如何使用 LinkedHashMap 實現 LRU 快取?
本文已收錄到 AndroidFamily,技術和職場問題,請關注公眾號 [彭旭銳] 提問。
大家好,我是小彭。
在上一篇文章裡,我們聊到了 HashMap 的實現原理和原始碼分析,在原始碼分析的過程中,我們發現一些 LinkedHashMap 相關的原始碼,當時沒有展開,現在它來了。
那麼,LinkedHashMap 與 HashMap 有什麼區別呢?其實,LinkedHashMap 的使用場景非常明確 —— LRU 快取。今天,我們就來討論 LinkedHashMap 是如何實現 LRU 快取的。
本文原始碼基於 Java 8 LinkedHashMap。
小彭的 Android 交流群 02 群已經建立啦,掃描文末二維條碼進入~
思維導圖:
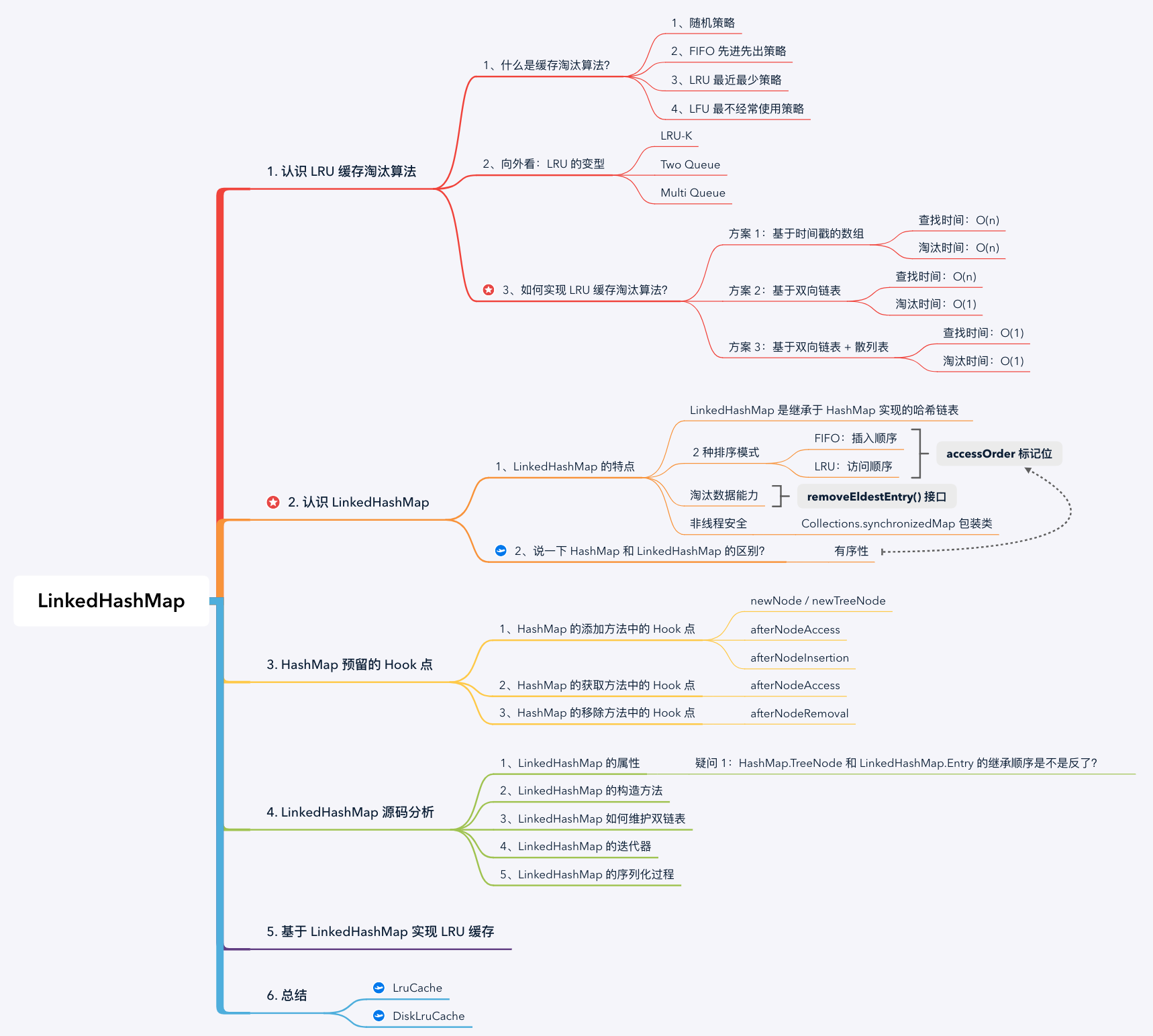
1. 認識 LRU 快取淘汰演演算法
1.1 什麼是快取淘汰演演算法?
快取是提高資料讀取效能的通用技術,在硬體和軟體設計中被廣泛使用,例如 CPU 快取、Glide 記憶體快取,資料庫快取等。由於快取空間不可能無限大,當快取容量佔滿時,就需要利用某種策略將部分資料換出快取,這就是快取的替換策略 / 淘汰問題。常見快取淘汰策略有:
-
1、隨機策略: 使用一個亂數生成器隨機地選擇要被淘汰的資料塊;
-
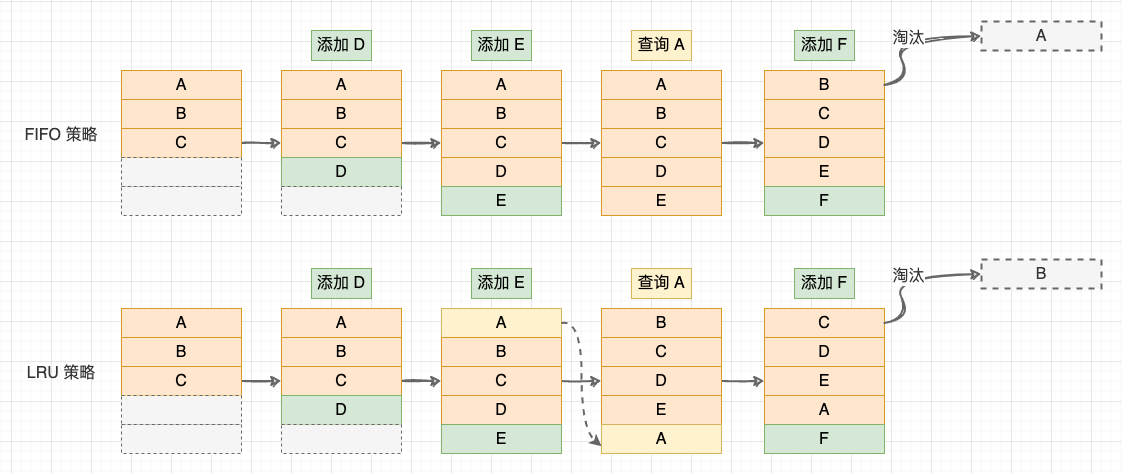
2、FIFO 先進先出策略: 記錄各個資料塊的存取時間,最早存取的資料最先被淘汰;
-
3、LRU (Least Recently Used)最近最少策略: 記錄各個資料塊的存取 「時間戳」 ,最近最久未使用的資料最先被淘汰。與前 2 種策略相比,LRU 策略平均快取命中率更高,這是因為 LRU 策略利用了 「區域性性原理」:最近被存取過的資料,將來被存取的機率較大,最近很久未存取的資料,將來存取的機率也較小;
-
4、LFU (Least Frequently Used)最不經常使用策略: 與 LRU 相比,LFU 更加註重使用的 「頻率」 。LFU 會記錄每個資料塊的存取次數,最少存取次數的資料最先被淘汰。但是有些資料在開始時使用次數很高,以後不再使用,這些資料就會長時間汙染快取。可以定期將計數器右移一位,形成指數衰減。
FIFO 與 LRU 策略
1.2 向外看:LRU 的變型
其實,在標準的 LRU 演演算法上還有一些變型實現,這是因為 LRU 演演算法本身也存在一些不足。例如,當資料中熱點資料較多時,LRU 能夠保證較高的命中率。但是當有偶發的批次的非熱點資料產生時,就會將熱點資料寄出快取,使得快取被汙染。因此,LRU 也有一些變型:
- LRU-K: 提供兩個 LRU 佇列,一個是存取計數佇列,一個是標準的 LRU 佇列,兩個佇列都按照 LRU 規則淘汰資料。當存取一個資料時,資料先進入存取計數佇列,當資料存取次數超過 K 次後,才會進入標準 LRU 佇列。標準的 LRU 演演算法相當於 LRU-1;
- Two Queue: 相當於 LRU-2 的變型,將存取計數佇列替換為 FIFO 佇列淘汰資料資料。當存取一個資料時,資料先進入 FIFO 佇列,當第 2 次存取資料時,才會進入標準 LRU 佇列;
- Multi Queue: 在 LRU-K 的基礎上增加更多佇列,提供多個級別的緩衝。
小彭在 Redis 和 Vue 中有看到這些 LRU 變型的應用,在 Android 領域的框架中還沒有看到具體應用,你知道的話可以提醒我。
1.3 如何實現 LRU 快取淘汰演演算法?
這一小節,我們嘗試找到 LRU 快取淘汰演演算法的實現方案。經過總結,我們可以定義一個快取系統的基本操作:
- 操作 1 - 新增資料: 先查詢資料是否存在,不存在則新增資料,存在則更新資料,並嘗試淘汰資料;
- 操作 2 - 刪除資料: 先查詢資料是否存在,存在則刪除資料;
- 操作 3 - 查詢資料: 如果資料不存在則返回 null;
- 操作 4 - 淘汰資料: 新增資料時如果容量已滿,則根據快取淘汰策略一個資料。
我們發現,前 3 個操作都有 「查詢」 操作, 所以快取系統的效能主要取決於查詢資料和淘汰資料是否高效。 下面,我們用遞推的思路推導 LRU 快取的實現方案,主要分為 3 種方案:
-
方案 1 - 基於時間戳的陣列: 在每個資料塊中記錄最近存取的時間戳,當資料被存取(新增、更新或查詢)時,將資料的時間戳更新到當前時間。當陣列空間已滿時,則掃描陣列淘汰時間戳最小的資料。
- 查詢資料: 需要遍歷整個陣列找到目標資料,時間複雜度為 O(n);
- 淘汰資料: 需要遍歷整個陣列找到時間戳最小的資料,且在移除陣列元素時需要搬運資料,整體時間複雜度為 O(n)。
-
方案 2 - 基於雙向連結串列: 不再直接維護時間戳,而是利用連結串列的順序隱式維護時間戳的先後順序。當資料被存取(新增、更新或查詢)時,將資料插入到連結串列頭部。當空間已滿時,直接淘汰連結串列的尾節點。
- 查詢資料:需要遍歷整個連結串列找到目標資料,時間複雜度為 O(n);
- 淘汰資料:直接淘汰連結串列尾節點,時間複雜度為 O(1)。
-
方案 3 - 基於雙向連結串列 + 雜湊表: 使用雙向連結串列可以將淘汰資料的時間複雜度降低為 O(1),但是查詢資料的時間複雜度還是 O(n),我們可以在雙向連結串列的基礎上增加雜湊表,將查詢操作的時間複雜度降低為 O(1)。
- 查詢資料:通過雜湊表定位資料,時間複雜度為 O(1);
- 淘汰資料:直接淘汰連結串列尾節點,時間複雜度為 O(1)。
方案 3 這種資料結構就叫 「雜湊連結串列或鏈式雜湊表」,我更傾向於稱為雜湊連結串列,因為當這兩個資料結構相結合時,我們更看重的是它作為連結串列的排序能力。
我們今天要討論的 Java LinkedHashMap 就是基於雜湊連結串列的資料結構。
2. 認識 LinkedHashMap 雜湊連結串列
2.1 說一下 LinkedHashMap 的特點
需要注意:LinkedHashMap 中的 「Linked」 實際上是指雙向連結串列,並不是指解決雜湊衝突中的分離連結串列法。
-
1、LinkedHashMap 是繼承於 HashMap 實現的雜湊連結串列,它同時具備雙向連結串列和雜湊表的特點。事實上,LinkedHashMap 繼承了 HashMap 的主要功能,並通過 HashMap 預留的 Hook 點維護雙向連結串列的邏輯。
- 1.1 當 LinkedHashMap 作為雜湊表時,主要體現出 O(1) 時間複雜度的查詢效率;
- 1.2 當 LinkedHashMap 作為雙向連結串列時,主要體現出有序的特性。
-
2、LinkedHashMap 支援 2 種排序模式,這是通過構造器引數
accessOrder標記位控制的,表示是否按照存取順序排序,預設為 false 按照插入順序。- 2.1 插入順序(預設): 按照資料新增到 LinkedHashMap 的順序排序,即 FIFO 策略;
- 2.2 存取順序: 按照資料被存取(包括插入、更新、查詢)的順序排序,即 LRU 策略。
-
3、在有序性的基礎上,LinkedHashMap 提供了維護了淘汰資料能力,並開放了淘汰判斷的介面
removeEldestEntry()。在每次新增資料時,會回撥removeEldestEntry()介面,開發者可以重寫這個介面決定是否移除最早的節點(在 FIFO 策略中是最早新增的節點,在 LRU 策略中是最早未存取的節點); -
4、與 HashMap 相同,LinkedHashMap 也不考慮執行緒同步,也會存線上程安全問題。可以使用 Collections.synchronizedMap 包裝類,其原理也是在所有方法上增加 synchronized 關鍵字。
2.2 說一下 HashMap 和 LinkedHashMap 的區別?
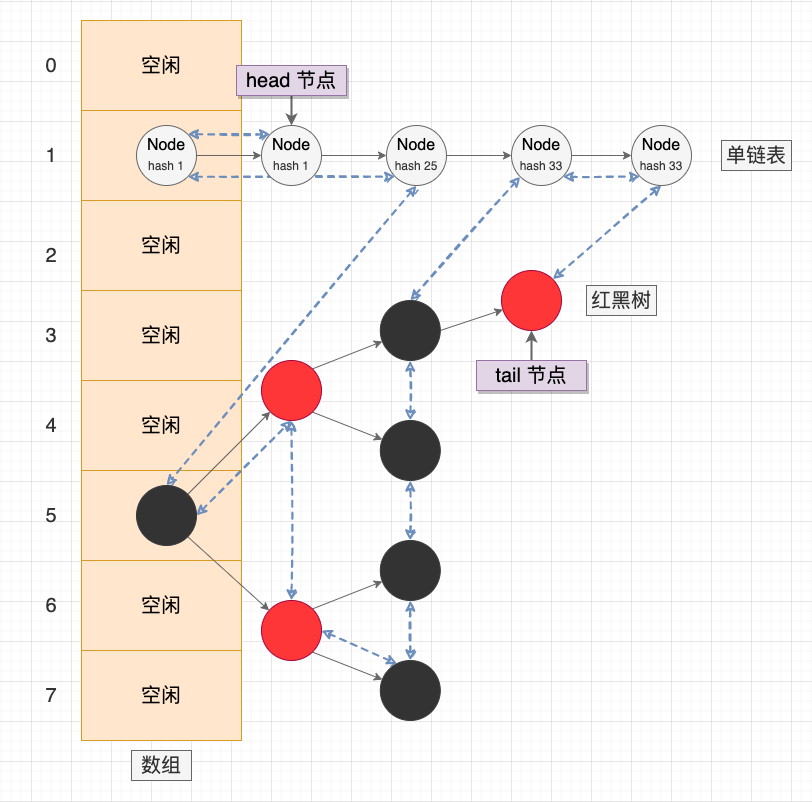
事實上,HashMap 和 LinkedHashMap 並不是平行的關係,而是繼承的關係,LinkedHashMap 是繼承於 HashMap 實現的雜湊連結串列。
兩者主要的區別在於有序性: LinkedHashMap 會維護資料的插入順序或存取順序,而且封裝了淘汰資料的能力。在迭代器遍歷時,HashMap 會按照陣列順序遍歷桶節點,從開發者的視角看是無序的。而是按照雙向連結串列的順序從 head 節點開始遍歷,從開發者的視角是可以感知到的插入順序或存取順序。
LinkedHashMap 示意圖
3. HashMap 預留的 Hook 點
LinkedHashMap 繼承於 HashMap,在後者的基礎上通過雙向連結串列維護節點的插入順序或存取順序。因此,我們先回顧下 HashMap 為 LinkedHashMap 預留的 Hook 點:
- afterNodeAccess: 在節點被存取時回撥;
- afterNodeInsertion: 在節點被插入時回撥,其中有引數
evict標記是否淘汰最早的節點。在初始化、反序列化或克隆等構造過程中,evict預設為 false,表示在構造過程中不淘汰。 - afterNodeRemoval: 在節點被移除時回撥。
HashMap.java
// 節點存取回撥
void afterNodeAccess(Node<K,V> p) { }
// 節點插入回撥
// evict:是否淘汰最早的節點
void afterNodeInsertion(boolean evict) { }
// 節點移除回撥
void afterNodeRemoval(Node<K,V> p) { }
除此了這 3 個空方法外,LinkedHashMap 也重寫了部分 HashMap 的方法,在其中插入雙連結串列的維護邏輯,也相當於 Hook 點。在 HashMap 的新增、獲取、移除方法中,與 LinkedHashMap 有關的 Hook 點如下:
3.1 HashMap 的新增方法中的 Hook 點
LinkedHashMap 直接複用 HashMap 的新增方法,也支援批次新增:
- HashMap#put: 逐個新增或更新鍵值對;
- HashMap#putAll: 批次新增或更新鍵值對。
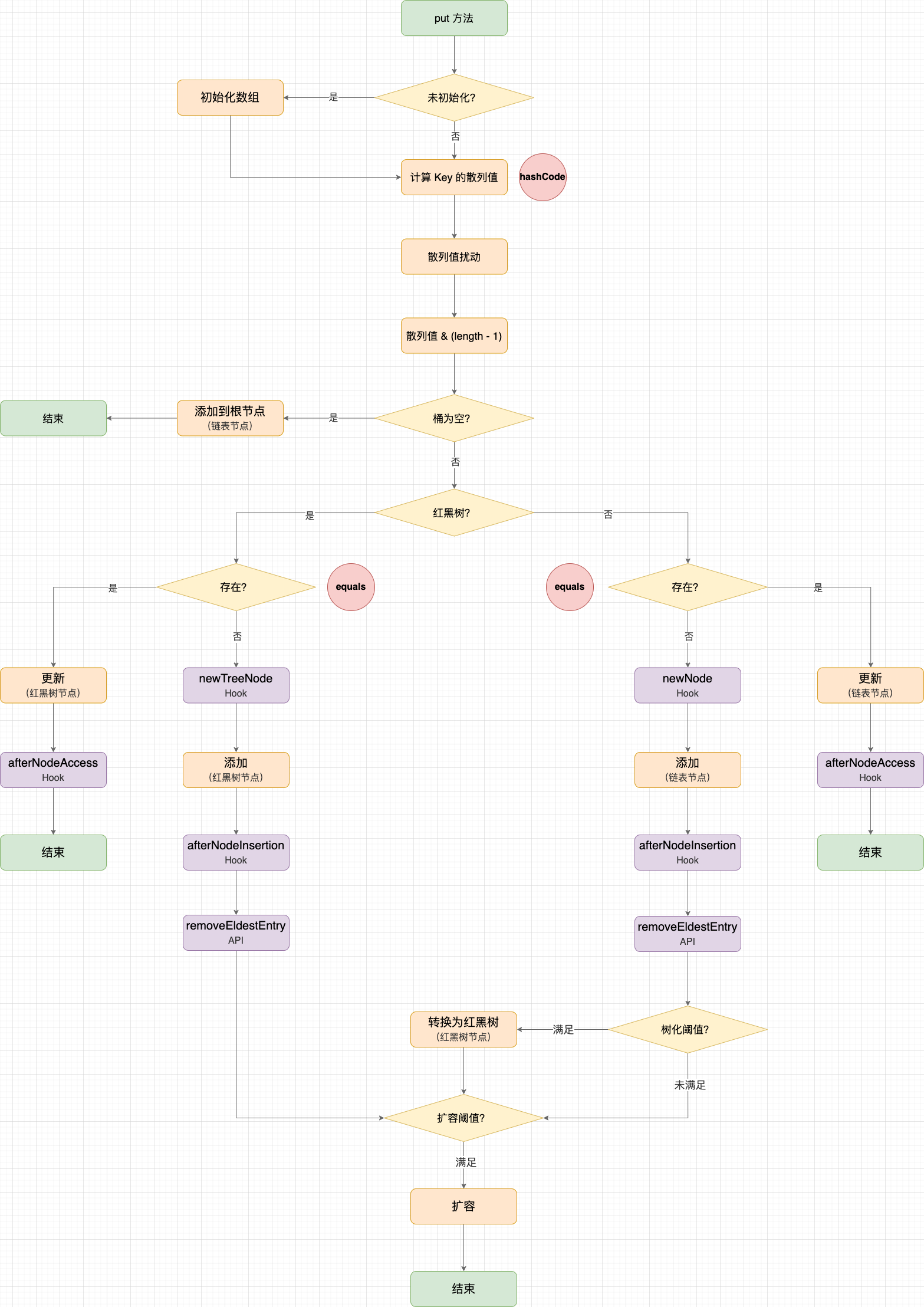
不管是逐個新增還是批次新增,最終都會先通過 hash 函數計算鍵(Key)的雜湊值,再通過 HashMap#putVal 新增或更新鍵值對,這些都是 HashMap 的行為。關鍵的地方在於:LinkedHashMap 在 HashMap#putVal 的 Hook 點中加入了雙線連結串列的邏輯。區分 2 種情況:
- 新增資料: 如果資料不存在雜湊表中,則呼叫
newNode()或newTreeNode()建立節點,並回撥afterNodeInsertion(); - 更新資料: 如果資料存在雜湊表中,則更新 Value,並回撥
afterNodeAccess()。
HashMap.java
// 新增或更新鍵值對
public V put(K key, V value) {
return putVal(hash(key) /*計算雜湊值*/, key, value, false, true);
}
// hash:Key 的雜湊值(經過擾動)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n;
int i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash:雜湊值轉陣列下標
if ((p = tab[i = (n - 1) & hash]) == null)
// 省略遍歷桶的程式碼,具體分析見 HashMap 原始碼講解
// 1.1 如果節點不存在,則新增節點
p.next = newNode(hash, key, value, null);
// 2.1 如果節點存在更新節點 Value
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 2.2 Hook:存取節點回撥
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 擴容
if (++size > threshold)
resize();
// 1.2 Hook:新增節點回撥
afterNodeInsertion(evict);
return null;
}
HashMap#put 示意圖
3.2 HashMap 的獲取方法中的 Hook 點
LinkedHashMap 重寫了 HashMap#get 方法,在 HashMap 版本的基礎上,增加了 afterNodeAccess() 回撥。
HashMap.java
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
LinkedHashMap.java
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
// Hook:節點存取回撥
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
// Hook:節點存取回撥
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
HashMap#get 示意圖
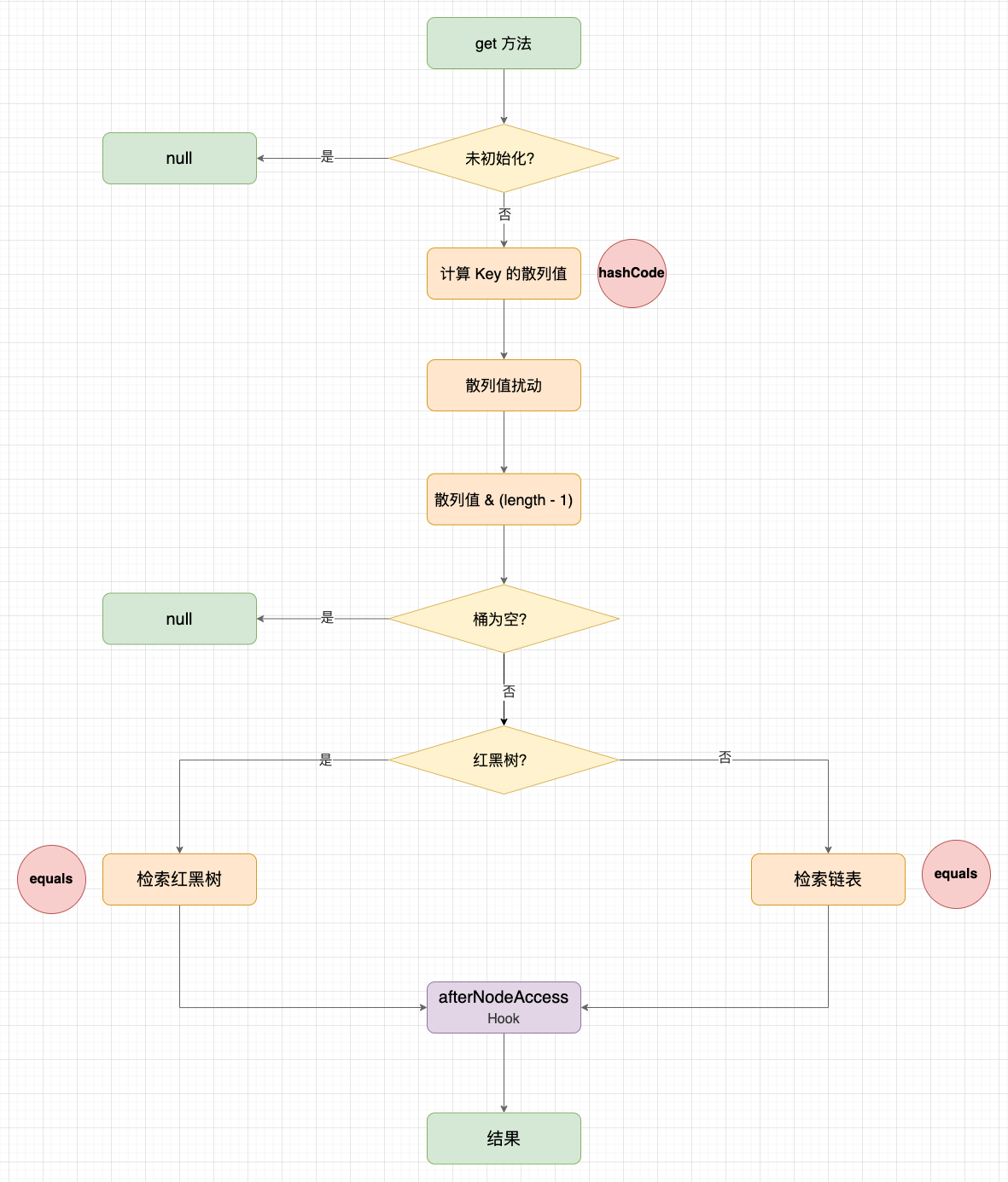
3.3 HashMap 的移除方法中的 Hook 點
LinkedHashMap 直接複用 HashMap 的移除方法,在移除節點後,增加 afterNodeRemoval() 回撥。
HashMap.java
// 移除節點
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key)/*計算雜湊值*/, key, null, false, true)) == null ? null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab;
Node<K,V> p;
int n, index;
// (n - 1) & hash:雜湊值轉陣列下標
if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
// 省略遍歷桶的程式碼,具體分析見 HashMap 原始碼講解
// 刪除 node 節點
if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) {
// 省略刪除節點的程式碼,具體分析見 HashMap 原始碼講解
++modCount;
--size;
// Hook:刪除節點回撥
afterNodeRemoval(node);
return node;
}
}
return null;
}
HashMap#remove 示意圖

4. LinkedHashMap 原始碼分析
這一節,我們來分析 LinkedHashMap 中主要流程的原始碼。
4.1 LinkedHashMap 的屬性
- LinkedHashMap 繼承於 HashMap,並且新增
head和tail指標指向連結串列的頭尾節點(與 LinkedList 類似的頭尾節點); - LinkedHashMap 的雙連結串列節點 Entry 繼承於 HashMap 的單連結串列節點 Node,而 HashMap 的紅黑樹節點 TreeNode 繼承於 LinkedHashMap 的雙連結串列節點 Entry。
節點繼承關係
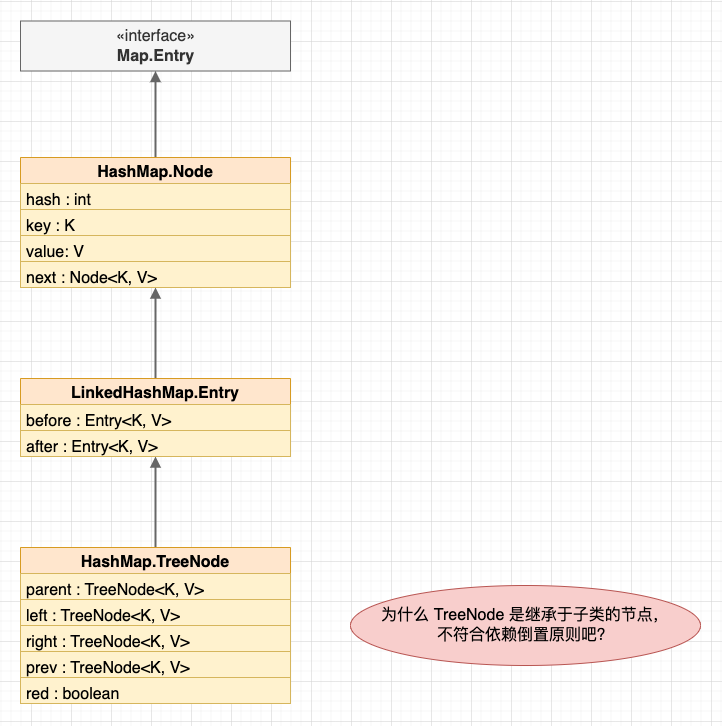
LinkedHashMap.java
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {
// 頭指標
transient LinkedHashMap.Entry<K,V> head;
// 尾指標
transient LinkedHashMap.Entry<K,V> tail;
// 是否按照存取順序排序
final boolean accessOrder;
// 雙向連結串列節點
static class Entry<K,V> extends HashMap.Node<K,V> {
// 前驅指標和後繼指標(用於雙向連結串列)
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next/*單連結串列指標(用於雜湊表的衝突解決)*/) {
super(hash, key, value, next);
}
}
}
LinkedList.java
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
// 頭指標(// LinkedList 中也有類似的頭尾節點)
transient Node<E> first;
// 尾指標
transient Node<E> last;
// 雙向連結串列節點
private static class Node<E> {
// 節點資料
// (型別擦除後:Object item;)
E item;
// 前驅指標
Node<E> next;
// 後繼指標
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
LinkedHashMap 的屬性很好理解的,不出意外的話又有小朋友出來舉手提問了: