PGL圖學習之圖神經網路ERNIESage、UniMP進階模型[系列八]
PGL圖學習之圖神經網路ERNIESage、UniMP進階模型[系列八]
原專案連結:fork一下即可:https://aistudio.baidu.com/aistudio/projectdetail/5096910?contributionType=1
相關專案參考:(其餘圖神經網路相關專案見主頁)
關於圖計算&圖學習的基礎知識概覽:前置知識點學習(PGL)[系列一] https://aistudio.baidu.com/aistudio/projectdetail/4982973?contributionType=1
圖機器學習(GML)&圖神經網路(GNN)原理和程式碼實現(前置學習系列二):https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1
圖學習【參考資料1】詞向量word2vec https://aistudio.baidu.com/aistudio/projectdetail/5009409?contributionType=1
圖學習【參考資料2】-知識補充與node2vec程式碼註解 https://aistudio.baidu.com/aistudio/projectdetail/5012408?contributionType=1
1.Open Graph Benchmark(OGB)
1.1 OGB概述
如何進一步推進圖學習的研究呢?從歷史上看,高質量和大規模的資料集在推進研究中發揮了重要的作用,例如計算機視覺領域的IMAGENET、MS COCO,自然語言處理領域的GLUE BENCHMARK、SQUAD,語言處理領域的LIBRISPEECH、CHIME等。但是,當前在圖學習研究中常用的資料集和評估程式可能會對未來的發展產生負面影響。
當前基準資料集存在的問題:
與實際應用中的圖相比,大多數常用資料集都非常小。例如廣泛使用的Cora、Citeseer、Pubmed資料集,在節點分類任務中只用2700至20000個節點。由於在這些小型資料集上廣泛開發了模型,因此大多數模型都無法擴充套件到較大的圖;其次,較小的資料集很難去嚴格地評估需要大量資料的模型,例如圖神經網路(GNNs)。
沒有統一且通常遵循的實驗協定。不同的研究採用自己的資料集劃分、評估指標和交叉驗證協定,因此比較各種研究報告的成績具有挑戰性。另外,許多研究使用隨機分割來生成train /test sets,這對於真實世界的應用是不現實的或無用的,並且通常導致過於樂觀的效能結果。
因此,迫切需要一套完整的現實世界基準測試套件,該套件將來自不同領域的各種大小的資料集組合在一起。資料拆分以及評估指標很重要,因此可以以一致且可重複的方式衡量進度。最後,基準測試還需要提供不同型別的任務,例如節點分類,連結預測和圖分類。OGB就這樣應運而生。
開放圖譜基準 (OGB) 是圖機器學習的基準資料集、資料載入器和評估器的集合。資料集涵蓋各種圖形機器學習任務和實際應用。OGB旨在提供涵蓋重要圖機器學習任務、多樣化資料集規模和豐富領域的圖資料集。
論文連結:https://arxiv.org/abs/2005.00687
OGB官網:https://ogb.stanford.edu/
GitHub地址:https://github.com/snap-stanford/ogb
-
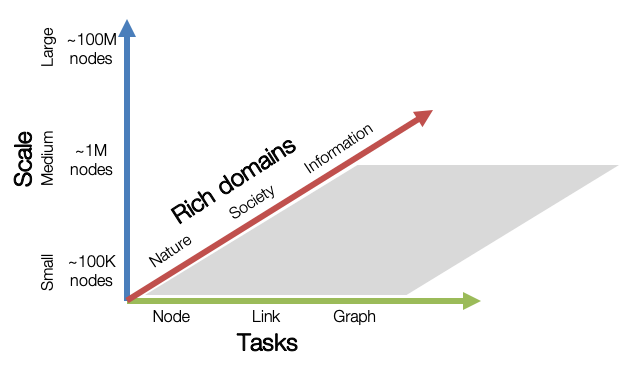
Graph ML Tasks: 涵蓋了三個基本的圖機器學習任務:節點屬性預測,連結屬性預測,圖屬性預測。
-
Diverse scale: 小型圖形資料集可以在單個 GPU 中處理,而中型和大型圖形可能需要多個 GPU 或巧妙的取樣/分割區技術。分為small、medium、large三個規模,具體為small:超過10萬個節點和超過100萬條邊;medium:超過100萬個節點或超過1000萬條邊;large:大約1億個節點或10億條邊。
-
Rich domains: 圖資料集來自從科學領域到社會/資訊網路的不同領域,還包括異構知識圖譜。nature:包含生物網路和分子圖;society:包含學術圖和電子商務網路;information:包含知識圖譜等。
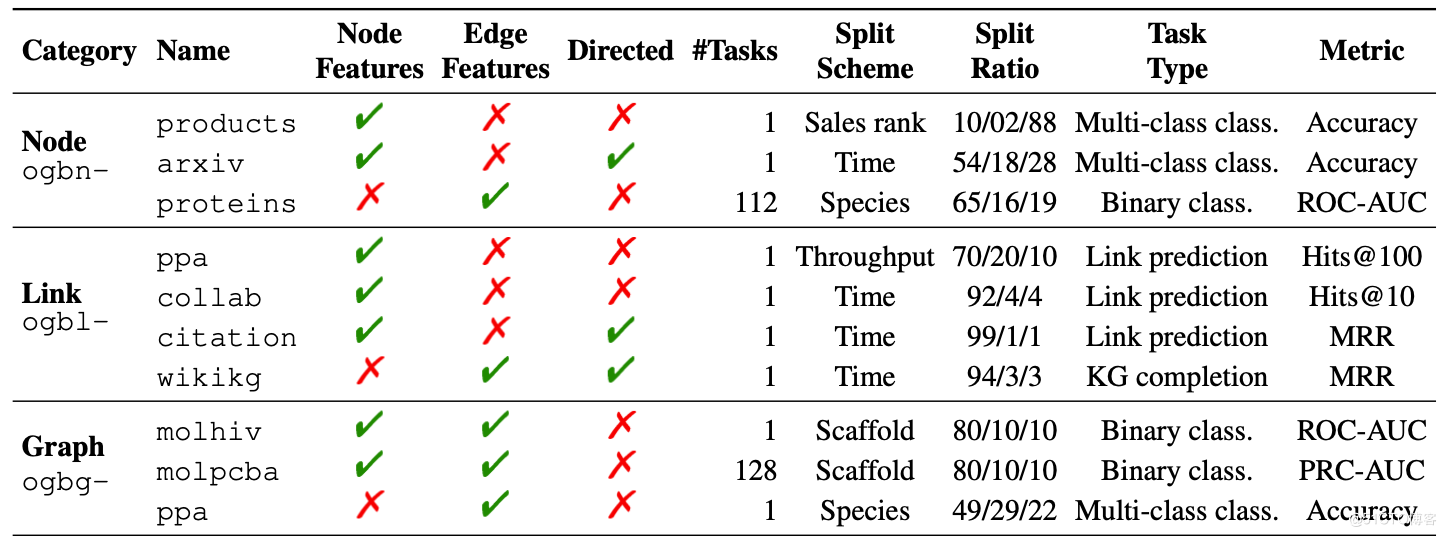
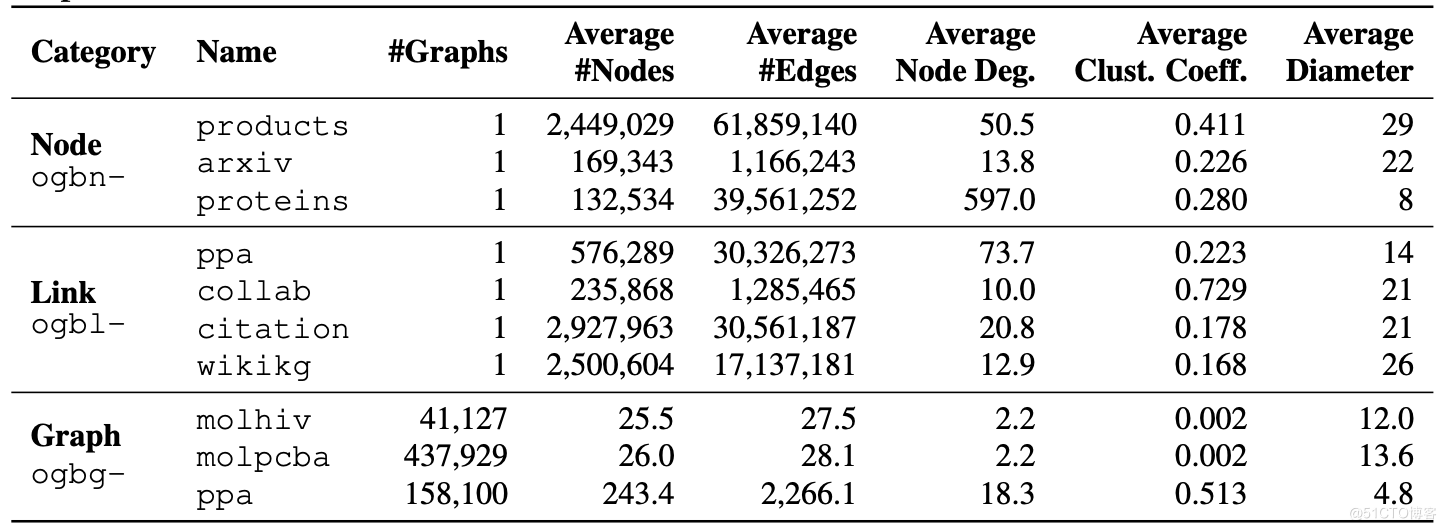
看一下 OGB 現在包含的資料集和資料集的統計明細:
1.2 OGB資料集簡介
1.2.1 OGB節點屬性預測
ogbn-products:亞馬遜產品共同購買網路。
- 節點代表在Amazon銷售的產品,兩個產品之間的邊表示產品是一起購買的。節點特徵是通過從產品描述中提取詞袋特徵來生成的,然後進行主成分分析將維度減小到100。
- 預測任務:在多類別分類設定中預測產品的類別,其中有47個頂級類別用於目標標籤。
- 資料集劃分:使用銷售排名(受歡迎程度)將節點劃分為訓練/驗證/測試集,根據產品的銷售排名對產品進行排序,並使用前10%作為訓練集,然後使用前2%作為驗證集,其餘用於測試集。
ogbn-proteins:蛋白質關聯網路
- 節點代表蛋白質,邊表示蛋白質之間不同型別的有生物學意義的聯絡。所有的邊都具有8維特徵,其中每個維度表示單個關聯型別的強度,值在0到1之間。這些蛋白質來自8個物種。
- 預測任務:在一個多標籤二元分類系統中預測蛋白質功能的存在,該系統中總共有112種標籤需要預測。通過112個任務的ROC-AUC分數的平均值來衡量效能。
- 資料集分割:根據蛋白質來源的物種,將蛋白質節點分成訓練/驗證/測試集。
實驗中為了簡單起見,使用傳入邊的平均邊緣特徵作為節點特徵。
ogbn-arxiv:論文參照網路
- 每個節點都是一篇Arxiv論文,每條有向邊表示一篇論文參照了另一篇論文。每篇論文都有一個128維的特徵向量,它是通過對標題和摘要中單詞的嵌入進行平均得到的。
- 預測任務:預測Arxiv論文的主要類別,這是一個40類的分類問題。
- 資料集分割:考慮一個基於論文發表日期的現實資料分割。建議將2017年及以前發表的論文作為訓練集,將2018年發表的論文作為驗證集,將2019年以後發表的論文作為測試集。
實驗中為了簡單起見,將有向圖轉換為無向圖。從下面的結果可以看出,探索如何考慮邊緣方向資訊以及節點時間資訊(例如論文發表的年份)以提高預測效能將是富有成效的。
ogbn-papers100M:論文參照網路
- MAG(Microsoft Academic Graph)索引的1.11億篇論文的有向引文圖。此資料集的數量級比任何現有的節點分類資料集大。
- 預測任務:預測在Arxiv中發表的論文的子集的主題領域。有172個Arxiv主題領域,這使預測任務成為172類分類問題。
- 資料集分割:考慮一個基於論文發表日期的現實資料分割。建議將2017年及以前發表的論文作為訓練集,將2018年發表的論文作為驗證集,將2019年以後發表的論文作為測試集。
實驗中為了簡單起見,將有向圖轉換為無向圖。從下面的結果可以看出,SGC嚴重擬合不足,表明使用更具表現力的GNNs可能會同時改善訓練和測試準確性。
ogbn-mag:異構微軟學術圖(MAG)
- 由Microsoft Academic Graph (MAG)的一個子集組成的異構網路。它包含四種型別的實體(論文、作者、機構和研究領域),以及連線兩種型別實體的四種有向關係。每一篇論文具有128維的特徵。
- 預測任務:根據給定的內容、參考文獻、作者和作者的隸屬關係來預測每篇論文的會議地點。ogbn-mag中共有349個不同的會議地點,這使得該任務成為349類分類問題。
- 資料集分割:遵循相同的基於時間的策略。用2018年之前發表的所有論文的訓練模型,並用2018年和2019年以後發表的論文分別驗證和測試模型。
對於GCN和GRAPHSAGE,實驗中在同構子圖上應用模型。從下面的結果可以看出嗎,利用圖的異構性質對於在這個資料集上取得良好的效能是至關重要的。
1.2.2 OGB連結屬性預測
ogbl-ppa:蛋白質關聯網路
- 節點表示來自58個不同物種的蛋白質,邊表示蛋白質之間的生物學上有意義的關聯。每個節點都包含一個58維的one-hot特徵向量,該向量指示相應蛋白質所來自的物種。
- 預測任務:在給定訓練邊的情況下預測新的關聯邊。評估基於模型對positive測試邊勝過negative測試邊的等級。具體來說,針對3,000,000個隨機取樣的negative邊對驗證/測試集中的每個positive邊進行排名,並計算排名在第K位或更高(Hits@K)的positive邊的比率。發現K=100是評估模型效能的一個很好的閾值。
- 資料集分割:根據邊的生物學吞吐量分為訓練/驗證/測試邊。
實驗結果如下所示,GNN訓練效果不佳表明,僅靠GNN無法捕獲的位置資訊對於適應訓練邊並獲得有意義的節點嵌入可能至關重要。
ogbl-collab:作者合作網路
- 每個節點代表一個作者,邊表示作者之間的合作。 所有節點都具有128維特徵,這些特徵是通過平均作者發表的論文的詞嵌入獲得的。所有邊都與兩種型別的元資訊相關聯:年份和邊緣權重,代表當年發表的合作論文的數量。
- 預測任務:根據給定的過去合作來預測未來的作者合作關係。評估指標類似於ogbl-ppa,希望該模型將真實共同作業的等級高於虛假共同作業。 具體來說,在100,000個隨機取樣的negative共同作業中對每個真實共同作業進行排名,並計算排名在K位或更高(Hits@K)的positive邊的比率。在初步實驗中,發現K=50是一個很好的閾值。
- 資料集分割:根據時間拆分資料,以便在共同作業推薦中模擬實際應用。具體來說,將直到2017年的合作作為訓練邊,將2018年的合作作為驗證邊,並將2019年的合作作為測試邊。
實驗結果如下圖,值得注意的是,MATRIXFACTORIZATION可以達到近乎完美的訓練結果,但是即使應用大量的正則化處理,也無法將良好的結果轉移到驗證和測試拆分中。總體而言,探索將位置資訊注入GNN並開發更好的正則化方法是富有成果的。
ogbl-ddi:藥品互動網路
- 節點代表FDA批准的或實驗藥物,邊代表藥物之間的相互作用,並且可以解釋為一種現象,其中將兩種藥物合用的聯合效果與預期的藥物彼此獨立起作用的效果有很大不同。
- 預測任務:在已知藥物相互作用的基礎上預測藥物相互作用。評估指標與ogbl-collab相似,希望該模型將真實藥物相互作用的排名高於非相互作用藥物對。具體來說,在大約100,000個隨機取樣的negative藥物相互作用中對每個真實藥物相互作用進行排名,並計算在K位或更高(Hits@K)處排名的positive邊緣的比率。在初步實驗中,發現K = 20是一個很好的閾值。
- 資料集分割:開發了一種蛋白質-靶標拆分,這意味著根據那些藥物在體內靶向的蛋白質來拆分藥物邊緣。
實驗結果如下所示,有趣的是,GNN模型和MATRIXFACTORIZATION方法都比NODE2 VEC獲得了明顯更高的訓練結果。但是,只有GNN模型才能在某種程度上將這種效能傳遞給測試集,這表明關係資訊對於使模型推廣到看不見的互動作用至關重要。
ogbl-citation:論文參照網路
- 從MAG提取的論文子集之間的引文網路,與ogbn-arxiv相似,每個節點都是具有128維WORD2VEC特徵的論文,該論文總結了其標題和摘要,並且每個有向邊都表示一篇論文參照了另一篇論文。所有節點還帶有表示相應論文發表年份的元資訊。
- 預測任務:根據給定的現有參照來預測缺少的參照。具體來說,對於每篇原始論文,將隨機刪除其兩個參考文獻,並且希望模型將缺失的兩個參考文獻的排名高於1,000個negative參考候選集。negetive參照是從源論文未參照的所有先前論文中隨機抽取的。評估指標是Mean Reciprocal Rank(MRR),其中針對每份原始論文計算真實參考文獻在negative候選者中的互惠等級,然後取所有原始論文的平均值。
- 資料集分割:為了模擬引文推薦中的實際應用,會根據時間劃分邊緣(例如,使用者正在撰寫一篇新論文,並且已經參照了幾篇現有論文,但希望被推薦為其他參考)。為此,使用最新論文(2019年發表)作為要推薦參考文獻的原始論文。對於每篇原始論文,從參考文獻中刪除兩篇——所得到的兩個下降邊(從原始論文指向刪除的論文)指向分別用於驗證和測試。 其餘所有邊緣均用於訓練。
從下面的實驗結果可以看出,mini-batch技術的效能要比full-batch差,這與節點分類資料集(例如ogbn-products和ogbn-mag)相反,基於小批次的模型有更強的泛化效能。與用於節點預測的技術不同,這種限制為將小批次處理技術應用於連結預測提出了一個獨特的挑戰。
ogbl-wikikg:Wikidata知識圖
- 從Wikidata知識庫中提取的知識圖(KG)。它包含一組三元組邊緣(頭部、關係、尾部)其捕獲了世界各實體之間的不同型別的關係。檢索了Wikidata中的所有關係語句,並過濾掉稀有實體。該KG中包含了2,500,604個實體和535個關係型別。
- 預測任務:在給定訓練邊緣的情況下預測新的三元組邊緣。評估指標遵循KG中廣泛使用的標準過濾指標。具體來說,通過用隨機取樣的1,000個negative實體(頭部為500個,尾部為500個)替換其頭部或尾部來破壞每個測試三元組邊緣,同時確保生成的三元組不會出現在KG中。目標是將真實的頭部(或尾部)實體排名高於negative實體,該排名由平均互惠排名(MRR)衡量。
- 資料集分割:根據時間劃分三元組,模擬一個現實的KG完成方案,該方案旨在填充在某個時間戳上不存在的缺失三元組。具體來說,在三個不同的時間戳17(2015年5月,8月和11月)下載了Wikidata,並構建了三個KG,其中僅保留最早出現在5月KG中的實體和關係型別。使用五月 KG中的三元組進行訓練,並使用八月和11月KG中的三元組分別進行驗證和測試。
實驗結果如下表所示,從表的上半部分可以看到,當使用有限的嵌入維數時,COMPLEX在四個基線中表現最佳。從表的下半部分可以看出,隨著維數的增加,所有四個模型都能夠在訓練、驗證和測試集上實現更高的MRR。這表明使用足夠大的嵌入維數在此資料集中實現良好效能的重要性。
ogbl-biokg:生物醫學知識圖
- 是一個知識圖(KG),使用了大量生物醫學資料庫中的資料建立了該圖。它包含5種型別的實體:疾病(10,687個節點)、蛋白質(17,499個節點)、藥物(10,533個節點)、副作用(9,969個節點)和蛋白質功能(45,085個節點)。有51種型別的有向關係將兩種型別的實體聯絡起來,包括39種藥物相互作用,8種蛋白質相互作用等 。所有關係都被建模為有向邊,其中連線相同實體型別(例如蛋白質-蛋白質,藥物-藥物,功能-功能)的關係始終是對稱的,即邊是雙向的。KG中的三元組來自具有各種置信度級別的來源,包括實驗讀數,人工策劃的註釋以及自動提取的後設資料。
- 預測任務:在給定訓練三元組的情況下預測新的三元組。評估協定ogbl-wikikg完全相同,這裡只考慮針對相同型別的實體進行排名。例如,當破壞蛋白質型別的頭部實體時,僅考慮negative蛋白質實體。
- 資料集分割:對於此資料集,採用隨機分割。雖然根據時間劃分三元組是一種有吸引力的選擇,但注意到,要獲得有關何時進行三元組的個別實驗和觀察的準確資訊非常困難。努力在OGB的未來版本中提供其他資料集拆分。
實驗結果如下圖所示,在這四個模型中,COMPLEX達到了最佳的測試MRR,而TRANSE與其他模型相比,效能明顯差。TRANSE的較差效能可以通過以下事實來解釋:TRANSE無法為該資料集中普遍存在的對稱關係建模,例如,蛋白質-蛋白質和藥物-藥物關係都是對稱的。總體而言,進一步提高模型效能具有重大的實踐意義。 一個有前途的方向是為異構知識圖開發一種更專門的方法,該方法中存在多個節點型別,並且整個圖遵循預定義的架構。
1.2.3OGB圖屬性預測
ogbg-mol*:分子圖
- ogbg-molhiv和ogbg-molpcba是兩個大小不同的分子屬性預測資料集:ogbg-molhiv (small)和ogbg-molpcba(medium)。所有分子均使用RDKIT進行預處理。每個圖表示一個分子,其中節點表示原子,而邊表示化學鍵。輸入節點特徵為9維,包含原子序數和手性,以及其他附加原子特徵,例如形式電荷和原子是否在環中。輸入邊特徵是3維的,包含鍵型別,鍵立體化學以及指示鍵是否共軛的附加鍵特徵。
- 預測任務:儘可能準確地預測目標分子特性,其中分子特性被標記為二元標記,例如分子是否抑制HIV病毒複製。對於ogbg-molhiv,使用ROC-AUC進行評估。 對於ogbg-molpcba,由於類平衡嚴重偏斜(僅1.4%的資料為positive),並且資料集包含多個分類任務,因此將任務平均後的精確召回曲線(PRC)-AUC作為評估指標。
- 資料集分割:採用支架分割程式,該程式根據分子的二維結構框架風格分子。支架分割試圖將結構上不同的分子分為不同的子集,這在預期的實驗環境中提供了對模型效能的更現實的估計。總體而言,OGB與它們的資料載入器一起提供了有意義的資料拆分和改進的分子功能,從而使對MOLECULENET資料集的評估和比較更加容易和標準化。
實驗結果如下圖所示,可以看到具有附加功能的GIN和虛擬節點在兩個資料集中提供了最佳效能。
ogbg-ppa:蛋白質關聯網路
- 從1,581個不同物種的蛋白質關聯網路中提取的一組無向蛋白質關聯鄰域,涵蓋了37個廣泛的生物分類群。從每種物種中隨機選擇了100種蛋白質,並以每個選定的蛋白質為中心構建了2-hop蛋白質關聯鄰域。然後,從每個鄰域中刪除中心節點,並對鄰域進行二次取樣,以確保最終的蛋白質關聯圖足夠小(少於300個節點)。每個蛋白質關聯圖中的節點表示蛋白質,邊表示蛋白質之間的生物學上有意義的關聯。邊與7維特徵相關,其中每個元素取0到1之間的值,並代表特定型別的蛋白質關聯的強度。
- 預測任務:給定一個蛋白質關聯鄰域圖,該任務是一個37-way多分類,以預測該圖源自哪個分類組。
- 資料集分割:與ogbn-proteins類似,採用物種分割方法,其中驗證和測試集中的鄰域圖是從在訓練過程中未發現但屬於37個分類組之一的物種蛋白質關聯網路中提取的。
實驗結果如下表,類似於ogbg-mol *資料集,帶有VIRTUAL NODE的GIN提供了最佳效能。儘管如此,泛化差距仍然很大(將近30個百分點)。
ogbg-code:原始碼的抽象語法樹
- 從大約45萬個Python方法定義中獲得的抽象語法樹(AST)的集合。方法是從GITHUB上最受歡迎的專案的總共13,587個不同的儲存庫中提取的。Python方法集合來自GITHUB Code Search-Net,它是用於基於機器學習的程式碼檢索的資料集和基準的集合。
- 預測任務:給定AST表示的Python方法主體及其節點特徵,任務是預測組成方法名稱的子標記——節點型別(來自97種型別的池)、節點屬性(例如變數名,詞彙量為10002),AST中的深度、預遍歷索引
- 資料集分割:採用專案分割,其中訓練集的AST是從GITHUB專案中獲得的,這些專案未出現在驗證和測試集中。這種劃分尊重實際情況,即在大量原始碼上訓練模型,然後將其用於在單獨的程式碼庫上預測方法名稱。
1.3 OGB Package
OGB Package包旨在通過自動化資料載入和評估部分,使研究人員易於存取OGB管道。OGB與Pytorch及其關聯的圖形庫完全相容:PyG和DGL。OGB還提供了與庫無關的資料集物件,可用於任何其他Python深度學習框架(如Tensorflow和Mxnet)。下面,將解釋資料載入和評估。為簡單起見,專注於使用PyG進行圖屬性預測的任務。有關其他任務詳見官網。
OGB資料載入器:OGB Package使獲取與PyG完全相容的資料集物件變得容易僅用一行程式碼即可完成操作,終端使用者只需指定資料集的名稱即可。然後,OGB Package將下載、處理、儲存並返回所請求的資料集物件。此外,可以從資料集物件中輕鬆獲得標準化的資料集分割。
OGB評估器:OGB還可以通過ogb.*.Evaluator類實現標準化和可靠的評估。如下面的代買所示,終端使用者首先指定他們要評估其模型的資料集,然後使用者可以瞭解需要傳遞給Evaluator物件的輸入格式。輸入格式取決於資料集,例如,對於ogbg-molpcba資料集,Evaluator物件需要輸入一個字典,其中包含y_true(儲存真實二進位制標籤的矩陣)和y_pred(儲存模型輸出的分數的矩陣)。終端使用者通過指定的詞典作為輸入後,評估程式物件將返回適合手頭資料集的模型效能,例如ogbg-molpcba的PRC-AUC。
2.ERNIESage (鄰居聚合)
2.1模型概述
ERNIE-Sage 是 ERNIE SAmple aggreGatE 的簡稱,該模型可以同時建模文字語意與圖結構資訊,有效提升 Text Graph 的應用效果。
論文連結:https://aclanthology.org/2020.textgraphs-1.11/
論文介紹了百度 PGL 團隊設計的系統,該系統在 TextGraphs 2020 共用任務中獲得第一名。 該任務的重點是為基礎科學問題提供解釋。 給定一個問題及其相應的正確答案,被要求從大型知識庫中選擇可以解釋為什麼該問題和回答 (QA) 的答案是正確的事實。 為了解決這個問題,PGL團隊使用預訓練的語言模型來回憶每個問題的前 K 個相關解釋。 然後,他們採用基於預訓練語言模型的重新排序方法對候選解釋進行排序。 為了進一步提高排名,還開發了一種由強大的預訓練變壓器和 GNN 組成的架構,以解決多跳推理問題。
2.2 原理介紹
在很多工業應用中,往往出現如下圖所示的一種特殊的圖:Text Graph。顧名思義,圖的節點屬性由文字構成,而邊的構建提供了結構資訊。如搜尋場景下的Text Graph,節點可由搜尋詞、網頁標題、網頁正文來表達,使用者反饋和超鏈資訊則可構成邊關係。
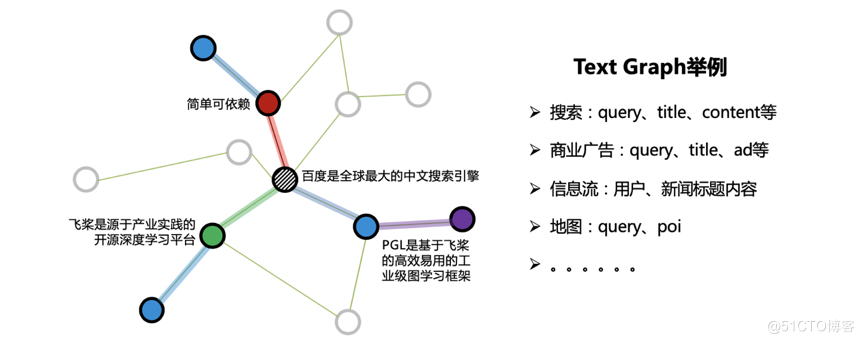
ERNIE-Sage 是 ERNIE 與 GraphSAGE 碰撞的結果,是 ERNIE SAmple aggreGatE 的簡稱,它的結構如下圖所示,主要思想是通過 ERNIE 作為聚合函數(Aggregators),建模自身節點和鄰居節點的語意與結構關係。ERNIE-Sage 對於文字的建模是構建在鄰居聚合的階段,中心節點文字會與所有鄰居節點文字進行拼接;然後通過預訓練的 ERNIE 模型進行訊息匯聚,捕捉中心節點以及鄰居節點之間的相互關係;最後使用 ERNIESage 搭配獨特的鄰居互相看不見的 Attention Mask 和獨立的 Position Embedding 體系,就可以輕鬆構建 TextGraph 中句子之間以及詞之間的關係。
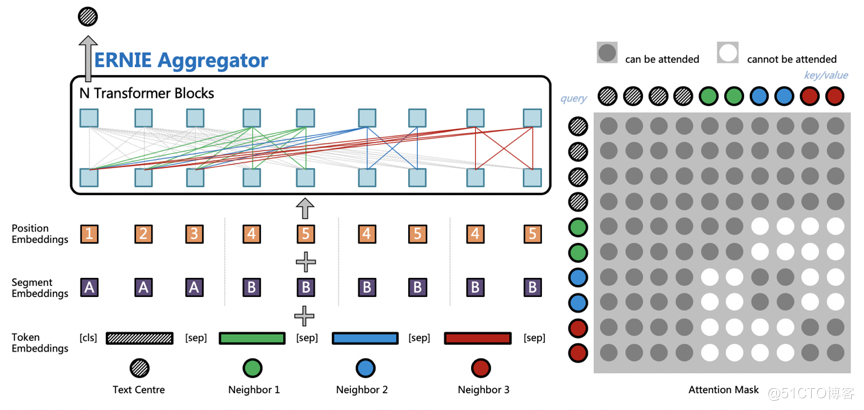
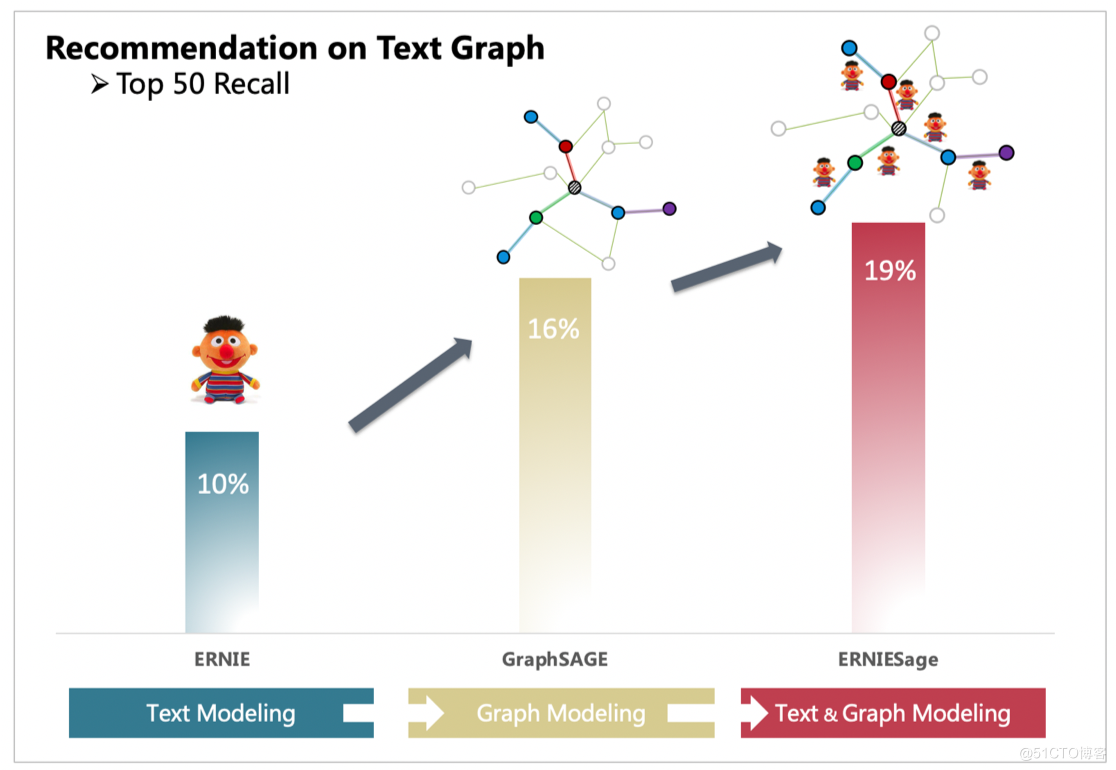
使用 ID 特徵的 GraphSAGE 只能夠建模圖的結構資訊,而單獨的ERNIE只能處理文字資訊。通過 PGL 搭建的圖與文字的橋樑,ERNIESage能夠很簡單的把 GraphSAGE 以及 ERNIE 的優點結合一起。以下面 TextGraph 的場景,ERNIESage 的效果能夠比單獨的 ERNIE 以及 GraphSAGE 模型都要好。
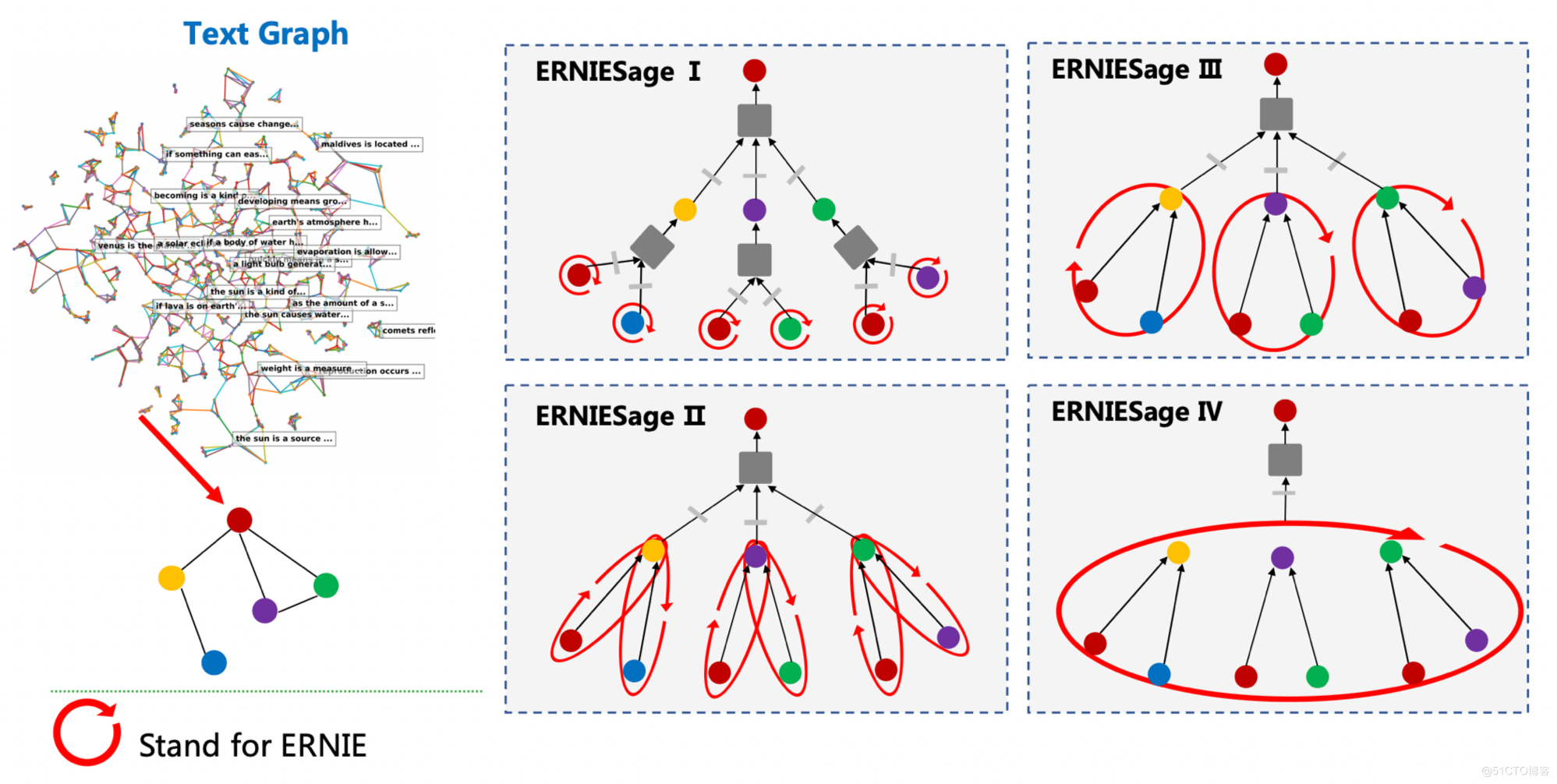
ERNIE-Sage 可以很輕鬆地在 PGL 中的訊息傳遞正規化中進行實現,目前提供了4個版本的 ERNIESage 模型:
- ERNIE-Sage v1: ERNIE 作用於text graph節點上;
- ERNIE-Sage v2: ERNIE 作用在text graph的邊上;
- ERNIE-Sage v3: ERNIE 作用於一階鄰居及起邊上;
- ERNIE-Sage v4: ERNIE 作用於N階鄰居及邊上;
模型效果
TextGraph 2020 效果當時的SOTA

應用場景
文字匹配、Query 推薦等
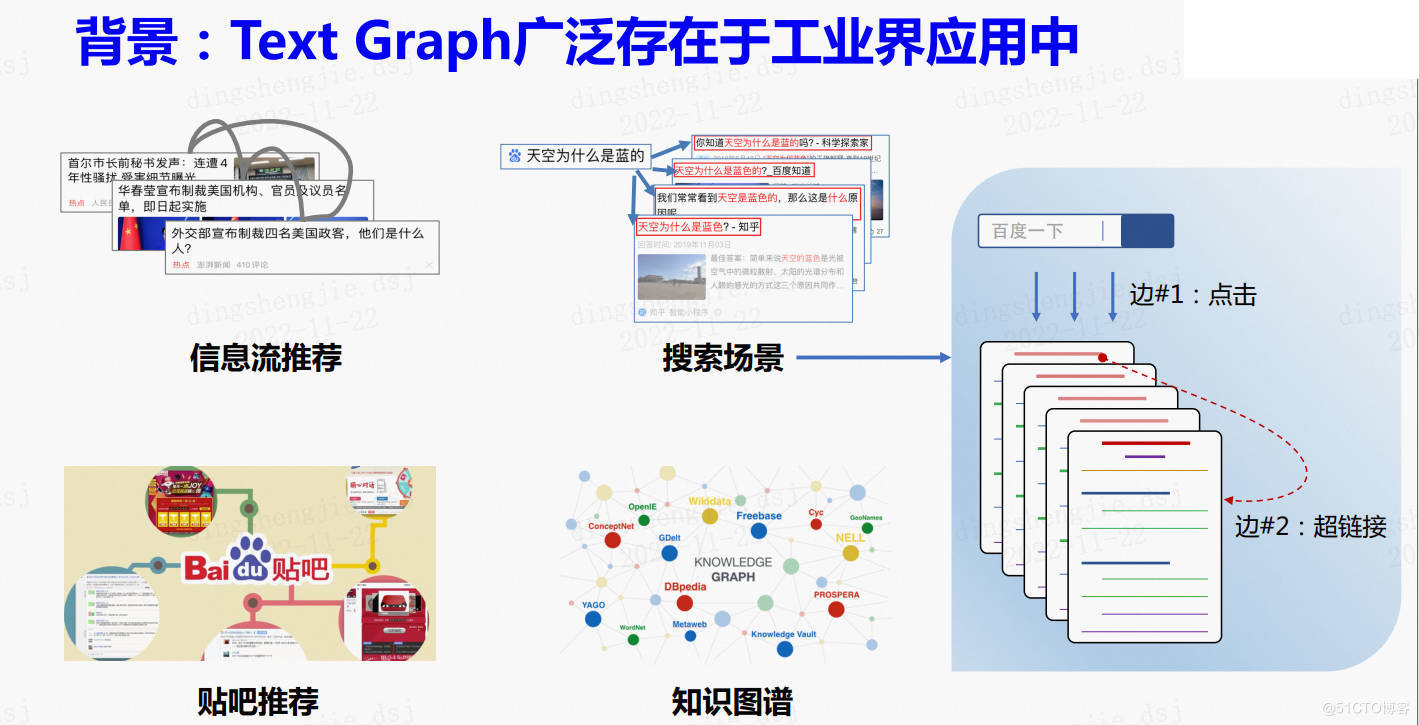
2.3 如何對Text Graph進行建模
上個專案講到的GraphSage只關注結構資訊,無法完成語意理解,而NLP對應的預訓練模型卻反之,這時候ErnieSage就能很好實現兩者達到圖語意理解
簡單提一下Ernie 1.0核心是知識增強,通過詞級別的Masked Language Model(MLM)任務以及持續學習思想取得優異效能
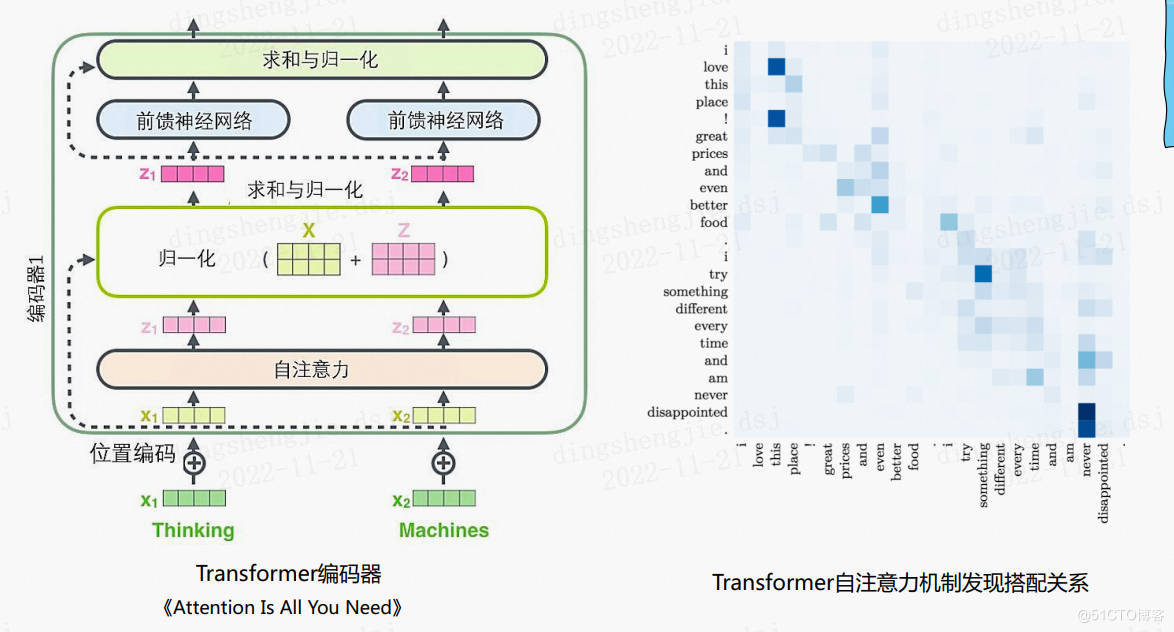
Transformer基礎結構
transformer好比全連通圖,圖節點類比token外加了自注意機制。
持續學習效果
將ERNIE作用於Graph的各大元素:
- ERNIESage V1 模型核心流程---ERNIE 作用於Text Graph的Node(節點) 上
- ERNIE提取節點語意 -> GNN聚合
- 利用ERNIE獲得節點表示
- 聚合鄰居特徵,進行訊息傳遞
- 將當前節點和聚合後的鄰居特徵進行concat,更新節點特徵
- ERNIESage V2 核心程式碼---------ERNIE聚合Text Graph的Edge(邊) 上資訊
- GNN send 文字id -> ERNIE提取邊語意 -> GNN recv 聚合鄰居語意 -> ERNIE提取中心節點語意並concat

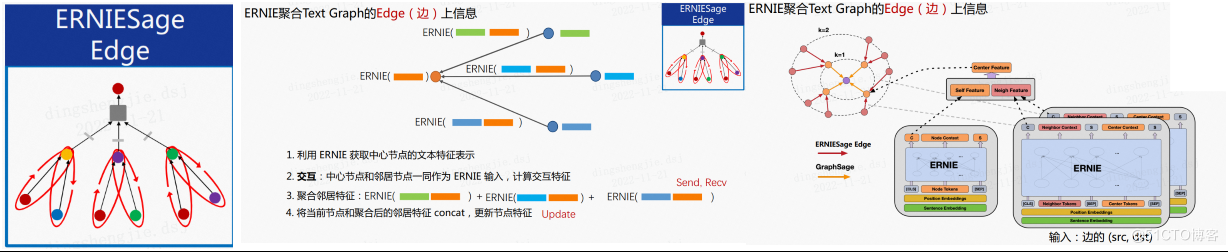
- 利用 ERNIE 獲取中心節點的文字特徵表示
- 特徵互動:中心節點和鄰居節點一同作為 ERNIE 輸入,計算互動特徵
- 聚合鄰居特徵
- 將當前節點和聚合後的鄰居特徵 concat,更新節點特徵
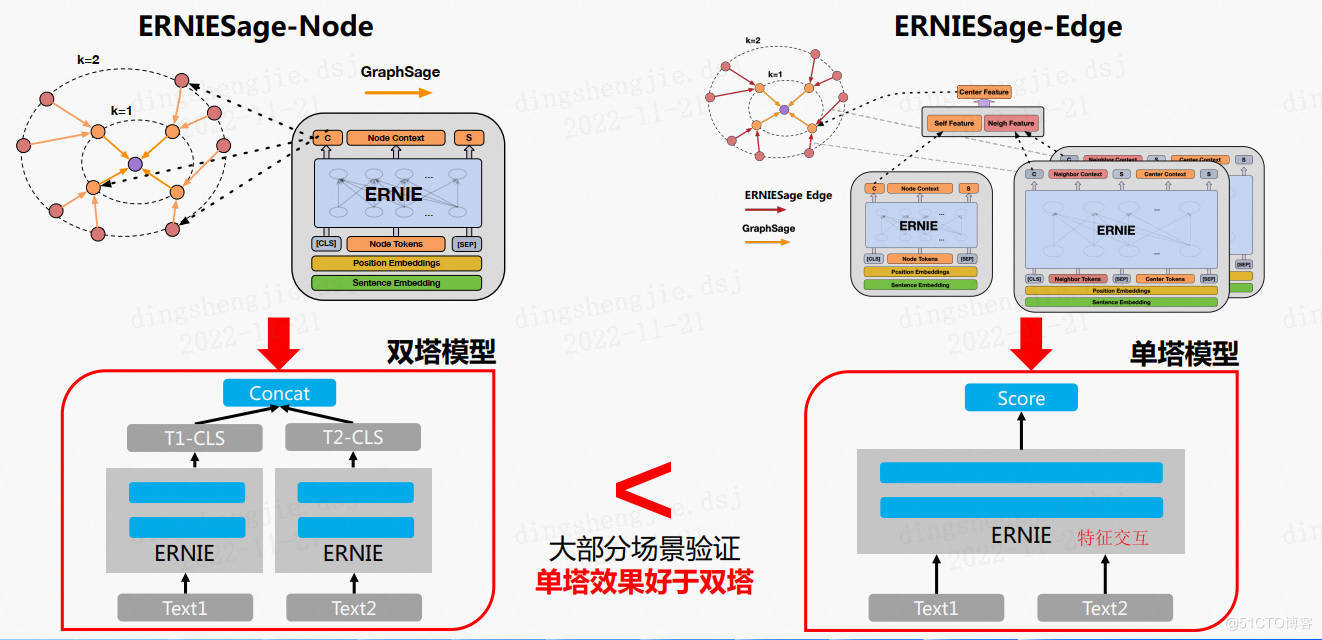
ERNIESage Node與ERNIESage Edge對比
大部分單塔模型優於雙塔模型因為含有特徵互動資訊更充分,做連結預測問題思路:將兩個節點進行內積得到一個值,和閾值對比假設大於0.5則邊存在
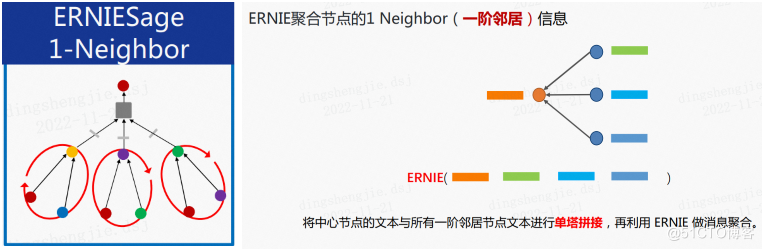
- ERNIESage V3 核心過程--------ERNIE聚合節點的1 Neighbor( 一階鄰居) 資訊
- GNN send 文字id序列 -> GNN recv 拼接文字id序列 -> ERNIE同時提取中心和多個鄰居語意表達
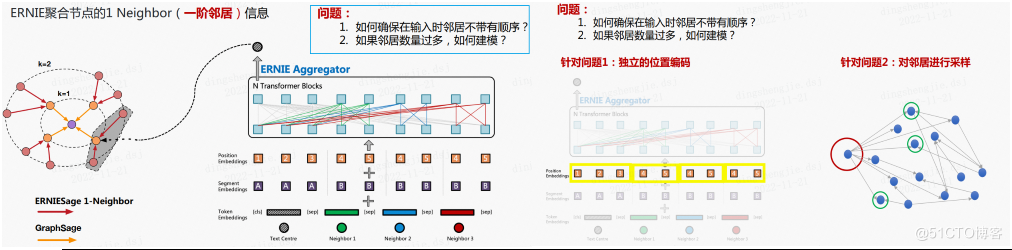
將中心節點的文字與所有一階鄰居節點文字進行單塔拼接,再利用 ERNIE 做訊息聚合;這樣就會遇到:
- 如何確保在輸入時鄰居不帶有順序?
- 如果鄰居數量過多,如何建模?
解決方案如下:針對問題一採用獨立位置編碼,鄰居節點編碼相同不受順序影響;針對問題提二:進行鄰居取樣
2.4 基於PGL演演算法實現
PGL&paddle 2.x+版本
ErnieSage可以很輕鬆地在基於PaddleNLP構建基於Ernie的圖神經網路,目前PaddleNLP提供了V2版本的ErnieSage模型:
ErnieSage V2: ERNIE 作用在text graph的邊上;
核心部分包含:
- 資料集部分
- example_data - 簡單的輸入檔案,格式為每行query \t answer,可作簡單的執行範例使用。
- 模型檔案和設定部分
- ernie_config.json - ERNIE模型的組態檔。
- vocab.txt - ERNIE模型所使用的詞表。
- ernie_base_ckpt/ - ERNIE模型引數。
- config/ - ERNIESage模型的組態檔
- 程式碼部分
- local_run.sh - 入口檔案,通過該入口可完成預處理、訓練、infer三個步驟。
- preprocessing資料夾 - 包含dump_graph.py,在預處理部分,首先需要進行建圖,將輸入的檔案構建成一張圖。由於所研究的是Text Graph,因此節點都是文字,將文字表示為該節點對應的node feature(節點特徵),處理文字的時候需要進行切字,再對映為對應的token id。
- dataset/ - 該資料夾包含了資料ready的程式碼,以便於在訓練的時候將訓練資料以batch的方式讀入。
- models/ - 包含了ERNIESage模型核心程式碼。
- train.py - 模型訓練入口檔案。
- learner.py - 分散式訓練程式碼,通過train.py呼叫。
- infer.py - infer程式碼,用於infer出節點對應的embedding。
- 評價部分
- build_dev.py - 用於將的驗證集修改為需要的格式。
- mrr.py - 計算MRR值。
部分結果展示:
[2022-11-23 14:18:01,252] [ INFO] - global step 890, epoch: 27, batch: 25, loss: 0.005078, speed: 1.70 step/s
[2022-11-23 14:18:06,836] [ INFO] - global step 900, epoch: 28, batch: 3, loss: 0.004688, speed: 1.79 step/s
[2022-11-23 14:18:12,588] [ INFO] - global step 910, epoch: 28, batch: 13, loss: 0.004492, speed: 1.74 step/s
[2022-11-23 14:18:18,633] [ INFO] - global step 920, epoch: 28, batch: 23, loss: 0.005273, speed: 1.65 step/s
[2022-11-23 14:18:24,022] [ INFO] - global step 930, epoch: 29, batch: 1, loss: 0.004687, speed: 1.86 step/s
[2022-11-23 14:18:29,897] [ INFO] - global step 940, epoch: 29, batch: 11, loss: 0.004492, speed: 1.70 step/s
[2022-11-23 14:18:35,727] [ INFO] - global step 950, epoch: 29, batch: 21, loss: 0.007814, speed: 1.72 step/s
[2022-11-23 14:18:41,339] [ INFO] - global step 960, epoch: 29, batch: 31, loss: 0.012500, speed: 1.78 step/s
INFO 2022-11-23 14:18:47,170 launch.py:402] Local processes completed.
INFO 2022-11-23 14:18:47,170 launch.py:402] Local processes completed.
執行完畢後,會產生較多的檔案,這裡進行簡單的解釋。
-
graph_workdir/ - 這個資料夾主要會儲存和圖相關的資料資訊。
-
output/ - 主要的輸出資料夾,包含了以下內容:
- (1)模型檔案,根據config檔案中的save_per_step可調整儲存模型的頻率,如果設定得比較大則可能訓練過程中不會儲存模型;
- (2)last資料夾,儲存了停止訓練時的模型引數,在infer階段會使用這部分模型引數;
- (3)part-0檔案,infer之後的輸入檔案中所有節點的Embedding輸出。
預測結果見/output part-0,部分結果展示:
1 幹部走讀之所以成為「千夫所指」,是因為這種行為增加了行政成本。 0.08133 -0.18362 0.00346 -0.01038 -0.05656 -0.05691 -0.09882 0.12029 0.05317 -0.02939 -0.14508 -0.07692 -0.02769 -0.04896 0.09963 -0.14497 -0.13574 0.02424 0.10587 -0.07323 -0.06388 0.01103 0.00944 -0.07593 -0.00731 -0.11897 0.11635 -0.05529 0.04156 0.01942 -0.07949 -0.02761 0.00033 -0.06539 0.05739 0.02487 0.03389 0.18369 0.05038 -0.02183 0.02685 0.09735 -0.13134 0.01999 -0.04034 -0.03441 0.07738 0.14992 0.06287 -0.20294 -0.05325 0.07003 0.02595 0.01826 0.12306 0.06234 -0.11179 -0.09813 0.14834 -0.16425 0.13985 0.06430 0.01662 -0.01184 0.02659 0.13431 0.05327 -0.07269 0.06539 -0.12416 -0.03247 0.12320 -0.06268 -0.06711 -0.01775 -0.02475 0.12867 0.05980 0.09311 0.11515 -0.06987 0.07372 0.09891 -0.10539 -0.03451 0.02539 -0.05701 -0.06300 0.03582 0.13427 -0.07082 -0.01588 -0.10033 0.04229 -0.02681 0.22213 0.00073 0.00075 -0.16839 0.12594 0.00807 -0.00040 -0.07686 0.08944 -0.04361 -0.13446 -0.15051 -0.08336 0.13476 -0.07999 0.00719 0.04443 -0.21426 -0.02944 0.04165 0.14448 -0.07233 -0.07226 -0.01737 -0.05904 -0.08729 0.01087 0.11581 -0.00041 -0.04341 0.01526 -0.01272 -0.15089
1 承擔縣人大常委會同市人大常委會及鄉鎮人大的工作聯絡。 0.06494 -0.25502 -0.00777 -0.02933 -0.03097 -0.08472 -0.15055 0.03232 0.04819 -0.03571 -0.18642 0.01614 0.07226 0.04660 0.06138 -0.14811 -0.01807 -0.00931 0.11350 0.04235 -0.14285 0.08077 0.10746 -0.03673 -0.12217 -0.05147 0.15980 -0.02051 -0.08356 0.00127 0.02313 0.14206 0.02116 -0.02332 -0.02032 0.03704 0.04234 0.05832 -0.03426 -0.02491 0.07948 0.11802 0.10158 -0.06468 -0.11558 0.00161 0.02030 0.06531 -0.04109 -0.13033 -0.04947 0.10836 -0.06057 0.01797 0.00183 0.18616 -0.13693 -0.17120 0.02910 0.01781 0.24061 -0.03953 0.10843 0.05329 -0.08753 -0.09504 0.05383 -0.11522 0.05172 -0.02633 0.06554 0.18186 -0.03937 -0.09151 -0.01045 -0.01857 0.10766 0.04191 0.10127 -0.00513 -0.02739 -0.10974 0.07810 -0.17015 -0.07228 -0.05809 -0.08627 -0.02947 -0.01907 0.12695 -0.09196 0.03067 -0.09462 0.15618 -0.05241 0.17382 -0.06615 0.02156 0.07060 0.09616 -0.02560 0.01197 -0.00582 -0.06037 -0.11539 -0.11853 -0.16872 0.00075 0.13284 0.02941 -0.01361 -0.01200 -0.12901 0.06944 -0.03066 0.09824 -0.01635 0.04351 -0.08985 0.08947 0.00923 -0.02436 0.10783 0.00891 0.10256 0.01953 -0.06292 -0.04989
# 接下來,計算MRR得分。
# 注意,執行此程式碼的前提是,已經將config對應的yaml組態檔中的input_data引數修改為了:"train_data.txt"
# 並且注意訓練的模型是針對train_data.txt的,如果不符合,請重新訓練模型。
!python mrr.py --emb_path output/part-0
# 由於僅是為了提供一個可執行的範例,計算出來的MRR值可能比較小,需要的同學可以自己更換資料集來測試更多的結果。
1021it [00:00, 19102.78it/s]
46it [00:00, 68031.73it/s]
100%|█████████████████████████████████████████| 46/46 [00:00<00:00, 2397.52it/s]
MRR 0.22548099768841945
PGL&paddle 1.x+版本
提供多版本供大家學習復現,含核心模型程式碼講解
專案連結:
https://aistudio.baidu.com/aistudio/projectdetail/5097085
3.UniMP(標籤遷移)
UniMP:融合標籤傳遞和圖神經網路的統一模型
論文名:Masked Label Prediction:用於半監督分類的統一訊息傳遞模型
論文連結:https://arxiv.org/abs/2009.03509
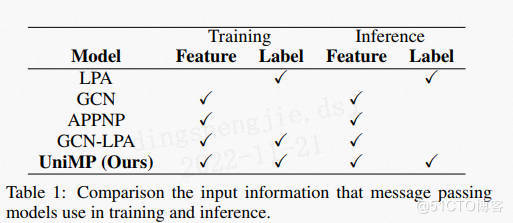
圖神經網路(GNN)和標籤傳播演演算法(LPA)都是訊息傳遞演演算法,在半監督分類中取得了優越的效能。GNN 通過神經網路執行特徵傳播來進行預測,而 LPA 使用跨圖鄰接矩陣的標籤傳播來獲得結果。然而,目前還沒有有效的方法將這兩種演演算法直接結合起來。為了解決這個問題,提出了一種新穎的統一訊息傳遞模型 (UniMP),它可以在訓練和推理時結合特徵和標籤傳播。首先,UniMP採用Graph Transformer網路,將feature embedding和label embedding作為輸入資訊進行傳播。其次,為了在自迴圈輸入標籤資訊中不過度擬合地訓練網路,UniMP 引入了一種遮蔽標籤預測策略,其中一定比例的輸入標籤資訊被隨機遮蔽,然後進行預測。UniMP 在概念上統一了特徵傳播和標籤傳播,並且在經驗上是強大的。它在 Open Graph Benchmark (OGB) 中獲得了新的最先進的半監督分類結果。
此外,提出UniMP_large通過增加來擴充套件基本模型的寬度,並通過合併APPNPhead_num使其更深。此外,他們首先提出了一種新的基於注意力的 APPNP來進一步提高模型的效能。
APPNP:Predict then Propagate: Graph Neural Networks meet Personalized PageRank https://arxiv.org/abs/1810.05997
用於圖形半監督分類的神經訊息傳遞演演算法最近取得了巨大成功。然而,為了對節點進行分類,這些方法僅考慮距離傳播幾步之遙的節點,並且這個使用的鄰域的大小很難擴充套件。在本文中,利用圖折積網路 (GCN) 與 PageRank 之間的關係,推匯出一種基於個性化 PageRank 的改進傳播方案。利用這種傳播過程來構建一個簡單的模型、神經預測的個性化傳播 (PPNP) 及其快速近似 APPNP。模型的訓練時間與以前的模型相同或更快,其引數數量與以前的模型相同或更少。它利用一個大的、可調整的鄰域進行分類,並且可以很容易地與任何神經網路相結合。表明,在迄今為止對類 GCN 模型所做的最徹底的研究中,該模型優於最近提出的幾種半監督分類方法。的實施可線上獲得。
3.1背景介紹
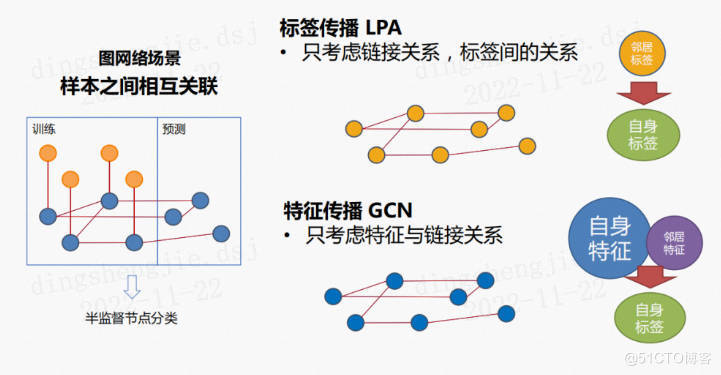
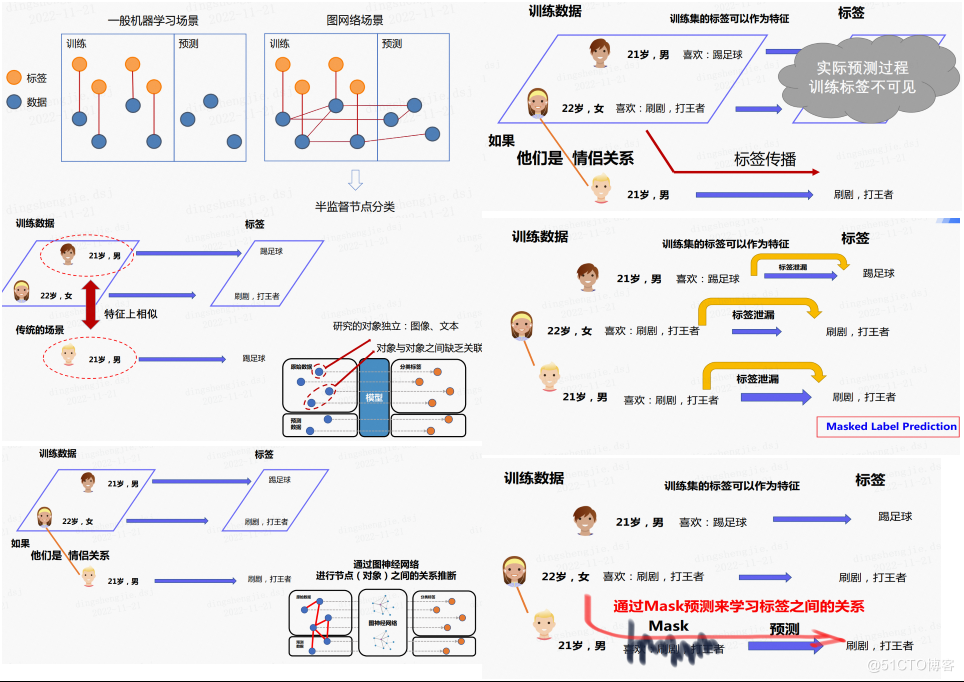
在半監督圖節點分類場景下,節點之間通過邊相連線,部分節點被打上標籤。任務要求模型通過監督學習的方式,擬合被標註節點資料,並對未標註的節點進行預測。如下圖所示,在一般機器學習的問題上,已標註的訓練資料在新資料的推斷上,並不能發揮直接的作用,因為資料的輸入是獨立的。然而在圖神經網路的場景下,已有的標註資料可以從節點與節點的連線中,根據圖結構關係推廣到新的未標註資料中。
一般應用於半監督節點分類的演演算法分為圖神經網路和標籤傳遞演演算法兩類,它們都是通過訊息傳遞的方式(前者傳遞特徵、後者傳遞標籤)進行節點標籤的學習和預測。其中經典標籤傳遞演演算法如LPA,只考慮了將標籤在圖上進行傳遞,而圖神經網路演演算法大多也只是使用了節點特徵以及圖的連結資訊進行分類。但是單純考慮標籤傳遞或者節點特徵都是不足夠的。
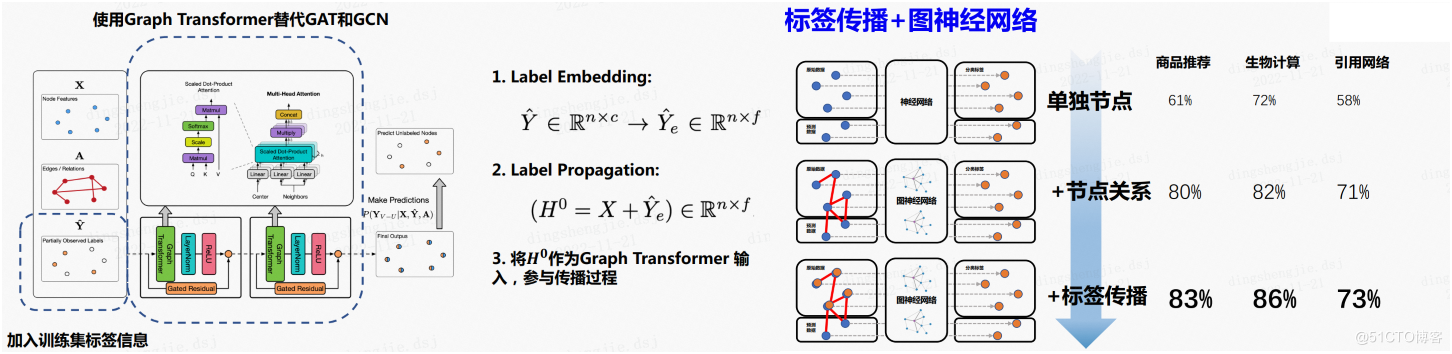
百度PGL團隊提出的統一訊息傳遞模型 UniMP,將上述兩種訊息統一到框架中,同時實現了節點的特徵與標籤傳遞,顯著提升了模型的泛化效果。UniMP以Graph Transformer模型作為基礎骨架,聯合使用標籤嵌入方法,將節點特徵和部分節點標籤同時輸入至模型中,從而實現了節點特徵和標籤的同時傳遞。
簡單的加入標籤資訊會帶來標籤洩漏的問題,即標籤資訊即是特徵又是訓練目標。實際上,標籤大部分是有順序的,例如在參照網路中,論文是按照時間先後順序出現的,其標籤也應該有一定的先後順序。在無法得知訓練集標籤順序的情況下,UniMP提出了標籤掩碼學習方法。UniMP每一次隨機將一定量的節點標籤掩碼為未知,用部分已有的標註資訊、圖結構資訊以及節點特徵來還原訓練資料的標籤。最終,UniMP在OGB上取得SOTA效果,並在論文的消融實驗上,驗證了方法的有效性。
通過:Masked Label Prediction 解決標籤洩露問題
模型結構
論文一些資料模擬展示:【資料集情況等】
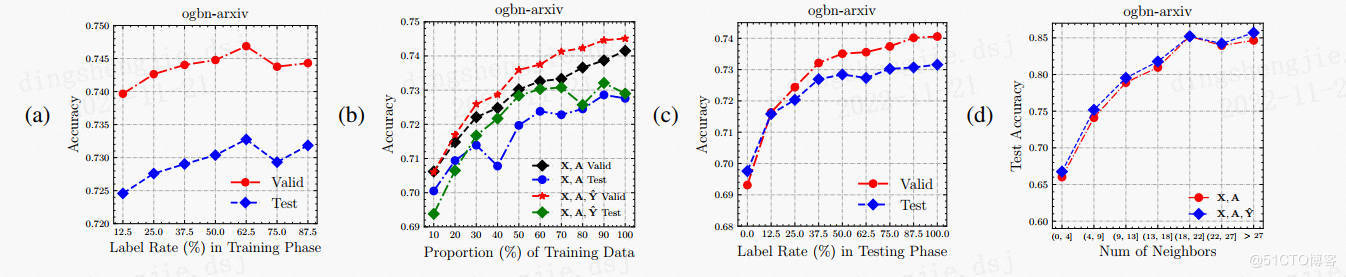
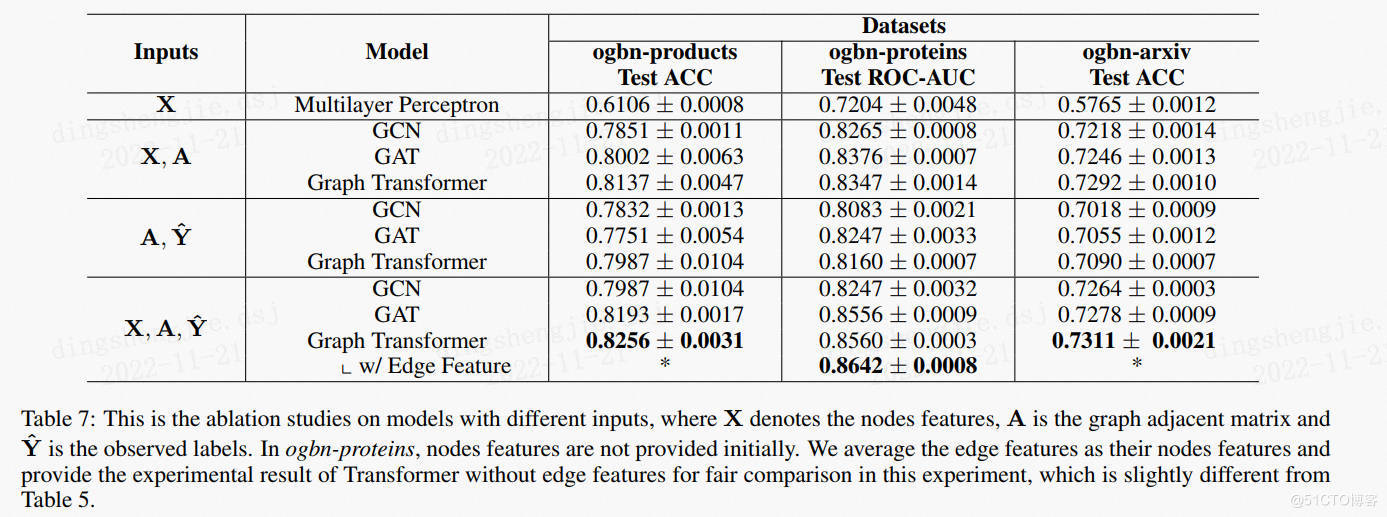
3.2原理介紹

部分作者提出質疑也是值得探討的:

3.3 基於碼源詳細闡釋
3.3.1 為何引入MaskLabel?
簡單的加入標籤資訊會帶來標籤洩漏的問題,即標籤資訊即是特徵又是訓練目標。可以想象直接將標籤作為網路輸入,要求輸出也向標籤靠攏,勢必會造成「1=1」的訓練結果,無法用於預測。
在參照網路中,論文是按照時間先後順序出現的,其標籤也應該有一定的先後順序。在無法得知訓練集標籤順序的情況下,UniMP提出了MaskLabel學習方法。每一次隨機將一定量的節點標籤掩碼為未知,用部分已有的標註資訊、圖結構資訊以及節點特徵來還原訓練資料的標籤。
def label_embed_input(self, feature):
label = F.data(name="label", shape=[None, 1], dtype="int64")
label_idx = F.data(name='label_idx', shape=[None, 1], dtype="int64")
label = L.reshape(label, shape=[-1])
label_idx = L.reshape(label_idx, shape=[-1])
embed_attr = F.ParamAttr(initializer=F.initializer.NormalInitializer(loc=0.0, scale=1.0))
embed = F.embedding(input=label, size=(self.out_size, self.embed_size), param_attr=embed_attr)
feature_label = L.gather(feature, label_idx, overwrite=False)
feature_label = feature_label + embed
feature = L.scatter(feature, label_idx, feature_label, overwrite=True)
lay_norm_attr = F.ParamAttr(initializer=F.initializer.ConstantInitializer(value=1))
lay_norm_bias = F.ParamAttr(initializer=F.initializer.ConstantInitializer(value=0))
feature = L.layer_norm(feature, name='layer_norm_feature_input', param_attr=lay_norm_attr, bias_attr=lay_norm_bias)
return feature
在上面的程式碼中可以看到,對於已知標籤的節點,首先將其embedding成和節點特徵同樣維度(這裡是100維),然後就可以直接與節點特徵相加,進而完成了標籤資訊與特徵資訊的融合,一塊送入graph_transformer進行訊息傳遞。
改進:這裡,最核心的一句程式碼是feature_label = feature_label + embed,它完成了標籤和特徵的融合,由此可以想到控制兩者的權重,得到:
feature_label = alpha*feature_label + (1-alpha)*embed
alpha可以設定為固定值,也可以通過學習獲得。參考model_unimp_large.py中的門控殘差連線:
if gate:
temp_output = L.concat([skip_feature, out_feat, out_feat - skip_feature], axis=-1)
gate_f = L.sigmoid(linear(temp_output, 1, name=name + '_gate_weight', init_type='lin'))
out_feat = skip_feature * gate_f + out_feat * (1 - gate_f)
else:
out_feat = skip_feature + out_feat
可以寫出:
temp = L.concat([feature_label,embed,feature_label-embed], axis=-1)
alpha = L.sigmoid(linear(temp, 1, name='alpha_weight', init_type='lin'))
feature_label = alpha*feature_label + (1-alpha)*embed
當然也可以直接經過一層FC後再將兩者相加:
feature_label = L.fc(feature_label, size=100) + L.fc(embed, size=100)
而做這些的目的,都是為了尋找能使標籤資訊和特徵資訊融合的更好的方式。
3.3.2 Res連線&Dense連線?
(1)殘差網路(或稱深度殘差網路、深度殘差學習,英文ResNet)屬於一種折積神經網路。相較於普通的折積神經網路,殘差網路採用了跨層恆等連線,以減輕折積神經網路的訓練難度。殘差網路的一種基本模組如下所示:
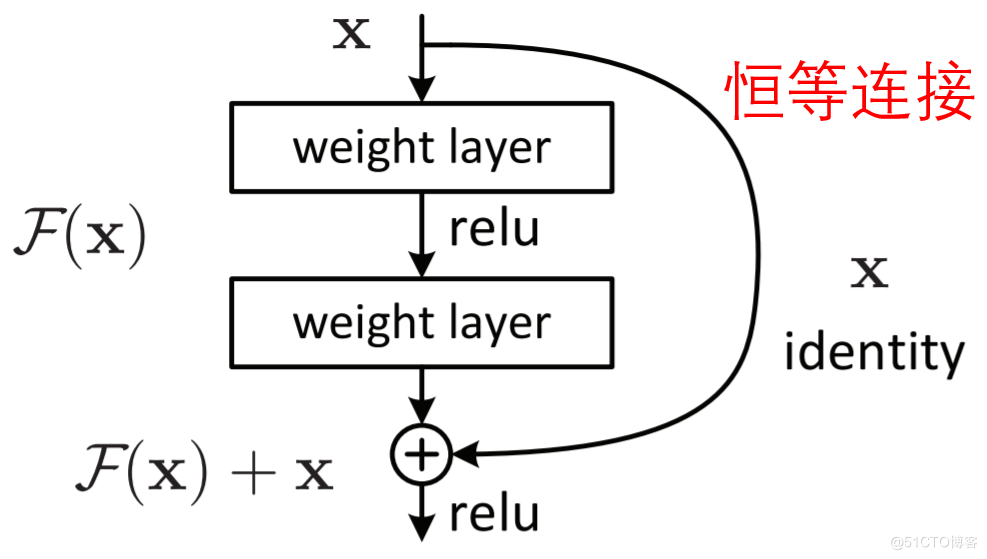
實現起來比較簡單,這裡不予贅述。
(2)DenseNet原文:Densely Connected Convolutional Networks
相比ResNet,DenseNet提出了一個更激進的密集連線機制:即互相連線所有的層,具體來說就是每個層都會接受其前面所有層作為其額外的輸入。DenseNet的網路結構如下所示:
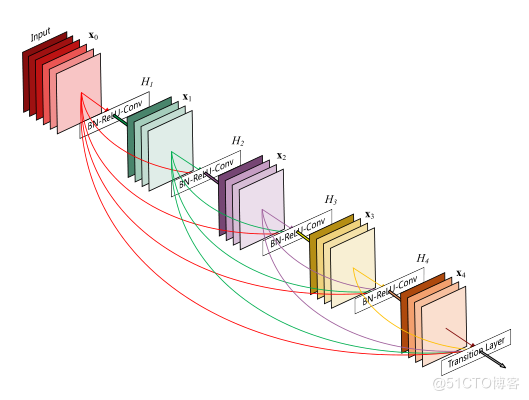
以下程式碼實現了Dense連線:
dense=[feature]
for i in range(self.num_layers - 1):
ngw = pgl.sample.edge_drop(graph_wrapper, edge_dropout)
res_feature = feature
feature, _, cks = graph_transformer(str(i), ngw, feature,
hidden_size=self.hidden_size,
num_heads=self.heads,
concat=True, skip_feat=True,
layer_norm=True, relu=True, gate=True)
if dropout > 0:
feature = L.dropout(feature, dropout_prob=dropout, dropout_implementation='upscale_in_train')
dense.append(feature)
feature = L.fc(dense, size=self.hidden_size, name="concat_feature")
3.3.3 注意力機制?
注意力機制就是將注意力集中於區域性關鍵資訊的機制,可以分成兩步:第一,通過全域性掃描,發現區域性有用資訊;第二,增強有用資訊並抑制冗餘資訊。SENet是一種非常經典的注意力機制下的深度學習方法。它可以通過一個小型的子網路,自動學習得到一組權重,對特徵圖的各個通道進行加權。其含義在於,某些特徵通道是較為重要的,而另一些特徵通道是資訊冗餘的;那麼,我們就可以通過這種方式增強有用特徵通道、削弱冗餘特徵通道。SENet的一種基本模組如下所示:
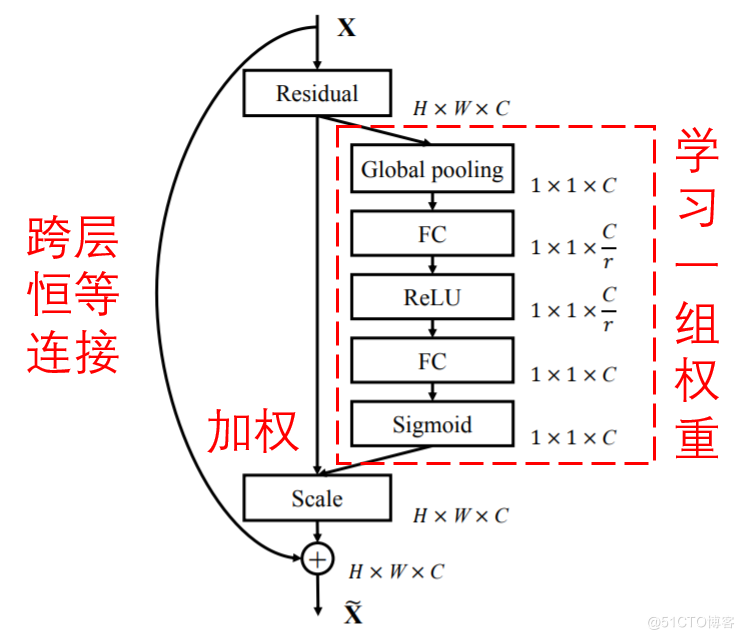
值得指出的是,通過這種方式,每個樣本都可以有自己獨特的一組權重,可以根據樣本自身的特點,進行獨特的特徵通道加權調整。
Unimp中的注意力機制出現在Graph Transformer以及最後的輸出層attn_appnp,attn_appnp的程式碼為:
def attn_appnp(gw, feature, attn, alpha=0.2, k_hop=10):
"""Attention based APPNP to Make model output deeper
Args:
gw: Graph wrapper object (:code:`StaticGraphWrapper` or :code:`GraphWrapper`)
attn: Using the attntion as transition matrix for APPNP
feature: A tensor with shape (num_nodes, feature_size).
k_hop: K Steps for Propagation
Return:
A tensor with shape (num_nodes, hidden_size)
"""
def send_src_copy(src_feat, dst_feat, edge_feat):
feature = src_feat["h"]
return feature
h0 = feature
attn = L.reduce_mean(attn, 1)
for i in range(k_hop):
msg = gw.send(send_src_copy, nfeat_list=[("h", feature)])
msg = msg * attn
feature = gw.recv(msg, "sum")
feature = feature * (1 - alpha) + h0 * alpha
return feature
在呼叫函數時,其中的alpha為前面的graph_transformer學習到的引數,用於更好的融合各層特徵。
3.4基於PGL演演算法實現
3.4.1 基於斯坦福 OGB (1.2.1) 基準測試
實驗基於斯坦福 OGB (1.2.1) 基準測試,
To_do list:
- UniMP_large in Arxiv
- UniMP_large in Products
- UniMP_large in Proteins
- UniMP_xxlarge
這裡給出giyhub官網程式碼連結:https://github.com/PaddlePaddle/PGL/tree/main/ogb_examples/nodeproppred/unimp
因為在安裝環境中需要安裝torch,在aistudio上嘗試多次仍無法執行,下面給出程式碼流程和官網結果。感興趣同學私下本地執行吧。比較吃算力!
超引數介紹:
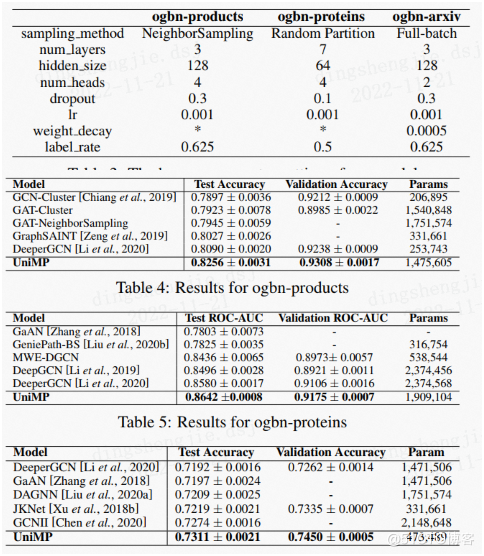
Arxiv_dataset(Full Batch): Products_dataset(NeighborSampler): Proteins_dataset(Random Partition):
--num_layers 3 --num_layers 3 --num_layers 7
--hidden_size 128 --hidden_size 128 --hidden_size 64
--num_heads 2 --num_heads 4 --num_heads 4
--dropout 0.3 --dropout 0.3 --dropout 0.1
--lr 0.001 --lr 0.001 --lr 0.001
--use_label_e True --use_label_e True --use_label_e True
--label_rate 0.625 --label_rate 0.625 --label_rate 0.5
--weight_decay. 0.0005
結果展示:
OGB的模擬效能:
| Model | Test Accuracy | Valid Accuracy | Parameters | Hardware |
|---|---|---|---|---|
| Arxiv_baseline | 0.7225 ± 0.0015 | 0.7367 ± 0.0012 | 468,369 | Tesla V100 (32GB) |
| Arxiv_UniMP | 0.7311 ± 0.0021 | 0.7450 ± 0.0005 | 473,489 | Tesla V100 (32GB) |
| Arxiv_UniMP_large | 0.7379 ± 0.0014 | 0.7475 ± 0.0008 | 1,162,515 | Tesla V100 (32GB) |
| Products_baseline | 0.8023 ± 0.0026 | 0.9286 ± 0.0017 | 1,470,905 | Tesla V100 (32GB) |
| Products_UniMP | 0.8256 ± 0.0031 | 0.9308 ± 0.0017 | 1,475,605 | Tesla V100 (32GB) |
| Proteins_baseline | 0.8611 ± 0.0017 | 0.9128 ± 0.0007 | 1,879,664 | Tesla V100 (32GB) |
| Proteins_UniMP | 0.8642 ± 0.0008 | 0.9175 ± 0.0007 | 1,909,104 | Tesla V100 (32GB) |
改進 OGBN 蛋白質的更多技巧
評估中的隨機分割區大小,隨機分割區在訓練過程中表現得像DropEdge,發現的模型可以從這種策略中受益。,但在評估中,發現較小的分割區大小可以提高分數。
# To compare
python train.py --place 0 --use_label_e --log_file eval_partition_5 --eval_partition 5
python train.py --place 0 --use_label_e --log_file eval_partition_3 --eval_partition 3
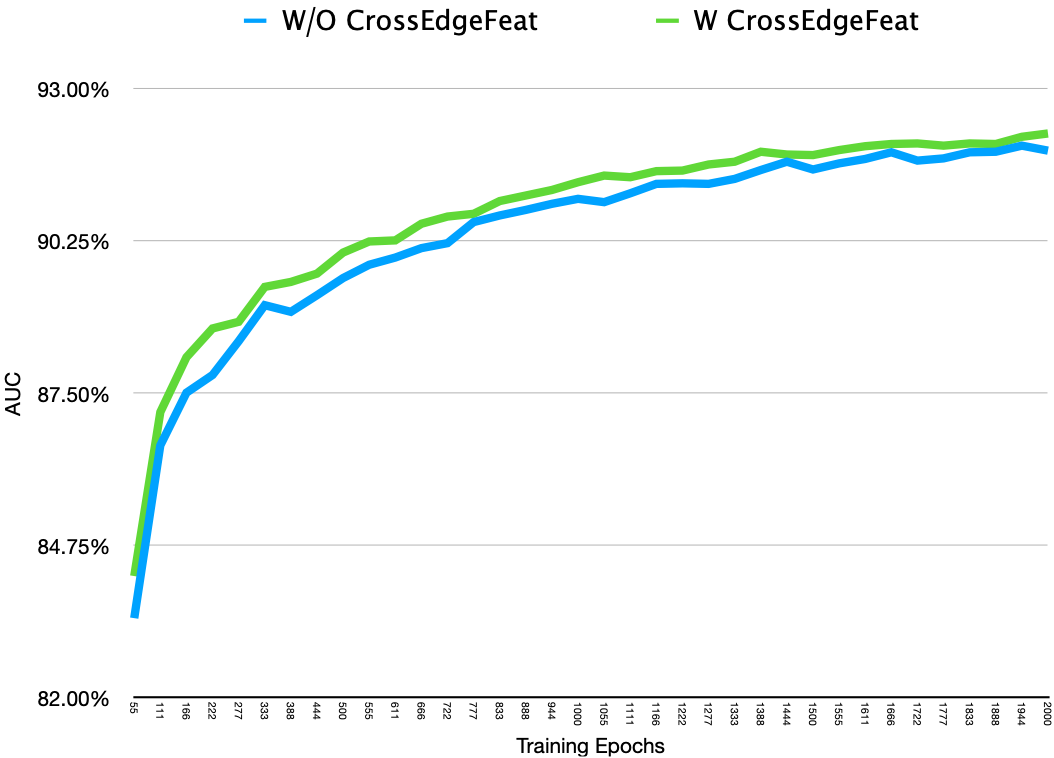
使用 Self-Attention 聚合 Neighbor Feature
OGBN-Proteins 中 UniMP 和其他類似 DeeperGCN 的原始程式碼使用平均邊緣特徵作為初始節點特徵。採用這些模組作為可學習的聚合器。為每個節點取樣大約 64 個邊,並使用變換器 [3 * (Self-Attention + Residual + ReLU + LayerNorm) + Mean Pooling] 作為聚合器來獲取初始化節點特徵。簡單地稱它為CrossEdgeFeat。你可以在cross_edge_feat.py
最初的 ogbn-proteins 工具獲得了大約0.9175的驗證分數和0.864的測試分數。並且通過CrossEdgeFeat,可以促進快速收斂並獲得更高的分數。
# To compare
python train.py --place 0 --use_label_e --log_file with_cross_edge_feat --cross_edge_feat 3
python train.py --place 0 --use_label_e --log_file without_cross_edge_feat --cross_edge_feat 0
訓練曲線(驗證 AUC)如下:
3.4.2 圖學習之基於PGL-UniMP演演算法的論文參照網路節點分類任務[系列九]
內容過多引到下一篇專案
專案連結:https://aistudio.baidu.com/aistudio/projectdetail/5116458?contributionType=1
fork一下即可
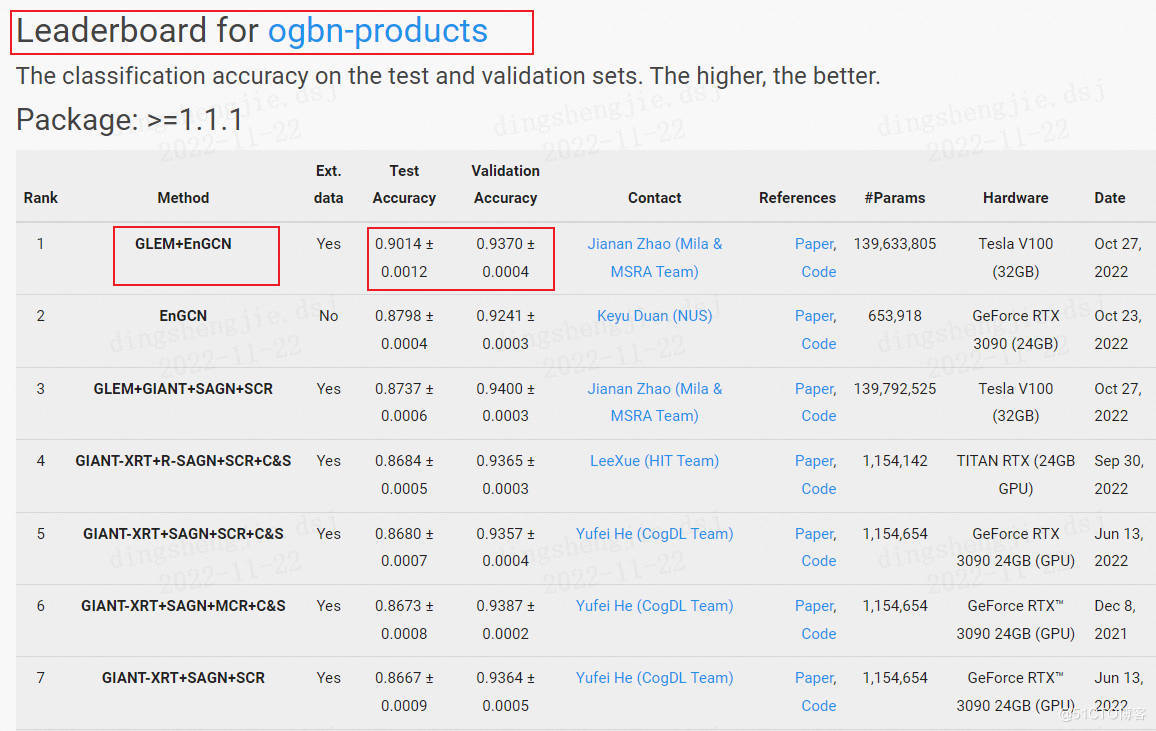
4.OGB最新榜單部分展示
這裡就展示了節點預測的,更多的可以自行去官網檢視獲得最新模型
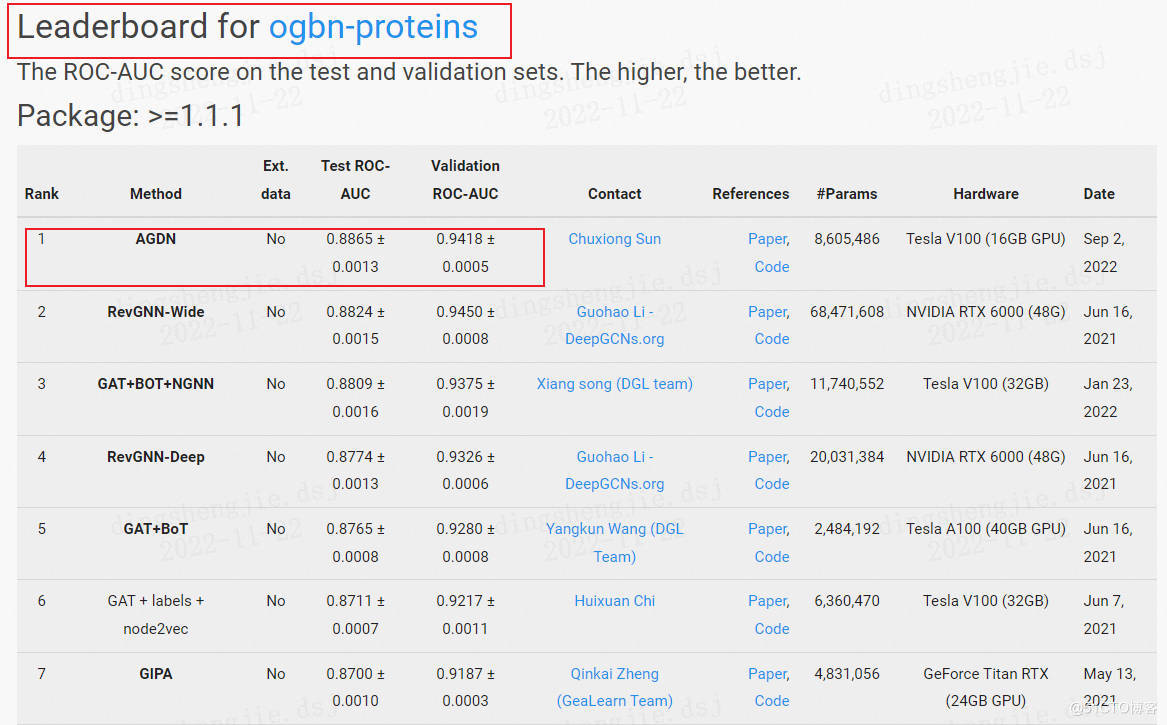
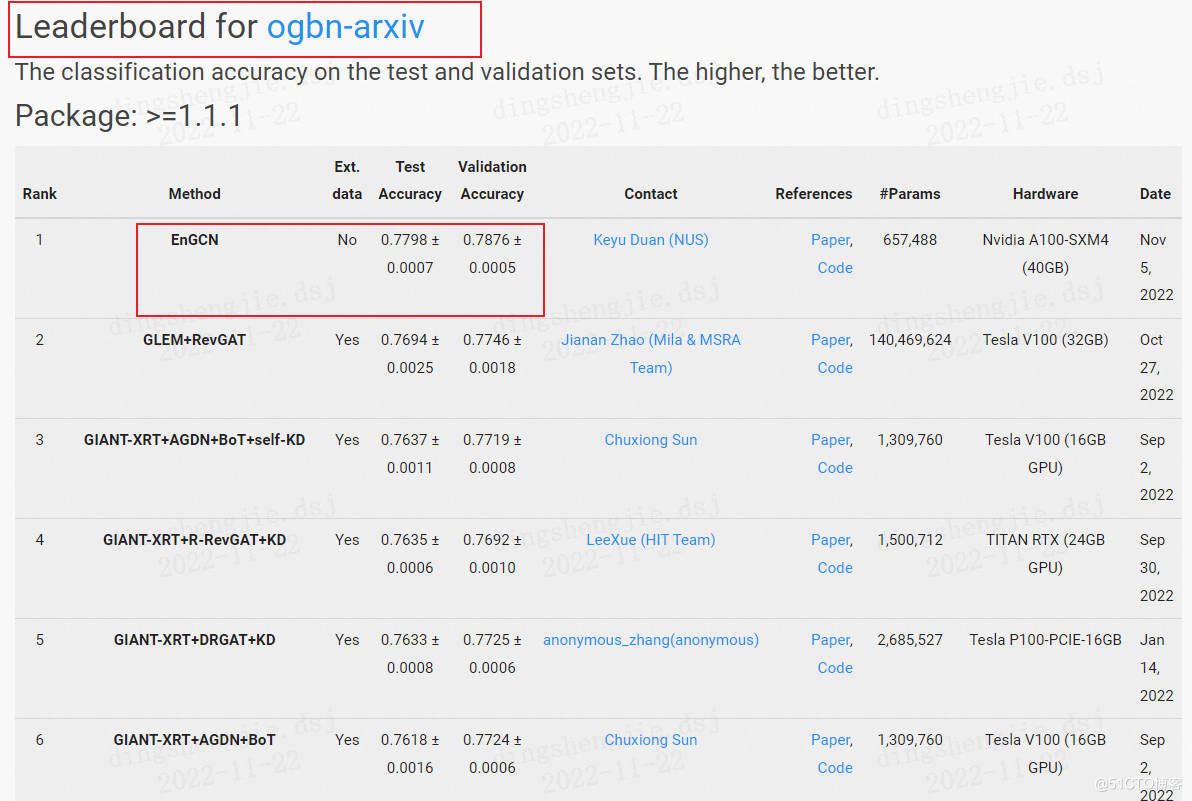
5.總結
通過以上兩個版本的模型程式碼簡單的講解,可以知道他們的不同點,其實主要就是在訊息傳遞機制的部分有所不同。ERNIESageV1版本只作用在text graph的節點上,在傳遞訊息(Send階段)時只考慮了鄰居本身的文字資訊;而ERNIESageV2版本則作用在了邊上,在Send階段同時考慮了當前節點和其鄰居節點的文字資訊,達到更好的互動效果。
為了實現可延伸的,健壯的和可重現的圖學習研究,提出了Open Graph Benchmark (OGB)——具有規模大、領域廣、任務類別多樣化的現實圖資料集。在特定於應用程式的使用案例的驅動下,對給定的資料集採用了實際的資料分割方法。通過廣泛的基準實驗,強調OGB資料集對於圖學習模型在現實的資料分割方案下處理大規模圖並進行準確的預測提出了重大挑戰。總而言之,OGB為未來的研究提供了豐富的機會,以推動圖學習的前沿。
OGB還在不斷的擴充套件中,相信之後會有更多資料集,也將產生更多優秀的模型,推動圖學習的研究,瞭解和掌握相關內容還是很有必要的。
原專案連結:fork一下即可:https://aistudio.baidu.com/aistudio/projectdetail/5096910?contributionType=1