搞定實體識別、關係抽取、事件抽取,我用指標網路
PointerNet_Chinese_Information_Extraction
程式碼地址:https://github.com/taishan1994/PointerNet_Chinese_Information_Extraction
利用指標網路進行資訊抽取,包含命名實體識別、關係抽取、事件抽取。
整體結構:
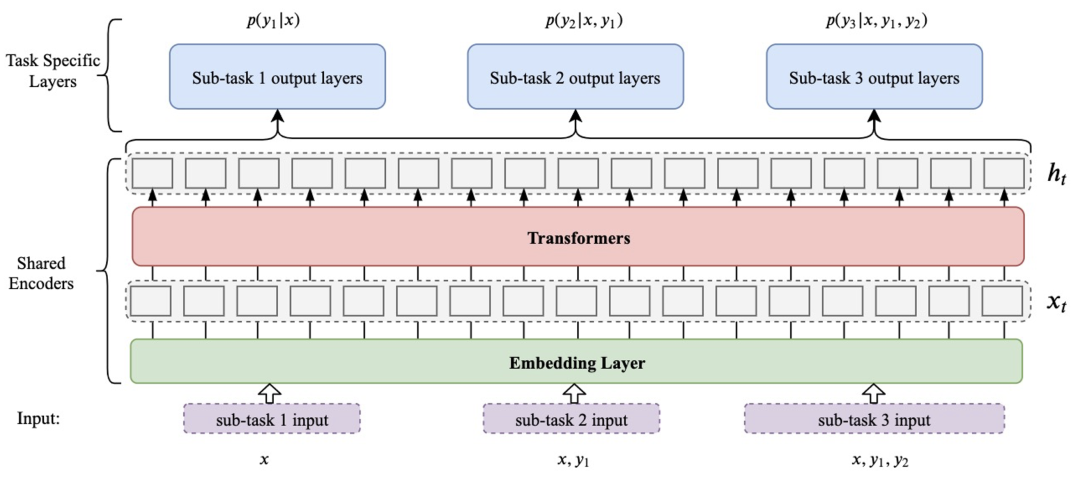
整個目錄結構非常簡潔,
--[ee/ner/re]_main.py為主執行程式,包含訓練、驗證、測試和預測。
--[ee/ner/re]_data_loader.py為資料載入模型。
--[ee/ner/re]_predictor.py是聯合預測的檔案。
--config.py:組態檔,實體識別、關係抽取、事件抽取引數設定。
--model.py是模型。
前期準備,在hugging face上下載chinese-bert-wwm-ext到model_hub/chinese-bert-wwm-ext資料夾下。
依賴
pytorch
transformers
命名實體識別任務
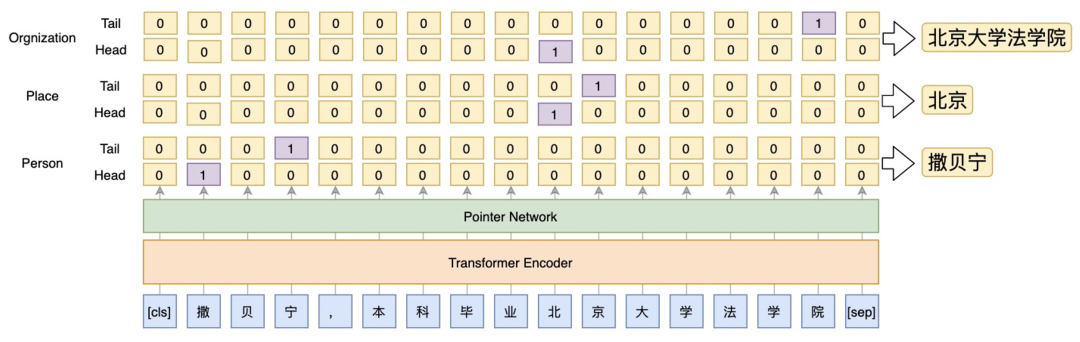
識別每一個型別實體的首位置和尾位置。資料位於data/ner/cner/下,資料的具體格式是:
[
{
"id": 0,
"text": "高勇:男,中國國籍,無境外居留權,",
"labels": [
[
"T0",
"NAME",
0,
2,
"高勇"
],
[
"T1",
"CONT",
5,
9,
"中國國籍"
]
]
},
...
]
執行:python ner_main.py,可進行訓練、驗證、測試和預測,如若只需要部分的功能,註釋相關程式碼即可。結果:
[eval] precision=0.9471 recall=0.9389 f1_score=0.9430
precision recall f1-score support
TITLE 0.94 0.93 0.94 854
RACE 1.00 1.00 1.00 14
CONT 1.00 1.00 1.00 28
ORG 0.94 0.93 0.93 571
NAME 1.00 1.00 1.00 112
EDU 0.99 0.97 0.98 115
PRO 0.89 0.91 0.90 35
LOC 1.00 0.83 0.91 6
micro-f1 0.95 0.94 0.94 1735
顧建國先生:研究生學歷,正高階工程師,現任本公司董事長、馬鋼(集團)控股有限公司總經理。
{'TITLE': [('正高階工程師', 12), ('董事長', 24), ('總經理', 40)], 'ORG': [('本公司', 21)], 'NAME': [('顧建國', 0)], 'EDU': [('研究生學歷', 6)]}
關係抽取任務
該任務只要由四個部分組成:實體識別、主體抽取、主體-客體抽取、關係分類。由於GPU的限制,在re_main.py裡面載入驗證和測試資料時限制了取10000條,可自行修改。
實體識別
用於識別出主體或者客體的型別。實體識別是可選的,因為有的資料是不需要識別實體的。
主體抽取
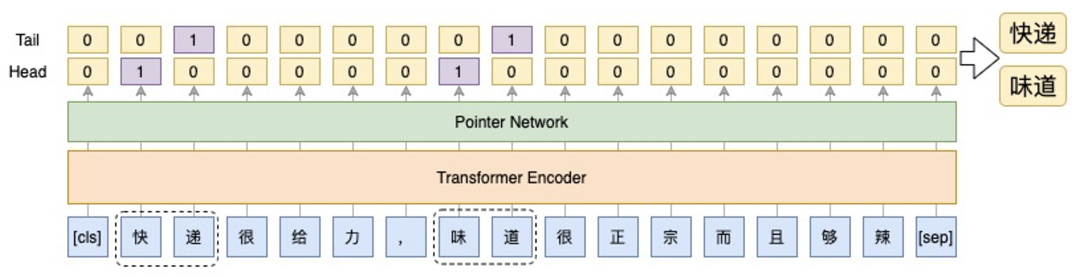
主體抽取是實體識別類似,只不過這裡只有一類,識別主體的首、尾位置。
主體-客體抽取
客體抽取要首先知道主體,然後輸入是:[CLS]主體[SEP]文字[SEP]。同樣的,抽取的是客體的首、尾位置。
關係分類
關係分類採用的是多標籤分類,因為主客體之間可能存在多個關係,輸入是:[CLS]主體[SEP]客體[SEP]文字[SEP]。注意這裡是對整個句子進行分類,不再是token級別的了。
資料位於data/re/ske/下,資料的具體格式為:
[{"tokens": ["《", "步", "步", "驚", "心", "》", "改", "編", "自", "著", "名", "作", "家", "桐", "華", "的", "同", "名", "清", "穿", "小", "說", "《", "甄", "嬛", "傳", "》", "改", "編", "自", "流", "瀲", "紫", "所", "著", "的", "同", "名", "小", "說", "電", "視", "劇", "《", "何", "以", "笙", "簫", "默", "》", "改", "編", "自", "顧", "漫", "同", "名", "小", "說", "《", "花", "千", "骨", "》", "改", "編", "自", "f", "r", "e", "s", "h", "果", "果", "同", "名", "小", "說", "《", "裸", "婚", "時", "代", "》", "是", "月", "影", "蘭", "析", "創", "作", "的", "一", "部", "情", "感", "小", "說", "《", "琅", "琊", "榜", "》", "是", "根", "據", "海", "宴", "同", "名", "網", "絡", "小", "說", "改", "編", "電", "視", "劇", "《", "宮", "鎖", "心", "玉", "》", ",", "又", "名", "《", "宮", "》", "《", "雪", "豹", "》", ",", "該", "劇", "改", "編", "自", "網", "絡", "小", "說", "《", "特", "戰", "先", "驅", "》", "《", "我", "是", "特", "種", "兵", "》", "由", "紅", "遍", "網", "絡", "的", "小", "說", "《", "最", "後", "一", "顆", "子", "彈", "留", "給", "我", "》", "改", "編", "電", "視", "劇", "《", "來", "不", "及", "說", "我", "愛", "你", "》", "改", "編", "自", "匪", "我", "思", "存", "同", "名", "小", "說", "《", "來", "不", "及", "說", "我", "愛", "你", "》"], "entities": [{"type": "圖書作品", "start": 1, "end": 5}, {"type": "人物", "start": 13, "end": 15}, {"type": "圖書作品", "start": 23, "end": 26}, {"type": "人物", "start": 30, "end": 33}, {"type": "圖書作品", "start": 44, "end": 49}, {"type": "人物", "start": 53, "end": 55}, {"type": "圖書作品", "start": 60, "end": 63}, {"type": "人物", "start": 67, "end": 74}, {"type": "圖書作品", "start": 79, "end": 83}, {"type": "人物", "start": 85, "end": 89}, {"type": "圖書作品", "start": 99, "end": 102}, {"type": "人物", "start": 106, "end": 108}, {"type": "影視作品", "start": 132, "end": 134}, {"type": "作品", "start": 146, "end": 150}, {"type": "影視作品", "start": 152, "end": 157}, {"type": "作品", "start": 167, "end": 176}, {"type": "影視作品", "start": 183, "end": 190}, {"type": "圖書作品", "start": 183, "end": 190}, {"type": "人物", "start": 194, "end": 198}], "relations": [{"type": "作者", "head": 4, "tail": 5}, {"type": "改編自", "head": 14, "tail": 15}, {"type": "作者", "head": 0, "tail": 1}, {"type": "作者", "head": 2, "tail": 3}, {"type": "作者", "head": 6, "tail": 7}, {"type": "作者", "head": 8, "tail": 9}, {"type": "作者", "head": 10, "tail": 11}, {"type": "改編自", "head": 12, "tail": 13}, ... ]
執行:python re_main.py,可進行訓練、驗證、測試和預測,如若只需要部分的功能,註釋相關程式碼即可。需要注意的是,我們要在config.py裡面設定ReArgs類裡面的tasks=["ner or sbj or obj or rel"]來選擇相應的子任務。結果:
# 實體識別
test】 precision=0.7862 recall=0.8263 f1_score=0.8057
precision recall f1-score support
行政區 0.33 0.17 0.22 6
人物 0.81 0.91 0.85 1405
氣候 0.00 0.00 0.00 3
文學作品 0.00 0.00 0.00 5
Text 0.65 0.64 0.65 56
學科專業 0.00 0.00 0.00 0
作品 0.00 0.00 0.00 8
獎項 0.00 0.00 0.00 14
國家 0.90 0.61 0.73 62
電視綜藝 0.69 0.88 0.77 25
影視作品 0.77 0.79 0.78 253
企業 0.69 0.62 0.66 125
語言 0.00 0.00 0.00 1
歌曲 0.87 0.81 0.84 159
Date 0.82 0.87 0.84 127
企業/品牌 0.00 0.00 0.00 3
地點 0.88 0.29 0.44 24
Number 0.79 0.83 0.81 23
圖書作品 0.76 0.81 0.78 179
景點 0.00 0.00 0.00 2
城市 0.00 0.00 0.00 4
學校 0.69 0.83 0.76 65
音樂專輯 0.70 0.81 0.75 32
機構 0.69 0.75 0.72 107
micro-f1 0.79 0.83 0.81 2688
《父老鄉親》是由是由由中國人民解放軍海政文工團創作的軍旅歌曲,石順義作詞,王錫仁作曲,範琳琳演唱
{'人物': [('石順義', 31), ('王錫仁', 37), ('範琳琳', 43)], '歌曲': [('父老鄉親', 1)]}
# 主體抽取
【test】 precision=0.8090 recall=0.8466 f1_score=0.8273
precision recall f1-score support
主體 0.81 0.85 0.83 2646
micro-f1 0.81 0.85 0.83 2646
# 客體抽取
【test】 precision=0.8017 recall=0.5274 f1_score=0.6362
precision recall f1-score support
客體 0.80 0.53 0.64 1771
micro-f1 0.80 0.53 0.64 1771
# 關係多標籤分類
【test】 precision=0.9302 recall=0.9187 f1_score=0.9244
precision recall f1-score support
編劇 0.79 0.59 0.68 44
修業年限 0.00 0.00 0.00 0
畢業院校 1.00 0.98 0.99 49
氣候 1.00 1.00 1.00 3
配音 1.00 1.00 1.00 18
註冊資本 1.00 1.00 1.00 5
成立日期 1.00 1.00 1.00 94
父親 0.91 0.95 0.93 88
面積 1.00 1.00 1.00 1
專業程式碼 0.00 0.00 0.00 0
作者 0.94 0.97 0.96 188
首都 0.00 0.00 0.00 2
丈夫 0.88 0.93 0.90 86
嘉賓 0.63 0.89 0.74 19
官方語言 0.00 0.00 0.00 1
作曲 0.75 0.69 0.72 52
號 1.00 1.00 1.00 10
票房 1.00 1.00 1.00 11
簡稱 1.00 0.93 0.97 15
母親 0.82 0.75 0.78 53
製片人 0.86 0.75 0.80 8
導演 0.94 0.95 0.95 101
歌手 0.91 0.87 0.89 119
改編自 0.00 0.00 0.00 11
海拔 1.00 1.00 1.00 1
佔地面積 1.00 1.00 1.00 3
出品公司 0.95 0.97 0.96 39
上映時間 1.00 1.00 1.00 37
所在城市 1.00 1.00 1.00 2
主持人 0.91 0.78 0.84 27
作詞 0.74 0.67 0.70 51
人口數量 1.00 1.00 1.00 2
祖籍 1.00 1.00 1.00 7
校長 1.00 1.00 1.00 16
朝代 1.00 1.00 1.00 36
主題曲 1.00 0.96 0.98 23
獲獎 1.00 1.00 1.00 14
代言人 1.00 1.00 1.00 3
主演 0.97 0.99 0.98 239
所屬專輯 1.00 1.00 1.00 35
飾演 1.00 1.00 1.00 17
董事長 1.00 0.96 0.98 56
主角 0.67 0.80 0.73 5
妻子 0.89 0.88 0.89 86
總部地點 1.00 1.00 1.00 16
國籍 1.00 1.00 1.00 67
創始人 0.85 1.00 0.92 11
郵政編碼 0.00 0.00 0.00 0
沒有關係 0.00 0.00 0.00 0
micro avg 0.93 0.92 0.92 1771
macro avg 0.80 0.80 0.80 1771
weighted avg 0.92 0.92 0.92 1771
samples avg 0.91 0.92 0.92 1771
事件抽取
事件抽取由兩個部分組成:事件型別抽取、事件論元抽取。
事件型別抽取
可以當作實體識別。
事件論元抽取
可以當作obj的抽取,輸入為:[CLS]事件型別對應的論元[SEP]文字[SEP]。
資料位於data/ee/duee/下,資料格式為:
{"text": "消失的「外企光環」,5月份在華裁員900餘人,香餑餑變「臭」了", "id": "cba11b5059495e635b4f95e7484b2684", "event_list": [{"event_type": "組織關係-裁員", "trigger": "裁員", "trigger_start_index": 15, "arguments": [{"argument_start_index": 17, "role": "裁員人數", "argument": "900餘人", "alias": []}, {"argument_start_index": 10, "role": "時間", "argument": "5月份", "alias": []}], "class": "組織關係"}]}
每一行是一條記錄。
執行:python ee_main.py,可進行訓練、驗證、測試和預測,如若只需要部分的功能,註釋相關程式碼即可。需要注意的是,我們要在config.py裡面設定EeArgs類裡面的tasks=["ner or obj"]來選擇相應的子任務。結果:
# 事件型別抽取
【test】 precision=0.8572 recall=0.8587 f1_score=0.8579
precision recall f1-score support
財經/交易-出售/收購 0.88 0.88 0.88 24
財經/交易-跌停 0.93 0.87 0.90 15
財經/交易-加息 1.00 1.00 1.00 3
財經/交易-降價 1.00 0.70 0.82 10
財經/交易-降息 1.00 1.00 1.00 4
財經/交易-融資 0.93 0.81 0.87 16
財經/交易-上市 1.00 0.75 0.86 8
財經/交易-漲價 1.00 0.60 0.75 5
財經/交易-漲停 1.00 1.00 1.00 28
產品行為-釋出 0.85 0.87 0.86 153
產品行為-獲獎 0.59 0.62 0.61 16
產品行為-上映 0.91 0.91 0.91 35
產品行為-下架 1.00 0.96 0.98 24
產品行為-召回 0.95 1.00 0.97 36
交往-道歉 0.73 1.00 0.84 19
交往-點贊 0.85 1.00 0.92 11
交往-感謝 0.78 0.88 0.82 8
交往-會見 0.90 1.00 0.95 9
交往-探班 1.00 0.82 0.90 11
競賽行為-奪冠 0.71 0.74 0.72 65
競賽行為-晉級 0.89 0.89 0.89 36
競賽行為-禁賽 0.88 0.78 0.82 18
競賽行為-勝負 0.82 0.79 0.81 271
競賽行為-退賽 0.85 0.94 0.89 18
競賽行為-退役 0.92 1.00 0.96 11
人生-產子/女 0.85 0.73 0.79 15
人生-出軌 1.00 0.75 0.86 4
人生-訂婚 0.80 0.89 0.84 9
人生-分手 0.89 0.89 0.89 18
人生-懷孕 1.00 0.88 0.93 8
人生-婚禮 0.75 1.00 0.86 6
人生-結婚 0.86 0.86 0.86 43
人生-離婚 0.95 0.95 0.95 38
人生-慶生 0.71 0.75 0.73 16
人生-求婚 0.91 1.00 0.95 10
人生-失聯 0.77 0.71 0.74 14
人生-死亡 0.83 0.84 0.84 107
司法行為-罰款 0.94 0.88 0.91 33
司法行為-拘捕 0.87 0.92 0.90 90
司法行為-舉報 0.86 1.00 0.92 12
司法行為-開庭 0.81 0.93 0.87 14
司法行為-立案 0.80 0.89 0.84 9
司法行為-起訴 0.76 0.90 0.83 21
司法行為-入獄 0.86 0.86 0.86 21
司法行為-約談 0.97 1.00 0.99 33
災害/意外-爆炸 1.00 0.80 0.89 10
災害/意外-車禍 0.75 0.77 0.76 35
災害/意外-地震 0.88 0.75 0.81 20
災害/意外-洪災 0.67 0.57 0.62 7
災害/意外-起火 0.93 0.86 0.89 29
災害/意外-坍/垮塌 1.00 0.91 0.95 11
災害/意外-襲擊 0.71 0.71 0.71 17
災害/意外-墜機 0.85 0.85 0.85 13
組織關係-裁員 1.00 0.82 0.90 22
組織關係-辭/離職 0.84 0.97 0.90 71
組織關係-加盟 0.89 0.74 0.80 53
組織關係-解僱 0.85 0.85 0.85 13
組織關係-解散 1.00 1.00 1.00 10
組織關係-解約 0.83 1.00 0.91 5
組織關係-停職 1.00 1.00 1.00 11
組織關係-退出 0.77 0.77 0.77 22
組織行為-罷工 0.89 1.00 0.94 8
組織行為-閉幕 1.00 1.00 1.00 9
組織行為-開幕 0.91 0.97 0.94 30
組織行為-遊行 0.89 0.67 0.76 12
micro-f1 0.86 0.86 0.86 1783
富國銀行收縮農業與能源貸款團隊 裁減200多名銀行家
{'組織關係-裁員': [('裁減', 16)]}
# 事件論元抽取
【test】 precision=0.7829 recall=0.7406 f1_score=0.7612
precision recall f1-score support
答案 0.78 0.74 0.76 3682
micro-f1 0.78 0.74 0.76 3682
富國銀行收縮農業與能源貸款團隊 裁減200多名銀行家
組織關係-裁員_裁員方
['富國銀行']
聯合預測
實體識別預測
python ner_predictor.py
文字: 顧建國先生:研究生學歷,正高階工程師,現任本公司董事長、馬鋼(集團)控股有限公司總經理。
實體:
TITLE [('正高階工程師', 12), ('董事長', 24), ('總經理', 40)]
ORG [('本公司', 21)]
NAME [('顧建國', 0)]
EDU [('研究生學歷', 6)]
關係抽取預測
python re_predictor.py
文字: 《神之水滴》改編自亞樹直的同名漫畫,是日本電視臺2009年1月13日製作並播放的電視劇,共九集
實體:
人物 [('亞樹直', 9)]
影視作品 [('神之水滴', 1)]
Date [('2009年1月13日', 24)]
主體: ['神之水滴', '亞樹直', '日本電視臺2009年1月13日', '2009年1月13日']
客體: [['神之水滴', '2009年1月13日'], ['亞樹直', '2009年1月13日'], ['日本電視臺2009年1月13日', '2009年1月13日'], ['2009年1月13日', '2009年1月13日']]
關係: [('神之水滴', '上映時間', '2009年1月13日'), ('亞樹直', '上映時間', '2009年1月13日'), ('日本電視臺2009年1月13日', '上映時間', '2009年1月13日'), ('2009年1月13日', '上映時間', '2009年1月13日')]
效果不是很好,因為資料集太大,這裡只選取了訓練集裡面的10000條資料,訓練了不到3個epoch,GPU足夠的可以嘗試資料多點,訓練就一些。
事件抽取預測
python ee_predictor.py
文字: 2019年7月12日,國家市場監督管理總局缺陷產品管理中心,在其官方網站和微信公眾號上釋出了《上海施耐德低壓終端電器有限公司召回部分剩餘電流保護裝置》,看到這條訊息,確實令人震驚!
作為傳統的三大外資品牌之一,竟然發生如此大規模質量問題的召回,而且生產持續時間長達一年!從採購,檢驗,生產,測試,包裝,銷售,這麼多環節竟沒有反饋出問題,處於無人知曉狀態,問題出在哪裡?希望官方能有一個解釋了。
實體:
產品行為-召回 [('召回', 62), ('召回', 119)]
事件型別: 產品行為-召回
實體: [['產品行為-召回_時間', '2019年7月12日'], ['產品行為-召回_召回內容', '部分剩餘電流保護裝置'], ['產品行為-召回_召回方', '上海施耐德低壓終端電器有限公司']]
補充
Q:怎麼訓練自己的資料?
A:參考每一個範例下面資料的格式。
Q:評價指標一直為0?
A:指標網路的收斂速度挺慢的,耐心等待。
Q:怎麼進行觀點評論抽取?
A:同樣的可以轉換任務為:ner、sbj、obj、rel。比如實體識別就是識別出文字裡面的方面及評價,主體識別就是方面,客體識別就是評價,關係分類就是評價的情感,不過這裡要做修改,因為不是多標籤分類,而是多分類。
這裡不提供訓練好的模型了,自行訓練即可。
參考
一種基於Prompt的通用資訊抽取(UIE)框架_阿里技術的部落格-CSDN部落格 (思想和大部分圖片都來自這)