Lakehouse架構指南
你曾經是否有構建一個開源資料湖來儲存資料以進行分析需求?
資料湖包括哪些元件和功能?
不瞭解 Lakehouse 和 資料倉儲 之間的區別?
或者只是想管理數百到數千個檔案並擁有更多類似資料庫的功能但不知道如何操作?
本文解釋了資料湖的細節以及哪些技術可以構建一個Lakehouse,以避免建立沒有結構和孤立檔案的資料沼澤。 並討論資料湖的分析能力以及如何構建,我們將介紹何時不使用資料湖以及有哪些替代方案。
隨著 Databricks 開源了完整的 Delta Lake 2.0,包含了很多高階功能以及 Snowflake 宣佈整合 Iceberg 表,市場現在很火爆。
什麼是資料湖,為什麼需要資料湖?
資料湖是一種儲存系統,具有底層資料湖檔案格式及其不同的資料湖表格式,可儲存大量非結構化和半結構化資料,並按原樣儲存,但沒有特定用途。廣泛的技術和非技術資料消費者可以存取該資料以進行分析用例和機器學習模型,包括商業智慧和報告。
資料湖還消除了通過傳統 BI 工具轉換資料需要使用專有格式的需要。將資料載入到資料湖中,資料團隊花費時間構建和維護複雜 ETL 管道的舊瓶頸消失了,並且跳過了等待數週的資料存取請求。
有了資料湖,資料變得越來越可用,早期採用者發現他們可以通過為業務服務構建新應用程式來獲取洞察力。資料湖支援使用多種不同型別的資料以低成本大規模捕獲和儲存原始資料。一種在頂層執行轉換的可存取方式,即使最終需要哪些分析還不精確——主要是快速迭代轉換並探索業務價值。
資料湖(2014 年的初始資料湖論文)可以基於多種技術構建,例如 Hadoop、NoSQL、Amazon Simple Storage Service、關聯式資料庫,或各種組合和不同格式(例如 Excel、CSV、文字、紀錄檔、Apache Parquet、Apache Arrow、Apache Avro,稍後會詳細介紹)。
每個資料湖都從一個簡單的儲存提供程式、一種資料湖檔案格式開始,然後使用我們將在本文後面探討的資料湖表格式擴充套件關鍵的類似資料庫的功能。
資料湖、資料倉儲 和 Lakehouse 之間有什麼區別
那麼從資料湖到Lakehouse有什麼區別呢?Lakehouse是資料湖和資料倉儲的組合(可能還有很多其他意見)。Lakehouse具有開放的資料管理架構,結合了資料湖的靈活性、成本效益和規模。與資料湖一樣,它還具有資料湖表格式(Delta Lake、Apache Iceberg 和 Apache Hudi)提供的資料庫功能。
與資料湖相比,Lakehouse具有額外的資料治理。它包括叢集計算框架和 SQL 查詢引擎。更多功能豐富的 Lakehouse 還支援資料目錄和最先進的編排。
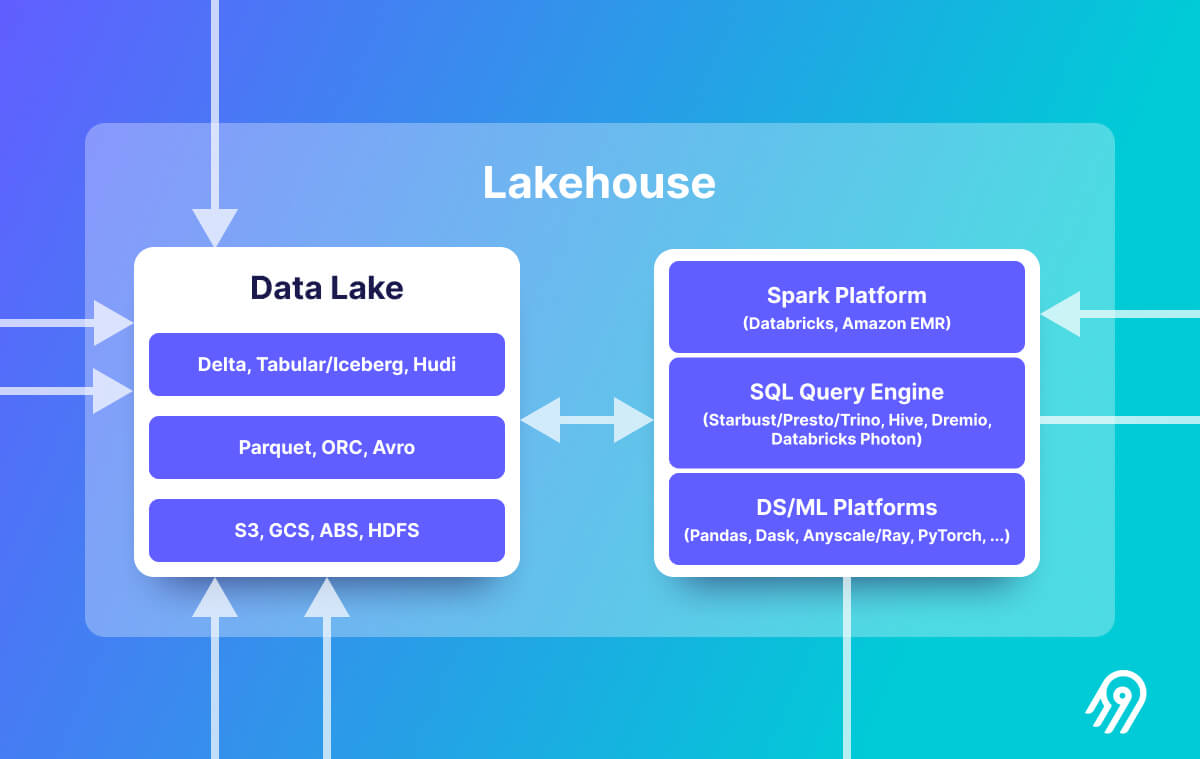
關於資料湖和Lakehouse請參閱有關現代資料基礎架構的新興架構的完整架構。
在現代資料基礎設施的新興架構中,Lakehouse架構越來越得到認可,並通過知名供應商(包括 AWS、Databricks、Google Cloud、Starburst 和 Dremio)和資料倉儲先驅的採用情況驗證了這點。 Lakehouse 的基本價值在於將強大的儲存層與一系列強大的資料處理引擎(如 Spark、Presto、Apache Druid/Clickhouse 和 Python 庫)適配。
為了結束Lakehouse與資料倉儲進行比較,我們可以說:Lakehouse更開放(開放格式),並且隨著更多的 DIY 和將不同工具,可以支援不同用例,而資料倉儲更封閉(主要是閉源),為 BI 構建,完全託管,擴充套件成本更高。
Databricks 在 2021 年的 CIDR 論文中最先提出了Lakehosue的概念。
資料湖的元件
我們將在本部分討論資料湖的三個主要組成部分。首先是物理儲存資料的層,接下來有一個資料湖檔案格式,它主要壓縮資料以用於面向行或面向列的寫入或查詢,最後資料湖表格式位於這些檔案格式之上,以提供強大的功能。
資料湖的演變:資料湖及其演變的簡史:
- Hadoop & Hive:使用 MapReduce 的第一代資料湖表格式。支援 SQL 表示式。
- AWS S3:下一代簡單資料湖儲存。維護工作大大減少,並且具有出色的程式設計 API 介面。
- 資料湖檔案格式:適用於雲的檔案格式,具有面向列、壓縮良好並針對分析負載進行了優化。例如 Apache Parquet、ORC 和 Apache Avro格式。
- 資料湖表格式:Delta Lake、Apache Iceberg 和 Hudi,具有成熟的類資料庫功能。
儲存層/物件儲存(AWS S3、Azure Blob Storage、Google Cloud Storage)
從儲存層開始,我們擁有來自三大雲提供商 AWS S3、Azure Blob Storage 和 Google Cloud Storage 的物件儲存服務。 Web 使用者介面易於使用,它的功能非常簡單,事實上這些物件儲存可以很好地儲存分散式檔案,它們還具有高度可設定性,內建了可靠的安全性和可靠性。
作為 Hadoop 的繼承者,它們非常適合雲中的非結構化和半結構化資料,AWS S3 是將任何格式的檔案上傳到雲的事實上的標準。
資料湖檔案格式(Apache Parquet、Avro、ORC)
資料湖檔案格式更面向列,並使用附加功能壓縮大檔案。這裡的主要參與者是 Apache Parquet、Apache Avro 和 Apache Arrow。它是物理儲存,實際檔案分佈在儲存層上的不同儲存桶中。
資料湖檔案格式有助於儲存資料,在系統和處理框架之間共用和交換資料。這些檔案格式具有其他功能,例如拆分能力和模式演變。
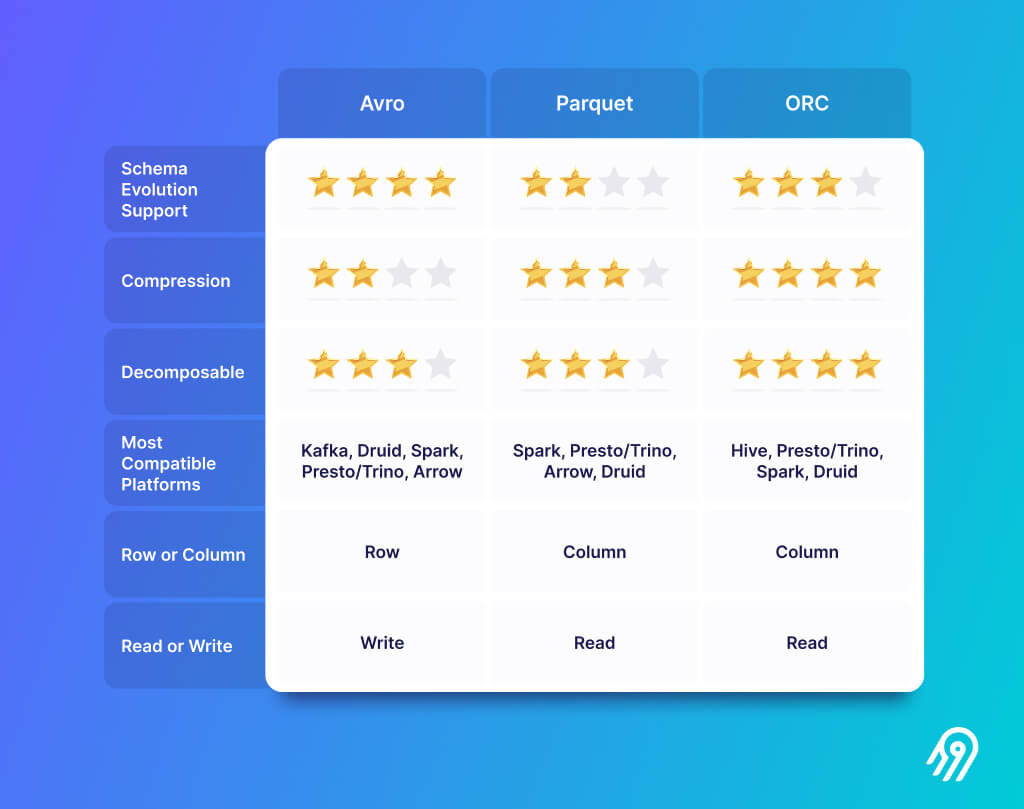
在選擇哪種資料湖檔案格式時,Apache Parquet 似乎更佔優勢。 Avro 也很好,因為它具有複雜的模式描述語言來描述資料結構並支援模式演變。
Schema Evolution 不太重要,因為下一章中的資料湖表格式也支援這些。
資料湖表格式
資料湖表格式非常有吸引力,因為它們是資料湖上的資料庫。與表相同,一種資料湖表格式將分散式檔案捆綁到一個很難管理的表中。可以將其視為物理資料檔案之間的抽象層,以及它們的結構以形成表格。
想象一下一次插入數百個檔案。它們是上述其中一種開源資料湖檔案格式,可優化列儲存並高度壓縮,資料湖表格式允許直接從資料湖中高效地查詢資料,不需要進行轉換。
資料湖表格式是資料湖檔案格式的引擎。檔案格式擅長以壓縮方式儲存巨量資料並將其返回以進行面向列的分析查詢,但是它們缺乏額外的特性,例如 ACID 事務和對關聯式資料庫中每個人都知道的標準 ANSI SQL 的支援。藉助資料湖表格式及其開源解決方案,我們可以獲得這些想要的基本功能,並且還可以獲得更多,如下一章所示。
問題:在採用資料湖表格式之前思考
- 哪種格式具有我需要的最先進和最穩定的功能
- 哪種格式使我能夠使用 SQL 輕鬆存取我的資料?
- 哪種格式有動力和良好的社群支援?
- 哪種格式提供最強大的版本控制工具?
資料湖表格式的特點
如何使用所有三種重要格式共用的資料湖表格式功能將資料庫功能新增到 S3。此外該功能還有助於遵循 GDPR 政策、跟蹤和審計,以及刪除請求的刪除。
為什麼所有這些功能都是必不可少的?想象一下需要將分析資料儲存在 S3 上的 parquet 檔案中。你需要對所有檔案進行聚類,記錄模式,同時讀取和更新所有檔案,找到一種備份和回滾的方法,以防你犯了錯誤,編寫模擬更新或刪除語句的繁重函數等等。這就是為什麼會出現這些資料湖表格式,因為每個人都需要它們並建立了一個標準。
DML 和 SQL 支援:選擇、插入、更新插入、刪除
直接在分散式檔案上提供合併、更新和刪除。除了 SQL,有些還支援 Scala/Java 和 Python API。
向後相容 Schema Evolution 和 Enforcement
自動模式演化是資料湖表格式的一個關鍵特性,因為改變格式仍然是當今資料工程師工作中的一個難題。 Schema Evolution 意味著在不破壞任何內容甚至擴大某些型別的情況下新增新列,甚至可以重新命名或重新排序列,儘管這可能會破壞向後相容性。不過我們可以更改一張表格,表格格式負責在所有分散式檔案上切換它,最重要的是不需要重寫表和基礎檔案。
ACID 事務、回滾、並行控制
ACID 事務確保所有更改都成功提交或回滾。確保永遠不會以不一致的狀態結束。有不同的並行控制,例如保證讀取和寫入之間的一致性。每種資料湖表格式在此處都有其他實現和功能。
時間旅行,帶有事務紀錄檔和回滾的審計歷史
隨著時間的推移,資料湖表格式會版本化儲存在資料湖中的巨量資料。您可以存取該資料的任何歷史版本,通過易於稽核簡化資料管理,在意外寫入或刪除錯誤的情況下回滾資料,並重現實驗和報告。時間旅行支援可重現的查詢,可以同時查詢兩個不同的版本。
所有版本都使用時間旅行功能進行快照,它簡化了其他複雜方法的實施,例如漸變維度(型別 2)。甚至可以像通常使用更改資料捕獲 (CDC) 一樣提取變更。
事務紀錄檔是每個事務自開始以來的有序記錄。事務紀錄檔是通過上述許多功能使用的通用元件,包括 ACID 事務、可延伸的後設資料處理和時間旅行。例如,Delta Lake 建立一個名為 _delta_log的資料夾。
可延伸的後設資料處理:這些表通過自動檢查點和彙總來大規模處理大量檔案及其後設資料。
分割區
分割區和分割區 Evolution 處理為表中的行生成分割區值的繁瑣且容易出錯的任務,並自動跳過不必要的分割區和檔案。快速查詢不需要額外的過濾器,表格佈局可以隨著資料的變化而更新。
檔案大小調整、資料Clustering與壓縮
可以在 Delta Lake 中使用 OPTIMIZE壓縮資料,並通過 VACUUM 設定保留日期刪除舊版本(其他資料湖表格式具有類似功能)。開箱即用支援資料壓縮,您可以選擇不同的重寫策略,例如分箱或排序,以優化檔案佈局和大小。優化在解決小檔案問題時特別有效,您會隨著時間的推移攝取小檔案,但查詢數千個小檔案很慢,優化可以將檔案重新碎片化為更大的檔案,從而在許多方面提高效能。
統一的批次處理和流式處理
統一的批次處理和流式處理意味著 Lambda 架構已過時。資料架構無需在批次處理和流式中區分——它們都以相同的表結束,複雜性更低,速度更快。
無論是從流還是批次處理中讀取都沒有關係。開箱即用的 MERGE 語句適用於更改應用於分散式檔案的流式傳輸情況。這些資料湖表格式支援單個 API 和目標接收器。可以在 Beyond Lambda: Introducing Delta Architecture 或一些程式碼範例中看到很好的解釋。
資料共用
減少資料重複的一個新的令人興奮和需要的功能是資料共用。在 Delta 世界裡,它被稱為 Delta Sharing。 Snowflake 宣佈他們也將在 Iceberg 表中具有此功能。據我瞭解這些是 Databricks 和 Snowflake 中的專有功能。
雖然用於安全資料共用的開源 Delta 共用協定使得與其他組織共用資料變得簡單,無論他們使用哪種計算平臺。
變更資料流 (CDF)
更改資料流 (CDF) 功能允許表跟蹤表版本之間的行級更改。啟用後,執行時會記錄寫入表中的所有資料的「更改事件」。 CDF 包括行資料和後設資料,指示是否插入、刪除或更新了指定的行。
資料湖表格式(Delta、Iceberg、Hudi)
現在我們有了開源資料湖表格式最顯著的特點,讓我們來看看已經提到過幾次的三個最突出的產品:Delta Lake、Apache Iceberg 和 Apache Hudi。
Delta Lake
Delta Lake 是一個由 Databricks 建立的開源專案,並於 2019 年 4 月 22 日通過其首次公開的 GitHub Commit 開源。 最近宣佈的 Delta Lake 2.0。
使用 Spark SQL 在 Delta Lake 中建立表的範例
--creating
CREATE TABLE default.people10m (id INT, firstName STRING, gender STRING ) USING DELTA PARTITIONED BY (gender)
LOCATION 's3a://my-bucket/delta/people10m'
--writing
INSERT INTO default.people10m VALUES (1, 'Bruno', 'M'), (2, 'Adele', 'F');
INSERT INTO default.people10m SELECT * FROM source
--reading
SELECT COUNT(*) > 0 AS 'Partition exists' FROM default.people10m WHERE gender = "M"
Apache Iceberg
Apache Iceberg 最初是在 Netflix 開發的,目的是使用 PB 級的大型表來解決長期存在的問題。 它於 2018 年作為 Apache 孵化器專案開源,並於 2020 年 5 月 19 日從孵化器畢業。他們的第一次公開提交是 2017 年 12 月 19 日——更多關於 Apache Iceberg 簡介的故事的見解。
在 Apache Iceberg 中使用 Spark SQL 建立表的範例
--creating
CREATE TABLE local.db.table (id bigint, data string, category string)
USING iceberg
LOCATION 's3://my-bucket/iceberg/table/'
PARTITIONED BY (category)
--writing
INSERT INTO local.db.table VALUES (1, 'a'), (2, 'b'), (3, 'c');
INSERT INTO local.db.table SELECT id, data FROM source WHERE length(data) = 1;
--reading
SELECT count(1) as count, category FROM local.db.table GROUP BY category
Apache Hudi
Apache Hudi 最初於 2016 年在 Uber 開發(代號和發音為「Hoodie」),2016 年底開源(2016-12-16 首次提交),並於 2019 年 1 月提交給 Apache 孵化器。 關於 Apache 軟體基金會的背景故事宣佈 Apache® Hudi™ 為頂級專案。
在 Apache Hudi 中使用 Spark SQL 建立表的範例
--creating
create table if not exists hudi_table (id int, name string, price double)
using hudi options ( type = 'cow' )
partitioned by (name)
location 's3://my-bucket//hudi/hudi_table';
--writing (dynamic partition)
insert into hudi_table partition (name) select 1, 'a1', 20;
--reading
select count(*) from hudi_table
資料湖表格式比較:Delta Lake vs Apache Hudi vs Apache Iceberg
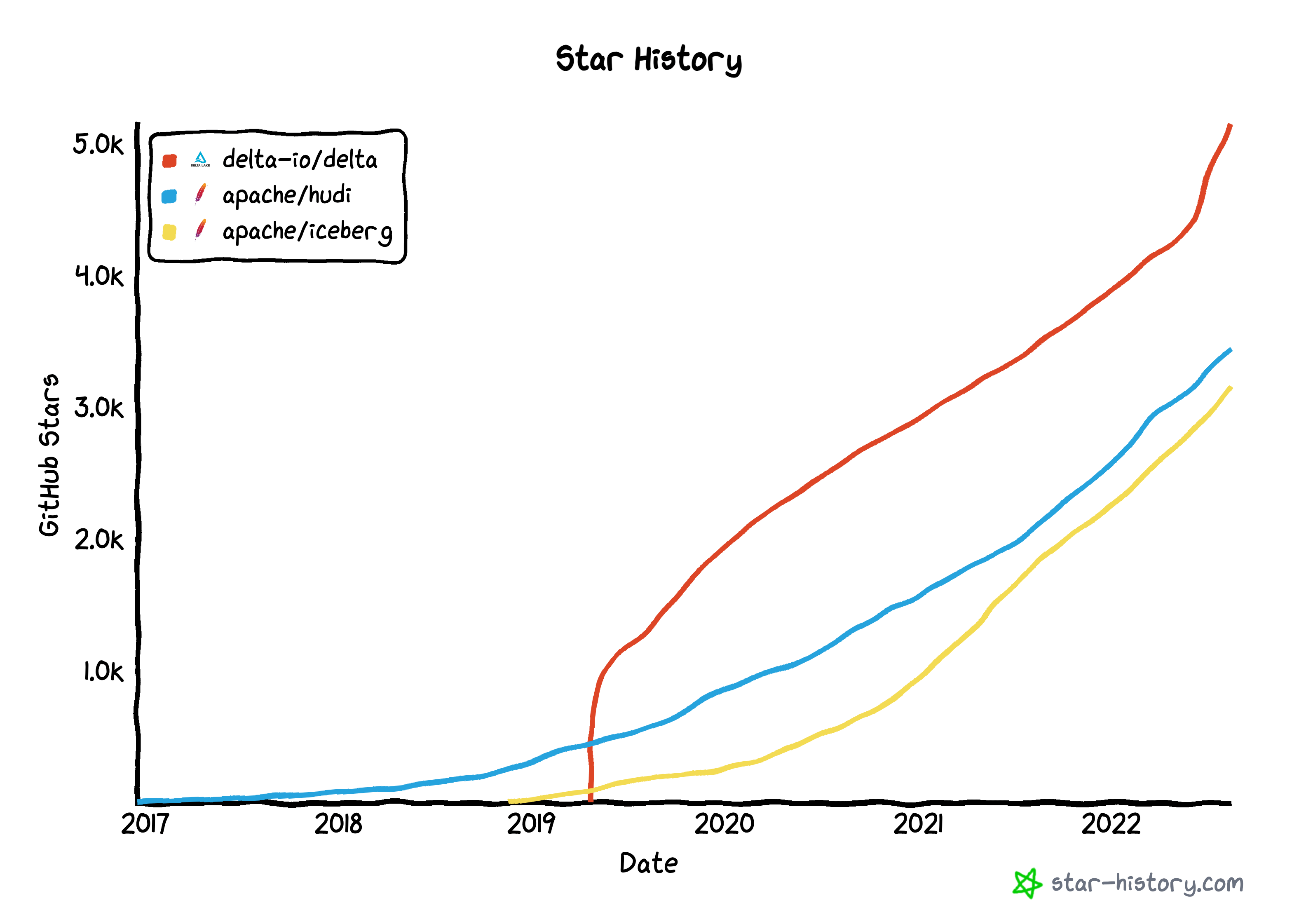
Delta Lake 在 GitHub 上的 star 最多,可能是 Delta Lake 2.0 釋出以來最成熟的。 Apache Iceberg 和 Hudi 的 GitHub 貢獻者比 Delta 多得多,Delta 大約 80% 來自 Databricks。
Hudi 開源時間最長,功能最多。 Iceberg 和 Delta 在最近的公告中勢頭強勁,Hudi 為流式處理提供了最大的便利,Iceberg 支援與資料湖檔案格式(Parquet、Avro、ORC)的大多數整合。
Onehouse.ai 的讀/寫功能的全面概述:

Onehouse.ai 的資料湖表服務比較:

請檢視完整的文章 Apache Hudi vs. Delta Lake vs. Apache Iceberg 以獲得精彩而詳細的功能比較,包括表服務和支援的平臺和生態系統的插圖。另外兩個優秀的分別是 Dremio資料湖表格式比較,和 Hudi、Iceberg 和 Delta Lake:LakeFS 比較的資料湖表格式。
關於 Hudi 版本控制的有趣評論,其中 Hudi 支援不同的源系統,以及它如何基於提交併且可以為單個源系統維護。
資料湖市場趨勢
隨著最近在Snowflake峰會和資料與人工智慧峰會上的公告,開源資料湖表格式市場火爆。 Snowflake 和 Databricks 宣佈了 Apache Iceberg Tables(解說視訊)的重要一步,將開源 Apache Iceberg 的功能與 Apache Parquet 相結合。 Databricks 開源了所有 Delta Lake,包括以前的高階功能,例如 Delta Lake 2.0 的 OPTIMIZE 和 Z-ORDER。
其他市場趨勢正在進一步將資料湖表格式商業化,例如 Onehouse for Apache Hudi 以及 Starburst 和 Dremio 都推出了他們的 Apache Iceberg 產品。 4 月谷歌在今年早些時候宣佈支援 BigLake 和 Iceberg,但它現在也支援 Hudi 和 Delta。
資料湖表格式有很大的發展空間;每個大供應商要麼自己擁有一個,要麼正在尋找完美的開源。到現在為止,你也應該明白為什麼了。對我們有利的是所有這些技術都建立在開源資料湖檔案格式(Apache Parquet、ORC、Avro)之上,這對我們所有人來說都是好訊息。

如何將資料湖變成 Lakehouse
資料湖和Lakehouse的一個重要部分是資料治理。治理主要圍繞資料質量、可觀察性、監控和安全性,沒有它將直接進入資料沼澤。
資料治理對大公司來說是一件大事。在這種情況下 Lakehouse 的實現和功能在這裡有所幫助。這些專注於可靠性和強大的治理,並具有更多整合功能。但許多資料治理也設定了正確的流程和存取許可權。讓跨職能團隊以透明的方式快速處理資料。
總結到目前為止的基本部分,從簡單的 S3 儲存擴充套件到成熟的Lakehouse,可以按照以下步驟操作:
- 選擇合適的資料湖檔案格式
- 將上述內容與要使用的最能支援您的用例的資料湖表格式相結合
- 選擇要儲存實際檔案的雲提供商和儲存層
- 在 Lakehouse 之上和組織內部構建一些資料治理。
- 將資料載入到資料湖或Lakehouse中
替代方案或何時不使用資料湖或Lakehouse:如果需要資料庫。不要使用 JSON 代替 Postgres-DB。當需要在不行動資料的情況下快速查詢多個資料來源時可以利用資料虛擬化技術。
總結
在本文中我們瞭解了資料湖和Lakehouse之間的區別。 2022 年市場在做什麼,如何將資料湖變成資料湖。它的儲存層、資料湖檔案格式和資料湖表格式這三個層次都具有強大的功能,其中開源表格式有 Apache Hudi、Iceberg 和 Delta Lake。
另一個問題是如何在資料湖或Lakehouse中獲取資料。 Airbyte 可以通過整合資料的 190 多個源聯結器為您提供支援。假設想按照以下步驟動手構建資料湖。可以參考教學:關於使用 Dremio 構建開放資料 Lakehouse;使用Delta Lake 表格格式將資料載入到 Databricks Lakehouse 並執行簡單分析。
PS:如果您覺得閱讀本文對您有幫助,請點一下「推薦」按鈕,您的「推薦」,將會是我不竭的動力!
作者:leesf 掌控之中,才會成功;掌控之外,註定失敗。
出處:http://www.cnblogs.com/leesf456/
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線,否則保留追究法律責任的權利。
如果覺得本文對您有幫助,您可以請我喝杯咖啡!

