SQL一文入門助記
什麼是SQL
SQL(Structured Query Language)是用於運算元據庫的語言。一個部落格有許多網站,一個遊戲要儲存許多遊戲的賬號密碼,這些都離不開資料庫操作。
關係型資料庫與NoSQL
關係型資料庫就是一個表格,每一個橫行就是每一條資料,每一個縱列就是每條資料有哪些資訊:
| id | name | score | gender |
|---|---|---|---|
| 1 | Alice | 90 | F |
| 2 | Bob | 92 | M |
| 3 | Carol | 90 | F |
| 4 | David | 98 | M |
常見的關係型資料庫: Oracle、MySql、Microsoft SQL Server、SQLite
非關係型資料庫就是沒有這些限制的資料庫,他們結構更自由,通常資料自身就以物件的方式儲存,NoSQL 往往為某些特別資料量身打造,在許多場合效率更高。
常見的 NoSQL 資料庫:MongoDB、Redis、Memcached、HBase
但總體而言,SQL 的使用場合多得多,NoSQL 意為"Not Only SQL",用於輔助 SQL 資料庫,而非取而代之。
MySQL, SQL 與 InnoDB
SQL 是一種結構化查詢語言,是一門 ANSI 標準的計算機語言,但是仍然存在著多種不同版本的 SQL 語言。在不同的軟體裡,每款資料庫的 SQL 語法通常有區別。但在基本的增刪改查功能上他們是一樣的,但某個特型資料庫提供的 SQL 語句可能就不能在其他地方執行了。
SQL語句通常不區分大小寫,但一般關鍵字用大寫;SQL語句末尾要打分號。SQL以--comment為單行註釋,/* comment */為多行註釋。
MySQL 是一款優秀的 SQL 軟體,是目前應用最廣泛的開源關聯式資料庫之一。MySQL最早是由瑞典的 MySQL AB 公司開發,該公司在2008年被 SUN 公司收購,緊接著,SUN 公司在 2009 年被 Oracle 公司收購,所以 MySQL 最終就變成了 Oracle 旗下的產品。這篇文章以 MySQL 為載體,介紹最簡單的 SQL 語句。
而 MySQL 本身也只是一個介面,內部的引擎(真正做增刪改查的)被分離出來了,稱作資料庫引擎,常用的引擎之一是 InnoDB。
MySQL 分免費版和付費版,他們的程式碼功能是一樣的,付費版多出來的功能是一些管理功能。
免費版下載:https://dev.mysql.com/downloads/mysql/
Mysql 和 mysqld
安裝完成後通常服務會自己啟動,這個服務是執行在後臺的,此時我們可以用 python,node 等連線,也可以用mysql控制檯連線:
mysql -u root -p
-u代表使用者名稱,-p代表接下來輸入密碼,預設密碼應該是root。見到提示符mysql>後,就可以手動操作了。
如果重啟了電腦,後臺SQL服務就關閉了,輸入mysqld即可再次啟動。
建立資料庫和資料表
一個軟體裡有幾個資料庫,一個資料庫裡有幾個資料表;SHOW databases;檢視資料庫;USE ***;選中一個資料庫;SHOW tables;檢視這個資料庫裡面的資料表。
CREATE DATABASE test; --建立資料庫
USE test;
CREATE TABLE students(
id INT,
name varchar(100),
score INT,
gender varchar(100)
); --建立表
SHOW CREATE TABLE students; --檢視剛剛建立students的語句
DESC students; --檢視表的欄位資訊
TRUNCATE TABLE students; --清空表資料,但表還在
DROP TABLE students; --刪除表
DROP DATABASE test; --刪除資料庫
DESC 將輸出欄位資訊:
+-------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(100) | YES | | NULL | |
+-------+--------------+------+-----+---------+-------+
SELECT 查詢
SELECT用於選取資料。
SELECT * FROM table1; --從table1中選取所有資料
SELECT id,score FROM students; --從students中選取id列和score列(name列不會返回,返回的資料是兩列)
SELECT score/2 FROM students; -- 輸出score除以2的值,列名就叫score/2
SELECT DISTINCT score FROM students; --列出score列其中所有不同的值,返回的score列裡同分的只保留一個
AS 選取別名
你可以為每個列名選取一個別名,直接附在列名的後面就可以了
SELECT id AS stunumber,score AS point FROM students;
輸出列表頭的id會變成stunumber。AS通常可以省略
WHERE 條件
WHERE 子句用於提取那些引數滿足指定條件的記錄。
WHERE後的條件是布林判斷值可以使用關係運算子,不等號用<>表示,不能連等,字串按字典序;也可以用NOT AND OR邏輯運運算元,優先順序從前往後,可以加上括號改變優先順序。
SELECT * FROM students WHERE score>=95; --只返回score值大於等於95的橫行記錄
SELECT * FROM students WHERE 85<=score AND score<=90 AND gender = 'M';
--返回score在85到90且gender是M的行
BETWEEN、LIKE 和 IN
-
BETWEEN表示「在……之間」,如85<=score AND score<=90等價於BETWEEN 85 AND 90(左閉右閉); -
IN表示「在這……其中」,可在多個之中選擇,如gender='M' OR gener='F'等價於gender IN ('M', 'F'); -
LIKE用於字串通配,如WHERE name LIKE '%a'表示「以a結尾的」。在SQL中,%代表0,1或多個任意字元,_代表一個任意字元;[a-z]和[^123]等則代表選定的字元集之一,規則同正規表示式
ORDER BY 排序
這個用於排序,排序輸出的資料。
SELECT id,score FROM students ORDER BY score; --按score從小到大
SELECT id,score FROM students ORDER BY score DESC; --按score從大到小
SELECT id,score FROM students ORDER BY score DESC, id; --按score從大到小,同分再按id從小到大
語句是串聯起來的,ORDER BY放到WHERE之後,先篩選,再排序。
LIMIT 只返回部分資料
如果返回的資料太多了,我們可以使用LIMIT只返回一部分資料
SELECT * from table1 LIMIT 3; --只取前三個資料
SELECT * from table1 ORDER BY score LIMIT 3; --排序後取前三個
SELECT * from table1 LIMIT 3 OFFSET 4; --從第四個資料開始(0based)只取前三個資料,即4, 5, 6行。超出下標的忽略
並非所有資料庫都支援LIMIT - OFFSET語法,但每款軟體都有自己的選取資料語法。
INDEX 索引
如果經常根據某一列進行查詢,可以根據這一列建立索引:
CREATE INDEX indexofscore ON students (score);
ALTER TABLE students ADD INDEX indexofscore (score, id); --都可以建立索引
CREATE UNIQUE INDEX indexofscore ON students (score);--建立一個唯一索引,保證 score 唯一
ALTER TABLE students DROP INDEX indexofscore; --刪除索引
索引的效率取決於索引列的值是否雜湊,即該列的值如果越互不相同,那麼索引效率越高。反過來,如果記錄的列存在大量相同的值,例如gender 列,大約一半的記錄值是 M,另一半是 F,因此,對該列建立索引就沒有意義。
索引將加入額外資訊維護資料,使查詢更快;但在增刪改時也要更新索引,所以修改資料會變慢。
增刪改
INSERT INTO 插入
插入幾行資料
INSERT INTO table1 VALUES (value1,value2,value3);
--插入一列(value1,value2,value3)到table1表,按順序對應原來的列
INSERT INTO students (score,id,gender)
VALUES (89,5,'M'), (90,6,'M'); --可以指定每個資料對應的列,可以插入多個資料
修改完成後會返回資訊,有多少行被修改
Query OK, 6 rows affected (0.02 sec)
Rows matched: 6 Changed: 6 Warnings: 0
UPDATE 更新
修幾行的資料
UPDATE table1
SET column1 = value1, column2 = value2, ...
WHERE condition;
對於每個符合 WHERE 條件的行,修改 SET 裡指定的資料列,如果沒有WHERE條件,就修改全部的資料
UPDATE students SET score=100 WHERE gender='M'; --gender為M的全部修改為100分
UPDATE students SET score=score+id WHERE gender='M'; --gender為M的全部加上id。(不能用+=)
DELETE 刪除
刪除一些行的資料
DELETE FROM table1 WHERE condition;
DELETE FROM students WHERE score>100;
每個符合 WHERE 條件的行都會被刪除,如果沒有WHERE條件,整個表的行都被刪除。
JOIN 連線查詢
現在每個學生還有一個班,為了表示每個學生的班,再加一列 class:
| id | name | score | gender | class |
|---|---|---|---|---|
| 1 | Alice | 90 | F | 1 |
| 2 | Bob | 92 | M | 2 |
| 3 | Carol | 90 | F | 3 |
| 4 | David | 98 | M | 2 |
在另一個表 classes 裡,是每一個班的名字:
| id | name |
|---|---|
| 1 | 火箭班 |
| 2 | 自動化 |
| 3 | 程式設計班 |
| 4 | 戰神班 |
現在要查詢全體學生所在的班,也就是查詢 student 表的同時根據 student.class 再到 classes 表中附上一列 class.name,這就要用到連線查詢。
SELECT * FROM students /*選取 students 裡的資料*/
INNER JOIN classes /*並和 classes 取積*/
ON students.class=classes.id; /* 保留 students.class=classes.id 的值*/
我們得到的兩個表拼起來後的輸出:
+----+-------+-------+--------+-------+----+-----------+
| id | class | name | gender | score | id | name |
+----+-------+-------+--------+-------+----+-----------+
| 1 | 1 | Alice | F | 90 | 1 | 火箭班 |
| 2 | 1 | Bob | M | 92 | 1 | 火箭班 |
| 3 | 1 | Carol | F | 90 | 1 | 火箭班 |
| 4 | 2 | David | M | 98 | 2 | 自動化 |
+----+-------+-------+--------+-------+----+-----------+
如果沒有 ON,那麼就不會篩選資料,直接取兩個表的直積(16個資料)
AS 給表取別名
上面表中 id 和 name 都重複出現了,如果不用 SELECT *,而是隻取部分列,要用「表名.列名」的方式區分開(students.id 和 classes.id),而表的名字多次出現 太長了,可以為他設定別名(AS 可以省略)。
SELECT s.id, c.name AS classname, s.name, s.gender, s.score FROM students AS s
INNER JOIN classes AS c
ON s.class=c.id;
這樣就符合我們的閱讀習慣了:
+----+-----------+-------+--------+-------+
| id | classname | name | gender | score |
+----+-----------+-------+--------+-------+
| 1 | 火箭班 | Alice | F | 90 |
| 2 | 火箭班 | Bob | M | 92 |
| 3 | 火箭班 | Carol | F | 90 |
| 4 | 自動化 | David | M | 98 |
+----+-----------+-------+--------+-------+
各種形式的 JOIN
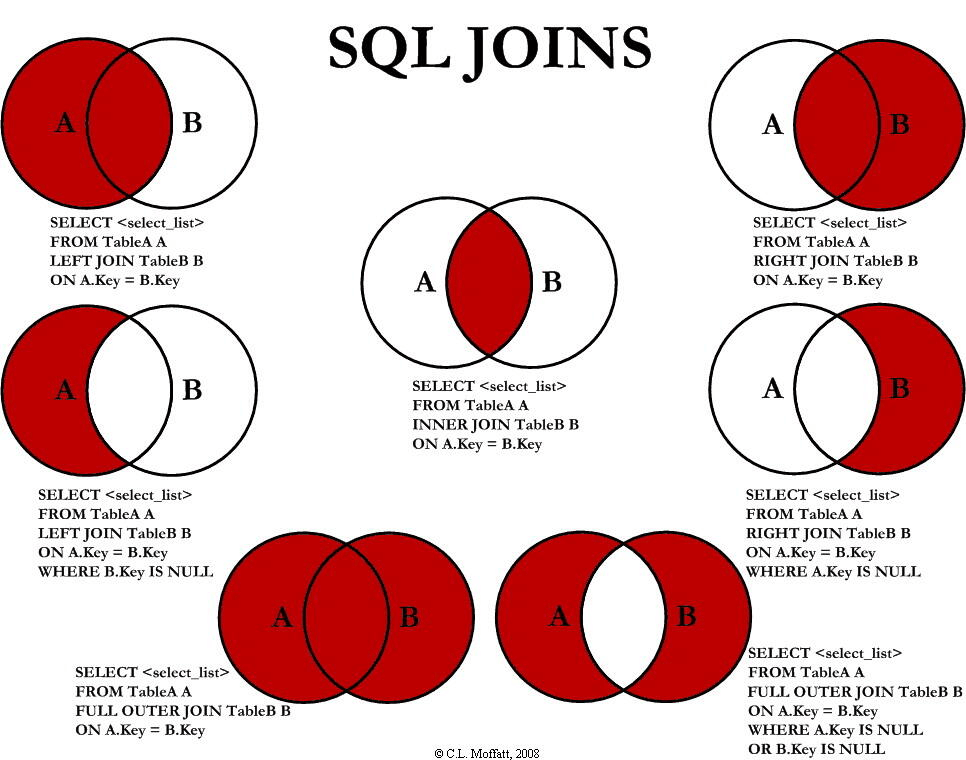
-
INNER JOIN:將集合取直積,並只返回符合條件的資料。
-
LEFT (OUTER) JOIN:確保左表的每一行都保留,如果左表有一行配不上任何右表,他仍會顯示出來,在右表有關的列顯示 NULL。
-
RIGHT (OUTER) JOIN:同上,確保左表的每一行都保留。如果把上面的例子改成 RIGHT JOIN,就會多出一行沒有人的「戰神班」,其他列全為 NULL
-
FULL (OUTER) JOIN:結果上,FULL JOIN 同時擁有 LEFT JOIN 和 RIGHT JOIN 多出來的行。MySQL 是不支援 FULL JOIN 的。
資料庫操作和關係模型
Primary Key 主鍵
關聯式資料庫裡,每一行是一條「記錄」,每一列是一個「欄位」。兩條記錄不能完全相同,至少要有一個能區分他們的欄位,使每條資料都不相同,這個欄位叫做主鍵(Primary Key)。比如在上面的 students 表裡,性別和分數可以相同,名字也可以一樣,id就適合成為主鍵,每個 id 可以唯一定位到一個人。
主鍵是用來直接定位一個記錄的,一旦插入就最好不要更改。
資料型別
這是關聯式資料庫,所以每個欄位要有唯一的型別,在 students 表中,id、score是整數,而 name、gender則是字串。
| 一些型別 | 描述 |
|---|---|
| INT | 32位元有符號整數 |
| BIGINT | 64位元有符號整數 |
| REAL/FLOAT | 32位元IEEE浮點 |
| DOUBLE | 64位元IEEE浮點 |
| DECIMAL(p,s) | 精確十進位制實數,最多p位,小數位最多s位 |
| CHAR(n) | 定長度為 n 的字串 |
| VARCHAR(n) | 變長字串,最長為n |
| BOOLEAN | true或者false |
| DATE/TIME/DATETIME | 儲存日期,時間。不同資料庫規則有差異 |
一般最常見的就是整數 INT 和 字串 VARCHAR(n)。
Constraints 約束
每一個欄位都可以有自己的約束規則,比如不能為空(NOT NULL),唯一(UNIQUE)等等。上面的PRIMARY KEY也是一種約束。約束在建立表的時候就可以新增在資料型別後面或者使用CONSTRAINT單獨新增。
CREATE TABLE table_name(
column_name1 type constraint_name,
column_name2 type constraint_name,
column_name3 type constraint_name,
CONSTRAINT constraint_name ……
);
CREATE TABLE Orders(
O_Id int NOT NULL,
OrderNo int NOT NULL CHECK (OrderNo>0),
P_Id int,
PRIMARY KEY (O_Id),
CONSTRAINT fk_PerOrders FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)
)
-
NOT NULL:表示本欄位不接受 NULL 值,必須給定值。
-
UNIQUE:保證該欄位在表中不重複
-
PRIMARY KEY:表示這是主鍵,主鍵只能有一個,資料上的限制相當於 NOT NULL 加上 UNIQUE
-
FOREIGN KEY:表示這是外來鍵,每個外來鍵中的值對應另一個表中的 UNIQUE,比如 students.class 就是指向 classes.id 的外來鍵。邏輯上, students.class 就是用來對應 classes.id 的,即使沒有顯式指明外來鍵也能連線查詢;指定外來鍵後語意更明確,程式會預防插入非法值,外來鍵必須在另一個表裡存在,但使用外來鍵也會佔用更多的資源。
-
CHECK:為欄位新增條件約束,如
CHECK (OrderNo>0)限制只能取正數 -
DEFAULT:為欄位新增預設值,如
score INT DEFAULT 60不給定分數的值,預設賦值60 -
AUTO_INCREMENT:表明該欄位無需賦值,每次建立時都會自動加一,多用於沒有實際意義的主鍵。
NULL 的應用
沒有限定NOT NULL,沒有預設值又沒有給定值的資料就是 NULL。WHERE 條件中判定 NULL 不能用等於號。
SELECT score FROM students WHERE score IS NOT NULL; --IS NULL表示是NULL;IS NOT NULL表示不是NULL
SELECT id, IFNULL(score,0) FROM students; --有分數的輸出分數,分數為NULL的輸出成0
函數
SQL 語句裡提供豐富的函數供我們使用,一類是聚合(aggregate)函數,另一類是標量(scalar)函數。
標量函數
這些函數進一個值,出一個值,沒有什麼特殊的。如:
- LEN():字串長度
- ROUND():浮點數四捨五入
- UCASE():字串轉為大寫
- NOW():當前時間
聚合函數
聚合函數引數是表中的一列,輸出一個數。
- AVG():返回平均值
- SUM():返回和
- COUNT():返回長度
- MIN() MAX():返回最值
SELECT COUNT(id) FROM students; --一共有多少個id,即資料數量,輸出列名就是COUNT(id),只有一條資料
SELECT AVG(score) FROM students; --求平均分
SELECT class, AVG(score) FROM students; --這是錯誤的,class列有四行,AVG(score)只有一行,拼不出表
GROUP BY 分組查詢
上面的第三句失敗了,如果我想查詢每個班的平均分,那應該使用 GROUP BY 查詢:
SELECT class, AVG(score) FROM students
GROUP BY class;
按照class分組,每一組計算一個 AVG(score),所以 AVG(score) 有了三行,class也是三行,輸出的就是每個班的平均分。GROUP BY也可以接受幾個值,把值不一樣的都分開統計,比如GROUP BY class, gender可以統計每個班每個性別的平均分。
GROUP BY 想和條件篩選一起用怎麼辦?WHERE 可以在 GROUP BY 之前用,但不能放在 GROUP BY 之後,如果是函數算出的東西還要篩選,HAVING 就排上了用場。
SELECT class, AVG(score) FROM students GROUP BY class
HAVING AVG(score)>90; --篩選平均分大於90的班