移動 VR 開發時要避免的 PC 渲染技術
更新:本文是為 Quest 1 開發人員編寫的。雖然 Quest 2 建立在相同的架構上,但現在更容易為陰影貼圖(以及其他需要從先前渲染過程中生成的紋理讀取的簡單技術)做預算。
儘管移動晶片組可以支援下面概述的大多數技術,但我們強烈建議你不要這樣做。不過,這並不總是一成不變的規則,因為我有看到開發者有實現下述技術但依然達到幀速率的要求。但通過避免下文提及的 PC 渲染技術,你會避免很多麻煩。
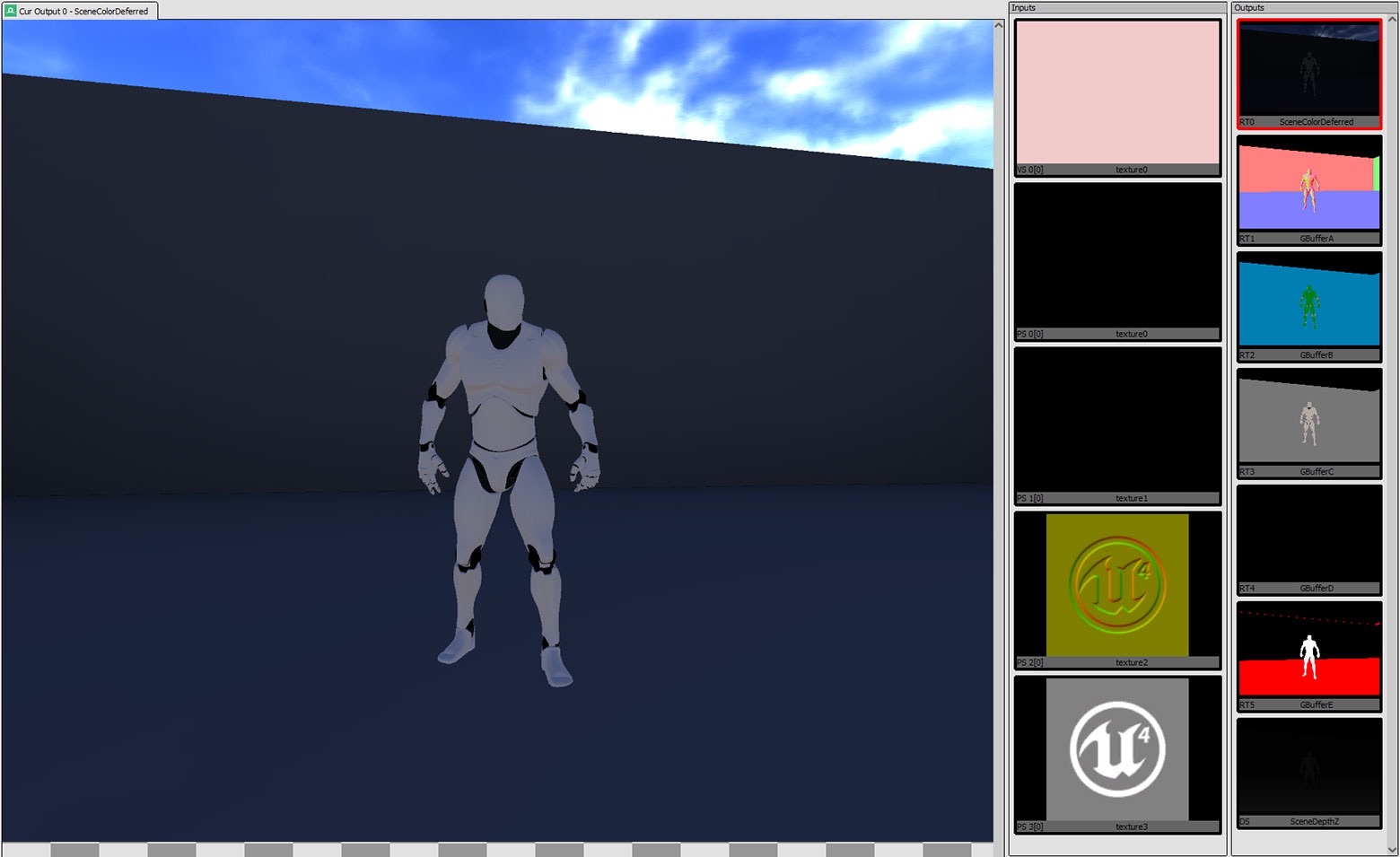
延遲渲染
延遲渲染(或(延遲 shader)[https://en.wikipedia.org/wiki/Deferred_shading]), 這種技術是將光照/渲染計算推遲到第二步進行計算。這樣做的目的是為了避免多次渲染同一個畫素。延遲渲染主要分為兩步:在第一步中,渲染場景,但只是簡單地將幾何資訊(位置座標,法線向量,紋理座標和反射係數等等)儲存在中間緩衝區中;在第二步中,從中間緩衝區讀取資訊,應用反射模型,計算出每個畫素的最終顏色。
延遲渲染對 PC 開發非常有效,因為它可以將幾何圖形與照明分離,你只需更新每個照明所觸達的畫素,即可在更少的 GPU 週期內渲染更多照明。
為何不適合移動開發?
原因有很多,但主要原因是 resolve 成本問題。什麼是 resolve 成本?在我告訴你什麼是 resolve 成本之前,你首先需要了解 tiled GPU 的工作原理。
為了以更低功耗實現更高的吞吐量,移動 GPU(例如 Oculus Quest 中使用的 Snapdragon 835)通常使用 tiled 架構,其中每個渲染目標都被分解成塊狀網格或「tiles」 (從 16x16 畫素到 256x256 畫素的任何位置,具體取決於硬體和畫素格式)。所謂 Tile,就是將幾何資料轉換成小矩形區域的過程,然後提交給非同步處理器,非同步處理器執行渲染工作以計算每個「tile」的影象結果。一旦計算出每個圖塊影象,GPU 必須從片上記憶體中將圖塊複製回通用記憶體。這實際上非常慢,因為它需要通過匯流排傳輸資料。我們將此轉移稱為「resolve」,因此所需的時間稱為「resolve 成本」。維基百科對[tiled rendering][https://en.wikipedia.org/wiki/tiled_rendering]有更詳細的描述,供進一步閱讀。
因為要渲染的每個 texture 都需要 resolve,並且延遲渲染需要在計算照明之前渲染大量紋理,所以你的 resolve 成本將從正向渲染的大約 1ms 增加至 3ms 以上。如你所見,你可能沒有這樣的時間。
除了 resolve 成本之外,延遲渲染僅在你的幾何體複雜且有多光照時才有優勢。無論如何,這兩者都無法在移動裝置上真正實現,因為 GPU 處理大量頂點和計算畫素填充的能力有限。
暫時的答案是堅持使用 forward 渲染。也可能有一個好的 forward+ 實現的地方,雖然我還沒有看到一個。
Depth pre-pass
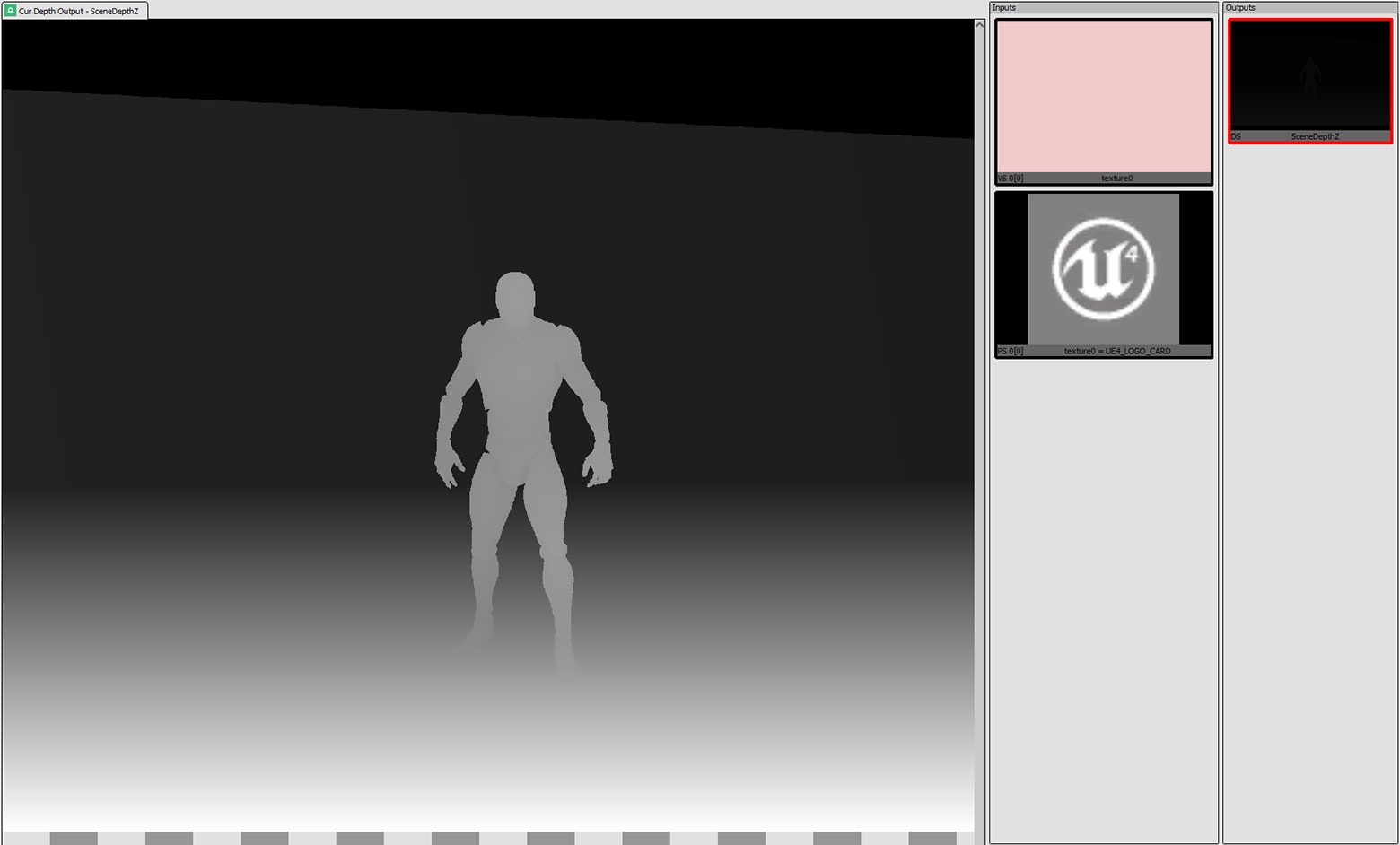
depth/Z pre-pass 是一種常用技術,其中所有場景幾何圖形都作為第一步渲染,而不填充幀緩衝區,僅生成深度緩衝區值。然後渲染第二步,檢查每個畫素的計算深度是否等於深度緩衝區中該畫素的值。如果不是,你可以跳過對該片段進行著色。由於在 PC 上處理頂點往往比著色畫素快得多,因此可以節省大量時間。
為何不適合移動開發?
首先,如果在提交繪製呼叫之前對幾何進行排序,通過進行 Depth Pre-Pass 而節省的片段填充時間應該最少。來回繪製會導致常規深度測試拒絕你的畫素,所以你只能避免對未正確排序或兩個物件在不同點彼此重疊的幾何圖形進行畫素填充。
其次,這需要繪製呼叫加倍,因為你必須先提交所有內容以進行 Depth Pre-Pass,然後再才是 Forward Pass。由於繪製呼叫對 cpu 的佔用非常大,所以你需要避免這種情況。
第三,所有頂點都需要處理兩次,這通常會增加 GPU 時間,而不是避免兩次填充幾個畫素所節省的時間。這是因為頂點處理在移動裝置上比在 PC 上花費的時間相對更多,並且處理片段相對較少(因為幀緩衝區大小通常較小,片段程式往往不那麼複雜)。
第三,所有頂點都需要處理兩次,與通過避免填充少數畫素兩次而節省的時間相比,你通常增加的 GPU 時間會更多。這是因為移動裝置的頂點處理會在 PC 耗費更多的時間,並且處理片段的時間同樣相對較少(因為 framebuffer 大小通常較小,fragment program 往往不那麼複雜)。
HDR textures
resolve 成本與影象中的位元組數直接相關,而不與畫素數直接相關,所以,儘管我們通常以 32 位 RGBA 畫素來思考量度,但如今大多數開發者都在使用 HDR 紋理,即每畫素 64 位。這會將你的 resolve 成本增加一倍,並且由於顯示器僅支援每通道 8 位,所以你在 resolve HDR 紋理時會浪費大量時間。更不用說移動 GPU 是針對 32 位幀緩衝區進行優化。
後處理
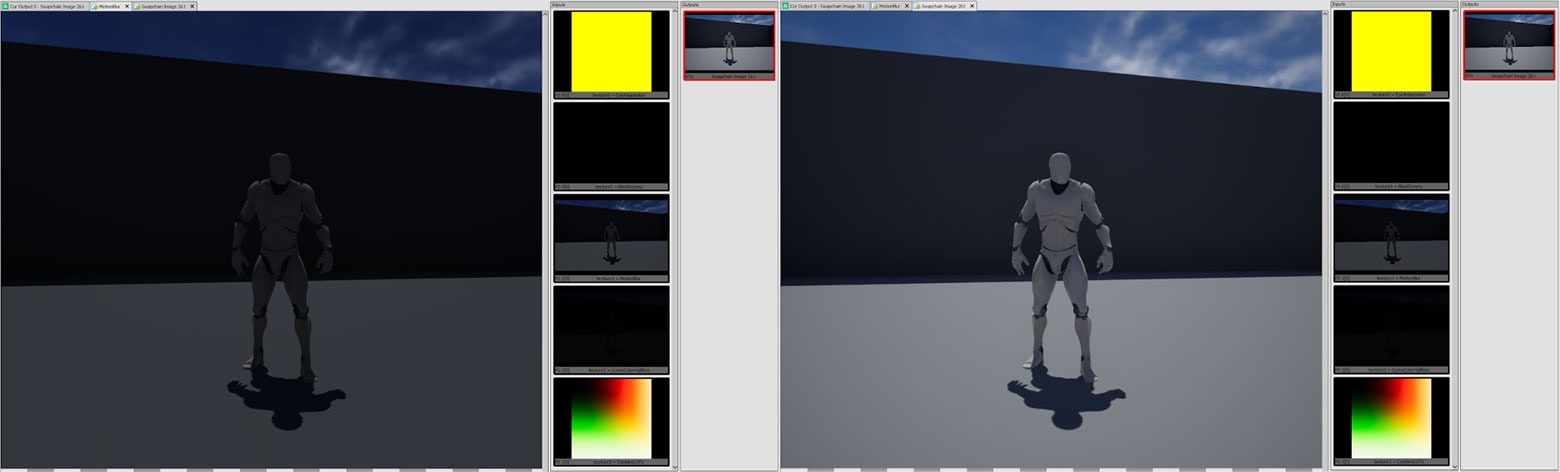
後處理是一種經常用於為遊戲施加多種效果的技術,如 Color Grading,Bloom 照明和運動模糊。具體的實現方式是獲取遊戲渲染的輸出,然後對影象執行全螢幕通道以產生新影象,然後再將其呈現給玩家。一些後期處理效果是作為一個額外的通道執行(如顏色分級),另一些則需要多個通道。
對於移動裝置,後處理的主要問題同樣是解析成本。生成第二張影象將引起另一次解析,並會立即消耗大約 1 毫秒的時間。更不用說計算後處理效果所花費的時間,取決於效果,這可能會佔用大量資源。所以,最好避免進行後處理。
以下是替代常見後處理效果的方案:
Color grading
與其在後處理中執行 Color Grading,不如在每個片段著色器的末尾新增一個函數呼叫以執行相同的數學運算。這將產生相同的視覺結果,但無需額外的解析。
Bloom
真正的 Bloom 效果非常耗時。最好的選擇是「偽造」。採用包含 blob 紋理的 billboarding sprite 可以產生非常接近的效果。
實時陰影
我認為這是最有爭議的一項技術。一系列具有完整實時陰影的應用已成功支援移動裝置。但是,這樣做存在大量的折衷,而我認為值得避免使用。
實時陰影的一種常用技術是級聯陰影貼圖,這意味著場景會以各種視口大小進行多次渲染。對於必須由 GPU 處理的幾何,這會令次數增加 1 到 4 倍,這從根本上限制了場景可以支援的頂點數量。它同時增加了陰影貼圖紋理的解析成本(與紋理大小有關)。在 GPU 管道的另一端,在對陰影貼圖進行取樣時有兩個選項:硬陰影和軟陰影。硬陰影可以更快地渲染,但具有不可避免的鋸齒問題。
由於陰影貼圖的工作方式,這個測試只能得出二進位制結果。你無法對陰影貼圖進行雙線性取樣,因為它表示深度值而非顏色值。應該避免使用軟陰影,因為它們需要將多個取樣放到陰影貼圖中,而這當然很慢。最好的選擇是烘烤所有可能的陰影,而如果需要實時陰影,請尋找另一種方法。如果照明大部分都是漫反射,則通常可以接受 blob 陰影。如果需要強光照明並且陰影表面是平面,則幾何陰影的效果同樣相當出色。
深度(及幀緩衝區)取樣
對於 PC,你可以在著色器中取樣當前的深度紋理(Unity 將其顯示為_CameraDepthTexture)。之所以可行,是因為深度紋理只是 PC 上的另一種紋理,並且由於每個繪製呼叫都接連發生,所以深度紋理的狀態將是上一次繪製呼叫之後的狀態。但對於基於圖塊渲染,當前深度不在紋理之中,而是僅儲存在你的圖塊記憶體中,所以無法將其作為普通紋理進行取樣。
考慮到上述情況,有一個 GLES 擴充套件可允許你查詢深度緩衝區(和幀緩衝區)的當前狀態。問題是它們非常慢,只能支援你對相同畫素的值進行取樣(無法查詢附近的畫素),並且在啟用 MSAA 時它們會產生一系列的問題。
啟用 MSAA 時,圖塊實際上具有一個足夠大,能夠容納所有取樣的緩衝區(即 2×MSAA 的畫素為 2 倍,4×MSAA 的畫素為 4 倍)。這意味著預設情況下,如果對深度緩衝區進行取樣,則必須按每個取樣執行片段著色器,這意味著時間密集度將比預期高 2 倍或 4 倍。存在一種「解決方案」,即呼叫 glDisable(FETCH_PER_SAMPLE_ARM)。但這樣做的問題是,它將僅檢索第一個取樣的值,而不是混合取樣的結果,所以在啟用所述功能後,MSAA 將被禁用。
除非絕對必要,否則你應避免它們對幀時間產生的影響。
幾何著色器
幾何著色器允許你在執行時生成額外的頂點,這對於諸如動態細分等功能十分有用。但是,對於基於圖塊渲染的 GPU 而言,幾何著色器會產生問題。生成額外頂點的步驟阻止了合併過程的進行,這意味著 GPU 不能這樣做,所以它會切換為「立即」模式(完全跳過分塊過程)。可以猜到,這非常緩慢。所以,最好避免使用幾何著色器,並且如果有必要,選擇 CPU 生成頂點。
Mirrors/Portals
如果你用天真的方式實現它們……對於「天真的方式」,我是指分配兩個眼睛緩衝區大小的紋理,計算反射矩陣,然後將場景渲染到兩個紋理中。然後,你的 mirror 幾何將進行螢幕空間紋理取樣,從而顯示反射。這種方法存在眾多明顯的缺陷:
- 繪製呼叫增加了兩倍。
- 填充的畫素比螢幕可見的畫素要多。
- 必須解析另外兩個紋理。
我發現的最低提升是限制了 mirror camera 的視口,並更改了相應的投影矩陣,只能在視錐中渲染 camera 平面邊界框。這對上面的第二點問題有所幫助。理想情況下,你同時可以使用多檢視,通過一組繪製呼叫來渲染左右眼,但 Unity 目前不支援這項功能,它不能解決上面的第三點問題 ,並且會令第二點問題更加惡化,因為你只能為兩隻眼睛使用單個視口,所以你必須使用兩個 mirror 邊界框的重疊。所以,理想的解決方案將首先解決第三點問題,這意味著一次繪製 mirror 場景和非 mirror 場景。
有一種解決方案可以利用修改後的著色器和模板緩衝區。場景中的每種材質都將具有兩種版本的著色器,一種僅在模板緩衝區中的特定位為 0 時繪製,而另一種僅在 1 時繪製。然後,你將使用材質繪製 mirror 網格。它會在模具緩衝區中設定所述位,使用第一組著色器繪製場景,使用反射矩陣設定 camera,並且在最後使用第二組著色器繪製場景。這將產生你想要的反射,同時不會填充超出所需畫素的畫素,並且避免了不必要的解析。然而,它無法避免繪製一堆物件兩次(任何解決方案都無法避免)。
儘管這聽起來很容易,但如果是使用 Unity,你將會遇到很多問題(我在 Unreal 中沒有遇到過,但你可能會遇到類似的挑戰)。首先,在啟用 Single Pass Stereo(多檢視)後,Unity 將不允許你修改 camera 的投影矩陣,所以你不能使用反射 camera(如果關心 CPU 效能,你絕對應該使用這個 camera)。其次,這沒有考慮 Late-Latching(在渲染執行緒啟動時更新 camera 矩陣,從而儘可能減少延遲)。通常來說,這是一次純粹的勝利,但如果你使用 mirror camera,則反射 camera 的變形將不再與頭部變形匹配,所以你會得到奇怪的偽影,鏡面中的元素不會按照預期方式排列。
最簡單的解決方案是「偽造」。如果你的鏡面是靜態,則只需建立所有世界幾何的反射副本,然後將其放在場景中即可。你需要使用指令碼來移動任何動態物件的「反射」副本,從而模仿包括玩家在內的「真實」版本位置,但這將是最快、最簡單的渲染解決方案,無需複雜的矩陣數學。如果可以看到鏡子後面,你將不得不使用兩組具有不同模板蒙版的著色器,但如果玩家由於牆壁等原因而無法看到後面,則可以只保留一組著色器。
總結
無論你是從零開始一個新專案,還是要從 PC 移植到移動裝置,明確哪裡可以沿用原有的知識經驗,哪裡又需要採取創新的解決方案是獲得最佳遊戲效果的關鍵。 但是,你不必遵循本文的建議。請自由探索,並尋找最適合自己的方案。
原文:https://developer.oculus.com/blog/pc-rendering-techniques-to-avoid-when-developing-for-mobile-vr/