Android 記憶體快取框架 LruCache 的實現原理,手寫試試?
本文已收錄到 AndroidFamily,技術和職場問題,請關注公眾號 [彭旭銳] 提問。
前言
大家好,我是小彭。
在之前的文章裡,我們聊到了 LRU 快取淘汰演演算法,並且分析 Java 標準庫中支援 LUR 演演算法的資料結構 LinkedHashMap。當時,我們使用 LinkedHashMap 實現了簡單的 LRU Demo。今天,我們來分析一個 LRU 的應用案例 —— Android 標準庫的 LruCache 記憶體快取。
小彭的 Android 交流群 02 群已經建立啦,掃描文末二維條碼進入~
思維導圖:
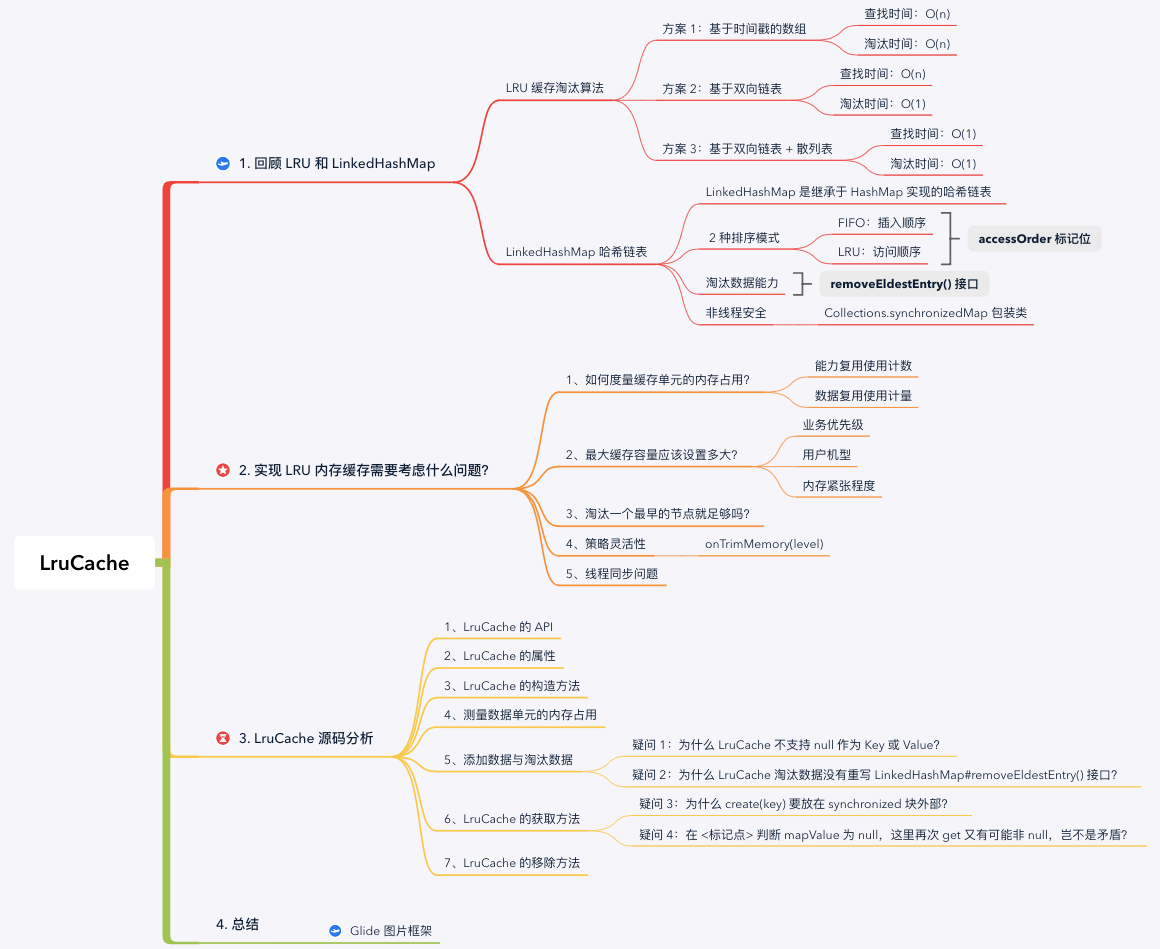
1. 回顧 LRU 和 LinkedHashMap
在具體分析 LruCache 的原始碼之前,我們先回顧上一篇文章中討論的 LRU 快取策略以及 LinkedHashMap 實現原理。
LRU (Least Recently Used)最近最少策略是最常用的快取淘汰策略。LRU 策略會記錄各個資料塊的存取 「時間戳」 ,最近最久未使用的資料最先被淘汰。與其他幾種策略相比,LRU 策略利用了 「區域性性原理」,平均快取命中率更高。
FIFO 與 LRU 策略
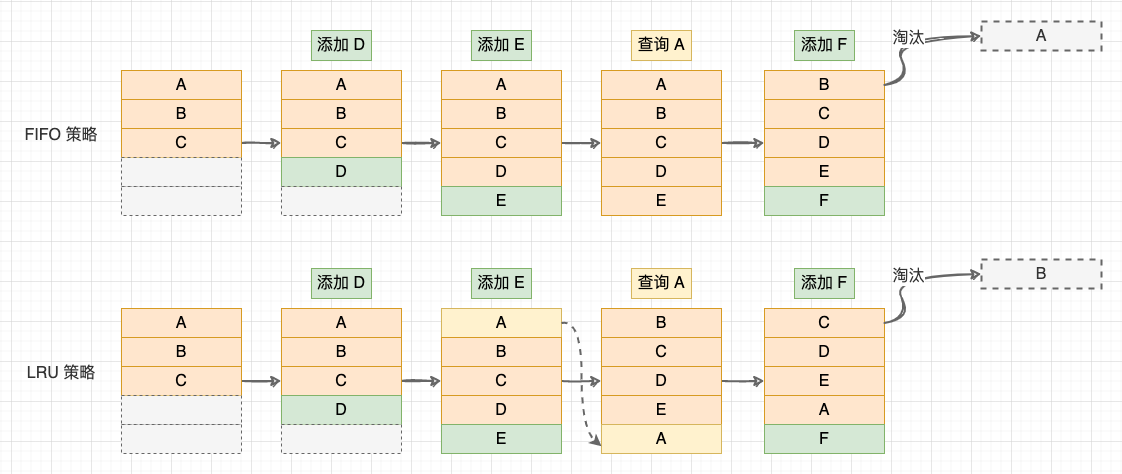
經過總結,我們可以定義一個快取系統的基本操作:
- 操作 1 - 新增資料: 先查詢資料是否存在,不存在則新增資料,存在則更新資料,並嘗試淘汰資料;
- 操作 2 - 刪除資料: 先查詢資料是否存在,存在則刪除資料;
- 操作 3 - 查詢資料: 如果資料不存在則返回 null;
- 操作 4 - 淘汰資料: 新增資料時如果容量已滿,則根據快取淘汰策略一個資料。
我們發現,前 3 個操作都有 「查詢」 操作,所以快取系統的效能主要取決於查詢資料和淘汰資料是否高效。為了實現高效的 LRU 快取結構,我們會選擇採用雙向連結串列 + 雜湊表的資料結構,也叫 「雜湊連結串列」,它能夠將查詢資料和淘汰資料的時間複雜度降低為 O(1)。
- 查詢資料: 通過雜湊表定位資料,時間複雜度為 O(1);
- 淘汰資料: 直接淘汰連結串列尾節點,時間複雜度為 O(1)。
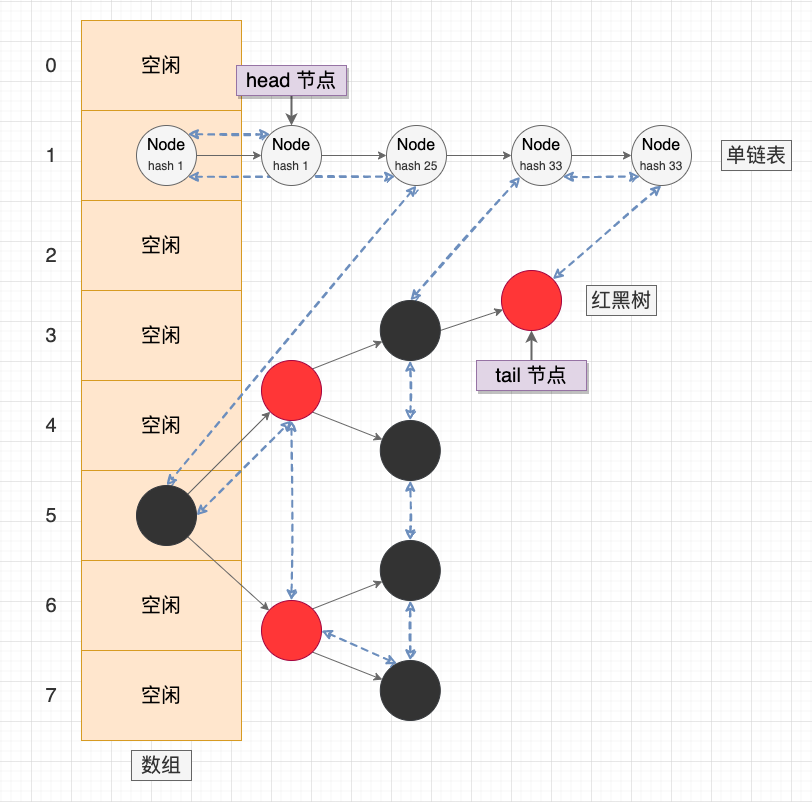
在 Java 標準庫中,已經提供了一個通用的雜湊連結串列 —— LinkedHashMap。使用 LinkedHashMap 時,主要關注 2 個 API:
accessOrder標記位: LinkedHashMap 同時實現了 FIFO 和 LRU 兩種淘汰策略,預設為 FIFO 排序,可以使用 accessOrder 標記位修改排序模式。removeEldestEntry()介面: 每次新增資料時,LinkedHashMap 會回撥 removeEldestEntry() 介面。開發者可以重寫 removeEldestEntry() 介面決定是否移除最早的節點(在 FIFO 策略中是最早新增的節點,在 LRU 策略中是最久未存取的節點)。
LinkedHashMap 示意圖
LinkedHashMap#put 示意圖
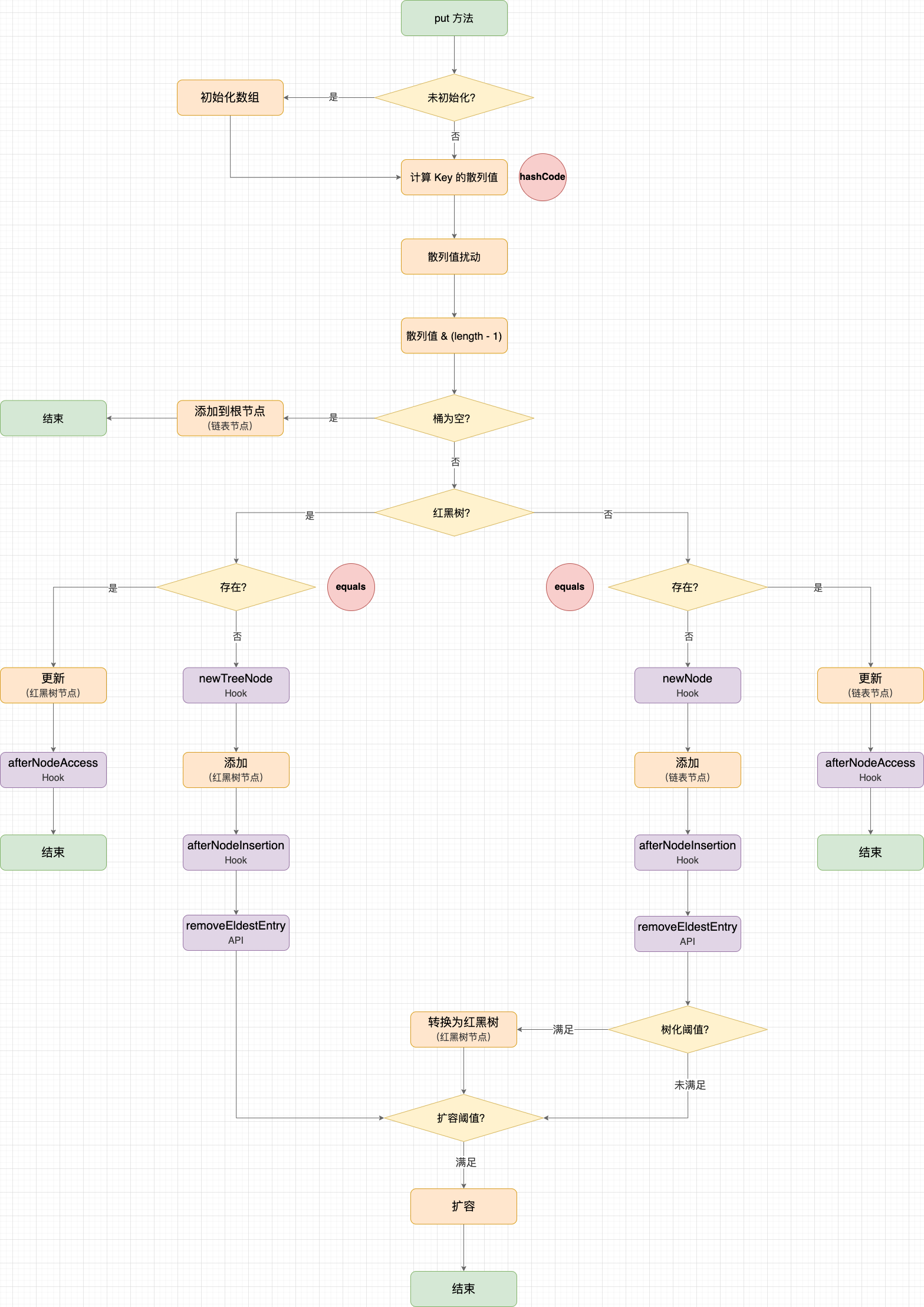
2. 實現 LRU 記憶體快取需要考慮什麼問題?
在閱讀 LruCache 原始碼之前,我們先嚐試推導 LRU 記憶體快取的實現思路,帶著問題和結論去分析原始碼,也許收穫會更多。
2.1 如何度量快取單元的記憶體佔用?
快取系統應該實時記錄當前的記憶體佔用量,在新增資料時增加記憶體記錄,在移除或替換資料時減少記憶體記錄,這就涉及 「如何度量快取單元的記憶體佔用」 的問題。計數 or 計量,這是個問題。比如說:
- 舉例 1: 實現圖片記憶體快取,如何度量一個圖片資源的記憶體佔用?
- 舉例 2: 實現資料模型物件記憶體快取,如何度量一個資料模型物件的記憶體佔用?
- 舉例 3: 實現資源記憶體預讀,如何度量一個資源的記憶體佔用?
我將這個問題總結為 2 種情況:
-
1、能力複用使用計數: 這類記憶體快取場景主要是為了複用物件能力,物件本身持有的資料並不多,但是物件的結構卻有可能非常複雜。而且,再加上參照複用的因素,很難統計物件實際的記憶體佔用。因此,這類記憶體快取場景應該使用計數,只統計快取單元的個數,例如複用資料模型物件,資源預讀等;
-
2、資料複用使用計量: 這類記憶體快取場景主要是為了複用物件持有的資料,資料對記憶體的影響遠遠大於物件記憶體結構對記憶體的影響,是否度量除了資料外的部分記憶體對快取幾乎沒有影響。因此, 這裡記憶體快取場景應該使用計量,不計算快取單元的個數,而是計算快取單元中主資料欄位的記憶體佔用量,例如圖片的記憶體快取就只記錄 Bitmap 的畫素資料記憶體佔用。
還有一個問題,物件記憶體結構中的物件頭和對齊空間需要計算在內嗎?一般不考慮,因為在大部分業務開發場景中,相比於物件的範例資料,物件頭和對齊空間的記憶體佔用幾乎可以忽略不計。
| 度量策略 | 舉例 |
|---|---|
| 計數 | 1、Message 訊息物件池:最多快取 50 個物件 2、OkHttp 連線池:預設最多快取 5 個空閒連線 3、資料庫連線池 |
| 計量 | 1、圖片記憶體快取 2、點陣圖池記憶體快取 |
2.2 最大快取容量應該設定多大?
網上很多資料都說使用最大可用堆記憶體的八分之一,這樣籠統地設定方式顯然並不合理。到底應該設定多大的空間沒有絕對標準的做法,而是需要開發者根據具體的業務優先順序、使用者機型和系統實時的記憶體緊張程度做決定:
-
業務優先順序: 如果是高優先順序且使用頻率很高的業務場景,那麼最大快取空間適當放大一些也是可以接受的,反之就要考慮適當縮小;
-
使用者機型: 在最大可用堆記憶體較小的低端機型上,最大快取空間應該適當縮小;
-
記憶體緊張程度: 在系統記憶體充足的時候,可以放大一些快取空間獲得更好的效能,當系統記憶體不足時再及時釋放。
2.3 淘汰一個最早的節點就足夠嗎?
標準的 LRU 策略中,每次新增資料時最多隻會淘汰一個資料,但在 LRU 記憶體快取中,只淘汰一個資料單元往往並不夠。例如在使用 「計量」 的記憶體圖片快取中,在加入一個大圖片後,只淘汰一個圖片資料有可能依然達不到最大快取容量限制。
因此,在複用 LinkedHashMap 實現 LRU 記憶體快取時,前文提到的 LinkedHashMap#removeEldestEntry() 淘汰判斷介面可能就不夠看了,因為它每次最多隻能淘汰一個資料單元。這個問題,我們後文再看看 Android LruCache 是如何解決的。
2.4 策略靈活性
LruCache 的淘汰策略是在快取容量滿時淘汰,當快取容量沒有超過最大限制時就不會淘汰。除了這個策略之外,我們還可以增加一些輔助策略,例如在 Java 堆記憶體達到某個閾值後,對 LruCache 使用更加激進的清理策略。
在 Android Glide 圖片框架中就有策略靈活性的體現:Glide 除了採用 LRU 策略淘汰最早的資料外,還會根據系統的記憶體緊張等級 onTrimMemory(level) 及時減少甚至清空 LruCache。
Glide · LruResourceCache.java
@Override
public void trimMemory(int level) {
if (level >= android.content.ComponentCallbacks2.TRIM_MEMORY_BACKGROUND) {
// Entering list of cached background apps
// Evict our entire bitmap cache
clearMemory();
} else if (level >= android.content.ComponentCallbacks2.TRIM_MEMORY_UI_HIDDEN || level == android.content.ComponentCallbacks2.TRIM_MEMORY_RUNNING_CRITICAL) {
// The app's UI is no longer visible, or app is in the foreground but system is running
// critically low on memory
// Evict oldest half of our bitmap cache
trimToSize(getMaxSize() / 2);
}
}
2.5 執行緒同步問題
一個快取系統往往會在多執行緒環境中使用,而 LinkedHashMap 與 HashMap 都不考慮執行緒同步,也會存線上程安全問題。這個問題,我們後文再看看 Android LruCache 是如何解決的。
3. LruCache 原始碼分析
這一節,我們來分析 LruCache 中主要流程的原始碼。
3.1 LruCache 的 API
LruCache 是 Android 標準庫提供的 LRU 記憶體快取框架,基於 Java LinkedHashMap 實現,當快取容量超過最大快取容量限制時,會根據 LRU 策略淘汰最久未存取的快取資料。
用一個表格整理 LruCache 的 API:
| public API | 描述 |
|---|---|
| V get(K) | 獲取快取資料 |
| V put(K,V) | 新增 / 更新快取資料 |
| V remove(K) | 移除快取資料 |
| void evictAll() | 淘汰所有快取資料 |
| void resize(int) | 重新設定最大記憶體容量限制,並呼叫 trimToSize() |
| void trimToSize(int) | 淘汰最早資料直到滿足最大容量限制 |
| Map<K, V> snapshot() | 獲取快取內容的映象 / 拷貝 |
| protected API | 描述 |
| void entryRemoved() | 資料移除回撥(可用於回收資源) |
| V create() | 建立資料(可用於建立預設資料) |
| Int sizeOf() | 測量資料單元記憶體 |
3.2 LruCache 的屬性
LruCache 的屬性比較簡單,除了多個用於資料統計的屬性外,核心屬性只有 3 個:
- 1、size: 當前快取佔用;
- 2、maxSize: 最大快取容量;
- 3、map: 複用 LinkedHashMap 的 LRU 控制能力。
LruCache.java
public class LruCache<K, V> {
// LRU 控制
private final LinkedHashMap<K, V> map;
// 當前快取佔用
private int size;
// 最大快取容量
private int maxSize;
// 以下屬性用於資料統計
// 設定資料次數
private int putCount;
// 建立資料次數
private int createCount;
// 淘汰資料次數
private int evictionCount;
// 快取命中次數
private int hitCount;
// 快取未命中數
private int missCount;
}
3.3 LruCache 的構造方法
LruCache 只有 1 個構造方法。
由於快取空間不可能設定無限大,所以開發者需要在構造方法中設定快取的最大記憶體容量 maxSize。
LinkedHashMap 物件也會在 LruCache 的構造方法中建立,並且會設定 accessOrder 標記位為 true,表示使用 LRU 排序模式。
LruCache.java
// maxSize:快取的最大記憶體容量
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
// 快取的最大記憶體容量
this.maxSize = maxSize;
// 建立 LinkedHashMap 物件,並使用 LRU 排序模式
this.map = new LinkedHashMap<K, V>(0, 0.75f, true /*LRU 模式*/);
}
使用範例
private static final int CACHE_SIZE = 4 * 1024 * 1024; // 4Mib
LruCache bitmapCache = new LruCache(CACHE_SIZE);
3.4 測量資料單元的記憶體佔用
開發者需要重寫 LruCache#sizeOf() 測量快取單元的記憶體佔用量,否則快取單元的大小預設視為 1,相當於 maxSize 表示的是最大快取數量。
LruCache.java
// LruCache 內部使用
private int safeSizeOf(K key, V value) {
// 如果開發者重寫的 sizeOf 返回負數,則丟擲異常
int result = sizeOf(key, value);
if (result < 0) {
throw new IllegalStateException("Negative size: " + key + "=" + value);
}
return result;
}
// 測量快取單元的記憶體佔用
protected int sizeOf(K key, V value) {
// 預設為 1
return 1;
}
使用範例
private static final int CACHE_SIZE = 4 * 1024 * 1024; // 4Mib
LruCache bitmapCache = new LruCache(CACHE_SIZE){
// 重寫 sizeOf 方法,用於測量 Bitmap 的記憶體佔用
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getByteCount();
}
};
3.5 新增資料與淘汰資料
LruCache 新增資料的過程基本是複用 LinkedHashMap 的新增過程,我將過程概括為 6 步:
- 1、統計新增計數(putCount);
- 2、size 增加新 Value 記憶體佔用;
- 3、設定資料(LinkedHashMap#put);
- 4、size 減去舊 Value 記憶體佔用;
- 5、資料移除回撥(LruCache#entryRemoved);
- 6、自動淘汰資料:在每次新增資料後,如果當前快取空間超過了最大快取容量限制,則會自動觸發
trimToSize()淘汰一部分資料,直到滿足限制。
淘汰資料的過程則是完全自定義,我將過程概括為 5 步:
- 1、取最找的資料(LinkedHashMap#eldest);
- 2、移除資料(LinkedHashMap#remove);
- 3、size 減去舊 Value 記憶體佔用;
- 4、統計淘汰計數(evictionCount);
- 5、資料移除回撥(LruCache#entryRemoved);
- 重複以上 5 步,滿足要求或者快取為空,才會退出。
邏輯很好理解,不過還是攔不住一些小朋友出來舉手提問了