Docker 工作原理分析
docker 容器原理分析
docker 的工作方式
當我們的程式執行起來的時候,在計算機中的表現就是一個個的程序,一個 docker 容器中可以跑各種程式,容器技術的核心功能,就是通過約束和修改程序的動態表現,從而為其創造出一個「邊界」。
Docker 容器啟動的程序還是在宿主機中執行的,和宿主機中其他執行的程序是沒有區別的,只是 docker 容器會給這些程序,新增各種各樣的 Namespace 引數,使這些程序和宿主機中的其它程序隔離開來,感知不到有其它程序的存在。
對於 Docker 等大多數 Linux 容器來說,Cgroups 技術是用來進行資源限制,而 Namespace 技術用來做隔離作用。
容器是一種特殊的程序:
docker 容器在建立程序時,指定了這個程序所需要啟用的一組 Namespace 引數。這樣,容器就只能「看」到當前 Namespace 所限定的資源、檔案、裝置、狀態,或者設定。而對於宿主機以及其他不相關的程式,它就完全看不到了。
容器中啟動的程序,還是在宿主機中執行的,只是 docker 容器會給這些程序,新增各種各樣的 Namespace 引數,使這些程序和宿主機中的其它程序隔離開來,感知不到有其它程序的存在。
下面來看下 docker 容器中,Namespace 和 Cgroups 的具體作用
Namespace
Namespace 是 Linux 中隔離核心資源的方式,通過 Namespace 可以這些程序只能看到自己 Namespace 的相關資源,這樣和其它 Namespace 的程序起到了隔離的作用。
Linux namespaces 是對全域性系統資源的一種封裝隔離,使得處於不同 namespace 的程序擁有獨立的全域性系統資源,改變一個 namespace 中的系統資源只會影響當前 namespace 裡的程序,對其他 namespace 中的程序沒有影響。
docker 容器的實現正是用到了 Namespace 的隔離,docker 容器通過啟動的時候給程序新增 Namespace 引數,這樣,容器就只能「看」到當前 Namespace 所限定的資源、檔案、裝置、狀態,或者設定。而對於宿主機以及其他不相關的程式,它就完全看不到了。
容器對比虛擬機器器
虛擬機器器
使用虛擬機器器,就需要使用 Hypervisor 來負責建立虛擬機器器,這個虛擬機器器是真實存在的,並且裡面需要執行 Guest OS 才能執行使用者的應用程序,這就不可避免會帶來額外的資源消耗和佔用。
虛擬機器器本身的執行就會佔用一定的資源,同時虛擬機器器對宿主機檔案的呼叫,就不可避免的需要經過虛擬化軟體的連線和處理,這本身就是一層效能消耗,尤其對計算資源、網路和磁碟 I/O 的損耗非常大。
容器
容器化後的應用,還是宿主機上的一個普通的程序,不會存在虛擬化帶來的效能損耗,同時容器使用的是 Namespace 進行隔離的,所以不需要單獨的 Guest OS,這就使得容器額外的資源佔用幾乎可以忽略不計。
容器的缺點
基於 Linux Namespace 的隔離機制相比於虛擬化技術也有很多不足之處,其中最主要的問題就是:隔離得不徹底。
1、容器只是執行在宿主機中的一中特殊的程序,容器時間使用的還是同一個宿主機的作業系統核心;
儘管你可以在容器裡通過 Mount Namespace 單獨掛載其他不同版本的作業系統檔案,比如 CentOS 或者 Ubuntu,但這並不能改變共用宿主機核心的事實。這意味著,如果你要在 Windows 宿主機上執行 Linux 容器,或者在低版本的 Linux 宿主機上執行高版本的 Linux 容器,都是行不通的。
2、在 Linux 核心中,有很多資源和物件是不能被 Namespace 化的,最典型的例子就是:時間;
如果容器中的程式使用了 settimeofday(2) 系統呼叫修改了時間,整個宿主機的時間都會被隨之修改,所以容器中我們應該儘量避免這種操作。
3、容器共用宿主機核心,會給應用暴露出更大的攻擊面。
在是生產環境中,不會把物理機中 Linux 的容器直接暴露在公網上。
Cgroups
docker 容器中的程序使用 Namespace 來進行隔離,使得這些在容器中執行的程序像是執行在一個獨立的環境中一樣。但是,被隔離的程序還是執行在宿主機中的,如果這些程序沒有對資源進行限制,這些程序可能會佔用很多的系統資源,影響到其他的程序。Docker 使用 Linux cgroups 來限制容器中的程序允許使用的系統資源。
Linux Cgroups 的全稱是 Linux Control Group。它最主要的作用,就是限制一個行程群組能夠使用的資源上限,包括 CPU、記憶體、磁碟、網路頻寬等等。
在 Linux 中,Cgroups 給使用者暴露出來的操作介面是檔案系統,即它以檔案和目錄的方式組織在作業系統的 /sys/fs/cgroup 路徑下。
centos 7.2 下面的檔案
# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpuacct,cpu)
cgroup on /sys/fs/cgroup/net_cls type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
...
Linux Cgroups 的設計還是比較易用的,簡單粗暴地理解呢,它就是一個子系統目錄加上一組資源限制檔案的組合。而對於 Docker 等 Linux 容器專案來說,它們只需要在每個子系統下面,為每個容器建立一個控制組(即建立一個新目錄),然後在啟動容器程序之後,把這個程序的 PID 填寫到對應控制組的 tasks 檔案中就可以了。
總結下來就是,一個正在執行的 Docker 容器,其實就是一個啟用了多個 Linux Namespace 的應用程序,而這個程序能夠使用的資源量,則受 Cgroups 設定的限制。
容器看到的檔案
Mount namespace
首先來了解下 Mount namespace
Mount namespace 為程序提供獨立的檔案系統檢視。簡單點說就是,mount namespace 用來隔離檔案系統的掛載點,這樣程序就只能看到自己的 mount namespace 中的檔案系統掛載點。
程序的 mount namespace 中的掛載點資訊可以在 /proc/[pid]/mounts、/proc/[pid]/mountinfo 和 /proc/[pid]/mountstats 這三個檔案中找到。
每個 mount namespace 都有一份自己的掛載點列表。當我們使用 clone 函數或 unshare 函數並傳入 CLONE_NEWNS 標誌建立新的 mount namespace 時, 新 mount namespace 中的掛載點其實是從呼叫者所在的 mount namespace 中拷貝的。但是在新的 mount namespace 建立之後,這兩個 mount namespace 及其掛載點就基本上沒啥關係了(除了 shared subtree 的情況),兩個 mount namespace 是相互隔離的。
Mount Namespace 修改的,是容器程序對檔案系統「掛載點」的認知。但是,這也就意味著,只有在「掛載」這個操作發生之後,程序的檢視才會被改變。而在此之前,新建立的容器會直接繼承宿主機的各個掛載點。
這就是 Mount Namespace 跟其他 Namespace 的使用略有不同的地方:它對容器程序檢視的改變,一定是伴隨著掛載操作(mount)才能生效。
chroot
當一個容器被建立的時候,我們希望容器中程序看到的檔案是一個獨立的隔離環境,我們可以在容器程序重啟之前掛載整個根目錄 /,由於 Mount Namespace 的存在,這個掛載對宿主機不可見,所以容器程序就可以在裡面隨便折騰了。
在 Linux 中可以使用 chroot 來改變某程序的根目錄。
來看下 chroot
chroot 主要是用來改換根目錄的,在新設定的虛擬根目錄中執行指定的命令或互動 Shell。一個執行在這個環境下,經由 chroot 設定根目錄的程式,它不能夠對這個指定根目錄之外的檔案進行存取動作,不能讀取,也不能更改它的內容。
rootfs
為了讓容器這個根目錄看起來更'真實',一般會在容器的根目錄下面掛載一個完整的作業系統的檔案系統,比如 Ubuntu16.04 的 ISO。這樣,在容器啟動之後,我們在容器裡通過執行 ls / 檢視根目錄下的內容,就是 Ubuntu 16.04 的所有目錄和檔案。
這個掛載到容器根目錄,用來給容器提供隔離後的執行環境的檔案系統,稱為為'容器映象',或者 rootfs(根檔案系統)。
對於 Docker 來講,最核心的原理就是為待建立的使用者程序執行下面三個操作:
1、啟用 Linux Namespace 設定;
2、設定指定的 Cgroups 引數;
3、切換程序的根目錄(Change Root)。
第三步,程序根目錄的切換,Docker 會優先使用 pivot_root 系統呼叫,如果系統不支援,才會使用 chroot。
rootfs 是一個作業系統包含的所有的檔案、設定和目錄,並不包括作業系統核心。同一宿主機中的容器都共用主機作業系統的核心。
正是由於 rootfs 的存在,容器中的一個很重要的特性才能實現,一致性。
因為 rootfs 中打包的不止是應用,還包括整個作業系統的檔案和目錄,應用和應用執行的所有依賴都會被封裝在一起。這樣無在任何一臺機器中,只需要解壓打包好的映象,直接執行即可,因為映象裡面已經包含了應用執行的所有環境。
對於基礎 rootfs 的製作,如果後續有更改的需求,一個很簡單的操作就是,新 fork 一個然後修改,這樣的缺點就是有很多碎片化的版本。
rootfs 的製作,也是支援增量的方式進行操作的,Docker 在映象的設計中,引入了層(layer)的概念。也就是說,使用者製作映象的每一步操作,都會生成一個層,也就是一個增量 rootfs。
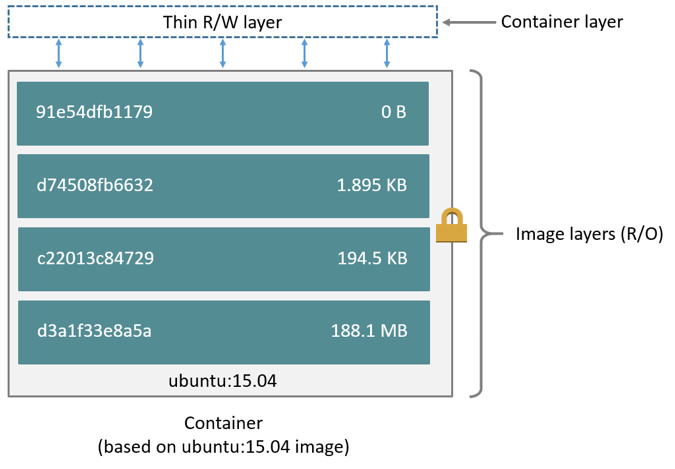
上面的讀寫層也稱為容器層,下面的唯讀稱為映象層,所有的增刪查改都只會作用在容器層,相同的檔案上層會覆蓋下層。
上面的讀寫層,在沒有檔案寫入之前裡面是空的,如果在容器裡面做了修改,修改的內容就會以增量的方式出現在這個層中。
例如進行檔案的修改,首先會從上到下查詢有沒有這個檔案,找到,就複製到容器層中,修改,對容器來講可以看到容器層中的這個檔案,看不到映象層中的這個檔案。
進行刪除的時候,也是在讀寫層做個標記,當這兩個層被聯合掛載之後,讀寫層的檔案刪除標記,會把容器中對應的檔案「遮擋」起,對外面展示的效果就是該檔案找不到了,被刪除了。
最上面的可讀可寫層,就是專門存放修改後 rootfs 後產生的增量,修改,新增,刪除產生的檔案都會被記錄到這裡。這就是 rootfs 製作能支援增量模式的最主要實現。
這些增量的 rootfs,還可以使用 docker commit 和 push 指令,儲存這個被修改過的可讀寫層,並上傳到 Docker Hub 上。同時,原先唯讀層中的內容不會發生任何變化。當然這些讀寫層的增量 rootfs 在 commit 之後就會變成一個新的唯讀層了。
Volume(資料卷)
Volume 機制,允許將宿主機中指定的目錄或者檔案,掛載到容器中進行取和修改操作。
Volume 有兩種掛載方式
$ docker run -v /test ...
$ docker run -v /home:/test ...
兩種掛載方式實質上是一樣的,第一種,沒有指定掛載的宿主機的目錄,docker 就會預設在宿主機上建立一個臨時目錄 /var/lib/docker/volumes/[VOLUME_ID]/_data,然後把它掛載到容器的 /test 目錄上。
第二種,指定了宿主機中的目錄,docker 就會把指定的宿主機中的 /home 目錄掛載到容器的 /test 目錄上。
docker 中使用了 rootfs 機制和 Mount Namespace,構建出了一個同宿主機完全隔離開的檔案系統環境。對於 Volume 掛載又是如何實現的呢?這裡來具體的分析下。
當容器程序被建立之後,儘管開啟了 Mount Namespace,但是在它執行 chroot(或者 pivot_root)之前,容器程序一直可以看到宿主機上的整個檔案系統。
所以只需要在 rootfs 準備好之後,在執行 chroot 之前,把 Volume 指定的宿主機目錄掛載到容器中的目錄上即可,這樣 Volume 掛載工作就完成了。
在執行這個掛載操作時,「容器程序」已經建立了,也就意味著此時 Mount Namespace 已經開啟了。所以,這個掛載事件只在這個容器裡可見。你在宿主機上,是看不見容器內部的這個掛載點的。這就保證了容器的隔離性不會被 Volume 打破。
這裡用到了 Linux 的繫結掛載(bind mount)機制,它的主要作用就是,允許你將一個目錄或者檔案,而不是整個裝置,掛載到一個指定的目錄上。並且,這時你在該掛載點上進行的任何操作,只是發生在被掛載的目錄或者檔案上,而原掛載點的內容則會被隱藏起來且不受影響。
繫結掛載實際上是一個 inode 替換的過程,在 Linux 作業系統中,inode 可以理解為存放檔案內容的"物件",dentry 也叫目錄項,就是存取 inode 所有的指標。

上面圖片的栗子
mount --bind /home /test,會將 /home 掛載到 /test 上。其實相當於將 /test 的 dentry,重定向到了 /home 的 inode。這樣當我們修改 /test 目錄時,實際修改的是 /home 目錄的 inode。
如果執行 umount 命令,解除繫結,/test 檔案中的內容就會恢復,因為修改發生的目錄是在 /home 中。
同樣如果對這個映象執行 commit 操作,docker 容器 Volume 裡的資訊也是不會被提交的,但是這個掛載點的 /test 空目錄會被提交。
打包一個go映象
瞭解了 docker 的基本原理,這裡來構建一個簡單的 docker 映象
首先一個簡單的 go 服務,範例程式碼
package main
import (
"encoding/json"
"log"
"net/http"
)
func main() {
http.HandleFunc("/hello", sayHello)
log.Println("【預設專案】服務啟動成功 監聽埠 80")
er := http.ListenAndServe("0.0.0.0:80", nil)
if er != nil {
log.Fatal("ListenAndServe: ", er)
}
}
func sayHello(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "application/json; charset=utf-8")
log.Println("request hello")
data := map[string]interface{}{
"status": "ok",
"message": "hello",
}
json.NewEncoder(w).Encode(&data)
}
交叉編譯
export CGO_ENABLED=0
export GOOS=linux
export GOARCH=amd64
go build -o go-server .
編寫 Dockerfile 檔案
# 基礎映象
FROM alpine
# Dockerfile 後面的操作都以這一句指定的 /app 目錄作為當前目錄
WORKDIR /app
# 將編譯好的go程式,複製到 app 目錄下
COPY ./go-server ./app
# 允許外接存取的埠
EXPOSE 80
CMD ["/app/go-server"]
Dockerfile 中的命令都是按照順序執行的。
最後使用 CMD 來啟動 go 應用,在 Dockerfile 中除了 CMD 還可以使用 ENTRYPOINT 來執行一些容器中的命令操作。
預設情況下,Docker 會為你提供一個隱含的 ENTRYPOINT,即:/bin/sh -c。所以,在不指定 ENTRYPOINT 時,比如在我們這個例子裡,實際上執行在容器裡的完整程序是:/bin/sh -c 「/app/go-server」,即 CMD 的內容就是 ENTRYPOINT 的引數。
總結
1、對於 Docker 來講,最核心的原理就是為待建立的使用者程序執行下面三個操作:
-
1、啟用 Linux Namespace 設定;
-
2、設定指定的 Cgroups 引數;
-
3、切換程序的根目錄(Change Root)。
2、Docker 容器啟動的程序還是在宿主機中執行的,和宿主機中其他執行的程序是沒有區別的,只是 docker 容器會給這些程序,新增各種各樣的 Namespace 引數,使這些程序和宿主機中的其它程序隔離開來,感知不到有其它程序的存在;
3、Docker 通過 Namespace 可以這些程序只能看到自己 Namespace 的相關資源,這樣和其它 Namespace 的程序起到了隔離的作用,使得這些在容器中執行的程序像是執行在一個獨立的環境中一樣;
4、Docker 使用 Linux cgroups 來限制容器中的程序允許使用的系統資源,防止這些程序可能會佔用很多的系統資源,影響到其他的程序;
5、Mount namespace 為程序提供獨立的檔案系統檢視。簡單點說就是,mount namespace 用來隔離檔案系統的掛載點,這樣程序就只能看到自己的 mount namespace 中的檔案系統掛載點;
6、當一個容器被建立的時候,我們希望容器中程序看到的檔案是一個獨立的隔離環境,為了讓容器這個根目錄看起來更'真實',一般會在容器的根目錄下面掛載一個完整的作業系統的檔案系統,比如 Ubuntu16.04 的 ISO。這樣,在容器啟動之後,我們在容器裡通過執行 ls / 檢視根目錄下的內容,就是 Ubuntu 16.04 的所有目錄和檔案;
7、rootfs 是一個作業系統包含的所有的檔案、設定和目錄,並不包括作業系統核心。同一宿主機中的容器都共用主機作業系統的核心;
8、正是由於 rootfs 的存在,容器中的一個很重要的特性才能實現,一致性;
9、對於基礎 rootfs 的製作,如果後續有更改的需求,一個很簡單的操作就是,新 fork 一個然後修改,這樣的缺點就是有很多碎片化的版本。rootfs 的製作,也是支援增量的方式進行操作的,Docker 在映象的設計中,引入了層(layer)的概念。也就是說,使用者製作映象的每一步操作,都會生成一個層,也就是一個增量 rootfs。
參考
【深入剖析 Kubernetes】https://time.geekbang.org/column/intro/100015201?code=UhApqgxa4VLIA591OKMTemuH1%2FWyLNNiHZ2CRYYdZzY%3D
【Linux Namespace】https://www.cnblogs.com/sparkdev/p/9365405.html
【淺談 Linux Namespace】https://xigang.github.io/2018/10/14/namespace-md/
【理解Docker(4):Docker 容器使用 cgroups 限制資源使用 】https://www.cnblogs.com/sammyliu/p/5886833.html
【Linux Namespace : Mount 】https://www.cnblogs.com/sparkdev/p/9424649.html
【About storage drivers】https://docs.docker.com/storage/storagedriver/
【Docker工作原理分析】https://boilingfrog.github.io/2022/11/27/docker實現原理/