.NET效能優化-ArrayPool同時複用陣列和物件
前兩天在微信後臺收到了讀者的私信,問了一個這樣的問題,由於私信回覆有字數和篇幅限制,我在這裡統一回復一下。讀者的問題是這樣的:
大佬您好,之前讀了您的文章受益匪淺,我們有一個專案經常佔用 7-8GB 的記憶體,使用了您推薦的
ArrayPool以後降低到 4GB 左右,我還想著能不能繼續優化,於是 dump 看了一下,發現是ArrayPool對應的一個陣列有幾萬個物件,這個類有 100 多個屬性。我想問有沒有方法能複用這些物件?感謝!
根據讀者的問題,我們摘抄出重點,現在他的陣列已經得到池化,但是陣列裡面存的物件很大,從而導致記憶體很大。
我覺得一個類有 100 多個屬性應該是不太正常的,當然也可能是報表匯出之類的需求,如果是普通類有 100 多個屬性,那應該做一些抽象和拆分了。
如果是少部分的大物件需要重用,那其實可以使用ObjectPool,如果是數萬個物件要重用,那麼ObjectPool裡面的 CAS 演演算法會成為瓶頸,那有沒有更好的方式呢?其實解決方案就在ArrayPool類本身,可能大家平時沒有注意過。
再聊 ArrayPool
我們再來回顧一下ArrayPool的用法,它的用法很簡單,核心就是Rent和Return兩個方法,演示程式碼如下所示:
using System.Buffers;
namespace BenchmarkPooledList;
public class ArrayPoolDemo
{
public void Demo()
{
// get array from pool
var pool = ArrayPool<byte>.Shared.Rent(10);
try
{
// do something
}
finally
{
// return
ArrayPool<byte>.Shared.Return(pool);
}
}
}
其實對於上面的這個問題,ArrayPool已經有了解決方案,不知道大家有沒有注意Return方法有一個預設引數clearArray=false.
public abstract void Return (T[] array, bool clearArray = false);
其中clearArray的含義就是當陣列被歸還到池時,是不是清空陣列,也就是會不會將陣列的所有元素重置為null,看下面的例子就明白了。
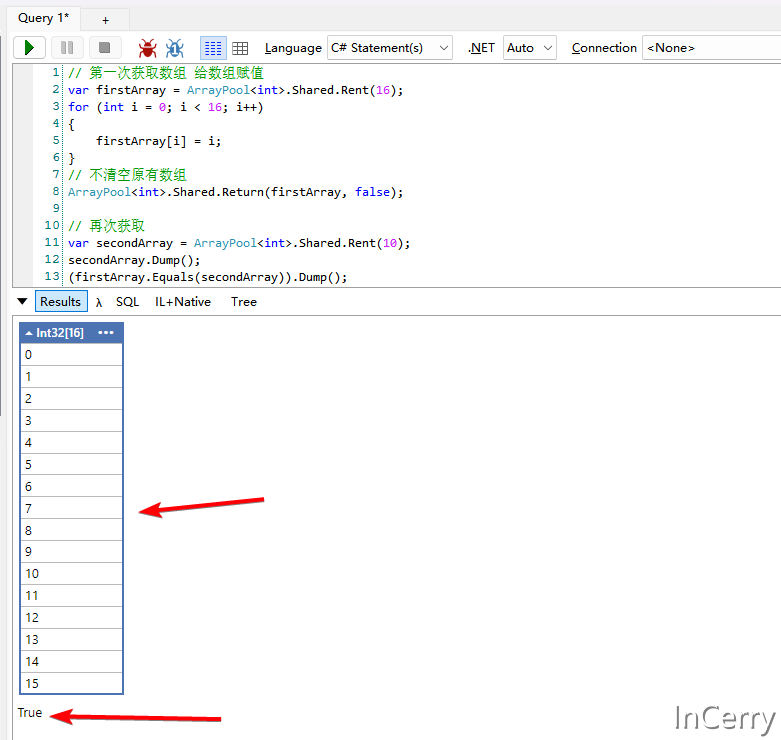
可以發現只要在歸還到陣列時不清空,那麼第二次拿到的陣列還是會保留值,基於這樣一個設計,我們就可以在複用陣列的同時複用對應的元素物件。
效能比較
那麼這樣是否能解決之前提到的問題呢?我們很簡單就可以構建一個測試用例,一個在程式碼裡面使用new每次建立物件,另外一個儘量複用物件,為null時才建立。
// 定義一個大物件,放了40個屬性
public class BigObject
{
public string P1 { get; set; }
public string P2 { get; set; }
public string P3 { get; set; }
.....
}
然後建立一個資料集,生成1000條資料,使用預設的方式,每次都new物件。
private static readonly string[] Datas = Enumerable.Range(0, 1000).Select(c => c.ToString()).ToArray();
[Benchmark(Baseline = true)]
public long UseArrayPool()
{
var pool = ArrayPool<BigObject?>.Shared.Rent(Datas.Length);
try
{
for (int i = 0; i < Datas.Length; i++)
{
pool[i] = new BigObject
{
P1 = Datas[i],
P2 = Datas[i],
P3 = Datas[i]
// .... 省略賦值程式碼
};
}
return pool.Length;
}
finally
{
ArrayPool<BigObject?>.Shared.Return(pool);
}
}
另外一種方式就是複用物件池的物件,只有為null時才建立:
[Benchmark]
public long UseArrayPoolNeverClear()
{
var pool = ArrayPool<BigObject?>.Shared.Rent(Datas.Length);
try
{
for (int i = 0; i < Datas.Length; i++)
{
// 複用obj 為null時才建立
var obj = pool[i] ?? (pool[i] = new BigObject());
obj.P1 = Datas[i];
obj.P2 = Datas[i];
obj.P3 = Datas[i];
// .... 省略賦值程式碼
}
return pool.Length;
}
finally
{
ArrayPool<BigObject?>.Shared.Return(pool, false);
}
}
可以看一下 Benchmark 的結果:
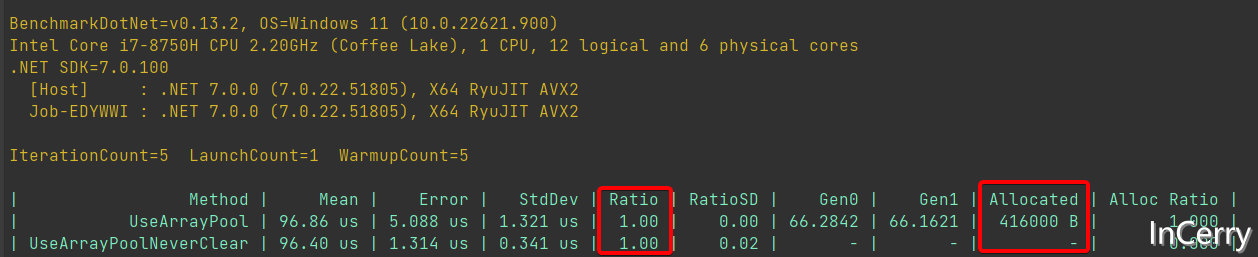
複用大物件的場景下,在沒有造成效能的下降的情況下,記憶體分配幾乎為0。
ArrayObjectPool
之前筆者實現了一個類,優化了一下上面程式碼的效能,但是之前換了電腦,沒有備份一些雜亂資料,現在找不到了。
具體優化原理是每一次都要進行null比較還是比較麻煩,而且如果能確定其陣列不變的話,這些 null 判斷是可以移除的。
憑藉記憶寫了一個 Demo,主要是確立在池裡的陣列是私有的,初始化一次以後就不需要再初始化,所以只要檢測第一個元素是否為null就行,實現如下所示:
// 應該要實現IList<T>介面 和 ICollection<T> 等等的介面
// 不過這只是簡單的demo 各位可以自行實現
public class ArrayObjectPool<T> : IDisposable // , IList<T>
where T : new()
{
// 建立一個獨享的池
private static ArrayPool<T> _pool = ArrayPool<T>.Create();
private readonly T[] _items;
public ArrayObjectPool(int size)
{
Length = size;
_items = _pool.Rent(size);
if (_items[0] is not null) return;
// 如果第一個元素為null 說明是沒初始化的
// 那麼需要初始化
for (int i = 0; i < _items.Length; i++)
{
_items[i] = new T();
}
}
// 為了安全只實現get
public T this[int index]
{
get
{
if (index < 0 || index > Length)
throw new ArgumentOutOfRangeException(nameof(index));
return _items[index];
}
set => throw new NotSupportedException();
}
public int Length { get; }
// 釋放時返回資料
public void Dispose()
{
_pool.Return(_items);
}
/// <summary>
/// 當ArrayPool過大時 可以重新建立
/// 舊的池就會被GC 回收
/// </summary>
public static void Flush()
{
_pool = ArrayPool<T>.Create();
}
}
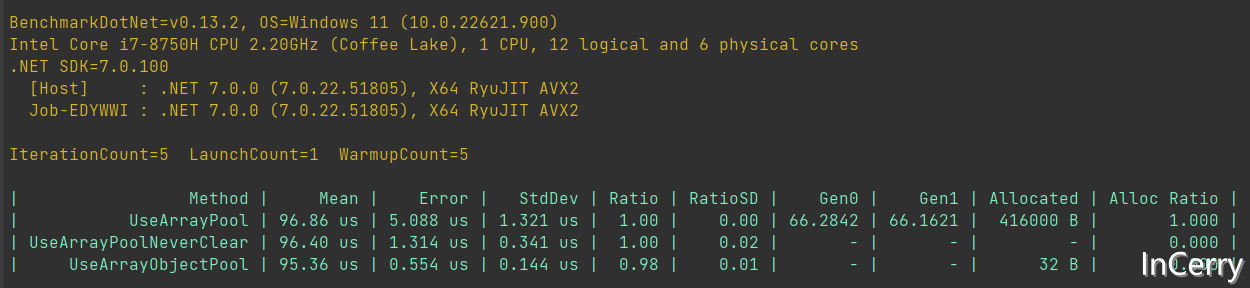
同樣的,對比了一下效能,因為會建立一個物件,所以記憶體佔用比直接使用ArrayPool要高几十個位元組,但是由於不用比較null,是實現裡面最快的(當然也快不了多少,就 2%):
總結
我相信這個應該已經能回答提出的問題,我們可以在複用陣列的時候複用陣列所對應的物件,當然你必須確保複用物件沒有副作用,比如複用了舊的髒資料。
如果不是經常寫這樣的程式碼,像筆者一樣封裝一個ArrayObjectPool也沒有必要,筆者本人也就寫過那麼一次,如果經常有這樣的場景,那可以封裝一個安全的ArrayObjectPool,想必也不是什麼困難的事情。
感謝閱讀,如果您有什麼關於效能優化的疑問,歡迎在公眾號留言。
.NET 效能優化交流群
相信大家在開發中經常會遇到一些效能問題,苦於沒有有效的工具去發現效能瓶頸,或者是發現瓶頸以後不知道該如何優化。之前一直有讀者朋友詢問有沒有技術交流群,但是由於各種原因一直都沒建立,現在很高興的在這裡宣佈,我建立了一個專門交流.NET 效能優化經驗的群組,主題包括但不限於:
- 如何找到.NET 效能瓶頸,如使用 APM、dotnet tools 等工具
- .NET 框架底層原理的實現,如垃圾回收器、JIT 等等
- 如何編寫高效能的.NET 程式碼,哪些地方存在效能陷阱
希望能有更多志同道合朋友加入,分享一些工作中遇到的.NET 效能問題和寶貴的效能分析優化經驗。由於已經達到 200 人,可以加我微信,我拉你進群: ls1075