京東零售巨量資料雲原生平臺化實踐
導讀: 今天為大家介紹京東零售巨量資料的雲原生平臺化實踐,主要包括以下幾大方面內容:
-
雲原生的定義和理解
-
雲原生相關技術的演化
-
京東巨量資料在雲原生平臺化上的實踐
-
雲原生應用平臺的發展
分享嘉賓:劉仲偉 京東 架構師
編輯整理:張明宇 廣州某銀行
出品社群:DataFun
01/雲原生的定義和理解
1. 雲原生的定義
雲原生這個概念大家已經很熟悉了,但是否有一個準確的定義呢?每個人都在說雲原生,但大家對雲原生的理解是不同的。
CNCF對雲原生的定義如下:

很多時候,大家會想應用容器化就等於雲原生化,應用上了Kubernetes是否等於雲原生化,使用了Kubernetes的API是否等於雲原生化?答案是不一定,因為雲原生的定義在變化。
2015年CNCF成立,對雲原生的定義如下:

Pivotal在2019年也對雲原生做了定義。雖然Pivotal現在已經被收購,但其在雲原生的定義和發展方面起了很大的作用。Pivotal對雲原生的定義涉及幾個方面:Devops, Continuous Delivery, Microservices和Containers。
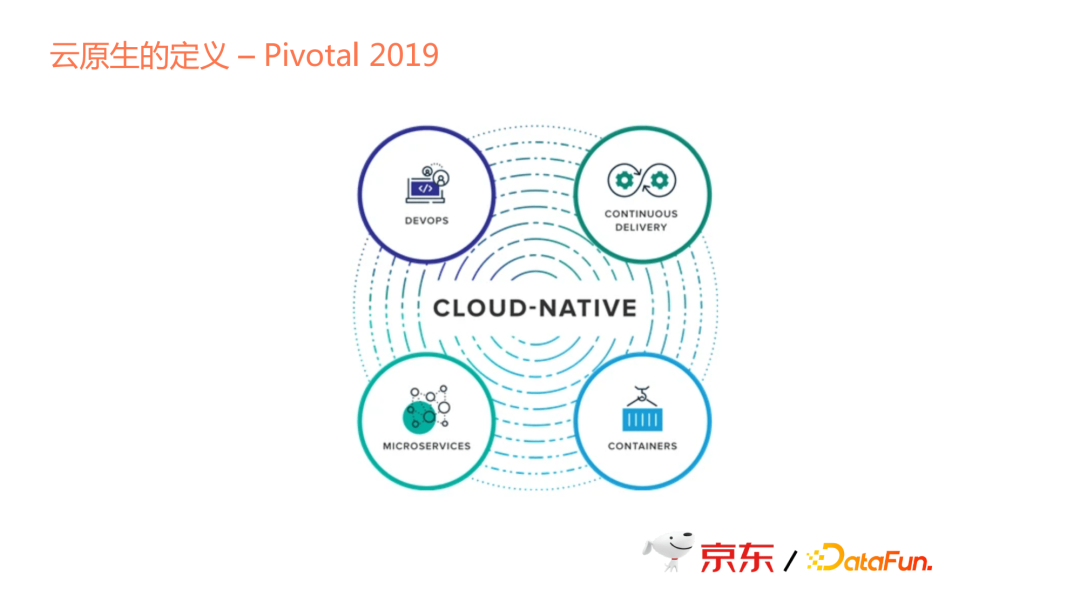
綜上所述,不同公司或不同的組織,對其定義不同。隨著時間的變化,雲原生的定義也發生著變化。
2. 雲原生的理解
我們今天所討論的雲原生是巨量資料範疇內的雲原生。雲原生可以分為雲和原生兩部分。
- 雲(Cloud)
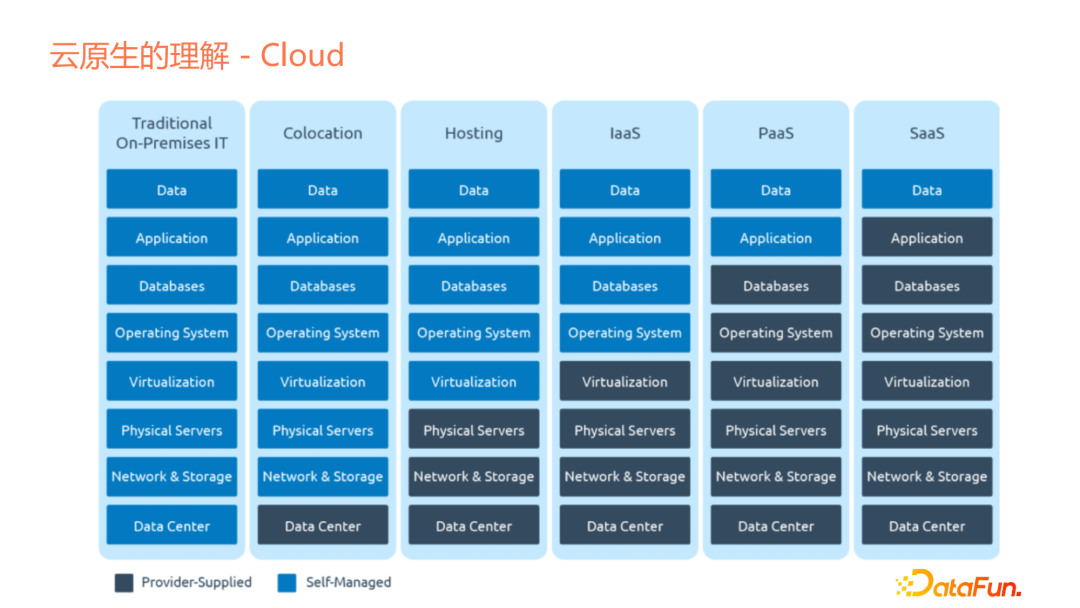
雲(Cloud)是什麼?我們回顧雲的發展,起初沒有云,只有Traditional On-Premises IT,經過後續的發展,雲(上圖中深色部分)作為提供的基礎設施(或服務)變得越來越多。作為一個企業或企業的應用開發者,需要維護的東西越來越少,雲會提供許多服務。
- 原生(Native)
流行詞典中對native的定義如下:

如上圖中所示,native相當於土著,即在何處出生、生活。前幾年大家做的最多的是上雲或遷移到雲這個動作,即你的產品、應用並不是在雲上設計的,而是在雲還沒有提供服務之前就已經設計好了。Hadoop剛出來時,整個生態並不是為雲設計的,如果雲已經像今天這樣成熟的話,那麼可能就是另外一個樣子了,因為Yarn做的很多事情是編排排程。現在,編排排程或容器化的服務,已經完全跟Hadoop當年提出時不同,所以從Hadoop生態來說,它其實並不是On the Cloud。
對於雲原生,我提出這樣的理解:生於雲,長於雲。

生於雲即應用或整個產品在設計時,是按照有云服務進行設計的,公有云、私有云或者混合雲的形式,為應用或產品提供很多特性或服務。我要做的是專注於本身應用的特性和邏輯,把可延伸性、彈性、安全性等特性,放到雲上或雲提供的能力上來使用,而不是我的應用自己去做。
長於雲是指除了在應用設計時利用雲服務,在應用的維護和演進過程中,也會使用雲提供的服務。隨著雲服務能力的不斷壯大,應用的新需求也會考慮使用雲服務新特性來實現,達到「長於雲」。
巨量資料雲原生意味著什麼?容器化上Kubernetes的確是一種雲原生,但如果現在新設計一些應用或產品,可能不只是上Kubernetes這麼簡單,而是要考慮這個產品哪些部分是可以剝離出來的、不用在自己的應用裡面去考慮的,以及哪些部分是可以直接依託於雲廠商或平臺去做的。
02/雲原生相關技術的演化
雲原生技術有哪些?我這裡列了一些時間點。
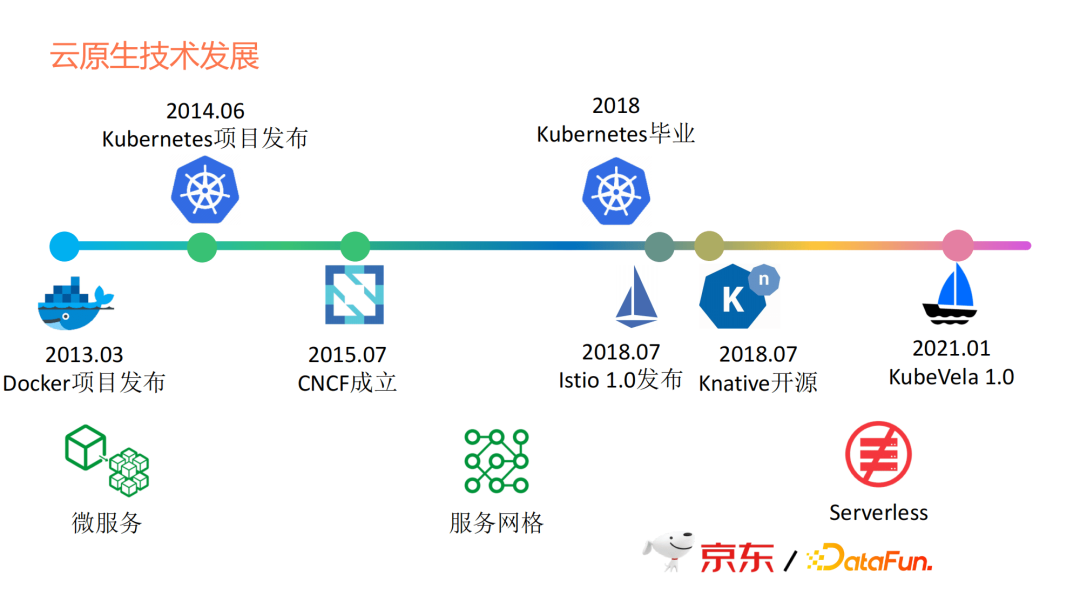
更早期的虛擬化技術我沒有列,因為那些技術屬於上一個時代的事情,我從docker開始。因為docker開始,大家對於容器化有了共同的認知。
2013年有了docker,2014年有了Kubernetes,但2014年Kubernetes剛釋出時並未掀起太多風浪。2015年,CNCF正式成立,它把Kubernetes當成第一個專案去運作。2018年Kubernetes畢業時,雲原生彷彿有了依託,上Kubernetes就變成了雲原生,Kubernetes變成了一個事實性的標準。後面像Istio的釋出,Knative的開源,這些技術的出現,相當於是在Kubernetes上添磚加瓦,讓Kubernetes變得更加豐富,Istio相當於容器間的通訊者,Knative相當於無伺服器的平臺框架。
如上圖下方所示,雲原生從微服務時代發展到服務網格時代,最後步入Serverless時代。
2021年1月,KubeVela1.0釋出,KubeVela 1.0可能沒有前面這幾個專案那麼有名。一是因為推出的時間晚,二是因為不是由Google推出。kubeVela相當於是阿里雲推出的一個專案,是作為應用PaaS層的一個框架,有點類似於Knative作為一個無伺服器的平臺框架。
03/京東巨量資料在雲原生平臺化上的實踐
1. 雲原生技術選型
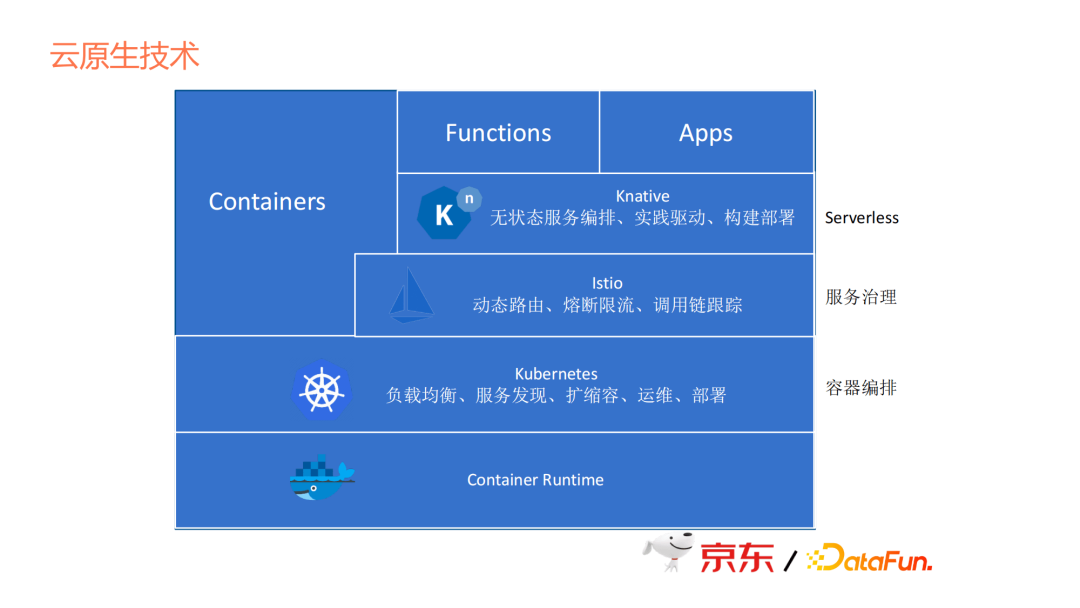
先看Knative這部分,上文中提到它是一個無服務的PaaS框架。對於京東巨量資料,Knative並不是好的選擇。因為它必須是一個無狀態的http服務,而且還不能掛載PVC,所以只能去做無伺服器短時任務的排程。
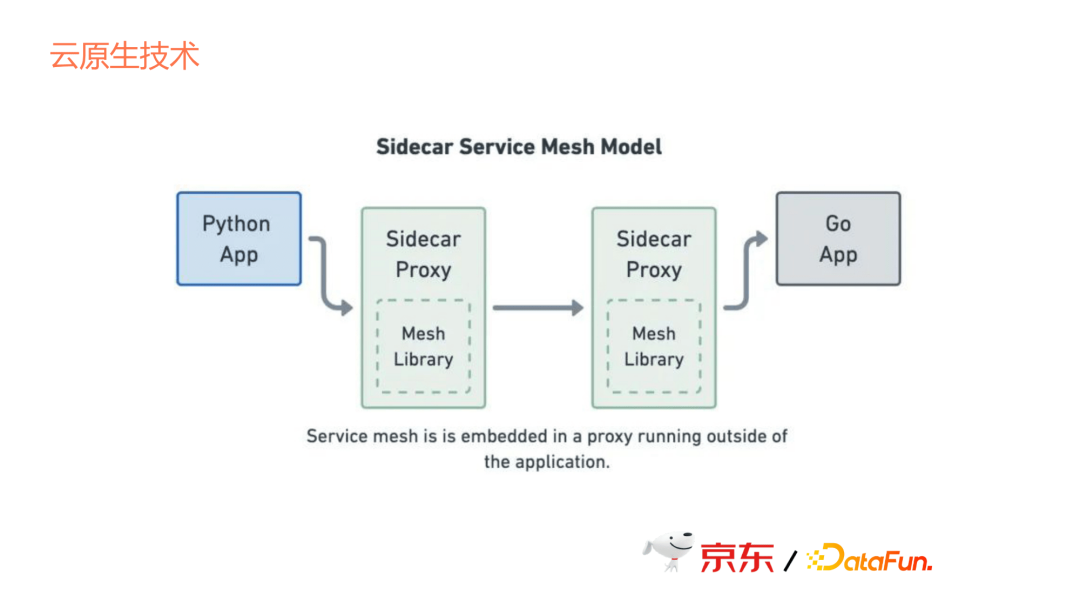
再看Service Mesh,它通過Sidecar的方式去提供容器間通訊,但這個通訊有成本,因為它本來是兩個app之間的通訊,變成了要通過sidecar去跳,那麼這個跳就意味著通訊成本的增加,所以也不是很好的選擇。因此,我們現在並沒有直接使Service Mesh來管理容器間的通訊。

除了上述幾個技術之外,在開源界的另一選擇是在Kubernetes上面去做Operator,就像Operators Hub,大家可以看到有很多開源服務它本身已經提供了Operator,而且也方便用,但問題是每個Operator都是各個組織自己開發的,並沒有一個公共的抽象,我們想改的話,需要對每個Operator進行修改,成本很大,所以這也不是我們的選擇。
2. 京東巨量資料的實踐
接下來看一下我們在京東的雲原生方式。
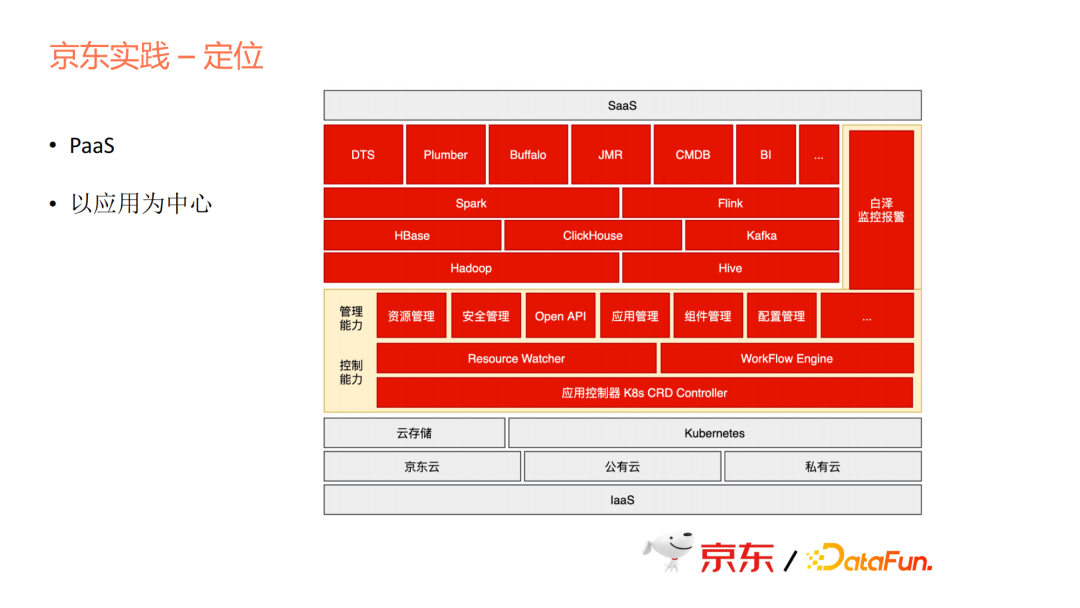
首先我們要定位。定位是一個PaaS層,但PaaS層是在Kubernetes的基礎之上去提供一些能力,包括資源、安全、API、應用元件設定等一系列管理能力,也包括控制能力。為什麼單獨講控制能力呢?因為我們做的方式跟社群的Operator邏輯一致,但又有些不同,我們把它抽象成一個統一的模型來做,而不是每個產品都做一個Operator。
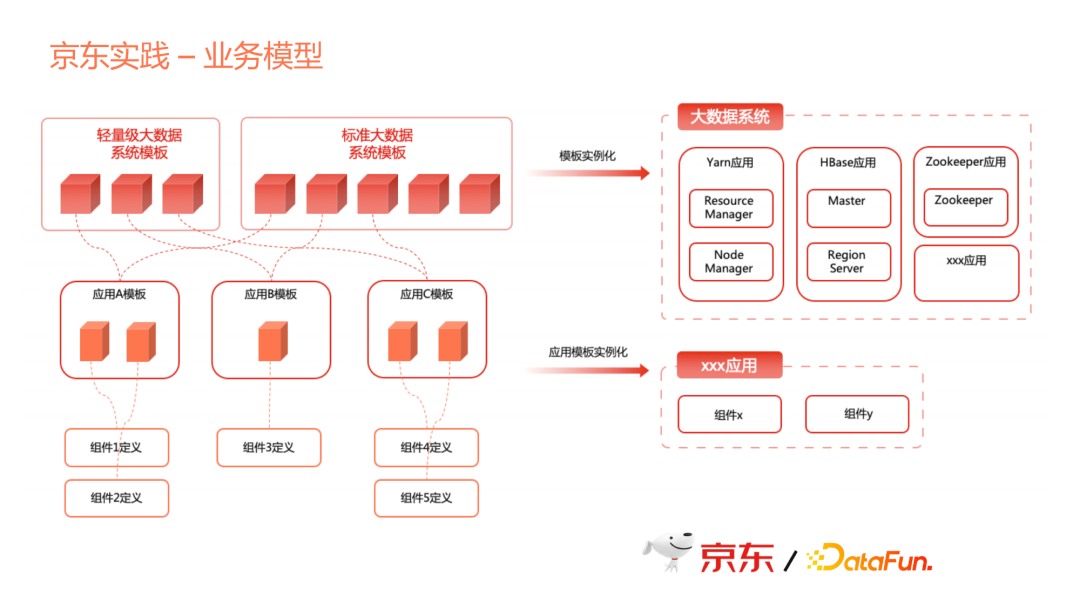
業務模型分成三層,第一層是元件。Yarn裡面Node Manager或Resource Manager本身就一個程式,可以定義成一個元件。
第二層是應用模版。多個元件組合在一起就是一個應用,這個應用模板定義了一個應用。比如Yarn這個應用,它由多個元件組成。一個應用可能是單元件,也可能是多個元件,每個應用可以自己靈活組裝,提供了應用定義的靈活性。
第三層是系統模板。我們提供一個巨量資料的平臺,巨量資料平臺不是僅有一個Hadoop,而是帶著一系列產品,包括HBase、Yarn、Spark,還可以帶著資料傳輸、資料排程、資料管理、資料分析、甚至BI等一系列應用在一起,組合成一個巨量資料系統。
這個巨量資料系統可能會對不同的部門,或對不同的服務物件,可能存在不同的組合。有的可能是一個輕量級的,由最精簡的幾個應用組合成一個系統;有的可能很大規模,所以我們需要帶一系列標準。對於後面的使用者來說,只需要一個範例化的過程就可以使用。
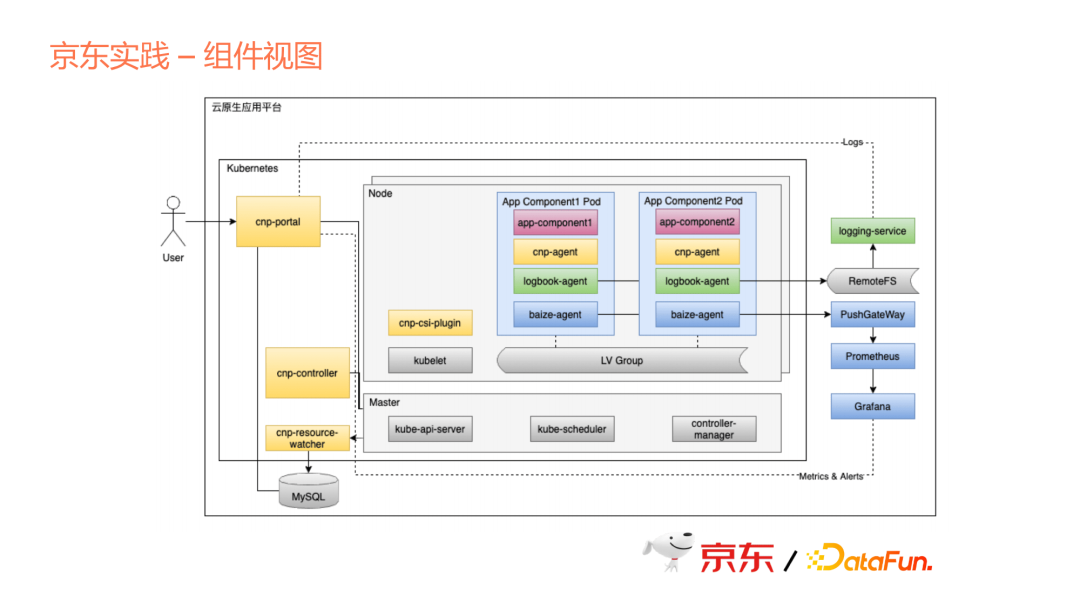
上圖中可以看到我們有幾個主要的元件,一個是Portal,這部分是我們的管控臺,在這個管控臺裡面去定義上文中說的應用。從元件開始定義,元件裡面又包含了各個元件的組態檔、元件的映象image、一些動態設定,哪些設定項可以動態生成,在元件或者應用建立時,需要動態輸入。
另外,上文說的去組合成一個應用模板,以及組合成一個系列,這一系列都在合作區,由使用者來定義,定義之後會渲染出來Kubernetes裡面一個應用crd,應用crd由controller負責生成應用。Resource Watcher也是一個重要的元件,是去watch Kubernetes上面各個資源的狀態,然後再更新到外部資料庫中。
我們用了Sidecar的模式提供很多應用特性。上文說到雲原生的關鍵是可以提供一些平臺級的特性,這些特性我們是作為Sidecar來以平臺的方式統一提供,但是各個應用可以選擇性地去設定。當然每個特性其實都在於背後的一些服務,我們會作為一個平臺統一去提供。
這裡其實是一個具體的翻譯過程,從使用者提供的具體映象,映象裡面需要帶組態檔、一些指令碼、一些二進位制、包括Docker file,相當於是把這些應用的差異性下沉到應用元件裡面,由元件內部去控制差異性。如果把每個應用組態檔都做在每個Operator裡面,必然會導致整個Operator的膨脹。所以,我們的做法更多是將這些差異性放到每個元件內部,但是我們的控制器會負責呼叫這些指令碼,由這些指令碼把差異性實現出來。
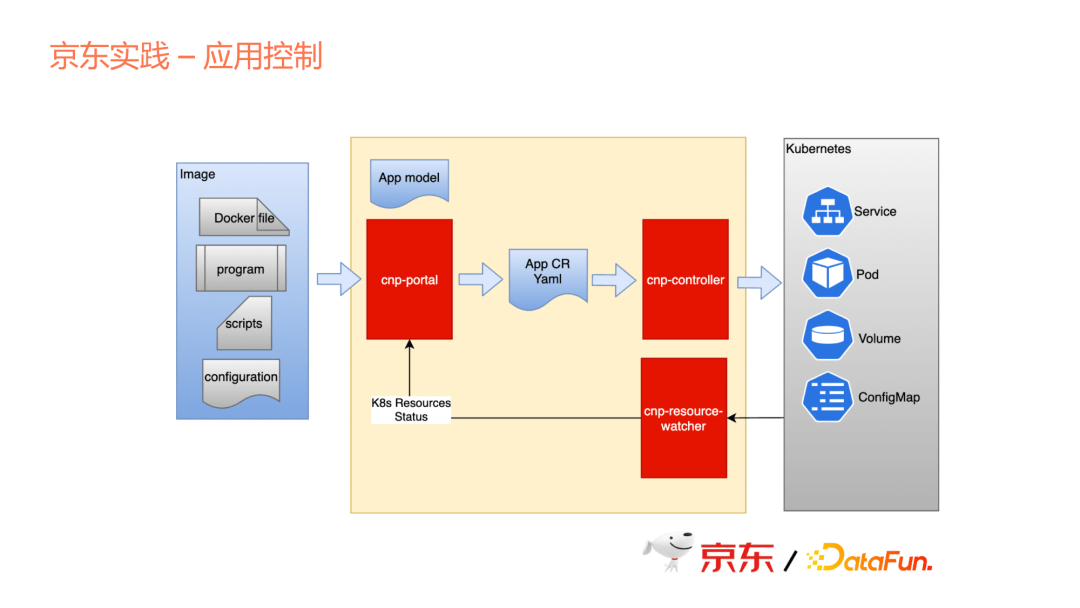
整個過程與上文相同,從Portal裡面產生Application的Yaml,這是我們自定義的一個資源格式,然後再由controller翻譯成Kubernetes裡面的Service、Pod、Volume、ConfigMap等資源。
從這裡可以看出,對於使用者來說,不管是應用的生產者,還是使用者,都不需要太關心Kubernetes的這些概念。因為對於整個行業的從業者來說,Kubernetes並非一個很簡單的東西,特別是隨之衍生出來的Knative或者Istio,很難讓大家都理解這些,並能熟練地應用所有的資源。只要我們能夠提供一層平臺,就可以把這些遮蔽掉,想要用哪個應用就用哪個。

再看一下應用crd的例子。
我們定義為cnp,我們內部的一個Cloud Native Platform,在這個Application裡面我們可以看到它的volumes的定義,這個volumes跟Kubernetes裡面的volumes不太相同,裡面更多是具體的PVC的關聯宣告。Volumes template是我們自己獨創的一個概念,在這個模板裡面,可以定義這個模板如何宣告,為每個Pod宣告出自己對應的volume。在每個Application裡面有多個Components,我們這個components是一個抽象的邏輯概念。在Application裡面分成多個Components,每個component可以有自己的定義。這個是對於HBase而言的,分成Master和Region Server。這裡我們特意加了一系列的Sidecar containers,這是我們平臺提供的一個特性,裡面提供一些監控或紀錄檔的能力。每個Sidecar會在Application裡面根據Portal取得它的定義和選擇,把Sidecar定義進來。
大家如果熟悉KubeVela的專案,會看到我們在概念上有一些類似,比如我們都有統一的Application,也都有Components這樣的概念。但我們的特點在於我們是平臺直接構建Application的能力和特性,而不是一個開發框架。
因為我們是要提供一個平臺,京東內部會統一去使用,對外提供商業化服務時也是基於這個平臺提供巨量資料產品和應用,所以並不需要把這個平臺做成一個框架。
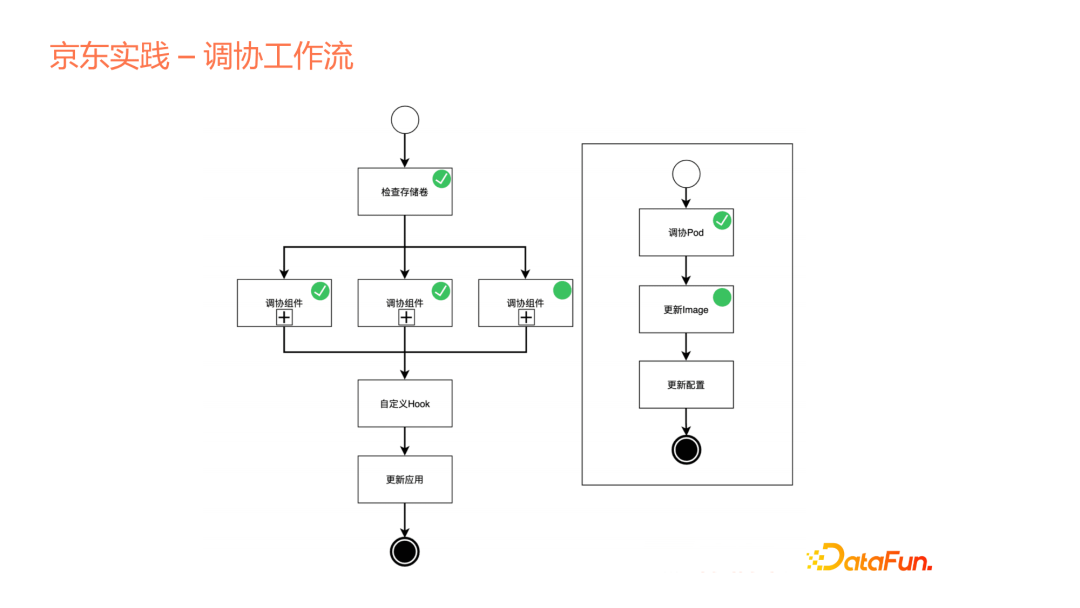
再介紹我們平臺中的一個特別點——協調工作流。
上文說到我們的controller跟雲原生operation裡面的controller是一致的,但也有不同,不同就在於引入了工作流的概念。我們使用宣告式的API來宣告,或者說建立一個Application的時候,並不是讓這個Application建立的過程完全變成一個controller內部的黑盒,我們是把這個controller協調的邏輯開放出來,展示給使用者看,整個Application是如何去協調出來的,包括儲存卷的檢查、申請和後面各個元件如何去做,然後在元件內部,依然可以結合成子工作流的方式,把內部的流程再一步步展露出來。
第二個目的是可以去做自定義的Hook,這是我們平臺可以支撐多個產品的一個原因。我們可以把一些Hook點暴露出來,讓各個產品有機會在這些節點上去做自己的定義。比如在多個元件都已經啟動後,會做叢集的初始化動作,在這邊定義後,會把這個命令傳遞到叢集各個Pod裡面去。另外還可以支援元件之間的傳遞,比如component A建立或啟動之後,會產生一個dns,我們會把這個dns引數作為下一個元件的輸入。這個很常見,在巨量資料裡面,比如需要啟動一個Zookeeper,啟動了Zookeeper這個多節點叢集之後,這個Zookeeper會作為下一個服務輸入,比如Hbase或其它多個元件。
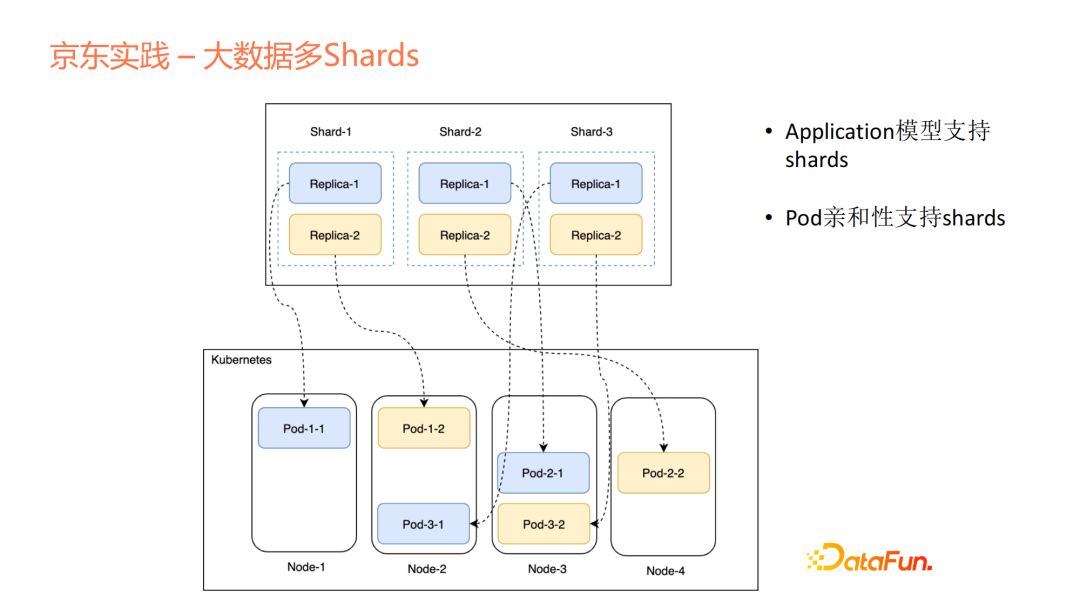
在Kubernetes的很多其他擴充套件work node中,不支援這種巨量資料裡面的多shard概念。對於每個應用來說,pod相對來說是獨立或平等的,在巨量資料裡面自然存在一種shard的概念。舉個例子,上了1、2、3,那1、2、3每個裡面存在自己的replica,我們會支援shard的定義,既支援多shard,也支援單shard。如果存在多shard,我們會對每個shard做親和性和反親和性的支援。pod的命名比較有意思,對於一些多shard應用來說,我們的命名方式可以很清晰地看到這個pod是屬於哪個shard裡面的第幾個副本分片,這也是我們的特點之一。
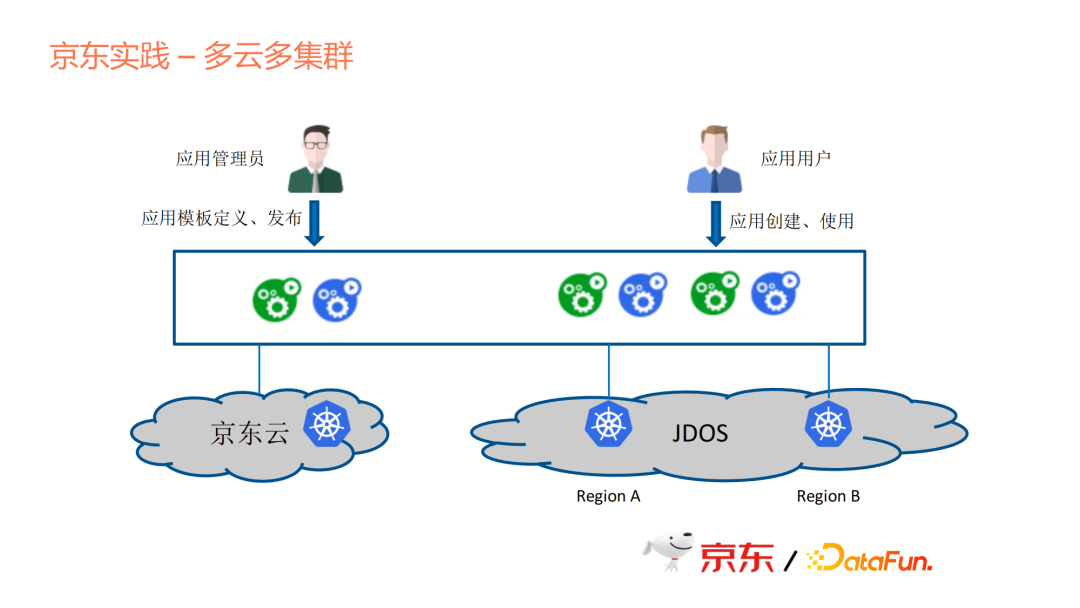
上圖是一個典型的應用場景,作為一個應用管理員,京東內部的這些巨量資料產品裡面有很多團隊,每個團隊整合到應用平臺的時候,他來負責應用模板的定義和釋出,釋出到應用市場。對於使用者來說,他需要做的是應用的建立和使用。
京東內部有多個雲臺盤,比如京東雲,是對外開放的一個公有云市場,我們在京東雲上面,自己申請資源去做開發和測試的一些工作。Jdos是我們的一個生產環節的雲,我們在這上面將多地區多叢集進行部署,然後連到平臺上統一管理。但是我們現在還沒有去做跨叢集的部署能力,這是後面會考慮的事情。我們現在更多是把應用放在單個叢集,因為從需求優先順序來說,在單機群上的效率會更高。後面如果考慮多叢集的高可用支援,我們也會考慮到地域分佈和叢集間的通訊,綜合考量如何去做多叢集的高可用。
04/雲原生應用平臺的發展
我們再來看一下過去十幾年PaaS的發展,也由此展望後續的發展方向。
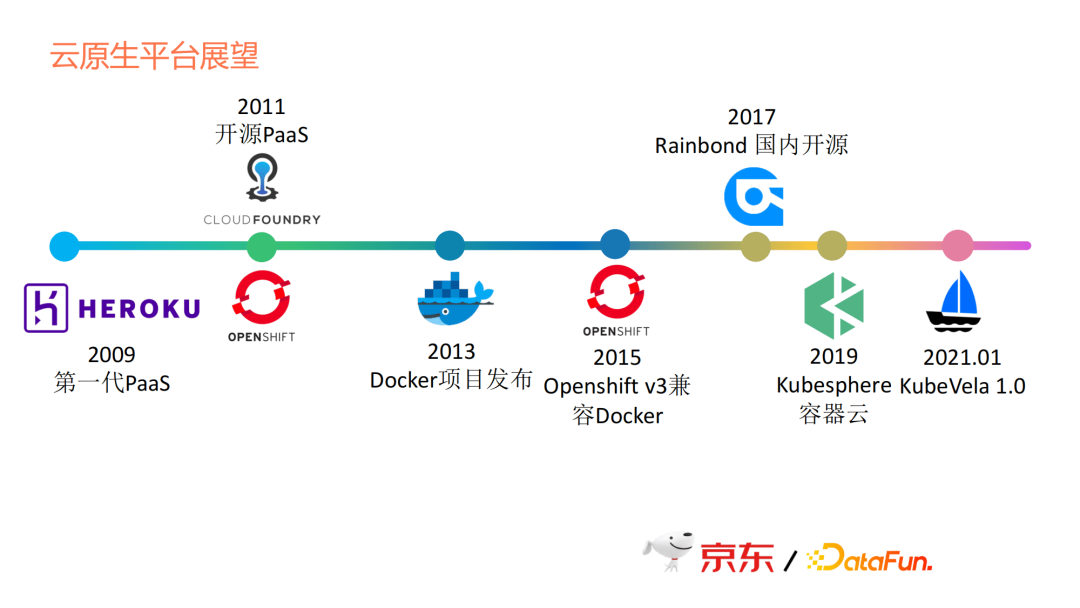
- Heroku
2009年提出,在推動雲原生髮展過程中起到了關鍵作用,不過Heroku在2010年就被Sales Force收購了,但現在Heroku仍然作為一個產品對外銷售,它是一個企業級的應用,平臺做得很成熟。但有一點很可惜,它是一個閉源的系統,你必須是一個資深的Heroku使用者,才能參與到開發和客製化的工作。
- Cloud Foundry
這是第一個開源的PaaS平臺,由Pivotal公司提供。
- Openshift
Openshift是紅帽的。因為它們有自己的容器化技術,不是我們後面所認知的容器化標準,所以造成了它現在的生命力問題。雖然到15年的時候,Open shift第三版相容了Docker,但很複雜,很難迭代。從開源或者社群角度來說,大家去選擇或模仿它的動力不足。
- 國內專案
Rainbond、Kubesphere是青雲提供的容器雲概念,把現在流行的好用的元件都裝在了上面。但它並不是一個完整的應用抽象的概念,而是把一堆好用的元件集合在一起。
接下來是KubeVela,它提出的是雲原生應用的概念,以應用為中心去做雲原生,但它提供的是PaaS的開發框架。從我們自己的思考來看,我們並沒有完全使用這樣一個框架,因為我們有些思路和他們的定義並不完全一致。
我希望通過今天的這個分享引導大家去思考各自公司的雲原生平臺該如何設計,主要有兩部分,一部分是它是否生於雲,另一部分是這個平臺後續的發展是不是長在雲上。
今天的分享就到這裡,謝謝大家。
分享嘉賓:
