學習MySQL必須瞭解的13個關鍵字(總結分享)

程式設計師必備介面測試偵錯工具:
推薦學習:
1、三正規化
- 第一規格化:每個表的每一列都要保持它的原子性,也就是表的每一列是不可分割的;
- 第二正規化:在滿足第一規格化的基礎上,每個表都要保持唯一性,也就是表的非主鍵欄位完全依賴於主鍵欄位;
- 第三正規化:在滿足第一規格化和第二正規化的基礎上,表中不能產生傳遞關係,要消除表中的冗餘性;
2、字元集
字元集規定了字元在資料庫中的儲存格式,比如佔多少空間,支援哪些字元等等。不同的字元集有不同的編碼規則,在有些情況下,甚至還有校對規則的存,校對規則是指一個字元集的排序,在運維和使用MySQL資料庫中,選取合適的字元集非常重要,如果選擇不恰當,輕則影響資料庫效能,嚴重的可能導致資料儲存亂碼。
常見的MySQl字元集主要有以下四種:
| 字元集 | 長度 | 說明 |
|---|---|---|
| GBK | 2 | 支援中文,但不是國際通用字元集 |
| UTF-8 | 3 | 支援中英文混合場景,是國際通用字元集 |
| latin1 | 1 | MySQL預設字元集 |
| utf8mb4 | 4 | 完全相容UTF-8,用四個位元組儲存更多的字元 |
MySQL資料庫在開發運維中,字元集選用規則如下:
- 如果系統開發面向國外業務,需要處理不同國家、不同語言,則應該選擇utf-8或者utf8mb4;
- 如果只需要支援中文,沒有國外業務,則為了效能考慮,可以採用GBK;
3、自定義變數
自定義變數是一個用來儲存內容的臨時容器,在連線MySQL的整個過程中都存在。可以使用set的方式定義。
SET @last_week := CURRENT_DATE-INTERVAL 1 WEEK;SELECT id,name from user where create_time > @last_week;
登入後複製使用自定義變數的注意事項:
使用自定義變數的查詢,無法使用快取;
不能在使用常數或識別符號的地方使用自定義變數,比如表名、列名和limit子句中;
自定義變數的生命週期實在一個連線中有效,不能用它們做連線間的通訊;
避免重複查詢剛剛更新的資料
如果在更新行的同時又想獲得該行的資訊,要怎麼做才能避免重複的查詢呢?
一般都這樣做:
update user set update_time = now() where id = 1;select update_time from user where id = 1;
登入後複製使用自定義變數可以對其進行優化:
update user set update_time = now() where id = 1 and @now := now();select @now;
登入後複製看上去還是兩個查詢,但是第二次查詢無須存取任何資料表,所以會快很多。
4、選擇優化的資料型別
MySQL支援的資料型別非常多,選擇正確的資料型別對於獲得高效能至關重要。
(1)更小的
一般情況下,應該儘量使用較小的資料型別,更小的資料型別通常更快,因為佔用更少的磁碟、記憶體和CPU快取,處理時需要的CPU週期更短。
(2)更簡單的
簡單的資料型別通常需要更少的CPU週期,整形比字串型別代價更低,因為字元集和校驗規則使字元比較比整形比較更復雜。
(3)儘量避免NULL
很多表都包含可為NULL的列,即使應用程式並不需要儲存NULL也是如此,因為可為NULL是列的預設屬性,通常情況下,最好指定列為NOT NULL。
如果查詢中包含可為NULL的列,對MySQL來說更難優化,因為可為NULL的列使索引、索引統計和值的比較都更復雜。可為NULL的列會使用更多的儲存空間,在MySQL裡也需要特殊處理,可為NULL的列被索引時,每個索引記錄需要一個額外的位元組,在MyISAM裡甚至還可能導致固定大小的索引變成可變大小的索引。
5、檢視
檢視(view)是一種虛擬存在的表,是一個邏輯表,本身並不包含資料。作為一個select語句儲存在資料字典中的。對多張表的複雜查詢,使用檢視可以簡化查詢,當檢視使用臨時表時,無法使用where條件,也不能使用索引。
單表檢視一般用於查詢和修改,會改變基本表的資料,多表檢視一般用於查詢,不會改變基本表的資料。
使用檢視的目的是為了保障資料安全性,提高查詢效率。
檢視的優勢:
使用檢視的使用者完全不需要關心後面對應的表的結構、關聯條件和篩選條件,對使用者來說已經是過濾好的複合條件的結果集。
使用檢視的使用者只能存取他們被允許查詢的結果集,對錶的許可權管理並不能限制到某個行某個列,但是通過檢視就可以簡單的實現。
一旦檢視的結構確定了,可以遮蔽表結構變化對使用者的影響,源表增加列對檢視沒有影響;源表修改列名,則可以通過修改檢視來解決,不會造成對存取者的影響。
6、快取表和彙總表
有時提升效能最好的方法是在同一張表中儲存衍生的冗餘資料,有時候還需要建立一張完全獨立的彙總表或快取表。
- 快取表用來儲存那些獲取很簡單,但速度較慢的資料;
- 彙總表用來儲存使用group by語句聚合查詢的資料;
對於快取表,如果主表使用InnoDB,用MyISAM作為快取表的引擎將會得到更小的索引佔用空間,並且可以做全文檢索。
在使用快取表和彙總表時,必須決定是實時維護資料還是定期重建。哪個更好依賴於應用程式,但是定期重建並不只是節省資源,也可以保持表不會有很多碎片,以及有完全順序組織的索引。
當重建彙總表和快取表時,通常需要保證資料在操作時依然可用,這就需要通過使用影子表來實現,影子表指的是一張在真實表背後建立的表,當完成了建表操作後,可以通過一個原子的重新命名操作切換影子表和原表。
為了提升讀的速度,經常建一些額外索引,增加冗餘列,甚至是建立快取表和彙總表,這些方法會增加寫的負擔媽也需要額外的維護任務,但在設計高效能資料庫時,這些都是常見的技巧,雖然寫操作變慢了,但更顯著地提高了讀的效能。
7、分割區表
通常情況下,同一張表的資料在物理層面都是存放在一起的。隨著業務增長,當同一張表的資料量過大時,會帶來管理上的不便。而分割區特性可以將一張表從物理層面根據一定的規則將資料劃分為多個分割區,多個分割區可以單獨管理,甚至存放在不同的磁碟/檔案系統上,提升效率。
分割區表的優勢:
資料可以跨磁碟儲存,適合儲存大量資料;
資料管理起來很方便,以分割區為單位元運算資料,不影響其他分割區的正常執行;
查詢時可以通過鎖定分割區的特性,縮小查詢範圍,提高查詢效能;
8、外來鍵
外來鍵通常都要求每次在修改資料時都要在另外一張表中進行一次額外的查詢操作,雖然InnoDB強制外來鍵使用索引,但還是無法消除這種約束檢查的開銷。如果外來鍵的選擇性很低,則會導致一個選擇性很低的索引。
不過在某些場景下,外來鍵會提升一些效能,比如想確保兩個相關表始終有一致的資料,那麼使用外來鍵比在應用程式中檢查一致性的效能要高的多,此外。外來鍵在相關資料的刪除和更新上,也比在應用中維護要更高效,不過,外來鍵維護操作時逐行進行的,這樣的更新會比批次刪除和更新要慢些。
外來鍵約束使查詢時額外存取一些別的表,也就是需要額外的鎖。如果向子表中寫入一條記錄,外來鍵約束會讓InnoDB檢查對應的父表的記錄,也就是需要對父表的對應記錄進行加鎖操作,來確保這條記錄不會在這個事務完成之時就被刪除了。這會導致額外的鎖等待,甚至會導致一些死鎖。因為沒有直接存取這些表,所以這類死鎖問題很難排查。
所以,在目前的很多專案中,為了效能的考慮,已經不使用外來鍵了。
9、查詢快取
MySQL查詢快取儲存查詢返回的完整結果,當查詢命中該快取,MySQL會立刻返回結果,跳過解析、優化和執行過程。
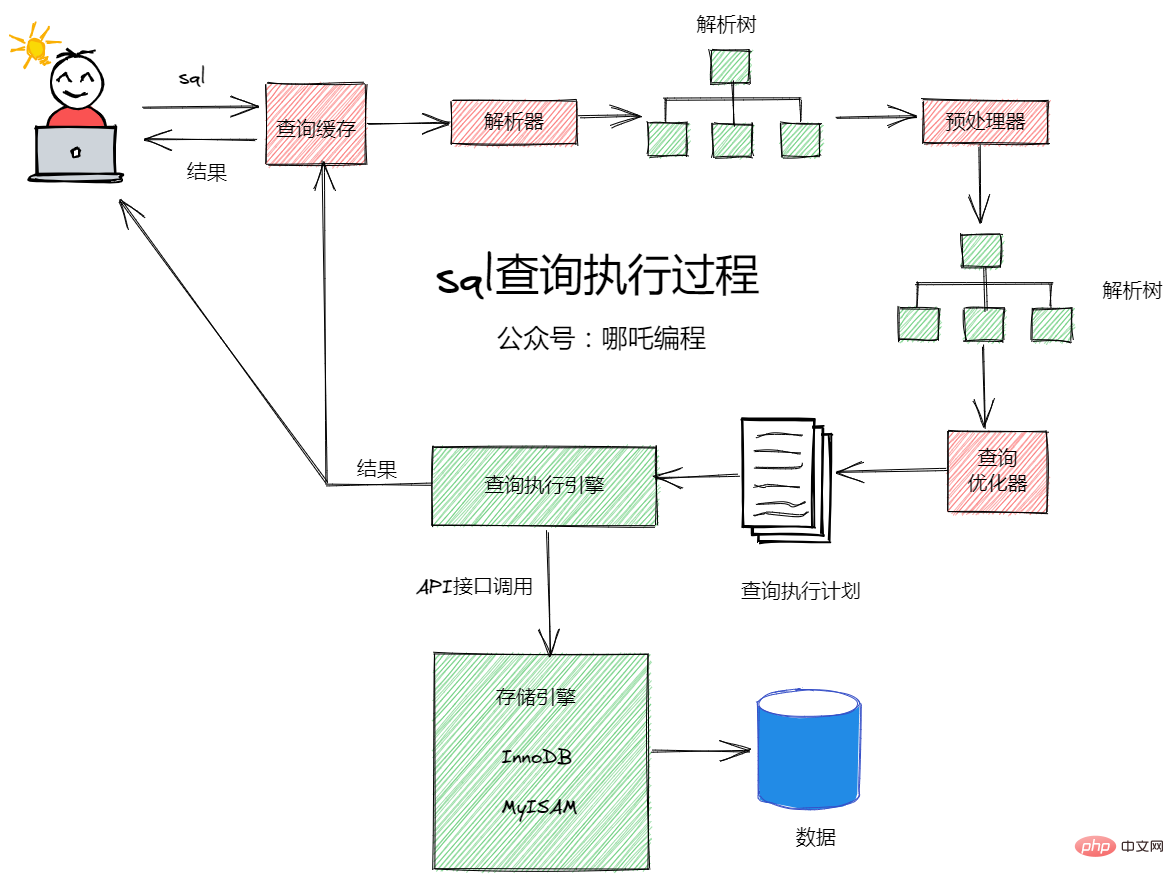
查詢快取系統會跟蹤查詢中涉及的每個表,如果這些表發生變化,那麼和這個表相關的所有的快取資料都將失效,這種機制效率看起來比較低,因為資料表變化時可能對查詢結果並沒有影響,但是這種簡單實現代價很小,而這點對於一個非常繁忙的系統來說非常重要。
(1)MySQL如何判斷快取命中
判斷是否命中時,MySQL不會解析,而是直接使用SQL語句和使用者端傳送過來的其它原始資訊。任何字元上的不同,例如空格、註釋,丟回導致快取的不命中。通常使用統一的編碼規則是一個好的習慣,會讓你的系統執行的更快。
當查詢語句中有一些不確定的資料時,不會被快取,比如函數now()。實際上,如果快取中包含任何使用者自定義函數、儲存函數、使用者變數、臨時表、MySQL系統表、或者任何包含列級別許可權的表,都不會被快取。
(2)使用查詢快取需謹慎
開啟查詢快取對讀和寫操作都會帶來額外的消耗:
讀查詢在執行之前要先檢查是否命中快取;
如果讀查詢可以被快取,那麼當完成執行後,MySQL如果發現快取中沒有這個查詢,會將其結果存入查詢快取,這會帶來額外的系統消耗;
對寫操作也有影響,因為當向某個表寫入資料的時候,MySQL必須將對應表的所有快取設定失效。如果查詢快取非常大或者碎片很多,這個操作就可能會帶來很大的系統消耗;
雖然如此,查詢快取仍然會給系統帶來效能的提升。但是,上述的額外消耗也可能不斷增加,再加上對查詢快取操作是一個加鎖排它操作,這個消耗也不小。
對InnoDB使用者來說,事務的一些特性會限制查詢快取的使用。當一個語句在事務中修改了某個表,在事務提交前,MySQL都會將這個表對應的查詢快取設定失效,因此,長時間執行的事務,會大大降低查詢快取的命中率。
(3)如何分析和設定查詢快取
10、儲存過程
儲存過程是一組為了完成特定功能的SQL 語句集合,經編譯後儲存在資料庫中,通過指定儲存過程的名字並給出引數的值,也可以返回結果。
儲存過程的優點:
減少網路流量
提高執行速度
減少資料庫連線次數
安全性高
複用性高
儲存過程的缺點:
可移植性差
11、事務
事務內的語句,要麼全執行,要麼全不執行。事務具有ACID特性,ACID表示原子性(atomicity)、一致性(consistency)、隔離性(isolation)、永續性(durability)。
(1)原子性(atomicity)
一個事務必須被視為一個不可分割的最小工作單元,整個事務中的所有操作要麼全執行提交成功,要麼全不失敗回滾。
(2)一致性(consistency)
資料庫總是從一個一致性的狀態轉換到另一個一致性的狀態。
(3)隔離性(isolation)
一個事務所做的修改在最終提交以前,對其它事務是不可見的。
(4)永續性(durability)
事務一旦提交,則七所做的修改就會永久的儲存在資料庫中。
12、索引
索引是儲存引擎用於快速查詢記錄的一種資料結構。我覺得資料庫中最重要的知識點,就是索引。
儲存引擎以不同的方式使用B-Tree索引,效能也各有不同,各有優劣。例如MyISAM使用字首壓縮技術使得索引更小,但InnoDB則按照原資料格式進行儲存。MyISAM索引通過資料的物理位置參照被索引的行,而InnoDB則根據主鍵參照被索引的行。
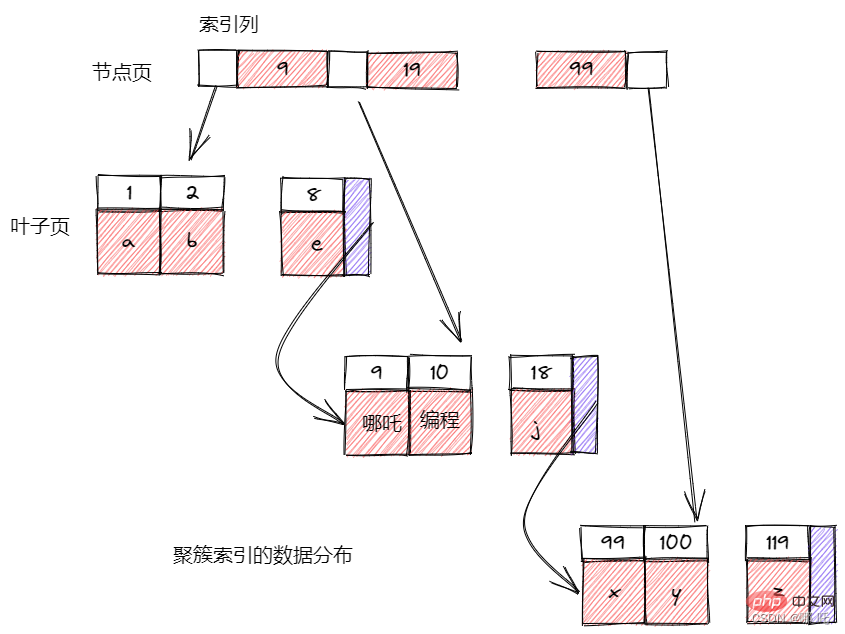
B-Tree通常意味著所有的值都是按順序儲存的,並且每一個葉子頁到根的距離相同。
B-Tree索引能夠加快存取資料的速度,因為儲存引擎不再需要進行全表掃描來獲取需要的資料,取而代之的是從索引的根結點開始進行搜尋。根結點的槽中存放了指向子結點的指標,儲存引擎根據這些指標向下層查詢。通過比較節點頁的值和要查詢的值可以找到合適的指標進入下層子節點,這些指標實際上定義了子節點頁中值的上限和下限。最終儲存引擎要麼找到對應的值,要麼該記錄不存在。
葉子節點比較特別,它們的指標指向的是被索引的資料,而不是其他的節點頁。B-Tree對索引列是順序組織儲存的,所有很適合查詢範圍資料。B-Tree適用於全鍵值、鍵值範圍或鍵字首查詢。
因為索引樹中的節點是有序的,所以除了按值查詢之外,索引還可以用於查詢中的order by操作。一般來說,如果B-Tree可以按照某種方式查詢到值,那麼也可以按照這種方式用於排序。
13、全文索引
全文索引的目的是 通過關鍵字的匹配進行查詢過濾,基於相似度的查詢,而不是精確查詢。
全文索引利用分詞技術分析出文字中某關鍵字的頻率和重要性,並按照一定的演演算法智慧的篩選出我們想要的結果。
全文索引一般用於字串中某關鍵字的查詢,比如char、varchar、text,也支援自然語言全文索引和布林全文索引。
推薦學習:
以上就是學習MySQL必須瞭解的13個關鍵字(總結分享)的詳細內容,更多請關注TW511.COM其它相關文章!