協程Part1-boost.Coroutine.md
首先,在電腦科學中 routine 被定義為一系列的操作,多個 routine 的執行形成一個父子關係,並且子 routine 一定會在父 routine 結束前結束,也就是一個個的函數執行和巢狀執行形成了父子關係。
coroutine 也是廣義上的 routine,不同的是 coroutine 能夠通過一些操作保持執行狀態,顯式地掛起和恢復,相對於 routine 的單控制流,coroutine 能提供一個加強版的控制流。
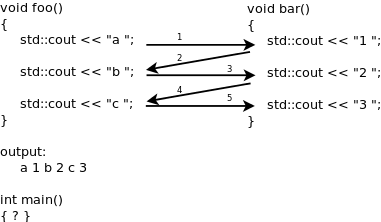
協程執行轉移
如圖中的處理流程,多個 coroutine 通過一些機制,首先執行 routine foo 上的 std::cout << "a" 然後切換到 routine bar 上執行 std::cout << "b",再切換回 routine foo 直到兩個 routine 都執行完成。
coroutine 如何執行?
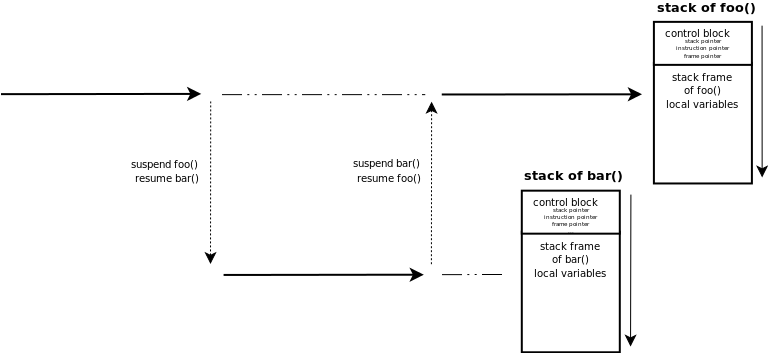
通常每個 corotuine 都有自己的 stack 和 control-block,類似於執行緒有自己的執行緒棧和control-block,當協程觸發切換的時候,當前 coroutine 所有的非易失(non-volatile)暫存器都會儲存到 control-block 中,新的 coroutine 需要從自己相關聯的 control-block 中恢復。
協程的分類
A. 根據協程的執行轉移機制可以分為非對稱協程和對程協程:
- 非對稱協程能知道其呼叫方,呼叫一些方法能讓出當前的控制回到呼叫方手上。
- 對程協程都是平等的,一個對程協程能把控制讓給任意一個協程,因此,當對稱協程讓出控制的時候,必須指定被讓出的協程是哪一個。
B. 根據執行時協程棧的分配方式又能分為有棧協程和無棧協程:
通常情況下,有棧協程比無棧協程的功能更加強大,但是無棧協程有更高的效率,除此之外還有下面這些區別:
有棧協程能夠在巢狀的棧幀中掛起並且在之前巢狀的掛起點恢復,而無棧協程只有最外層的 coroutine 才能夠掛起,由頂層 routine 呼叫的 sub-routine 是不能夠被掛起的。
有棧協程通常需要分配一個確定且固定的記憶體用來適配 runtime-stack,上下文的切換的時候相比於無棧協程也更加消耗資源,比如無棧協程僅僅只需要儲存一個程式計數器(EIP)。有棧協程在語言(編譯器)的支援下,有棧協程能夠利用編譯期計算得到非遞迴協程棧的最大大小,因此,記憶體的使用方面能夠有所優化。無棧協程,不是代表沒有執行時的棧,無棧只是代表著無棧協程所使用的棧是當前所在上下文的棧(比如一個函數 ESP~EBP 的區間內),所以能夠正常呼叫遞迴函數。相反,有棧協程呼叫遞迴函數的時候,所使用的棧是該協程所申請的棧。
分三個方面來總結的話就是:
-
記憶體資源使用:無棧協程藉助函數的棧幀來儲存一些暫存器狀態,可以呼叫遞迴函數。而有棧協程會要申請一個記憶體棧用來儲存暫存器資訊,呼叫遞迴函數可能會爆棧。
-
速度:無棧協程的上下文比較少,所以能夠進行更快的使用者態上下文切換。
-
功能性:有棧協程能夠在巢狀的協程中進行掛起/恢復,而無棧協程只能對頂層的協程進行掛起,被呼叫方是不能掛起的。
Boost.Coroutine
C++ Boost 庫在 2009 年就提供了一個子庫叫做 Boost.Coroutine 實現了有棧協程,且實現了對稱(symmetric)和非對程(symmetric)協程。
1. 非對程協程(Asymmetric coroutine)
非對程協程提供了 asymmetric_coroutine<T>::push_type 和 asymmetric_coroutine<T>::pull_type 兩種型別用於處理協程的共同作業。由命名可以理解,非對程協程像是建立了一個管道,通過push_type寫入資料,通過pull_type拉取資料。
協程例子 A
boost::coroutines::asymmetric_coroutine<int>::pull_type source(
[&](boost::coroutines::asymmetric_coroutine<int>::push_type& sink){
int first=1,second=1;
sink(first);
sink(second);
for(int i=0;i<8;++i){
int third=first+second;
first=second;
second=third;
sink(third);
}
});
for(auto i : source)
std::cout << i << " ";
output:
1 1 2 3 5 8 13 21 34 55
上面的例子是協程實現的斐波那契數列計算,在上面的例子中,push_type 的範例構造時接受了一個函數作為建構函式入參,而這個函數就是 協程函數(coroutine function),coroutine 在 pull_type 建立的上下文下執行。
該協程函數的入參是一個以 push_type&,當範例化外層上下文中 pull_type 的時候,Boost 庫會自動合成一個 push_type 傳遞給協程函數使用,每當呼叫 asymmetric_coroutine<>::push_type::operator() 的時候,協程會重新把控制權交還給push_type所在的上下文。其中asymmetric_coroutine<T> 的模板引數 T 定義了協程共同作業時使用的資料型別。
由於 pull_type 提供了input iterator,過載了 std::begin和std::end所以能夠用 range-based for 迴圈方式來輸出結果。
另外要注意的是,當第一次範例化pull_type的時候,控制權就會轉移到協程上,執行協程函數,就好比要拉取(pull)資料需要有資料先寫入(push)。
協程例子 B
struct FinalEOL{
~FinalEOL(){
std::cout << std::endl;
}
};
const int num=5, width=15;
boost::coroutines::asymmetric_coroutine<std::string>::push_type writer(
[&](boost::coroutines::asymmetric_coroutine<std::string>::pull_type& in){
// finish the last line when we leave by whatever means
FinalEOL eol;
// pull values from upstream, lay them out 'num' to a line
for (;;){
for(int i=0;i<num;++i){
// when we exhaust the input, stop
if(!in) return;
std::cout << std::setw(width) << in.get();
// now that we've handled this item, advance to next
in();
}
// after 'num' items, line break
std::cout << std::endl;
}
});
std::vector<std::string> words{
"peas", "porridge", "hot", "peas",
"porridge", "cold", "peas", "porridge",
"in", "the", "pot", "nine",
"days", "old" };
std::copy(boost::begin(words),boost::end(words),boost::begin(writer));
output:
peas porridge hot peas porridge
cold peas porridge in the
pot nine days old
接下來的這個例子主要說明了控制的反轉,通過在主上下文中範例化的型別是push_type,逐個傳遞一系列字串給到協程函數完成格式化輸出,其建構函式是以pull_type&作為入參的匿名函數,在範例化push_type的過程中,庫仍然會合成一個pull_type傳遞給該匿名函數,也就是協程函數。
與範例化pull_type不同,在主上下文中範例化push_type並不會直接進入到協程函數中,而是需要呼叫push_type::operator() 才能切換到協程上。
asymmetric_coroutine<T> 的模板引數 T 的型別不是 void 的時候,在協程函數中,可以通過pull_type::get()來獲取資料,並通過pull_type::bool()判斷協程傳遞的資料是否合法。
協程函數會以一個簡單的return語句回到呼叫方的routine上,此時pull_type和push_type都會變成完成狀態,也就是pull_type::operator bool()和push_type::operator bool() 都會變成 false;
協程的例外處理
coroutine函數內的程式碼不能阻止 unwind 的異常,不然會 stack-unwinding失敗。
stack unwinding 通常和例外處理一起討論,當異常丟擲的時候,執行許可權會立即向上傳遞直到任意一層 catch 住丟擲的異常,而在向上傳遞前,需要適當地回收、解構本地自動變數,如果一個自動變數在異常丟擲的時候被合適地被釋放了就可以稱為"unwound"了。
try {
// code that might throw
} catch(const boost::coroutines::detail::forced_unwind&) {
throw;
} catch(...) {
// possibly not re-throw pending exception
}
在 coroutine 內部捕獲到了 detail::forced_unwind 異常時要繼續丟擲異常,否則會 stack-unwinding 失敗,另外在 push_type 和 pull_type 的構造引數 attribute 也控制是是否需要 stack-unwinding。
2. 對稱協程(Symmetric coroutine)
相對於非對稱協程來說,對稱協程能夠轉移執行控制給任意對稱協程。
std::vector<int> merge(const std::vector<int>& a,const std::vector<int>& b)
{
std::vector<int> c;
std::size_t idx_a=0,idx_b=0;
boost::coroutines::symmetric_coroutine<void>::call_type* other_a=0,* other_b=0;
boost::coroutines::symmetric_coroutine<void>::call_type coro_a(
[&](boost::coroutines::symmetric_coroutine<void>::yield_type& yield) {
while(idx_a<a.size())
{
if(b[idx_b]<a[idx_a]) // test if element in array b is less than in array a
yield(*other_b); // yield to coroutine coro_b
c.push_back(a[idx_a++]); // add element to final array
}
// add remaining elements of array b
while ( idx_b < b.size())
c.push_back( b[idx_b++]);
});
boost::coroutines::symmetric_coroutine<void>::call_type coro_b(
[&](boost::coroutines::symmetric_coroutine<void>::yield_type& yield) {
while(idx_b<b.size())
{
if (a[idx_a]<b[idx_b]) // test if element in array a is less than in array b
yield(*other_a); // yield to coroutine coro_a
c.push_back(b[idx_b++]); // add element to final array
}
// add remaining elements of array a
while ( idx_a < a.size())
c.push_back( a[idx_a++]);
});
other_a = & coro_a;
other_b = & coro_b;
coro_a(); // enter coroutine-fn of coro_a
return c;
}
std::vector< int > a = {1,5,6,10};
std::vector< int > b = {2,4,7,8,9,13};
std::vector< int > c = merge(a,b);
print(a);
print(b);
print(c);
output:
a : 1 5 6 10
b : 2 4 7 8 9 13
c : 1 2 4 5 6 7 8 9 10 13
上面的例子是使用對稱協程實現的一個有序陣列的合併,對稱協程提供了相類似的symmetric_coroutine<>::call_type 和 symmetric_coroutine<>::yield_type 兩種型別用於對稱協程的共同作業。call_type 在範例化的時候,需要接受一個以yield_type& 作為引數的(協程)函數進行構造,Boost庫會自動合成一個yield_type作為實參進行傳遞,並且範例化 call_type 的時候,不會轉移控制到協程函數上,而是在第一次呼叫call_type::operator()的時候才會進入到協程內。
yield_type::operator() 的呼叫需要提供兩個引數,分別是需要轉移控制的協程和需要傳遞的值,如果 symmetric_coroutine<T> 的模板引數型別是 void,那麼不需要提供值,只是簡單的轉移控制。
在例外處理和退出方面,對稱協程和非對稱協程基本一致,非對程提供了一種多協程共同作業方案。
結語
雖然 Boost.Coroutine 庫已經被標記為標記為已過時(deprecated)了,但是可以從歷史的角度來理解協程的分類和基本工作原理,為現在多樣化的協程探索拓寬道路。
本文來自部落格園,作者:pokpok,轉載請註明原文連結:https://www.cnblogs.com/pokpok/p/16932735.html