MySQL主從同步
1.什麼是MySQL主從同步?
「主」指的是MySQL主伺服器(master),負責寫請求。「從」指的是MySQL從伺服器(slave),負責讀請求。主從同步指的是將主伺服器上的資料同步至從伺服器。
2.為什麼需要主從同步?
針對大流量,一臺伺服器已經不能滿足要求。這個時候往往是將MySQL叢集部署,但是這樣會存在資料一致性的問題,即使用者端相同的請求,存取不同的節點,如何能夠得到相同的存取結果。通常的部署架構有一主多從和多主多從。
一主多從,主伺服器負責寫請求,從伺服器負責讀請求,從伺服器的資料同步自主伺服器。每臺伺服器都擁有所有的資料,因此可以解決資料一致性問題。使用多臺伺服器共同來處理請求,也達到了負責均衡的效果,之所以從伺服器比主伺服器多,原因是實際生產中,讀請求遠多於寫請求。
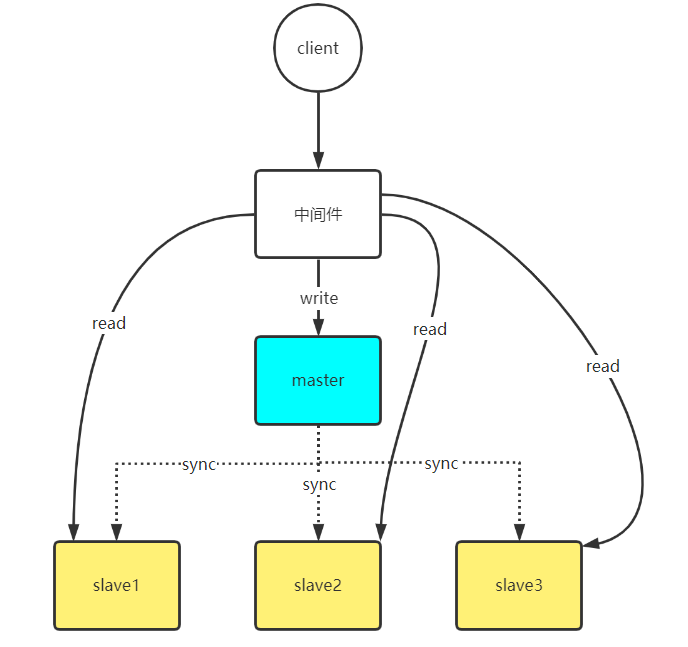
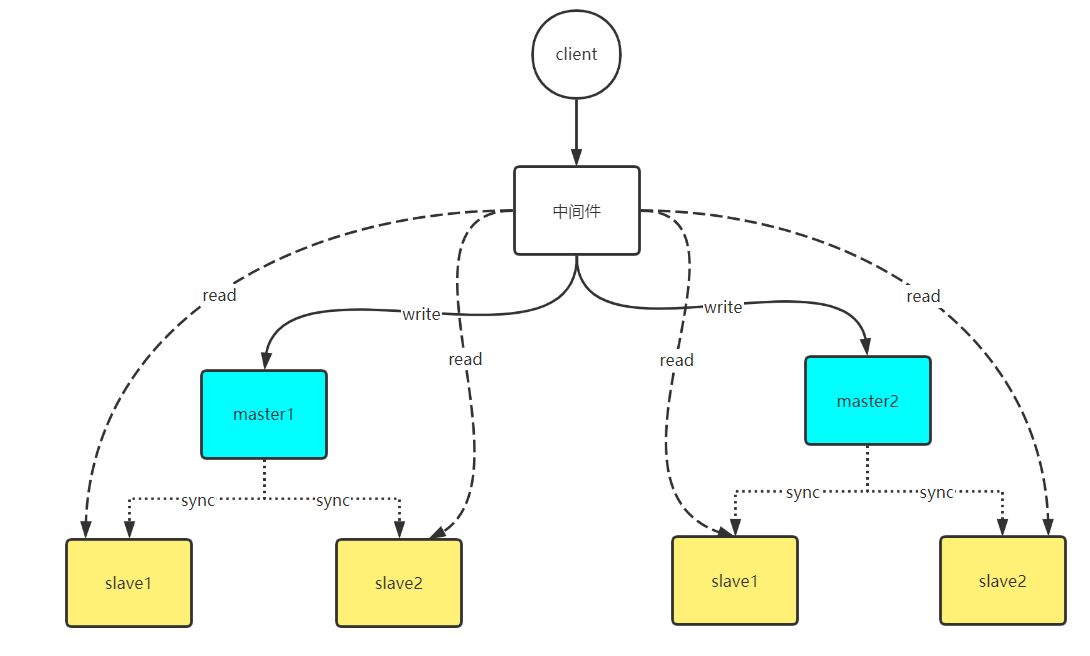
多主多從,一主多從在業務量大的時候,主庫的寫入速度就會成為效能瓶頸。這個時候可以使用分庫分表,讓資料分佈在多個master中,每個master又有多個從庫,負責寫請求。那麼client端在請求資料時,怎麼知道資料在哪個節點上呢?對於分庫分表,每個表都會有一個欄位作為分庫鍵,中介軟體(比如MyCat)在查詢時會根據分庫鍵計算出資料在哪一個庫上。
<mycat:schema xmlns:mycat="http://io.mycat/"> <!--邏輯庫,物理層面由db1、db2、db3組成--> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"> <!--邏輯表,由不同的資料庫中的表組成--> <table name="t_user" dataNode="dn1,dn2,dn3" rule="crc32slot" /> </schema> <!--dataNode,可以理解為一個master和他的從庫組成的一個邏輯節點--> <dataNode name="dn1" dataHost="localhost1" database="db1" /> <dataNode name="dn2" dataHost="localhost1" database="db2" /> <dataNode name="dn3" dataHost="localhost1" database="db3" /> <!--dataNode的連線資訊--> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <!--主節點(master節點)--> <writeHost host="hostM1" url="localhost:3306" user="root" password="root"> <!--從節點(slave節點)--> <readHost host="hostS2" url="192.168.1.200:3306"user="root"password="root" /> </writeHost> </dataHost> </mycat:schema>
3.主從同步如何使用?
3.1 設定主節點
- 設定log_bin和server_id
在/etc/my.cnf中增加如下設定
log-bin=mysql-bin # binlog名稱
server-id=1 # 伺服器id
- 建立複製賬號
create user 'data_copy'@'%' identified by 'Test@1234'; # 建立複製賬號
grant FILE on *.* to 'data_copy'@'192.168.126.132' identified by 'Test@1234'; # 授予複製賬號FILE許可權,允許從庫IP存取主庫
grant replication slave on *.* to 'data_copy'@'192.168.126.132' identified by 'Test@1234'; # 授予賬號主從同步許可權
flush privileges; # 重新整理許可權
- 重啟伺服器
service mysql start
- 檢視主伺服器狀態

3.2 設定從節點
- 設定server_id
在/etc/my.cnf中增加如下設定
server-id=2 # 伺服器id
- 重啟伺服器
service mysql start
- 在從節點上設定主節點資訊
stop slave;
# 設定當前伺服器對應的master change master to master_host='192.168.126.134', master_user='data_copy' ,master_password='Test@1234', master_log_file='mysql-bin.000005' ,master_log_pos=0; start slave;
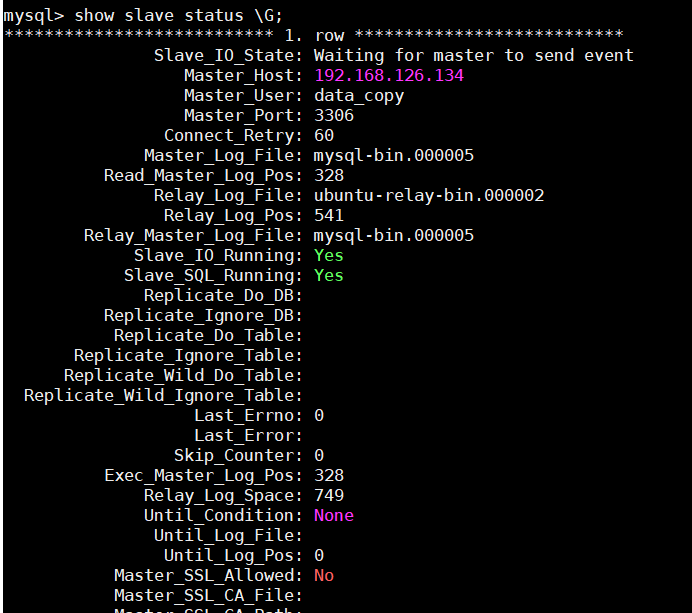
- 檢視從節點狀態
show slave status \G;
4.主從同步的原理
4.1 主從同步的步驟
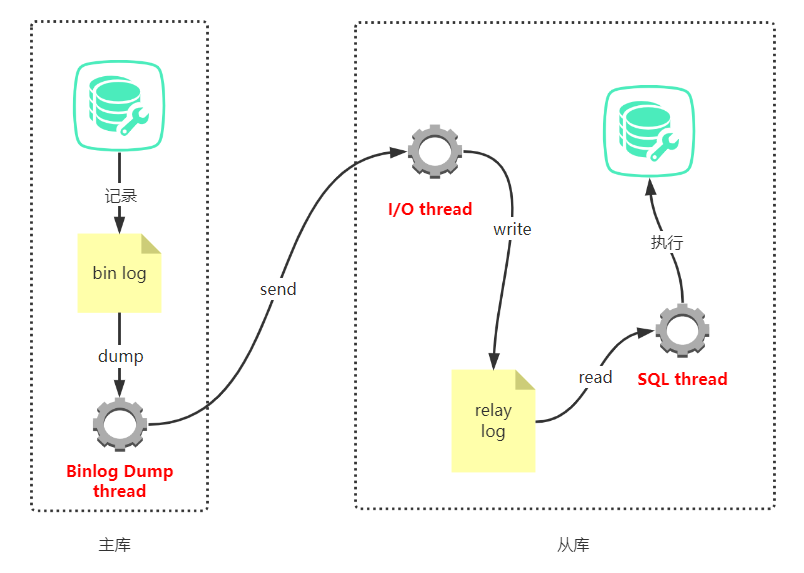
如上圖,複製主要分為以下幾個步驟:
1.主庫將資料的更改記錄到二進位制檔案中(binary log)
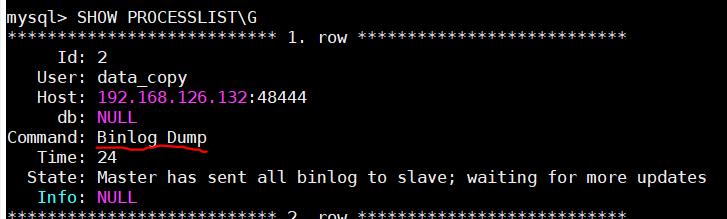
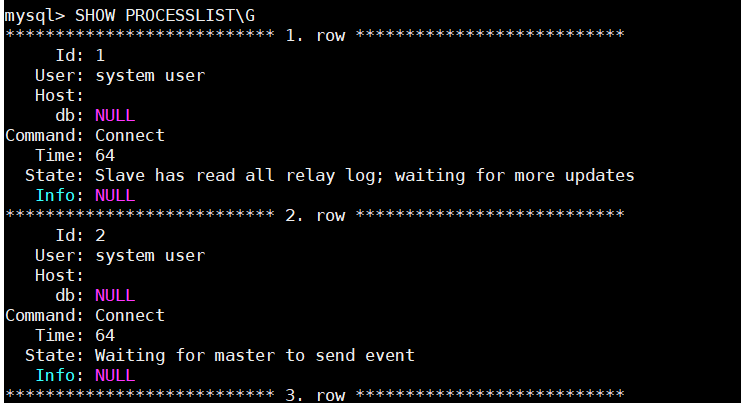
2.從庫連線主庫,此時會在從庫上建立兩個執行緒:I/O執行緒和SQL執行緒,在主庫上建立一個執行緒:Binlog Dump執行緒。可以在主庫和從庫上使用 SHOW PROCESSLIST命令檢視
Binlog Dump執行緒
I/O執行緒和SQL執行緒
3.Binlog Dump執行緒會將Binlog中的事件傳送給從庫
4.從庫中的I/O執行緒接收到事件後,將事件寫入relay log
5.SQL執行緒重放relay log中的事件,達到將主庫的資料複製到從庫的目的
從以上的步驟可以看出,這種複製架構將事件獲取和事件重放完全解耦開來。是典型的生產者和消費者模式的運用,mysql主執行緒負責生產Binlog,Binlog Dump執行緒負責消費;I/O執行緒負責生產relay log,SQL執行緒消費relay log。
4.2 主從同步原理
基於語句的複製
基於語句的複製,binlog會記錄造成資料或者表結構更改的語句,從庫重放事件時,相當於把這些語句再執行一遍。
基於行的複製
基於行的複製,binlog直接記錄更改後的資料
這兩種模式各有優劣,mysql會在這兩種模式之間動態切換。
5.主從同步的延遲問題
由於主從同步是非同步的,難免會存在主從同步延遲問題,一般情況下這種延遲可以忽略,但是對於資料一致性要求比較高的場景,就必須想辦法解決。
1.對於不能容忍半點資料不一致的情況:強制讀主庫
2.對於可以稍微容忍不一致的情況:可以在卸庫完成後,sleep 500m後再讀取