真正「搞」懂HTTP協定05之What's HTTP?
前面幾篇文章,我從縱向的空間到橫向的時間,再到一個具體的小栗子,可以說是全方位,無死角的覆蓋了HTTP的大部分基本框架,但是我聊的都太寬泛了,很多內容都是一筆帶過,再加上一句後面再說就草草結束了。並且我還漏了一點東西,就是HTTP本身。
所以那,這一章,我們回到我們的核心論點,來聊一聊HTTP的特性以及起始行中的核心內容。
一、What is HTTP?
這個問題如果大家看過前面幾篇文章,肯定能很輕易的回答:HTTP是應用層協定,用來傳輸超文字,或者可以說是用來傳輸超媒體的一種協定,HTTP是無狀態的基於請求-響應模型的。你說的沒錯,接下來我也可能會聊到你想到的這些。但是還有呢?還有呢?下面,我們就來捋一捋HTTP的特點,來說一下這「還有」的部分是什麼。
1)靈活且容易擴充套件
靈活易擴充套件,可以說是HTTP這個協定的最大的特點,也是最有價值的特點。為什麼這麼說呢?大家如果跟著這個系列閱讀到了這裡,肯定能理解,因為這個特點是HTTP可以發展至今經久不衰的原因。我們先來看一點點圖片,要不然都是字挺無聊的。

上圖,是RFC1945也就是HTTP/1.0的Additional Features部分,這部分增加了一些請求方法和頭欄位規定,注意我之前說過,HTTP/1.0還算不上是標準,只是個備忘錄,但是在這個備忘錄的最後,已經確定了一部分未來的標準的內容。
我們再來看張圖:

這是RFC2616也就是HTTP/1.1標準的頭欄位的部分定義,是不是有些欄位看上去很熟悉。沒錯,有些1945中的附加內容,在2616中就已經變成標準了。這也算是可以體現HTTP協定靈活且易擴充套件的一個方面了吧。
這些RFC檔案,實際上更像是對於已有擴充套件的承認和標準化,實現了「從實踐中來,到實踐中去」的良性迴圈。這也是為啥HTTP可以經久不衰的原因了。
靈活且易擴充套件這個特性也會在接下來的文章中一再的強調,因為你會逐漸的發現除了極少的部分,HTTP幾乎沒有不能擴充套件的部分。
2)可靠傳輸:值得依賴的背後的人
其實說HTTP協定可靠協定並不是特別的準確,HTTP的可靠性一部分來自於HTTP協定自身,一部分來自於它所依賴的上層TCP協定。
TCP本身就是一個可靠的傳輸協定,它的可靠性其實就是來自於三次握手,通過使用者端與伺服器的溝通來確定是否建立連線,UDP就沒這麼麻煩,傳過去就完事了,我管你收沒收到。所以基於這樣的因素,TCP就不可避免的要比UDP慢不少。犧牲了速度,確保了穩定。
而HTTP可靠的另外一部分,則是來自於它本身的封包的形式,也就是它加上的那一層HTTP頭。
我們說HTTP是可靠的協定,但是它的可靠,並不是絕對的純粹的可靠,只是一種理論場景下的可靠。也就是說在正常網路環境和物理裝置的情況下,HTTP會盡可能的把資料準確傳遞到另一端。只是儘可能。
比如,光纖斷了,你啥玩意來了都傳輸不過去。哈哈哈哈
3)應用層協定
這個東西顯而易見啦~但是我還得磨嘰兩句,如果你讀了空間穿梭就會知道其實應用層協定有很多。為啥只有HTTP應用如此廣泛和出名呢?嗯……因為它比較能打,怎麼用都行,又因為具有靈活可延伸的特點,所以它幾乎可以傳輸一切內容。
所以像比如FTP、SSH啥的,只能在特定的領域使用,固然就沒有HTTP應用這麼廣泛,這麼知名了。
4)請求-應答模型
這個我之前也說過。HTTP是基於請求-應答模型的應用層協定。簡單來說就是一來一回,有來有回。
請求-應答模型還有一點就是:明確的規定了HTTP協定裡雙方的定位,永遠是請求方先發起連線和請求,是主動的,應答方只能在接收到請求後進行答覆,是被動的。注意我說的話,我說的是請求方和應答方,而沒有絕對的說是瀏覽器方和伺服器方,因為發起請求的一方不一定僅僅只是瀏覽器,伺服器也可以作為請求的發起方,比如代理伺服器。
另外,HTTP的請求-應答模式,也恰好契合了傳統的 C/S(Client/Server)系統架構,請求方作為使用者端、應答方作為伺服器。所以,隨著網際網路的發展就出現了 B/S(Browser/Server)架構,用輕量級的瀏覽器代替笨重的使用者端應用,實現零維護的「瘦」使用者端,而伺服器則擯棄私有通訊協定轉而使用 HTTP 協定。
最後,請求 - 應答模式也完全符合 RPC(Remote Procedure Call)的工作模式,可以把 HTTP 請求處理封裝成遠端函數呼叫,導致了 WebService、RESTful 和 gRPC 等的出現。
嗯,這段話是我抄的~
5)無狀態
這個東西想必大家也很熟悉了吧,我印象中我之前也提到過這個無狀態。那我想問你個問題,TCP是有狀態還是無狀態的呢?你猜一猜。答案我放在文末了。
HTTP的無狀態主要體現在封包的一次性上,我發完了就不管了,收到資訊就處理,使用者端和伺服器都不會記錄之前傳送過的包的任何資訊。HTTP報文字身沒有互相的聯絡,這一次的包和上一次的包也沒有任何關聯,它僅有的聯絡在傳送和響應的過程中也顯得微不足道,嗯……我說的這個聯絡其實指的僅僅是發過去了,收到了,返回了,結束了,這樣的聯絡(好像跟沒聯絡也差不多~)。
當然,這種無狀態也可以通過一點點小手段來解決,哈哈哈哈,我猜你猜到是啥了,嗯,就是cookie。
最後,要著重說的特點就這些,但是你發現一個問題沒有,其實好多特點,都算是靈活可延伸的子特點,那麼還可以說出有關靈活可延伸所延伸出的哪些特點呢?
二、HTTP的優缺點:其實我並沒有你想象得那麼好。
其實這一小節可以和上一小節合併一下,但是計劃都已經寫到這了,就這樣吧。
HTTP的特點有很多,但是特點不代表優點,其中也有不少缺點,其實整個HTTP的歷史,實際上在做的事情就是揚長避短,發揮它的長處,儘量彌補它的短處。唉……果然到哪裡都要做到全方位多面體發展,就連一個協定都要這麼卷,心累~。
1)HTTP的優點
我們先來稍微說下HTTP的優點吧。
靈活易擴充套件
這肯定沒毛病吧,要是沒有這個優點,你現在都不一定用學HTTP,可能在學另外一個應用層協定,幻想一下,可能叫做ZakingTTP。哈哈哈哈。
正是因為靈活,所以才容易擴充套件,而容易擴充套件正好驗證了HTTP的靈活,所以其實靈活與易擴充套件是相輔相成的,互為表裡的,不可拆分的一個優點。HTTP裡幾乎每一個核心要素都沒有被硬性的要求一定要怎麼樣怎麼樣,給予了開發者極大的便利和自由,這個我們再後面也會再次強調。
靈活易擴充套件的特性不僅僅應用其自身,它不限制具體的下層協定,你隨便,只要你理論上是可靠的就行。
簡單
簡單這個優點可能有點讓人無語,HTTP簡單麼?簡單為什麼我學了這麼久感覺還是差點什麼。
其實我個人理解,HTTP是簡單的,但是正是因為它的簡單,所以它才沒有那麼容易。簡單的是它的設計,是它的學習門檻,誇張一點說,你甚至不用學習HTTP,僅僅看報文的名字都能猜到個一二。
也正是因為它的簡單,所以才可以靈活易擴充套件,這兩個優點,就意味著HTTP有無限的可能。無限的可能,就意味著它的內容會很多,很雜,甚至可以自行設計,對於初學者,就或許沒那麼友好了。
應用廣泛、環境成熟
HTTP的另一大特點就是應用廣泛,軟硬體環境都非常成熟。你幾乎可以在任意的網際網路通訊場景中找到HTTP的影子,比如Web頁面,比如桌上型電腦的瀏覽器,手機上的APP等等,從你看到新聞、視訊、手機上的遊戲,都離不開HTTP。
不僅僅是在應用領域,在開發領域,HTTP協定也得到了廣泛的支援。它並不限定某種程式語言或者作業系統,所以天然具有跨平臺,跨語言的優越性。而且因為HTTP本身的簡單性,幾乎所有的程式語言都有HTTP的呼叫庫和相關的測試工具。
所以你現在知道HTTP有多重要了吧。
2)HTTP的缺點
無狀態
其實無狀態並不算是確切的缺點,但是我把它歸類到缺點裡了。因為我個人覺得,無狀態所帶來的好處並不足以覆蓋它所帶來的問題。
無狀態的好處是它減少了伺服器因為需要「記憶」而產生的額外的儲存需要和效能耗費。
另外一個好處就是,正是因為它是無狀態的,所以它可以很容易的進行組合,讓負載均衡把請求轉發到任意一臺伺服器,不會因為狀態不一致而導致出錯。
那麼我們繼續說說無狀態所帶來的問題,沒有狀態就意味著我無法關聯兩次請求,無法支援多個相互關聯且連續的「事務」。比如購物車買東西,你是要知道使用者身份的,無狀態我怎麼能知道是誰買的呢?再比如網站的登入系統,也是一定要攜帶使用者標識加以區分是「你」還是「我」的問題。
而正是因為這個問題,所以才有了cookie,這個小餅乾。
明文
這肯定是實打實的缺點了,明文意味著誰都可以獲取傳送的報文,甚至隨意修改和更換。它的明文雖然可以方便閱讀和偵錯,但是所帶來的安全性問題實在是無法被忽視的。
不安全
這個缺點,其實一部分來自於明文,而其它的不安全的地方則是由於HTTP自身的欠缺。明文只是機密性方面的一個缺點,而在身份認證和完整性校驗上面,HTTP也是欠缺的。
身份認證,簡單來說就是你怎麼證明你是你。那在現實生活中你是怎麼證明你是你得呢?身份證!沒錯,HTTP缺了一個類似身份證一樣的東西。
而完整性校驗則是說,HTTP的資料在傳輸的過程中如果被篡改了是無法被感知且無法驗證其真偽的。雖然我們或許可以加上一些數位摘要,但是又由於它是明文的,還是可以被第三方獲取和篡改,本質並沒有什麼區別。
所以,正是由於明文和不安全的問題,才出現了HTTPS,甚至是現在幾乎要求所有的網站都使用HTTPS,無一例外。這個我們聊到HTTPS的時候再說哈。
效能一般
為什麼HTTP的效能一般呢?實際上本質的問題就是隊頭阻塞,前面的卡住了,後面的就要一直等一直等。很好理解,對吧?
HTTP的發展,一直致力於解決這樣的效能問題,換句話說就是解決隊頭阻塞的問題,雖然在HTTP/1.1,HTTP/2中一定程度上解決了HTTP的隊頭阻塞問題,但是卻無法解決TCP的隊頭阻塞,所以才有了HTTP/3的終極方案,直接不用TCP了。
三、HTTP方法簡介:最熟悉的陌生人
我相信你很熟悉HTTP的方法,天天都在用,怎麼可能會不熟悉。但是你真的熟悉HTTP的方法了麼?我覺得並沒有,看完這一小節,我相信你就會真正的熟悉了你每天都要面對的最熟悉的陌生人。
首先,RFC1945的規定的方法只有三個:GET、HEAD、POST,而2616則在此基礎上又多了五個:PUT、DELETE、TRACE、CONNECT、OPTIONS,還有安全和冪等。要注意,這些單詞都必須是大寫的。
我們簡單來看下這些方法都代表了什麼意思:
- GET:獲取資源,主要的目的是從目標Request-URI獲取資源。
- HEAD:獲取資源的頭資訊。
- POST:就是向Request-URI上傳資料,或者提交資料。
- PUT:類似於POST。
- DELETE:刪除目標資源。
- TRACE:追蹤請求-響應的路徑。
- CONNECT:建立一個特殊的連線隧道。
- OPTIONS:列出允許對該資源使用的方法。
我們簡單的羅列了一下HTTP所規定的請求方法。其中前四個比較常用,GET和POST這兩個是最常用的。後面的四個用的就很少了,甚至有些實踐中幾乎沒有使用。我們先看看這些方法,它都對資源做了哪些事情?增刪改查!
沒毛病,你的觀察力很強。那我有個問題,我向伺服器提交了一個DELETE請求,希望刪除伺服器的某個資源,伺服器一定會按照我的請求刪除該資源麼?答案是你請求你的,我聽不聽的決定權在我。所以,使用者端只有建議,無法要求。
舉個小例子,你希望可以通過GET請求獲取伺服器的私密檔案,這個檔案儲存了所有使用者的賬號和密碼,地址是:https://www.zaking.com/users/password.txt。然後你開開心心的發出了你的請求,伺服器接收到你的請求一看,臥槽,這逼要請求這個檔案,這是來黑我伺服器了吧?果斷甩個500就不搭理你了。
我們簡單的理解了下方法有哪些,方法能幹啥。那麼下面,我們就來詳細的解釋下這些方法。
1)GET
GET方法,不用說,是HTTP中最古老的方法,沒有之一,從HTTP誕生一直輝煌至今,無人可以替代。
GET的含義就是從伺服器獲取資源,這個資源既可以是靜態的文字、頁面、圖片、視訊等媒體資源,也可以是由後端語言比如PHP、JAVA等動態生成的各種型別資料。
但是GET方法並不單純,在規範中,還有兩種型別的GET:conditional GET 和 partial GET。也就是有條件的GET請求和部分GET請求。什麼意思呢,當GET請求與If-Modified-Since欄位配合使用,就變成了conditional GET,僅當資源被修改的時候才會執行GET操作。而partial GET則是Range欄位和GET一起使用的情況下產生的,只會返回整體資料的一部分。
這樣做的目的,其實就是為了節省資源。
2)HEAD
HEAD方法與GET方法是完全相同的,也是從伺服器獲取資源,伺服器的處理機制也與GET一樣,只不過不會返回body,只會傳回響應頭,也就是資源的「元資訊」。
HEAD作用是為了解決某些無需body的場景下使用GET請求造成的資源浪費,比如我只需要確定我是否可以對伺服器上對應的資源做某些指定的操作,那我們直接使用HEAD方法就可以了。
3)POST
POST方法與GET正好相反,是向伺服器傳輸資料,傳輸的資料就放在body裡。
POST方法算是在日常工作實踐中使用頻率僅次於GET請求的HTTP方法,甚至在某些個性化約束下,專案中所有的請求都使用POST,連GET都不用。
4)PUT
PUT方法和POST方法十分類似,也可以向伺服器提交資料。但是這兩者其實有一點點微妙的不同,PUT方法目的在於「修改」,而POST則是「新建」。
好吧,你說我知道這個東西有啥用嘛~其實我個人覺得用處不大,因為大多數的實踐用由於兩者太過相似,壓根就不適用PUT,一個POST解決所有的問題。
5)DELETE
DELETE方法用於刪除伺服器的資源,但是由於這個操作對於伺服器來說太過危險,所以伺服器往往都會忽略這個方法,友好一點的就做個假刪除,給資源打個刪除的標記。甚至強硬一點的,直接不搭理你。
6)TRACE
該方法,本意是用於對HTTP請求鏈路的測試和診斷,可以顯示請求-響應的路徑,出發點是好的,但是無奈存在漏洞,會洩漏網站的資訊,所以也是會被伺服器拒絕的。
7)CONNECT
這個方法比較特殊,要求伺服器為使用者端和另外一臺伺服器建立一條通道,這時候,被請求的伺服器就充當了代理的角色。
8)OPTIONS
該方法要求伺服器列出可對該資源使用的方法列表,會在響應頭的Allow欄位中返回。它的功能有限,用處不大,所以有些伺服器根本就沒有對他的實現,比如Nginx。
9)擴充套件
這八個方法我們大致瞭解了一下,總結來說就是常用的經常用,不常用的幾乎沒用,好吧~又廢話了。
還記得我們之前說過,HTTP是靈活且易擴充套件的,所以,對於HTTP的方法來說,也是可以擴充套件的。只要你和伺服器都做好了約定,你可以隨意擴充套件你的HTTP方法。不知道大家還有沒有印象,有一個著名的愚人節玩笑,官方釋出了一個基於HTTP的協定,叫做HTCPCP協定,即超文字咖啡壺協定,為HTTP協定增加了用來煮咖啡的BREW方法,哈哈哈哈。大家有興趣可以看一下,還有RFC檔案呢,編號是2324。
除了HTCPCP對HTTP的玩笑性擴充套件,還有一些在實際應用中擴充套件的請求方法。比如PATCH、LOCK、UNLOCK等,如果有合適的場景,你也完全可以使用這些方法,當然,注意要獲得伺服器的支援。
10)安全與冪等
這兩個概念,還是挺重要的,安全是指請求方法不會破壞伺服器上的資源,冪等則是指多次執行相同請求,每次返回的結果也應該是相同的。
那麼在HTTP的方法裡,GET和HEAD方法是安全的,POST、PUT、DELETE則是不安全的。GET、HEAD、DELETE、PUT則是冪等的,POST則不是冪等的。為啥POST不是冪等的呢,因為多次提交資料會建立多個資源,還記得我們之前說過POST是建立,PUT是更新吧,而多次使用PUT更新一個資源,還是第一次更新的狀態,所以PUT是冪等的。
好啦,方法我們大概都理解了。我們繼續~
四、URI:爸爸和雙胞胎兄弟
額,其實我在之前的一些文章中有過對URI的詳細的講解,比如瀏覽器原理之跨域?跨站?你真的不懂我!和真正「搞」懂HTTP協定01之背景故事中都聊過URI。我在這裡簡單的說說吧,更詳細的可以去檢視這兩篇內容。
其實URI是一個總稱,算是爸爸的角色,而URL和URN則是一個雙胞胎兄弟,URI叫做統一資源識別符號,說白了就是用來在網上找資源的。而URL則是統一資源定位符,用資源在網際網路上的地址作為標識,URN呢則是叫做統一資源名稱,通過檔名來定位網路上的資源。
但是大家再接觸這些東西的時候為啥會覺得混亂呢?其實就是一個兒子太出名了,一個兒子不咋出名,所以漸漸的就忘了那個不咋出名的兒子,把出名的兒子和爸爸搞混了。嗯……就這樣~
這裡我要額外的強調一點,不知道大家在日常的工作中,針對拼接URL往往會有這樣的規範:「/」加頭不加尾。什麼意思呢?比如我們要拼接一個URL字串:
// ok /data-center/queryList // 不ok data-center/queryList/
為啥會這樣要求呢。是因為關於URI的組成的規範。我們簡單來了解下。
一個URI通常由五部分組成:

其實你也可以理解為四部分,"://"是個固定操作。我們分別來解釋下。
1)scheme
其實就是協定名,標識資源應該使用哪種協定來存取。最常見的就是http,當然還有https、ftp等等。
緊隨著scheme後面的就是「://」,它把協定和後面的部分分隔開。這個東東,其實並不是必要的,這個不必要是指從發明者的設計角度來說的,現在,你不得不接受,所以它在使用它是必須的。
2)authority
在「://」之後,就是authority部分,通常就是主機名加埠號的形式,主機名可以是ip或者域名的形式,必須要有。但是埠號可以省略,會有一個預設值,你知道這個預設值是啥麼?
3)path
有了協定、主機名、埠號,再加上這個path,就可以存取網際網路上的資源了。而這個path,就對應了我們最開始所說的那個實踐中拼接URL字串的規範的原因了。
URI裡的path採用了類似檔案系統的「目錄」、「路徑」的表示方式,因為早起的網際網路上的計算機多是UNIX系統,所以就採用了UNIX的「/」風格。它與「://」後面的部分是一致的。這裡要尤其注意的是,URI的path部分必須與「/」開始,也就是必須包含「/」,「/」是path的部分,不是authority的部分。這回你理解了為啥會這樣制定開發規範了吧。
我們再來看個例子:
file:///D:/baidu_download/file
這是我編的啊~~怎麼有三個「/」?這是file協定的特例,它中間省略了主機名,預設就是localhost。你存取原生的機器,自然可以在該協定下省略主機名,但是在網際網路上的可絕對不行噢。
五、HTTP狀態碼:媽媽,他騙我!
這是本篇的最後一節了,我們來聊聊狀態碼。狀態碼是響應頭中最為重要的一個概念,在RFC1945中就定義了一些,當然只有十來個,到了2616,隨著頭欄位的擴充套件,狀態碼也變得多了起來,大概有四十多個,那~~我們需要記住所有的狀態碼麼?甚至於那些在實踐中幾乎用不到的那些?顯然,沒必要,咱們只記住一些核心狀態碼的應用就好了,不是還有Reason呢嘛?如果你記不住數位含義,Reason還可以起到一定的輔助作用。
狀態碼有三十多個,但是在實際的開發應用中,真正最常見的,差不多就是200、500還有301、302、404這幾個。甚至於剛入門的同學們只知道200和500,再甚至於伺服器對一些場景響應的狀態碼,不管什麼原因,直接拋個500就完事了。
狀態碼的核心作用,是告知使用者端伺服器對該次請求的處理結果,是表達伺服器對資料的處理狀態,使用者端可以依據狀態碼來進行後續的處理。
狀態碼很多,但是好在它是有分類的。我們接下來就先來了解一下狀態碼的分類。
RFC標準把狀態碼分為了五類,從100到599,別問為啥,問就是標準規定的。這五類的具體含義,大概是這樣的:
- 1xx:提示資訊,表示請求處理的中間狀態,還需要後續的操作。
- 2xx:成功,報文已經收到並被正確處理。
- 3xx:重定向,資源位置發生了變動,需要使用者端重新傳送請求。
- 4xx:使用者端錯誤,請求報文有問題,伺服器無法處理。
- 5xx:伺服器錯誤,伺服器在處理請求時內部發生了問題。
總共就這五種,但是其實在使用者端與伺服器的請求-應答的模型中,正確的理解這些狀態碼並不僅僅是單方的責任,是伺服器和使用者端都必須要達成一致的理解的。
使用者端作為請求的發起方,在獲取響應報文後,需要正確的理解狀態碼,才能知道後續如何操作,是傳送新的請求還是丟擲一個錯誤?是獲取本地快取資源還是拉去伺服器資料?等等等等,都需要雙方正確理解狀態碼的含義。
而伺服器作為請求的接收方,也要正確的理解運用狀態碼,選擇正確的狀態碼返回給使用者端,指示使用者端下一步要如何操作,特別是在出錯的時候,返回正確的狀態碼就顯得更為重要。
好啦,我們現在對狀態碼有了一個整體的認識和了解,接下來,我們來具體學習一下在實踐中比較容易接觸到的狀態碼,其它沒有聊到的,大家可以自行查閱RFC標準或者來看我之前的翻譯也可以,完全翻譯自RFC標準。
1)1xx
在100這個分類下面,最常見的就是101了。101的含義是Switching Protocol,也就是選擇協定。它需要配合Upgrade欄位,要求在HTTP協定的基礎上改成其它協定繼續通訊,比如WebSocket。如果伺服器同意變更,就會傳送101狀態碼,之後的資料傳輸就不會再使用HTTP協定了。
2)2xx
2xx這個分類表示請求成功,在1945的時候,只有200(OK)、201(Created)、202(Accept)和204(No Content)這四個,到了2616則又擴充套件了三個:203(Non-Authoritative Information)、205(Reset Content)、206(Partial Content),所以在HTTP/1.1的標準中,成功的狀態碼一共有七個。
我們挑兩個重要的來看看。
首先就是200,200這個狀態碼錶示伺服器成功收到了使用者端傳送的訊息,並且成功處理了使用者端的請求,並且成功的返回了使用者端想要的資料。反正就是一切順利~
其次是204,它與200的含義基本上是一模一樣的,也是一切順利,沒啥問題,但是與200的區別是,204不會返回body。對於伺服器來說,正確的區分200和204是很有必要的。
最後是206,這個東西很重要,大家要額外注意一下,206是部分傳輸,是HTTP分塊傳輸或者斷點續傳的基礎,當用戶端傳送「範圍請求」、要求獲取整體資源的部分資料時會出現。它與200的內在含義並無區別,只是伺服器會返回部分資料。206的狀態碼通常會伴隨著「Content-Range」頭欄位,表示響應報文裡資料的具體範圍。
3)3xx
這個類別含義就是重定向,以前的資源找不到了,你得向新的地址重新傳送請求。3xx的狀態碼一共也有八個,但是其中廢棄了一個306,所以只剩下7個了,其中重要的如301、302、304。不那麼重要的比如300——多種選擇(Multiple Choices)、303——參見其他(See Other)、305——使用代理(Use Proxy)、307——臨時重定向(Temporary Redirect)。
我們來著重瞭解下重要的三個3xx狀態碼。
首先是301,永久重定向,意味著你存取的資源已經不存在了,需要通過Location頭欄位指明後續要跳轉到的URI。
與301相似的是302,臨時重定向,它與301最終的結果是一樣的,都會跳轉到新的Location地址,但是兩者在語意和使用場景上有著核心的區別。301是永久,302是臨時。比如你網站的資源位置發生了永久性的變動,或者再比如從http升級到了https協定,但是你不能直接刪除原來的地址,因為老客戶還要用,為了可以直接使用新的https,你需要把請求到舊的地址的請求重定向到新的地址。而302,則意味著資源的位置只是臨時變化,比如午夜的緊急維護,這個時候有睡不著的客戶點進來之後,就可以讓他臨時跳轉到一個新的維護頁面,但是到了第二天維護好了,這個臨時重定向也就不需要了。
304,這個東東稍微有點意思,它的含義是Not Modified,沒有修改。它主要用於If-Modified-Since等條件請求,用於快取控制。它通常不具有任何跳轉含義,但是可以理解為跳轉到了快取,也即快取重定向。
4)4xx
這個分類,意味著使用者端錯誤,整個4xx下的狀態碼有18個之多,我們挑一些來稍微詳細的聊一聊。
400:Bad Request,這個意味著使用者端錯誤,但是也僅僅是使用者端錯誤,伺服器無法理解這次請求,但是具體是什麼錯誤,並沒有詳細準確的說明,只是告訴你錯了,但是卻不告訴你哪裡錯了,實在是讓人惱火,所以,在實踐應用中,儘可能不要出現400這個狀態碼。
403:Forbidden,實際上不是使用者端的請求出錯,而是伺服器拒絕了對該資源的存取。拒絕的原因可能有很多,完全由伺服器控制,如果伺服器友善一點,可能會給你返回原因,但是實踐中大多數都懶得告訴你。
404:Not Found,它的本意是資源不存在,無法在伺服器上找到,所以無法返回給使用者端。但是,在實踐中,不管啥錯誤都可能會被伺服器返回個404,挺煩人的,一點不友好。
你發現了沒有,其實大多數場景下的決定權都在伺服器手裡,使用者端只能對之作出響應,要求,建議,而無法左右。好啦,稍稍跑了下題,我們繼續。剩下的都比較好理解,Reason都把語意說的很清楚。
比如:
405:Method Not Allowed,請求行中指定的方法不允許用於請求URI中標識的資源。響應必須包含一個Allow頭欄位,其中包含對請求資源有效的方法列表。
406:Not Acceptable,資源無法滿足使用者端的條件,比如要請求一箇中文的內容,但是目前只有英文的。
408:Request Timeout,請求超時,很好理解吧。
5)5xx
伺服器錯誤意味著使用者端的請求是沒問題的,但是伺服器在處理時內部發生了錯誤,無法返回應有的響應資料。在2616中,500的狀態碼有6個,我們來看下:
500:Internal Server Error,伺服器錯誤,跟400類似,也是一個通用的伺服器錯誤狀態碼,沒有明確表明到底伺服器到底出了什麼錯,也是我們最常見的伺服器錯誤狀態碼。但是與400不同的是,500的狀態碼可以很有效的避免伺服器洩漏可能的隱私資訊,所以在實踐中幾乎只要報錯就是500就完事了。
501:Not Implemented,大概意思就是使用者端請求的功能還不支援,敬請期待,期待到啥時候,那不知道。
502:Bad Gateway,通常是伺服器作為閘道器或者代理時出現的錯誤,表示伺服器沒問題,但是存取後端服務出了問題,具體啥問題不告訴你。
503:Service Unavailable,表示伺服器當前正忙,暫時無法響應服務,503是一個臨時的狀態,很可能過一會兒就不忙了,可以通過Retry-After欄位可以在多久後再次嘗試。
6)DIY
最後,你猜599這個狀態碼是什麼含義麼?嗯……這個不能留做問題,我得告訴你答案,答案就是,這是我自己定義的狀態碼,Reason叫做Zaking Received。換句話說,HTTP協定是可延伸的,所以狀態碼也是可以擴充套件的,只要你自己定義的狀態碼沒有和標準規定的衝突,那麼你就可以使用,當然,還有個前提,我們之前聊方法的時候也說過,就是必須使用者端和伺服器都可以理解,要做好約定。
然後,最新的RFC9110其實新增了點狀態碼。
六、一個POST請求的小栗子
我們先來寫個使用者端的程式碼,就是個index.html,程式碼如下:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width, initial-scale=1.0" /> <title>Zaking HTTP Demo -05</title> </head> <body> <button id="btn">點我發起請求</button> </body> <script> const btnDom = document.getElementById("btn"); function requestFn() { const xhr = new XMLHttpRequest(); const url = "http://www.zaking.com:8090"; xhr.open("POST", url); xhr.onreadystatechange = function () { if (xhr.readyState === XMLHttpRequest.DONE && xhr.status === 200) { console.log(xhr); console.log(xhr.responseText); } }; xhr.send(); } btnDom.addEventListener("click", requestFn); </script> </html>
很簡單,就是一個原生的ajax請求。然後我們需要提供了一個clinet.js服務,通過讀取index.html返回到頁面上:
const http = require("http");
const fs = require("fs");
const path = require("path");
const hostname = "127.0.0.1";
const port = 9000;
const server = http.createServer((req, res) => {
let sourceCode = fs.readFileSync(
path.resolve(__dirname, "./index.html"),
"utf8"
);
res.end(sourceCode);
});
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
});
也特別簡單,就是讀一下檔案,返回檔案。最後,我們稍稍修改下我們之前用過的那個server.js:
const http = require("http");
const hostname = "127.0.0.1";
const port = 8090;
const server = http.createServer((req, res) => {
res.setHeader("Access-Control-Allow-Origin", "*");
res.end("Hello Zaking World!This is Node");
});
server.listen(port, hostname, () => {
console.log(`Server running at http://${hostname}:${port}/`);
});
因為兩個埠號,所以會有跨域的問題,我們除了加了一個CORS的頭,其他的跟上一小節的那個小小栗子的程式碼沒有任何的區別。
當然,其實這塊也可以通過一個服務來解決問題,通過path來返回不同的內容。一般情況下「/」這個path下就是我們的前端頁面的靜態檔案,然後會通過一些特定的path,比如/api來作為介面的路徑,這樣就沒有跨域的問題,只需要一個服務。只不過我們這裡選擇了另外一種方式作為範例,不重要哈。
然後,見證奇蹟的時刻,我們需要開啟兩個命令列工具,分別輸入這樣的命令:
node ./05/server.js node ./05/client.js
當然,這個具體的命令可能跟你的檔案所在位置的不同稍微有點不同,不重要,理解了就好了。然後,開啟http://www.zaking.com:9000/這個地址,你會看到這樣的介面:

然後,別忘了開啟控制檯的Network,點選發起請求的按鈕:

這就是這次請求的所有內容,我們不關注它的欄位都是幹啥的哈。在Response中,我們也可以拿到正常返回的字串:

或者,我們之前的index.html裡也列印了:
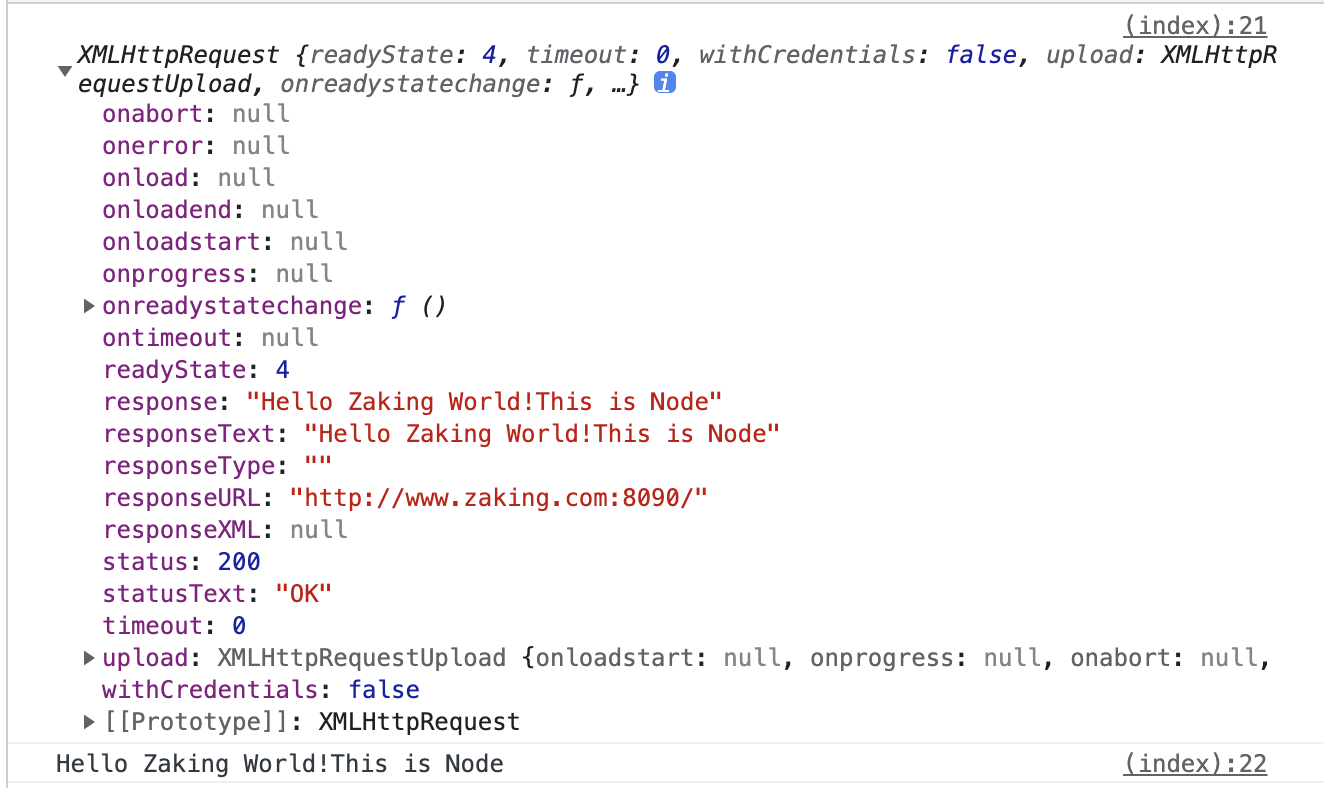
所以,無論從什麼角度來說,這次實驗的請求都是完美成功!
但是,不知道到了這裡你有沒有什麼疑問?我有~~~我server的程式碼明明什麼都沒改啊?怎麼就POST請求也沒啥問題呢。那是不是意味著我用啥請求都行?嗯……我們試試唄,反正程式碼都在這呢,隨便我們怎麼玩,我們把requestFn裡的POST改成PUT:
xhr.open("PUT", url);
然後重新啟動下使用者端的服務,再點下傳送請求:

報錯了?額。。怪我怪我,這個報錯跟我們的核心內容沒關係,還是跨域的問題,我們再給server.js加一行程式碼:
const server = http.createServer((req, res) => { res.setHeader("Access-Control-Allow-Origin", "*"); res.setHeader("Access-Control-Allow-Methods", "*"); res.end("Hello Zaking World!This is Node"); });
再啟動下server.js,然後點下按鈕:
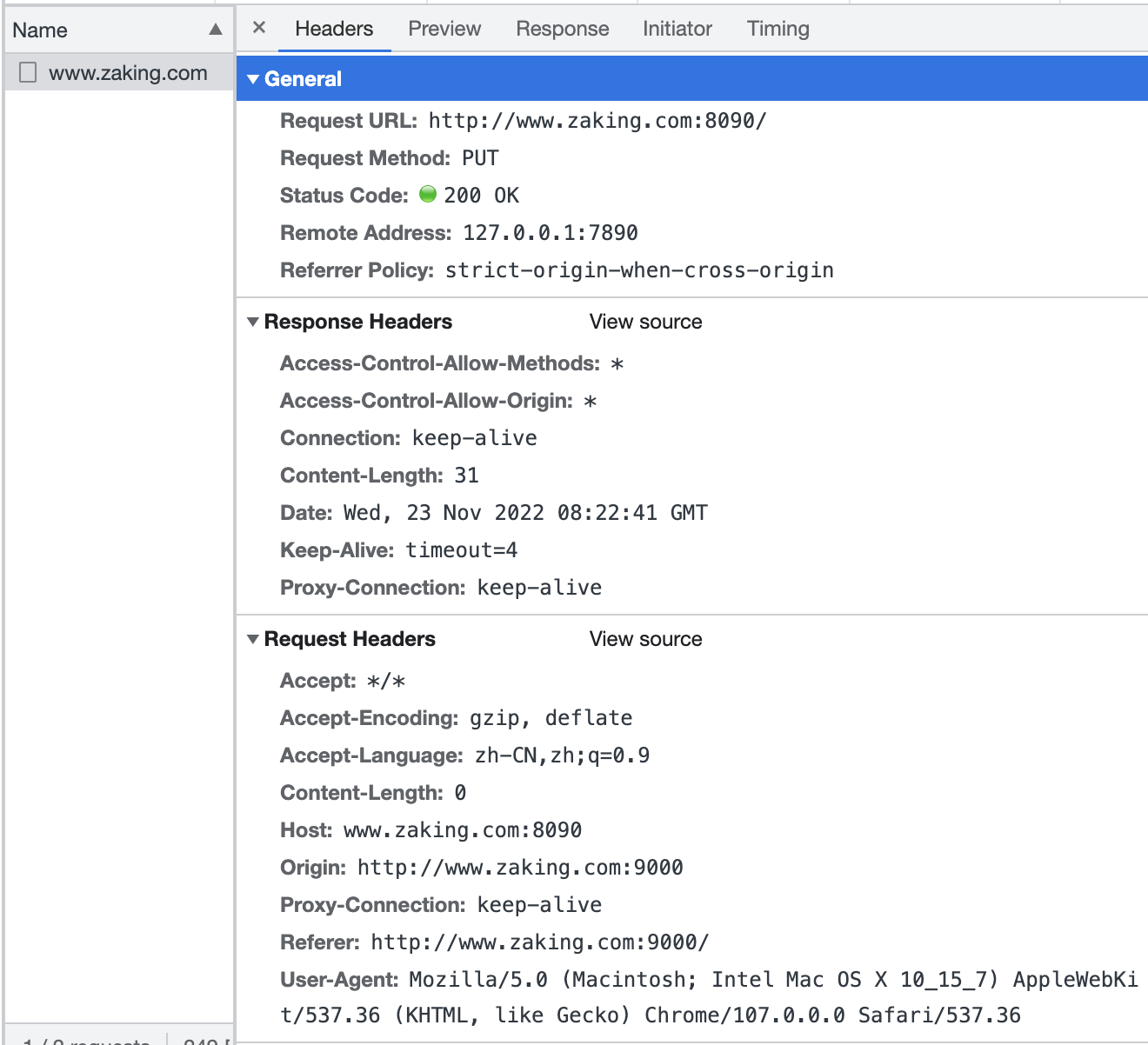
沒問題~~~,再試下DELETE?竟然還是一樣。那再試下HEAD、OPTIONS?你會發現HEAD沒有返回body,OPTIONS跟前面幾個的返回一樣。最後既然都到這裡了,我們就都試一下,也不差這兩個了試下TRACE和CONNECT。我們可以看到TRACE方法報錯了:

還記得我們之前說過的TRACE方法會暴露伺服器資料,不安全,所以注意這裡:是瀏覽器直接報錯了,那這個請求發沒發到伺服器呢?我們在sever.js中列印一下:
const server = http.createServer((req, res) => { console.log("received"); res.setHeader("Access-Control-Allow-Origin", "*"); res.setHeader("Access-Control-Allow-Methods", "*"); res.end("Hello Zaking World!This is Node"); });
然後再重複下之前的步驟。我們發現伺服器壓根沒有列印,所以這個請求直接被瀏覽器攔截,沒有到達伺服器。最後,試試CONNECT。竟然也報錯了,跟TRACE的報錯一樣。好吧。
經過以上的測試,我們發現TRACE和CONNECT方法在瀏覽器中竟然都不支援,OPTIONS、GET、POST、PUT、DELETE等方法如果伺服器沒有去處理這些方法,從感知上來說,竟然沒有區別。HEAD則按照規範要求,沒有返回body。
那我們說TRACE方法,可能會造成問題,所以不被支援,這個還可以理解,但是CONNECT方法為啥也不支援啊?嗯……因為我們試驗的場景是瀏覽器環境下的http請求,如果是伺服器對伺服器發起請求,是否就可以使用CONNECT了呢?再有,GET請求是不能傳送body的,但是在伺服器作為發起方的時候是否就可以傳送body了呢?
我們先來看看GET能不能發body,我們建立一個request-server.js,程式碼如下,也是從官網複製下來的:
const http = require("http");
const postData = JSON.stringify({
msg: "Hello World!",
});
const options = {
hostname: "www.zaking.com",
port: 8090,
path: "/",
method: "GET",
headers: {
"Content-Type": "application/json",
"Content-Length": Buffer.byteLength(postData),
},
};
const req = http.request(options, (res) => {
console.log(`STATUS: ${res.statusCode}`);
console.log(`HEADERS: ${JSON.stringify(res.headers)}`);
res.setEncoding("utf8");
res.on("data", (chunk) => {
console.log(`BODY: ${chunk}`);
});
res.on("end", () => {
console.log("No more data in response.");
});
});
req.on("error", (e) => {
console.error(`problem with request: ${e.message}`);
});
// Write data to request body
req.write(postData);
req.end();
啥也沒動哈,就是官網的程式碼。然後,我們直接執行這個服務,怎麼啟動就不多說了。結果是這樣的:
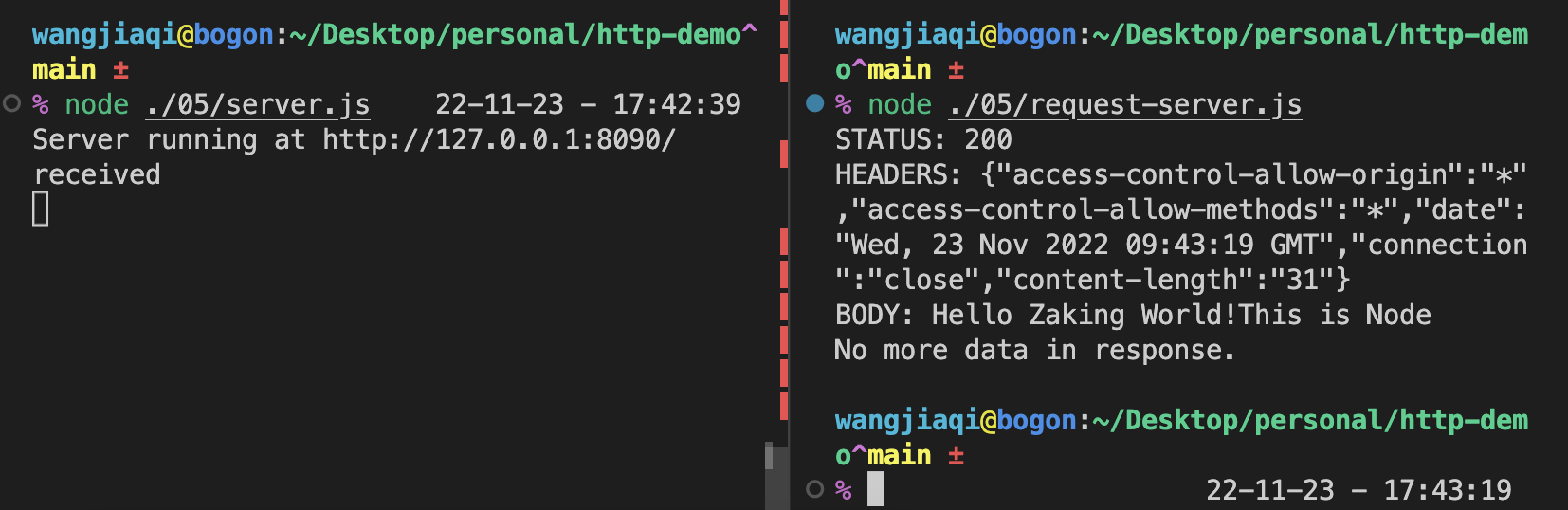
是可以的對吧?
CONNECT有點複雜,我也不會了,就這樣吧。哈哈哈哈。我猜測CONNECT和TRACE其實都可以在伺服器端得到支援,只是我不知道怎麼搞這個例子。
快完事了~我們在來看看返回一些狀態碼是什麼樣的。就先看看500吧。回到之前的程式碼,我們稍微修改下server.js:
const server = http.createServer((req, res) => { console.log("received"); res.setHeader("Access-Control-Allow-Origin", "*"); res.setHeader("Access-Control-Allow-Methods", "*"); res.statusCode = 500; res.end("Hello Zaking World!This is Node"); });
然後把index.html中的請求方法改成GET。我們發現一個問題:

返回了500,沒問題,但是~

結果還是返回到瀏覽器了,但是控制檯卻沒有列印,只有個500的錯誤:

這說明資料還是從伺服器返回到瀏覽器了,但是因為瀏覽器發現是500,就沒有把body再傳給javascript引擎去處理了。當然,還有其他的各種方法,這裡就不再多說,大家有興趣可以自己用程式碼試一下。還有一些特殊的狀態碼要配合頭欄位使用的,後面我還會詳細的聊。
我們再試一個有趣的我之前說過的,叫做599的狀態碼。程式碼呢這樣改:
const server = http.createServer((req, res) => { console.log("received"); res.setHeader("Access-Control-Allow-Origin", "*"); res.setHeader("Access-Control-Allow-Methods", "*"); res.statusCode = 599; res.statusMessage = "Zaking Not Know"; res.end("Hello Zaking World!This is Node"); });
結果是這樣的:

是不是,很有趣?
終於~這一章結束啦~
七、總結
這一章我們聊的內容不少,需要大家好好消化一下,是我們後面學習的重要的基礎。我們稍微回顧一下我們都學了什麼。首先我們先學了下HTTP的優缺點,讓大家對HTTP有一點稍微詳細的認識。
再往後,我們學了下HTTP的方法,HTTP的方法不少,但是實際上我們在實際使用中的就那麼幾個,大家要注重學習,另外要額外關注下安全和冪等的含義。
然後,我們還簡單學了下URI,這部分其實很重要,但是我之前寫過了,所以不想再重複的寫,大家要深入的瞭解可以再去看看我之前寫的文章。
最後,理論的部分就只剩下狀態碼了,狀態碼很多,有40多個。我簡單的講解了其中一些常見的狀態碼,還有一部分,會在後續的學習中更加深入的去學習。
在理論結束之後,我們還寫了個小例子,這個例子測試了瀏覽器發起的各種請求方法。還試了一下500狀態碼的樣子。
最後,按照慣例,留點小問題給大家:
1、其實我在第四節所畫出來的URI是簡寫形式,你知道它的完全體是什麼樣的麼?為什麼完全體很少使用呢?
2、URI後的query部分可以傳輸Object或者Array型別的資料麼?或者說,GET方法可以傳Object或者Array型別的資料麼?
3、伺服器發起的GET請求可以傳送body麼?瀏覽器呢?
4、HTTP的狀態碼一定符合它的描述麼?
5、為什麼在狀態碼的那一小節,我會起一個那樣的標題呢?
本篇所有內容,只是限定在RFC2616,其實說起來有點過時了,但是重要的內容確實也還是這些,後續可能會因為講解深入再涉及到,也可能會涉及不到,關於方法和狀態碼的最新的額外的內容,大家其實完全可以自行學習了。
填坑
- TCP是有狀態的協定,他需要通過狀態來維護通訊雙方的連線狀態,可以理解為連線雙方的一個標誌,用來記錄連線建立到了什麼階段,後續的情況如何處理等等。詳情可以參考之前聊過的三次握手和四次揮手。順帶說一句,TCP是有連線有狀態的,而UDP是無連線無狀態的。
- HTTP關於靈活可延伸延伸的特點有:比如,壓縮,國際化,快取,身份認證也就是HTTPS啦,等等,等等。
- 最後,其實本篇留下了個connect的那個坑,但是那個坑我覺得不太重要,我又確實不會,所以就不填了。