上帝視角一覽巨量資料開發體系
前言
不知道大家有沒有過在百度搜尋旅遊的關鍵字,不久就可能收到機票的推銷的經驗。如今是巨量資料的時代,資料的價值越來越重要。資料即資產,想必大家都聽說過。最近公司的專案中也用到了一些巨量資料的技術,本文對巨量資料相關的知識體系做了一個整體的梳理。
什麼是巨量資料
巨量資料,你可能就簡單理解為資料量大,那是多大才算巨量資料呢?如果只有資料量大是不是太片面單一了,實際上如果你說是從事巨量資料開發, 那麼起碼要滿足下面的5大特徵。

5大特徵
1.資料量大
- 需要採集的資料量大
- 需要儲存的資料量大
- 需要計算de 資料量大
- 資料總體規模起碼要TB、PB級別起步
2.資料種類、來源多樣化
- 資料的種類多樣,可能是類似MySQL一樣的結構化資料,也可能是文字的非結構化資料,或者介於二者之間的半結構化資料
- 資料的格式來源也多樣,可以是業務資料、紀錄檔文字檔案,甚至是圖片、視訊等。
3.低價值密度
- 資訊海量但是有價值的少,也就是價值密度低
- 深度複雜的挖掘分析需要機器學習參與
4.速度快
- 資料增長速度快
- 獲取資料速度快
- 資料處理速度塊
5.資料的質量
- 資料的準確性要求高
- 資料的可信賴度
資料分析方向
針對海量資料的分析,針對不同的業務場景,大致可以分為3個方向,離線分析,實時分析和預測分析。
離線分析
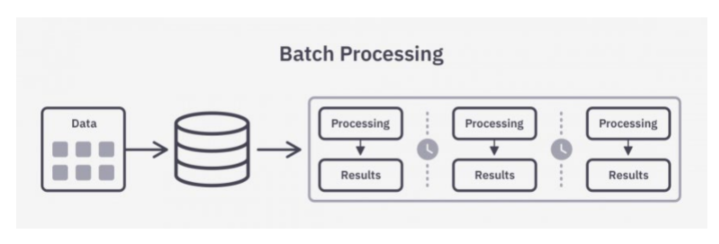
離線分析,也就是所謂的批次處理,主要分析過去的歷史資料,可以每週(T+7)或者每天(T+1)的方式分析歷史的資料,找出隱藏在資料背後的深層次原因,從而做出調整優化。比如說分析過去一個月的使用者運算元據等。
這種分析方式一般資料量非常大,通常採用Hadoop生態技術體系解決,比如HDFS、Yarn、Hbase等技術。
實時分析
實時分析,也叫流計算,主要是面向當下,實時處理分析資料,你可以想象成流水一樣,源源不斷的處理資料,對時效性要求比較高,可到秒級甚至毫秒級。比如說在金融領域中,你發起一筆交易,可以通過實時分析判斷當前筆交易是否存在欺詐風險,從而保護資金安全。
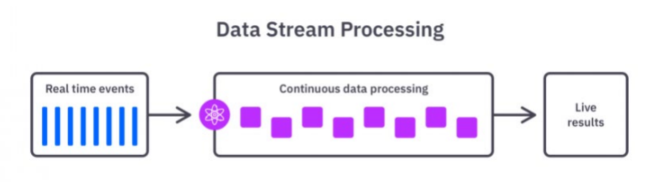
目前Storm、Flink、SparkStreaming 都是比較流行的流式處理框架。
預測分析
預測分析,實際就是通過機器學習的手段,基於歷史資料和當下產生的實時資料預測未來發生的事情。更側重於數學演演算法的運用,如分類、聚類、關聯、預測,但是也離開不了資料,需要通過歷史的資料進行訓練,得出可預測的模型,比較典型的應用比如說電商領域"猜你喜歡"。
資料分析步驟
我們都知道資料的重要性,那資料分析的整個生命週期是怎麼樣的呢?什麼時候來,要做什麼處理,都有什麼步驟呢?
- 明確分析目的和思路
- 要弄清楚你的業務場景,找到分析的目的,目的是整個分析流程的起點,需要為資料的收集、處理及分析提供清晰的指引方向。
- 釐清分析的思路,比如先分析什麼,後分析什麼,使各分析點之間具有邏輯聯絡,保證分析維度的完整性,分析結果的有效性以及正確性,需要資料分析方法論進行支撐;
- 資料收集
- 資料從無到有的過程:比如感測器收集氣象資料、埋點收集使用者行為資料
- 資料傳輸搬運的過程:比如採集資料庫資料到資料分析平臺

- 資料預處理
- 資料預處理需要對收集到的資料進行加工整理,形成適合資料分析的樣式,主要包括資料淨化、資料轉化、資料提取、資料計算;
- 資料預處理可以保證資料的一致性和有效性,讓資料變成乾淨規整的結構化資料。
- 資料分析
- 用適當的分析方法及分析工具,對處理過的資料進行分析,提取有價值的資訊,形成有效結論的過程;
- 需要掌握各種資料分析方法,還要熟悉資料分析軟體的操作;
- 資料展現
- 通過圖表、報表等方式形象直觀的展示出資料分析的結果,這也叫做資料視覺化。
- 報告撰寫
- 資料分析報告是對整個資料分析過程的一個總結與呈現
- 把資料分析的起因、過程、結果及建議完整地呈現出來,供決策者參考
巨量資料主流技術棧
前面講解了巨量資料分析的整個過程,需要涉及到很多步驟,每個步驟都需要一些工具和方法支援,作為開發人員,我們可能更加關注用到的一些主流技術棧,目前最主流的還是基於Hadoop生態。
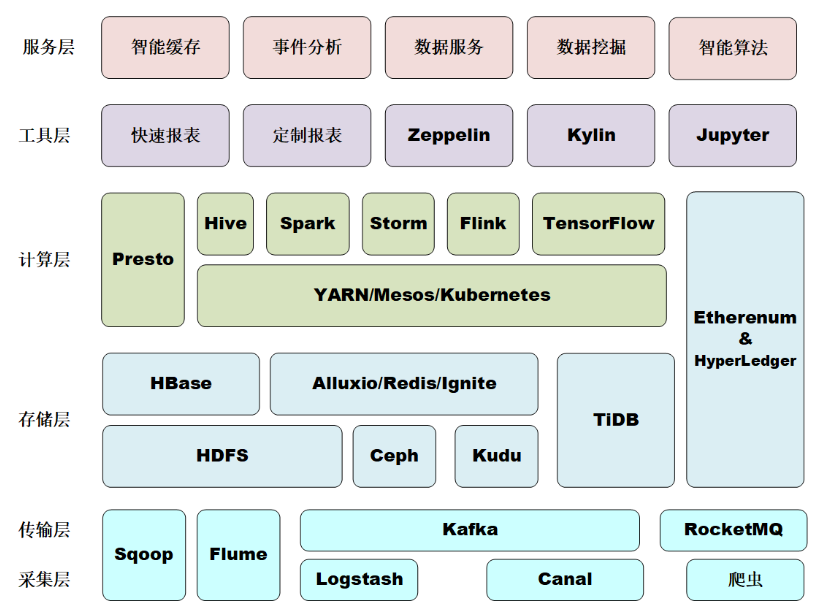
- 資料採集和傳輸層
- Flume
Flume一個分散式、可靠的、高可用的用於資料採集、聚合和傳輸的系統,常用於紀錄檔採集系統中。
- Logstash
ELK中的一員,也常用於資料採集。
- Sqoop
Sqoop主要通過一組命令進行資料匯入匯出的工具,主要用於Hadoop(如HDFS、Hive、HBase)和RDBMS(如mysql、oracle)之間的資料匯入匯出。
- Kafka/RocketMQ
高效能的的訊息佇列,主要應用在資料緩衝、非同步通訊、彙集資料、系統解耦等方面。
- 資料儲存層
- HDFS
分散式檔案儲存系統,HDFS非常適合大規模資料集上的應用,提供高吞吐量的資料存取,可部署在廉價的機器上。
- HBase
是一款基於HDFS的資料庫,是一種NoSQL資料庫,主要適用於海量明細資料(十億、百億)的隨機實時查詢,如紀錄檔明細、交易清單、軌跡行為等。
HBase可以認為是HDFS的一個包裝。他的本質是資料儲存,是個NoSql資料庫;HBase部署於HDFS之上,並且克服了HDFS不能隨機讀寫的問題。
- Kudu
介於HDFS和HBase之間的基於列式儲存的分散式資料庫。兼具了HBase的實時性、HDFS的高吞吐,以及傳統資料庫的sql支援。
- 資料計算與分析層
- MapReduce
分散式運算程式的程式設計框架,適用於離線資料處理場景。
- Yarn
Yarn是一個資源排程平臺,負責為運算程式分配資源和排程,不參與使用者程式內部工作。
- Hive
Hive是基於Hadoop的一個資料倉儲工具,可以將結構化的資料檔案對映為一張資料庫表,並提供HQL語句(類SQL語言)查詢功能,儲存依賴於HDFS。本質上是把好寫的hive的sql轉換為複雜難寫的map-reduce程式。
- Spark
Spark是一個快速、通用、可延伸、可容錯的、記憶體迭代式計算的巨量資料分析引擎。目前生態體系主要包括用於批資料處理的SparkRDD、SparkSQL,用於流資料處理的SparkStreaming,用於機器學習的Spark MLLib,用於圖計算的Graphx以及用於統計分析的SparkR。
- Flink
Flink是一個分散式的實時計算引擎,可以對有限資料流和無限資料流進行有狀態的計算。
- Storm
Storm是一個沒有批次處理能力的資料流處理計算引擎,是由Twitter開源後歸於Apache管理的分散式實時計算系統。
- Phoenix
構建在HBase之上的一個SQL層,能讓我們通過標準的JDBC API操作HBase中的資料。
小結:
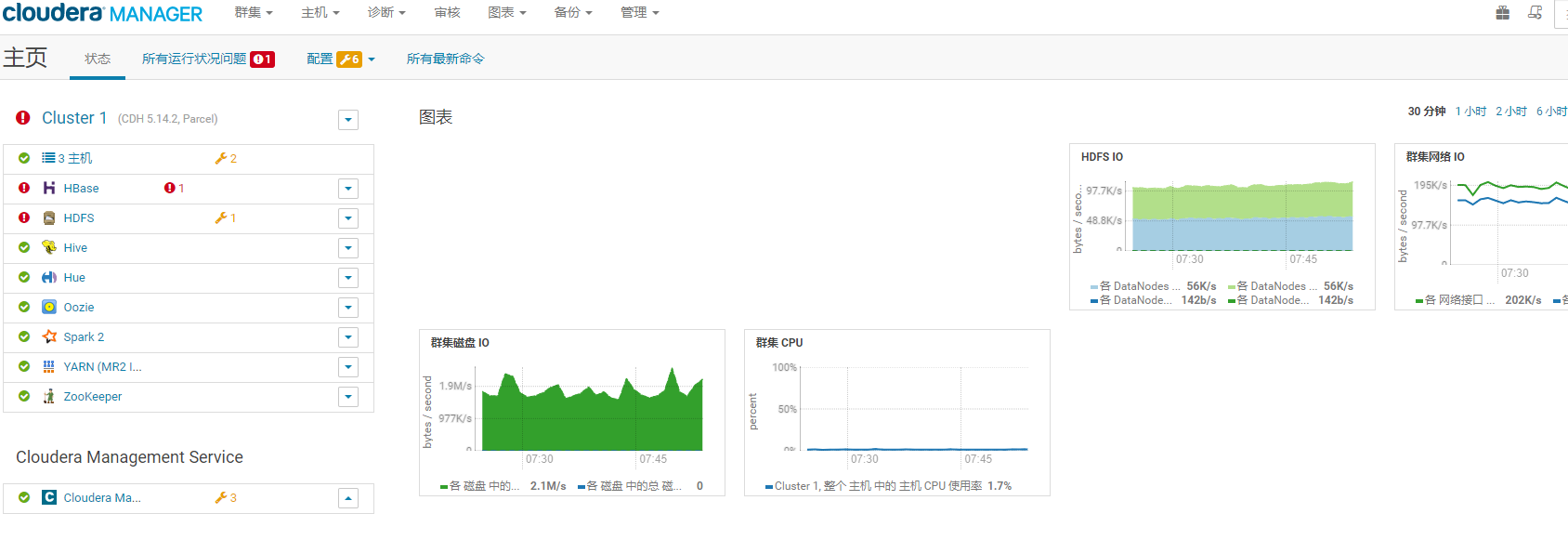
巨量資料生態元件眾多,上面只是列出了其中一部分,目前一般會通過CDH等平臺統一進行安裝管理,如下圖所示:
總結
本文講解了從上帝視角看巨量資料分析,瞭解了資料分析的方向和步驟,同時整理了目前市面上常見的一些巨量資料元件,希望對大家入門巨量資料學習有一個初步的認識。
如果本文對你有幫助的話,請留下一個贊吧
更多技術幹活和學習資料盡在個人公眾號——JAVA旭陽

本文來自部落格園,作者:JAVA旭陽,轉載請註明原文連結:https://www.cnblogs.com/alvinscript/p/16962492.html