go語言有哪些型別
go語言的型別有布林型(bool)、整型(int8、byte、int16等)、浮點型(float32、float64)、複數型別(complex64、complex128)、字串、字元型、錯誤型、指標、陣列、切片、字典、通道、結構體、介面。浮點型別採用IEEE-754標準的表達方式;複數實際上由兩個實數(在計算機中用浮點數表示)構成,一個表示實部,一個表示虛部。

php入門到就業線上直播課:進入學習
Apipost = Postman + Swagger + Mock + Jmeter 超好用的API偵錯工具:
本教學操作環境:windows7系統、GO 1.18版本、Dell G3電腦。
Go語言的型別
Go語言內建以下這些基礎型別:
布林型別:bool。
整型:int8、byte、int16、int、uint、uintptr等。
浮點型別:float32、float64。
複數型別:complex64、complex128。
字串:string。
字元型別:rune。
錯誤型別:error。
此外,Go語言也支援以下這些複合型別:
指標(pointer)
陣列(array)
切片(slice)
字典(map)
通道(chan)
結構體(struct)
介面(interface)
在這些基礎型別之上Go還封裝了下面這幾種型別:
int、uint和uintptr等。這些型別的特點在於使用方便,但使用者不能對這些型別的長度做任何假設。對於常規的開發來說,用int和uint就可以了,沒必要用int8之類明確指定長度的型別,以免導致移植困難。【相關推薦:Go視訊教學】
布林型別
Go 語言中以 bool 型別進行宣告布林型別資料,布林型資料只有 true
和 false 兩個值,需要注意的是:
go 語言中不允許將整型強制轉換為布林型
布林型別變數預設值為 false
布林型無法參與數值運算,也無法與其他型別進行轉換

Go語言中的布林型別與其他語言基本一致,關鍵字也為bool,可賦值為預定義的true和false範例程式碼如下:
var v1 bool
v1 = true
v2 := (1 == 2) // v2也會被推導為bool型別
登入後複製布林型別不能接受其他型別的賦值,不支援自動或強制的型別轉換。
以下的範例是一些錯誤的用法,會導致編譯錯誤:
var b bool
b = 1 // 編譯錯誤
b = bool(1) // 編譯錯誤
以下的用法才是正確的:
var b bool
b = (1!=0) // 編譯正確
fmt.Println("Result:", b) // 列印結果為Result: true登入後複製整型
整型是所有程式語言裡最基礎的資料型別。Go語言支援表2-1所示的這些整型型別。



1. 型別表示
需要注意的是,int和int32在Go語言裡被認為是兩種不同的型別,編譯器也不會幫你自動做型別轉換,比如以下的例子會有編譯錯誤:
var value2 int32
value1 := 64 // value1將會被自動推導為int型別
value2 = value1 // 編譯錯誤
登入後複製編譯錯誤類似於:
cannot use value1 (type int) as type int32 in assignment
登入後複製使用強制型別轉換可以解決這個編譯錯誤:
value2 = int32(value1) // 編譯通過
登入後複製當然,開發者在做強制型別轉換時,需要注意資料長度被截短而發生的資料精度損失(比如將浮點數強制轉為整數)和值溢位(值超過轉換的目標型別的值範圍時)問題。
型別轉換
Go 語言中只有強型別轉換,沒有隱式轉換。該語法只能在兩個型別
之間支援相互轉換的時候使用。強制轉換的語法如下:

範例如下:

2. 數值運算
Go語言支援下面的常規整數運算:+、-、*、/和%
加減乘除就不詳細解釋了,需要說下的是,% 和在C語言中一樣是求餘運算,比如:
5 % 3 // 結果為:2
登入後複製3. 比較運算
Go語言支援以下的幾種比較運運算元:>、<、==、>=、<=和!=
這一點與大多數其他語言相同,與C語言完全一致。
下面為條件判斷語句的例子:
i, j := 1, 2
if i == j {
fmt.Println("i and j are equal.")
}登入後複製兩個不同型別的整型數不能直接比較,比如int8型別的數和int型別的數不能直接比較,但各種型別的整型變數都可以直接與字面常數(literal)進行比較,比如
var i int32
var j int64
i, j = 1, 2
if i == j { // 編譯錯誤
fmt.Println("i and j are equal.")
}
if i == 1 || j == 2 { // 編譯通過
fmt.Println("i and j are equal.")
}登入後複製4. 位運算
Go語言支援表2-2所示的位運運算元。

Go語言的大多數位運運算元與C語言都比較類似,除了取反在C語言中是~x,而在Go語言中是^x。
程式語言中表示固定值的符號叫做字面量常數,簡稱字面量。如整形
字面量八進位制:「012」或者「0o17」,十六進位制: 「0x12」,二進位制:」0b101」,
輸出表示如下圖:

浮點型
字面量八進位制:「012」或者「0o17」,十六進位制: 「0x12」,二進位制:」0b101」,
輸出表示如下圖:
浮點型用於表示包含小數點的資料,比如1.234就是一個浮點型資料。Go語言中的浮點型別採用IEEE-754標準的表達方式
1. 浮點數表示
Go語言定義了兩個型別float32和float64,其中float32等價於C語言的float型別,float64等價於C語言的double型別

在Go語言裡,定義一個浮點數變數的程式碼如下:
var fvalue1 float32
fvalue1 = 12
fvalue2 := 12.0 // 如果不加小數點,fvalue2會被推導為整型而不是浮點型
登入後複製對於以上例子中型別被自動推導的fvalue2,需要注意的是其型別將被自動設為float64,而不管賦給它的數位是否是用32位元長度表示的。因此,對於以上的例子,下面的賦值將導致編譯錯誤:
fvalue1 = fvalue2
登入後複製而必須使用這樣的強制型別轉換:
fvalue1 = float32(fvalue2)
登入後複製2. 浮點數比較
因為浮點數不是一種精確的表達方式,所以像整型那樣直接用==來判斷兩個浮點數是否相等是不可行的,這可能會導致不穩定的結果
下面是一種推薦的替代方案:
import "math"
// p為使用者自定義的比較精度,比如0.00001
func IsEqual(f1, f2, p float64) bool {
return math.Fdim(f1, f2) < p
}登入後複製複數型別
複數實際上由兩個實數(在計算機中用浮點數表示)構成,一個表示實部(real),一個表示虛部(imag)。如果瞭解了數學上的複數是怎麼回事,那麼Go語言的複數就非常容易理解了。
複數有實部和虛部,complex64 的實部和虛部為 32 位,complex128的實部和虛部為 64 位。

1. 複數表示
複數表示的範例如下:
var value1 complex64 // 由2個float32構成的複數型別
value1 = 3.2 + 12i
value2 := 3.2 + 12i // value2是complex128型別
value3 := complex(3.2, 12) // value3結果同 value2
登入後複製2. 實部與虛部
對於一個複數z = complex(x, y),就可以通過Go語言內建函數real(z)獲得該複數的實部,也就是x,通過imag(z)獲得該複數的虛部,也就是y。
字串
Go 語言中的字串以原生資料型別出現,使用字串就像使用其他
原生資料型別一樣。Go 語言裡的字串的內部實現使用 utf-8 編碼。字串的值為雙引號中的內容,如

在Go語言中,字串也是一種基本型別。相比之下, C/C++語言中並不存在原生的字元型別,通常使用字元陣列來表示,並以字元指標來傳遞。
Go語言中字串的宣告和初始化非常簡單,舉例如下:
var str string // 宣告一個字串變數
str = "Hello world" // 字串賦值
ch := str[0] // 取字串的第一個字元
fmt.Printf("The length of \"%s\" is %d \n", str, len(str))
fmt.Printf("The first character of \"%s\" is %c.\n", str, ch)登入後複製輸出結果為:
The length of "Hello world" is 11
The first character of "Hello world" is H.
登入後複製字串的內容可以用類似於陣列下標的方式獲取,但與陣列不同,字串的內容不能在初始化後被修改,比如以下的例子:
str := "Hello world" // 字串也支援宣告時進行初始化的做法
str[0] = 'X' // 編譯錯誤
登入後複製編譯器會報類似如下的錯誤:
cannot assign to str[0]
登入後複製在這個例子中我們使用了一個Go語言內建的函數len()來取字串的長度。這個函數非常有用,我們在實際開發過程中處理字串、陣列和切片時將會經常用到。
Printf()函數的用法與C語言執行庫中的printf()函數如出一轍。
Go編譯器支援UTF-8的原始碼檔案格式。這意味著原始碼中的字串可以包含非ANSI的字元,比如「Hello world. 你好,世界!」可以出現在Go程式碼中。但需要注意的是,如果你的Go程式碼需要包含非ANSI字元,儲存原始檔時請注意編碼格式必須選擇UTF-8。特別是在Windows下一般編輯器都預設存為本地編碼,比如中國地區可能是GBK編碼而不是UTF-8,如果沒注意這點在編譯和執行時就會出現一些意料之外的情況。
字串的編碼轉換是處理文字檔案(比如TXT、XML、HTML等)非常常見的需求,不過可惜的是Go語言僅支援UTF-8和Unicode編碼。對於其他編碼,Go語言標準庫並沒有內建的編碼轉換支援。不過,所幸的是我們可以很容易基於iconv庫用Cgo包裝一個。這裡有一個開源專案:https://github.com/xushiwei/go-iconv。
1. 字串操作
平時常用的字串操作如表2-3所示。
更多的字串操作,請參考標準庫strings包。
2. 字串遍歷
Go語言支援兩種方式遍歷字串。一種是以位元組陣列的方式遍歷:
str := "Hello,世界"n := len(str) for i := 0; i < n; i++ {
ch := str[i] // 依據下標取字串中的字元,型別為byte
fmt.Println(i, ch) }登入後複製這個例子的輸出結果為:
0 72 1 101 2 108 3 108 4 111 5 44 6 32 7 228 8 184 9 150 10 231 11 149 12 140
登入後複製可以看出,這個字串長度為13。儘管從直觀上來說,這個字串應該只有9個字元。這是因為每個中文字元在UTF-8中佔3個位元組,而不是1個位元組
另一種是以Unicode字元遍歷:
str := "Hello,世界"for i, ch := range str {
fmt.Println(i, ch)//ch的型別為rune }登入後複製輸出結果為:
0 72 1 101 2 108 3 108 4 111 5 44 6 32 7 19990 10 30028
登入後複製以Unicode字元方式遍歷時,每個字元的型別是rune(早期的Go語言用int型別表示Unicode字元),而不是byte。
字串的常見操作

字元型別
在Go語言中支援兩個字元型別,一個是byte(實際上是uint8的別名),代表UTF-8字串的單個位元組的值;另一個是rune,代表單個Unicode字元。
關於rune相關的操作,可查閱Go標準庫的unicode包。另外unicode/utf8包也提供了UTF8和Unicode之間的轉換。
出於簡化語言的考慮,Go語言的多數API都假設字串為UTF-8編碼。儘管Unicode字元在標準庫中有支援,但實際上較少使用。
byte 和 rune 型別
字元指類字形單位或符號,包括字母、數位、運運算元號、標點符
號和其他符號,以及一些功能性符號。每個字元在計算機中都有相應的二進位制程式碼
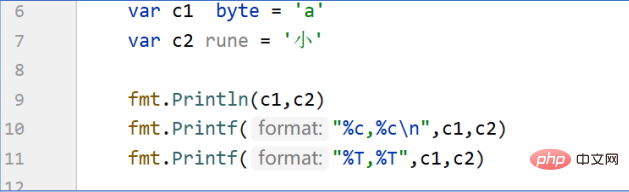
Go 語言內建兩種字元型別:
一種是 byte 的位元組型別,它是 uint8 的別名。
另一種是 Unicode 編碼的 rune 型別,它是 int32 型別的別名。
Go 語言預設的字元編碼就是 UTF-8 型別的。
遍歷字串
如下:

UTF-8 編碼下一個中文漢字由 3-4 個位元組組成,所以我們不能簡
單的按照位元組去遍歷一個包含中文字元的字串。
字串底層是一個 byte 陣列,所以可以和[]byte 型別相互轉換。
字串是不能修改的,字串由 byte 位元組組成,所以字串的長度
就是 byte 位元組的長度。rune 型別用來表示 utf-8 字元,一個 rune 字
符由一個或多個 byte 組成。
修改字串
要修改字串,需要先將其轉換成[]rune 或者[]byte,修改以後,再轉換為 string。
無論哪種轉換,都會重新分配記憶體並複製位元組陣列。如下:

常見的跳脫字元

多行字串的顯示,可以使用反引號進行,需要注意的是反引號間換行將被作為字串中的換行,但是所有的跳脫字元均無效,文字將會原樣輸出

陣列
陣列是Go語言程式設計中最常用的資料結構之一。顧名思義,陣列就是指一系列同一型別資料的集合。陣列中包含的每個資料被稱為陣列元素(element),一個陣列包含的元素個數被稱為陣列的長度。
以下為一些常規的陣列宣告方法:
[32]byte // 長度為32的陣列,每個元素為一個位元組
[2*N] struct { x, y int32 } // 複雜型別陣列
[1000]*float64 // 指標陣列
[3][5]int // 二維陣列
[2][2][2]float64 // 等同於[2]([2]([2]float64))登入後複製從以上型別也可以看出,陣列可以是多維的,比如[3][5]int就表達了一個3行5列的二維整型陣列,總共可以存放15個整型元素。
在Go語言中,陣列長度在定義後就不可更改,在宣告時長度可以為一個常數或者一個常數表示式(常數表示式是指在編譯期即可計算結果的表示式)。陣列的長度是該陣列型別的一個內建常數,可以用Go語言的內建函數len() 來獲取。
下面是一個獲取陣列arr元素個數的寫法:
arrLength := len(arr)
登入後複製1. 元素存取
可以使用陣列下標來存取陣列中的元素。與C語言相同,陣列下標從0開始,len(array)-1則表示最後一個元素的下標。下面的範例遍歷整型陣列並逐個列印元素內容:
for i := 0; i < len(array); i++ {
fmt.Println("Element", i, "of array is", array[i])
}登入後複製Go語言還提供了一個關鍵字range,用於便捷地遍歷容器中的元素。當然,陣列也是range的支援範圍。上面的遍歷過程可以簡化為如下的寫法:
for i, v := range array {
fmt.Println("Array element[", i, "]=", v)
}登入後複製在上面的例子裡可以看到
range具有兩個返回值,第一個返回值是元素的陣列下標,第二個返回值是元素的值。
2. 值型別
需要特別注意的是,在Go語言中陣列是一個值型別(value type)。所有的值型別變數在賦值和作為引數傳遞時都將產生一次複製動作。
如果將陣列作為函數的引數型別,則在函數呼叫時該引數將發生資料複製。因此,在函數體中無法修改傳入的陣列的內容,因為函數內操作的只是所傳入陣列的一個副本。
下面用例子來說明這一特點:
package main
import "fmt"
func modify(array [10]int) {
array[0] = 10 // 試圖修改陣列的第一個元素
fmt.Println("In modify(), array values:", array)
}
func main() {
array := [5]int{1,2,3,4,5} // 定義並初始化一個陣列
modify(array) // 傳遞給一個函數,並試圖在函數體內修改這個陣列內容
fmt.Println("In main(), array values:", array)
}登入後複製該程式的執行結果為:
In modify(), array values: [10 2 3 4 5]
In main(), array values: [1 2 3 4 5]
登入後複製從執行結果可以看出,函數modify()內操作的那個陣列跟main()中傳入的陣列是兩個不同的範例。
陣列切片
我們已經提過陣列的特點:陣列的長度在定義之後無法再次修改;陣列是值型別,每次傳遞都將產生一份副本。顯然這種資料結構無法完全滿足開發者的真實需求。
不用失望,Go語言提供了陣列切片(slice) 這個非常酷的功能來彌補陣列的不足。
初看起來,陣列切片就像一個指向陣列的指標,實際上它擁有自己的資料結構,而不僅僅是個指標。
陣列切片的資料結構可以抽象為以下3個變數:
一個指向原生陣列的指標;
陣列切片中的元素個數;
陣列切片已分配的儲存空間。
從底層實現的角度來看,陣列切片實際上仍然使用陣列來管理元素,因此它們之間的關係讓C++程式設計師們很容易聯想起STL中std::vector和陣列的關係。基於陣列,陣列切片新增了一系列管理功能,可以隨時動態擴充存放空間,並且可以被隨意傳遞而不會導致所管理的元素被重複複製。
1. 建立陣列切片
建立陣列切片的方法主要有兩種——基於陣列和直接建立,下面我們來簡要介紹一下這兩種方法。
基於陣列
陣列切片可以基於一個已存在的陣列建立。陣列切片可以只使用陣列的一部分元素或者整個陣列來建立,甚至可以建立一個比所基於的陣列還要大的陣列切片。程式碼清單2-1演示瞭如何基於一個陣列的前5個元素建立一個陣列切片。
程式碼清單2-1 slice.go
package main
import "fmt"
func main() {
// 先定義一個陣列
var myArray [10]int = [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
// 基於陣列建立一個陣列切片
var mySlice []int = myArray[:5]
fmt.Println("Elements of myArray: ")
for _, v := range myArray {
fmt.Print(v, " ")
}
fmt.Println("\nElements of mySlice: ")
for _, v := range mySlice {
fmt.Print(v, " ")
}
fmt.Println()
}登入後複製執行結果為:
Elements of myArray:
1 2 3 4 5 6 7 8 9 10
Elements of mySlice:
1 2 3 4 5
登入後複製Go語言支援用myArray[first:last]這樣的方式來基於陣列生成一個陣列切片,而且這個用法還很靈活,比如下面幾種都是合法的。
基於myArray的所有元素建立陣列切片:
mySlice = myArray[:]
登入後複製基於myArray的前5個元素建立陣列切片:
mySlice = myArray[:5]
登入後複製基於從第5個元素開始的所有元素建立陣列切片:
mySlice = myArray[5:]
登入後複製直接建立
並非一定要事先準備一個陣列才能建立陣列切片。Go語言提供的內建函數make()可以用於靈活地建立陣列切片。下面的例子示範了直接建立陣列切片的各種方法。
建立一個初始元素個數為5的陣列切片,元素初始值為0:
mySlice1 := make([]int, 5)
登入後複製建立一個初始元素個數為5的陣列切片,元素初始值為0,並預留10個元素的儲存空間:
mySlice2 := make([]int, 5, 10)
登入後複製直接建立並初始化包含5個元素的陣列切片:
mySlice3 := []int{1, 2, 3, 4, 5}登入後複製當然,事實上還會有一個匿名陣列被建立出來,只是不需要我們來操心而已。
2. 元素遍歷
運算元組元素的所有方法都適用於陣列切片,比如陣列切片也可以按下標讀寫元素,用len()函數獲取元素個數,並支援使用range關鍵字來快速遍歷所有元素。
傳統的元素遍歷方法如下:
for i := 0; i <len(mySlice); i++ {
fmt.Println("mySlice[", i, "] =", mySlice[i])
}登入後複製使用range關鍵字可以讓遍歷程式碼顯得更整潔。range表示式有兩個返回值,第一個是索引,第二個是元素的值:
for i, v := range mySlice {
fmt.Println("mySlice[", i, "] =", v)
}登入後複製對比上面的兩個方法,我們可以很容易地看出使用range的程式碼更簡單易懂。
3. 動態增減元素
可動態增減元素是陣列切片比陣列更為強大的功能。與陣列相比,陣列切片多了一個儲存能力(capacity)的概念,即元素個數和分配的空間可以是兩個不同的值。合理地設定儲存能力的值,可以大幅降低陣列切片內部重新分配記憶體和搬送記憶體塊的頻率,從而大大提高程式效能。
假如你明確知道當前建立的陣列切片最多可能需要儲存的元素個數為50,那麼如果你設定的儲存能力小於50,比如20,那麼在元素超過20時,底層將會發生至少一次這樣的動作——重新分配一塊「夠大」的記憶體,並且需要把內容從原來的記憶體塊複製到新分配的記憶體塊,這會產生比較明顯的開銷。給「夠大」這兩個字加上引號的原因是系統並不知道多大才是夠大,所以只是一個簡單的猜測。比如,將原有的記憶體空間擴大兩倍,但兩倍並不一定夠,所以之前提到的記憶體重新分配和內容複製的過程很有可能發生多次,從而明顯降低系統的整體效能。但如果你知道最大是50並且一開始就設定儲存能力為50,那麼之後就不會發生這樣非常耗費CPU的動作,從而達到空間換時間的效果。
陣列切片支援Go語言內建的cap()函數和len()函數,程式碼清單2-2簡單示範了這兩個內建函數的用法。可以看出,cap()函數返回的是陣列切片分配的空間大小,而len()函數返回的是陣列切片中當前所儲存的元素個數。
程式碼清單2-2 slice2.go
package main
import "fmt"
func main() {
mySlice := make([]int, 5, 10)
fmt.Println("len(mySlice):", len(mySlice))
fmt.Println("cap(mySlice):", cap(mySlice))
}登入後複製該程式的輸出結果為:
len(mySlice): 5
cap(mySlice): 10
登入後複製如果需要往上例中mySlice已包含的5個元素後面繼續新增元素,可以使用append()函數。
下面的程式碼可以從尾端給mySlice加上3個元素,從而生成一個新的陣列切片:
mySlice = append(mySlice, 1, 2, 3)
登入後複製函數append()的第二個引數其實是一個不定引數,我們可以按自己需求新增若干個元素,甚至直接將一個陣列切片追加到另一個陣列切片的末尾:
mySlice2 := []int{8, 9, 10}
// 給mySlice後面新增另一個陣列切片
mySlice = append(mySlice, mySlice2...)登入後複製需要注意的是,我們在第二個引數mySlice2後面加了三個點,即一個省略號,如果沒有這個省略號的話,會有編譯錯誤,因為按append()的語意,從第二個引數起的所有引數都是待附加的元素。因為mySlice中的元素型別為int,所以直接傳遞mySlice2是行不通的。加上省略號相當於把mySlice2包含的所有元素打散後傳入。
上述呼叫等同於:
mySlice = append(mySlice, 8, 9, 10)
登入後複製陣列切片會自動處理儲存空間不足的問題。如果追加的內容長度超過當前已分配的儲存空間(即cap()呼叫返回的資訊),陣列切片會自動分配一塊足夠大的記憶體。
4. 基於陣列切片建立陣列切片
類似於陣列切片可以基於一個陣列建立,陣列切片也可以基於另一個陣列切片建立。下面的例子基於一個已有陣列切片建立新陣列切片:
oldSlice := []int{1, 2, 3, 4, 5}
newSlice := oldSlice[:3] // 基於oldSlice的前3個元素構建新陣列切片登入後複製有意思的是,選擇的oldSlicef元素範圍甚至可以超過所包含的元素個數,比如newSlice可以基於oldSlice的前6個元素建立,雖然oldSlice只包含5個元素。只要這個選擇的範圍不超過oldSlice儲存能力(即cap()返回的值),那麼這個建立程式就是合法的。newSlice中超出oldSlice元素的部分都會填上0。
5. 內容複製
陣列切片支援Go語言的另一個內建函數copy(),用於將內容從一個陣列切片複製到另一個陣列切片。如果加入的兩個陣列切片不一樣大,就會按其中較小的那個陣列切片的元素個數進行復制。下面的範例展示了copy()函數的行為:
slice1 := []int{1, 2, 3, 4, 5}
slice2 := []int{5, 4, 3}
copy(slice2, slice1) // 只會複製slice1的前3個元素到slice2中
copy(slice1, slice2) // 只會複製slice2的3個元素到slice1的前3個位置登入後複製map
在C++/Java中,map一般都以庫的方式提供,比如在C++中是STL的std::map<>,在C#中是Dictionary<>,在Java中是Hashmap<>,在這些語言中,如果要使用map,事先要參照相應的庫。而在Go中,使用map不需要引入任何庫,並且用起來也更加方便。
map是一堆鍵值對的未排序集合。比如以身份證號作為唯一鍵來標識一個人的資訊,則這個map可以定義為程式碼清單 2-3所示的方式。
程式碼清單2-3 map1.go
package main
import "fmt"
// PersonInfo是一個包含個人詳細資訊的型別
type PersonInfo struct {
ID string
Name string
Address string
}
func main() {
var personDB map[string] PersonInfo
personDB = make(map[string] PersonInfo)
// 往這個map裡插入幾條資料
personDB["12345"] = PersonInfo{"12345", "Tom", "Room 203,..."}
personDB["1"] = PersonInfo{"1", "Jack", "Room 101,..."}
// 從這個map查詢鍵為"1234"的資訊
person, ok := personDB["1234"]
// ok是一個返回的bool型,返回true表示找到了對應的資料
if ok {
fmt.Println("Found person", person.Name, "with ID 1234.")
} else {
fmt.Println("Did not find person with ID 1234.")
}
}登入後複製上面這個簡單的例子基本上已經覆蓋了map的主要用法,下面對其中的關鍵點進行細述。
1. 變數宣告
map的宣告基本上沒有多餘的元素,比如:
var myMap map[string] PersonInfo
登入後複製其中,myMap是宣告的map變數名,string是鍵的型別,PersonInfo則是其中所存放的值型別。
2. 建立
我們可以使用Go語言內建的函數make()來建立一個新map。下面的這個例子建立了一個鍵型別為string、值型別為PersonInfo的map:
myMap = make(map[string] PersonInfo)
登入後複製也可以選擇是否在建立時指定該map的初始儲存能力,下面的例子建立了一個初始儲存能力為100的map:
myMap = make(map[string] PersonInfo, 100)
登入後複製建立並初始化map的程式碼如下:
myMap = map[string] PersonInfo{
"1234": PersonInfo{"1", "Jack", "Room 101,..."},
}登入後複製3. 元素賦值
賦值過程非常簡單明瞭,就是將鍵和值用下面的方式對應起來即可:
myMap["1234"] = PersonInfo{"1", "Jack", "Room 101,..."}登入後複製4. 元素刪除
Go語言提供了一個內建函數delete(),用於刪除容器內的元素。下面我們簡單介紹一下如何用delete()函數刪除map內的元素:
delete(myMap, "1234")
登入後複製上面的程式碼將從myMap中刪除鍵為「1234」的鍵值對。如果「1234」這個鍵不存在,那麼這個呼叫將什麼都不發生,也不會有什麼副作用。但是如果傳入的map變數的值是nil,該呼叫將導致程式丟擲異常(panic)
5. 元素查詢
在Go語言中,map的查詢功能設計得比較精巧。而在其他語言中,我們要判斷能否獲取到一個值不是件容易的事情。判斷能否從map中獲取一個值的常規做法是:
(1) 宣告並初始化一個變數為空;
(2) 試圖從map中獲取相應鍵的值到該變數中;
(3) 判斷該變數是否依舊為空,如果為空則表示map中沒有包含該變數。
這種用法比較囉唆,而且判斷變數是否為空這條語句並不能真正表意(是否成功取到對應的值),從而影響程式碼的可讀性和可維護性。有些庫甚至會設計為因為一個鍵不存在而丟擲異常,讓開發者用起來膽戰心驚,不得不一層層巢狀try-catch語句,這更是不人性化的設計。在Go語言中,要從map中查詢一個特定的鍵,可以通過下面的程式碼來實現:
value, ok := myMap["1234"]
if ok { // 找到了
// 處理找到的value
}登入後複製判斷是否成功找到特定的鍵,不需要檢查取到的值是否為nil,只需檢視第二個返回值ok,這讓表意清晰很多。配合:=操作符,讓你的程式碼沒有多餘成分,看起來非常清晰易懂。
更多程式設計相關知識,請存取:!!
以上就是go語言有哪些型別的詳細內容,更多請關注TW511.COM其它相關文章!