詳解redis網路IO模型
前言
"redis是單執行緒的" 這句話我們耳熟能詳。但它有一定的前提,redis整個服務不可能只用到一個執行緒完成所有工作,它還有持久化、key過期刪除、叢集管理等其它模組,redis會通過fork子程序或開啟額外的執行緒去處理。所謂的單執行緒是指從網路連線(accept) -> 讀取請求內容(read) -> 執行命令 -> 響應內容(write),這整個過程是由一個執行緒完成的,至於為什麼redis要設計為單執行緒,主要有以下原因:
- 基於記憶體。redis命令操作主要都是基於記憶體,這已經足夠快,不需要藉助多執行緒。
- 高效的資料結構。redis底層提供了動態簡單動態字串(SDS)、跳錶(skiplist)、壓縮列表(ziplist)等資料結構來高效存取資料。
- 保持簡單。引入多執行緒會使redis變得複雜,例如需要考慮多執行緒並行存取資源競爭問題,資料結構也會變得複雜,hash就不能是單純的hash,需要像java一樣設計一個ConcurrentHashMap。還需要考慮執行緒切換帶來的效能損耗,基於第一點,當程式執行已經足夠快,多執行緒並不能帶來正面收益。
按照redis官方介紹,單個節點的redis qps可以達到10w+,已經非常優秀,如果有更高的要求,則可以通過部署主從、叢集方式進一步提升。
單執行緒不是沒有缺點的,我們需要辯證的看待問題,不然所有的元件都可以使用redis替代了。首先是基於記憶體的操作有丟失資料的風險,儘管你可以設定appendfsync always每次將執行請求通過aof檔案持久化,但這也會帶來效能的下降。另外單執行緒的執行意味著所有的請求都需要排隊執行,如果有一個命令阻塞了,其它命令也都執行不了,可以與之比較的是mysql,如果有一條sql語句執行比較慢,只要它不完全拖垮資料庫,其它請求的sql語句還是可以執行。最後,從上面可以看到從接收網路連線到寫回響應內容,對於網路請求部分的處理其實是可以多執行緒執行來提升網路IO效率的。
redis 6.0
從redis 6.0開始,網路連線(accept) -> 讀取請求內容(read) -> 執行命令 -> 響應內容(write) 這個過程中的「執行命令」這個步驟依然保持單執行緒執行,而對於網路IO讀寫是多執行緒執行的了。原因是這部分是網路IO的解析、響應處理,已經不是單純的記憶體操作,可以充分利用多核CPU的優勢提升效能,對於這部分的效能需求其實一直都存在,社群也有KeyDB這樣的產品,其核心就是在redis的基礎上對多執行緒的支援,這多redis來說無疑是一種挑戰,所有redis6.0開始在網路IO處理支援多執行緒就顯得非常必要了。
我們知道redis使用者端連線是可以有很多個的,最多可以有maxclients引數設定的數量,預設是10000個,那麼redis是如何高效處理這麼多連線的呢?以及6.0和之前的版本是如何具體處理從接收連線到響應整個過程的,或者說redis執行緒模型是怎麼樣的,清楚的瞭解這些有助於我們更好的學習redis,其中的知識在以後學習其它中介軟體也可以很好的借鑑。
linux IO模型
在學習redis網路IO模型之前我們必須先了解一下linux的IO模型,以為redis也是基於作業系統去設計的。I/O是Input/Output的縮寫,是指作業系統與外部裝置進行讀取、輸出的互動過程,外部裝置可以是網路卡、磁碟等。作業系統一般都分為核心和使用者空間兩部分,核心負責與底層硬體互動,使用者程式讀寫資料都需要經過核心空間,也就是資料會不斷的在核心-使用者空間進行復制,不同的IO模型在這個複製過程使用者執行緒有不同的表現,有的是阻塞,有的是非阻塞,有的是同步,有的是非同步。
以linux為例,常見的IO模型有阻塞IO、非阻塞IO、IO多路複用、訊號驅動IO、非同步IO 5種,這次我們主要關注前3個,重點是IO多路複用,另外兩個在使用上有一些侷限性,實際應用並不多。這5種IO模型我們在這一篇已經有詳細的介紹,這裡簡單再複習一遍。
以一個最簡單例子,現在有兩個使用者端需要連線、傳送資料到我們的伺服器端,看下伺服器端在各種IO模型下是如何接收、讀取請求的。
阻塞IO(Blocking IO)
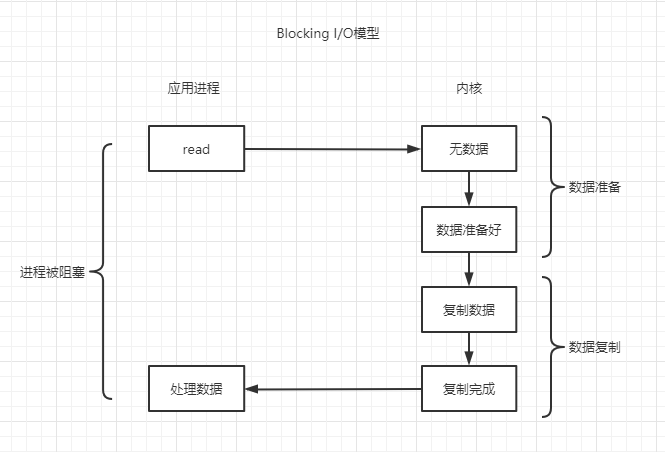
假設伺服器端只開啟一個執行緒處理請求,第一個請求到來,開始呼叫核心read函數,然後就會發生阻塞,第二個請求到來時伺服器端將無法處理,只能等第一個請求讀取完成。這種方式的缺點很明顯,每次只能處理一個請求,無法發揮cpu多核優勢,效能低下。
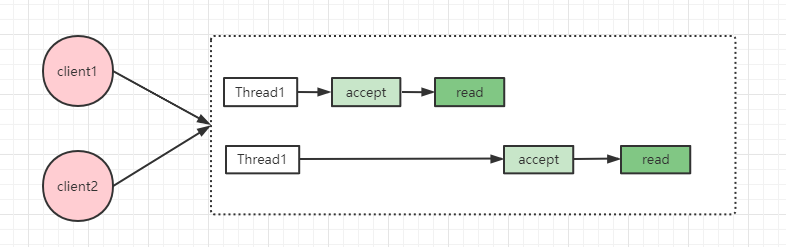
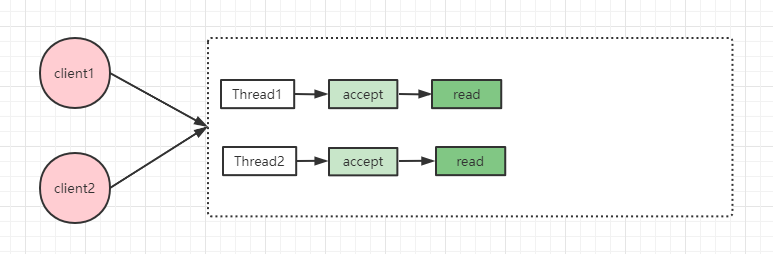
為了解決這個問題,我們可以引入多執行緒,這樣就可以同時處理多個請求了,但伺服器端可能同時有成千上萬的請求需要處理,隨之而來的是執行緒數膨脹,頻繁建立、銷燬執行緒帶來的效能影響,當然我們可以使用執行緒池,但服務能處理的總體數量就會受限於執行緒池執行緒數量。
非阻塞IO(NON-Blocking IO)
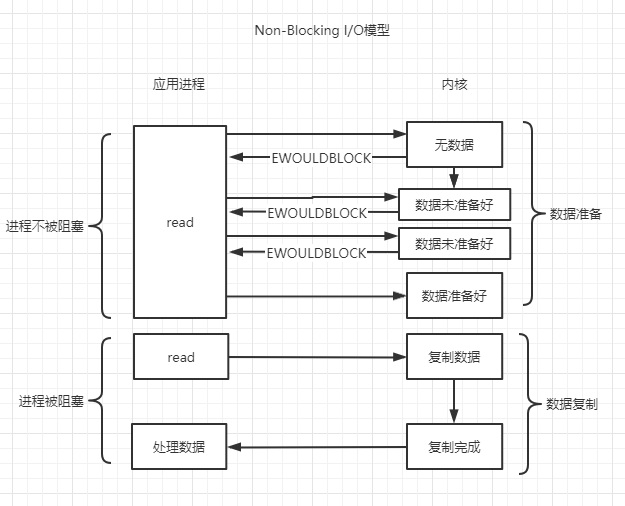
相比阻塞IO,非阻塞IO會立即返回,呼叫者不會阻塞,此時可以做一些其它事情,例如處理其它請求。但是非阻塞IO需要主動輪詢是否有資料需要處理,且這種輪詢需要從使用者態切換到核心態這,假如沒有資料產生就會有很多空輪詢,白白浪費cpu資源。
阻塞IO、非阻塞IO,要麼需要開啟更多執行緒去處理IO,要麼需要從使用者態切換到核心態輪詢IO事件,那麼有沒有一種機制,使用者程式只需要將請求提交給核心,由核心用少量的執行緒去監聽,有事件就通知使用者程式呢?這就是IO多路複用。
IO多路複用(IO Multiplexing)
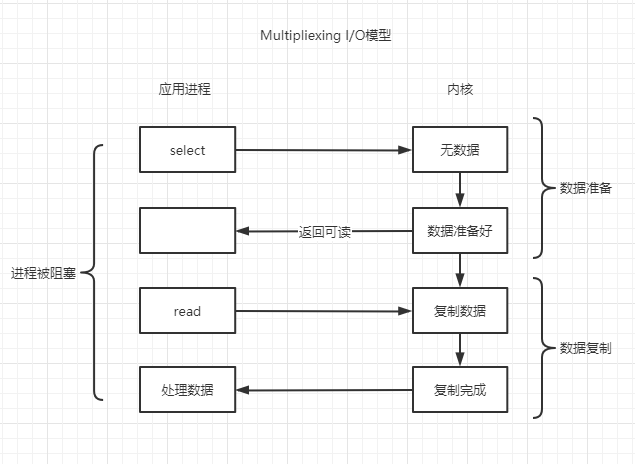
IO多路複用機制是指一個執行緒處理多個IO流,多路是指網路連線,複用指的是同一個執行緒。
如果簡單從圖上看IO多路複用相比阻塞IO似乎並沒有什麼高明之處,假設服務只處理少量的連線,那麼相比阻塞IO確實沒有太大的提升,但如果連線數非常多,差距就會立竿見影。
首先IO多路複用會提交一批需要監聽的檔案控制程式碼(socket也是一種檔案控制程式碼)到核心,由核心開啟一個執行緒負責監聽,把輪詢工作交給核心,當有事件發生時,由核心通知使用者程式。這不需要使用者程式開啟更多的執行緒去處理連線,也不需要使用者程式切換到核心態去輪詢,用一個執行緒就能處理大量網路IO請求。
redis底層採用的就是IO多路複用模型,實際上基本所有中介軟體在處理網路IO這一塊都會使用到IO多路複用,如kafka,rocketmq等,所以本次學習之後對其它中介軟體的理解也是很有幫助的。
select/poll/epoll
這三個函數是實現linux io多路複用的核心函數,我們簡單瞭解下。
linux最開始提供的是select函數,方法如下:
select(int nfds, fd_set *r, fd_set *w, fd_set *e, struct timeval *timeout)
該方法需要傳遞3個集合,r,e,w分別表示讀、寫、異常事件集合。集合型別是bitmap,通過0/1表示該位置的fd(檔案描述符,socket也是其中一種)是否關心對應讀、寫、異常事件。例如我們對fd為1和2的讀事件關心,r引數的第1,2個bit就設定為1。
使用者程序呼叫select函數將關心的事件傳遞給核心系統,然後就會阻塞,直到傳遞的事件至少有一個發生時,方法呼叫會返回。核心返回時,同樣把發生的事件用這3個引數返回回來,如r引數第1個bit為1表示fd為1的發生讀事件,第2個bit依然為0,表示fd為2的沒有發生讀事件。使用者程序呼叫時傳遞關心的事件,核心返回時返回發生的事件。
select存在的問題:
- 大小有限制。為1024,由於每次select函數呼叫都需要在使用者空間和核心空間傳遞這些引數,為了提升拷貝效率,linux限制最大為1024。
- 這3個集合有相應事件觸發時,會被核心修改,所以每次呼叫select方法都需要重新設定這3個集合的內容。
- 當有事件觸發select方法返回,需要遍歷集合才能找到就緒的檔案描述符,例如傳1024個讀事件,只有一個讀事件發生,需要遍歷1024個才能找到這一個。
- 同樣在核心級別,每次需要遍歷集合檢視有哪些事件發生,效率低下。
poll函數對select函數做了一些改進
poll(struct pollfd *fds, int nfds, int timeout)
struct pollfd {
int fd;
short events;
short revents;
}
poll函數需要傳一個pollfd結構陣列,其中fd表示檔案描述符,events表示關心的事件,revents表示發生的事件,當有事件發生時,核心通過這個引數返回回來。
poll相比select的改進:
- 傳不固定大小的陣列,沒有1024的限制了(問題1)
- 將關心的事件和實際發生的事件分開,不需要每次都重新設定引數(問題2)。例如poll陣列傳1024個fd和事件,實際只有一個事件發生,那麼只需要重置一下這個fd的revent即可,而select需要重置1024個bit。
poll沒有解決select的問題3和4。另外,雖然poll沒有1024個大小的限制,但每次依然需要在使用者和核心空間傳輸這些內容,數量大時效率依然較低。
這幾個問題的根本實際很簡單,核心問題是select/poll方法對於核心來說是無狀態的,核心不會儲存使用者呼叫傳遞的資料,所以每次都是全量在使用者和核心空間來回拷貝,如果呼叫時傳給核心就儲存起來,有新增檔案描述符需要關注就再次呼叫增量新增,有事件觸發時就只返回對應的檔案描述符,那麼問題就迎刃而解了,這就是epoll做的事情。
epoll對應3個方法
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
epoll_create負責建立一個上下文,用於儲存資料,底層是用紅黑樹,以後的操作就都在這個上下文上進行。
epoll_ctl負責將檔案描述和所關心的事件註冊到上下文。
epoll_wait用於等待事件的發生,當有有事件觸發,就只返回對應的檔案描述符了。
reactor模式
前面我們介紹的IO多路複用是作業系統的底層實現,藉助IO多路複用我們實現了一個執行緒就可以處理大量網路IO請求,那麼接收到這些請求後該如何高效的響應,這就是reactor要關注的事情,reactor模式是基於事件的一種設計模式。在reactor中分為3中角色:
Reactor:負責監聽和分發事件
Acceptor:負責處理連線事件
Handler:負責處理請求,讀取資料,寫回資料
從執行緒角度出發,reactor又可以分為單reactor單執行緒,單reactor多執行緒,多reactor多執行緒3種。
單reactor單執行緒
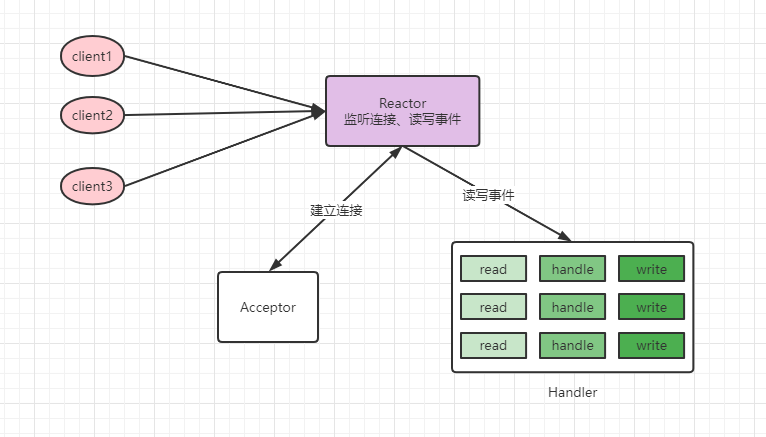
處理過程:reactor負責監聽連線事件,當有連線到來時,通過acceptor處理連線,得到建立好的socket物件,reactor監聽scoket物件的讀寫事件,讀寫事件觸發時,交由handler處理,handler負責讀取請求內容,處理請求內容,響應資料。
可以看到這種模式比較簡單,讀取請求資料,處理請求內容,響應資料都是在一個執行緒內完成的,如果整個過程響應都比較快,可以獲得比較好的結果。缺點是請求都在一個執行緒內完成,無法發揮多核cpu的優勢,如果處理請求內容這一塊比較慢,就會影響整體效能。
單reactor多執行緒
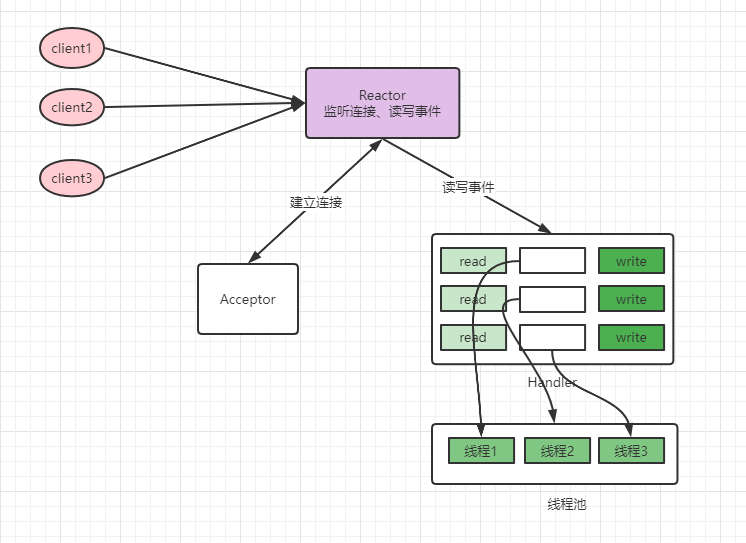
既然處理請求這裡可能由效能問題,那麼這裡可以開啟一個執行緒池來處理,這就是單reactor多執行緒模式,請求連線、讀寫還是由主執行緒負責,處理請求內容交由執行緒池處理,相比之下,多執行緒模式可以利用cpu多核的優勢。單仔細思考這裡依然有效能優化的點,就是對於請求的讀寫這裡依然是在主執行緒完成的,如果這裡也可以多執行緒,那效率就可以進一步提升。
多reactor多執行緒
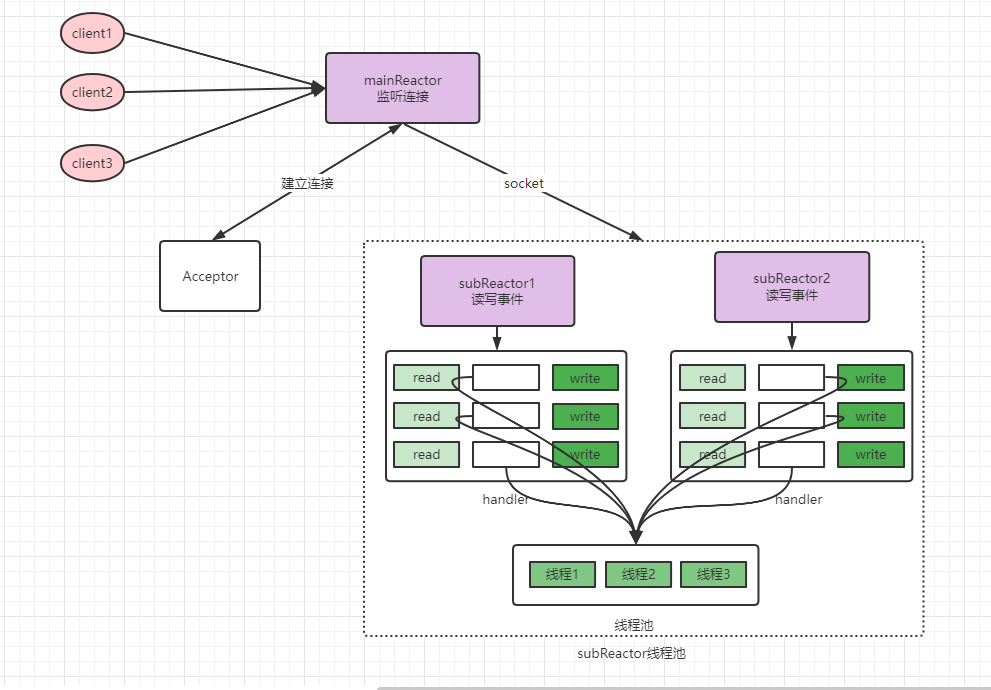
多reactor多執行緒下,mainReactor接收到請求交由acceptor處理後,mainReactor不再讀取、寫回網路資料,直接將請求交給subReactor執行緒池處理,這樣讀取、寫回資料多個請求之間也可以並行執行了。
redis網路IO模型
redis網路IO模型底層使用IO多路複用,通過reactor模式實現的,在redis 6.0以前屬於單reactor單執行緒模式。如圖:
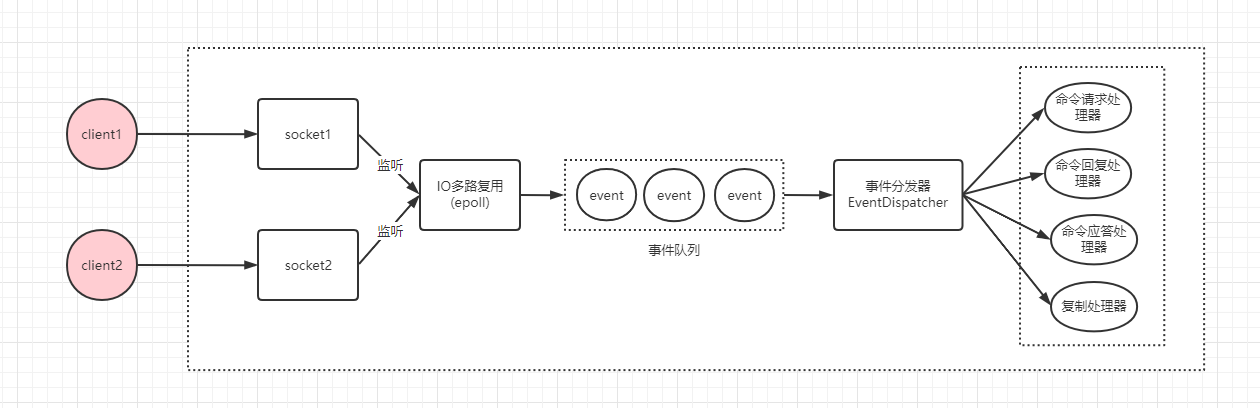
在linux下,IO多路複用程式使用epoll實現,負責監聽伺服器端連線、socket的讀取、寫入事件,然後將事件丟到事件佇列,由事件分發器對事件進行分發,事件分發器會根據事件型別,分發給對應的事件處理器進行處理。我們以一個get key簡單命令為例,一次完整的請求如下:
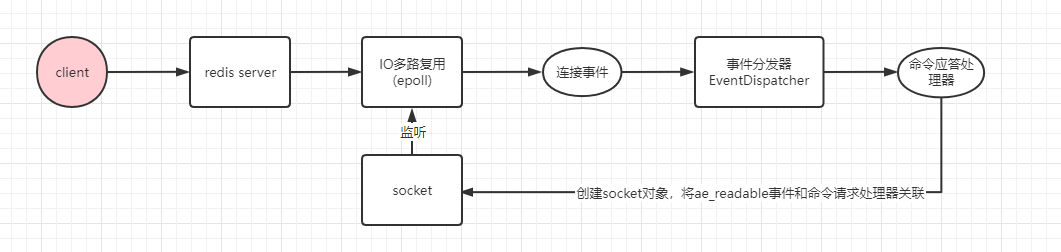
請求首先要建立TCP連線(TCP3次握手),過程如下:
redis服務啟動,主執行緒執行,監聽指定的埠,將連線事件繫結命令應答處理器。
使用者端請求建立連線,連線事件觸發,IO多路複用程式將連線事件丟入事件佇列,事件分發器將連線事件交由命令應答處理器處理。
命令應答處理器建立socket物件,將ae_readable事件和命令請求處理器關聯,交由IO多路複用程式監聽。
連線建立後,就開始執行get key請求了。如下:
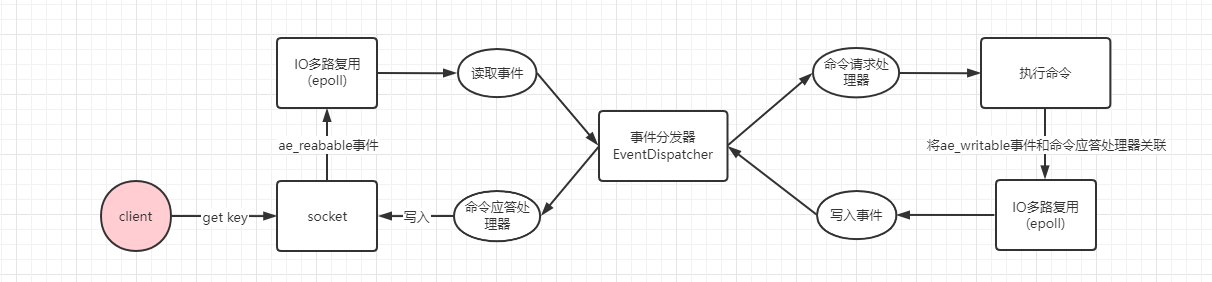
使用者端傳送get key命令,socket接收到資料變成可讀,IO多路複用程式監聽到可讀事件,將讀事件丟到事件佇列,由事件分發器分發給上一步繫結的命令請求處理器執行。
命令請求處理器接收到資料後,對資料進行解析,執行get命令,從記憶體查詢到key對應的資料,並將ae_writeable寫事件和響應處理器關聯起來,交由IO多路複用程式監聽。
使用者端準備好接收資料,命令請求處理器產生ae_writeable事件,IO多路複用程式監聽到寫事件,將寫事件丟到事件佇列,由事件分發器發給命令響應處理器進行處理。
命令響應處理器將資料寫回socket返回給使用者端。
reids 6.0以前網路IO的讀寫和請求的處理都在一個執行緒完成,儘管redis在請求處理基於記憶體處理很快,不會稱為系統瓶頸,但隨著請求數的增加,網路讀寫這一塊存在優化空間,所以redis 6.0開始對網路IO讀寫提供多執行緒支援。需要知道的是,redis 6.0對多執行緒的預設是不開啟的,可以通過 io-threads 4 引數開啟對網路寫資料多執行緒支援,如果對於讀也要開啟多執行緒需要額外設定 io-threads-do-reads yes 引數,該引數預設是no,因為redis認為對於讀開啟多執行緒幫助不大,但如果你通過壓測後發現有明顯幫助,則可以開啟。
redis 6.0多執行緒模型思想上類似單reactor多執行緒和多reactor多執行緒,但不完全一樣,這兩者handler對於邏輯處理這一塊都是使用執行緒池,而redis命令執行依舊保持單執行緒。如下:
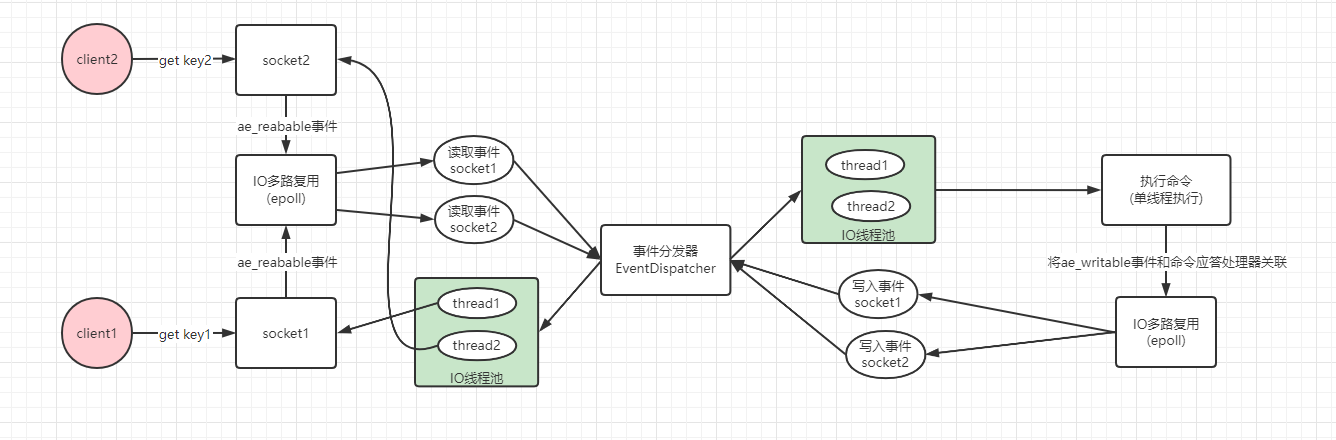
可以看到對於網路的讀寫都是提交給執行緒池去執行,充分利用了cpu多核優勢,這樣主執行緒可以繼續處理其它請求了。
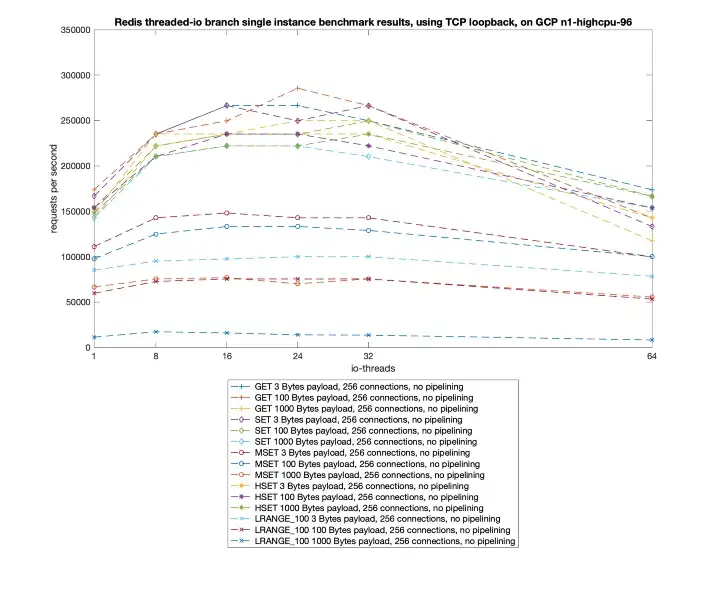
開啟多執行緒後多redis進行壓測結果可以參考這裡,如下圖可以看到,對於簡單命令qps可以達到20w左右,相比單執行緒有一倍的提升,效能提升效果明顯,對於生產環境如果大家使用了新版本的redis,現在7.0也出來了,建議開啟多執行緒。
總結
本篇我們學習redis單執行緒具體是如何單執行緒以及在不同版本的區別,通過網路IO模型知道IO多路複用如何用一個執行緒處理監聽多個網路請求,並詳細瞭解3種reactor模型,這是在IO多路複用基礎上的一種設計模式。最後學習了redis單執行緒、多執行緒版本是如何基於reactor模型處理請求。其中IO多路複用和reactor模型在許多中介軟體都有使用到,後續再接觸到就不陌生了。
歡迎關注我的github:https://github.com/jmilktea/jtea