規則引擎Drools在貸後催收業務中的應用
作者:vivo 網際網路伺服器團隊- Feng Xiang
在日常業務開發工作中我們經常會遇到一些根據業務規則做決策的場景。為了讓開發人員從大量的規則程式碼的開發維護中釋放出來,把規則的維護和生成交由業務人員,為了達到這種目的通常我們會使用規則引擎來幫助我們實現。
本篇文章主要介紹了規則引擎的概念以及Kie和Drools的關係,重點講解了Drools中規則檔案編寫以及匹配演演算法Rete原理。文章的最後為大家展示了規則引擎在催收系統中是如何使用的,主要解決的問題等。
一、業務背景
1.1 催收業務介紹
消費貸作為vivo錢包中的重要業務板塊當出現逾期的案件需要處理時,我們會將案件統計收集後匯入到催收系統中,在催收系統中定義了一系列的規則來幫助業務方根據客戶的逾期程度、風險合規評估、操作成本及收益回報最大原則制定催收策略。例如「分案規則」 會根據規則將不同型別的案件分配到不同的佇列,再通過佇列分配給各個催收崗位和催收員,最終由催收員去進行催收。下面我會結合具體場景進行詳細介紹。
1.2 規則引擎介紹
1.2.1 問題的引入
案例:根據上述分案規則我們列舉了如下的規則集:
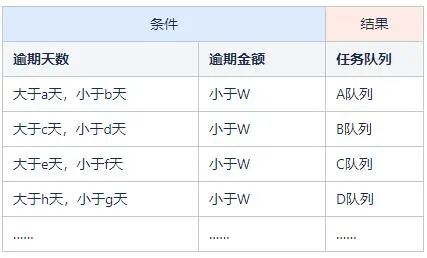
程式碼實現:將以上規則集用程式碼實現
if(overdueDays>a && overdueDays<b && overdueAmt <W){
taskQuene = "A佇列";
}
else if(overdueDays>c && overdueDays<d && overdueAmt <W){
taskQuene = "B佇列";
}
else if(overdueDays>e && overdueDays<f && overdueAmt <W){
taskQuene = "C佇列";
}
else if(overdueDays>h && overdueDays<g && overdueAmt <W){
taskQuene = "D佇列";
}
……
業務變化:
- 條件欄位和結果欄位可能會增長而且變動頻繁。
- 上面列舉的規則集只是一類規則,實際上在我們系統中還有很多其他種類的規則集。
- 規則最好由業務人員維護,可以隨時修改,不需要開發人員介入,更不希望重啟應用。
問題產生:可以看出如果規則很多或者比較複雜的場景需要在程式碼中寫很多這樣if else的程式碼,而且不容易維護一旦新增條件或者規則有變更則需要改動很多程式碼。
此時我們需要引入規則引擎來幫助我們將規則從程式碼中分離出去,讓開發人員從規則的程式碼邏輯中解放出來,把規則的維護和設定交由業務人員去管理。
1.2.2 什麼是規則引擎
規則引擎由推理引擎發展而來,是一種嵌入在應用程式中的元件, 實現了將業務決策從應用程式程式碼中分離出來,並使用預定義的語意模組編寫業務決策。
通過接收資料輸入解釋業務規則,最終根據業務規則做出業務決策。常用的規則引擎有:Drools,easyRules等等。本篇我們主要來介紹Drools。
二、Drools
2.1 整體介紹
2.1.1 KIE介紹
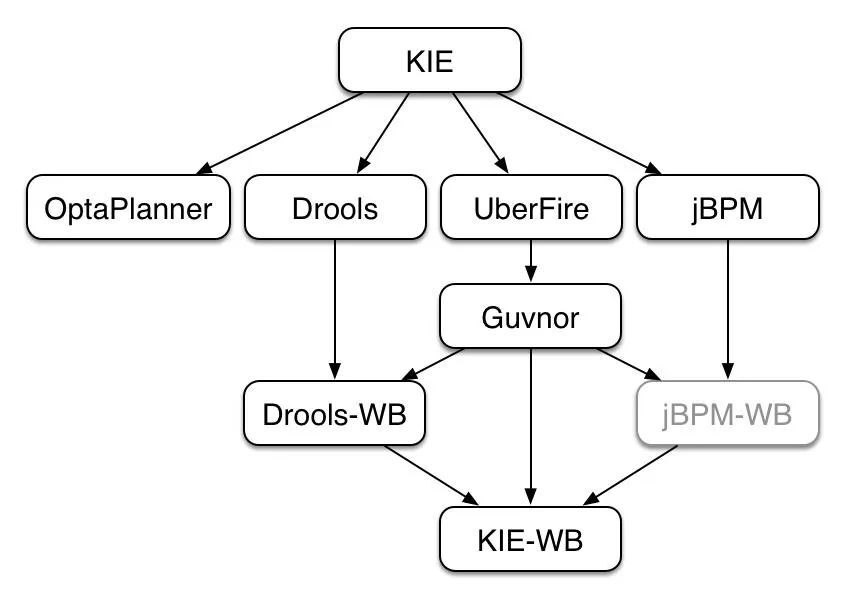
在介紹Drools之前我們不得不提到一個概念KIE,KIE(Knowledge Is Everything)是一個綜合性專案,將一些相關技術整合到一起,同時也是各個技術的核心,這裡面就包含了今天要講到的Drools。
技術組成:
- Drools是一個業務規則管理系統,具有基於前向鏈和後向鏈推理的規則引擎,允許快速可靠地評估業務規則和複雜的事件處理。
- jBPM是一個靈活的業務流程管理套件,允許通過描述實現這些目標所需執行的步驟來為您的業務目標建模。
- OptaPlanner是一個約束求解器,可優化員工排班、車輛路線、任務分配和雲優化等用例。
- UberFire是一個基於 Eclipse 的富使用者端平臺web框架。
2.1.2 Drools介紹
Drools 的基本功能是將傳入的資料或事實與規則的條件進行匹配,並確定是否以及如何執行規則。
Drools的優勢:基於Java編寫易於學習和掌握,可以通過決策表動態生成規則指令碼對業務人員十分友好。
Drools 使用以下基本元件:
- rule(規則):使用者定義的業務規則,所有規則必須至少包含觸發規則的條件和規則規定的操作。
- Facts(事實):輸入或更改到 Drools 引擎中的資料,Drools 引擎匹配規則條件以執行適用規則。
- production memory(生產記憶體):用於存放規則的記憶體。
- working memory(工作記憶體):用於存放事實的記憶體。
- Pattern matcher(匹配器):將規則庫中的所有規則與工作記憶體中的fact物件進行模式匹配,匹配成功後放入議程中
- Agenda(議程):存放匹配器匹配成功後啟用的規則以準備執行。
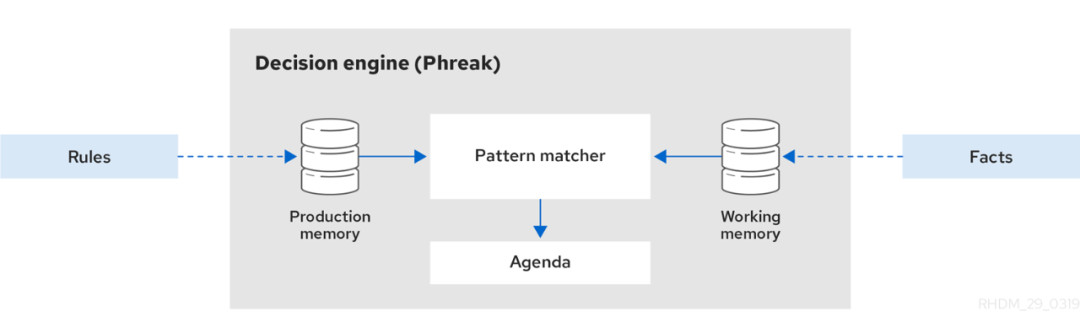
當用戶在 Drools 中新增或更新規則相關資訊時,該資訊會以一個或多個事實的形式插入 Drools 引擎的工作記憶體中。Drools 引擎將這些事實與儲存在生產記憶體中的規則條件進行模式匹配。
當滿足規則條件時,Drools 引擎會啟用並在議程中註冊規則,然後Drools 引擎會按照優先順序進行排序並準備執行。
2.2 規則(rule)
2.2.1 規則檔案解析
DRL(Drools 規則語言)是在drl文字檔案中定義的業務規則。主要包含:package,import,function,global,query,rule end等,同時Drools也支援Excel檔案格式。
package //包名,這個包名只是邏輯上的包名,不必與物理包路徑一致。
import //匯入類 同java
function // 自定義函數
query // 查詢
global // 全域性變數
rule "rule name" // 定義規則名稱,名稱唯一不能重複
attribute // 規則屬性
when
// 規則條件
then
// 觸發行為
end
rule "rule2 name"
...
-
function
規則檔案中的方法和我們平時程式碼中定義的方法類似,提升規則邏輯的複用。
使用案例:
function String hello(String applicantName) {
return "Hello " + applicantName + "!";
}
rule "Using a function"
when
// Empty
then
System.out.println( hello( "James" ) );
end
-
query
DRL 檔案中的查詢是在 Drools 引擎的工作記憶體中搜尋與 DRL 檔案中的規則相關的事實。在 DRL 檔案中新增查詢定義,然後在應用程式程式碼中獲取匹配結果。查詢搜尋一組定義的條件,不需要when或then規範。
查詢名稱對於 KIE 庫是全域性的,因此在專案中的所有其他規則查詢中必須是唯一的。返回查詢結果ksession.getQueryResults("name"),其中"name"是查詢名稱。
使用案例:
規則:
query "people under the age of 21"
$person : Person( age < 21 )
end
QueryResults results = ksession.getQueryResults( "people under the age of 21" );
System.out.println( "we have " + results.size() + " people under the age of 21" );
-
全域性變數global
通過 KIE 對談設定在 Drools 引擎的工作記憶體中設定全域性值,在 DRL 檔案中的規則上方宣告全域性變數,然後在規則的操作 ( then) 部分中使用它。
使用案例:
List<String> list = new ArrayList<>();
KieSession kieSession = kiebase.newKieSession();
kieSession.setGlobal( "myGlobalList", list );
global java.util.List myGlobalList;
rule "Using a global"
when
// Empty
then
myGlobalList.add( "My global list" );
end
-
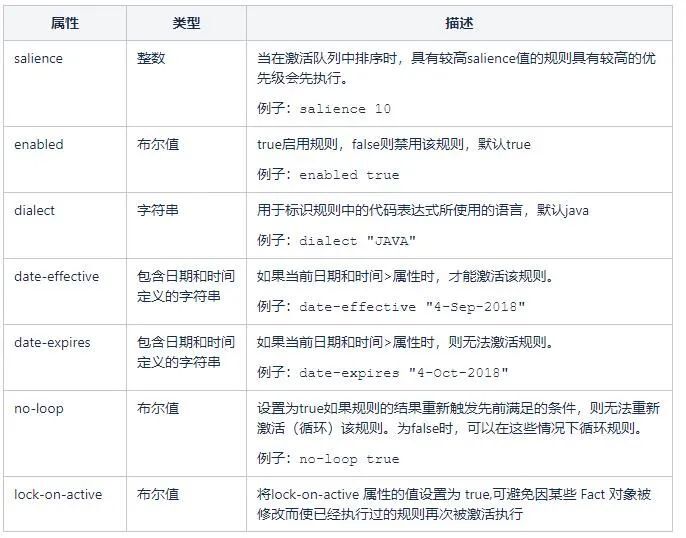
規則屬性
-
模式匹配
當事實被插入到工作記憶體中後,規則引擎會把事實和規則庫裡的模式進行匹配,對於匹配成功的規則再由 Agenda 執行推理演演算法中規則的(then)部分。
-
when
規則的「when」部分也稱為規則的左側 (LHS)包含執行操作必須滿足的條件。如果該when部分為空,則預設為true。如果規則條件有多個可以使用(and,or),預設連詞是and。如銀行要求貸款申請人年滿21歲,那麼規則的when條件是Applicant(age < 21)
rule "Underage"
when
application : LoanApplication()//表示存在Application事實物件且age屬性滿足<21
Applicant( age < 21 )
then
// Actions
end
-
then
規則的「then」部分也稱為規則的右側(RHS)包含在滿足規則的條件部分時要執行的操作。如銀行要求貸款申請人年滿 21 歲(Applicant( age < 21 ))。不滿足則拒絕貸款setApproved(false)
rule "Underage"
when
application : LoanApplication()
Applicant( age < 21 )
then
application.setApproved( false );
end
-
內建方法
Drools主要通過insert、update方法對工作記憶體中的fact資料進行操作,來達到控制規則引擎的目的。
操作完成之後規則引擎會重新匹配規則,原來沒有匹配成功的規則在我們修改完資料之後有可能就匹配成功了。
注意:這些方法會導致重新匹配,有可能會導致死迴圈問題,在編寫中最好設定屬性no-loop或者lock-on-active屬性來規避。
(1)insert:
作用:向工作記憶體中插入fact資料,並讓相關規則重新匹配
rule "Underage"
when
Applicant( age < 21 )
then
Applicant application = new application();
application.setAge(22);
insert(application);//插入fact重新匹配規則,age>21的規則直接被觸發
end
(2)update:
作用:修改工作記憶體中fact資料,並讓相關規則重新匹配
rule "Underage"
when
Applicant( age < 21 )
then
Applicant application = new application();
application.setAge(22);
insert(application);//插入fact重新匹配規則,age>21的規則直接被觸發
end
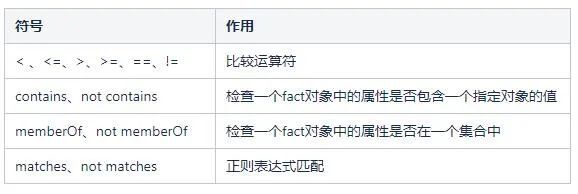
比較操作符
2.3 工程引入
2.3.1 組態檔的引入
需要有一個組態檔告訴程式碼規則檔案drl在哪裡,在drools中這個檔案就是kmodule.xml,放置到resources/META-INF目錄下。
說明:kmodule是6.0 之後引入的一種新的設定和約定方法來構建 KIE 庫,而不是使用之前的程式化構建器方法。
<kmodule xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.drools.org/xsd/kmodule">
<kbase name="KBase1" default="true" packages="org.domain.pkg1">
<ksession name="KSession2_1" type="stateful" default="true"/>
<ksession name="KSession2_2" type="stateless" default="false"/>
</kbase>
<kbase name="KBase2" default="false" packages="org.domain.pkg2, org.domain.pkg3">
<ksession name="KSession3_1" type="stateful" default="false">
</ksession>
</kbase>
</kmodule>
-
Kmodule 中可以包含一個到多個 kbase,分別對應 drl 的規則檔案。
-
Kbase 是所有應用程式知識定義的儲存庫,包含了若干的規則、流程、方法等。需要一個唯一的name,可以取任意字串。
KBase的default屬性表示當前KBase是不是預設的,如果是預設的則不用名稱就可以查詢到該 KBase,但每個 module 最多隻能有一個預設 KBase。
KBase下面可以有一個或多個 ksession,ksession 的 name 屬性必須設定,且必須唯一。
-
packages 為drl檔案所在resource目錄下的路徑,多個包用逗號分隔,通常drl規則檔案會放在工程中的resource目錄下。
2.3.2 程式碼中的使用
KieServices:可以存取所有 Kie 構建和執行時的介面,通過它來獲取的各種物件(例如:KieContainer)來完成規則構建、管理和執行等操作。
KieContainer:KieContainer是一個KModule的容器,提供了獲取KBase的方法和建立KSession的方法。其中獲取KSession的方法內部依舊通過KBase來建立KSession。
KieSession:KieSession是一個到規則引擎的對話連線,通過它就可以跟規則引擎通訊,並且發起執行規則的操作。例如:通過kSession.insert方法來將事實(Fact)插入到引擎中,也就是Working Memory中,然後通過kSession.fireAllRules方法來通知規則引擎執行規則。
KieServices kieServices = KieServices.Factory.get();
KieContainer kContainer = kieServices.getKieClasspathContainer();
KieBase kBase1 = kContainer.getKieBase("KBase1"); //獲取指定的KBase
KieSession kieSession1 = kContainer.newKieSession("KSession2_1"); //獲取指定的KSession
kieSession1.insert(facts);//規則插入到工作記憶體
kSession.fireAllRules();//開始執行
kSession.dispose();//關閉對話
說明:以上案例是使用的Kie的API(6.x之後的版本)
2.4 模式匹配演演算法-RETE
Rete演演算法由Charles Forgy博士發明,並在1978-79年的博士論文中記錄。Rete演演算法可以分為兩部分:規則編譯和執行時執行。
編譯演演算法描述瞭如何處理生產記憶體中的規則以生成有效的決策網路。在非技術術語中,決策網路用於在資料通過網路傳播時對其進行過濾。
網路頂部的節點會有很多匹配,隨著網路向下延伸匹配會越來越少,在網路的最底部是終端節點。
關於RETE演演算法官方給出的說明比較抽象,這裡我們結合具體案例進行說明。
2.4.1 案例說明
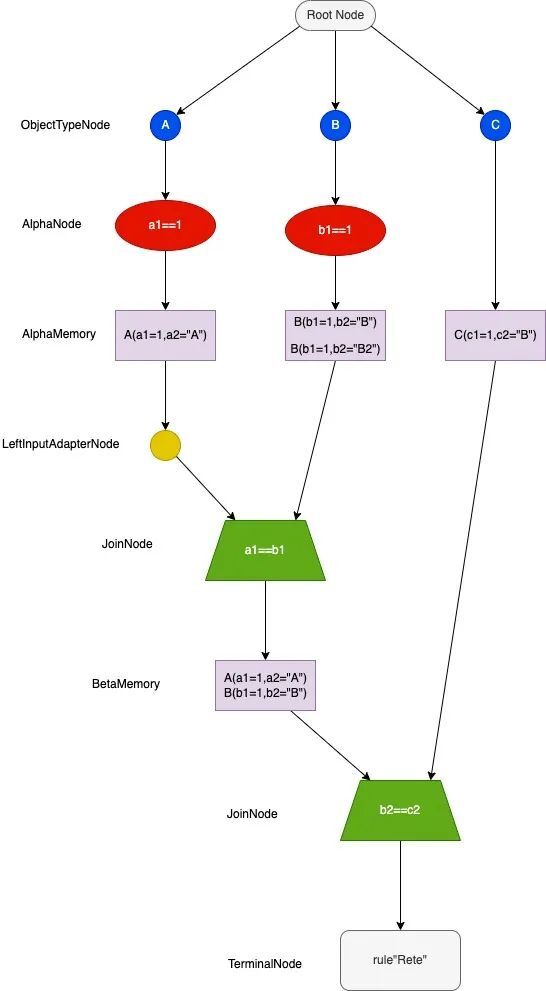
假設有以下事實物件:
A(a1=1,a2="A")
A(a1=2,a2="A2")
B(b1=1,b2="B")
B(b1=1,b2="B2")
B(b1=2,b2="B3")
C(c1=1,c2="B")
現有規則:
rule "Rete"
when
A(a1==1,$a:a1)
B(b1==1,b1==$a,$b:b2)
C(c2==$b)
then
System.out.print("匹配成功");
end
Bete網路:
2.4.2 節點說明
1.Root Node:根節點是所有物件進入網路的地方
2.one-input-node(單輸入節點)
【ObjectTypeNode】:物件型別節點是根節點的後繼節點,用來判斷型別是否一致
【AlphaNode】:用於判斷文字條件,例如(name == "cheddar",strength == "strong")
【LeftInputAdapterNode】:將物件作為輸入並傳播單個物件。
3.two-input-node(雙輸入節點)
【BetaNode】:用於比較兩個物件,兩個物件可能是相同或不同的型別。上述案例中用到的join node就是betaNode的一種型別。join node 用於連線左右輸入,左部輸入的是事實物件列表,右部輸入一個事實物件,在Join節點按照物件型別或物件欄位進行比對。BetaNodes 也有記憶體。左邊的輸入稱為 Beta Memory,它會記住所有傳入的物件列表。右邊的輸入稱為 Alpha Memory,它會記住所有傳入的事實物件。
4.TerminalNode:
表示一條規則已匹配其所有條件,帶有「或」條件的規則會為每個可能的邏輯分支生成子規則,因此一個規則可以有多個終端節點。
2.4.3 RETE網路構建流程
- 建立虛擬根節點
- 取出一個規則,例如 "Rete"
- 取出一個模式例如a1==1(模式:就是指when語句的條件,這裡when條件可能是有幾個更小的條件組成的大條件。模式就是指的不能再繼續分割下去的最小的原子條件),檢查引數型別(ObjectTypeNode),如果是新型別則加入一個型別節點;
- 檢查模式的條件約束:對於單型別約束a1==1,檢查對應的alphaNode是否已存在,如果不存在將該約束作為一個alphaNode加入鏈的後繼節點;
- 若為多型別約束a1==b1,則建立相應的betaNode,其左輸入為LeftInputAdapterNode,右輸入為當前鏈的alphaNode;
- 重複4,直到該模式的所有約束處理完畢;
- 重複3-5,直到所有的模式處理完畢,建立TerminalNode,每個模式鏈的末尾連到TerminalNode;
- 將(Then)部分封裝成輸出節點。
2.4.4 執行時執行
- 從工作記憶體中取一工作儲存區元素WME(Working Memory Element,簡稱WME)放入根節點進行匹配。WME是為事實建立的元素,是用於和非根結點代表的模式進行匹配的元素。
- 遍歷每個alphaNode和ObjectTypeNode,如果約束條件與該WME一致,則將該WME存在該alphaNode的匹配記憶體中,並向其後繼節點傳播。
- 對每個betaNode進行匹配,將左記憶體中的物件列表與右記憶體中的物件按照節點約束進行匹配,符合條件則將該事實物件與左部物件列表合併,並傳遞到下一節點。
- 和3都完成之後事實物件列表進入到TerminalNode。對應的規則被觸活,將規則註冊進議程(Agenda)。
- 對Agenda裡的規則按照優先順序執行。
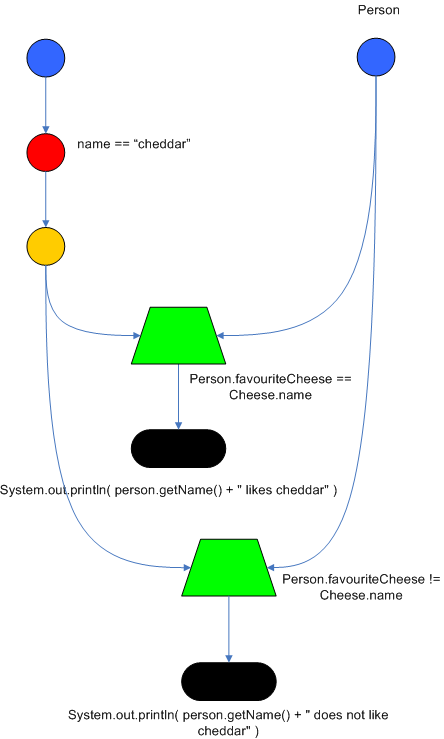
2.4.5 共用模式
以下是模式共用的案例,兩個規則共用第一個模式Cheese( $cheddar : name == "cheddar" )
rule "Rete1"
when
Cheese( $cheddar : name == "cheddar" )
$person : Person( favouriteCheese == $cheddar )
then
System.out.println( $person.getName() + " likes cheddar" );
end
rule "Rete2"
when
Cheese( $cheddar : name == "cheddar" )
$person : Person( favouriteCheese != $cheddar )
then
System.out.println( $person.getName() + " does not like cheddar" );
end
網路圖:(左邊的型別為Cheese,右邊型別為Person)
2.4.6 小結
rete演演算法本質上是通過共用規則節點和快取匹配結果,獲得效能提升。
【狀態儲存】:
事實集合中的每次變化,其匹配後的狀態都被儲存到alphaMemory和betaMemory中。在下一次事實集合發生變化時(絕大多數的結果都不需要變化)通過從記憶體中取值,避免了大量的重複計算。
Rete演演算法主要是為那些事實集合變化不大的系統設計的,當每次事實集合的變化非常劇烈時,rete的狀態儲存演演算法效果並不理想。
【節點共用】:
例如上面的案例不同規則之間含有相同的模式,可以共用同一個節點。
【hash索引】:
每次將 AlphaNode 新增到 ObjectTypeNode 後繼節點時,它都會將文字值作為鍵新增到 HashMap,並將 AlphaNode 作為值。當一個新範例進入 ObjectType 節點時,它不會傳播到每個 AlphaNode,而是可以從HashMap 中檢索正確的 AlphaNode,從而避免不必要的文字檢查。
存在問題:
- 存在狀態重複儲存的問題,匹配過多個模式的事實要同時儲存在這些模式的節點快取中,將佔用較多空間並影響匹配效率。
- 不適合頻繁變化的資料與規則(資料變化引起節點儲存的臨時事實頻繁變化,這將讓rete失去增量匹配的優勢;資料的變化使得對規則網路的種種優化方法如索引、條件排序等失去效果)。
- rete演演算法使用了alphaMemory和betaMemory儲存已計算的中間結果, 以犧牲空間換取時間, 從而加快系統的速度。然而當處理海量資料與規則時,beta記憶體根據規則的條件與事實的數目而成指數級增長, 所以當規則與事實很多時,會耗盡系統資源。
在Drools早期版本中使用的匹配演演算法是Rete,從6.x開始引入了phreak演演算法來解決Rete帶來的問題。
關於phreak演演算法可以看官方介紹:https://docs.drools.org/6.5.0.Final/drools-docs/html/ch05.html
三、催收業務中的應用
3.1 問題解決
文章開頭問題引出的例子中可以通過編寫drl規則指令碼實現,每次規則的變更只需要修改drl檔案即可。
package vivoPhoneTaskRule;
import com.worldline.wcs.service.rule.CaseSumNewWrapper;
rule "rule1"
salience 1
when
caseSumNew:CaseSumNewWrapper(overdueDD > a && overdueDD < b && overdueAmt <= W)
then
caseSumNew.setTaskType("A佇列");
end
rule "rule2"
salience 2
when
caseSumNew:CaseSumNewWrapper(overdueDD > c && overdueDD < d && overdueAmt <= W)
then
caseSumNew.setTaskType("B佇列");
end
rule "rule3"
salience 3
when
caseSumNew:CaseSumNewWrapper(overdueDD > e && overdueDD < f && overdueAmt <= W)
then
caseSumNew.setTaskType("C佇列");
end
rule "rule4"
salience 4
when
caseSumNew:CaseSumNewWrapper(overdueDD > h && overdueDD < g && overdueAmt > W)
then
caseSumNew.setTaskType("D佇列");
end
產生一個新的問題:
雖然通過編寫drl可以解決規則維護的問題,但是讓業務人員去編寫這樣一套規則指令碼顯然是有難度的,那麼在催收系統中是怎麼做的呢,我們繼續往下看。
3.2 規則的設計
3.2.1 決策表設計
催收系統自研了一套決策表的解決方案,將drl中的條件和結果語句抽象成結構化資料進行儲存並在前端做了視覺化頁面提供給業務人員進行編輯不需要編寫規則指令碼。例如新增規則:
將逾期天數大於a天小於b天且逾期總金額小於等於c的案件分配到A佇列中。
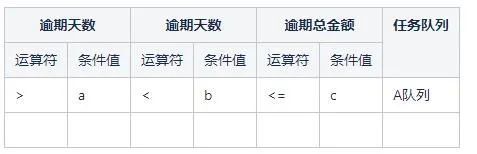
表中的每一行都對應一個rule,業務人員可以根據規則情況進行修改和新增,同時也可以根據條件定義對決策表進行拓展。
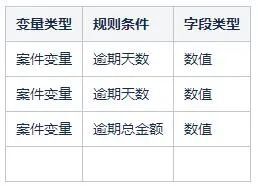
決策表的主要構成:

- 規則條件定義:定義了一些規則中用到的條件,例如:逾期天數,逾期金額等。
- 規則結果定義:定義了一些規則中的結果,例如:分配到哪些佇列中,在佇列中停留時間等。
- 條件欄位:在編輯一條規則時,需要用到的條件欄位(從條件定義列表中選取)。
- 比較操作符與值:比較操作符包括:< 、<=、>、>=、==、!=,暫時不支援contain,member Of,match等。
條件值目前包含數位和字元。條件欄位+比較操作符+值,就構成了一個條件語句。
-
結果:滿足條件後最終得到的結果也就是結果定義中的欄位值。
3.2.2 規則生成
催收系統提供了視覺化頁面設定來動態生成指令碼的功能(業務人員根據條件定義和結果定義來編輯決策表進而制定相應規則)。
核心流程:

1.根據規則型別解析相應的事實物件對映檔案,並封裝成條件實體entitys與結果實體resultDefs,檔案內容如下圖:
事實物件對映xml
<rule package="phoneTask">
<entitys>
<entity note="collectionCaseInfo" cls="com.worldline.wcs.service.rule.FactWrapper" alias="caseSumNew">
<attribute attr="caseSumNew.overdueDD" />
<attribute attr="caseSumNew.totalOverdueAmt"/>
</entity>
</entitys>
<resultDefs>
<resultDef key="1" seq="1" enumKey="ruleTaskType">
<script><![CDATA[caseSumNew.setTaskType("@param");]]></script>
</resultDef>
</resultDefs>
</rule>
2.根據規則型別查詢規則集完整資料
3.將規則集資料與xml解析後的物件進行整合,拼裝成一個drl指令碼
4.將拼裝好的指令碼儲存到資料庫規則集表中
/**
* 生成規則指令碼
* rule規則基本資訊:包括規則表欄位名定義等
* def 業務人員具體錄入規則集的條件和結果等資料
*/
public String generateDRLScript(DroolsRuleEditBO rule, DroolsRuleTableBO def) {
//解析事實物件對映XML檔案,生成條件定義與結果定義
RuleSetDef ruleSetDef = RuleSetDefHelper.getRuleSetDef(rule.getRuleTypeCode());
// 1.宣告規則包
StringBuilder drl = new StringBuilder("package ").append(rule.getRuleTypeCode()).append(";\n\n");
HashMap<String, String> myEntityMap = Maps.newHashMap(); // k,v => caseSumNew,CaseSumNewWrapper
// 2.匯入 entity 對應執行類
ruleSetDef.getEntitys().forEach(d -> {
String cls = d.getCls();
drl.append("import ").append(cls).append(";\n\n");
myEntityMap.put(d.getAlias(), cls.substring(cls.lastIndexOf('.') + 1));
});
// 3.規則指令碼註釋
drl.append("// ").append(rule.getRuleTypeCode()).append(" : ").append(rule.getRuleTypeName()).append("\n");
drl.append("// version : ").append(rule.getCode()).append("\n");
drl.append("// createTime : ").append(DateUtil.getSysDate(DateUtil.PATTERN_TIME_DEFAULT)).append("\n\n");
Map<String, String> myResultMap = def.getResultDefs().stream().collect(Collectors.toMap(DroolsRuleCondBO::getCondKey, DroolsRuleCondBO::getScript));
// 4.寫規則
AtomicInteger maxRowSize = new AtomicInteger(0); // 總規則數
rule.getTables().forEach(table -> {
String tableCode = table.getTableCode();
table.getRows().stream().filter(r -> !Objects.equals(r.getStatus(), 3))
.forEach(row -> {
// 3.1.規則屬性及優先順序
drl.append("// generated from row: ").append(row.getRowCode()).append("\n");
//TODO 需要保證row.getRowSort()不重複,否則生成同樣的規則編號
drl.append("rule \"").append(rule.getRuleTypeCode()).append("_").append(tableCode).append("_TR_").append(row.getRowSort()).append("\"\n"); // pkg_tableCode_TR_rowSort
drl.append("\tsalience ").append((maxRowSize.incrementAndGet())).append("\n");
// 4.2.條件判定
drl.append("\twhen\n");
// 每個entity一行,多條件合併
// when=condEntityKey:cls(condKeyMethod colOperator.drlStr colValue), 其中cls=myEntityMap.value(key=condEntityKey)
drl.append(
row.getColumns()
.stream().collect(Collectors.groupingBy(d -> d.getCondition().getCondEntityKey()))
.entrySet().stream()
.map(entityType -> "\t\t" + entityType.getKey() + ":" + myEntityMap.get(entityType.getKey()) + "(" +
entityType.getValue().stream()
.filter(col -> StringUtils.isNotBlank(col.getColValue())) // 排除無效條件
.sorted(Comparator.comparing(col -> col.getCondition().getCondSort())) // 排序
.map(col -> {
String condKey = col.getCondition().getCondKey();
String condKeyMethod = condKey.substring(condKey.indexOf('.') + 1);
String[] exec = ParamTypeHelper.get(col.getColOperator()).getDrlStr(condKeyMethod, col.getColValue());
if (exec.length > 0) {
return Arrays.stream(exec).filter(StringUtils::isNotBlank).collect(Collectors.joining(" && "));
}
return null;
})
.collect(Collectors.joining(" && ")) + ")\n"
)
.collect(Collectors.joining()));
// 4.3.規則結果
drl.append("\tthen\n");
row.getResults().forEach(r -> {
String script = myResultMap.get(r.getResultKey());
drl.append("\t\t").append(script.replace("@param", r.getResultValue())).append("\n"); // 使用 resultValue 替換 @param
});
drl.append("end\n\n");
});
});
return drl.toString();
}
3.2.3 規則執行
核心流程:

//核心流程程式碼: KnowledgeBuilder kb = KnowledgeBuilderFactory.newKnowledgeBuilder(); kb.add(ResourceFactory.newByteArrayResource(script.getBytes(StandardCharsets.UTF_8)), ResourceType.DRL); //script為規則指令碼 InternalKnowledgeBase base = KnowledgeBaseFactory.newKnowledgeBase(); KieSession ksession = base.newKieSession(); AgendaFilter filter = RuleConstant.DroolsRuleNameFilter.getFilter(ruleTypeCode);//獲取一個過濾器 kSession.insert(fact); kSession.fireAllRules(filter); kSession.dispose();
- 根據規則型別從規則集表中查詢drl指令碼
- 將腳步新增至KnowledgeBuilder中構建知識庫
- 獲取知識庫InternalKnowledgeBase(在新版本中對應 Kmodule中的Kbase)
- 通過InternalKnowledgeBase建立KieSession對談連結
- 建立AgendaFilter來制定執行某一個或某一些規則
- 呼叫insert方法將事實物件fact插入工作記憶體
- 呼叫fireAllRules方法執行規則
- 最後呼叫dispose關閉連線
四、總結
本文主要由催收系統中的一個案例引出規則引擎Drools,然後詳細介紹了Drools的概念與用法以及模式匹配的原理Rete演演算法。最後結合催收系統給大家講解了Drools在催收系統中是如何使用的。
通過規則引擎的引入讓開發人員不再需要參與到規則的開發與維護中來,極大節約了開發成本。通過自研的催收系統視覺化決策表,讓業務人員可以在系統中靈活設定維護規則而不需要每次編寫複雜的規則指令碼,解決了業務人員的痛點。系統本質上還是執行的規則指令碼,我們這裡是把指令碼的生成做了優化處理,先通過視覺化頁面錄入規則以結構化的資料進行儲存,再將其與規則定義進行整合拼裝,最終由系統自動生成規則指令碼。
當前催收系統中的規則引擎仍然存在著一些問題,例如:
- 催收系統通過動態生成指令碼的方式適合比較簡單的規則邏輯,如果想實現較為複雜的規則,需要寫很多複雜的程式碼,維護成本比較高。
- 催收系統雖然使用的drools7.x版本,但是使用的方式依然使用的是5.x的程式化構建器方法(Knowledge API)
- 催收系統目前規則固定頁面上只能編輯無法新增規則,只能通過初始化資料庫表的方式新增規則。
後續我們會隨著版本的迭代不斷升級優化,感謝閱讀。
參考檔案: