MySQL 的 NULL 值是怎麼儲存的?
大家好,我是小林。
之前有位讀者在面位元組的時候,被問到這麼個問題:

如果你知道 MySQL 一行記錄的儲存結構,那麼這個問題對你沒什麼難度。
如果你不知道也沒關係,這次我跟大家聊聊 MySQL 一行記錄是怎麼儲存的?
知道了這個之後,除了能應解鎖前面這道面試題,你還會解鎖這些面試題:
- MySQL 的 NULL 值會佔用空間嗎?
- MySQL 怎麼知道 varchar(n) 實際佔用資料的大小?
- varchar(n) 中 n 最大取值為多少?
- 行溢位後,MySQL 是怎麼處理的?
這些問題看似毫不相干,其實都是在圍繞「 MySQL 一行記錄的儲存結構」這一個知識點,所以攻破了這個知識點後,這些問題就引刃而解了。
好了,話不多說,發車!
MySQL 的資料存放在哪個檔案?
大家都知道 MySQL 的資料都是儲存在磁碟的,那具體是儲存在哪個檔案呢?
MySQL 儲存的行為是由儲存引擎實現的,MySQL 支援多種儲存引擎,不同的儲存引擎儲存的檔案自然也不同。
InnoDB 是我們常用的儲存引擎,也是 MySQL 預設的儲存引擎。所以,本文主要以 InnoDB 儲存引擎展開討論。
先來看看 MySQL 資料庫的檔案存放在哪個目錄?
mysql> SHOW VARIABLES LIKE 'datadir';
+---------------+-----------------+
| Variable_name | Value |
+---------------+-----------------+
| datadir | /var/lib/mysql/ |
+---------------+-----------------+
1 row in set (0.00 sec)
我們每建立一個 database(資料庫) 都會在 /var/lib/mysql/ 目錄裡面建立一個以 database 為名的目錄,然後儲存表結構和表資料的檔案都會存放在這個目錄裡。
比如,我這裡有一個名為 my_test 的 database,該 database 裡有一張名為 t_order 資料庫表。
然後,我們進入 /var/lib/mysql/my_test 目錄,看看裡面有什麼檔案?
[root@xiaolin ~]#ls /var/lib/mysql/my_test
db.opt
t_order.frm
t_order.ibd
可以看到,共有三個檔案,這三個檔案分別代表著:
- db.opt,用來儲存當前資料庫的預設字元集和字元校驗規則。
- t_order.frm ,t_order 的表結構會儲存在這個檔案。在 MySQL 中建立一張表都會生成一個.frm 檔案,該檔案是用來儲存每個表的後設資料資訊的,主要包含表結構定義。
- t_order.ibd,t_order 的表資料會儲存在這個檔案。表資料既可以存在共用表空間檔案(檔名:ibdata1)裡,也可以存放在獨佔表空間檔案(檔名:表名字.idb)。這個行為是由引數 innodb_file_per_table 控制的,若設定了引數 innodb_file_per_table 為 1,則會將儲存的資料、索引等資訊單獨儲存在一個獨佔表空間,從 MySQL 5.6.6 版本開始,它的預設值就是 1 了,因此從這個版本之後, MySQL 中每一張表的資料都存放在一個獨立的 .idb 檔案。
好了,現在我們知道了一張資料庫表的資料是儲存在「 表名字.idb 」的檔案裡的,這個檔案也稱為獨佔表空間檔案。
表空間檔案的結構是怎麼樣的?
表空間由段(segment)、區(extent)、頁(page)、行(row)組成,InnoDB儲存引擎的邏輯儲存結構大致如下圖:
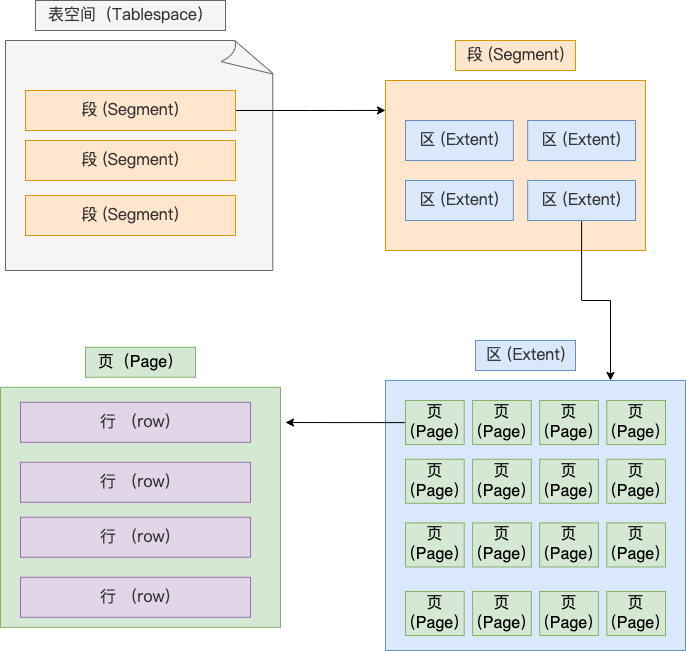
下面我們從下往上一個個看看。
1、行(row)
資料庫表中的記錄都是按行(row)進行存放的,每行記錄根據不同的行格式,有不同的儲存結構。
後面我們詳細介紹 InnoDB 儲存引擎的行格式,也是本文重點介紹的內容。
2、頁(page)
記錄是按照行來儲存的,但是資料庫的讀取並不以「行」為單位,否則一次讀取(也就是一次 I/O 操作)只能處理一行資料,效率會非常低。
因此,InnoDB 的資料是按「頁」為單位來讀寫的,也就是說,當需要讀一條記錄的時候,並不是將這個行記錄從磁碟讀出來,而是以頁為單位,將其整體讀入記憶體。
預設每個頁的大小為 16KB,也就是最多能保證 16KB 的連續儲存空間。
頁是 InnoDB 儲存引擎磁碟管理的最小單元,意味著資料庫每次讀寫都是以 16KB 為單位的,一次最少從磁碟中讀取 16K 的內容到記憶體中,一次最少把記憶體中的 16K 內容重新整理到磁碟中。
頁的型別有很多,常見的有資料頁、undo 紀錄檔頁、溢位頁等等。資料表中的行記錄是用「資料頁」來管理的,資料頁的結構這裡我就不講細說了,之前文章有說過,感興趣的可以去看這篇文章:換一個角度看 B+ 樹
總之知道表中的記錄儲存在「資料頁」裡面就行。
3、區(extent)
我們知道 InnoDB 儲存引擎是用 B+ 樹來組織資料的。
B+ 樹中每一層都是通過雙向連結串列連線起來的,如果是以頁為單位來分配儲存空間,那麼連結串列中相鄰的兩個頁之間的物理位置並不是連續的,可能離得非常遠,那麼磁碟查詢時就會有大量的隨機I/O,隨機 I/O 是非常慢的。
解決這個問題也很簡單,就是讓連結串列中相鄰的頁的物理位置也相鄰,這樣就可以使用順序 I/O 了,那麼在範圍查詢(掃描葉子節點)的時候效能就會很高。
那具體怎麼解決呢?
在表中資料量大的時候,為某個索引分配空間的時候就不再按照頁為單位分配了,而是按照區(extent)為單位分配。每個區的大小為 1MB,對於 16KB 的頁來說,連續的 64 個頁會被劃為一個區,這樣就使得連結串列中相鄰的頁的物理位置也相鄰,就能使用順序 I/O 了。
4、段(segment)
表空間是由各個段(segment)組成的,段是由多個區(extent)組成的。段一般分為資料段、索引段和回滾段等。
- 索引段:存放 B + 樹的非葉子節點的區的集合;
- 資料段:存放 B + 樹的葉子節點的區的集合;
- 回滾段:存放的是回滾資料的區的集合,之前講事務隔離的時候就介紹到了 MVCC 利用了回滾段實現了多版本查詢資料。
好了,終於說完表空間的結構了。接下來,就具體講一下 InnoDB 的行格式了。
之所以要繞一大圈才講行記錄的格式,主要是想讓大家知道行記錄是儲存在哪個檔案,以及行記錄在這個表空間檔案中的哪個區域,有一個從上往下切入的視角,這樣理解起來不會覺得很抽象。
InnoDB 行格式有哪些?
行格式(row_format),就是一條記錄的儲存結構。
InnoDB 提供了 4 種行格式,分別是 Redundant、Compact、Dynamic和 Compressed 行格式。
- Redundant 是很古老的行格式了, MySQL 5.0 版本之前用的行格式,現在基本沒人用了。
- 由於 Redundant 不是一種緊湊的行格式,所以 MySQL 5.0 之後引入了 Compact 行記錄儲存方式,Compact 是一種緊湊的行格式,設計的初衷就是為了讓一個資料頁中可以存放更多的行記錄,從 MySQL 5.1 版本之後,行格式預設設定成 Compact。
- Dynamic 和 Compressed 兩個都是緊湊的行格式,它們的行格式都和 Compact 差不多,因為都是基於 Compact 改進一點東西。從 MySQL5.7 版本之後,預設使用 Dynamic 行格式。
Redundant 行格式我這裡就不講了,因為現在基本沒人用了,這次重點介紹 Compact 行格式,因為 Dynamic 和 Compressed 這兩個行格式跟 Compact 非常像。
所以,弄懂了 Compact 行格式,之後你們在去了解其他行格式,很快也能看懂。
COMPACT 行格式長什麼樣?
先跟 Compact 行格式混個臉熟,它長這樣:
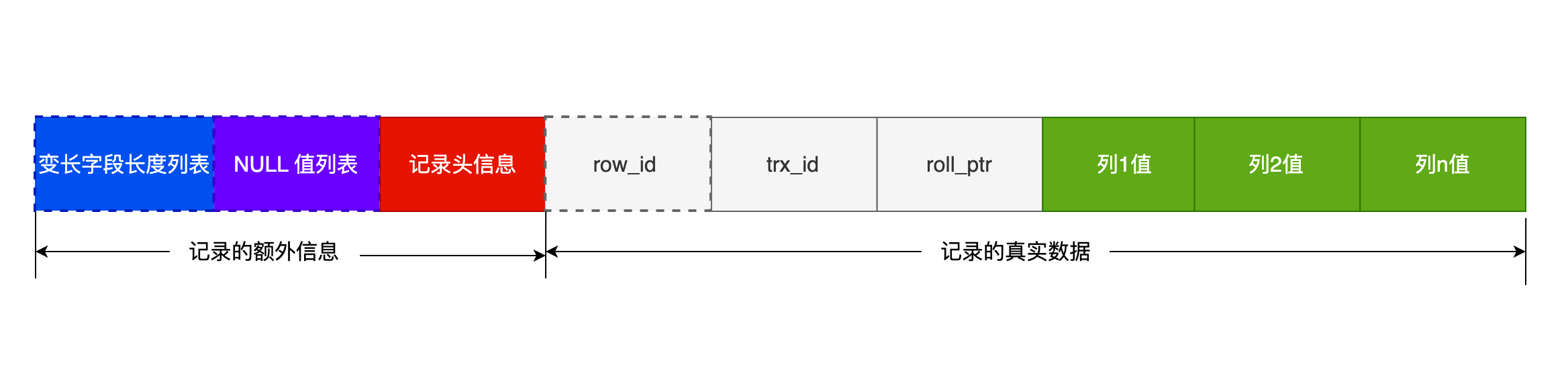
可以看到,一條完整的記錄分為「記錄的額外資訊」和「記錄的真實資料」兩個部分。
接下里,分別詳細說下。
記錄的額外資訊
記錄的額外資訊包含 3 個部分:變長欄位長度列表、NULL 值列表、記錄頭資訊。
1. 變長欄位長度列表
varchar(n) 和 char(n) 的區別是什麼,相信大家都非常清楚,char 是定長的,varchar 是變長的,變長欄位實際儲存的資料的長度(大小)不固定的。
所以,在儲存資料的時候,也要把資料佔用的大小存起來,存到「變長欄位長度列表」裡面,讀取資料的時候才能根據這個「變長欄位長度列表」去讀取對應長度的資料。其他 TEXT、BLOB 等變長欄位也是這麼實現的。
為了展示「變長欄位長度列表」具體是怎麼儲存「變長欄位的真實資料佔用的位元組數」,我們先建立這樣一張表,字元集是 ascii(所以每一個字元佔用的 1 位元組),行格式是 Compact,t_user 表中 name 和 phone 欄位都是變長欄位:
CREATE TABLE `t_user` (
`id` int(11) NOT NULL,
`name` VARCHAR(20) NOT NULL,
`phone` VARCHAR(20) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT;
現在 t_user 表裡有這三條記錄:
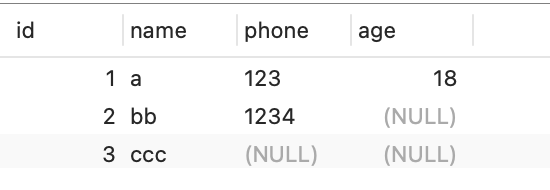
接下來,我們看看看看這三條記錄的行格式中的 「變長欄位長度列表」是怎樣儲存的。
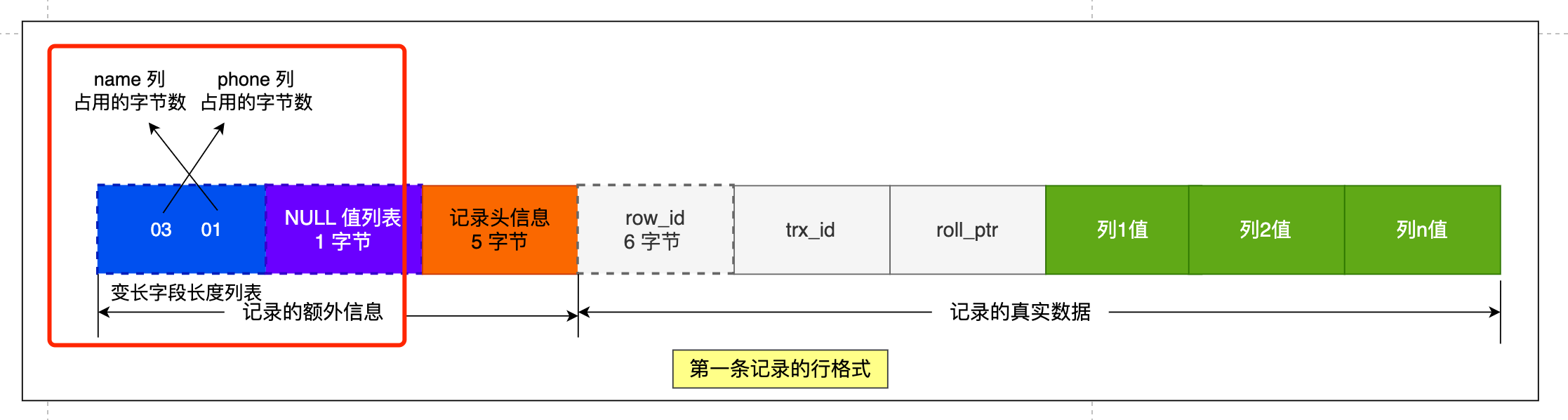
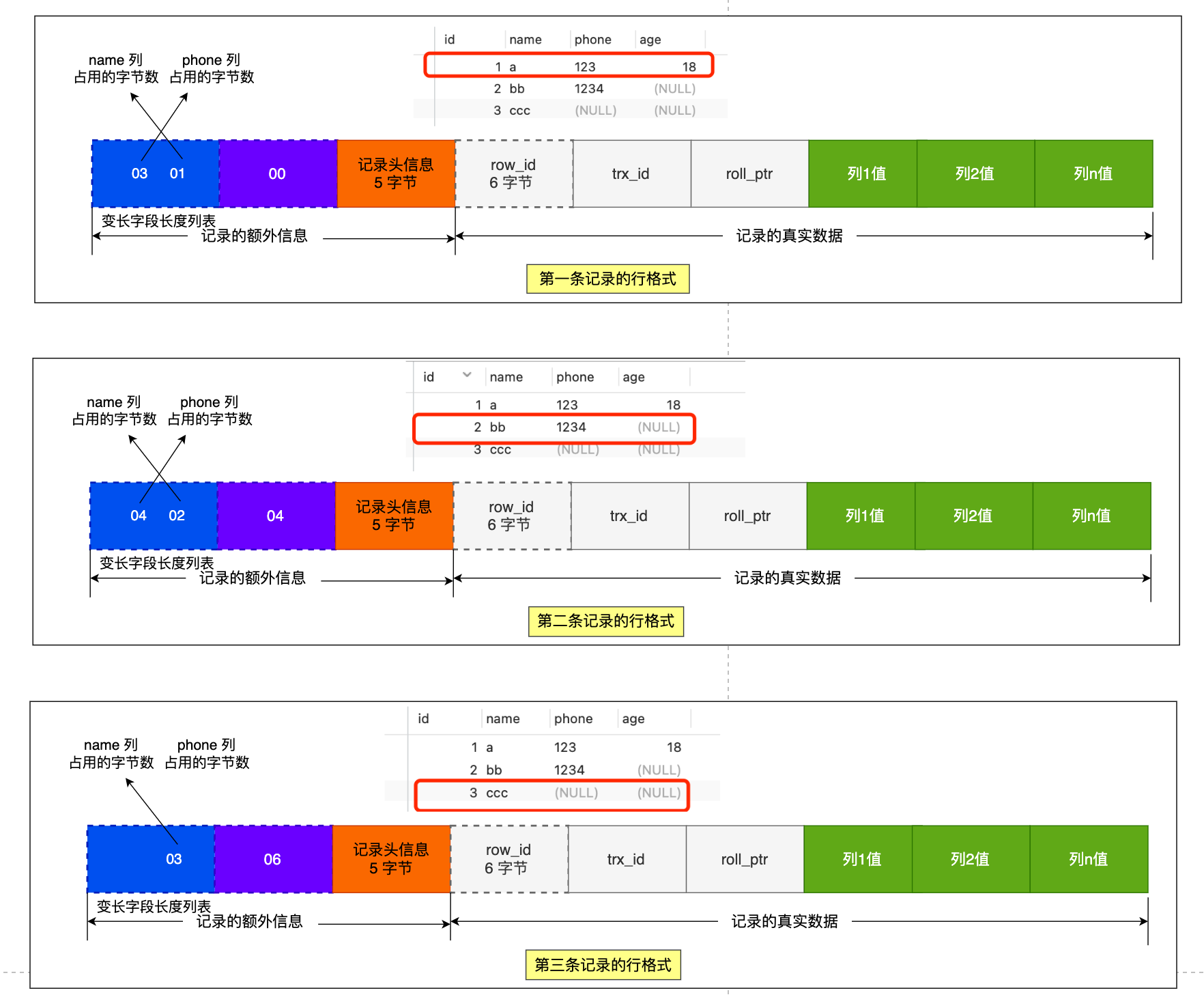
先來看第一條記錄:
- name 列的值為 a,真實資料佔用的位元組數是 1 位元組,十六進位制 0x01;
- phone 列的值為 123,真實資料佔用的位元組數是 3 位元組,十六進位制 0x03;
- age 列和 id 列不是變長欄位,所以這裡不用管。
這些變長欄位的真實資料佔用的位元組數會按照列的順序逆序存放(等下會說為什麼要這麼設計),所以「變長欄位長度列表」裡的內容是「 03 01」,而不是 「01 03」。
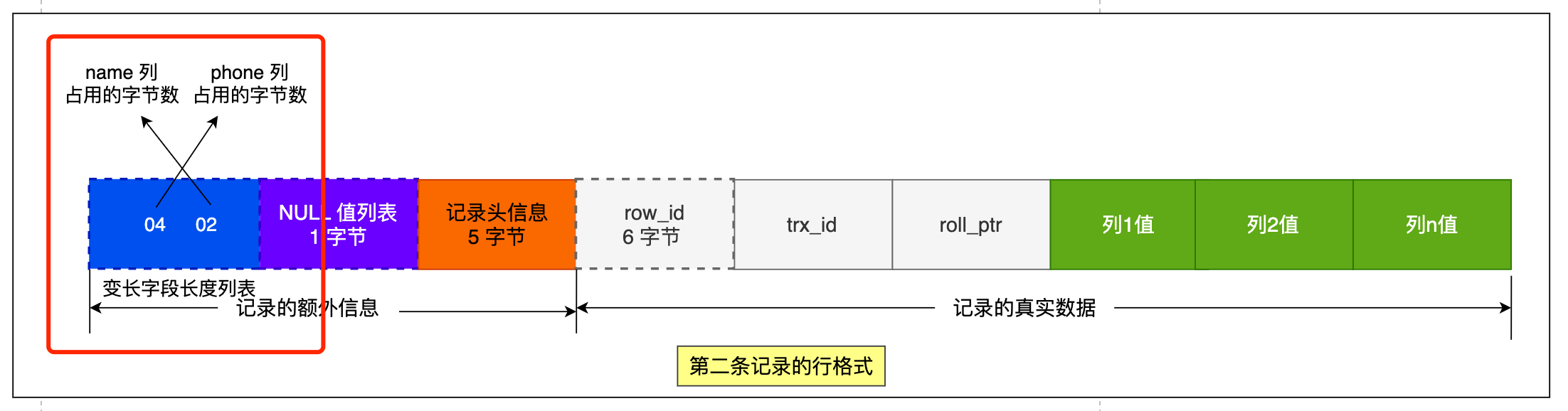
同樣的道理,我們也可以得出第二條記錄的行格式中,「變長欄位長度列表」裡的內容是「 04 02」,如下圖:
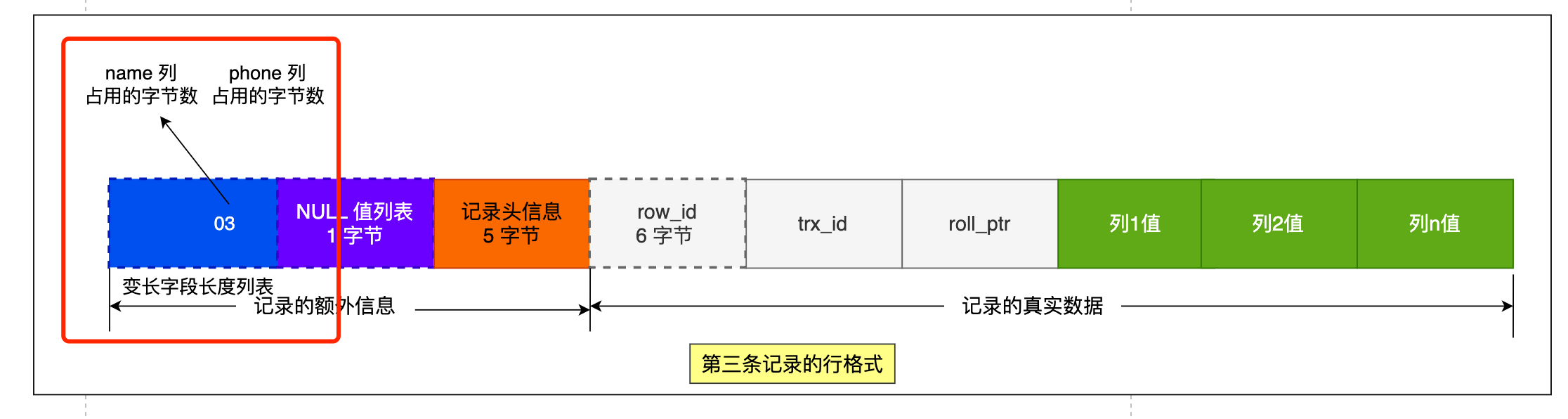
第三條記錄中 phone 列的值是 NULL,NULL 是不會存放在行格式中記錄的真實資料部分裡的,所以「變長欄位長度列表」裡不需要儲存值為 NULL 的變長欄位的長度。
為什麼「變長欄位長度列表」的資訊要按照逆序存放?
這個設計是有想法的,主要是因為「記錄頭資訊」中指向下一個記錄的指標,指向的是下一條記錄的「記錄頭資訊」和「真實資料」之間的位置,這樣的好處是向左讀就是記錄頭資訊,向右讀就是真實資料,比較方便。
「變長欄位長度列表」中的資訊之所以要逆序存放,是因為這樣可以使得位置靠前的記錄的真實資料和資料對應的欄位長度資訊可以同時在一個 CPU Cache Line 中,這樣就可以提高 CPU Cache 的命中率。
同樣的道理, NULL 值列表的資訊也需要逆序存放。
如果你不知道什麼是 CPU Cache,可以看這篇文章,這屬於計算機組成的知識。
每個資料庫表的行格式都有「變長欄位位元組數列表」嗎?
其實變長欄位位元組數列表不是必須的。
當資料表沒有變長欄位的時候,比如全部都是 int 型別的欄位,這時候表裡的行格式就不會有「變長欄位長度列表」了,因為沒必要,不如去掉以節省空間。
所以「變長欄位長度列表」只出現在資料表有變長欄位的時候。
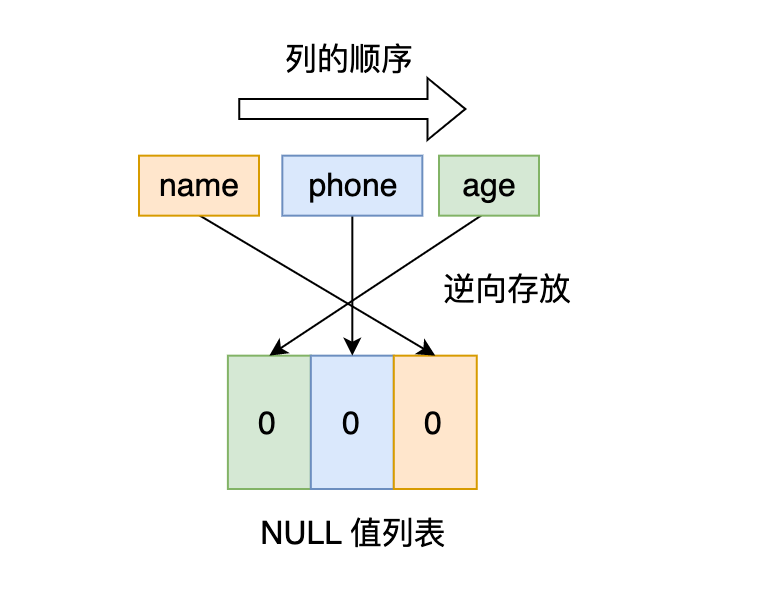
2. NULL 值列表
表中的某些列可能會儲存 NULL 值,如果把這些 NULL 值都放到記錄的真實資料中會比較浪費空間,所以 Compact 行格式把這些值為 NULL 的列儲存到 NULL值列表中。
如果存在允許 NULL 值的列,則每個列對應一個二進位制位(bit),二進位制位按照列的順序逆序排列。
- 二進位制位的值為
1時,代表該列的值為NULL。 - 二進位制位的值為
0時,代表該列的值不為NULL。
另外,NULL 值列表必須用整數個位元組的位表示(1位元組8位元),如果使用的二進位制位個數不足整數個位元組,則在位元組的高位補 0。
還是以 t_user 表的這三條記錄作為例子:
接下來,我們看看看看這三條記錄的行格式中的 NULL 值列表是怎樣儲存的。
先來看第一條記錄,第一條記錄所有列都有值,不存在 NULL 值,所以用二進位制來表示是醬紫的:
但是 InnoDB 是用整數位節的二進位制位來表示 NULL 值列表的,現在不足 8 位,所以要在高位補 0,最終用二進位制來表示是醬紫的:
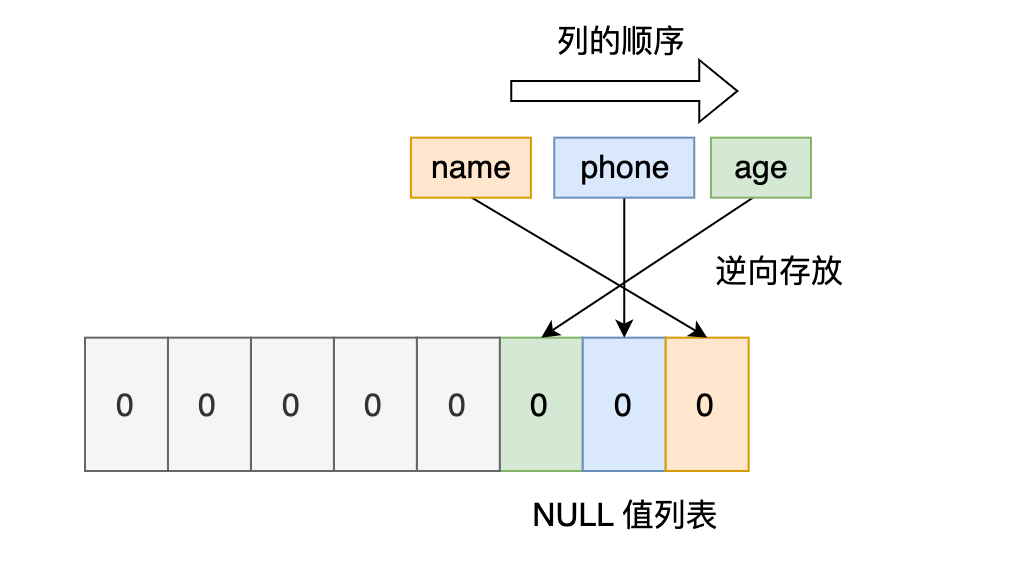
所以,對於第一條資料,NULL 值列表用十六進位製表示是 0x00。
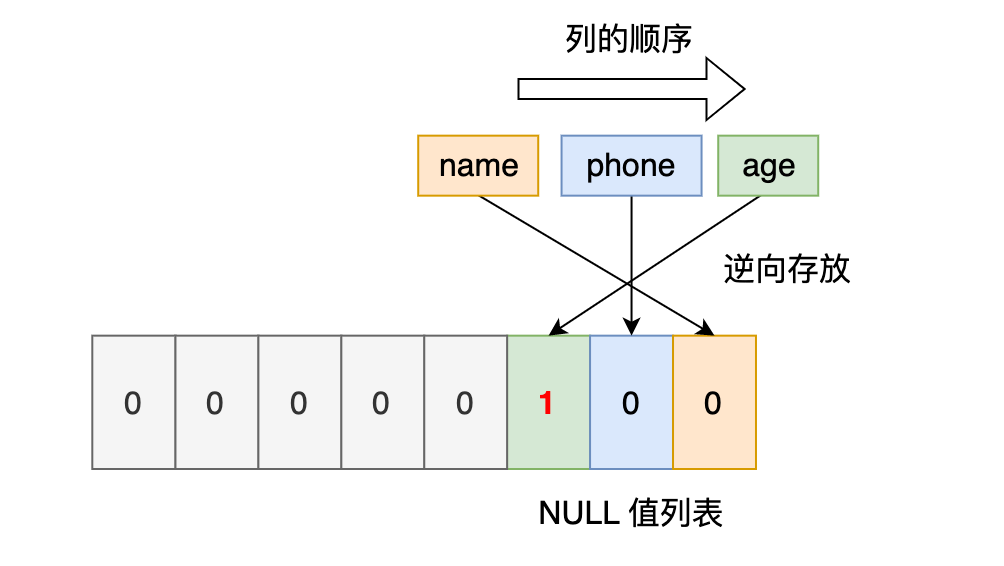
接下來看第二條記錄,第二條記錄 age 列是 NULL 值,所以,對於第二條資料,NULL值列表用十六進位製表示是 0x04。
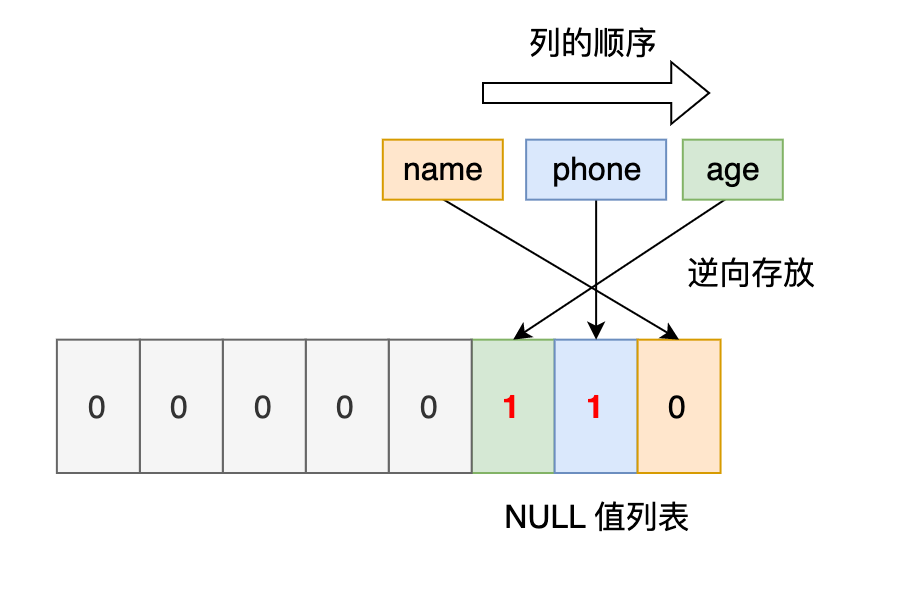
最後第三條記錄,第三條記錄 phone 列 和 age 列是 NULL 值,所以,對於第三條資料,NULL 值列表用十六進位製表示是 0x06。
我們把三條記錄的 NULL 值列表都填充完畢後,它們的行格式是這樣的:
每個資料庫表的行格式都有「NULL 值列表」嗎?
NULL 值列表也不是必須的。
當資料表的欄位都定義成 NOT NULL 的時候,這時候表裡的行格式就不會有 NULL 值列表了。所以在設計資料庫表的時候,通常都是建議將欄位設定為 NOT NULL,這樣可以節省 1 位元組的空間(NULL 值列表佔用 1 位元組空間)。
「NULL 值列表」是固定 1 位元組空間嗎?如果這樣的話,一條記錄有 9 個欄位值都是 NULL,這時候怎麼表示?
「NULL 值列表」的空間不是固定 1 位元組的。
當一條記錄有 9 個欄位值都是 NULL,那麼就會建立 2 位元組空間的「NULL 值列表」,以此類推。
3. 記錄頭資訊
記錄頭資訊中包含的內容很多,我就不一一列舉了,這裡說幾個比較重要的:
- delete_mask :標識此條資料是否被刪除。從這裡可以知道,我們執行 detele 刪除記錄的時候,並不會真正的刪除記錄,只是將這個記錄的 delete_mask 標記為 1。
- next_record:下一條記錄的位置。從這裡可以知道,記錄與記錄之間是通過連結串列組織的。在前面我也提到了,指向的是下一條記錄的「記錄頭資訊」和「真實資料」之間的位置,這樣的好處是向左讀就是記錄頭資訊,向右讀就是真實資料,比較方便。
- record_type:表示當前記錄的型別,0表示普通記錄,1表示B+樹非葉子節點記錄,2表示最小記錄,3表示最大記錄
記錄的真實資料
記錄真實資料部分除了我們定義的欄位,還有三個隱藏欄位,分別為:row_id、trx_id、roll_pointer,我們來看下這三個欄位是什麼。

- row_id
如果我們建表的時候指定了主鍵或者唯一約束列,那麼就沒有 row_id 隱藏欄位了。如果既沒有指定主鍵,又沒有唯一約束,那麼 InnoDB 就會為記錄新增 row_id 隱藏欄位。row_id不是必需的,佔用 6 個位元組。
- trx_id
事務id,表示這個資料是由哪個事務生成的。 trx_id是必需的,佔用 6 個位元組。
- roll_pointer
這條記錄上一個版本的指標。roll_pointer 是必需的,佔用 7 個位元組。
如果你熟悉 MVCC 機制,你應該就清楚 trx_id 和 roll_pointer 的作用了,如果你還不知道 MVCC 機制,可以看完這篇文章,一定要掌握,面試也很經常問 MVCC 是怎麼實現的。
varchar(n) 中 n 最大取值為多少?
我們要清楚一點,MySQL 規定除了 TEXT、BLOBs 這種大物件型別之外,其他所有的列(不包括隱藏列和記錄頭資訊)佔用的位元組長度加起來不能超過 65535 個位元組。
也就是說,一行記錄除了 TEXT、BLOBs 型別的列,限制最大為 65535 位元組,注意是一行的總長度,不是一列。
知道了這個前提之後,我們再來看看這個問題:「varchar(n) 中 n 最大取值為多少?」
varchar(n) 欄位型別的 n 代表的是最多儲存的字元數量,並不是位元組大小哦。
要算 varchar(n) 最大能允許儲存的位元組數,還要看資料庫表的字元集,因為字元集代表著,1個字元要佔用多少位元組,比如 ascii 字元集, 1 個字元佔用 1 位元組,那麼 varchar(100) 意味著最大能允許儲存 100 位元組的資料。
單欄位的情況
前面我們知道了,一行記錄最大隻能儲存 65535 位元組的資料。
那假設資料庫表只有一個 varchar(n) 型別的列且字元集是 ascii,在這種情況下, varchar(n) 中 n 最大取值是 65535 嗎?
不著急說結論,我們先來做個實驗驗證一下。
我們定義一個 varchar(65535) 型別的欄位,字元集為 ascii 的資料庫表。
CREATE TABLE test (
`name` VARCHAR(65535) NULL
) ENGINE = InnoDB DEFAULT CHARACTER SET = ascii ROW_FORMAT = COMPACT;
看能不能成功建立一張表:

可以看到,建立失敗了。
從報錯資訊就可以知道一行資料的最大位元組數是 65535(不包含 TEXT、BLOBs 這種大物件型別),其中包含了 storage overhead。
問題來了,這個 storage overhead 是什麼呢?其實就是「變長欄位長度列表」和 「NULL 值列表」,也就是說一行資料的最大位元組數 65535,其實是包含「變長欄位長度列表」和 「NULL 值列表」所佔用的位元組數的。所以, 我們在算 varchar(n) 中 n 最大值時,需要減去 storage overhead 佔用的位元組數。
這是因為我們儲存欄位型別為 varchar(n) 的資料時,其實分成了三個部分來儲存:
- 真實資料
- 真實資料佔用的位元組數
- NULL 標識,如果不允許為NULL,這部分不需要
本次案例中,「NULL 值列表」所佔用的位元組數是多少?
前面我建立表的時候,欄位是允許為 NULL 的,所以會用 1 位元組來表示「NULL 值列表」。
本次案例中,「變長欄位長度列表」所佔用的位元組數是多少?
「變長欄位長度列表」所佔用的位元組數 = 所有「變長欄位長度」佔用的位元組數之和。
所以,我們要先知道每個變長欄位的「變長欄位長度」需要用多少位元組表示?具體情況分為:
- 條件一:如果變長欄位允許儲存的最大位元組數小於等於 255 位元組,就會用 1 位元組表示「變長欄位長度」;
- 條件二:如果變長欄位允許儲存的最大位元組數大於 255 位元組,就會用 2 位元組表示「變長欄位長度」;
我們這裡欄位型別是 varchar(65535) ,字元集是 ascii,所以代表著變長欄位允許儲存的最大位元組數是 65535,符合條件二,所以會用 2 位元組來表示「變長欄位長度」。
因為我們這個案例是隻有 1 個變長欄位,所以「變長欄位長度列表」= 1 個「變長欄位長度」佔用的位元組數,也就是 2 位元組。
因為我們在算 varchar(n) 中 n 最大值時,需要減去 「變長欄位長度列表」和 「NULL 值列表」所佔用的位元組數的。所以,在資料庫表只有一個 varchar(n) 欄位且字元集是 ascii 的情況下,varchar(n) 中 n 最大值 = 65535 - 2 - 1 = 65532。
我們先來測試看看 varchar(65533) 是否可行?

可以看到,還是不行,接下來看看 varchar(65532) 是否可行?

可以看到,建立成功了。說明我們的推論是正確的,在算 varchar(n) 中 n 最大值時,需要減去 「變長欄位長度列表」和 「NULL 值列表」所佔用的位元組數的。
當然,我上面這個例子是針對字元集為 ascii 情況,如果採用的是 UTF-8,varchar(n) 最多能儲存的資料計算方式就不一樣了:
- 在 UTF-8 字元集下,一個字串最多需要三個位元組,varchar(n) 的 n 最大取值就是 65532/3 = 21844。
上面所說的只是針對於一個欄位的計算方式。
多欄位的情況
如果有多個欄位的話,要保證所有欄位的長度 + 變長欄位位元組數列表所佔用的位元組數 + NULL值列表所佔用的位元組數 <= 65535。
這裡舉個多欄位的情況的例子(感謝@Emoji同學提供的例子)

行溢位後,MySQL 是怎麼處理的?
MySQL 中磁碟和記憶體互動的基本單位是頁,一個頁的大小一般是 16KB,也就是 16384位元組,而一個 varchar(n) 型別的列最多可以儲存 65532位元組,一些大物件如 TEXT、BLOB 可能儲存更多的資料,這時一個頁可能就存不了一條記錄。這個時候就會發生行溢位,多的資料就會存到另外的「溢位頁」中。
如果一個資料頁存不了一條記錄,InnoDB 儲存引擎會自動將溢位的資料存放到「溢位頁」中。在一般情況下,InnoDB 的資料都是存放在 「資料頁」中。但是當發生行溢位時,溢位的資料會存放到「溢位頁」中。
當發生行溢位時,在記錄的真實資料處只會儲存該列的一部分資料,而把剩餘的資料放在「溢位頁」中,然後真實資料處用 20 位元組儲存指向溢位頁的地址,從而可以找到剩餘資料所在的頁。大致如下圖所示。
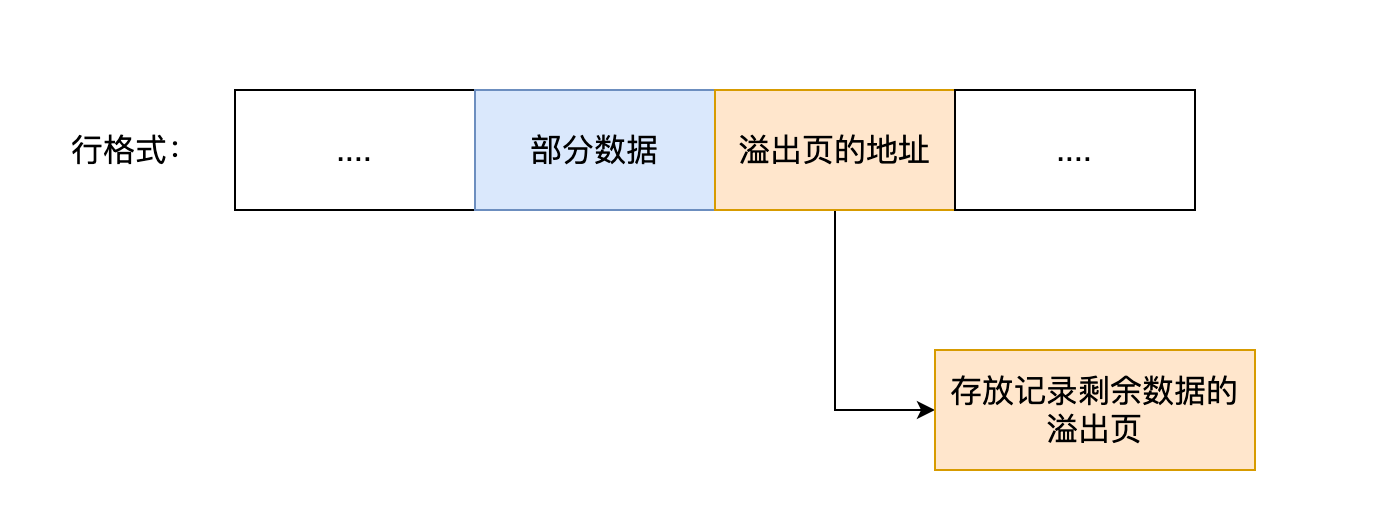
上面這個是 Compact 行格式在發生行溢位後的處理。
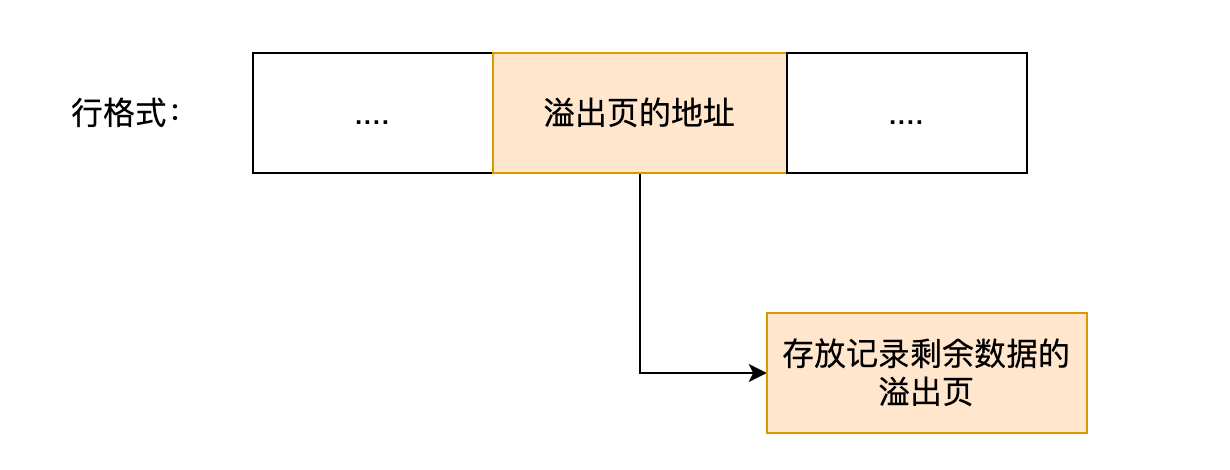
Compressed 和 Dynamic 這兩個行格式和 Compact 非常類似,主要的區別在於處理行溢位資料時有些區別。
這兩種格式採用完全的行溢位方式,記錄的真實資料處不會儲存該列的一部分資料,只儲存 20 個位元組的指標來指向溢位頁。而實際的資料都儲存在溢位頁中,看起來就像下面這樣:
總結
MySQL 的 NULL 值是怎麼存放的?
MySQL 的 Compact 行格式中會用「NULL值列表」來標記值為 NULL 的列,NULL 值並不會儲存在行格式中的真實資料部分。
NULL值列表會佔用 1 位元組空間,當表中所有欄位都定義成 NOT NULL,行格式中就不會有 NULL值列表,這樣可節省 1 位元組的空間。
MySQL 怎麼知道 varchar(n) 實際佔用資料的大小?
MySQL 的 Compact 行格式中會用「變長欄位長度列表」儲存變長欄位實際佔用的資料大小。
varchar(n) 中 n 最大取值為多少?
一行記錄最大能儲存 65535 位元組的資料,但是這個是包含「變長欄位位元組數列表所佔用的位元組數」和「NULL值列表所佔用的位元組數」。所以, 我們在算 varchar(n) 中 n 最大值時,需要減去這兩個列表所佔用的位元組數。
如果一張表只有一個 varchar(n) 欄位,且允許為 NULL,字元集為 ascii。varchar(n) 中 n 最大取值為 65532。
計算公式:65535 - 變長欄位位元組數列表所佔用的位元組數 - NULL值列表所佔用的位元組數 = 65535 - 2 - 1 = 65532。
如果有多個欄位的話,要保證所有欄位的長度 + 變長欄位位元組數列表所佔用的位元組數 + NULL值列表所佔用的位元組數 <= 65535。
行溢位後,MySQL 是怎麼處理的?
如果一個資料頁存不了一條記錄,InnoDB 儲存引擎會自動將溢位的資料存放到「溢位頁」中。
Compact 行格式針對行溢位的處理是這樣的:當發生行溢位時,在記錄的真實資料處只會儲存該列的一部分資料,而把剩餘的資料放在「溢位頁」中,然後真實資料處用 20 位元組儲存指向溢位頁的地址,從而可以找到剩餘資料所在的頁。
Compressed 和 Dynamic 這兩種格式採用完全的行溢位方式,記錄的真實資料處不會儲存該列的一部分資料,只儲存 20 個位元組的指標來指向溢位頁。而實際的資料都儲存在溢位頁中。
參考資料:
- 《MySQL 是怎樣執行的》
- 《MySQL技術內幕 InnoDB儲存引擎》
