label studio 結合 MMDetection 實現資料集自動標記、模型迭代訓練的閉環
前言
一個 AI 方向的朋友因為標資料集發了篇 SCI 論文,看著他標了兩個多月的資料集這麼辛苦,就想著人工智慧都能站在圍棋巔峰了,難道不能動動小手為自己標資料嗎?查了一下還真有一些能夠滿足此需求的框架,比如 cvat 、 doccano 、 label studio 等,經過簡單的對比後發現還是 label studio 最好用。本文首先介紹了 label studio 的安裝過程;然後使用 MMDetection 作為後端人臉檢測標記框架,並通過 label studio ml 將 MMDetection 模型封裝成 label studio 後端服務,實現資料集的自動標記[1];最後參考 label studio ml 範例,為自己的 MMDetection 人臉標記模型設計了一種迭代訓練方法,使之能夠不斷隨著標記資料的增加而跟進訓練,最終實現了模型自動標記資料集、資料集更新迭代訓練模型的閉環。
依賴安裝
本專案涉及的原始碼已開源在 label-studio-demo 中,所使用的軟體版本如下,其中 MMDetection 的版本及設定參考 MMDetection 使用範例:從入門到出門 :
| 軟體 | 版本 |
|---|---|
| label-studio | 1.6.0 |
| label-studio-ml | 1.0.8 |
| label-studio-tools | 0.0.1 |
本文最終專案目錄結構如下:
LabelStudio
├── backend // 後端功能
│ ├── examples // label studio ml 官方範例(非必須)
│ ├── mmdetection // mmdetection 人臉檢測模型
│ ├── model // label studio ml 生成的後端服務 (自動生成)
│ ├── workdir // 模型訓練時工作目錄
│ | ├── fcos_common_base.pth // 後端模型基礎權重檔案
│ | └── latest.pth // 後端模型最新權重檔案
│ └── runbackend.bat // 生成並啟動後端服務的指令碼檔案
├── dataset // 實驗所用資料集(非必須)
├── label_studio.sqlite3 // label studio 資料庫檔案
├── media
│ ├── export
│ └── upload // 上傳的待標記資料集
└── run.bat // 啟動 label studio 的指令碼檔案(非必須)
label studio 安裝啟動
label-studio 是一個開源的多媒體資料標註工具(用來提供基本標註功能的GUI),並且可以很方便的將標註結果匯出為多種常見的資料格式。其安裝方法主要有以下幾種:
- Docker
docker pull heartexlabs/label-studio:latest
- pip
pip install label-studio
建議是通過 pip 安裝,其設定更清晰方便。環境安裝完成後在任意位置開啟命令列,使用以下命令啟動 label studio :
label-studio --data-dir LabelStudio -p 80
其中 --data-dir 用於指定工作目錄, -p 用來指定執行埠,執行成功後會當前目錄會生成 LabelStudio 目錄:
並彈出瀏覽器開啟 label studio 工作介面,建立使用者後即可登入使用:
label studio ml 安裝
label studio ml 是 label studio 的後端設定,其主要提供了一種能夠快速將AI模型封裝為 label studio 可使用的預標記服務(提供模型預測服務)。其安裝方法有以下幾種:
- GitHub 安裝
git clone https://github.com/heartexlabs/label-studio-ml-backend
cd label-studio-ml-backend
pip install -U -e .
- pip 安裝:
pip install label-studio-ml
仍然建議通過 pip 安裝,GitHub 安裝可能會有依賴問題。安裝完成後使用 label-studio-ml -h 命令檢查是否安裝成功。
前端設定
在 label studio 前端主頁中選擇建立專案:
- 專案基本資訊
- 匯入資料
直接將圖片選中拖入資料框即可。
- 選擇標記模板
label studio 內建了很多常見的深度學習標記模板,本範例是臉部辨識,所以選擇 Object Detection with Bounding Boxes 模板,確定後將模板內自帶的 Airplane 、 Car 標籤刪除,然後新增自定義的標籤 face (標籤的類別數量可以比後端支援的類別多,也可以更少,但是同類別的標籤名必須一致)。
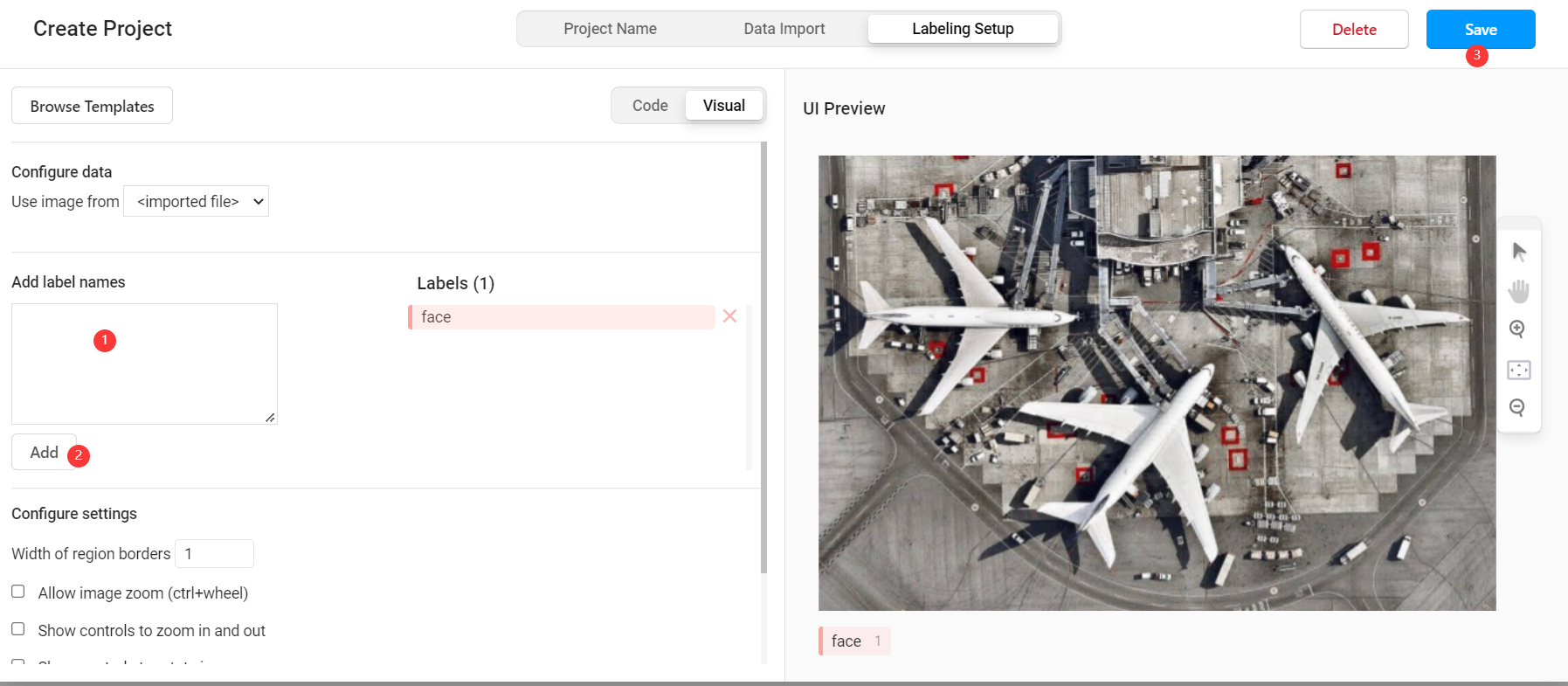
此時我們已經可以通過 label studio 進行普通的圖片標記工作,如果要使用其提供的輔助預標記功能,則需要進行後續設定。
後端設定
選取後端模型
在 MMDetection 使用範例:從入門到出門 中,我們已經完成了基於 celeba100 資料集的人臉檢測模型的訓練,本文將直接使用其中訓練的結果模型。
後端服務實現
引入後端模型
在根目錄下建立 backend 目錄,並將 MMDetection 使用範例:從入門到出門 中的整個專案檔案複製其中,此時專案目錄為:
.
├── backend
│ └── mmdetection // 複製的 mmdetection 資料夾
│ ├── checkpoints
│ ├── completion.json
│ ├── configs
│ ├── conf.yaml
│ ├── detect.py
│ ├── label_studio_backend.py // 需要自己實現的後端模型
│ ├── mmdet
│ ├── model
│ ├── test.py
│ ├── tools
│ └── train.py
├── dataset
├── export
├── label-studio-ml-backend
├── label_studio.sqlite3
├── media
└── run.bat
建立後端模型
label studio 的後端模型有自己固定的寫法,只要繼承 label_studio_ml.model.LabelStudioMLBase 類並實現其中的介面都可以作為 label studio 的後端服務。在 mmdetection 資料夾下建立 label_studio_backend.py 檔案,然後在檔案中引入通用設定:
ROOT = os.path.join(os.path.dirname(__file__))
print('=> ROOT = ', ROOT)
# label-studio 啟動的前端服務地址
os.environ['HOSTNAME'] = 'http://localhost:80'
# label-studio 中對應使用者的 API_KEY
os.environ['API_KEY'] = '37edbb42f1b3a73376548ea6c4bc7b3805d63453'
HOSTNAME = get_env('HOSTNAME')
API_KEY = get_env('API_KEY')
print('=> LABEL STUDIO HOSTNAME = ', HOSTNAME)
if not API_KEY:
print('=> WARNING! API_KEY is not set')
with open(os.path.join(ROOT, "conf.yaml"), errors='ignore') as f:
conf = yaml.safe_load(f)
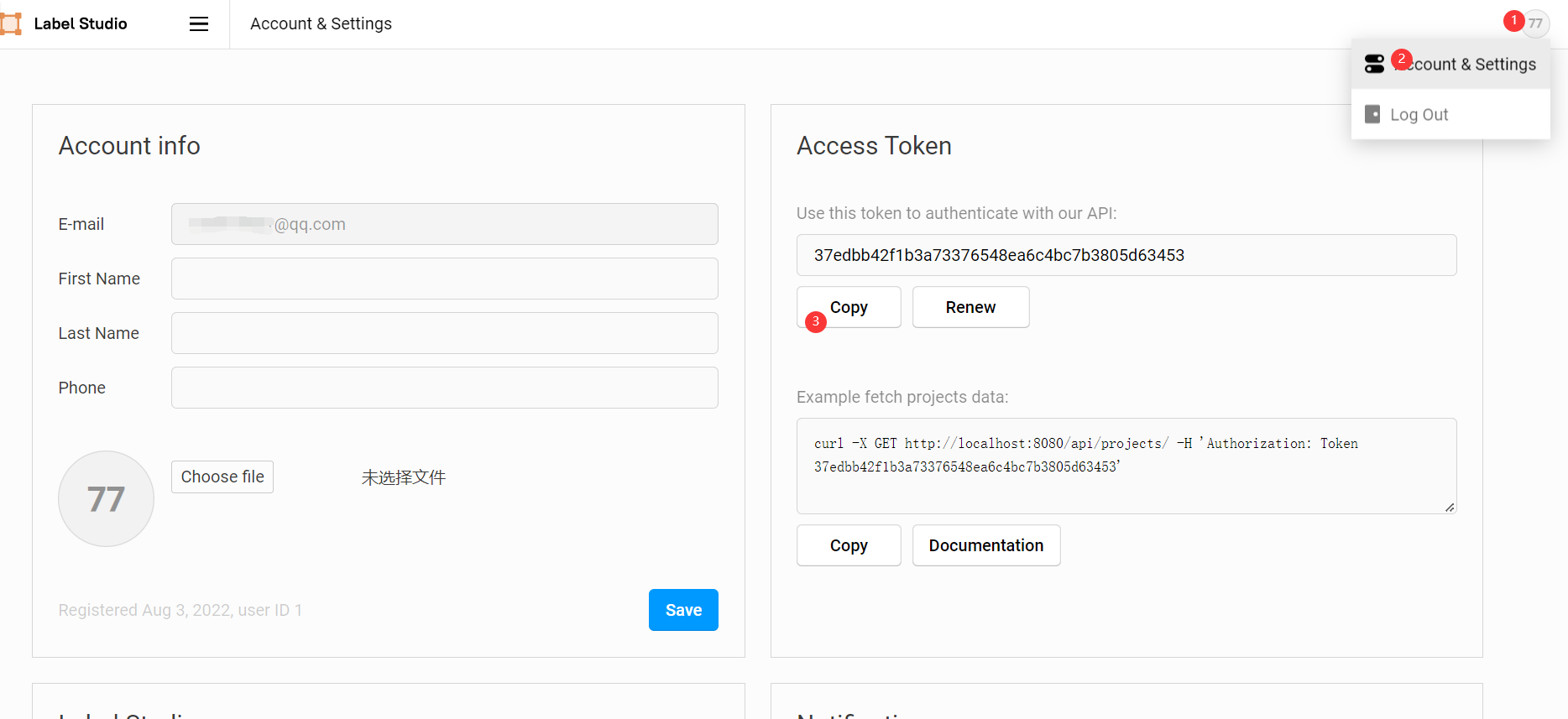
這裡的 API_KEY 可以在前端的 Account & Settings 中找到。
然後在 label_studio_backend.py 中建立自己預標記模型的類,使其繼承 label_studio_ml.model.LabelStudioMLBase 並實現關鍵方法,不同方法對應不同功能,後面會陸續實現:
class MyModel(LabelStudioMLBase):
def __init__(self, **kwargs):
pass
def predict(self, tasks, **kwargs):
pass
def fit(self, completions, batch_size=32, num_epochs=5, **kwargs):
pass
def gen_train_data(self, project_id):
pass
完成其中的 __init__ 方法,以實現模型初始化功能(必須):
def __init__(self, **kwargs):
super(MyModel, self).__init__(**kwargs)
# 按 mmdetection 的方式載入模型及權重
if self.train_output:
self.detector = init_detector(conf['config_file'], self.train_output['model_path'], device=conf['device'])
else:
self.detector = init_detector(conf['config_file'], conf['checkpoint_file'], device=conf['device'])
# 獲取後端模型標籤列表
self.CLASSES = self.detector.CLASSES
# 前端設定的標籤列表
self.labels_in_config = set(self.labels_in_config)
# 一些專案相關常數
self.from_name, self.to_name, self.value, self.labels_in_config = get_single_tag_keys(self.parsed_label_config, 'RectangleLabels', 'Image') # 前端獲取任務屬性
完成其中的 predict 方法,以實現預標記模型的標記功能(必須):
def predict(self, tasks, **kwargs):
# 獲取待標記圖片
images = [get_local_path(task['data'][self.value], hostname=HOSTNAME, access_token=API_KEY) for task in tasks]
for image_path in images:
w, h = get_image_size(image_path)
# 推理演示影象
img = mmcv.imread(image_path)
# 以 mmdetection 的方法進行推理
result = inference_detector(self.detector, img)
# 手動獲取標記框位置
bboxes = np.vstack(result)
# 手動獲取推理結果標籤
labels = [np.full(bbox.shape[0], i, dtype=np.int32) for i, bbox in enumerate(result)]
labels = np.concatenate(labels)
# 推理分數 FCOS演演算法結果會多出來兩個分數極低的檢測框,需要將其過濾掉
scores = bboxes[:, -1]
score_thr = 0.3
inds = scores > score_thr
bboxes = bboxes[inds, :]
labels = labels[inds]
results = [] # results需要放在list中再返回
for id, bbox in enumerate(bboxes):
label = self.CLASSES[labels[id]]
if label not in self.labels_in_config:
print(label + ' label not found in project config.')
continue
results.append({
'id': str(id), # 必須為 str,否則前端不顯示
'from_name': self.from_name,
'to_name': self.to_name,
'type': 'rectanglelabels',
'value': {
'rectanglelabels': [label],
'x': bbox[0] / w * 100, # xy 為左上角座標點
'y': bbox[1] / h * 100,
'width': (bbox[2] - bbox[0]) / w * 100, # width,height 為寬高
'height': (bbox[3] - bbox[1]) / h * 100
},
'score': float(bbox[4] * 100)
})
avgs = bboxes[:, -1]
results = [{'result': results, 'score': np.average(avgs) * 100}]
return results
完成其中的 gen_train_data 方法,以獲取標記完成的資料用來訓練(非必須,其實 label studio 自帶此類方法,但在實踐過程中有各種問題,所以自己寫了一遍):
def gen_train_data(self, project_id):
import zipfile
import glob
download_url = f'{HOSTNAME.rstrip("/")}/api/projects/{project_id}/export?export_type=COCO&download_all_tasks=false&download_resources=true'
response = requests.get(download_url, headers={'Authorization': f'Token {API_KEY}'})
zip_path = os.path.join(conf['workdir'], "train.zip")
train_path = os.path.join(conf['workdir'], "train")
with open(zip_path, 'wb') as file:
file.write(response.content) # 通過二進位制寫檔案的方式儲存獲取的內容
file.flush()
f = zipfile.ZipFile(zip_path) # 建立壓縮包物件
f.extractall(train_path) # 壓縮包解壓縮
f.close()
os.remove(zip_path)
if not os.path.exists(os.path.join(train_path, "images", str(project_id))):
os.makedirs(os.path.join(train_path, "images", str(project_id)))
for img in glob.glob(os.path.join(train_path, "images", "*.jpg")):
basename = os.path.basename(img)
shutil.move(img, os.path.join(train_path, "images", str(project_id), basename))
return True
完成其中的 fit 方法,以實現預標記模型的自訓練功能(非必須):
def fit(self, completions, num_epochs=5, **kwargs):
if completions: # 使用方法1獲取 project_id
image_urls, image_labels = [], []
for completion in completions:
project_id = completion['project']
u = completion['data'][self.value]
image_urls.append(get_local_path(u, hostname=HOSTNAME, access_token=API_KEY))
image_labels.append(completion['annotations'][0]['result'][0]['value'])
elif kwargs.get('data'): # 使用方法2獲取 project_id
project_id = kwargs['data']['project']['id']
if not self.parsed_label_config:
self.load_config(kwargs['data']['project']['label_config'])
if self.gen_train_data(project_id):
# 使用 mmdetection 的方法訓練模型
from tools.mytrain import MyDict, train
args = MyDict()
args.config = conf['config_file']
data_root = os.path.join(conf['workdir'], "train")
args.cfg_options = {}
args.cfg_options['data_root'] = data_root
args.cfg_options['runner'] = dict(type='EpochBasedRunner', max_epochs=num_epochs)
args.cfg_options['data'] = dict(
train=dict(img_prefix=data_root, ann_file=data_root + '/result.json'),
val=dict(img_prefix=data_root, ann_file=data_root + '/result.json'),
test=dict(img_prefix=data_root, ann_file=data_root + '/result.json'),
)
args.cfg_options['load_from'] = conf['checkpoint_file']
args.work_dir = os.path.join(data_root, "work_dir")
train(args)
checkpoint_name = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time())) + ".pth"
shutil.copy(os.path.join(args.work_dir, "latest.pth"), os.path.join(conf['workdir'], checkpoint_name))
print("model train complete!")
# 權重檔案儲存至執行環境,將在下次執行 init 初始化時載入
return {'model_path': os.path.join(conf['workdir'], checkpoint_name)}
else:
raise "gen_train_data error"
上述完整程式碼如下:
import os
import yaml
import time
import shutil
import requests
import numpy as np
from label_studio_ml.model import LabelStudioMLBase
from label_studio_ml.utils import get_image_size, get_single_tag_keys
from label_studio_tools.core.utils.io import get_local_path
from label_studio_ml.utils import get_env
from mmdet.apis import init_detector, inference_detector
import mmcv
ROOT = os.path.join(os.path.dirname(__file__))
print('=> ROOT = ', ROOT)
os.environ['HOSTNAME'] = 'http://localhost:80'
os.environ['API_KEY'] = '37edbb42f1b3a73376548ea6c4bc7b3805d63453'
HOSTNAME = get_env('HOSTNAME')
API_KEY = get_env('API_KEY')
print('=> LABEL STUDIO HOSTNAME = ', HOSTNAME)
if not API_KEY:
print('=> WARNING! API_KEY is not set')
with open(os.path.join(ROOT, "conf.yaml"), errors='ignore') as f:
conf = yaml.safe_load(f)
class MyModel(LabelStudioMLBase):
def __init__(self, **kwargs):
super(MyModel, self).__init__(**kwargs)
# 按 mmdetection 的方式載入模型及權重
if self.train_output:
self.detector = init_detector(conf['config_file'], self.train_output['model_path'], device=conf['device'])
else:
self.detector = init_detector(conf['config_file'], conf['checkpoint_file'], device=conf['device'])
# 獲取後端模型標籤列表
self.CLASSES = self.detector.CLASSES
# 前端設定的標籤列表
self.labels_in_config = set(self.labels_in_config)
# 一些專案相關常數
self.from_name, self.to_name, self.value, self.labels_in_config = get_single_tag_keys(self.parsed_label_config, 'RectangleLabels', 'Image') # 前端獲取任務屬性
def predict(self, tasks, **kwargs):
# 獲取待標記圖片
images = [get_local_path(task['data'][self.value], hostname=HOSTNAME, access_token=API_KEY) for task in tasks]
for image_path in images:
w, h = get_image_size(image_path)
# 推理演示影象
img = mmcv.imread(image_path)
# 以 mmdetection 的方法進行推理
result = inference_detector(self.detector, img)
# 手動獲取標記框位置
bboxes = np.vstack(result)
# 手動獲取推理結果標籤
labels = [np.full(bbox.shape[0], i, dtype=np.int32) for i, bbox in enumerate(result)]
labels = np.concatenate(labels)
# 推理分數 FCOS演演算法結果會多出來兩個分數極低的檢測框,需要將其過濾掉
scores = bboxes[:, -1]
score_thr = 0.3
inds = scores > score_thr
bboxes = bboxes[inds, :]
labels = labels[inds]
results = [] # results需要放在list中再返回
for id, bbox in enumerate(bboxes):
label = self.CLASSES[labels[id]]
if label not in self.labels_in_config:
print(label + ' label not found in project config.')
continue
results.append({
'id': str(id), # 必須為 str,否則前端不顯示
'from_name': self.from_name,
'to_name': self.to_name,
'type': 'rectanglelabels',
'value': {
'rectanglelabels': [label],
'x': bbox[0] / w * 100, # xy 為左上角座標點
'y': bbox[1] / h * 100,
'width': (bbox[2] - bbox[0]) / w * 100, # width,height 為寬高
'height': (bbox[3] - bbox[1]) / h * 100
},
'score': float(bbox[4] * 100)
})
avgs = bboxes[:, -1]
results = [{'result': results, 'score': np.average(avgs) * 100}]
return results
def fit(self, completions, num_epochs=5, **kwargs):
if completions: # 使用方法1獲取 project_id
image_urls, image_labels = [], []
for completion in completions:
project_id = completion['project']
u = completion['data'][self.value]
image_urls.append(get_local_path(u, hostname=HOSTNAME, access_token=API_KEY))
image_labels.append(completion['annotations'][0]['result'][0]['value'])
elif kwargs.get('data'): # 使用方法2獲取 project_id
project_id = kwargs['data']['project']['id']
if not self.parsed_label_config:
self.load_config(kwargs['data']['project']['label_config'])
if self.gen_train_data(project_id):
# 使用 mmdetection 的方法訓練模型
from tools.mytrain import MyDict, train
args = MyDict()
args.config = conf['config_file']
data_root = os.path.join(conf['workdir'], "train")
args.cfg_options = {}
args.cfg_options['data_root'] = data_root
args.cfg_options['runner'] = dict(type='EpochBasedRunner', max_epochs=num_epochs)
args.cfg_options['data'] = dict(
train=dict(img_prefix=data_root, ann_file=data_root + '/result.json'),
val=dict(img_prefix=data_root, ann_file=data_root + '/result.json'),
test=dict(img_prefix=data_root, ann_file=data_root + '/result.json'),
)
args.cfg_options['load_from'] = conf['checkpoint_file']
args.work_dir = os.path.join(data_root, "work_dir")
train(args)
checkpoint_name = time.strftime("%Y%m%d%H%M%S", time.localtime(time.time())) + ".pth"
shutil.copy(os.path.join(args.work_dir, "latest.pth"), os.path.join(conf['workdir'], checkpoint_name))
print("model train complete!")
# 權重檔案儲存至執行環境,將在下次執行 init 初始化時載入
return {'model_path': os.path.join(conf['workdir'], checkpoint_name)}
else:
raise "gen_train_data error"
def gen_train_data(self, project_id):
import zipfile
import glob
download_url = f'{HOSTNAME.rstrip("/")}/api/projects/{project_id}/export?export_type=COCO&download_all_tasks=false&download_resources=true'
response = requests.get(download_url, headers={'Authorization': f'Token {API_KEY}'})
zip_path = os.path.join(conf['workdir'], "train.zip")
train_path = os.path.join(conf['workdir'], "train")
with open(zip_path, 'wb') as file:
file.write(response.content) # 通過二進位制寫檔案的方式儲存獲取的內容
file.flush()
f = zipfile.ZipFile(zip_path) # 建立壓縮包物件
f.extractall(train_path) # 壓縮包解壓縮
f.close()
os.remove(zip_path)
if not os.path.exists(os.path.join(train_path, "images", str(project_id))):
os.makedirs(os.path.join(train_path, "images", str(project_id)))
for img in glob.glob(os.path.join(train_path, "images", "*.jpg")):
basename = os.path.basename(img)
shutil.move(img, os.path.join(train_path, "images", str(project_id), basename))
return True
啟動後端服務
以下命令為 window 指令碼,皆在 backend 根目錄下執行。
- 根據後端模型生成服務程式碼
label-studio-ml init model --script mmdetection/label_studio_backend.py --force
label-studio-ml init 命令提供了一種根據後端模型自動生成後端服務程式碼的功能, model 為輸出目錄, --script 指定後端模型路徑, --force 表示覆蓋生成。該命令執行成功後會在 backend 目錄下生成 model 目錄。
2. 複製 mmdetection 依賴檔案
由於 label-studio-ml 生成的後端服務程式碼只包含基本的 label_studio_backend.py 中的內容,而我們所用的 mmdetection 框架的執行需要大量額外的依賴,所以需要手動將這些依賴複製到生成的 model 目錄中。使用以下命令完成自動複製依賴:
md .\model\mmdet
md .\model\model
md .\model\configs
md .\model\checkpoints
md .\model\tools
md .\model\workdir
xcopy .\mmdetection\mmdet .\model\mmdet /S /Y /Q
xcopy .\mmdetection\model .\model\model /S /Y /Q
xcopy .\mmdetection\configs .\model\configs /S /Y /Q
xcopy .\mmdetection\checkpoints .\model\checkpoints /S /Y /Q
xcopy .\mmdetection\tools .\model\tools /S /Y /Q
copy .\mmdetection\conf.yaml .\model\conf.yaml
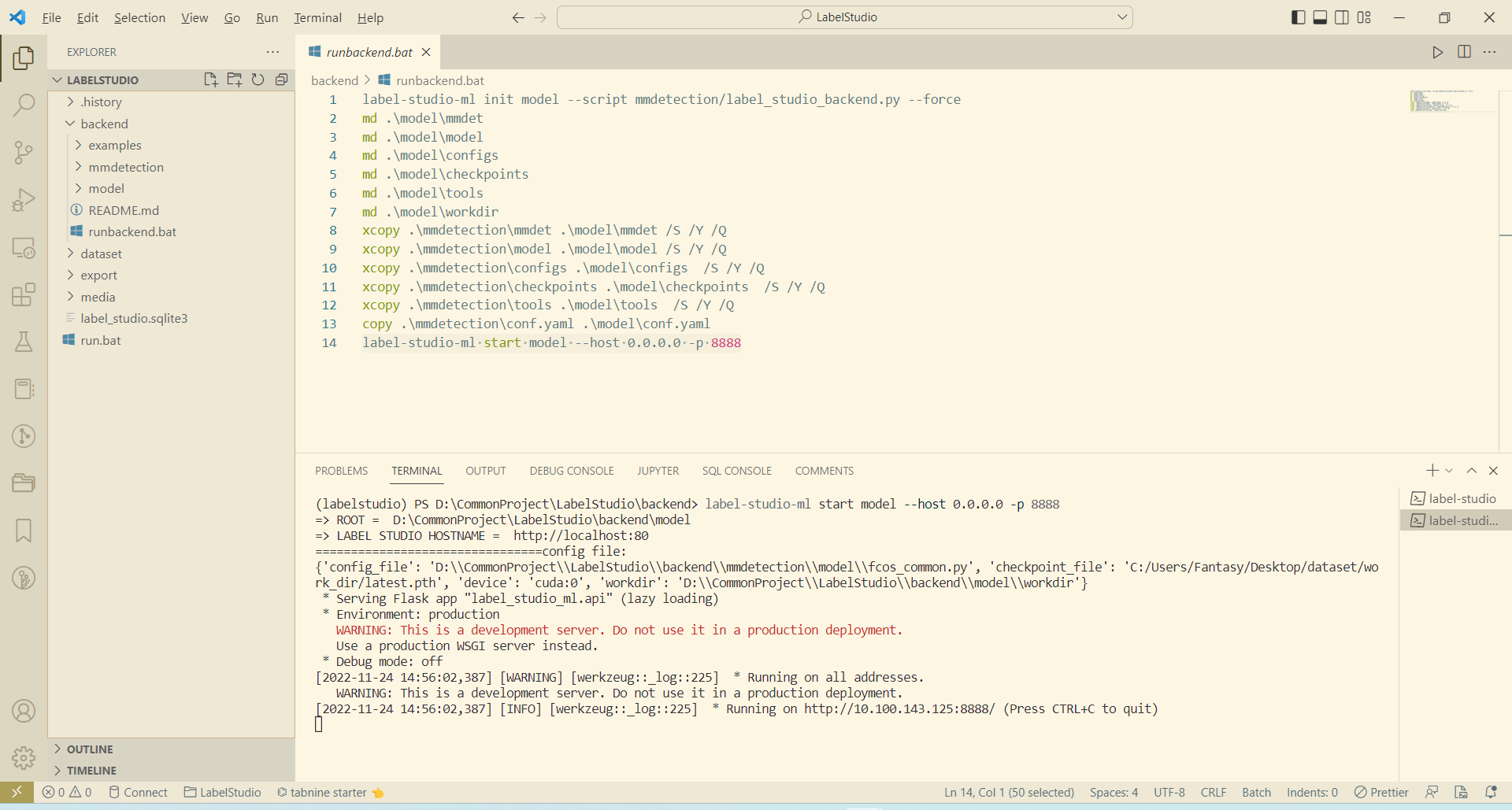
- 啟動後端服務
label-studio-ml start model --host 0.0.0.0 -p 8888
啟動成功後效果如下:
前端自動標註
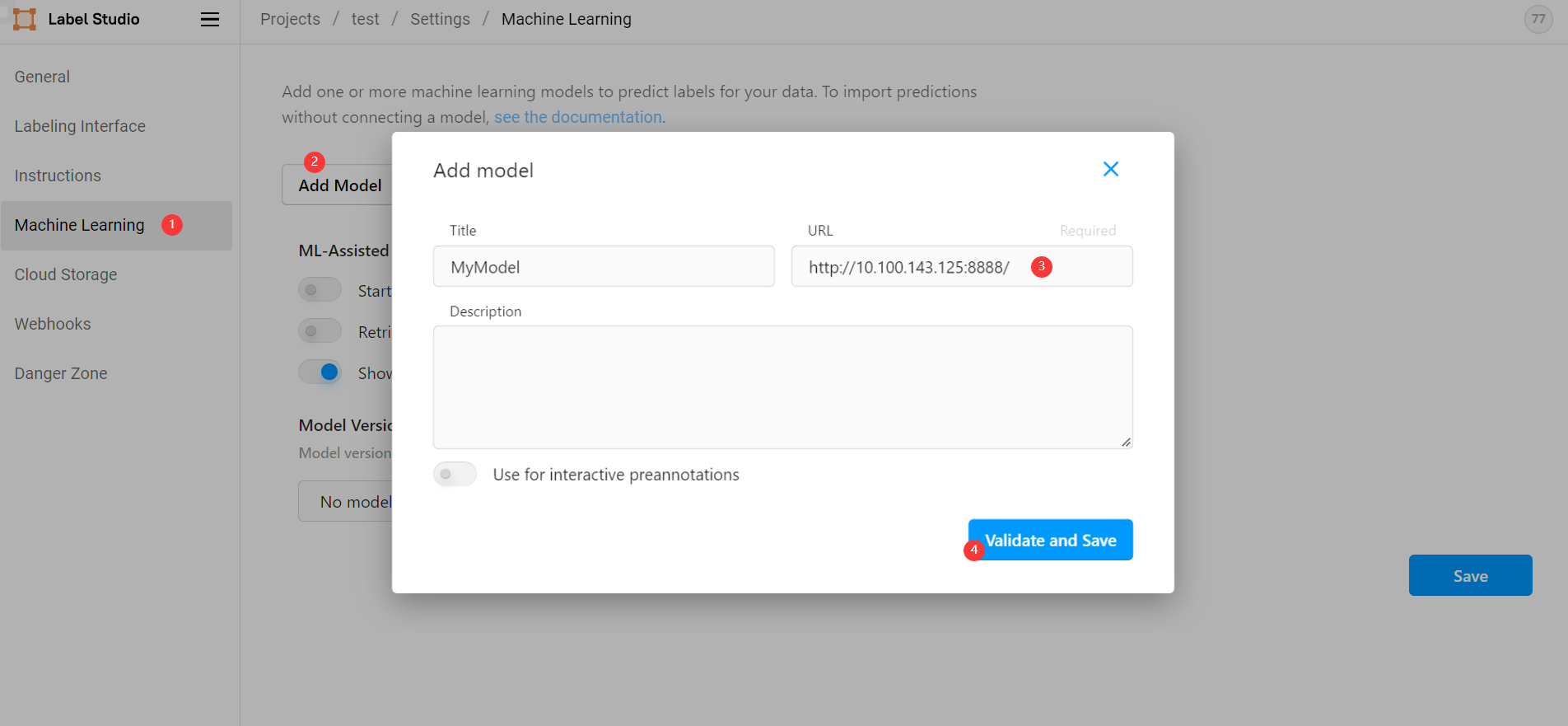
前面我們已經能夠從 label studio 前端正常手動標註圖片,要想實現自動標註,則需要在前端引入後端服務。在我們建立的專案中依次選擇 Settings ->
Machine Learning -> Add model ,然後輸入後端地址 http://10.100.143.125:8888/ 點選儲存(此地址為命令列列印地址,而非 http://127.0.0.1:8888/ ):
此時我們從前端專案中開啟待標記圖片,前端會自動請求後端對其進行標記(呼叫後端的 predict 方法),等待片刻後即可看見預標記結果,我們只需要大致核對無誤後點選 submit 即可:
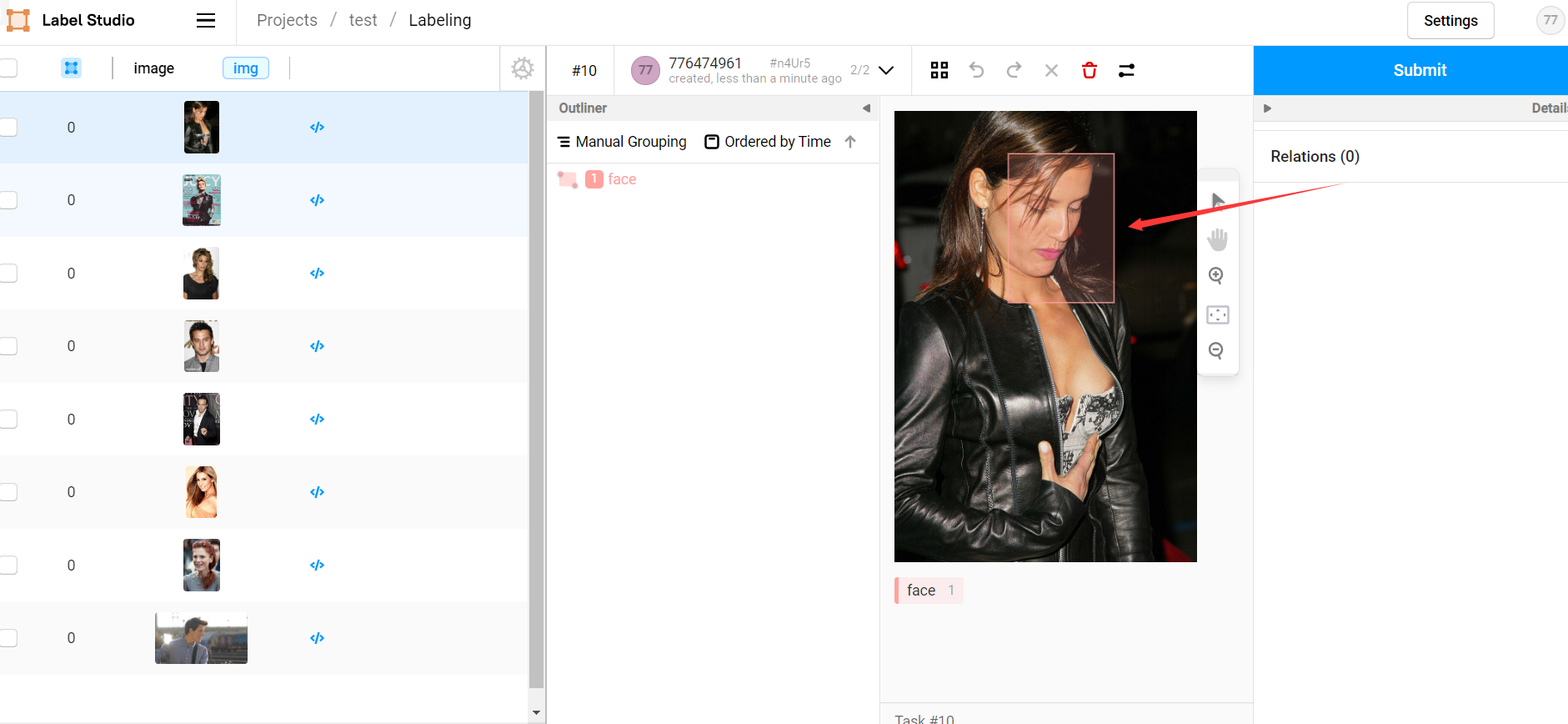
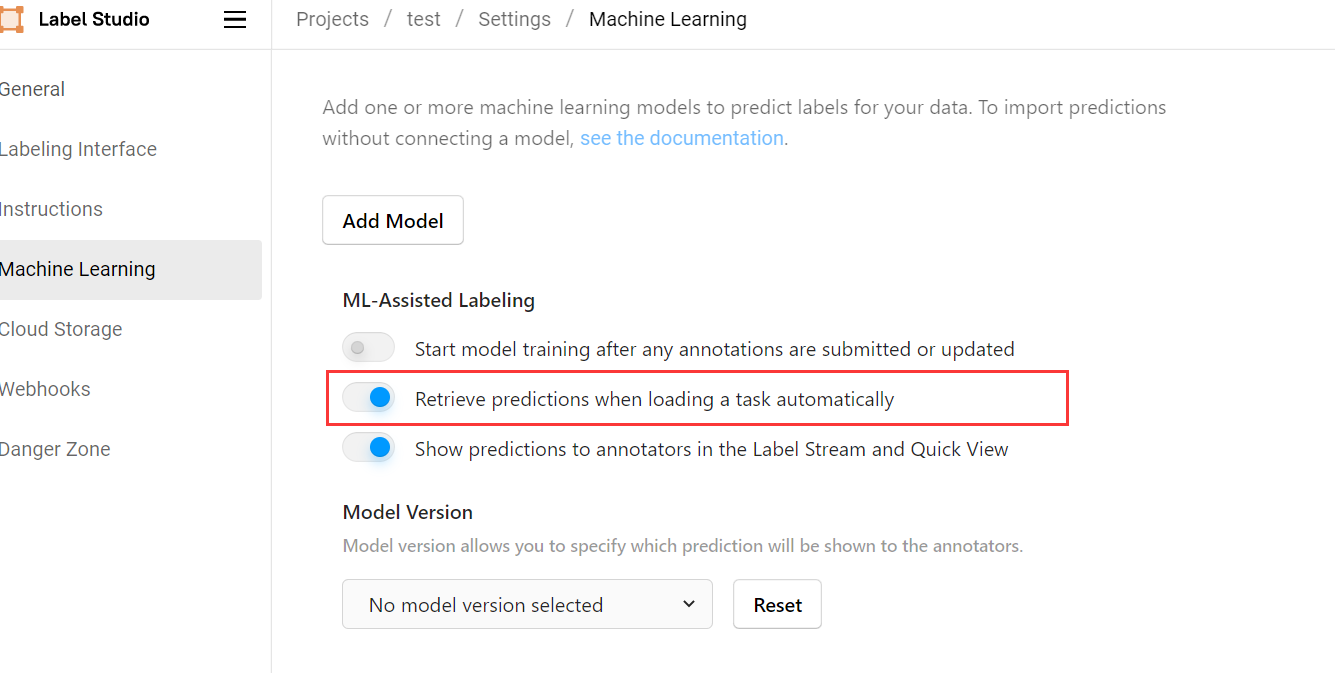
如果覺得每次開啟圖片都需要等待片刻才會收到後端預測結果比較費時,可以在 Settings -> Machine Learning 設定中選擇開啟 Retrieve predictions when loading a task automatically ,此後前端會在我們每次開啟專案時自動對所有任務進行自動預測,基本能夠做到無等待:
後端自動訓練
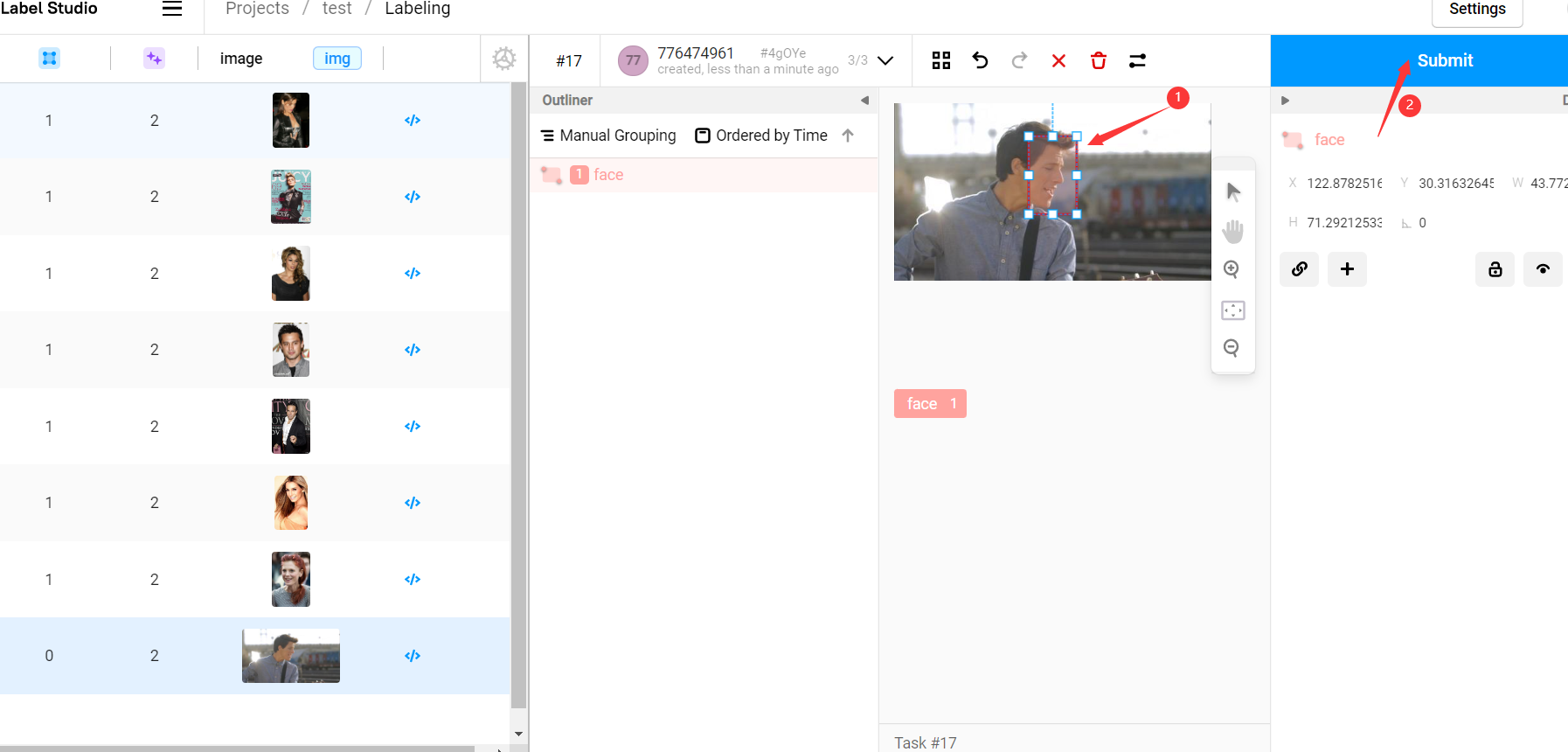
現在所有的圖片都已經有了與標註資訊,我們先檢查所有圖片,檢查並改進所有標註資訊然後點選 submit 提交:
在 Settings -> Machine Learning 中點選後端服務的 Start Training 按鈕,即可呼叫後端模型使用已標記資訊進行訓練:
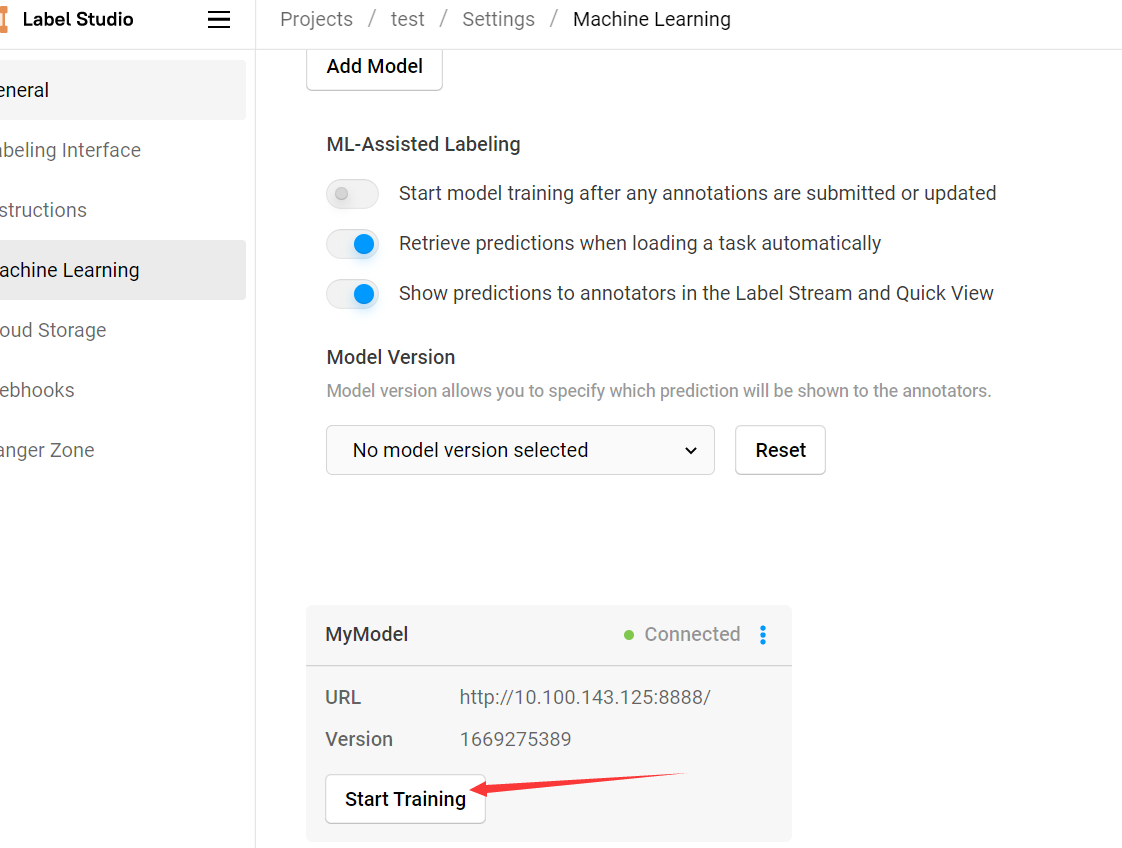
該操作會呼叫後端模型的 fit 方法對模型進行訓練,可以在後端命令列介面看見訓練過程,訓練完成後的所有新資料集都會使用新的模型進行預測:
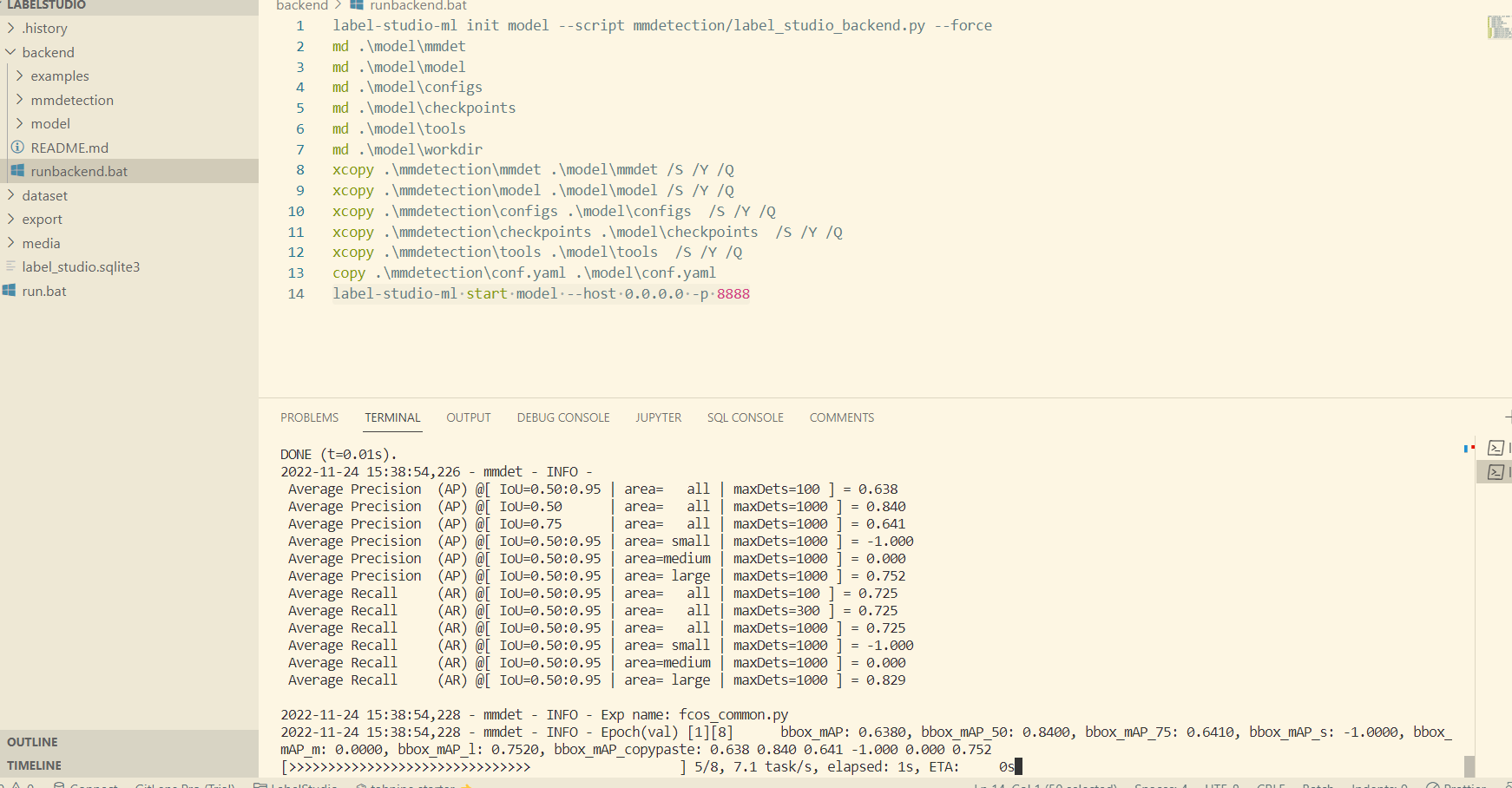
也可以 Settings -> Machine Learning 中允許模型自動訓練,但訓練頻率過高會影響程式效率。
部分常見問題
Q: 一種存取許可權不允許的方式做了一個存取通訊端的嘗試。
A: label-studio-ml start 啟動時指定埠 -p 8888
Q: Can't connect to ML backend http://127.0.0.1:8888/, health check failed. Make sure it is up and your firewall is properly configured.
A: label-studio-ml start 啟動後會列印一個監聽地址,label studio 前端新增該地址而非 http://127.0.0.1:8888/ 。
Q: FileNotFoundError: Can't resolve url, neither hostname or project_dir passed: /data/upload/1/db8f065a-000001.jpg
A: 介面返回的是專案的相對地址,無法通過該地址直接讀取到圖片原件,需要配合 get_local_path 函數使用。
Q: UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 2: illegal multibyte sequence
A: 修改 C:\Users\Fantasy.conda\envs\labelstudio\lib\json_init_.py#line 179 為:
for chunk in iterable:
fp.write(chunk.replace(u'\xa0', u''))
參考
Cai Yichao. label_studio自動預標註功能. CSDN. [2022-01-19] ↩︎