Flink同步Kafka資料到ClickHouse分散式表
公眾號文章都在個人部落格網站:https://www.ikeguang.com/ 同步,歡迎存取。
業務需要一種OLAP引擎,可以做到實時寫入儲存和查詢計算功能,提供高效、穩健的實時資料服務,最終決定ClickHouse。
什麼是ClickHouse?
ClickHouse是一個用於聯機分析(OLAP)的列式資料庫管理系統(DBMS)。
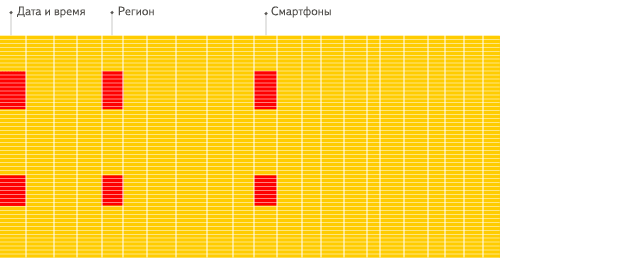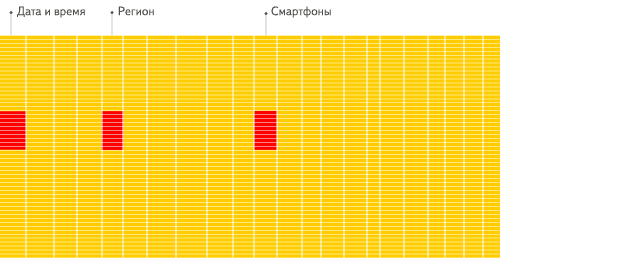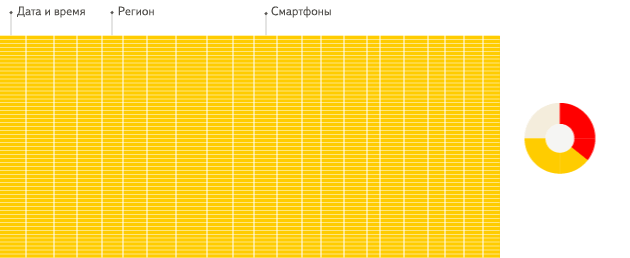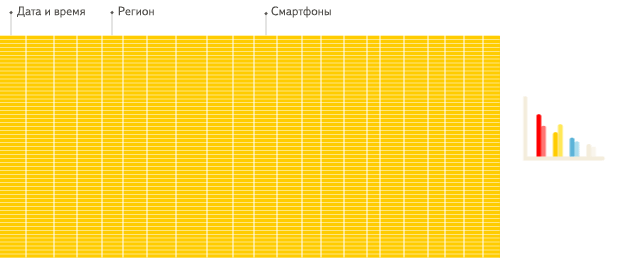
列式資料庫更適合於OLAP場景(對於大多數查詢而言,處理速度至少提高了100倍),下面詳細解釋了原因(通過圖片更有利於直觀理解),圖片來源於ClickHouse中文官方檔案。
行式
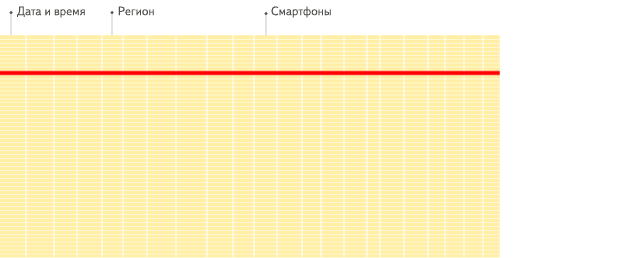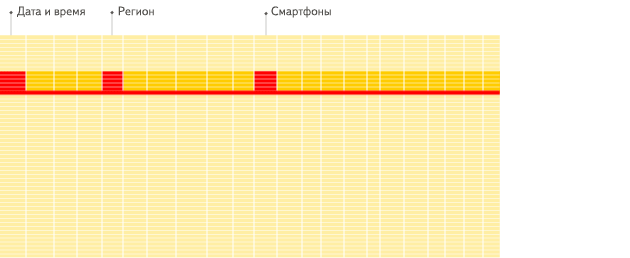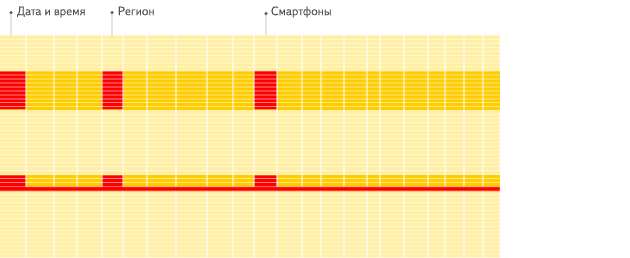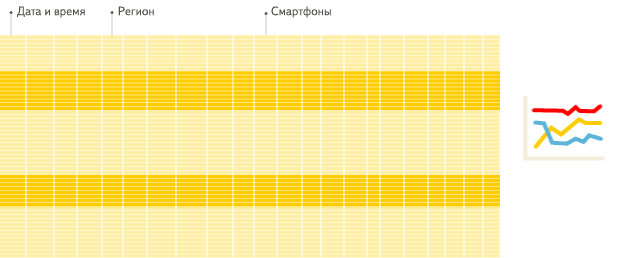
列式
我們使用Flink編寫程式,消費kafka裡面的主題資料,清洗、歸一,寫入到clickhouse裡面去。
這裡的關鍵點,由於第一次使用,無法分清應該建立什麼格式的clickhouse表,出現了一些問題,最大的問題就是程式將資料寫入了,查詢發現資料不完整,只有一部分。我也在網上查了一些原因,總結下來。
為什麼有時看不到已經建立好的表並且查詢結果一直抖動時多時少?
- 常見原因1:
建表流程存在問題。ClickHouse的分散式叢集搭建並沒有原生的分散式DDL語意。如果您在自建ClickHouse叢集時使用create table建立表,查詢雖然返回了成功,但實際這個表只在當前連線的Server上建立了。下次連線重置換一個Server,您就看不到這個表了。
解決方案:
建表時,請使用create table <table_name> on cluster default語句,on cluster default宣告會把這條語句廣播給default叢集的所有節點進行執行。範例程式碼如下。
Create table test on cluster default (a UInt64) Engine = MergeTree() order by tuple();
在test表上再建立一個分散式表引擎,建表語句如下。
Create table test_dis on cluster default as test Engine = Distributed(default, default, test, cityHash64(a));
- 常見原因2:
ReplicatedMergeTree儲存表設定有問題。ReplicatedMergeTree表引擎是對應MergeTree表引擎的主備同步增強版,在單副本範例上限定只能建立MergeTree表引擎,在雙副本範例上只能建立ReplicatedMergeTree表引擎。
解決方案:
在雙副本範例上建表時,請使用ReplicatedMergeTree(‘/clickhouse/tables/{database}/{table}/{shard}’, ‘{replica}’)或ReplicatedMergeTree()設定ReplicatedMergeTree表引擎。其中,ReplicatedMergeTree(‘/clickhouse/tables/{database}/{table}/{shard}’, ‘{replica}’)為固定設定,無需修改。
這裡引出了複製表的概念,這裡介紹一下,只有 MergeTree 系列裡的表可支援副本:
- ReplicatedMergeTree
- ReplicatedSummingMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedAggregatingMergeTree
ReplicatedCollapsingMergeTree - ReplicatedVersionedCollapsingMergeTree
- ReplicatedGraphiteMergeTree
副本是表級別的,不是整個伺服器級的。所以,伺服器裡可以同時有複製表和非複製表。副本不依賴分片。每個分片有它自己的獨立副本。
建立複製表
先做好準備工作,該建表的建表,然後編寫程式。在表引擎名稱上加上 Replicated 字首。例如:ReplicatedMergeTree。
- 首先建立一個分散式資料庫
create database test on cluster default_cluster;
- 建立本地表
由於clickhouse是分散式的,建立本地表本來應該在每個節點上建立的,但是指定on cluster關鍵字可以直接完成,建表語句如下:
CREATE TABLE test.test_data_shade on cluster default_cluster
(
`data` Map(String, String),
`uid` String,
`remote_addr` String,
`time` Datetime64,
`status` Int32,
...其它欄位省略
`dt` String
)
ENGINE = ReplicatedMergeTree()
partition by dt
order by (dt, sipHash64(uid));
這裡表引擎為ReplicatedMergeTree,即有副本的表,根據dt按天分割區,提升查詢效率,sipHash64是一個hash函數,根據uid雜湊使得相同uid資料在同一個分片上面,如果有去重需求,速度更快,因為可以計算每個分片去重,再彙總一下即可。
- 建立分散式表
CREATE TABLE test.test_data_all on cluster default_cluster as test.test_data_shade ENGINE = Distributed('default_cluster', 'test', 'test_data_shade', sipHash64(uid));
在多副本分散式 ClickHouse 叢集中,通常需要使用 Distributed 表寫入或讀取資料,Distributed 表引擎自身不儲存任何資料,它能夠作為分散式表的一層透明代理,在叢集內部自動開展資料的寫入、分發、查詢、路由等工作。
通過jdbc寫入
這個我是看的官方檔案,裡面有2種選擇,感興趣的同學可以都去嘗試一下。
這裡貼一下我的Pom依賴
<dependency>
<groupId>ru.yandex.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.1-patch</version>
<classifier>shaded</classifier>
<exclusions>
<exclusion>
<groupId>*</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
Flink主程式,消費kafka,做清洗,然後寫入clickhouse,這都是常規操作,這裡貼一下關鍵程式碼吧。
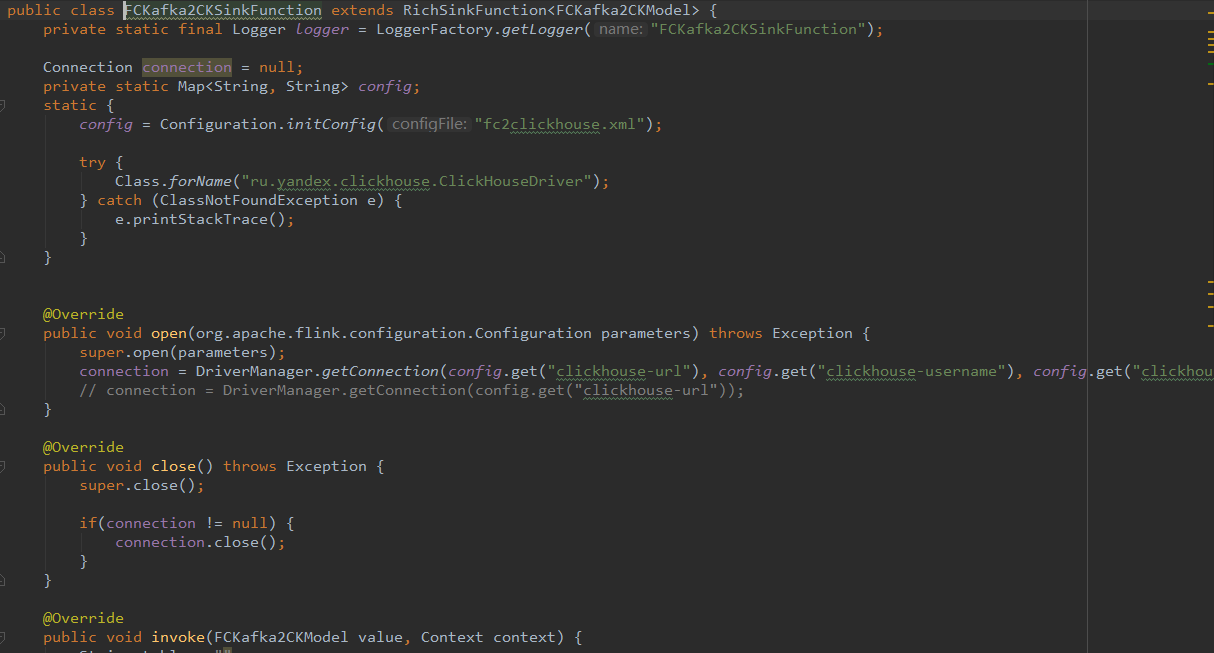
連線clickhouse有2種方式,8123埠的http方式,和基於9000埠的tcp方式。
這裡官方推薦的是連線驅動是0.3.2:
<dependency>
<!-- please stop using ru.yandex.clickhouse as it's been deprecated -->
<groupId>com.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.3.2-patch11</version>
<classifier>all</classifier>
<exclusions>
<exclusion>
<groupId>*</groupId>
<artifactId>*</artifactId>
</exclusion>
</exclusions>
</dependency>
Note: ru.yandex.clickhouse.ClickHouseDriver has been deprecated and everything under ru.yandex.clickhouse will be removed in 0.3.3.

官方推薦升級到0.3.2,上面表格給出了升級方法,檔案地址:
https://github.com/ClickHouse/clickhouse-jdbc/tree/master/clickhouse-jdbc