作者推薦 | 【分散式技術專題】「架構設計方案」圖解學習法總結叢集模式下的各種軟負載均衡策略實現及原理分析
背景介紹
在分散式系統中,負載均衡是非常重要的環節,通過負載均衡將請求派發到網路中的一個或多個節點上進行處理。
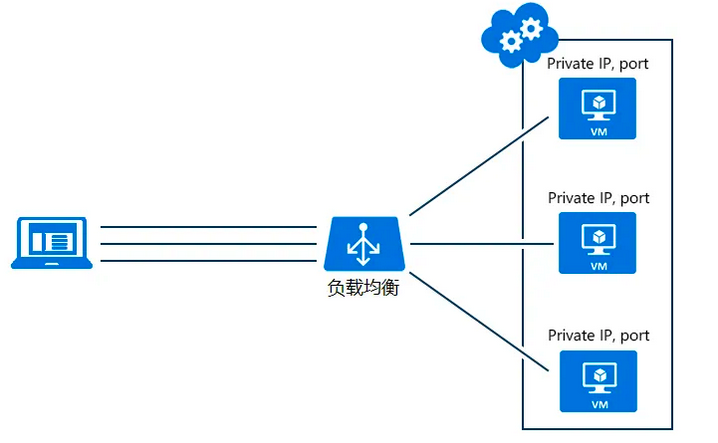
通常來說,負載均衡分為硬體負載均衡及軟體負載均衡。硬體負載均衡,顧名思義,在伺服器節點之間安裝專門的硬體進行負載均衡的工作,F5或者A10便為其中的佼佼者。軟體負載均衡則是通過在伺服器上安裝的特定的負載均衡軟體或是自帶負載均衡模組完成對請求的分配派發。例如,平時我們使用的Nginx或者API-Gateway閘道器服務就主要採用負載均衡的方式去轉發分派下游服務。
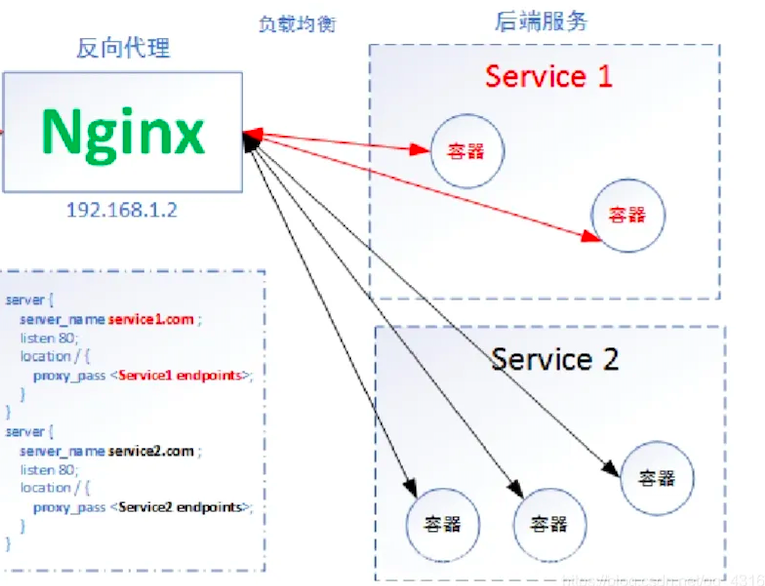
負載均衡的演演算法策略
一般而言,有以下幾種常見的負載均衡策略:
輪詢機制(一般預設的策略)
【輪詢機制】作為非常經典的負載均衡策略,早期該策略應用地非常廣泛。
演演算法原理
其原理很簡單,給每個請求標記一個序號,然後將請求依次派發到伺服器節點中,適用於叢集中各個節點提供服務能力等同且無狀態的場景。演演算法實現原理圖如下所示。
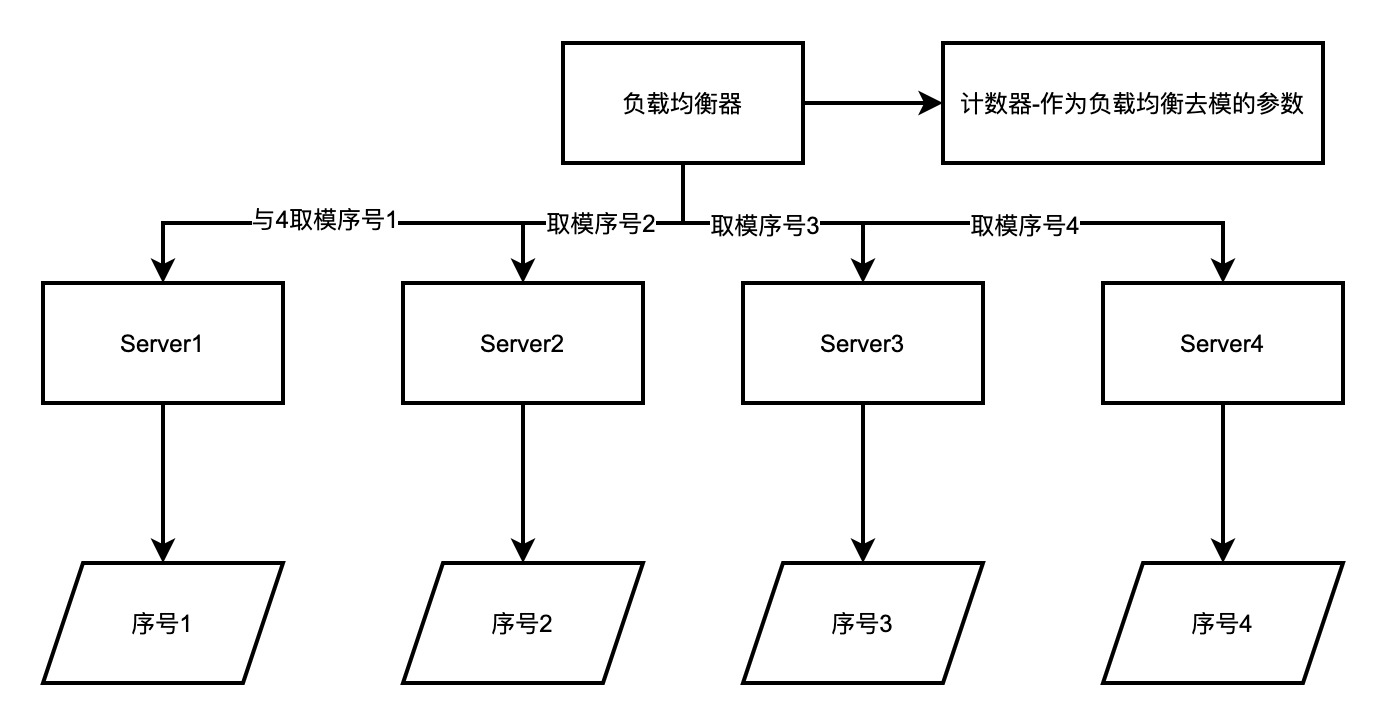
該演演算法原理三要素
-
為每個伺服器進行建立一個編號或者序號(作為唯一標識)。
-
負載均衡器這一側需要建立一個全域性的計數器,作為負載均衡的引數。每次呼叫都進行+1
-
當負載均衡器的計數器當前值與下游服務的數量取模之後,會得出對應的序號值,則回去進行分派到對應序號值的下游服務即可。
缺略優點
實現比較簡單,均衡化較好,每一個節點都屬於公平化分配,(上面也說到了)比較適合相同場景和條件規則下的所有下游服務。
策略缺點
缺點也非常明顯,該策略將節點視為等同,與實際中複雜的環境不符。加權輪詢為輪詢的一個改進策略,每個節點會有權重屬性,但是因為權重的設定難以做到隨實際情況變化,仍有一定的不足。
隨機機制
【隨機機制】與輪詢相似,只是不需要對每個請求進行編號,每次隨機取一個下游服務節點即可。
演演算法原理
其原理也很簡單,就是採用隨機演演算法或者雜湊演演算法將請求服務進行隨機雜湊到下游的不同的服務節點,該策略也將後端的每個節點是為等同的。
另外同樣也有改進的加權隨機的演演算法,不再贅述,然後將請求依次派發到伺服器節點中,適用於叢集中各個節點提供服務能力等同且無狀態的場景。演演算法實現原理圖如下所示。
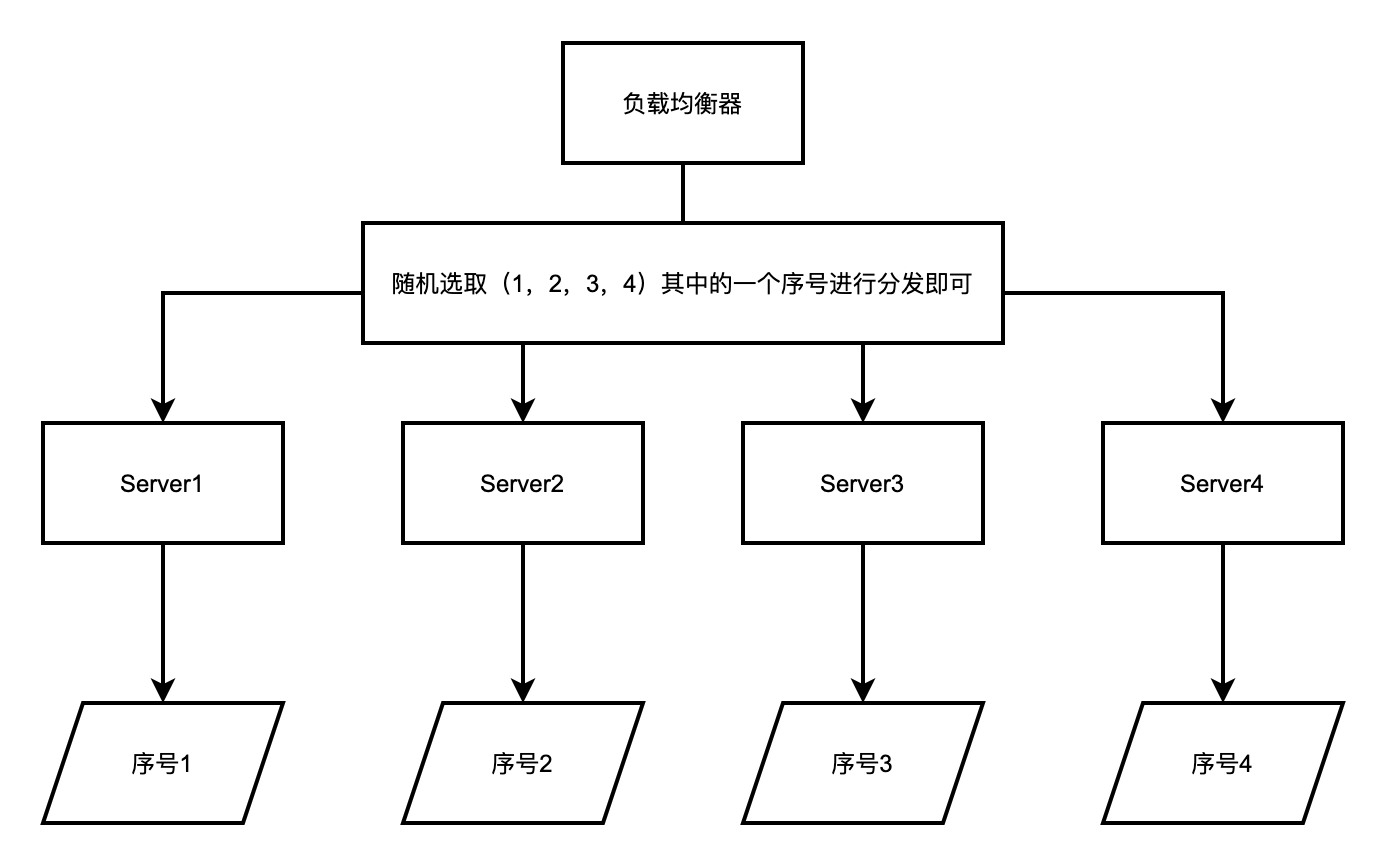
主要依靠於隨機演演算法或者隨機元件去生產隨機值之後在進行取模就可以。
該演演算法原理三要素
-
為每個伺服器進行建立一個編號或者序號(作為唯一標識)。
-
負載均衡器這一側需要建立一個亂數演演算法元件。每次呼叫都進行分配。
-
然後選取隨機值對應的服務元件即可(可以取模、也可以採用亂數從該範圍內選取的方式)
缺略優點
實現比較簡單,隨機性較好,每一個節點都屬於公平化分配,(上面也說到了)比較適合相同場景和條件規則下的所有下游服務。
策略缺點
缺點也非常明顯,該策略將節點視為等同,與實際中複雜的環境不符。加權輪詢為輪詢的一個改進策略,每個節點會有權重屬性,但是因為權重的設定難以做到隨實際情況變化,仍有一定的不足。
最小響應時間
通過記錄每次請求所需的時間,得出平均的響應時間,然後根據響應時間選擇最小的響應時間。
演演算法原理
該策略能較好地反應伺服器的狀態,但是由於是平均響應時間的關係,時間上有些滯後,無法滿足快速響應的要求。因此在此基礎之上,會有一些改進版本的策略,如只計算最近若干次的平均時間的策略等。演演算法需要進行有狀態話的方式進行統計每一次請求,演演算法實現原理圖如下所示。
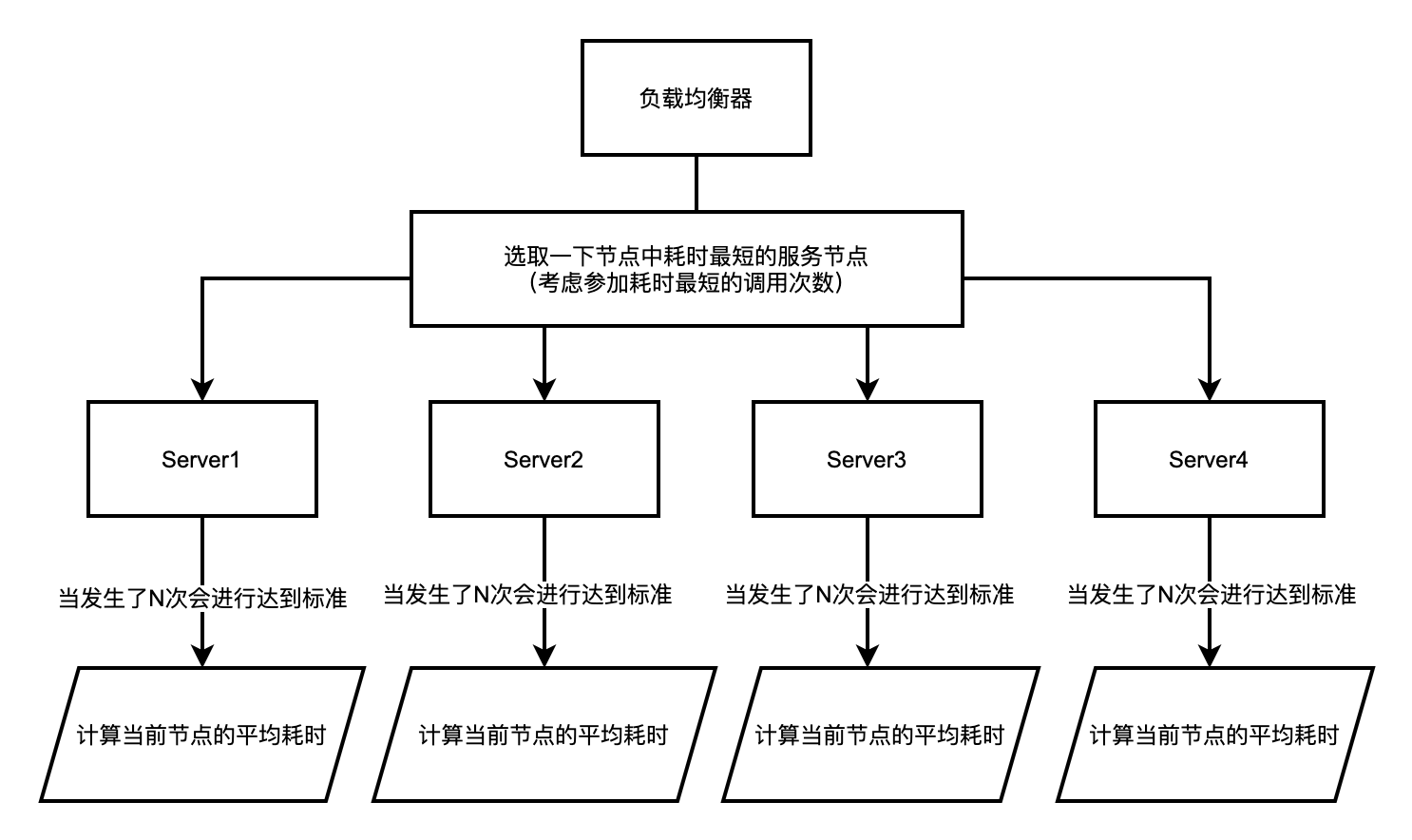
主要依靠於隨機演演算法或者隨機元件去生產隨機值之後在進行取模就可以。
該演演算法原理三要素
-
不需要為每一個服務節點建立序號了,但是需要進行對每一個服務節點採用一個bucket儲存對應的呼叫次數以及呼叫的耗時總和。作為計算平均耗時的依據。
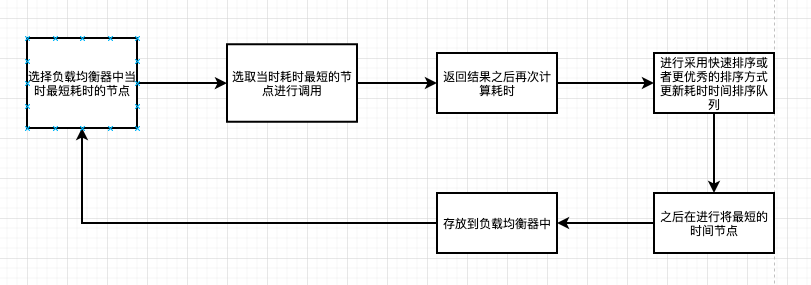
-
耗時選擇器:在負載均衡器端呼叫的時候,將建立一個順序性佇列,存放依據最短耗時(正序)排序的方式儲存的佇列模型,故此每次可以取隊首位置的元素節點作為最短耗時服務節點。
- 當然,也可以將每次最短的耗時時間的服務節點直接儲存在負載均衡器節點中,這樣會提高相應的效能,
-
然後選取隨機值對應的服務元件即可(可以取模、也可以採用亂數從該範圍內選取的方式)
缺略優點
-
可以依據實際情況進行動態計算最合適的服務節點進行呼叫,可以實現能者多勞,讓優秀的服務節點更加出色的發揮其作用,慢慢的可以遮蔽掉不好用或者有問題的節點。
-
可以促使效能和服務能力、可以體驗度達到一個比較高的高度和效果。
策略缺點
-
效能會造成一段時間的影響,如果不考慮絕對一致性,也可以後臺進行非同步計算進行可以能減低每次計算排序服務節點所造成的耗時。
-
此外還可以考慮當不存在最短耗時記錄的時候其演演算法是存在短時間不可靠的問題,隨意最好可以做一下提前預熱模式。
-
客觀問題是否如何排除,當由於網路因素導致某幾次該節點的耗時耗費很久,會導致演演算法模式的影響,所以是否以及選取合適的呼叫次數統計閾值是一個需要好好考慮的問題。例如只有當呼叫5次以上才進行計算平均耗時,否則不會考慮其計算,好比一個服務節點只呼叫了一次並且耗時非常少,其實這個節點耗時計算過於主觀以及巧合。
最小並行數
使用者端的每一次請求服務在伺服器停留的時間可能會有較大的差異,隨著工作時間加長,如果採用簡單的輪循或隨機均衡演演算法,每一臺伺服器上的連線程序可能會產生較大的不同,並沒有達到真正的負載均衡。
演演算法原理
最小並行數的策略則是記錄了當前時刻,每個備選節點正在處理的事務數,然後選擇並行數最小的節點。該策略能夠快速地反應伺服器的當前狀況,較為合理地將負責分配均勻,適用於對當前系統負載較為敏感的場景。
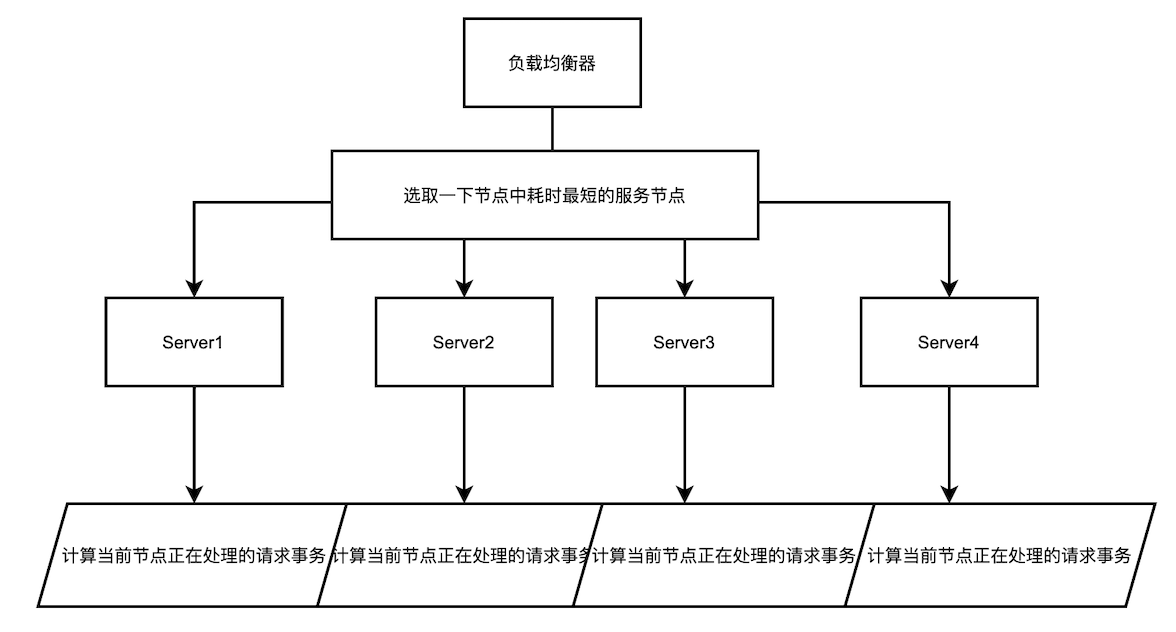
該演演算法原理三要素
-
當處理請求接收的時候為該節點的計數器+1
-
當返回並且釋放請求的時候為該節點的計數器-1
-
每次依據每個後臺非同步計算的排序佇列進行選取最短的節點作為每次請求的首選服務節點。(排序規則為:從小打到去進行依據當前處理事務數進行排序),
缺略優點
-
可以依據實際情況進行動態計算最合適的服務節點進行呼叫,可以讓大家動態化實現的均衡模式進行分配,讓每一個節點都可以充分進行處理請求,而不是壓在某一個或者某幾個服務節點進行處理,其他節點變得過於空閒。適用於叢集中各個節點提供服務能力等同且無狀態的場景,比起輪詢模式其動態化更好。
-
可以促使效能和服務能力、可以體驗度達到一個比較高的高度和效果。
策略缺點
- 與最小耗時相同,效能會造成一段時間的影響,如果不考慮絕對一致性,也可以後臺進行非同步計算進行可以能減低每次計算排序服務節點所造成的耗時。
雜湊雜湊
在後端節點有狀態的情況下,需要使用雜湊的方法進行負載均衡,此種情況下情況比較複雜。可以理解為輪詢模式的升級版,在這裡不是單純的考慮取模的計算方式,而是採用key的方式進行計算-依賴於hash函數進行計算。
演演算法三要素
-
hash值對映表,用於計算提供路由能力,方便負載均衡器選取計算後的Hash值與節點的Hash標準值進行匹配路由。
-
hash值計算器:主要用於計算每一個服務節點的hash計算值,以及每次請求的hash值,從而進行資料對比。
演演算法優點
- 雜湊性和公平性更加的優秀和完善
- 效能計算非常的不錯,接近於O(1)的時間複雜度。
- 與輪詢一樣,思路較為簡單。
- 可以實現相同的條件,會實現資料指紋模式,資料請求追蹤方式,例如:原始ip - 會匹配相同的服務節點,達成請求的有狀態話。目前nginx常會使用 ip-hash演演算法、url-hash演演算法模式。
演演算法缺點
- 強依賴於Hash演演算法和Hash元件
- 對於時間複雜度而言降低很多,但是其依靠的是增加了空間複雜度。
分散式系統容錯性因素分析
分散式系統面臨著遠比單機系統更加複雜的環境,包括不同的網路環境、執行平臺、機器設定等等。在如此複雜的環境中,發生錯誤是不可避免的,然後如何能夠做到容錯性,將發生錯誤的代價降低到最低是在分散式系統中必須要考慮的問題。
分散式系統演演算法的實際選擇
前提背景
選擇不同的負載均衡策略將會有非常大的不同,考慮下列的情況。完成請求需要如下四個叢集,A,B,C,D,其中,假定完成呼叫需要呼叫叢集B3次,B叢集共有5臺伺服器。
單次呼叫概率計算
當叢集B中的某臺伺服器出現故障而導致無法提供服務,若叢集中其他容錯手段尚未生效,那麼理想情況下,4/5的請求不受影響。
採用輪詢或隨機的負載均衡策略
單次請求派發到正常節點的概率為4/5,那麼該請求成功的機率為 (4/5) * (4/5) * (4/5) = 64/125 :約為二之一,低於4/5的理想狀態。
在因此,在此種情況下,若僅僅採用此種策略,會使故障的影響範圍擴散,不符合預期。
採用最小並行數的複雜均衡策略
假定正常一個請求需耗時10ms,超時時間設定為1s,那麼,按照最小並行數的策略,異常節點的提供服務的能力為1,正常節點提供服務能力為100,則派發到異常節點的概率為1/(100 * 4+1)=1/401,該請求成功的機率為1(400/401)^3≈99.25%,高於4/5。
計算的公式
更加一般地,設叢集中發生故障的故障機器的比例p,那麼呼叫失敗的預期概率為
1/(100 * 4+1)=1/401
p * 1/401 = N
N為最後的預測呼叫失敗的概率,對應的成功的概率就為:
(1-p) * 1/401 = M 或 1 - N
計算的公式
整個請求需要呼叫k次,若採用輪詢或隨機的負載均衡策略,那麼單次派發到正常節點的概率為多少?有上面的計算分析的思路可以瞭解到:(1-P)為正常機器的比例,那麼K次就是:(1-P)的K次方。請求的成功率便會下降低於單次的(1-P)。
當k為3的時候,得到成功率f(p)與p的關係:
f(p) = (1-p) ^n
從上面的公式可知,在p在增大的時候,請求的成功率f(p)便會有明顯的下降,故而在對可靠性要求比較高的分散式系統中,不能簡單地採用此種策略。
採用最小並行數的策略
假設叢集伺服器的總數為m,假定異常情況下服務能力下降到正常的1/q,那麼單位時間內,叢集能提供服務的總數為:m * (1- 1/q) ,那麼單次派發到正常節點的概率為:
m * (1- 1/q) / m
請求的成功率則是上述值的k次方,即
m * (1- 1/q) / m ^k
-
當p在較小的區間內變化時(如(0,0.4]),隨著p的增大,成功率f(p)並未有明顯的下降,在每個節點可以承受服務壓力的情況下,可以良好地處理多個節點故障的異常狀況。
-
換個角度思考,再挖掘一下上述等式,若p為恆定,即叢集中若已有一定數量的機器發生了故障。
-
所以服務的超時時間無須設定地過大,一般來說,設定為10倍的正常提供伺服器時間即可。
在此種情況下,會導致失敗大大提升,即使只有較小比例的叢集出現異常,也會使得請求大量失敗,故而還需要其他手段檢測到此型別的異常。
最後的總結
在實際應用中,使用者端的並行數可能存在一直維持在一個較低的水平上,由於使用者端的並行數並不能代表伺服器端的並行情況,會造成在使用者端並行數較小的情況下,伺服器端實際負載不均衡的狀況。
故而,最小並行數的負載均衡策略不適用於在使用者端做負載均衡,且使用者端負載較小的情況。這種情況下,目前採用隨機的方法解決負載不均衡的問題。當然,在實際的分散式系統中,因為一個節點異常而導致其他節點的壓力增大,可能會使其他節點的效能下降,他們之間的關係難以用上述的等式簡單地描述。
本文來自部落格園,作者:洛神灬殤,轉載請註明原文連結:https://www.cnblogs.com/liboware/p/16971936.html,任何足夠先進的科技,都與魔法無異。