詳解 Redis 中 big keys 發現和解決
在使用 Redis 時,可能會出現請求響應慢、網路卡頓、資料丟失的情況。排查問題的時候,發現是 big keys 的問題。
什麼是 big keys
在 Redis 中,一個字串型別最大可以達到 512MB,其他非字串型別的集合型別(list、set、hash、zset等)可以儲存 40 億個(2^32-1),但在實際業務場景中,並不需要這麼大的記憶體。而且對於一個請求量大的網際網路軟體,對資料的大小要求更加的嚴格。如果達到如下標準,就可以認定是 big keys 了:
- String 型別的 key 對應的值超過 5 MB。
- list、set、hash、zset等集合型別,集合元素個數超過 2000。
以上對 big keys 的判斷標準並不是唯一,只是一個大題的標準。在實際業務開發中,對 big keys 的判斷是需要根據具體的使用場景做不同的判斷。比如操作某個 key 導致請求響應時間變慢,那麼這個 key 就可以判定成 big keys。
big keys 是如何產生的
一般來說,big keys 的產生都是由於程式的設計不當,或者對資料的規模沒有一個大體的估算。比如:
- 統計類:例如統計某個網站的存取使用者資訊,網站的存取量越來越多,這個 key 的元素也會越來越大。變成了 big keys。
- 社交類:例如某個大V微博粉絲量很大,如果不做合理的設計,也是 big keys。
- 快取類:一般快取類的資訊存取都比較頻繁,是將從資料庫查詢出來的資料序列化到Redis快取中,這裡的快取如果設計不當,或者為了方便,把所有的資料都存在一個 key 下,或者隨著業務的擴大,對應的快取也增多,也是形成 big keys。
以上幾種型別都是在實際運維中遇到的。在開發中需要根據預估的資料大小來合理的設計快取資料。
big keys 的危害
在系統中如果存在 big keys,會導致請求資料響應變慢、請求超時或者系統不穩定。
1、響應變慢、超時阻塞
Redis 是單執行緒工作的,同一時間只能處理一個請求,操作 big keys 時比較耗時,請求響應也變慢。其他請求也處於阻塞狀態,導致請求超時。除了查詢 big keys 比較耗時,刪除 big keys 也會導致一樣的問題。
2、網路擁塞
請求單個 big keys 產生的網路流量比較大,假設一個 big keys 為 1MB,使用者端每秒存取量是 1000,那麼每秒產生 1000MB 的流量,普通的千兆網路卡承受不了這麼大的流量。而且一般會在單機部署多個Redis範例,一個 big keys 可能也會影響其他範例。
3、記憶體分佈不均
Redis 叢集模式中,key根據不同的hash嘈分配到不同的節點上,當大部分的 big keys 分佈在同一個節點,導致記憶體傾斜在同一個節點上,記憶體分佈不均。在水平擴容時,需要以最大容量的節為準,浪費記憶體。
如何發現 big keys
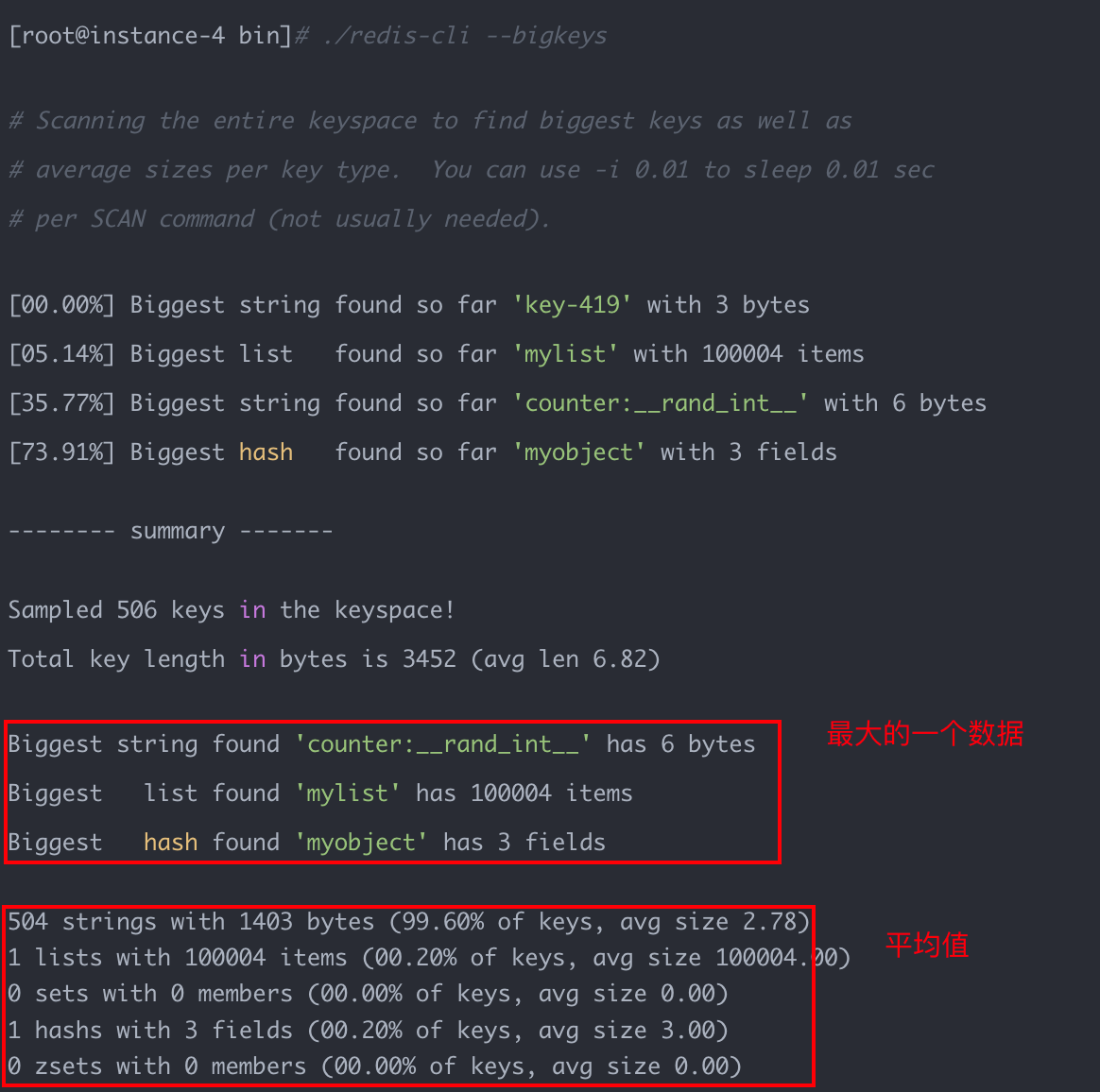
Redis4.0 後提供了 --bigkeys命令,比如:
./redis-cli --bigkeys
獲取每個資料型別最大的 big keys,同時給出每個型別鍵的個數和平均大小。因為 Redis 是單執行緒工作的,為了減少對線上請求的影響,執行--bigkeys命令需要注意一下幾點:
- 最好在 slave 節點執行,因為
--bigkeys也是掃描資料,會造成其他執行緒阻塞。 - 使用
--i引數,降低掃描的執行速度,比如--i 0.1表示 100 毫秒執行一次。 - 只能統計每個資料型別最大的資料。
big keys 處理
非同步刪除 big keys
找到 big keys 之後,首先需要刪除對應的big keys,但是使用 del 命令刪除 big keys 是比較耗時的。Redis4.0 後可以使用 unlink 刪除,和 del 命令相比,unlink 是非阻塞的非同步刪除。
非字串的 big keys,使用 hscan、sscan、zscan 方式漸進式刪除,同時要注意防止big keys 過期時間自動刪除問題(例如一個 200 萬的 zset 設定1小時過期,會觸發del操作,造成阻塞)。
big key 拆分
字串型別的資料是減少字串的長度,將一個字串拆成幾個小的字串。非字串的是減少元素數量。這些都是講一個 key 拆成多個 key,比如:
- 字串型別的資料,根據資料的屬性拆分。比如商品資訊,根據的類別拆分 key。
- 非字串型別的資料,根據資料的屬性拆分,可以按照日期拆分,比如每天登入人的集合,按照日期拆分,key20220101、key20220102.
如果 big keys 無法避免,那獲取資料儘量不要把所有的資料都取出來,就使用分段的方式取出資料。刪除的方式也類似,分段刪除資料。
總結
- big keys 會造成請求變慢、網路阻塞、資料丟失的問題。
- big keys 是字串位元組達到很大的數量(比如 5MB),非字串型別元素型別達到 1000 個都可以判定成 big keys,具體還需要看具體的場景。
- big keys 的產生可能由於設計不合理或者對資料大小估算錯誤,導致資料偏大。
- 解決 big keys 先緊急使用非同步刪除 unlink 命令刪除快取。然後將單個 key 拆分成多個小 key。
- 如果無法避免 big keys,就使用分段查詢的方式查詢資料。
- 要從幾個方面分析,
- big keys 會帶來哪些問題。
- big keys 一般怎麼產生的,線上如果產生了big key,線上先怎麼緊急處理。
- 有哪些優化方案,各自有什麼應用場景。