深度學習煉丹-不平衡樣本的處理
前言
在機器學習的經典假設中往往假設訓練樣本各類別數目是均衡的,但在實際場景中,訓練樣本資料往往都是不均衡(不平衡)的。比如在影象二分類問題中,一個極端的例子是,訓練集中有 95 個正樣本,但是負樣本只有 5 個。這種類別資料不均衡的情況下,如果不做不平衡樣本的處理,會導致模型在數目較少的類別上出現「欠學習」現象,即可能在測試集上完全喪失對負樣本的預測能力。
除了常見的分類、迴歸任務,類似影象語意分割、深度估計等畫素級別任務中也是存在不平衡樣本問題的。
解決不平衡樣本問題的處理方法一般有兩種:
- 從「資料層面」入手:分為資料取樣法和類別平衡取樣法。
- 從「演演算法層面」入手:代價敏感方法。
注意本文只介紹不平衡樣本的處理思想和策略,不涉及具體程式碼,在實際專案中,需要針對具體人物,結合不平衡樣本的處理策略來設計具體的資料集處理或損失函數程式碼,從而解決對應問題。
一,資料層面處理方法
資料層面的處理方法總的來說分為資料擴充和資料取樣法,資料擴充會直接改變資料樣本的數量和豐富度,取樣法的本質是使得輸入到模型的訓練集樣本趨向於平衡,即各類樣本的數目趨向於一致。
資料層面的取樣處理方法主要有兩種策略:
- 資料重取樣方法,發生在資料預處理階段,會改變整體訓練集的數目和分佈。
- 類別平衡取樣方法,發生在資料載入階段(這裡的載入是指載入到模型中,不是指從硬碟中讀取檔案),通過設定取樣策略來使得不同類別樣本送入模型訓練總的次數是近似的。
1.1,資料擴充
所謂資料不平衡,其實就是某些類別的資料量太少,那就直接增加一些唄,簡單直接。如果有的選,那肯定是優先選擇重新採取資料的辦法了,當然大部分時候我們都沒得選,這個時候最有效的辦法自然是通過資料增強來擴充資料了。
資料增強的手段有多種,常見的如下:
- 水平 / 豎直翻轉
- 90°,180°,270° 旋轉
- 翻轉 + 旋轉(旋轉和翻轉其實是保證了資料特徵的旋轉不變效能被模型學習到,折積層面的方法可以參考論文
ACNet) - 亮度,飽和度,對比度的隨機變化
- 隨機裁剪(Random Crop)
- 隨機縮放(Random Resize)
- 加模糊(Blurring)
- 加高斯噪聲(Gaussian Noise)
值得注意的是資料增強手段的使用必須結合具體任務而來,除了前三種以外,其他的要慎重考慮。因為不同的任務場景下資料特徵依賴不同,比如高斯噪聲,在天池鋁材缺陷檢測競賽中,如果高斯噪聲增加不當,有些圖片原本在採集的時候相機就對焦不準,導致工件難以看清,倘若再增加高斯模糊屬性,部分圖片樣本基本就廢了。
參考文章 如何針對資料不平衡做處理。
雖然目前深度學習框架中都自帶了一些資料增強函數,但更多更強的資料增強手段可以使用一些影象增強庫,比如 imgaug 這個 python 庫。
模型訓練過程中,pytorch 框架如何在資料構建 pipeline 階段使用 imgaug 庫可以參考文章 資料增強-imgaug。
1.2,資料(重)取樣
簡單的資料重取樣方法分為資料上取樣(over-sampling、up-sampling,也叫資料過取樣) 或 也叫資料欠取樣資料下取樣(under-sampling 、down-sampling )。
1,對於樣本數目較少的類別,可用資料過取樣方法(over-sampling),即通過複製方法使得該類影象數目增至與樣本最多類的樣本數一致。
2,而對於樣本數較多的類別,可使用資料欠取樣(Under-sampling,也叫資料欠取樣)方法。對於深度學習和計算機視覺領域的任務來說,下取樣並不是直接隨機丟棄一部分影象,正確的下取樣策略是: 在批次處理訓練時(資料載入階段 dataloader),對於樣本較多的類別,嚴格控制每批(batch)隨機抽取的影象數目,使得每批讀取的資料中正負樣本是均衡的(類別均衡)。以二分類任務為例,假設原始資料分佈情況下每批次處理訓練正負樣本平均數量比例為 9:1,如僅使用下取樣策略,則可在每批隨機挑選訓練樣本時每 9 個正樣本只取 1 個作為該批訓練集的正樣本,負樣本選擇策略不變,這樣可使得每批讀取的訓練資料中正負樣本時平衡的。
資料過取樣和欠取樣示意圖如下所示。
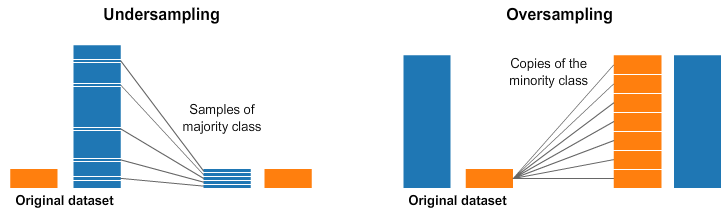
資料取樣方法總結
資料過取樣和欠取樣本質的簡單理解就是「增加圖片」和「刪圖片」:
- 過取樣:重複正比例資料,實際上沒有為模型引入更多形式資料,過分強調正比例資料,會放大正比例噪音對模型的影響。
- 欠取樣:丟棄大類別的部分資料,和過取樣一樣會存在過擬合的問題。
同時兩種資料重取樣方法都是會改變資料原始分佈的,比如資料過取樣增加較小類別的樣本數,資料欠取樣減少較大類別的樣本數,有可能產生模型過擬合等問題。
這裡的較小類別的意思是樣本數目較少的類別,較大類別即樣本數目較多的類別。
以上內容都是對解決類別不平衡問題中資料取樣方法的策略描述,但想要在實際任務中解決問題,還要求我們加深對任務(task)的分析、對資料的理解分析,以及要求我們有更多的資料處理、資料取樣的程式碼經驗,即良好的策略 + 熟練的工具。
需要注意的是,因為僅僅使用資料上取樣策略有可能會引起模型過擬合問題,所以在實際任務中,更為保險的資料取樣策略哇往往是將上取樣和下取樣結合起來使用。
1.3,類別平衡取樣
前面的資料重取樣策略是著重於類別樣本數量,而另一類取樣策略則是直接著重於類別本身,不改變資料總體樣本數,即類別平衡取樣方法。其簡單策略是把樣本按類別分組,每個類別生成一個樣本列表,訓練過程中隨機選擇 1 個或幾個類別,然後從每個類別所對應的樣本列表中隨機選擇樣本,這樣可保證每個類別參與訓練的機會比較均衡。
上述類別平衡方法過於簡單,實際應用中有很多限制,比如在類別數很多的多分類任務中(如 ImageNet 資料集)。由此,在類別平衡取樣的基礎上,國內海康威視研究院提出了一種「類別重組取樣」的平衡方法。
類別重組法是在《解析折積神經網路》這本書中看到的,可惜沒在網上找到原論文和程式碼,但這個方法感覺還是很有用的,且也比較好復現。
如下圖所示,類別重組方法步驟如下:
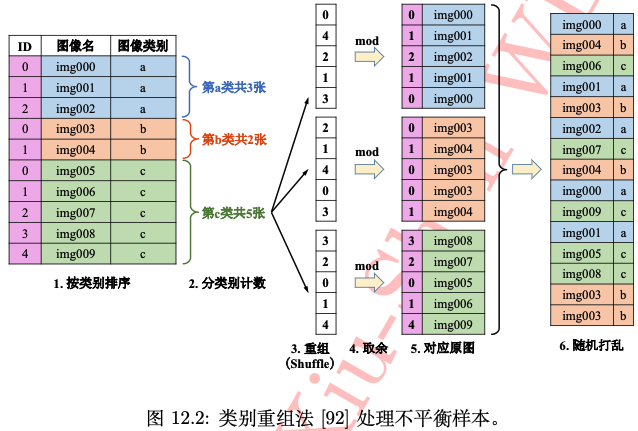
- 對原始樣本的每個類別的樣本分別排序好,計算每個類別的樣本數目,並記錄樣本數最多的那個類別的樣本數量
max_num。 - 基於最大樣本數
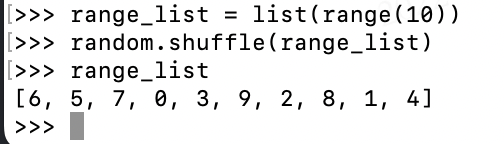
max_num產生一個亂數列表,然後用此列表中的亂數對各自類別的樣本數求餘,得到對應索引值列表index_list。random.shuffle(list(range(max_num))) - 根據該索引值列表
index_list,從該類的影象資料中提取影象,生成該類的影象隨機列表。 - 最後吧所有類別的隨機列表連線在一起後一起隨機打亂次序,即可得到最終的影象列表,可以發現最終的這個影象隨機列表中每個類別的樣本數目是一致的(樣本數較少的類別,影象會存在多次取樣)。然後每輪(
epoch)都對此列表進行遍歷資料用於模型訓練,如此重複。
類別重組法對有點很明顯,在設計好重組程式碼函數後,只需要原始影象列表即可,所有操作都在記憶體中線上完成,易於實現且更通用。其實仔細深究可以發現,海康提出的這個類別重組法和前面的資料取樣方法是很類似的,其本質都是通過取樣(sampler)策略讓類別不均衡的各類資料在每輪訓練中出現的次數是一致的。
二,演演算法(損失函數)層面處理方法
類別不平衡問題的本質是導致樣本數目較少的類別出現「欠學習」這一機器學習現象,直觀表現是較小樣本的損失函數權重佔比也較少。一個很自然的解決辦法是增加小樣本錯分的懲罰代價,並將此代價直接體現在目標函數(損失函數)裡,這就是「代價敏感」的方法。「代價敏感」方法的本質可以理解為調整模型在小類別上的注意力。
2.1,Focal Loss
Focal Loss 是在二分類問題的交叉熵(CE)損失函數的基礎上引入的,主要是為了解決 one-stage 目標檢測中正負樣本比例嚴重失衡的問題,該損失函數降低了大量簡單負樣本在訓練中所佔的權重,也可理解為一種困難樣本挖掘,經實踐證明 Focal Loss 在 one-stage 目標檢測中還是很有效的,但是在多分類中不一定有效。
Focal Loss 作者通過在交叉熵損失函數上加上一個調整因子(modulating factor)\((1-p_t)^\gamma\),把高置信度 \(p\)(易分樣本)樣本的損失降低一些。Focal Loss 定義如下:
Focal Loss 有兩個性質:
- 當樣本被錯誤分類且 \(p_t\) 值較小時,調變因子接近於
1,loss幾乎不受影響;當 \(p_t\) 接近於1,調質因子(factor)也接近於0,容易分類樣本的損失被減少了權重,整體而言,相當於增加了分類不準確樣本在損失函數中的權重。 - \(\gamma\) 引數平滑地調整容易樣本的權重下降率,當 \(\gamma = 0\) 時,
Focal Loss等同於CE Loss。 \(\gamma\) 在增加,調變因子的作用也就增加,實驗證明 \(\gamma = 2\) 時,模型效果最好。
直觀地說,調變因子減少了簡單樣本的損失貢獻,並擴大了樣本獲得低損失的範圍。例如,當\(\gamma = 2\) 時,與 \(CE\) 相比,分類為 \(p_t = 0.9\) 的樣本的損耗將降低 100 倍,而當 \(p_t = 0.968\) 時,其損耗將降低 1000 倍。這反過來又增加了錯誤分類樣本的重要性(對於 \(pt≤0.5\) 和 \(\gamma = 2\),其損失最多減少 4 倍)。在訓練過程關注物件的排序為正難 > 負難 > 正易 > 負易。
| 難 | 易 | |
|---|---|---|
| 正 | 1. 正難 | 3. 正易,\(\gamma\) 衰減 |
| 負 | 2. 負難,\(\alpha\) 衰減 | 4. 負易,\(\alpha、\gamma\)衰減 |
在實踐中,我們通常採用帶 \(\alpha\) 的 Focal Loss:
作者在實驗中採用這種形式,發現它比非 \(\alpha\) 平衡形式(non-\(\alpha\)-balanced)的精確度稍有提高。實驗表明 \(\gamma\) 取 2,\(\alpha\) 取 0.25 的時候效果最佳。
更多理解參考 focal loss 論文。
2.2,損失函數加權
除了 Focal Loss 這種高明的損失函數策略外,針對影象分類問題,還有一種簡單直接的損失函數加權方法,即在計算損失函數過程中,對每個類別的損失做加權處理,具體的 PyTorch 實現方式如下:
weights = torch.FloatTensor([1, 1, 8, 8, 4]) # 類別權重分別是 1:1:8:8:4
# pos_weight_weight(tensor): 1-D tensor,n 個元素,分別代表 n 類的權重,
# 為每個批次元素的損失指定的手動重新縮放權重,
# 如果你的訓練樣本很不均衡的話,是非常有用的。預設值為 None。
criterion = nn.BCEWithLogitsLoss(pos_weight=weights).cuda()