火山引擎 DataLeap 的 Data Catalog 系統公有云實踐
Data Catalog 通過彙總技術和業務後設資料,解決巨量資料生產者組織梳理資料、資料消費者找數和理解數的業務場景。本篇內容源自於火山引擎巨量資料研發治理套件 DataLeap 中的 Data Catalog 功能模組的實踐,主要介紹 Data Catalog 在公有云部署和釋出中遇到挑戰及解決方案。
背景
-
Data Catalog 是一種後設資料管理的服務,會收集技術後設資料,並在其基礎上提供更豐富的業務上下文與語意,通常支援後設資料編目、查詢、詳情瀏覽等功能。目前 Data Catalog 作為火山引擎巨量資料研發治理套件 DataLeap 產品的核心功能之一,經過多年打磨,服務於位元組跳動內部幾乎所有核心業務線,解決了資料生產者和消費者對於後設資料和資產管理的各項核心需求。
-
DataLeap 作為一站式資料中臺套件,彙集了位元組內部多年積累的資料整合、開發、運維、治理、資產、安全等全套資料中臺建設的經驗,助力 ToB 市場客戶提升資料研發治理效率、降低管理成本。
-
Data Catalog 作為 DataLeap 的核心功能之一,本文彙集了 Data Catalog 團隊在最近一年公有云從 0 到 1 實踐的整體經驗,主要講解遇到的各項挑戰和對應的解決方案。
Data Catalog 公有云發展歷程
Data Catalog 已經隨著 DataLeap 一起作為公有云產品正式在火山引擎對外發布,下面是 Data Catalog 在功能演進上的一些重要時間節點:
-
2021 年 9 月,Data Catalog 隨著 DataLeap 完成在火山引擎公有云首個版本部署和釋出,包含 60%內部核心功能,支援 EMR Hive 資料來源後設資料管理。
-
2022 年 2 月,Data Catalog 隨著 DataLeap 完成火山引擎公有云 Beta 版本釋出,吸引了一批客戶試用。
-
2022 年 5 月,Data Catalog 隨著 DataLeap 完成火山引擎公有云 GA 版本釋出,正式對外開放。
-
2021 年 9 月至 2022 年 5 月,Data Catalog 釋出 10+版本,對齊 95%內部核心功能以及釋出新功能 20+,包括支援 LAS/ByteHouse 資料來源、OpenAPI 和後設資料採集等 ToB 場景新特性。
Data Catalog 公有云整體架構

Data Catalog 支援綜合搜尋、血緣分析、庫表管理、後設資料採集、備註問答、專題管理、OpenAPI 等功能,和 DataLeap 其他功能模組(如資料開發、資料整合、資料質量、資料安全等)一起提供了巨量資料研發和治理場景的一站式解決方案。同時,Data Catalog 公有云產品是基於火山引擎提供的資料引擎和雲基礎設施來部署和服務的,下面會簡單介紹下我們所依賴和使用的產品和服務:
-
資料引擎:是火山引擎提供的資料分析、資料倉儲和資料湖相關產品,包括 ByteHouse/EMR/LAS 等產品。通常 Data Catalog 會從這類系統內採集元並儲存後設資料,進行處理加工後,再提供搜尋、血緣分析等功能;另外,庫表管理模組也會依賴這類系統提供對應的介面來做建庫建表等操作。
-
內部公共服務:是火山引擎為支援公司內部產品上公有云提供的若干公共基礎服務,主要作用是方便內部產品能快速在公有云部署,提供和公司內部相容性比較高的公共服務,降低改造和遷移成本。其中 Data Catalog 使用較多的包括:API 閘道器、網路代理、存取控制、安全認證、監控報警等。
-
基礎服務:這類服務或產品相較於上面說的內部公共服務主要區別是,他們是火山引擎對外售賣的標準雲服務,內外部使用者都可使用,且和業界主流雲廠商能力是基本對齊的,不過會和公司內部一些類似的基礎服務會有不少差異。Data Catalog 主要使用這類基礎服務來進行自身服務的部署運維,並且進行較多的相容性改造,包括容器部署、網路打通、內外部 CICD 和監控報警流程一致性等方面。
-
資料庫和中介軟體:是和業界主流雲廠商對齊的儲存和中介軟體領域的標準雲服務,和公司內部對應元件也會有若干差異,Data Catalog 為此也做了多版本的相容。Data Catalog 在後設資料儲存上使用到了 Hbase/MySQL/ES/Redis,然後在後設資料採集和同步場景使用了 Kafka,同時用到了紀錄檔服務來提高研發運維效率。
Data Catalog 公有云遇到的挑戰
Data Catalog 經歷了一個從 0 到 1 在火山引擎公有云部署並逐步優化和迭代釋出 10+版本的過程,在這個過程中經歷不少挑戰,下面將介紹其中比較典型的問題以及我們探索並實踐的一些解決方案。
網路和資料安全
為保證網路安全和多租戶資料安全,火山引擎上公有云產品部署的環境劃分為「公共服務區」和「售賣區」,同時售賣區又分割為若干私有網路(即 VPC),然後公共服務區和售賣區以及售賣區的 VPC 之間都是網路隔離的。
Data Catalog 會依賴一些內部公共服務,這類服務通常都部署在公共服務區,而按照網路和資料安全規範,Data Catalog 作為獨立雲產品需要部署在售賣區獨立 VPC 內,類似的情況 Data Catalog 依賴的資料中臺產品也需部署在獨立 VPC 內,例如 EMR、LAS 和 Bytehouse。另外,Data Catalog 對外會提供 OpenAPI,外部客戶可以通過火山引擎的 API 閘道器來存取這些 API,但 API 閘道器服務是在公共服務區,無法直接存取到 Data Catalog 服務,基於以上情況,為了正常對外提供服務,我們需要解決網路隔離問題同時還要保證安全性。
解決方案:
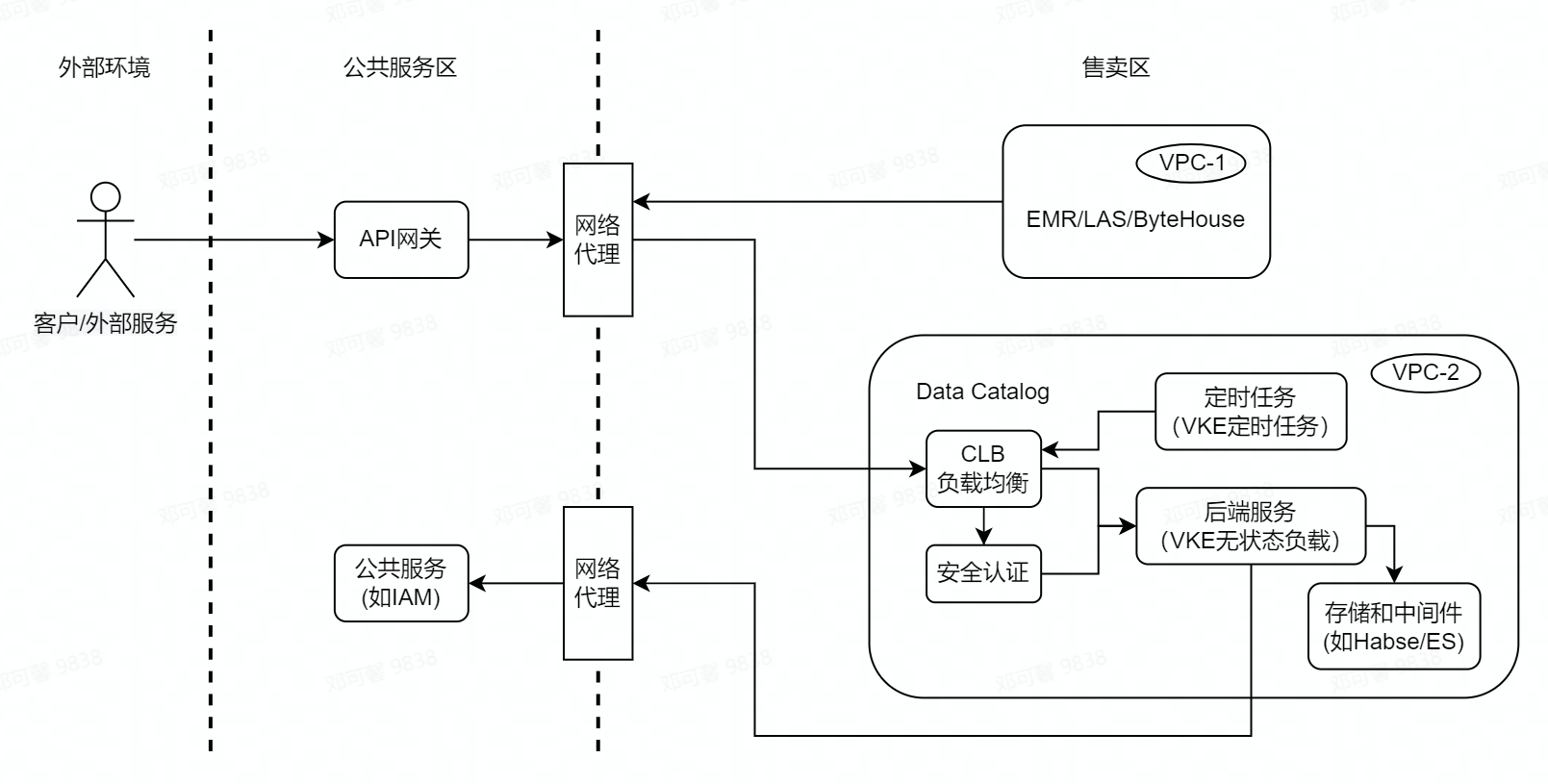
服務部署:為了能夠在售賣區部署,經過調研我們選擇火山引擎提供的容器服務(VKE)和負載均衡(CLB)來進行基礎服務部署和構建,其中 CLB 提供四層負載均衡能力,容器服務是高效能 Kubernetes 容器叢集管理服務。Data Catalog 基於容器服務提供的無狀態負載(Deployment)、定時任務(CronJob)、服務(Service)等雲原生容器管理功能進行基本服務和排程任務部署,同時也使用火山引擎的儲存和中介軟體,以上元件均在同一個 VPC 內,能夠保證網路連通以及資料安全。
-
網路打通:為解決上文所說的網路隔離問題,經過調研我們使用了公司通用的網路代理服務(PLB/Shuttle),該網路代理可做到網路打通的同時保證四層網路流量的安全,從而達到我們和各依賴方如公共服務(API 閘道器、IAM 等、獨立部署的雲服務(EMR/LAS 等)的網路連通目標。
-
資料安全:火山引擎部署環境做網路隔離,主要是保證安全性,我們雖然使用網路代理打通網路,但是仍需保證各個環節的安全性,考慮到服務間互動都是通過 HTTP 請求,我們對和外部互動的介面都增加了 SSL 和雙向認證的機制,同時在安全認證方面,我們沒有使用 Nginx 或 Java 原生的方案,而是藉助於火山引擎內部安全服務中的 ZTI 團隊的 envoy 元件來實現,同時使用 sidecar 模式和我們後端服務容器整合部署,既降低了伺服器端部署改造成本,也解耦了伺服器端業務邏輯和安全認證邏輯。
多租戶適配
這裡先對多租戶相關概念做一些解釋:
-
租戶:一個客戶、公司、個人開通或購買了火山引擎的雲產品,火山引擎就會通知對應的服務提供者,對應雲產品會感知到他的開通,這個客戶就是這個雲產品的一個租戶,實際場景可以類比於一個公司是一個租戶,不同的公司是不同的租戶。
-
多租戶服務:雲服務要為多個租戶提供服務,需要做到租戶隔離,保證各租戶的存取控制、資料、服務響應等各方面的使用都是隔離的,彼此互不感知互不影響的。要做到租戶隔離,就需要雲服務能通過邏輯或物理隔離的方式來將各租戶對應資料和存取隔離開來,避免互相影響。
此前,在位元組跳動內部實踐中不存在多租戶場景,所以面向公有云使用者服務時,Data Catalog 針對支援多租戶服務的能力,需要進行專門適配。
解決方案:
Data Catalog 在後設資料儲存層借用了 Apache Atlas 的設計與實現。Atlas 的底層使用 JanusGraph 做圖引擎,JanusGraph 是基於 Gremlin 圖查詢語意實現的計算引擎,而社群版 Atlas 不支援多租戶場景。我們通過在 Atlas 上增加 JanusGraph Partition Strategy 適配,實現儲存層租戶邏輯隔離。
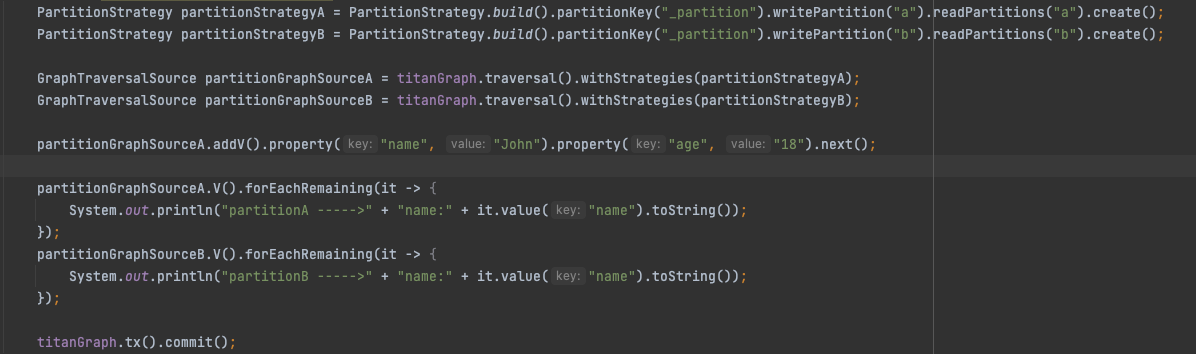
參考以上範例,JanusGraph 的 Partition Strategy 可以支援設定的 read/write Partition 的 value,並保證唯讀/寫指定 Partition 的資料,從而達到資料隔離,我們將租戶資訊和 Partition Strategy 相結合,實現了多租戶場景下讀寫資料的邏輯隔離,保證了資料安全性。
內外部功能一致
Data Catalog 在位元組跳動內部已打磨多年,產品形態和技術架構比較成熟,但隨著公有云部署和 ToB 產品迭代,因內部外基礎服務差異和 ToB 引入新的使用場景和上下游元件導致內外部產品功能和技術實現的差異也越來越多。
在前幾個版本中,我們嘗試使用獨立的程式碼分支和版本來支援 ToB 功能,避免內部新功能對 ToB 產生影響,但我們發現隨著版本差異越來越大,程式碼和功能的合併和相容就變得非常困難,在其中一次整體程式碼合併時,出現了好幾千的檔案 diff 和上百處 merge conflict,我們花費了一週時間多的時間合併程式碼和進行多環境測試迴歸驗證,最終完成了合併。功能和程式碼的不一致已經成為影響研發效率和需求交付進度的很重要因素,必須要進行優化。
解決方案:
我們主要從產品功能和程式碼版本兩方面來處理內外部一致性問題:
產品功能
-
產品功能的標準化:原則上所有功能都應做到內外部一致,只允許部分功能點的實現區別。我們期望能將各功能都進行標準化,基礎模組和通用能力(如後設資料模型、搜尋、血緣)原則上需保持內外一致,內外部依賴或需求場景差異較大的功能(如後設資料接入和採集、庫表管理)改造為標準化流程,將差異部分儘量減小,做到只通過設定、外掛、版本控制工具等方式就能適配,減少研發和運維成本。
-
明確的一致性規劃:從模組到功能點逐個對比內部外實現情況,制定長期 roadmap,明確差異點的支援排期,並提高對齊內部功能的工作優先順序,逐步減少差異。
-
新功能的相容性:新功能的設計需考慮內外部一致性,包括產品的互動和研發的技術方案都需考慮外部場景並明確相容方案,原則上對特殊場景客製化化功能都需考慮通用場景適配,儘量保持多環境的相容性。
技術實現
-
統一的程式碼分支管理規範:原則上內外部的程式碼是一致的即統一的分支。具體來說,不管域內外功能都需相容多環境並在多環境驗證才能合併程式碼,外部如公有云在發版週期中會基於內部主分支程式碼(如 master 分支)建立一個新的 release-x.x.x 分支,進行迴歸驗證和公有云上線,同時線上持續使用 release-x.x.x 分支以保證線上環境穩定,release-x.x.x 分支需定期合回主分支。新的版本會繼續基於主分支開發,並持續保持該規範。
-
明確的發版規劃:根據實際情況,內部通常迭代比較敏捷發版頻率較快,而外部通常要求穩定性,會定期發版(如每月一個版本),考慮到發版週期的差異,我們會以外部固定週期為標準,細粒度控制需求評估、功能開發、QA 測試、迴歸測試等各環節所在時間段,明確封板時間,降低內外部互相影響。
-
一致性意識和自動化多環境驗證:通過多輪分享和培訓在技術團隊內部對齊一致性意識,清楚內外部差異點 FAQ 等,另外,如上所說新功能技術設計方案需明確多環境相容性。同時,引入自動化的多環境驗證環節,儘早發現不相容或不一致的問題,減少人工判斷和測試的成本。
OpenAPI
在 DataLeap Beta 版本釋出之後,有內外部客戶在試用,當時就有客戶提出 OpenAPI 的需求,但在 Beta 版本我們還未支援 OpenAPI。公司內部有 OpenAPI 規範和平臺,Data Catalog 也藉助相關平臺實現了內部的 OpenAPI,但是 ToB 場景的公共平臺不同且會遇到 ToB 場景特定的問題(如安全認證、多租戶、API 開通計費等),需要綜合考慮來對外提供解決方案。
解決方案:
如前文介紹,火山引擎內部公共服務有 API 閘道器的通用服務(TOP),並有若干 API 釋出規範,Data Catalog 調研了該 API 閘道器並解決以上核心問題來支援 ToB OpenAPI。以下介紹一下主要流程和關注點:
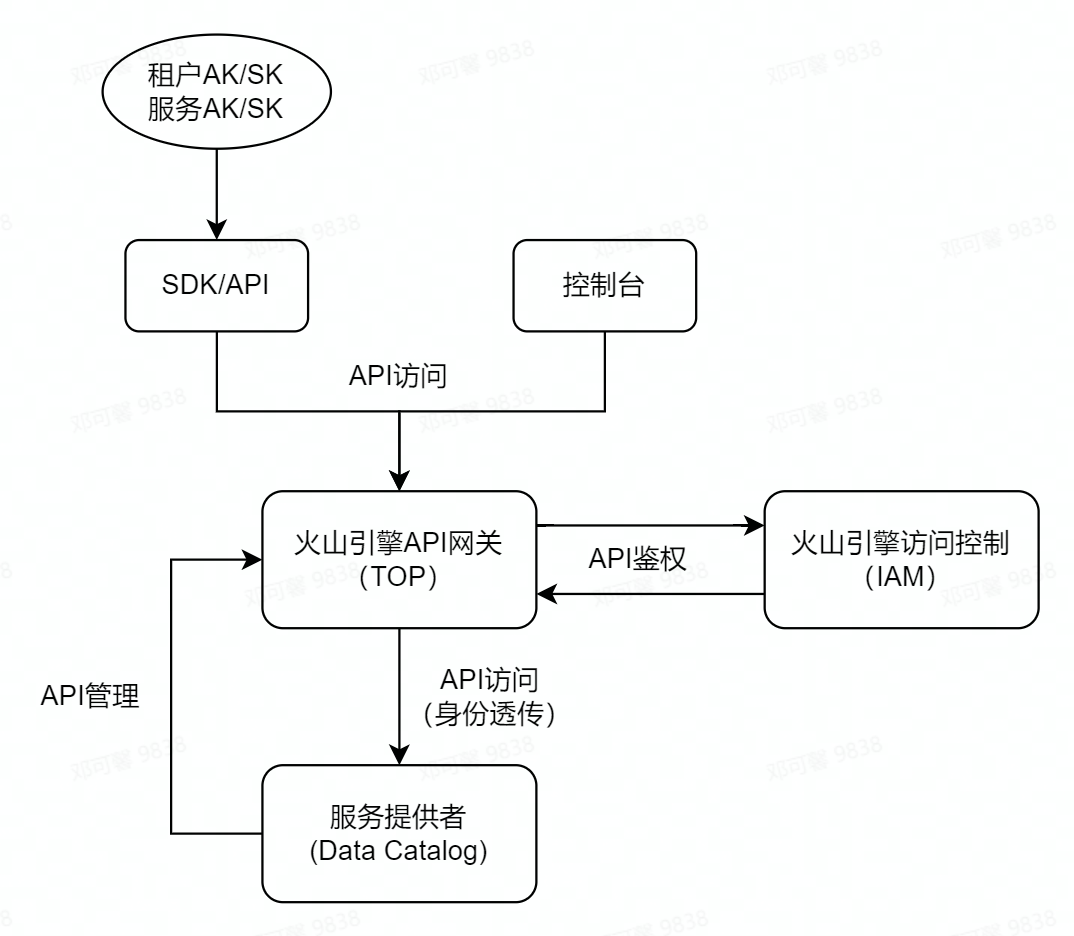
API 管理
-
Data Catalog 藉助於 API 閘道器管理 OpenAPI,包括註冊和開通、存取控制、限流等。
-
API 規範:火山引擎 OpenAPI 有明確的引數規範,Data Catalog 也需符合該規範,但因內部 OpenAPI 引數格式不同,需做相容,考慮到新 API 的支援成本,藉助於 Spring 的 Interceptor 和 Advice 以及客製化 JSON 序列化和反序列化邏輯,實現了自動的引數格式轉化,降低 API 格式相容的開發成本。
-
存取控制:火山引擎作為雲服務提供商,使用業界規範的 AKSK 金鑰管理規範,API 使用者需建立 AKSK 並通過該資訊來存取 API 才可通過存取控制,而 API 閘道器會通過 IAM 進行鑑權,通過後會給服務提供者也就是 API 註冊者透傳使用者的身份(如租戶 ID,使用者 ID),方便 API 提供者使用。
-
安全認證:處理 API 閘道器提供的基礎鑑權,Data Catalog 也增加了更多機制來保障安全性,包括雙向認證、租戶開通狀態檢測等。
-
API 檔案:對於每一個 OpenAPI 都根據火山引擎規範編寫了詳細的引數說明,彙總為一個正式 API 檔案,方便使用者查閱使用。
API 請求流程
-
使用者或服務通過 AKSK 存取 API,或者通過前端控制檯間接存取 API。
-
API 閘道器通過 IAM 進行鑑權,將識別到的使用者身份通過 HTTP header 透傳給服務提供者。
-
服務提供者接收到請求並通過 HTTP header 獲取使用者身份,進行下一步處理。
總結
火山引擎 Data Catalog 產品是基於位元組跳動內部平臺,經過多年打磨業務場景和產品能力,在公有云進行部署和釋出,期望幫忙更多外部客戶創造資料價值。目前公有云產品已包含內部成熟的產品功能同時擴充套件若干 ToB 核心功能,正在逐步對齊業界領先 Data Catalog 雲產品各項能力。
文中提及的內容其實還有繼續優化的空間,以及隨著客戶的使用,還有面臨一些新的問題,包括多租戶效能優化、服務穩定性保障等,我們都在持續探索和解決,期望能更好的支援 ToB 客戶的業務訴求並實現商業價值的同時,提供優質穩定的服務和豐富的擴充套件能力。
點選跳轉火山引擎巨量資料研發治理套件DataLeap瞭解更多