資料統計與視覺化複習總結(二):非引數檢驗、生存分析

前面所介紹的各種檢驗法,是在總體分佈型別已知的情況下,對其中的未知引數進行檢驗統稱為引數檢驗.
在實際問題中,有時我們並不能確切預知總體服從何種分佈,這時就需要根據來自總體的樣本對總體分佈進行推斷,以判斷總體服從何種分佈, 這類統計檢驗稱為非引數檢驗.解決這類問題的工具是英國統計學家K.皮爾遜在1900年發表的一篇文章中引進的所謂\(\chi^2\)檢驗法,不少人把此項工作視為近代統計學的開端.
非引數檢驗
分佈擬合優度檢驗
卡方檢驗
卡方檢驗的基本思想
\(\chi^2\)檢驗法是在總體X 的分佈未知時, 根據來自總體的樣本,檢驗關於總體分佈的假設的一種檢驗方法.
具體進行檢驗時,先提出原假設:
如果總體分佈為離散型,則假設具體為
如果總體分佈為連續型,則假設具體為
然後根據樣本的經驗分佈和所假設的理論分佈之間的吻合程度來決定是否接受原假設, 這種檢驗通常稱作擬合優度檢驗,它是一種非引數檢驗.
一般地,我們總是根據樣本觀察值用直方圖和經驗分佈函數,推斷出可能服從的分佈,然後作檢驗.
卡方檢驗的基本原理和步驟
-
提出原假設H_0:總體X的分佈函數為F(x).
-
將總體X的取值方位分成k個互不相交的小區間,記為\(A_1,A_2,...,A_k\),如可取為
\[\left(a_{0}, a_{1}\right],\left(a_{1}, a_{2}\right], \cdots,\left(a_{k-2}, a_{k-1}\right],\left(a_{k-1}, a_{k}\right) \]其中 $ a_{0} $可取 $ -\infty$, $a_{k} $ 可取 $+\infty $. 區間的劃分視具體情況而定, 使每個小區間所含樣本值個數不小於5,而區間個數k不要太大也不要太小.
-
把落入第\(i\) 個小區間\(A_i\)的樣本值的個數記作\(f_i\)稱為組頻數,所有組頻數之和\(f_1+f_2+...+f_k\)等於樣本容量n.

皮爾遜證明了下列 定理:
定理 當n充分大 $ (n \geq 50)$ 時, \(\chi^{2}\)近似服從$\chi^{2}(k-1) $ 分佈.
- 根據定理, 對給定的顯著性水平 $ \alpha$ , 確定 \(l\) 值, 使 $ P\left{\chi^{2}>l\right}=\alpha$ , 查 $\chi^{2} $ 分佈表得, \(l=\chi_{\alpha}^{2}(k-1)\) , 所以拒絕域為$\chi{2}>\chi_{\alpha}{2}(k-1) $.
通常是一個單邊(右側)檢驗。雙邊的情況下,左側檢驗「too good to be true」
- 若由所給的樣本值 $ x_{1}, x_{2}, \cdots, x_{n}$ 算得統計量 $ \chi^{2} $ 的實測值落入拒絕域, 則拒絕原假設 \(H_{0}\) , 否則就認為差異不顯著而接受原假設 $ H_{0}$ .
總體含未知引數的情形

OR卡方檢驗:ODDS RATIO CHI SQUARE TEST
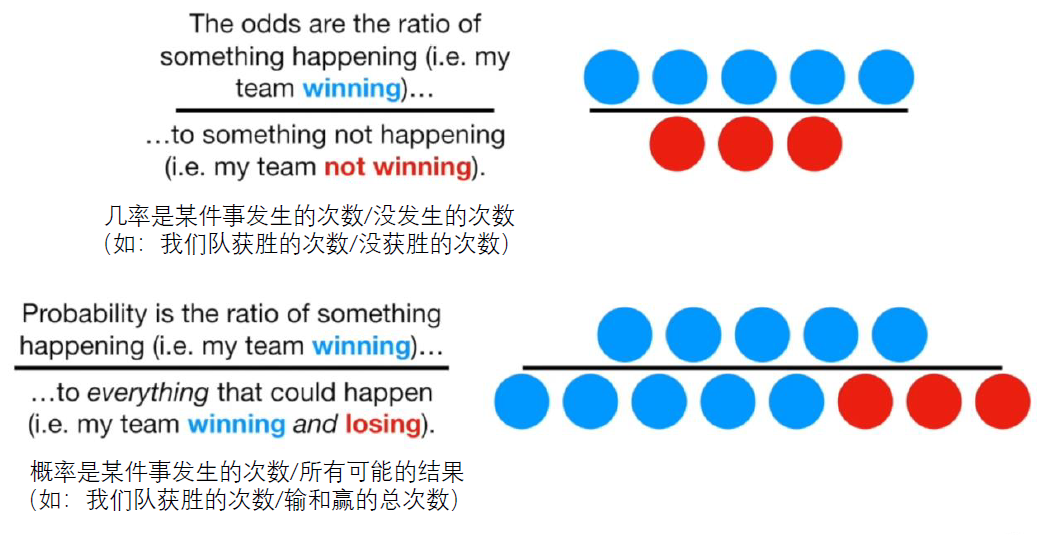
機率
在統計學中,列聯表Contingency tables(也稱為交叉表或交叉列表)是一種矩陣式的表格,它可以顯示變數的(多變數)頻率分佈。
注:概率之比的對數稱為logit 函數 它是邏輯迴歸的基礎

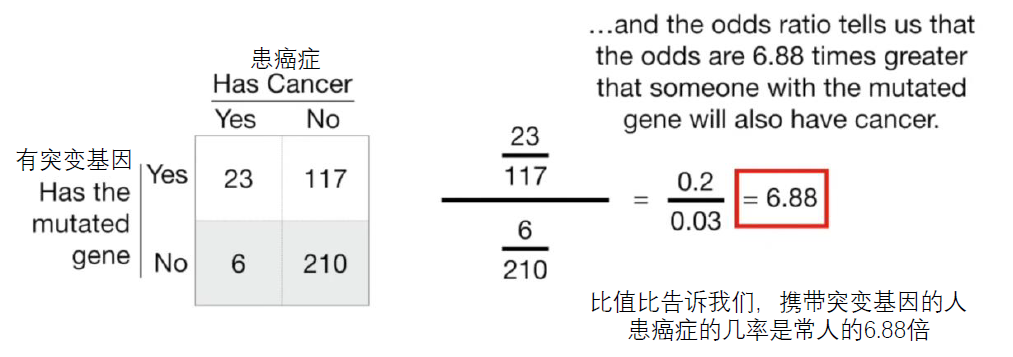
與odds 相關的另一個概念 OR
OR值( odds ratio )又稱 機率比、比值比、 優勢比,主要指病例組中暴露人數與
非暴露人數的比值除以對照組中暴露人數與非暴露人數的比值,是流行病學 研究中
病例對照研究中的一個常用指標

有三種方法可以確定比值比或其對數是否具有統計學意義:

卡方檢驗
常用於檢驗行和列變數之間是否相關的檢驗方法是卡方檢驗。卡方檢驗首先假設行和列變數之間是相互獨立的,並得到期望頻數,通過比較所有期望頻數和實際觀測頻數的差異來構造一個卡方統計量,如果卡方統計量大於臨界值,則說明差異過大,因而假設不成立,行變數和列變數不相互獨立;反之,則認為行和列變數相互獨立。卡方統計量的計算公式為:
$f_{i j} $ 表示實際觀測頻數;$f_{i j}^{e} $表示期望頻數;r和c分別代表行和列變數的各類個數
對於二項分佈檢驗
p值是發現比觀察值「更極端」的可能性。
如果test prop = 0.5,採用雙側檢驗,否則單側檢驗。
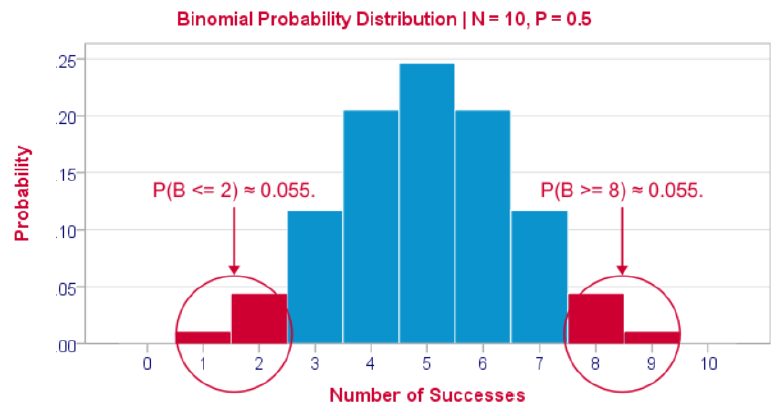
Binomial Test – A further explanation:二項分佈—進一步的解釋
如果總體比例為0.5,我們選取10個觀察結果,最可能的結果是5次成功:P(B=5)≈0.24。4或6次成功也是可
能的結果(P≈0.2)。發現兩次或更少成功的概率是0.055。這是單側p值。現在,非常低或非常高的成功概
率都是不可能的結果,都應該讓我們對零假設產生懷疑。因此,我們考慮了相反結果的p值——8次或更多的成
功——也就是0.055。
就像這樣,我們得到了雙邊p值為0.11。如果我們抽取1000個樣本而不是1個,那麼當總體比例為0.5時,大
約11%的樣本會產生2(-)或8(+)次成功。我們的樣本結果應該出現在一個合理的百分比的樣本中。由於11%
的概率不是很小,我們的樣本並不能反駁原假設。
對於N = 100的樣本,根據中心極限定理,二項分佈實際上與正態分佈無異。結果是,對於較大的樣本量,對單個比例的z檢驗(使用標準正態分佈)將產生與二項檢驗(使用二項分佈)幾乎相同的p值。但為什麼我們更喜歡z檢驗而不是二項檢驗呢? 原因如下:
• 我們可以用兩側(雙邊)z檢驗。然而,除非p=0.5,二項檢驗總是單側的。
• z檢驗允許我們計算樣本佔比的置信區間。我們可以很容易地估計z檢驗的勢(power),但二項檢驗卻不行。
• z檢驗的計算量較小,特別是對於較大的樣本量。
什麼時候可以用z檢驗代替二項檢驗呢?經驗法則是pn和(1 - p)n必須都> 5
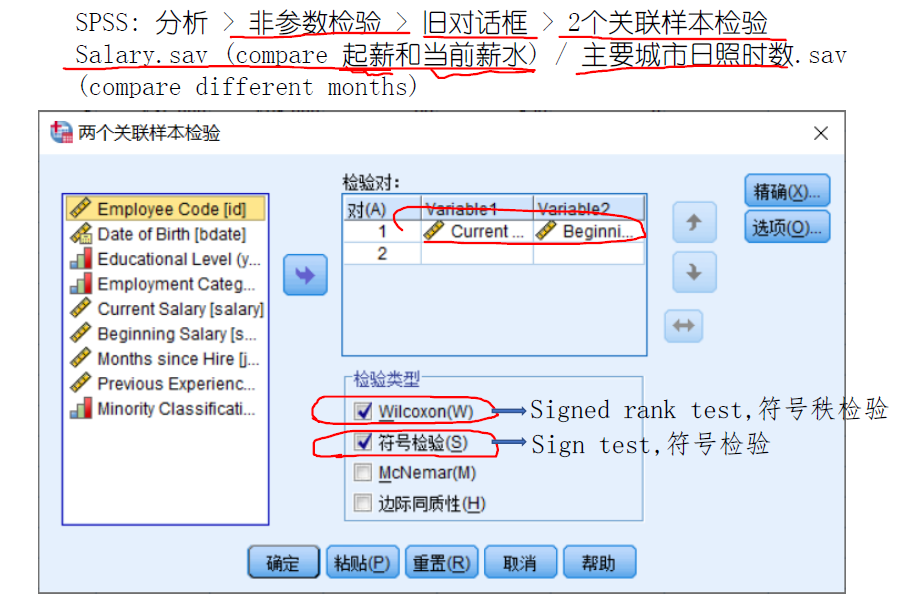
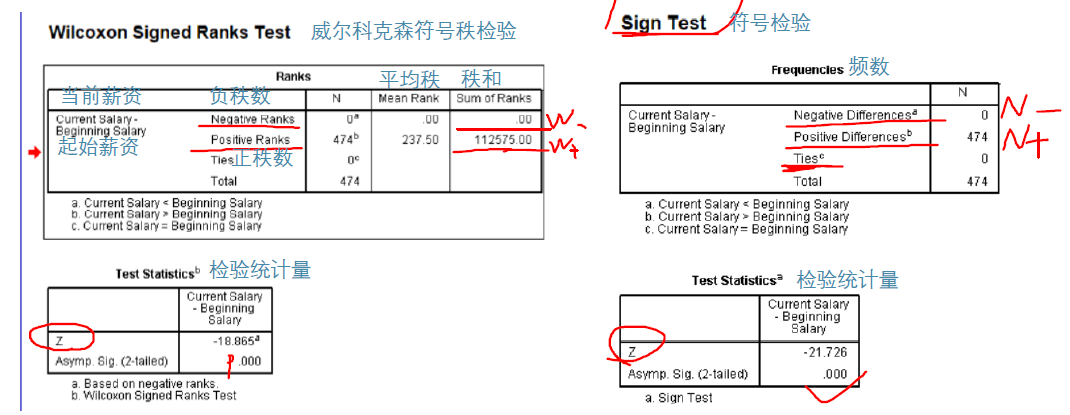
麥克尼馬爾檢驗:McNemar's test
McNemar的檢驗要麼是「被試物件內卡方檢驗」,要麼是「列聯表的邊際同質性檢驗」。如果資料是成對的,則使用McNemar‘s檢驗,如果資料是「未成對」的,則使用卡方檢驗。麥克內馬爾發現,有些人會從「是」轉變為「否」,有些人則會隨機地從「否」轉變為「是」。如果治療沒有效果,從「是」到「否」的人數應該與從「否」到「是」的人數大致相等。即c/(b+c)應該是二項的(預期p = 0.5)
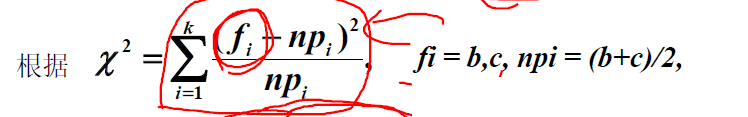

考慮Yates ContinuityCorrection(耶茨連續性修正)時,未修正的麥克內馬爾統計量是標準化的兩個計數的差值的平方;連續性修正對兩者都適用,但對較大(B和C中)的是-1/2,對較小的(B和C中)是+ 1/2因此,修正後|B-C|始終為-1。
耶茨連續性修正。如果2 ×2卡方表的總N小於約40,則使用耶茨(Yates)連續校正來補償理論(平滑)概率分佈的偏差。得到的卡方值更小,得到的統計推斷更保守
機器學習中的應用:Interpret the McNemar’s Test forClassifiers (麥克尼瑪爾檢驗用於分類器)

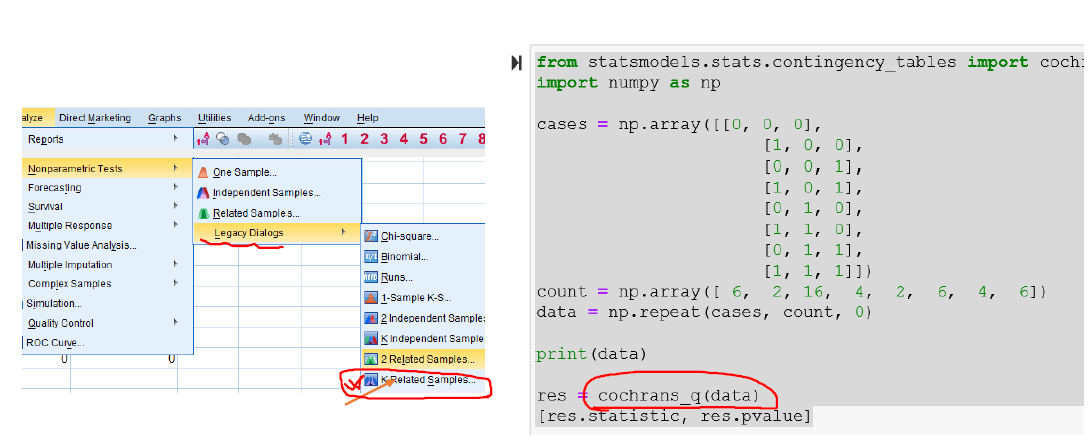
Cochran Q Test A extension to McNemar Test Cochran Q 測試 McNemar 測試的延伸

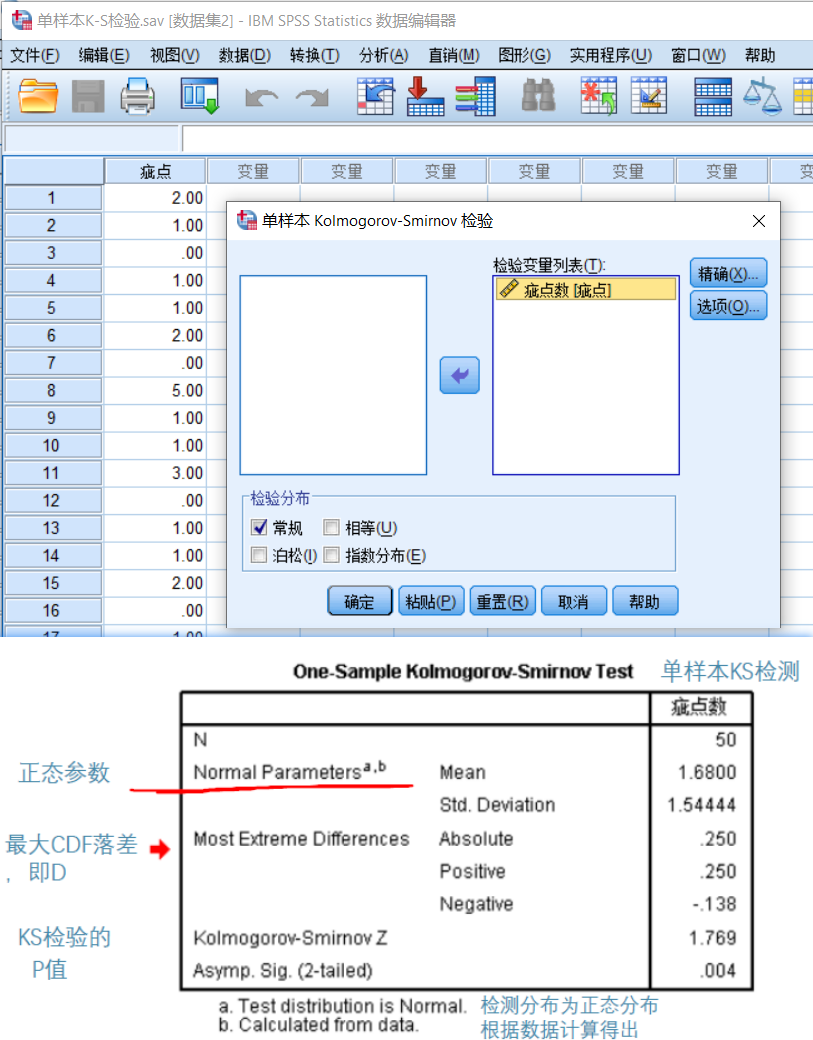
K-S檢驗
K-S檢驗用於對連續型隨機變數進行檢驗,卡方則針對離散型變數【分組資料】進行檢驗
KS-檢驗:比較累積分佈函數
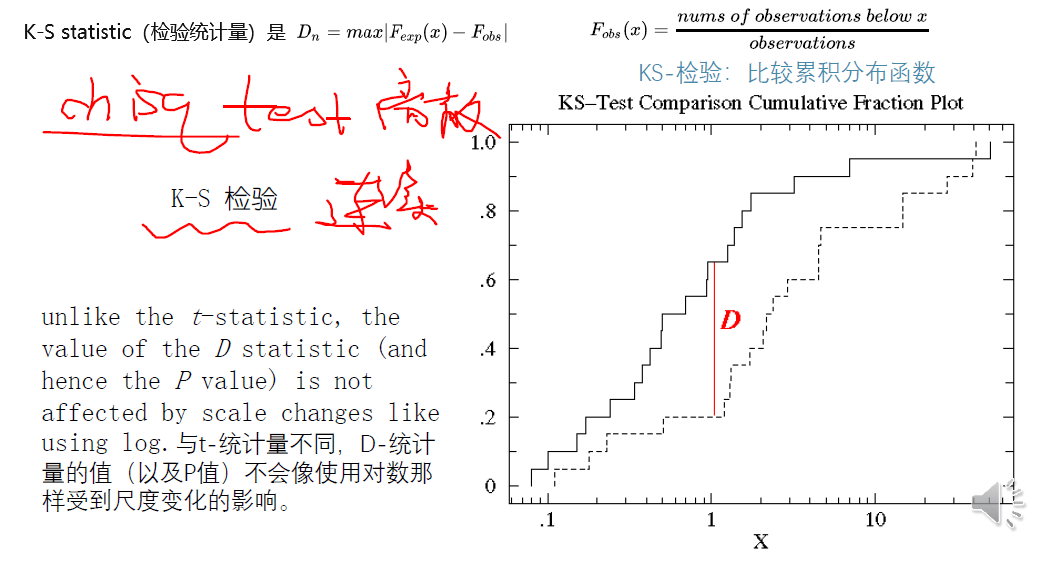
卡方檢驗用於將已離散化的資料例如直方圖 與另一組已離散化的資料或以同樣方式離散化的模型的預測進行比
較。
將K-S 檢驗應用於未裝箱(未離散化)資料,以比較兩種分佈的累積頻率或將累積頻率與累積頻率的模型預測進行比較。
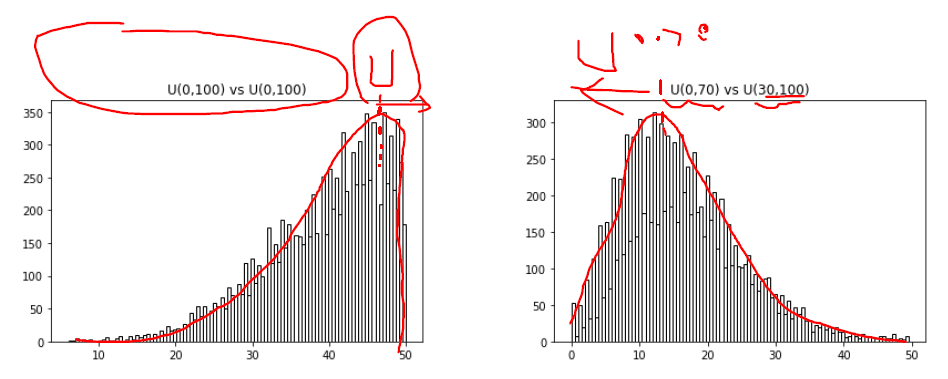
Wilcoxon 秩和檢驗(Rank Sum Test)
在統計學中,曼-惠特尼U檢驗(也稱為曼-惠特尼-威爾科克斯(MWW),威爾科克斯秩和檢驗,或威爾科克斯-曼-惠特尼檢驗)是一種非引數檢驗。
該測試可用於確定兩個獨立的(獨立、非配對)樣本是否是由具有相同特徵的人群中選出的。該測試可用於確定兩個獨立的(獨立、非配對)樣本是否來自同分布(更準確地,中位數是否相同)。
選擇秩和檢驗而不是獨立t檢驗的原因是:
- 你不能假設你的資料是interval的(具有絕對的大小,而非相對排序、名義或類標籤)
- 你不能假設你的資料是正態分佈的。


符號檢驗The Sign Test for Median
檢驗中位數m是否取特定值.

如果零假設為真,即m= m0 ,那麼N-和N+都遵循引數n和p=1/2二項分佈。

我們可以將符號檢驗擴充套件到兩個/組樣本的情況。
兩個樣本配對符號檢驗相當於對配對的差異(diff)進行單樣本符號檢驗。
零假設:這兩個樣本來自於具有相同中位數的總體。
Wilcoxon 符號秩檢驗
符號秩檢驗(Wilcoxon signed-rank test)是一種非引數檢驗,可用於確定兩個因果(配對樣本)是否來自同分布的總體。
相比於Sign Test, Wilcoxon 符號秩檢驗的p值更小,檢驗的勢(power)更大。
原因: 前者僅考慮了sign(大於/小於median),後者還考慮了與median的距離大小(distance)。
符號秩檢驗的H0暗含了對差異對稱性的假設,而符號檢驗則不需要。
另一方面,如果總體中存在近似對稱,而且一側的tail不是很重,那麼符號秩有更大的勢(power)。
適用條件:1. 非正態(non-Gaussian) 2. 對稱性(symmetry)
K-W檢驗(Kruskal-Wallis Test)
(Mann-Whitney或Wilcoxon)秩和檢驗比較兩組,而Kruskal-Wallis檢驗比較3組及以上。Kruskal-Wallis檢驗是一種非引數的單因素方差分析。它是基於秩(排序的,只考慮相對大小)的。
- Kruskal-Wallis檢驗用於確定三個或更多組獨立群體的中位數之間是否存在統計學上的顯
著差異。 - 該檢驗是單因素方差分析的非引數版本,通常在不符合正態性假設時使用。
Kruskal-Wallis檢驗不假定資料的正態性,對異常值的敏感度比單因素方差分析低得
多。 - K-W比「中位數檢驗」具有更大的勢(power),對於相同樣本,前者p值更小。

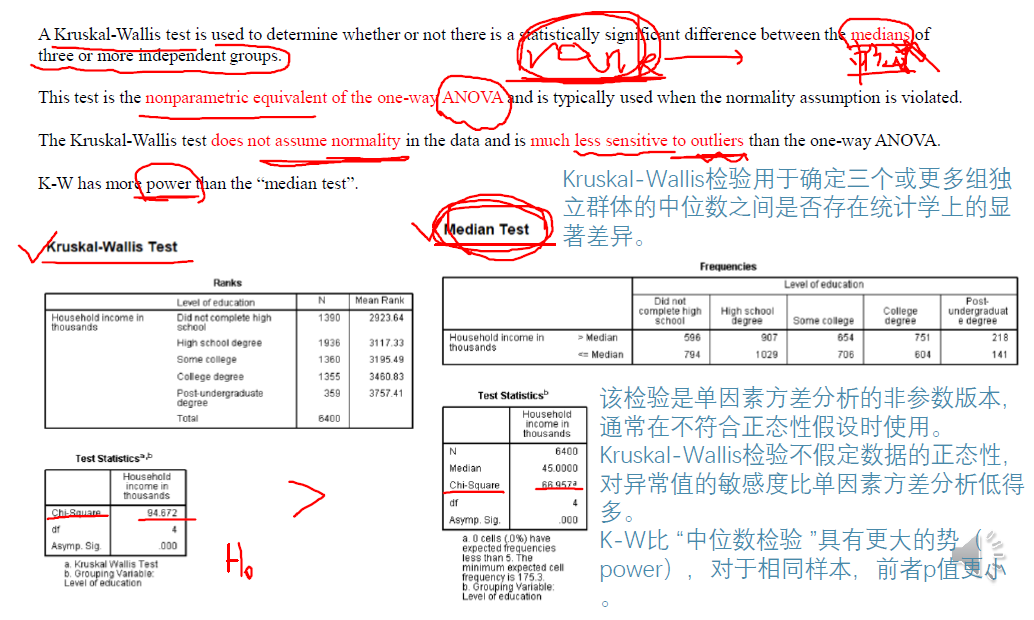
中位數檢驗是獨立性卡方檢驗的一種特殊情況。給定k組樣本,
n1, n2 …… nk觀測值,計算所有n1 +n2 + ……+nk觀測值的中位數。
然後構造一個2xk列聯表,其中第一行包含k個樣本的中位數以上
的觀測值,第二行包含k個樣本的中位數以下或等於中位數的觀
測值。然後可以對該表應用獨立性卡方檢驗。更具體地說:
H0 :所有k總體有相同的中位數
Ha :至少2個總體的中位數不同
檢測統計量:
其中:
a 觀測值大於所有樣本的中位數的樣本數
b 小於或等於所有樣本中位數的樣本數
N 總樣本數
\(O_1i\) 第i組中觀測值大於樣本中位數的樣本數
顯著性水平:α
臨界區域: \(T>\chi_{1-\alpha ; k-1}^{2}\)
結論:$