MySQL進階實戰6,快取表、檢視、計數器表
一、快取表和彙總表
有時提升效能最好的方法是在同一張表中儲存衍生的冗餘資料,有時候還需要建立一張完全獨立的彙總表或快取表。
- 快取表用來儲存那些獲取很簡單,但速度較慢的資料;
- 彙總表用來儲存使用group by語句聚合查詢的資料;
對於快取表,如果主表使用InnoDB,用MyISAM作為快取表的引擎將會得到更小的索引佔用空間,並且可以做全文檢索。
在使用快取表和彙總表時,必須決定是實時維護資料還是定期重建。哪個更好依賴於應用程式,但是定期重建並不只是節省資源,也可以保持表不會有很多碎片,以及有完全順序組織的索引。
當重建彙總表和快取表時,通常需要保證資料在操作時依然可用,這就需要通過使用影子表來實現,影子表指的是一張在真實表背後建立的表,當完成了建表操作後,可以通過一個原子的重新命名操作切換影子表和原表。
為了提升讀的速度,經常建一些額外索引,增加冗餘列,甚至是建立快取表和彙總表,這些方法會增加寫的負擔媽也需要額外的維護任務,但在設計高效能資料庫時,這些都是常見的技巧,雖然寫操作變慢了,但更顯著地提高了讀的效能。
二、檢視與物化檢視
1、檢視
檢視可以理解為一張表或多張表的與計算,它可以將所需要查詢的結果封裝成一張虛擬表,基於它建立時指定的查詢語句返回的結果集。
查詢者並不知道使用了哪些表、哪些欄位,只是將預編譯好的SQL執行,返回結果集。每次查詢檢視都需要執行查詢語句。
2、物化檢視
為了防止每次都查詢,先將結果集儲存起來,這種有真實資料的檢視,稱為物化檢視。
MySQL並不原生支援物化檢視,可以使用Justin Swanhart的開源工具Flexviews實現。
相對於傳統的臨時表和彙總表,Flexviews可以通過提取對源表的更改,增量地重新計算物化檢視的內容。
三、加快alter table操作的速度
MySQL的alter table 操作的效能對大表來說是個大問題。MySQL執行大部分修改表結構的操作的方法使用新的結構建立一個空表,從舊錶中查出所有資料插入新表,然後刪除舊錶。
這樣操作可能需要花費很長時間,如果記憶體不足而表又很大,而且還有很多索引的情況下更為嚴重。
改善的方法有兩種:
- 第一種是先在一臺不提供服務的機器上執行alter table操作,然後和提供服務的主表進行切換;
- 第二種方式是通過影子拷貝,影子拷貝的技巧是用要求的表結構建立一張和源表無關的新表,然後通過重新命名和刪表的操作交換兩張表。
四、計數器表
通常建立一張表來儲存使用者的點贊數、網站存取數等。
create table like_count(num int unsigned not null) engine=InnoDB;
每次點贊都會導致計數器進行更新:
update like_count set num = num + 1;
問題在於,對於任何想要更新這一行的事務來說,這條記錄上都有一個全域性的互斥鎖mutex。這會使這些事務都只能序列執行,要獲得更高的並行更新效能,可以將計數器儲存在多行中,每次隨機選擇一行進行更新。
create table like_count(
slot tinyint unsigned not null primary key,
num int unsigned not null
) engine=InnoDB;
預先在這張表中新增10條資料,然後選擇一個隨機的槽slot進行更新:
注意:為了研究之後遇到的問題,後來又插入了一條~
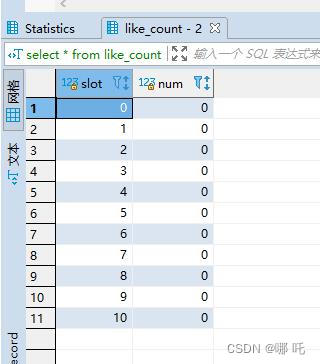
update like_count set num = num + 1 where slot = floor(rand() * 10);
更新了兩行,這是為什麼呢?
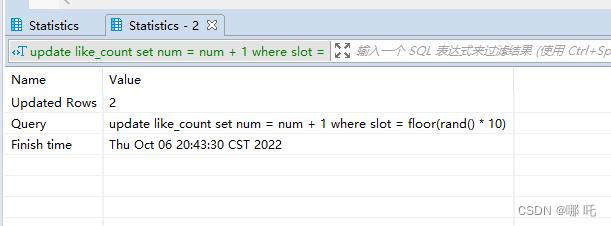
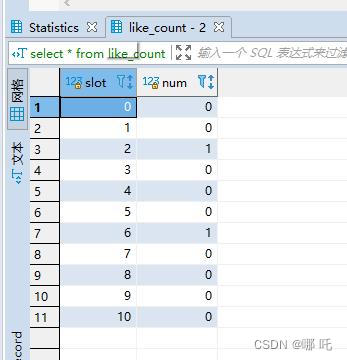
select一下,查詢結果,有的時候0條,有的時候1條,有的時候2條,有的時候3條,驚呆了,這麼有趣的事情,我怎麼能放過,讓我們一起一探究竟。
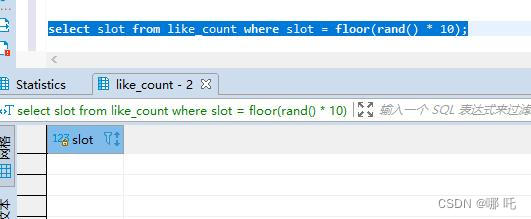
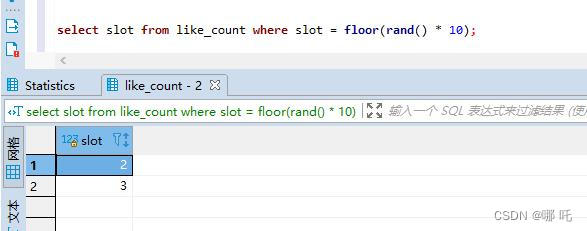
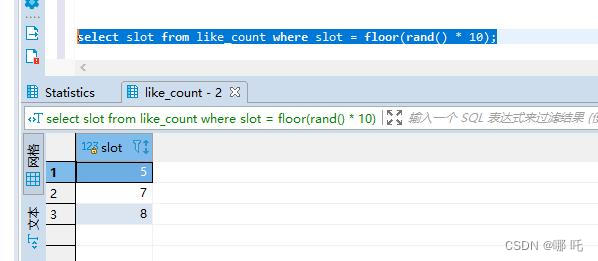
讓我們一起一探究竟:
- floor() 函數的作用:返回小於等於該值的最大整數;
- rand()函數的作用:獲得0到1之間的隨機值;
在ORDER BY或GROUP BY子句中使用帶有RAND()值的列可能會產生意想不到的結果,因為對於這兩個子句,RAND()表示式都可以對同一行計算多次,每次返回不同的結果。要從一組行中隨機選擇一個樣本,將ORDER BY RAND()和LIMIT配合使用。
在MySQL的官方手冊裡,針對RAND()的提示大概意思就是,在ORDER BY從句裡面不能使用RAND()函數,因為這樣會導致資料列被多次掃描。
這就完了?