解讀數倉中的資料物件及相關關係
摘要:為實現不同的功能,GaussDB(DWS)提供了不同的資料物件型別,包括索引、行存表、列存表及其輔助表等。這些資料物件在特定的條件下實現不同的功能,為資料庫的快速高效提供了保證,本文對部分資料物件進行介紹。
本文分享自華為雲社群《GaussDB(DWS)之資料物件及相互關係總結》,作者:我的橘子呢 。
為實現不同的功能,GaussDB(DWS)提供了不同的資料物件型別,包括索引、行存表、列存表及其輔助表等。這些資料物件在特定的條件下實現不同的功能,為資料庫的快速高效提供了保證,本文對部分資料物件進行介紹。
1.索引(index)
索引是關係型資料庫中對某一列或者多個列的值進行預排序的資料結構。如果資料庫的記錄非常多,通過建立索引可以獲得非常快的查詢速度,當對某一列建立索引之後,通過該列進行相關查詢時資料庫系統就不必掃描整個表,而是直接通過索引定位到符合條件的記錄,在一定程度上能夠大幅提升查詢得速度。
假如需要執行如下的語句進行查詢:
SELECT name FROM test_1 WHERE number =10;
一般情況下資料庫需要對每一行進行遍歷查詢,直到找到所有滿足條件number=10的元組資訊。當資料庫的記錄很多,而滿足where條件的記錄又很少時,順序掃描的效能就會很差。這時如果在表test_1的number屬性上建立索引,用於快速定位需要匹配的元組資訊,資料庫只需要根據索引的資料結構進行搜尋,由於常用的索引結構有B-Tree、Hash、GiSt、GIN等,這些索引結構的查詢都是快速高效的,因此可以在少數幾步內完成查詢,大大提高了查詢效率。
對錶test_1的number屬性建立索引語句如下:
CREATE INDEX numberIndex ON test_1(number);
由於GaussDB裡的所有索引都是「從屬索引」,索引在物理檔案上與原來的表檔案分離,執行上述建立索引語句後,系統會生成relname為numberIndex的索引型別。表和索引都是資料庫物件,在pg_class裡會有該索引的記錄,有與之相對應的oid,同時在pg_index表裡會記錄索引及其對應主表的資訊。對應屬性資訊如圖1所示。

圖1 pg_index部分屬性
2.toast表
toast(The Oversized-Atttibute Storage Techhnique)即超尺寸欄位儲存技巧,是資料庫提供的一種儲存巨量資料的機制。只有一些具有變長表現形式的資料型別才會支援toast,比如TEXT型別。由於在GaussDB(DWS)的行儲存方式中,一條資料的所有列組合在一起稱之為一個tuple,多個tuple組成一個page。page是資料在檔案儲存中的基本單位,其大小是固定的且只能在編譯器指定,之後無法修改,預設發大小為8KB,當某行資料很大超過page的大小時,資料庫系統就會啟動toast,對資料進行壓縮和切片。實際資料以行外儲存的形式儲存在另外一張表中,這張表就是toast表。
當一張表的任何一個屬性是可以toast的,則這張表會有一張關聯的toast表,在pg_class裡表的reltoastrelid屬性裡記錄了該toast表的oid,如果沒有關聯的toast表,reltoastrelid=0。那麼如何判斷一張表的屬性是否是可以toast的呢?我們可以在表的Storage選項中檢視對應屬性的儲存策略。有以下四種不同的儲存策略:
- PLAIN:避免壓縮或者行外儲存;此外,它禁止為變長型別使用單位元組的頭。 這隻對那些不能TOAST的資料型別的列才有可能。
- EXTENDED:允許壓縮和行外儲存。 這是大多數TOAST資料型別的預設策略。首先會嘗試對資料進行壓縮, 如果行仍然太大,則進行行外儲存。
- EXTERNAL:允許行外儲存,但是不許壓縮。 使用EXTERNAL,將使那些資料型別為text和bytea的欄位上的子字串操作更快 (代價是增加了儲存空間),因為這些操作是經過優化的:如果行外資料沒有壓縮,那麼它們只會獲取需要的部分。
- MAIN:允許壓縮,但不允許行外儲存。 實際上,在這樣的欄位上仍然會進行行外儲存, 但只是作為沒有辦法把資料行變得更小以使之足以放置在一個頁面中的最後選擇。
假如建立表語句如下:
CREATE TABLE test_t(id int,description text);
建立了一張test_t表,該表有id和description兩個屬性,分別屬於int和text型別,檢視該表的屬性對應的Storage策略:
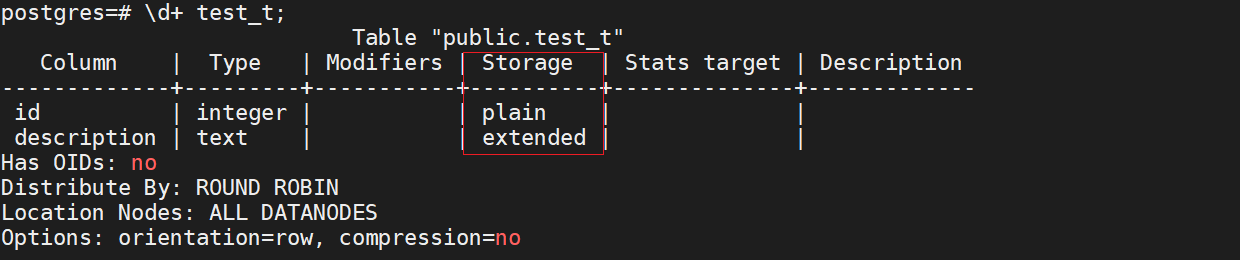
圖2 test_t表相關資訊
我們可以看出description屬性的Storage策略為EXTENDED,是可以toast的,系統會為test_t表建立一張關聯的toast表。

圖3 test_t表對應toast表
通過查詢pg_class,可以的看到表test_t關聯的toast表的oid為52579,進一步以此oid為條件在pg_class裡就會得到toast表的相關資訊。

圖4 toast表相關資訊
下圖為test_t表和其對應的toast表之間的關係,以及toast表一些基本屬性的介紹。
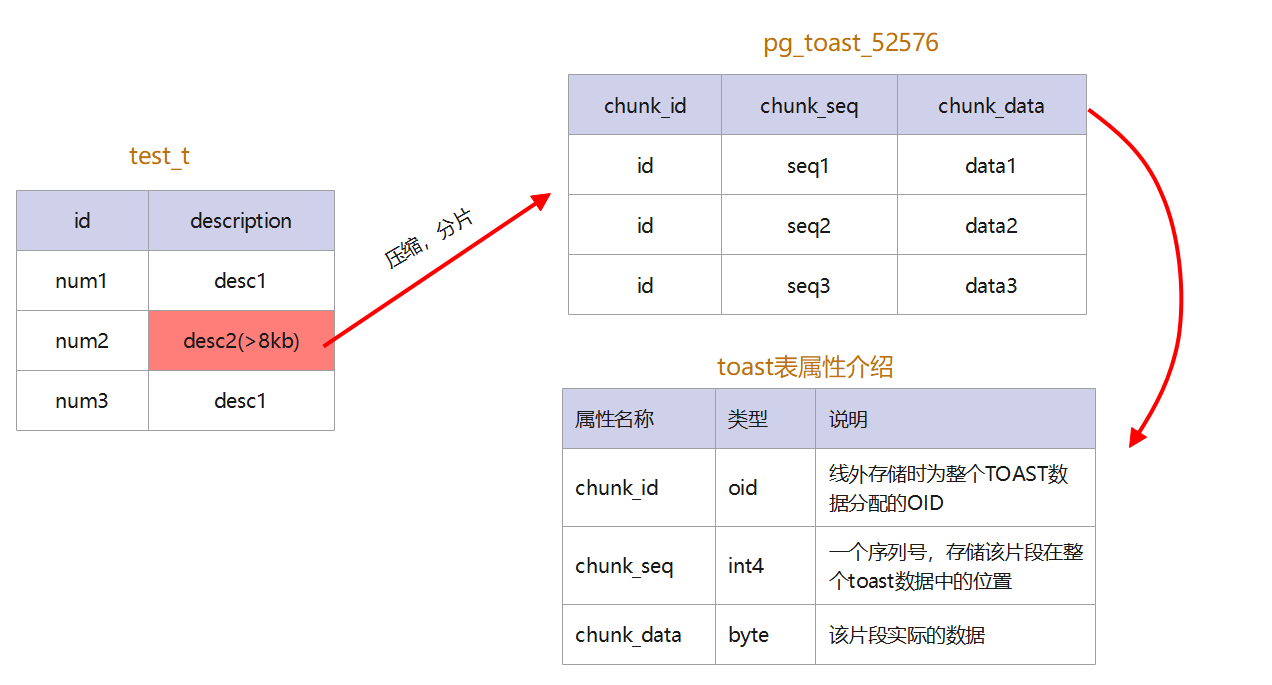
圖5 test_t與其toast表關係圖
3.cudesc表
GaussDB(DWS)除了提供行儲存方式外,還支援列儲存方式。列儲存方式在資料壓縮、列批次資料的運算、巨量資料統計分析等場景中有著顯著的優勢。CU(Compress Unit)壓縮單元是列儲存的最小單位,每列預設60000行儲存在一個CU中,CU生成後資料 固定不可更改。CUDesc本身是一張行存表,它用來輔助記錄列存表的cu資訊,該表的每一行描述一個CU,包括最大值最小值以及CU在檔案中的偏移量和大小,連續多個行中各個不同的列的cu_id相同,可以認為就是把連續多個行截斷拿出來,然後再根據不同的列,放到不同的cu中,這些CU所在的行數都是一致的,用一個cu_id表示,但是col_id不一樣。同時還增加了一個col_id=-10的列,這個列為VCU,表示這些連續的行中,有哪些行已經是被刪除了,用delete_map記錄刪除資訊。如圖6所示。
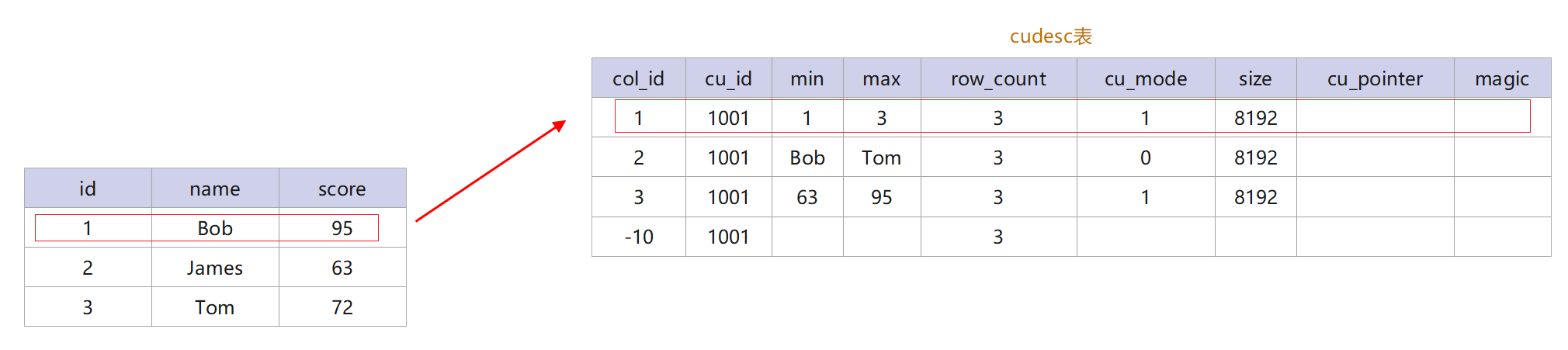
圖6 cudesc表示意圖
每張列存表都有一張對應的CUDesc表,CUDesc表的oid可以在pg_class中對應列存表元組的relcudescrelid屬性中查到,所有CUDesc表預設儲存在namespace oid = 100,name為cstore的namespace下。
4.delta表
在列儲存方式中,無論是向列存表中插入1條還是60000條資料,都只會生成一個CU,在多次插入少量資料時,不能有效的利用列存壓縮能力,導致資料膨脹影響查詢的效能和磁碟使用率。CU只支援追加寫的方式,也就是說,後面對這個CU中的資料做更新或刪除都不會真正更改這個CU,刪除是將老資料在字典中標記為作廢,更新操作是標記老資料刪除後,再寫入一條新記錄到新CU,原來的CU不會有任何的修改。
從這裡我們可以看出,在對列存表進行多次更新/刪除,或每次只插入很少量的資料後,會導致列存表空間膨脹,大量空間無法有效利用,這是因為列存表在設計上就是為了大批次資料匯入以及海量資料按列儲存/查詢。Delta表正是為了解決這兩個問題。在啟用delta表後,單條或者小批次資料匯入時,資料將進入delta表中,避免小CU的產生,delta表的增刪改查與行存表一致。開啟delta表後,將顯著提升列存表單條匯入的效能。
delta表同樣是一張行存表,為了輔助列存表而存在。在建立列存表時系統會為該列存表建立一張對應的delta表,delta表的oid可以在pg_class中對應列存表元組的reldeltarelid屬性中查到,所有delta表也預設儲存在namespace oid = 100,name為cstore的namespace下。
建立一張列存表col_test,同時設定reloption屬性enable_delta=true。在pg_class中檢視該表對應的delta表oid。

圖7 建立列存表並開啟delta表
進一步根據該oid資訊可以查到delta表的對應資訊。

圖8 查詢delta表相關資訊
可以指定reloption選項設定是否為該列存表開啟delta表:

圖9 開啟/關閉delta表操作
5.分割區表
分割區表就是把邏輯上的一張表根據某種方案分成幾張物理塊進行儲存。這張邏輯上的表稱之為分割區表,物理塊稱之為分割區。分割區表是一張邏輯表,不儲存資料,資料實際是儲存在分割區上的。分割區表的定義不難理解,下面我們通過一個例子說明分割區表的用法。
建立一張有id和name兩個屬性的分割區表part_test,該表以id的大小進行分割區,其中id<10的資料儲存在分割區location_1,10≤id<20的資料儲存在分割區location_2,所有id≥20的資料儲存在分割區location_3。
CREATE TABLE part_test(id int,name text) partition BY range(id) (partition locatition_1 values less than (10),partition locatition_2 values less than (20),partition locatition_3 values less than (maxvalue));
建立好part_test表後,我們所有的增刪改查都是直接對part_test表操作的,對使用者操作來說part_test表與普通表沒有什麼區別,但實際的儲存方式卻是嚴格按照分割區的劃分方式進行儲存的,資料儲存在各個分割區上,part_test表作為一張邏輯表不儲存資料。我們可以通過pg_partition這張系統表查詢到一張分割區表的分割區資訊。
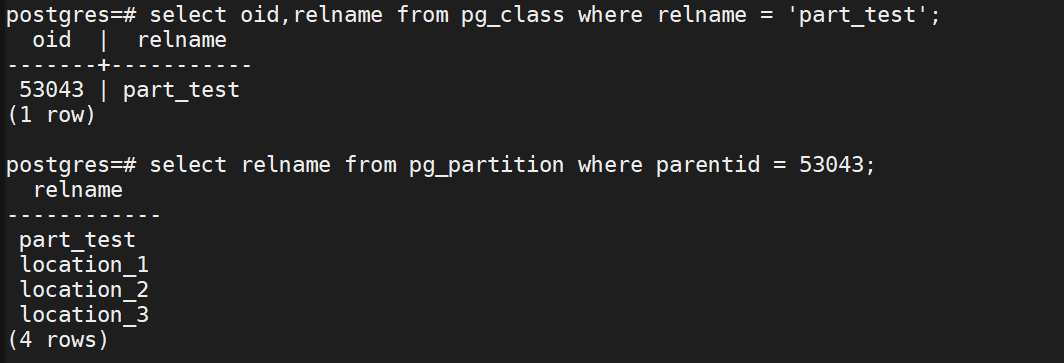
圖10 part_test表分割區資訊
分割區表和分割區的關係如圖所示:
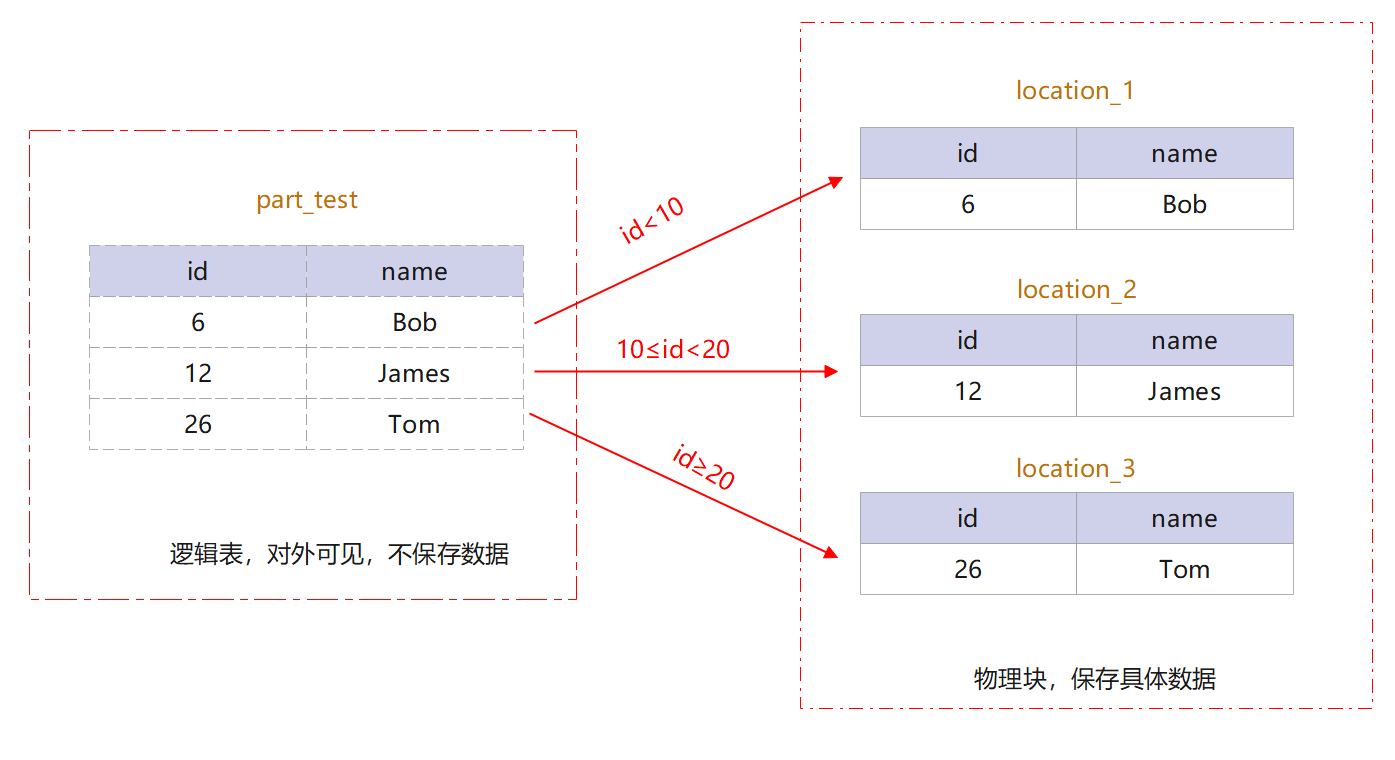
圖11 分割區表和分割區關係圖
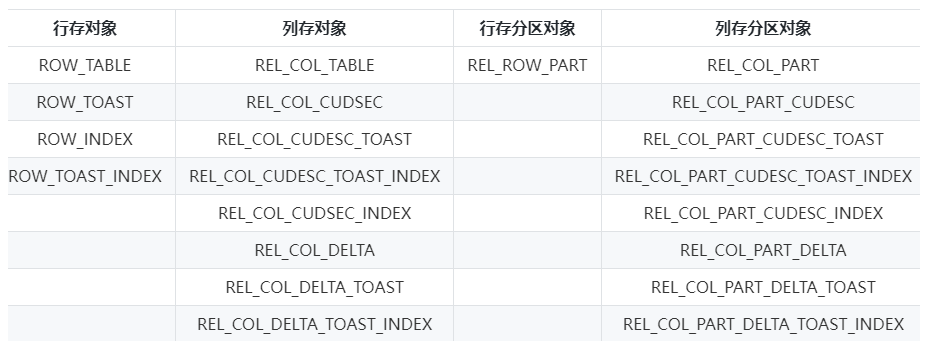
6.各類表相關物件總結