視訊超分之BasicVSR-閱讀筆記
1.介紹
對於視訊超分提出了很多方法,EDVR中採用了多尺度可變形對齊模組和多個注意層進行對齊和定位並且從不同的幀聚合特徵,在RBPN中,多個投影模組用於順序聚合多個幀中的特徵。這樣的設計是有效的,但不可避免地增加了執行時和模型的複雜性。此外,與SISR不同,VSR方法的潛在複雜和不同設計在實施和擴充套件現有方法方面造成了困難,妨礙了再現性和公平比較。我們首先根據功能將流行的VSR方法分解為子模組,大多數現有方法包含四個相互關聯的元件,即傳播、對齊、聚合和上取樣。在上述四個元件中,傳播和對齊元件的選擇可能會導致效能和效率的大幅波動。我們的實驗建議使用雙向傳播方案來最大化資訊收集,並使用基於光流的方法來估計兩個相鄰幀之間的對應關係,以便進行特徵對齊。通過使用聚合(即特徵串聯)和上取樣(即畫素洗牌)的常用設計簡化這些傳播和對齊元件,BasicVSR在效能和效率方面都優於現有的最新技術。
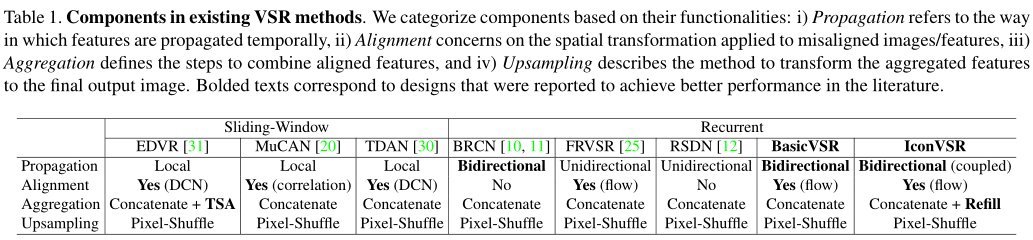
通過使用BasicVSR作為基礎,我們提出了ICONVSR,它包括兩個新的擴充套件以改進聚集和傳播分量。第一個擴充套件名為information refill。該機制利用附加模組從稀疏選擇的幀(關鍵幀)中提取特徵,然後將特徵插入到主網路中進行特徵細化。第二個擴充套件是耦合傳播方案,它促進了前向和後向傳播分支之間的資訊交換。這兩個模組不僅減少了傳播過程中由於遮擋和影象邊界造成的誤差累積,而且允許傳播以序列形式存取完整資訊,以生成高質量的特徵。通過這兩種新設計,IconVSR超過了BasicVSR,峰值訊雜比提高了。
2.相關工作
現有的VSR方法主要可分為兩個框架——滑動視窗和迴圈。滑動視窗框架中的早期方法預測低解析度(LR)幀之間的光流,併為對齊執行空間扭曲。後來的方法求助於更復雜的隱式對齊方法。例如,TDAN採用可變形折積(DCN)在特徵級別對齊不同的幀。EDVR進一步以多尺度方式使用DCN,以實現更精確的對齊。DUF利用動態上取樣過濾器隱式處理運動。有些方法採用迴圈框架。RSDN提出了一種結構塊和隱藏狀態自適應模組,以增強對外觀變化和錯誤累積的魯棒性。RRN在具有標識跳過連線的層之間採用殘差對映,以確保流暢的資訊流,並長期儲存紋理資訊。IconVSR中的資訊重新填充機制讓人想起基於區間的處理概念。這些方法將視訊幀劃分為以關鍵幀和非關鍵幀為特徵的獨立間隔。然後關鍵幀和非關鍵幀通過不同的管道進行處理。IconVSR通過傳播分支將間隔連線起來進行一次推進。通過這種設計,長期資訊可以在相互關聯的時間間隔內傳播,從而進一步提高效率。
3方法
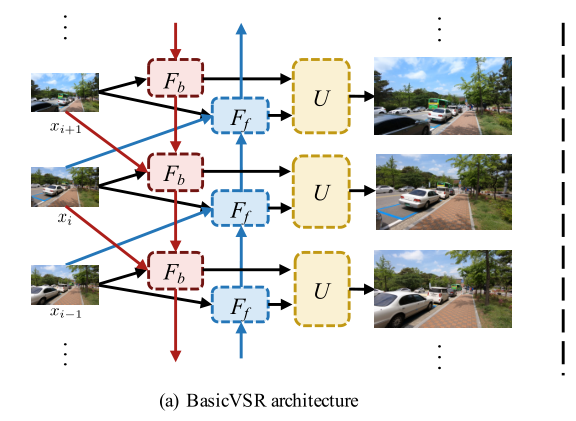
為了發現有助於VSR方法分析和開發的通用框架,我們將研究侷限於通常採用的元素,如光流和殘差塊。BasicVSR的概述如圖所示。
3.1傳播
傳播是VSR中最有影響力的組成部分之一。它指定如何利用視訊序列中的資訊。現有的傳播方案可分為三大類: 區域性傳播、單向傳播、雙向傳播。
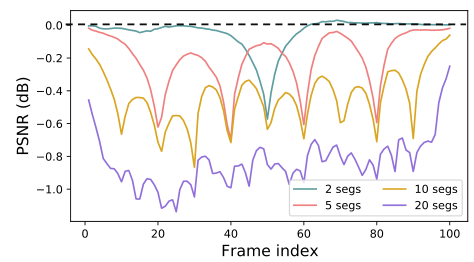
區域性傳播:該視窗方法將區域性視窗內的LR影象作為輸入,並利用區域性資訊進行恢復。可存取的資訊被限制在本地。遠端幀的省略不可避免地限制了滑動視窗方法的潛力。我們從一個全域性感受野(在時間維度)開始,然後逐漸減少感受野。我們將測試序列分成K個片段,並使用我們的BasicVSR獨立地恢復每個片段。圖中描繪了與情況K=1(全域性傳播)的PSNR差。首先,當節段數減少時,PSNR的差異減小(即效能更好)。這表明,遠距離幀中的資訊有利於恢復,不應忽視。在每段的兩端,峰值訊雜比的差異最大,這表明有必要採用長序列來積累長期資訊。
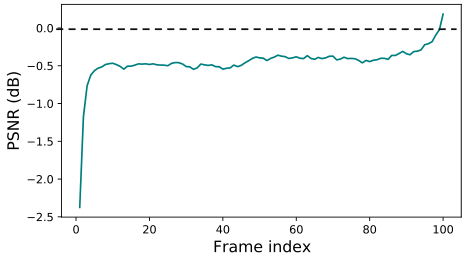
單向傳播:資訊從第一幀順序傳播到最後一幀,不同幀接收的資訊是不平衡的。第一幀除了自身之外不接收來自視訊序列的資訊,而最後一幀接收來自整個序列的資訊。因此,早期幀的結果可能不太理想,將BasicVSR(使用雙向傳播)與其單向變體(具有可比的網路複雜度)進行了比較。我們可以看到,在早期時間,單向模型獲得的峰值訊雜比(PSNR)明顯低於雙向傳播,並且隨著幀數的增加,更多資訊被聚集,差異逐漸減小。此外,在僅使用部分資訊的情況下,觀察到一致的效能下降0.5 dB。這些觀察揭示了單向傳播的次優性。通過從序列的最後一幀傳回資訊,可以提高輸出質量。
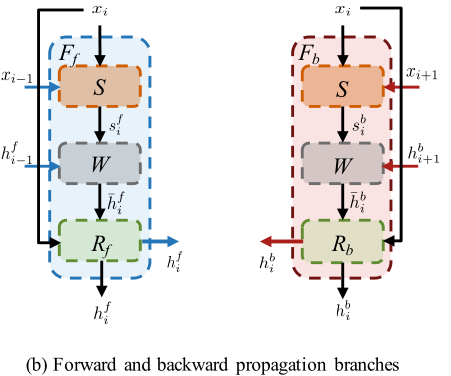
雙向傳播:上述兩個問題可以通過雙向傳播同時解決,其中特徵在時間上獨立地向前和向後傳播。BasicVSR採用了一種典型的雙向傳播方案。給定LR影象xi和鄰幀xi-1和xi+1,以及來著鄰幀相應的特徵傳播,定義為hfi-1和hbi+1,Fb和Ff分別表示反向和正向傳播分支:
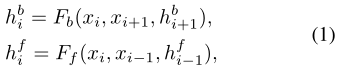
3.2對齊
空間對齊在VSR中起著重要作用,因為它負責對齊高度相關但沒有對齊影象/用於後續聚合的功能。主流作品可分為三類:無對齊、影象對齊和特徵對齊。進行實驗來分析每一個類別,並驗證我們對特徵對齊的選擇。
無對齊:現有的遞迴方法通常不會在傳播期間執行對齊。不一致的特徵/影象阻礙聚合,最終導致效能不達標。這種次優性可以通過我們的實驗反映出來,我們移除了BasicVSR中的空間對齊模組。在這種情況下,我們直接連線不對齊的特徵進行恢復。如果沒有適當的對齊,傳播的特徵就不會與輸入影象在空間上對齊。因此,像折積這樣的區域性操作具有相對較小的感受野,無法有效地聚合來自相應位置的資訊。且psnr下降的很多。
影象對齊:早期的工作通過計算光流並在恢復之前扭曲影象來執行對齊。將空間對齊從影象級移動到特徵級會產生顯著的改善。我們比較了BasicVSR變體上的影象扭曲和特徵扭曲。由於光流估計不準確,扭曲影象不可避免地受到模糊和不正確的影響。細節的丟失最終導致產出下降。當採用影象對齊時,觀察到0.17 dB的下降。這一觀察證實了將空間對齊轉移到特徵級別的必要性。
特徵對齊:移除影象對齊的較差效能促使我們求助於特徵對齊。BasicVSR採用光流進行空間對齊,我們沒有像以前的作品那樣扭曲影象,而是對特徵進行扭曲以獲得更好的效能。然後將對齊的特徵傳遞給多個殘差塊進行細化:
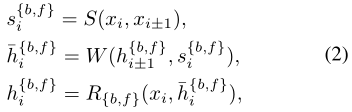
S和W分別表示流估計和空間扭曲模組,R{b,f}表示殘差塊的堆疊。
3.3聚合和上取樣
BasicVSR採用基本元件進行聚合和上取樣。具體地說,給定中間特徵h{b,f}i,使用由多個折積和pixelshuffle組成的上取樣模組來生成輸出HR影象,U為上取樣模組

總結:上述分析推動了BasicVSR的設計選擇。對於傳播,BasicVSR選擇了雙向傳播,重點是長期和全域性傳播。對於對齊,BasicVSR採用了一種簡單的基於流的對齊,但在功能級別進行。對於聚合和上取樣,選擇流行的特徵串聯和畫素混洗就足夠了。儘管BasicVSR是一種簡單而簡潔的方法,但它在恢復質量和效率方面都取得了很好的效果。BasicVSR也具有高度的通用性,因為它可以方便地容納額外的元件,以處理更具挑戰性的場景。
3.4從BasicVSR到IconVSR
IconVSR引入了兩個新元件——資訊填充機制和耦合傳播,以減輕傳播過程中的錯誤積累,並促進資訊聚合。
Information-Refill:在遮擋區域和影象邊界上的不準確對齊是一個突出的挑戰,可能會導致錯誤累積,尤其是如果我們在我們的框架中採用長期傳播。為了緩解這些錯誤特徵帶來的不良影響,我們提出了一種用於特徵細化的資訊填充機制。 另一個特徵提取器用於從輸入幀(關鍵幀)的子集及其各自的鄰居中提取深度特徵。然後通過折積將提取的特徵與對齊的特徵h_i(等式2)融合:
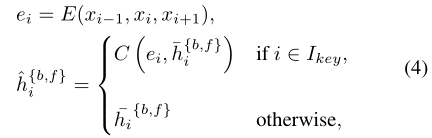
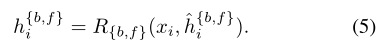
其中E和C分別對應於特徵提取器和折積。Ikey表示選定關鍵幀的索引集。然後,細化後的特徵被傳遞給殘差塊,以進一步細化。特徵提取和特徵融合僅應用於稀疏選擇的關鍵幀。資訊重新填充機制帶來的計算負擔微不足道。
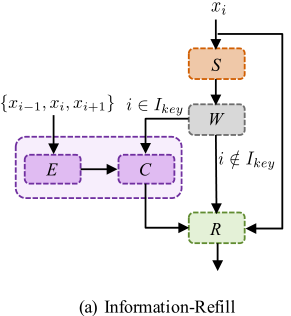
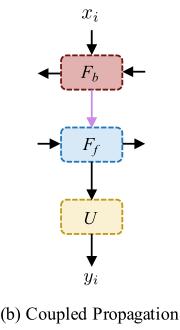
Coupled Propagation:在雙向設定中,特徵通常在兩個相反的方向上獨立傳播。在這種設計中,每個傳播分支中的特徵都是基於之前幀或未來幀的部分資訊來計算的。為了利用序列中的資訊,我們提出了一種耦合傳播方案,其中傳播模組相互連線,在耦合傳播中,將反向傳播的特徵hbi作為正向傳播模組中的輸入(等式1,3),通過耦合傳播,前向傳播分支接收來自過去和未來幀的資訊,從而產生更高質量的特徵,從而獲得更好的輸出。更重要的是,由於耦合傳播只需要改變分支連線,因此可以在不引入計算開銷的情況下獲得效能增益。
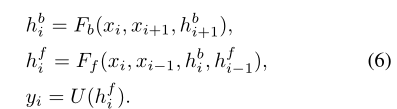
4.實驗
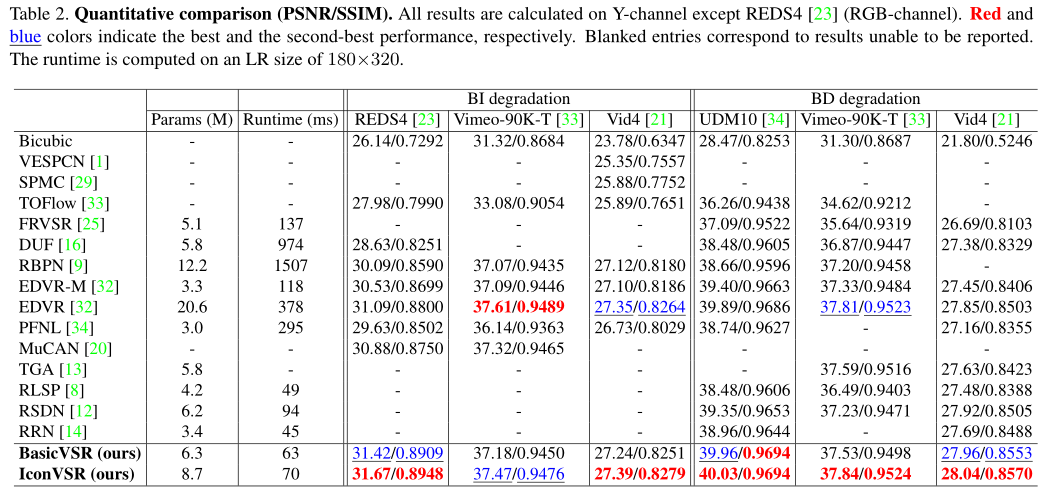
資料集設定:REDS和Vimeo-90K。對於REDS,使用REDS-4作為測試集。我們還將REDS-val4定義為我們的驗證集。剩下的用於訓練。我們使用Vid4、UDM10和Vimeo-90K-T以及Vimeo-90K作為測試集。我們使用雙三次(BI)和模糊下取樣(BD)兩種退化方法,對我們的模型進行了4倍下取樣測試。 我們分別使用經過預訓練的SPyNet和EDVR-M4作為流量估計模組和特徵提取器。我們採用Adam優化器和餘弦退火方案。特徵抽取器和流量估計器的初始學習率設定為1×10-4和2.5×10-5,其他設定為2*10-4。總迭代次數為300K,在前5000次迭代中,特徵抽取器和流估計器的權重是固定的。批次大小為8,輸入LR幀的修補程式大小為64×64。我們使用Charbonnier的loss。
各個資料上表現:
5.消融研究
5.1從BasicVSR到IconVSR
Information-Refill:我們定性地視覺化資訊填充前後的特徵,以深入瞭解其機制。填充前扭曲特徵中的邊界畫素由於不存在通訊而變為零。丟失的資訊不可避免地會惡化特徵質量,導致輸出質量下降。 通過我們的資訊補充機制,附加功能可用於在功能對齊不良的區域「補充」丟失的資訊。然後,檢索到的資訊可用於後續的特徵細化和傳播。

耦合傳播:為了消除耦合傳播方案,我們禁用了資訊填充機制,並將IconVSR與BasicVSR進行了比較。在圖中,黃色框表示在先前幀中被遮擋的區域,並且BasicVSR中的前向傳播分支無法接收該區域的資訊。紅色框表示序列的所有幀中都存在一個區域,因此可以在後面的幀中找到該區域的大量「快照」。通過耦合傳播,可以更有效地利用反向傳播的特徵,從而重建更多細節和更精細的邊緣。


5.2 Tradeoff in IconVSR
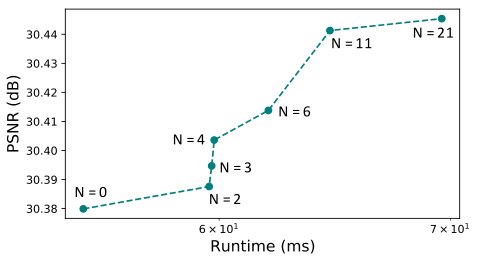
雖然IconVSR使用固定的關鍵幀間隔進行訓練,但可以減少關鍵幀的數量以加快推理。PSNR使用不同數量的關鍵幀。我們發現PSNR與關鍵幀的數量正相關,驗證了資訊填充機制的貢獻。在沒有關鍵幀的極端情況下,IconVSR退化為迴圈網路。儘管如此,它仍然在REDS-val4上實現了30.38 dB的峰值訊雜比,比BasicVSR高0.21 dB。這證明了我們的耦合傳播方案的有效性,它可以在不引入額外計算開銷的情況下使用。
6.結論
這項工作致力於尋找通用和有效的VSR基線,以便於VSR方法的分析和擴充套件。通過對現有元素的分解和分析,我們提出了BasicVSR,這是一種簡單而有效的網路,其效能優於現有的技術水平,具有很高的效率。我們在BasicVSR的基礎上,提出了IconVSR和兩個新元件,以進一步提高效能。BasicVSR和IconVSR可以作為未來工作的強大基線,架構設計的發現可能會擴充套件到其他低階視覺任務,如視訊去模糊、去噪和著色。
附錄
結構:都採用SPyNet作為流量估計器。我們在每個傳播分支中使用30個殘差塊。特性通道設定為64。在IconVSR中,我們採用EDVRM作為額外的特徵提取器,因為它在效率和質量之間保持了良好的平衡。表總結了這些元件的複雜性。BasicVSR和IconVSR共用相同的流量估計器和主網路。主網路是一個輕量級網路,僅由490萬個引陣列成。流量估計器和特徵提取器與主網路一起進行微調。在我們所有的實驗中,每五幀被選為關鍵幀。請注意,特徵提取程式僅應用於關鍵幀。因此,它帶來的計算負擔是微不足道的。

實驗設定:當在REDS上訓練時,我們使用15幀序列作為輸入,並計算15幅輸出影象的損失。在Vimeo-90K上訓練時, 我們通過翻轉原始影象來臨時增加輸入序列來臨時增加序列以允許更長的傳播時間。 換句話說,我們用14幀的序列進行訓練。在推理過程中,我們將整個視訊序列作為輸入。
損失函數:我們使用Charbonnier loss,因為它能更好地處理異常值,並比傳統的l2損失更好,zi表示基本真值HR幀,N表示畫素數。
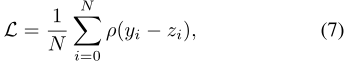
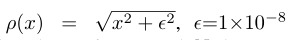
退化:我們使用兩種降階方法——雙三次(BI)和模糊降取樣(BD)對模型進行4倍降取樣訓練和測試。對於BI使用MATLAB函數imresize進行下取樣。對於BD使用σ=1.6的高斯濾波器模糊gt,然後每四個畫素進行一次子取樣。
總結:BasicVSR是視訊超分非常好的一個baseline,使用雙向傳播以及光流對齊,簡單,效果好,可以考慮在該模型上進行創新。
論文連結:https://arxiv.org/pdf/2012.02181.pdf
程式碼連結:https://github.com/open-mmlab/mmediting/blob/master/configs/restorers/basicvsr/README.md