Easy-Classification-分類框架設計
2022-11-23 12:01:32
1. 框架介紹
Easy-Classification是一個應用於分類任務的深度學習框架,它整合了眾多成熟的分類神經網路模型,可幫助使用者簡單快速的構建分類訓練任務。
1.1 框架功能
1.1.1 資料載入
- 資料夾形式
- 其它自定義形式,在專案應用中,參考案例編寫DataSet自定義載入。如基於組態檔,csv,路徑解析等。
1.1.2 擴充套件網路
本框架擴充套件支援如下網路模型,可在classification_model_enum.py列舉類中檢視具體的model。
- Resnet系列,Densenet系列,VGGnet系列等所有[pretrained-models.pytorch]支援的網路
- ShuffleNetV2,[MicroNet]
1.1.3 優化器
- Adam
- SGD
- AdaBelief
- AdamW
1.1.4 學習率衰減
- ReduceLROnPlateau
- StepLR
- MultiStepLR
- SGDR
1.1.5 損失函數
- 直接呼叫PyTorch相關的損失函數
- 交叉熵
- Focalloss
1.1.6 其他
- Metric(acc, F1)
- 訓練結果acc,loss過程圖片儲存
- 交叉驗證
- 梯度裁剪
- Earlystop
- weightdecay
- 凍結/解凍 除最後的全連線層的特徵層
1.2 框架設計
Easy-Classification是一個簡單輕巧的分類框架,目前版本主要包括兩大模組,框架通用模組和專案應用模組。為方便使用者快速體驗,框架中目前包括簡單手寫數位識別和驗證碼識別兩個範例專案。
1.2.1 通用模組設計
Easy-Classification通用模組整體結構如下:
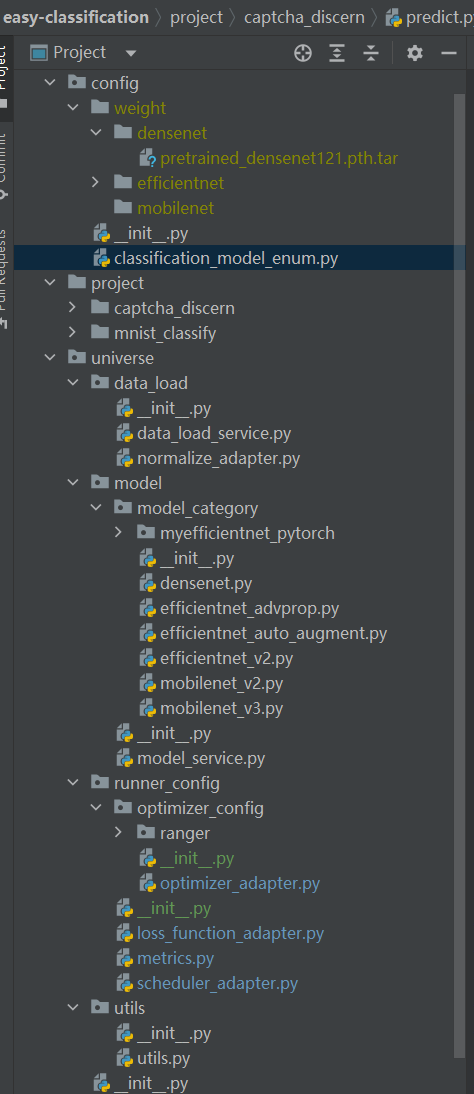
通用模組核心類/檔案介紹說明:
|
目錄
|
子項
|
功能說明
|
擴充套件說明
|
|
config
|
|
框架基礎設定目錄
|
|
|
|
weight
|
預訓練權重模型儲存目錄
|
各種神經網路的模型檔案,下載後儲存在該目錄下
|
|
|
classification_model_enum.py
|
列舉出當前分類框架,目前支援的分類神經網路模型。
列舉中的神經網路名稱,與組態檔中的名稱一樣,表示載入對應的網路模型。
|
後續新增網路時,需在該列舉類中注入
|
|
project
|
|
分類框架下的專案應用模組,詳細使用參考後續專案應用模組。
|
分類專案目錄名稱如:驗證碼識別,簡單手寫數位識別
|
|
universe
|
|
框架通用模組主目錄。
|
後續通用的功能,均可放在該目錄下。
|
|
|
data_load
|
基礎資料載入類
|
載入訓練資料,驗證資料,預測資料等
|
|
|
data_load_service.py
|
基於組態檔,載入設定路徑下的基礎資料,返回對應的張量資訊。
不同的分類任務,使用者構建DataSet模式不同,該模組提供函數,接收使用者構建的DataSet物件。做統一資料載入處理。
|
目前支援目錄模式載入。
|
|
|
normalize_adapter.py
|
歸一化設定類
|
其他新增網路的歸一化引數,可設定在此類中。
|
|
|
model
|
定義目前框架中,支援的所有分類網路模型。
|
新增網路放入到model_category目錄下。
|
|
|
model_service.py
|
分類網路模型的對外暴露類,基於組態檔,可指定具體使用哪個分類網路,專案應用時,只需呼叫moel_service。
moel_service.py:代理者的角色。類似於java中的代理模式。
|
新增的分類網路,要注入到moel_service.py中,對所有分類網路的統一攔截,加紀錄檔等功能可在model_service中實現。
|
|
runner_config
|
|
訓練設定的目錄,定義訓練過程中的一些設定資訊。
|
定義如優化器,學習率調整,損失函數等。
深度學習執行前,設定相關的模組均可放在該目錄下。
|
|
|
optimizer_adapter.py
|
優化器適配類,根據組態檔,可返回一個具體的優化器。
|
常用優化器如:Adam,AdamW,SGD,AdaBelief,Ranger
|
|
|
loss_function_adapter.py
|
自定義損失函數適配類,可基於組態檔,返回一個具體的損失函數。
|
損失函數也可使用 PyTorch中提供的。
|
|
|
scheduler_adapter.py
|
學習率調整適配類,可基於組態檔,返回具體的調整類。
|
擴充套件支援ReduceLROnPlateau,StepLR,MultiStepLR, SGDR
|
|
utils
|
utils.py
|
常用的工具函數,如載入檔案,全連線處理等
|
一些專案通用的工具類函數,如儲存acc,loss等記錄。
|
組態檔是設定在具體應用專案的目錄下,組態檔可根據專案需求自定義編寫,但每個組態檔需包含如下關鍵key欄位:
|
key欄位
|
解釋
|
參考值
|
|
model_name
|
分類網路模型名稱,如mobilenetv3,efficientnet_advprop,具體值參考ClassificationModelEnum列舉類中定義的值
|
efficientnet_advprop
|
|
GPU_ID
|
多GPU時,設定的GPU編碼,無GPU時,該值設定為空
|
0
|
|
class_number
|
目標輸出分類數量,如簡單數位識別,輸出值10
|
10
|
|
random_seed
|
亂數種子
|
43
|
|
num_workers
|
DataLoad載入資料時,是否啟用多個執行緒載入資料
|
4
|
|
train_path
|
訓練影象對應的儲存目錄地址
|
"data/train"
|
|
val_path
|
驗證影象對應的儲存目錄地址
|
"data/val"
|
|
test_path
|
預測影象對應的儲存目錄地址
|
"data/test"
|
|
pretrained
|
預載入模型權重的檔案儲存路徑,無值時,設定為空‘’
|
'../../out/mobilenetv3.pth'
|
|
save_best_only
|
訓練時,是否只儲存最優的模型
|
true
|
|
target_img_size
|
影象轉換為網路模型對應的目標影象尺寸,如mobilenet v3,接收圖為:[224,224]
|
[224,224]
|
|
learning_rate
|
初始化學習率值
|
0.001
|
|
batch_size
|
訓練時,DataLoad一次載入資料的批次數量
|
64
|
|
test_batch_size
|
預測時,DataLoad一次載入資料的批次數量
|
1
|
|
epochs
|
訓練總次數
|
100
|
|
optimizer
|
優化器型別,列舉值:Ranger,AdaBelief,SGD,AdamW,Adam
|
SGD
|
|
scheduler
|
學習衰減率調整策略,列舉值:default,step,SGDR,multi
|
default
|
|
loss
|
損失函數,若使用pytorch提供的損失函數,可不管該值。使用框架提供的需設定。列舉值:CE,CE2,Focalloss
|
|
|
early_stop_patient
|
提前結束,當後續訓練輪次出現N次,acc小於歷史值時,就提前結束
|
7
|
|
model_path
|
模型預測時,訓練生成的權重檔案儲存路徑
|
'../../out/mobilenetv3_e22_0.97.pth'
|
|
dropout
|
為了防止過擬合,設定值,表示隨機多少比例的神經元失效,取值服務[0,1]
|
0.5
|
|
class_weight
|
訓練資料類別分配不均勻,防止過擬合等情況出現,設定的懲罰值。預設值設定為None。
|
呼叫:n.CroEntropyLoss(),設定不同類別的懲罰值,三個類別,如[0.8,0.1,0.1]。
|
|
weight_decay
|
在與梯度做運算時,當前權重先減去一定比例的大小。
|
0.01
|
1.2.2 專案應用模組設計
Easy-Classification專案應用模組整體結構如下:

專案應用模組核心類/檔案介紹說明:
|
目錄
|
子項
|
功能說明
|
擴充套件說明
|
|
mnist_caassify
|
|
分類專案主目錄
|
表示一個具體的分類專案,本例為簡單手寫數位識別
|
|
|
data
|
該專案的訓練資料,驗證資料,推理資料等
|
與訓練流程,推理流程等相關的資料,包括圖片和label等設定資訊。
|
|
|
output
|
專案的輸出結果
|
訓練過程中的acc,loss圖,模型權重檔案,預測結果等,全部輸出到這個目錄。
|
|
|
scripts
|
構建訓練資料,驗證資料等的指令碼檔案
|
基於指令碼檔案,生產對應的訓練資料,驗證資料到data目錄下。主要功能如:
1.生產圖片,生成label;
2.解析檔案,並基於影象做一定的前期調整。清洗訓練資料,提前加工部分資料。
|
|
|
service
|
分類任務,主要的專案應用模組,使用者自定義程式碼儲存目錄。
|
|
|
|
xxx_config.py
|
分類專案的組態檔,每一個分類專案都存在一個單獨的組態檔。
|
常用的設定引數,如指定使用什麼模型,影象大小調整等,具體參考案例的組態檔
|
|
|
xxx_dataset.py
|
分類專案的資料載入類
|
每個分類任務的資料載入模式不一定完全一樣,該模組屬於使用者自定義模組。可做影象的預處理,最終將影象轉換為張量資訊。
|
|
|
xxx_runner_service.py
|
分類專案的執行類
|
包括設定執行引數,訓練流程定義,預測流程處理等。
|
|
|
train.py,prectict.py
|
訓練類,預測類
|
主要是載入組態檔,獲取訓練資料,載入網路模型,初始化訓練過程的設定引數,呼叫訓練函數開始訓練。
|
1.3 框架使用
1.3.1 基礎使用
使用者在簡單使用Easy-Classification分類框架時,只需編寫專案應用模組的程式碼,參考給出的兩個案例,結合專案自身情況,需做如下步驟處理:
- 在project 目錄下,建立一個目錄作為專案名稱,目錄名稱命名為專案名稱,如mnist_classsify。
- 在mnist_classsify目錄下,建立一個data目錄,用於儲存訓練,驗證,推理等相關的基礎數。
- scripts目錄,根據實際情況,若專案提前準備好資料了,可不編寫。若需要通過一定的指令碼預處理訓練資料,可在該目錄下編寫指令碼處理。
- 在mnist_classsify目錄下,建立一個service目錄。
- 編寫組態檔,xxx_config.py,組態檔的key值一定要和案例中的設定key名稱一樣(不然通用模組無法載入)。
- 編寫DataSet自定義類,xxx_dataset.py,參考案例中的DataSet類,編寫自定義Dataset類時,初始化引數需定義為source_img, cfg。否則資料載入通用模組,data_load_service.py模組會報錯。(source_img :傳入的影象地址資訊集合。基於組態檔,載入檔案的路徑資訊。 cfg:傳入的設定類,是組態檔xxx_config.py。)
- 編寫專案執行類,xxx_runner_service.py,參考案例中的專案執行類,注意輸出張量資訊處理,acc計算等根據實際情況調整。
- 編寫train.py,prectict.py,參考案例中的程式碼,載入資料時,傳入編寫的xxx_dataset類,呼叫xxx_runner_service.py中提供的訓練函數,預測函數即可。
1.3.2 擴充套件使用
目前框架的功能還比較基礎,若發現框架中有不支援的網路模型,或其他的一些優化器,學習率調整等,均可通過調整原始碼的模式自定義擴充套件增強。原始碼中關鍵類的功能參考章節1.2.1中的介紹。如自定義一個網路模型可通過如下流程:
- 在model/model_category目錄下,新增對應的網路模型如:test_model.py。
- 在config/classification_model_enum.py檔案中,新增新增的網路模型。
- 在model_service.py中,注入新增的網路模型。
- 在組態檔中,設定使用的模型名稱,如:test_model。
2. 框架案例介紹
框架設計與案例參考檔案:
3. 參考文獻
2. warmup
4. 易大師
喜歡請讚賞一下啦^_^
 微信讚賞
微信讚賞
 支付寶讚賞
支付寶讚賞