使用.NET7和C#11打造最快的序列化程式-以MemoryPack為例
譯者注
本文是一篇不可多得的好文,MemoryPack 的作者 neuecc 大佬通過本文解釋了他是如何將序列化程式效能提升到極致的;其中從很多方面(可變長度、字串、集合等)解釋了一些效能優化的技巧,值得每一個開發人員學習,特別是框架的開發人員的學習,一定能讓大家獲益匪淺。
簡介
我釋出了一個名為MemoryPack 的新序列化程式,這是一種特定於 C# 的新序列化程式,其執行速度比其他序列化程式快得多。
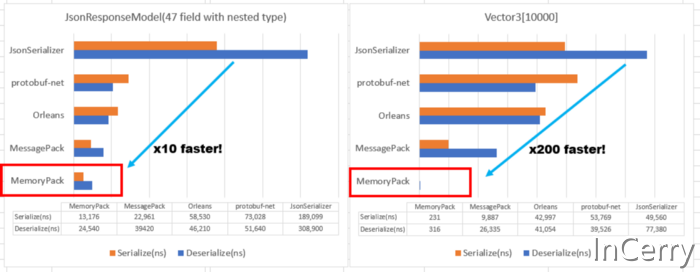
與MessagePack for C# (一個快速的二進位制序列化程式)相比標準物件的序列化庫效能快幾倍,當資料最優時,效能甚至快 50~100 倍。最好的支援是.NET 7,但現在支援.NET Standard 2.1(.NET 5,6),Unity 甚至 TypeScript。它還支援多型性(Union),完整版本容錯,迴圈參照和最新的現代 I/O API(IBufferWriter,ReadOnlySeqeunce,Pipelines)。
序列化程式的效能基於「資料格式規範」和「每種語言的實現」。例如,雖然二進位制格式通常比文字格式(如 JSON)具有優勢,但 JSON 序列化程式可能比二進位制序列化程式更快(如Utf8Json 所示)。那麼最快的序列化程式是什麼?當你同時瞭解規範和實現時,真正最快的序列化程式就誕生了。
多年來,我一直在開發和維護 MessagePack for C#,而 MessagePack for C# 是 .NET 世界中非常成功的序列化程式,擁有超過 4000 顆 GitHub 星。它也已被微軟標準產品採用,如 Visual Studio 2022,SignalR MessagePack Hub協定和 Blazor Server 協定(blazorpack)。
在過去的 5 年裡,我還處理了近 1000 個問題。自 5 年前以來,我一直在使用 Roslyn 的程式碼生成器進行 AOT 支援,並對其進行了演示,尤其是在 Unity、AOT 環境 (IL2CPP) 以及許多使用它的 Unity 手機遊戲中。
除了 MessagePack for C# 之外,我還建立了ZeroFormatter(自己的格式)和Utf8Json(JSON)等序列化程式,它們獲得了許多 GitHub Star,所以我對不同格式的效能特徵有深刻的理解。此外,我還參與了 RPC 框架MagicOnion,記憶體資料庫MasterMemory,PubSub 使用者端AlterNats以及幾個遊戲的使用者端(Unity)/伺服器實現的建立。
MemoryPack 的目標是成為終極的快速,實用和多功能的序列化程式。我想我做到了。
增量源生成器
MemoryPack 完全採用 .NET 6 中增強的增量源生成器。在用法方面,它與 C# 版 MessagePack 沒有太大區別,只是將目標型別更改為部分型別。
using MemoryPack;
// Source Generator makes serialize/deserialize code
[MemoryPackable]
public partial class Person
{
public int Age { get; set; }
public string Name { get; set; }
}
// usage
var v = new Person { Age = 40, Name = "John" };
var bin = MemoryPackSerializer.Serialize(v);
var val = MemoryPackSerializer.Deserialize<Person>(bin);
源生成器的最大優點是它對 AOT 友好,無需反射即可為每種型別自動生成優化的序列化程式程式碼,而無需由 IL.Emit 動態生成程式碼,這是常規做法。這使得使用 Unity 的 IL2CPP 等可以安全地工作。初始啟動速度也很快。
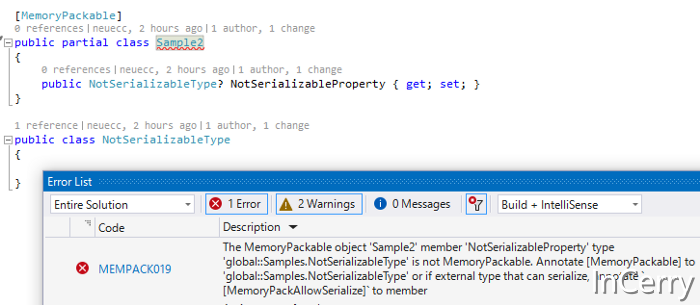
源生成器還用作分析器,因此它可以通過在編輯時發出編譯錯誤來檢測它是否可安全序列化。
請注意,由於語言/編譯器版本原因,Unity 版本使用舊的源生成器而不是增量源生成器。
C# 的二進位制規範
MemoryPack 的標語是「零編碼」。這不是一個特例,例如,Rust 的主要二進位制序列化器bincode 也有類似的規範。FlatBuffers還可以讀取和寫入類似於記憶體資料的內容,而無需解析實現。
但是,與 FlatBuffers 和其他產品不同,MemoryPack 是一種通用的序列化程式,不需要特殊型別,並且可以針對 POCO 進行序列化/反序列化。它還具有對架構成員新增和多型性支援 (Union) 的高容忍度的版本控制。
可變編碼與固定編碼
Int32 是 4 個位元組,但在 JSON 中,例如,數位被編碼為字串,可變長度編碼為 1~11 個位元組(例如,1 或 -2147483648)。許多二進位制格式還具有 1 到 5 位元組的可變長度編碼規範以節省大小。例如,Protocol-buffers 數位型別具有可變長度整數編碼,該編碼以 7 位儲存值,並以 1 位 (varint) 儲存是否存在以下的標誌。這意味著數位越小,所需的位元組就越少。相反,在最壞的情況下,該數位將增長到 5 個位元組,大於原來的 4 個位元組。MessagePack和CBOR類似地使用可變長度編碼進行處理,小數位最小為 1 位元組,大數位最大為 5 位元組。
這意味著 varint 執行比固定長度情況額外的處理。讓我們在具體程式碼中比較兩者。可變長度是 protobuf 中使用的可變 + 之字折線編碼(負數和正陣列合)。
// Fixed encoding
static void WriteFixedInt32(Span<byte> buffer, int value)
{
ref byte p = ref MemoryMarshal.GetReference(buffer);
Unsafe.WriteUnaligned(ref p, value);
}
// Varint encoding
static void WriteVarInt32(Span<byte> buffer, int value) => WriteVarInt64(buffer, (long)value);
static void WriteVarInt64(Span<byte> buffer, long value)
{
ref byte p = ref MemoryMarshal.GetReference(buffer);
ulong n = (ulong)((value << 1) ^ (value >> 63));
while ((n & ~0x7FUL) != 0)
{
Unsafe.WriteUnaligned(ref p, (byte)((n & 0x7f) | 0x80));
p = ref Unsafe.Add(ref p, 1);
n >>= 7;
}
Unsafe.WriteUnaligned(ref p, (byte)n);
}
換句話說,固定長度是按原樣寫出 C# 記憶體(零編碼),很明顯,固定長度更快。
當應用於陣列時,這一點更加明顯。
// https://sharplab.io/
Inspect.Heap(new int[]{ 1, 2, 3, 4, 5 });

在 C# 中的結構陣列中,資料按順序排列。如果結構沒有參照型別(非託管型別)則資料在記憶體中完全對齊;讓我們將程式碼中的序列化過程與 MessagePack 和 MemoryPack 進行比較。
// Fixed-length(MemoryPack)
void Serialize(int[] value)
{
// Size can be calculated and allocate in advance
var size = (sizeof(int) * value.Length) + 4;
EnsureCapacity(size);
// MemoryCopy once
MemoryMarshal.AsBytes(value.AsSpan()).CopyTo(buffer);
}
// Variable-length(MessagePack)合
void Serialize(int[] value)
{
foreach (var item in value)
{
// Unknown size, so check size each times
EnsureCapacity(); // if (buffer.Length < writeLength) Resize();
// Variable length encoding per element
WriteVarInt32(item);
}
}
在固定長度的情況下,可以消除許多方法呼叫並且只有一個記憶體副本。
C# 中的陣列不僅是像 int 這樣的基元型別,對於具有多個基元的結構也是如此,例如,具有 (float x, float y, float z) 的 Vector3 陣列將具有以下記憶體佈局。

浮點數(4 位元組)是 MessagePack 中 5 個位元組的固定長度。額外的 1 個位元組以識別符號為字首,指示值的型別(整數、浮點數、字串...)。具體來說,[0xca, x, x, x, x, x, x].MemoryPack 格式沒有識別符號,因此 4 個位元組按原樣寫入。
以 Vector3[10000] 為例,它比基準測試好 50 倍。
// these fields exists in type
// byte[] buffer
// int offset
void SerializeMemoryPack(Vector3[] value)
{
// only do copy once
var size = Unsafe.SizeOf<Vector3>() * value.Length;
if ((buffer.Length - offset) < size)
{
Array.Resize(ref buffer, buffer.Length * 2);
}
MemoryMarshal.AsBytes(value.AsSpan()).CopyTo(buffer.AsSpan(0, offset))
}
void SerializeMessagePack(Vector3[] value)
{
// Repeat for array length x number of fields
foreach (var item in value)
{
// X
{
// EnsureCapacity
// (Actually, create buffer-linked-list with bufferWriter.Advance, not Resize)
if ((buffer.Length - offset) < 5)
{
Array.Resize(ref buffer, buffer.Length * 2);
}
var p = MemoryMarshal.GetArrayDataReference(buffer);
Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset), (byte)0xca);
Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset + 1), item.X);
offset += 5;
}
// Y
{
if ((buffer.Length - offset) < 5)
{
Array.Resize(ref buffer, buffer.Length * 2);
}
var p = MemoryMarshal.GetArrayDataReference(buffer);
Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset), (byte)0xca);
Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset + 1), item.Y);
offset += 5;
}
// Z
{
if ((buffer.Length - offset) < 5)
{
Array.Resize(ref buffer, buffer.Length * 2);
}
var p = MemoryMarshal.GetArrayDataReference(buffer);
Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset), (byte)0xca);
Unsafe.WriteUnaligned(ref Unsafe.Add(ref p, offset + 1), item.Z);
offset += 5;
}
}
}
使用 MessagePack,它需要 30000 次方法呼叫。在該方法中,它會檢查是否有足夠的記憶體進行寫入,並在每次完成寫入時新增偏移量。
使用 MemoryPack,只有一個記憶體副本。這實際上會使處理時間改變一個數量級,這也是本文開頭圖中 50 倍~100 倍加速的原因。
當然,反序列化過程也是單個副本。
// Deserialize of MemoryPack, only copy
Vector3[] DeserializeMemoryPack(ReadOnlySpan<byte> buffer, int size)
{
var dest = new Vector3[size];
MemoryMarshal.Cast<byte, Vector3>(buffer).CopyTo(dest);
return dest;
}
// Require read float many times in loop
Vector3[] DeserializeMessagePack(ReadOnlySpan<byte> buffer, int size)
{
var dest = new Vector3[size];
for (int i = 0; i < size; i++)
{
var x = ReadSingle(buffer);
buffer = buffer.Slice(5);
var y = ReadSingle(buffer);
buffer = buffer.Slice(5);
var z = ReadSingle(buffer);
buffer = buffer.Slice(5);
dest[i] = new Vector3(x, y, z);
}
return dest;
}
這是 MessagePack 格式本身的限制,只要遵循規範,速度的巨大差異就無法以任何方式逆轉。但是,MessagePack 有一個名為「ext 格式系列」的規範,它允許將這些陣列作為其自身規範的一部分進行特殊處理。事實上,MessagePack for C# 有一個特殊的 Unity 擴充套件選項,稱為 UnsafeBlitResolver,它可以執行上述操作。
但是,大多數人可能不會使用它,也沒有人會使用會使 MessagePack 不相容的專有選項。
因此,對於 MemoryPack,我想要一個預設情況下能提供最佳效能的規範 C#。
字串優化
MemoryPack 有兩個字串規範:UTF8 或 UTF16。由於 C# 字串是 UTF16,因此將其序列化為 UTF16 可以節省編碼/解碼為 UTF8 的成本。
void EncodeUtf16(string value)
{
var size = value.Length * 2;
EnsureCapacity(size);
// Span<char> -> Span<byte> -> Copy
MemoryMarshal.AsBytes(value.AsSpan()).CopyTo(buffer);
}
string DecodeUtf16(ReadOnlySpan<byte> buffer, int length)
{
ReadOnlySpan<char> src = MemoryMarshal.Cast<byte, char>(buffer).Slice(0, length);
return new string(src);
}
但是,MemoryPack 預設為 UTF8。這是因為有效負載大小問題;對於 UTF16,ASCII 字元的大小將是原來的兩倍,因此選擇了 UTF8。
但是,即使使用 UTF8,MemoryPack 也具有其他序列化程式所沒有的一些優化。
// fast
void WriteUtf8MemoryPack(string value)
{
var source = value.AsSpan();
var maxByteCount = (source.Length + 1) * 3;
EnsureCapacity(maxByteCount);
Utf8.FromUtf16(source, dest, out var _, out var bytesWritten, replaceInvalidSequences: false);
}
// slow
void WriteUtf8StandardSerializer(string value)
{
var maxByteCount = Encoding.UTF8.GetByteCount(value);
EnsureCapacity(maxByteCount);
Encoding.UTF8.GetBytes(value, dest);
}
var bytes = Encoding.UTF8.GetBytes(value)是絕對的不允許的,字串寫入中不允許 byte[] 分配。許多序列化程式使用 Encoding.UTF8.GetByteCount,但也應該避免它,因為 UTF8 是一種可變長度編碼,GetByteCount 完全遍歷字串以計算確切的編碼後大小。也就是說,GetByteCount -> GetBytes 遍歷字串兩次。
通常,允許序列化程式保留大量緩衝區。因此,MemoryPack 分配三倍的字串長度,這是 UTF8 編碼的最壞情況,以避免雙重遍歷。在解碼的情況下,應用了進一步的特殊優化。
// fast
string ReadUtf8MemoryPack(int utf16Length, int utf8Length)
{
unsafe
{
fixed (byte* p = &buffer)
{
return string.Create(utf16Length, ((IntPtr)p, utf8Length), static (dest, state) =>
{
var src = MemoryMarshal.CreateSpan(ref Unsafe.AsRef<byte>((byte*)state.Item1), state.Item2);
Utf8.ToUtf16(src, dest, out var bytesRead, out var charsWritten, replaceInvalidSequences: false);
});
}
}
}
// slow
string ReadStandardSerialzier(int utf8Length)
{
return Encoding.UTF8.GetString(buffer.AsSpan(0, utf8Length));
}
通常,要從 byte[] 中獲取字串,我們使用Encoding.UTF8.GetString(buffer)。但同樣,UTF8 是一種可變長度編碼,我們不知道 UTF16 的長度。UTF8 也是如此。GetString我們需要計算長度為 UTF16 以將其轉換為字串,因此我們在內部掃描字串兩次。在虛擬碼中,它是這樣的:
var length = CalcUtf16Length(utf8data);
var str = String.Create(length);
Encoding.Utf8.DecodeToString(utf8data, str);
典型序列化程式的字串格式為 UTF8,它不能解碼為 UTF16,因此即使您想要長度為 UTF16 以便作為 C# 字串進行高效解碼,它也不在資料中。
但是,MemoryPack 在檔頭中記錄 UTF16 長度和 UTF8 長度。因此,String.Create<TState>(Int32, TState, SpanAction<Char,TState>) 和 Utf8.ToUtf16的組合為 C# String 提供了最有效的解碼。
關於有效負載大小
與可變長度編碼相比,整數的固定長度編碼的大小可能會膨脹。然而,在現代,使用可變長度編碼只是為了減小整數的小尺寸是一個缺點。
由於資料不僅僅是整數,如果真的想減小大小,應該考慮壓縮(LZ4,ZStandard,Brotli等),如果壓縮資料,可變長度編碼幾乎沒有意義。如果你想更專業和更小,面向列的壓縮會給你更大的結果(例如,Apache Parquet)。為了與 MemoryPack 實現整合的高效壓縮,我目前有 BrotliEncode/Decode 的輔助類作為標準。我還有幾個屬性,可將特殊壓縮應用於某些原始列,例如列壓縮。
[MemoryPackable]
public partial class Sample
{
public int Id { get; set; }
[BitPackFormatter]
public bool[] Data { get; set; }
[BrotliFormatter]
public byte[] Payload { get; set; }
}
BitPackFormatter表示 bool[],bool 通常為 1 個位元組,但由於它被視為 1 位,因此在一個位元組中儲存八個布林值。因此,序列化後的大小為 1/8。BrotliFormatter直接應用壓縮演演算法。這實際上比壓縮整個檔案的效能更好。
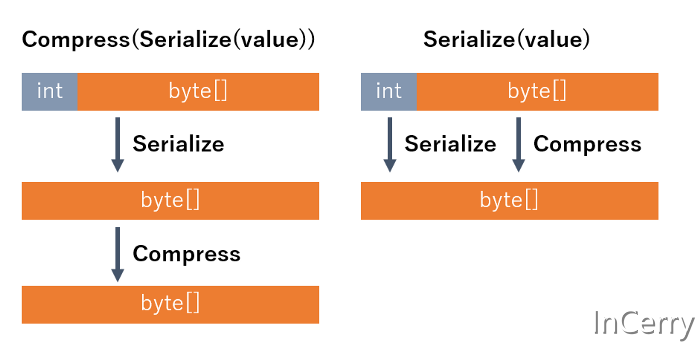
這是因為不需要中間副本,壓縮過程可以直接應用於序列化資料。Uber 工程部落格上的使用CLP 將紀錄檔記錄成本降低兩個數量級一文中詳細介紹了通過根據資料以自定義方式應用處理而不是簡單的整體壓縮來提取效能和壓縮率的方法。
使用 .NET7 和 C#11 新功能
MemoryPack 在 .NET Standard 2.1 的實現和 .NET 7 的實現中具有略有不同的方法簽名。.NET 7 是一種更積極、面向效能的實現,它利用了最新的語言功能。
首先,序列化程式介面利用靜態抽象成員,如下所示:
public interface IMemoryPackable<T>
{
// note: serialize parameter should be `ref readonly` but current lang spec can not.
// see proposal https://github.com/dotnet/csharplang/issues/6010
static abstract void Serialize<TBufferWriter>(ref MemoryPackWriter<TBufferWriter> writer, scoped ref T? value)
where TBufferWriter : IBufferWriter<byte>;
static abstract void Deserialize(ref MemoryPackReader reader, scoped ref T? value);
}
MemoryPack 採用源生成器,並要求目標型別為[MemoryPackable]public partial class Foo,因此最終的目標型別為
[MemortyPackable]
partial class Foo : IMemoryPackable
{
static void IMemoryPackable<Foo>.Serialize<TBufferWriter>(ref MemoryPackWriter<TBufferWriter> writer, scoped ref Foo? value)
{
}
static void IMemoryPackable<Foo>.Deserialize(ref MemoryPackReader reader, scoped ref Foo? value)
{
}
}
這避免了通過虛擬方法呼叫的成本。
public void WritePackable<T>(scoped in T? value)
where T : IMemoryPackable<T>
{
// If T is IMemoryPackable, call static method directly
T.Serialize(ref this, ref Unsafe.AsRef(value));
}
//
public void WriteValue<T>(scoped in T? value)
{
// call Serialize from interface virtual method
IMemoryPackFormatter<T> formatter = MemoryPackFormatterProvider.GetFormatter<T>();
formatter.Serialize(ref this, ref Unsafe.AsRef(value));
}
MemoryPackWriter/MemoryPackReader使用 ref欄位。
public ref struct MemoryPackWriter<TBufferWriter>
where TBufferWriter : IBufferWriter<byte>
{
ref TBufferWriter bufferWriter;
ref byte bufferReference;
int bufferLength;
換句話說,ref byte bufferReference,int bufferLength的組合是Span<byte>的內聯。此外,通過接受 TBufferWriter 作為 ref TBufferWriter,現在可以安全地接受和呼叫可變結構 TBufferWriter:IBufferWrite<byte>。
// internally MemoryPack uses some struct buffer-writers
struct BrotliCompressor : IBufferWriter<byte>
struct FixedArrayBufferWriter : IBufferWriter<byte>
針對所有型別的型別進行優化
例如,對於通用實現,集合可以序列化/反序列化為 IEnumerable<T>,但 MemoryPack 為所有型別的提供單獨的實現。為簡單起見,List<T> 可以處理為:
public void Serialize(ref MemoryPackWriter writer, IEnumerable<T> value)
{
foreach(var item in source)
{
writer.WriteValue(item);
}
}
public void Serialize(ref MemoryPackWriter writer, List<T> value)
{
foreach(var item in source)
{
writer.WriteValue(item);
}
}
這兩個程式碼看起來相同,但執行完全不同:foreach to IEnumerable<T> 檢索IEnumerator<T>,而 foreach to List<T>檢索結構List<T>.Enumerator,y 一個優化的專用結構。
但是,MemoryPack 進一步優化了它。
public sealed class ListFormatter<T> : MemoryPackFormatter<List<T?>>
{
public override void Serialize<TBufferWriter>(ref MemoryPackWriter<TBufferWriter> writer, scoped ref List<T?>? value)
{
if (value == null)
{
writer.WriteNullCollectionHeader();
return;
}
writer.WriteSpan(CollectionsMarshal.AsSpan(value));
}
}
// MemoryPackWriter.WriteSpan
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public void WriteSpan<T>(scoped Span<T?> value)
{
if (!RuntimeHelpers.IsReferenceOrContainsReferences<T>())
{
DangerousWriteUnmanagedSpan(value);
return;
}
var formatter = GetFormatter<T>();
WriteCollectionHeader(value.Length);
for (int i = 0; i < value.Length; i++)
{
formatter.Serialize(ref this, ref value[i]);
}
}
// MemoryPackWriter.DangerousWriteUnmanagedSpan
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public void DangerousWriteUnmanagedSpan<T>(scoped Span<T> value)
{
if (value.Length == 0)
{
WriteCollectionHeader(0);
return;
}
var srcLength = Unsafe.SizeOf<T>() * value.Length;
var allocSize = srcLength + 4;
ref var dest = ref GetSpanReference(allocSize);
ref var src = ref Unsafe.As<T, byte>(ref MemoryMarshal.GetReference(value));
Unsafe.WriteUnaligned(ref dest, value.Length);
Unsafe.CopyBlockUnaligned(ref Unsafe.Add(ref dest, 4), ref src, (uint)srcLength);
Advance(allocSize);
}
來自 .NET 5 的 CollectionsMarshal.AsSpan 是列舉 List<T> 的最佳方式。此外,如果可以獲得 Span<T>,則只能在 List<int>或 List<Vector3>的情況下通過複製來處理。
在反序列化的情況下,也有一些有趣的優化。首先,MemoryPack 的反序列化接受參照 T?值,如果值為 null,則如果傳遞該值,它將覆蓋內部生成的物件(就像普通序列化程式一樣)。這允許在反序列化期間零分配新物件建立。在List<T> 的情況下,也可以通過呼叫 Clear() 來重用集合。
然後,通過進行特殊的 Span 呼叫,它全部作為 Span 處理,避免了List<T>.Add的額外開銷。
public sealed class ListFormatter<T> : MemoryPackFormatter<List<T?>>
{
public override void Deserialize(ref MemoryPackReader reader, scoped ref List<T?>? value)
{
if (!reader.TryReadCollectionHeader(out var length))
{
value = null;
return;
}
if (value == null)
{
value = new List<T?>(length);
}
else if (value.Count == length)
{
value.Clear();
}
var span = CollectionsMarshalEx.CreateSpan(value, length);
reader.ReadSpanWithoutReadLengthHeader(length, ref span);
}
}
internal static class CollectionsMarshalEx
{
/// <summary>
/// similar as AsSpan but modify size to create fixed-size span.
/// </summary>
public static Span<T?> CreateSpan<T>(List<T?> list, int length)
{
list.EnsureCapacity(length);
ref var view = ref Unsafe.As<List<T?>, ListView<T?>>(ref list);
view._size = length;
return view._items.AsSpan(0, length);
}
// NOTE: These structure depndent on .NET 7, if changed, require to keep same structure.
internal sealed class ListView<T>
{
public T[] _items;
public int _size;
public int _version;
}
}
// MemoryPackReader.ReadSpanWithoutReadLengthHeader
public void ReadSpanWithoutReadLengthHeader<T>(int length, scoped ref Span<T?> value)
{
if (length == 0)
{
value = Array.Empty<T>();
return;
}
if (!RuntimeHelpers.IsReferenceOrContainsReferences<T>())
{
if (value.Length != length)
{
value = AllocateUninitializedArray<T>(length);
}
var byteCount = length * Unsafe.SizeOf<T>();
ref var src = ref GetSpanReference(byteCount);
ref var dest = ref Unsafe.As<T, byte>(ref MemoryMarshal.GetReference(value)!);
Unsafe.CopyBlockUnaligned(ref dest, ref src, (uint)byteCount);
Advance(byteCount);
}
else
{
if (value.Length != length)
{
value = new T[length];
}
var formatter = GetFormatter<T>();
for (int i = 0; i < length; i++)
{
formatter.Deserialize(ref this, ref value[i]);
}
}
}
EnsurceCapacity(capacity),可以預先擴充套件儲存 List<T> 的內部陣列的大小。這避免了每次都需要內部放大/複製。
但是 CollectionsMarshal.AsSpan,您將獲得長度為 0 的 Span,因為內部大小不會更改。如果我們有 CollectionMarshals.AsMemory,我們可以使用 MemoryMarshal.TryGetArray 組合從那裡獲取原始陣列,但不幸的是,沒有辦法從 Span 獲取原始陣列。因此,我強制型別結構與 Unsafe.As 匹配並更改List<T>._size,我能夠獲得擴充套件的內部陣列。
這樣,我們可以以僅複製的方式優化非託管型別,並避免 List<T>.Add(每次檢查陣列大小),並通過Span<T>[index] 打包值,這比傳統序列化、反序列化程式效能要高得多。。
雖然對List<T>的優化具有代表性,但要介紹的還有太多其他型別,所有型別都經過仔細審查,並且對每種型別都應用了最佳優化。
Serialize 接受 IBufferWriter<byte> 作為其本機結構,反序列化接受 ReadOnlySpan<byte> 和 ReadOnlySequence<byte>。
這是因為System.IO.Pipelines 需要這些型別。換句話說,由於它是 ASP .NET Core 的伺服器 (Kestrel) 的基礎,因此通過直接連線到它,您可以期待更高效能的序列化。
IBufferWriter<byte> 特別重要,因為它可以直接寫入緩衝區,從而在序列化過程中實現零拷貝。對 IBufferWriter<byte> 的支援是現代序列化程式的先決條件,因為它提供比使用 byte[] 或 Stream 更高的效能。開頭圖表中的序列化程式(System.Text.Json,protobuf-net,Microsoft.Orleans.Serialization,MessagePack for C#和 MemoryPack)支援它。
MessagePack 與 MemoryPack
MessagePack for C# 非常易於使用,並且具有出色的效能。特別是,以下幾點比 MemoryPack 更好
- 出色的跨語言相容性
- JSON 相容性(尤其是字串鍵)和人類可讀性
- 預設完美版本容錯
- 物件和匿名型別的序列化
- 動態反序列化
- 嵌入式 LZ4 壓縮
- 久經考驗的穩定性
MemoryPack 預設為有限版本容錯,完整版容錯選項的效能略低。此外,因為它是原始格式,所以唯一支援的其他語言是 TypeScript。此外,二進位制檔案本身不會告訴它是什麼資料,因為它需要 C# 架構。
但是,它在以下方面優於 MessagePack。
- 效能,尤其是對於非託管型別陣列
- 易於使用的 AOT 支援
- 擴充套件多型性(聯合)構造方法
- 支援迴圈參照
- 覆蓋反序列化
- 打字稿程式碼生成
- 靈活的基於屬性的自定義格式化程式
在我個人看來,如果你在只有 C#的環境中,我會選擇 MemoryPack。但是,有限版本容錯有其怪癖,應該事先理解它。MessagePack for C# 仍然是一個不錯的選擇,因為它簡單易用。
MemoryPack 不是一個只關注效能的實驗性序列化程式,而且還旨在成為一個實用的序列化程式。為此,我還以 MessagePack for C# 的經驗為基礎,提供了許多功能。
- 支援現代 I/O API(
IBufferWriter<byte>,ReadOnlySpan<byte>,ReadOnlySequence<byte>) - 基於本機 AOT 友好的源生成器的程式碼生成,沒有動態程式碼生成(IL.Emit)
- 無反射非泛型 API
- 反序列化到現有範例
- 多型性(聯合)序列化
- 有限的版本容限(快速/預設)和完整的版本容錯支援
- 迴圈參照序列化
- 基於管道寫入器/讀取器的流式序列化
- TypeScript 程式碼生成和核心格式化程式 ASP.NET
- Unity(2021.3) 通過 .NET 源生成器支援 IL2CPP
我們計劃進一步擴充套件可用功能的範圍,例如對MasterMemory 的 MemoryPack支援和對 MagicOnion的序列化程式更改支援等。我們將自己定位為Cysharp C# 庫生態系統的核心。我們將付出很多努力來種下這一棵樹,所以對於初學者來說,請嘗試一下我們的庫!
版權資訊
已獲得原作者授權
原文版權:neuecc
翻譯版權:InCerry
.NET效能優化交流群
相信大家在開發中經常會遇到一些效能問題,苦於沒有有效的工具去發現效能瓶頸,或者是發現瓶頸以後不知道該如何優化。之前一直有讀者朋友詢問有沒有技術交流群,但是由於各種原因一直都沒建立,現在很高興的在這裡宣佈,我建立了一個專門交流.NET效能優化經驗的群組,主題包括但不限於:
- 如何找到.NET效能瓶頸,如使用APM、dotnet tools等工具
- .NET框架底層原理的實現,如垃圾回收器、JIT等等
- 如何編寫高效能的.NET程式碼,哪些地方存在效能陷阱
希望能有更多志同道合朋友加入,分享一些工作中遇到的.NET效能問題和寶貴的效能分析優化經驗。由於已經達到200人,可以加我微信,我拉你進群: ls1075