輕量級模型設計與部署總結
文章同步發於 github 倉庫 和 csdn 部落格,最新板以
github為主。
本人水平有限,文章如有問題,歡迎及時指出。如果看完文章有所收穫,一定要先點贊後收藏。畢竟,贈人玫瑰,手有餘香。
前言
關於如何手動設計輕量級網路的研究,目前還沒有廣泛通用的準則,只有一些指導思想,和針對不同晶片平臺(不同晶片架構)的一些設計總結,建議大家從經典論文中吸取指導思想和建議,然後自己實際做各個硬體平臺的部署和模型效能測試。
一些關鍵字理解
計算量 FLOPs
FLOPs:floating point operations指的是浮點運算次數,理解為計算量,可以用來衡量演演算法/模型時間的複雜度。FLOPS:(全部大寫),Floating-point Operations Per Second,每秒所執行的浮點運算次數,理解為計算速度, 是一個衡量硬體效能/模型速度的指標,即一個晶片的算力。MACCs:multiply-accumulate operations,乘-加操作次數,MACCs大約是FLOPs的一半。將 w[0]∗x[0]+... 視為一個乘法累加或1個MACC。
記憶體存取代價 MAC
MAC: Memory Access Cost 記憶體存取代價。指的是輸入單個樣本(一張影象),模型/折積層完成一次前向傳播所發生的記憶體交換總量,即模型的空間複雜度,單位是 Byte。
FLOPs和MAC的計算方式,請參考我之前寫的文章 神經網路模型複雜度分析。
GPU 記憶體頻寬
GPU的記憶體頻寬決定了它將資料從記憶體 (vRAM) 移動到計算核心的速度,是比GPU記憶體速度更具代表性的指標。GPU的記憶體頻寬的值取決於記憶體和計算核心之間的資料傳輸速度,以及這兩個部分之間匯流排中單獨並行鏈路的數量。
NVIDIA RTX A4000 建立在 NVIDIA Ampere 架構之上,其晶片規格如下所示:

A4000 晶片配備 16 GB 的 GDDR6 視訊記憶體、256 位視訊記憶體介面(GPU 和 VRAM 之間匯流排上的獨立鏈路數量),因為這些與視訊記憶體相關的特性,所以 A4000 記憶體頻寬可以達到 448 GB/s。
Latency and Throughput
參考英偉達-Ashu RegeDirector of Developer Technology 的
ppt檔案 An Introduction to Modern GPU Architecture。
深度學習領域延遲 Latency 和吞吐量 Throughput的一般解釋:
- 延遲 (
Latency): 人和機器做決策或採取行動時都需要反應時間。延遲是指提出請求與收到反應之間經過的時間。大部分人性化軟體系統(不只是 AI 系統),延遲都是以毫秒來計量的。 - 吞吐量 (
Throughput): 在給定建立或部署的深度學習網路規模的情況下,可以傳遞多少推斷結果。簡單理解就是在一個時間單元(如:一秒)內網路能處理的最大輸入樣例數。
CPU 是低延遲低吞吐量處理器;GPU 是高延遲高吞吐量處理器。
Volatile GPU Util
一般,很多人通過 nvidia-smi 命令檢視 Volatile GPU Util 資料來得出 GPU 利用率,但是!關於這個利用率(GPU Util),容易產生兩個誤區:
- 誤區一:
GPU的利用率 =GPU內計算單元幹活的比例。利用率越高,算力就必然發揮得越充分。 - 誤區二: 同條件下,利用率越高,耗時一定越短。
但實際上,GPU Util 的本質只是反應了,在取樣時間段內,一個或多個核心(kernel)在 GPU 上執行的時間百分比,取樣時間段取值 1/6s~1s。
原文為 Percent of time over the past sample period during which one or more kernels was executing on the GPU. The sample period may be between 1 second and 1/6 second depending on the product. 來原始檔 nvidia-smi.txt
通俗來講,就是,在一段時間範圍內, GPU 核心執行的時間佔總時間的比例。比如 GPU Util 是 69%,時間段是 1s,那麼在過去的 1s 中內,GPU 核心執行的時間是 0.69s。如果 GPU Util 是 0%,則說明 GPU 沒有被使用,處於空閒中。
也就是說它並沒有告訴我們使用了多少個 SM 做計算,或者程式有多「忙」,或者記憶體使用方式是什麼樣的,簡而言之即不能體現出算力的發揮情況。
GPU Util的本質參考知乎文章-教你如何繼續壓榨GPU的算力 和 stackoverflow 問答。
英偉達 GPU 架構
GPU 設計了更多的電晶體(transistors)用於資料處理(data process)而不是資料緩衝(data caching)和流控(flow control),因此 GPU 很適合做高度平行計算(highly parallel computations)。同時,GPU 提供比 CPU 更高的指令吞吐量和記憶體頻寬(instruction throughput and memory bandwidth)。
CPU 和 GPU 的直觀對比圖如下所示

最後簡單總結下英偉達 GPU 架構的一些特點:
SIMT(Single Instruction Multiple Threads) 模式,即多個Core同一時刻只能執行同樣的指令。雖然看起來與現代CPU的SIMD(單指令多資料)有些相似,但實際上有著根本差別。- 更適合計算密集與資料並行的程式,原因是缺少
Cache和Control。
2008-2020 英偉達 GPU 架構進化史如下圖所示:

另外,英偉達 GPU 架構從 2010 年開始到 2020 年這十年間的架構演進歷史概述,可以參考知乎的文章-英偉達GPU架構演進近十年,從費米到安培。
GPU 架構的深入理解可以參考部落格園的文章-深入GPU硬體架構及執行機制。
CNN 架構的理解
在一定的程度上,網路越深越寬,效能越好。寬度,即通道(channel)的數量,網路深度,及 layer 的層數,如 resnet18 有 18 層網路。注意我們這裡說的和寬度學習一類的模型沒有關係,而是特指深度折積神經網路的(通道)寬度。
- 網路深度的意義:
CNN的網路層能夠對輸入影象資料進行逐層抽象,比如第一層學習到了影象邊緣特徵,第二層學習到了簡單形狀特徵,第三層學習到了目標形狀的特徵,網路深度增加也提高了模型的抽象能力。 - 網路寬度的意義:網路的寬度(通道數)代表了濾波器(
3維)的數量,濾波器越多,對目標特徵的提取能力越強,即讓每一層網路學習到更加豐富的特徵,比如不同方向、不同頻率的紋理特徵等。
手動設計高效 CNN 架構建議
一些結論
- 分析模型的推理效能得結合具體的推理平臺(常見如:英偉達
GPU、行動端ARMCPU、端側NPU晶片等);目前已知影響CNN模型推理效能的因素包括: 運算元計算量FLOPs(引數量Params)、折積block的記憶體存取代價(訪存頻寬)、網路並行度等。但相同硬體平臺、相同網路架構條件下,FLOPs加速比與推理時間加速比成正比。 - 建議對於輕量級網路設計應該考慮直接
metric(例如速度speed),而不是間接metric(例如FLOPs)。 FLOPs低不等於latency低,尤其是在有加速功能的硬體 (GPU、DSP與TPU)上不成立,得結合具硬體架構具體分析。- 不同網路架構的
CNN模型,即使是FLOPs相同,但其MAC也可能差異巨大。 - 大部分時候,對於
GPU晶片,Depthwise折積運算元實際上是使用了大量的低FLOPs、高資料讀寫量的操作。因為這些具有高資料讀寫量的操作,再加上多數時候GPU晶片算力的瓶頸在於訪存頻寬,使得模型把大量的時間浪費在了從視訊記憶體中讀寫資料上,導致GPU的算力沒有得到「充分利用」。結論來源知乎文章-FLOPs與模型推理速度。
一些建議
- 在大多數的硬體上,
channel數為16的倍數比較有利高效計算。如海思351x系列晶片,當輸入通道為4倍數和輸出通道數為16倍數時,時間加速比會近似等於FLOPs加速比,有利於提供NNIE硬體計算利用率。(來源海思351X晶片檔案和MobileDets論文) - 低
channel數的情況下 (如網路的前幾層),在有加速功能的硬體使用普通convolution通常會比separable convolution有效率。(來源 MobileDets 論文) - shufflenetv2 論文 提出的四個高效網路設計的實用指導思想: G1同樣大小的通道數可以最小化
MAC、G2-分組數太多的折積會增加MAC、G3-網路碎片化會降低並行度、G4-逐元素的操作不可忽視。 GPU晶片上 \(3\times 3\) 折積非常快,其計算密度(理論運算量除以所用時間)可達 \(1\times 1\) 和 \(5\times 5\) 折積的四倍。(來源 RepVGG 論文)- 從解決梯度資訊冗餘問題入手,提高模型推理效率。比如 CSPNet 網路。
- 從解決
DenseNet的密集連線帶來的高記憶體存取成本和能耗問題入手,如 VoVNet 網路,其由OSA(One-Shot Aggregation,一次聚合)模組組成。
輕量級網路模型部署總結
在閱讀和理解經典的輕量級網路 mobilenet 系列、MobileDets、shufflenet 系列、cspnet、vovnet、repvgg 等論文的基礎上,做了以下總結:
- 低算力裝置-手機行動端
cpu硬體,考慮mobilenetv1(深度可分離卷機架構-低FLOPs)、低FLOPs和 低MAC的shuffletnetv2(channel_shuffle運算元在推理框架上可能不支援) - 專用
asic硬體裝置-npu晶片(地平線x3/x4等、海思3519、安霸cv22等),目標檢測問題考慮cspnet網路(減少重複梯度資訊)、repvgg(直連架構-部署簡單,網路並行度高有利於發揮GPU算力,量化後有掉點風險) - 英偉達
gpu硬體-t4晶片,考慮repvgg網路(類vgg折積架構-高並行度帶來高速度、單路架構省視訊記憶體/記憶體)
MobileNet block (深度可分離折積 block, depthwise separable convolution block)在有加速功能的硬體(專用硬體設計-NPU 晶片)上比較沒有效率。
這個結論在 CSPNet 和 MobileDets 論文中都有提到。
除非晶片廠商做了客製化優化來提高深度可分離折積 block 的計算效率,比如地平線機器人 x3 晶片對深度可分離折積 block 做了客製化優化。
下表是 MobileNetv2 和 ResNet50 在一些常見 NPU 晶片平臺上做的效能測試結果。
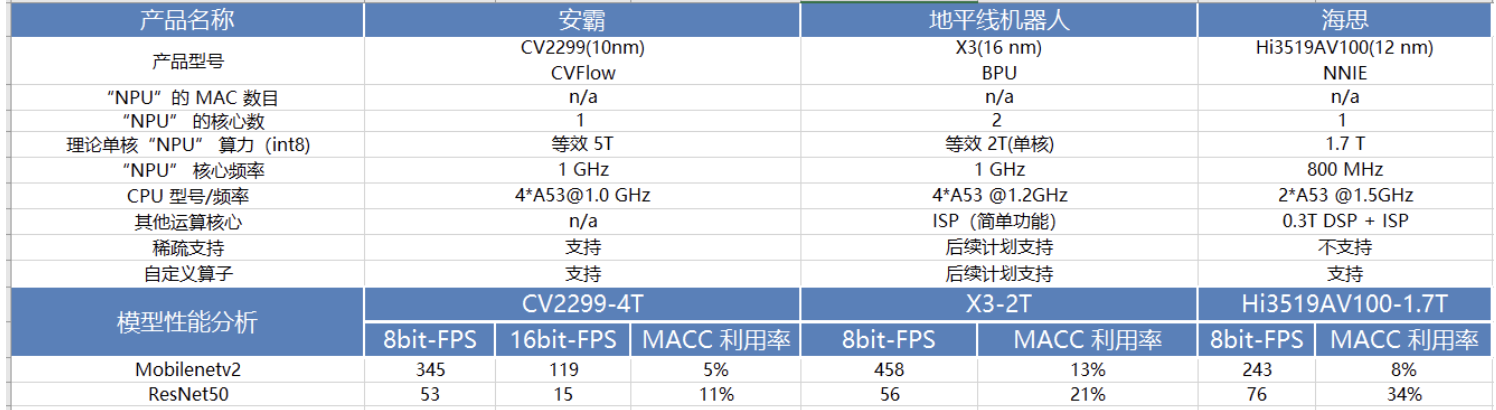
以上,均是看了輕量級網路論文總結出來的一些不同硬體平臺部署輕量級模型的經驗,實際結果還需要自己手動執行測試。