《Hierarchical Text-Conditional Image Generation with CLIP Latents》閱讀筆記
概括
模型總述
本篇論文主要介紹DALL·E 2模型,它是OpenAI在2022年4月推出的一款模型,OpenAI在2021年1月推出了DALL·E模型,2021年年底推出了GLIDE模型。
DALL·E 2可以根據文字描述去生成原創性的、真實的影象,這些影象從來沒有在訓練集裡出現過,模型真的學習到了文字影象特徵,可以任意地組合其概念、屬性、風格。
DALL·E 2除了根據文字生成影象,還能根據文字對已有的影象進行編輯和修改——可以任意新增或者移除影象裡的物體,修改時甚至可以把陰影、光線和物體紋理都考慮在內。
DALL·E 2可以在沒有文字輸入的情況下,做一些影象生成的工作——比如給定一張影象,它可以根據已有的影象和它的風格,去生成很多類似這種風格的影象。
DALL·E 2顛覆了人們對於AI的傳統理解——AI不止可以處理重複性工作,也能勝任創造性工作。
DALL·E 2和DALL·E相比,解析度是前者的四倍,且生成的影象更真實,與文字描述更貼切。
考慮到安全性和倫理性方面,DALL·E 2沒有開源,連API也沒有開放。
發展歷程

標題
基於CLIP的分層文字條件影象生成——使用CLIP訓練好的特徵,來做層級式的依託於文字的影象生成工作。
所謂的層級式,意思是DALL·E 2模型是先生成一個64 * 64的小解析度影象,再利用一個模型上取樣到256 * 256,然後繼續利用一個模型上取樣到1024 * 1024,得到最終的一個高清大圖,所以說是一個層級式的結構。
摘要
本文提出了一個兩階段的模型:
- prior根據給定的文字描述,生成類似於CLIP的影象特徵,prior嘗試了自迴歸模型和擴散模型,發現擴散模型效率高且效果好;
- decoder根據生成的影象特徵生成影象,decoder用的是擴散模型。
該模型有兩個亮點:
- 生成的影象的寫實程度和文字匹配度非常高;
- 可以實時利用文字資訊引導模型生成、編輯各種影象,且不需要訓練(zero-shot)。

引言
CLIP的優點:
- 對影象分佈的變化很敏感,具有很強的zero-shot能力,並經過微調,在各式的視覺和語言任務中表現優異。
生成擴散模型的優點:
- 很有前景,在近期的研究中,它利用了一種引導技術,通過犧牲一部分多樣性,從而達到更好的影象保真度。

在圖示中,虛線的上半部分是CLIP的訓練過程,虛線的下半部分描述的DALL·E 2的訓練過程。
對於CLIP,在訓練時,將文字以及對應的影象分別輸入文字編碼器和影象編碼器,然後得到輸出的文字特徵和影象特徵,這兩個特徵就是一個正樣本,該文字特徵與其他影象生成的影象特徵就是負樣本,通過對比學習,訓練文字編碼器和影象編碼器,從而實現文字的特徵和影象的特徵聯絡在一起,成為一個合併的多模態的特徵空間。一旦CLIP模型訓練結束,文字編碼器和影象編碼器就凍結了。在DALL·E 2的訓練過程中,CLIP就處於凍結狀態,沒有進行任何訓練和微調。
對於DALL·E 2,在訓練時,首先將文字和對應的影象分別輸入CLIP的文字編碼器和影象編碼器,在拿到文字特徵後,將其喂入prior模型,由它生成影象特徵,在這個過程中,由CLIP影象編碼器生成的影象特徵充當了ground truth的角色進行監督;在推理時,也就是隻有文字沒有配對影象的時候,其過程就是將文字輸入CLIP文字編碼器生成文字特徵,文字特徵通過prior模型生成影象特徵,影象特徵通過擴散模型生成最後的影象。DALL·E 2其實就是把CLIP和GLIDE合在一起,GLIDE模型是一個基於擴散模型的文字影象生成的方法。
DALL·E 2也被作者稱為unCLIP。對於CLIP來說,它是給定文字和影象,然後得到特徵,可以拿特徵去做影象匹配、影象檢索之類的工作,是一個從輸入到特徵的過程;對於DALL·E 2來說,它是通過文字特徵,然後到影象特徵,最後到影象的過程,其實就是CLIP的反過程,把特徵又還原到資料,所以整個框架叫做unCLIP。
方法
訓練資料集採用影象文字對,給定影象x,用zi表示從CLIP出來的影象特徵,zt表示從CLIP出來的文字特徵,整個模型的網路結構被分成prior模型和decoder模型。

首先準備一個CLIP模型,然後訓練DALL·E 2的影象生成模型——給定任意文字將它通過CLIP的文字編碼器,得到一個文字特徵,然後用prior模型把文字特徵變成影象特徵,再通過一個解碼器,把影象特徵變成了幾張影象。

P(x|y)表示給定一個文字y,生成影象x的概率;
P(x,zi|y)表示給定一個文字y,生成影象x和影象特徵zi的概率。因為影象特徵zi和影象是一對一的關係,所以zi和x是對等的,所以左邊第一個等號成立;
P(x|zi,y)表示給定一個文字y和影象特徵zi去生成影象x的概率(decoder);
P(zi|y)表示給定一個文字y,生成影象特徵zi的概率(prior)。
decoder
本文的解碼器其實就是GLIDE模型的變體,用了CLIP guidance和classifier-free guidance。
guidance訊號要麼來自CLIP模型,要麼來自於文字,作者隨機設10%的時間令CLIP的特徵為0,並且訓練的時候有50%的時間把文字直接丟棄。
在生成影象時採用級聯式生成的方法,由64 * 64逐步生成得到1024 * 1024的高清大圖,為了訓練的穩定性,在訓練時加了很多噪聲。
prior

prior模型不論是用自迴歸模型還是擴散模型,都使用了classifier-free guidance。
對於擴散prior來說,作者訓練了一個Transformer的decoder,因為它的輸入輸出是embedding,所以不合適用U-Net,選擇直接用Transformer處理這個序列。
應用
影象生成
生成給定影象的很多類似影象,所生成的影象風格和原始影象一致,影象中所出現的物體也大體一致。
其方法是當用戶給定一張影象的時候,通過CLIP的影象編碼器得到一個影象特徵,把影象特徵變成文字特徵,再把文字特徵輸入給prior模型生成另外一個影象特徵,這個影象特徵再生成新的影象。

兩個影象之間做內插
給定兩張影象,在兩張影象的影象特徵之間做內插,當插出來的特徵更偏向於某個影象時,所生成的影象也就更多地具有該影象的特徵。

兩個文字之間做內插

結果

不足
不能很好地把物體和屬性聯絡起來(很有可能是CLIP模型的原因)。

當生成的影象裡有文字時,文字是錯誤的(有可能是文字編碼器使用了BPE編碼)。

不能生成特別複雜的場景,很多細節生成不出來。

相關概念
Generative Adversarial Networks(GAN):生成對抗網路
GAN包含有兩個模型,一個是生成模型(generative model),一個是判別模型(discriminative model)。
生成模型的任務是生成看起來自然真實的、和原始資料相似的範例。判別模型的任務是判斷給定的範例看起來是自然真實的還是人為偽造的(真實範例來源於資料集,偽造範例來源於生成模型)。
這可以看做一種零和遊戲,生成模型像「一個造假團伙,試圖生產和使用假幣」,而判別模型像「檢測假幣的警察」。生成器(generator)試圖欺騙判別器(discriminator),判別器則努力不被生成器欺騙。模型經過交替優化訓練,兩種模型都能得到提升,但最終我們要得到的是效果提升到很高很好的生成模型(造假團伙),這個生成模型(造假團伙)所生成的產品能達到真假難分的地步。因為GAN的目標函數是用來以假亂真的,所以截至目前為止,GAN生成的影象保真度非常高,引燃了DeepFakes的火爆,但是它的多樣性不好,且不太具備原創性,這也是最近的模型如DALL·E 2和Imagen都是用擴散模型的原因,因為擴散模型多樣性好,還有創造力。
GAN的缺點
- 訓練不夠穩定,最主要的原因是要同時訓練兩個網路,所以有一個平衡的問題,容易發生模型的訓練坍塌;
- 生成影象的多樣性不好,本質是創造性不好;
- 不是一個概率模型,它的生成都是隱式的,就是通過一個網路去完成,無法獲知它到底做了什麼、遵循了什麼分佈,所以GAN在數學上不如後續的VAE,或者擴散模型。
Auto-Encoder(AE):自編碼器
是一種無監督式的學習模型,它基於反向傳播演演算法與最佳化方法(如梯度下降法),利用輸入資料X本身作為監督,來指導神經網路嘗試學習一個對映關係,從而得到一個重構輸出XR。
演演算法模型包含Encoder(編碼器)和Decoder(解碼器)。
編碼器的作用是把高維輸入X編碼成低維隱變數h從而強迫神經網路學習最有資訊量的特徵;
解碼器的作用是把隱藏層的隱變數h還原到初始維度,最好的狀態就是解碼器的輸出能夠完美地或者近似恢復出原來的輸入, 即XR≈X 。

從輸入層 ->隱藏層的原始資料X的編碼過程:
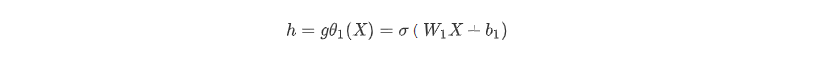
從隱藏層 -> 輸出層的解碼過程:

演演算法的優化目標函數:

其中dist為二者的距離度量函數,通常用MSE(均方方差)。
自編碼可以實現類似於PCA等資料降維、資料壓縮的特性。如果輸入層神經元的個數n大於隱層神經元個數m,那麼就相當於把資料從n維降到了m維;然後可以利用這m維的特徵向量,重構原始的資料。這個跟PCA降維一模一樣,只不過PCA是通過求解特徵向量進行降維,是一種線性的降維方式,而自編碼是一種非線性降維。
Denoising Auto-Encoder(DAE):去噪自編碼器
先向輸入注入噪聲,然後把經過擾亂的輸入傳給編碼器,讓解碼器重構不含噪聲的輸入。
這種方法可以讓訓練的模型非常穩健,不容易過擬合,部分原因是因為影象畫素冗餘度太高了,所以即使把原來的影象做一些汙染,模型還是能抓住它的本質,將它重建出來。
Variational Auto-Encoder(VAE):變分自編碼器
VAE其實跟AE很不一樣,它不再是學習固定的隱藏層特徵了,而是在學習一種分佈,比如假設這個分佈是一個高斯分佈,可以用均值和方差描述,編碼器不再直接輸出h,而是輸出h分佈的均值和方差,再從這個分佈中取樣得到h,然後h再通過解碼器。簡而言之,VAE預測的是一個分佈。
Vector Quantized VAE(VQ-VAE):向量量化的變分自編碼器
就是把VAE做量化,它採用的是離散的隱變數,不像VAE那樣採用連續的隱變數。
VQ-VAE2
把隱空間分成了兩個,一個上層隱空間(top latent space),一個下層隱空間(bottom latent space)。上層隱向量 用於表示全域性資訊,下層隱向量 用於表示 區域性資訊。
DALL·E
由OpenAI提出的能根據文字描述生成類似超現實主義影象的影象生成器。
autoregressive models(AR):自迴歸模型
自迴歸模型是統計上一種處理時間序列的方法,用同一變數例如x的之前各期,亦即x1至xt-1來預測本期xt的表現,並假設它們為線性關係。因為這是從迴歸分析中的線性迴歸發展而來,只是不用x預測y,而是用x預測 x(自己),所以叫做自迴歸。神經網路中的自迴歸模型,將聯合概率拆成了條件概率累乘的形式。
diffusion models:生成擴散模型
diffusion models名字來源於熱力學的啟發,工作原理從本質上來說是通過連續新增高斯噪聲來破壞訓練資料,然後通過反轉這個噪聲過程,來學習恢復資料。
它是Encoder-Decoder架構的模型,分為擴散階段和逆擴散階段。
-
在擴散階段,通過不斷對原始資料新增噪聲,使資料從原始分佈變為我們期望的分佈,例如通過不斷新增高斯噪聲將原始資料分佈變為正態分佈。
-
在逆擴散階段,使用神經網路(U-Net,一個CNN)將資料從正態分佈恢復到原始資料分佈。
訓練後,可以使用該模型將原始輸入的影象去噪生成新影象。
優點是正態分佈上的每個點都是真實資料的對映,模型具有更好的可解釋性。缺點是迭代取樣速度慢,導致模型訓練和預測效率低。
擴散模型早在2015年或者更早的時候就被提出來了,但當時只是一個想法,一直到2020年6月DDPM提出來後,擴散模型才開始火爆,DDPM算是擴散模型的開山之作。
DDPM對原始的擴散模型做了一些改進,把優化過程變得簡單,有兩個最重要的貢獻:
- 之前大家都是xt預測xt-1,做影象到影象的轉化,而DDPM預測xt-1到xt的噪聲是怎麼加的,有點像ResNet,本來是直接用x預測y,現在理解成y=x+residual,轉而預測殘差residual就可以了;
- 原本預測一個正態分佈,要去學它的均值和方差,作者提出可以把方差視為一個常數,只要去預測均值就可以了,再次降低了模型優化的難度。
DDPM和VAE有很多相似之處,都是編碼器、解碼器的結構,不同點在於:
- 在擴散模型中,編碼器的一步步運算是一個固定的過程,對於VAE來說,編碼器則不是這樣;
- 在擴散模型中,每一步中間過程的輸出跟剛開始的輸入都是同樣維度的大小,對於VAE來說,它中間的bottleneck特徵往往比輸入小得多;
- 在擴散模型中,從隨機噪聲開始,要經過很多步才能生成一個影象,所以它有time step、time embedding的概念,而且在所有的time step裡面它的U-Net模型都是共用引數的,在VAE裡就不存在這一點。
improved DDPM相較於DDPM做了一些改進:
- 學習了正態分佈裡的方差,效果更好;
- 把新增噪聲的schedule改了,從一個線性的schedule改成了餘弦的schedule,效果更好;
- 簡單嘗試了一下給擴散模型上更大的模型,效果更好。
基於improved DDPM的第三個改進,有人發表了論文《Diffusion model beats GAN》,即擴散模型比GAN強。在文中:
- 作者把模型加大加寬,增加自注意力頭(attention head)的數量;
- 發現single-scale的attention不夠用,改用multi-scale的attention;
- 提出新的歸一化方式,叫做adaptive group normalization,根據步數去做自適應的歸一化;
- 使用classifier guidance的方法,去引導模型做取樣和生成,這不僅讓生成的影象更加逼真,而且也加速了方向取樣的速度。論文中表明做25次取樣,就能從一個噪聲生成一個非常好的影象。

classifier guidance diffusion是說在我們訓練擴散模型的同時,再訓練一個影象分類器,這個分類器是在ImagNet上的影象加上噪聲訓練來的。分類器的作用是對於影象xt,它可以計算一個交叉熵目標函數,得到一些梯度,然後使用這個梯度,去幫助模型進行取樣和影象生成。分類器可以根據需求進行選擇,把分類器換成CLIP模型,那麼文字和影象就聯絡起來了,此時我們不光可以利用梯度去引導模型的取樣和生成,甚至可以利用文字去控制影象的取樣和生成。
classifier guidance diffusion的成本很高,它要求我們要麼有一個pre-trained的模型,要麼得重新訓練一個模型,所以引出來後續的classifier-free guidance。
classifier-free guidance不使用分類器,而是在訓練模型的時候讓它生成兩個輸出,一個是在有條件時生成的,一個是在無條件時生成的。比如用影象文字對訓練的時候,用文字去做這個guidance訊號,生成一個影象,然後不用這個文字,而用一個空的序列,再去生成另外一個影象。假設生成的兩個影象在一個空間裡,那麼就會有一個方向能從這種無文字得到的影象指向有文字得到的影象,通過訓練得到二者之間的距離,那麼等到反向擴散的時候,即使我們的影象輸出是沒有使用文字生成的,我們也能做出一個比較合理的推理,從一個沒有條件生成的x變成一個有條件生成的x,擺脫分類器的限制。這個方法因為產生兩個輸出,模型的訓練成本是很大的。在GLIDE、DALL·E 2、Imagen都使用了classifier-free guidance。
Contrastive Learning:對比學習
是一種自監督學習方法,用於在沒有標籤的情況下,通過讓模型學習哪些資料點相似或不同來學習資料集的一般特徵。
zero-shot learning:零次學習
它是利用訓練集資料訓練模型,使得模型能夠對測試集的物件進行分類,但是訓練集類別和測試集類別之間沒有交集,期間是藉助類別的描述,來建立訓練集和測試集之間的聯絡,從而使得模型有效。對於要分類的類別物件,是一次也不學習的。
PCA( Principal Component Analysis ):主成分分析
是一種使用最廣泛的資料降維演演算法。PCA的主要思想是將n維特徵對映到k維上,這k維是全新的正交特徵也被稱為主成分,是在原有n維特徵的基礎上重新構造出來的k維特徵。PCA的工作就是從原始的空間中順序地找一組相互正交的座標軸,新的座標軸的選擇與資料本身是密切相關的。其中,第一個新座標軸選擇是原始資料中方差最大的方向,第二個新座標軸選取是與第一個座標軸正交的平面中使得方差最大的,第三個軸是與第1,2個軸正交的平面中方差最大的。依次類推,可以得到n個這樣的座標軸。
Embedding:嵌入層
它能把萬物嵌入萬物,是溝通兩個世界的橋樑。數學定義即:它是單射且同構的。
簡單來說,我們常見的地圖就是對於現實地理的Embedding,現實的地理地形的資訊其實遠遠超過三維,但是地圖通過顏色和等高線等來最大化表現現實的地理資訊。通過它,我們在現實世界裡的文字、影象、語言、視訊就能轉化為計算機能識別、能使用的語言,且轉化的過程中資訊不丟失。
可以通過矩陣乘法進行降維,假如我們有一個100W X10W的矩陣,用它乘上一個10W X 20的矩陣,我們可以把它降到100W X 20,瞬間量級降了10W/20=5000倍;也可以進行升維,對低維的資料進行升維時,可能把一些其他特徵給放大了,或者把籠統的特徵給分開了。
Feature Embedding:特徵嵌入
將資料轉換(降維)為固定大小的特徵表示(向量),以便於處理和計算(如求距離)。
Image Embedding:影象嵌入
將影象轉換成n維的特徵向量。
Word Embedding:詞嵌入
將非結構化的文字轉換為n維結構化的特徵向量。
- 可以將文字通過一個低維向量來表達,不像 one-hot 那麼長;
- 語意相似的詞在向量空間上也會比較相近;
- 通用性很強,可以用在不同的任務中。
latent space:潛在空間
原始資料壓縮(編碼)後的表示(即特徵向量)所在的空間,即為潛在空間。
- 潛在空間只是壓縮資料的表示,其中相似的資料點在空間上更靠近在一起;
- 潛在空間對於學習資料特徵和查詢更簡單的資料表示形式以進行分析很有用;
- 可以通過分析潛在空間中的資料(通過流形,聚類等)來了解資料點之間的模式或結構相似性;
- 可以在潛在空間內插值資料,並使用模型的解碼器來「生成」資料樣本(比如生成新影象);
- 可以使用t-SNE和LLE之類的演演算法來視覺化潛在空間,該演演算法將潛在空間表示形式轉換為2D或3D。
State Of The Art (SOTA)
表示效果最好的方法。
主要參考
- DALL·E 2【論文精讀】;
- 網上相關參考資料。