一言不合就重構
hello,大家好呀,我是小樓。
前段時間不是在忙麼,忙的內容之一就是花了點時間重構了一個服務的健康檢查元件,目前已經慢慢在灰度線上,本文就來分享下這次重構之旅,也算作個總結吧。
背景
服務健康檢查簡介
服務健康檢查是應對分散式應用下某些服務節點不健康問題的一種解法。如下圖,消費者呼叫提供方叢集,通常通過註冊中心獲取提供方的地址,根據負載均衡演演算法選取某臺具體機器發起呼叫。
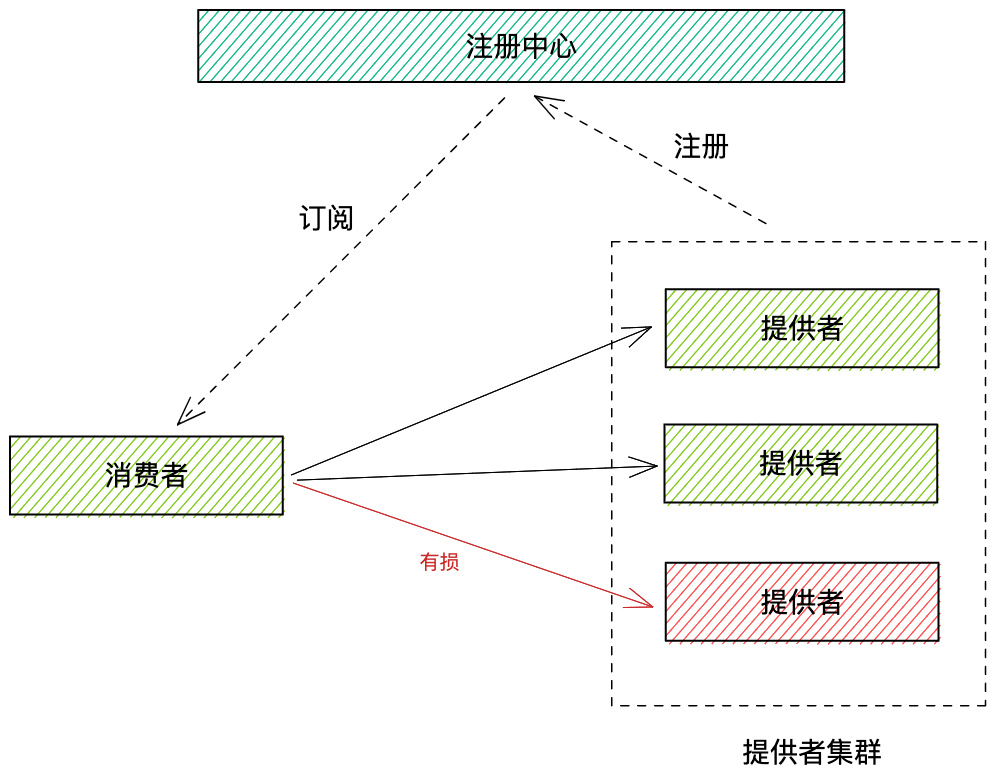
假設某臺機器意外宕機,服務消費方不能感知,就會導致流量有損,如果此時有一種檢測服務節點健康狀態並及時剔除的機制,就能大大增加線上服務的穩定性。
原服務健康檢查實現原理
我們是自研的註冊中心,健康檢查也算註冊中心的一部分,其原理很簡單,可分為三個階段:
- 從註冊中心獲取需要檢查的範例(即地址,由ip、port組成)
- 對每個地址發起 TCP 建鏈請求,建鏈成功視為健康
- 對判定為不健康的範例進行摘除,對原不健康現在健康的範例進行恢復,摘除恢復通過呼叫註冊中心提供的介面實現

當然這是大致流程,還有不少細節,例如獲取探活範例時一些不需要探活的服務會被排除(如一些基礎服務如MySQL、Redis);為了防止網路抖動導致健康狀態判定有誤,會增加一些判定策略,如連續 N 次建連失敗視為不健康;對不健康範例摘除時也計算了摘除閾值,如一個叢集的機器都被判定為不健康,那也不能把它們全摘了,因為此時全摘和不摘差別不大(請求都會報錯),甚至全摘還要承擔風險,考慮叢集容量問題,可以設個閾值,如最多隻能摘三分之一的機器。
原服務健康檢查存在的問題
1. 容量問題
原元件是物理機時代的產物,當時範例數量並不多,所以最初是單機設計,只部署在一臺物理機上,隨著公司業務發展,範例數量增多,單機達到瓶頸,於是做了一次升級,通過組態檔來指定每個節點的健康檢查任務分片。

2. 容災問題
單機就必然存在宕機風險,即使檢查任務已經做了分片,但是寫在設定中,無法動態調配,當某個節點宕機,則它負責的範例健康檢查就會失效。
3.部署效率問題
部署在物理機且分片是寫在設定中,無論是擴容還是機器過保置換,都要修改設定,人為操作效率太低,而且容易出錯。
4. 新需求支援效率問題
隨著雲原生時代的邁進,對健康檢查提出了一些新的需求,例如只探埠的聯通性可能不能代表服務的健康程度,甚至公司內還有一些其他不在註冊中心上的服務也想複用這個健康檢查元件的能力,日益增長的需求同原元件沉重的歷史包袱之間存在著不可調和的矛盾。
5. 迭代過程中的穩定性問題
原元件沒有灰度機制,開發了新功能上線是一把梭,如果出問題,就是個大故障,影響面非常廣。
需要解決這麼多問題,如果在原基礎上改,穩定性和效率都非常令人頭疼,於是一個念頭油然而生:重構!
技術方案調研
業界常見服務健康檢查方案
在設計新方案前,我們看看業界對於健康檢查都是怎麼做的,從兩個角度展開調研,註冊中心的健康檢查和非註冊中心的健康檢查
註冊中心健康檢查
| 方案 | 代表產品 | 優點 | 缺點 |
|---|---|---|---|
| SDK 心跳上報 | Nacos 1.x 臨時範例 | 處理心跳消耗資源過多 | |
| SDK 長連線 + 心跳保持 | Nacox 2.x 臨時範例、SofaRegistry、Zookeeper | 感知快 | SDK 實現複雜 |
| 集中式主動健康檢查 | Nacos 永久範例 | 無需SDK參與,可實現語意級探活 | 集中式壓力大時,時延增大 |
非註冊中心健康檢查
K8S 健康檢查 — LivenessProbe
與集中式健康檢查做對比
| LivenessProbe | 原健康檢查元件 | |
|---|---|---|
| 實現方式 | k8s原生,分散式(sidecar模式) | 自研,集中式 |
| 檢查發起者 | kubelet,與業務容器在同一物理機 | 集中部署的服務 |
| 適用範圍 | k8s容器(彈性雲) | 容器、物理機、虛擬機器器等 |
| 支援的檢查方式 | tcp、http、exec、grpc | tcp、http |
| 健康檢查基本設定 | 容器啟動延時探活時間、檢查間隔時間、檢查超時時間、最小連續成功數、最小連續失敗數 | 探活超時時間、連續失敗次數、最大摘除比例 |
| 檢測不健康時動作 | 殺死容器,容器再根據重啟策略決定是否重啟 | 從註冊中心上摘除 |
| 兜底 | 無 | 有,可配摘除比例 |
結合公司背景進行選型
我們的大背景是技術棧不統一,程式語言有 Java、Go、PHP、C++等,基於成本考慮,我們更傾向瘦SDK的方案。
於是註冊中心常見的 SDK 長連線+心跳保持方案被排除,SDK主動上報心跳也不考慮。
而 K8S 的健康檢查方案僅僅使用於 K8S 體系,我們還有物理機,而且 K8S 的 LivenessProbe 並不能做到開箱即用,至少我們不想讓節點不健康時被殺死,兜底策略也需要重新開發。
所以最終我們還是選擇了與原健康檢查元件相同的方案 — 集中式主動健康檢查。
理想態
基於原健康檢查元件在使用中的種種問題,我們總結出一個好的健康檢查元件該有的樣子:
- 故障自動轉移
- 可水平擴容
- 快速支援豐富靈活的需求
- 新需求迭代,本身的穩定性需要有保障
設計開發
總體設計
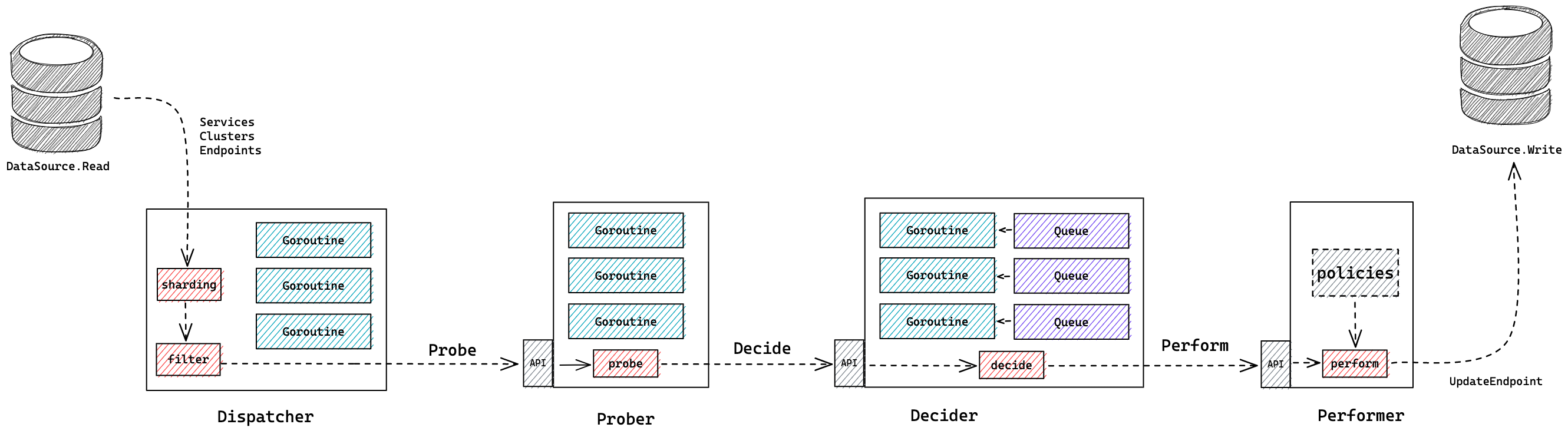
元件由四大模組組成:
- Dispatcher:負責從資料來源獲取資料,生成並派發任務
- Prober:負責健康檢查任務的執行
- Decider:根據健康檢查結果決策是否需要變更健康狀態
- Performer:根據決策結果執行相應動作
各模組對外暴露介面,隱藏內部實現。資料來源面向介面程式設計,可替換。
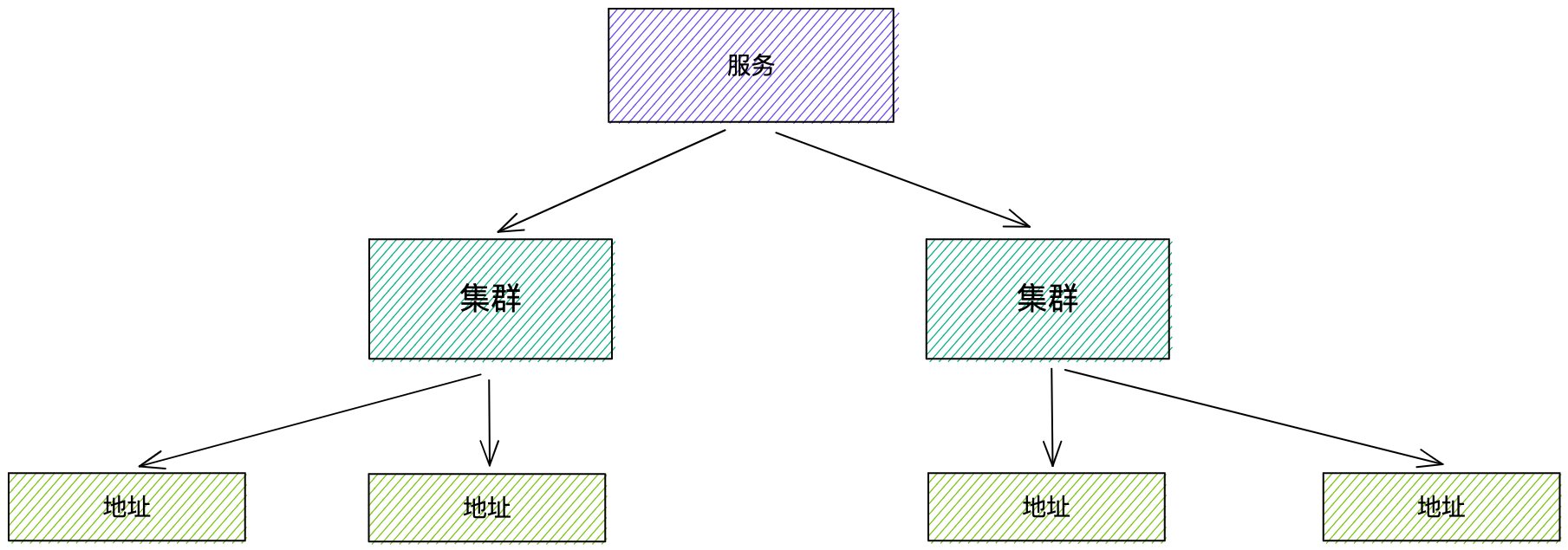
服務發現模型
在詳細介紹各個模組的設計之前,先簡單介紹一下我們的服務發現模型,有助於後續的表述和理解。
一個服務名在公司內是唯一的,呼叫時需指定服務名,獲取對應的地址。
一個服務又可以包含多個叢集,叢集可以是物理上的隔離叢集,也可以是邏輯上的隔離叢集,叢集下再包含地址。
協程模型設計
程式語言我們選擇的是 Go,原因有二:第一是健康檢查這種 IO 密集型任務與 Go 的協程排程比較契合,開發速度,資源佔用都還可以;第二是我們組一直用 Go,經驗豐富,所以語言選擇我們沒有太多的考慮。
但在協程模型的設計上,我們做了一些思考。
資料來源的獲取,由於服務、叢集資訊不經常變化,所以快取在記憶體中,每分鐘進行一次同步,地址資料需要實時拉取。
Dispatcher 先獲取所有的服務,然後根據服務獲取叢集,到這裡都是在一個協程內完成,接下來獲取地址有網路開銷,所以開 N 個協程,每個協程負責一部分叢集地址,每個地址都生成一個單獨的任務,派發給 Prober。
Prober 負責健康檢查,完全是 IO 操作,內部用一個佇列存放派發來的任務,然後開很多協程從佇列中取任務去做健康檢查,檢查完成後將結果交給 Decider 做決策。
Decider 決策時比較重要的是需要算出是否會被兜底,這裡有兩點需要考慮:
一是最初獲取的範例狀態可能不是最新了,需要重新獲取一次;
二是對於同一個叢集不能並行地去決策,決策應該序列才不會導致決策混亂,舉個反例,如果一個叢集3臺機器,最多摘除1臺,如果2臺同時掛掉,並行決策時,2個協程各自以為能摘,最後結果是摘除了2臺,和預期只摘1臺不符。這個如何解決?我們最後搞了 N 個佇列存放健康檢查結果,按服務+叢集的雜湊值路由到佇列,保證每個叢集的檢測結果都路由到同一個佇列,再開 N 個協程,每個協程消費一個佇列,這樣就做到了順序執行。
決策之後的動作執行就是呼叫更新介面,所以直接共用決策的協程。用一張大圖來總結:
水平擴容 & 故障自動轉移
水平擴容與故障自動轉移只要能做到動態地資料分片即可,每個健康檢查元件在啟動時將自己註冊到一箇中心的協調器(可以是 etcd),並且監聽其他節點的線上狀態,派發任務時,按服務名雜湊,判斷該任務是否應該由自己排程,是則執行,否則丟棄。
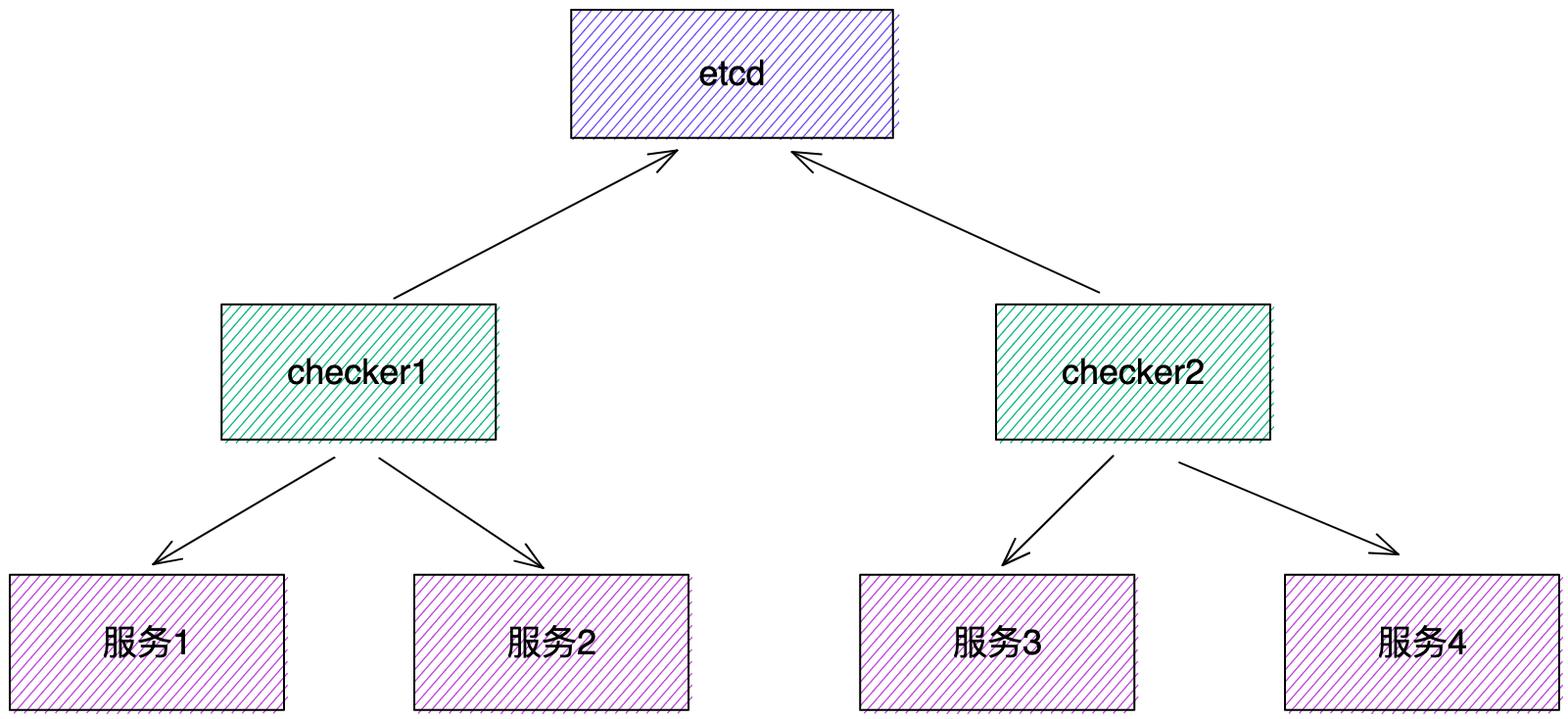
當某個節點掛掉或者擴容時,每個節點都能感知到當前叢集的變化,自動進行資料分片的重新劃分。
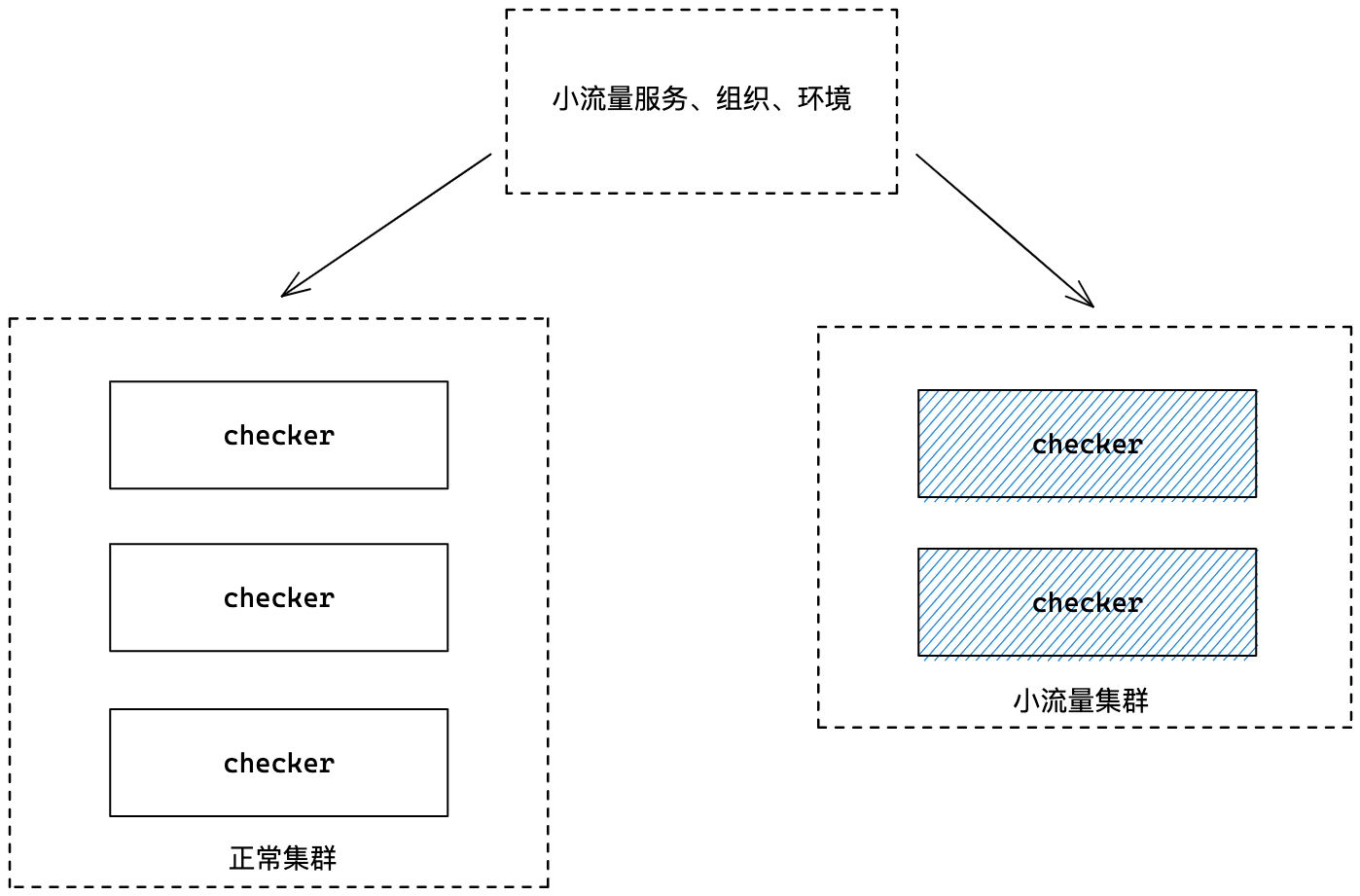
小流量機制
小流量的實現採取部署兩個叢集的方式,一個正常叢集,一個小流量叢集,小流量叢集負責部分不重要的服務,作為灰度,正常叢集負責其他服務的健康檢查任務。
只需要共用一個小流量的設定即可,我們按組織、服務、叢集、環境等維度去設計這個設定,基本可以任意粒度設定。
可延伸性
可延伸性也是設計裡非常重要的一環,可從資料來源、檢查方式擴充套件、過濾器等方面稍微一些。
資料來源可插拔
面向介面程式設計,我們將資料來源抽象為讀資料來源與寫資料來源,只要符合這兩個介面的資料來源,就能無縫對接。
檢查方式易擴充套件
健康檢查其實就是給定一個地址,再加一堆設定去進行檢查,至於怎麼檢查可以自己實現,目前已實現的有TCP、HTTP方式,未來還可能會實現諸如Dubbo、gRPC、thrift等的語意級別的檢查方式。
過濾器
在派發任務時,有一個可能會隨時修改的邏輯是過濾掉一些不需要探活的服務、叢集、範例,這塊用責任鏈的模式就能很好地實現,後期想增刪就只需要插拔鏈中的一環即可。
可延伸性是程式碼層面的內容,所以這裡只列舉了部分比較典型的例子。
灰度上線
由於我們是重寫了一個元件來代替原元件,所以上線還挺麻煩,為此我們做了2方面的工作:
- 設計了一個可按組織、服務、叢集、環境等維度的降級開關,降級分為3檔,不降級、半降級、全降級。不降級很好理解,就是啥也不做,全降級就是不工作,相當於一鍵關停健康檢查元件,半降級是隻恢復健康但不摘除的一個工作模式。試想如果健康檢查在上線過程中,誤摘除,此時降級,豈不是無法恢復健康?所以我們讓它保留恢復能力。
- 我們利用上述的小流量設計來逐步將服務遷移到新元件上來,灰度的服務新元件負責,非灰度的服務老元件負責,等全部灰度完成,停掉老元件,新元件的灰度叢集再切換為正常叢集。
踩坑調優
在灰度過程中,我們發現了一個問題,有的一個叢集機器非常多,超過了1000臺,而我們的決策是順序執行,而且決策時還會去實時查詢範例狀態,假設每次查詢10ms(已經很快了),1000臺順序決策完也得10s,我們期望每輪的檢測要在3秒左右完成,光這一個叢集就得10秒,顯然不能接受。
為了我們做了第一次的優化:
我們當時線上上環境測試,一個叢集有2000多臺機器,但大部分機器是禁用的狀態,也就是這部分機器其實做健康檢查是個無用功,禁用的機器,無論是否健康都不會被消費,所以我們的第一個優化便是在派發任務時過濾掉禁用的機器,這樣就解決了線下環境的問題。
但我們上到生產環境時仍然發現決策很慢,線上一個叢集只有少量的機器被禁用,第一次的優化基本就沒什麼效果了,而且線上機器數量可能更多,任務堆積會很嚴重,我們發現其他的佇列可能比較空閒,只有大叢集所在的佇列很忙。
所以我們進行了第二次優化:
從業務視角出發,其實需要順序決策的只有不健康的範例,對於健康的範例決策時不需要考慮兜底,所以我們將按檢查結果進行分類,健康的檢查結果隨機派發到任意佇列處理,不健康的檢查結果嚴格按服務+叢集路由到特定佇列處理,這樣既保證了兜底決策時的順序,也解決了佇列負載不均衡的狀況。
總結
本文從健康檢查的背景,原元件存在的問題,以及我們的理想態出發,調研了業界的方案,結合實際情況,選擇了適合的方案,並總結之前系統的問題,設計一個更加合理的新系統,從開發閉環到上線。
我覺得系統設計是一個取捨的過程,別人的方案不見得是最優的,適合的才是最好的,而且有時並不是純技術解決問題,可能從業務角度去思考,可能更加豁然開朗。
推薦閱讀
與本文相關的文章也順便推薦給你,如果覺得還不錯,記得關注、點贊、在看
- 搜尋關注微信公眾號"捉蟲大師",後端技術分享,架構設計、效能優化、原始碼閱讀、問題排查、踩坑實踐。