零基礎入門金融風控之貸款違約預測挑戰賽——簡單實現
零基礎入門金融風控之貸款違約預測挑戰賽
賽題理解
賽題以金融風控中的個人信貸為背景,要求選手根據貸款申請人的資料資訊預測其是否有違約的可能,以此判斷是否通過此項貸款,這是一個典型的分類問題。通過這道賽題來引導大家瞭解金融風控中的一些業務背景,解決實際問題,幫助競賽新人進行自我練習、自我提高。
專案地址:https://github.com/datawhalechina/team-learning-data-mining/tree/master/FinancialRiskControl
比賽地址:https://tianchi.aliyun.com/competition/entrance/531830/introduction
資料形式
對於訓練集資料來說,其中有特徵如下:
- id 為貸款清單分配的唯一信用證標識
- loanAmnt 貸款金額
- term 貸款期限(year)
- interestRate 貸款利率
- installment 分期付款金額
- grade 貸款等級
- subGrade 貸款等級之子級
- employmentTitle 就業職稱
- employmentLength 就業年限(年)
- homeOwnership 借款人在登記時提供的房屋所有權狀況
- annualIncome 年收入
- verificationStatus 驗證狀態
- issueDate 貸款發放的月份
- purpose 借款人在貸款申請時的貸款用途類別
- postCode 借款人在貸款申請中提供的郵政編碼的前3位數位
- regionCode 地區編碼
- dti 債務收入比
- delinquency_2years 借款人過去2年信用檔案中逾期30天以上的違約事件數
- ficoRangeLow 借款人在貸款發放時的fico所屬的下限範圍
- ficoRangeHigh 借款人在貸款發放時的fico所屬的上限範圍
- openAcc 借款人信用檔案中未結信用額度的數量
- pubRec 貶損公共記錄的數量
- pubRecBankruptcies 公開記錄清除的數量
- revolBal 信貸週轉餘額合計
- revolUtil 迴圈額度利用率,或借款人使用的相對於所有可用迴圈信貸的信貸金額
- totalAcc 借款人信用檔案中當前的信用額度總數
- initialListStatus 貸款的初始列表狀態
- applicationType 表明貸款是個人申請還是與兩個共同借款人的聯合申請
- earliesCreditLine 借款人最早報告的信用額度開立的月份
- title 借款人提供的貸款名稱
- policyCode 公開可用的策略_程式碼=1新產品不公開可用的策略_程式碼=2
- n系列匿名特徵 匿名特徵n0-n14,為一些貸款人行為計數特徵的處理
還有一列為目標列isDefault代表是否違約。
預測指標
賽題要求採用AUC作為評價指標。
具體演演算法
匯入相關庫
import pandas as pd
import numpy as np
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.metrics import roc_auc_score, roc_curve, mean_squared_error,mean_absolute_error, f1_score
import lightgbm as lgb
import xgboost as xgb
from sklearn.ensemble import RandomForestRegressor as rfr
from sklearn.linear_model import LinearRegression as lr
from sklearn.model_selection import KFold, StratifiedKFold,GroupKFold, RepeatedKFold
import warnings
warnings.filterwarnings('ignore') #消除warning
讀入資料
train_data = pd.read_csv("train.csv")
test_data = pd.read_csv("testA.csv")
print(train_data.shape)
print(test_data.shape)
(800000, 47)
(200000, 47)
資料處理
由於等下需要對特徵進行變化,因此我先將訓練集和測試集堆疊在一起,一起處理才方便,再加入一列作為區分即可。
target = train_data["isDefault"]
train_data["origin"] = "train"
test_data["origin"] = "test"
del train_data["isDefault"]
data = pd.concat([train_data, test_data], axis = 0, ignore_index = True)
data.shape
(1000000, 47)
那麼接下來就是對data進行處理,可以先看看其大致的資訊:
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000000 entries, 0 to 999999
Data columns (total 47 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 1000000 non-null int64
1 loanAmnt 1000000 non-null float64
2 term 1000000 non-null int64
3 interestRate 1000000 non-null float64
4 installment 1000000 non-null float64
5 grade 1000000 non-null object
6 subGrade 1000000 non-null object
7 employmentTitle 999999 non-null float64
8 employmentLength 941459 non-null object
9 homeOwnership 1000000 non-null int64
10 annualIncome 1000000 non-null float64
11 verificationStatus 1000000 non-null int64
12 issueDate 1000000 non-null object
13 purpose 1000000 non-null int64
14 postCode 999999 non-null float64
15 regionCode 1000000 non-null int64
16 dti 999700 non-null float64
17 delinquency_2years 1000000 non-null float64
18 ficoRangeLow 1000000 non-null float64
19 ficoRangeHigh 1000000 non-null float64
20 openAcc 1000000 non-null float64
21 pubRec 1000000 non-null float64
22 pubRecBankruptcies 999479 non-null float64
23 revolBal 1000000 non-null float64
24 revolUtil 999342 non-null float64
25 totalAcc 1000000 non-null float64
26 initialListStatus 1000000 non-null int64
27 applicationType 1000000 non-null int64
28 earliesCreditLine 1000000 non-null object
29 title 999999 non-null float64
30 policyCode 1000000 non-null float64
31 n0 949619 non-null float64
32 n1 949619 non-null float64
33 n2 949619 non-null float64
34 n3 949619 non-null float64
35 n4 958367 non-null float64
36 n5 949619 non-null float64
37 n6 949619 non-null float64
38 n7 949619 non-null float64
39 n8 949618 non-null float64
40 n9 949619 non-null float64
41 n10 958367 non-null float64
42 n11 912673 non-null float64
43 n12 949619 non-null float64
44 n13 949619 non-null float64
45 n14 949619 non-null float64
46 origin 1000000 non-null object
dtypes: float64(33), int64(8), object(6)
memory usage: 358.6+ MB
最重要的是對缺失值和異常值的處理,那麼來看看哪些特徵的缺失值和異常值最多:
missing = data.isnull().sum() / len(data)
missing = missing[missing > 0 ]
missing.sort_values(inplace = True)
x = np.arange(len(missing))
fig, ax = plt.subplots()
ax.bar(x,missing)
ax.set_xticks(x)
ax.set_xticklabels(list(missing.index), rotation = 90, fontsize = "small")
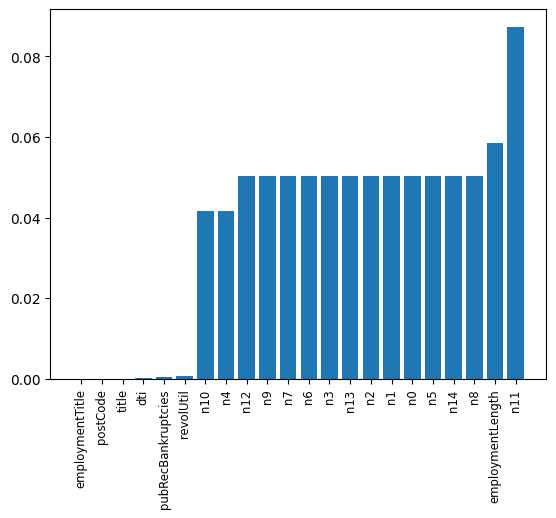
可以發現那些匿名特徵的異常值都是很多的,還有employmentLength特徵的異常值也很多。後續會進行處理。
另外,還有很多特徵並不是能夠直接用來訓練的特徵,因此需要對其進行處理,比如grade、subGrade、employmentLength、issueDate、earliesCreditLine,需要進行預處理.
print(sorted(data['grade'].unique()))
print(sorted(data['subGrade'].unique()))
['A', 'B', 'C', 'D', 'E', 'F', 'G']
['A1', 'A2', 'A3', 'A4', 'A5', 'B1', 'B2', 'B3', 'B4', 'B5', 'C1', 'C2', 'C3', 'C4', 'C5', 'D1', 'D2', 'D3', 'D4', 'D5', 'E1', 'E2', 'E3', 'E4', 'E5', 'F1', 'F2', 'F3', 'F4', 'F5', 'G1', 'G2', 'G3', 'G4', 'G5']
那麼現在先對employmentLength特徵進行處理:
data['employmentLength'].value_counts(dropna=False).sort_index()
1 year 65671
10+ years 328525
2 years 90565
3 years 80163
4 years 59818
5 years 62645
6 years 46582
7 years 44230
8 years 45168
9 years 37866
< 1 year 80226
NaN 58541
Name: employmentLength, dtype: int64
# 對employmentLength該列進行處理
data["employmentLength"].replace(to_replace="10+ years", value = "10 years",
inplace = True)
data["employmentLength"].replace(to_replace="< 1 year", value = "0 years",
inplace = True)
def employmentLength_to_int(s):
if pd.isnull(s):
return s # 如果是nan還是nan
else:
return np.int8(s.split()[0]) # 按照空格分隔得到第一個字元
data["employmentLength"] = data["employmentLength"].apply(employmentLength_to_int)
轉換後的效果為:
0.0 80226
1.0 65671
2.0 90565
3.0 80163
4.0 59818
5.0 62645
6.0 46582
7.0 44230
8.0 45168
9.0 37866
10.0 328525
NaN 58541
Name: employmentLength, dtype: int64
下面是對earliesCreditLine這個時間列進行處理:
data['earliesCreditLine'].sample(5)
375743 Jun-2003
361340 Jul-1999
716602 Aug-1995
893559 Oct-1982
221525 Nov-2004
Name: earliesCreditLine, dtype: object
為了簡便起見,我們就只選取年份:
data["earliesCreditLine"] = data["earliesCreditLine"].apply(lambda x:int(x[-4:]))
效果為:
data['earliesCreditLine'].value_counts(dropna=False).sort_index()
1944 2
1945 1
1946 2
1949 1
1950 7
1951 9
1952 7
1953 6
1954 6
1955 10
1956 12
1957 18
1958 27
1959 52
1960 67
1961 67
1962 100
1963 147
1964 215
1965 301
1966 307
1967 470
1968 533
1969 717
1970 743
1971 796
1972 1207
1973 1381
1974 1510
1975 1780
1976 2304
1977 2959
1978 3589
1979 3675
1980 3481
1981 4254
1982 5731
1983 7448
1984 9144
1985 10010
1986 11415
1987 13216
1988 14721
1989 17727
1990 19513
1991 18335
1992 19825
1993 27881
1994 34118
1995 38128
1996 40652
1997 41540
1998 48544
1999 57442
2000 63205
2001 66365
2002 63893
2003 63253
2004 61762
2005 55037
2006 47405
2007 35492
2008 22697
2009 14334
2010 13329
2011 12282
2012 8304
2013 4375
2014 1863
2015 251
Name: earliesCreditLine, dtype: int64
接下來就是對一些類別的特徵進行處理,爭取將其轉換為ont-hot向量:
cate_features = ["grade",
"subGrade",
"employmentTitle",
"homeOwnership",
"verificationStatus",
"purpose",
"postCode",
"regionCode",
"applicationType",
"initialListStatus",
"title",
"policyCode"]
for fea in cate_features:
print(fea, " 型別數目為:", data[fea].nunique())
grade 型別數目為: 7
subGrade 型別數目為: 35
employmentTitle 型別數目為: 298101
homeOwnership 型別數目為: 6
verificationStatus 型別數目為: 3
purpose 型別數目為: 14
postCode 型別數目為: 935
regionCode 型別數目為: 51
applicationType 型別數目為: 2
initialListStatus 型別數目為: 2
title 型別數目為: 47903
policyCode 型別數目為: 1
可以看到其中一些特徵的類別數目比較少,就適合轉換成one-hot向量,但是那些類別數目特別多的就不適合,那麼參考baseline採取的做法就是增加計數和排序兩類特徵。
先將部分轉換為one-hot向量:
data = pd.get_dummies(data, columns = ['grade', 'subGrade',
'homeOwnership', 'verificationStatus',
'purpose', 'regionCode'],
drop_first = True)
# drop_first就是k個類別,我只用k-1個來表示,那個沒有表示出來的類別就是全0
對特別高維的:
# 高維類別特徵需要進行轉換
for f in ['employmentTitle', 'postCode', 'title']:
data[f+'_cnts'] = data.groupby([f])['id'].transform('count')
data[f+'_rank'] = data.groupby([f])['id'].rank(ascending=False).astype(int)
del data[f]
# cnts的意思就是:對f特徵的每一個取值進行計數,例如取值A有3個,B有5個,C有7個
# 那麼那些f特徵取值為A的,在cnt中就是取值為3,B的就是5,C的就是7
# 而rank就是對取值為A的三個排序123,對B的排12345,C的排1234567,各個取值內部排序
# 然後ascending=False就是從後面開始給,最後一個取值為A的給1,倒數第二個給2,倒數第三個給3
處理過後得到的資料為:
data.shape
(1000000, 154)
那麼再劃分為訓練資料和測試資料:
train = data[data["origin"] == "train"].reset_index(drop=True)
test = data[data["origin"] == "test"].reset_index(drop=True)
features = [f for f in data.columns if f not in ['id','issueDate','isDefault',"origin"]] # 這些特徵不用參與訓練
x_train = train[features]
y_train = target
x_test = test[features]
選取模型
我選取了xgboost和lightgbm,然後進行模型融合,後續有時間再嘗試其他的組合吧:
lgb_params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'min_child_weight': 5,
'num_leaves': 2 ** 5,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.1,
'seed': 2020,
'nthread': 28,
'n_jobs':24,
'verbosity': 1,
'verbose': -1,
}
folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=1)
valid_lgb = np.zeros(len(x_train))
predict_lgb = np.zeros(len(x_test))
for fold_, (train_idx,valid_idx) in enumerate(folds.split(x_train, y_train)):
print("當前第{}折".format(fold_ + 1))
train_data_now = lgb.Dataset(x_train.iloc[train_idx], y_train[train_idx])
valid_data_now = lgb.Dataset(x_train.iloc[valid_idx], y_train[valid_idx])
watchlist = [(train_data_now,"train"), (valid_data_now, "valid_data")]
num_round = 10000
lgb_model = lgb.train(lgb_params, train_data_now, num_round,
valid_sets=[train_data_now, valid_data_now], verbose_eval=500,
early_stopping_rounds = 800)
valid_lgb[valid_idx] = lgb_model.predict(lgb.Dataset(x_train.iloc[valid_idx]),
ntree_limit = lgb_model.best_ntree_limit)
predict_lgb += lgb_model.predict(lgb.Dataset(x_test), num_iteration=
lgb_model.best_iteration) / folds.n_splits
這部分訓練過程在我之前的整合學習實戰部落格中已經介紹了,因此也是套用那部分思路。
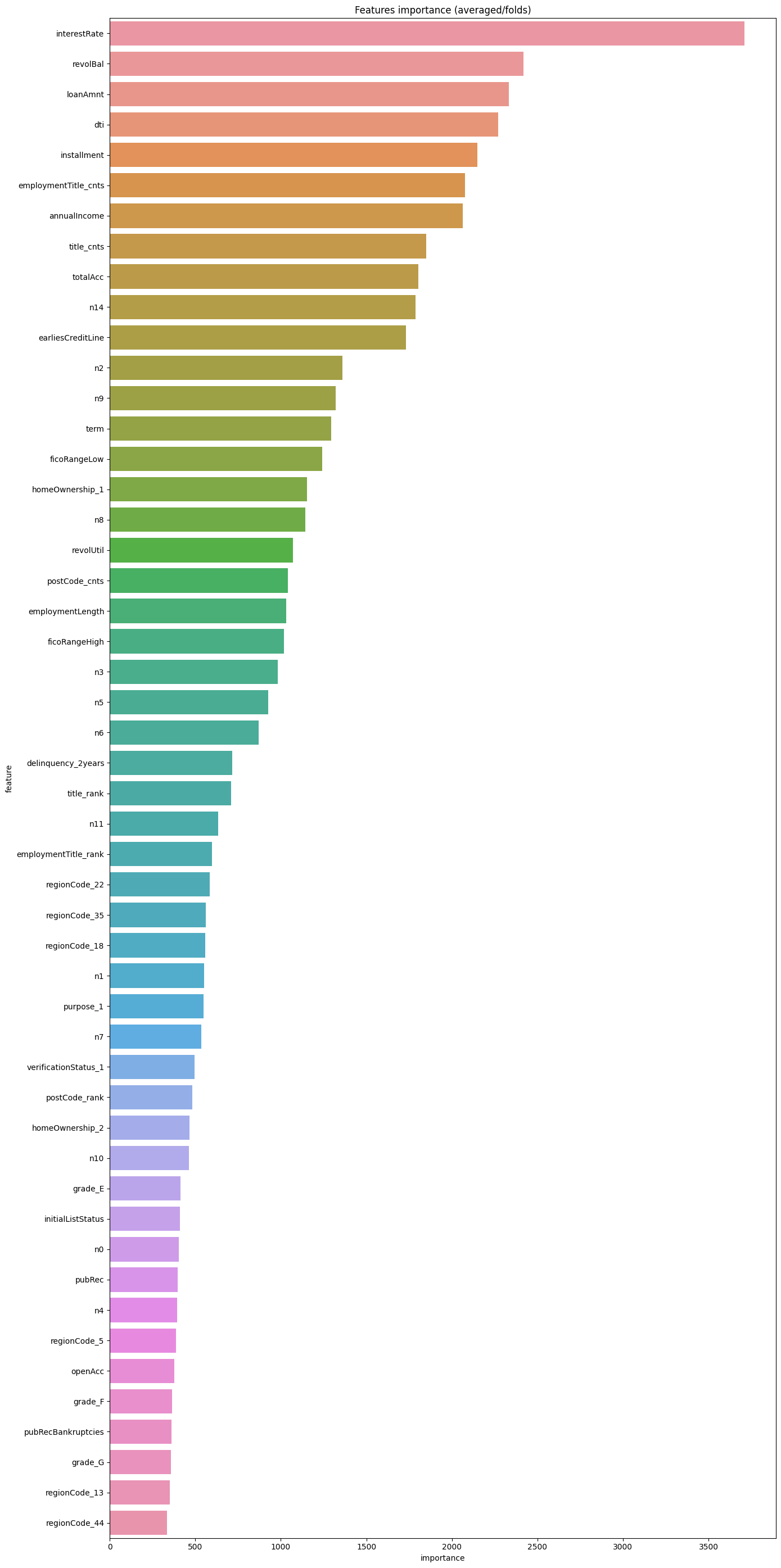
同樣,也可以看看特徵重要性:
pd.set_option("display.max_columns", None) # 設定可以顯示的最大行和最大列
pd.set_option('display.max_rows', None) # 如果超過就顯示省略號,none表示不省略
#設定value的顯示長度為100,預設為50
pd.set_option('max_colwidth',100)
df = pd.DataFrame(data[features].columns.tolist(), columns=['feature'])
df['importance'] = list(lgb_model.feature_importance())
df = df.sort_values(by = "importance", ascending=False)
plt.figure(figsize = (14,28))
sns.barplot(x = 'importance', y = 'feature', data = df.head(50))
plt.title('Features importance (averaged/folds)')
plt.tight_layout() # 自動調整適應範圍
# xgboost模型
xgb_params = {'booster': 'gbtree',
'objective': 'binary:logistic',
'eval_metric': 'auc',
'gamma': 1,
'min_child_weight': 1.5,
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.04,
'tree_method': 'exact',
'seed': 1,
'nthread': 36,
"verbosity": 1,
}
folds = StratifiedKFold(n_splits=5, shuffle=True, random_state=1)
valid_xgb = np.zeros(len(x_train))
predict_xgb = np.zeros(len(x_test))
for fold_, (train_idx,valid_idx) in enumerate(folds.split(x_train, y_train)):
print("當前第{}折".format(fold_ + 1))
train_data_now = xgb.DMatrix(x_train.iloc[train_idx], y_train[train_idx])
valid_data_now = xgb.DMatrix(x_train.iloc[valid_idx], y_train[valid_idx])
watchlist = [(train_data_now,"train"), (valid_data_now, "valid_data")]
xgb_model = xgb.train(dtrain = train_data_now, num_boost_round = 3000,
evals = watchlist, early_stopping_rounds = 500,
verbose_eval = 500, params = xgb_params)
valid_xgb[valid_idx] =xgb_model.predict(xgb.DMatrix(x_train.iloc[valid_idx]),
ntree_limit = xgb_model.best_ntree_limit)
predict_xgb += xgb_model.predict(xgb.DMatrix(x_test),ntree_limit
= xgb_model.best_ntree_limit) / folds.n_splits
放一下部分訓練過程吧:
當前第5折
[0] train-auc:0.69345 valid_data-auc:0.69341
[500] train-auc:0.73811 valid_data-auc:0.72788
[1000] train-auc:0.74875 valid_data-auc:0.73066
[1500] train-auc:0.75721 valid_data-auc:0.73194
[2000] train-auc:0.76473 valid_data-auc:0.73266
[2500] train-auc:0.77152 valid_data-auc:0.73302
[2999] train-auc:0.77775 valid_data-auc:0.73307
那麼接下來的模型融合我就採用了簡單的邏輯迴歸:
# 模型融合
train_stack = np.vstack([valid_lgb, valid_xgb]).transpose()
test_stack = np.vstack([predict_lgb, predict_xgb]).transpose()
folds_stack = RepeatedKFold(n_splits = 5, n_repeats = 2, random_state = 1)
valid_stack = np.zeros(train_stack.shape[0])
predict_lr2 = np.zeros(test_stack.shape[0])
for fold_, (train_idx, valid_idx) in enumerate(folds_stack.split(train_stack, target)):
print("當前是第{}折".format(fold_+1))
train_x_now, train_y_now = train_stack[train_idx], target.iloc[train_idx].values
valid_x_now, valid_y_now = train_stack[valid_idx], target.iloc[valid_idx].values
lr2 = lr()
lr2.fit(train_x_now, train_y_now)
valid_stack[valid_idx] = lr2.predict(valid_x_now)
predict_lr2 += lr2.predict(test_stack) / 10
print("score:{:<8.8f}".format(roc_auc_score(target, valid_stack)))
score:0.73229269
預測與儲存
testA = pd.read_csv("testA.csv")
testA['isDefault'] = predict_lr2
submission_data = testA[['id','isDefault']]
submission_data.to_csv("myresult.csv",index = False)
接下來就可以去提交啦!
完結!