Crane如何做到利用率提升3倍穩定性還不受損?
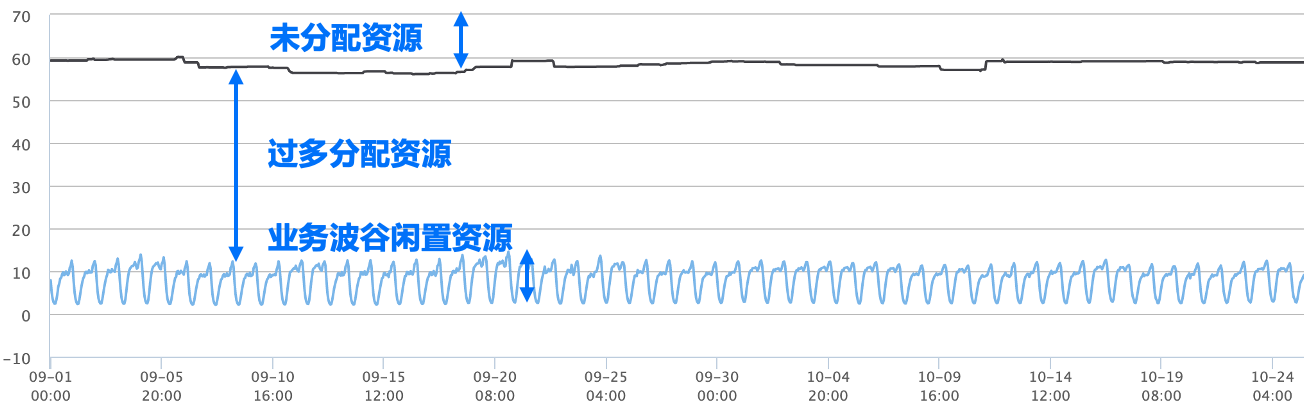
作為雲平臺使用者,我們都希望購買的伺服器物盡其用,能夠達到最大利用率。然而要達到理論上的節點負載目標是很的,計算節點總是存在一些裝箱碎片和低負載導致的閒置資源。下圖展示了某個生產系統的CPU資源現狀,從圖中可以看出,浪費主要來自以下幾個方面:
- 業務需求與節點可排程資源很難完全匹配,因此在每個節點上都可能剩餘一些碎片資源無法被分配出去。
- 業務通常為了絕對穩定,會申請超出自身需求的資源,這會導致業務鎖定了資源但事實上未能有效利用。
- 資源用量存在波峰波谷,很多線上業務都是有著規律性的服務高峰和低峰的,如通常白天負載較高,資源用量較大,而夜間線上存取降低,資源用量也會跌入低谷。
Crane提供了Request推薦、副本數推薦、HPA推薦以及EPA等業務優化能力,能輔助業務自動化決策進行資源設定優化。然而在較大的組織中,業務改需要所有業務元件負責人的支援和配合,週期長、見效慢。如何在不改造業務的前提下,迅速提升叢集資源利用率,在提升部署密度的同時保證延遲敏感和高優業務的穩定性和服務質量不受干擾,Crane混部能力給出了答案。
Crane提供了高優敏感業務與低優批次處理業務的混部能力,能將叢集利用率提升3倍!
混部的核心挑戰
所謂混部,就是將不同優先順序的工作負載混合部署到相同叢集中。一般來說,支撐線上服務的延遲敏感型(Latency Sensitive)業務優先順序較高,支撐離線計算的高吞吐型(Batch)業務優先順序通常較低。
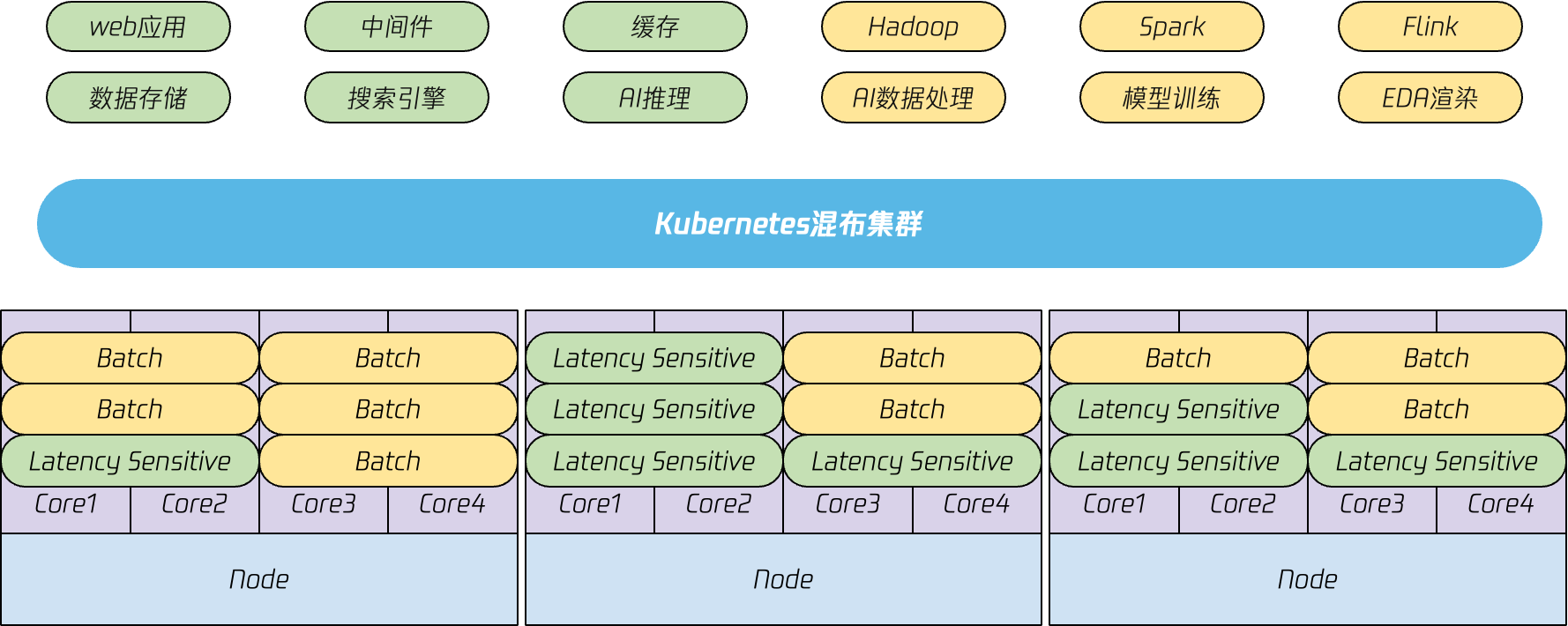
看起來將這些不同型別的業務部署在相同叢集,複用計算資源,就可以有效提升資源利用率,那麼為什麼混部只有在頂尖科技公司才有大規模應用呢?理想很美好,現實很骨感,如果只是簡單的將不同業務型別部署到一起,而不進行任何層面的資源隔離,那麼線上業務服務質量必然會被影響,這也是為什麼混部難以落地的核心原因。
干擾的來源
Kubernetes將計算資源分為不可壓縮資源和可壓縮資源。不可壓縮資源是指實體記憶體等被應用程式獨佔的資源,在某個時刻一旦分配給某個程序,就不可以再被重新分配;可壓縮資源是指比如可以分時複用的CPU資源,多個程序可以共用同一CPU核,雖然在CPU在某個時鐘週期只為單一任務服務,但從宏觀時間維度,CPU是可以同時服務於多個程序的。當多個程序都有CPU需求時,這些需求交給作業系統統一分配和排程。當多個程序爭搶資源時,可能會導致應用效能下降,這便是我們所說的干擾。
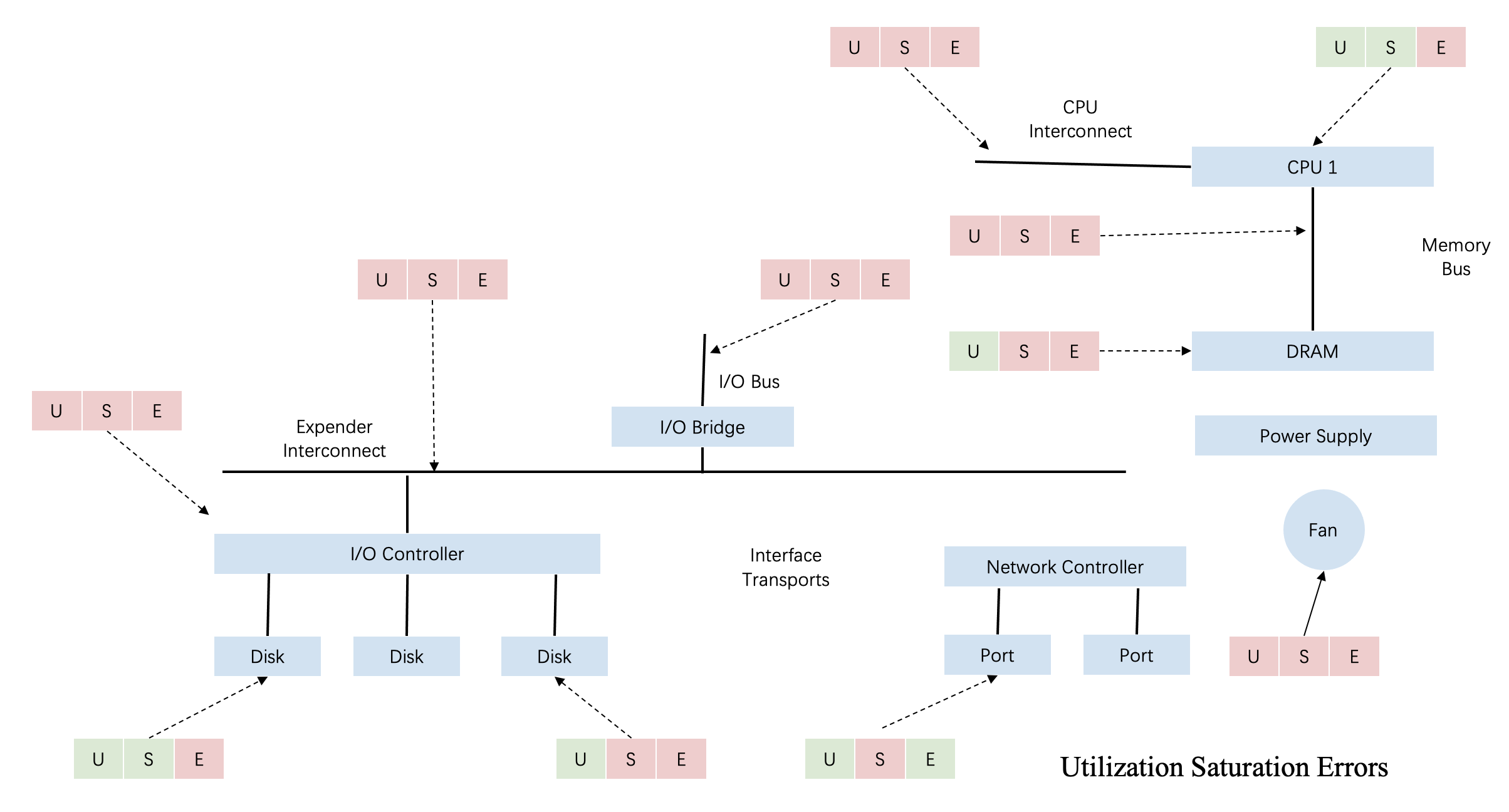
USE方法(Utilization,Saturation,Errors)是效能測試領域中廣泛採用的指導理論。在評估系統效能時,通過資源利用率,飽和度和錯誤率,來迅速的定位資源的瓶頸和錯誤所在。如下圖所示,針對不同資源都可以通過USE方法指導我們如何進行干擾檢測。
首先從資源維度,干擾可能發生在任何一個資源維度,比如常見的CPU以及CPU相關的L1,、L2、LLC快取、記憶體頻寬、磁碟IO、網路IO等。其次從干擾發生的層級來看,干擾可能發生在應用程式碼、作業系統、硬體等不同層級。
對於應用而言,任何一環都可能成為干擾的來源;同時這些因素之間也會互相關聯,例如應用網路流量上升,不僅會造成頻寬的搶佔,通常還會導致CPU資源消耗上升;又比如一個應用雖然計算邏輯簡單,但需要頻繁存取記憶體資料,如果此時快取失效,則應用需要存取實體記憶體,而CPU負載會因為忙等而上升。
因此判斷干擾是否發生,進一步尋找干擾源,並通過技術手段避免干擾是複雜的,這是干擾檢測自動化門檻高的核心原因,如何能在關聯的因素中識別干擾以及繞過表象找到真實的干擾源是混部需要解決的核心問題。
Crane的混部方案
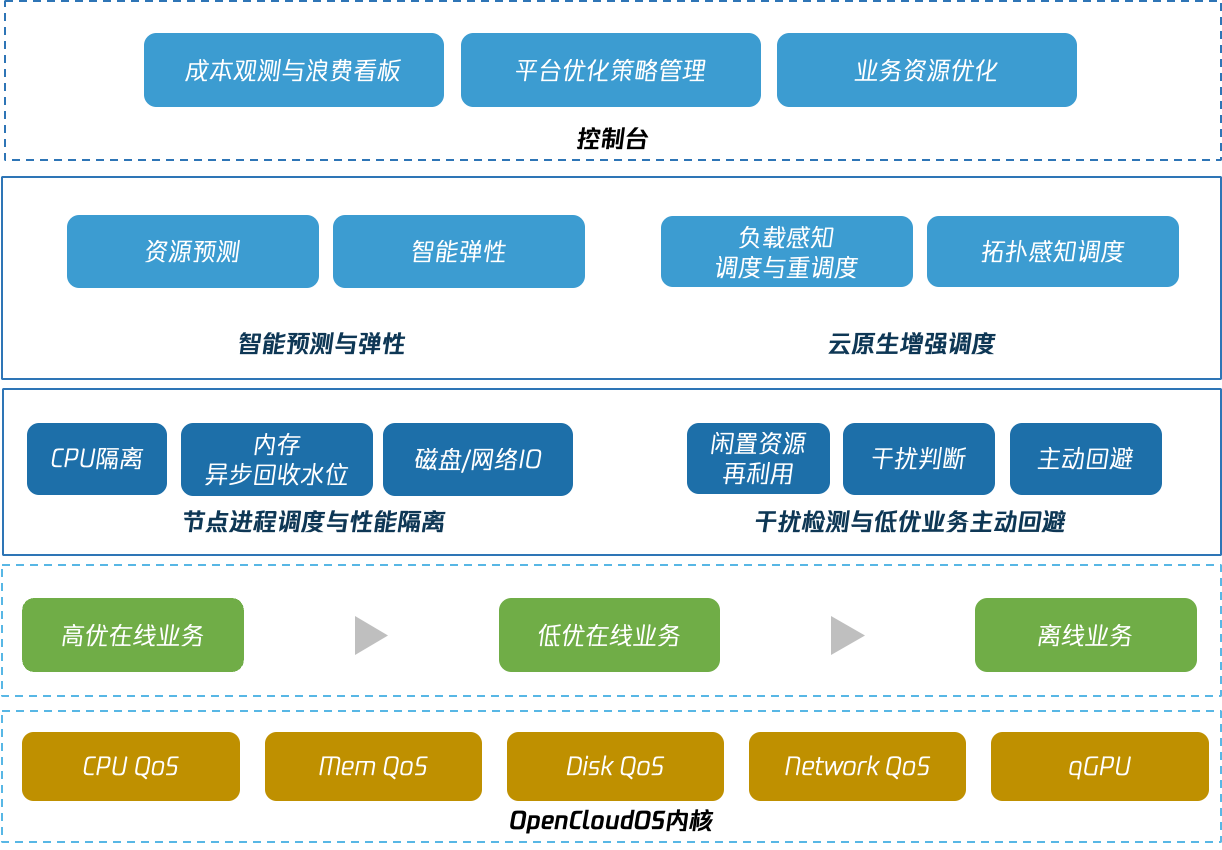
Crane為混部場景提供了一套開箱即用的解決方案,藉助Kubernetes CRD,該方案可靈活適配於多優先順序的線上混部場景以及在離線混部場景,混部方案的能力概覽如下:
- 節點負載畫像與彈性資源回收
Crane實時採集節點利用率資料,並基於多種預測演演算法計算出未來的閒置資源,為節點構建畫像,並將其以擴充套件資源形式更新成節點可排程資源。彈性資源的多少隨高優業務真實用量變化,高優業務用量上升,彈性資源減少。 - 彈性資源再分配
低優業務使用彈性資源,排程器確保低優業務首次排程時有足夠彈性資源可用,防止節點過載。 - 基於自定義水位線的干擾檢測和主動迴避能力
- NodeQoS API允許叢集運維定義節點水位,包括總CPU水位,或者彈性資源分配率、彈性資源水位等,並定義當真實用量達到水位時的迴避動作。
- PodQoS API 定義不同型別工作負載的資源隔離策略,如CPU排程優先順序,磁碟IO等,同時定義該型別業務允許的迴避動作。
- AvoidanceAction定義排程禁止、壓制、驅逐等動作引數,當節點水位被觸發,只有允許某個動作的業務Pod才可以執行該操作。
- 基於核心隔離的增強QoS能力
Crane的開源方案中,可以通過動態調節CGroup壓制干擾源資源上限。同時,為支撐大規模生產系統的的隔離需求,Crane基於騰訊RUE核心,通過多級CPU排程優先順序,以及絕對搶佔等特性,保證高優業務不受低優業務的影響。 - 支援模擬排程的優雅驅逐等增強的重排程能力
當壓制不足以抑制干擾時,就需要從節點中驅逐低優Pod以確保高優業務的服務質量。Crane支援模擬排程的優雅驅逐重排程能力能夠藉助叢集全域性視角和預排程能力降低重排程對應用的影響。
閒置資源回收
雖然Kubernetes提供了叢集自動擴縮容能力,能夠讓雲使用者在業務負載降低時縮小叢集規模,節省成本。然而叢集擴縮容效率依賴基礎架構和資源供給等因素約束,通常不是一個高頻操作,絕大多數雲使用者的業務還執行在採用包年包月的固定節點池。
混部的第一步是從叢集中識別出閒置資源並轉換成可被臨時借用的彈性算力,並更新成為節點可分配資源。Crane藉助資源預測和本地實時檢測兩種手段計算節點可用彈性資源。
Crane Agent啟動時會自動依據如下的預設模版為節點建立TSP物件,Craned中的資源預測元件獲取該TSP物件以後立即讀取節點資源用量歷史,通過內建預測演演算法進行預測,並將預測結果更新至TSP.Status。
apiVersion: v1
data:
spec: |
predictionMetrics:
- algorithm:
algorithmType: dsp
dsp:
estimators:
fft:
- highFrequencyThreshold: "0.05"
lowAmplitudeThreshold: "1.0"
marginFraction: "0.2"
maxNumOfSpectrumItems: 20
minNumOfSpectrumItems: 10
historyLength: 3d
sampleInterval: 60s
resourceIdentif ier: cpu
type: ExpressionQuery
expressionQuery:
expression: 'sum(count(node_cpu_seconds_total{mode="idle",instance=~"({{.metadata.name}})(:\\d+)?"}) by (mode, cpu)) - sum(irate(node_cpu_seconds_total{mode="idle",instance=~"({{.metadata.name}})(:\\d+)?"}[5m]))'
predictionWindowSeconds: 3600
kind: ConfigMap
metadata:
name: noderesource-tsp-template
namespace: default
Crane Agent中的Node Resource Controller元件週期性檢測該節點的實時負載資訊,並按如下公式計算實時彈性CPU:
彈性CPU = 節點可分配CPU*(1-預留比例) -(節點實際CPU用量 - 彈性資源用量 + 綁核業務獨佔的CPU)
- 節點可分配CPU:節點可分配CPU,即Node.Status.Allocatable.CPU
- 預留比例:保證始終有一定的空閒資源不能被複用,保證叢集的穩定
- 節點實際CPU用量:節點實際的CPU用量,即node_cpu_seconds_total
- 彈性資源用量:節點實際用量包含了使用彈性資源的部分業務,而這部分開銷是是彈性資源,因此需要算入彈性CPU中
- 綁核業務獨佔的CPU:被業務繫結的CPU不可二次分配,因此需要再彈性CPU中扣除
Node Resource Controller 同時監聽節點TSP物件變化,當讀取到TSP物件的狀態變化時,同時參考本地實時可回收彈性資源以及預測結果,並取其中較小的值更新為節點彈性資源gocrane.io/cpu。記憶體等其他資源原理與CPU一致。
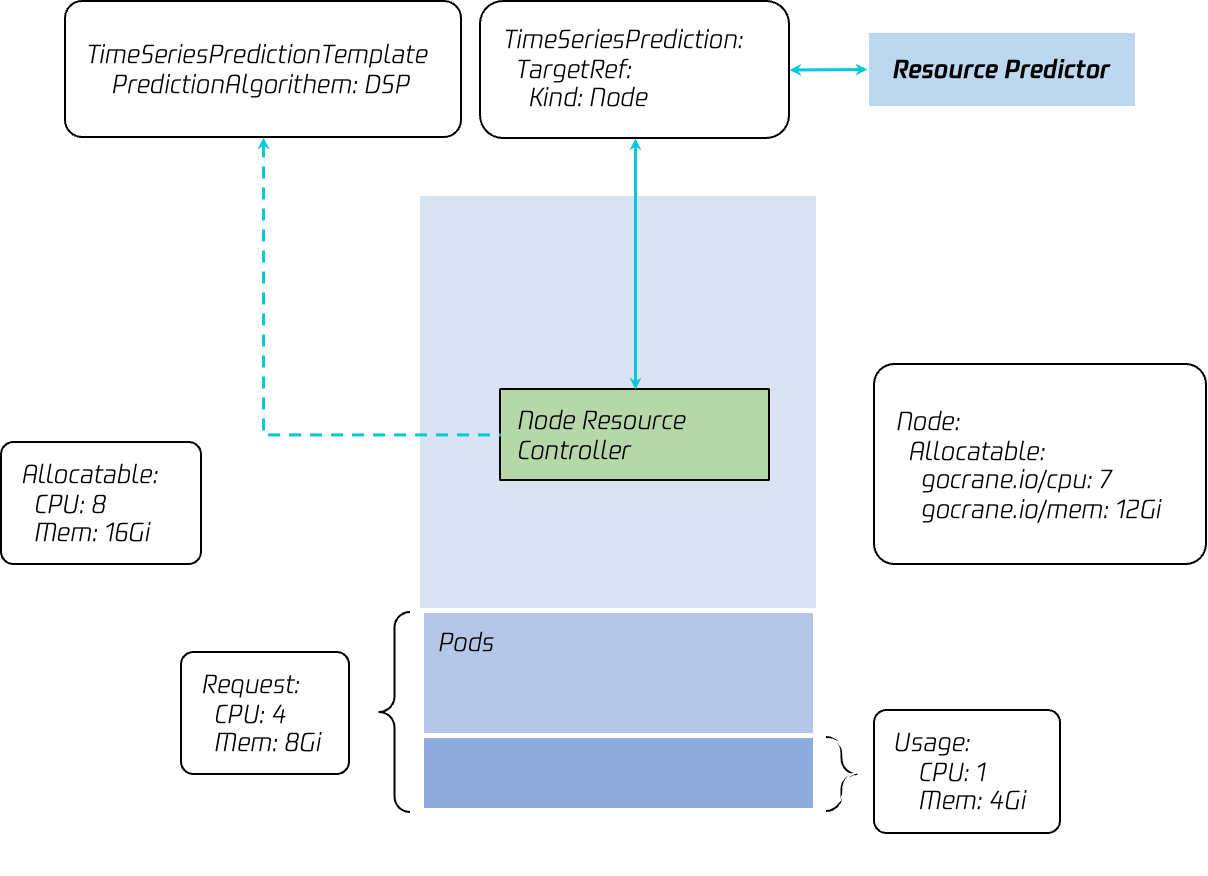
彈性資源使用
彈性資源更新成為節點Allocatable Resource以後,低優業務即可通過資源宣告將彈性資源利用起來,Kubernetes排程器確保節點彈性資源能夠滿足業務需求才能成功排程。
spec:
containers:
- image: nginx
name: extended-resource-demo
resources:
limits:
gocrane.io/cpu: "2"
gocrane.io/memory: "2000Mi"
requests:
gocrane.io/cpu: "2"
gocrane.io/memory: "2000Mi"
干擾檢測與主動迴避
彈性資源再分配能有效提升單節點業務部署密度,而更高的部署密度意味著業務面臨的資源競爭的可能性更大。Crane實時對節點和應用進行多維度的指標檢測,通過靈活可配的異常定義規則和篩選策略,判斷干擾是否發生,並且在干擾發生時犧牲低優Pod以確保高優業務的服務等級不變。
全維度指標採集
Crane Agent通過多種手段收集全維度指標,將這些指標統一儲存在stateMap中,用於資源回收和干擾檢測。
基於多種手段:
通過解析系統檔案、呼叫cAdvisor介面、eBPF Hook等多種手段,採集包括CPU 利用率、CPI、虛擬機器器CPU Steal Time、記憶體利用率、進出網路流量和磁碟讀寫IO等指標,Crane使用者也可以編寫外掛採集自定義指標。
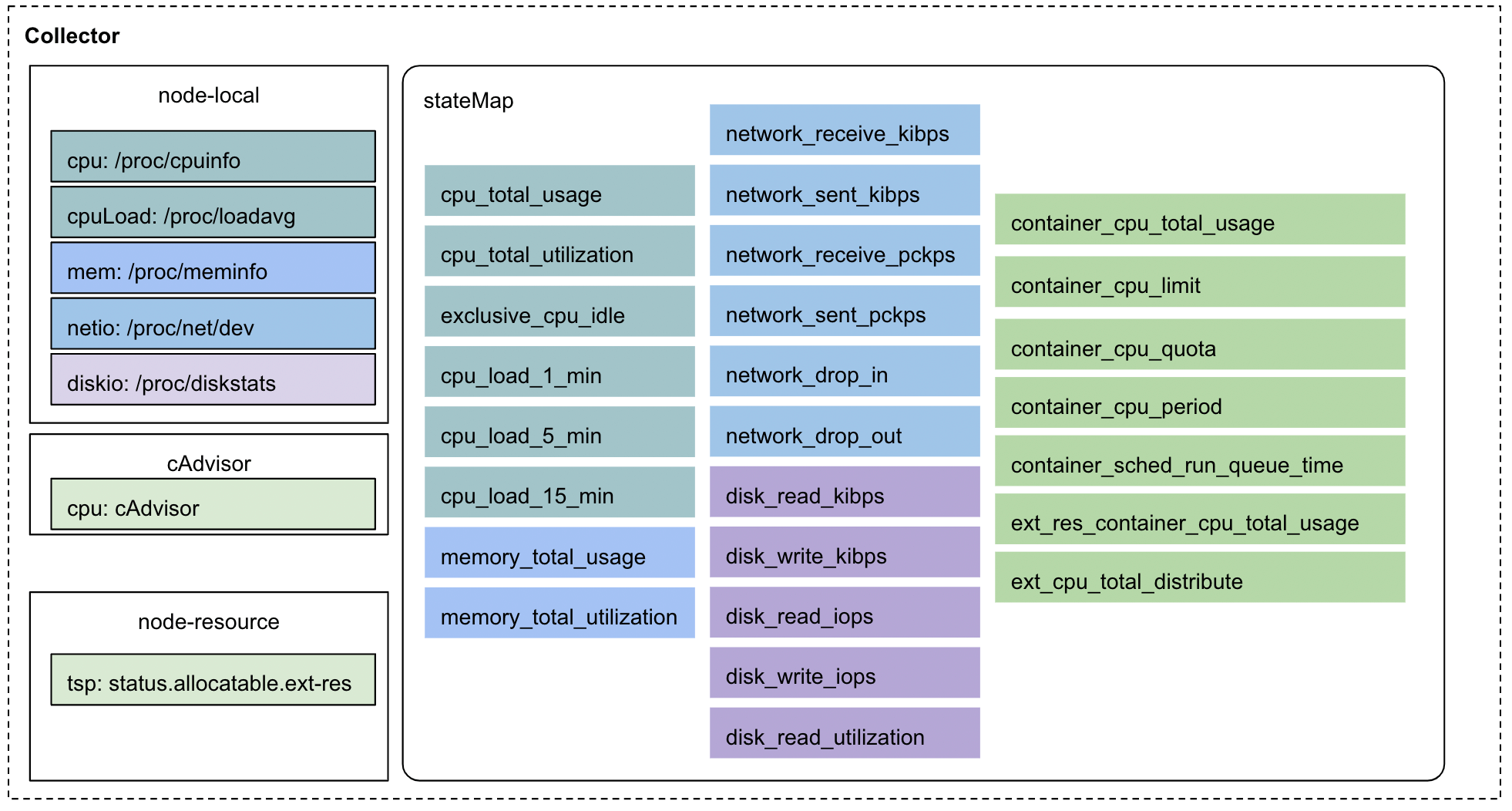
完整的指標檢測有助於干擾的分析,為之後更為完善的應用畫像,應用特性分析,應用之間的干擾情況提供充分的依據。
干擾判斷
下圖展示了Crane Agent的核心元件,在State Collector定期採集全維度指標以後,stateMap會交由Analyzer進行干擾判斷。
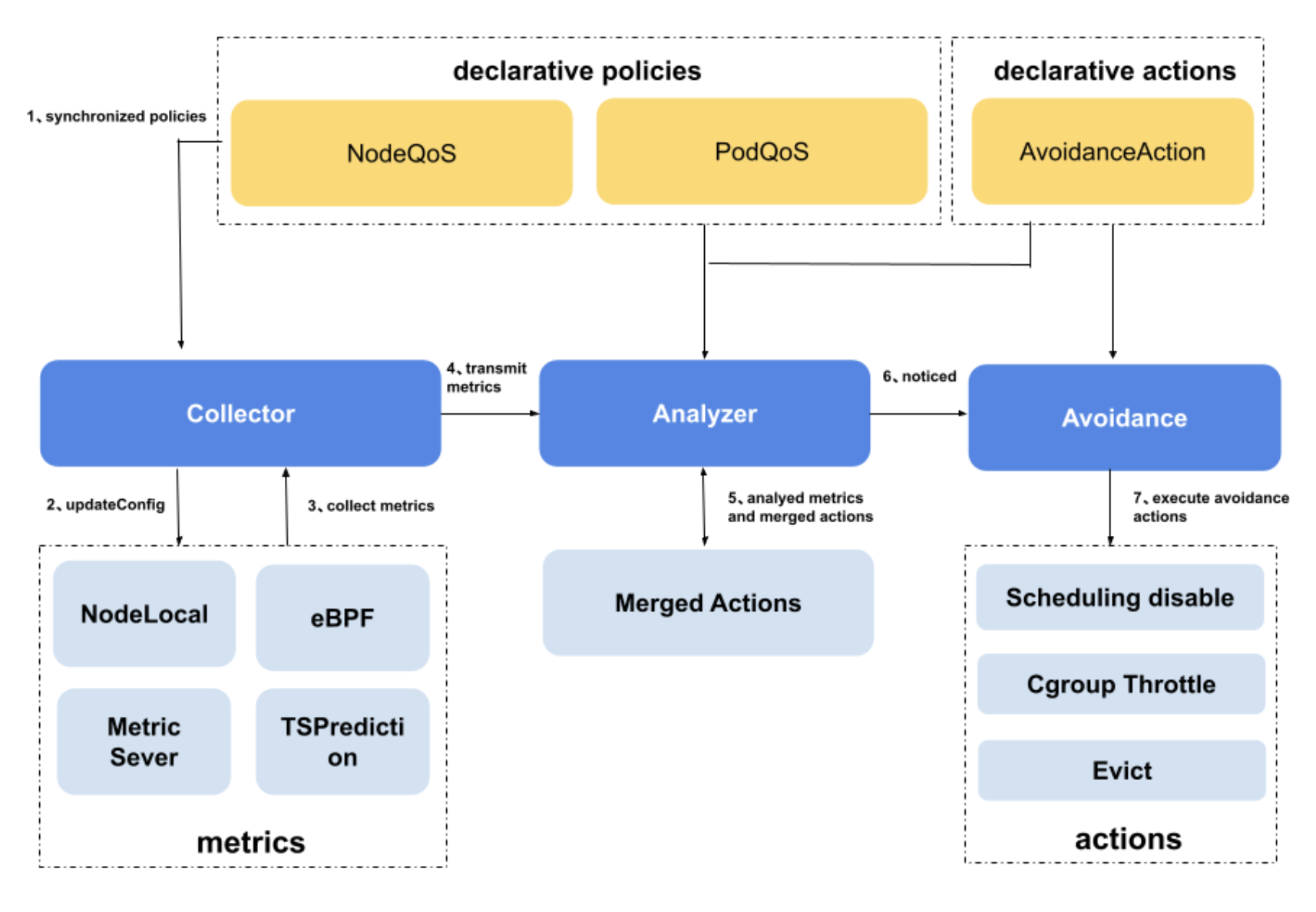
當前的干擾判斷規則沿用了Kubernetes健康檢查的判斷邏輯,使用者可基於NodeQOS物件定義干擾判斷規則。該物件可定義指標採集規則,干擾判斷所依賴的指標名稱以及其對應的干擾水位線等,同時通過AvoidanceAction定義干擾發生時需要執行的迴避動作,詳情參見下面的設定範例:
apiVersion: ensurance.crane.io/v1alpha1
kind: NodeQOS
metadata:
name: "cpu-usage-percent-watermark"
spec:
nodeQualityProbe:
timeoutSeconds: 10
nodeLocalGet:
localCacheTTLSeconds: 60
rules:
- name: "cpu-usage-percent"
avoidanceThreshold: 2 # 當達到閾值並持續多次,則規則被觸發
restoreThreshold: 2 # 當閾值未達到並繼續多次, 則規則恢復
actionName: "throttle" # 當觸發閾值時執行的 AvoidanceAction 名稱
strategy: "None" # 動作的策略,可以將其設定為Preview以不實際執行
metricRule:
name: "cpu_total_utilization" # 水位線指標名稱
value: 80 # 水位線指標的閾值,cpu用量達到80%
NodeQOS中的actionName屬性關聯了迴避動作的名稱,需要建立AvoidanceAction物件完成迴避動作的完整引數設定,當前支援 Scheduling Disable(關閉節點排程)、Throttle(通過Cgroup調節Pod的可用資源上限), Eviction(驅逐Pod)三類操作操作;同時,如果節點干擾消失,Crane Agent也會自行執行逆操作,恢復節點和業務的資源設定狀態。
下面的AvoidanceAction範例展示瞭如何通過調節CGroup對Pod的可用資源進行壓制:
apiVersion: ensurance.crane.io/v1alpha1
kind: AvoidanceAction
metadata:
name: throttle
labels:
app: system
spec:
coolDownSeconds: 300
throttle:
cpuThrottle:
minCPURatio: 10 #CPU 配額的最小比例,Pod不會被限制低於此值
stepCPURatio: 10 #在觸發的迴避動作中減少相應Pod的CPU配額佔比,也是恢復動作中增加的CPU配額佔比
description: "throttle low priority pods"
壓制目標的選擇
NodeQOS定義了干擾判斷規則以及當干擾發生時需要執行的迴避動作,那麼迴避動作會應用在哪些物件上呢?
Crane針對Kubelet內建驅逐規則做了一定程度的擴充套件,這些內建規則包括:
- 是否使用了彈性資源
- 比較優先順序與QOSClass
- 比較CPU/記憶體用量的絕對值
- 比較實際用量與彈性資源上限的比值
- 執行時間等
Crane使用者也可以針對自定義水位線指標實現特定的驅逐選擇規則。
除此之外,Crane使用者可以通過定義PodQOS來定義特定Namespace、特定優先順序、特定標籤的Pod允許執行特定的驅逐動作。如下面的例子,為有preemptible_job: "true"標籤的離線BestEffort Pod設定可被壓制操作。通過PodQOS的精細化管控,我們實現了業務側的個性化需求:比如 logstash服務的負責人希望這類業務接受驅逐但不接受壓制;而執行了數個星期的AI訓練任務寧願被壓制而不是被驅逐。
apiVersion: ensurance.crane.io/v1alpha1
kind: PodQOS
metadata:
name: all-elastic-pods
spec:
allowedActions:
- throttle
labelSelector:
matchLabels:
preemptible_job: "true"
scopeSelector:
matchExpressions:
- operator: In
scopeName: QOSClass
values:
- BestEffort
支援優雅驅逐的重排程器
Crane Agent是執行在每個節點的Daemonset Pod,它所做的決策都是基於節點而缺乏全域性視角。當多個節點同時發生干擾,Agent需要對某低優業務進行驅逐時,若無PDB對最大可用副本數進行保護,很可能會導致該業務的多個Pod同時被驅逐,進而造成服務質量下降。
Crane Agent支援與中心化部署的重排程器聯動,由Crane Agent為待驅逐Pod打上標籤,並交由重排程器統一進行驅逐。
Crane增強的Descheduler支援優雅驅逐能力,包括:
- 支援模擬排程,叢集資源不足時可停止驅逐,該過程模擬Filter,PreFilter過程,不僅包含了Scheduler預設包含的外掛,同時支援排程器擴充套件外掛,模擬實際排程過程
- 有全域性檢視,在多Workload並行,同一Workload內序列驅逐,適用於固定時間視窗騰空節點和基於特定標籤批次驅逐Pod/Workload/母機的場景
- 可以通過先擴容後縮容的方式實現無感驅逐,保證Workload可用性
RUE核心提供混部的穩定底座
如意,TencentOS RUE(Resource Utilization Enhancement),是 TencentOS 產品矩陣 中一款專為雲原生場景下伺服器資源 QoS 設計,提升資源利用率,降低運營成本的產品。如意統一排程分配雲上機器的 CPU、IO、網路、記憶體等資源,相比傳統的伺服器資源管理方案,如意更適用於雲場景,能夠顯著提升雲上機器的資源使用效率,降低雲上客戶的運營成本,為公有云、混合雲、私有云等客戶提供資源增值服務。如意的核心技術能做到不同優先順序的業務之間不互相干擾,實現資源利用率、資源隔離效能、資源服務質量的高效統一。
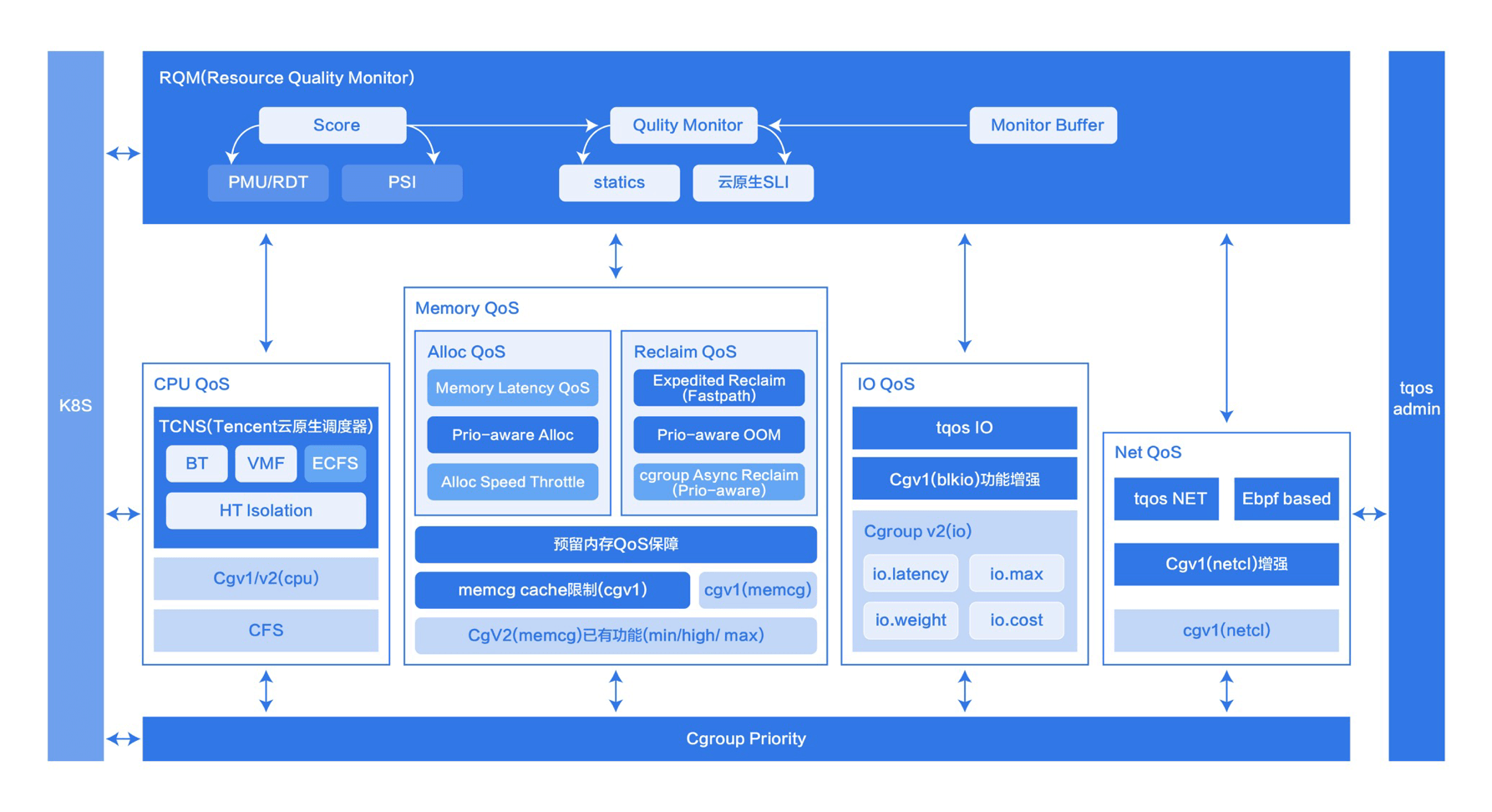
相比傳統的資源管理方案,如意具有以下特點:
- 為雲而生:對接 K8S 等主流資源管理平臺,以容器為物件進行資源排程。
- 多優先順序:支援三檔基礎優先順序,支援更多優先順序擴充套件。
- 多種資源:對CPU、IO、網路、記憶體等伺服器資源進行全面統一排程。
- 資源隔離:低優先順序器可以使用空閒資源,不會對高優先順序容器造成影響。
- 穩定有效:在騰訊雲百萬級別資料中心上驗證,服務眾多客戶。
以干擾最容易發生的CPU資源為例,如意CPU QoS 允許使用者將伺服器上的容器劃分成不同優先順序,根據優先順序分配 CPU 資源,保障低優先順序容器不會對高優先順序容器造成干擾(包括排程時延,CPU 使用時間等),同時允許低優先順序容器使用空閒 CPU 資源,從而提升 CPU 利用率,降低計算成本。


Crane涵蓋了RUE的大部分功能,涉及CPU,記憶體,IO,網路等多個維度,通過PodQOS和NodeQOS為應用提供批次化的RUE隔離能力,使得使用者無需關注複雜的CGroup設定便能輕鬆實現核心層面的資源隔離和保障。
最佳實踐
安裝設定
參考教學安裝 Crane 和 Fadvisor部分,即可安裝Crane-Agent和Crane,其中NodeResource作為FeatureGate控制彈性資源複用功能的開啟,目前預設開啟,使用者無需設定;如需使用到節點彈性資源TSP預測,需要同時部署監控元件,參考教學安裝 Prometheus 和 Grafana部分,CraneTimeSeriesPrediction作為FeatureGate控制預測功能的開啟,預設開啟,使用者無需再做設定。
Crane-Agent支援Docker和Containerd,自動探測無需使用者設定;支援cgroupfs,systemd兩種cgroup-driver,預設使用cgroupfs,如需更改,command新增--cgroup-driver="systemd"即可。
下面以將業務分為高低兩個優先順序為例說明如何設定使用;
- 通過PodQOS支援的scopeSelector為業務做區分和分級;同時設定低優先順序的資源設定使用彈性資源,如gocrane.io/cpu
- 為每級業務建立對應的PodQOS,指定其對應範圍和允許的迴避動作以及資源隔離策略
- 建立NodeQOS指定一條或多條水位線和對應的迴避操作,比如60%時開始壓制,70%時開始驅逐等
apiVersion: ensurance.crane.io/v1alpha1
kind: PodQOS
metadata:
name: high
...
allowedActions:
scopeSelector:
...
resourceQOS:
cpuQOS:
cpuPriority: 0
apiVersion: ensurance.crane.io/v1alpha1
kind: PodQOS
metadata:
name: low
...
allowedActions:
- eviction
scopeSelector:
...
resourceQOS:
cpuQOS:
cpuPriority: 7
apiVersion: ensurance.crane.io/v1alpha1
kind: NodeQOS
metadata:
name: "watermark"
...
actionName: throttle
metricRule:
name: cpu_total_utilization
value: 70
Housekeeper
隨著 Housekeeper(騰訊雲原生運維新正規化)的推出,QoS Agent 已經結合原生節點的能力提供了可搶佔式 Job 的能力。該型別 Job 使用的資源是叢集中的閒置資源,不佔用叢集/節點真實的剩餘可排程量,在發生資源競爭時,該部分資源會被優先回收,保證正常使用節點資源的業務的穩定性。更多請參考:可搶佔式Job(https://cloud.tencent.com/document/product/457/81751)
擴充套件閱讀
混部在離線作業排程時應優先選擇滿足彈性資源用量中真實負載較低的節點進行部署,避免節點負載不均;同時,需保障高優和延遲敏感業務的資源訴求,如排程到資源寬裕的節點,滿足NUMA拓撲的綁核需求等。Crane通過真實負載排程和CPU拓撲感知排程滿足瞭如上需求,具體可參考Crane-Scheduler和CPU拓撲感知排程。
【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多幹貨!!
