(四) 一文搞懂 JMM
2022-12-06 06:00:53
4、JMM - 記憶體模型
1、JMM記憶體模型
JMM與happen-before
1、可見性問題產生原因
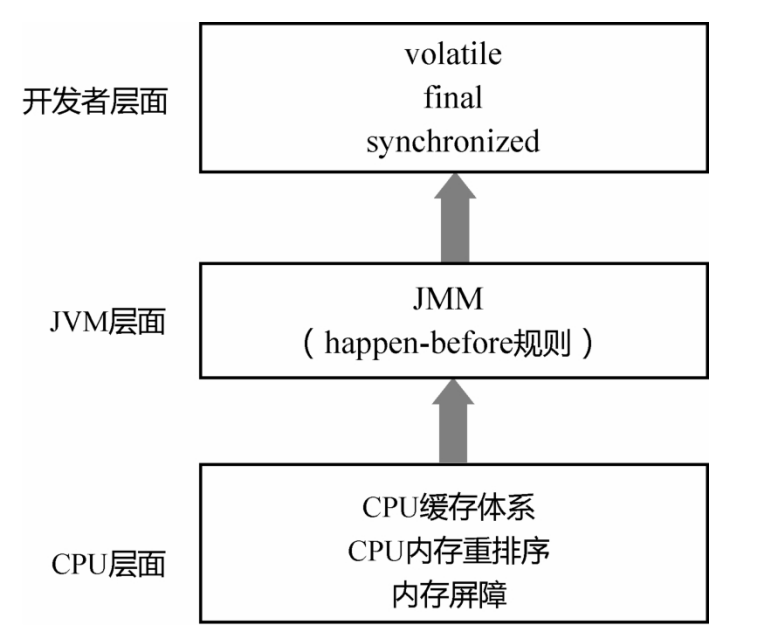
- 下圖為x86架構下CPU快取的佈局,即在一個
CPU 4核下,L1、L2、L3三級快取與主記憶體的佈局。 每個核上面有L1、L2快取,L3快取為所有核共用。
- 因為存在
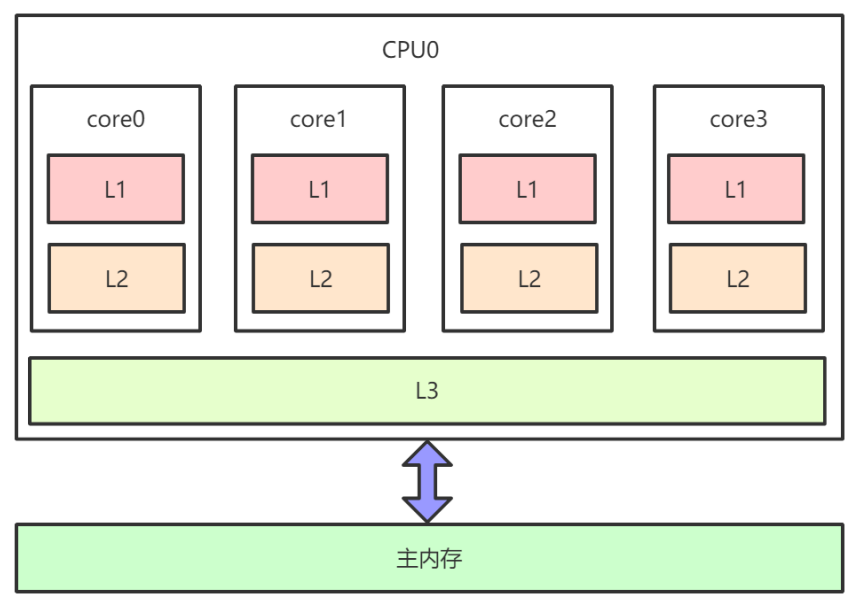
CPU快取一致性協定,例如MESI,多個CPU核心之間快取不會出現不同步的問題,不會有 「記憶體可見性」問題。 - 快取一致性協定對
效能有很大損耗,為了解決這個問題,又進行了各種優化。例如,在計算單元和 L1之間加了Store Buffer、Load Buffer(還有其他各種Buffer),如下圖:
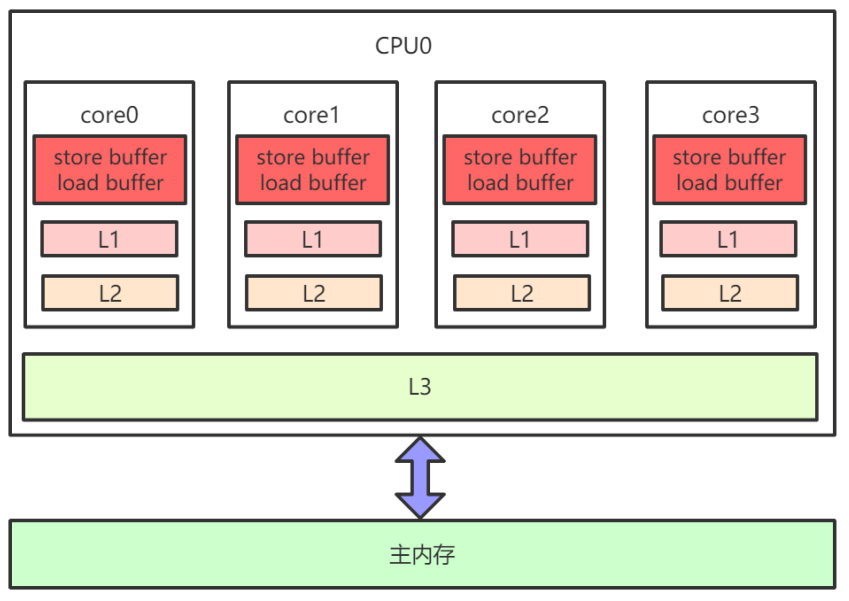
L1、L2、L3和主記憶體之間是同步的,有快取一致性協定的保證,但是Store Buffer、Load Buffer和 L1之間卻是非同步的。向記憶體中寫入一個變數,這個變數會儲存在Store Buffer裡面,稍後才非同步地寫入 L1中,同時同步寫入主記憶體中。- 作業系統核心視角下的CPU快取模型:
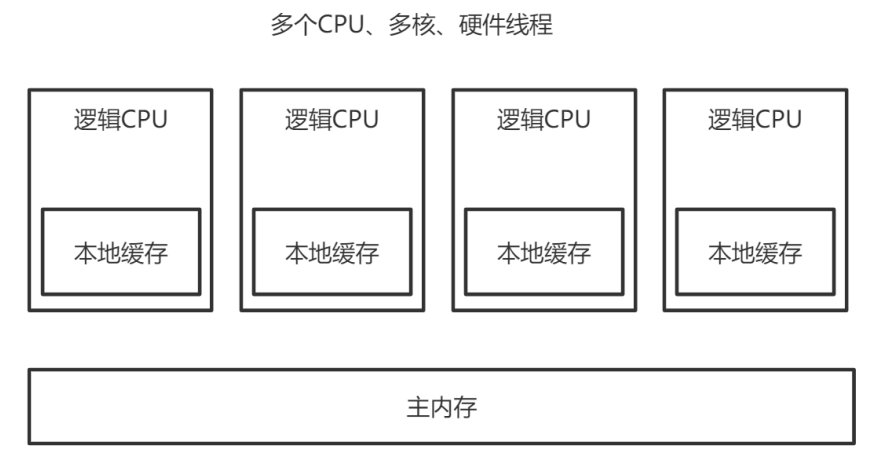
- 多CPU,每個CPU多核,每個核上面可能還有多個硬體執行緒,對於作業系統來講,就相當於一個個的邏輯
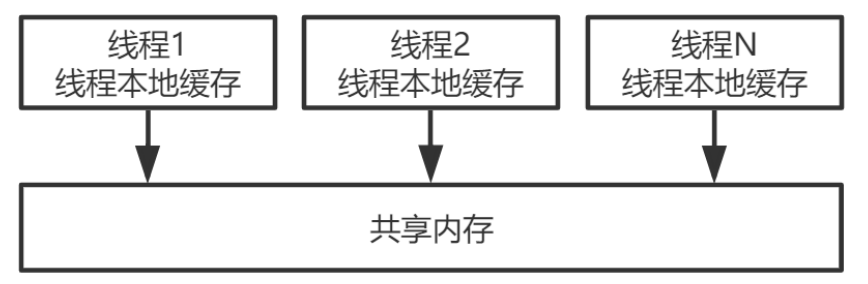
CPU。每個邏輯CPU都有自己的快取,這些快取和主記憶體之間不是完全同步的。 - 對應到Java裡,就是JVM抽象記憶體模型,如下圖所示:
2、重排序與記憶體可見性的關係
-
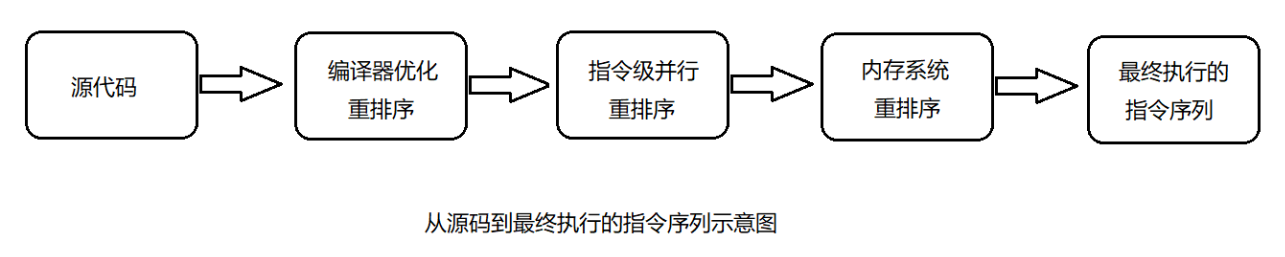
Store Buffer(儲存緩衝區)的延遲寫入是重排序的一種,稱為記憶體重排序(Memory Ordering)。除此之外,還 有編譯器和CPU的指令重排序。 -
重排序型別:
-
-
編譯器重排序。
對於沒有先後依賴關係的語句,編譯器可以重新調整語句的執行順序。
-
-
-
CPU指令重排序。
在指令級別,讓沒有依賴關係的多條指令並行。
-
-
-
CPU記憶體重排序。
CPU有自己的快取,指令的執行順序和寫入主記憶體的順序不完全一致。
-
-
- 在三種重排序中,
第三類就是造成記憶體可見性問題的主因,如下案例:
// 執行緒1中
x=1;
a=y;
// 執行緒2中
y=1;
b=x;
- 假設X、Y是兩個全域性變數,初始的時候,X=0,Y=0。請問,這兩個執行緒執行完畢之後,a、b的正確結果應該是什麼?
- 很顯然,執行緒1和執行緒2的執行先後順序是不確定的,可能順序執行,也可能交叉執行,最終正確的 結果可能是:
1. a=0,b=1
2. a=1,b=0
3. a=1,b=1
- 也就是不管誰先誰後,執行結果應該是這三種場景中的一種。但實際可能是a=0,b=0。
- 兩個執行緒的指令都沒有重排序,執行順序就是程式碼的順序,但仍然可能出現a=0,b=0。原因是
執行緒1先執行x=1,後執行a=Y,但此時x=1還在自己的Store Buffer(儲存緩衝區)裡面,沒有及時寫入主記憶體中。所以,執行緒2看到的x還是0。執行緒2的道理與此相同。 - 雖然執行緒1覺得自己是按程式碼順序正常執行的,但線上程2看來,a=Y和X=1順序卻是顛倒的。指令沒 有重排序,是寫入記憶體的操作被延遲了,也就是記憶體被重排序了,這就造成記憶體可見性問題。
3、記憶體屏障
- 為了禁止
編譯器重排序和CPU 重排序,在編譯器和 CPU 層面都有對應的指令,也就是記憶體屏障 (Memory Barrier)。這也正是JMM和happen-before規則的底層實現原理。 - 編譯器的記憶體屏障,只是為了告訴編譯器不要對指令進行重排序。當編譯完成之後,這種記憶體屏障就消失了,CPU並不會感知到編譯器中記憶體屏障的存在。
- 而CPU的記憶體屏障是
CPU提供的指令,可以由開發者顯示呼叫。 - 記憶體屏障是很底層的概念,對於 Java 開發者來說,一般用
volatile關鍵字就足夠了。但從JDK 8開 始,Java在Unsafe類中提供了三個記憶體屏障函數,如下所示。
public final class Unsafe {
// ...
public native void loadFence();
public native void storeFence();
public native void fullFence();
// ...
}
- 在理論層面,可以把基本的CPU記憶體屏障分成四種:
- LoadLoad:禁止讀和讀的重排序。
- StoreStore:禁止寫和寫的重排序。
- LoadStore:禁止讀和寫的重排序。
- StoreLoad:禁止寫和讀的重排序。
- Unsafe中的方法:
- loadFence=LoadLoad+LoadStore
- storeFence=StoreStore+LoadStore
- fullFence=loadFence+storeFence+StoreLoad
4、as-if-serial語意
- 重排序的原則是什麼?什麼場景下可以重排序,什麼場景下不能重排序呢?
- 單執行緒程式的重排序規則
- 無論什麼語言,站在編譯器和CPU的角度來說,不管怎麼重排序,單執行緒程式的執行結果不能改變,這就是單執行緒程式的重排序規則。
- 即只要操作之間沒有資料依賴性,編譯器和CPU都可以任意重排序,因為執行結果不會改變,程式碼看起來就像是完全序列地一行行從頭執行到尾,這也就是as-if-serial語意。
- 對於
單執行緒程式來說,編譯器和CPU可能做了重排序,但開發者感知不到,也不存在記憶體可見性問題。
- 多執行緒程式的重排序規則
- 編譯器和CPU的這一行為對於單執行緒程式沒有影響,但對多執行緒程式卻有影響。
- 對於多執行緒程式來說,執行緒之間的資料
依賴性太複雜,編譯器和CPU沒有辦法完全理解這種依賴性、並據此做出最合理的優化。 - 編譯器和CPU只能保證
每個執行緒的as-if-serial語意。 - 執行緒之間的資料依賴和相互影響,需要編譯器和CPU的上層來確定。
- 上層要告知編譯器和CPU在多執行緒場景下什麼時候可以重排序,什麼時候不能重排序。
5、happen-before是什麼
使用happen-before描述兩個操作之間的記憶體可見性。
- java記憶體模型(JMM)是一套規範,在多執行緒中,一方面,要讓編譯器和CPU可以靈活地重排序; 另一方面,要對開發者做一些承諾,明確告知開發者不需要感知什麼樣的重排序,需要感知什麼樣的重排序。然後,根據需要決定這種重排序對程式是否有影響。如果有影響,就需要開發者顯示地通過
volatile、synchronized等執行緒同步機制來禁止重排序。 - 關於happen-before:
- 如果A
happen-before(在.. 之前)B,意味著A的執行結果必須對B可見,也就是保證執行緒間的記憶體可見性。A happen before B不代表A一定在B之前執行。因為,對於多執行緒程式而言,兩個操作的執行順序是不確定的。happen-before只確保如果A在B之前執行,則A的執行結果必須對B可見。定義了記憶體可見性的約束,也就定義了一系列重排序的約束。- 基於happen-before的這種描述方法,JMM對開發者做出了一系列承諾:
- 單執行緒中的每個操作,happen-before 對應該執行緒中任意後續操作(也就是 as-if-serial語意保證)。
- 對
volatile變數的寫入,happen-before對應 後續對這個變數的讀取。 - 對synchronized的解鎖,happen-before對應後續對這個鎖的加鎖。
- JMM對編譯器和CPU 來說,volatile 變數不能
重排序;非 volatile 變數可以任意重排序。
- 基於happen-before的這種描述方法,JMM對開發者做出了一系列承諾:
6 happen-before的傳遞性
除了這些基本的happen-before規則,happen-before還具有傳遞性,即若A happen-before B,B happen-before C,則A happen-before C。
- 如果一個變數不是volatile變數,當一個執行緒讀取、一個執行緒寫入時可能有問題。那豈不是說,在多執行緒程式中,我們要麼加鎖,要麼必須把所有變數都宣告為volatile變數?這顯然不可能,而這就得歸功於happen-before的傳遞性。
class A {
private int a = 0;
private volatile int c = 0;
public void set() {
a = 5; // 操作1
c = 1; // 操作2
}
public int get() {
int d = c; // 操作3
return a; // 操作4
}
}
- 假設執行緒A先呼叫了set,設定了a=5;之後執行緒B呼叫了get,返回值一定是a=5。為什麼呢?
- 操作1和操作2是在同一個執行緒記憶體中執行的,操作1 happen-before 操作2,同理,操作3 happenbefore操作4。又因為c是volatile變數,對c的寫入happen-before對c的讀取,所以操作2 happenbefore操作3。利用happen-before的傳遞性,就得到:
- 操作1 happen-before 操作2 happen-before 操作3 happen-before操作4。
- 所以,操作1的結果,一定對操作4可見。
class A {
private int a = 0;
private int c = 0;
public synchronized void set() {
a = 5; // 操作1
c = 1; // 操作2
}
public synchronized int get() {
return a;
}
}
- 假設執行緒A先呼叫了set,設定了a=5;之後執行緒B呼叫了get,返回值也一定是a=5。
- 因為與
volatile一樣,synchronized同樣具有happen-before語意。展開上面的程式碼可得到類似於下 面的虛擬碼:
執行緒A:
加鎖; // 操作1
a = 5; // 操作2
c = 1; // 操作3
解鎖; // 操作4
執行緒B:
加鎖; // 操作5
讀取a; // 操作6
解鎖; // 操作7
- 根據
synchronized的happen-before語意,操作4 happen-before 操作5,再結合傳遞性,最終就 會得到: 操作1 happen-before 操作2……happen-before 操作7。所以,a、c都不是volatile變數,但仍然有記憶體可見性。
2、volatile
1、64位元寫入的原子性(Half Write)
- 如,對於一個long型變數的賦值和取值操作而言,在多執行緒場景下,
執行緒A呼叫set(100),執行緒B調 用get(),在某些場景下,返回值可能不是100。
public class MyClass {
private long a = 0;
// 執行緒A呼叫set(100)
public void set(long a) {
this.a = a;
}
// 執行緒B呼叫get(),返回值一定是100嗎?
public long get() {
return this.a;
}
}
- 因為JVM的規範並沒有要求64位元的long或者double的寫入是原子的。在32位元的機器上,一個64位元變數的寫入可能被拆分成兩個32位元的寫操作來執行。這樣一來,讀取的執行緒就可能讀到「一半的值」。解決 辦法也很簡單,在long前面加上volatile關鍵字。
2、重排序:DCL問題
- 單例模式的執行緒安全的寫法不止一種,常用寫法為
DCL(Double Checking Locking),如下所示:
public class Singleton {
private static Singleton instance;
public static Singleton getInstance() {
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null) {
// 此處程式碼有問題
instance = new Singleton();
}
}
}
return instance;
}
}
- 上述的 instance = new Singleton(); 程式碼有問題:其底層會分為
三個操作:- 分配一塊記憶體。
- 在記憶體上初始化成員變數。
- 把instance參照指向記憶體。
- 在這三個操作中,操作2和操作3
可能重排序,即先把instance指向記憶體,再初始化成員變數,因為二者並沒有先後的依賴關係。此時,另外一個執行緒可能拿到一個未完全初始化的物件。這時,直接存取裡面的成員變數,就可能出錯。這就是典型的「構造方法溢位」問題。 - 解決辦法也很簡單,就是為instance變數加上
volatile修飾。 - volatile的三重功效:
64位元寫入的原子性、記憶體可見性和禁止重排序。
3、volatile實現原理
- 由於不同的CPU架構的快取體系不一樣,重排序的策略不一樣,所提供的記憶體屏障指令也就有差異。
- 這裡只探討為了實現volatile關鍵字的語意的一種參考做法:
- 在volatile寫操作的前面插入一個StoreStore屏障。保證volatile
寫操作不會和之前的寫操作重排序。 - 在volatile寫操作的後面插入一個StoreLoad屏障。保證volatile
寫操作不會和之後的讀操作重排序。 - 在volatile讀操作的後面插入一個LoadLoad屏障+LoadStore屏障。保證volatile
讀操作不會和之後的讀操作、寫操作重排序。
- 在volatile寫操作的前面插入一個StoreStore屏障。保證volatile
- 具體到x86平臺上,其實不會有LoadLoad、LoadStore和StoreStore重排序,只有StoreLoad一種 重排序(記憶體屏障),也就是隻需要在volatile寫操作後面加上StoreLoad屏障。
4、JSR-133對volatile語意的增強
- 在JSR -133之前的舊記憶體模型中,一個64位元long / double型變數的讀/ 寫操作可以被拆分為兩個32位元 的讀/寫操作來執行。從JSR -133記憶體模型開始 (即從JDK5開始),僅僅只允許把一個64位元long/ double 型變數的寫操作拆分為兩個32位元的寫操作來執行,任意的讀操作在JSR -133中都必須具有原子性(即 任意讀操作必須要在單個讀事務中執行)。
- 這也正體現了Java對
happen-before規則的嚴格遵守。
3、final
1、構造方法溢位問題
- 考慮下面的程式碼:
public class MyClass {
private int num1;
private int num2;
private static MyClass myClass;
public MyClass() {
num1 = 1;
num2 = 2;
}
/**
* 執行緒A先執行write()
*/
public static void write() {
myClass = new MyClass();
}
/**
* 執行緒B接著執行write()
*/
public static void read() {
if (myClass != null) {
int num3 = myClass.num1;
int num4 = myClass.num2;
}
}
}
- num3和num4的值是否一定是1和2?
- num3、num4不見得一定等於1,2。和DCL的例子類似,也就是構造方法溢位問題。
- myClass = new MyClass()這行程式碼,分解成三個操作:
- 分配一塊記憶體;
- 在記憶體上初始化i=1,j=2;
- 把myClass指向這塊記憶體。
- 操作2和操作3可能重排序,因此執行緒B可能看到未正確初始化的值。對於構造方法溢位,就是一個物件的構造並不是
「原子的」,當一個執行緒正在構造物件時,另外一個執行緒卻可以讀到未構造好的「一半物件」。
2、final的happen-before語意
- 要解決這個問題,不止有一種辦法。
- 辦法1:給num1,num2加上volatile關鍵字。
- 辦法2:為read/write方法都加上synchronized關鍵字。
- 如果num1,num2只需要初始化一次,還可以使用final關鍵字。
- 之所以能解決問題,是因為同
volatile一樣,final關鍵字也有相應的happen-before語意:- 對final域的寫(構造方法內部),happen-before於後續對final域所在物件的讀。
- 對final域所在物件的讀,happen-before於後續對final域的讀。
- 通過這種happen-before語意的限定,保證了final域的賦值,一定在構造方法之前完成,不會出現另外一個執行緒讀取到了物件,但物件裡面的變數卻還沒有初始化的情形,避免出現構造方法溢位的問題。
happen-before規則總結
- 單執行緒中的每個操作,happen-before於該執行緒中任意後續操作。
- 對volatile變數的寫,happen-before於後續對這個變數的讀(寫的結果,對讀可見,寫在讀之前完成)。
- 對synchronized的解鎖,happen-before於後續對這個鎖的加鎖。
- 對final變數的寫,happen-before於final域物件的讀,happen-before於後續對final變數的讀。
- 四個基本規則再加上happen-before的傳遞性,就構成JMM對開發者的整個承諾。在這個承諾以外的部分,程式都可能被重排序,都需要開發者小心地處理記憶體可見性問題。