深度學習-網路訓練流程說明
2022-11-22 21:01:19
1.背景
分類神經網路模型:Mobilenetv3。
深度學習框架:PyTorch。
Mobilenetv3簡單的手寫數位識別:
- 任務輸入:一系列手寫數點陣圖片,其中每張圖片都是28x28的畫素矩陣。
- 任務輸出:經過了大小歸一化和居中處理,輸出對應的0~9數位標籤。
專案程式碼:https://github.com/wuya11/easy-classification
1.1 說明
本文基於Mobilenetv3神經網路,識別數位分類。將分類模型的訓練,驗證等流程分解,逐一詳細說明並做適當擴充套件討論。本文適合有一定深度學習理論知識的讀者,旨在基於理論結合程式碼,闡述分類神經網路的一般流程。背景資料參考如下:
- 深度學習理論知識:參考黃海廣博士組織翻譯的吳恩達深度學習課程筆記,連結:《深度學習筆記》
- Pytorch常用函數,nn.Module,載入資料等功能,參考連結:《Pytorch中文檔案》
- Mobilenetv3分類,瞭解折積網路構建引數,開始輸入和最終網路模型輸出size,不做過多底層的瞭解。參考連結:《Mobilenetv3解析》
1.2 資料集來源
下載開源的訓練圖片庫:http://yann.lecun.com/exdb/mnist/。
在專案根目錄下新建data目錄用於放置訓練集,測試集,驗證集資料。執行專案中make_fashionmnist.py指令碼,解壓檔案,最終得到神經網路的訓練資料,參考如圖:

說明:
- 標籤生成為目錄,每個目錄裡面為具體的數點陣圖片。比如0目錄的圖片均是手寫數位為0的圖片。
- 每個影象解析後,size為28*28。(若後續模型的入參需求為224*224,可以在此處調整影象大小。但不建議在一開始就修改,在影象轉為張量處調整更合理,不同的模型入參不一定相同)
- 訓練集、驗證集和測試集各自的作用,參考說明:《資料集說明》
1.3 構建神經網路模型
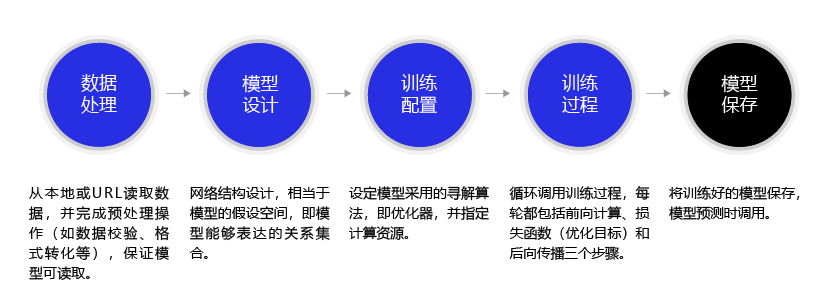
構建神經網路模型基本流程如下:
參考教學:《深度學習入門必看-手寫數位識別》

2.資料處理
2.1 載入組態檔
定義專案中的設定資訊,方便統一設定引數,便於修改和維護。舉例config.py部分設定如:
cfg = {
### Global Set
"model_name": "mobilenetv3", #shufflenetv2 adv-efficientnet-b2 se_resnext50_32x4d xception
"class_number": 10,
"random_seed":42,
"cfg_verbose":True,
"num_workers":4,
### Train Setting
'train_path':"./data/train",
'val_path':"./data/val",
### Test
'model_path':'output/mobilenetv3_e50_0.77000.pth',#test model
'eval_path':"./data/test",#test with label,get test acc
'test_path':"./data/test",#test without label, just show img result
### 更多參考專案中的config.py檔案
}
呼叫設定資訊
from config import cfg path=cfg["train_path"] #獲取config檔案中的train_path變數
2.2 載入訓練集圖片資訊

2.2.1 獲取原始影象
從影象目錄下載入影象資訊,部分程式碼參考如下:
train_data = getFileNames(self.cfg['train_path']) val_data = getFileNames(self.cfg['val_path']) def getFileNames(file_dir, tail_list=['.png','.jpg','.JPG','.PNG']): L=[] for root, dirs, files in os.walk(file_dir): for file in files: if os.path.splitext(file)[1] in tail_list: L.append(os.path.join(root, file)) return L
2.2.2 原始影象調整
針對訓練集資料,需隨機打亂處理。若訓練資料較大,一次只想獲取部分資料訓練,可做一個設定引數設定訓練數目,基於引數動態調整。影象調整部分程式碼參考如下:
# 隨機處理訓練集 train_data.sort(key = lambda x:os.path.basename(x)) train_data = np.array(train_data) random.shuffle(train_data) # 調整訓練時的資料量 if self.cfg['try_to_train_items'] > 0: train_data = train_data[:self.cfg['try_to_train_items']] val_data = val_data[:self.cfg['try_to_train_items']]
2.2.3 影象調整
本例基於Mobilenetv3神經網路處理分類,入參影象大小為224*224(每個模型的入參影象大小不一定相同,可基於組態檔設定,如"img_size": [224, 224])。由於基礎訓練影象大小為28*28。需做訓練影象調整,部分程式碼參考如下:
class TrainDataAug: def __init__(self, img_size): self.h = img_size[0] self.w = img_size[1] def __call__(self, img): # opencv img, BGR img = cv2.resize(img, (self.h,self.w)) img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) img = Image.fromarray(img) return img
2.2.4 影象生成張量
影象生成張量,主要使用transforms.Compose()函數,做影象處理。相關知識點參考:
影象生成張量資訊,部分程式碼參考如下:
my_normalize = getNormorlize(cfg['model_name']) data_aug_train = TrainDataAug(cfg['img_size']) transforms.Compose([ # 調整影象大小 data_aug_train, # 影象轉換為張量 transforms.ToTensor(), # 歸一化處理 my_normalize, ])
歸一化引數設定,不同模型的值不一樣,參考如下(歸一化引數值可參考網路,論文等獲取):
def getNormorlize(model_name): if model_name in ['mobilenetv2','mobilenetv3']: my_normalize = transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) elif model_name == 'xception': my_normalize = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) elif "adv-eff" in model_name: my_normalize = transforms.Lambda(lambda img: img * 2.0 - 1.0) elif "resnex" in model_name or 'eff' in model_name or 'RegNet' in model_name: my_normalize = transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) #my_normalize = transforms.Normalize([0.4783, 0.4559, 0.4570], [0.2566, 0.2544, 0.2522]) elif "EN-B" in model_name: my_normalize = transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) else: print("[Info] Not set normalize type! Use defalut imagenet normalization.") my_normalize = transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) return my_normalize
自定義一個Dataset物件,重寫__getitem__方法:
class TensorDatasetTestClassify(Dataset): def __init__(self, train_jpg, transform=None): self.train_jpg = train_jpg if transform is not None: self.transform = transform else: self.transform = None def __getitem__(self, index): img = cv2.imread(self.train_jpg[index]) if self.transform is not None: img = self.transform(img) return img, self.train_jpg[index] def __len__(self): return len(self.train_jpg)
影象生成為張量,基於DataLoade資料載入器。DataLoade組合資料集和取樣器,並在資料集上提供單程序或多程序迭代器。參考連結:《DataLoader 使用說明》。部分程式碼參考:
分組說明:比如存在1000條資料,每64條資料為一組,可分為1000/64=15.625 組,不能整除時,最後一組會drop_last 引數做剔除或是允許該組資料不完整。迭代器為16組,在一次訓練時,會迴圈16次跑完訓練的資料。
my_dataloader = TensorDatasetTestClassify train_data = getFileNames(self.cfg['train_path']) train_loader = torch.utils.data.DataLoader( my_dataloader(train_data, transforms.Compose([ data_aug_train, transforms.ToTensor(), my_normalize, ])), batch_size=cfg['batch_size'], shuffle=True, num_workers=cfg['num_workers'], pin_memory=True)
2.2.5 小節總結
- 獲取到原始影象資訊時,需要隨機打亂影象,避免訓練集精度問題。
- 基於Pytorch 框架,自定義DataSet時,需定義item返回的物件資訊(返回圖片資訊,圖片張量資訊,標籤資訊等可自定義)。
- 影象轉換為張量時,引入歸一化,對生成的張量資訊做處理。
- DataLoade資料載入器,分組跑資料,提升效率,也可以自行編寫for實現,但框架已有,呼叫框架的方便。
2.3 載入其他圖片資訊
載入驗證集圖片資訊,載入測試集圖片資訊,流程同載入訓練圖片資訊一致,根據實際需求可做部分邏輯調整。
3.模型設計
3.1 Pytorch 構建網路
- 經典的網路模型,目前均可在網上找到開源的網路模型構建程式碼。Pytorch也封裝了部分網路模型的程式碼,詳情參考:《torchvision.models》
- 自定義網路模型,主要是構建網路骨幹,基於折積層,啟用函數等組合使用。最後根據任務分類,構建對應的全連線層。詳情參考:《PyTorch-OpCounter》,《構建神經網路常用實現函數》
- 構建Mobilenetv3網路,可直接呼叫torchvision.models中已經封裝好的模型。自定義實現也可參考《Pytorch:影象分類經典網路_MobileNet(V1、V2、V3)》
3.2 預訓練模型
預訓練模型是在大型基準資料集上訓練的模型,用於解決相似的問題。由於訓練這種模型的計算成本較高,因此,匯入已釋出的成果並使用相應的模型是比較常見的做法。
載入預訓練權重時,需注意是不同硬體資源之間的差異(GPU模型權過載入到CPU或其他轉換),載入預訓練常規異常及處理方案參考:《PyTorch載入模型不匹配處理》。
預訓練模型載入參考程式碼:
self.pretrain_model = MobileNetV3() # 預訓練模型權重路徑 if self.cfg['pretrained']: state_dict = torch.load(self.cfg['pretrained']) # 模型與預訓練不一致時,邏輯處理 state_dict = {k.replace('pretrain_', ''):v for k, v in state_dict.items()} state_dict = {k.replace('model.', ''): v for k, v in state_dict.items()} # 跳過不一致的地方 self.pretrain_model.load_state_dict(state_dict,False)
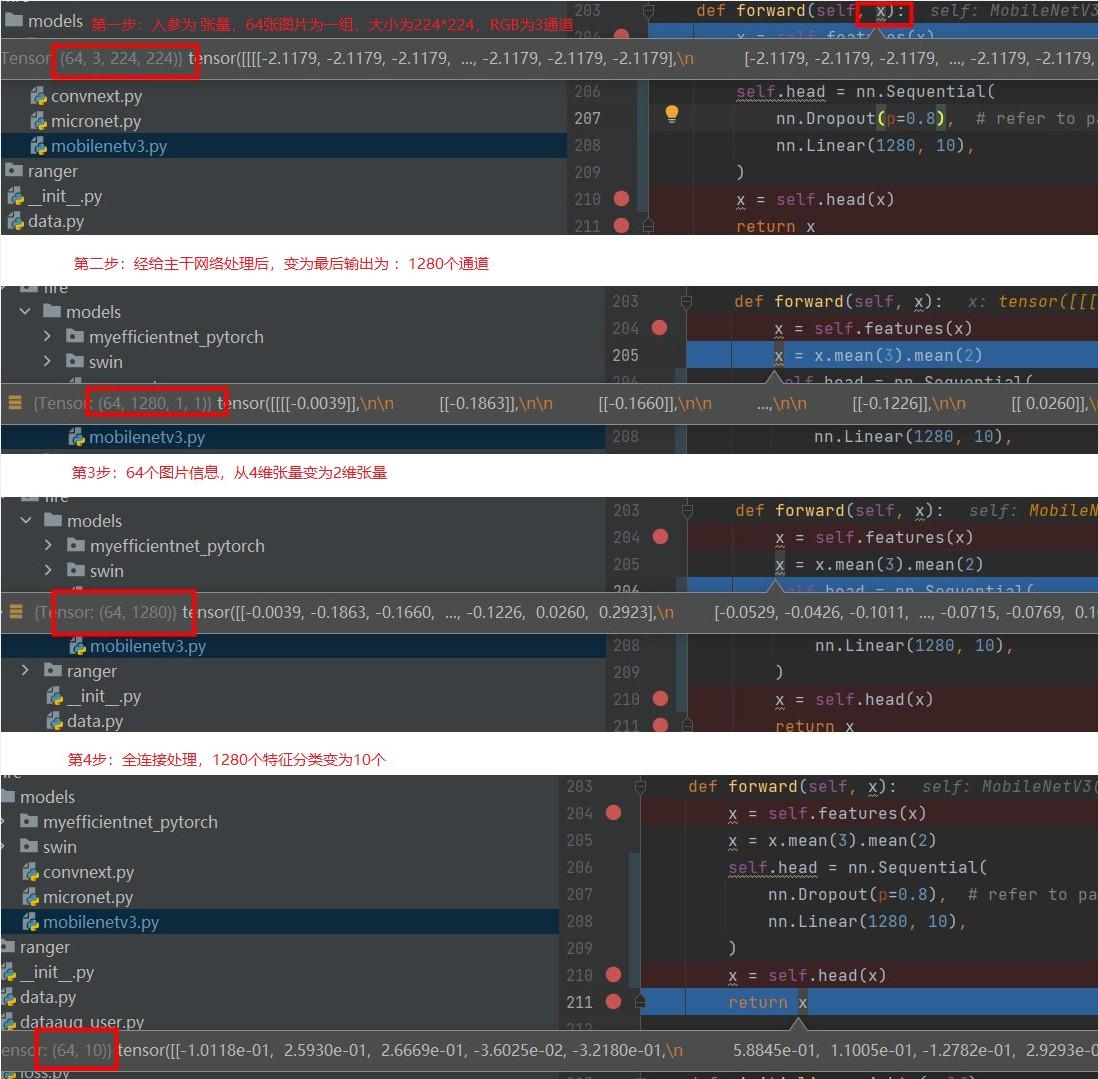
3.3 構建全連線層
全連線層是2維張量與2維張量的轉換,主要是骨幹層輸出特徵資訊後,比如維度為1028,實際任務分類只需要10類,此刻需要建立全連線層做轉換。構建全連線層相關知識參考如下:
構建一個網路模型時,需定義模型的輸出函數,在此處接入全連線層,參考程式碼如下:
def forward(self, x): x = self.features(x) x = x.mean(3).mean(2) #張量維度換 4轉2 last_channel=1280 # mobilenetv3 large最終輸出為1280 # 構建一個全連線層 self.classifier = nn.Sequential( nn.Dropout(p=dropout), # refer to paper section 6 nn.Linear(last_channel, 10), #數位0-9共10個分類 x = self.classifier(x) return x
3.4 小節總結
- 經典網路的實現,可當作黑盒對待。不做過多深入的研究。參考網路模型實現程式碼時,注意開始的輸入張量和最終骨幹網路的輸出張量資訊。
- 網上部分部落格,關於Mobilenetv3-small,最終輸出有寫 1280,也有寫1024的,參考論文應該是1024,最終層這種也可自定義,但建議還是以論文為準。
- 選用一個經典的網路模型,主要是使用其骨幹層訓練的結果,在根據自身任務的分類特性,做全連線層處理。
- 訓練一個新任務時,根據使用的分類模型,一般不建議從零開始訓練,可基於已經存在的模型權重,做預訓練微調處理。
4.訓練設定
訓練設定需定義訓練過程中使用的硬體資源資訊,優化器,損失函數,學習率調整策略等。部分程式碼參考如下:
class ModelRunner(): def __init__(self, cfg, model): # 定義載入組態檔 self.cfg = cfg # 定義裝置資訊 if self.cfg['GPU_ID'] != '' : self.device = torch.device("cuda") else: self.device = torch.device("cpu") self.model = model.to(self.device) # gpu加速,cpu模式無效 self.scaler = torch.cuda.amp.GradScaler() # loss 定義損失函數 self.loss_func = getLossFunc(self.device, cfg) # 定義優化器 self.optimizer = getOptimizer(self.cfg['optimizer'], self.model, self.cfg['learning_rate'], self.cfg['weight_decay']) # 定義調整學習率的策略 self.scheduler = getSchedu(self.cfg['scheduler'], self.optimizer)
4.1 裝置硬體資源
判斷伺服器是否支援GPU,可檢視《torch.cuda》。特別注意硬體的特性,如預訓練載入時,儲存的模型權重是基於GPU的,若載入時採用CPU模式,會報錯。
4.2 損失函數
損失函數相關知識參考連結:
定義一個多分類CrossEntropyLoss:
class CrossEntropyLoss(nn.Module): def __init__(self, label_smooth=0, weight=None): super().__init__() self.weight = weight self.label_smooth = label_smooth self.epsilon = 1e-7 def forward(self, x, y, sample_weights=0, sample_weight_img_names=None): one_hot_label = F.one_hot(y, x.shape[1]) if self.label_smooth: one_hot_label = labelSmooth(one_hot_label, self.label_smooth) #y_pred = F.log_softmax(x, dim=1) # equal below two lines y_softmax = F.softmax(x, 1) #print(y_softmax) y_softmax = torch.clamp(y_softmax, self.epsilon, 1.0-self.epsilon)# avoid nan y_softmaxlog = torch.log(y_softmax) # original CE loss loss = -one_hot_label * y_softmaxlog loss = torch.mean(torch.sum(loss, -1)) return loss
4.3 優化器
訓練過程採用二層迴圈巢狀方式,訓練完成後需要儲存模型引數,以便後續使用。
- 內層迴圈:負責整個資料集的一次遍歷,遍歷資料集採用分批次(batch)方式。
- 外層迴圈:定義遍歷資料集的次數,如訓練中外層迴圈100次,訓練次數可通過設定引數設定。
優化器應用於內層迴圈,優化器相關知識參考連結:《torch.optim》,《優化演演算法Optimizer比較和總結》,常用優化器程式碼參考:
def getOptimizer(optims, model, learning_rate, weight_decay): if optims=='Adam': optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay) elif optims=='AdamW': optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay) elif optims=='SGD': optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9, weight_decay=weight_decay) elif optims=='AdaBelief': optimizer = AdaBelief(model.parameters(), lr=learning_rate, eps=1e-12, betas=(0.9,0.999)) elif optims=='Ranger': optimizer = Ranger(model.parameters(), lr=learning_rate, weight_decay=weight_decay) else: raise Exception("Unkown getSchedu: ", optims) return optimizer
4.4 學習率調整
scheduler 相關知識參考:《PyTorch中的optimizer和scheduler》,《訓練時的學習率調整知識》。scheduler.step()按照Pytorch的定義是用來更新優化器的學習率的,一般是按照epoch為單位進行更換,即多少個epoch後更換一次學習率,因而scheduler.step()一般放在epoch這個大回圈下。學習率調整相關程式碼參考:
def getSchedu(schedu, optimizer): if 'default' in schedu: factor = float(schedu.strip().split('-')[1]) patience = int(schedu.strip().split('-')[2]) scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=factor, patience=patience,min_lr=0.000001) elif 'step' in schedu: step_size = int(schedu.strip().split('-')[1]) gamma = int(schedu.strip().split('-')[2]) scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=gamma, last_epoch=-1) elif 'SGDR' in schedu: T_0 = int(schedu.strip().split('-')[1]) T_mult = int(schedu.strip().split('-')[2]) scheduler = optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=T_0, T_mult=T_mult) elif 'multi' in schedu: milestones = [int(x) for x in schedu.strip().split('-')[1].split(',')] gamma = float(schedu.strip().split('-')[2]) scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=gamma, last_epoch=-1) else: raise Exception("Unkown getSchedu: ", schedu) return scheduler
4.5 小節總結
- 在訓練之前,首先確定硬體環境,cpu跑的慢,能用GPU的,優先使用GPU。Pytorch版本安裝時,也需根據硬體設定選擇,安裝地址:《Pytorch Get Start》。
- 損失函數可用Pytorch封裝了常用損失函數,或參考數學公式自定義編寫。損失函數實現邏輯可不過分深究,當作黑盒模式對待。正確傳入損失函數入參的引數,在不同任務場景下,測試或參考論文,選擇或編寫合適的損失函數。
- 優化器,學習率調整均可當作黑盒模式對待。會傳參和呼叫即可。優化器,學習率存在多種解決方案,在不同任務場景下,測試或參考論文,選擇合適該任務的方案。
5.訓練過程
5.1 訓練流程概述
一個完整的訓練過程,包括多次對準備的全量訓練集資料,驗證集資料做迭代處理。執行過程參考程式碼如下:
def train(self, train_loader, val_loader): # step 1:定義訓練開始時一些全域性的變數,如是否過早停止表示,執行時間等 self.onTrainStart() # step 2: 外層大輪詢次數,每次輪詢 全量 train_loader,val_loader for epoch in range(self.cfg['epochs']): # step 3: 非必須,過濾處理部分次數,做凍結訓練處理 self.freezeBeforeLinear(epoch, self.cfg['freeze_nonlinear_epoch']) # step 4: 訓練集資料處理 self.onTrainStep(train_loader, epoch) # step 5: 驗證集資料處理,最好訓練模型權重儲存,過早結束邏輯處理 self.onValidation(val_loader, epoch) # step 6: 滿足過早結束條件時,退出迴圈,結束訓練 if self.earlystop: break # step 7:訓練過程結束,釋放資源 self.onTrainEnd()
5.2 凍結訓練
凍結訓練其實也是遷移學習的思想,在目標檢測任務中用得十分廣泛。因為目標檢測模型裡,主幹特徵提取部分所提取到的特徵是通用的,把backbone凍結起來訓練可以加快訓練效率,也可以防止權值被破壞。在凍結階段,模型的主幹被凍結了,特徵提取網路不發生改變,佔用的視訊記憶體較小,僅對網路進行微調。在解凍階段,模型的主幹不被凍結了,特徵提取網路會發生改變,佔用的視訊記憶體較大,網路所有的引數都會發生改變。精確凍結指定網路層參考連結:《精確凍結模型中某一層引數》
凍結整個網路層參考程式碼:
# freeze_epochs :設定凍結的標識,小於該值時凍結 # epoch: 輪詢次數值,從0開始 def freezeBeforeLinear(self, epoch, freeze_epochs=2): if epoch < freeze_epochs: for child in list(self.model.children())[:-1]: for param in child.parameters(): param.requires_grad = False # 等於標識值後,解凍 elif epoch == freeze_epochs: for child in list(self.model.children())[:-1]: for param in child.parameters(): param.requires_grad = True
5.3 訓練資料
訓練資料按批次處理,如總訓練集1000條,64條資料為一批。內部迴圈1000/64次,批次輪詢時,更新優化器資訊,重新計算梯度(如從山頂向谷底走,逐步下降)。訓練過程優化處理,參考連結:《Torch優化訓練的17種方法》,《訓練過程梯度調整》,訓練參考程式碼:
# 定義模型為訓練 self.model.train() # 輪詢處理批次資料 for batch_idx, (data, target, img_names) in enumerate(train_loader): one_batch_time_start = time.time() # 來源於dataset物件,item中定義的物件 target = target.to(self.device) # 張量複製到硬體資源上 data = data.to(self.device) # gpu模式下,加快訓練,混合精度 with torch.cuda.amp.autocast(): # 模型訓練輸出張量,參考模型定義的forward返回方法 output = self.model(data).double() # 計算損失函數,可自定義或呼叫PyTorch常用的 loss = self.loss_func(output, target, self.cfg['sample_weights'], sample_weight_img_names=img_names) # 一個batchSize 求和 total_loss += loss.item() # 把梯度置零 self.optimizer.zero_grad() # loss.backward() #計算梯度 # self.optimizer.step() #更新引數 # 基於GPU scaler 加速 self.scaler.scale(loss).backward() self.scaler.step(self.optimizer) self.scaler.update() ### 返回 batchSize個最大張量值對應的陣列下標值 pred = output.max(1, keepdim=True)[1] # 訓練影象對應的 分類標籤 if len(target.shape) > 1: target = target.max(1, keepdim=True)[1] # 統計一組資料batchSize 中訓練出來的分類值與 實際影象分類標籤一樣的資料條數 correct += pred.eq(target.view_as(pred)).sum().item() # 統計總訓練資料條數 count += len(data) # 計算準確率 train_acc = correct / count train_loss = total_loss / count
5.4 驗證資料
驗證資料流程同訓練資料流程類似,但不需要求導,更新梯度等流程,參考程式碼如下:
# 定義模型為驗證 self.model.eval() # 重點,驗證流程定義不求導 with torch.no_grad(): pres = [] labels = [] # 基於批次迭代驗證資料 for (data, target, img_names) in val_loader: data, target = data.to(self.device), target.to(self.device) # GPU下加速處理 with torch.cuda.amp.autocast(): # 模型輸出張量,參考模型定義的forward返回方法 output = self.model(data).double() # 定義交叉損失函數 self.val_loss += self.loss_func(output, target).item() # sum up batch loss pred_score = nn.Softmax(dim=1)(output) # print(pred_score.shape) pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability if self.cfg['use_distill']: target = target.max(1, keepdim=True)[1] # 真實值與驗證值一致求和數量 self.correct += pred.eq(target.view_as(pred)).sum().item() batch_pred_score = pred_score.data.cpu().numpy().tolist() batch_label_score = target.data.cpu().numpy().tolist() pres.extend(batch_pred_score) labels.extend(batch_label_score) # print('\n',output[0],img_names[0]) pres = np.array(pres) labels = np.array(labels) # print(pres.shape, labels.shape) self.val_loss /= len(val_loader.dataset) # 計算準確率 self.val_acc = self.correct / len(val_loader.dataset) # 當次值記錄為最優,後續應用和歷史最優值做比較 self.best_score = self.val_acc
5.5 儲存最優的模型權重
單次模型驗證結束後,會通過如acc,F1 score等維度評估模型的效果,記錄該次驗證的評分。外部迴圈多次時,最終記錄最優的一次驗證結果,儲存為模型的最優權重。
儲存模型權重參考程式碼如下:
def checkpoint(self, epoch): # 當前值小於歷史記錄的值時 if self.val_acc <= self.early_stop_value: if self.best_score <= self.early_stop_value: if self.cfg['save_best_only']: pass else: save_name = '%s_e%d_%.5f.pth' % (self.cfg['model_name'], epoch + 1, self.best_score) self.last_save_path = os.path.join(self.cfg['save_dir'], save_name) self.modelSave(self.last_save_path) else: # 儲存最優權重資訊 if self.cfg['save_one_only']: if self.last_save_path is not None and os.path.exists(self.last_save_path): os.remove(self.last_save_path) save_name = '%s_e%d_%.5f.pth' % (self.cfg['model_name'], epoch + 1, self.best_score) self.last_save_path = os.path.join(self.cfg['save_dir'], save_name) torch.save(self.model.state_dict(), save_name)
5.6 提前終止
模型在驗證集上的誤差在一開始是隨著訓練集的誤差的下降而下降的。當超過一定訓練步數後,模型在訓練集上的誤差雖然還在下降,但是在驗證集上的誤差卻不在下降了。此時模型繼續訓練就會出現過擬合情況。因此可以觀察訓練模型在驗證集上的誤差,一旦當驗證集的誤差不再下降時,就可以提前終止訓練的模型。相關知識參考:《深度學習技巧之Early Stopping》
提前終止參考程式碼如下:
def earlyStop(self, epoch): ### earlystop 設定下降次數,如當前值小於歷史值出現7次,就提前終止 if self.val_acc > self.early_stop_value: self.early_stop_value = self.val_acc if self.best_score > self.early_stop_value: self.early_stop_value = self.best_score self.early_stop_dist = 0 self.early_stop_dist += 1 if self.early_stop_dist > self.cfg['early_stop_patient']: self.best_epoch = epoch - self.cfg['early_stop_patient'] + 1 print("[INFO] Early Stop with patient %d , best is Epoch - %d :%f" % ( self.cfg['early_stop_patient'], self.best_epoch, self.early_stop_value)) self.earlystop = True if epoch + 1 == self.cfg['epochs']: self.best_epoch = epoch - self.early_stop_dist + 2 print("[INFO] Finish trainging , best is Epoch - %d :%f" % (self.best_epoch, self.early_stop_value)) self.earlystop = True
5.7 釋放資源
訓練驗證結束後,及時清空快取,垃圾回收處理釋放記憶體。
def onTrainEnd(self): # 刪除模型範例 del self.model # 垃圾回收 gc.collect() # 清空gpu上面的快取 torch.cuda.empty_cache()
5.8 小節總結
- 訓練過程綜合使用了損失函數,優化器,學習率,梯度下降等知識,一般基於內外兩個大回圈訓練資料,最終產生模型的權重引數,並儲存下來。
- 儲存的模型權重可用於評估和實際使用。也可以當作其他任務的預載入模型權重。
- 訓練過程是訓練集資料,驗證集資料交替進行的,單獨的只進行訓練集資料的處理無明細意義。
- 訓練集資料需要求導(凍結訓練層除外),做前向計算和反向傳播處理。驗證集不需要,在訓練之後,只做驗證結果的評分處理。
6.評估與應用
6.1 評估與應用
模型訓練結束後,儲存模型權重資訊。在評估和預測影象分類時,載入模型權重資訊。載入評估資料模型和載入訓練集資料的模式一樣。(若評估的影象與模型入參不一致,需轉換調整),模型評估參考如下程式碼:
# 載入訓練的模型權重 runner.modelLoad(cfg['model_path']) # 評估跑資料 runner.evaluate(train_loader) # 評估函數 def evaluate(self, data_loader): self.model.eval() correct = 0 # 驗證不求導 with torch.no_grad(): pres = [] labels = [] for (data, target, img_names) in data_loader: data, target = data.to(self.device), target.to(self.device) with torch.cuda.amp.autocast(): output = self.model(data).double() pred_score = nn.Softmax(dim=1)(output) pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability if self.cfg['use_distill']: target = target.max(1, keepdim=True)[1] correct += pred.eq(target.view_as(pred)).sum().item() batch_pred_score = pred_score.data.cpu().numpy().tolist() batch_label_score = target.data.cpu().numpy().tolist() pres.extend(batch_pred_score) labels.extend(batch_label_score) pres = np.array(pres) labels = np.array(labels) # acc評分 acc = correct / len(data_loader.dataset) print('[Info] acc: {:.3f}% \n'.format(100. * acc)) # f1評分 if 'F1' in self.cfg['metrics']: precision, recall, f1_score = getF1(pres, labels) print(' precision: {:.5f}, recall: {:.5f}, f1_score: {:.5f}\n'.format( precision, recall, f1_score))
模型預測參考如下程式碼:
# 載入權重 runner.modelLoad(cfg['model_path']) # 開始預測 res_dict = runner.predict(test_loader) # 預測函數 def predict(self, data_loader): self.model.eval() correct = 0 res_dict = {} with torch.no_grad(): pres = [] labels = [] for (data, img_names) in data_loader: data = data.to(self.device) output = self.model(data).double() pred_score = nn.Softmax(dim=1)(output) pred = output.max(1, keepdim=True)[1] # get the index of the max log-probability batch_pred_score = pred_score.data.cpu().numpy().tolist() for i in range(len(batch_pred_score)): res_dict[os.path.basename(img_names[i])] = pred[i].item() # 儲存影象與預測結果 res_df = pd.DataFrame.from_dict(res_dict, orient='index', columns=['label']) res_df = res_df.reset_index().rename(columns={'index':'image_id'}) res_df.to_csv(os.path.join(cfg['save_dir'], 'pre.csv'), index=False,header=True)
6.2 分類結果展示
隨機抽參與預測的四個影象資訊如下:

最終輸出預測結果如下:編號為10,1015圖片預測分類與實際情況一樣。編號為1084,1121的圖片預測結果與實際結果不一樣。

喜歡請讚賞一下啦^_^
 微信讚賞
微信讚賞
 支付寶讚賞
支付寶讚賞