圖神經網路之預訓練大模型結合:ERNIESage在連結預測任務應用
1.ERNIESage執行範例介紹(1.8x版本)
本專案原連結:https://aistudio.baidu.com/aistudio/projectdetail/5097085?contributionType=1
本專案主要是為了直接提供一個可以執行ERNIESage模型的環境,
https://github.com/PaddlePaddle/PGL/blob/develop/examples/erniesage/README.md
在很多工業應用中,往往出現如下圖所示的一種特殊的圖:Text Graph。顧名思義,圖的節點屬性由文字構成,而邊的構建提供了結構資訊。如搜尋場景下的Text Graph,節點可由搜尋詞、網頁標題、網頁正文來表達,使用者反饋和超鏈資訊則可構成邊關係。
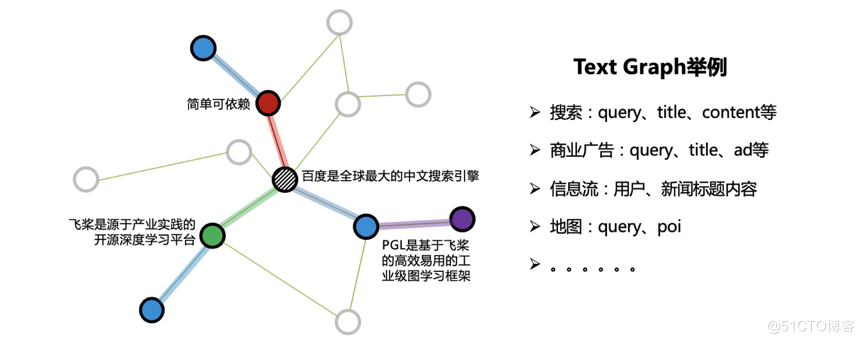
ERNIESage 由PGL團隊提出,是ERNIE SAmple aggreGatE的簡稱,該模型可以同時建模文字語意與圖結構資訊,有效提升 Text Graph 的應用效果。其中 ERNIE 是百度推出的基於知識增強的持續學習語意理解框架。
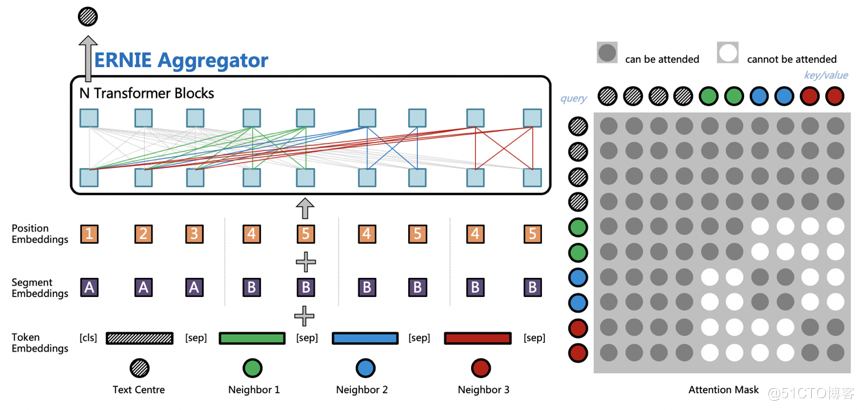
ERNIESage 是 ERNIE 與 GraphSAGE 碰撞的結果,是 ERNIE SAmple aggreGatE 的簡稱,它的結構如下圖所示,主要思想是通過 ERNIE 作為聚合函數(Aggregators),建模自身節點和鄰居節點的語意與結構關係。ERNIESage 對於文字的建模是構建在鄰居聚合的階段,中心節點文字會與所有鄰居節點文字進行拼接;然後通過預訓練的 ERNIE 模型進行訊息匯聚,捕捉中心節點以及鄰居節點之間的相互關係;最後使用 ERNIESage 搭配獨特的鄰居互相看不見的 Attention Mask 和獨立的 Position Embedding 體系,就可以輕鬆構建 TextGraph 中句子之間以及詞之間的關係。
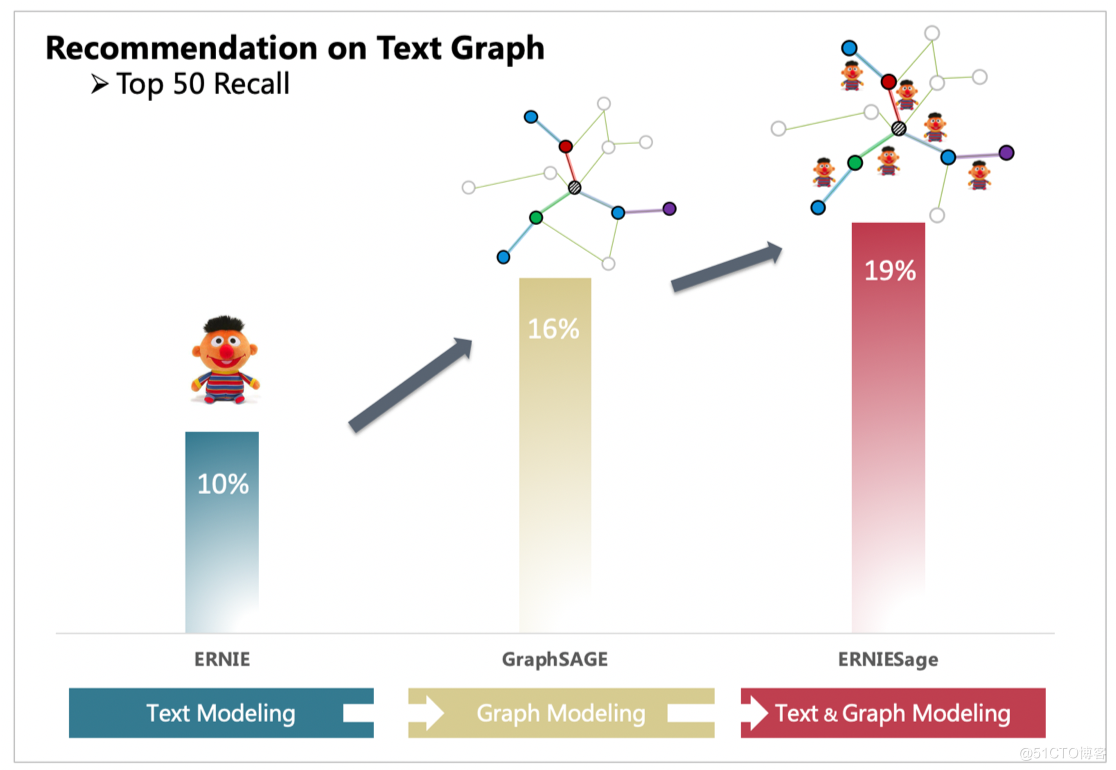
使用ID特徵的GraphSAGE只能夠建模圖的結構資訊,而單獨的ERNIE只能處理文字資訊。通過PGL搭建的圖與文字的橋樑,ERNIESage能夠很簡單的把GraphSAGE以及ERNIE的優點結合一起。以下面TextGraph的場景,ERNIESage的效果能夠比單獨的ERNIE以及GraphSAGE模型都要好。
ERNIESage可以很輕鬆地在PGL中的訊息傳遞正規化中進行實現,目前PGL在github上提供了3個版本的ERNIESage模型:
- ERNIESage v1: ERNIE 作用於text graph節點上;
- ERNIESage v2: ERNIE 作用在text graph的邊上;
- ERNIESage v3: ERNIE 作用於一階鄰居及起邊上;
主要會針對ERNIESageV1和ERNIESageV2版本進行一個介紹。
1.1演演算法實現
可能有同學對於整個專案程式碼檔案都不太瞭解,因此這裡會做一個比較簡單的講解。
核心部分包含:
- 資料集部分
- data.txt - 簡單的輸入檔案,格式為每行query \t answer,可作簡單的執行範例使用。
- 模型檔案和設定部分
- ernie_config.json - ERNIE模型的組態檔。
- vocab.txt - ERNIE模型所使用的詞表。
- ernie_base_ckpt/ - ERNIE模型引數。
- config/ - ERNIESage模型的組態檔,包含了三個版本的組態檔。
- 程式碼部分
- local_run.sh - 入口檔案,通過該入口可完成預處理、訓練、infer三個步驟。
- preprocessing資料夾 - 包含dump_graph.py, tokenization.py。在預處理部分,我們首先需要進行建圖,將輸入的檔案構建成一張圖。由於我們所研究的是Text Graph,因此節點都是文字,我們將文字表示為該節點對應的node feature(節點特徵),處理文字的時候需要進行切字,再對映為對應的token id。
- dataset/ - 該資料夾包含了資料ready的程式碼,以便於我們在訓練的時候將訓練資料以batch的方式讀入。
- models/ - 包含了ERNIESage模型核心程式碼。
- train.py - 模型訓練入口檔案。
- learner.py - 分散式訓練程式碼,通過train.py呼叫。
- infer.py - infer程式碼,用於infer出節點對應的embedding。
- 評價部分
- build_dev.py - 用於將我們的驗證集修改為需要的格式。
- mrr.py - 計算MRR值。
要在這個專案中執行模型其實很簡單,只要執行下方的入口命令就ok啦!但是,需要注意的是,由於ERNIESage模型比較大,所以如果AIStudio中的CPU版本執行模型容易出問題。因此,在執行部署環境時,建議選擇GPU的環境。
另外,如果提示出現了GPU空間不足等問題,我們可以通過調小對應yaml檔案中的batch_size來調整,也可以修改ERNIE模型的組態檔ernie_config.json,將num_hidden_layers設小一些。在這裡,我僅提供了ERNIESageV2版本的gpu執行過程,如果同學們想執行其他版本的模型,可以根據需要修改下方的命令。
執行完畢後,會產生較多的檔案,這裡進行簡單的解釋。
- workdir/ - 這個資料夾主要會儲存和圖相關的資料資訊。
- output/ - 主要的輸出資料夾,包含了以下內容:(1)模型檔案,根據config檔案中的save_per_step可調整儲存模型的頻率,如果設定得比較大則可能訓練過程中不會儲存模型; (2)last資料夾,儲存了停止訓練時的模型引數,在infer階段我們會使用這部分模型引數;(3)part-0檔案,infer之後的輸入檔案中所有節點的Embedding輸出。
為了可以比較清楚地知道Embedding的效果,我們直接通過MRR簡單判斷一下data.txt計算出來的Embedding結果,此處將data.txt同時作為訓練集和驗證集。
1.2 核心模型程式碼講解
首先,我們可以通過檢視models/model_factory.py來判斷在本專案有多少種ERNIESage模型。
from models.base import BaseGNNModel
from models.ernie import ErnieModel
from models.erniesage_v1 import ErnieSageModelV1
from models.erniesage_v2 import ErnieSageModelV2
from models.erniesage_v3 import ErnieSageModelV3
class Model(object):
@classmethod
def factory(cls, config):
name = config.model_type
if name == "BaseGNNModel":
return BaseGNNModel(config)
if name == "ErnieModel":
return ErnieModel(config)
if name == "ErnieSageModelV1":
return ErnieSageModelV1(config)
if name == "ErnieSageModelV2":
return ErnieSageModelV2(config)
if name == "ErnieSageModelV3":
return ErnieSageModelV3(config)
else:
raise ValueError
可以看到一共有ERNIESage模型一共有3個版本,另外我們也提供了基本的GNN模型和ERNIE模型,感興趣的同學可以自行查閱。
接下來,我主要會針對ERNIESageV1和ERNIESageV2這兩個版本的模型進行關鍵部分的講解,主要的不同其實就是訊息傳遞機制(Message Passing)部分的不同。
1.2.1 ERNIESageV1關鍵程式碼
# ERNIESageV1的Message Passing程式碼
# 查詢路徑:erniesage_v1.py(__call__中的self.gnn_layers) -> base.py(BaseNet類中的gnn_layers方法) -> message_passing.py
# erniesage_v1.py
def __call__(self, graph_wrappers):
inputs = self.build_inputs()
feature = self.build_embedding(graph_wrappers, inputs[-1]) # 將節點的文字資訊利用ERNIE模型建模,生成對應的Embedding作為feature
features = self.gnn_layers(graph_wrappers, feature) # GNN模型的主要不同,訊息傳遞機制入口
outputs = [self.take_final_feature(features[-1], i, "final_fc") for i in inputs[:-1]]
src_real_index = L.gather(graph_wrappers[0].node_feat['index'], inputs[0])
outputs.append(src_real_index)
return inputs, outputs
# base.py -> BaseNet
def gnn_layers(self, graph_wrappers, feature):
features = [feature]
initializer = None
fc_lr = self.config.lr / 0.001
for i in range(self.config.num_layers):
if i == self.config.num_layers - 1:
act = None
else:
act = "leaky_relu"
feature = get_layer(
self.config.layer_type, # 對於ERNIESageV1, 其layer_type="graphsage_sum",可以到config資料夾中檢視
graph_wrappers[i],
feature,
self.config.hidden_size,
act,
initializer,
learning_rate=fc_lr,
name="%s_%s" % (self.config.layer_type, i))
features.append(feature)
return features
# message_passing.py
def graphsage_sum(gw, feature, hidden_size, act, initializer, learning_rate, name):
"""doc"""
msg = gw.send(copy_send, nfeat_list=[("h", feature)]) # Send
neigh_feature = gw.recv(msg, sum_recv) # Recv
self_feature = feature
self_feature = fluid.layers.fc(self_feature,
hidden_size,
act=act,
param_attr=fluid.ParamAttr(name=name + "_l.w_0", initializer=initializer,
learning_rate=learning_rate),
bias_attr=name+"_l.b_0"
)
neigh_feature = fluid.layers.fc(neigh_feature,
hidden_size,
act=act,
param_attr=fluid.ParamAttr(name=name + "_r.w_0", initializer=initializer,
learning_rate=learning_rate),
bias_attr=name+"_r.b_0"
)
output = fluid.layers.concat([self_feature, neigh_feature], axis=1)
output = fluid.layers.l2_normalize(output, axis=1)
return output
通過上述程式碼片段可以看到,關鍵的訊息傳遞機制程式碼就是graphsage_sum函數,其中send、recv部分如下。
def copy_send(src_feat, dst_feat, edge_feat):
"""doc"""
return src_feat["h"]
msg = gw.send(copy_send, nfeat_list=[("h", feature)]) # Send
neigh_feature = gw.recv(msg, sum_recv) # Recv
通過程式碼可以看到,ERNIESageV1版本,其主要是針對節點鄰居,直接將當前節點的鄰居節點特徵求和。再看到graphsage_sum函數中,將鄰居節點特徵進行求和後,得到了neigh_feature。隨後,我們將節點本身的特徵self_feature和鄰居聚合特徵neigh_feature通過fc層後,直接concat起來,從而得到了當前gnn layer層的feature輸出。
1.2.2ERNIESageV2關鍵程式碼
ERNIESageV2的訊息傳遞機制程式碼主要在erniesage_v2.py和message_passing.py,相對ERNIESageV1來說,程式碼會相對長了一些。
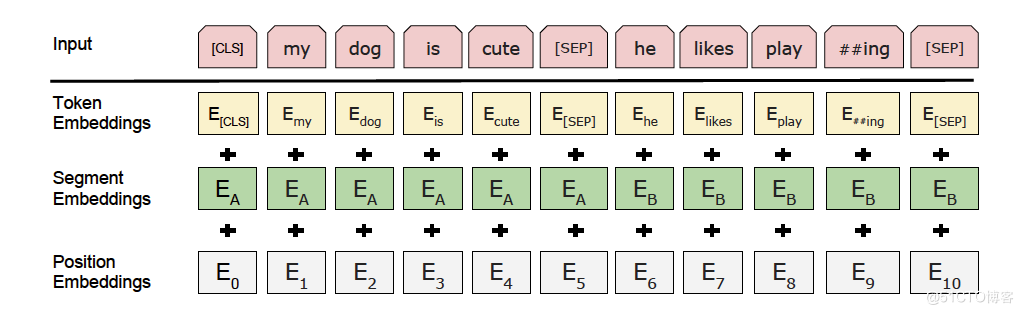
為了使得大家對下面有關ERNIE模型的部分能夠有所瞭解,這裡先貼出ERNIE的主模型框架圖。
具體的程式碼解釋可以直接看註釋。
# ERNIESageV2的Message Passing程式碼
# 下面的函數都在erniesage_v2.py的ERNIESageV2類中
# ERNIESageV2的呼叫函數
def __call__(self, graph_wrappers):
inputs = self.build_inputs()
feature = inputs[-1]
features = self.gnn_layers(graph_wrappers, feature)
outputs = [self.take_final_feature(features[-1], i, "final_fc") for i in inputs[:-1]]
src_real_index = L.gather(graph_wrappers[0].node_feat['index'], inputs[0])
outputs.append(src_real_index)
return inputs, outputs
# 進入self.gnn_layers函數
def gnn_layers(self, graph_wrappers, feature):
features = [feature]
initializer = None
fc_lr = self.config.lr / 0.001
for i in range(self.config.num_layers):
if i == self.config.num_layers - 1:
act = None
else:
act = "leaky_relu"
feature = self.gnn_layer(
graph_wrappers[i],
feature,
self.config.hidden_size,
act,
initializer,
learning_rate=fc_lr,
name="%s_%s" % ("erniesage_v2", i))
features.append(feature)
return features
接下來會進入ERNIESageV2主要的程式碼部分。
可以看到,在ernie_send函數用於將我們的鄰居資訊傳送到當前節點。在ERNIESageV1中,我們在Send階段對鄰居節點通過ERNIE模型得到Embedding後,再直接求和,實際上當前節點和鄰居節點之間的文字資訊在訊息傳遞過程中是沒有直接互動的,直到最後才**concat**起來;而ERNIESageV2中,在Send階段,源節點和目標節點的資訊會直接concat起來,通過ERNIE模型得到一個統一的Embedding,這樣就得到了源節點和目標節點的一個資訊互動過程,這個部分可以檢視下面的ernie_send函數。
gnn_layer函數中包含了三個函數:
1. ernie_send: 將src和dst節點對應文字concat後,過Ernie後得到需要的msg,更加具體的解釋可以看下方程式碼註釋。
2. build_position_ids: 主要是為了建立位置ID,提供給Ernie,從而可以產生position embeddings。
3. erniesage_v2_aggregator: gnn_layer的入口函數,包含了訊息傳遞機制,以及聚合後的訊息feature處理過程。
# 進入self.gnn_layer函數
def gnn_layer(self, gw, feature, hidden_size, act, initializer, learning_rate, name):
def build_position_ids(src_ids, dst_ids): # 此函數用於建立位置ID,可以對應到ERNIE框架圖中的Position Embeddings
# ...
pass
def ernie_send(src_feat, dst_feat, edge_feat):
"""doc"""
# input_ids,可以對應到ERNIE框架圖中的Token Embeddings
cls = L.fill_constant_batch_size_like(src_feat["term_ids"], [-1, 1, 1], "int64", 1)
src_ids = L.concat([cls, src_feat["term_ids"]], 1)
dst_ids = dst_feat["term_ids"]
term_ids = L.concat([src_ids, dst_ids], 1)
# sent_ids,可以對應到ERNIE框架圖中的Segment Embeddings
sent_ids = L.concat([L.zeros_like(src_ids), L.ones_like(dst_ids)], 1)
# position_ids,可以對應到ERNIE框架圖中的Position Embeddings
position_ids = build_position_ids(src_ids, dst_ids)
term_ids.stop_gradient = True
sent_ids.stop_gradient = True
ernie = ErnieModel( # ERNIE模型
term_ids, sent_ids, position_ids,
config=self.config.ernie_config)
feature = ernie.get_pooled_output() # 得到傳送過來的msg,該msg是由src節點和dst節點的文字特徵一起過ERNIE後得到的embedding
return feature
def erniesage_v2_aggregator(gw, feature, hidden_size, act, initializer, learning_rate, name):
feature = L.unsqueeze(feature, [-1])
msg = gw.send(ernie_send, nfeat_list=[("term_ids", feature)]) # Send
neigh_feature = gw.recv(msg, lambda feat: F.layers.sequence_pool(feat, pool_type="sum")) # Recv,直接將傳送來的msg根據dst節點來相加。
# 接下來的部分和ERNIESageV1類似,將self_feature和neigh_feature通過concat、normalize後得到需要的輸出。
term_ids = feature
cls = L.fill_constant_batch_size_like(term_ids, [-1, 1, 1], "int64", 1)
term_ids = L.concat([cls, term_ids], 1)
term_ids.stop_gradient = True
ernie = ErnieModel(
term_ids, L.zeros_like(term_ids),
config=self.config.ernie_config)
self_feature = ernie.get_pooled_output()
self_feature = L.fc(self_feature,
hidden_size,
act=act,
param_attr=F.ParamAttr(name=name + "_l.w_0",
learning_rate=learning_rate),
bias_attr=name+"_l.b_0"
)
neigh_feature = L.fc(neigh_feature,
hidden_size,
act=act,
param_attr=F.ParamAttr(name=name + "_r.w_0",
learning_rate=learning_rate),
bias_attr=name+"_r.b_0"
)
output = L.concat([self_feature, neigh_feature], axis=1)
output = L.l2_normalize(output, axis=1)
return output
return erniesage_v2_aggregator(gw, feature, hidden_size, act, initializer, learning_rate, name)
2.總結
通過以上兩個版本的模型程式碼簡單的講解,我們可以知道他們的不同點,其實主要就是在訊息傳遞機制的部分有所不同。ERNIESageV1版本只作用在text graph的節點上,在傳遞訊息(Send階段)時只考慮了鄰居本身的文字資訊;而ERNIESageV2版本則作用在了邊上,在Send階段同時考慮了當前節點和其鄰居節點的文字資訊,達到更好的互動效果。