MySQL鎖,鎖的到底是什麼?
MySQL鎖系列文章已經鴿了挺久了,最近趕緊擠了擠時間,和大家聊一聊MySQL的鎖。
只要學計算機,「鎖」永遠是一個繞不過的話題。MySQL鎖也是一樣。
一句話解釋MySQL鎖:
MySQL鎖是解決資源競爭的一種方案。
短短一句話卻包含了3點值得我們注意的事情:
- 對什麼資源進行競爭?
- 競爭的方式(或者說情形)有哪些?
- 鎖是如何解決競爭的?
這篇文章開始帶你循序漸進地理解這幾個問題。
1. 資源的競爭方式
MySQL對資源的操作無非就是讀、寫兩種方式,但是由於事務並行執行的存在,因此對同一資源的並行存取存在3種形式:
- 讀—讀:並行事務同時讀取相同資源。由於讀操作不會改變資源本身,因此這種情況下並不存在並行安全性問題。
- 讀—寫/寫—讀:一個事務對資源進行讀操作,另一個事務對資源進行寫操作。
- 寫—寫:並行事務同時對同一個資源進行寫操作。
2. 讀—寫/寫—讀下的問題
假設一種情形,一個事務先對某個資源進行讀操作,然後另一個事務再對該資源進行寫操作,如果兩個事務到此為止,必然不會導致並行問題。
可是事務這種東西,一般情況下就是包含有很多個子操作啊。
2.1. 幻讀
想象一下啊,假設事務T1和T2並行執行,T1先查詢了所有name為「王剛蛋」的使用者資訊,此時發現擁有這個硬漢名字的使用者只有一個。然後T2插入了一個同樣叫做「王剛蛋」的使用者的資訊,並且提交了。
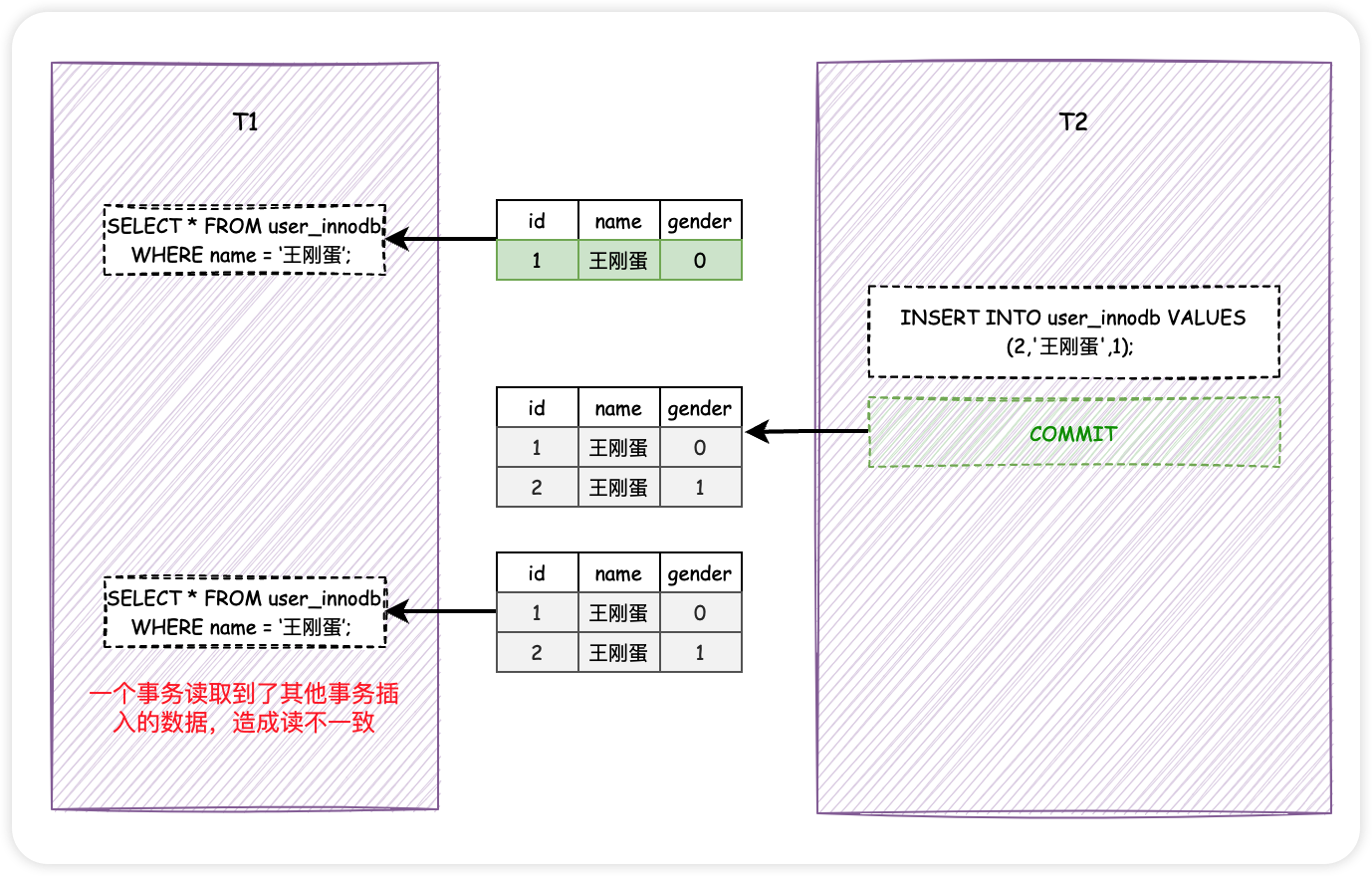

2.2. 不可重複讀
再來,同樣是T1和T2兩個事務,T1通過id = 1查詢到了一條資料,然後T2緊接著UPDATE(DELETE也可以)了該條記錄,不同的是,T2緊接著通過COMMIT提交了事務。
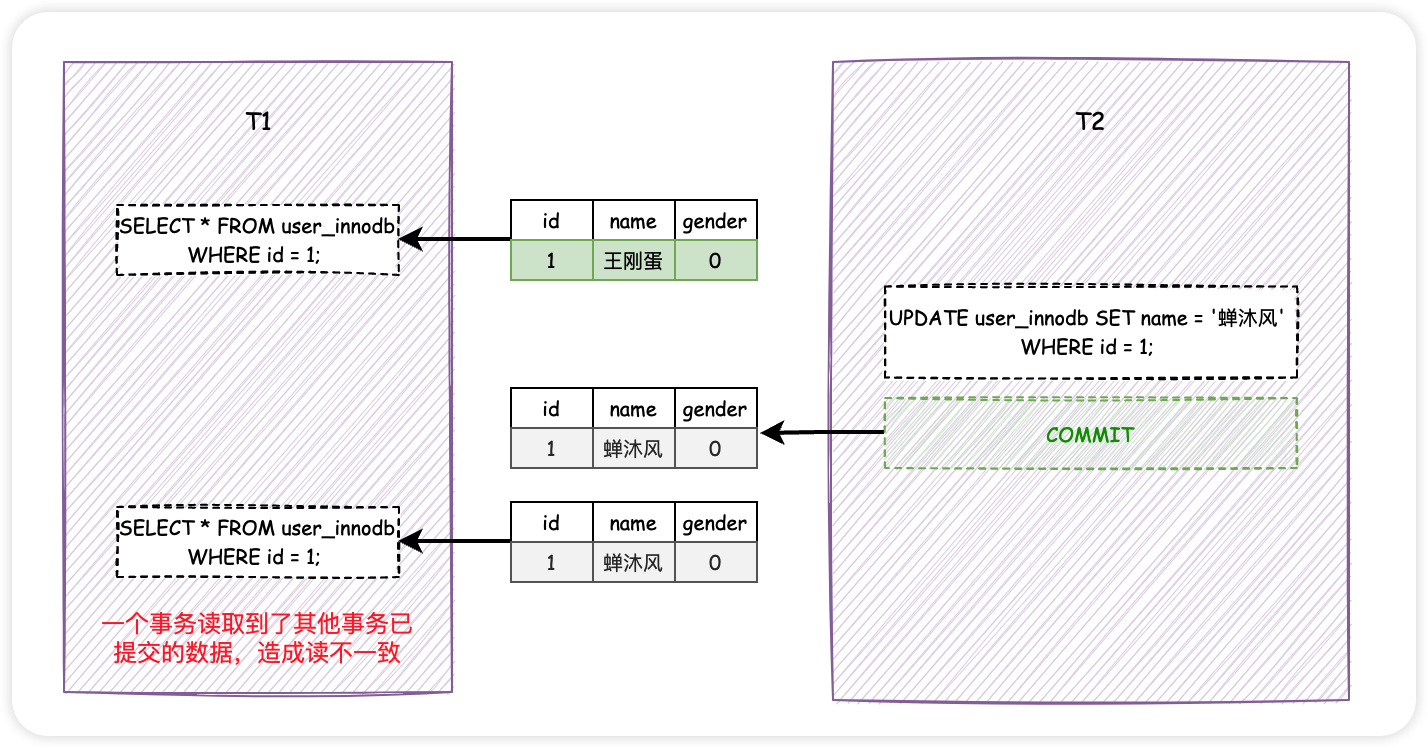
此時,T1再次執行相同的查詢操作,會發現資料發生了變化,name欄位由「王剛蛋」變成了「蟬沐風」。
如果一個事務讀到了另一個已提交事務修改過的(或者是刪除的)資料,而導致了前後兩次讀取的資料不一致的情況,這種事務並行問題叫做不可重複讀。
2.3. 髒讀
事情還沒結束,假設T1和T2都要存取user_innodb表中id為1的資料,不同的是T1先讀取資料,緊接著T2修改了資料的name欄位,需要注意的是,T2並沒有提交!
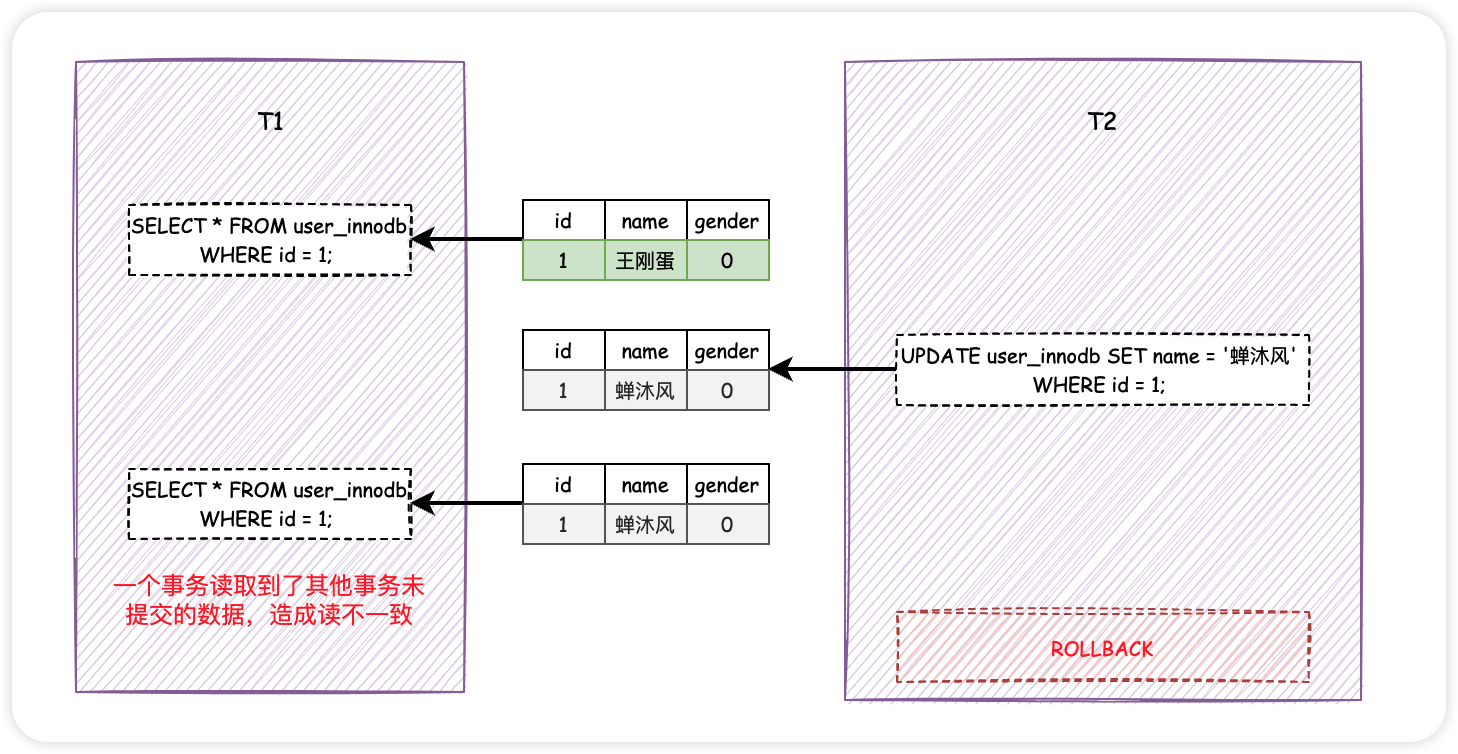
此時,T1再次執行相同的查詢操作,會發現資料發生了變化,name欄位由「王剛蛋」變成了「蟬沐風」。
如果一個事務讀到了另一個未提交事務修改過的資料,而導致了前後兩次讀取的資料不一致的情況,這種事務並行問題叫做髒讀。
2.4. 鎖與MVCC的關係
總結一下:我們在讀—寫,寫—讀的情況下會遇到3種讀不一致性的問題,髒讀、不可重複讀以及幻讀。
那寫—寫呢?很顯然,在不做任何措施的情況下,並行會出現更大的問題。那該怎麼辦呢?
一切的並行問題都可以通過序列化解決,但是序列化效率太低了!
再優化一下,一切並行問題都可以通過加鎖來解決,這種方案我們稱為基於鎖的並行控制(Lock Bases Concurrency Control, LBCC)!但是在讀多寫少的環境下,使用者端連讀取幾條記錄都需要排隊,效率還是太低了!
因此,MySQL的設計者為事務之間的隔離性提供了不同的級別,使得開發者可以根據自己的業務場景設定不同的隔離級別,來解決(或者部分解決)讀—寫/寫—讀下的讀一致性問題,而不是一上來就加鎖。
這種機制叫做MVCC,如果你對這個概念不是很瞭解,我建議你暫停一下,讀一下我的事務的隔離性與MVCC這篇文章,寫得賊好!!(自賣自誇一下)
那有了MVCC是不是在讀—寫/寫—讀的情況下就不需要鎖了呢?那也不是。
MVCC解決的是讀—寫/寫—讀中「比較純粹的讀」遇到的一致性問題,原諒我,這是我自己編的詞兒。那什麼是不純粹的?拿存款業務舉個例子。
假設陀螺要存一筆錢,系統需要先把陀螺的餘額讀出來,然後在餘額的基礎上加上本次存款的金額,最後再寫入到資料庫中。在將餘額讀出來之後,如果不想讓其他事務繼續存取該餘額,直到整個存款事務完成之後,其他事務才可以對該餘額繼續進行操作,這種情況下就必須為餘額的讀取操作新增鎖。
再總結一下:MVCC是MySQL預設的解決讀—寫/寫—讀下一致性問題的方式,不需要加鎖。而鎖是實現一致性的最終兜底方案,在某些特殊場景下,鎖的使用不可避免。
說得更準確一點,MVCC是MySQL在
READ COMMITTED、REPEATABLE READ這兩種隔離級別之下執行普通SELECT操作時預設解決一致性問題的方式。具體為什麼只是這兩種隔離級別,建議你看看事務的隔離性與MVCC。
2.5. 鎖與事務的關係
事務是多個操作的集合,比如我們可以把「把大象裝冰箱」這件事情作為一個事務。

事務有A(原子性)、C(一致性)、I(隔離性)、D(永續性)4大特性,而鎖就是實現隔離性的其中一種方案(比如還有MVCC等方案)。
事務的隔離性針對不同場景需求又實現了不同的隔離級別,不同的隔離級別下,事務使用鎖的方式又會有所不同。舉個例子。
在READ COMMITTED、REPEATABLE READ這兩種隔離級別之下,SELECT操作是不需要加鎖的,直接使用MVCC機制即可滿足當前隔離級別的需求。但是在SERIALIZABLE隔離級別,並且在禁用自動提交時(autocommit=0),MySQL會將普通的SELECT語句轉化為SELECT ... LOCK IN SHARE MODE這樣的加鎖語句,如果你看不懂這句話也沒關係,你只需要知道MySQL自動加鎖了就行,更詳細的下文再說。
另外,一個事務可能會加很多個鎖,但是某個鎖一定只屬於一個事務。這就好比一個管理員可以管理多個保險櫃,一個保險櫃一定只被一個管理員管理。
3. 寫—寫情況
寫—寫的情況下肯定要加鎖的了,所以接下來終於要聊一聊鎖了。
我們首先研究一下鎖住的東西的大小,也就是鎖的粒度。
4. 鎖的粒度
舉一個非常應景的例子。疫情防控的時候,是封鎖整個小區還是封鎖某棟樓的某個單元,這完全是兩種概念。
對應到MySQL鎖的粒度,那就是表鎖和行鎖。
很容易想到,封鎖小區的行為遠比封鎖某棟樓某單元的行為粗曠,因此,
從鎖定粒度上來看,表鎖 > 行鎖
直接堵住小區的門口要比進入小區找到具體某棟樓的某個單元要快不少,因此,
從加鎖效率上來看,表鎖 > 行鎖
直接鎖住小區大概率會影響其他樓居民的正常生活和各種社會活動的開展,而鎖住某棟樓某單元頂多影響這一個單元的居民的生活,因此,
從衝突概率來看,表鎖 > 行鎖
從並行效能來看,表鎖 < 行鎖
MySQL支援很多儲存引擎,而不同的儲存引擎對鎖的支援也不盡相同。對於MyISAM、MERGE、MEMORY這些儲存引擎而言,只支援表鎖;而InnoDB儲存引擎既支援表鎖也支援行鎖,下文討論的所有內容均針對InnoDB儲存引擎。
說完鎖的粒度,還有一件事情需要我們仔細考慮一下。上文說過,READ COMMITTED、REPEATABLE READ這兩種隔離級別之下,SELECT操作預設採用MVCC機制就可以了,壓根兒不需要加鎖,那麼問題來了,萬一我就是想加鎖呢?
你可能會說,「簡單啊,那就加鎖!把資料鎖死!除了我誰也別動!」
很好,但是對於大部分讀—讀而言,由於不會出現讀一致性問題,所以不讓其他事務進行讀操作並不合理。
你可能又說,「那行吧,那就讓讀操作加鎖的時候允許其他事務對鎖住的資料進行讀操作,但是不允許寫操作。」
嗯,想得確實更細緻了一些。但是再想想我上文中舉過的陀螺存錢的例子,有時候SELECT操作需要獨佔資料,其他事務既不能讀,更不能寫。

我們把這種共用和排他的性質稱為鎖的基本模式。
5. 鎖的基本模式
5.1. 共用鎖
共用鎖(Shared Lock),簡稱S鎖,可以同時被多個事務共用,也就是說,如果一個事務給某個資料資源新增了S鎖,其他事務也被允許獲取該資料資源的S鎖。
由於S鎖通常被用於讀取資料,因此也被稱為讀鎖。
那怎麼給資料新增S鎖呢?
我們可以用 SELECT ... LOCK IN SHARE MODE; 的方式,在讀取資料之前就為資料新增一把S鎖。如果當前事務執行了該語句,那麼會為讀取到的記錄新增S鎖,同時其他事務也可以使用SELECT ... LOCK IN SHARE MODE; 方式繼續獲取這些資料的S鎖。
我們通過以下的例子驗證一下S鎖是否可以重複獲取。

5.2. 排他鎖
排他鎖(Exclusive Lock),簡稱X鎖。只要一個事務獲取了某資料資源的X鎖,其他的事務就不能再獲取該資料的X鎖和S鎖。
由於X鎖通常被用於修改資料,因此也被稱為寫鎖。
X鎖的新增方式有兩種,
-
自動新增
X鎖我們對記錄進行增刪改時,通常情況下會自動對其新增
X鎖。 -
手動加鎖
我們可以用
SELECT ... FOR UPDATE;的方式,在讀取資料之前就為資料新增一把X鎖。如果當前事務執行了該語句,那麼會為讀取到的記錄新增X鎖,這樣既不允許其他事務獲取這些記錄的S鎖,也不允許獲取這些記錄的X鎖。
我們用下面的例子驗證一下X鎖的排他性。
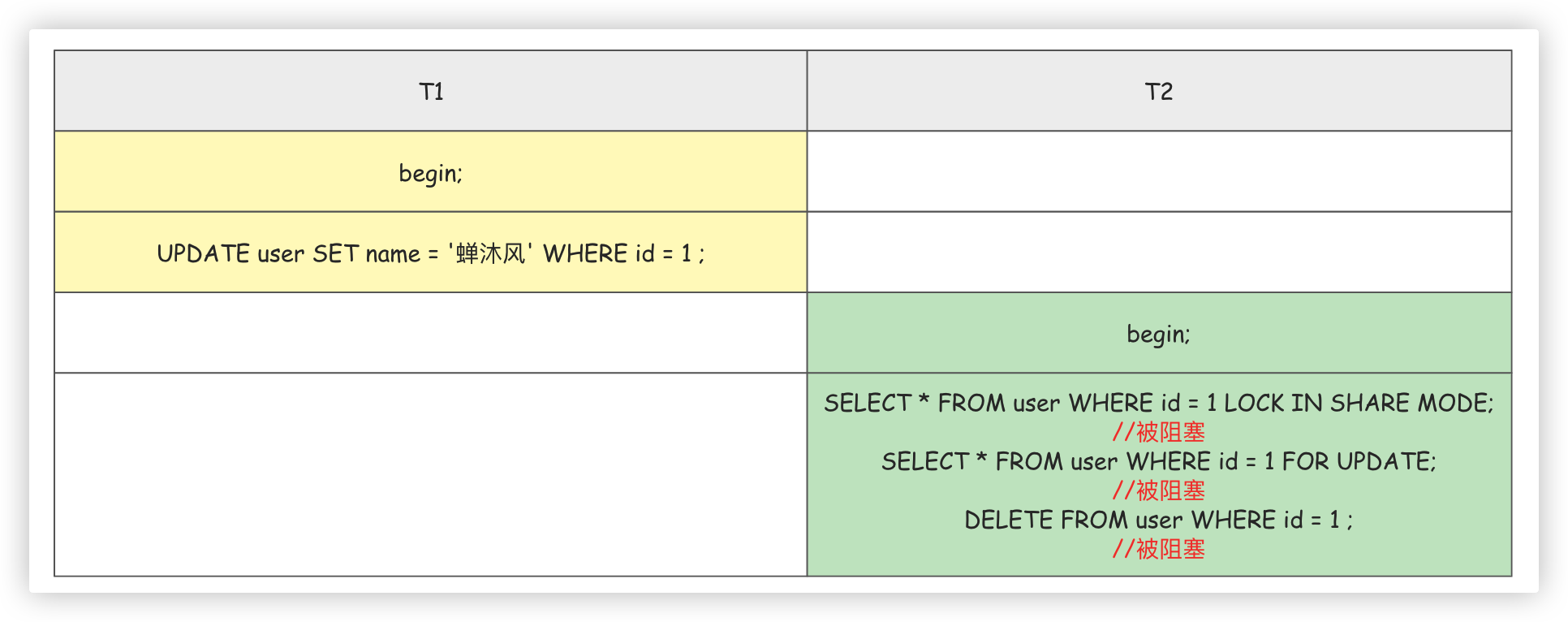
通常情況下,事務提交或結束事務時,鎖會被釋放。
6. 意向鎖
6.1. 背景
前面提到的S鎖和X鎖的語法規則其實是針對記錄的,也就是行鎖,原因是InnoDB中行鎖用的最多。如果將鎖的粒度和鎖的基本模式排列組合一下,就會出現如下4種情況:
- 行級
S鎖 - 行級
X鎖 - 表級
S鎖 - 表級
X鎖
那麼接下來的描述,也就順理成章了。
如果事務給一個表新增了表級S鎖,則:
- 其他事務可以繼續獲得該表的
S鎖,但是無法獲取該表的X鎖; - 其他事務可以繼續獲得該表某些行的
S鎖,但是無法獲取該表某些行的X鎖。
如果事務給一個表新增了表級X鎖,則:
- 不論是該表的
S鎖、X鎖,還是該表某些行的S鎖、X鎖,其他事務都只能乾瞪眼兒,啥也獲取不了。
挺好理解的吧,總之就是S鎖只能和S鎖相容,X鎖和其他任何鎖都互斥。問題來了,雖然用的不多,但是萬一我真的想給整個表新增一個S鎖或者X鎖怎麼辦?
假如我要給表user新增一個S鎖,那就必須保證user在表級別上和行級別上都不能有X鎖,表級別上還好說一點,無非就是1個記憶體結構罷了,但是行X鎖呢?必須得逐行遍歷是否有行X鎖嗎?
同理,假如我要給表user新增一個X鎖,那就必須保證user在表級別上和行級別上都不能有任何鎖(S和X都不能有),難不成得逐行遍歷是否有S或X鎖嗎?
遍歷是不可能遍歷的!這輩子都不可能遍歷的!於是,意向鎖(Intension Lock)誕生了。
6.2. 概念
我們要避免遍歷,那最好的辦法就是在給行加鎖時,先在表級別上新增一個標識。
- 意向共用鎖(Intension Shared Lock):簡稱
IS鎖,當事務試圖給行新增S鎖時,需要先在表級別上新增一個IS鎖; - 意向排他鎖(Intension Exclusive Lock):簡稱
IX鎖,當事務試圖給行新增X鎖時,需要先在表級別上新增一個IX鎖。
這樣一來:
- 如果想給
user表新增一個S鎖(表級鎖),就先看一下user表有沒有IX鎖;如果有,就說明user表的某些行被加了X鎖(行鎖),需要等到行的X鎖釋放,隨即IX鎖被釋放,才可以在user表中新增S鎖; - 如果想給
user表新增一個X鎖(表級鎖),就先看一下user有沒有IS鎖或IX鎖;如果有,就說明user表的某些行被加了S鎖或X鎖(行鎖),需要等到所有行鎖被釋放,隨即IS鎖或IX鎖被釋放,才可以在user表中新增X鎖。
需要注意的是,意向鎖和意向鎖之間是不衝突的,意向鎖和行鎖之間也不衝突。
只有在對錶新增
S鎖或X鎖時才需要判斷當前表是否被新增了IS鎖或IX鎖,當為表新增IS鎖或IX鎖時,不需要關心當前表是否已經被新增了其他IS鎖或IX鎖。
目前為止MySQL鎖的基本模式就介紹完了,接下來回到這片文章的題目,MySQL鎖,鎖住的到底是什麼?由於InnoDB的行鎖用的最多,這裡的鎖自然指的是行鎖。
7. 行鎖的原理
既然都叫行鎖了,我們姑且猜測一下,行鎖鎖住的是一行資料。我們做個實驗。
7.1. 沒有任何索引的表
我們先建立一張沒有任何索引的普通表,語句如下
CREATE TABLE `user_t1` (
`id` int DEFAULT NULL,
`name` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
表中資料如下:
mysql> SELECT * FROM user_t1;
+------+-------------+
| id | name |
+------+-------------+
| 1 | chanmufeng |
| 2 | wanggangdan |
| 3 | wangshangju |
| 4 | zhaotiechui |
+------+-------------+
接下來我們在兩個session中開啟兩個事務。
- 事務1,我們通過
WHERE id = 1「鎖住」第1行資料; - 事務2,我們通過
WHERE id = 2"鎖住"第2行資料。

一件詭異的事情是,第2個加鎖的操作被阻塞了。實際上,T2中不管我們要給user_t1中哪行資料加鎖,都會失敗!
為什麼我SELECT一條資料,卻給我鎖住了整個表?這個實驗直接推翻了我們的猜測,InnoDB的行鎖並非直接鎖定Record行。
為什麼沒有索引的情況下,給某條語句加鎖會鎖住整個表呢?別急,我們繼續。
7.2. 有主鍵索引的表
我們再建立一個表user_t2,語句如下:
CREATE TABLE `user_t2` (
`id` int NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
和user_t1的不同之處在於為id建立了一個主鍵索引。表中資料依然如下:
mysql> SELECT * FROM user_t2;
+------+-------------+
| id | name |
+------+-------------+
| 1 | chanmufeng |
| 2 | wanggangdan |
| 3 | wangshangju |
| 4 | zhaotiechui |
+------+-------------+
同樣開啟兩個事務:
- 事務1,通過
WHERE id = 1「鎖住」第1行資料; - 事務2
- 依然使用
WHERE id = 1嘗試加鎖,加鎖失敗; - 使用
WHERE id = 2嘗試加鎖,加鎖成功。
- 依然使用

既然鎖的不是Record行,難不成鎖的是id這一列嗎?
我們再做最後一個實驗。
7.3. 有唯一索引的表
我們再建立一個表user_t3,語句如下:
CREATE TABLE `user_t3` (
`id` int NOT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY (`uk_name`) (`name`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8mb4;
和user_t2的不同之處在於為name列建立了一個唯一索引。表中資料依然如下:
mysql> SELECT * FROM user_t3;
+------+-------------+
| id | name |
+------+-------------+
| 1 | chanmufeng |
| 2 | wanggangdan |
| 3 | wangshangju |
| 4 | zhaotiechui |
+------+-------------+

兩個事務:
- 事務1,通過
name欄位 「鎖住」name為「chanmufeng」的資料; - 事務2
- 依然使用
WHERE name = 「chanmufeng」嘗試加鎖,可以預料,加鎖失敗; - 使用
WHERE id = 1嘗試給同樣的行加鎖,加鎖失敗。
- 依然使用
通過3個實驗我們發現,行鎖鎖住的既不是Record行,也不是Column列,那到底鎖住的是什麼?我們對比一下,上文的3張表的不同點在於索引不同,其實InnoDB的行鎖,就是通過鎖住索引來實現的。
索引是個啥?再給你推薦一下我之前寫的文章,
接下來回答3個問題。
8. 三個問題
8.1. 鎖住索引?沒有索引怎麼辦?
你說鎖住索引?如果我不建立索引,MySQL鎖定個啥?
如果我們沒有設定主鍵,InnoDB會優先選取一個不包含NULL值的Unique鍵作為主鍵,如果表中連Unique鍵也沒有的話,就會自動為每一條記錄新增一個叫做DB_ROW_ID的列作為預設主鍵,只不過這個主鍵我們看不到罷了。
下圖是資料的行格式。看不懂的話強烈推薦看一下我上面給出的兩篇文章,說得非常明白。

8.2. 為什麼第一個實驗會鎖表?
因為SELECT沒有用到索引,會進行全表掃描,然後把DB_ROW_ID作為預設主鍵的聚簇索引都給鎖住了。
8.3. 為什麼通過唯一索引給資料加鎖,主鍵索引也會被鎖住?
不管是Unique索引還是普通索引,它們的葉子結點中儲存的資料都不完整,其中只是儲存了作為索引並且排序好的列資料以及對應的主鍵值。
因此我們通過索引查詢資料資料實際上是在索引的B+樹中先找到對應的主鍵,然後根據主鍵再去主鍵索引的B+樹的葉子結點中找到完整資料,最後返回。所以雖然是兩個索引樹,但實際上是同一行資料,必須全部鎖住。
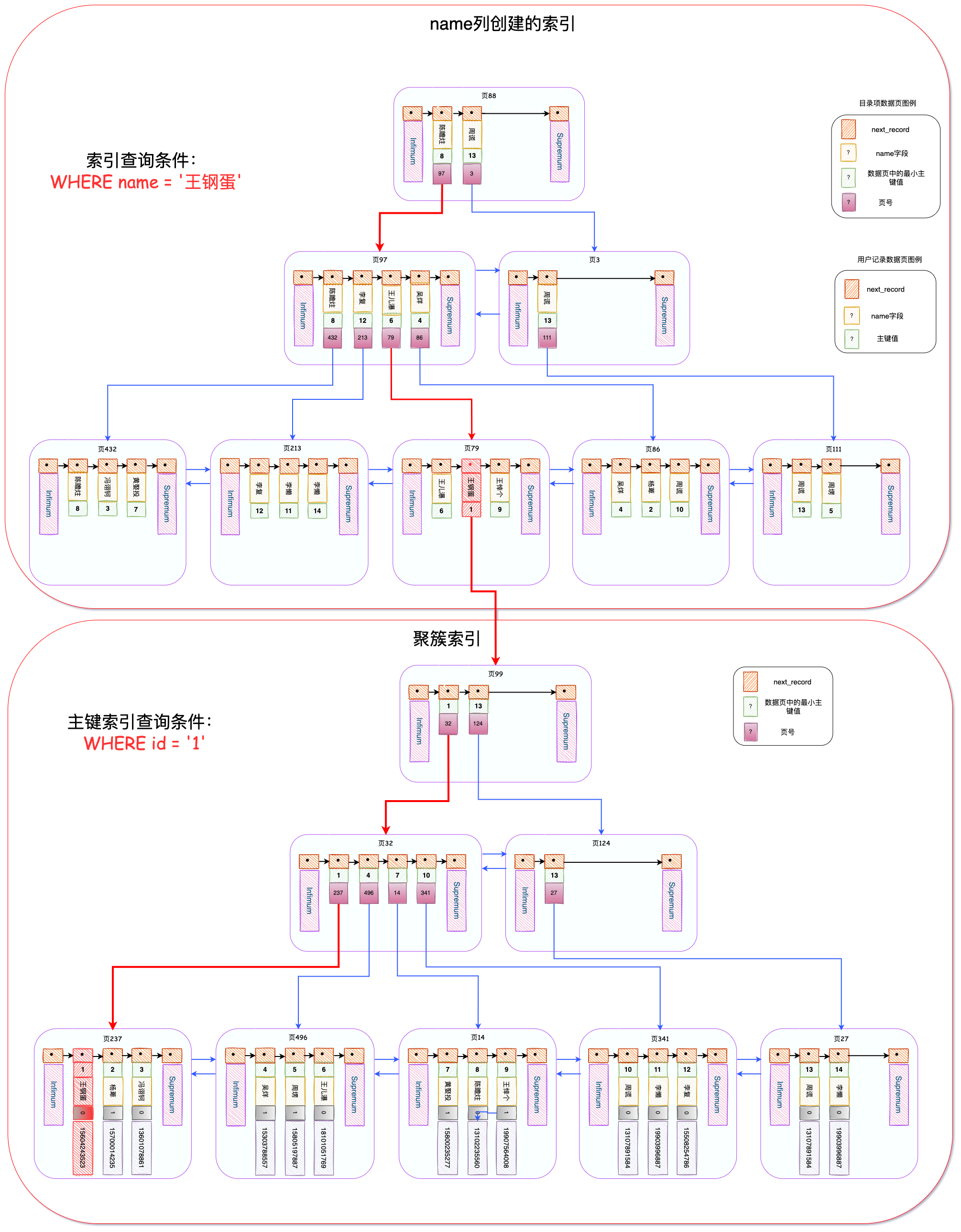
下面給了一張圖,讓不瞭解索引的朋友大致瞭解一下。上半部分是name列建立的唯一索引的B+樹,下半部分是主鍵索引(也叫聚簇索引)。
假如我們通過WHERE name = '王鋼蛋'對資料進行查詢,會先用到name列的唯一索引,最終定位到主鍵值為1,然後再到主鍵索引中查詢id = 1的資料,最終拿到完整的行資料。
這兩張圖在我索引文章中都有哦~
9. 總結
至此,我已經回答了文章開頭的絕大多數問題。
MySQL鎖,是解決資源競爭問題的一種手段。有哪些競爭呢?讀—寫/寫—讀,寫—寫中都會出現資源競爭問題,不同的是前者可以通過MVCC的方式來解決,但是某些情況下你也不得不用鎖,因此我也順便解釋了鎖和MVCC的關係。
然後介紹了MySQL鎖的基本模式,包括共用鎖(S鎖)和排他鎖(X鎖),還引入了意向鎖。
最後解釋了鎖到底鎖的是什麼的問題。通過3個實驗,最終解釋了InnoDB鎖本質上鎖的是索引。
本文並沒有介紹MySQL中具體的鎖演演算法,也就是如何解決資源競爭的,比如Record Locks、Gap Locks、Next-Key Locks等,更細節的內容下期見嘍~
作者:蟬沐風
個人站點:https;https://www.chanmufeng.com
公眾號:蟬沐風的碼場