【Datawhale】動手學資料分析
動手學資料分析
第一章:資料載入及初步觀察
載入資料
任務一:匯入numpy和pandas
import numpy as np
import pandas as pd
任務二:載入資料
train_data = pd.read_csv("train.csv")
train_data.head(5)
train_data = pd.read_table("train.csv")
train_data.head(5)
這兩個讀取方式的區別在於read_csv讀取的是預設分割符為逗號,而read_csv讀取預設分隔符為製表符。
任務三:每1000行為一個資料模組,逐塊讀取
chunker = pd.read_csv("train.csv", chunksize = 1000)
print(type(chunker))
【思考】什麼是逐塊讀取?為什麼要逐塊讀取呢?
答:比如後續遍歷,像一個資料迭代器一樣方便讀取
【提示】大家可以chunker(資料塊)是什麼型別?用for迴圈列印出來出處具體的樣子是什麼?
答:<class 'pandas.io.parsers.TextFileReader'>,for遍歷每次列印出來1000行
將表頭改成中文
train_data = pd.read_csv("train.csv", names=['乘客ID','是否倖存','倉位等級','姓名','性別','年齡','兄弟姐妹個數','父母子女個數','船票資訊','票價','客艙','登船港口'],index_col='乘客ID', header=0)
train_data.head(5)
【思考】所謂將表頭改為中文其中一個思路是:將英文列名錶頭替換成中文。還有其他的方法嗎?
答:可以讀入後再進行修改
初步觀察
任務一:檢視資料的基本資訊
train_data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 891 entries, 1 to 891
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 是否倖存 891 non-null int64
1 倉位等級 891 non-null int64
2 姓名 891 non-null object
3 性別 891 non-null object
4 年齡 714 non-null float64
5 兄弟姐妹個數 891 non-null int64
6 父母子女個數 891 non-null int64
7 船票資訊 891 non-null object
8 票價 891 non-null float64
9 客艙 204 non-null object
10 登船港口 889 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 83.5+ KB
【提示】有多個函數可以這樣做,你可以做一下總結
- df.info(): # 列印摘要
- df.describe(): # 描述性統計資訊
- df.values: # 資料
- df.to_numpy() # 資料
(推薦) - df.shape: # 形狀 (行數, 列數)
- df.columns: # 列標籤
- df.columns.values: # 列標籤
- df.index: # 行標籤
- df.index.values: # 行標籤
- df.head(n): # 前n行
- df.tail(n): # 尾n行
- pd.options.display.max_columns=n: # 最多顯示n列
- pd.options.display.max_rows=n: # 最多顯示n行
- df.memory_usage(): # 佔用記憶體(位元組B)
任務二:觀察表格前10行和後15行的資料
train_data.head(10)
train_data.tail(15)
任務三:判斷資料是否為空,為空的地方返回true,否則返回false
train_data.isnull().head(10)
【思考】對於一個資料,還可以從哪些方面來觀察?找找答案,這個將對下面的資料分析有很大的幫助
答:從分佈方面
儲存資料
任務一:將你載入並做出改變的資料,在工作目錄下儲存為一個新檔案train_chinese.csv
# 注意:不同的作業系統儲存下來可能會有亂碼。大家可以加入`encoding='GBK' 或者 ’encoding = ’utf-8‘‘`
train_data.to_csv("train_chinese.csv",encoding='GBK')
知道你的資料叫什麼
任務一:pandas中有兩個資料型別DateFrame和Series,通過查詢簡單瞭解他們。然後自己寫一個關於這兩個資料型別的小例子
myself = {"name":"FavoriteStar",'age':18,"gender":"男性"}
example = pd.Series(myself)
example
myself2 = {"愛好":["打籃球",'唱歌','躺平'], "程度":[100, 90, 80]}
example2 = pd.Series(myself2)
example2
愛好 [打籃球, 唱歌, 躺平]
程度 [100, 90, 80]
dtype: object
任務二:根據上節課的方法載入"train.csv"檔案
train_data = pd.read_csv("train_chinese.csv",encoding='GBK')
# 在儲存的時候用了GBK,載入就也要用,否則會亂碼
任務三:檢視DataFrame資料的每列的名稱
train_data.columns
Index(['乘客ID', '是否倖存', '倉位等級', '姓名', '性別', '年齡', '兄弟姐妹個數', '父母子女個數', '船票資訊','票價', '客艙', '登船港口'],dtype='object')
任務四:檢視"Cabin"這列的所有值
train_data['客艙'].unique()
train_data.客艙.unique()
任務五:載入檔案"test_1.csv",然後對比"train.csv",看看有哪些多出的列,然後將多出的列刪除
test_data = pd.read_csv("test_1.csv")
test_data_drop = test_data.drop('a',axis = 1)
test_data.head(5)
【思考】還有其他的刪除多餘的列的方式嗎?
del test_data['a']
df.drop(columns='a')
df.drop(columns=['a'])
任務六: 將['PassengerId','Name','Age','Ticket']這幾個列元素隱藏,只觀察其他幾個列元素
test_data_drop.drop(['PassengerId','Name','Age','Ticket'],axis=1).head(3)
# 這裡隱藏後返回,並不是在原來的資料上進行修改
【思考】對比任務五和任務六,是不是使用了不一樣的方法(函數),如果使用一樣的函數如何完成上面的不同的要求呢?
【思考回答】如果想要完全的刪除你的資料結構,使用inplace=True,因為使用inplace就將原資料覆蓋了,所以這裡沒有用
篩選的邏輯
任務一: 我們以"Age"為篩選條件,顯示年齡在10歲以下的乘客資訊
train_data[train_data['年齡']<10].head(10)
任務二: 以"Age"為條件,將年齡在10歲以上和50歲以下的乘客資訊顯示出來,並將這個資料命名為midage
midage = train_data[(train_data["年齡"] > 10) & (train_data["年齡"]< 50)]
任務三:將midage的資料中第100行的"Pclass"和"Sex"的資料顯示出來
midage = midage.reset_index(drop=True)
# 用這個重置索引的目的是因為可能我們前面用了乘客ID作為索引,就達不到取出第100行的目的,就會取出乘客id為100的
midage.loc[[100],["倉位等級","性別"]]
任務四:使用loc方法將midage的資料中第100,105,108行的"Pclass","Name"和"Sex"的資料顯示出來
midage.loc[[100,105,108],["倉位等級","性別"]]
任務五:使用iloc方法將midage的資料中第100,105,108行的"Pclass","Name"和"Sex"的資料顯示出來
midage.iloc[[100,105,108],[2,3,4]]
【思考】對比iloc和loc的異同
答:iloc傳入的列的索引為真正的索引,而loc傳入的為列的名稱
瞭解你的資料嗎
任務一:利用Pandas對範例資料進行排序,要求升序
obj1 = pd.DataFrame({"a":[800,400,200],"c":[900,700,400],"b":[700,500,100]},index = ['A','C','B'])
bj1.sort_values(by=['a'])
【問題】:大多數時候我們都是想根據列的值來排序,所以將你構建的DataFrame中的資料根據某一列,升序排列
obj1 = pd.DataFrame({"a":[800,400,200],"c":[900,700,400],"b":[700,500,100]},index = ['A','C','B'])
obj1
obj1.sort_values(by='A',axis='columns')
【思考】通過書本你能說出Pandas對DataFrame資料的其他排序方式嗎?
答:rank可能也有用,還有sort_index
【總結】下面將不同的排序方式做一個總結
1.讓行索引升序排序
obj1 = pd.DataFrame({"a":[800,400,200],"c":[900,700,400],"b":[700,500,100]},index = ['A','C','B'])
obj1.sort_index(axis = 0)
2.讓列索引升序排序
obj1 = pd.DataFrame({"a":[800,400,200],"c":[900,700,400],"b":[700,500,100]},index = ['A','C','B'])
obj1.sort_index(axis = 1)
3.讓列索引降序排序
obj1 = pd.DataFrame({"a":[800,400,200],"c":[900,700,400],"b":[700,500,100]},index = ['A','C','B'])
obj1.sort_index(axis = 0, ascending=False)
4.讓任選兩列資料同時降序排序
obj1 = pd.DataFrame({"a":[800,400,200],"c":[900,700,400],"b":[700,500,100]},index = ['A','C','B'])
obj1.sort_values(by=['a','b'],ascending=False)
任務二:對泰坦尼克號資料(trian.csv)按票價和年齡兩列進行綜合排序(降序排列),從這個資料中你可以分析出什麼
train_data.head(5)
train_data.sort_values(by=['票價','年齡'],ascending=False).head(20)
【思考】排序後,如果我們僅僅關注年齡和票價兩列。根據常識我知道發現票價越高的應該客艙越好,所以我們會明顯看出,票價前20的乘客中存活的有14人,這是相當高的一個比例
多做幾個資料的排序
train_data.sort_values(by=['性別'],ascending=False).head(20)
按照年齡排序的話前20人只有5人存活,並且可以看到年齡最高人20人很多人的父母子女個數都為0
任務三:利用Pandas進行算術計算,計算兩個DataFrame資料相加結果
frame_a = pd.DataFrame(np.arange(9.).reshape(3, 3),
columns=['a', 'b', 'c'],
index=['one', 'two', 'three'])
frame_b = pd.DataFrame(np.arange(12.).reshape(4, 3),
columns=['a', 'e', 'c'],
index=['first', 'one', 'two', 'second'])
frame_a + frame_b

任務四:通過泰坦尼克號資料如何計算出在船上最大的家族有多少人
(train_data['兄弟姐妹個數'] + train_data['父母子女個數']).max()
max(train_data['兄弟姐妹個數'] + train_data['父母子女個數'])
答案為10
任務五:學會使用Pandas describe()函數檢視資料基本統計資訊
frame2 = pd.DataFrame([[1.4, np.nan],
[7.1, -4.5],
[np.nan, np.nan],
[0.75, -1.3]
], index=['a', 'b', 'c', 'd'], columns=['one', 'two'])
frame2.describe()

任務六:分別看看泰坦尼克號資料集中 票價、父母子女 這列資料的基本統計資料,你能發現什麼
train_data[['票價','父母子女個數']].describe()
資料淨化及特徵清理
缺失值觀察與處理
任務一:缺失值觀察
(1) 請檢視每個特徵缺失值個數
(2) 請檢視Age, Cabin, Embarked列的資料 以上方式都有多種方式
train_data.isnull().sum()
train_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
train_data[['Age','Cabin','Embarked']].head(10)
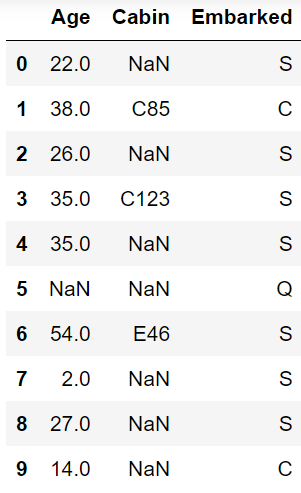
任務二:對缺失值進行處理
(1)處理缺失值一般有幾種思路
(2) 請嘗試對Age列的資料的缺失值進行處理
(3) 請嘗試使用不同的方法直接對整張表的缺失值進行處理
train_data['Age'].dropna() # 丟棄
train_data['Age'].fillna(method='ffill') # 線性插值
train_data['Age'].fillna(value=20) # 全部按照20填充
【思考1】dropna和fillna有哪些引數,分別如何使用呢
- dropna()
- axis:為1或者index就刪除含有缺失值的行,為0或者columns則刪除列
- how:為all就刪除全是缺失值的,any就刪除任何含有缺失值的
- thresh=n:刪除缺失值大於等於n的
- subset:定義在哪些列中查詢缺失值
- inplace:是否原地修改
- fillna()
- inplace
- method:取值為pad、ffill、backfill、bfill、None
- limit:限制填充個數
- axis:修改填充方向
【思考】檢索空缺值用np.nan,None以及.isnull()哪個更好,這是為什麼?如果其中某個方式無法找到缺失值,原因又是為什麼?
數值列讀取資料後,空缺值的資料型別為float64,所以用None一般索引不到,比較的時候最好用np.nan
重複值觀察與處理
任務一:請檢視資料中的重複值
train_data.duplicated()
這個函數就是返回某一行的資料是否已經在之前的行中出現了,如果是就是重複資料就返回true。
任務二:對重複值進行處理
train_data = train_data.drop_duplicates()
train_data.head(5)
任務三:將前面清洗的資料儲存為csv格式
train_data.to_csv('test_clear.csv')
特徵觀察與處理
任務一:對年齡進行分箱(離散化)處理
(1) 分箱操作是什麼?
(2) 將連續變數Age平均分箱成5個年齡段,並分別用類別變數12345表示
(3) 將連續變數Age劃分為[0,5) [5,15) [15,30) [30,50) [50,80)五個年齡段,並分別用類別變數12345表示
(4) 將連續變數Age按10% 30% 50% 70% 90%五個年齡段,並用分類變數12345表示
(5) 將上面的獲得的資料分別進行儲存,儲存為csv格式
【答】分箱操作就相當於將連續資料劃分為幾個離散值,再用離散值來替代連續資料。
train_data['newAge'] = pd.cut(train_data['Age'], 5, labels=[1,2,3,4,5])
train_data.head(5)
train_data.to_csv("test_avg.csv")
bins = [0,5,15,30,50,80]
train_data['newAge'] = pd.cut(train_data['Age'],bins, right=False, labels=[1,2,3,4,5])
train_data.head(5)
train_data.to_csv("test_cut.csv")
train_data['newAge'] = pd.qcut(train_data['Age'],[0,0.1,0.3,0.5,0.7,0.9],labels=[1,2,3,4,5])
train_data.head(5)
train_data.to_csv("test_pr.csv")
任務二:對文字變數進行轉換
(1) 檢視文字變數名及種類
(2) 將文字變數Sex, Cabin ,Embarked用數值變數12345表示
(3) 將文字變數Sex, Cabin, Embarked用one-hot編碼表示
train_data['Embarked'].value_counts()
train_data['Sex'].unique()
train_data['Sex'].value_counts()
train_data['Sex_num'] = train_data['Sex'].replace(['male','female'],[1,2])
train_data.head(5)
train_data['Sex_num'] = train_data['Sex'].map({"male":1,'female':2})
train_data.head(5)
以上兩種適用於性別這樣離散值很少的,那麼如果對於另外兩種資料離散值很多就不行,用以下的方法:
from sklearn.preprocessing import LabelEncoder
for feat in ['Cabin', 'Ticket']:
lbl = LabelEncoder()
label_dict = dict(zip(train_data[feat].unique(), range(train_data[feat].nunique())))
train_data[feat + "_labelEncode"] = train_data[feat].map(label_dict)
train_data[feat + "_labelEncode"] = lbl.fit_transform(train_data[feat].astype(str))
train_data.head(5)
# 轉換為ont-hot編碼
for feat in ['Sex', 'Cabin','Embarked']:
x = pd.get_dummies(train_data[feat], prefix=feat)
# prefix就是讓生成的列的名稱為feat+取值
train_data = pd.concat([train_data,x],axis=1)
train_data.head(5)
任務三:從純文字Name特徵裡提取出Titles的特徵(所謂的Titles就是Mr,Miss,Mrs等)
train_data['Title'] = train_data.Name.str.extract('([A-Za-z]+)\.', expand=False)
train_data.head()
train_data.to_csv('test_fin.csv')
資料的合併
任務一:將data資料夾裡面的所有資料都載入,觀察資料的之間的關係
train_left_up = pd.read_csv("data\\train-left-up.csv")
train_left_up.info()
train_left_down = pd.read_csv("data\\train-left-down.csv")
train_left_down.info()
train_right_up = pd.read_csv("data\\train-right-up.csv")
train_right_down = pd.read_csv("data\\train-right-down.csv")
任務二:使用concat方法:將資料train-left-up.csv和train-right-up.csv橫向合併為一張表,並儲存這張表為result_up
result_up = pd.concat([train_left_up, train_right_up],axis = 1)
result_up.head(5)
任務三:使用concat方法:將train-left-down和train-right-down橫向合併為一張表,並儲存這張表為result_down。然後將上邊的result_up和result_down縱向合併為result
result_down = pd.concat([train_left_down, train_right_down],axis = 1)
result = pd.concat([result_up, result_down], axis=0)
result.head(5)
任務四:使用DataFrame自帶的方法join方法和append:完成任務二和任務三的任務
result_up = train_left_up.join(train_right_up)
result_up.head(5)
result_down = train_left_down.join(train_right_down)
result = result_up.append(result_down)
result.head(4)
任務五:使用Panads的merge方法和DataFrame的append方法:完成任務二和任務三的任務
result_up = pd.merge(train_left_up,train_right_up,left_index=True,right_index=True)
result_up.head(5)
result_down = pd.merge(train_left_down,train_right_down,left_index=True,right_index=True)
result = result_up.append(result_down)
result.head(5)
任務六:完成的資料儲存為result.csv
result.to_csv("data\\result.csv")
換一種角度看資料
任務一:將我們的資料變為Series型別的資料
train_data = pd.read_csv('result.csv')
train_data.head()
unit_result=train_data.stack().head(20)
# stack是轉置,索引不變,然後內容轉置。
unit_result.head()
unit_result.to_csv('unit_result.csv')
資料運用
任務一:通過教材《Python for Data Analysis》P303、Google or anything來學習瞭解GroupBy機制
這部分還是很推薦去看看書進行學習,很有用。
任務二:計算泰坦尼克號男性與女性的平均票價
result['Fare'].groupby(result['Sex']).mean()
Sex
female 44.479818
male 25.523893
Name: Fare, dtype: float64
任務三:統計泰坦尼克號中男女的存活人數
result['Survived'].groupby(result['Sex']).sum()
Sex
female 233
male 109
Name: Survived, dtype: int64
任務四:計算客艙不同等級的存活人數
result['Survived'].groupby(result['Pclass']).sum()
Pclass
1 136
2 87
3 119
Name: Survived, dtype: int64
【思考】從資料分析的角度,上面的統計結果可以得出那些結論
【答】女性平均票價高,生存人數高,1號客艙生存人數多
【思考】從任務二到任務三中,這些運算可以通過agg()函數來同時計算。並且可以使用rename函數修改列名。你可以按照提示寫出這個過程嗎?
result.groupby('Sex').agg({'Fare': 'mean', 'Pclass': 'count'}).rename(columns={'Fare': 'mean_fare', 'Pclass': 'count_pclass'})
任務五:統計在不同等級的票中的不同年齡的船票花費的平均值
result.groupby(['Pclass','Age'])['Fare'].mean()
Pclass Age
1 0.92 151.5500
2.00 151.5500
4.00 81.8583
11.00 120.0000
14.00 120.0000
...
3 61.00 6.2375
63.00 9.5875
65.00 7.7500
70.50 7.7500
74.00 7.7750
Name: Fare, Length: 182, dtype: float64
任務六:將任務二和任務三的資料合併,並儲存到sex_fare_survived.csv
g1 = result['Fare'].groupby(result['Sex']).mean()
g2 = result['Survived'].groupby(result['Sex']).sum()
g_con = pd.concat([g1,g2],axis=1)
g_con.to_csv("data\\sex_fare_survived.csv")
任務七:得出不同年齡的總的存活人數,然後找出存活人數最多的年齡段,最後計算存活人數最高的存活率(存活人數/總人數)
survived_age = result.groupby('Age')['Survived'].sum()
Age
0.42 1
0.67 1
0.75 2
0.83 2
0.92 1
..
70.00 0
70.50 0
71.00 0
74.00 0
80.00 1
Name: Survived, Length: 88, dtype: int64
survived_age_max = survived_age[survived_age.values == survived_age.max()]
Age
24.0 15
Name: Survived, dtype: int64
survived_age_max_num = int(survived_age_max.values)
15
survived_age_max_num_rate =survived_age_max_num/ result['Survived'].sum()
0.043859649122807015
如何讓人一眼看懂你的資料
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
result = pd.read_csv("data\\result.csv")
result.head(5)
任務一:跟著書本第九章,瞭解matplotlib,自己建立一個資料項,對其進行基本視覺化
略
任務二:視覺化展示泰坦尼克號資料集中男女中生存人數分佈情況(用柱狀圖試試)
sex = result.groupby('Sex')['Survived'].sum()
sex.plot.bar()
plt.title('survived_count')

【思考】計算出泰坦尼克號資料集中男女中死亡人數,並視覺化展示?如何和男女生存人數視覺化柱狀圖結合到一起?看到你的資料視覺化,說說你的第一感受(比如:你一眼看出男生存活人數更多,那麼性別可能會影響存活率)。
sex_die = result.groupby('Sex')['Survived'].count() - result.groupby('Sex')['Survived'].sum()
sex_die.plot.bar()

任務三:視覺化展示泰坦尼克號資料集中男女中生存人與死亡人數的比例圖(用柱狀圖試試)
sex_sur_rate = result.groupby(['Sex','Survived'])['Survived'].count().unstack()
sex_sur_rate.plot(kind='bar',stacked=True)

任務四:視覺化展示泰坦尼克號資料集中不同票價的人生存和死亡人數分佈情況。(用折線圖試試)(橫軸是不同票價,縱軸是存活人數)
# 排序後繪折線圖
fig = plt.figure(figsize=(20, 18))
fare_sur = text.groupby(['Fare'])['Survived'].value_counts().sort_values(ascending=False)
fare_sur.plot(grid=True)
plt.legend()
plt.show()
任務五:視覺化展示泰坦尼克號資料集中不同倉位等級的人生存和死亡人員的分佈情況。(用柱狀圖試試)
Pclass_sur = result.groupby(['Pclass','Survived'])['Survived'].value_counts()
import seaborn as sns
sns.countplot(x="Pclass", hue="Survived", data=result)

任務六:視覺化展示泰坦尼克號資料集中不同年齡的人生存與死亡人數分佈情況。(不限表達方式)
facet = sns.FacetGrid(result, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, result['Age'].max()))
facet.add_legend()

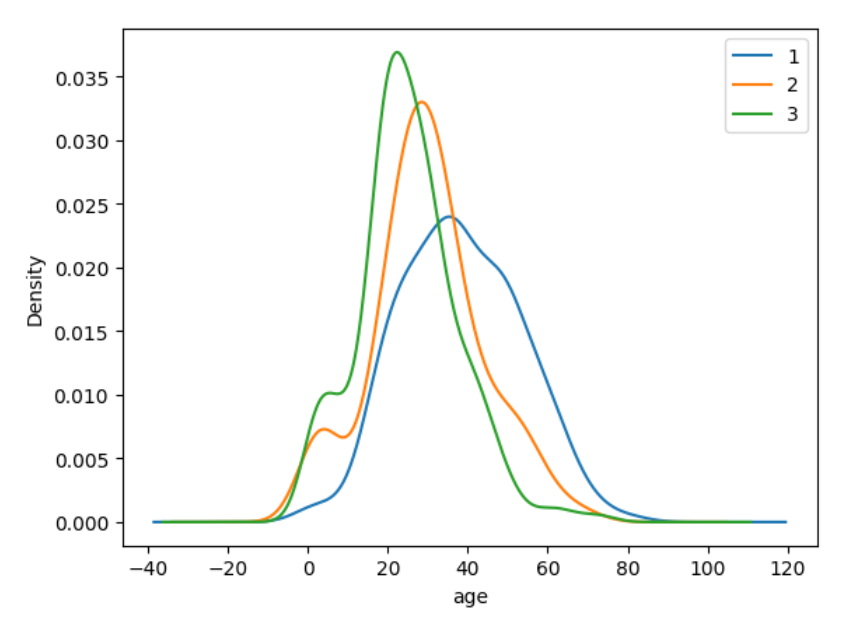
任務七:視覺化展示泰坦尼克號資料集中不同倉位等級的人年齡分佈情況。(用折線圖試試)
result.Age[result.Pclass == 1].plot(kind='kde')
result.Age[result.Pclass == 2].plot(kind='kde')
result.Age[result.Pclass == 3].plot(kind='kde')
plt.xlabel("age")
plt.legend((1,2,3),loc="best") # best就是最不礙眼的位置
第三章 模型搭建和評估--建模
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from IPython.display import Image
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標籤
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
plt.rcParams['figure.figsize'] = (10, 6) # 設定輸出圖片大小
載入資料
clear_data = pd.read_csv("clear_data.csv")
train_data = pd.read_csv("train.csv)
模型搭建
任務一:切割訓練集和測試集
- 將資料集分為自變數和因變數
- 按比例切割訓練集和測試集(一般測試集的比例有30%、25%、20%、15%和10%)
- 使用分層抽樣
- 設定隨機種子以便結果能復現
from sklearn.model_selection import train_test_split
train_label = train_data['Survived'] # 作為標籤,訓練集就是我們的clear_data
x_train, x_test, y_train, y_test = train_test_split(clear_data, train_label, test_size=0.3, random_state=0, stratify = train_label)
x_train.shape # (623, 11)
x_test.shape # (268, 11)
【思考】什麼情況下切割資料集的時候不用進行隨機選取
【答】資料本身就是隨機的
任務二:模型建立
- 建立基於線性模型的分類模型(邏輯迴歸)
- 建立基於樹的分類模型(決策樹、隨機森林)
- 分別使用這些模型進行訓練,分別的到訓練集和測試集的得分
- 檢視模型的引數,並更改引數值,觀察模型變化
from sklearn.linear_model import LogisticRegression
lr_l1 = LogisticRegression(penalty="l1", C=0.5, solver="liblinear")
lr_l1.fit(x_train, y_train)
print("訓練集得分為:",lr_l1.score(x_train,y_train))
print("測試集得分為:",lr_l1.score(x_test,y_test))
訓練集得分為: 0.7897271268057785
測試集得分為: 0.8134328358208955
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
clf = DecisionTreeClassifier(random_state=0) # 設定亂數種子
rfc = RandomForestClassifier(random_state=0)
clf.fit(x_train, y_train)
rfc.fit(x_train, y_train)
clf_score = clf.score(x_test, y_test)
rfc_score = rfc.score(x_test, y_test)
print("決策樹訓練集得分為:",clf.score(x_train,y_train))
print("決策樹測試集得分為:",clf.score(x_test,y_test))
print("隨機森林訓練集得分為:",rfc.score(x_train,y_train))
print("隨機森林測試集得分為:",rfc.score(x_test,y_test))
# 可以看到決策樹已經過擬合
決策樹訓練集得分為: 1.0
決策樹測試集得分為: 0.7611940298507462
隨機森林訓練集得分為: 1.0
隨機森林測試集得分為: 0.8283582089552238
任務三:輸出模型預測結果
- 輸出模型預測分類標籤
- 輸出不同分類標籤的預測概率
一般監督模型在sklearn裡面有個predict能輸出預測標籤,predict_proba則可以輸出標籤概率
pred_result = lr_l1.predict(x_train) # 輸出為array
pred_result[:10]
array([0, 0, 0, 1, 0, 0, 0, 0, 1, 0], dtype=int64)
# 輸出概率
pred_prob = lr_l1.predict_proba(x_train)
pred_prob[:10]
array([[0.89656205, 0.10343795],
[0.85447589, 0.14552411],
[0.91449841, 0.08550159],
[0.13699148, 0.86300852],
[0.9381094 , 0.0618906 ],
[0.81157396, 0.18842604],
[0.91822815, 0.08177185],
[0.72434838, 0.27565162],
[0.47558837, 0.52441163],
[0.86624392, 0.13375608]])
【思考】預測標籤的概率對我們有什麼幫助
【答】輸出概率可以讓我們知道該預測的資訊分數
模型評估
- 模型評估是為了知道模型的泛化能力。
- 交叉驗證(cross-validation)是一種評估泛化效能的統計學方法,它比單次劃分訓練集和測試集的方法更加穩定、全面。
- 在交叉驗證中,資料被多次劃分,並且需要訓練多個模型。
- 最常用的交叉驗證是 k 折交叉驗證(k-fold cross-validation),其中 k 是由使用者指定的數位,通常取 5 或 10。
- 準確率(precision)度量的是被預測為正例的樣本中有多少是真正的正例
- 召回率(recall)度量的是正類樣本中有多少被預測為正類
- f-分數是準確率與召回率的調和平均
任務一:交叉驗證
from sklearn.model_selection import cross_val_score
lr_l1 = LogisticRegression(penalty="l1", C=0.5, solver="liblinear")
lr_l1.fit(x_train, y_train)
scores = cross_val_score(lr_l1, x_train, y_train,cv = 10)
print("score:",scores)
print("score.mean():",scores.mean())
score: [0.74603175 0.76190476 0.85714286 0.75806452 0.85483871 0.79032258
0.72580645 0.83870968 0.70967742 0.80645161]
score.mean(): 0.7848950332821301
clf = DecisionTreeClassifier(random_state=0) # 設定亂數種子
rfc = RandomForestClassifier(random_state=0)
clf.fit(x_train, y_train)
rfc.fit(x_train, y_train)
scores_clf = cross_val_score(clf, x_train, y_train,cv = 10)
scores_rfc = cross_val_score(rfc, x_train, y_train,cv = 10)
print("scores_clf.mean_10:",scores_clf.mean())
print("scores_rfc.mean_10:",scores_rfc.mean())
scores_clf = cross_val_score(clf, x_train, y_train,cv = 5)
scores_rfc = cross_val_score(rfc, x_train, y_train,cv = 5)
print("scores_clf.mean_5:",scores_clf.mean())
print("scores_rfc.mean_5:",scores_rfc.mean())
scores_clf.mean_10: 0.7397849462365592
scores_rfc.mean_10: 0.8186635944700461
scores_clf.mean_5: 0.7496129032258064
scores_rfc.mean_5: 0.8138322580645161
【思考】k折越多的情況下會帶來什麼樣的影響?
【答】擬合效果不好
任務二:混淆矩陣
- 計算二分類問題的混淆矩陣
- 計算精確率、召回率以及f-分數
【思考】什麼是二分類問題的混淆矩陣,理解這個概念,知道它主要是運算到什麼任務中的
【答】這個可以很好的應用到任務為樣本不太均衡的場景
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
pred = lr_l1.predict(x_train)
confusion_matrix(y_train, pred)
array([[328, 56],
[ 75, 164]], dtype=int64)
print(classification_report(y_train, pred))
precision recall f1-score support
0 0.81 0.85 0.83 384
1 0.75 0.69 0.71 239
accuracy 0.79 623
macro avg 0.78 0.77 0.77 623
weighted avg 0.79 0.79 0.79 623
任務三:ROC曲線
【思考】什麼是ROC曲線,OCR曲線的存在是為了解決什麼問題?
【答】主要是用來確定一個模型的 閾值。同時在一定程度上也可以衡量這個模型的好壞
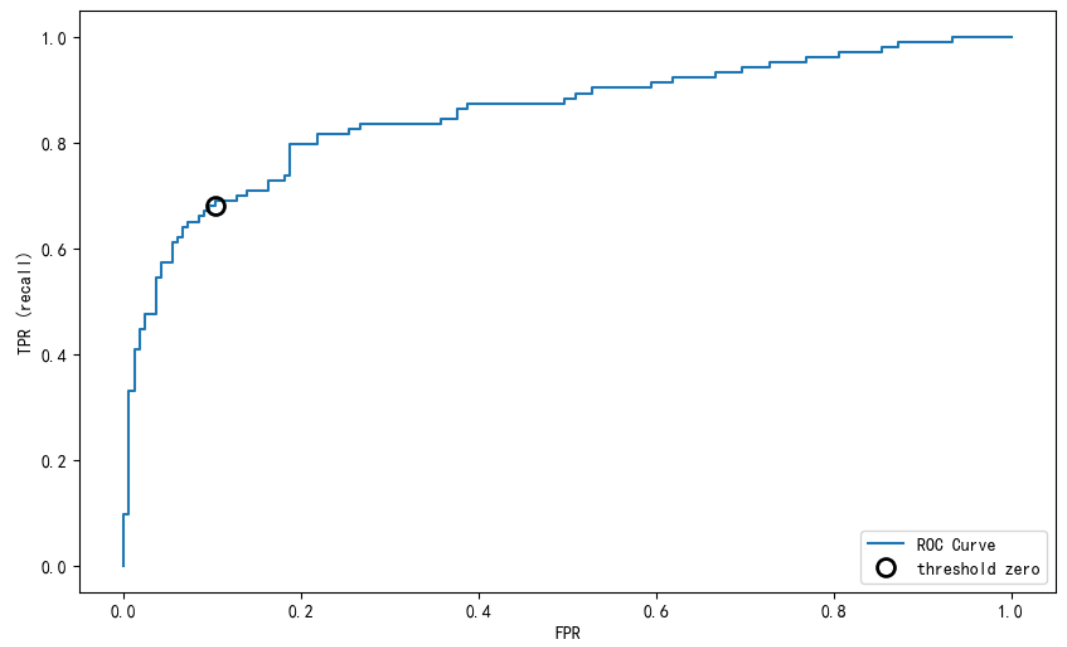
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, lr_l1.decision_function(x_test))
plt.plot(fpr, tpr, label="ROC Curve")
plt.xlabel("FPR")
plt.ylabel("TPR (recall)")# 找到最接近於0的閾值
close_zero = np.argmin(np.abs(thresholds))
plt.plot(fpr[close_zero], tpr[close_zero], 'o', markersize=10, label="threshold zero", fillstyle="none", c='k', mew=2)
plt.legend(loc=4)
【思考】對於多分類問題如何繪製ROC曲線
【答】對每一個類別畫一條ROC曲線最後取平均