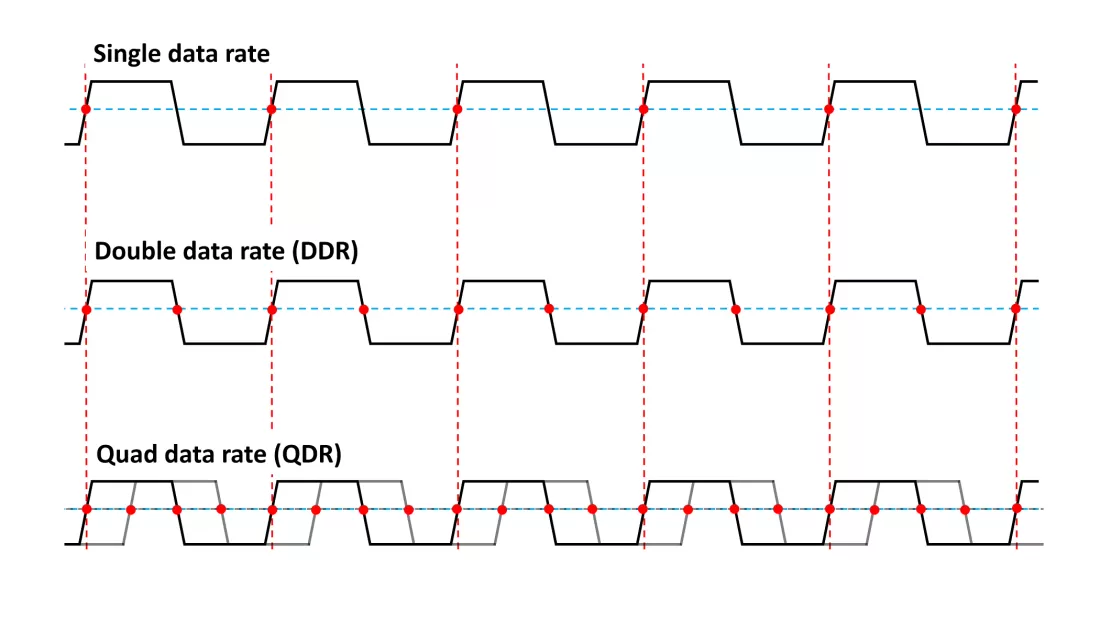
單速率、雙速率、四速率對比圖。
GPU內部有大量的記憶體流量生成器。邏輯圖形管線的不同階段都有自己的請求流:命令和頂點屬性提取、著色器紋理提取和載入/儲存,以及畫素深度和顏色讀寫。在每個邏輯階段,通常有多個獨立的單元來提供並行吞吐量,都是獨立的記憶體請求者。當在記憶體系統中檢視時,有大量不相關的請求正在執行,是與DRAM優選的參考模式(pattern)的自然不匹配。一種解決方案是GPU的記憶體控制器為不同的DRAM組保持單獨的流量堆,並等待特定DRAM行有足夠的流量等待,然後啟用該行並同時傳輸所有流量。請注意,累積未決請求雖然有利於DRAM行位置,從而有效地使用資料匯流排,但會導致較長的平均等待時間,正如請求者等待其他請求所看到的那樣。設計必須注意,任何特定的請求都不會等待太長時間,否則一些處理單元可能會等待資料,最終導致相鄰處理器閒置。
GPU記憶體子系統被佈置為多個記憶體分割區,每個記憶體分割區包括完全獨立的記憶體控制器和一個或兩個DRAM裝置,這些DRAM裝置由該分割區完全和獨佔擁有。為了實現最佳的負載平衡,並因此接近n個分割區的理論效能,地址在所有記憶體分割區之間均勻地精細交錯,分割區交錯步長通常是幾百位元組的塊,記憶體分割區的數量旨在平衡處理器和其他記憶體請求者的數量。
19.9.4.2 快取
GPU工作負載通常具有數百兆位元組量級的非常大的工作集,以生成單個圖形幀。與CPU不同,在足夠大的晶片上構建快取以容納接近圖形應用程式全部工作集的內容是不現實的。儘管CPU可以假設非常高的快取命中率(99.9%或更高),但GPU的命中率接近90%,因此必須應對執行中的許多未命中。雖然CPU可以合理地設計為在等待罕見的快取未命中時停滯,但GPU需要處理混合的未命中和命中。我們稱之為流快取架構(streaming cache architecture)。
GPU快取必須為其使用者端提供非常高的頻寬。考慮紋理快取的情況,典型的紋理單元可以為每個時鐘週期四個畫素中的每一個執行兩個雙線性插值,並且GPU可以具有許多這樣的紋理單元,所有這些紋理單元都獨立地操作。每個雙線性插值需要四個單獨的紋素,每個紋素可能是64位元值,四個16位元元件是典型的,因此總頻寬為2×4×4×64=2048位元/時鐘。每個單獨的64位元紋素都是獨立定址的,因此快取需要每個時鐘處理32個唯一的地址。這自然有利於SRAM陣列的多組和/或多埠佈置。
19.9.4.3 MMU
現代GPU能夠將虛擬地址轉換為實體地址。在GeForce 8800上,所有處理單元都在40位虛擬地址空間中生成記憶體地址。對於計算,載入和儲存執行緒指令使用32位元位元組地址,通過新增40位偏移量將其擴充套件為40位虛擬地址。記憶體管理單元執行虛擬到實體地址轉換;硬體從本地記憶體中讀取頁表,以代表分佈在處理器和渲染引擎之間的翻譯後備緩衝區的層次結構來響應未命中。除了物理頁面位之外,GPU頁面表條目還指定了每個頁面的壓縮演演算法,頁面大小從4到128 KB不等。
CUDA公開了不同的記憶體空間,以允許程式設計師以最佳效能的方式儲存資料值。下圖是CPU和GPU記憶體請求路線:
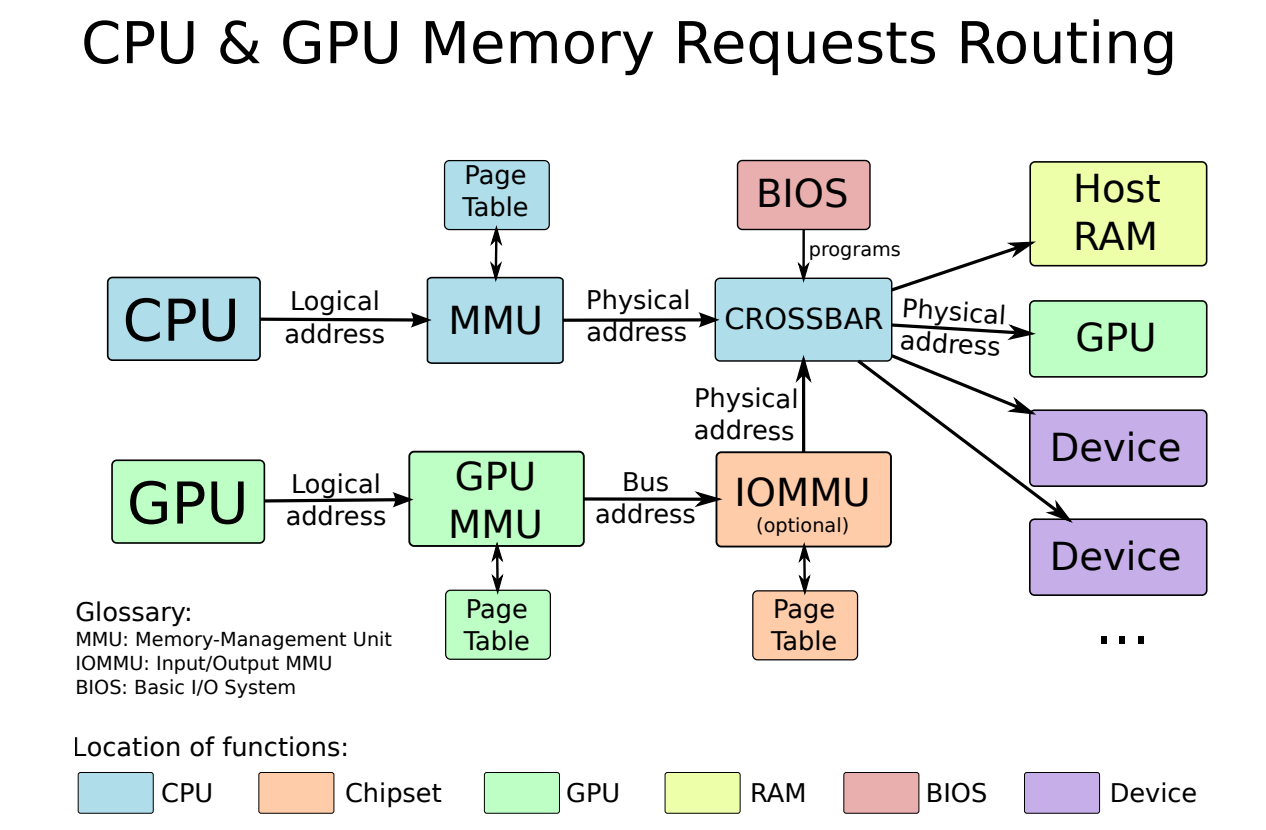
GTT/GART作為CPU-GPU共用緩衝區用於通訊:
後面小節的討論以NVIDIA Tesla架構GPU為基準。
19.9.4.4 全域性記憶體
全域性記憶體儲存在外部DRAM中,不是任何一個物理流多處理器(SM)的區域性,因為它用於不同網格中不同CTA(執行緒塊)之間的通訊。事實上,參照全域性記憶體中某個位置的許多CTA可能不會同時在GPU中執行,通過設計,在CUDA中,程式設計師不知道CTA執行的相對順序。由於地址空間均勻分佈在所有記憶體分割區之間,因此必須有從任何流式多處理器到任何DRAM分割區的讀/寫路徑。
不同執行緒(和不同處理器)對全域性記憶體的存取不能保證具有順序一致性。執行緒程式看到一個寬鬆的(relaxed)記憶體排序模型,線上程中,記憶體對同一地址的讀寫順序被保留,但對不同地址的存取順序可能不會被保留。不同執行緒請求的記憶體讀取和寫入是無序的,在CTA中,屏障同步指令bar.sync可用於在CTA的執行緒之間獲得嚴格的記憶體排序。membar執行緒指令提供了一個記憶體屏障/柵欄操作,該操作提交先前的記憶體存取,並在繼續之前使其他執行緒可見。執行緒還可以使用原子記憶體操作來協調它們共用的記憶體上的工作。
19.9.4.5 共用記憶體
逐CTA共用記憶體僅對屬於該CTA的執行緒可見,並且共用記憶體僅從建立CTA到終止CTA期間佔用儲存空間,因此共用記憶體可以駐留在晶片上。這種方法有以下好處:
- 共用記憶體流量不需要與全域性記憶體參照所需的有限片外頻寬競爭。
- 在晶片上構建非常高頻寬的記憶體結構以支援每個流式多處理器的讀/寫需求是可行的。事實上,共用記憶體與流式多處理器緊密耦合。
每個流式多處理器包含八個物理執行緒處理器。在一個共用記憶體時鐘週期內,每個執行緒處理器可以處理兩個執行緒的指令,因此每個時鐘必須處理16個執行緒的共用記憶體請求。因為每個執行緒都可以生成自己的地址,並且地址通常是唯一的,所以共用記憶體是使用16個可獨立定址的SRAM bank構建的。對於常見的存取模式,16個bank足以保持吞吐量,但也可能存在極端情況,例如所有16個執行緒可能恰好存取一個SRAM組上的不同地址。必須能夠將請求從任何執行緒通道路由到任何SRAM組,因此需要16*16的互連網路。
19.9.4.6 區域性記憶體
逐執行緒區域性記憶體是僅對單個執行緒可見的專用記憶體。區域性記憶體在架構上大於執行緒的暫存器檔案,程式可以將地址計算到區域性記憶體中。為了支援區域性記憶體的大量分配(回想一下,總分配是每執行緒分配乘以活動執行緒數),區域性記憶體分配在外部DRAM中。雖然全域性和逐執行緒區域性記憶體駐留在晶片外,但它們非常適合快取在晶片上。
19.9.4.7 常數記憶體
常數記憶體對SM上執行的程式是唯讀的(可以通過命令寫入GPU),儲存在外部DRAM中,並快取在SM中。因為通常SIMT warp中的大多數或所有執行緒都是從常數記憶體中的同一地址讀取的,所以每個時鐘的單個地址查詢就足夠了。常數快取被設計為向每個warp中的執行緒廣播標量值。
19.9.4.8 紋理記憶體
紋理記憶體儲存大型唯讀資料陣列,用於計算的紋理與用於3D圖形的紋理具有相同的屬性和功能。雖然紋理通常是二維影象(畫素值的2D陣列),但也可以使用1D(線性)和3D(體積)紋理。
計算程式使用tex指令參照紋理,運算元包括用於命名紋理的識別符號,以及基於紋理維度的一個、兩個或三個座標。浮點座標包括指定樣本位置的分數部分,通常位於紋素位置之間。在將結果返回到程式之前,非整數座標呼叫四個最接近值(對於2D紋理)的雙線性加權插值。
紋理提取快取在流快取層次結構中,該層次結構旨在優化數千個並行執行緒的紋理提取吞吐量。一些程式使用紋理提取作為快取全域性記憶體的方法。
19.9.4.9 表面(Surface)
表面是一維、二維或三維畫素值陣列及其相關格式的通用術語,定義了多種格式,例如4個8位元RGBA整數分量或4個16位元浮點分量。程式核心不需要知道表面型別,tex指令根據表面格式將其結果值重新轉換為浮點。
19.9.4.10 載入/儲存存取
帶有整數位節定址的載入/儲存指令允許用C和C++等傳統語言編寫和編譯程式,CUDA程式使用載入/儲存指令來存取記憶體。
為了提高記憶體頻寬並減少開銷,當地址位於同一塊中並滿足對齊標準時,區域性和全域性載入/儲存指令將來自同一warp的單個並行執行緒請求合併為單個記憶體塊請求。將單個小記憶體請求合併為巨量資料塊請求可以顯著提高單獨請求的效能,大的執行緒數,加上支援許多未完成的負載請求,有助於覆蓋外部DRAM中實現的區域性和全域性記憶體的負載使用延遲。
19.9.4.11 ROP
NVIDIA Tesla架構GPU包括可延伸流處理器陣列(SPA)和可延伸記憶體系統,可延伸流處理陣列執行GPU的所有可程式化計算,可延伸記憶體系統包括外部DRAM控制和固定功能光柵操作處理器(Raster Operation Processor,ROP),可直接在記憶體上執行顏色和深度幀緩衝操作。每個ROP單元與特定的記憶體分割區配對,ROP分割區通過互連網路被SM填充資料。每個ROP負責深度和模板測試和更新,以及顏色混合。ROP和記憶體控制器共同作業實現無失真顏色和深度壓縮(高達8:1),以減少外部頻寬需求,ROP單元還對記憶體執行原子操作。
19.9.5 浮點運算
如今的GPU使用IEEE 754相容的單精度32位元浮點運算在可程式化處理器核心中執行大多數算術運算,早期GPU的定點演演算法是由16位元、24位元和32位元浮點,然後是IEEE 754相容的32位元浮點繼承的。GPU中的一些固定功能邏輯,如紋理過濾硬體,繼續使用專有的數位格式,部分GPU還提供IEEE 754相容的雙精度64位元浮點指令。
19.9.5.1 支援的格式
IEEE 754浮點算術標準規定了基本格式和儲存格式。GPU使用兩種基本的計算格式,32位元和64位元二進位制浮點,通常稱為單精度和雙精度,該標準還指定了16位元二進位制儲存浮點格式,半精度。GPU和Cg著色語言採用窄16位元半資料格式,以實現高效的資料儲存和移動,同時保持高動態範圍,GPU在紋理過濾單元和光柵操作單元內以半精度執行許多紋理過濾和畫素混合計算。Industrial Light and Magic[2003]開發的OpenEXR高動態範圍影象檔案格式在計算機成像和運動影象應用中使用相同的半格式顏色分量值。
半精度(half precision):一種16位元二進位制浮點格式,具有1個符號位、5位指數、10位小數和一個隱含整數位。
19.9.5.2 基本算術
GPU可程式化核心中常見的單精度浮點運算包括加法、乘法、乘法、最小值、最大值、比較、設定判斷以及整數和浮點數之間的轉換,浮點指令通常為求反和絕對值提供源運算元修飾符。
乘加(multiply-add,MAD):一種執行復合運算的單浮點指令——乘法後相加。
今天大多數GPU的浮點加法和乘法運算都與IEEE 754標準相容,適用於單精度FP數,包括非數位(NaN)和無窮大值。FP加法和乘法運算使用IEEE舍入到最接近,甚至作為預設舍入模式。為了提高浮點指令吞吐量,GPU通常使用複合乘加指令(mad),mad運算執行帶截斷的FP乘法,然後執行帶舍入到最接近偶數的FP加法。它在一個發出週期內提供兩個浮點運算,而不需要指令排程器排程兩個單獨的指令,但計算沒有融合,並在加法之前截斷乘積,使得它不同於後面討論的融合乘加(fused multiply-add)指令。GPU通常會將非規範化的源運算元重新整理為符號保留零,並在舍入後將目標輸出指數範圍下溢的結果重新整理為符號保持零。
19.9.5.3 特殊算術
GPU提供硬體來加速特殊函數計算、屬性插值和紋理過濾,特殊函數指令包括餘弦、正弦、二元指數、二元對數、倒數和平方根倒數。屬性插值指令提供了從平面方程求值匯出的畫素屬性的有效生成,前面介紹的特殊函數單元(SFU)計算特殊函數並插值平面屬性。
特殊函數單元(special function unit,SFU):計算特殊函數和插值平面屬性的硬體單元。
有幾種方法可用於執行硬體中的特殊功能。已經表明,基於增強的Minimax逼近的二次插值是一種非常有效的硬體函數逼近方法,包括倒數、倒數平方根、\(log_2x\)、\(2^x\)、sin和cos。
我們可以總結SFU二次插值的方法。對於具有n位有效位的二進位制輸入運算元X,有效位分為兩部分:\(X_u\)是包含m位的上部,\(X_l\)是包含n-m位的下部。較高的m位\(X_u\)用於查詢一組三個查詢表,以返回三個有限域係數C0、C1和C2。要近似的每個函數都需要一組唯一的表,這些係數用於近似\(X_u ≤ X < X_u+2^{−m}\)範圍內的給定函數f(X),通過計算表示式:
每個函數計算的精度範圍為22到24個有效位,範例功能統計如下圖所示。
IEEE 754標準規定了除法和平方根的精確舍入要求,但對於許多GPU應用程式,不需要嚴格遵守,相反,更高的計算吞吐量比最後一位精度更重要。對於SFU特殊函數,CUDA數學庫提供了全精度函數和具有SFU指令精度的快速函數。
GPU中的另一種特殊算術運算是屬性插值,通常為構成要渲染的場景的圖元的頂點指定關鍵點屬性,例如顏色、深度和紋理座標。必須根據需要在(x,y)螢幕空間內插入這些屬性,以確定每個畫素位置的屬性值,(x,y)平面中給定屬性U的值可以使用以下形式的平面方程表示:
其中A、B和C是與每個屬性U關聯的插值引數,插值引數A、B、C都表示為單精度浮點數。
考慮到畫素著色器處理器中同時需要函數求值器和屬性插值器,可以設計一個執行這兩個函數以提高效率的SFU。兩個函數都使用乘積和運算來插值結果,兩個函數中要求和的項數非常相似。
紋理對映和過濾是GPU中另一組關鍵的專用浮點算術運算。用於紋理對映的操作包括:
1.接收當前螢幕畫素(x,y)的紋理地址(s,t),其中s和t是單精度浮點數。
2.計算細節級別以識別正確的紋理MIPmap級別。
3.計算三線性插值分數。
4.縮放所選MIP對映級別的紋理地址(s,t)。
5.存取記憶體並檢索期望的紋素(紋理元素)。
6.對紋素執行過濾操作。
MIP-map:包含不同解析度的預計算影象,用於提高渲染速度和減少偽影。
紋理對映對於全速操作需要大量的浮點計算,其中大部分是以16位元半精度完成的,例如除了傳統的IEEE單精度浮點指令外,GeForce 8800 Ultra還為紋理對映指令提供了約500GFLOPS的專有格式浮點計算。
浮點加法和乘法運算硬體是完全管線化的,延遲被優化以平衡延遲和麵積。雖然採用管線,但特殊函數的吞吐量小於浮點加法和乘法運算,特殊函數的四分之一速度吞吐量是現代GPU的典型效能,一個SFU由四個SP核共用。相比之下,CPU對於類似的功能(如除法和平方根)通常具有明顯更低的吞吐量,儘管結果更準確。屬性插值硬體通常完全管線化,以啟用全速畫素著色器。
19.9.5.4 雙精度
Tesla T10P等GPU也支援硬體中的IEEE 754 64位元雙精度操作。雙精度標準浮點算術運算包括加法、乘法以及不同浮點和整數格式之間的轉換。2008年IEEE 754浮點標準包括融合乘加(fused-multiply-add,FMA)操作的規範,FMA操作執行浮點乘法,然後執行加法,並進行一次舍入,融合的乘法和加法運算在中間計算中保持了完全的精度。這種行為可以實現更精確的浮點計算,包括積的累加,包括點積、矩陣乘法和多項式求值。FMA指令還實現了精確舍入除法和平方根的高效軟體實現,無需硬體除法或平方根單元。
雙精度硬體FMA單元實現64位元加法、乘法、轉換和FMA運算本身,雙精度FMA單元的體系結構可在輸入和輸出上實現全速非標準化數支援。下圖顯示了FMA單元的結構。
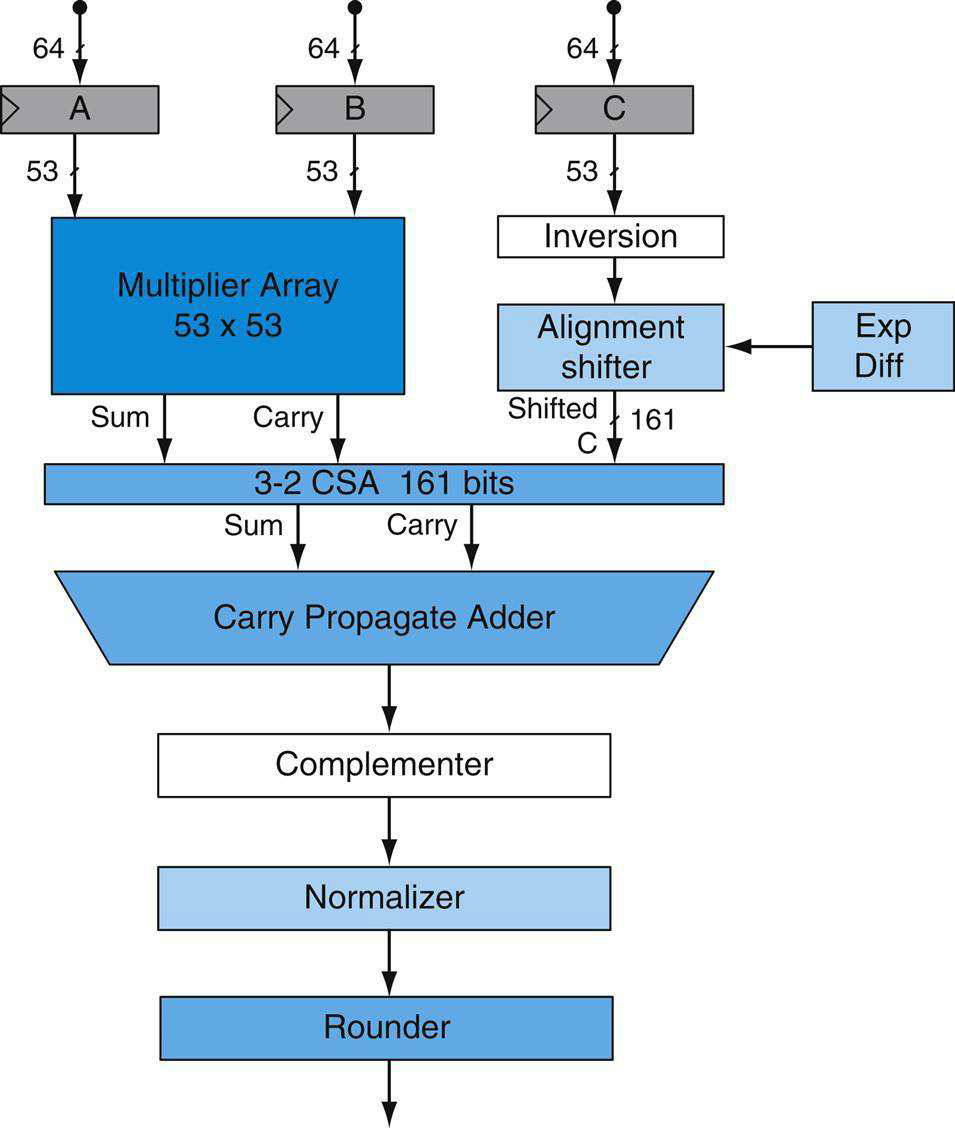
雙精度融合乘加(FMA)單元,硬體實現雙精度浮點A×B+C。
如上圖所示,A和B的有效位相乘形成106位乘積,結果保留進位形式,並行地,53位加數C有條件地反轉並與106位乘積對齊,106位乘積的和和進位結果通過161位寬進位儲存加法器(CSA)與對齊的加數相加。然後,進位儲存輸出在進位傳播加法器中相加,以產生一個非冗餘二進位制二補數形式的非舍入結果。結果被有條件地重新計算,以便以符號大小形式返回結果,二補數結果被歸一化,然後被舍入以符合目標格式。
19.9.6 可程式化GPU
程式設計多處理器GPU與程式設計其他多處理器(如多核CPU)有本質上的不同。GPU比CPU提供了兩到三個數量級的執行緒和資料並行性,可延伸到數百個處理器核心和數萬個並行執行緒。GPU繼續提高其並行性,大約每12到18個月將其翻倍,這是摩爾定律提高積體電路密度和提高架構效率的結果。為了跨越不同細分市場的廣泛價格和效能範圍,不同的GPU產品實現了不同數量的處理器和執行緒。然而,使用者希望遊戲、圖形、影象和計算應用程式能夠在任何GPU上執行,無論它執行多少並行執行緒或擁有多少並行處理器核心,而且他們希望更昂貴的GPU(具有更多執行緒和核心)能夠更快地執行應用程式。因此,GPU程式設計模型和應用程式被設計為透明地擴充套件到廣泛的並行度。
GPU中大量並行執行緒和核心背後的驅動力是實時圖形效能——需要以每秒至少60幀的互動式幀速率以高解析度渲染複雜的3D場景。相應地,圖形著色語言(如Cg、HLSL、GLSL)的可延伸程式設計模型被設計為通過許多獨立的並行執行緒利用大程度的並行性,並可延伸到任意數量的處理器核。CUDA可延伸並行程式設計模型類似地使通用平行計算應用程式能夠利用大量並行執行緒,並可延伸到任意數量的並行處理器核心,對應用程式透明。
在這些可延伸程式設計模型中,程式設計師為單個執行緒編寫程式碼,GPU並行執行無數執行緒範例,所以程式可以在廣泛的硬體並行性上透明地擴充套件。這種簡單的範例源自圖形API和描述如何對一個頂點或一個畫素進行著色的著色語言,自20世紀90年代末以來,隨著GPU快速提高其並行性和效能,一直是一個有效的範例。
本節簡要介紹使用圖形API和程式語言為實時圖形應用程式程式設計GPU,然後介紹使用C語言和CUDA程式設計模型為視覺化計算和通用平行計算應用程式程式設計GPU。
API在GPU和處理器的快速、成功開發中發揮了重要作用。有兩個主要的標準圖形API:OpenGL和Direct3D。OpenGL是一種開放標準,最初由Silicon Graphics Incorporated提出並定義,OpenGL標準的持續開發和擴充套件由行業協會Khronos管理。Direct3D是一種事實上的標準,由微軟和合作夥伴定義並向前發展。OpenGL和Direct3D的結構相似,並隨著GPU硬體的進步不斷快速發展,它們定義了對映到GPU硬體和處理器上的邏輯圖形處理管線,以及可程式化管道階段的程式設計模型和語言。
下圖說明了Direct3D 10邏輯圖形管線,OpenGL具有類似的圖形管線結構。API和邏輯管線為可程式化著色器階段提供了流資料流基礎設施和管道,如藍色所示。3D應用程式向GPU傳送分組為幾何圖元點、線、三角形和多邊形的頂點序列,輸入裝配程式收集頂點和基元。頂點著色器程式執行逐頂點處理,包括將頂點3D位置轉換為螢幕位置並照亮頂點以確定其顏色,幾何著色器程式執行逐圖元處理,並可以新增或刪除圖元,設定和光柵化單元生成由幾何圖元覆蓋的畫素片段(片段是對畫素的潛在貢獻)。
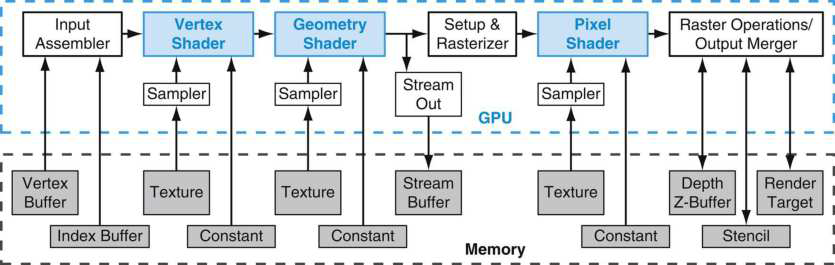
畫素著色器程式執行每片段處理,包括插值每片段引數、紋理和著色。畫素著色器使用插值浮點座標,廣泛使用取樣和過濾查詢到大型1D、2D或3D陣列(稱為紋理)中。著色器使用貼圖、函數、貼花、影象和資料的紋理存取。光柵操作處理(或輸出合併)階段執行Z緩衝深度測試和模板測試,這可以丟棄隱藏的畫素片段或用片段的深度替換畫素的深度,並執行顏色混合操作,該操作將片段顏色與畫素顏色相結合,並用混合的顏色寫入畫素。
圖形API和圖形管道為處理每個頂點、圖元和畫素片段的著色器程式提供輸入、輸出、記憶體物件和基礎結構。
19.9.6.1 程式設計平行計算應用程式
圖形處理模型實際上是多執行緒、多程式設計和SIMD執行的組合,NVIDIA稱其型號為SIMT(單指令、多執行緒)。讓我們看看NVIDIA的SIMT執行模型。
程式設計師首先用CUDA程式語言編寫程式碼。CUDA代表計算統一裝置架構,是C/C++的自定義擴充套件,由NVIDIA的nvcc編譯器編譯,以在CPU的ISA(用於CPU)和PTX指令集(用於GPU)中生成程式碼。CUDA程式包含一組在GPU上執行的核心和一組在主機CPU上執行的函數。主機CPU上的功能將資料傳輸到GPU和從GPU傳輸資料,初始化變數,並協調GPU上核心的執行,核心被定義為在GPU上並行執行的函數。圖形硬體為每個CUDA核心建立多個副本,每個副本在單獨的執行緒上執行。
GPU將每個這樣的執行緒對映到SP核心。可以為單個CUDA核心無縫建立和執行數百個執行緒。有些人可能會認為,如果多個副本的程式碼相同,那麼執行多個副本有什麼意義。答案是程式碼並不完全相同,程式碼隱式地將執行緒的id作為輸入,例如,如果我們為每個CUDA核心生成100個執行緒,那麼每個執行緒在集合[0...99]中都有一個唯一的id,CUDA核心中的程式碼根據執行緒的id執行適當的處理。許多單獨應用程式的執行緒可能同時執行,每個SM的MT釋出邏輯排程執行緒並協調其執行。這種架構中的SM可以處理多達768個執行緒。
如果我們並行執行多個應用程式,那麼GPU作為一個整體將需要排程數千個執行緒,排程開銷過高。因此,為了簡化排程任務,GeForce 8800 GPU將一組32個執行緒組合成一個warp。每個SM可以管理24個warp,warp是執行緒的原子單位,warp中的所有執行緒都被排程,或者warp中沒有執行緒被排程。此外,warp中的所有執行緒都屬於同一核心,並且從完全相同的地址開始。然而,在它們啟動之後,可以有不同的程式計數器。
每個SM將warp的執行緒對映到SP核心,它按指令執行warp指令,類似於經典的SIMD執行,我們在多個資料流上執行一條指令,然後轉到下一條指令。SM為warp中的每個執行緒執行一條指令,在所有執行緒完成該指令後,它執行下一條指令。如果核心有一個依賴於資料或執行緒的分支,那麼SM只為那些在正確的分支路徑中有指令的執行緒執行指令。GeForce GPU使用預測指令,對於錯誤路徑上的指令,判斷條件為false,因此這些指令被nop指令動態替換。一旦分支路徑(已執行和未執行)重新合併,warp中的所有執行緒將再次啟用。與SIMD模型的主要區別在於,在SIMD處理器中,同一執行緒處理同一指令中的多個資料流。然而,在這種情況下,同一條指令在多個執行緒中執行,每條指令對不同的資料流進行操作。在warp中執行指令後,MT執行單元可能會排程相同的warp、來自相同應用程式的另一個warp或來自另一個應用程式的warp。GPU本質上實現了warp級別的細粒度多執行緒,下圖顯示了一個範例。
Warp的排程。
對於32執行緒的執行,SM通常使用4個週期。在第一個週期中,它向8個SP核心中的每一個發出8個執行緒。在第二個週期中,它向SFU再發出8個執行緒。由於兩個SFU各有4個功能單元,因此它們可以並行處理8個指令,而不會產生任何結構衝突。在第三個週期中,又向SP核心傳送了8個執行緒,最後在第四個週期中向兩個SFU核心傳送8個執行緒。這種在使用SFU和SP核心之間切換的策略確保了兩個單元都保持忙碌。由於warp是一個原子單元,它不能在SM之間拆分,並且warp的每條指令必須在所有活動執行緒上執行完畢,然後才能執行warp中的下一條指令。我們可以在概念上將warp的概念等同於32通道寬的SIMD機器,同一應用程式中的多個warp可以獨立執行。為了在warp之間進行同步,我們需要使用全域性記憶體,或者現代GPU中可用的複雜同步原語。
CUDA、Brook和CAL是GPU的程式設計介面,專注於資料平行計算而不是圖形。CAL(計算抽象層)是AMD GPU的低階組合語言介面,Brook是Buck等人的一種適用於GPU的流式語言,由NVIDIA開發的CUDA是C和C++語言的擴充套件,用於多核GPU和多核CPU的可延伸並行程式設計。
憑藉新模型,GPU在資料並行和吞吐量計算方面表現出色,可執行高效能運算應用程式和圖形應用程式。
為了有效地將大型計算問題對映到高度並行的處理架構,程式設計師或編譯器將問題分解為許多可以並行解決的小問題。例如,程式設計師將一個大的結果資料陣列劃分為塊,並將每個塊進一步劃分為元素,從而可以並行地獨立計算結果塊,並且並行地計算每個塊內的元素。下圖顯示了將結果資料陣列分解為3×2塊網格,其中每個塊進一步分解為5×3元素陣列。兩級並行分解自然對映到GPU架構:並行多處理器計算結果塊,並行執行緒計算結果元素。
將結果資料分解為要平行計算的元素塊網格。
程式設計師編寫一個程式來計算一系列結果資料網格,將每個結果網格劃分為粗粒度的結果塊,這些塊可以獨立平行計算。程式使用細粒度並行執行緒陣列計算每個結果塊,線上程之間劃分工作,以便每個執行緒計算一個或多個結果元素。
19.9.6.2 CUDA程式設計
CUDA可延伸並行程式設計模型擴充套件了C和C++語言,以在高度並行的多處理器(特別是GPU)上為通用應用程式開發大量並行性,早期經驗表明,許多複雜的程式可以用一些容易理解的抽象來表達。自2007年NVIDIA釋出CUDA以來,開發人員迅速開發了可延伸的並行程式,用於廣泛的應用,包括地震資料處理、計算化學、線性代數、稀疏矩陣求解器、排序、搜尋、物理模型和視覺化計算,這些應用程式可以透明地擴充套件到數百個處理器核心和數千個並行執行緒。具有Tesla統一圖形和計算架構的NVIDIA GPU執行CUDA C程式,並廣泛用於筆記型電腦、PC、工作站和伺服器。CUDA模型也適用於其他共用記憶體並行處理架構,包括多核CPU。
CUDA提供了三個關鍵抽象——執行緒組的層次結構、共用記憶體和屏障同步,為層次結構中的一個執行緒提供了與傳統C程式碼的清晰並行結構。多級執行緒、記憶體和同步提供細粒度資料並行和執行緒並行,巢狀在粗粒度資料並行和任務並行中,抽象指導程式設計師將問題劃分為可以獨立並行解決的粗略子問題,然後劃分為可以並行解決的更精細的部分。程式設計模型可以透明地擴充套件到大量處理器核心:編譯後的CUDA程式可以在任意數量的處理器上執行,只有執行時系統才需要知道物理處理器的數量。
CUDA是C和C++程式語言的最小擴充套件,程式設計師編寫一個呼叫並行核心的序列程式,可以是簡單的函數,也可以是完整的程式。核心跨一組並行執行緒並行執行,程式設計師將這些執行緒組織成執行緒塊的層次結構和執行緒塊的網格。執行緒塊是一組並行執行緒,它們可以通過屏障同步和共用存取塊專用的記憶體空間來相互共同作業。網格是一組執行緒塊,每個執行緒塊可以獨立執行,因此可以並行執行。
核心(kernel):一個執行緒的程式或函數,設計為可由多個執行緒執行。
執行緒塊(thread block):一組並行執行緒,它們執行相同的執行緒程式,並可以共同作業計算結果。
網格(grid):執行同一核心程式的一組執行緒塊。
執行緒、塊和網格之間的關係。
CUDA術語與GPU硬體元件等效對映如下表:
| CUDA術語 | 定義 | 等效的GPU硬體元件 |
|---|---|---|
| 核心(Kernel) | 在GPU上執行的函數形式的並行程式碼 | 不適用 |
| 執行緒(Thread) | GPU上核心的範例 | GPU/CUDA處理器核心 |
| 塊(Block) | 分配給特定SM的一組執行緒 | CUDA多處理器(SM) |
| 網格(Grid) | GPU | GPU |
CUDA程式自然對映到GPU的結構。我們首先在CUDA中編寫一個核心,該核心根據執行時分配給它的執行緒id執行一組操作,核心的動態範例是執行緒(類似於CPU上下文中的執行緒)。我們將一組執行緒分組為一個塊(block)或CTA(共同作業執行緒陣列),塊或CTA對應於warp,一個塊中可以有1-512個執行緒,每個SM在任何時間點最多可以緩衝8個塊的狀態。塊中的每個執行緒都有一個唯一的執行緒id,類似地,塊被分組在一個網格中,網格包含應用程式的所有執行緒,不同的塊(或warp)可以彼此獨立地執行,除非我們明確實施某種形式的同步。在我們的簡單範例中,將塊視為執行緒的線性陣列,將網格視為塊的線性陣列。此外,可以將塊定義為執行緒的2D或3D陣列,或者將網格定義為塊的2D或三維陣列。
現在來看一個小型CUDA程式,它新增了兩個n元素陣列,讓我們部分考慮CUDA排程。在下面的程式碼片段中,初始化了三個陣列a、b和c,希望新增a和b元素,並將結果儲存在c中。
#define N 1024
void main()
{
// 宣告陣列
int a[N], b[N], c[N];
// 在GPU中宣告相應的陣列
int size = N * sizeof(int);
int *gpu_a, *gpu_b, *gpu_c;
// 為GPU中的陣列分配空間
cudaMalloc((void**) &gpu_a, size);
cudaMalloc((void**) &gpu_b, size);
cudaMalloc((void**) &gpu_c, size);
// 初始化陣列
(...)
// 拷貝陣列到GPU
cudaMemcpy (gpu_a, a, size, cudaMemcpyHostToDevice);
cudaMemcpy (gpu_b, b, size, cudaMemcpyHostToDevice);
}
在這個程式碼片段中,宣告了三個陣列(a、b和c),其中包含N個元素,隨後定義了它們在gpu中的相應儲存位置。然後,使用cudaMalloc呼叫在GPU中為它們分配空間。接下來,用值初始化陣列a和b(程式碼未顯示),然後使用CUDA函數cudaMemcpy將這些陣列複製到gpu中的相應位置(gpu_a和gpu_b),它使用名為cudaMemcpyHostToDevice的標誌,其中主機是CPU,裝置是GPU。
下一個操作是在gpu中新增向量gpu_a和gpu_b。為此,我們需要編寫一個vectorAdd函數來新增向量。此函數應包含三個引數,由兩個輸入向量和一個輸出向量組成。下面展示呼叫此函數的程式碼。
vectorAdd <<< N/32, 32 >>> (gpu_a, gpu_b, gpu_c);
我們使用三個引數呼叫vectorAdd函數:gpu_a、gpu_b和gpu_c。表示式<<< N/32, 32 >>>向GPU表明,有N=32個塊,每個塊包含32個執行緒。假設GPU神奇地新增了兩個陣列,並將結果儲存在其實體記憶體空間中的陣列gpu_c中。主功能的最後一步是從GPU獲取結果,並釋放GPU中的空間,其程式碼如下。
/* Copy from the GPU to the CPU */
cudaMemcpy(c, gpu_c, size, cudaMemcpyDeviceToHost);
/* free space in the GPU */
cudaFree(gpu_a);
cudaFree(gpu_b);
cudaFree(gpu_c);
/* end of the main function */
現在,讓我們定義需要在GPU上執行的vectorAdd函數。
/* The GPU kernel */
__global__ void vectorAdd( int *gpu a, int *gpu b, int *gpu c)
{
/* compute the index */
int idx = threadIdx.x + blockIdx.x * blockDim.x;
/* perform the addition */
gpu_c[idx] = gpu_a[idx] + gpu_b[idx];
}
上述程式碼中,存取CUDA執行時填充的一些內建變數,通常情況網格和塊有三個軸(x, y, z)。因為我們在這個例子中假設塊和網格中只有一個軸,所以我們只使用x軸。變數blockDim.x等於塊中的執行緒數。如果我們考慮二維網格,那麼塊的尺寸將是blockDim.x*blockDim.y,blockIdx.x是塊的索引,threadIdx.x是塊中執行緒的索引,因此表示式threadIdx.x+blockIdx.x * blockDim.x表示執行緒的索引。注意此範例中,陣列的每個元素與一個執行緒相關聯。由於建立、初始化和切換執行緒的開銷很小,因此我們可以在GPU的情況下采用這種方法,如果CPU在建立和管理執行緒時開銷很大,那麼這種方法是不可行的。一旦計算了執行緒的索引,就執行加法運算。
GPU建立此核心的N個副本,並將其分發給N個執行緒。每個核心計算不同的索引,然後執行加法運算。然而,使用CUDA擴充套件到C/C++,可以編寫極其複雜的程式,其中包含同步語句和條件分支語句。
下面再舉個並行程式設計的一個簡單的例子,假設我們得到了n個浮點數的兩個向量x和y,並且希望計算某個標量值a的y=ax+y的結果,正是BLAS線性代數庫定義的所謂SAXPY核心。下面顯示了使用CUDA在序列處理器和並行處理器上執行此計算的C程式碼。
// 用序列迴圈計算y=ax+y
void saxpy_serial( int n, float alpha, float * x, float )
{
for( int i=0; i<n; ++i)
y[i] = alpha * x[i] + y[i];
}
// 呼叫序列SAXPY核心
saxpy_serial(n, 2.0, x, y);
// 用CUDA平行計算y=ax+y
__global__
void saxpy_parallel( int n, float alpha, float *x, float *y)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if(i < n)
y[i] = alpha * x[i] + y[i];
}
// Invoke parallel SAXPY kernel (256 threads per block)
int nblocks = (n + 255) / 256;
saxpy_parallel<<< nblocks, 256>>> ( n, 2.0, x, y);
__global__宣告說明符表示過程是核心入口點,CUDA程式使用擴充套件函數呼叫語法啟動並行核心:
kernel<<<dimGrid, dimBlock>>>(… parameter list …);
其中,dimGrid和dimBlock是dim3型別的三個元素向量,分別指定網格在塊中的尺寸和執行緒中的塊的尺寸。未指定的尺寸預設為1。
上述程式碼啟動了一個由n個執行緒組成的網格,為向量的每個元素分配一個執行緒,並在每個塊中放置256個執行緒。每個單獨的執行緒根據其執行緒和塊ID計算元素索引,然後對相應的向量元素執行所需的計算。比較這段程式碼的序列和並行版本,會發現它們非常相似,是一種相當常見的模式。序列程式碼由一個迴圈組成,其中每個迭代都獨立於所有其他迭代。這樣的迴圈可以機械地轉換為並行核心:每個迴圈迭代都成為一個獨立的執行緒。通過為每個輸出元素分配一個執行緒,避免了在將結果寫入記憶體時執行緒之間的任何同步。
CUDA核心的文字只是一個順序執行緒的C函數,因此通常很容易編寫,並且比為向量運算編寫並行程式碼更簡單。通過在啟動核心時指定網格及其執行緒塊的維度,可以明確地確定並行性。
並行執行和執行緒管理是自動的,所有執行緒的建立、排程和終止都由底層系統為程式設計師處理。事實上,Tesla架構GPU直接在硬體中執行所有執行緒管理。塊的執行緒同時執行,並且可以通過呼叫__syncthreads()內在函數在同步屏障處同步,以此保證在塊中的所有執行緒都到達屏障之前,塊中的任何執行緒都不能繼續。在通過屏障之後,這些執行緒還可以確保在屏障之前看到塊中的執行緒對記憶體執行的所有寫入。因此,塊中的執行緒可以通過在同步屏障處寫入和讀取每個塊共用記憶體來彼此通訊。
同步屏障(synchronization barrier):執行緒在同步屏障處等待,直到執行緒塊中的所有執行緒到達該屏障。
由於塊中的執行緒可以共用記憶體並通過屏障進行同步,因此它們將一起駐留在同一物理處理器或多處理器上,但執行緒塊的數量可能大大超過處理器的數量。CUDA執行緒程式設計模型將處理器虛擬化,並使程式設計師能夠靈活地以最方便的粒度進行並行化。虛擬化為執行緒和執行緒塊允許直觀的問題分解,因為塊的數量可以由正在處理的資料的大小決定,而不是由系統中的處理器數量決定,它還允許相同的CUDA程式擴充套件到不同數量的處理器核心。
為了管理這種處理元素虛擬化並提供可延伸性,CUDA要求執行緒塊能夠獨立執行,必須能夠以任何順序並行或序列執行塊。不同的塊沒有直接通訊的方式,儘管它們可以通過例如原子遞增佇列指標,使用對所有執行緒可見的全域性記憶體上的原子記憶體操作來協調它們的活動。這種獨立性要求允許跨任意數量的核心以任意順序排程執行緒塊,從而使CUDA模型可跨任意數量核心以及多種並行架構進行擴充套件,也有助於避免死鎖的可能性。應用程式可以獨立或獨立地執行多個網格,給定足夠的硬體資源,獨立網格可以同時執行。從屬網格按順序執行,其間有一個隱式核心間屏障,從而保證第一個網格的所有塊在第二個從屬網格的任何塊開始之前完成。
原子記憶體操作(atomic memory operation):一種記憶體讀取、修改、寫入操作序列,在沒有任何干預存取的情況下完成。
執行緒在執行過程中可以從多個記憶體空間存取資料,每個執行緒都有一個專用區域性記憶體,CUDA對不適合執行緒暫存器的執行緒專用變數以及堆疊幀和暫存器溢位使用本地記憶體。每個執行緒塊都有一個共用記憶體,該記憶體對該塊的所有執行緒都可見,並且與該塊具有相同的生存期。最後,所有執行緒都可以存取相同的全域性記憶體,程式使用__shared__和__device__型別限定符在共用和全域性記憶體中宣告變數。在Tesla架構的GPU上,這些記憶體空間對應於物理上獨立的記憶體:每個塊共用記憶體是一個低延遲的片上RAM,而全域性記憶體駐留在圖形板上的快速DRAM中。
區域性記憶體(local memory):執行緒專用的逐執行緒區域性記憶體。
共用記憶體(shared memory):塊的所有執行緒共用的逐塊記憶體。
全域性記憶體(global memory):所有執行緒共用的逐應用程式記憶體。
共用記憶體應該是每個處理器附近的低延遲記憶體,很像L1快取,因此它可以線上程塊的執行緒之間提供高效能通訊和資料共用。由於它的生存期與其對應的執行緒塊相同,核心程式碼通常會初始化共用變數中的資料,使用共用變數進行計算,並將共用記憶體結果複製到全域性記憶體。順序相關網格的執行緒塊通過全域性記憶體進行通訊,使用它來讀取輸入和寫入結果。
下圖顯示了執行緒、執行緒塊和執行緒塊網格的巢狀級別圖,還顯示了相應的記憶體共用級別:逐執行緒、逐執行緒塊和逐應用程式資料共用的區域性、共用和全域性記憶體。
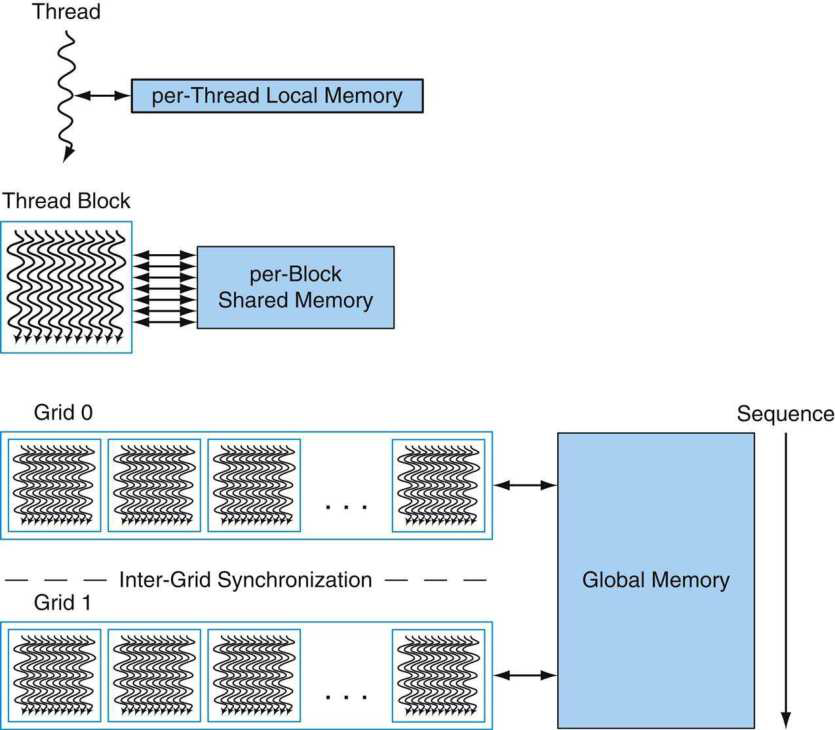
巢狀粒度級別執行緒、執行緒塊和網格具有相應的區域性、共用和全域性記憶體共用級別。逐執行緒區域性記憶體是執行緒專用的,逐塊共用記憶體由塊的所有執行緒共用,逐應用程式的全域性記憶體由所有執行緒共用。
程式通過呼叫CUDA執行時(如cudaMalloc()和cudaFree())來管理核心可見的全域性記憶體空間。核心可以在物理上獨立的裝置上執行,就像在GPU上執行核心一樣,所以應用程式必須使用cudaMemcpy()在分配的空間和主機系統記憶體之間複製資料。
CUDA程式設計模型在風格上類似於熟悉的單程式多資料(SPMD)模型,它顯式地表示並行性,每個核心在固定數量的執行緒上執行。然而,CUDA比SPMD的大多數實現更靈活,因為每個核心呼叫都會動態地建立一個新的網格,其中包含正確數量的執行緒塊和應用程式步驟的執行緒。程式設計師可以為每個核心使用方便的並行度,而不必設計計算的所有階段來使用相同數量的執行緒。下圖顯示了類似SPMD的CUDA程式碼序列的範例。它首先在3×2塊的2D網格上範例化核心F,其中每個2D執行緒塊由5×3個執行緒組成。然後,它在四個一維執行緒塊的一維網格上範例化核心G,每個一維執行緒塊有六個執行緒。因為kernelG依賴於kernelF的結果,所以它們被核心間同步屏障分隔開。
單程式多資料(single-program multiple data,SPMD):一種並行程式設計模型,其中所有執行緒執行同一程式。SPMD執行緒通常與屏障同步協調。
在2D執行緒塊的2D網格上範例化的核心F序列,是一個核心間同步屏障,之後是1D執行緒塊的1D網格上的核心G。
執行緒塊的並行執行緒表示細粒度資料並行和執行緒並行,網格的獨立執行緒塊表示粗粒度資料並行性,獨立網格表示粗粒度任務並行性。核心只是層次結構中一個執行緒的C程式碼。
請注意,我們將GPU核心與CPU執行的程式碼合併為一個程式,NVIDIA的編譯器將單個檔案拆分為兩個二進位制檔案,一個二進位制在CPU上執行並使用CPU的指令集,另一個二進位制執行在GPU上並使用PTX指令集。這是一個典型的MPMD執行方式的例子,在不同的指令集和多個資料流中有不同的程式。因此,可以將GPU的並行程式設計模型視為SIMD、MPMD和warp級別的細粒度多執行緒的組合(下圖)。
為了提高效率並簡化其實現,CUDA程式設計模型有一些限制。執行緒和執行緒塊只能通過呼叫並行核心而不是從並行核心中建立,再加上執行緒塊所需的獨立性,使得使用簡單的排程器執行CUDA程式成為可能,該排程器引入了最小的執行時開銷。事實上,Tesla GPU架構實現了執行緒和執行緒塊的硬體管理和排程。
任務並行性可以線上程塊級別表達,但很難線上程塊中表達,因為執行緒同步障礙在塊的所有執行緒上執行。為了使CUDA程式能夠在任意數量的處理器上執行,同一核心網格內的執行緒塊之間的依賴關係是不允許的。由於CUDA要求執行緒塊是獨立的並且允許以任何順序執行塊,組合由多個塊生成的結果通常必須通過線上程塊的新網格上啟動第二個核心來完成(儘管執行緒塊可以通過例如原子遞增佇列指標來使用對所有執行緒可見的全域性記憶體上的原子記憶體操作來協調其活動)。
CUDA核心中當前不允許遞迴函數呼叫,遞迴在大規模並行核心中不具備吸引力,因為為數以萬計的活動執行緒提供堆疊空間需要大量記憶體。通常使用遞迴(如快速排序)表示的序列演演算法通常最好使用巢狀資料並行而不是顯式遞回來實現。
為了支援將CPU和GPU結合在一起的異構系統架構,CUDA程式必須在主機記憶體和裝置記憶體之間複製資料和結果。通過使用DMA塊傳輸引擎和快速互連,CPU與GPU互動和資料傳輸的開銷最小化,大到需要GPU效能提升的計算密集型問題比小問題更好地分攤開銷。
圖形和計算的並行程式設計模型使得GPU架構不同於CPU架構,驅動GPU處理器架構的GPU程式的關鍵方面是:
- 廣泛使用細粒度資料並行性:著色器程式描述如何處理單個畫素或頂點,CUDA程式描述如何計算單個結果。
- 高執行緒程式設計模型:著色器執行緒程式處理單個畫素或頂點,CUDA執行緒程式可以生成單個結果。GPU必須以每秒60幀的速度每幀建立和執行數百萬個這樣的執行緒程式。
- 可延伸性:當提供額外的處理器時,程式必須自動提高效能,而無需重新編譯。
- 密集型浮點(或整數)計算。
- 支援高吞吐量計算。
19.9.6.3 NVIDIA GPU記憶體結構
下圖顯示了NVIDIA GPU的記憶體結構,每個多執行緒SIMD處理器原生的片上記憶體稱為區域性記憶體。它由多執行緒SIMD處理器內的SIMD通道共用,但此記憶體不在多執行緒SIMC處理器之間共用,整個GPU和所有執行緒塊共用的片外DRAM稱為GPU記憶體。
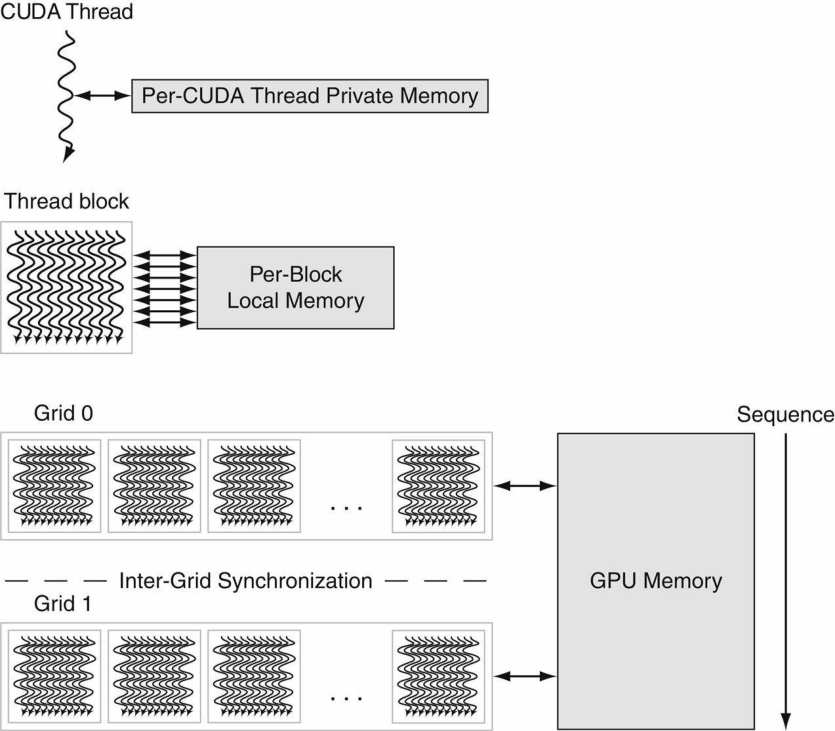
GPU記憶體結構。GPU記憶體由向量化迴圈共用,執行緒塊中SIMD指令的所有執行緒共用區域性記憶體。
GPU傳統上使用較小的流式快取,並依賴SIMD指令執行緒的廣泛多執行緒處理來隱藏DRAM的長延遲,而不是依賴於大型快取來包含應用程式的整個工作集,因為它們的工作集可能是數百M位元組。因此,它們不適合多核微處理器的最後一級快取。考慮到使用硬體多執行緒來隱藏DRAM延遲,系統處理器中用於快取的晶片區域被用於計算資源和大量暫存器,以儲存SIMD指令的許多執行緒的狀態。
雖然隱藏記憶體延遲是基本原理,但請注意,最新的GPU和向量處理器增加了快取,例如最近的Fermi架構增加了快取,但它們被認為是減少GPU記憶體需求的頻寬過濾器,或者是多執行緒無法隱藏延遲的少數變數的加速器。用於堆疊幀、函數呼叫和暫存器溢位的本地記憶體與快取非常匹配,因為呼叫函數時延遲很重要。快取也可以節省能量,因為片上快取存取比存取多個外部DRAM晶片消耗的能量少得多。
在高層次上,具有SIMD指令擴充套件的多核計算機確實與GPU有相似之處,下圖總結了相似性和差異。兩者都是MIMD,其處理器使用多個SIMD通道,儘管GPU有更多的處理器和更多的通道。兩者都使用硬體多執行緒來提高處理器利用率,儘管GPU對更多執行緒具有硬體支援。兩者都使用快取,儘管GPU使用較小的流快取,而多核計算機使用大型多級快取,試圖完全包含整個工作集。兩者都使用64位元地址空間,儘管GPU中的物理主記憶體要小得多。雖然GPU在頁面級別支援記憶體保護,但它們還不支援按需分頁。
| 特性 | 帶SIMD的多核(CPU) | GPU |
|---|---|---|
| SIMD處理器 | 4到8 | 8到16 |
| 每個處理器的SIMD通道數 | 2到4 | 8到16 |
| SIMD執行緒的多執行緒硬體支援 | 2到4 | 16到32 |
| 最大的快取尺寸 | 8M | 0.75M |
| 記憶體地址尺寸 | 64-bit | 64-bit |
| 主記憶體尺寸 | 8G到256G | 4G到16G |
| 頁面級別的記憶體保護 | 是 | 是 |
| 按需分頁 | 是 | 否 |
| 快取一致性 | 是 | 否 |
SIMD處理器也類似於向量處理器。GPU中的多個SIMD處理器充當獨立的MIMD核心,就像許多向量計算機具有多個向量處理器一樣。這種觀點認為Fermi GTX 580是一個16核機器,具有多執行緒硬體支援,每個核有16個通道。最大的區別是多執行緒,這是GPU的基礎,也是大多數向量處理器所缺少的。
GPU和CPU在電腦架構譜系中不會追溯到共用祖先,沒有缺失連結可以解釋這兩者。由於這種不同尋常的傳統,GPU沒有使用計算機架構社群中常見的術語,導致了對GPU是什麼以及它們如何工作的困惑。為了幫助解決混淆,下圖列出了本文部分使用的更具描述性的術語,與主流計算最接近的術語。
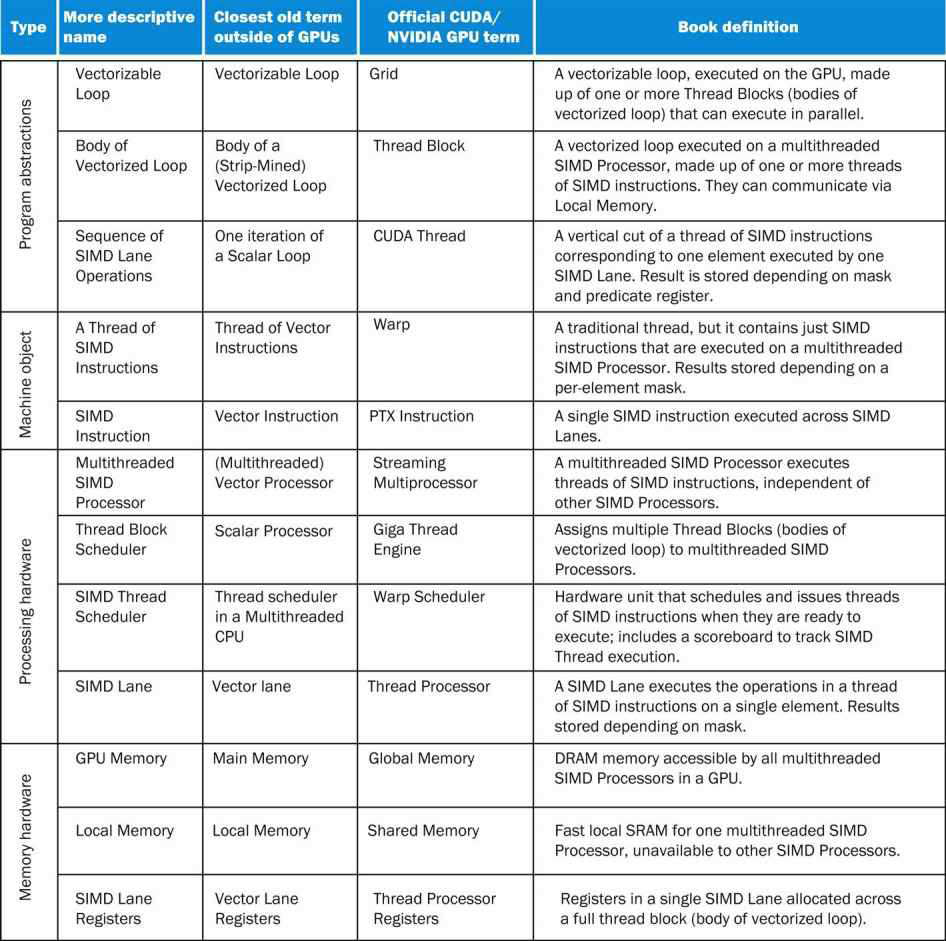
儘管GPU正朝著主流計算方向發展,但他們不能放棄繼續在圖形方面取得優異成績的責任。因此,當架構師問,考慮到為做好圖形而投入的硬體,我們如何補充它以提高更廣泛應用程式的效能時,GPU的設計可能更有意義?
關於GPU的更多技術細節可參閱:深入GPU硬體架構及執行機制。
19.9.7 i7 960和Tesla GPU效能
Intel研究人員在2010年發表了一篇論文,將四核Intel core i7 960與上一代GPU NVIDIA Tesla GTX 280的多媒體SIMD擴充套件進行了比較。下表列出了這兩種系統的特點。酷睿i7採用英特爾的45納米半導體技術,而GPU採用臺積電的65納米技術。儘管由中立方或兩個相關方進行比較可能更公平,但本節的目的不是確定一種產品比另一種產品快多少,而是試圖瞭解這兩種截然不同的架構風格的特徵的相對價值。
| 特性 | Core i7-960 | GTX 280 | GTX 480 | 280/i7的比率 | 480/i7的比率 |
|---|---|---|---|---|---|
| 處理元素(核或SM)的數量 | 4 | 30 | 15 | 7.5 | 3.8 |
| 時脈頻率(GHz) | 3.2 | 1.3 | 1.4 | 0.41 | 0.44 |
| 模具(Die)尺寸 | 263 | 576 | 520 | 2.2 | 2.0 |
| 技術 | Intel 45 nm | TSMC 65 nm | TSMC 40 nm | 1.6 | 1.0 |
| 功率(晶片,非模組) | 130 | 130 | 167 | 1.0 | 1.3 |
| 電晶體 | 700 M | 1400 M | 3030 M | 2.0 | 4.4 |
| 記憶體頻寬(G/sec) | 32 | 141 | 177 | 4.4 | 5.5 |
| 單精度SIMD寬 | 4 | 8 | 32 | 2.0 | 8.0 |
| 雙精度SIMD寬 | 2 | 1 | 16 | 0.5 | 8.0 |
| 峰值單精度標量FLOPS(GFLOP/sec) | 26 | 117 | 63 | 4.6 | 2.5 |
| 峰值單精度SIMD FLOPS(GFLOP/sec) | 102 | 311-933 | 515-1344 | 3.0-9.1 | 6.6-13.1 |
| SP 1相加或相乘 | N/A | 311 | 515 | 3.0 | 6.6 |
| SP 1指令融合乘法-加法 | N/A | 622 | 1344 | 6.1 | 13.1 |
| 特殊的SP雙問題融合乘加乘 | N/A | 933 | N/A | 9.1 | - |
| 峰值雙精度SIMD FLOPS(GFLOP/sec) | 51 | 78 | 515 | 1.5 | 10.1 |
下圖中的Core i7 960和GTX 280的曲線說明了計算機的差異。GTX280不僅具有更高的記憶體頻寬和雙精度浮點效能,而且它的雙精度脊點也位於左側。GTX 280的雙精度脊點為0.6,而Core i7為3.1。如上所述,曲線的脊點越靠近左側,就越容易達到峰值計算效能。對於單精度效能,兩臺計算機的脊點都會向右移動,因此很難達到單精度效能的頂點。請注意,核心的算術強度基於進入主記憶體的位元組,而不是進入快取的位元組。因此,如上所述,如果大多數參照真的到了快取,快取可以改變特定計算機上核心的算術強度。還請注意,這兩種架構中的單位步長存取都使用此頻寬,GTX 280和Core i7上的真實聚集分散地址可能會更慢。
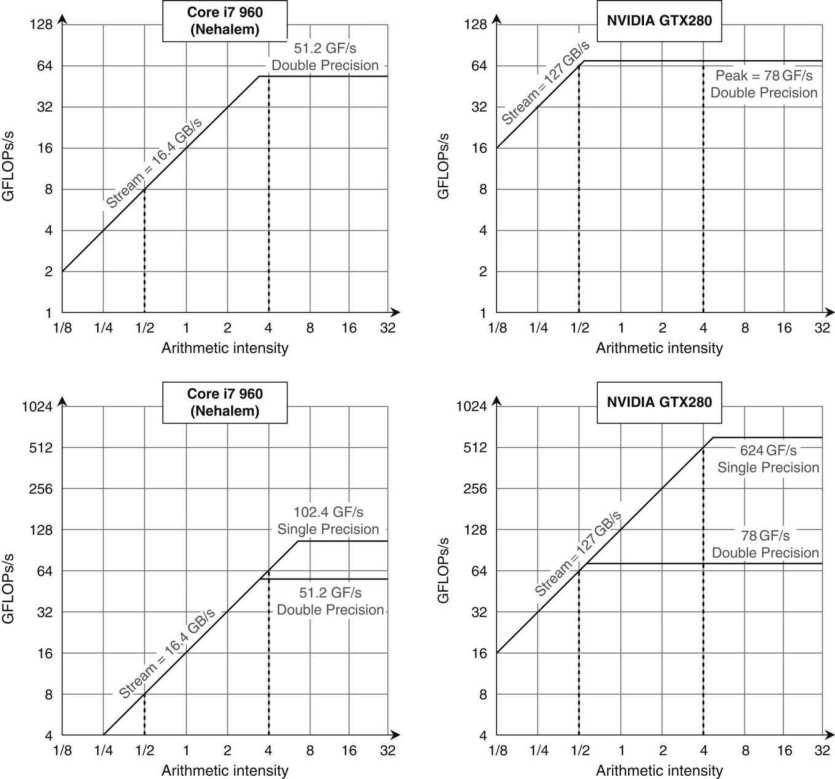
這些曲線在頂行顯示雙精度浮點效能,在底行顯示單精度效能。(DP FP效能上限也在最下面一行,以提供透檢視。)左側的Core i7 960的DP FP效能峰值為51.2 GFLOP/sec,SP FP峰值為102.4 GFLOP/sec,峰值記憶體頻寬為16.4 GBytes/sec。NVIDIA GTX 280的DP FP峰值為78 GFLOP/秒,SP FP峰值為624 GFLOP//秒,記憶體頻寬為127 GB/秒。左側的垂直虛線表示0.5 FLOP/位元組的算術強度,在Core i7上,記憶體頻寬限制為不超過8 DP GFLOP/sec或8 SP GFLOP/sec。右側的垂直虛線的算術強度為4 FLOP/位元組。在Core i7上,它的計算速度僅限於51.2 DP GFLOP/sec和102.4 SP GFLOP/sec,在GTX 280上,它僅限於78 DP GFLOp/sec和624 SP GFLOp/sec。要在Core i8上達到最高的計算速度,需要使用所有四個核心和SSE指令,並使用相同數量的乘法和加法。對於GTX 280,需要在所有多執行緒SIMD處理器上使用融合乘-加指令。
研究人員通過分析最近提出的四個基準套件的計算和記憶體特性來選擇基準程式,然後「制定了一組捕獲這些特性的吞吐量計算核心」。下圖顯示了效能結果,數位越大意味著速度越快,曲線有助於解釋本案例研究中的相對效能。
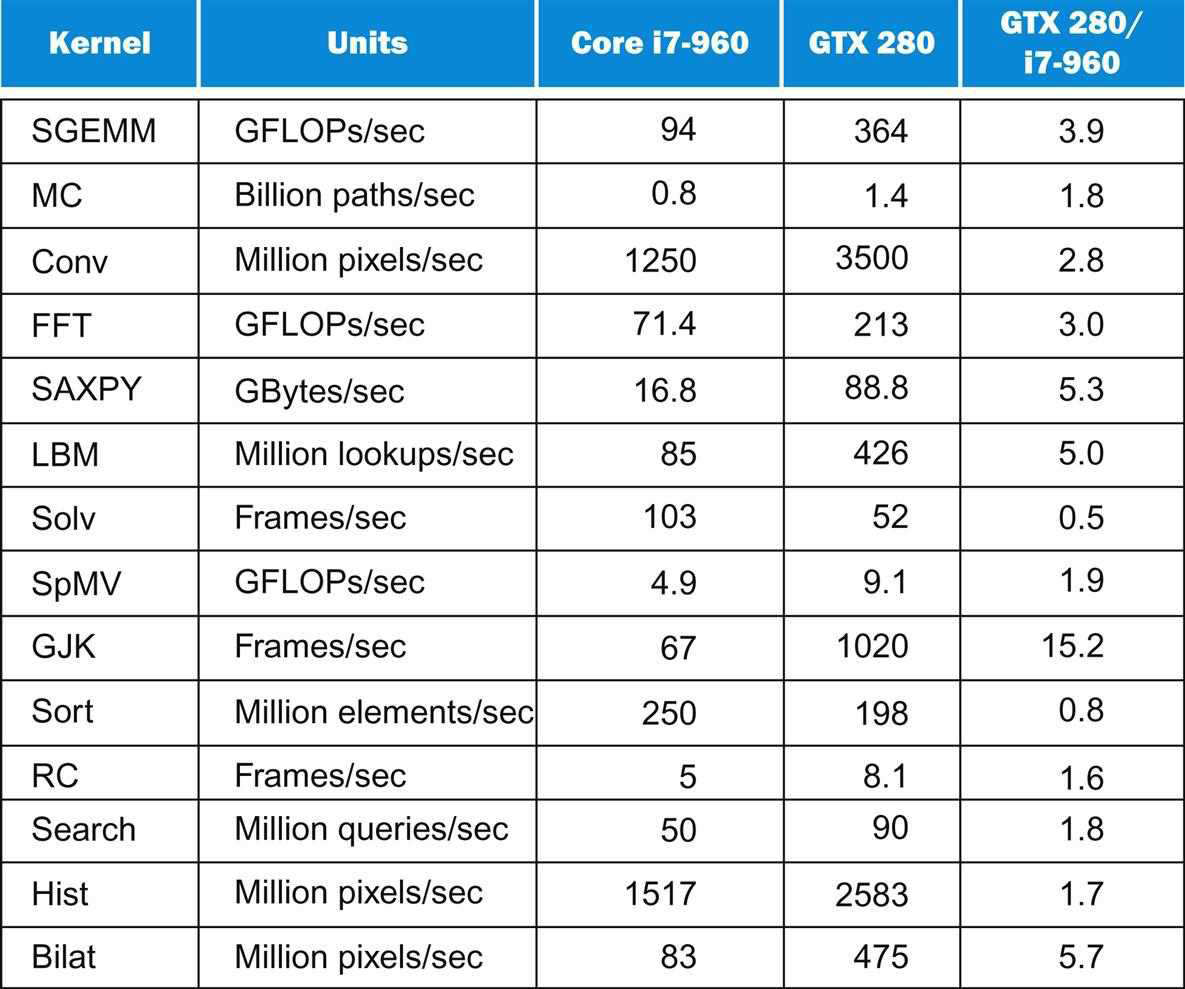
鑑於GTX 280的原始效能規格從2.5倍慢(時鐘速率)到7.5倍快(每個晶片的核心數)不等,而效能從2.0倍慢(Solv)到15.2倍快(GJK)不等,Intel研究人員決定找出差異的原因:
- 記憶體頻寬。GPU具有4.4倍的記憶體頻寬,有助於解釋為什麼LBM和SAXPY的執行速度分別為5.0和5.3倍,它們的工作集有數百兆位元組,因此不適合Core i7快取,為了集中存取記憶體,它們故意不使用快取阻塞(cache blocking),曲線的坡度解釋了它們的效能。SpMV也有一個大的工作集,但它的執行速度僅為1.9倍,因為GTX 280的雙精度浮點運算速度僅為Core i7的1.5倍。
- 計算頻寬。剩下的五個核心是計算密集的:SGEMM、Conv、FFT、MC和Bilat,GTX的速度分別為3.9、2.8、3.0、1.8和5.7倍。前三個使用單精度浮點運算,GTX 280單精度運算速度快3到6倍,MC使用雙倍精度,這解釋了為什麼DP效能只快1.5倍,所以它只快1.8倍。Bilat使用GTX 280直接支援的超越函數,Core i7將三分之二的時間用於計算Bilat的超越函數,因此GTX 280的速度要快5.7倍。這一觀察有助於指出硬體支援工作負載中發生的操作的價值:雙精度浮點運算,甚至可能是超驗運算。
- 快取優勢。光線投射(RC)在GTX上的速度僅為1.6倍,因為Core i7快取的快取阻塞阻止了它成為記憶體頻寬限制,就像在GPU上一樣,快取阻塞也可以幫助搜尋。如果索引樹很小,可以放入快取,那麼Core i7的速度是它的兩倍,較大的索引樹使其記憶體頻寬受限,總體而言,GTX 280的搜尋速度快1.8倍,快取阻塞也有助於排序。雖然大多數程式設計師不會在SIMD處理器上執行排序,但它可以用一個稱為拆分的1位排序原語來編寫,但分割演演算法執行的指令比標量排序多得多,所以Core i7的執行速度是GTX 280的1.25倍。請注意,快取也有助於Core i7上的其他核心,因為快取阻塞允許SGEMM、FFT和SpMV成為計算繫結。這一觀察再次強調了快取阻塞優化的重要性。
- 分散-聚集。如果資料分散在主記憶體儲器中,多媒體SIMD擴充套件幾乎沒有幫助,只有當對資料的存取在16位元組邊界上對齊時,才能獲得最佳效能。因此,GJK從Core i7上的SIMD中獲得的好處很少。如上所述,GPU提供了向量架構中的聚集-分散定址,但大多數SIMD擴充套件中都忽略了這種定址,記憶體控制器甚至一起批次存取同一DRAM頁。這種組合表明GTX 280以驚人的15.2倍於Core i7的速度執行GJK,比上上圖中的任何單個物理引數都要大。這一觀察結果強化了SIMD擴充套件中缺少的向量和GPU架構的聚集散射的重要性。
- 同步。同步效能受到原子更新的限制,儘管Core i7具有硬體獲取和增量指令,但原子更新佔Core i7總執行時間的28%。因此,Hist在GTX 280上的速度僅為1.7倍,Solv在少量計算中解決了一批獨立約束,然後進行了屏障同步。Core i7得益於原子指令和記憶體一致性模型,即使不是以前對記憶體層次結構的所有存取都已完成,也能確保正確的結果。在沒有記憶體一致性模型的情況下,GTX 280版本從系統處理器啟動了一些批次處理,導致GTX 280的執行速度是Core i7的0.5倍。這一觀察結果指出了同步效能對於某些資料並行問題的重要性。
令人驚訝的是,Intel研究人員選擇的核心發現的Tesla GTX 280中的弱點,已經在Tesla的後續架構中得到了解決:Fermi具有更快的雙精度浮點效能、更快的原子運算和快取。同樣有趣的是,比SIMD指令早了幾十年的向量架構的聚集-分散支援對於這些SIMD擴充套件的有效有用性非常重要,有些人在比較之前就已經預測到了這一點。Intel的研究人員指出,14個核心中的6個核心可以更好地利用SIMD,在Core i7上提供更高效的聚集-分散支援。這項研究也肯定了快取阻塞的重要性。
19.9.8 NVidia Tesla架構
下圖顯示了Tesla架構,讓我們從圖的頂部開始解釋。主機CPU通過專用匯流排向圖形處理器傳送命令和資料序列,然後,專用匯流排將一組命令和資料傳輸到GPU上的緩衝區,隨後GPU的單元處理資訊。在下圖中,工作從上到下流動。GPU本質上是一組非常簡單的有序核心,此外,它還有大量額外的硬體來協調複雜任務的執行,並將工作分配給一組核心。GPU還支援多級記憶體層次結構,並具有專門執行少數圖形特定操作的專用單元。
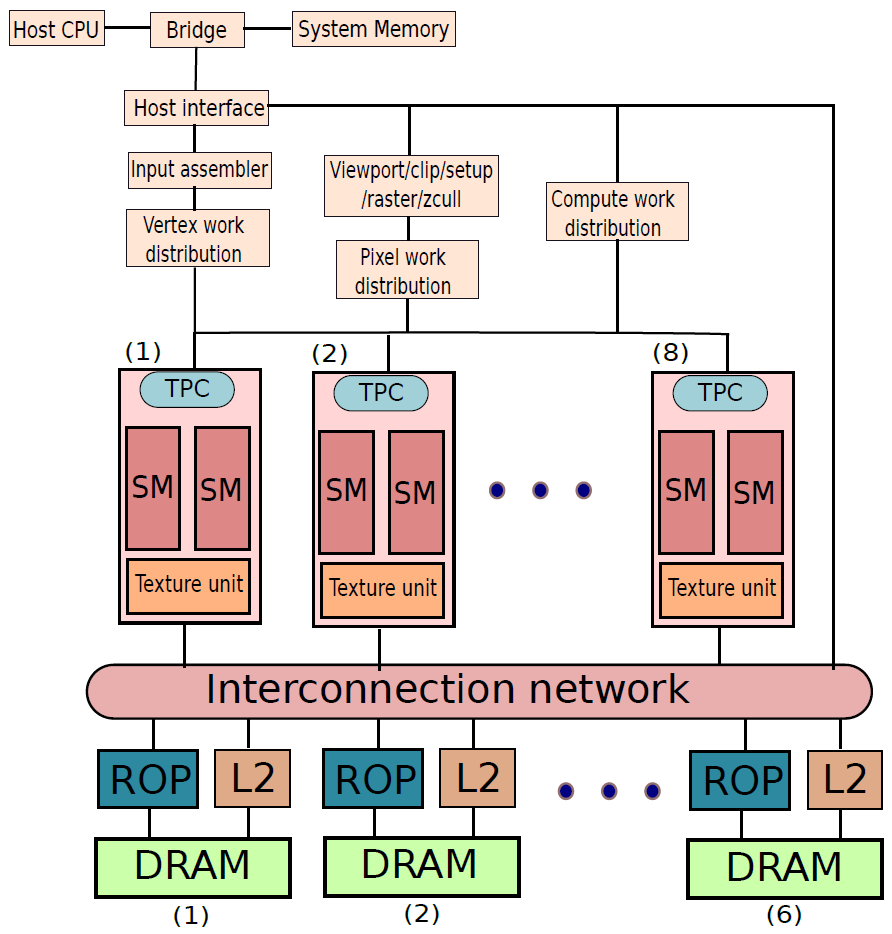
NVIDIA Tesla架構。
19.9.8.1 工作分配
GPU可以分配三種工作:頂點處理、畫素處理和常規計算工作。GPU定義自己的組合程式碼,使用PTX和SASS指令集,這些指令集中的每個指令都在GPU上執行基本操作,它使用暫存器運算元或記憶體運算元。與CPU不同,GPU中暫存器檔案的結構通常不暴露於軟體,程式設計師需要使用無限數量的虛擬暫存器,GPU或裝置驅動程式將它們對映到實際暫存器。
現在,對於處理頂點,低階圖形軟體向GPU傳送一系列裝配指令。GPU有一個硬體組合程式,它生成二進位制程式碼,並將其傳送到一個專用的頂點處理單元,該單元協調和分配GPU核心之間的工作。或者,CPU可以向GPU傳送畫素處理操作,GPU執行光柵化、片段處理和深度緩衝的過程。GPU中的一個專用單元為這些操作生成程式碼片段,並將其傳送到畫素處理單元,該畫素處理單元將工作項分配給GPU核心集。第三個單元是計算工作分配器,它接受CPU的常規計算任務,例如新增兩個矩陣或計算兩個向量的點積。程式設計師指定一組子任務,計算工作分配引擎的作用是將這些子任務集傳送到GPU中的核心。
在這個階段之後,GPU或多或少地忽略了指令的來源,注意,這部分工程是GPU成功背後的關鍵貢獻。設計師已經成功地將GPU的功能分為兩層,第一層特定於操作型別(圖形或通用)。在此階段,每個流水線的作用是將特定的操作序列轉換為一組通用的操作,這樣無論高階操作的性質如何,都可以使用相同的硬體單元。現在來看看包含計算引擎的GPGPU的後半部分。
19.9.8.2 GPU計算引擎
GeForce 8800 GPU有128個核心。核心小組分為8組,每個組稱為TPC(紋理/處理器叢集),每個TPC包含兩個SM(流式多處理器)。此外,每個SM包含8個稱為流處理器(SP)的核心,每個SP都是一個簡單的有序核心,具有符合IEEE 754的浮點ALU、分支和記憶體存取單元。除了一組簡單的核心外,每個SM都包含一些專用的記憶體結構。這些記憶體結構包含常數、紋理資料和GPU指令。所有SP都可以並行執行一組指令,並且彼此緊密同步。
19.9.8.3 互連網路、DRAM模組、二級快取和ROP
8個TPC通過互連網路連線到一組快取、DRAM模組和ROP(光柵操作處理器)。SM包含一級快取,在快取未命中時,SP核心通過NOC存取相關的二級快取庫。在GPU的情況下,二級快取是在儲存體(bank)級別上分割的共用快取,在二級快取之下,GPU有一個大的外部DRAM記憶體。GeForce 8800有384個引腳可連線到外部DRAM模組,該組引腳分為6組,每組包含64個引腳。實體記憶體空間也被分成6個部分,跨越6個組。光柵化操作通常需要一些專門的處理例程,不幸的是,這些例程在TPC上執行效率低下,因此GeForce 8800晶片具有6個ROP,每個ROP處理器每個週期最多可以處理4個畫素,它主要對畫素的顏色進行插值,並執行顏色混合操作。
19.9.9 NVidia RTX 4090架構和特性
前不久,NVIDIA宣佈推出Ada Lovelace GeForce一代時,曾有過一些大膽的宣告,光線跟蹤效能的有效翻倍,在測試了一系列流行的渲染引擎之後,確實如此。

RTX 4090 GPU晶片結構。
Ada Lovelace一代帶來了第四代Tensor磁芯和改進的光流。在建立過程中,這些功能加速了降噪等功能,而在遊戲應用中,它們通過DLSS 3.0進行了升級。在光線跟蹤核心方面,Ada Lovelace推出了第三代實現,並在很大程度上提供比Ampere一代提高2倍的效能。
其他值得注意的功能是Shader Execution Reordering,它進一步提高了光線跟蹤效能,包括在遊戲中,其中一個例子顯示《賽博朋克2077》中有44%的提升。此外,Intel率先推出AV1加速GPU編碼器,NVIDIA也緊隨其後,Ada Lovelace也推出了一款。有趣的是,NVIDIA提供了板載雙編碼器,它聲稱這將使編碼時間減半。我們將通過即將推出的完整創作者效能外觀來探索這一點。
在開始瞭解NVIDIA最新旗艦的渲染效能之前,先看看NVIDIA官方正版的硬體引數:
| GPU型號 | 核心數 | 最大頻率 | 峰值FP32 | 記憶體 | 頻寬 | 總功率 |
|---|---|---|---|---|---|---|
| RTX 4090 | 16,384 | 2,520 | 82.6 TFLOPS | 24GB | 1008 GB/s | 450W |
| RTX 4080 16GB | 9,728 | 2,510 | 48.8 TFLOPS | 16GB | 717 GB/s | 320W |
| RTX 3090 Ti | 10,752 | 1,860 | 40 TFLOPS | 24GB | 1008 GB/s | 450W |
| RTX 3080 Ti | 10,240 | 1,670 | 34.1 TFLOPS | 12GB | 912 GB/s | 350W |
| RTX 3070 Ti | 6,144 | 1,770 | 21.7 TFLOPS | 8GB | 608 GB/s | 290W |
| RTX 3060 Ti | 4,864 | 1,670 | 16.2 TFLOPS | 8GB | 448 GB/s | 200W |
RTX 4090配備了這一代的第一款Ada Lovelace GPU:AD102。但值得注意的是,這款旗艦卡中使用的晶片並不是全核,儘管其規格表已經非常龐大。其核心是16384個CUDA核心,分佈在128個流式多處理器(SM)上,意味著比RTX 3090 Ti的GA102 GPU(其本身就是完整的Ampere核心)增加了52%。

上:RTX 4090內的AD102結構;下:完整的AD102 GPU結構。
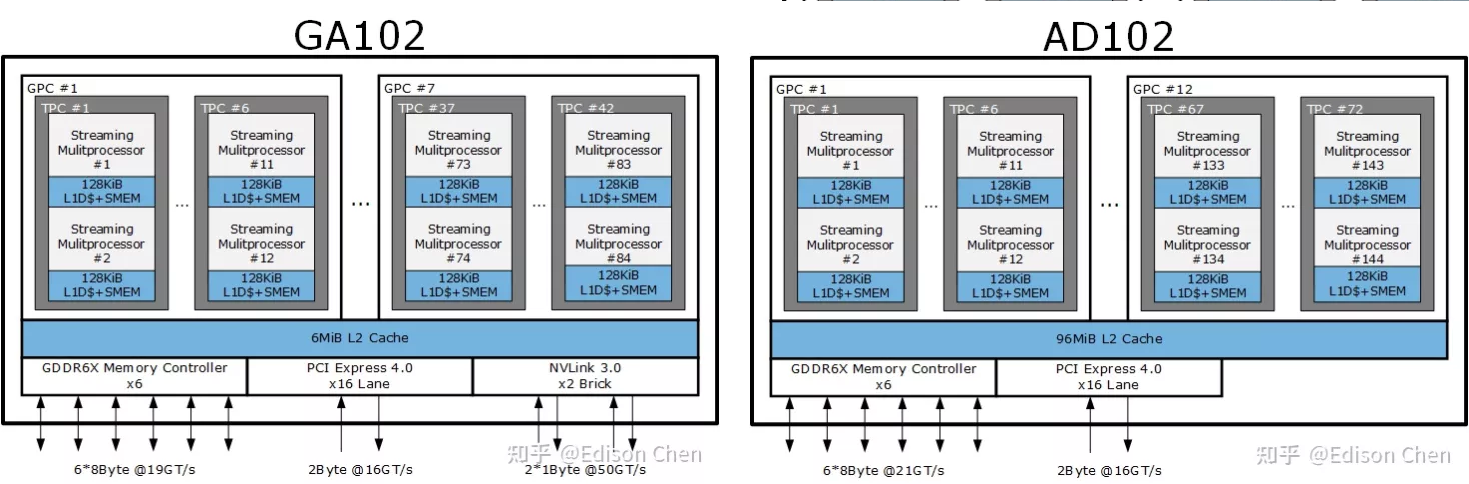
GA102和AD102架構對比圖。
完整的AD102晶片包括18432個CUDA核心和144個SM,也意味著將看到144個第三代RT核心和576個第四代Tensor核心。如果英偉達願意,RTX 4090 Ti甚至Titan都有足夠的空間。
Ada Lovelace和Ampere架構的SM對比圖。
記憶體變化不大,同樣是24GB的GDDR6X以21Gbps的速度執行,可提供1008GB/秒的記憶體頻寬。下表是GeForce RTX 4090和GeForce RTX 3090 Ti的部分引數對比圖:
| GeForce RTX 4090 | GeForce RTX 3090 Ti | |
|---|---|---|
| 架構 | Ada Lovelace | Ampere |
| CUDA核心 | 16,432 | 10,752 |
| SM | 128 | 84 |
| RT核心 | 128 | 84 |
| Tensor核心 | 512 4代 | 336 3代 |
| ROP | 176 | 112 |
| 最大頻率 | 2,520MHz | 1,860MHz |
| 記憶體 | 24GB GDDR6X | 24GB GDDR6X |
| 記憶體速度 | 21Gbps | 21Gbps |
| 記憶體頻寬 | 1,008GB/s | 1,008GB/s |
| 匯流排寬 | 384 | 384 |
| L1 | L2快取 | 16,384KB | 73,728KB | 10,752KB | 6,144KB |
| 製作工藝 | 5nm TSMC | 8nm Samsung |
| 電晶體 | 763億 | 283億 |
| 晶片面積 | 608.5mm² | 628.5mm² |
| 總功率 | 450W | 450W |
在方程式的原始著色器方面,事情也沒有從Ampere架構中真正發展到那麼遠。每個SM仍然使用相同的64個專用FP32單元,但具有64個單元的輔助流,可以根據需要在浮點和整數計算之間進行拆分,與Ampere引入的相同。
當檢視RTX 3090和RTX 4090之間的相對效能差異時,可以從光柵化的角度看到這兩種架構有多相似。
如果忽略光線追蹤和放大,則相應的效能提升僅略高於AD102 GPU中額外的CUDA核心數量。儘管業績增長「略高於」相應水平,但確實表明在這一水平上存在一些差異。
部分原因在於英偉達用於Ada Lovelace GPU的新4納米生產工藝。與Ampere的8納米三星工藝相比,據說臺積電製造的4N工藝在相同功率下提供了兩倍的效能,或者在相同效能下提供了一半的效能。
這意味著英偉達可以在時鐘速度方面具有超強的攻擊性,RTX 4090的提升時鐘為2520MHz。實際上,我們在測試中看到了Founders Edition卡的平均頻率為2716MHz,比上一代的RTX 3090快了整整1GHz。
而且,由於工藝的縮減,英偉達與臺積電合作的工程師已經在AD102核心中塞進了驚人的763億個電晶體。考慮到608.5mm²的Ada GPU包含的電晶體比GA102矽的283億電晶體還要多,它可能比628.4mm²的Ampere晶片小得多。
事實上,英偉達能夠繼續將數量不斷增加的電晶體塞進單片晶片中,並仍然不斷縮小其實際管芯尺寸,這證明了該領域先進工藝節點的威力。作為參考,RTX 2080 Ti的TU102晶片面積為754mm²,僅容納186億個12nm電晶體。但並不意味著單片GPU可以永遠繼續,不受限制。GPU的競爭對手AMD承諾將於11月推出新的RDNA 3晶片,轉而使用圖形計算晶片。考慮到AD102 GPU的複雜性僅次於先進的814mm²Nvidia Hopper矽的800億電晶體,它肯定是一種昂貴的晶片。然而,較小的計算晶片應該會降低成本,提高產量。
更多引數規格和特性如下所示:

但至少到目前,暴力的整體方法仍在為英偉達帶來回報。
當想要更高的速度,並且已經儘可能多地安裝了先進的電晶體時,還能做什麼?答案是可以在包中新增更多的快取,是AMD在其Infinity Cache中取得的巨大效果,儘管英偉達不一定會採用一些花哨的新品牌方法,但它在Ada核心中增加了大量L2快取。
上一代GA102包含6144KB的共用二級快取,位於其SM的中間,Ada將其增加16倍,以建立98304KB的二級快取池,供AD102 SM使用。對於RTX 4090版本的晶片,其容量降至73728KB,但仍有大量快取。每個SM的L1數量沒有變化,但因為現在晶片內總共有更多的SM,這也意味著與Ampere相比,L1快取的數量也更大。
但如今,光柵化並不是GPU的全部。當圖靈首次在遊戲中引入實時光線追蹤時,可能會有這樣的感覺,現在它幾乎已經成為PC遊戲的標準組成。升級也是如此,因此架構如何接近PC遊戲的這兩大支柱,對於整體理解設計至關重要。
如今的所有三家顯示卡製造商都專注於光線追蹤效能以及升級技術的複雜性,儼然成為他們之間的一場全新戰爭。
RTX 4090的規格為450W,是一款耗電的GPU,因此PSU越大越好。NVIDIA規定的最低功率為850W,在進行密集的3DMark測試時,已經達到了650W的峰值。RTX 4090需要3個8針電源聯結器,或者一個帶有新的PCIe 5支援PSU的電源聯結器。由於測試平臺的PSU剛好符合最低要求,將在未來轉向更大的PSU。
關於RTX 4090的冷卻器,其設計與上一代RTX 3090相似,但發動機罩下的改進有利於溫度。最新型號的風扇更大,同時減少了葉片數量。經過對RTX 4090進行了足夠的測試,在3DMark Fire Strike Ultra測試期間,它比3090(總功率650W)多了100W。
闡述完它的硬體規格,下面聊聊其渲染特性。
Ada流式多處理器中發生了真正的變化。光柵化元件可能非常相似,但第三代RT Core已經發生了巨大變化。前兩代RT Core包含一對專用單元,即長方體相交引擎和三角體相交引擎,在計算光線跟蹤核心的邊界體積層次(BVH)演演算法時,這兩個單元從SM的其餘部分中提取了大量RT工作量。
Ada引入了另外兩個獨立的單元來解除安裝SM的更多工作: Opacity Micromap Engine(OME)和Displaced Micro-Mesh Engine。第一種方法在處理場景中的透明度時大大加快了計算速度,第二種方法旨在分解幾何上覆雜的物件,以減少完成整個BVH計算所需的時間。

左:Ampere三角形相交示意圖,其中射線可能會多次擊中淺黃色的三角形,每次擊中都會觸發一次anyhit著色器。右:Ada的OPACITY MICRO MAPS Shading(OMMS)的紋理渲染技術,配合OME可以顯著減少Alpha遍歷後的計算。透過 OMMS 技術,射線遇到上圖中淺藍色部分的時候直接忽略掉 anyhit 計算,從而顯著提升這類物件的計算量。
Displaced Micro-Mesh Engine工作機制示意圖。
除此之外,Nvidia還稱之為「GPU的一項重大創新,就像20世紀90年代CPU的無序執行一樣」。建立了著色器執行重新排序(SER)來切換著色工作負載,從而允許Ada晶片通過實時重新排程任務來大大提高圖形管線的效率。
Intel一直在為其鍊金術師GPU(在新索引標籤中開啟)開發類似的功能,執行緒排序單元,以幫助光線跟蹤場景中的發散光線。據報道,它的設定不需要開發人員的輸入。目前,Nvidia需要一個特定的API來將SER整合到開發者的遊戲程式碼中,正在與微軟和其他公司合作,將該功能引入DirectX 12和Vulkan等標準圖形API中。
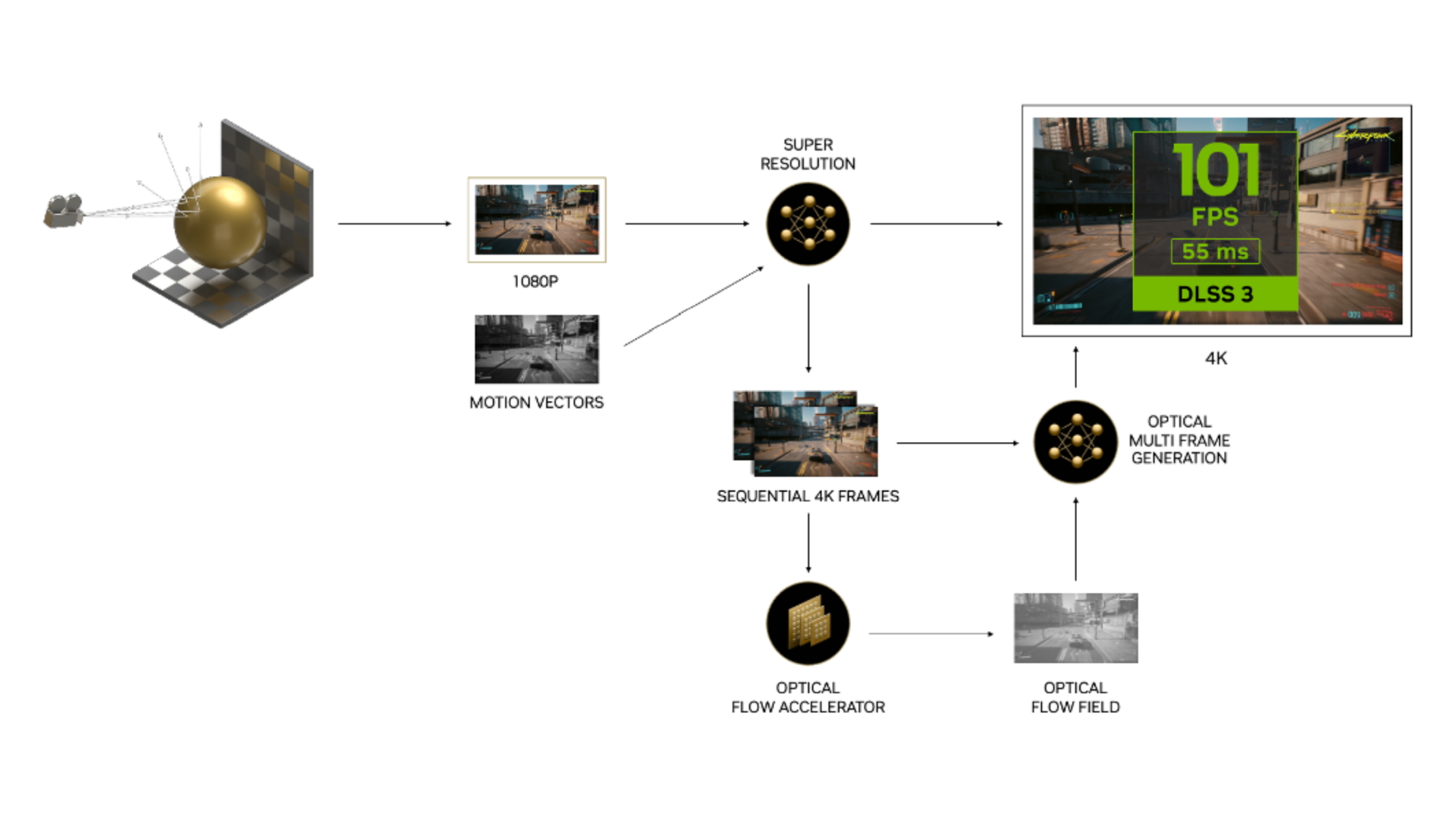
最後來看看DLSS 3.0,它的王牌:幀生成,DLSS 3現在不僅會升級,還會自己建立整個遊戲幀。不一定是從頭開始,而是通過使用AI和深度學習的力量,對下一幀的外觀進行最佳猜測,如果真的要渲染它,然後它在下一個真正渲染的幀之前注入AI生成的幀。
這是巫毒,是黑魔法,是黑暗的藝術,而且相當壯觀。它使用第四代張量核內的增強型硬體單元(稱為光流單元)進行所有這些飛行計算,然後利用神經網路將先前幀中的所有資料、場景中的運動向量和光流單元拉到一起,以幫助建立一個全新的幀,該幀還能夠包括光線追蹤和後期處理效果。
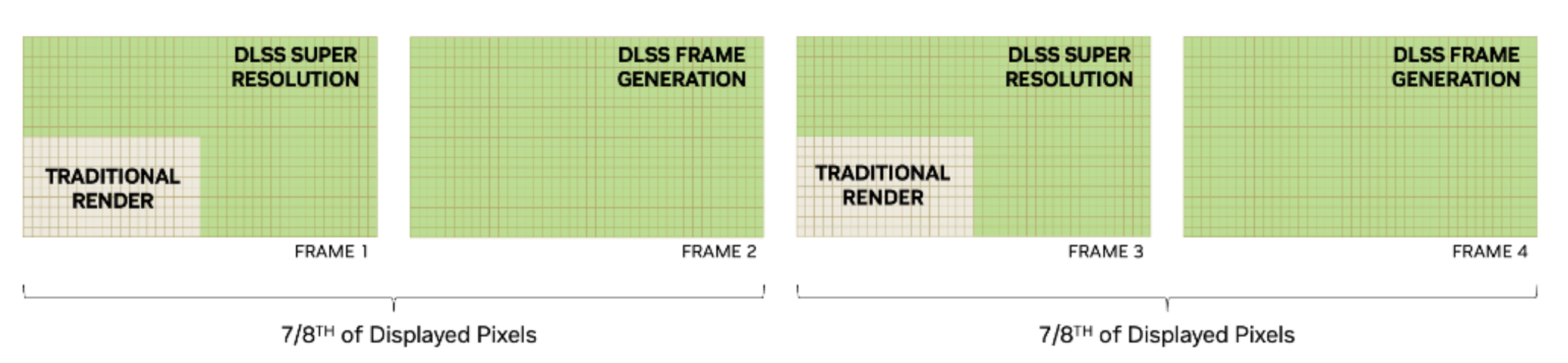
英偉達與DLSS升級(現在稱為DLSS超級解析度)一起工作時表示,在某些情況下,AI將通過升級生成初始幀的四分之三,然後使用幀生成生成整個第二幀。總的來說,它估計AI正在建立所有顯示畫素的八分之七。它在3DMark Time Spy Extreme的得分是大安培核心的兩倍,在光線追蹤或DLSS加入之前,原始矽提供的4K幀速率也是《賽博朋克2077》的兩倍。
賽博朋克2077的對比資料如下:
在能效方面,4090的平均功率高於3090約18%,每瓦特的效能是3090的1.75倍(1080P),平均溫度比3090低約4.5%。
19.9.10 謬論與陷阱
GPU的發展和變化如此之快,以至於出現了許多謬誤和陷阱,此節介紹其中一部分。
19.9.10.1 謬論:GPU只是SIMD向量多處理器
很容易得出這樣的錯誤結論:GPU只是簡單的SIMD向量多處理器。GPU有一個SPMD風格的程式設計模型,程式設計師可以編寫一個在多個執行緒範例中使用多個資料執行的程式,但這些執行緒的執行不是單純的SIMD或向量,實際上它是單指令多執行緒(SIMT)。每個GPU執行緒都有自己的標量暫存器、執行緒專用記憶體、執行緒執行狀態、執行緒ID、獨立執行和分支路徑以及有效的程式計數器,並且可以獨立地定址記憶體。儘管當用於執行緒的PC相同時,一組執行緒(如32個執行緒的warp)執行效率更高,但不是必需的,所以多處理器並非純粹的SIMD。執行緒執行模型是MIMD,具有屏障同步和SIMT優化。如果單個執行緒載入/儲存記憶體存取也可以合併為塊存取,則執行效率更高,但不是絕對必要。在純SIMD向量架構中,不同執行緒的記憶體/暫存器存取必須以規則向量模式對齊,GPU對暫存器或記憶體存取沒有這種限制,然而,如果執行緒的warp存取區域性資料塊,則執行效率更高。
與純SIMD模型相比,SIMT GPU可以同時執行多個執行緒warp。在圖形應用中,可能有多組頂點程式、畫素程式和幾何程式同時在多處理器陣列中執行,計算程式也可以在不同的warp中同時執行不同的程式。
19.9.10.2 謬論:GPU效能的增長速度不能超過摩爾定律
摩爾定律只是一個速率,不是任何其他速率的「光速」限制。摩爾定律描述了一種預期,即隨著時間的推移,隨著半導體技術的進步和電晶體的變小,每個電晶體的製造成本將呈指數下降。換言之,在製造成本不變的情況下,電晶體的數量將成倍增加。戈登·摩爾(Gordon Moore)預測,在相同的製造成本下,每年將提供大約兩倍的電晶體數量,後來將其修改為每2年增加一倍。儘管摩爾在1965年做出了最初的預測,當時每個積體電路只有50個元件,但事實證明這一預測非常一致。電晶體尺寸的減小在歷史上也有其他好處,例如每個電晶體的功率更低,恆定功率下的時鐘速度更快。
越來越多的電晶體被晶片設計師用來製造處理器、記憶體和其他元件。一段時間以來,CPU設計者使用額外的電晶體以類似摩爾定律的速度提高處理器效能,以至於許多人認為每18-24個月處理器效能增長兩倍是摩爾定律。事實上,事實並非如此。
微處理器設計人員將一些新電晶體用於處理器核心,改進了架構和設計,並通過流水線實現了更高的時鐘速度。其餘的新電晶體用於提供更多的快取,以加快記憶體存取速度。相比之下,GPU設計者幾乎不使用任何新電晶體來提供更多快取,大多數電晶體用於改進處理器核心和新增更多處理器核心。GPU通過四種機制加快速度:
- GPU設計人員通過應用成倍增加的電晶體來構建更並行、從而更快的處理器,直接獲得摩爾定律的好處。
- GPU設計者可以隨著時間的推移改進架構,提高處理效率。
- 摩爾定律假設成本不變,因此,如果花費更多的錢購買更大的晶片和更多的電晶體,顯然可以超過摩爾定律的比率。
- GPU記憶體系統通過使用更快的記憶體、更寬的記憶體、資料壓縮和更好的快取,以幾乎與處理速度相當的速度增加了有效頻寬。
這四種方法的結合在歷史上允許GPU效能定期翻倍,大約每12到18個月一次,超過了摩爾定律的速度,已經在圖形應用程式上演示了大約10年,並且沒有明顯放緩的跡象。最具挑戰性的限速器似乎是記憶體系統,但競爭性創新也在迅速推進。
19.9.10.3 謬論:GPU僅渲染3D圖形不能做通用計算
GPU用於渲染3D圖形以及2D圖形和視訊。為了滿足圖形軟體開發人員在圖形API的介面和效能/功能要求中所表達的需求,GPU已經成為大規模並行可程式化浮點處理器。在圖形領域,這些處理器通過圖形API和晦澀難懂的圖形程式語言(OpenGL和Direct3D中的GLSL、Cg和HLSL)進行程式設計。然而,沒有什麼可以阻止GPU架構師將並行處理器核心暴露給沒有圖形API或神祕圖形語言的程式設計師。
事實上,Tesla架構的GPU系列通過一個名為CUDA的軟體環境來暴露處理器,該軟體環境允許程式設計師使用C語言和C++開發通用應用程式。GPU是圖靈完備的處理器,因此它們可以執行CPU可以執行的任何程式,儘管可能不太好,也許更快。
19.9.10.4 謬論:GPU無法快速執行雙精度浮點程式
在過去,GPU根本無法執行雙精度浮點程式,除非通過軟體模擬,但軟體模擬一點都不快。GPU已經從索引算術表示(顏色查詢表)到每個顏色分量8位元整數,再到定點算術,再到單精度浮點,後又增加了雙精度。現代GPU幾乎所有計算都採用單精度IEEE浮點運算,並且開始使用雙精度運算。
GPU可以支援雙精度浮點和單精度浮點,只需少量額外成本。如今,雙精度執行速度比單精度執行速度慢,大約慢5到10倍。對於增加的額外成本,隨著更多應用的需要,雙精度效能可以在階段中相對於單精度提高。
19.9.10.5 謬論:GPU不能正確執行浮點運算
至少在Tesla體系結構系列處理器中,GPU執行IEEE 754浮點標準規定的單精度浮點處理。因此,就精度而言,GPU與任何其他符合IEEE 754的處理器一樣。
如今的GPU沒有實現標準中描述的某些特定功能,例如處理非規範化的數位和提供精確的浮點異常,但Tesla T10P GPU提供了完整的IEEE舍入、融合乘加和雙精度非規範化數位支援。
19.9.10.6 謬論:O(n)演演算法很難加速
無論GPU處理資料的速度有多快,向裝置傳輸資料和從裝置傳輸資料的步驟可能會限制具有O(n)複雜性的演演算法的效能(每個資料的工作量很小)。當使用DMA傳輸時,PCIe匯流排上的最高傳輸速率約為48 GB/秒,而對於非DMA傳輸則稍低,相比之下,CPU對系統記憶體的存取速度通常為8–12 GB/秒。例如向量加法,將受到輸入到GPU的傳輸和計算返回輸出的限制,有三種方法可以克服傳輸資料的成本:
- 儘量將資料留在GPU上,而不是在複雜演演算法的不同步驟中來回行動資料。CUDA故意在兩次啟動之間將資料單獨留在GPU中以支援這一點。
- GPU支援複製入、複製出和計算的並行操作,因此資料可以在裝置進行計算時流入和流出裝置。該模型對於任何可以在到達時處理的資料流都很有用。例如視訊處理、網路路由、資料壓縮/解壓縮,甚至更簡單的計算,如大向量數學。
- 將CPU和GPU一起使用,通過將工作的子集分配給每一個來提高效能,將系統視為異構計算平臺。CUDA程式設計模型支援將工作分配給一個或多個GPU,以及在不使用執行緒的情況下繼續使用CPU(通過非同步GPU功能),因此保持所有GPU和CPU同時工作以更快地解決問題相對簡單。
19.9.10.7 陷阱:只需使用更多的執行緒來覆蓋更長的記憶體延遲
CPU核心通常被設計為以全速執行單個執行緒。要全速執行,每個指令及其資料都需要在該指令執行時可用。如果下一條指令未就緒或該指令所需的資料不可用,則該指令無法執行,處理器將停滯。外部記憶體與處理器相距較遠,因此從記憶體中獲取資料需要許多週期的浪費執行。
因此,CPU需要大型區域性快取來保持執行而不停滯,記憶體延遲很長,因此可以通過努力在快取中執行來避免。在某些情況下,程式工作集的需求可能比任何快取都大,一些CPU使用多執行緒來容忍延遲,但每個核心的執行緒數通常被限制在一個小數目。
GPU策略不同。GPU核心設計為同時執行多個執行緒,但一次只能從任何執行緒執行一條指令。另一種說法是GPU緩慢地執行每個執行緒,但總體上高效地執行執行緒。每個執行緒都可以容忍一定的記憶體延遲,因為有其他執行緒可以執行。
這樣做的缺點是需要多個多執行緒來覆蓋記憶體延遲。此外,如果記憶體存取線上程之間分散(scattered)或不是相關的(correlated),那麼記憶體系統在響應每個單獨的請求時會逐漸變慢,最終即使是多個執行緒也無法覆蓋延遲。因此,陷阱在於,對於「只使用更多執行緒」策略來覆蓋延遲,必須有足夠的執行緒,並且執行緒必須在記憶體存取的位置方面表現良好。
19.10 電源
本節著重闡述移動裝置的電源技術。

智慧手機已成為我們日常生活中不可替代的商品。無論是職業還是個人生活,每項任務都以某種方式或其他方式與這些裝置相關。為了滿足我們日益增長的依賴,這些智慧手機每天都在變得更加強大。強大的處理器、更多的儲存空間和改進的攝像頭是每個買家都想要的功能。
除了作業系統,消費者還使用各種應用程式,這些應用程式使用我們裝置的不同感測器和處理能力。所有這些過程都需要一個電源來執行,移動裝置中則是一個電池。這些電池必須不時充電,以保持流程正常執行。更長的電池壽命是選擇智慧手機的另一個重要標準,與電池壽命優化相關的技術發展速度與智慧手機行業的其他垂直行業不同。
通過硬體和軟體技術可以提高智慧手機的電池壽命。改變硬體可能意味著安裝更大的電池,但也意味著增加智慧手機的尺寸。設計高效的電源管理單元和高效的積體電路(IC)是一種可行的解決方案。此外,作業系統中管理電池密集型應用程式和明智使用可用電池的軟體改進也被視為該問題的另一個潛在解決方案。
下圖是一款行動式產品的電源管理:
智慧手機的耗電元件多種多樣,常見的如下圖所示:
19.10.1 電源硬體
不同的嵌入式系統、晶片、處理器和感測器整合在一起,同步工作,使這些移動裝置變得智慧。它的每個硬體裝置在執行時都會消耗電力。在所有這些電子模組中,收發器模組消耗最大的功率,因為它在很長時間內保持活動狀態以接收傳入的分組。已經討論了各種軟體技術來優化這些分組的資料傳輸。數位訊號處理器(DSP)是這些收發器模組的關鍵部件,它處理大量資料以供多媒體使用,降低DSP的電源電壓是降低功耗的直接方法。
為了延長電池壽命,智慧手機的DSP在通話期間需要低功耗和高吞吐量乘法累加(MAC),在等待期間需要低功率間歇操作。1V多閾值CMOS電路通過簡單的並行架構和使用嵌入式處理器的電源管理技術滿足這些要求,嵌入式處理器與適用於電源控制的改進DFF一起使用。
除了處理器和收發器,螢幕是電池電量的另一個主要消耗源。需要背光的LED螢幕更耗電,因此可以被更省電的顯示器(如OLED)取代,後者耗電更少。與LED和LCD顯示器不同,OLED不需要背光,OLED中的每個畫素都有自己獨立的顏色和光源。因此,OLED上的黑色影象將是完全黑色的,但LED和LCD的情況並非如此。
研究表明,隨著時間的推移,電池壽命的下降也可能是由於聚偏氟乙烯(PVDF)。PVDF是一種用於防止電池中石墨陽極剝落的粘合劑,不導電,並且由於粘附率差而溶解在電解質中。還存在一種新的n型共軛共聚物——雙亞氨基並萘醌對亞苯基(BP)粘合劑,其效能優於傳統的PVDF基粘合劑,延長了電池壽命,並防止了電池老化時的退化。
MC13892的電源結構圖。包含電池、介面控制等元件。
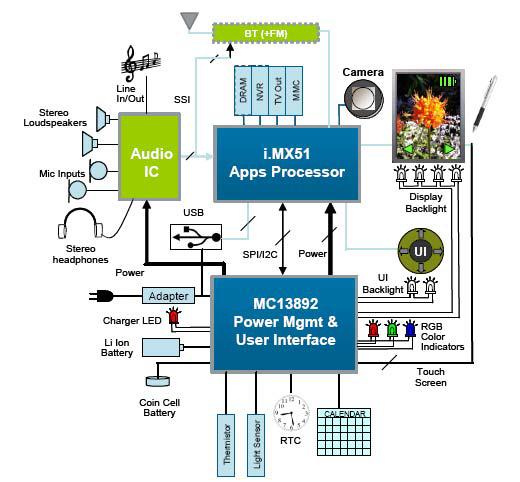
MC13892電源管理和使用者介面結構圖。
研究人員還提出了一種動態電源管理單元(Power Management Unit,PMU),它在智慧手機上執行不同應用程式時,收集處理器和輸入/輸出裝置的不同引數的資訊,然後PMU將基於收集的資訊提出預測功率感知管理方案。
一款名為nRF5340中的電源和時鐘管理系統針對超低功耗應用進行了優化,以確保最大功率效率。電源和時鐘管理系統的核心是電源管理單元(PMU),如下圖所示。

PMU在任何給定時間自動跟蹤系統中不同元件所需的電源和時鐘資源。為了實現可能的最低功耗,PMU通過評估電源和時鐘請求、自動啟動和停止時鐘源以及選擇調節器操作模式來優化系統。
PMU一般有系統開啟模式(System ON)、系統關閉(System OFF)、強制關閉(Force OFF)3個模式,具體詳情如下所述。
系統開啟(System ON)模式是通電覆位後的預設操作模式。在System ON(系統開啟)中,所有功能塊(如CPU和外圍裝置)都可以處於IDLE(空閒)或RUN(執行)狀態,取決於軟體設定的設定和正在執行的應用程式的狀態。網路核心的CPU和外圍裝置可以處於空閒狀態、執行狀態或強制關閉模式。
PMU可以根據電源要求開啟和關閉適當的內部電源。外圍裝置的電源需求與其活動級別直接相關,當觸發特定任務或生成事件時,活動級別會增加或減少。
-
電壓和頻率縮放。nRF5340自動調整內部電壓以優化功率效率。一些設定選項要求更高的內部電壓,被視為功耗的增加。這些設定如下:
- 將應用程式核心時鐘的頻率設定為128 MHz。當CPU休眠時,例如在執行WFI(等待中斷)或WFE(等待事件)指令後,也會觀察到此模式下的功耗增加。通過在進入CPU休眠之前將應用程式核心的時鐘設定為64 MHz,可以降低CPU和外圍裝置處於空閒狀態休眠時系統開啟期間的功耗。
- 使用96 MHz時脈頻率的QSPI。
- 使用USB外圍裝置。
- 偵錯時。
- 使用VREQCTRL請求VREGRADIO電源上的額外電壓-電壓請求控制。
-
電源子模式(Power submode)。在系統開啟模式下,當CPU和所有外圍裝置處於空閒狀態時,系統可以處於兩種電源子模式之一。
電源子模式包括:- 恆定延遲。在恆定延遲模式下,CPU喚醒延遲和PPI任務響應將保持恆定並保持在最小值,是由一組始終啟用的資源保護的。與低功耗模式相比,具有恆定和可預測的延遲的優勢是以增加功耗為代價的,通過觸發CONSTRAT任務選擇恆定延遲模式。
- 低功耗。在低功率模式下,自動電源管理系統選擇最省電的電源選項,實現最低功率是以CPU喚醒延遲和PPI任務響應的變化為代價的。通過觸發LOWPWR任務選擇低功率模式。
當系統進入system ON(系統開啟)時,預設為Low power(低功率)子模式。
系統關閉(System OFF)是系統可以進入的最深省電模式。在此模式下,系統的核心功能關閉,所有正在進行的任務都將終止。使用暫存器SYSTEMOFF將裝置置於System OFF(系統關閉)模式。以下操作將從System OFF(關閉)啟動喚醒:
- GPIO外圍裝置生成的DETECT訊號。
- LPCOMP外圍裝置生成的ANADETECT訊號。
- 由NFCT外圍裝置產生的SENSE訊號在現場喚醒。
- 檢測到VBUS引腳上的有效USB電壓。
- 偵錯對談已啟動。
- A引腳復位。
當裝置從系統關閉狀態喚醒時,將執行系統重置。根據外圍VMC-易失性記憶體控制器中的RAM保留設定,一個或多個RAM部分可以保留在系統關閉狀態。在進入系統關閉之前,當進入系統關閉時,啟用EasyDMA的外圍裝置不得處於活動狀態。還建議網路核心處於空閒狀態,意味著外圍裝置已停止,CPU處於空閒狀態。
強制關閉(Force-OFF)模式僅適用於網路核心。
應用程式核心使用暫存器介面RESET-RESET控制元件強制網路核心進入強制關閉模式。在此模式下,網路核心被停止,以實現可能的最低功耗。當網路核心處於強制關閉模式時,只有應用程式核心可以釋放該模式,導致網路核心喚醒並再次啟動CPU。
在應用程式核心將網路核心設定為強制關閉模式之前,建議網路核心處於IDLE狀態,如下所示:
- 所有外圍裝置均已停止。
- 使用VREQCTRL-電壓請求控制取消VREGRADIO電源上的附加電壓。
- CPU處於IDLE狀態,這意味著它正在執行WFI或WFE指令。
當網路核心從強制關閉模式喚醒時,它將被重置。根據外圍VMC-易失性記憶體控制器中的RAM保留設定,可以在強制關閉模式下保留幾個RAM部分。
19.10.2 電源軟體
具有更高處理能力和更快網際網路連線的現代智慧手機的巨大普及也增加了Android和iOS中資料和硬體密集型應用程式的數量,WhatsApp、Instagram、Skype等應用程式不僅需要CPU資源,還需要全天候的網際網路連線。研究表明,在空閒狀態下,網際網路使用約佔耗電量的62%。此外,與Wi-Fi相比,當頻繁交換小尺寸封包時,3G/4G消耗更多的電池。
資料壓縮、封包聚合和批次排程等多種軟體技術可用於優化電池壽命。智慧手機上不同應用程式的亂資料傳輸會消耗更多的電池,因此,可以使用批次處理排程機制通過應用程式重複傳輸資料來最大化睡眠時間並最小化喚醒頻率。
從3G/4G到Wi-Fi的資料解除安裝是提高電池壽命的另一種有效方式,因為Wi-Fi在資料傳輸方面比3G/4G更高效。另一種軟體技術是將更高的計算任務(如CPU密集型軟體)解除安裝到雲上進行計算。該策略可用於在移動裝置上執行Office 365和MATLAB等軟體,但這會增加雲與裝置之間的通訊成本。應用狀態代理(ASP)是另一種技術,其中不僅使用CPU資源而且還使用Internet資料的後臺應用程式被抑制並傳輸到另一裝置上,並且僅在請求時才被帶到裝置上。
智慧手機行業在處理能力和其他功能方面的進步速度遠快於電池,研究人員現在正專注於通過軟體和硬體手段來有效管理可用電池能量的電源管理技術,上述不同技術正被用於將智慧手機的電池壽命提高多倍。
將能耗分配給並行執行的應用程式具有挑戰性,因為功率狀態傳輸有時是不同應用程式動作的累積結果。
例如,假設當每秒傳送N個分組時,Wi-Fi介面從低功率狀態傳輸到高功率狀態。現在假設兩個應用程式以每秒N/2個封包的速度傳輸,導致Wi-Fi介面進入高功率狀態。類似地,設想一個應用程式以每秒N個封包的速度傳輸,另一個應用以每秒9N個資料。在這兩種情況下,Wi-Fi介面都處於高功率狀態,但不清楚如何為每個應用程式分配功率使用。在第一種情況下,兩個應用程式都不會單獨觸發高功率狀態,因此為它們充電有意義嗎?在第二種情況下,兩個應用程式都會觸發高功率狀態,因此應該大致相同的充電量,但應該是多少?
一種可能的解決方案是根據應用程式的工作負載在每個應用程式之間分配元件功率,意味著在第一種情況下,每個應用程式將被分配高功率狀態功率的一半,而在第二種情況下一個應用程式將分配1/10的功率,另一個將分配9/10的功率。該解決方案具有有利的性質,即應用程式功耗的總和等於全域性功耗。然而,這種解決方案是幼稚的,因為電力使用不是傳輸速率的線性函數,所以用這種方式來分解它沒有什麼意義。當我們考慮到Wi-Fi介面的功耗不是一個一維函數時,這個解決方案似乎更加可疑。
相反,我們需要一個獨立於每個元件的強大功能工作的解決方案,並且對應用程式開發人員(PowerTutor的主要目標使用者)來說是直觀的。對於每個元件,我們計算功耗,就像每個特定應用程式單獨執行一樣,意味著在情況1中,每個應用程式將為低功率Wi-Fi狀態充電,而在情況2中,每個應用將為高功率狀態充電。這就失去了應用程式功耗之和等於全域性功耗的良好特性(正如這兩個案例所說明的那樣,它既不是低估值,也不是高估值)。然而,通過這個定義,我們可以獨立於其他正在執行的應用程式來理解應用程式的功耗,使得PowerTutor的使用者可以觀察到類似的應用程式級功率特性,而不考慮資源共用:對於專注於優化特定應用程式的工程師來說是一個有用的特性。請注意,PowerTutor還報告了準確的系統級功耗。
PowerTutor介面。(a) 應用程式檢視。(b) 圖表檢視。(c) 餅狀檢視。圖中無意但不適當地使用智慧手機硬體元件。
此解決方案存在侷限性。第一,如果應用程式正在爭奪資源,那麼很難預測它們單獨執行時的行為。第二,在某些情況下,我們看到一個應用程式呼叫另一個來執行某項任務。在這種情況下,如何分配功耗尚不清楚。在真實的Android系統中,媒體伺服器程序經常發生這種行為。第三,使用巧妙技術的應用程式,如與其他應用程式同時進行傳輸,不會在該方案中獲得收益。然而,對於第一個案例,我們無能為力。解決其他兩個問題需要對所涉及的應用程式的語意有一個高層次的理解,這目前超出了我們工具的範圍。
下表顯示了ADP1和ADP2手機的內部和內部電源型號變化。型別內變化是由同一型別手機樣本的平均值歸一化的標準差,型別間差異是兩種型別手機的樣本均值之間的差異。注意,表中的功率模型引數也可以被視為特定工作負載的功率測量,即功率模型引數的變化與預測誤差線性相關。例如,對於使用音訊裝置的應用程式,我們預計使用為ADP1匯出的功率模型預測另一個ADP1的音訊裝置功耗時,預測誤差小於4%。這些資料為以下結論提供了一些支援。
Android系統中的圖形架構如下:
下圖顯示了DRS(Dynamic Resolution Scaling,動態解析度縮放)系統的架構。為了實現解析度縮放,在現有Android系統中新增了兩個新層:
- 第一層是DRS上層,位於應用層和OpenGL ES/EGL層之間,攔截必要的OpenGLES函數呼叫和EGL函數呼叫,以確保以適當的顯示解析度完成圖形渲染。它將縮放因子應用於必要的OpenGL ES/EGL函數呼叫的引數,以將預設顯示解析度轉換為目標解析度。
- 第二層是DRS下層,位於SurfaceFlinger層和Hardware Composer之間。該層攔截傳遞給硬體合成器的函數呼叫,以確保以正確的顯示解析度完成合成。第二層的作用是在DRS上層降低解析度後提高解析度,以便渲染的內容能夠以本地顯示解析度正確顯示在螢幕上。
這兩個DRS層彼此同步,以確保它們對BufferQueue中的相同圖形緩衝區使用相同的目標顯示解析度,此舉很有必要,因為如果使用者將目標顯示解析度更改為新值,DRS上層將開始使用新的縮放因子將圖形緩衝區生成到BufferQueue中。DRS下層需要確保舊的縮放因子用於先前生成的圖形緩衝區,並且新的縮放因子在合成期間僅應用於新生成的圖形緩衝器。
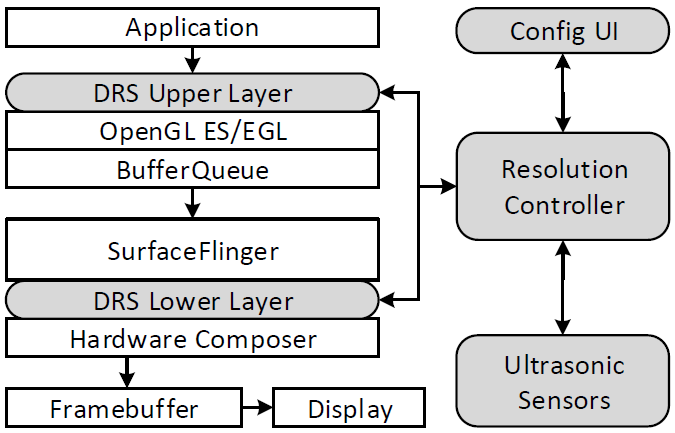
不同縮放因子下每幀遊戲和基準的標準化能量如下表:
從覆蓋率測試中的15個應用程式,包括14個遊戲和一個基準(上表中列出的名稱)來評估在不同的顯示解析度下可以節省多少電量。在S5手機上執行測試用例,並使用季風功率監視器測量系統功率,將手機切換到飛航模式,禁用不必要的硬體元件,如GPS和攝像頭,並將背光亮度設定為50%。將GPU頻率鎖定為500MHz,以避免GPU的DVFS推斷。在每次測試前都會對手機進行冷卻,以確保GPU能夠在500MHz下工作至少60秒。將每個測試重複三次,並報告平均結果。
採用每幀總系統能量(EPF)作為衡量標準來評估原型系統的節能。為了方便地比較不同的結果,將結果標準化為原生顯示解析度的情況。上表顯示了不同比例因子的歸一化EPF。縮放因子被歸一化為原生顯示解析度,即對於全解析度,縮放因子為1.0。當顯示解析度降低一半(即縮放因子為0.5,將顯示解析度從2560x1440畫素降低到1280x720畫素)時,對於16個測試用例,平均而言,可以將EPF降低30.1%,範圍從15.7%到60.5%。對於這14款遊戲,無論縮放因子是什麼值,它們總是以固定的幀速率執行。因此,在實踐中可以實現相同的功耗節省量(如果僅計算這14款比賽,則為24.9%)。對於兩種GFXBench情況,由於基準測試總是試圖用盡所有GPU處理能力,因此其功耗在所有縮放因子中幾乎保持不變。然而,解析度會極大地影響幀速率。對於較小的縮放因子,它們可以以較高的幀速率執行,從而提供更好的使用者體驗。
19.10.3 電源優化
在開始應用程式開發之前,分析並定義應用程式的需求、範圍和功能,以確保高效的功能和流暢的使用者體驗。為單一目的設計應用程式,並分析它如何最好地為使用者服務。
以下指南幫助您設計和開發適用於具有不同特性(如螢幕大小和輸入法支援)的移動裝置的應用程式:
- 瞭解目標使用者。瞭解誰將使用該應用程式,他們將使用它做什麼,以及擁有哪些移動裝置,然後設計應用程式以適應特定的使用環境。
- 小螢幕設計。移動裝置的螢幕尺寸明顯小於桌面裝置的螢幕大小。仔細考量在應用程式UI上顯示的最相關的內容是什麼,因為在桌面應用程式中嘗試將盡可能多的內容放入螢幕可能是不合理的。
- 多種螢幕尺寸的設計。將每個控制元件的位置和大小與顯示器的尺寸相關聯,使得同一組資訊能夠以所有解析度顯示在螢幕上,更高解析度的裝置只顯示更精細的圖形。
- 更改螢幕方向的設計。某些裝置支援螢幕旋轉,在這些裝置上,應用程式可以縱向或橫向顯示,考慮方向並在螢幕旋轉時動態調整顯示。
- 設計在應用程式中移動的直觀方式。移動裝置缺少滑鼠和全尺寸鍵盤,因此使用者必須使用觸控式螢幕或五嚮導航板在應用程式中移動,此外,許多使用者用一隻手控制裝置。要建立優化的使用者體驗,允許使用者一鍵存取資訊,不要讓它們捲動和鍵入。
- 有限輸入法設計。應用程式從使用者那裡收集有關手頭任務的資訊。除了觸控式螢幕輸入,一些裝置還包含物理鍵,如五嚮導航板、鍵盤和鍵盤。使用者通過使用螢幕控制元件(如列表、核取方塊、無線電鈕和文字欄位)輸入資訊。
- 縮短響應時間。延遲可能會導致使用者互動延遲。如果使用者認為某個應用程式速度慢,他們很可能會感到沮喪並停止使用它。
- 節省電池時間。移動裝置不總是連線到電源,而是依靠電池供電。優化功耗以將總功耗保持在可接受的水平,並防止使用者耗盡電池時間。
- 考慮網路問題。如果使用者沒有固定費率的資料計劃或WLAN支援,行動網路連線會讓他們花錢。此外,當用戶帶著裝置四處移動時,可用於連線的網路會不斷變化。
- 記住裝置的處理限制。裝置上可用的記憶體有限,應謹慎使用。儘管所有移動裝置都具有通用功能,但就可用資源和額外功能而言,每個裝置都是獨立的,因此必須考慮所有目標裝置的約束。
- 最大限度地提高應用程式的效率和電池壽命。
- 優化切換器效率(針對大部分時間使用處理器的地方)。
- 使用PFM、PWM-PS提高低功率條件下的效率。
- 最小化物料清單(BOM)成本和麵積。
- 電池技術(1、2或3個鋰離子電池)。
- 保持功耗在應用範圍內。
- 軟體驅動程式支援。
- 靈活的加電順序/預設電壓,支援多處理器和外圍裝置。
- PMIC內部或外部音訊。內部優勢:降低成本,節省電路板空間,外部優勢:噪音更小、更靈活。
- 使用動態解析度。詳見上節。
高通採用了整體系統方法,通過客製化關鍵技術塊和整個片上系統(SoC)來實現節能。
該系統方法涉及四個關鍵級別的功率和熱量優化:
-
專用處理引擎。客製化設計專用處理引擎和其他關鍵元件,如電源管理積體電路(PMIC)、射頻(RF)晶片等。
-
微架構。
aSMP和其它典型的SMP實現。
-
電路設計。
-
電晶體級別設計。
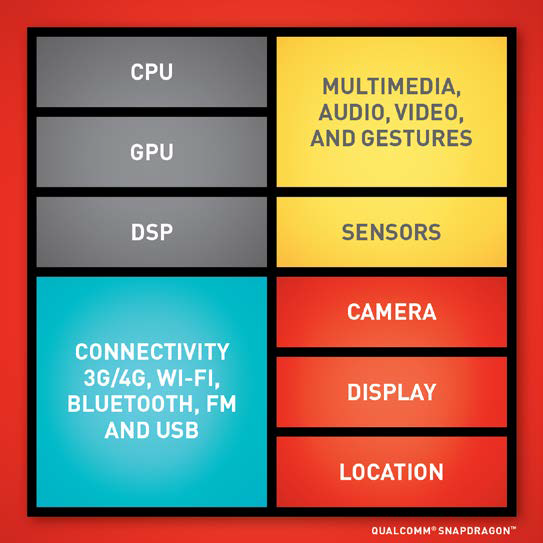
驍龍SoC內的處理引擎。
-
-
智慧整合。巧妙地整合了技術塊並設計了系統架構。
- 系統結構/互連。
- 快取和記憶體設計。
- 軟體與硬體加速。
-
優化系統軟體。將軟體與硬體緊密結合。
- 軟體工具和API。
- 軟體、OS和編譯器優化。
- 電源和熱量演演算法。
-
裝置級優化。仔細考量移動裝置上的所有其他元件,並優化了整個解決方案的操作。
- 電源和熱量模型。
- 裝置元件優化。
- OEM最佳實踐。
為了解決在具有功率和熱量限制的裝置中提供更高效能的日益增加的挑戰,以移動為中心的設計方法至關重要。高通採用整體系統方法進行電源和熱管理,其移動SoC通過設計專門的處理引擎,巧妙地整合它們,並優化系統軟體和整個裝置,實現了功率和熱效率的最佳平衡,使移動裝置能夠提供最佳的使用者體驗。
關於電源技術的更多詳情可參閱:
19.11 UE硬體
本章節將基於UE 5.1的原始碼解析涉及的硬體介面和邏輯。
19.11.1 CPU
下面的介面可以計算CPU的效能等級等引數:
// GenericPlatformSurvey.h
struct FSynthBenchmarkResults
{
FSynthBenchmarkStat CPUStats[2];
// 計算CPU效能等級,100表明是平局等級的CPU, 小於100更慢, 大於100更快。
float ComputeCPUPerfIndex(TArray<float>* OutIndividualResults = nullptr) const;
};
下面的介面可以追蹤CPU的效能,包含追蹤資料、利用率、分析器等:
// CpuProfilerTrace.h
struct FCpuProfilerTrace
{
static uint32 OutputEventType(const ANSICHAR* Name, const ANSICHAR* File = nullptr, uint32 Line = 0);
static uint32 OutputEventType(const TCHAR* Name, const ANSICHAR* File = nullptr, uint32 Line = 0);
static void OutputBeginEvent(uint32 SpecId);
static void OutputBeginDynamicEvent(const ANSICHAR* Name, const ANSICHAR* File = nullptr, uint32 Line = 0);
static void OutputBeginDynamicEvent(const TCHAR* Name, const ANSICHAR* File = nullptr, uint32 Line = 0);
static void OutputBeginDynamicEvent(const FName& Name, const ANSICHAR* File = nullptr, uint32 Line = 0);
static void OutputEndEvent();
static void OutputResumeEvent(uint64 SpecId, uint32& TimerScopeDepth);
static void OutputSuspendEvent();
class FEventScope
{
(...)
};
struct FDynamicEventScope
{
(...)
};
(...)
};
// CpuProfilerTraceAnalysis.h
class FCpuProfilerAnalyzer : public UE::Trace::IAnalyzer
{
public:
virtual void OnAnalysisBegin(const FOnAnalysisContext& Context) override;
virtual void OnAnalysisEnd(/*const FOnAnalysisEndContext& Context*/) override;
virtual bool OnEvent(uint16 RouteId, EStyle Style, const FOnEventContext& Context) override;
private:
IAnalysisSession& Session;
IEditableTimingProfilerProvider& EditableTimingProfilerProvider;
IEditableThreadProvider& EditableThreadProvider;
TMap<uint32, FThreadState*> ThreadStatesMap;
TMap<uint32, uint32> SpecIdToTimerIdMap;
TMap<const TCHAR*, uint32> ScopeNameToTimerIdMap;
uint32 CoroutineTimerId = ~0;
uint32 CoroutineUnknownTimerId = ~0;
uint64 TotalEventSize = 0;
uint64 TotalScopeCount = 0;
double BytesPerScope = 0.0;
(...)
};
以下介面包含CPU的時鐘、頻率、親緣性等資訊和介面:
// GenericPlatformTime.h
// 包含CPU利用率資料
struct FCPUTime
{
float CPUTimePct; // 上一個間隔的CPU利用率百分比。
float CPUTimePctRelative; // 上一個間隔相對於一個核心的CPU利用率百分比,因此如果CPUTimePct為8.0%,而裝置有6個核心,則該值將為48.0%。
};
// 時間
struct FGenericPlatformTime
{
// 時間、時鐘、頻率等介面
static TCHAR* StrDate( TCHAR* Dest, SIZE_T DestSize );
static TCHAR* StrTime( TCHAR* Dest, SIZE_T DestSize );
static const TCHAR* StrTimestamp();
static FString PrettyTime( double Seconds );
static bool UpdateCPUTime( float DeltaTime );
static bool UpdateThreadCPUTime(float = 0.0);
static void AutoUpdateGameThreadCPUTime(double UpdateInterval);
static FCPUTime GetCPUTime();
static FCPUTime GetThreadCPUTime();
static double GetLastIntervalCPUTimeInSeconds();
static double GetLastIntervalThreadCPUTimeInSeconds();
static double GetSecondsPerCycle();
static float ToMilliseconds( const uint32 Cycles );
static float ToSeconds( const uint32 Cycles );
static double GetSecondsPerCycle64();
static double ToMilliseconds64(const uint64 Cycles);
static double ToSeconds64(const uint64 Cycles);
(...)
protected:
static double SecondsPerCycle;
static double SecondsPerCycle64;
static double LastIntervalCPUTimeInSeconds;
};
// PlatformAffinity.h
struct FThreadAffinity
{
uint64 ThreadAffinityMask = FPlatformAffinity::GetNoAffinityMask();
uint16 ProcessorGroup = 0;
};
19.11.2 記憶體
以下程式碼包含記憶體的硬體資訊、分配、快取、池化等介面:
// GenericPlatformMemory.h
struct FGenericPlatformMemory
{
static bool bIsOOM; // 是否記憶體不足
static uint64 OOMAllocationSize; // 設定為觸發記憶體不足的分配大小,否則為零.
static uint32 OOMAllocationAlignment; // 設定為觸發記憶體不足的分配對齊,否則為零。
static void* BackupOOMMemoryPool; // 記憶體不足時要刪除的預分配緩衝區。用於OOM處理和崩潰報告。
static uint32 BackupOOMMemoryPoolSize; // BackupOOMMemoryPool的大小(位元組)。
// 可用於記憶體統計的各種記憶體區域。列舉的確切含義相對依賴於平臺,儘管一般的(物理、GPU)很簡單。一個平臺可以新增更多的記憶體,並且不會影響其他平臺,除了StatManager跟蹤每個區域的最大可用記憶體(使用陣列FPlatformMemory::MCR_max big)所需的少量記憶體之外.
enum EMemoryCounterRegion
{
MCR_Invalid, // not memory
MCR_Physical, // main system memory
MCR_GPU, // memory directly a GPU (graphics card, etc)
MCR_GPUSystem, // system memory directly accessible by a GPU
MCR_TexturePool, // presized texture pools
MCR_StreamingPool, // amount of texture pool available for streaming.
MCR_UsedStreamingPool, // amount of texture pool used for streaming.
MCR_GPUDefragPool, // presized pool of memory that can be defragmented.
MCR_PhysicalLLM, // total physical memory including CPU and GPU
MCR_MAX
};
// 使用的分配器.
enum EMemoryAllocatorToUse
{
Ansi, // Default C allocator
Stomp, // Allocator to check for memory stomping
TBB, // Thread Building Blocks malloc
Jemalloc, // Linux/FreeBSD malloc
Binned, // Older binned malloc
Binned2, // Newer binned malloc
Binned3, // Newer VM-based binned malloc, 64 bit only
Platform, // Custom platform specific allocator
Mimalloc, // mimalloc
};
static EMemoryAllocatorToUse AllocatorToUse;
enum ESharedMemoryAccess
{
Read = (1 << 1),
Write = (1 << 2)
};
// 共用記憶體區域的通用表示
struct FSharedMemoryRegion
{
TCHAR Name[MaxSharedMemoryName];
uint32 AccessMode;
void * Address;
SIZE_T Size;
};
// 記憶體操作.
static void Init();
static void OnOutOfMemory(uint64 Size, uint32 Alignment);
static void SetupMemoryPools();
static uint32 GetBackMemoryPoolSize()
static FMalloc* BaseAllocator();
static FPlatformMemoryStats GetStats();
static uint64 GetMemoryUsedFast();
static void GetStatsForMallocProfiler( FGenericMemoryStats& out_Stats );
static const FPlatformMemoryConstants& GetConstants();
static uint32 GetPhysicalGBRam();
static bool PageProtect(void* const Ptr, const SIZE_T Size, const bool bCanRead, const bool bCanWrite);
// 分配.
static void* BinnedAllocFromOS( SIZE_T Size );
static void BinnedFreeToOS( void* Ptr, SIZE_T Size );
static void NanoMallocInit();
static bool PtrIsOSMalloc( void* Ptr);
static bool IsNanoMallocAvailable();
static bool PtrIsFromNanoMalloc( void* Ptr);
// 虛擬記憶體塊及操作.
class FBasicVirtualMemoryBlock
{
protected:
void *Ptr;
uint32 VMSizeDivVirtualSizeAlignment;
public:
FBasicVirtualMemoryBlock(const FBasicVirtualMemoryBlock& Other) = default;
FBasicVirtualMemoryBlock& operator=(const FBasicVirtualMemoryBlock& Other) = default;
FORCEINLINE uint32 GetActualSizeInPages() const;
FORCEINLINE void* GetVirtualPointer() const;
void Commit(size_t InOffset, size_t InSize);
void Decommit(size_t InOffset, size_t InSize);
void FreeVirtual();
void CommitByPtr(void *InPtr, size_t InSize);
void DecommitByPtr(void *InPtr, size_t InSize);
void Commit();
void Decommit();
size_t GetActualSize() const;
static FPlatformVirtualMemoryBlock AllocateVirtual(size_t Size, ...);
static size_t GetCommitAlignment();
static size_t GetVirtualSizeAlignment();
};
// 資料和偵錯
static bool BinnedPlatformHasMemoryPoolForThisSize(SIZE_T Size);
static void DumpStats( FOutputDevice& Ar );
static void DumpPlatformAndAllocatorStats( FOutputDevice& Ar );
static EPlatformMemorySizeBucket GetMemorySizeBucket();
// 記憶體資料操作.
static void* Memmove( void* Dest, const void* Src, SIZE_T Count );
static int32 Memcmp( const void* Buf1, const void* Buf2, SIZE_T Count );
static void* Memset(void* Dest, uint8 Char, SIZE_T Count);
static void* Memzero(void* Dest, SIZE_T Count);
static void* Memcpy(void* Dest, const void* Src, SIZE_T Count);
static void* BigBlockMemcpy(void* Dest, const void* Src, SIZE_T Count);
static void* StreamingMemcpy(void* Dest, const void* Src, SIZE_T Count);
static void* ParallelMemcpy(void* Dest, const void* Src, SIZE_T Count, EMemcpyCachePolicy Policy = EMemcpyCachePolicy::StoreCached);
(...)
};
// 結構用於儲存所有平臺的通用記憶體常數。這些值不會在可執行檔案的整個生命週期內發生變化。
struct FGenericPlatformMemoryConstants
{
// 實際實體記憶體量,以位元組為單位(對於執行32位元程式碼的64位元裝置,需要處理>4GB)。
uint64 TotalPhysical;
// 虛擬記憶體量,以位元組為單位
uint64 TotalVirtual;
// 物理頁面的大小,以位元組為單位,也是物理RAM的PageProtection()、提交和屬性(例如存取能力)的粒度。
SIZE_T PageSize;
// 如果記憶體以大於PageSize的塊分配,則某些平臺具有優勢(例如VirtualAlloc()目前的粒度似乎為64KB),該值是系統將在後臺使用的最小分配大小。
SIZE_T OsAllocationGranularity;
// Binned2 malloc術語中「頁面」的大小,以位元組為單位,至少為64KB。BinnedMloc希望從BinnedAllocFromOS()返回的記憶體與BinnedPageSize邊界對齊。
SIZE_T BinnedPageSize;
// BinnedMalloc術語中的「分配粒度」,即BinnedMlloc將以該值的增量分配記憶體。如果為0,Binned將對此值使用BinnedPageSize.
SIZE_T BinnedAllocationGranularity;
// AddressLimit-第二個引數是BinnedAllocFromOS()預期返回的地址範圍的估計值。Binned Malloc將調整其內部結構,以查詢此範圍的記憶體分配O(1)。超出這個範圍是可以的,查詢會稍微慢一點
uint64 AddressLimit;
// 近似物理RAM(GB),除PC外的所有裝置上都有1。用於「course tuning」,如FPlatformMisc::NumberOfCores()。
uint32 TotalPhysicalGB;
};
// 用於儲存所有平臺的通用記憶體統計資訊,可能會在可執行檔案的整個生命週期內發生變化。
struct FGenericPlatformMemoryStats : public FPlatformMemoryConstants
{
// 當前可用的實體記憶體量,以位元組為單位。
uint64 AvailablePhysical;
// 當前可用的虛擬記憶體量(位元組)。
uint64 AvailableVirtual;
// 程序使用的實體記憶體量,以位元組為單位。
uint64 UsedPhysical;
// 程序使用的實體記憶體的峰值量,以位元組為單位
uint64 PeakUsedPhysical;
// 程序使用的虛擬記憶體總量。
uint64 UsedVirtual;
// 程序使用的虛擬記憶體的峰值量。
uint64 PeakUsedVirtual;
// 記憶體壓力狀態,適用於可用記憶體估計可能不考慮關閉非活動程序或訴諸交換可回收記憶體的平臺。
enum class EMemoryPressureStatus : uint8
{
Unknown,
Nominal,
Critical, // OOM(Out Of Memory)條件的高風險
};
EMemoryPressureStatus GetMemoryPressureStatus();
struct FPlatformSpecificStat
{
const TCHAR* Name;
uint64 Value;
};
TArray<FPlatformSpecificStat> GetPlatformSpecificStats() const;
uint64 GetAvailablePhysical(bool bExcludeExtraDevMemory) const;
// 由FCsvProfiler::EndFrame呼叫以設定特定於平臺的CSV統計資訊。
void SetEndFrameCsvStats() const {}
};
以下介面指示了D3D12的某些資源是CPU或GPU的可讀可寫性:
// D3D12Util.h
inline bool IsCPUWritable(D3D12_HEAP_TYPE HeapType, const D3D12_HEAP_PROPERTIES *pCustomHeapProperties = nullptr);
inline bool IsGPUOnly(D3D12_HEAP_TYPE HeapType, const D3D12_HEAP_PROPERTIES *pCustomHeapProperties = nullptr);
inline bool IsCPUAccessible(D3D12_HEAP_TYPE HeapType, const D3D12_HEAP_PROPERTIES* pCustomHeapProperties = nullptr);
以下程式碼是記憶體追蹤相關的型別和介面:
// MemoryTrace.h
enum EMemoryTraceRootHeap : uint8
{
SystemMemory, // RAM
VideoMemory, // VRAM
EndHardcoded = VideoMemory,
EndReserved = 15
};
// 追蹤堆標記。
enum class EMemoryTraceHeapFlags : uint16
{
None = 0,
Root = 1 << 0,
NeverFrees = 1 << 1, // The heap doesn't free (e.g. linear allocator)
};
ENUM_CLASS_FLAGS(EMemoryTraceHeapFlags);
enum class EMemoryTraceHeapAllocationFlags : uint8
{
None = 0,
Heap = 1 << 0, // Is a heap, can be used to unmark alloc as heap.
};
ENUM_CLASS_FLAGS(EMemoryTraceHeapAllocationFlags);
class FMalloc* MemoryTrace_Create(class FMalloc* InMalloc);
void MemoryTrace_Initialize();
HeapId MemoryTrace_HeapSpec(HeapId ParentId, const TCHAR* Name, EMemoryTraceHeapFlags Flags = EMemoryTraceHeapFlags::None);
HeapId MemoryTrace_RootHeapSpec(const TCHAR* Name, EMemoryTraceHeapFlags Flags = EMemoryTraceHeapFlags::None);
void MemoryTrace_MarkAllocAsHeap(uint64 Address, HeapId Heap, ...);
void MemoryTrace_UnmarkAllocAsHeap(uint64 Address, HeapId Heap);
void MemoryTrace_Alloc(uint64 Address, uint64 Size, uint32 Alignment, HeapId RootHeap = EMemoryTraceRootHeap::SystemMemory);
void MemoryTrace_Free(uint64 Address, HeapId RootHeap = EMemoryTraceRootHeap::SystemMemory);
void MemoryTrace_ReallocFree(uint64 Address, HeapId RootHeap = EMemoryTraceRootHeap::SystemMemory);
void MemoryTrace_ReallocAlloc(uint64 Address, uint64 NewSize, uint32 Alignment, HeapId RootHeap = EMemoryTraceRootHeap::SystemMemory);
(...)
以下程式碼涉及了GPU資源陣列的操作:
// ResourceArray.h
// 資源陣列的獨立於元素型別的介面。
class FResourceArrayInterface
{
public:
virtual const void* GetResourceData() const = 0;
virtual uint32 GetResourceDataSize() const = 0;
virtual void Discard() = 0;
virtual bool IsStatic() const = 0;
virtual bool GetAllowCPUAccess() const = 0;
virtual void SetAllowCPUAccess( bool bInNeedsCPUAccess ) = 0;
};
// 允許直接為批次資源型別分配GPU記憶體。
class FResourceBulkDataInterface
{
public:
virtual const void* GetResourceBulkData() const = 0;
virtual uint32 GetResourceBulkDataSize() const = 0;
virtual void Discard() = 0;
enum class EBulkDataType
{
Default,
MediaTexture,
VREyeBuffer,
};
virtual EBulkDataType GetResourceType() const;
};
// 允許直接為紋理資源分配GPU記憶體。
class FTexture2DResourceMem : public FResourceBulkDataInterface
{
public:
virtual void* GetMipData(int32 MipIdx) = 0;
virtual int32 GetNumMips() = 0;
virtual int32 GetSizeX() = 0;
virtual int32 GetSizeY() = 0;
virtual bool IsValid() = 0;
virtual bool HasAsyncAllocationCompleted() const = 0;
virtual void FinishAsyncAllocation() = 0;
virtual void CancelAsyncAllocation() = 0;
};
以下是作業系統頁快取分配器:
// CachedOSPageAllocator.h
struct FCachedOSPageAllocator
{
protected:
struct FFreePageBlock
{
void* Ptr;
SIZE_T ByteSize;
};
void* AllocateImpl(SIZE_T Size, uint32 CachedByteLimit, FFreePageBlock* First, FFreePageBlock* Last, ...);
void FreeImpl(void* Ptr, SIZE_T Size, uint32 NumCacheBlocks, uint32 CachedByteLimit, FFreePageBlock* First, ...);
void FreeAllImpl(FFreePageBlock* First, uint32& FreedPageBlocksNum, SIZE_T& CachedTotal, FCriticalSection* Mutex);
};
template <uint32 NumCacheBlocks, uint32 CachedByteLimit>
struct TCachedOSPageAllocator : private FCachedOSPageAllocator
{
void* Allocate(SIZE_T Size, uint32 AllocationHint = 0, FCriticalSection* Mutex = nullptr);
void Free(void* Ptr, SIZE_T Size, FCriticalSection* Mutex = nullptr, bool ThreadIsTimeCritical = false);
void FreeAll(FCriticalSection* Mutex = nullptr);
void UpdateStats();
uint64 GetCachedFreeTotal();
private:
FFreePageBlock FreedPageBlocks[NumCacheBlocks*2];
SIZE_T CachedTotal;
uint32 FreedPageBlocksNum;
};
// CachedOSVeryLargePageAllocator.h
// 超大頁面的快取分配器。
class FCachedOSVeryLargePageAllocator
{
// 將地址空間設定為所需的兩倍,並將第一個用於小池分配,第二個用於仍為==SizeOfSubPage的其他分配
#if UE_VERYLARGEPAGEALLOCATOR_TAKEONALL64KBALLOCATIONS
static constexpr uint64 AddressSpaceToReserve = ((1024LL * 1024LL * 1024LL) * UE_VERYLARGEPAGEALLOCATOR_RESERVED_SIZE_IN_GB * 2LL);
static constexpr uint64 AddressSpaceToReserveForSmallPool = AddressSpaceToReserve/2;
#else
static constexpr uint64 AddressSpaceToReserve = ((1024 * 1024 * 1024LL) * UE_VERYLARGEPAGEALLOCATOR_RESERVED_SIZE_IN_GB);
static constexpr uint64 AddressSpaceToReserveForSmallPool = AddressSpaceToReserve;
#endif
static constexpr uint64 SizeOfLargePage = (UE_VERYLARGEPAGEALLOCATOR_PAGESIZE_KB * 1024);
static constexpr uint64 SizeOfSubPage = (1024 * 64);
static constexpr uint64 NumberOfLargePages = (AddressSpaceToReserve / SizeOfLargePage);
static constexpr uint64 NumberOfSubPagesPerLargePage = (SizeOfLargePage / SizeOfSubPage);
public:
void* Allocate(SIZE_T Size, uint32 AllocationHint = 0, FCriticalSection* Mutex = nullptr);
void Free(void* Ptr, SIZE_T Size, FCriticalSection* Mutex = nullptr, bool ThreadIsTimeCritical = false);
void FreeAll(FCriticalSection* Mutex = nullptr);
void UpdateStats();
uint64 GetCachedFreeTotal();
bool IsPartOf(const void* Ptr);
private:
(...)
FLargePage* FreeLargePagesHead[FMemory::AllocationHints::Max]; // no backing store
FLargePage* UsedLargePagesHead[FMemory::AllocationHints::Max]; // has backing store and is full
FLargePage* UsedLargePagesWithSpaceHead[FMemory::AllocationHints::Max]; // has backing store and still has room
FLargePage* EmptyButAvailableLargePagesHead[FMemory::AllocationHints::Max]; // has backing store and is empty
FLargePage LargePagesArray[NumberOfLargePages];
TCachedOSPageAllocator<CACHEDOSVERYLARGEPAGEALLOCATOR_MAX_CACHED_OS_FREES, CACHEDOSVERYLARGEPAGEALLOCATOR_BYTE_LIMIT> CachedOSPageAllocator;
};
CORE_API extern bool GEnableVeryLargePageAllocator;
// PooledVirtualMemoryAllocator.h
// 此Class將從FMallocBinned2進行的OS分配彙集在一起。
struct FPooledVirtualMemoryAllocator
{
void* Allocate(SIZE_T Size, uint32 AllocationHint = 0, FCriticalSection* Mutex = nullptr);
void Free(void* Ptr, SIZE_T Size, FCriticalSection* Mutex = nullptr, bool ThreadIsTimeCritical = false);
void FreeAll(FCriticalSection* Mutex = nullptr);
// 描述特定大小池的結構
struct FPoolDescriptorBase
{
FPoolDescriptorBase* Next;
SIZE_T VMSizeDivVirtualSizeAlignment;
};
uint64 GetCachedFreeTotal();
void UpdateStats();
private:
enum Limits
{
NumAllocationSizeClasses = 64,
MaxAllocationSizeToPool = NumAllocationSizeClasses * 65536,
MaxOSAllocCacheSize = 64 * 1024 * 1024,
MaxOSAllocsCached = 64
};
int32 GetAllocationSizeClass(SIZE_T Size);
SIZE_T CalculateAllocationSizeFromClass(int32 Class);
int32 NextPoolSize[Limits::NumAllocationSizeClasses];
FPoolDescriptorBase* ClassesListHeads[Limits::NumAllocationSizeClasses];
FCriticalSection ClassesLocks[Limits::NumAllocationSizeClasses];
void DecideOnTheNextPoolSize(int32 SizeClass, bool bGrowing);
FPoolDescriptorBase* CreatePool(SIZE_T AllocationSize, int32 NumPooledAllocations);
void DestroyPool(FPoolDescriptorBase* Pool);
FCriticalSection OsAllocatorCacheLock;
TCachedOSPageAllocator<MaxOSAllocsCached, MaxOSAllocCacheSize> OsAllocatorCache;
};
以下是虛擬記憶體分配器:
// VirtualAllocator.h
class FVirtualAllocator
{
struct FFreeLink
{
void *Ptr = nullptr;
FFreeLink* Next = nullptr;
};
struct FPerBlockSize
{
int64 AllocBlocksSize = 0;
int64 FreeBlocksSize = 0;
FFreeLink* FirstFree = nullptr;
};
FCriticalSection CriticalSection;
uint8* LowAddress;
uint8* HighAddress;
size_t TotalSize;
size_t PageSize;
size_t MaximumAlignment;
uint8* NextAlloc;
FFreeLink* RecycledLinks;
int64 LinkSize;
bool bBacksMalloc;
FPerBlockSize Blocks[64];
void FreeVirtualByBlock(void* Ptr, FPerBlockSize& Block, size_t AlignedSize);
protected:
size_t SpaceConsumed;
virtual uint8* AllocNewVM(size_t AlignedSize)
{
uint8* Result = NextAlloc;
check(IsAligned(Result, MaximumAlignment) && IsAligned(AlignedSize, MaximumAlignment));
NextAlloc = Result + AlignedSize;
SpaceConsumed = NextAlloc - LowAddress;
return Result;
}
public:
uint32 GetPagesForSizeAndAlignment(size_t Size, size_t Alignment = 1) const;
void* AllocateVirtualPages(uint32 NumPages, size_t AlignmentForCheck = 1);
void FreeVirtual(void* Ptr, uint32 NumPages);
struct FVirtualAllocatorStatsPerBlockSize
{
size_t AllocBlocksSize;
size_t FreeBlocksSize;
};
struct FVirtualAllocatorStats
{
size_t PageSize;
size_t MaximumAlignment;
size_t VMSpaceTotal;
size_t VMSpaceConsumed;
size_t VMSpaceConsumedPeak;
size_t FreeListLinks;
FVirtualAllocatorStatsPerBlockSize BlockStats[64];
};
void GetStats(FVirtualAllocatorStats& OutStats);
};
19.11.3 GPU
下面的介面可以計算GPU的效能等級等引數:
// GenericPlatformSurvey.h
struct FSynthBenchmarkResults
{
FSynthBenchmarkStat GPUStats[7];
// 計算GPU效能等級,100表明是平局等級的CPU, 小於100更慢, 大於100更快。
float ComputeGPUPerfIndex(TArray<float>* OutIndividualResults = nullptr) const;
// 以秒為單位返回,用於檢查基準測試是否耗時過長(硬體速度非常慢,不要使用大型WorkScale進行測試).
float ComputeTotalGPUTime() const;
};
// GPU介面卡
struct FGPUAdpater
{
static const uint32 MaxStringLength = 260;
// 名稱
TCHAR AdapterName[MaxStringLength];
// 內部驅動版本
TCHAR AdapterInternalDriverVersion[MaxStringLength];
// 使用者驅動版本
TCHAR AdapterUserDriverVersion[MaxStringLength];
// 額外的資料
TCHAR AdapterDriverDate[MaxStringLength];
// 介面卡專用的記憶體
TCHAR AdapterDedicatedMemoryMB[MaxStringLength];
};
下面程式碼涉及了GPU驅動相關的資訊和操作:
// GenericPlatformDriver.h
// GPU驅動資訊。
struct FGPUDriverInfo
{
// DirectX VendorId,0(如果未設定),請使用以下函數設定/獲取
uint32 VendorId;
// e.g. "NVIDIA GeForce GTX 680" or "AMD Radeon R9 200 / HD 7900 Series"
FString DeviceDescription;
// e.g. "NVIDIA" or "Advanced Micro Devices, Inc."
FString ProviderName;
// e.g. "15.200.1062.1004"(AMD)
// e.g. "9.18.13.4788"(NVIDIA)
// 第一個數位是Windows版本(例如7:Vista、6:XP、4:Me、9:Win8(1)、10:Win7),最後5個數位編碼了UserDriver版本,也稱為技術版本號(https://wiki.mozilla.org/Blocklisting/Blocked_Graphics_Drivers)如果驅動程式檢測失敗,則TEXT("Unknown")
FString InternalDriverVersion;
// e.g. "Catalyst 15.7.1"(AMD) or "Crimson 15.7.1"(AMD) or "347.88"(NVIDIA)
// 也稱為商業版本號
FString UserDriverVersion;
// e.g. 3-13-2015
FString DriverDate;
// e.g. D3D11, D3D12
FString RHIName;
bool IsValid() const;
// get VendorId
bool IsAMD() const { return VendorId == 0x1002; }
// get VendorId
bool IsIntel() const { return VendorId == 0x8086; }
// get VendorId
bool IsNVIDIA() const { return VendorId == 0x10DE; }
bool IsSameDriverVersionGeneration(const TCHAR* InOpWithMultiInt) const;
static FString TrimNVIDIAInternalVersion(const FString& InternalVersion);
FString GetUnifiedDriverVersion() const;
};
// Hardware.ini檔案中的一個條目
struct FDriverDenyListEntry
{
// optional, e.g. "<=223.112.21.1", might includes comparison operators, later even things multiple ">12.22 <=12.44"
FString DriverVersionString;
// optional, e.g. "<=MM-DD-YYYY"
FString DriverDateString;
// optional, e.g. "D3D11", "D3D12"
FString RHIName;
// required
FString Reason;
void LoadFromINIString(const TCHAR* In);
bool IsValid() const;
bool IsLatestDenied() const;
};
// GPU硬體資訊
struct FGPUHardware
{
const FGPUDriverInfo DriverInfo;
FString GetSuggestedDriverVersion(const FString& InRHIName) const;
FDriverDenyListEntry FindDriverDenyListEntry() const;
bool IsLatestDenied() const;
FString GetVendorSectionName() const;
};
下面程式碼是GPU的裝箱分配器:
// MallocBinnedGPU.h
class FMallocBinnedGPU final : public FMalloc
{
struct FGPUMemoryBlockProxy
{
uint8 MemoryModifiedByCPU[32 - sizeof(void*)]; // might be modified for free list links, etc
void *GPUMemory; // pointer to the actual GPU memory, which we cannot modify with the CPU
};
struct FFreeBlock
{
uint16 BlockSizeShifted; // Size of the blocks that this list points to >> ArenaParams.MinimumAlignmentShift
uint8 PoolIndex; // Index of this pool
uint8 Canary; // Constant value of 0xe3
uint32 NumFreeBlocks; // Number of consecutive free blocks here, at least 1.
FFreeBlock* NextFreeBlock; // Next free block or nullptr
};
struct FPoolTable
{
uint32 BlockSize;
uint16 BlocksPerBlockOfBlocks;
uint8 PagesPlatformForBlockOfBlocks;
FBitTree BlockOfBlockAllocationBits; // one bits in here mean the virtual memory is committed
FBitTree BlockOfBlockIsExhausted; // one bit in here means the pool is completely full
uint32 NumEverUsedBlockOfBlocks;
FPoolInfoSmall** PoolInfos;
uint64 UnusedAreaOffsetLow;
};
struct FPtrToPoolMapping
{
private:
/** Shift to apply to a pointer to get the reference from the indirect tables */
uint64 PtrToPoolPageBitShift;
/** Shift required to get required hash table key. */
uint64 HashKeyShift;
/** Used to mask off the bits that have been used to lookup the indirect table */
uint64 PoolMask;
// PageSize dependent constants
uint64 MaxHashBuckets;
};
struct FBundleNode
{
FBundleNode* NextNodeInCurrentBundle;
union
{
FBundleNode* NextBundle;
int32 Count;
};
};
struct FBundle
{
FBundleNode* Head;
uint32 Count;
};
// 空閒的塊列表
struct FFreeBlockList
{
bool PushToFront(FMallocBinnedGPU& Allocator, void* InPtr, uint32 InPoolIndex, uint32 InBlockSize, const FArenaParams& LocalArenaParams);
bool CanPushToFront(uint32 InPoolIndex, uint32 InBlockSize, const FArenaParams& LocalArenaParams);
void* PopFromFront(FMallocBinnedGPU& Allocator, uint32 InPoolIndex);
FBundleNode* RecyleFull(FArenaParams& LocalArenaParams, FGlobalRecycler& GGlobalRecycler, uint32 InPoolIndex);
bool ObtainPartial(FArenaParams& LocalArenaParams, FGlobalRecycler& GGlobalRecycler, uint32 InPoolIndex);
FBundleNode* PopBundles(uint32 InPoolIndex);
private:
FBundle PartialBundle;
FBundle FullBundle;
};
// 逐執行緒的空閒塊列表
struct FPerThreadFreeBlockLists
{
static FPerThreadFreeBlockLists* Get(uint32 BinnedGPUTlsSlot);
static void SetTLS(FMallocBinnedGPU& Allocator);
static int64 ClearTLS(FMallocBinnedGPU& Allocator);
void* Malloc(FMallocBinnedGPU& Allocator, uint32 InPoolIndex);
bool Free(FMallocBinnedGPU& Allocator, void* InPtr, uint32 InPoolIndex, uint32 InBlockSize, const FArenaParams& LocalArenaParams);
bool CanFree(uint32 InPoolIndex, uint32 InBlockSize, const FArenaParams& LocalArenaParams);
FBundleNode* RecycleFullBundle(FArenaParams& LocalArenaParams, FGlobalRecycler& GlobalRecycler, uint32 InPoolIndex);
bool ObtainRecycledPartial(FArenaParams& LocalArenaParams, FGlobalRecycler& GlobalRecycler, uint32 InPoolIndex);
FBundleNode* PopBundles(uint32 InPoolIndex);
int64 AllocatedMemory;
TArray<FFreeBlockList> FreeLists;
};
// 全域性回收器
struct FGlobalRecycler
{
void Init(uint32 PoolCount);
bool PushBundle(uint32 NumCachedBundles, uint32 InPoolIndex, FBundleNode* InBundle);
FBundleNode* PopBundle(uint32 NumCachedBundles, uint32 InPoolIndex);
private:
struct FPaddedBundlePointer
{
FBundleNode* FreeBundles[BINNEDGPU_MAX_GMallocBinnedGPUMaxBundlesBeforeRecycle];
};
TArray<FPaddedBundlePointer> Bundles;
};
uint64 PoolIndexFromPtr(const void* Ptr);
uint8* PoolBasePtr(uint32 InPoolIndex);
uint64 PoolIndexFromPtrChecked(const void* Ptr);
bool IsOSAllocation(const void* Ptr);
void* BlockOfBlocksPointerFromContainedPtr(const void* Ptr, uint8 PagesPlatformForBlockOfBlocks, uint32& OutBlockOfBlocksIndex);
uint8* BlockPointerFromIndecies(uint32 InPoolIndex, uint32 BlockOfBlocksIndex, uint32 BlockOfBlocksSize);
FPoolInfoSmall* PushNewPoolToFront(FMallocBinnedGPU& Allocator, uint32 InBlockSize, uint32 InPoolIndex, uint32& OutBlockOfBlocksIndex);
FPoolInfoSmall* GetFrontPool(FPoolTable& Table, uint32 InPoolIndex, uint32& OutBlockOfBlocksIndex);
bool AdjustSmallBlockSizeForAlignment(SIZE_T& InOutSize, uint32 Alignment);
public:
FArenaParams& GetParams();
void InitMallocBinned();
virtual bool IsInternallyThreadSafe() const override;
virtual void* Malloc(SIZE_T Size, uint32 Alignment) override;
virtual void* Realloc(void* Ptr, SIZE_T NewSize, uint32 Alignment) override;
virtual void Free(void* Ptr) override;
virtual bool GetAllocationSize(void *Ptr, SIZE_T &SizeOut) override;
virtual SIZE_T QuantizeSize(SIZE_T Count, uint32 Alignment) override;
virtual bool ValidateHeap() override;
virtual void Trim(bool bTrimThreadCaches) override;
virtual void SetupTLSCachesOnCurrentThread() override;
virtual void ClearAndDisableTLSCachesOnCurrentThread() override;
virtual const TCHAR* GetDescriptiveName() override;
void FlushCurrentThreadCache();
void* MallocExternal(SIZE_T Size, uint32 Alignment);
void FreeExternal(void *Ptr);
bool GetAllocationSizeExternal(void* Ptr, SIZE_T& SizeOut);
MBG_STAT(int64 GetTotalAllocatedSmallPoolMemory();)
virtual void GetAllocatorStats(FGenericMemoryStats& out_Stats) override;
virtual void DumpAllocatorStats(class FOutputDevice& Ar) override;
uint32 BoundSizeToPoolIndex(SIZE_T Size);
uint32 PoolIndexToBlockSize(uint32 PoolIndex);
void Commit(uint32 InPoolIndex, void *Ptr, SIZE_T Size);
void Decommit(uint32 InPoolIndex, void *Ptr, SIZE_T Size);
(...)
// Pool tables for different pool sizes
TArray<FPoolTable> SmallPoolTables;
uint32 SmallPoolInfosPerPlatformPage;
PoolHashBucket* HashBuckets;
PoolHashBucket* HashBucketFreeList;
uint64 NumLargePoolsPerPage;
FCriticalSection Mutex;
FGlobalRecycler GGlobalRecycler;
FPtrToPoolMapping PtrToPoolMapping;
FArenaParams ArenaParams;
TArray<uint16> SmallBlockSizesReversedShifted; // this is reversed to get the smallest elements on our main cache line
uint32 BinnedGPUTlsSlot;
uint64 PoolSearchDiv; // if this is zero, the VM turned out to be contiguous anyway so we use a simple subtract and shift
uint8* HighestPoolBaseVMPtr; // this is a duplicate of PoolBaseVMPtr[ArenaParams.PoolCount - 1]
FPlatformMemory::FPlatformVirtualMemoryBlock PoolBaseVMBlock;
TArray<uint8*> PoolBaseVMPtr;
TArray<FPlatformMemory::FPlatformVirtualMemoryBlock> PoolBaseVMBlocks;
// Mapping of sizes to small table indices
TArray<uint8> MemSizeToIndex;
FCriticalSection FreeBlockListsRegistrationMutex;
TArray<FPerThreadFreeBlockLists*> RegisteredFreeBlockLists;
TArray<void*> MallocedPointers;
};
// GPUDefragAllocator.h
// 簡單的最適合分配器,無論何時何地都可以拆分和合並。不是執行緒安全的。使用TMap查詢給定指標的記憶體塊(可能與malloc/free主執行緒衝突)使用單獨的連結列表進行自由分配,假設由於合併導致相對較少的自由塊.
class FGPUDefragAllocator
{
public:
typedef TDoubleLinkedList<FAsyncReallocationRequest*> FRequestList;
typedef TDoubleLinkedList<FAsyncReallocationRequest*>::TDoubleLinkedListNode FRequestNode;
// 分配器設定的容器
struct FSettings
{
int32 MaxDefragRelocations;
int32 MaxDefragDownShift;
int32 OverlappedBandwidthScale;
};
enum EMemoryElementType
{
MET_Allocated,
MET_Free,
MET_Locked,
MET_Relocating,
MET_Resizing,
MET_Resized,
MET_Max
};
struct FMemoryLayoutElement
{
int32 Size;
EMemoryElementType Type;
};
// 分配器重新分配統計資訊的容器。
struct FRelocationStats
{
int64 NumBytesRelocated;
int64 NumBytesDownShifted;
int64 LargestHoleSize;
int32 NumRelocations;
int32 NumHoles;
int32 NumLockedChunks;
};
// 包含單個分配或空閒塊的資訊。
class FMemoryChunk
{
public:
uint8* Base;
int64 Size;
int64 OrigSize;
bool bIsAvailable;
int32 LockCount;
uint16 DefragCounter;
// 允許存取FBestFitAllocator成員,如FirstChunk、FirstFreeChunk和LastChunk。
FGPUDefragAllocator& BestFitAllocator;
FMemoryChunk* PreviousChunk;
FMemoryChunk* NextChunk;
FMemoryChunk* PreviousFreeChunk;
FMemoryChunk* NextFreeChunk;
uint32 SyncIndex;
int64 SyncSize;
void* UserPayload;
TStatId Stat;
bool bTail;
};
virtual void* Allocate(int64 AllocationSize, int32 Alignment, TStatId InStat, bool bAllowFailure);
virtual void Free(void* Pointer);
virtual void Lock(const void* Pointer);
virtual void Unlock(const void* Pointer);
void* Reallocate(void* OldBaseAddress, int64 NewSize);
void DefragmentMemory(FRelocationStats& Stats);
void SetUserPayload(const void* Pointer, void* UserPayload);
void* GetUserPayload(const void* Pointer);
int64 GetAllocatedSize(void* Pointer);
bool IsValidPoolMemory(const void* Pointer) const;
void DumpAllocs(FOutputDevice& Ar = *GLog);
int64 GetTotalSize() const;
int32 GetLargestAvailableAllocation(int32* OutNumFreeChunks = nullptr);
uint32 GetBlockedCycles() const
bool InBenchmarkMode() const
bool GetTextureMemoryVisualizeData(FColor* TextureData, int32 SizeX, int32 SizeY, int32 Pitch, const int32 PixelSize);
void GetMemoryLayout(TArray<FMemoryLayoutElement>& MemoryLayout);
virtual int32 Tick(FRelocationStats& Stats, bool bPanicDefrag);
bool FinishAllRelocations();
void BlockOnAsyncReallocation(FAsyncReallocationRequest* Request);
void CancelAsyncReallocation(FAsyncReallocationRequest* Request, const void* CurrentBaseAddress);
static bool IsAligned(const volatile void* Ptr, const uint32 Alignment);
int32 GetAllocationAlignment() const;
(...)
};
下面涉及了動態解析度:
// DynamicResolutionProxy.h
// 渲染執行緒代理是動態解析的啟發式方法
class FDynamicResolutionHeuristicProxy
{
public:
static constexpr uint64 kInvalidEntryId = ~uint64(0);
void Reset_RenderThread();
uint64 CreateNewPreviousFrameTimings_RenderThread(float GameThreadTimeMs, float RenderThreadTimeMs);
void CommitPreviousFrameGPUTimings_RenderThread(...);
void RefreshCurentFrameResolutionFraction_RenderThread();
float GetResolutionFractionUpperBound() const;
float QueryCurentFrameResolutionFraction_RenderThread() const;
float GetResolutionFractionApproximation_GameThread() const;
static TSharedPtr< class IDynamicResolutionState > CreateDefaultState();
private:
struct FrameHistoryEntry
{
float ResolutionFraction;
float GameThreadTimeMs;
float RenderThreadTimeMs;
float TotalFrameGPUBusyTimeMs;
float GlobalDynamicResolutionTimeMs;
bool bGPUTimingsHaveCPUBubbles;
};
TArray<FrameHistoryEntry> History;
int32 PreviousFrameIndex;
int32 HistorySize;
int32 NumberOfFramesSinceScreenPercentageChange;
int32 IgnoreFrameRemainingCount;
float CurrentFrameResolutionFraction;
uint64 FrameCounter;
};
下面程式碼嗎涉及了多GPU、GPU掩碼等邏輯:
// MultiGPU.h
/** A mask where each bit is a GPU index. Can not be empty so that non SLI platforms can optimize it to be always 1. */
struct FRHIGPUMask
{
private:
uint32 GPUMask;
uint32 ToIndex() const;
bool HasSingleIndex() const;
uint32 GetLastIndex() const;
uint32 GetFirstIndex() const;
bool Contains(uint32 GPUIndex) const;
bool ContainsAll(const FRHIGPUMask& Rhs) const;
bool Intersects(const FRHIGPUMask& Rhs) const;
bool operator ==(const FRHIGPUMask& Rhs) const;
bool operator !=(const FRHIGPUMask& Rhs) const;
uint32 GetNative() const;
static const FRHIGPUMask GPU0() { return FRHIGPUMask(1); }
static const FRHIGPUMask All() { return FRHIGPUMask((1 << GNumExplicitGPUsForRendering) - 1); }
static const FRHIGPUMask FilterGPUsBefore(uint32 GPUIndex) { return FRHIGPUMask(~((1u << GPUIndex) - 1)) & All(); }
struct FIterator
{
explicit FIterator(const uint32 InGPUMask) : GPUMask(InGPUMask), FirstGPUIndexInMask(0);
explicit FIterator(const FRHIGPUMask& InGPUMask) : FIterator(InGPUMask.GPUMask);
FIterator& operator++();
FIterator operator++(int);
private:
uint32 GPUMask;
unsigned long FirstGPUIndexInMask;
};
friend FRHIGPUMask::FIterator begin(const FRHIGPUMask& NodeMask);
friend FRHIGPUMask::FIterator end(const FRHIGPUMask& NodeMask);
};
// GPU掩碼實用程式,用於獲取有關AFR組和兄弟姐妹的資訊。AFR組是一起在同一幀上工作的一組GPU。AFR兄弟是其他組中的GPU,在後續幀上執行相同的工作。例如,在不同幀上渲染相同檢視的兩個GPU是AFR同級。對於具有2個AFR組的4 GPU設定:每個AFR組有2個GPU。0b1010和0b0101是兩個組, 每個GPU有一個同級GPU。0b1100和0b0011是兄弟姐妹。
struct AFRUtils
{
static inline uint32 GetNumGPUsPerGroup();
static inline uint32 GetGroupIndex(uint32 GPUIndex);
static inline uint32 GetIndexWithinGroup(uint32 GPUIndex);
static inline uint32 GetNextSiblingGPUIndex(uint32 GPUIndex);
static inline FRHIGPUMask GetNextSiblingGPUMask(FRHIGPUMask InGPUMask);
static inline uint32 GetPrevSiblingGPUIndex(uint32 GPUIndex);
static inline FRHIGPUMask GetPrevSiblingGPUMask(FRHIGPUMask InGPUMask);
static inline FRHIGPUMask GetGPUMaskForGroup(uint32 GPUIndex);
static inline FRHIGPUMask GetGPUMaskForGroup(FRHIGPUMask InGPUMask);
static inline FRHIGPUMask GetGPUMaskWithSiblings(uint32 GPUIndex);
static inline FRHIGPUMask GetGPUMaskWithSiblings(FRHIGPUMask InGPUMask);
#if WITH_MGPU
static TArray<FRHIGPUMask, TFixedAllocator<MAX_NUM_GPUS>> GroupMasks;
static TArray<FRHIGPUMask, TFixedAllocator<MAX_NUM_GPUS>> SiblingMasks;
#endif
};
以下型別或介面涉及了GPU廠商、驅動和特性:
// RHIDefinitions.h
enum class EGpuVendorId
{
Unknown = -1,
NotQueried = 0,
Amd = 0x1002,
ImgTec = 0x1010,
Nvidia = 0x10DE,
Arm = 0x13B5,
Broadcom = 0x14E4,
Qualcomm = 0x5143,
Intel = 0x8086,
Apple = 0x106B,
Vivante = 0x7a05,
VeriSilicon = 0x1EB1,
Kazan = 0x10003, // VkVendorId
Codeplay = 0x10004, // VkVendorId
Mesa = 0x10005, // VkVendorId
};
inline bool RHIHasTiledGPU(const FStaticShaderPlatform Platform);
inline EGpuVendorId RHIConvertToGpuVendorId(uint32 VendorId);
class FGenericDataDrivenShaderPlatformInfo
{
FName Language;
ERHIFeatureLevel::Type MaxFeatureLevel;
uint32 bIsMobile: 1;
uint32 bIsMetalMRT: 1;
uint32 bIsPC: 1;
uint32 bIsConsole: 1;
uint32 bIsAndroidOpenGLES: 1;
uint32 bSupportsDebugViewShaders : 1;
uint32 bSupportsMobileMultiView: 1;
uint32 bSupportsArrayTextureCompression : 1;
uint32 bSupportsDistanceFields: 1; // used for DFShadows and DFAO - since they had the same checks
uint32 bSupportsDiaphragmDOF: 1;
uint32 bSupportsRGBColorBuffer: 1;
uint32 bSupportsCapsuleShadows: 1;
uint32 bSupportsPercentageCloserShadows : 1;
uint32 bSupportsVolumetricFog: 1; // also used for FVVoxelization
uint32 bSupportsIndexBufferUAVs: 1;
uint32 bSupportsInstancedStereo: 1;
uint32 bSupportsMultiView: 1;
uint32 bSupportsMSAA: 1;
uint32 bSupports4ComponentUAVReadWrite: 1;
uint32 bSupportsRenderTargetWriteMask: 1;
uint32 bSupportsRayTracing: 1;
uint32 bSupportsRayTracingProceduralPrimitive : 1;
uint32 bSupportsRayTracingIndirectInstanceData : 1; // Whether instance transforms can be copied from the GPU to the TLAS instances buffer
uint32 bSupportsHighEndRayTracingReflections : 1; // Whether fully-featured RT reflections can be used on the platform (with multi-bounce, translucency, etc.)
uint32 bSupportsPathTracing : 1; // Whether real-time path tracer is supported on this platform (avoids compiling unnecessary shaders)
uint32 bSupportsGPUSkinCache: 1;
uint32 bSupportsGPUScene : 1;
uint32 bSupportsByteBufferComputeShaders : 1;
uint32 bSupportsPrimitiveShaders : 1;
uint32 bSupportsUInt64ImageAtomics : 1;
uint32 bRequiresVendorExtensionsForAtomics : 1;
uint32 bSupportsNanite : 1;
uint32 bSupportsLumenGI : 1;
uint32 bSupportsSSDIndirect : 1;
uint32 bSupportsTemporalHistoryUpscale : 1;
uint32 bSupportsRTIndexFromVS : 1;
uint32 bSupportsWaveOperations : 1; // Whether HLSL SM6 shader wave intrinsics are supported
uint32 bSupportsIntrinsicWaveOnce : 1;
uint32 bSupportsConservativeRasterization : 1;
uint32 bRequiresExplicit128bitRT : 1;
uint32 bSupportsGen5TemporalAA : 1;
uint32 bTargetsTiledGPU: 1;
uint32 bNeedsOfflineCompiler: 1;
uint32 bSupportsComputeFramework : 1;
uint32 bSupportsAnisotropicMaterials : 1;
uint32 bSupportsDualSourceBlending : 1;
uint32 bRequiresGeneratePrevTransformBuffer : 1;
uint32 bRequiresRenderTargetDuringRaster : 1;
uint32 bRequiresDisableForwardLocalLights : 1;
uint32 bCompileSignalProcessingPipeline : 1;
uint32 bSupportsMeshShadersTier0 : 1;
uint32 bSupportsMeshShadersTier1 : 1;
uint32 MaxMeshShaderThreadGroupSize : 10;
uint32 bSupportsPerPixelDBufferMask : 1;
uint32 bIsHlslcc : 1;
uint32 bSupportsDxc : 1; // Whether DirectXShaderCompiler (DXC) is supported
uint32 bSupportsVariableRateShading : 1;
uint32 NumberOfComputeThreads : 10;
uint32 bWaterUsesSimpleForwardShading : 1;
uint32 bNeedsToSwitchVerticalAxisOnMobileOpenGL : 1;
uint32 bSupportsHairStrandGeometry : 1;
uint32 bSupportsDOFHybridScattering : 1;
uint32 bNeedsExtraMobileFrames : 1;
uint32 bSupportsHZBOcclusion : 1;
uint32 bSupportsWaterIndirectDraw : 1;
uint32 bSupportsAsyncPipelineCompilation : 1;
uint32 bSupportsManualVertexFetch : 1;
uint32 bRequiresReverseCullingOnMobile : 1;
uint32 bOverrideFMaterial_NeedsGBufferEnabled : 1;
uint32 bSupportsMobileDistanceField : 1;
uint32 bSupportsFFTBloom : 1;
uint32 bSupportsInlineRayTracing : 1;
uint32 bSupportsRayTracingShaders : 1;
uint32 bSupportsVertexShaderLayer : 1;
uint32 bSupportsVolumeTextureAtomics : 1;
private:
static FGenericDataDrivenShaderPlatformInfo Infos[SP_NumPlatforms];
(...)
}
19.11.4 其它
以下程式碼提供了部分硬體的資訊和操作:
// GenericPlatformMisc.h
struct FGenericPlatformMisc
{
// 裝置/硬體
static FString GetDeviceId();
static FString GetUniqueAdvertisingId();
static void SubmitErrorReport( const TCHAR* InErrorHist, EErrorReportMode::Type InMode );
static bool IsRemoteSession();
static bool IsDebuggerPresent();
static EProcessDiagnosticFlags GetProcessDiagnostics();
static FString GetCPUVendor();
static uint32 GetCPUInfo();
static bool HasNonoptionalCPUFeatures();
static bool NeedsNonoptionalCPUFeaturesCheck();
static FString GetCPUBrand();
static FString GetCPUChipset();
static FString GetPrimaryGPUBrand();
static FString GetDeviceMakeAndModel();
static struct FGPUDriverInfo GetGPUDriverInfo(const FString& DeviceDescription);
static void PrefetchBlock(const void* InPtr, int32 NumBytes = 1);
static void Prefetch(void const* x, int32 offset = 0);
static const TCHAR* GetDefaultDeviceProfileName();
static int GetBatteryLevel();
static void SetBrightness(float bBright);
static float GetBrightness();
static bool SupportsBrightness();
static bool IsInLowPowerMode();
static float GetDeviceTemperatureLevel();
static inline int32 GetMaxRefreshRate();
static inline int32 GetMaxSyncInterval();
static bool IsPGOEnabled();
static TArray<uint8> GetSystemFontBytes();
static bool HasActiveWiFiConnection();
static ENetworkConnectionType GetNetworkConnectionType();
static bool HasVariableHardware();
static bool HasPlatformFeature(const TCHAR* FeatureName);
static bool IsRunningOnBattery();
static EDeviceScreenOrientation GetDeviceOrientation();
static void SetDeviceOrientation(EDeviceScreenOrientation NewDeviceOrientation);
static int32 GetDeviceVolume();
// 記憶體
static void MemoryBarrier();
static void SetMemoryWarningHandler(void (* Handler)(const FGenericMemoryWarningContext& Context));
static bool HasMemoryWarningHandler();
// I/O
static void InitTaggedStorage(uint32 NumTags);
static void ShutdownTaggedStorage();
static void TagBuffer(const char* Label, uint32 Category, const void* Buffer, size_t BufferSize);
static bool SetStoredValues(const FString& InStoreId, const FString& InSectionName, const TMap<FString, FString>& InKeyValues);
static bool SetStoredValue(const FString& InStoreId, const FString& InSectionName, const FString& InKeyName, const FString& InValue);
static bool GetStoredValue(const FString& InStoreId, const FString& InSectionName, const FString& InKeyName, FString& OutValue);
static bool DeleteStoredValue(const FString& InStoreId, const FString& InSectionName, const FString& InKeyName);
static bool DeleteStoredSection(const FString& InStoreId, const FString& InSectionName);
static TArray<FCustomChunk> GetOnDemandChunksForPakchunkIndices(const TArray<int32>& PakchunkIndices);
static TArray<FCustomChunk> GetAllOnDemandChunks();
static TArray<FCustomChunk> GetAllLanguageChunks();
static TArray<FCustomChunk> GetCustomChunksByType(ECustomChunkType DesiredChunkType);
static void ParseChunkIdPakchunkIndexMapping(TArray<FString> ChunkIndexRedirects, TMap<int32, int32>& OutMapping);
static int32 GetChunkIDFromPakchunkIndex(int32 PakchunkIndex);
static int32 GetPakchunkIndexFromPakFile(const FString& InFilename);
static FText GetFileManagerName();
static bool IsPackagedForDistribution();
static FString LoadTextFileFromPlatformPackage(const FString& RelativePath);
static bool FileExistsInPlatformPackage(const FString& RelativePath);
static bool Expand16BitIndicesTo32BitOnLoad();
static void GetNetworkFileCustomData(TMap<FString,FString>& OutCustomPlatformData);
static bool SupportsBackbufferSampling();
(...)
};
// GenericPlatformApplicationMisc.h
struct FGenericPlatformApplicationMisc
{
// 模組/上下文/裝置
static void LoadPreInitModules();
static void LoadStartupModules();
static FOutputDeviceConsole* CreateConsoleOutputDevice();
static FOutputDeviceError* GetErrorOutputDevice();
static FFeedbackContext* GetFeedbackContext();
static bool IsThisApplicationForeground();
static void RequestMinimize();
static bool RequiresVirtualKeyboard();
static void PumpMessages(bool bFromMainLoop);
// 螢幕/視窗
static void PreventScreenSaver();
static bool IsScreensaverEnabled();
static bool ControlScreensaver(EScreenSaverAction Action);
static struct FLinearColor GetScreenPixelColor(const FVector2D& InScreenPos, float InGamma);
static bool GetWindowTitleMatchingText(const TCHAR* TitleStartsWith, FString& OutTitle);
static void SetHighDPIMode();
static float GetDPIScaleFactorAtPoint(float X, float Y);
static bool IsHighDPIAwarenessEnabled();
static bool AnchorWindowWindowPositionTopLeft();
static EScreenPhysicalAccuracy GetPhysicalScreenDensity(int32& OutScreenDensity);
static EScreenPhysicalAccuracy ComputePhysicalScreenDensity(int32& OutScreenDensity);
static EScreenPhysicalAccuracy ConvertInchesToPixels(T Inches, T2& OutPixels);
static EScreenPhysicalAccuracy ConvertPixelsToInches(T Pixels, T2& OutInches);
// 控制器
static void SetGamepadsAllowed(bool bAllowed);
static void SetGamepadsBlockDeviceFeedback(bool bAllowed);
static void ResetGamepadAssignments();
static void ResetGamepadAssignmentToController(int32 ControllerId);
static bool IsControllerAssignedToGamepad(int32 ControllerId);
static FString GetGamepadControllerName(int32 ControllerId);
static class UTexture2D* GetGamepadButtonGlyph(...);
static void EnableMotionData(bool bEnable);
static bool IsMotionDataEnabled();
(...)
};
// 硬體查詢結果
struct FHardwareSurveyResults
{
static const int32 MaxDisplayCount = 8;
static const int32 MaxStringLength = 260;
TCHAR Platform[MaxStringLength];
TCHAR OSVersion[MaxStringLength];
TCHAR OSSubVersion[MaxStringLength];
uint32 OSBits;
TCHAR OSLanguage[MaxStringLength];
TCHAR RenderingAPI[MaxStringLength];
TCHAR MultimediaAPI_DEPRECATED[MaxStringLength];
uint32 HardDriveGB;
uint32 HardDriveFreeMB;
uint32 MemoryMB;
float CPUPerformanceIndex;
float GPUPerformanceIndex;
float RAMPerformanceIndex;
uint32 bIsLaptopComputer:1;
uint32 bIsRemoteSession:1;
uint32 CPUCount;
float CPUClockGHz;
TCHAR CPUBrand[MaxStringLength];
TCHAR CPUNameString[MaxStringLength];
uint32 CPUInfo;
uint32 DisplayCount;
FHardwareDisplay Displays[MaxDisplayCount];
FGPUAdpater RHIAdapter;
uint32 ErrorCount;
TCHAR LastSurveyError[MaxStringLength];
TCHAR LastSurveyErrorDetail[MaxStringLength];
TCHAR LastPerformanceIndexError[MaxStringLength];
TCHAR LastPerformanceIndexErrorDetail[MaxStringLength];
FSynthBenchmarkResults SynthBenchmark;
};
// 不同的平臺實現獲取FHardwareSurveyResults。
struct APPLICATIONCORE_API FGenericPlatformSurvey
{
static bool GetSurveyResults(FHardwareSurveyResults& OutResults, bool bWait);
};
// HardwareInfo.h
// 硬體資訊
struct ENGINE_API FHardwareInfo
{
static void RegisterHardwareInfo( const FName SpecIdentifier, const FString& HardwareInfo );
static FString GetHardwareInfo(const FName SpecIdentifier);
static const FString GetHardwareDetailsString();
};
下面程式碼提供了效能檢測功能:
// GenericPlatformSurvey.h
struct FSynthBenchmarkStat
{
// 計算線性效能指數(>0),在硬體良好的情況下約為100,但數位可能更高.
float ComputePerfIndex() const;
void SetMeasuredTime(const FTimeSample& TimeSample, float InConfidence = 90);
float GetNormalizedTime() const;
float GetMeasuredTotalTime() const;
float GetConfidence() const;
float GetWeight() const;
private:
// -1(如果未定義),以秒為單位,有助於檢視測試是否執行時間過長(某些較慢的GPU可能超時).
float MeasuredTotalTime;
// -1(如果未定義),則取決於測試(例如s/g畫素),WorkScale被劃分.
float MeasuredNormalizedTime;
// -1(如果未定義),則為標準GPU上預期的定時值(索引值100,此處為NVidia 670).
float IndexNormalizedTime;
// 0..100,100:完全自信
float Confidence;
// 1為正常權重,0為無權重,>1為無邊界附加權重.
float Weight;
};
下面的程式碼提供了磁碟的利用率追蹤:
// DiskUtilizationTracker.h
struct FDiskUtilizationTracker
{
struct UtilizationStats
{
double GetOverallThroughputBS() const;
double GetOverallThroughputMBS() const;
double GetReadThrougputBS() const;
double GetReadThrougputMBS() const;
double GetTotalIdleTimeInSeconds() const;
double GetTotalIOTimeInSeconds() const;
double GetPercentTimeIdle() const;
uint64 TotalReads;
uint64 TotalSeeks;
uint64 TotalBytesRead;
uint64 TotalSeekDistance;
double TotalIOTime;
double TotalIdleTime;
};
UtilizationStats LongTermStats;
UtilizationStats ShortTermStats;
FCriticalSection CriticalSection;
uint64 IdleStartCycle;
uint64 ReadStartCycle;
uint64 InFlightBytes;
int32 InFlightReads;
FThreadSafeBool bResetShortTermStats;
void StartRead(uint64 InReadBytes, uint64 InSeekDistance = 0);
void FinishRead();
uint32 GetOutstandingRequests() const;
const struct UtilizationStats& GetLongTermStats() const;
const struct UtilizationStats& GetShortTermStats() const;
void ResetShortTermStats();
private:
static float GetThrottleRateMBS();
static constexpr float PrintFrequencySeconds = 0.5f;
};
下面提供了儲存IO相關的資訊和介面:
// IoStore.h
// I/O儲存TOC檔頭。
struct FIoStoreTocHeader
{
static constexpr char TocMagicImg[] = "-==--==--==--==-";
uint8 TocMagic[16];
uint8 Version;
uint8 Reserved0 = 0;
uint16 Reserved1 = 0;
uint32 TocHeaderSize;
uint32 TocEntryCount;
uint32 TocCompressedBlockEntryCount;
uint32 TocCompressedBlockEntrySize; // For sanity checking
uint32 CompressionMethodNameCount;
uint32 CompressionMethodNameLength;
uint32 CompressionBlockSize;
uint32 DirectoryIndexSize;
uint32 PartitionCount = 0;
FIoContainerId ContainerId;
FGuid EncryptionKeyGuid;
EIoContainerFlags ContainerFlags;
uint8 Reserved3 = 0;
uint16 Reserved4 = 0;
uint32 TocChunkPerfectHashSeedsCount = 0;
uint64 PartitionSize = 0;
uint32 TocChunksWithoutPerfectHashCount = 0;
uint32 Reserved7 = 0;
uint64 Reserved8[5] = { 0 };
};
// 組合偏移量和長度。
struct FIoOffsetAndLength
{
public:
inline uint64 GetOffset() const;
inline uint64 GetLength() const;
inline void SetOffset(uint64 Offset);
inline void SetLength(uint64 Length);
private:
uint8 OffsetAndLength[5 + 5];
};
// TOC條目後設資料
struct FIoStoreTocEntryMeta
{
FIoChunkHash ChunkHash;
FIoStoreTocEntryMetaFlags Flags;
};
// 壓縮塊條目
struct FIoStoreTocCompressedBlockEntry
{
static constexpr uint32 OffsetBits = 40;
static constexpr uint64 OffsetMask = (1ull << OffsetBits) - 1ull;
static constexpr uint32 SizeBits = 24;
static constexpr uint32 SizeMask = (1 << SizeBits) - 1;
static constexpr uint32 SizeShift = 8;
inline uint64 GetOffset() const;
inline void SetOffset(uint64 InOffset);
inline uint32 GetCompressedSize() const;
inline void SetCompressedSize(uint32 InSize);
inline uint32 GetUncompressedSize() const;
inline void SetUncompressedSize(uint32 InSize);
inline uint8 GetCompressionMethodIndex() const;
inline void SetCompressionMethodIndex(uint8 InIndex);
private:
uint8 Data[5 + 3 + 3 + 1];
};
// TOC資源讀取操作
enum class EIoStoreTocReadOptions
{
Default,
ReadDirectoryIndex = (1 << 0),
ReadTocMeta = (1 << 1),
ReadAll = ReadDirectoryIndex | ReadTocMeta
};
ENUM_CLASS_FLAGS(EIoStoreTocReadOptions);
// TOC資料容器
struct FIoStoreTocResource
{
enum { CompressionMethodNameLen = 32 };
FIoStoreTocHeader Header;
TArray<FIoChunkId> ChunkIds;
TArray<FIoOffsetAndLength> ChunkOffsetLengths;
TArray<int32> ChunkPerfectHashSeeds;
TArray<int32> ChunkIndicesWithoutPerfectHash;
TArray<FIoStoreTocCompressedBlockEntry> CompressionBlocks;
TArray<FName> CompressionMethods;
FSHAHash SignatureHash;
TArray<FSHAHash> ChunkBlockSignatures;
TArray<FIoStoreTocEntryMeta> ChunkMetas;
TArray<uint8> DirectoryIndexBuffer;
static FIoStatus Read(const TCHAR* TocFilePath, EIoStoreTocReadOptions ReadOptions, FIoStoreTocResource& OutTocResource);
static TIoStatusOr<uint64> Write(const TCHAR* TocFilePath, FIoStoreTocResource& TocResource, ...);
static uint64 HashChunkIdWithSeed(int32 Seed, const FIoChunkId& ChunkId);
};
// 以下是IO的目錄、檔案、索引相關
// IoDirectoryIndex.h
struct FIoDirectoryIndexEntry
{
uint32 Name = ~uint32(0);
uint32 FirstChildEntry = ~uint32(0);
uint32 NextSiblingEntry = ~uint32(0);
uint32 FirstFileEntry = ~uint32(0);
};
struct FIoFileIndexEntry
{
uint32 Name = ~uint32(0);
uint32 NextFileEntry = ~uint32(0);
uint32 UserData = 0;
};
struct FIoDirectoryIndexResource
{
FString MountPoint;
TArray<FIoDirectoryIndexEntry> DirectoryEntries;
TArray<FIoFileIndexEntry> FileEntries;
TArray<FString> StringTable;
};
class FIoDirectoryIndexWriter
{
public:
void SetMountPoint(FString InMountPoint);
uint32 AddFile(const FString& InFileName);
void SetFileUserData(uint32 InFileEntryIndex, uint32 InUserData);
void Flush(TArray<uint8>& OutBuffer, FAES::FAESKey InEncryptionKey);
private:
uint32 GetDirectory(uint32 DirectoryName, uint32 Parent);
uint32 CreateDirectory(const FStringView& DirectoryName, uint32 Parent);
uint32 GetNameIndex(const FStringView& String);
uint32 AddFile(const FStringView& FileName, uint32 Directory);
static bool IsValid(uint32 Index);
FString MountPoint;
TArray<FIoDirectoryIndexEntry> DirectoryEntries;
TArray<FIoFileIndexEntry> FileEntries;
TMap<FString, uint32> StringToIndex;
TArray<FString> Strings;
};
// IoDispatcherPrivate.h
class FIoBatchImpl
{
public:
TFunction<void()> Callback;
FEvent* Event = nullptr;
FGraphEventRef GraphEvent;
TAtomic<uint32> UnfinishedRequestsCount;
};
下面程式碼提供了平臺無關的親緣性操作:
// GenericPlatformAffinity.h
class FGenericPlatformAffinity
{
public:
static const uint64 GetMainGameMask();
static const uint64 GetRenderingThreadMask();
static const uint64 GetRHIThreadMask();
static const uint64 GetRHIFrameOffsetThreadMask();
static const uint64 GetRTHeartBeatMask();
static const uint64 GetPoolThreadMask();
static const uint64 GetTaskGraphThreadMask();
static const uint64 GetAudioThreadMask();
static const uint64 GetNoAffinityMask();
static const uint64 GetTaskGraphBackgroundTaskMask();
static const uint64 GetTaskGraphHighPriorityTaskMask();
static const uint64 GetAsyncLoadingThreadMask();
static const uint64 GetIoDispatcherThreadMask();
static const uint64 GetTraceThreadMask();
static EThreadPriority GetRenderingThreadPriority();
static EThreadCreateFlags GetRenderingThreadFlags();
static EThreadPriority GetRHIThreadPriority();
static EThreadPriority GetGameThreadPriority();
static EThreadCreateFlags GetRHIThreadFlags();
static EThreadPriority GetTaskThreadPriority();
static EThreadPriority GetTaskBPThreadPriority();
};
下面定義了許多硬體、ISA、作業系統、編譯器、圖形API及它們的特性相關的宏:
// Platform.h
PLATFORM_WINDOWS
PLATFORM_XBOXONE
PLATFORM_MAC
PLATFORM_MAC_X86
PLATFORM_MAC_ARM64
PLATFORM_PS4
PLATFORM_IOS
PLATFORM_TVOS
PLATFORM_ANDROID
PLATFORM_ANDROID_ARM
PLATFORM_ANDROID_ARM64
PLATFORM_ANDROID_X86
PLATFORM_ANDROID_X64
PLATFORM_APPLE
PLATFORM_LINUX
PLATFORM_LINUXARM64
PLATFORM_SWITCH
PLATFORM_FREEBSD
PLATFORM_UNIX
PLATFORM_MICROSOFT
PLATFORM_HOLOLENS
PLATFORM_CPU_X86_FAMILY
PLATFORM_CPU_ARM_FAMILY
PLATFORM_COMPILER_CLANG
PLATFORM_DESKTOP
PLATFORM_64BITS
PLATFORM_LITTLE_ENDIAN
PLATFORM_SUPPORTS_UNALIGNED_LOADS
PLATFORM_EXCEPTIONS_DISABLED
PLATFORM_SUPPORTS_PRAGMA_PACK
PLATFORM_ENABLE_VECTORINTRINSICS
PLATFORM_MAYBE_HAS_SSE4_1
PLATFORM_MAYBE_HAS_AVX
PLATFORM_ALWAYS_HAS_AVX_2
PLATFORM_ALWAYS_HAS_FMA3
PLATFORM_HAS_CPUID
PLATFORM_ENABLE_POPCNT_INTRINSIC
PLATFORM_ENABLE_VECTORINTRINSICS_NEON
PLATFORM_USE_LS_SPEC_FOR_WIDECHAR
PLATFORM_USE_SYSTEM_VSWPRINTF
PLATFORM_COMPILER_DISTINGUISHES_INT_AND_LONG
PLATFORM_COMPILER_HAS_GENERIC_KEYWORD
PLATFORM_COMPILER_HAS_DEFAULTED_FUNCTIONS
PLATFORM_COMPILER_COMMON_LANGUAGE_RUNTIME_COMPILATION
PLATFORM_COMPILER_HAS_TCHAR_WMAIN
PLATFORM_COMPILER_HAS_DECLTYPE_AUTO
PLATFORM_COMPILER_HAS_IF_CONSTEXPR
PLATFORM_COMPILER_HAS_FOLD_EXPRESSIONS
PLATFORM_TCHAR_IS_4_BYTES
PLATFORM_WCHAR_IS_4_BYTES
PLATFORM_TCHAR_IS_CHAR16
PLATFORM_UCS2CHAR_IS_UTF16CHAR
PLATFORM_HAS_BSD_TIME
PLATFORM_HAS_BSD_THREAD_CPUTIME
PLATFORM_HAS_BSD_SOCKETS
PLATFORM_HAS_BSD_IPV6_SOCKETS
PLATFORM_HAS_BSD_SOCKET_FEATURE_IOCTL
PLATFORM_HAS_BSD_SOCKET_FEATURE_SELECT
PLATFORM_HAS_BSD_SOCKET_FEATURE_GETHOSTNAME
PLATFORM_SUPPORTS_UDP_MULTICAST_GROUP
PLATFORM_USE_PTHREADS
PLATFORM_MAX_FILEPATH_LENGTH_DEPRECATED
PLATFORM_SUPPORTS_TEXTURE_STREAMING
PLATFORM_SUPPORTS_VIRTUAL_TEXTURES
PLATFORM_SUPPORTS_VARIABLE_RATE_SHADING
PLATFORM_REQUIRES_FILESERVER
PLATFORM_SUPPORTS_MULTITHREADED_GC
PLATFORM_SUPPORTS_TBB
PLATFORM_USES_FIXED_RHI_CLASS
PLATFORM_HAS_TOUCH_MAIN_SCREEN
PLATFORM_SUPPORTS_STACK_SYMBOLS
PLATFORM_HAS_128BIT_ATOMICS
PLATFORM_USE_FULL_TASK_GRAPH
PLATFORM_HAS_FPlatformVirtualMemoryBlock
PLATFORM_USE_FULL_TASK_GRAPH
PLATFORM_IS_ANSI_MALLOC_THREADSAFE
PLATFORM_SUPPORTS_GPU_FRAMETIME_WITHOUT_MGPU
(...)
以下提供了平臺屬性、輸出裝置、堆疊遍歷等相關的操作:
// 輸出裝置在大多數平臺的通用實現
struct FGenericPlatformOutputDevices
{
static void SetupOutputDevices();
static FString GetAbsoluteLogFilename();
static FOutputDevice* GetLog();
static void GetPerChannelFileOverrides(TArray<FOutputDevice*>& OutputDevices);
static FOutputDevice* GetEventLog();
static FOutputDeviceError* GetError();
static FFeedbackContext* GetFeedbackContext();
protected:
static void ResetCachedAbsoluteFilename();
private:
static constexpr SIZE_T AbsoluteFileNameMaxLength = 1024;
static TCHAR CachedAbsoluteFilename[AbsoluteFileNameMaxLength];
static void OnLogFileOpened(const TCHAR* Pathname);
static FCriticalSection LogFilenameLock;
};
// 平臺屬性
struct FGenericPlatformProperties
{
static const char* GetPhysicsFormat();
static bool HasEditorOnlyData();
static const char* IniPlatformName();
static bool IsGameOnly();
static bool IsServerOnly();
static bool IsClientOnly();
static bool IsMonolithicBuild();
static bool IsProgram();
static bool IsLittleEndian();
static const char* PlatformName();
static bool RequiresCookedData();
static bool HasSecurePackageFormat();
static bool RequiresUserCredentials();
static bool SupportsBuildTarget( EBuildTargetType TargetType );
static bool SupportsAutoSDK();
static bool SupportsGrayscaleSRGB();
static bool SupportsMultipleGameInstances();
static bool SupportsWindowedMode();
static bool AllowsFramerateSmoothing();
static bool SupportsAudioStreaming();
static bool SupportsHighQualityLightmaps();
static bool SupportsLowQualityLightmaps();
static bool SupportsDistanceFieldShadows();
static bool SupportsDistanceFieldAO();
static bool SupportsTextureStreaming();
static bool SupportsMeshLODStreaming();
static bool SupportsMemoryMappedFiles();
static bool SupportsMemoryMappedAudio();
static bool SupportsMemoryMappedAnimation();
static int64 GetMemoryMappingAlignment();
static bool SupportsVirtualTextureStreaming();
static bool SupportsLumenGI();
static bool SupportsHardwareLZDecompression();
static bool HasFixedResolution();
static bool SupportsMinimize();
static bool SupportsQuit();
static bool AllowsCallStackDumpDuringAssert();
static const char* GetZlibReplacementFormat();
};
// 用於捕獲載入pdb所需的所有模組資訊。
struct FStackWalkModuleInfo
{
uint64 BaseOfImage;
uint32 ImageSize;
uint32 TimeDateStamp;
TCHAR ModuleName[32];
TCHAR ImageName[256];
TCHAR LoadedImageName[256];
uint32 PdbSig;
uint32 PdbAge;
struct
{
unsigned long Data1;
unsigned short Data2;
unsigned short Data3;
unsigned char Data4[8];
} PdbSig70;
};
// 與程式計數器相關的符號資訊。ANSI版本。
struct FProgramCounterSymbolInfo final
{
enum
{
/** Length of the string used to store the symbol's names, including the trailing character. */
MAX_NAME_LENGTH = 1024,
};
ANSICHAR ModuleName[MAX_NAME_LENGTH];
ANSICHAR FunctionName[MAX_NAME_LENGTH];
ANSICHAR Filename[MAX_NAME_LENGTH];
int32 LineNumber;
int32 SymbolDisplacement;
uint64 OffsetInModule;
uint64 ProgramCounter;
};
// 程式計數器符號資訊
struct FProgramCounterSymbolInfoEx
{
FString ModuleName;
FString FunctionName;
FString Filename;
uint32 LineNumber;
uint64 SymbolDisplacement;
uint64 OffsetInModule;
uint64 ProgramCounter;
};
// 堆疊遍歷
struct FGenericPlatformStackWalk
{
typedef FGenericPlatformStackWalk Base;
struct EStackWalkFlags
{
enum
{
AccurateStackWalk = 0,
FastStackWalk = (1 << 0),
FlagsUsedWhenHandlingEnsure = (FastStackWalk)
};
};
static void Init();
static bool InitStackWalking()
static bool InitStackWalkingForProcess(const FProcHandle& Process);
static bool ProgramCounterToHumanReadableString( int32 CurrentCallDepth, uint64 ProgramCounter, ...);
static bool SymbolInfoToHumanReadableString( const FProgramCounterSymbolInfo& SymbolInfo, ... );
static bool SymbolInfoToHumanReadableStringEx( const FProgramCounterSymbolInfoEx& SymbolInfo, FString& out_HumanReadableString );
static void ProgramCounterToSymbolInfo( uint64 ProgramCounter, FProgramCounterSymbolInfo& out_SymbolInfo);
static void ProgramCounterToSymbolInfoEx( uint64 ProgramCounter, FProgramCounterSymbolInfoEx& out_SymbolInfo);
static uint32 CaptureStackBackTrace( uint64* BackTrace, uint32 MaxDepth, void* Context = nullptr );
static uint32 CaptureThreadStackBackTrace(uint64 ThreadId, uint64* BackTrace, uint32 MaxDepth, void* Context = nullptr);
static void StackWalkAndDump(ANSICHAR* HumanReadableString, SIZE_T HumanReadableStringSize, ... );
static void StackWalkAndDump(ANSICHAR* HumanReadableString, SIZE_T HumanReadableStringSize, ...);
static TArray<FProgramCounterSymbolInfo> GetStack(int32 IgnoreCount, int32 MaxDepth = 100, ...);
static void ThreadStackWalkAndDump(ANSICHAR* HumanReadableString, SIZE_T HumanReadableStringSize, ...);
static void StackWalkAndDumpEx(ANSICHAR* HumanReadableString, SIZE_T HumanReadableStringSize, ...);
static void StackWalkAndDumpEx(ANSICHAR* HumanReadableString, SIZE_T HumanReadableStringSize, ...);
static int32 GetProcessModuleCount();
static int32 GetProcessModuleSignatures(FStackWalkModuleInfo *ModuleSignatures, const int32 ModuleSignaturesSize);
static TMap<FName, FString> GetSymbolMetaData();
protected:
static bool WantsDetailedCallstacksInNonMonolithicBuilds();
};
19.12 本篇總結
本篇主要闡述了計算機硬體體系的由底向上的只是,以及UE對硬體層的抽象和封裝,使得讀者對此模組有著大致的理解,至於更多技術細節和原理,需要讀者自己去研讀UE原始碼發掘。
特別說明
- 感謝所有參考文獻的作者,部分圖片來自參考文獻和網路,侵刪。
- 本系列文章為筆者原創,只發表在部落格園和知乎上。歡迎分享本文連結,但未經同意,不允許轉載!
- 系列文章,未完待續,完整目錄請戳剖析虛幻渲染體系-開篇說明。
- 關於某「大廠」的「技術磚家」對博主造謠的迴應
參考文獻
- Unreal Engine Source
- Rendering and Graphics
- Materials
- Graphics Programming
- Computer Organization and Architecture Tutorials
- 硬核作業系統講解----計算機架構部分
- John von Neumann
- 馮·諾伊曼結構
- Basic Computer Architecture
- ARM Cortex-A Series Programmer's Guide for ARMv7-A
- ARM: Introduction to Assembly Language
- ARM Instruction Reference
- ARM and Thumb instruction summary
- AssemblyFunctions
- How to Call a Function from Arm Assembler
- 深入GPU硬體架構及執行機制
- 深入淺出計算機組成原理
- intel-architecture-day-2021-presentation
- ISAs and Instruction Sets, File Types, & Memory
- [Computer Organization & Operating Systems](https://mrcet.com/downloads/digital_notes/ECE/III Year/coos.pdf)
- Intel® Architecture Instruction Set Extensions and Future Feature
- Essentials of Computer Organization and Architecture
- The RISC-V Instruction Set Manual Volume I: Unprivileged ISA
- [Computer Organization and Design RISC-V Edition](http://home.ustc.edu.cn/~louwenqi/reference_books_tools/Computer Organization and Design RISC-V edition.pdf)
- [Computer Organization and Architecture 10th - William Stallings](http://home.ustc.edu.cn/~louwenqi/reference_books_tools/Computer Organization and Architecture 10th - William Stallings.pdf)
- Electronics Fundamentals Circuits Devices and Applications 8th Edition By David M Buchla and Thomas L Floyd
- In Praise of Computer Organization and Design: The Hardware
- Computer Graphics: Principles and Practice - CS-UCY
- Gearing toward longer smartphone battery life with power-management techniques
- Optimizing Applications for Mobile Devices
- Power, Performance Modeling and Optimization for Mobile System and Applications
- Optimization in Power Usage of Smartphones
- Power and clock management
- Power Management Design for Mobile Devices
- Power Management for Portable Products - Analog Devices
- Optimization in Power Usage of Smartphones
- Optimizing Smartphone Power Consumption through Dynamic Resolution Scaling
- Designing Mobile Devices for Low Power and Thermal Efficiency
- RTX 4090: Everything we know about Nvidia’s next flagship GPU
- NVIDIA RTX 4090 FOUNDERS EDITION
- NVIDIA GeForce RTX 4090: The New Rendering Champion
- GeForce RTX™ 4090 GAMING X TRIO 24G - MSI
- GeForce RTX 4090 FE 架構及效能實測