視訊超分之BasicVSR++閱讀筆記
1.介紹
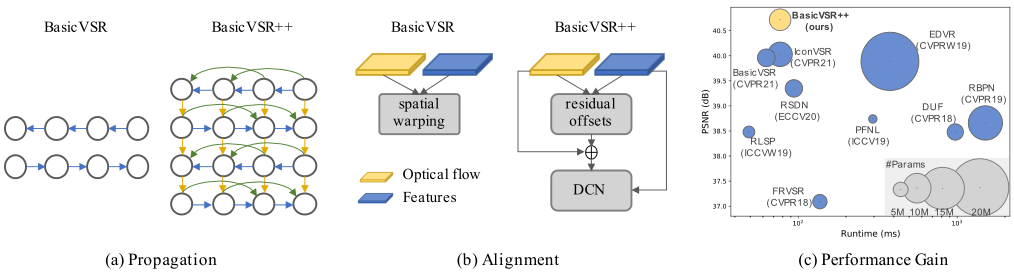
在這項工作中,我們通過設計二階網格傳播和流引導的可變形對齊來重新設計BasicVSR,使資訊能夠更有效地傳播和聚合。
如圖所示,提出的二階網格傳播解決了BasicVSR中的兩個限制:i)我們允許以類似網格的方式進行更積極的雙向傳播,ii)我們放鬆了BasicVSR中一階馬爾可夫特性的假設,並將二階連線併入網路,以便可以從不同的時空位置聚合資訊。這兩種修改都改善了網路中的資訊流,提高了網路對遮擋和精細區域的魯棒性。
BasicVSR顯示了使用光流進行時間對齊的優勢。然而,光流對遮擋並不魯棒。不準確的流量估計可能會危及恢復效能。為了在克服訓練不穩定性的同時利用可變形對齊,我們提出了流引導可變形對齊,如圖所示。在提出的模組中,我們沒有直接學習DCN偏移量,而是通過使用光流場作為基礎偏移量,通過流場殘差量進行細化,來減少偏移量學習的負擔。後者可以比原始DCN偏移更穩定地學習。
2.相關工作
Grid Connections:這些設計將給定的影象/特徵分解為多個解析度,並跨解析度採用網格來捕獲精細和粗糙資訊。BasicVSR++不採用多尺度設計。相反,網格結構的設計是為了以雙向方式跨時間傳播。我們將不同的框架與網格連線起來,以反覆優化特徵,提高表現力。
高階傳播:研究了高階傳播以改善梯度流。這些方法展示了不同任務的改進,包括分類和語言建模。然而,這些方法沒有考慮時間對齊,這在VSR的任務中至關重。為了在二階傳播中實現時間對齊,我們通過將流引導可變形對齊擴充套件到二階,將對齊合併到我們的傳播方案中。
可形變對齊:TDAN使用可變形折積在特徵級執行對齊。EDVR進一步提出了一種金字塔級聯可變形(PCD)對準,採用多尺度設計。受啟發,我們採用了可變形對齊,但採用了一種新的形式來克服訓練的不穩定性。我們的流動引導可變形對準不同於偏移保真度損失。後者使用光流作為訓練期間的損失函數。相比之下,我們直接將光流作為基本偏移量納入我們的模組,從而在訓練和推理過程中提供更明確的指導。
3.方法
BasicVSR++包含兩個有效的修改,如圖所示,給定一個輸入視訊,殘差塊是第一個用於從每幀中提取特徵,然後在我們的二階網格傳播方案下傳播特徵,其中對齊由我們的流引導可變形對齊執行。傳播後,聚集的特徵通過折積和畫素洗牌生成輸出影象。
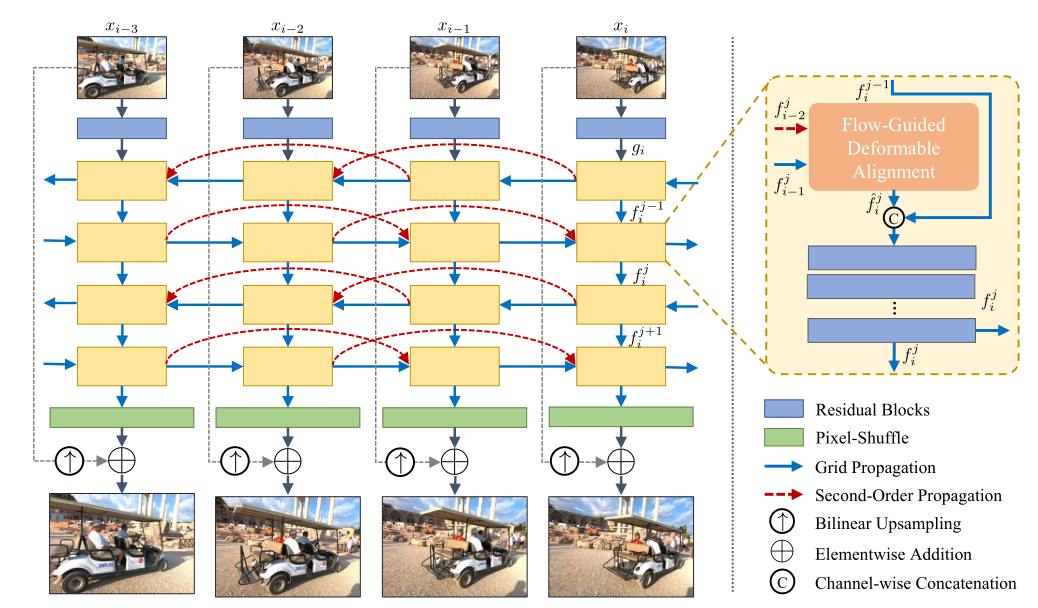
3.1二階網格傳播
基於雙向傳播的有效性,我們設計了一種網格傳播方案,通過傳播實現重複優化。更具體地說,中間特徵以交替的方式在時間上前後傳播。通過傳播,來自不同幀的資訊可以被「重新存取」並用於特徵細化。與只傳播一次特徵的現有工作相比,網格傳播重複地從整個序列中提取資訊,提高了特徵的表達能力。 為了進一步增強傳播的魯棒性,我們採用二階連線,實現了二階馬爾可夫鏈。通過這種放鬆,可以從不同的時空位置聚集資訊,提高在閉塞和精細區域的魯棒性和有效性。
設xi是輸入影象,gi是通過多個殘差塊從xi中提取的特徵,fji是在第j傳播分支的第i個時間步計算的特徵。我們描述了正向傳播的過程,反向傳播的過程也有類似的定義。 為了計算特徵jji,我們我們首先對齊fji-1和fji-2(遵循二階馬爾可夫鏈)使用我們提出的流引導可變形對準:
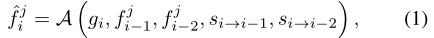
s i→i-1 s i→i-2是表示從第i幀到(i-1)幀和(i-2)幀的光流,A表示流引導可變形對齊。然後將這些特徵連線起來並傳遞到殘差塊的堆疊中,f0i=gi,R表示殘差塊,c表示沿通道維度的串聯。
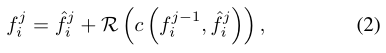
3.2光流指導的可形變對齊
為了在克服不穩定性的同時利用偏移多樣,我們提議利用光流來引導可變形對準,這是由可變形對準和基於流的對準之間的強大關係所驅動的。如圖所示。在本節的其餘部分中,我們將詳細介紹正向傳播的對齊過程。反向傳播過程的定義與此類似。
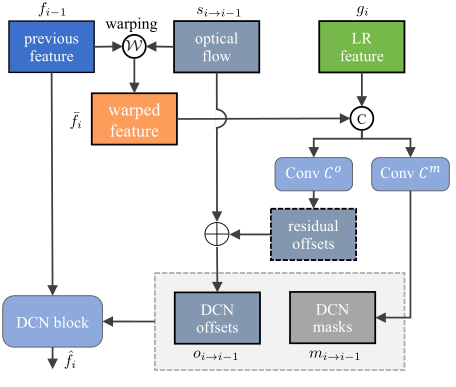
在第i個時間步,給定從第i個LR影象計算出的特徵gi,計算上一個時間步特徵fi-1,光流 s i→i-1為先前的幀,我們第一次用 s i→i-1 warp fi-1:
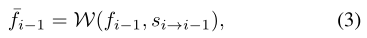
其中W表示空間warp操作。然後使用預先對齊的特徵計算DCN偏移量oi→i-1和調變mask mi→i−1.我們不直接計算DCN偏移,而是計算光流的殘差:
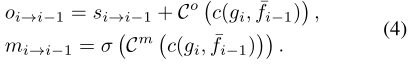
這裡C0,m表示折積的堆疊,σ表示sigmoid函數。然後將DCN應用於unwarp特徵fi-1,D為可形變折積:
![]()
上述公式僅用於對齊單個特徵,因此不直接適用於我們的二階傳播。適應二階設定最直觀的方法是將上述步驟應用於兩個功能fji-1和fji-2獨立。這需要加倍計算,導致效率降低。此外,單獨對齊可能會忽略來自特徵的補充資訊。因此,我們允許同時對齊兩個功能。我們連線warp特徵並且計算偏移量oi-p(p=1,2):
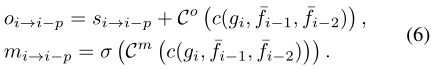
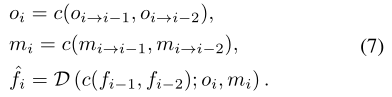
Discussion:與直接計算DCN偏移量的現有方法不同,我們提出的以流導向變形對準採用光流作為導向。好處是雙重的。首先,由於已知CNN具有區域性感受野,因此可以通過使用光流預對準特徵來輔助偏移的學習。其次,通過只學習殘差,網路只需要學習與光流的微小偏差,從而減輕典型可變形對準模組的負擔。此外,DCN中的調變mask不是直接連線warp特徵,而是充當注意圖來權衡不同畫素的貢獻,提供額外的靈活性。
4.實驗
訓練採用了兩種廣泛使用的資料集:REDS和Vimeo-90K。對於REDS,按照BasicVSR,我們使用REDS4作為測試集,使用REDSval4作為驗證集。剩下的片段用於訓練。我們使用Vid4、UDM10和Vimeo90K-T以及Vimeo-90K作為測試集。所有模型均使用兩種降級(雙三次(BI)和模糊下取樣(BD))進行4倍下取樣測試。 我們採用Adam優化器和餘弦退火方案。主網路和流量網路的初始學習率設定為1×10-4和2.5×10-5。總迭代次數為600K,在前5000次迭代中,流量網路的權重是固定的。批次大小為8,輸入LR幀的修補程式大小為64×64。我們使用Charbonnier損失,因為它能更好地處理異常值,並比傳統的l2-loss效能好。我們使用預先訓練好的SPyNet作為我們的流量網路。
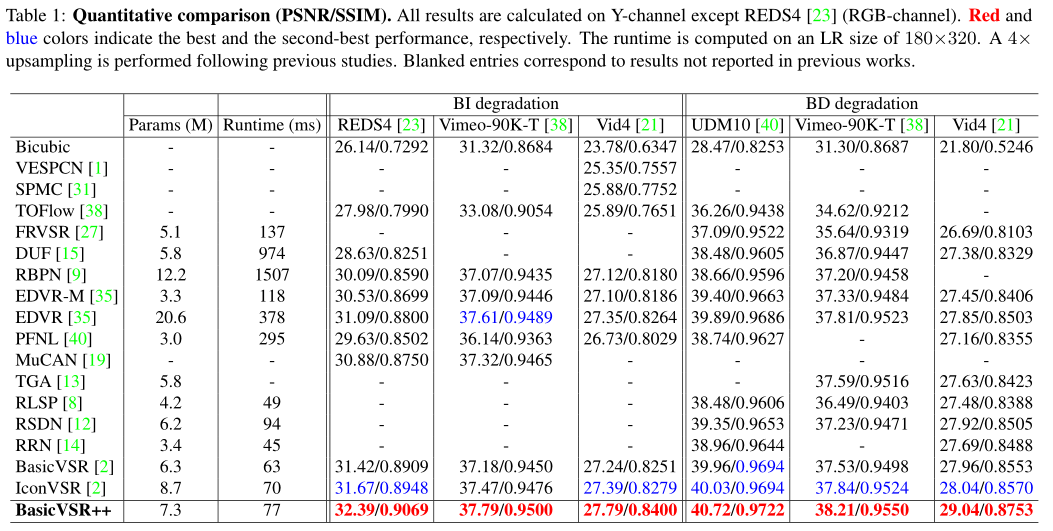
4.1和最新的方法比較
5.消融研究
為了瞭解各個元件的貢獻,我們從基線開始,逐步插入元件。從表3可以明顯看出,每個元件都帶來了相當大的改善,峰值訊雜比從0.14 dB到0.46 dB不等。 理論上,我們提出的傳播方案可以擴充套件到更高的階數和更多的傳播迭代。然而,當從一階增加到二階時和一到兩次迭代效能增益相當可觀,我們在初步實驗中觀察到,進一步增加迭代次數和次數並不會導致顯著改善(PSNR為0.05dB)。
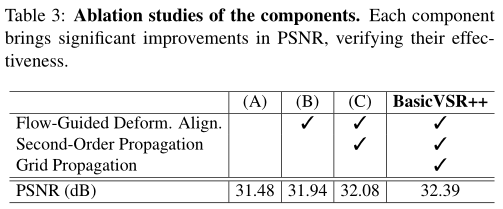
二階網格傳播:如圖的兩個範例所示,在包含精細細節和複雜紋理的區域中,二階傳播和網格傳播的貢獻更為顯著。在這些區域,當前幀中可用於重建的資訊有限。為了提高這些區域的輸出質量,需要從其他視訊幀進行有效的資訊聚合。通過我們的二階傳播方案,資訊可以通過魯棒有效的傳播進行傳輸。這些補充資訊基本上有助於恢復細節。如範例所示,網路使用我們的元件成功地恢復了細節,而沒有我們的元件的網路則會產生模糊的輸出。

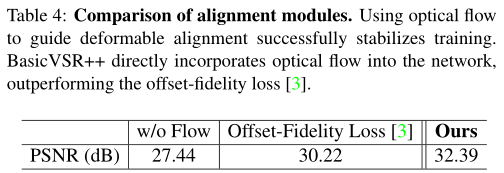
光流指導的可形變對齊:我們將偏移量與BasicVSR++中的流量估計模組計算的光流進行了比較。通過只學習光流的殘差,網路產生的偏移量與光流高度相似,但有明顯的差異。與僅從運動(光流)指示的一個空間位置聚合資訊的基線相比,我們提出的模組允許從周圍的多個位置檢索資訊,提供了額外的靈活性。

為了證明我們設計的優越性,我們將我們的對準模組與兩種變體進行了比較:(1)沒有使用光流(2)光流在offset-fidelity loss中使用,即光流僅用作損耗函數中的監控(而不是在我們的方法中用作基本偏移)。如果不使用光流作為指導,不穩定性會導致訓練崩潰,導致PSNR值非常低。當使用偏移保真度損失時,訓練是穩定的。然而,從我們的完整模型中觀察到了2.17 dB的下降。我們的光流指導可變形對準直接將光流整合到網路中,以提供更明確的引導,從而獲得更好的結果。
時間一致性:與滑動視窗框架相比,遞迴框架本質上保持了更好的時間一致性。在滑動視窗框架中,每個框架都是獨立重建的。在這種設計中,無法保證輸出之間的一致性。相比之下,在迴圈框架中,輸出通過中間特徵的傳播而相關。時間傳播本質上有助於保持更好的時間一致性。我們比較了BasicVSR++和兩種最先進的方法--EDVR和BasicVSR的時間剖面。對於滑動視窗法,EDVR的時間剖面包含大量噪聲,表明輸出視訊中存在閃爍偽影。相比之下,對於迴圈網路,在沒有明確的時間一致性建模的情況下,來自BasicVSR和BasicVSR++的組態檔顯示出更好的一致性。然而,BasicVSR的剖面仍然包含不連續性。得益於我們增強的傳播和對齊,BasicVSR++能夠從視訊幀中聚合更豐富的資訊,顯示更平滑的時間過渡。
6.總結
在這項工作中,我們使用兩個新元件重新設計了BasicVSR,以提高其傳播和對齊效能,從而實現視訊超解析度任務。我們的模型BasicVSR++在保持效率的同時,大大優於現有的先進水平。這些設計很好地推廣到其他視訊恢復任務,包括壓縮視訊增強。這些元件是通用的,我們推測它們將用於其他基於視訊的增強或恢復任務,如去模糊和去噪。
論文總結:個人覺得該論文最大的貢獻是提出了光流指導的可變形對齊以及二階網格傳播,告訴我們充分利用時間域的重要性。